爬虫 — Scrapy-Redis
目录
- 一、背景
- 1、数据库的发展历史
- 2、NoSQL 和 SQL 数据库的比较
- 二、Redis
- 1、特性
- 2、作用
- 3、应用场景
- 4、用法
- 5、安装及启动
- 6、Redis 数据库简单使用
- 7、Redis 常用五大数据类型
- 7.1 Redis-String
- 7.2 Redis-List (单值多value)
- 7.3 Redis-Hash
- 7.4 Redis-Set (不重复的)
- 7.5 Redis-Zset (有序集合)
- 8、Python 操作 Redis
- 8.1、安装
- 8.2、导入 Redis 模块和创建连接
- 8.3、字符串相关操作
- 8.4、列表相关操作
- 8.5、集合相关操作
- 8.6、哈希相关操作
- 8.7、有序集合相关操作
- 8.8、连接 Redis 数据库
- 三、Scrapy-分布式
- 1、启动 Redis
- 2、Scrapy-Redis 简介
- 3、Scrapy 工作流程
- 4、Scrapy-Redis 工作流程
- 5、github 示例代码
- 6、Scrapy-Redis 中的 settings 文件
- 7、Scrapy-Redis 运行
- 四、案例
- 1、页面分析
- 2、使用 Scrapy 框架实现
- 3、改写成 Scrapy-Redis
- 4、改写分布式总结
一、背景
随着互联网+大数据时代的来临,传统的关系型数据库已经不能满足中大型网站日益增长的访问量和数据量。这个时候就需要⼀种能够快速存取数据的组件来缓解数据库服务 I/O 的压力,来解决系统性能上的瓶颈。
1、数据库的发展历史
1、在互联网+大数据时代来临之前,企业的一些内部信息管理系统,一个单个数据库实例就能满足系统的需求。
2、随着系统访问用户的增多,数据量的增大,单个数据库实例已经无法满足系统的读取需求,采用缓存(memcache)+单数据库实例。
3、缓存可以缓解系统的读取压力,但是数据量的写入压力持续增大,使用缓存+主从数据库+读写分离。
4、数据量再次增大,读写分离以后,主数据库的写库压力出现瓶颈,使用缓存+主从数据库集群+读写分离+分库分表。
5、互联网+大数据时代来临,关系型数据库不能很好地存取一些并发性高、实时性高,并且数据格式不固定的数据,采用 NoSQL +主从数据库集群+读写分离+分库分表。
2、NoSQL 和 SQL 数据库的比较
1、适用场景不同:SQL 数据库适合用于关系特别复杂的数据查询场景,NoSQL 则相反。
2、事务:SQL 对事务的支持非常完善,而 NoSQL 基本不支持事务。
3、两者在不断的取长补短。
二、Redis
是⼀个高性能的,开源的,C 语言开发的,键值对存储数据的 nosql(not only sql,泛指非关系型数据库
) 数据库。
点击阅读官方文档
1、特性
Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis 不仅仅支持简单的 key-value 类型的数据,同时还提供 List、Set 等数据类型。
Redis 支持数据的备份。
2、作用
快速存取。
3、应用场景
点赞、秒杀、直播平台的在线好友列表、商品排行榜等。
4、用法
官方地址:https://redis.io/
命令地址:http://doc.redisfans.com/
5、安装及启动
查看帮助命令:
redis-server --help
启动服务:
redis-server.exe
连接客户端:
redis-cli.exe
6、Redis 数据库简单使用
DBSIZE 查看当前数据库的 key 数量
KEYS * 查看所有 key 的内容
FLUSHDB 清空当前数据库的所有 key
FLUSHALL 清空所有库的所有 key(谨慎使用)
EXISTS key 判断 key 是否存在
7、Redis 常用五大数据类型
7.1 Redis-String
Redis 中的 String 是最基本的数据类型,一个 key 对应一个 value。String 可以包含任何数据,但最大不能超过 512M。
常用操作
- SET:设置值
- GET:获取值
- MSET:设置多个值
- MGET:获取多个值
- APPEND:添加字段
- DEL:删除
- STRLEN:返回字符串长度
数值操作
- INCR:增加
- DECR:减少
- INCRBY:指定增加多少
- DECRBY:指定减少多少
范围操作
- GETRANGE:获取指定区间范围内的值,类似 SQL 中的 BETWEEN … AND …
- SETRANGE:从指定位置开始替换,索引从 0 开始,从 0 到 -1 表示全部
7.2 Redis-List (单值多value)
Redis 的 List 类型是一个简单的字符串列表,按照插入顺序排序,可以在列表的头部(左边)或尾部(右边)添加元素。它的底层实际上是一个链表。
常用操作
- LPUSH/RPUSH/LRANGE:从左/从右/获取指定长度
- LPOP/RPOP:移除最左/最右的元素
- LINDEX:按照索引下标获取元素
- LLEN:求列表长度
- LREM:删除指定数量的元素
- LTRIM:截取指定范围的值
- RPOPLPUSH:将最后一个元素从一个列表弹出并推入另一个列表的头部
- LSET:设置指定位置的元素值
- LINSERT:在指定元素前或后插入新元素
7.3 Redis-Hash
Redis 的 Hash 是一种键值对集合。它是一个字符串类型的字段和值的映射表,特别适合存储对象。
常用操作
- HSET/HGET/HMSET/HMGET/HGETALL/HDEL:设值/取值/设值多个值/取多个值/取全部值/删除值
- HLEN:求哈希长度
- HEXISTS:检查某个值是否存在
- HKEYS/HVALS:获取所有字段名/获取所有字段值
7.4 Redis-Set (不重复的)
Redis 的 Set 类型是一个无序集合,存储的值是唯一的。
常用操作
- SADD/SMEMBERS/SISMEMBER:添加/查看集合/查看是否存在
- SCARD:获取集合里的元素个数
- SREM:删除集合中的元素
- SPOP:随机移除集合中的一个元素
- SMOVE:将一个元素从一个集合移到另一个集合
- SDIFF/SINTER/SUNION:求差集/交集/并集
7.5 Redis-Zset (有序集合)
Redis 的 Zset 是一种有序集合,每个元素都关联着一个分数,根据分数的排名来排序。
常用操作
- ZADD/ZRANGE:添加元素/获取范围内的元素
- ZRANGEBYSCORE:根据分数范围获取元素
- ZREM:删除元素
- ZCARD:获取有序集合的总数
- ZCOUNT:获取分数范围内的元素个数
- ZRANK:获取元素在有序集合中的排名
8、Python 操作 Redis
8.1、安装
pip install redis
8.2、导入 Redis 模块和创建连接
# 导入 Redis 模块
import redis# 创建一个用于字符串操作的测试类
class TestString(object):def __init__(self):# 连接 Redis 服务器self.r = redis.StrictRedis(host='192.168.75.130', port=6379, db=0)# 创建一个用于列表操作的测试类
class TestList(object):def __init__(self):# 连接 Redis 服务器self.r = redis.StrictRedis(host='192.168.75.130', port=6379)# 创建一个用于集合操作的测试类
class TestSet(object):def __init__(self):# 连接 Redis 服务器self.r = redis.StrictRedis(host='192.168.75.130', port=6379)# 创建一个用于哈希操作的测试类
class TestHash(object):def __init__(self):# 连接 Redis 服务器self.r = redis.StrictRedis(host='192.168.75.130', port=6379)
8.3、字符串相关操作
# 设置值
def test_set(self):res = self.r.set('user1', 'juran-1') # 设置 key 'user1' 的值为 'juran-1'print(res)# 取值
def test_get(self):res = self.r.get('user1') # 获取 key 'user1' 的值print(res)# 设置多个值
def test_mset(self):d = {'user2': 'juran-2','user3': 'juran-3'}res = self.r.mset(d) # 批量设置多个键值对print(res)# 取多个值
def test_mget(self):l = ['user2', 'user3']res = self.r.mget(l) # 批量获取多个键的值print(res)# 删除
def test_del(self):self.r.delete('user2') # 删除 key 'user2'
8.4、列表相关操作
# 插入记录
def test_push(self):res = self.r.lpush('common', '1') # 将元素 '1' 插入到列表 'common' 的左边res = self.r.rpush('common', '2') # 将元素 '2' 插入到列表 'common' 的右边# 弹出记录
def test_pop(self):res = self.r.lpop('common') # 从列表 'common' 的左边弹出一个元素res = self.r.rpop('common') # 从列表 'common' 的右边弹出一个元素# 范围取值
def test_range(self):res = self.r.lrange('common', 0, -1) # 获取列表 'common' 中的所有元素print(res)
8.5、集合相关操作
# 添加数据
def test_sadd(self):res = self.r.sadd('set01', '1', '2') # 向集合 'set01' 中添加元素 '1' 和 '2'lis = ['Cat', 'Dog']res = self.r.sadd('set02', *lis) # 向集合 'set02' 中添加多个元素# 删除数据
def test_del(self):res = self.r.srem('set01', '1') # 从集合 'set01' 中删除元素 '1'# 随机删除数据
def test_pop(self):res = self.r.spop('set02') # 随机从集合 'set02' 中弹出一个元素
8.6、哈希相关操作
# 批量设值
def test_hset(self):dic = {'id': 1,'name': 'huawei'}res = self.r.hmset('mobile', dic) # 批量设置哈希表 'mobile' 的字段及对应的值# 批量取值
def test_hgetall(self):res = self.r.hgetall('mobile') # 获取哈希表 'mobile' 中的所有字段及对应的值# 判断是否存在 存在返回1 不存在返回0
