07 目标检测-YOLO的基本原理详解
一、YOLO的背景及分类模型
1、YOLO的背景
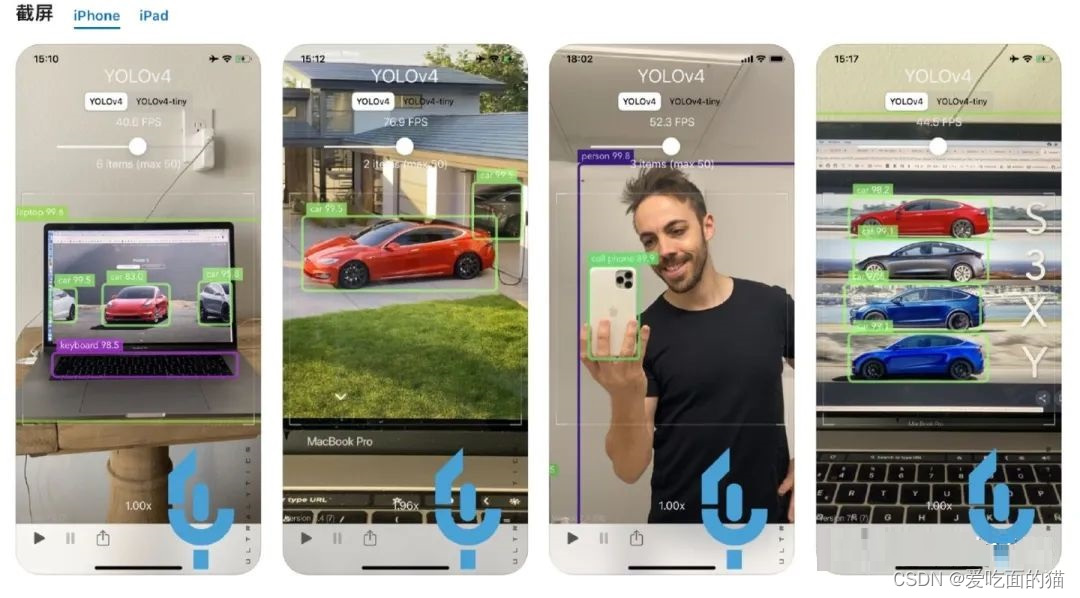
上图中是手机中的一个app,在任何场景下(工业场景,生活场景等等)都可以试试这个app和这个算法,这个app中间还有一个button,来调节app使用的模型的大小,更大的模型实时性差但精度高,更小的模型实时性好但精度差。
而YOLO v5其实一开始是以这一款app进入人们的视野的,就是上图的这个,叫:i detection(图上标的是YOLO v4,但其实算法是YOLO v5),值得一提的是,这款app就是YOLO v5的作者亲自完成的。
读到这里,你觉得YOLO v5的最大特点是什么?
答案就是:一个字:快,应用于移动端,模型小,速度快。
我们再看一张图:
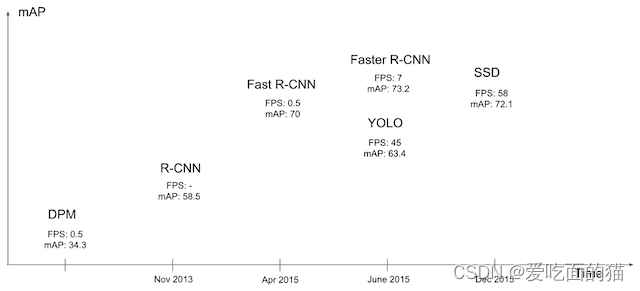
从图中可以看出YOLO的最大特点是速度快。YOLO在精度上仍然落后于目前最先进的检测系统。虽然它可以快速识别图像中的目标,但它在定位某些物体尤其是小的物体上精度不高。进入到真正端到端的目标检测:直接在网络中提取特征来预测物体分类和位置。因此YOLO的主要特点:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
- 泛化能力强。
2、分类模型
在进入目标检测任务之前首先得学会图像分类任务,这个任务的特点是输入一张图片,输出是它的类别。
对于输入图片,我们一般用一个矩阵表示。
对于输出结果,我们一般用一个one-hot vector表示: 【0,0,1,0,0,0】 ,例如我们有6个类别(猫、狗、人、马、鸡、猪),哪一维是1(人这一维是1),就代表图片属于哪一类(人)。
所以,在设计神经网络时,结构大致应该长这样:

这里的cbrp指的是conv,bn,relu,pooling的串联。
由于输入要是one-hot形式,所以最后我们设计了2个fc层(fully connencted layer),我们称之为“分类头”或者“决策层”。
二、YOLO系列思想的雏形:YOLO v0
1、框的表示方式
-
x,y,w,h(如图)
-
p1,p2,p3,p4(4个点坐标)
-
cx,cy,w,h(cx,cy为中心点坐标)
-
x,y,w,h,angle(还有的目标是有角度的,这时叫做Rotated Bounding Box)
-
......

所以框Bounding Box表示的方法很多,但输出的结果一定是一个vector。
2、分类器和检测器
上面我提到了分类器模型用来分类,分类器的输出是一个one-hot vector,而检测器的输出是一个框(Bounding Box),也是一个向量,是我们标注的结果。但二者的共同特点是结果都是向量。因此分类模型可以用来做检测,用分类模型可以把检测的任务当做是遍历性的分类任务,只是输出的结果是一个个one-hot vector而已。
3、遍历性的分类任务
如何遍历?首先我们先预设一个框的大小,然后在图片上用这个框遍历,每遍历1次,都对边框的区域进行二分类:属于脸或者不属于脸。

这种方法其实就是RCNN全家桶的初衷,专业术语叫做:滑动窗口分类方法。
但问题是:检测的耗时非常大。
4、改进思路
既然分类器输出一个one-hot vector:【0,0,1,0,0,0】,那我们把它换成(x,y,w,h,c),c表示confidence置信度,此时输出是Bounding Box的位置(x,y,w,h,c),因此就把检测问题转化成一个回归问题,而分类器也就可以变成了一个检测器。因此分类器变化如下:


