MapReduce YARN 的部署
1、部署说明
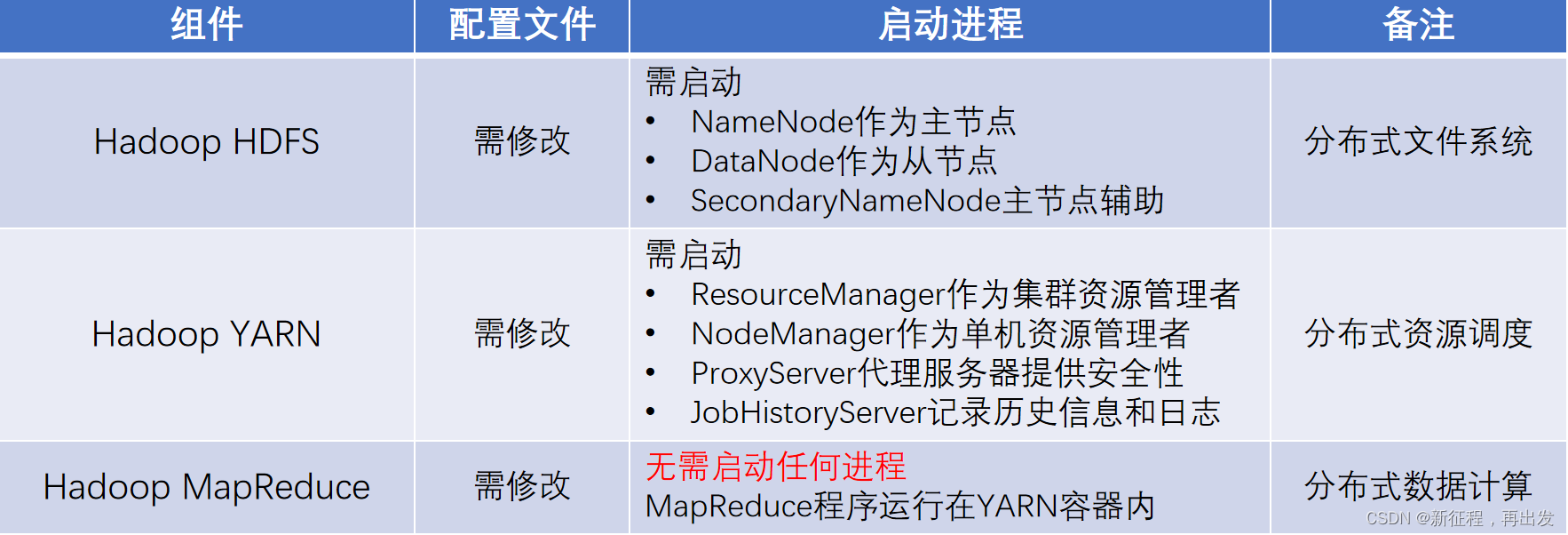
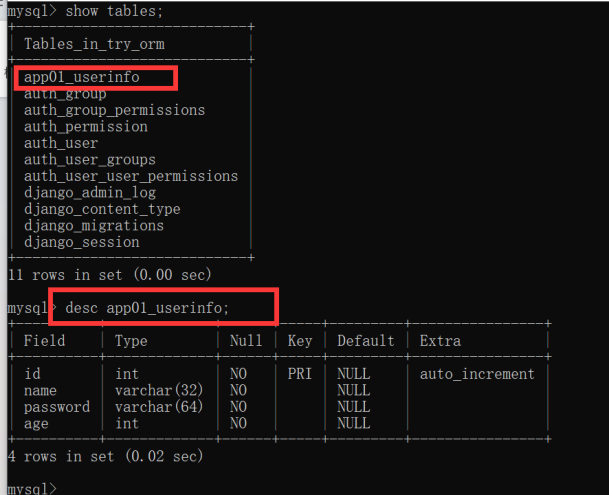
Hadoop HDFS分布式文件系统,我们会启动:
- NameNode进程作为管理节点
- DataNode进程作为工作节点
- SecondaryNamenode作为辅助
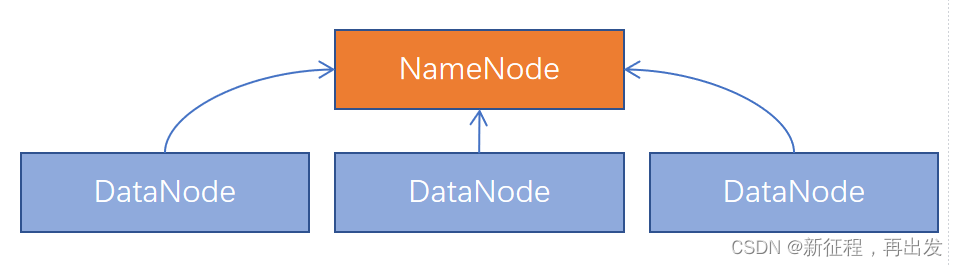
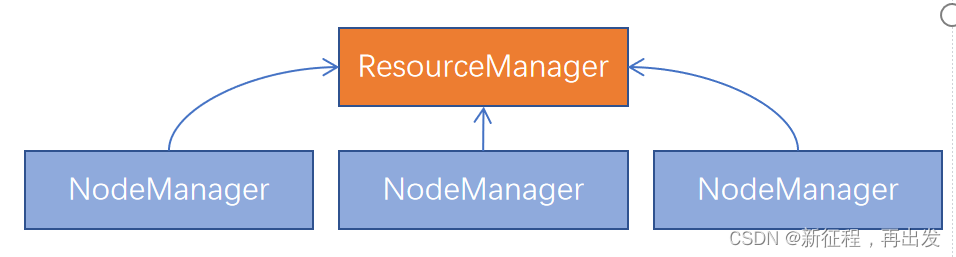
同理,Hadoop YARN分布式资源调度,会启动: - ResourceManager进程作为管理节点
- NodeManager进程作为工作节点
- ProxyServer、JobHistoryServer这两个辅助节点
MapReduce运行在YARN容器内,无需启动独立进程。
所以关于MapReduce和YARN的部署,其实就是2件事情:
- 关于MapReduce: 修改相关配置文件,但是没有进程可以启动。
- 关于YARN: 修改相关配置文件, 并启动ResourceManager、NodeManager进程以及辅助进程(代理服务器、历史服务器)。
2、部署
2.1、MapReduce配置文件
2.1.1、配置mapred-env.sh文件
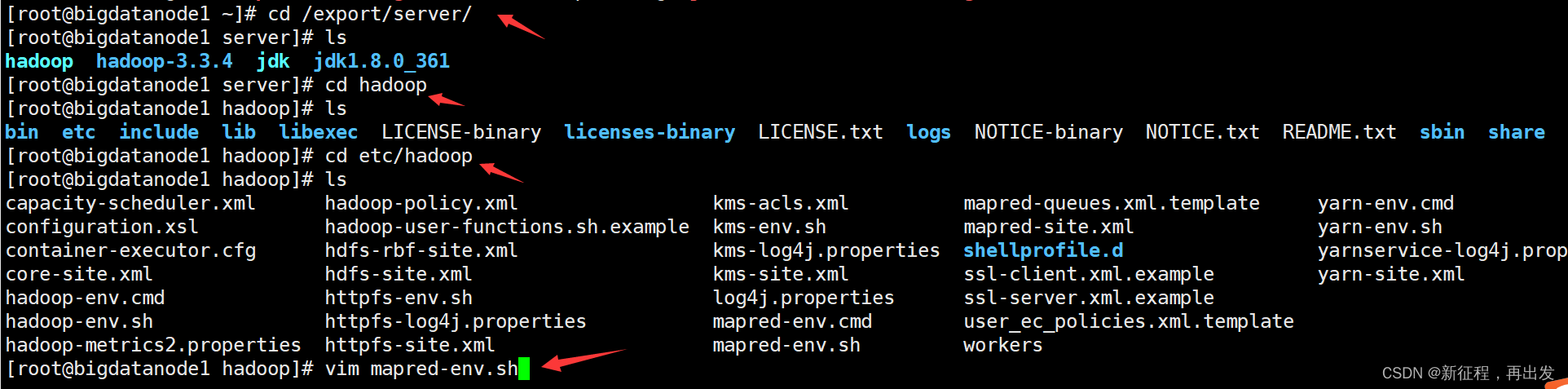
在 $HADOOP_HOME/etc/hadoop 文件夹内,修改mapred-env.sh文件
vim mapred-env.sh
添加如下环境变量
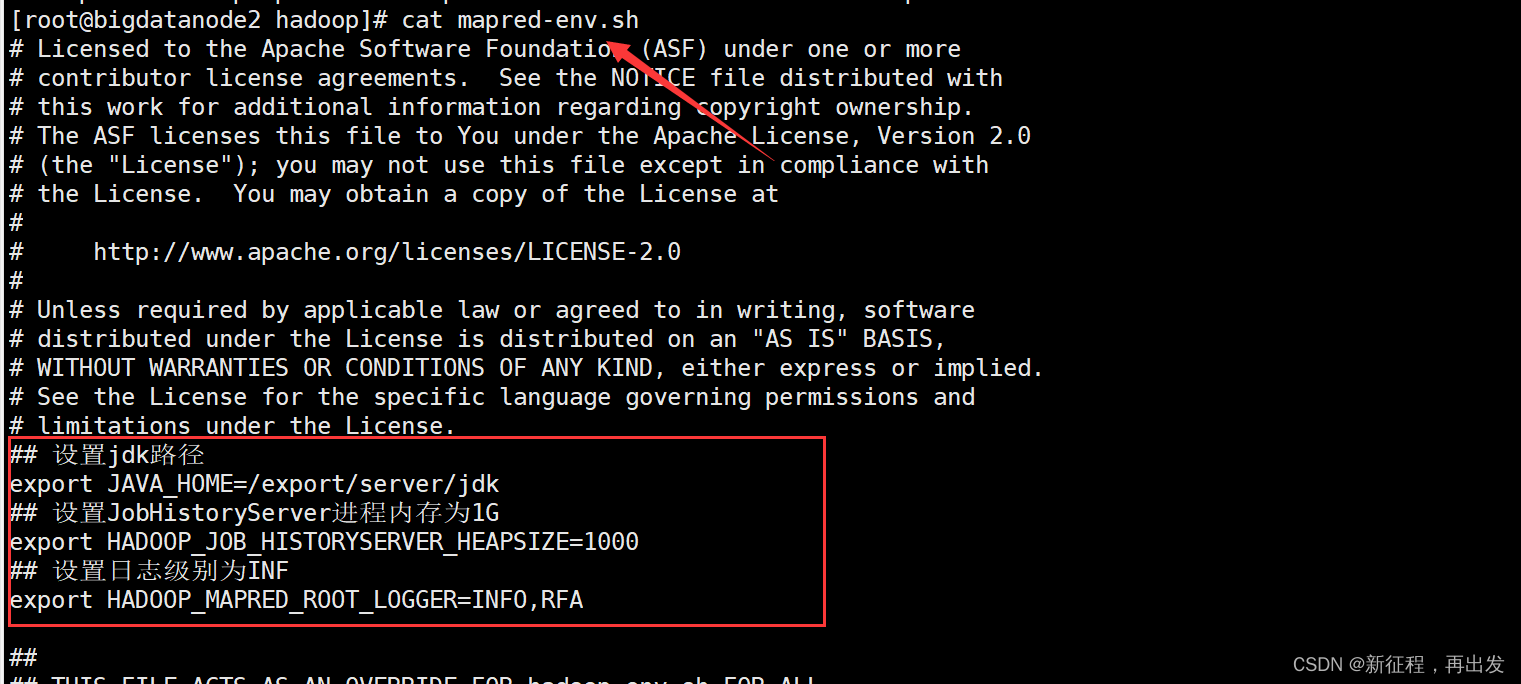
## 设置jdk路径
export JAVA_HOME=/export/server/jdk
## 设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
## 设置日志级别为INF
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
2.1.2、配置mapred-site.xml文件
mapred-site.xml文件,添加如下配置信息
vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description></description></property><property><name>mapreduce.jobhistory.address</name><value>bigdatanode1:10020</value><description></description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>bigdatanode1:19888</value><description></description></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description></description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description></description></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property>
</configuration>
2.2、YARN配置文件
2.2.1、配置yarn-env.sh文件
在 $HADOOP_HOME/etc/hadoop 文件夹内,修改:
yarn-env.sh文件
vim yarn-env.sh
yarn-env.sh文件,添加如下4行环境变量内容:
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
2.2.2、配置yarn-site.xml文件
yarn-site.xml文件,配置如下
<property><name>yarn.log.server.url</name><value>http://bigdatanode1:19888/jobhistory/logs</value><description></description>
</property><property><name>yarn.web-proxy.address</name><value>bigdatanode1:8089</value><description>proxy server hostname and port</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>Configuration to enable or disable log aggregation</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>Configuration to enable or disable log aggregation</description></property><property><name>yarn.resourcemanager.hostname</name><value>bigdatanode1</value><description></description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description></description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>Comma-separated list of paths on the local filesystem where logs are written.</description></property><property><name>yarn.nodemanager.log.retain-seconds</name><value>10800</value><description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>Shuffle service that needs to be set for Map Reduce applications.</description></property>
2.3、分发到node2,node3节点
MapReduce和YARN的配置文件修改好后,需要分发到其它的服务器节点中。
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml bigdatanode2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml bigdatanode3:`pwd`/
查看其他节点是否分发成功
2.4、集群启动命令介绍
2.4.1、介绍
常用的进程启动命令如下:
-
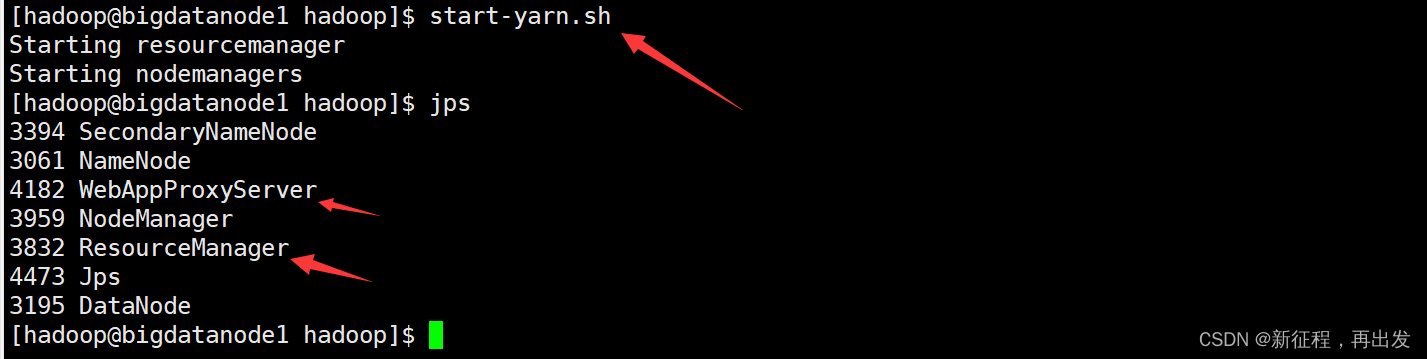
一键启动YARN集群: $HADOOP_HOME/sbin/start-yarn.sh
- 会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
- 会基于workers文件配置的主机启动NodeManager
