Selenium - Tracy 小笔记2
selenium本身是一个自动化测试工具。
它可以让python代码调用浏览器。并获取到浏览器中加们可以利用selenium提供的各项功能。帮助我们完成数据的抓取。它容易被网站识别到,所以有些网站爬不到。
它没有逻辑,只有相应的函数,直接搜索即可
提纲:
1.掌握 selenium发送请求,加载网页的方法
2.掌握 selenium简单的元素定位的方法
3.掌握 selenium的基础属性和方法
4.掌握 selenium退出的方法
安装
pip install selenium
用chrome浏览器
chrome驱动地址:http://chromedriver.storage.googleapis.com/index.html
需要下载对应版本的驱动,版本前三位一致即可,不用版本完全一致
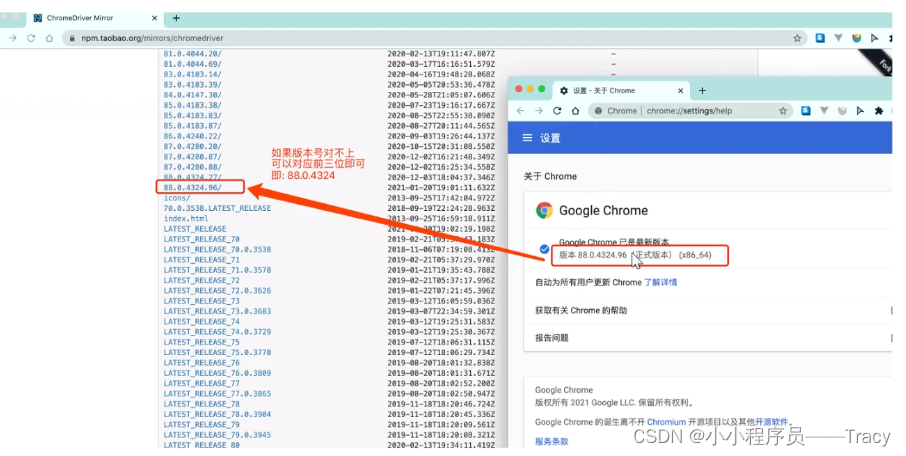
得到 chromdriver.exe 文件之后放在当前代码的文件夹下或者放在python解释器的文件夹内
Tips:Windwos: py-0p 查看Python路径
当谷歌浏览器自动更新之后 chromdriver.exe 就需要重新下载成对应的谷歌版本
版本不对的时候运行代码会报错
Selenium 使用过程:
1.加载网页
from selenium import webdriver //selenium的导包
from selenium.webdriver.common.by import By // 老版本就不需要写 By , 新版本就需要写 By
driver = webdriver.Chrome() // selenium创建driver对象,如果你的浏览器驱动放在了解释器文件夹,那么就不用写这个括号里的配置
driver = webdriver.Chrome(executable_path="chromedriver”) // 如果你的浏览器驱动放在了项目里这个配置就是为了告诉浏览器 chromedriver.exe 的位置在哪里#访问百度,根据 url 请求数据
driver.get("http://www.baidu.com/")
# 截图 只截取一屏
driver.save_screenshot("baidu.png")截取长图可以搜索 selenium 截长图2.定位和操作:
# 搜索关键字 杜卡迪
driver.find_element(By.ID,"kw").send keys("杜卡迪")
# 点击id为su的搜索按钮
driver.find_element(By.ID,"su").click()3、查看请求信息:
driver.page_source // 获取页面所有数据,如果之前还执行了滚动啊 点击啊 都会展示这些操作执行之后 这个页面所有的数据
# 获取页面内容
driver.get_cookies() // 获取 cookies 模拟登录
driver.current_url
4、退出
driver.close() # 退出当前页面
driver.quit ()# 退出浏览器time.sleep(3) //延迟3秒 需要 import time
元素定位的两种方式:
精确定位一个元素,返回结果为一个element对象,定位不到则报错
driver.find_element(By.xx, value) # 建议使用,新版本的写法
driver.find_element_by_xxx(value) // 老版本的写法By 之前需要引入
from selenium.webdriver.common.by import By定位一组元素,返回结果为element对象列表,定位不到返回空列表
driver.find_elements(By.xx,value) # 建议使用
driver.find_elements_by_xxx(value)元素定位的八种方法
以下方法在element之后添加“s”就变成能够获取一组元素的方法
定位后找到的原色都是节点(标签), 如果想要获取相关属性的值,需要调用相关的方法
By.ID 使用id值定位
el = driver.find element(By.ID,'') // 新版本写法
el = driver.find element by_id() //老版本写法
By.XPATH 使用xpath定位
el = driver.find element(By.XPATH,)
el = driver.find_element_by_xpath()driver.find_elements(By.XPATH,"//*[@id='s']/h1/a")