此时我们会发现,这种方法比刚才的滑动窗口分类方法简单太多了。这一版的思路我把它叫做YOLO v0,因为它是You Only Look Once最简单的版本。
因此YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
5、YOLO v0的进化(YOLO v1)
5.1、问题分析
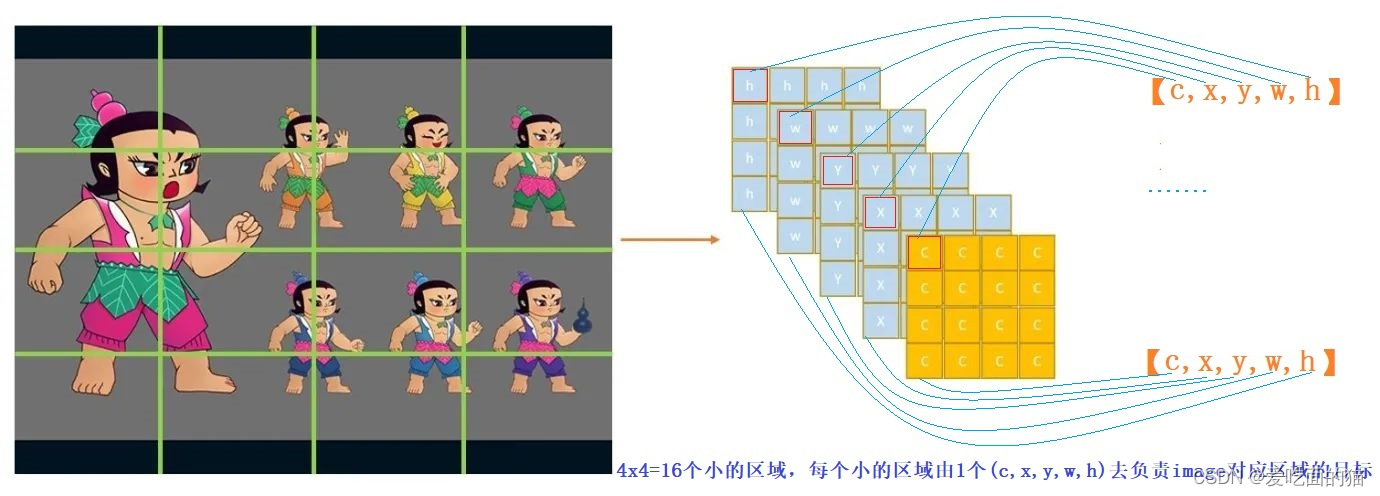
YOLO v0只能输出一个目标,那比如下图多个目标怎么办呢?为了保证所有目标都被检测到,我们应该输出尽量多的目标。所以我们的模型需要进行改进。


我们进一步的改进,让每个(c,x,y,w,h)去负责image某个区域的目标。因此我们需要对图片进行区域划分,如上图中我们可以将图片划分成4x4=16个小的区域,每个小的区域由1个(c,x,y,w,h)去负责image对应区域的目标。
因为conv操作是位置强相关的,原来的目标在哪里,卷积之后的feature map上还在哪里,所以图片划分为16个区域,结果也应该分布在16个区域上,所以我们的结果(Tensor)的维度size是:(5,4,4)。如下图所示:
5.2、c的真值设置
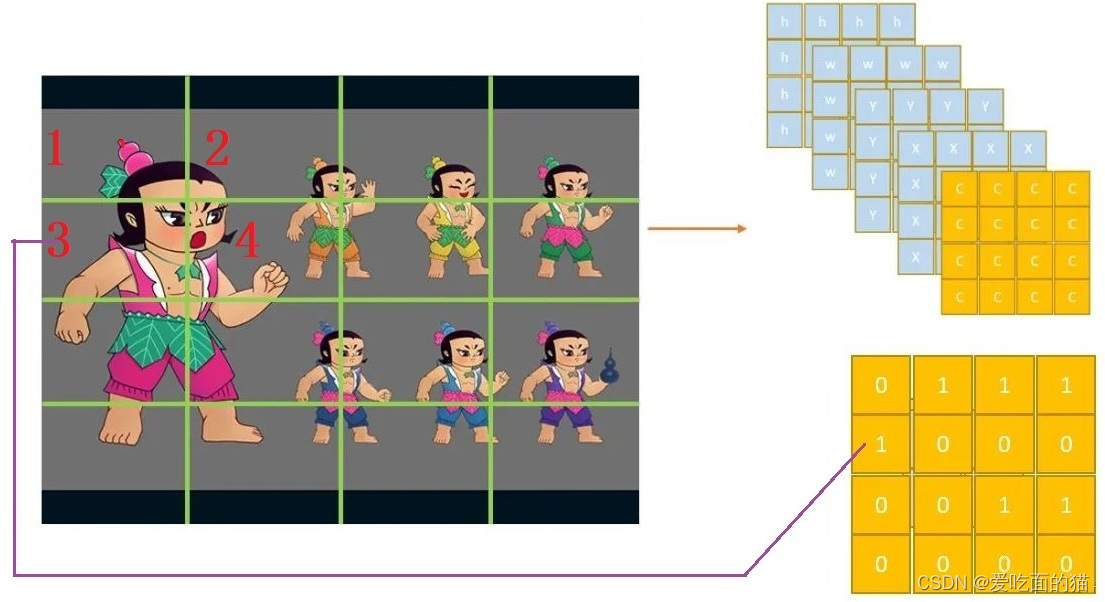
c的真值如何设置呢?c的真值取决于区域的中心点,如大娃脸部跨了4个区域(grid),但4个区域(grid)只能某一个grid的c=1,其他的3个区域c=0。那么该让哪一个grid的c=1呢?就看他的脸的中心落在了哪个grid里面。根据这一原则,c的真值为下图所示:
5.3、NMS(非极大值抑制)
上图中会发现7个葫芦娃,c的真值只有6个1,原因是第三行第三列的grid有2个目标。如何解决一个区域有多个目标的情况?
解决方案:
NMS(非极大值抑制)解决多目标检测。2个框重合度很高,大概率是一个目标,那就只取一个框。重合度的计算方法:交并比IOU=两个框的交集面积/两个框的并集面积。(推荐)
或者使用聚类,但聚类容易将2个目标本身比较近聚成了1个类。(不推荐)
或者细化网格:将网格细化,如将 4x4 区域变成 40x40 或者更大,使区域更密集,就可以缓解多个目标的问题,但无法从根本上去解决。(不推荐)
5.4、多类的目标
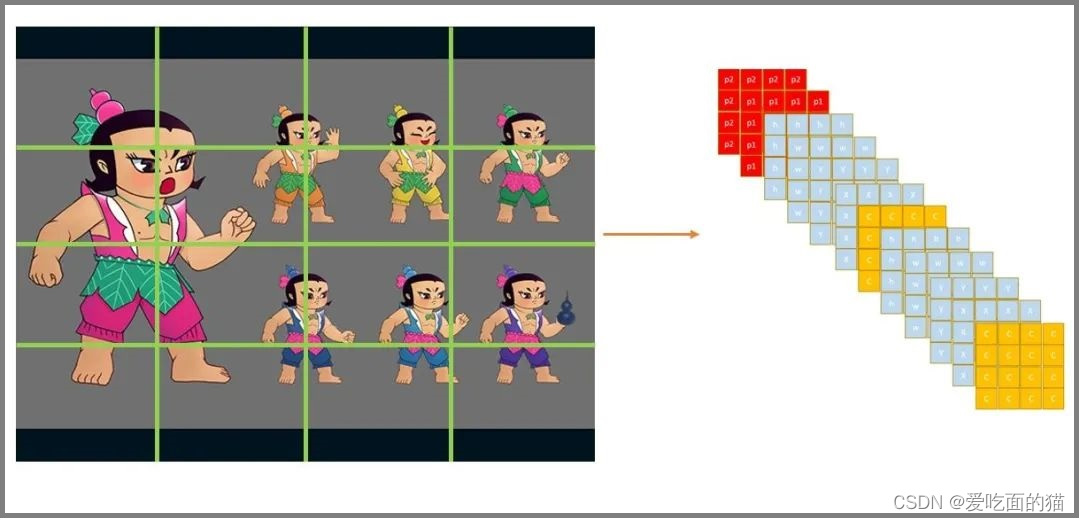
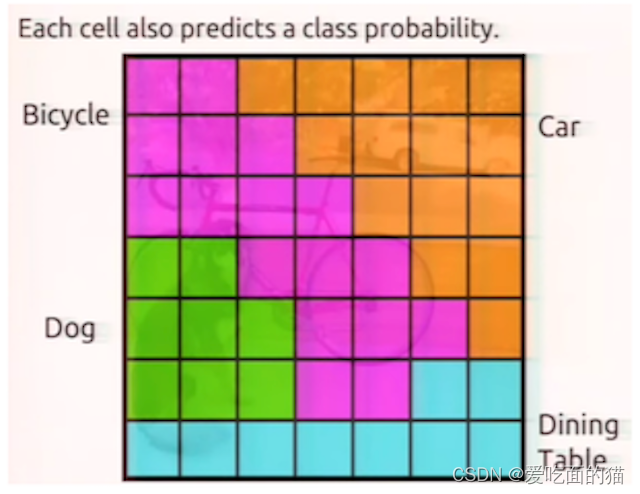
上面我将一直讲的是单类目标,如检测葫芦娃的脸,如果是多类目标如检测葫芦娃的脸,且检测葫芦,此时我们的设计改变为如下,多个类的问题也解决了。