def test_hexists(self):res = self.r.hexists('mobile', 'id') # 检查字段 'id' 是否存在于哈希表 'mobile'print(res)
8.7、有序集合相关操作
class TestSortedSet(object):def __init__(self):# 连接 Redis 服务器self.r = redis.StrictRedis(host='192.168.75.130', port=6379)# 批量设值
def test_zadd(self):score_members = {'v1': 60,'v2': 70,'v3': 80,'v4': 90,'v5': 100}res = self.r.zadd('zset01', score_members) # 向有序集合 'zset01' 添加带有分数的成员# 批量取值
def test_zrange(self):res = self.r.zrange('zset01', 0, -1) # 获取有序集合 'zset01' 中的所有成员print(res)
8.8、连接 Redis 数据库
def main():# 创建字符串操作测试类的实例test_string = TestString()# 调用字符串相关操作test_string.test_set()test_string.test_get()test_string.test_mset()test_string.test_mget()test_string.test_del()# 创建列表操作测试类的实例test_list = TestList()# 调用列表相关操作test_list.test_push()test_list.test_pop()test_list.test_range()# 创建集合操作测试类的实例test_set = TestSet()# 调用集合相关操作test_set.test_sadd()test_set.test_del()test_set.test_pop()# 创建哈希操作测试类的实例test_hash = TestHash()# 调用哈希相关操作test_hash.test_hset()test_hash.test_hgetall()test_hash.test_hexists()# 创建有序集合操作测试类的实例test_sorted_set = TestSortedSet()# 调用有序集合相关操作test_sorted_set.test_zadd()test_sorted_set.test_zrange()if __name__ == "__main__":main()
三、Scrapy-分布式
1、启动 Redis
点击下载 Redis
1、下载后解压到文件夹,进入解压后的目录下,在地址栏输入 cmd 后按回车。
2、启动 Redis 服务,运行命令:
redis-server
3、新开一个窗口,启动 Redis 客户端,运行命令:
redis-cli
2、Scrapy-Redis 简介
Scrapy-Redis 是 Scrapy 框架的一个扩展,用于实现分布式爬虫。它将 Scrapy 与 Redis 数据库集成,允许多个爬虫实例共享数据并协同工作,以提高爬取效率和可扩展性。
Scrapy-Redis 使用 Redis 的集合来进行 URL 的去重处理。每个爬虫实例都会在将 URL 添加到队列之前检查它是否已经存在于集合中,以避免重复爬取。
查看 GitHub 源代码
3、Scrapy 工作流程

4、Scrapy-Redis 工作流程

5、github 示例代码
安装 scrapy-redis,终端运行命令:
pip install scrapy-redis
在 github 上拉取示例代码,终端运行命令:
git clone https://github.com/rolando/scrapy-redis.git
6、Scrapy-Redis 中的 settings 文件
# Scrapy settings for example project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/topics/settings.html
#
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 指定那个去重⽅法给 request 对象去重
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定 Scheduler 队列
SCHEDULER_PERSIST = True # 队列中的内容是否持久保存,为 false 的时候在关闭 Redis 的时候,清空 Redis
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {'example.pipelines.ExamplePipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 400, # scrapy_redis 实现的 items 保存到 Redis 的 pipeline
}
LOG_LEVEL = 'DEBUG'
# Introduce an artificial delay to make use of parallelism. to speed up the crawl.
DOWNLOAD_DELAY = 1
7、Scrapy-Redis 运行
allowed_domains = ['dmoztools.net']
start_urls = ['http://www.dmoztools.net/']
scrapy crawl dmoz
运行结束后,Redis 中会多出三个键:
- “dmoz:requests”:存放待爬取的 requests 对象。
- “dmoz:item”:存放爬取到的信息。
- “dmoz:dupefilter”:存放爬取的 requests 的指纹信息。

四、案例
目标网站:https://www.daomubiji.com/
需求:
爬取整套小说,分为1级、2级、3级页面。
将爬取内容分门别类存放在文件夹中,有一个小说文件夹,里面新建文件夹,每一个文件夹存放每一套盗墓笔记。
小说具体内容保存为 txt 文件。
1、页面分析
1级页面:获取标题以及2级页面的 URL。
1级标题:‘//li[contains(@id, “menu-item”)]/a/text()’
2级 URL:‘//li[contains(@id, “menu-item”)]/a/@href’
2级页面:获取章节标题以及3级页面的 URL。
2级标题:a_lst = ‘//article/a/text()’
3级的 URL:a_url = ‘//article/a/@href’
3级页面:获取的文本内容。
content = response.xpath(‘//article/p/text()’)
2、使用 Scrapy 框架实现
1、在终端输入命令创建一个 Scrapy 框架。
scrapy startproject dmbj
cd dmbj
scrapy genspider dm daomubiji.com
2、修改 setting.py 文件。
# setting.py
LOG_LEVEL = 'WARNING'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'dmbj.pipelines.DmbjPipeline': 300,
}
3、在 dmbj 文件夹下新建一个 start.py 文件。
# start.py
# 使用 cmdline 模块来执行命令行命令
from scrapy import cmdline# 使用 Scrapy 执行名为 dm 的爬虫
cmdline.execute('scrapy crawl dm'.split())
4、编写 spiders 文件夹下的 dm.py 文件的代码,获取一级标题和二级 url。
# spiders/dm.py
import scrapy # 导入 Scrapy 库,用于构建爬虫# 创建一个名为 DmSpider 的 Scrapy 爬虫类
class DmSpider(scrapy.Spider):name = 'dm' # 爬虫的名称allowed_domains = ['daomubiji.com'] # 允许爬取的域名start_urls = ['http://daomubiji.com/'] # 起始 URL 列表# 解析函数,用于处理响应并提取数据def parse(self, response):a_list = response.xpath('//li[contains(@id, "menu-item")]/a')for a in a_list:# 一级标题first_title = a.xpath('./text()').get()# 二级 urlsecond_url = a.xpath('./@href').get()# 打印一级标题和二级 urlprint(first_title, second_url)
5、编写 item.py 文件的代码,保存一级标题。
# item.py
import scrapy # 导入 Scrapy 库,用于构建爬虫class DmbjItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 一级标题first_title = scrapy.Field()pass
6、编写 spiders 文件夹下的 dm.py 文件的代码,构造二级页面。
# spiders/dm.py
import scrapy # 导入 Scrapy 库,用于构建爬虫
from dmbj.items import DmbjItem # 导入自定义的 Item 类# 创建一个名为 DmSpider 的 Scrapy 爬虫类
class DmSpider(scrapy.Spider):name = 'dm' # 爬虫的名称allowed_domains = ['daomubiji.com'] # 允许爬取的域名start_urls = ['http://daomubiji.com/'] # 起始 URL 列表# 解析函数,用于处理响应并提取数据def parse(self, response):a_list = response.xpath('//li[contains(@id, "menu-item")]/a')for a in a_list:# 创建一个 DmbjItem 实例item = DmbjItem()# 一级标题item['first_title'] = a.xpath('./text()').get()# 二级 urlsecond_url = a.xpath('./@href').get()# 构造二级页面,使用 parse_article 方法处理yield scrapy.Request(url=second_url,meta={'item': item}, # 将 item 传递给下一个回调函数callback=self.parse_article)# 解析二级页面def parse_article(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 三级 url,章节标题a_lst = response.xpath('//article/a')for a in a_lst:# 存储章节标题到 item 对象item['second_title'] = a.xpath('./text()').get()# 三级 urlthird_url = a.xpath('./@href').get()print(item)