// 任意一个网页元素,都可以 f12 选中 右键 copy -> copy xpath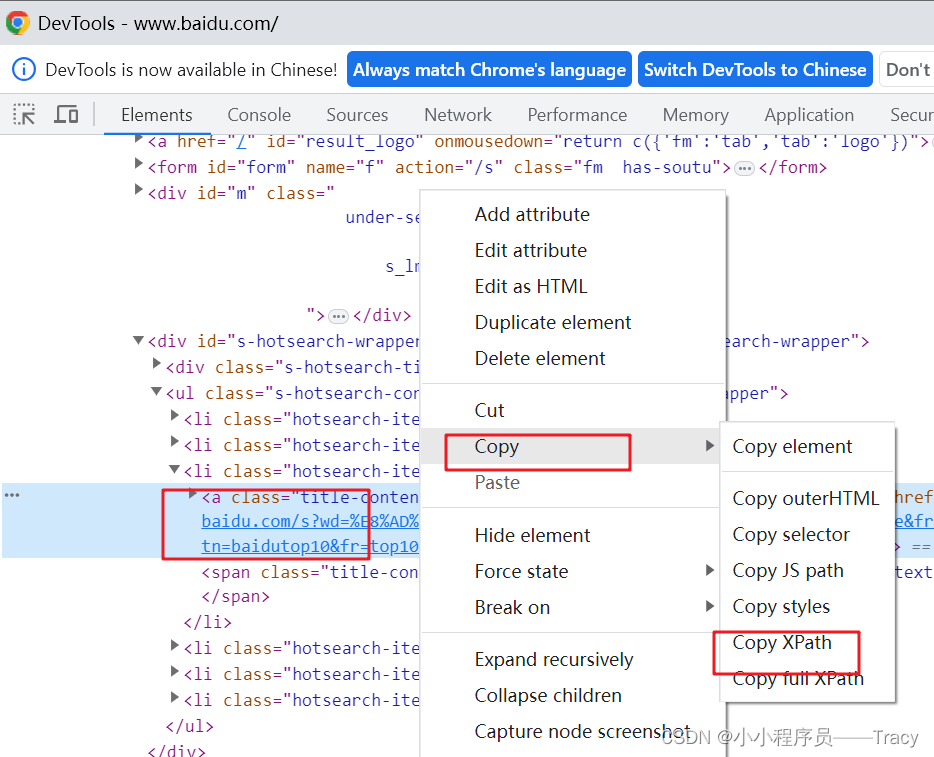
By.TAG_NAME.使用标签名定位
el = driver.find_element(By.TAG_NAME,')
el = driver.find element by_tag_name()a_list = driver.find_elements(By.TAG_NAME,"a") //查找所有 a 标签
By.LINK_TEXT使用超链接文本定位
el = driver.find_element(ByTLINK_TEXT,'')
el = driver.find _element by_link_text()driver.find_elements(By.LINK_TEXT,"下载豆瓣 App")By.PARTIAL LINK TEXT 使用部分超链接文本定位
比如模糊搜索 百度的百
el = driver.find_element(By.PARTIAL LINK TEX, '百')Tel = driver.find_element_by_partial_link_text(“百”)By.NAME 使用name属性值定位
el = driver.find_element(By.NAME, '')
el = driver.find_element_by_name()
By.CLASS_NAME使用class属性值定位
el = driver.find_element(By.CLASS NAME, '')
el = driver.find_element_by_class_name()driver.find_elements(By.CLASS_NAME, "box')
By.CSS_SELECTOR 使用css选择器定位
el = driver.find_element(By.CSS_SELECTOR,'')
el = driver.find_element_by_css_selector()
2、元素的操作
1.从定位到的元素中获取数据
el.get_attribufe(key) # 获取key属性名对应的属性值
el.text # 获取开闭标签之间的文本内容demo:
el.get_attribute("href")
href对应的链接,只对find_element()有效,列表对象没有这个属性
所以不能用 find_elements().get_arrtribute...1.对定位到的元素的操作
el.click() #对元素执行点击操作
el.submit() #对元素执行提交操作 比如说一个搜索框,输入文字之后,直接提交开始搜索方法
el.clear() # 清空可输入元素中的数据
el.send_keys(data) #向可输入元素输入数据
Cookie
获取cookie
dictCookies = driver.get cookies()设置cookie
driver.add_cookie(dictCookies)删除cookie
#删除一条cookie
driver.delete_cookie("CookieName")
# 删除所有的cookie
driver.delete_all_cookies()页面等等
为什么需要等待
如果网站采用了动态html技术,那么页面上的部分元素出现时间便不能确定,这个时候就可以设置一个时间,强制等待指定时间,等待结束之后进行元素定位,如果还是无法定位到则报错
也就是等待页面加载,放置还没有 load 完
显式等待(自动化web测试使用,爬虫基本不用)
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected conditions as ECWebDriverWait(driver,10,0.5).until( EC.presence of_element located((By.ID,"myDynamicElement")
#显式等待指定某个条件,然后设置最长等待时间19,在19秒内每隔8.5秒使用指定条件去定位元素,如果定位到元素则直接结束等待,如果在19秒结束之后仍未定位到元素则报错隐式等待 隐式等待设置之后代码中的所有元素定位都会做隐式等待
driver.implicitly_wait(10)# 在指定的n秒内每隔一段时间尝试定位元素,如果n秒结束还未被定位出
来则报错注意:
Selenium显示等待和隐式等待的区别
1I selenium的显示等待
原理,显示等待,就是明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception