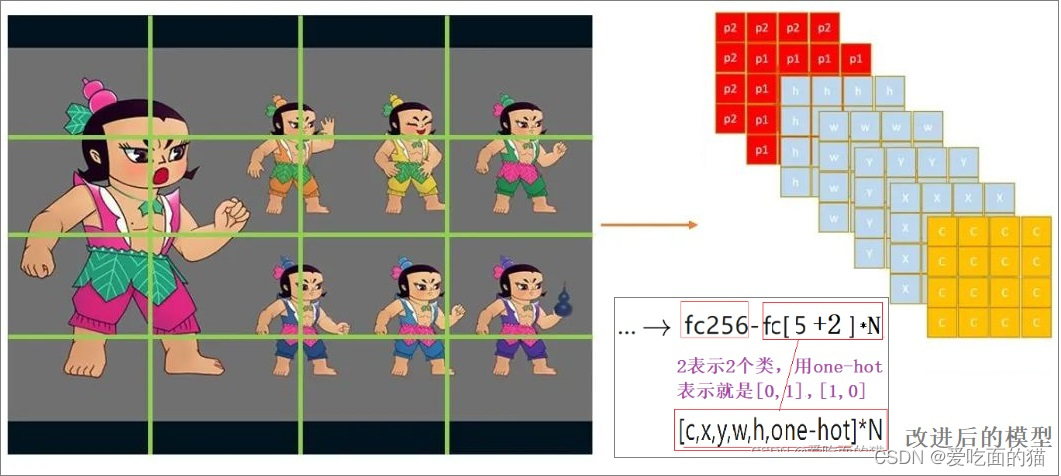
5.5、小目标检测
小目标总是检测不佳,所以我们专门设计神经元去拟合小目标。对于每个区域,我们用2个五元组(c,x,y,w,h),一个负责回归大目标,一个负责回归小目标,同样添加one-hot vector,one-hot就是[0,1],[1,0]这样子,来表示属于哪一类(葫芦娃的头or葫芦娃的葫芦)。此时设计的检测器其实就是YOLO v1思路,只是参数不同。
三、YOLO核心思想
YOLO是一种新的目标检测方法。以前的目标检测方法通过重新利用分类器来执行检测。后来使用深度学习算法,从R-CNN到Fast R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但是速度还不行。
YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
YOLO将目标检测看作回归问题,从空间上定位边界框(bounding box)并预测该框的类别概率。使用单个神经网络,在一次评估中直接从完整图像上预测边界框和类别概率。由于整个检测流程仅用一个网络,所以可以直接对检测性能进行端到端的优化。
四、YOLO算法系列的演变过程
YOLO算法系列的演变过程:YOLO->YOLO9000->YOLOv2->YOLOv3

五、YOLO结构
YOLO整体结构就是三部分组成:GoogleNet+4个卷积+2个FC,思路彩用的就是上面YOLO v0的进化思路,只是参数不同而已。
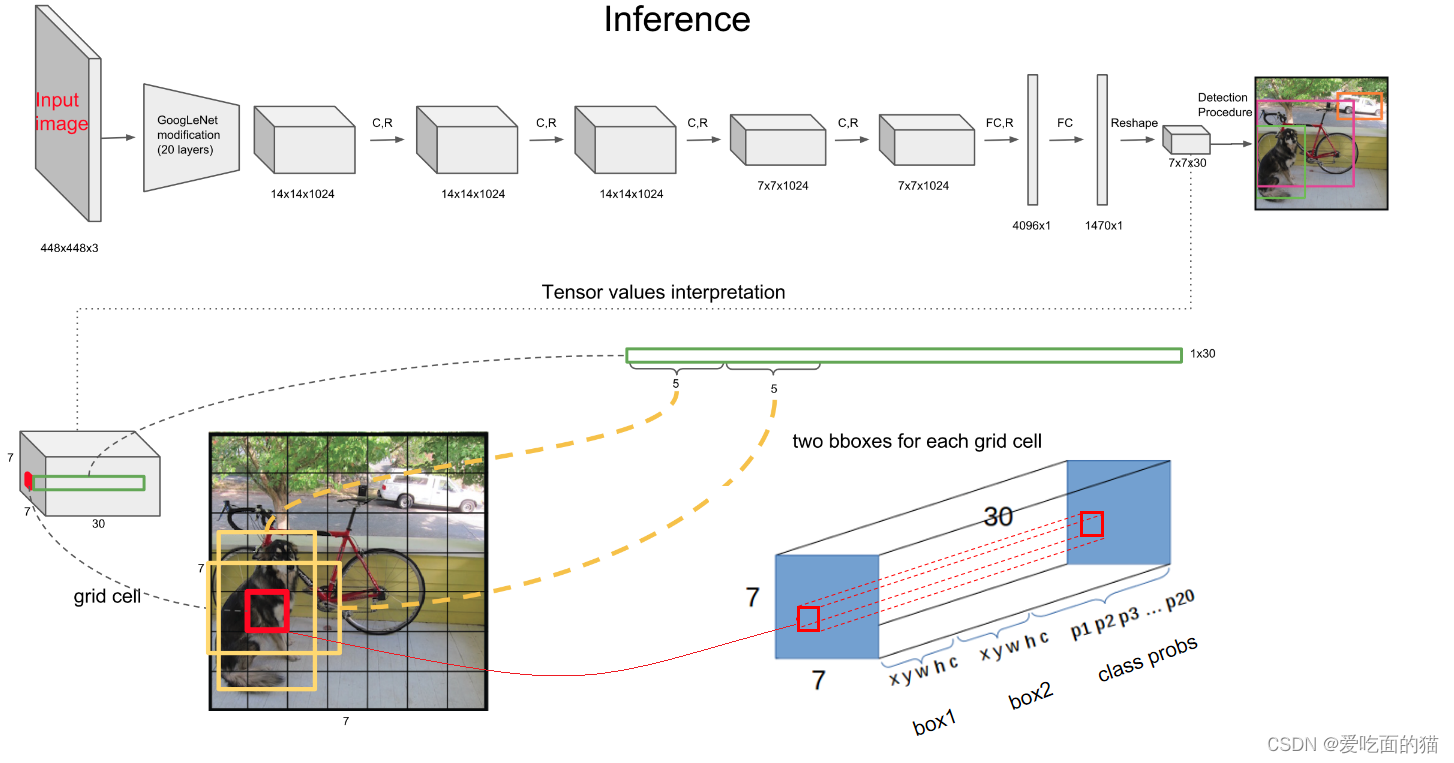