7、编写 item.py 文件的代码,保存二级标题。
# item.py
import scrapy # 导入 Scrapy 库,用于构建爬虫class DmbjItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 一级标题first_title = scrapy.Field()# 二级标题second_title = scrapy.Field()pass
8、编写 spiders 文件夹下的 dm.py 文件的代码,获取文章内容的段落。
# spiders/dm.py
import scrapy # 导入 Scrapy 库,用于构建爬虫
from dmbj.items import DmbjItem # 导入自定义的 Item 类# 创建一个名为 DmSpider 的 Scrapy 爬虫类
class DmSpider(scrapy.Spider):name = 'dm' # 爬虫的名称allowed_domains = ['daomubiji.com'] # 允许爬取的域名start_urls = ['http://daomubiji.com/'] # 起始 URL 列表# 解析函数,用于处理响应并提取数据def parse(self, response):a_list = response.xpath('//li[contains(@id, "menu-item")]/a')for a in a_list:# 创建一个 DmbjItem 实例item = DmbjItem()# 一级标题item['first_title'] = a.xpath('./text()').get()# 二级 urlsecond_url = a.xpath('./@href').get()# 构造二级页面,使用 parse_article 方法处理yield scrapy.Request(url=second_url,meta={'item': item}, # 将 item 传递给下一个回调函数callback=self.parse_article)# 解析二级页面def parse_article(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 三级 url,章节标题a_lst = response.xpath('//article/a')for a in a_lst:# 存储章节标题到 item 对象item['second_title'] = a.xpath('./text()').get()# 三级 urlthird_url = a.xpath('./@href').get()# print(item)# 向三级页面发请求yield scrapy.Request(url=third_url,meta={'item': item}, # 将 item 传递给下一个回调函数callback=self.parse_content)# 解析获取数据内容def parse_content(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 使用 XPath 选择器提取文章内容的段落content_lst = response.xpath('//article[@class="article-content"]/p/text()').getall()# 将段落文本连接成一个字符串,并存储到 item 对象item['content'] = '\n'.join(content_lst)print(item)# 将 item 传递给下一个处理管道yield item
9、编写 item.py 文件的代码,保存内容。
# item.py
import scrapy # 导入 Scrapy 库,用于构建爬虫class DmbjItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 一级标题first_title = scrapy.Field()# 二级标题second_title = scrapy.Field()# 内容content = scrapy.Field()pass
10、创建文件夹,保存获取的数据。
方式一:在 spiders 文件夹下的 dm.py 文件里编写代码。
# spiders/dm.py
import scrapy # 导入 Scrapy 库,用于构建爬虫
from dmbj.items import DmbjItem # 导入自定义的 Item 类
import re # 导入正则表达式模块
import os # 导入操作系统模块# 创建一个名为 DmSpider 的 Scrapy 爬虫类
class DmSpider(scrapy.Spider):name = 'dm' # 爬虫的名称allowed_domains = ['daomubiji.com'] # 允许爬取的域名start_urls = ['http://daomubiji.com/'] # 起始 URL 列表# 解析函数,用于处理响应并提取数据def parse(self, response):a_list = response.xpath('//li[contains(@id, "menu-item")]/a')for a in a_list:# 创建一个 DmbjItem 实例item = DmbjItem()# 一级标题s = a.xpath('./text()').get()# 二级 urlsecond_url = a.xpath('./@href').get()# 使用正则表达式替换一级标题中的特殊字符为下划线item['first_title'] = re.sub(r'[\\:<>*? ]', "_", s)# 构造一级标题的文件夹路径dir_path = r"小说/{}".format(item['first_title'])# 创建之前一定要做判断,如果文件夹不存在,则创建if not os.path.exists(dir_path):os.makedirs(dir_path)# 构造二级页面,使用 parse_article 方法处理yield scrapy.Request(url=second_url,meta={'item': item}, # 将 item 传递给下一个回调函数callback=self.parse_article)# 解析二级页面def parse_article(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 三级 url,章节标题a_lst = response.xpath('//article/a')for a in a_lst:# 存储章节标题到 item 对象item['second_title'] = a.xpath('./text()').get()# 三级 urlthird_url = a.xpath('./@href').get()# print(item)# 向三级页面发请求yield scrapy.Request(url=third_url,meta={'item': item}, # 将 item 传递给下一个回调函数callback=self.parse_content)# 解析获取数据内容def parse_content(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 使用 XPath 选择器提取文章内容的段落content_lst = response.xpath('//article[@class="article-content"]/p/text()').getall()# 将段落文本连接成一个字符串,并存储到 item 对象item['content'] = '\n'.join(content_lst)print(item)# 将 item 传递给下一个处理管道yield item
方式二:在管道文件 pipelines.py 中创建。
# pipelines.py
import re # 导入 re 模块,用于正则表达式操作# 定义 DmbjPipeline 类
class DmbjPipeline:# 处理爬取到的数据项def process_item(self, item, spider):# 构建保存小说文件的文件夹路径,使用一级标题和二级标题,将特殊字符替换为下划线dir_path = r'小说/{}/{}'.format(item['first_title'],re.sub(r'[\\:<>*? ]', "_", item['second_title']))# 构建保存小说内容的文件路径,加上 .txt 后缀filename = dir_path + '.txt'# 将小说内容写入文件中,使用 UTF-8 编码with open(filename, 'w', encoding='utf-8') as f:f.write(item['content'])# 返回 item 对象,用于后续的处理或保存return item
11、对数据做一个深拷贝处理,使用 Scrapy 框架实现就完成了。
# spiders/dm.py
import scrapy # 导入 Scrapy 库,用于构建爬虫
from dmbj.items import DmbjItem # 导入自定义的 Item 类
import re # 导入正则表达式模块
import os # 导入操作系统模块
from copy import deepcopy # 导入深拷贝函数# 创建一个名为 DmSpider 的 Scrapy 爬虫类
class DmSpider(scrapy.Spider):name = 'dm' # 爬虫的名称allowed_domains = ['daomubiji.com'] # 允许爬取的域名start_urls = ['http://daomubiji.com/'] # 起始 URL 列表# 解析函数,用于处理响应并提取数据def parse(self, response):a_list = response.xpath('//li[contains(@id, "menu-item")]/a')for a in a_list:# 创建一个 DmbjItem 实例item = DmbjItem()# 一级标题s = a.xpath('./text()').get()# 二级 urlsecond_url = a.xpath('./@href').get()# 使用正则表达式替换一级标题中的特殊字符为下划线item['first_title'] = re.sub(r'[\\:<>*? ]', "_", s)# 构造一级标题的文件夹路径dir_path = r"小说/{}".format(item['first_title'])# 创建之前一定要做判断,如果文件夹不存在,则创建if not os.path.exists(dir_path):os.makedirs(dir_path)# 构造二级页面,使用 parse_article 方法处理yield scrapy.Request(url=second_url,meta={'item': item}, # 将 item 传递给下一个回调函数callback=self.parse_article)# 解析二级页面def parse_article(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 三级 url,章节标题a_lst = response.xpath('//article/a')for a in a_lst:# 存储章节标题到 item 对象item['second_title'] = a.xpath('./text()').get()# 三级 urlthird_url = a.xpath('./@href').get()# print(item)# 向三级页面发请求yield scrapy.Request(url=third_url,meta={'item': deepcopy(item)}, # 将 item 传递给下一个回调函数callback=self.parse_content)# 解析获取数据内容def parse_content(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 使用 XPath 选择器提取文章内容的段落content_lst = response.xpath('//article[@class="article-content"]/p/text()').getall()# 将段落文本连接成一个字符串,并存储到 item 对象item['content'] = '\n'.join(content_lst)print(item)# 将 item 传递给下一个处理管道yield item
