使用Python构建强大的网络爬虫
介绍
网络爬虫是从网站收集数据的强大技术,而Python是这项任务中最流行的语言之一。然而,构建一个强大的网络爬虫不仅仅涉及到获取网页并解析其HTML。在本文中,我们将为您介绍创建一个网络爬虫的过程,这个爬虫不仅可以获取和保存网页内容,还可以遵循最佳实践。无论您是初学者还是经验丰富的开发人员,本指南都将为您提供构建既有效又尊重被抓取网站的网络爬虫所需的工具。
设置您的环境
在深入代码之前,请确保您的计算机上已安装Python。您还需要安装requests和BeautifulSoup库。您可以使用pip来安装它们:
pip install requests beautifulsoup4基本网络爬虫
让我们首先查看一个简单的网络爬虫脚本。此脚本获取一个网页,提取其标题和文本内容,并将它们保存到文本文件中。
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# ...(其余代码)为什么使用requests和BeautifulSoup?
Requests:此库允许您发送HTTP请求并处理响应,因此在获取网页时至关重要。
BeautifulSoup:此库用于解析HTML并提取所需的数据。
创建输出目录
在进行抓取之前,有一个目录可以保存抓取到的数据非常关键。
if not os.path.exists(output_folder):os.makedirs(output_folder)为什么这很重要?
创建专用的输出目录有助于组织抓取到的数据,使以后的分析更加容易。
网页遍历
该脚本使用广度优先搜索方法来遍历网页。它维护一个 visited 集合和一个 to_visit 的URL列表。
visited = set()
to_visit = [base_url]网页遍历的必要性
网页遍历对于从一个网站抓取多个页面非常重要。visited 的集合确保您不会重新访问相同的页面,而 to_visit 的列表则用作您打算抓取的页面的队列。
获取和解析网页
获取网页涉及发送HTTP GET请求,而解析涉及将HTML内容转换为BeautifulSoup对象。
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')为什么获取和解析?
获取可获取原始HTML内容,但解析允许您浏览此内容并提取所需的数据。
数据提取和存储
该脚本从各种HTML标签中提取标题和文本内容,并将它们保存到文本文件中。
title = soup.title.string if soup.title else "未找到标题"
# ...(其余代码)数据提取和存储的重要性
数据提取是网络爬虫的核心。有效存储这些数据有助于更容易地进行分析和共享。
错误处理和速率限制
该脚本检查HTTP状态码,但缺乏全面的错误处理和速率限制。
if response.status_code != 200:print(f"无法检索{url}。状态码:{response.status_code}")为什么需要错误处理和速率限制?
错误处理确保您的爬虫可以从意外问题中恢复,而速率限制可以防止您的爬虫过于频繁地访问服务器并被封锁IP地址。
网络爬虫的效用
网络爬虫不仅仅是一个技术练习;它具有现实世界的应用,可以推动业务决策、学术研究等各种领域。
为什么网络爬虫很重要?
数据汇总:网络爬虫允许您将来自各种来源的数据收集到一个地方。这对于市场研究、情感分析或竞争分析特别有用。
自动化:手动收集数据可能会耗费时间并且容易出错。网络爬虫自动化了这个过程,节省了时间并减少了错误。
内容监控:您可以使用网络爬虫来监控竞争对手网站、股价或新闻更新等内容的变化。
机器学习和数据分析:通过网络爬虫收集的数据可以用于训练机器学习模型或进行高级数据分析。
SEO监控:网络爬虫可以帮助跟踪您的网站的SEO表现,为您提供如何提高搜索引擎排名的见解。
强大网络爬虫的高级功能
虽然基本爬虫是功能性的,但缺少一些功能,这些功能可以使它更强大和多功能。让我们讨论一些您可能考虑添加的高级功能。
用户代理和头文件
一些网站可能会阻止不包含用户代理字符串的请求,该字符串用于识别发出请求的客户端。
headers = {'User-Agent': 'your-user-agent-string'}
response = requests.get(url, headers=headers)代理轮换
为了避免IP地址被封锁,您可以使用多个IP地址发出请求。
proxies = {'http': 'http://10.10.1.10:3128'}
response = requests.get(url, proxies=proxies)CAPTCHA处理
一些网站使用CAPTCHA来防止自动抓取。虽然可以使用selenium等库来处理这些挑战,但这可能会使您的爬虫变得更加复杂。
from selenium import webdriverdriver = webdriver.Firefox()
driver.get(url)
# ...(CAPTCHA处理代码)数据存储
您可以考虑使用MongoDB或SQL数据库来存储抓取的数据,而不是将其存储在文本文件中,以实现更结构化和可扩展的存储。
import pymongoclient = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["抓取的数据"]
collection = db["网页"]
collection.insert_one({"url": url, "title": title, "content": full_text})将它们组合起来
import os
import time
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoindef fetch_content(base_url, output_folder):if not os.path.exists(output_folder):os.makedirs(output_folder)visited = set()to_visit = [base_url]headers = {'User-Agent': 'your-user-agent-string'}while to_visit:url = to_visit.pop(0)if url in visited: continuetry:response = requests.get(url, headers=headers, timeout=10)response.raise_for_status()except requests.RequestException as e: print(f"无法检索{url}。错误:{e}") continuevisited.add(url)soup = BeautifulSoup(response.text, 'html.parser')title = soup.title.string if soup.title else "未找到标题"text_content = [] for paragraph in soup.find_all(['p', 'div', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6']):text_content.append(paragraph.text)full_text = "\n".join(text_content)output_file_path = os.path.join(output_folder, f"{len(visited)}.txt") with open(output_file_path, 'w', encoding='utf-8') as f:f.write(f"URL: {url}\n")f.write(f"Title: {title}\n")f.write("=====================================\n")f.write(f"Text Content:\n{full_text}\n\n") print(f"已保存从{url}抓取的数据到{output_file_path}") for a_tag in soup.find_all('a', href=True):next_url = urljoin(base_url, a_tag['href']) if base_url in next_url:to_visit.append(next_url)time.sleep(1) # 速率限制以避免过于频繁地访问服务器if __name__ == "__main__":base_url = "https://www.example.com/"output_folder = "抓取的页面"fetch_content(base_url, output_folder)关键添加
用户代理字符串:headers字典包含一个用户代理字符串,以帮助绕过网站上的基本安全检查。
headers = {'User-Agent': 'your-user-agent-string'}错误处理:在requests.get()方法周围的try-except块可以优雅地处理与网络相关的错误。
try:response = requests.get(url, headers=headers, timeout=10)response.raise_for_status()
except requests.RequestException as e: print(f"无法检索{url}。错误:{e}") continue速率限制:添加了time.sleep(1)以在请求之间暂停一秒钟,减少IP地址被封锁的风险。
time.sleep(1)通过添加这些功能,我们使网络爬虫更加强大,并确保其尊重与之交互的网站。这是一个很好的起点,随着您继续完善网络爬虫,您可以添加更多高级功能,如代理轮换、CAPTCHA处理和数据库存储。
结论和未来方向
网络爬虫是一个功能强大的工具,具有广泛的应用,从业务到学术都有。然而,构建一个强大的网络爬虫不仅仅涉及到获取网页并解析其HTML。本文为您提供了每个步骤的综合指南,不仅解释了如何实现每个功能,还解释了每个功能为什么必要。
在继续完善您的网络爬虫时,考虑添加高级功能,如用户代理字符串、代理轮换、CAPTCHA处理和数据库存储。这些功能将使您的爬虫更加强大、多功能,并确保尊重您正在抓取的网站。有了这些工具,您将成功迈向成为一个网络爬虫专家。祝愉快抓取!
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除
相关文章:
使用Python构建强大的网络爬虫
介绍 网络爬虫是从网站收集数据的强大技术,而Python是这项任务中最流行的语言之一。然而,构建一个强大的网络爬虫不仅仅涉及到获取网页并解析其HTML。在本文中,我们将为您介绍创建一个网络爬虫的过程,这个爬虫不仅可以获取和保存网…...