六、YOLO流程
通过结构图中我们可以看到,输入图片是4448x448,输出结构是7x7x30,YOLO(是很简单直观的图像处理系统)整体流程大体分为三步:
-
1、把图像缩放到448X448,图片分成7x7个网格(grid cell)
-
2、在图上运行卷积网络
-
3、根据模型的置信度对检测结果进行阈值处理
1、原始图片resize到448x448,图片分成7x7个网格(grid cell)
原始图片resize到448x448,图片分成7x7个网格(grid cell),某个目标物体的中心落在这些网格中的一个当中,这个网格就负责预测这个物体。例如狗的中心点就落到这些网格中的红色的框(5,2)位置,那么这个红色的框就负责狗这个物体的检测。

假如我们只检测一个目标狗,此时红框(5,2)这个格子所对应的物体置信度标签为1,而那些没有物体中心点落进来的格子,对应的物体置信度标签为0。这个设定就好比该网络在一开始,就将整个图片上的预测任务进行了分工,一共设定7x7个按照方阵列队的检测人员,每个人员负责检测一个物体,大家的分工界线,就是看被检测物体的中心点落在谁负责的格子里。当然,是7x7还是9x9参数可以自己修改,精度和性能会随之有些变化。
2、在图上运行卷积网络
CNN提取特征和预测,卷积部分负责提特征。全链接部分负责预测。
在CNN提取特征后,我们得到 feature maps ,利用Anchor思想,对 feature maps 中每个锚点(对应原图中的某个区域)都预定义 B 个 boublding box,此处为了方便,之后全链接部分负责预测每个网格单元都会预测B个边界框和这些框的置信度分数(confidence scores)。
3、根据模型的置信度对检测结果进行阈值处理
虽然通过CNN提取特征和预测,但还是会有很多 boublding box,但并不是每个都是我们需要的,所以此时需要根据模型的置信度对检测结果进行阈值处理。
4、图示流程及概述
原始图片resize到448x448,经过前面卷积网络之后,将图片输出成了一个7x7x30的结构。
为了方便理解,以图示的方式演示,默认7 x 7个单元格,这里用3 x 3的单元格图演示。

01、每个网格单元都会预测B个(此处让B=2)边界框和这些框的置信度分数(confidence scores)

02、进行NMS筛选,筛选概率以及IOU


5、概念详解
单元格(grid cell)
上面第二步是理解YOLO网络的关键。图片输入到YOLO之后只会得到7 x 7 x 30的输出结果。每个网格单元都会预测B个边界框和这些框的置信度分数(confidence scores),这些置信度分数反映了该模型对那个框内是否包含目标的信心,以及它对自己的预测的准确度的估量。