3、改写成 Scrapy-Redis
1、导入 Scrapy-Redis,修改继承类。
# spiders/dm.py
import scrapy # 导入 Scrapy 库,用于构建爬虫
from dmbj.items import DmbjItem # 导入自定义的 Item 类
import re # 导入正则表达式模块
import os # 导入操作系统模块
from copy import deepcopy # 导入深拷贝函数
from scrapy_redis.spiders import RedisSpider # 导入 Scrapy-Redis 中的 RedisSpider 类# 创建一个名为 DmSpider 的 Scrapy 爬虫类,继承自 RedisSpider
class DmSpider(RedisSpider):name = 'dm' # 爬虫的名称redis_key = 'daomu_key' # 指定 Redis 的键名,从中读取起始 URL# allowed_domains = ['daomubiji.com'] # 允许爬取的域名# start_urls = ['http://daomubiji.com/'] # 起始 URL 列表# 解析函数,用于处理响应并提取数据def parse(self, response):a_list = response.xpath('//li[contains(@id, "menu-item")]/a')for a in a_list:# 创建一个 DmbjItem 实例item = DmbjItem()# 一级标题s = a.xpath('./text()').get()# 二级 urlsecond_url = a.xpath('./@href').get()# 使用正则表达式替换一级标题中的特殊字符为下划线item['first_title'] = re.sub(r'[\\:<>*? ]', "_", s)# 构造一级标题的文件夹路径dir_path = r"小说/{}".format(item['first_title'])# 创建之前一定要做判断,如果文件夹不存在,则创建if not os.path.exists(dir_path):os.makedirs(dir_path)# 构造二级页面,使用 parse_article 方法处理yield scrapy.Request(url=second_url,meta={'item': item}, # 将 item 传递给下一个回调函数callback=self.parse_article)# 解析二级页面def parse_article(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 三级 url,章节标题a_lst = response.xpath('//article/a')for a in a_lst:# 存储章节标题到 item 对象item['second_title'] = a.xpath('./text()').get()# 三级 urlthird_url = a.xpath('./@href').get()# print(item)# 向三级页面发请求yield scrapy.Request(url=third_url,meta={'item': deepcopy(item)}, # 将 item 传递给下一个回调函数callback=self.parse_content)# 解析获取数据内容def parse_content(self, response):# 从响应的 meta 中获取之前传递的 item 对象item = response.meta.get('item')# 使用 XPath 选择器提取文章内容的段落content_lst = response.xpath('//article[@class="article-content"]/p/text()').getall()# 将段落文本连接成一个字符串,并存储到 item 对象item['content'] = '\n'.join(content_lst)print(item)# 将 item 传递给下一个处理管道yield item
2、修改 setting.py 文件。
# setting.py
# Scrapy settings for dmbj project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'dmbj'
LOG_LEVEL = 'WARNING'
SPIDER_MODULES = ['dmbj.spiders']
NEWSPIDER_MODULE = 'dmbj.spiders'# 设置用户代理信息
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
# 指定去重方式,给请求对象去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 设置调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 队列中的内容是否进行持久保留
# True redis 关闭的时候数据会保留
# False 不会保留
SCHEDULER_PERSIST = True
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"# LOG_LEVEL = 'DEBUG'# Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
DOWNLOAD_DELAY = 1# 配置 Redis 连接信息
REDIS_URL = "redis://127.0.0.1:6379"# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'dmbj (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'dmbj.middlewares.dmbjSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'dmbj.middlewares.dmbjDownloaderMiddleware': 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'dmbj.pipelines.DmbjPipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 400, # 保存数据到 Redis 数据库
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
3、启动 Redis
进入 Redis 目录,在地址栏输入 cmd 后按回车两次,分别启动 Redis 服务端和 Redis 客户端。
启动 Redis 服务端,运行命令:
redis-server
启动 Redis 客户端,运行命令:
redis-cli
在 Redis 客户端输入命令:
清空:
flushal
查询:
keys *
4、启动程序
在 Redis 客户端输入命令:
lpush Redis键名 网址
lpush daomu_key http://daomubiji.com/
在 Redis 服务端输入命令:
cd 项目的绝对路径
scrapy crawl dm
可以开多个终端运行以上两条命令,会同时爬取数据。
4、改写分布式总结
1、导入类,修改继承类。
from scrapy_redis.spiders import RedisSpider
class DmSpider(RedisSpider):
2、修改配置文件。
# 设置用户代理信息
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
# 指定去重方式,给请求对象去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 设置调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 队列中的内容是否进行持久保留
# True redis 关闭的时候数据会保留
# False 不会保留
SCHEDULER_PERSIST = True
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"# LOG_LEVEL = 'DEBUG'# Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
DOWNLOAD_DELAY = 1# 配置 Redis 连接信息
REDIS_URL = "redis://127.0.0.1:6379"# 管道
ITEM_PIPELINES = {'dmbj.pipelines.DmbjPipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 400, # 保存数据到 Redis 数据库
}
3、注意爬取数据前要在 Redis 客户端输入命令。
lpush Redis键名 网址
lpush daomu_key http://daomubiji.com/
记录学习过程,欢迎讨论交流,尊重原创,转载请注明出处~
相关文章:
爬虫 — Scrapy-Redis
目录 一、背景1、数据库的发展历史2、NoSQL 和 SQL 数据库的比较 二、Redis1、特性2、作用3、应用场景4、用法5、安装及启动6、Redis 数据库简单使用7、Redis 常用五大数据类型7.1 Redis-String7.2 Redis-List (单值多value)7.3 Redis-Hash7.4 Redis-Set (不重复的)7.5 Redis-Z…...