-
一键停止YARN集群: $HADOOP_HOME/sbin/stop-yarn.sh
-
在当前机器,单独启动或停止进程
- $HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
- start和stop决定启动和停止
- 可控制resourcemanager、nodemanager、proxyserver三种进程
-
历史服务器启动和停止
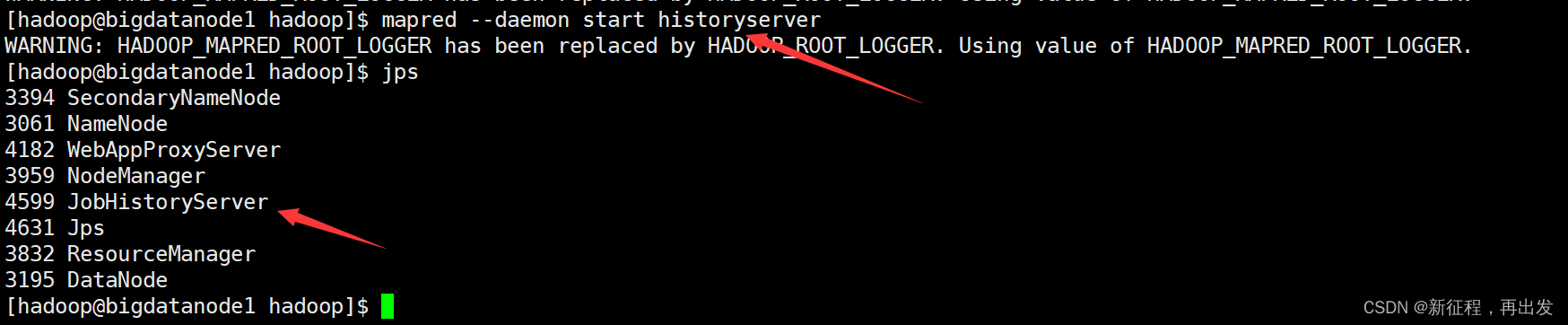
- $HADOOP_HOME/bin/mapred --daemon start|stop historyserver
2.4.2、启动
在node1服务器,以hadoop用户执行
- 首先执行
start-yarn.sh
- 其次执行
mapred --daemon start historyserver
- 一键停止
stop-yarn.sh
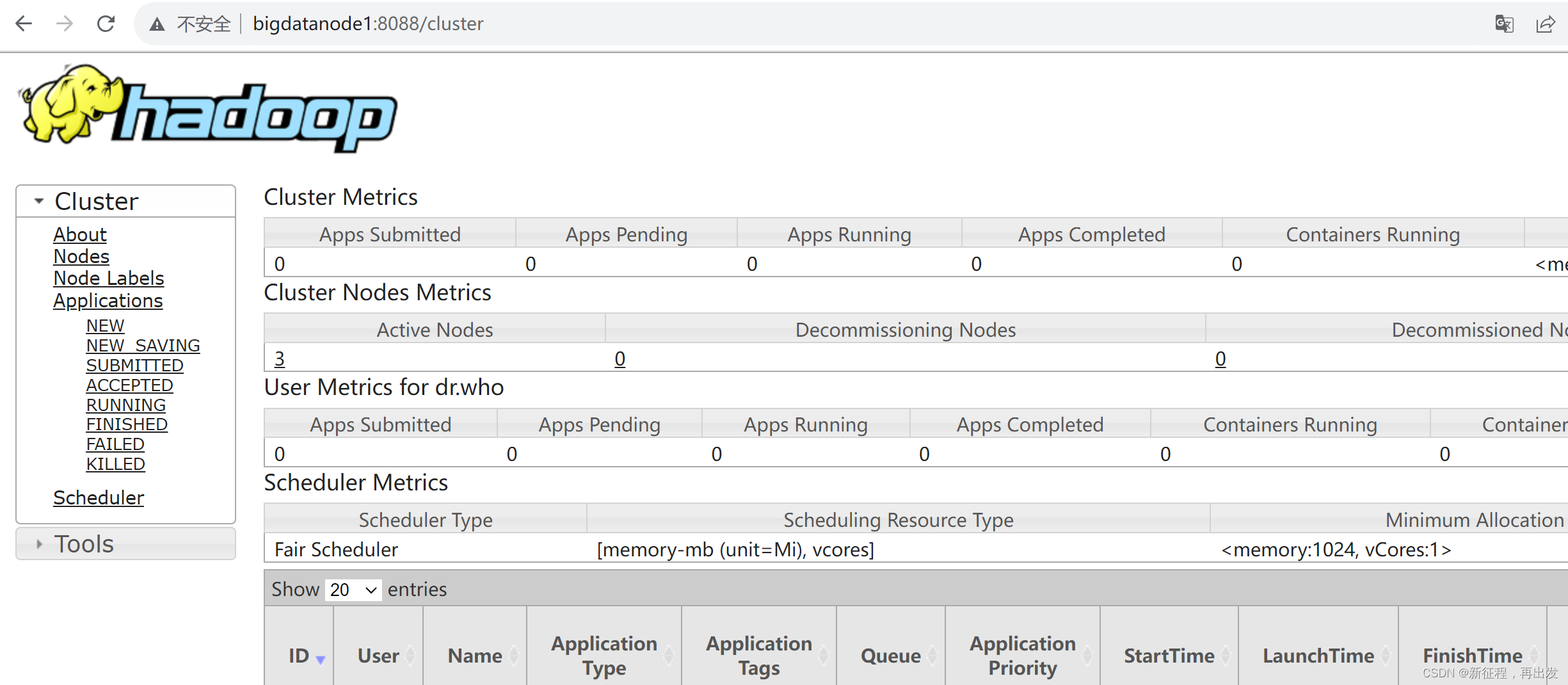
2.4.3、查看YARN的WEB UI页面
打开 http://bigdatanode1:8088 即可看到YARN集群的监控页面(ResourceManager的WEB UI)
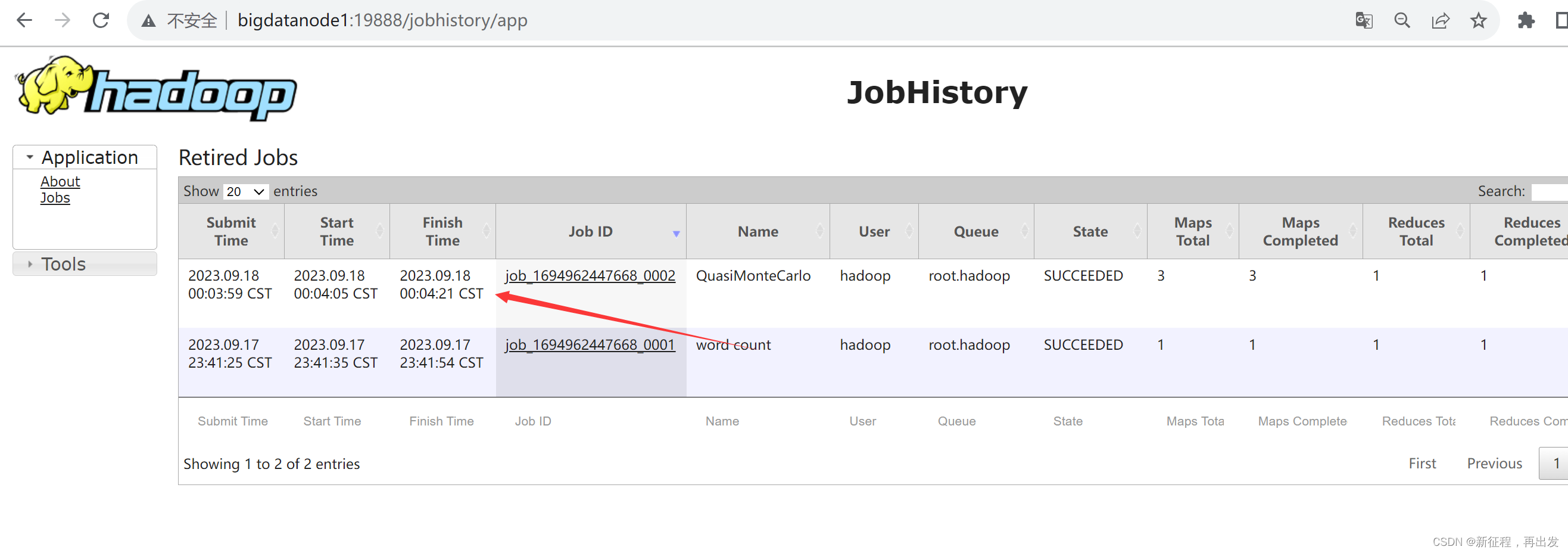
3、提交MapReduce任务到YARN执行
3.1、提交MapReduce程序至YARN运行
在部署并成功启动YARN集群后,我们就可以在YARN上运行各类应用程序了。
YARN作为资源调度管控框架,其本身提供资源供许多程序运行,常见的有:
- MapReduce程序
- Spark程序
- Flink程序
Hadoop官方内置了一些预置的MapReduce程序代码,我们无需编程,只需要通过命令即可使用。
常用的有2个MapReduce内置程序:
- wordcount:单词计数程序。
统计指定文件内各个单词出现的次数。 - pi:求圆周率
通过蒙特卡罗算法(统计模拟法)求圆周率。
这些内置的示例MapReduce程序代码,都在:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 这个文件内。
可以通过 hadoop jar 命令来运行它,提交MapReduce程序到YARN中。
语法: hadoop jar 程序文件 java类名 [程序参数] … [程序参数]
3.2、提交wordcount示例程序