(简而言之,就是直到元素出现才去操作,如果超时则报异常)
2、selenium的隐式等待
原理:隐式等待,就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段
时间,直到拿到某个元素位置。
注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素
3、switch方法切换的操作
3.1一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换。切换窗口的方法如下:
也可以使用 window handles 方法来获取每个窗口的操作对象。例如:
#1.获取当前所有的窗口
current windows = driver.window handles
#2.根据窗口索引进行切换
driver.switch_to.window(current_windows[1])
driver.switch_to.window(web.window handles[-1]) # 跳转到最后一个窗口driver.switch_to.window(current windows[o]) # 回到第一个窗口
iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是网不ameTw内容的,对应的解决思路是
传入的参数可以使iframe对应的id值,也可以是用元素定位之后的元素对象
driver.switch to.frame(name/el/id)
3.3 当你触发了某个事件之后,页面出现了弹窗提示,处理这个提示或者获取提示信息方法如下:
alert = driver.switch_to_alert()
页面前进和后退
driver.forward() # 前进
driver.back() # 后退
driver.refresh() # 刷新
driver.close() # 关闭当前窗口
设置浏览器最大窗口
driver.maximize window()#最大化浏览器窗口
模拟登录
//方式1,直接输入用户名密码验证码进行登录:
driver.find_element(byID, '验证码图片id').screenshot('code.png') //得到验证码图片//使用转码平台翻译这个验证码平台,这个基本是要花钱转译的。所以我们这里其实可以弄一个半自动自己来输入这个验证码
image_code = 一个转义的接口一般需要输入这个图片 url, 用户名,密码等driver.find_element(byID, '验证码输入框id').send_key(image_code)// 方式2, 保存 cookie 就不用每次登录了
cookies = driver.get_cookies() // 获取 cookies 模拟登录
console.log(cookies)
console.log(typeof(cookies))// 往文件里写入 cookies
写入文件方法1:
global.fs = require("fs");
fs.appendFileSync('tracy.json', stringify(cookies,null,4));
写入文件方法2:
with open('gsw.txt','w') as f
f.write(json.dumps(cookies)) //使用本地 cookies 进行登录
//读文件
with open('gsw.txt','r') as f
cookies = json.loads(f.read())这里可能还需要处理下 cookies 格式之类的
比如原来的cookie 是一个数组 那么需要遍历一下
for(cookie in cookits)
{cookit_dict = {};for( k, v in cookit.items){cookit_dict[k] = v}driver.add_cookie(cookit_dict)
}处理之后
driver.add_cookie(cookie) //把本地 cookies 存入网页 cookie 中
driver.refrech() //页面刷新 不刷新 cookie 可能没加载进去 会出现问题, 所以要刷新一下
刷新相当于重新访问服务器,这次携带了 cookie 来访问服务器 driver.get("登录成功之后进入的 url, 如个人中心")
异步加载的数据的访问
如:页面下滑加载更多
需要判断一下 是否已经到最后了,有些页面是一开始鼠标下滑往下请求然后需要点击加载更多按钮,然后会出现类似于“已经到最后啦”