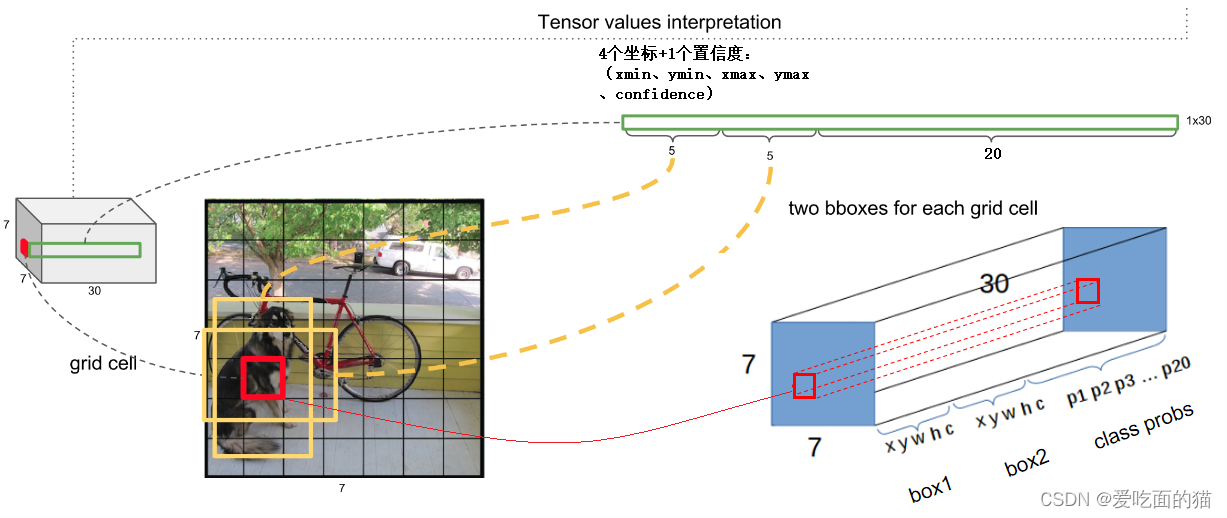
那么网络输出的 7 x 7 x 30 的特征图怎么理解?
7x7x30
7x7=49个像素值,理解成49个单元格,也可以理解成 49个 1*1*30,而每个1*1*30维度包含有类别预测和bbox坐标预测。
单元格需要做的两件事:每个单元格负责预测一个物体的类别,并且直接预测物体的概率值
每个单元格预测两个(默认)bbox位置,两个bbox有两个置信度(confidence)30 的组成:
30 = 2个 bbox + 20个类别信息
1个bbox =4个坐标+1个置信度:xmin、ymin、xmax、ymax、confidence
2个bbox:4 + 1 + 4 + 1 = 10(4个位置信息,1个置信度)
30 =(4 + 1 + 4 + 1) + 20个类别信息(预测概率结果)注意:20代表 20类类别的预测概率结果
2个bounding box共10个值,对应 1*1*30维度特征中的前10个。
1个置信度(confidence)代表一个bbox的结果
xmin、ymin相对于对应的网格归一化到0-1之间,xmax、ymax即 w,h用图像的width和height归一化到0-1之间
小结:(7*7)*30的维度。每个 1*1*30的维度对应原图7*7个cell中的一个,1*1*30中含有类别预测和bbox坐标预测。总得来讲就是让网格负责类别信息,bounding box主要负责坐标信息(部分负责类别信息:confidence也算类别信息)。
6、网格输出筛选
- 01 置信度比较
- 02 预测位置大小-回归offset代替直接回归坐标
01、置信度比较
Pascal VOC上评估YOLO,使用最终大小S=7,预测数量B=2。
假如(人工标记的)狗的真实值中心点在 8 的单元格位置,真实值信息如下图所示:
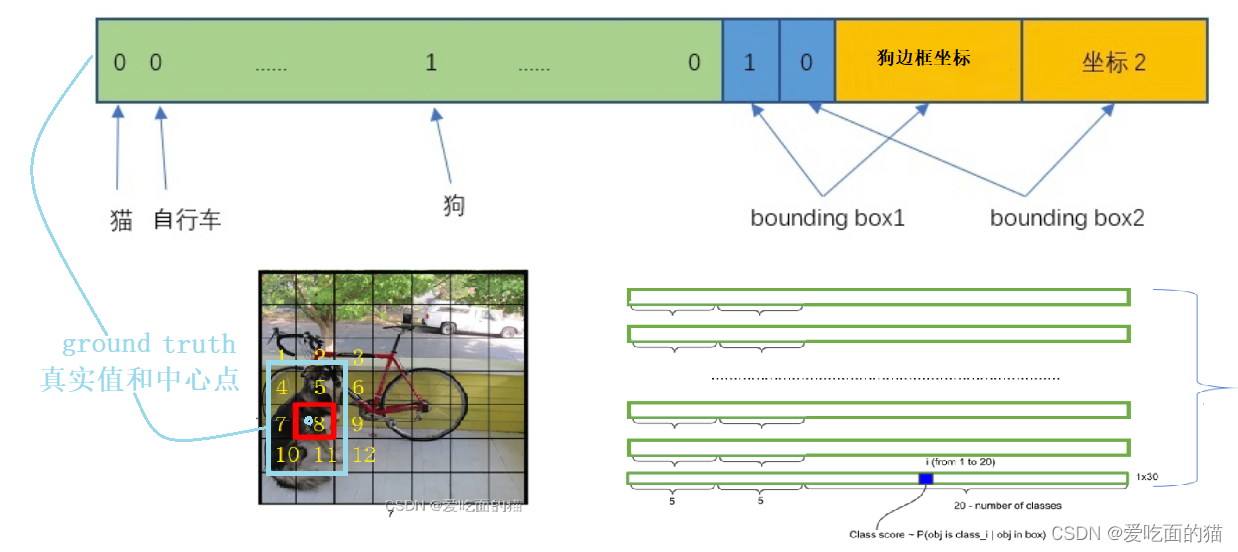
如果我们以每个网格的中心点为中心,每个网格单元都预测 2 个Bouding box,则上图中标注的1-12个单元格会有24个Bouding box,而这个 24 个 Bouding box 中,8 的单元格中心点距离目标的中心点最近,所以以 8 为单元格预测的两个 Bouding box 包含了(人工标记的)目标的中心点,此时,就用 8 这个单元格的两个 Bouding box 中的一个 Bouding box 负责检测。如下图:
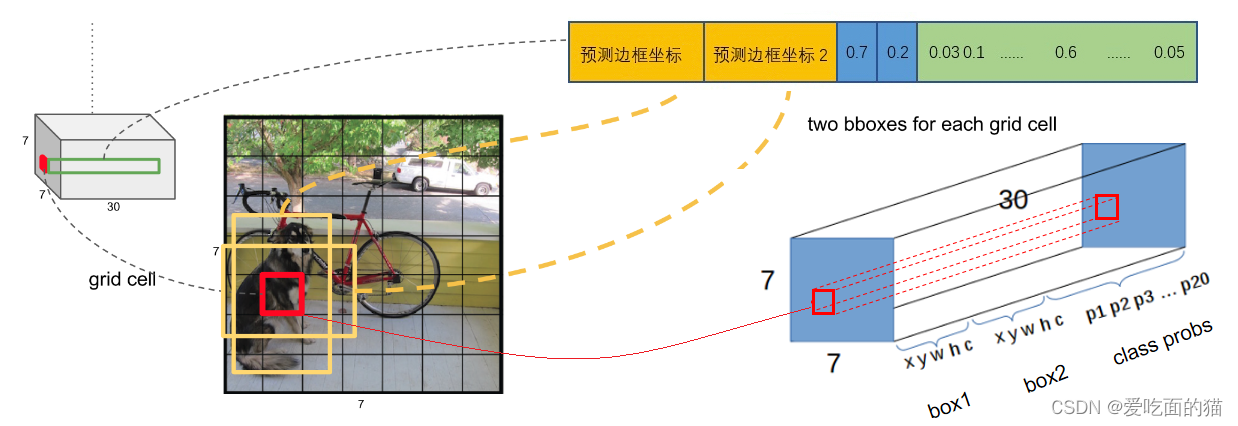
那么有两个 Bouding box ,我们用哪一个 Bouding box 来负责检测呢?此时需要通过置信度大小比较来确定。