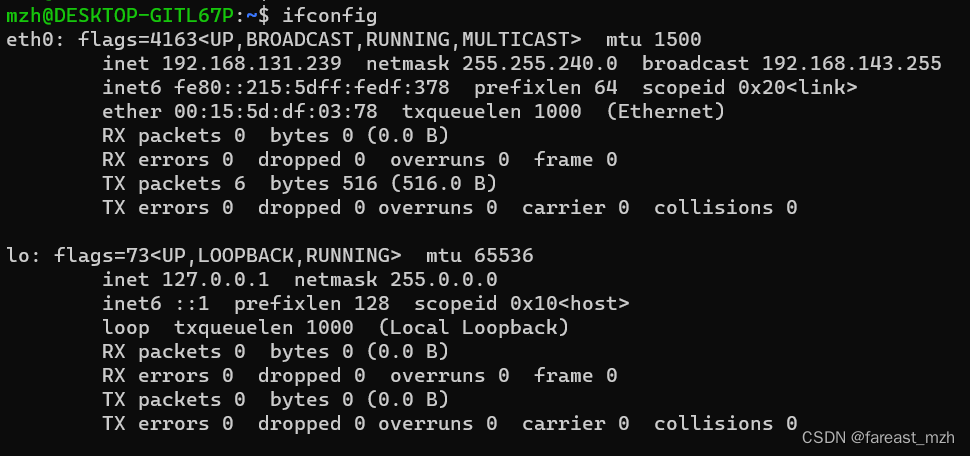
tcpdump常用命令
需要安装 tcpdump wireshark ifconfig找到网卡名称 eth0, ens192... tcpdump需要root权限 网卡eth0 经过221.231.92.240:80的流量写入到http.cap tcpdump -i eth0 host 221.231.92.240 and port 80 -vvv -w http.cap ssh登录到主机查看排除ssh 22端口的报文 tcpdump -i …...
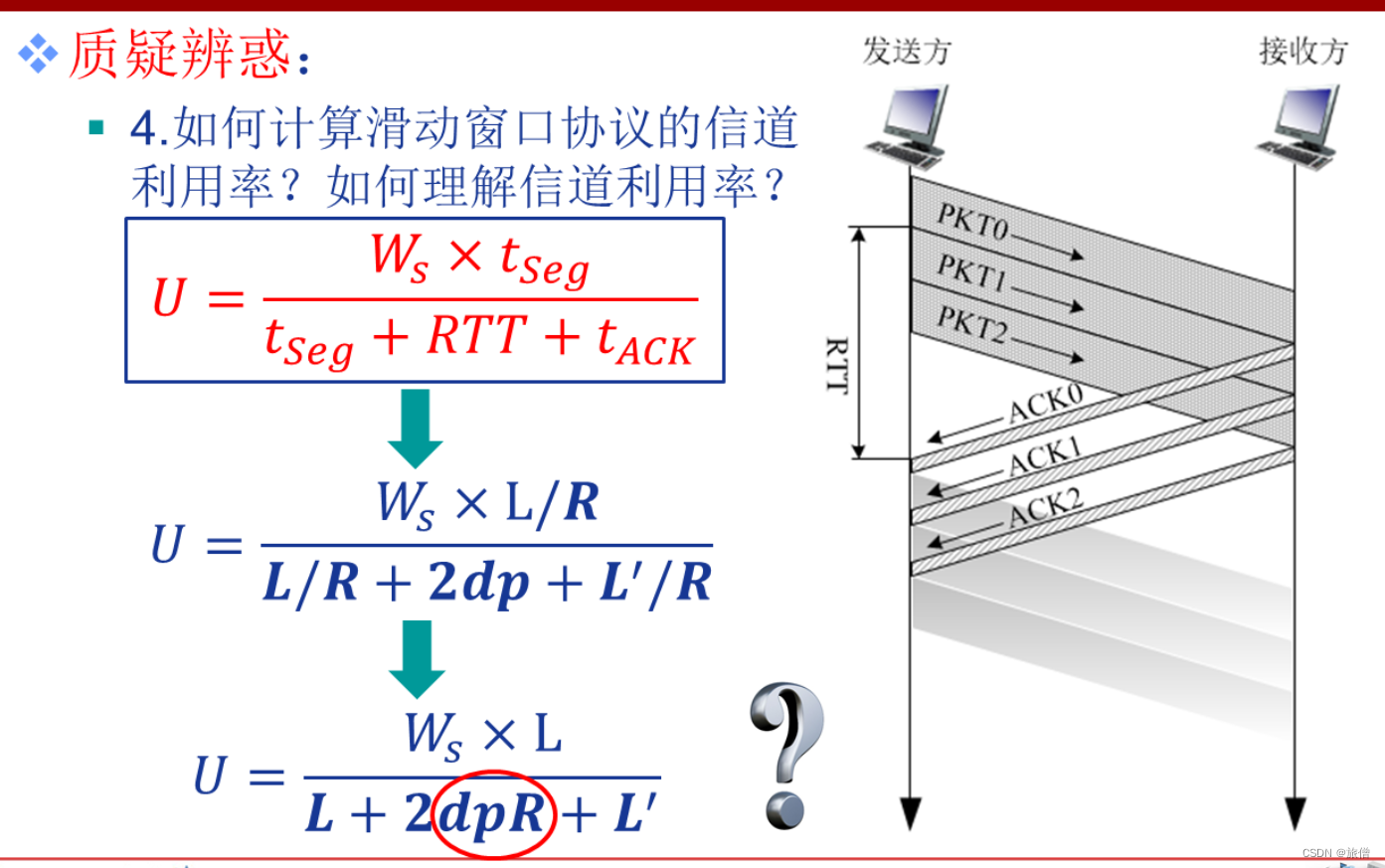
计算机网络运输层网络层补充
1 CDMA是码分多路复用技术 和CMSA不是一个东西 UPD是只确保发送 但是接收端收到之后(使用检验和校验 除了检验的部分相加 对比检验和是否相等。如果不相同就丢弃。 复用和分用是发生在上层和下层的问题。通过比如时分多路复用 频分多路复用等。TCP IP 应用层的IO多路复用。网…...

java CAS详解(深入源码剖析)
CAS是什么 CAS是compare and swap的缩写,即我们所说的比较交换。该操作的作用就是保证数据一致性、操作原子性。 cas是一种基于锁的操作,而且是乐观锁。在java中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等之前获得锁的线程释放锁之后&am…...
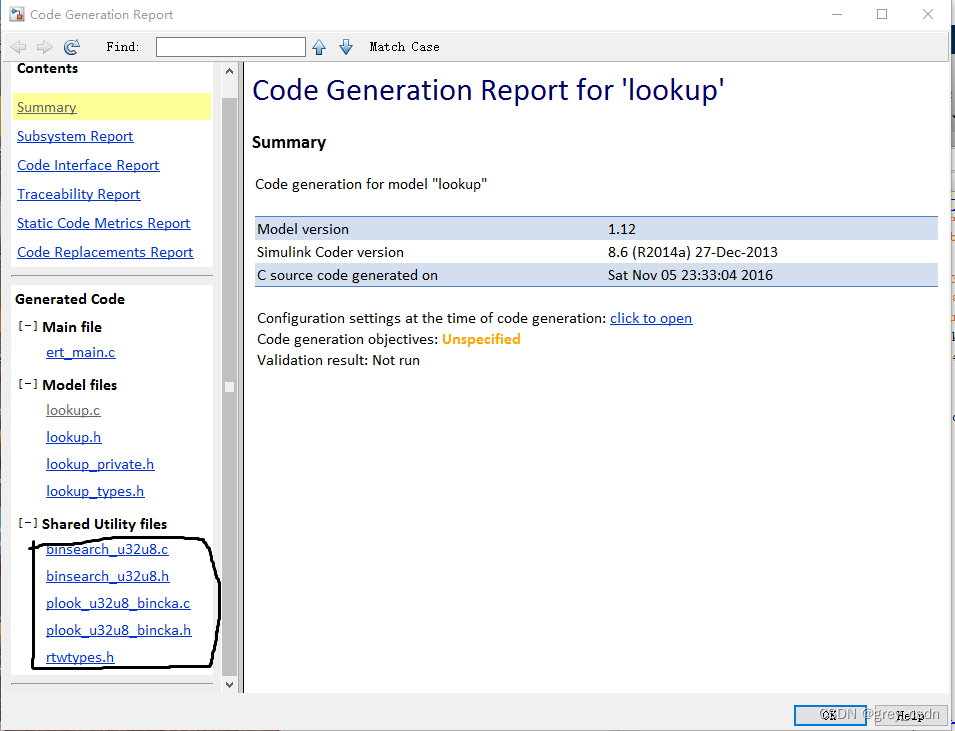
1786_MTALAB代码生成把通用函数生成独立文件
全部学习汇总: GitHub - GreyZhang/g_matlab: MATLAB once used to be my daily tool. After many years when I go back and read my old learning notes I felt maybe I still need it in the future. So, start this repo to keep some of my old learning notes…...