import time
// driver.execute_script()
seLenium执行js代码
这里执行js滚动条的事件time.sleep(5)
driver.execute_script('window.scrollBy(0, 1000)')滚动步长
step_length = 2000
需要滚动的距离,这里自己估计大概的数值
stop_length = 3000
// 开始滚动
scroll_window(driver,stop_length, step_length)//封装一个循环的滚动函数
function scroll_window(driver, stop_length=0, step_length=2000){if (!stop_lengt) breakif stop_length - step_length <= 0 break;// seLenium执行js代码driver.execute_script('window.scrollBy(' + step_length' + ')')stop_Length -= step_Length // 减去每次滚动的步长time.sleep(1)
}const more = driver.find_element(....) // 得到加载更多按钮
more.click();//有的时候点击事件报错,有可能是因为点击的这个标签有一层我们看不见的遮罩层
//我们就可以用 js 进行点击
driver.execute_script('arguments[0].click();',more)循环点击自己估计点击次数
for (i in 6){console.log("第" + i + "次点击")
time.sleep(3)}等上面的东西都加载好之后driver.page_sourcer // 获取之前滚动啊 加载啊 之后的所有数据selenium的优缺点
优点
- oselenium能够执行页面上的is,对于is渲染的数据和模拟登陆处理起来非常容易
- 使用难度简单
- 爬取速度慢,爬取频率更像人的行为,天生能够应对一些反爬措施
缺点
- 由于selenium操作浏览器,因此会将发送所有的请求,因此占用网络带宽。由于操作浏览器,因此占用的内存非常大(相比较之前的爬虫)
- 速度慢,对干效率要求高的话不建议使用
selenium的配置
https://blog.csdn.net/qg 35999017/article/details/123922952
https://blog.csdn.net/qg 27109535/article/details/125468643
无头浏览器
我们已经基本了解了selenium的基本使用了.但是呢,不知各位有没有发现,每次打开浏览器的时间都比较长,这就比较耗时了.我们写的是爬虫程序.目的是数据.并不是想看网页.那能不能让浏览器在后台跑呢? 答案是可以的
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
opt = Options()
opt.add argument("_-headless")
opt.add argument('--disable-gpu')
opt.add argument(“_-window-size=40,1600") # 设置窗口大小driver = Chrome(options=opt)相关文章:
Selenium - Tracy 小笔记2
selenium本身是一个自动化测试工具。 它可以让python代码调用浏览器。并获取到浏览器中加们可以利用selenium提供的各项功能。帮助我们完成数据的抓取。它容易被网站识别到,所以有些网站爬不到。 它没有逻辑,只有相应的函数,直接搜索即可 …...
SVN 和 GIT 命令对比
参考 https://blog.csdn.net/justry_deng/article/details/82259470 # TortoiseSVN打分支、合并分支、切换分支 https://www.huliujia.com/blog/802a64152bbbe877c95c84ef2fdf3857a056b536/ # 版本控制:Git与Svn的命令对应关系 TortoiseSVN打分支、合并分支、切换…...

LeetCode 之 移除元素
算法模拟: Algorithm Visualizer 在线工具: C 在线工具 如果习惯性使用Visual Studio Code进行编译运行,需要C11特性的支持,可参考博客: VisualStudio Code 支持C11插件配置 问题1:LeetCode 27.移除元素…...