根据上面定义的置信度公式:
首先 2 个 Bouding box 的4个值(位置坐标)分别与 GT(ground turth)进行IOU计算,哪个结果比较大,1x1x30中的概率就是对应的 Bouding box 的概率,也由此 Bouding box 负责检测。 例如 Bouding box1 和 Bouding box2 与GT进行IOU计算结果分别是1.2 和0.35,则概率就是对应的 Bouding box1 的概率,就由 Bouding box2 负责检测。
其次,使用 Bouding box1 的概率 和 计算IOU的结果相乘,就是置信度分数。

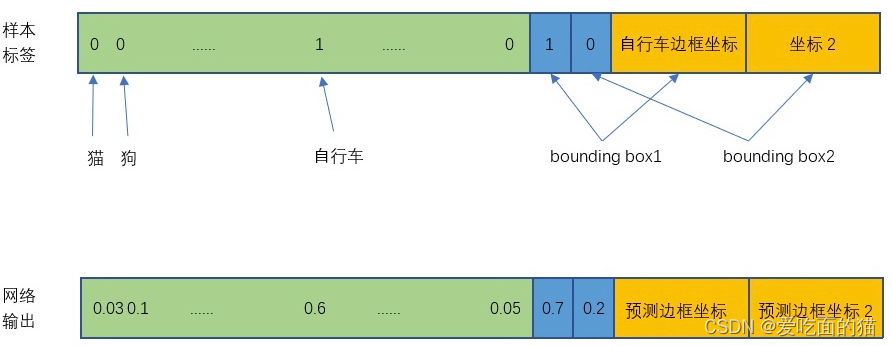
因为每个单元格有两个Bbox,上面评估计算是为了设置两个bbox的目标值,如果该单元格有物体,那么其中一个bbox的位置坐标与GT计算IOU值大的就是1。就由这个Bbox负责预测这个单元格的物体坐标。
下图是网络真实输出的置信度score和我们设置的目标值进行比较如下图对比。
02 预测位置大小-回归offset代替直接回归坐标
每个 bbox 包含5个预测值 (bx,by,bw,bh,bc),不直接回归中心点坐标数值,而是回归相对于格点左上角坐标的偏移量
-
(bx,by) 表示 box 的中心相对于 grid cell 原点的偏移值(原点, 即每个 grid cell 的 top-left 顶点, yolo 将之设置为(0, 0), bottom-right顶点设置为(1, 1), 所以(bx,by) 取值范围一定在(0,1)之内)。
-
(bw,bh) 为相对于整张图片的宽和高, 即使用图片的宽和高标准化自己, 使之取值范围也在(0, 1)之间。
预测相对于网格单元位置的位置坐标,这使得真实值的界限在0到1之间。由于我们限制位置预测,从而使网络因此参数化更容易学习,更加稳定。
举例理解:
如前所述,bx、by、bh、bw是相对于正在处理的网格单元计算而言的。下面通过一个例子来说明这一点。以包含汽车的网格为例,由于bx、by、bh、bw将仅相对于该网格计算。此网格的y标签将为(假设总共只有3个类别,分别是行人(c1)、汽车(c2)和摩托车(c3)):y=(1, bx, by, bh, bw, 0, 1, 0),由于这个网格中有一个对象为汽车,所以pc=1, c2=1,现在我们看看如何决定bx,by,bw,bh的取值,论文中分配给所有网格的坐标如下图所示:
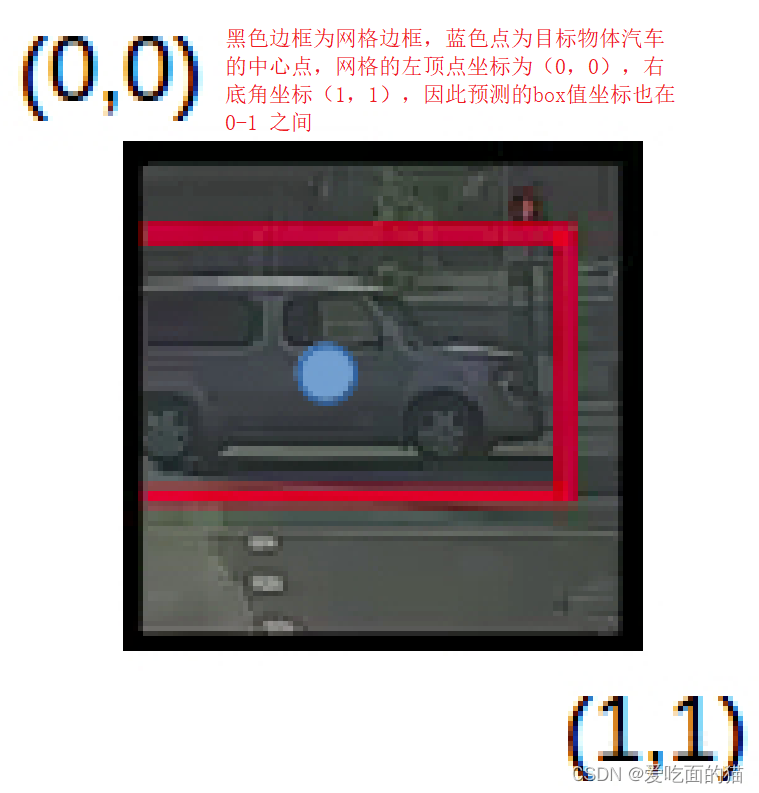
bh是边界框的高度与相应单元网格的高度之比,如图中假设bh=0.9,同理bw=0.5。所以最后预测的结果应该为:y=(1, 0.4, 0.3, 0.9, 0.5, 0, 1, 0)
注:bx和by将始终介于0和1之间,因为中心点始终位于网格内,而在边界框的尺寸大于网格尺寸的情况下,bh和bw可以大于1。同时关于 yolo 的预测的 bbox 中心坐标是相对于 grid cell 左上角的偏移值, 不是直接预测而是预测偏移值, 但是, 预测的 x, y 可能为负数啊, 这样 (x, y) 就不在该 cell 中了, yolo v2 通过 (sigmoid(x), sigmoid(y)) 来解决这个问题。
7、测试阶段
yolo 预测的不是类的概率而是类的条件概率,即条件为如果这个 cell 中包含物体(条件),那么这个物体是N 类前景中每一类的概率,即每个框有20个概率值,但是并不会直接使用这个值,这个概率可以理解为不属于任何一个bbox,而是属于这个单元格所预测的值。
最终: 测试的时候,条件类概率和每个框的预测的置信度值相乘得到每个框特定类别的置信度分数这些分数体现了该类出现在框中的概率以及预测框拟合目标的程度。
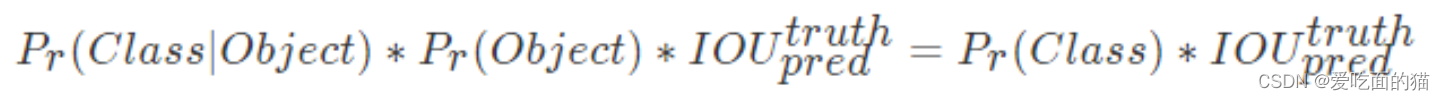
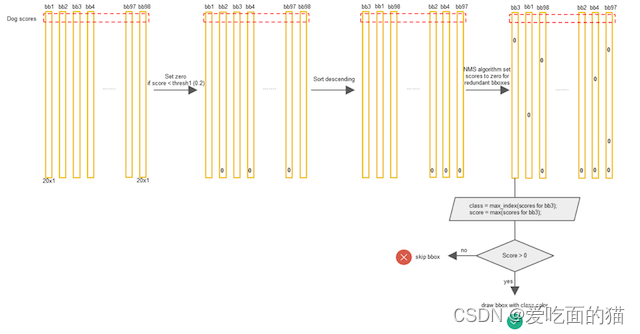
理解:这个乘积即 encode 了预测的 box 属于某一类的概率,也有该 box 准确度的信息。得到每个 box 的 class-specific confidence score 以后,设置阈值,滤掉得分低的 boxes,对保留的 boxes 进行 NMS 处理,就得到最终的检测结果。
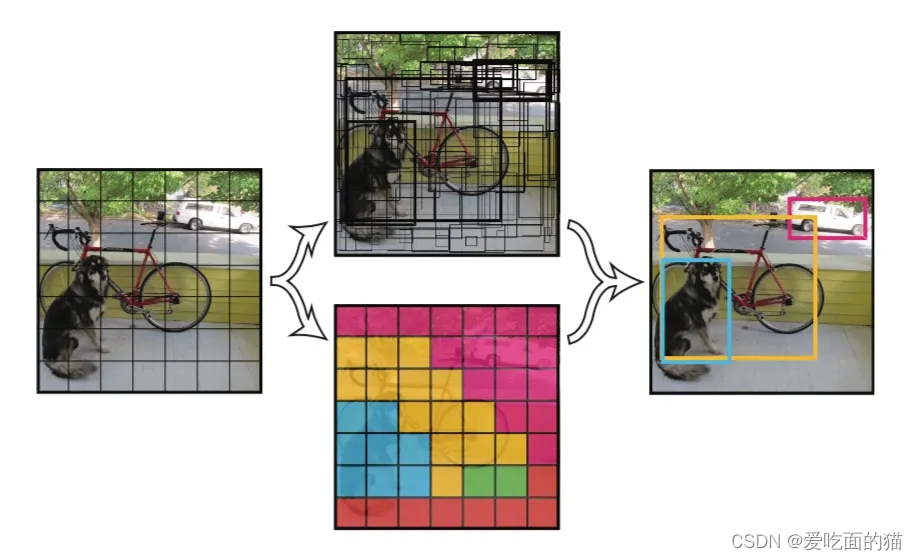
非最大抑制(NMS)
每个Bbox的Class-Specific Confidence Score以后,设置阈值,滤掉概率的低的bbox,对每个类别过滤IoU,就得到最终的检测结果
相关文章:
07 目标检测-YOLO的基本原理详解
一、YOLO的背景及分类模型 1、YOLO的背景 上图中是手机中的一个app,在任何场景下(工业场景,生活场景等等)都可以试试这个app和这个算法,这个app中间还有一个button,来调节app使用的模型的大小,更大的模型实时性差但精…...
)
每日一题 78子集(模板)
题目 78 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例 1: 输入:nums [1,2,3] 输出:[[],[1],[2]…...