3.2.1、单词计数示例程序
单词计数示例程序的功能很简单:
- 给定数据输入的路径(HDFS)、给定结果输出的路径(HDFS)
- 将输入路径内的数据中的单词进行计数,将结果写到输出路径
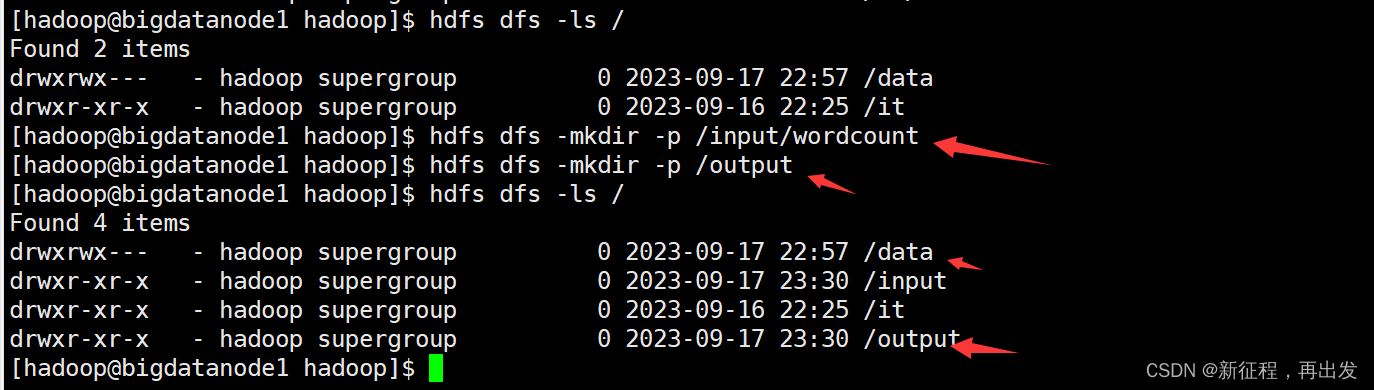
我们可以准备一份数据文件,并上传到HDFS中。
- 创建两个文件夹
hdfs dfs -mkdir -p /input/wordcount
hdfs dfs -mkdir -p /output
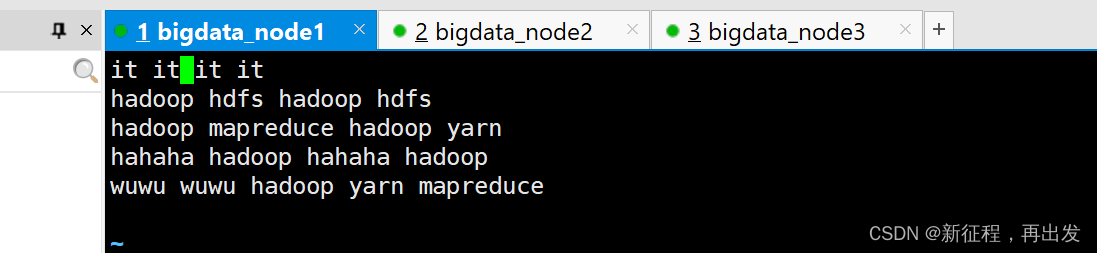
- 创建一个文件,输入一些内容
vim words.txt
- 上传到/input/wordcount/
hdfs dfs -put words.txt /input/wordcount/

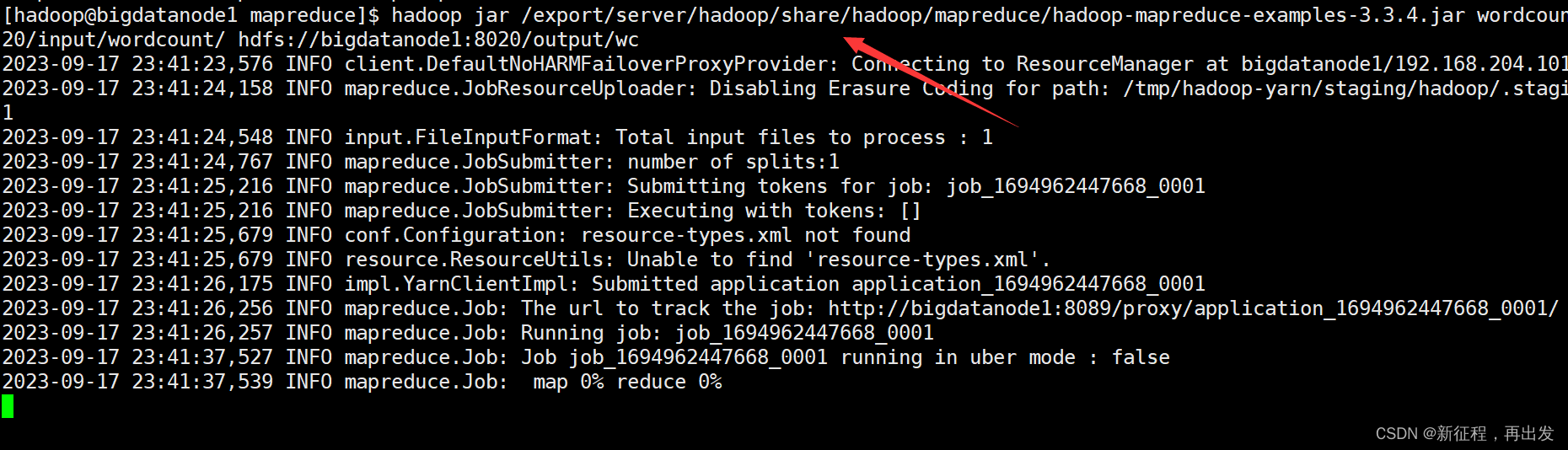
- 执行如下命令,提交示例MapReduce程序WordCount到YARN中执行
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount hdfs://bigdatanode1:8020/input/wordcount/ hdfs://bigdatanode1:8020/output/wc
- 执行完成后,可以查看HDFS上的输出结果

hdfs dfs -cat /output/wc/part-r-00000
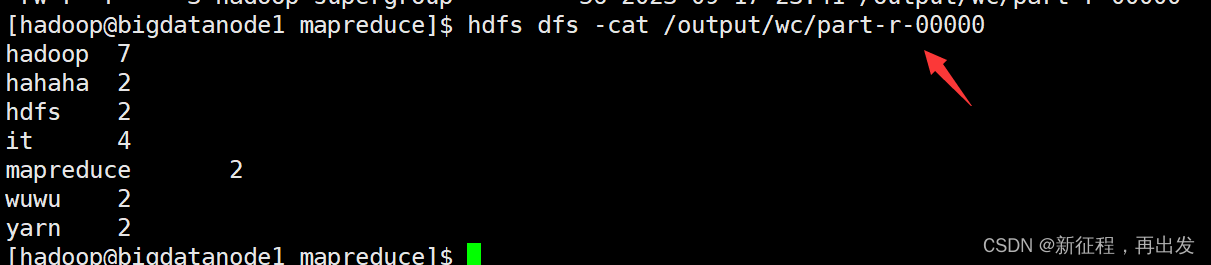
- _SUCCESS文件是标记文件,表示运行成功,本身是空文件
- part-r-00000,是结果文件,结果存储在以part开头的文件中
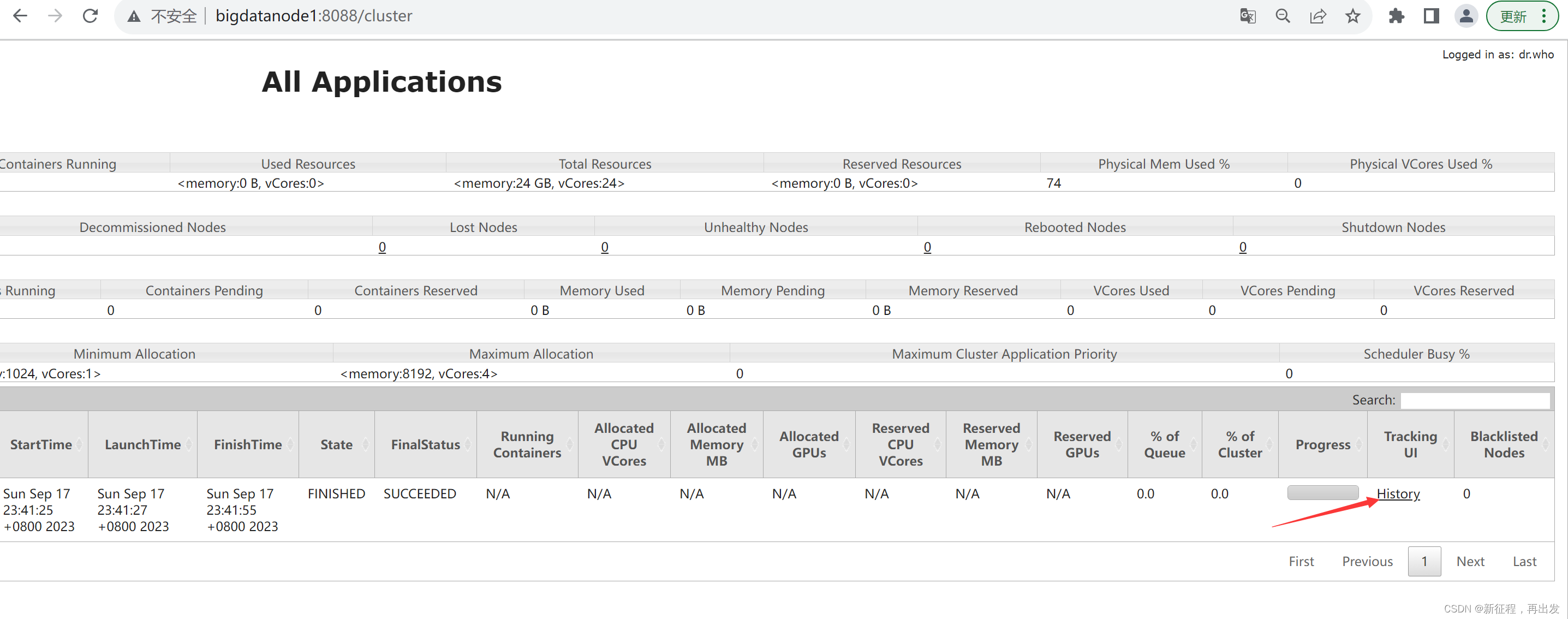
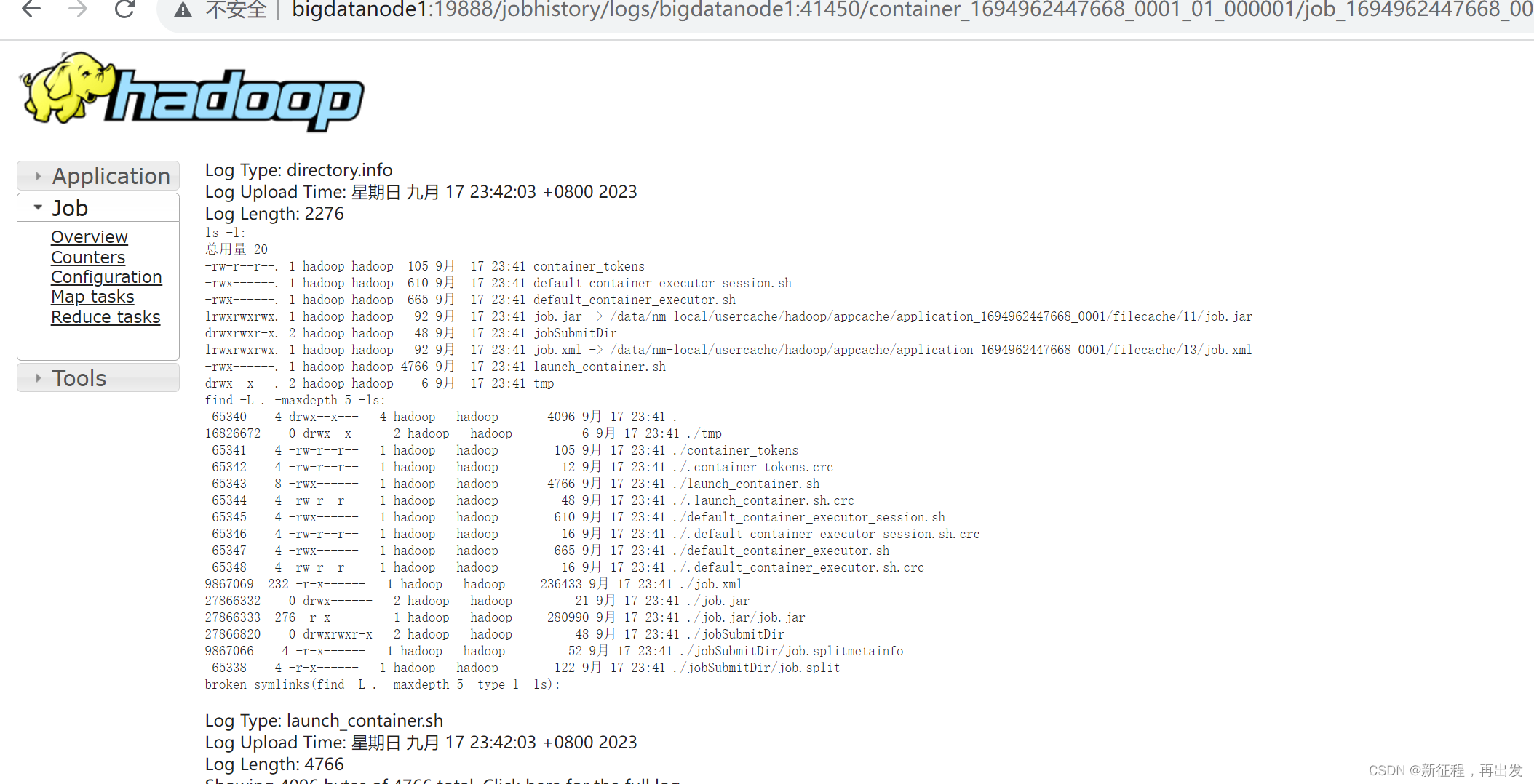
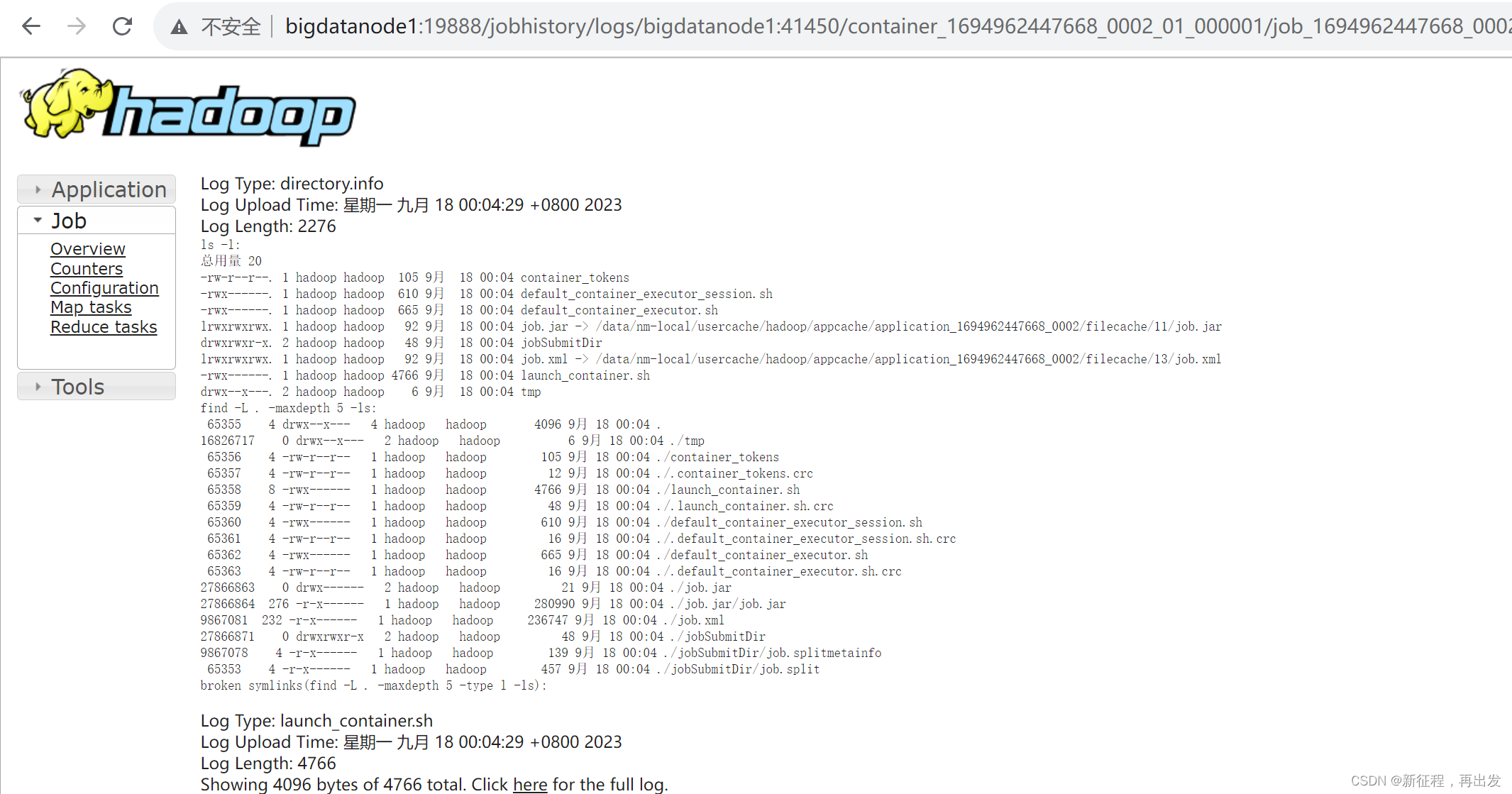
3.2.2、查看运行日志
此功能基于:
- 配置文件中配置了日志聚合功能,并设置了历史服务器

- 启动了代理服务器和历史服务器
- 历史服务器进程会将日志收集整理,形成可以查看的网页内容供我们查看。
3.2.3、提交求圆周率示例程序
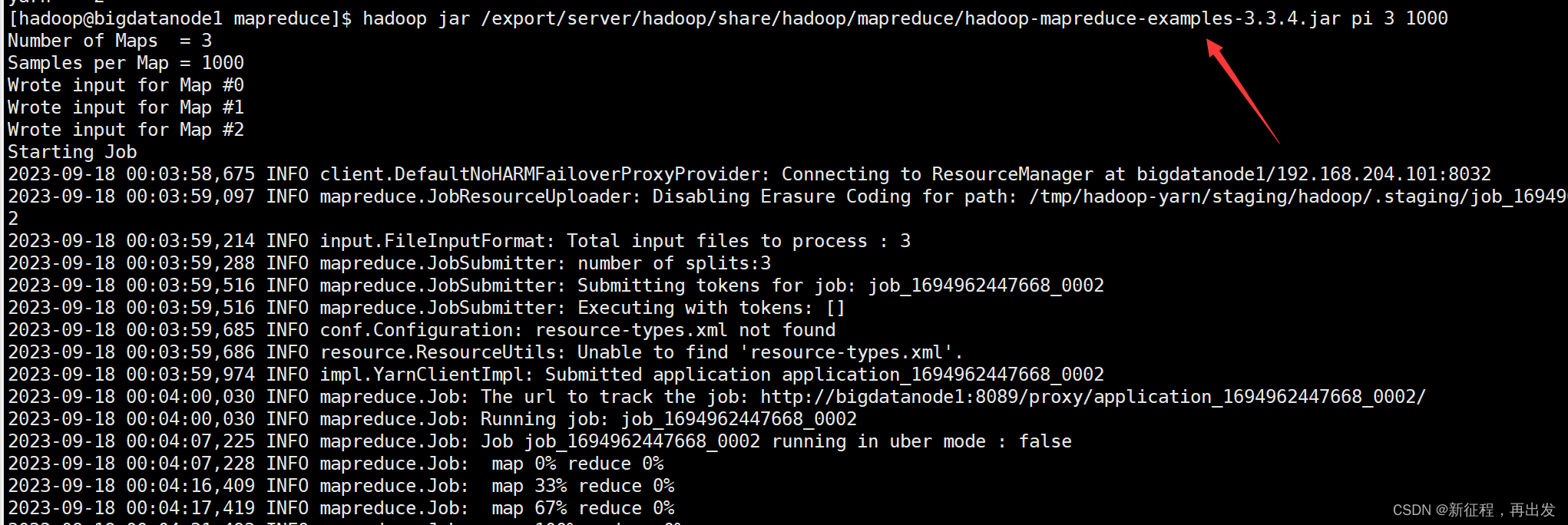
可以执行如下命令,使用蒙特卡罗算法模拟计算求PI(圆周率)