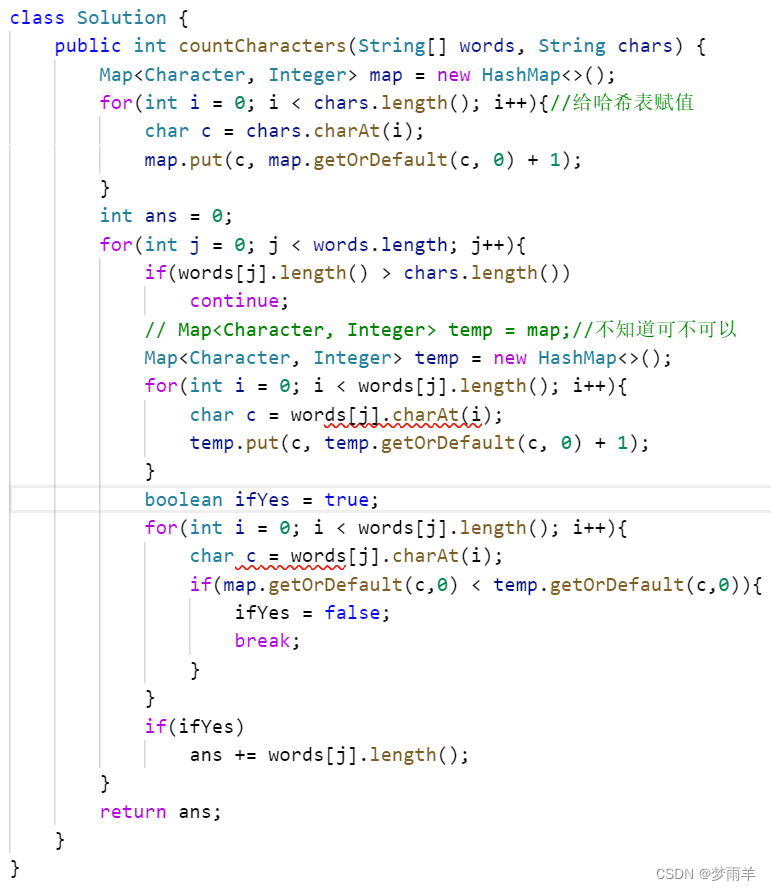
Leecode1160: 拼写单词
直接使用一个哈希表存整体的结果,一个临时的哈希表每次算一遍,但是1是要设置标志位来判断最后是否正确并加上长度,2是千万要记得每次新建一个空间来存哈希表绝对不能不空间就等于,会出事!!...

电脑死机的时候,CPU到底在做什么?
电脑死机,应该每个接触计算机的小伙伴都经历过吧。 尤其是早些年,电脑配置还没现在这么高的时候,多开几个重量级应用程序,死机就能如约而至,就算你把键盘上的CTRLALTDELETE按烂了,任务管理器也出不来&…...
jdk 中的 keytool 的使用,以及提取 jks 文件中的公钥和私钥
这里暂时只需要知道如何使用就可以了。 首先是生成一个密钥, keytool -genkeypair -alias fanyfull -keypass ffkp123456 -validity 365 -storepass ffsp123456 -keystore fanyfull.jks -keyalg RSA解释一下这里的选项, -alias 密钥对的名称-keypass …...
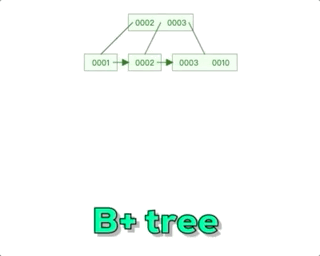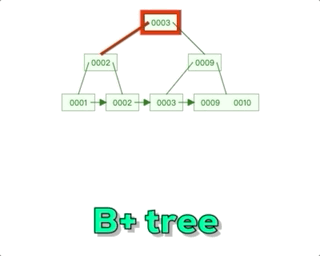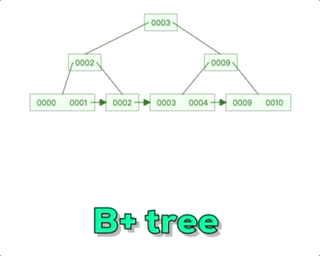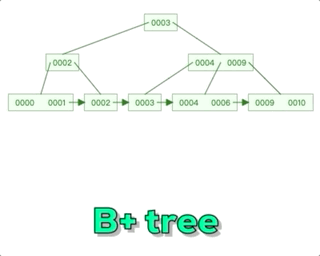
Mysql--技术文档--B+树-数据结构的认知
阿丹解读: 之前的文章中写道了有关mysql底层索引,那么在数据量特别大的情况下。mysql采用了B来管理索引。和存储的数据。 Mysql--技术文档--索引-《索引为什么查找数据快?》-超底层详细说明索引_一单成的博客-CSDN博客 B树解读:…...