OpenCV之形态学操作
形态学操作包含以下操作: 腐蚀 (Erosion)膨胀 (Dilation)开运算 (Opening)闭运算 (Closing)形态梯度 (Morphological Gradient)顶帽 (Top Hat)黑帽(Black Hat) 其中腐蚀和膨胀操作是最基本的操作,其他操作由这两个操作变换而来。 腐蚀 用一个结构元素…...
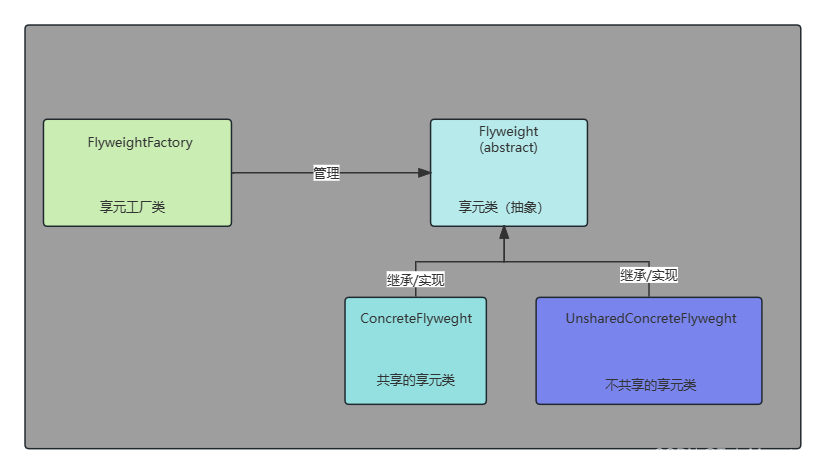
设计模式:享元模式
设计模式:享元模式 什么是享元模式 首先我们需要简单了解一下什么是享元模式。享元模式(Flyweight Pattern):主要用于减少创建对象的数量,以减少内存占用和提高性能。享元模式的重点就在这个享字,通过一些共享技术来减少对象的创建ÿ…...
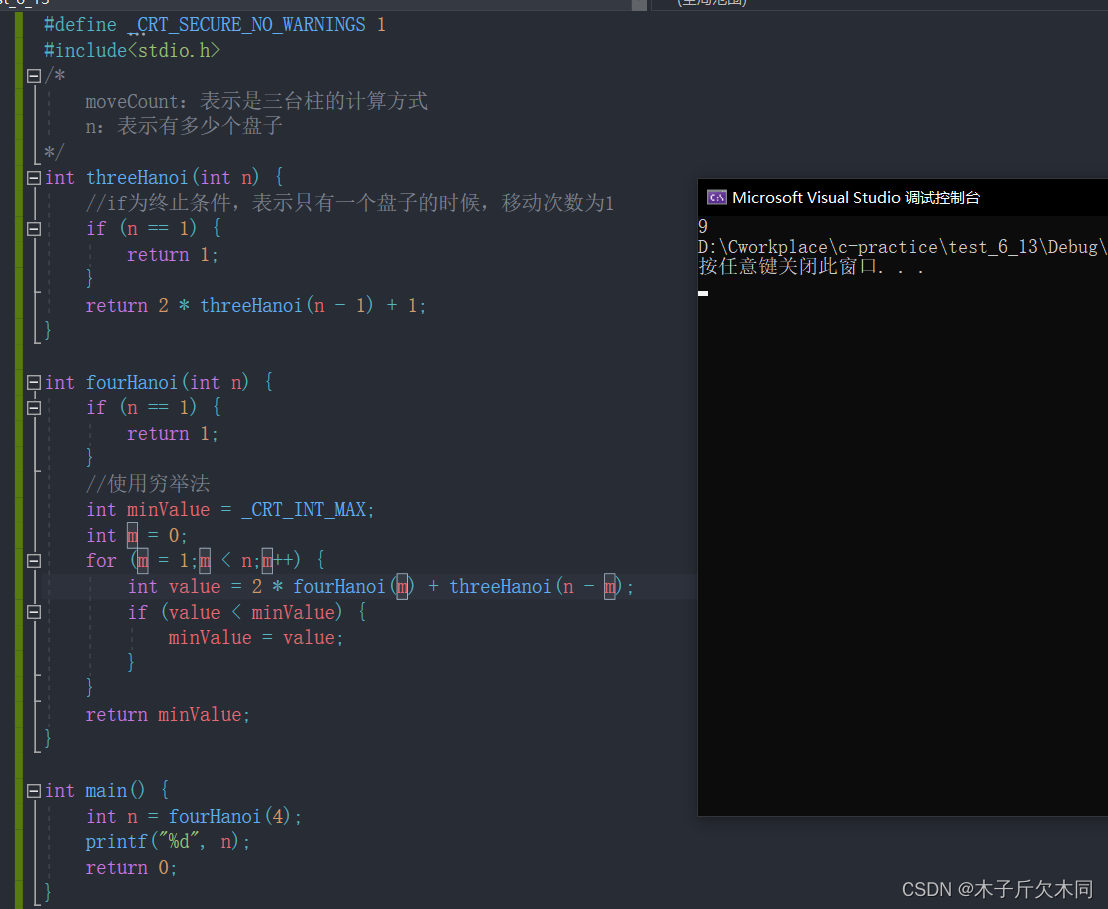
汉诺塔问题(包含了三台柱和四台柱)——C语言版本
目录 1. 什么是汉诺塔 2. 三座台柱的汉诺塔 2.1 思路 2.2 三座台柱的汉诺塔代码 3. 四座台柱的汉诺塔 3.1 思路 3.2 四座台柱的汉诺塔代码 1. 什么是汉诺塔 汉诺塔代码的功能:计算盘子的移动次数,由数学公式知,汉诺塔的盘子移动次数与…...
【实训项目】滴滴电竞APP
1.设计摘要 2013年国家体育总局决定成立一支由17人组成的电子竞技国家队,第四届亚室会中国电竞代表队 出战第四届亚洲室内和武道运动会。 2014年1月13日CCTV5《体育人间》播放英雄联盟皇族战队的纪录片。 在2015到2019年间,我国电竞战队取得的无数值得…...
C++核心编程--类篇
C核心编程 1.内存分区模型 C程序在执行时,将内存大方向分为4个区域 意义:不同区域存放数据,赋予不同的生命周期,更能灵活编程 代码区:存放函数体的二进制代码,由操作系统进行管理的全局区:存放…...

java中用feign远程调用注解FeignClient的时候不重写Encoder和Decoder怎么格式不对呢?
如果在使用 Feign 进行远程调用时,没有重写 Encoder 和 Decoder,但仍然遇到格式不对的问题,可能是由于以下原因之一: 服务端返回的数据格式与客户端期望的格式不匹配:Feign 默认使用基于 Jackson 的 Encoder 和 Decode…...

记录使用Docker Compose 部署《XAPI项目》遇道的问题及解决方案
《XAPI项目》:GitHub仓库(勿打🚫小破站一个) 这篇文档,主要内容是记录使用Docker Compose 部署《XAPI项目》遇道的问题及解决方案 目录 📚 本地MySQL数据如何导入到容器内的MySQL中❎ 解决报错:…...