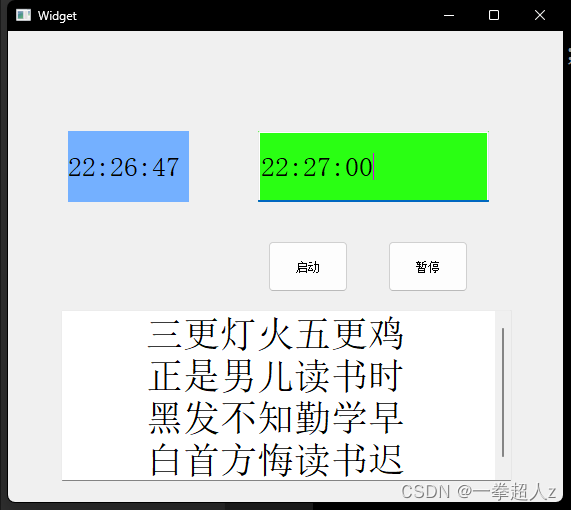
2023/09/19 qt day3
头文件 #ifndef WIDGET_H #define WIDGET_H #include <QWidget> #include <QDebug> #include <QTime> #include <QTimer> #include <QPushButton> #include <QTextEdit> #include <QLineEdit> #include <QLabel> #include &l…...
—— Docker Rootless 让你的容器更安全)
Docker 学习总结(78)—— Docker Rootless 让你的容器更安全
前言 在以 root 用户身份运行 Docker 会带来一些潜在的危害和安全风险,这些风险包括: 容器逃逸:如果一个容器以 root 权限运行,并且它包含了漏洞或者被攻击者滥用,那么攻击者可能会成功逃出容器,并在宿主系统上执行恶意操作。这会导致宿主系统的安全性受到威胁。 特权升…...
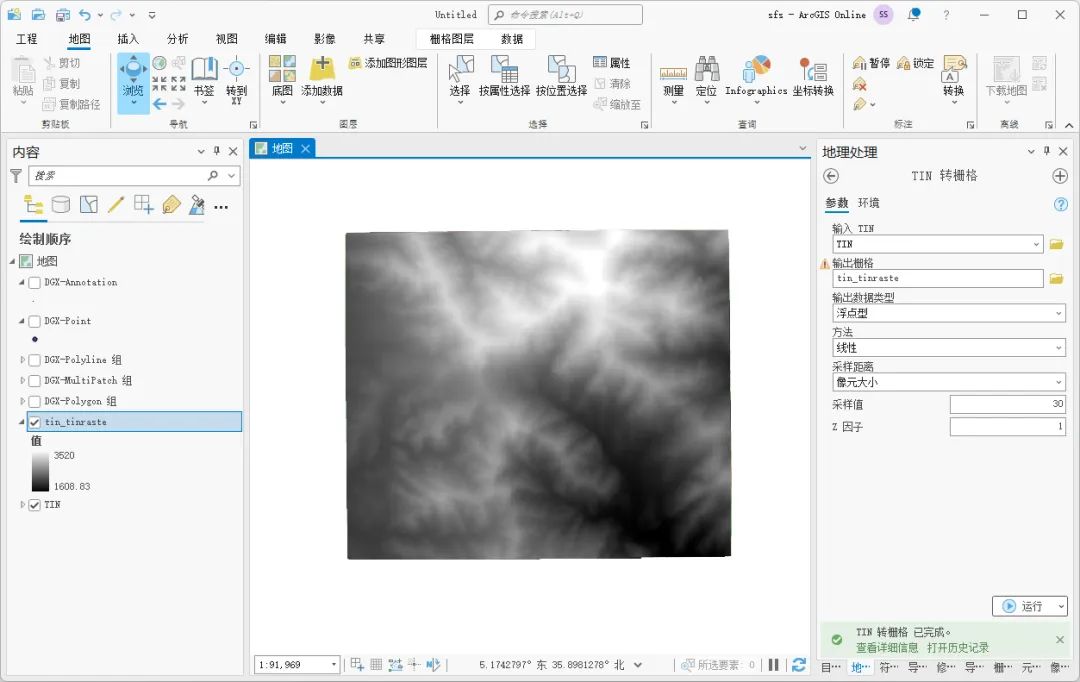
如何使用ArcGIS Pro将等高线转DEM
通常情况下,我们拿到的等高线数据一般都是CAD格式,如果要制作三维地形模型,使用栅格格式的DEM数据是更好的选择,这里就为大家介绍一下如何使用ArcGIS Pro将等高线转DEM,希望能对你有所帮助。 创建TIN 在工具箱中选择“…...

【爬虫基础】万字长文详解XPath
1. 引言 XPath(XML Path Language)是一种在XML和HTML文档中查找和定位信息的强大工具。XPath的重要性在于它允许我们以简洁而灵活的方式导航和选择文档中的元素和属性。本文将深入介绍XPath的基础知识,帮助你掌握这个强大的查询语言…...
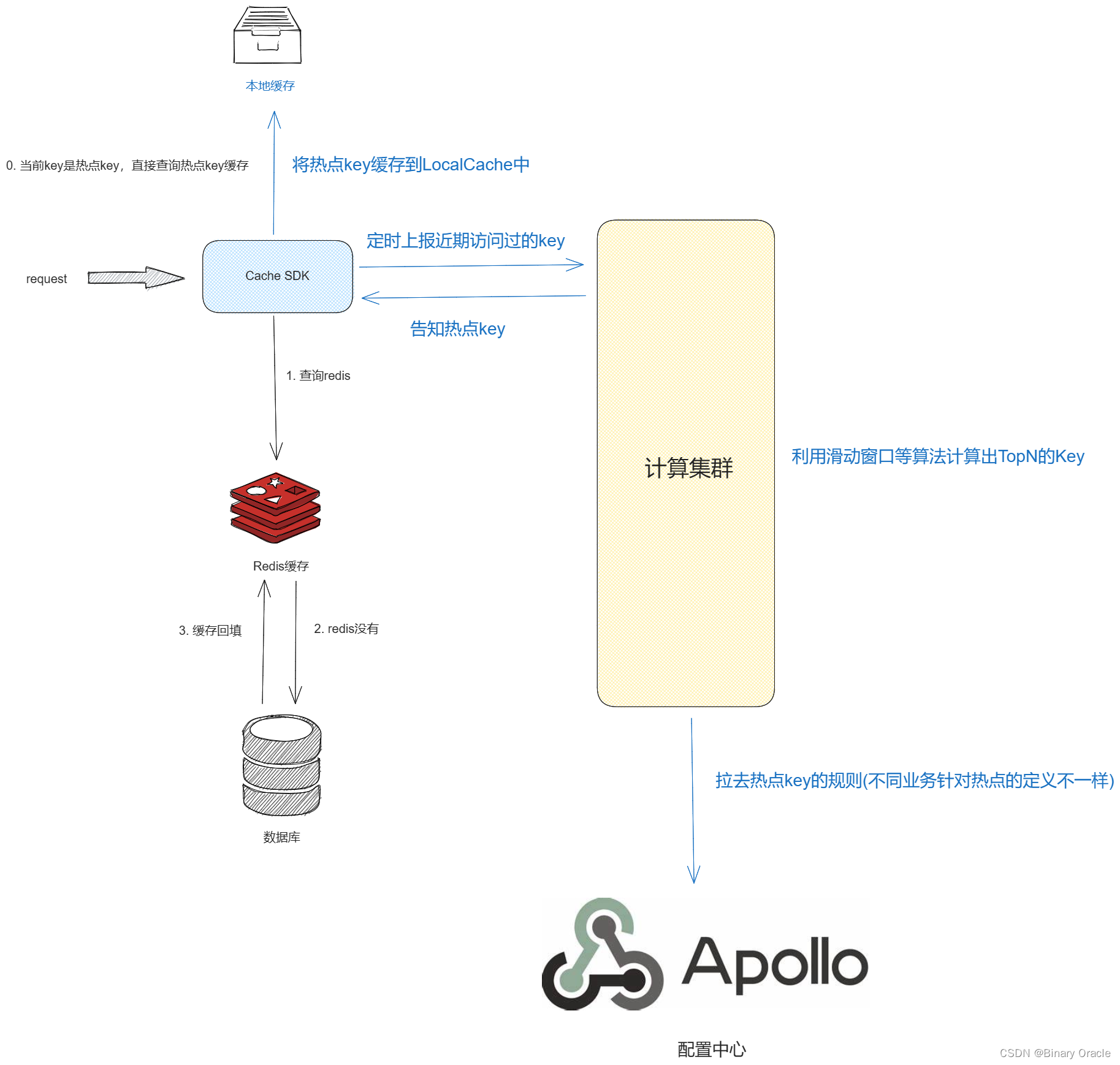
分布式多级缓存SDK设计的思考
分布式多级缓存SDK设计的思考 背景整体架构多层级组装回调埋点分区处理一致性问题缓存与数据库之间的一致性问题不同层级缓存之间的一致性问题不同微服务实例上,非共享缓存之间的一致性问题 小结 之前实习期间编写过一个简单的多级缓存SDK,后面了解到一些…...