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 3 1000
- 参数pi表示要运行的Java类,这里表示运行jar包中的求pi程序
- 参数3,表示设置几个map任务
- 参数1000,表示模拟求PI的样本数(越大求的PI越准确,但是速度越慢)

3.3、蒙特卡罗算法求PI的基础原理
Monte Carlo蒙特卡罗算法(统计模拟法)
Monte Carlo算法的基本思想是: 以模拟的”实验”形式、以大量随机样本的统计形式,来得到问题的求解。
比如,求圆周率,以数学的方式是非常复杂的,但是我们可以以简单的形式去求解:

示例代码
import java.util.Random; public class MonteCarloPi { public static void main(String[] args) { int totalPoints = 1000000; // 总共投点次数 int insidePoints = 0; // 落在圆内的点数 Random rand = new Random(); for (int i = 0; i < totalPoints; i++) { // 在-1到1之间随机生成x, y值 double x = 2.0 * rand.nextDouble() - 1.0; double y = 2.0 * rand.nextDouble() - 1.0; // 判断该点是否在单位圆内(圆心在(0, 0),半径为1) if (x * x + y * y <= 1.0) { insidePoints++; } } // 使用蒙特卡罗方法估算π的值,公式来源于圆的面积公式πr^2,这里r=1,所以π=4*(圆内点数/总点数) double piEstimate = 4.0 * insidePoints / totalPoints; System.out.println("π的估计值为: " + piEstimate); }
}
结束!!!!!!!
hy:37
人最大的痛苦,就是无法跨越“知道”和“做到”的鸿沟。
相关文章:
MapReduce YARN 的部署
1、部署说明 Hadoop HDFS分布式文件系统,我们会启动: NameNode进程作为管理节点DataNode进程作为工作节点SecondaryNamenode作为辅助 同理,Hadoop YARN分布式资源调度,会启动:ResourceManager进程作为管理节点NodeM…...