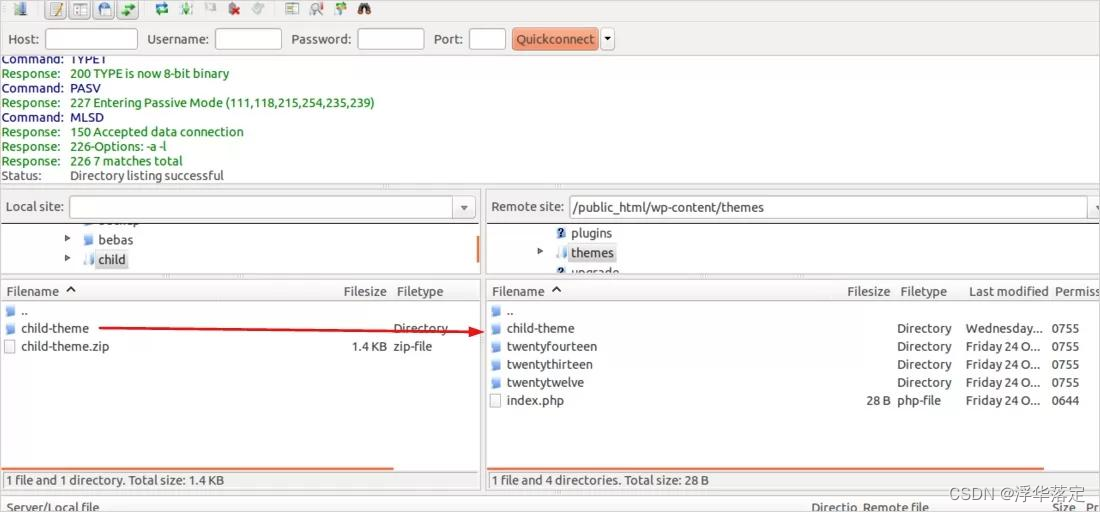
cms之wordpress主题安装
WordPress主题安装教程的方法有两种,分为在线安装和上传安装,下面是主题详细安装方法的步骤。 后台在线安装主题 从后台的主题界面在线安装主题是最方便的WordPress主题安装方式。方法如下: 1 在WordPress后台,转到外观→主题 …...
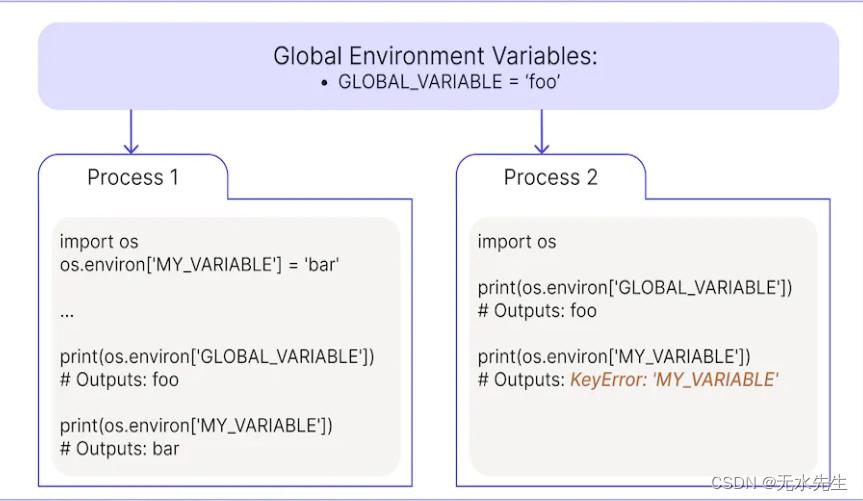
【Python程序设计】Python 中的环境变量【05/8】
一、说明 以下文章是有关 Python 数据工程系列文章的一部分,旨在帮助数据工程师、数据科学家、数据分析师、机器学习工程师或其他刚接触 Python 的人掌握基础知识。本篇将讲述环境变量的问题。 迄今为止,本初学者指南包括: 第 1 部分…...
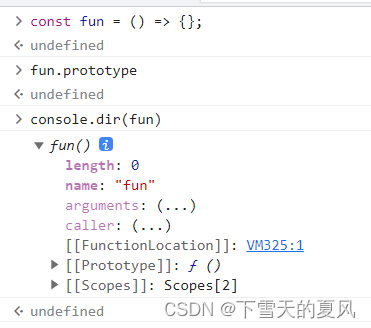
查漏补缺 - ES6
目录 1,let 和 const1,会产生块级作用域。2,如何理解 const 定义的变量不可被修改? 2,数组3,对象1,Object.is()2,属性描述符3,常用API4,得到除某个属性之外的新对象。 4…...