)
设计模式:适配器模式(C++实现)
适配器模式(Adapter Pattern)是一种结构设计模式,它允许将一个类的接口转换成客户端所期望的另一个接口。适配器模式通常用于连接两个不兼容的接口或类,使它们能够一起工作。 以下是一个简单的C适配器模式的示例: #in…...
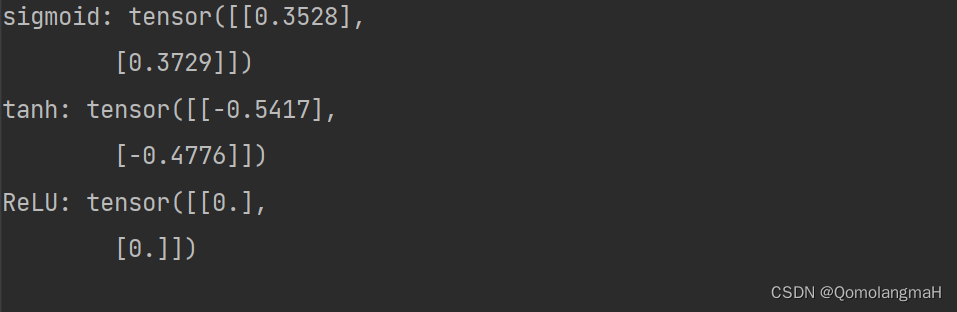
【深度学习实验】前馈神经网络(二):使用PyTorch实现不同激活函数(logistic、tanh、relu、leaky_relu)
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 定义激活函数 logistic(z) tanh(z) relu(z) leaky_relu(z, gamma0.1) 2. 定义输入、权重、偏置 3. 计算净活性值 4. 绘制激活函数的图像 5. 应用激活函数并…...
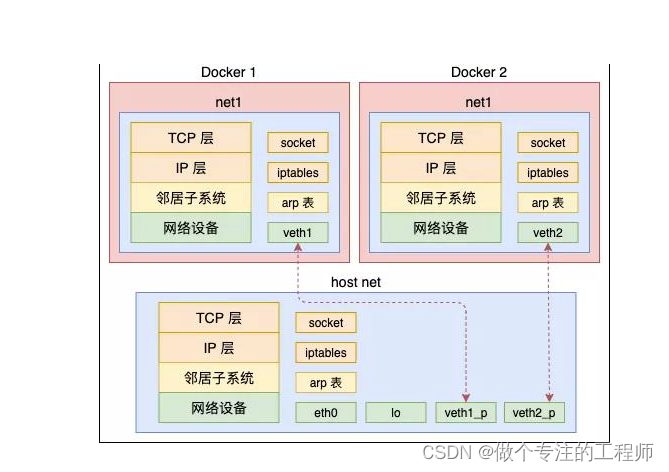
容器技术所涉及Linux内核关键技术
一、容器技术前世今生 1.1 1979年 — chroot 容器技术的概念可以追溯到1979年的UNIX chroot。 它是一套“UNIX操作系统”系统,旨在将其root目录及其它子目录变更至文件系统内的新位置,且只接受特定进程的访问。 这项功能的设计目的在于为每个进程提供…...
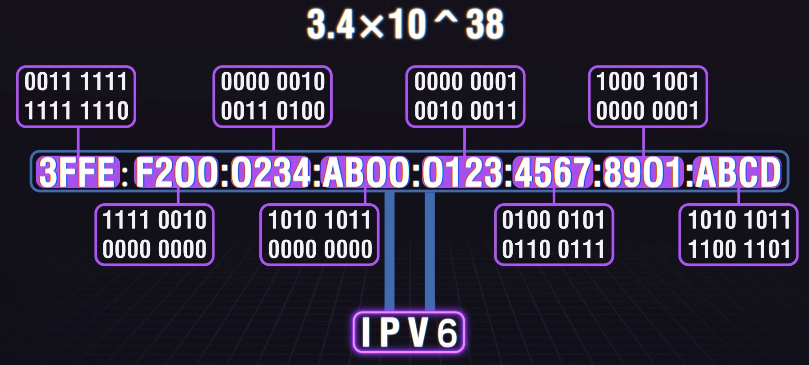
IPV4和IPV6,公网IP和私有IP有什么区别?
文章目录 1、什么是IP地址?1.1、背景1.2、交换机1.3、局域网1.4、广域网1.5、ISP 互联网服务提供商 2、IPV42.1、什么是IPV4?2.2、IPV4的组成2.3、NAT 网络地址转换2.4、端口映射 3、公网IP和私有IP4、IPV6 1、什么是IP地址? 1.1、背景 一台…...
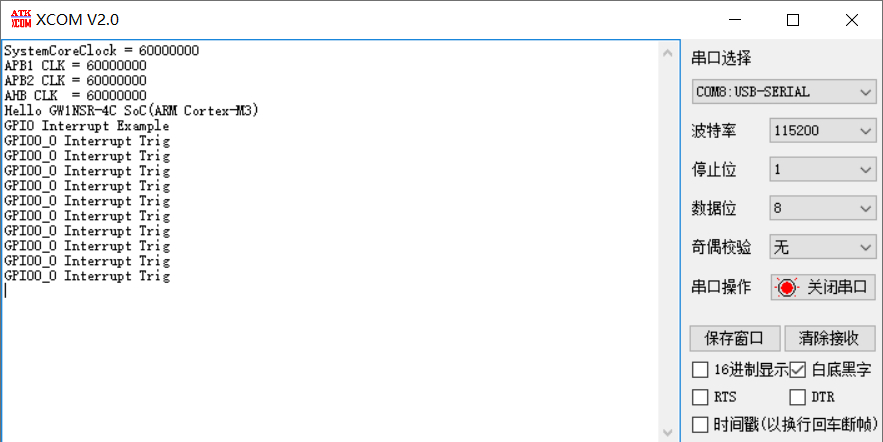
高云FPGA系列教程(7):ARM GPIO外部中断
文章目录 [toc]GPIO中断简介FPGA配置常用函数MCU程序设计工程下载 本文是高云FPGA系列教程的第7篇文章。 本篇文章介绍片上ARM Cortex-M3硬核处理器GPIO外部的使用,演示按键中断方式来控制LED亮灭,基于TangNano 4K开发板。 参考文档:Gowin_E…...