vue 引入zTree
下载js包解压后找个地方放文件夹内 引入 import "/common/zTree/js/jquery-1.4.4.min" import "/common/zTree/js/jquery.ztree.core.min.js" import "/common/zTree/js/jquery.ztree.excheck.min.js" import "/common/zTree/css/metroSt…...

链队列的基本操作(带头结点,不带头结点)
结构体 typedef struct linknode{int data;struct linknode* next;后继指针 }linknode; typedef struct {linknode* front, * rear;//队头队尾指针 }linkquene; 初始化队列(带头结点) int initquene(linkquene* q)//初始化队列 {q->front q->r…...

深入学习 Redis Cluster - 基于 Docker、DockerCompose 搭建 Redis 集群,处理故障、扩容方案
目录 一、基于 Docker、DockerCompose 搭建 Redis 集群 1.1、前言 1.2、编写 shell 脚本 1.3、执行 shell 脚本,创建集群配置文件 1.4、编写 docker-compose.yml 文件 1.5、启动容器 1.6、构建集群 1.7、使用集群 1.8、如果集群中,有节点挂了&am…...
笔记)
C现代方法(第3、4章)笔记
文章目录 C现代方法笔记(chapter3&4)第3章 格式化输入/输出3.1 printf函数3.1.1 转换说明3.1.2 转义序列 3.2 scanf函数3.2.1 scanf函数的工作方法3.2.2 格式串中的普通字符3.2.3 易混淆的printf函数和scanf函数 问与答编程题 第4章 表达式4.1 算术运…...
R语言绘制染色体变异位置分布图,RIdeogram包
变异位点染色体分布图 今天分享的内容是通过RIdeogram包绘制染色体位点分布图,并介绍一种展示差异位点的方法。 在遗传学研究中,通过测序等方式获得了基因组上某些位置的基因型信息。 如下表,第一列是变异位点的ID,第二列是染色体…...
每天10个小知识点)
Vue知识系列(7)每天10个小知识点
目录 系列文章目录Vue知识系列(1)每天10个小知识点Vue知识系列(2)每天10个小知识点Vue知识系列(3)每天10个小知识点Vue知识系列(4)每天10个小知识点Vue知识系列(5&#x…...
5分钟就能实现的API监控,有什么理由不做呢?
API深度影响着你的应用 今天的数字应用世界其实是一个以API为中心的世界,我们只是没有意识到这些API的重要性。比如在电子商务交易、社交媒体等对交互高度依赖的领域,可以说API决定了应用的质量一点也不为过。 以京东为例,用户的每一次操作背…...
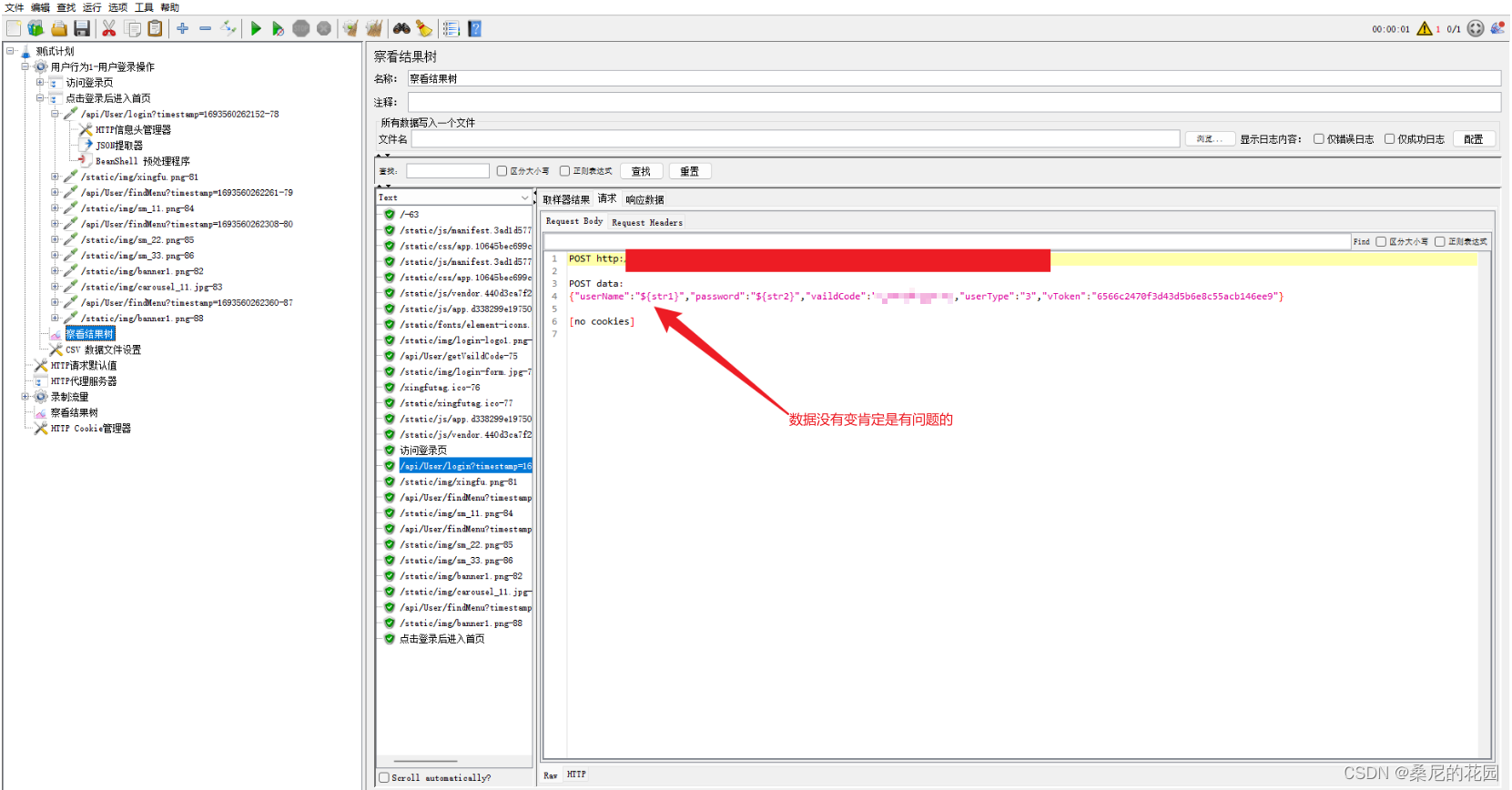
Jmeter引入外部jar包以满足加密数据的Post请求
目录 一、把项目打成jar包 1、创建一个Maven项目,并保证可以正常运行。 2、把工具类放置项目中,确保无报错且能够正常使用。 3、打包 4、验证 jar包是否有效 5、你想打多个工具类的包 二、在jmeter中使用 1、把jar包放到jmeter仓库下,…...

了解冒泡排序
package com.mypackage.array;import java.util.Arrays;public class Demo07 {public static void main(String[] args) {int[] a {3,2,6,7,4,5,6,34,56,7};int[] sort1 sort1(a); //调用我们自己写的排序方法后,返回一个排序后的数组System.out.println(Array…...