:最初的项目思路(SLAM))
基于视觉重定位的室内AR导航APP的大创项目思路(1):最初的项目思路(SLAM)
文章目录 最初的项目思路(SLAM):后文: 前情提要: 是第一次做项目的小白,文章内的资料介绍如有错误,请多包含! 最初的项目思路(SLAM): 由于我们在…...
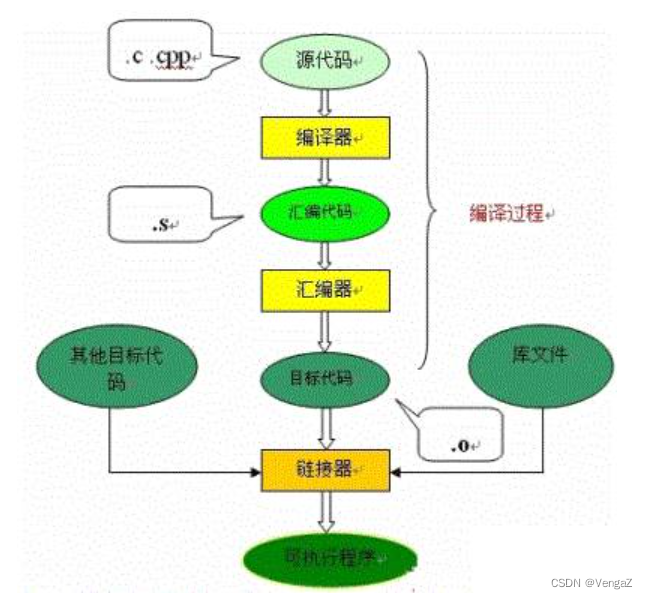
C 编译原理
C 编译原理 目录 C 编译原理引入GCC 工具链介绍C运行库 编译准备工作编译过程1.预处理2.编译3.汇编4.链接 分析ELF文件1.ELF文件的段2.反汇编ELF C语言编译过程 - 摘录编译预处理编译、优化汇编链接过程 引入 大家肯定都知道计算机程序设计语言通常分为机器语言、汇编语言和高…...

服务管理工具systemctl
服务管理工具systemctl Linux服务管理两种方式 service 和 systemctl systemd 是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动. systemd 对应的进程管理命令是systemctlsystemctl 是systemd的主命令,用于管理系统…...
Spring boot环境搭建
使用IDE工具:IntelliJ IDEA 目录 一、安装JAVA 二、安装maven(Java项目管理工具) 三、安装IDE 四、在IDE中配置spring boot项目环境 1、配置jdk 2、配置maven 3、安装创建spring boot项目插件:Spring Assistant 4、安装简…...

【C++】list的模拟实现【完整理解版】
目录 一、list的概念引入 1、vector与list的对比 2、关于struct和class的使用 3、list的迭代器失效问题 二、list的模拟实现 1、list三个基本函数类 2、list的结点类的实现 3、list的迭代器类的实现 3.1 基本框架 3.2构造函数 3.3 operator* 3.4 operator-> 3…...
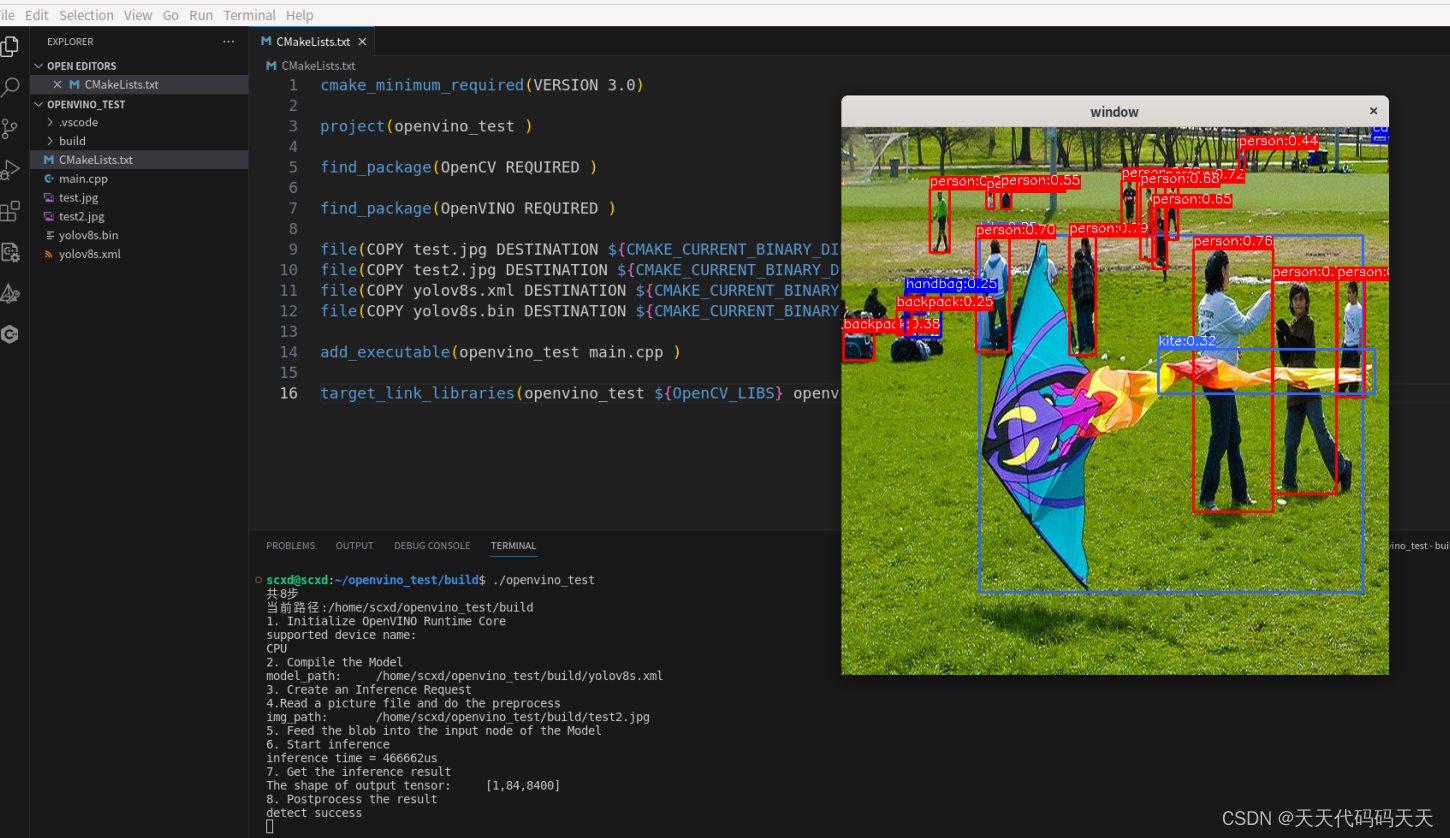
Linux C++ OpenVINO 物体检测 Demo