Python爬虫:动态获取页面
动态网站根据用户的某些操作产生一些结果。例如,当网页仅在向下滚动或将鼠标移动到屏幕上时才完全加载时,这背后一定有一些动态编程。当您将鼠标指针悬停在某些文本上时,它会为您提供一些选项,它还包含一些动态.这是是一篇关于动态…...

大数据平台迁移后yarn连接zookeeper 异常分析
大数据平台迁移后yarn连接zookeeper 异常分析 XX保险HDP大数据平台机房迁移异常分析。 异常现象: 机房迁移后大部分组件都能正常启动Yarn 启动后8088 8042等端口无法访问Hive spark 作业提交到yarn会出现卡死。 【备注】虽然迁移,但IP不变。 1. Yarn连…...

Ubuntu Nginx 配置 SSL 证书
首先需要在 Ubuntu 中安装 Nginx 服务, 打开终端执行以下命令: $ sudo apt update $ sudo apt install nginx -y然后启动 Nginx 服务并设置为开机时自动启动, 执行以下命令: $ sudo systemctl start nginx $ sudo systemctl enable nginx最后再验证一下 Nginx 服务的当前状态…...
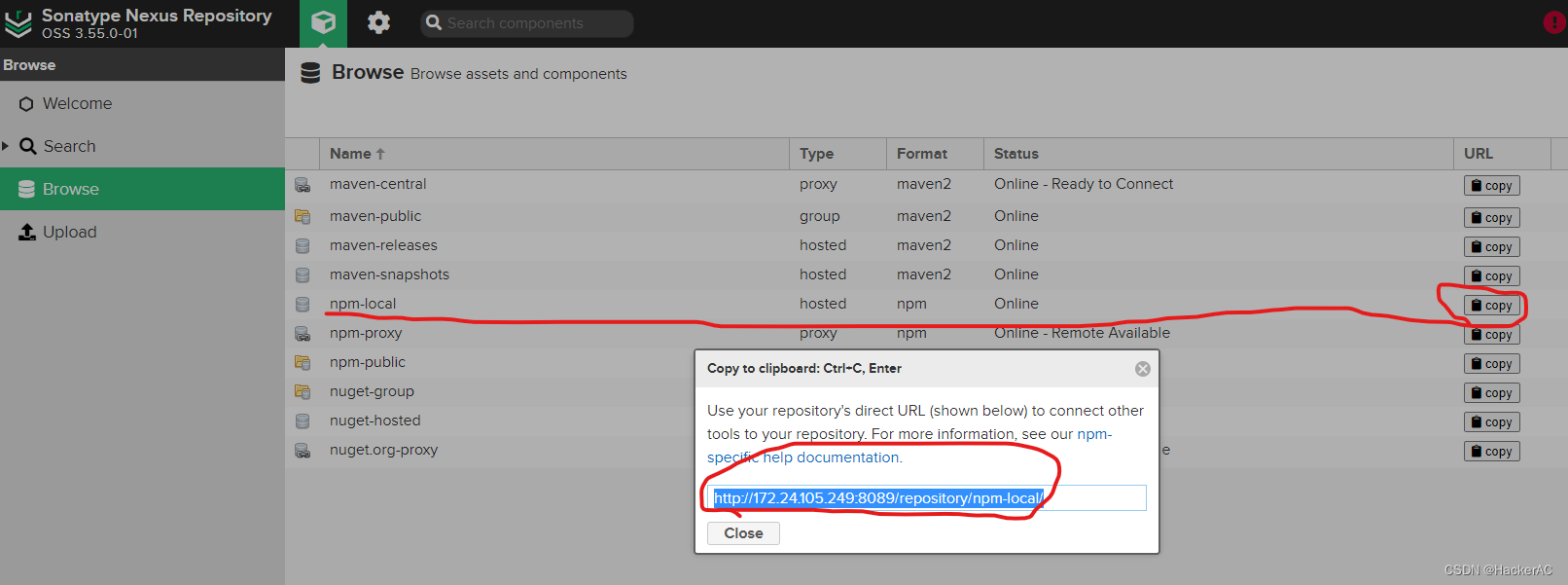
将本地前端工程中的npm依赖上传到Nexus
【问题背景】 用Nexus搭建了内网的依赖仓库,需要将前端工程中node_modules中的依赖上传到Nexus上,但是node_modules中的依赖已经是解压后的状态,如果直接机械地将其简单地打包上传到Nexus,那么无法通过npm install下载使用。故有…...
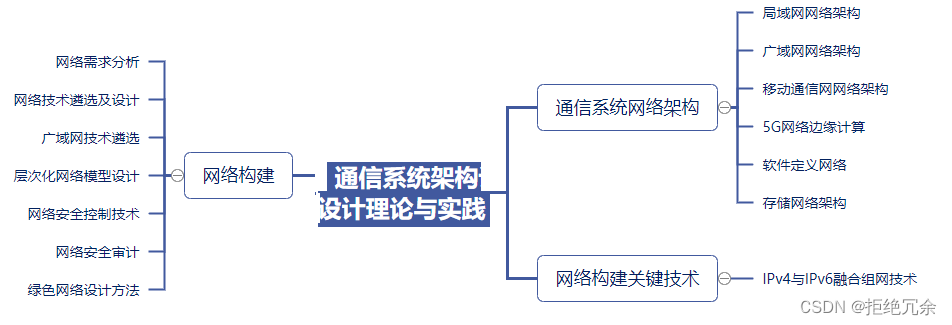
软考高级架构师下篇-16通信系统架构设计理论与实践
目录 1. 引言2. 通信系统网络架构3. 网络构建关键技术4. 网络构建5. 前文回顾1. 引言 此章节主要学习通信系统架构设计的理论和工作中的实践。根据新版考试大纲,本节知识点会涉及案例分析题(25分),而在历年考试中,案例题对该部分内容的考查并不多,虽在综合知识选择题目中…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
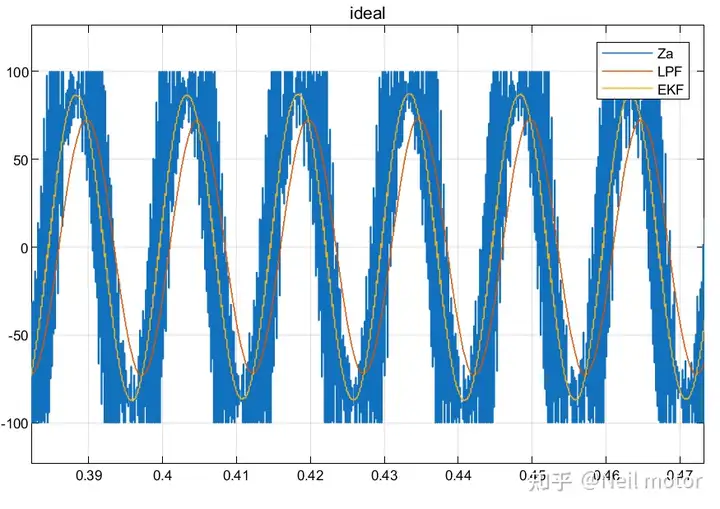
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...