腾讯云OCR实践 - 降低客服财务运营成本
一、 前言: 随着图片时代的飞速发展,大量的文字内容为了优化排版和表现效果,都采用了图片的形式发布和存储,这为内容的传播和安全性带来了很大的便利,需要做重复性劳动。 OCR文字扫描工具也逐渐的应运而生,…...

springboot+vue上传图片
这里是一个简单的示例,演示了如何在Spring Boot中从Vue.js上传图像: 1.前端Vue.js代码: <template><div><input type"file" change"handleFileUpload"><button click"uploadImage">…...

高压电缆护层接地环流及温度在线监测系统
高压电缆的金属护层是电缆的重要组成部分,当缆芯通过电流时,会在金属护层上产生环流,外护套的绝缘状态差、接地不良、金属护层接地方式不正确等等都会引起护套环流异常现象,严重威胁电缆运行安全。 当电缆金属护层环流出现异常时…...

无涯教程-JavaScript - IPMT函数
描述 IPMT函数根据定期,固定的还款额和固定的利率返回给定投资期限内的利息支付。 语法 IPMT (rate, per, nper, pv, [fv], [type])争论 Argument描述Required/OptionalRateThe interest rate per period.RequiredPerThe period for which you want to find the interest a…...

【EI会议征稿】第三届机械自动化与电子信息工程国际学术会议(MAEIE 2023)
第三届机械自动化与电子信息工程国际学术会议(MAEIE 2023) 第三届机械自动化与电子信息工程国际学术会议(MAEIE 2023)将于2023年12月15-17日在江苏南京举行。本会议通过与业内众多平台、社会各团体协力,聚集机械自动…...

手写实现LRN局部响应归一化算子
1、重写算子的需求 芯片推理过程中遇到很多算子计算结果不对的情况,原因是封装的算子会在某些特殊情况下计算超限,比如输入shape特别大或者数值特别大时,LRN算子计算会出现NAN值,所以需要重写算子。先对输入数据做一个预处理&…...

朗思科技数字员工通过统信桌面操作系统兼容性互认认证
近日,朗思科技数字员工与统信桌面操作系统V20进行了兼容互认,针对上述产品的功能、兼容性方面,通过共同严格测试表明——朗思科技数字员工在统信桌面操作系统 V20上整体运行稳定,满足功能及兼容性测试要求。 北京朗思智能科技有限…...
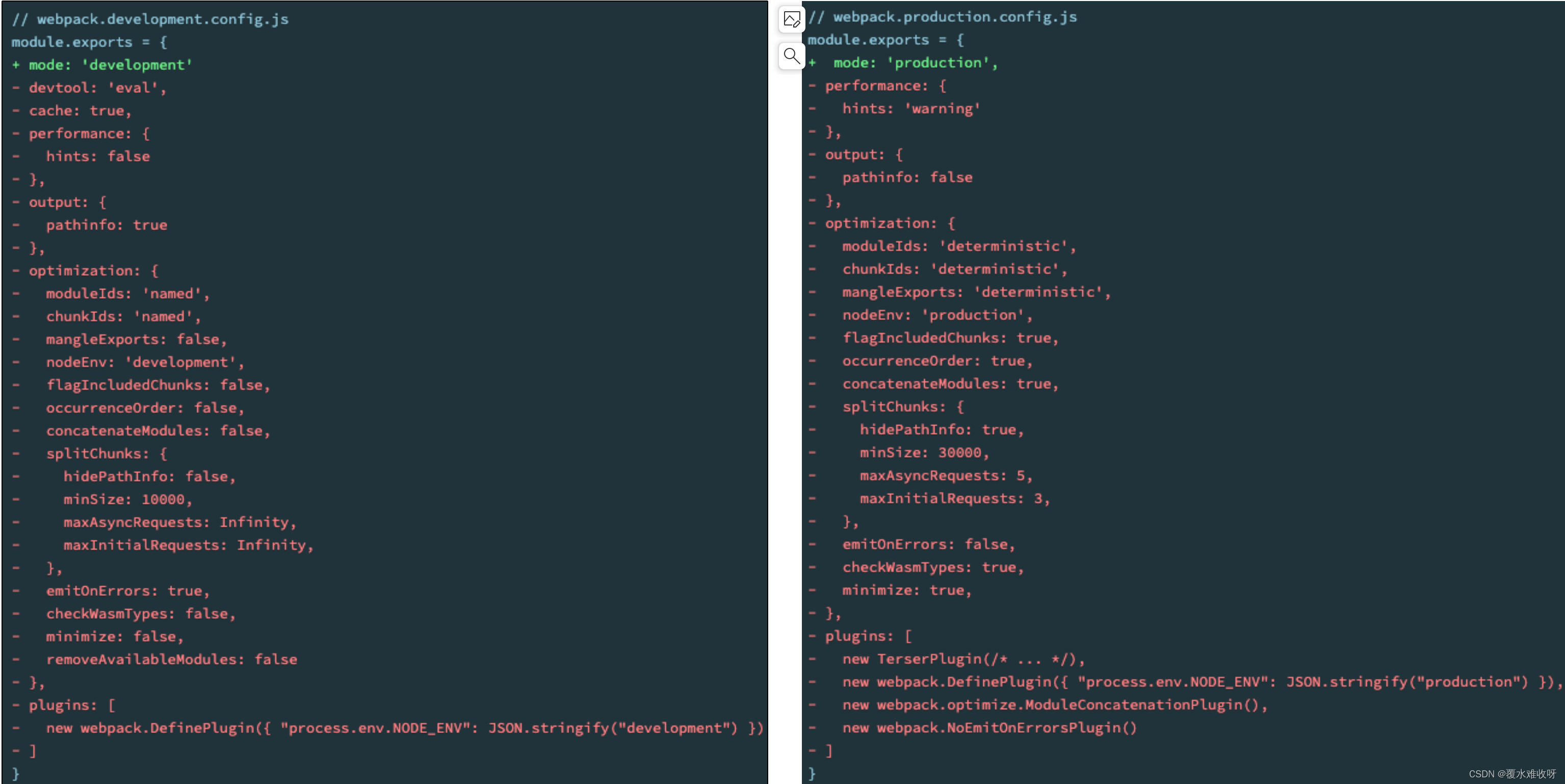
十六、Webpack常见的插件和模式
一、认识插件Plugin Webpack的另一个核心是Plugin,官方有这样一段对Plugin的描述: While loaders are used to transform certain types of modules, plugins can be leveraged to perform a wider range of tasks like bundle optimization, asset m…...

ChatGPT新增超强插件:文本直接生成视频、海报,支持自定义修改!
全球著名在线设计平台Canva,在ChatGPT Plus(GPT-4)上推出了插件功能,用户通过文本提示,几秒钟就能生成演示文稿、PPT插图、电子书封面、宴会邀请函等各种精美设计海报,同时支持生成视频。 该插件最强大的功…...

亚像素边缘提取的例子
求帮忙下载: 1.http://download.csdn.net/detail/pkma75/925394 pkma75 资源积分:1分 备注:pdf格式,用曲线拟合的方法计算亚像素,编程易实现,具有较强的实用价值 2.http://download.csdn.net/detail/kua…...

Wayland:推动Linux桌面进入下一代图形显示时代
文章首发地址 Wayland是Linux系统下的一种图形显示协议,旨在替代X Window System(X11)作为Linux桌面环境的图形显示服务。下面是对Wayland的详细解释: 背景: 传统的Linux桌面环境使用X Window System(X11&…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...