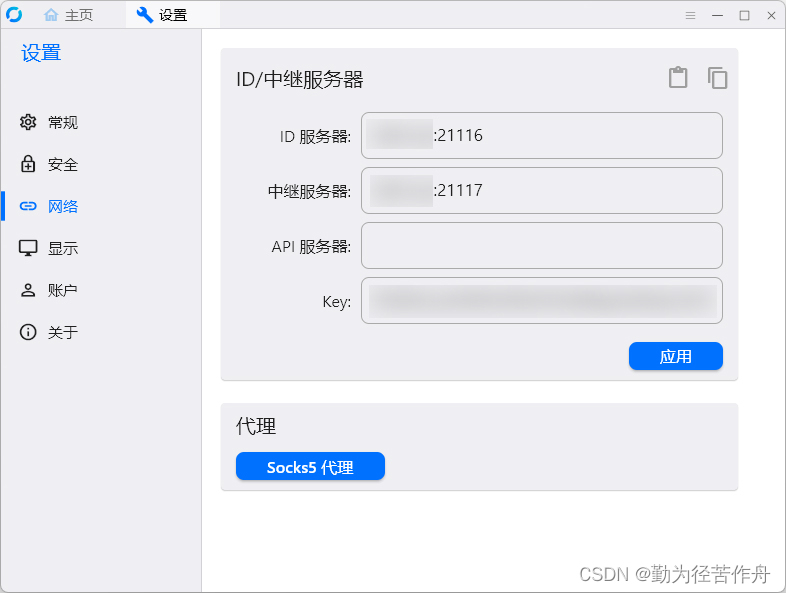
群辉 Synology NAS Docker 安装 RustDesk-server 自建服务器只要一个容器
from https://blog.zhjh.top/archives/M8nBI5tjcxQe31DhiXqxy 简介 之前按照网上的教程,rustdesk-server 需要安装两个容器,最近想升级下版本,发现有一个新镜像 rustdesk-server-s6 可以只安装一个容器。 The S6-overlay acts as a supervi…...
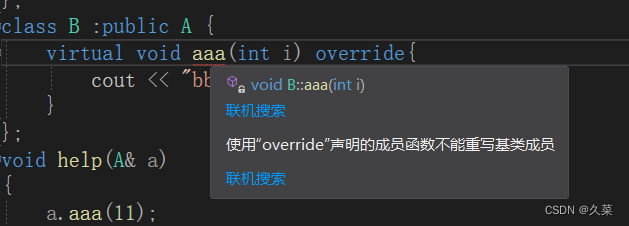
为什么要有override
多态一定会成功吗 因为逻辑是用户编写的,那么肯定会有遗漏的地方,那就要规则来限制。就比如多态,都知道条件之一是子类重写了父类的虚函数,但是如果子类没有严格遵守这个规则,就无法达到目的。就比如这个代码…...

Linux界的老古董
Slackware 是由 Patrick Volkerding 制作的 Linux 发行版,从 1993 年发布至今也一直在 Patrick 带领下进行维护。7 月 17 日,Slackware 才刚刚过完它 24 岁的生日,看似年纪轻轻的它,已然是 Linux 最古老的发行版。 Slackware 的发…...

安卓逆向 - Xposed入门教程
一、引言 Xposed框架,是Android中Hook技术的一个著名的框架,拥有非常丰富的模块,给我们分析app提供了极大的便利,Xposed框架是开源的。最高支持到Android 8(重要) github地址:GitHub - rovo89…...

【嵌入式】2024届校招岗位汇总
公司岗位博世嵌入式自动化测试工程师博世嵌入式开发(软件刷写及启动)工程师博世Linux/C软件工程师博世自动驾驶软件开发工程师博世嵌入式软件工程师(BSP)博世嵌入式电子工程师 (BMS&电源)博世物联网嵌入式开发工程师 …...
Docker搭建ELK日志采集服务及Kibana可视化图表展示
架构 ES docker network create elkmkdir -p /opt/ELK/es/datachmod 777 /opt/ELK/esdocker run -d --name elasticsearch --net elk -p 9200:9200 -p 9300:9300 -e "discovery.typesingle-node" -v /opt/ELK/es/plugins:/usr/share/elasticsearch/plugins -v /opt/…...

SpringBoot结合MyBatis实现多数据源配置
SpringBoot结合MyBatis实现多数据源配置 一、前提条件 1.1、环境准备 SpringBoot框架实现多数据源操作,首先需要搭建Mybatis的运行环境。 由于是多数据源,也就是要有多个数据库,所以,我们创建两个测试数据库,分别是…...

单个vue echarts页面
<template> <div ref"history" class"echarts"></div> </template> <script> export default{ data () { return {}; }, methods: { history(){ let myChart this.$echarts.init(this.$refs.history); // 绘制图表 myCha…...
【web开发】6、Django(1)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、Django是什么?二、使用步骤1.安装Django2.创建项目3.创建app4.快速上手5.模板继承 数据库操作1.安装第三方模块2.自己创建数据库3.DJango链接数据库…...
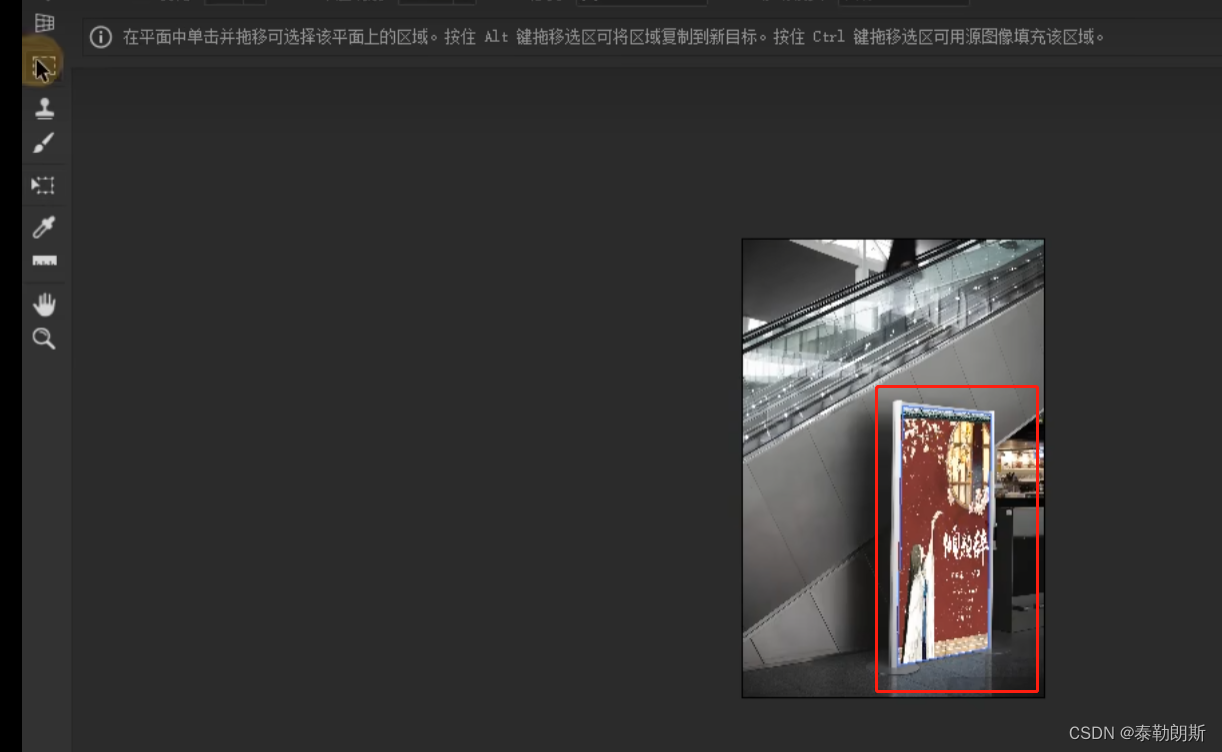
第29节-PhotoShop基础课程-滤镜库
文章目录 前言1.滤镜库2.Camera Raw滤镜 (用来对图片进行预处理,最全面的一个)3.神经滤镜(2022插件 需要先下载)4.液化(胖-> 瘦 矮->高)5.其它滤镜1.自适应广角2.镜头矫正 把图片放正3.消…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...