目录 main.cpp #include <iostream> #include <string> #include <vector> #include <openvino/openvino.hpp> #include <opencv2/opencv.hpp> #include <dirent.h> #include <stdio.h> #include <time.h> #include …...

解决运行Docker镜像报错:version `GLIBC_2.32‘ not found
解决运行Docker镜像,报错:version GLIBC_2.32’ not found 详细报错日志 xapi-backend % docker logs 036de55b5bc6 ./xapi-backend: /lib/aarch64-linux-gnu/libc.so.6: version GLIBC_2.32 not found (required by ./xapi-backend) ./xapi-backend: …...

网络层--IP协议
引入: IP协议主要解决什么问题呢? IP协议提供一种将数据从主机A 发送到 主机B的能力。(有能力不一定能做到,比如小明很聪明,可以考100分,但是他也不是每次搜能考100分࿰…...
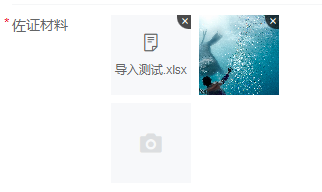
Vue2 | Vant uploader实现上传文件和图片
需求: 实现图片和文件的上传,单个图片超过1M则压缩,全部文件加起来不得超过10M。 效果: 1. html <van-form ref"form"><van-field name"uploader" label"佐证材料" required><t…...

第二十一章 Classes
文章目录 第二十一章 ClassesClasses类名和包类定义的基本内容 第二十一章 Classes Classes 类定义并不是 ObjectScript 的正式组成部分。相反,可以在类定义的特定部分中使用 ObjectScript(特别是在方法定义中,可以在其中使用其他实现语言&…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...

AD学习(3)
1 PCB封装元素组成及简单的PCB封装创建 封装的组成部分: (1)PCB焊盘:表层的铜 ,top层的铜 (2)管脚序号:用来关联原理图中的管脚的序号,原理图的序号需要和PCB封装一一…...