图像处理之《基于语义对象轮廓自动生成的生成隐写术》论文精读
一、相关知识 首先我们需要了解传统隐写和生成式隐写的基本过程和区别。传统隐写需要选定一幅封面图像,然后使用某种隐写算法比如LSB、PVD、DCT等对像素进行修改将秘密嵌入到封面图像中得到含密图像,通过信道传输后再利用算法的逆过程提出秘密信息。而生…...

Java 字节流
一、输入输出流 输入输出 ------- 读写文件 输入 ------- 从文件中获取数据到自己的程序中,接收处理【读】 输出 ------- 将自己程序中处理好的数据保存到文件中【写】 流 ------- 数据移动的轨迹 二、流的分类 按照数据的移动轨迹分为:输入流 输出流…...

华硕电脑怎么录屏?分享实用录制经验!
“华硕电脑怎么录屏呀,刚买的笔记本电脑,是华硕的,自我感觉挺好用的,但是不知道怎么录屏,最近刚好要录一个教程,怎么都找不到在哪里录制,有人能教教我吗?” 随着电脑技术的不断发展…...

python学习--python的异常处理机制
try…except try:n1int(input(请输入一个整数))n2int(input(请输入另一个整数))resultn1/n2print(结果为,result) except ZeroDivisionError: print(除数不能为0)try…except…else 如果try块中没有抛出异常,则执行else块,如果try中抛出异常࿰…...
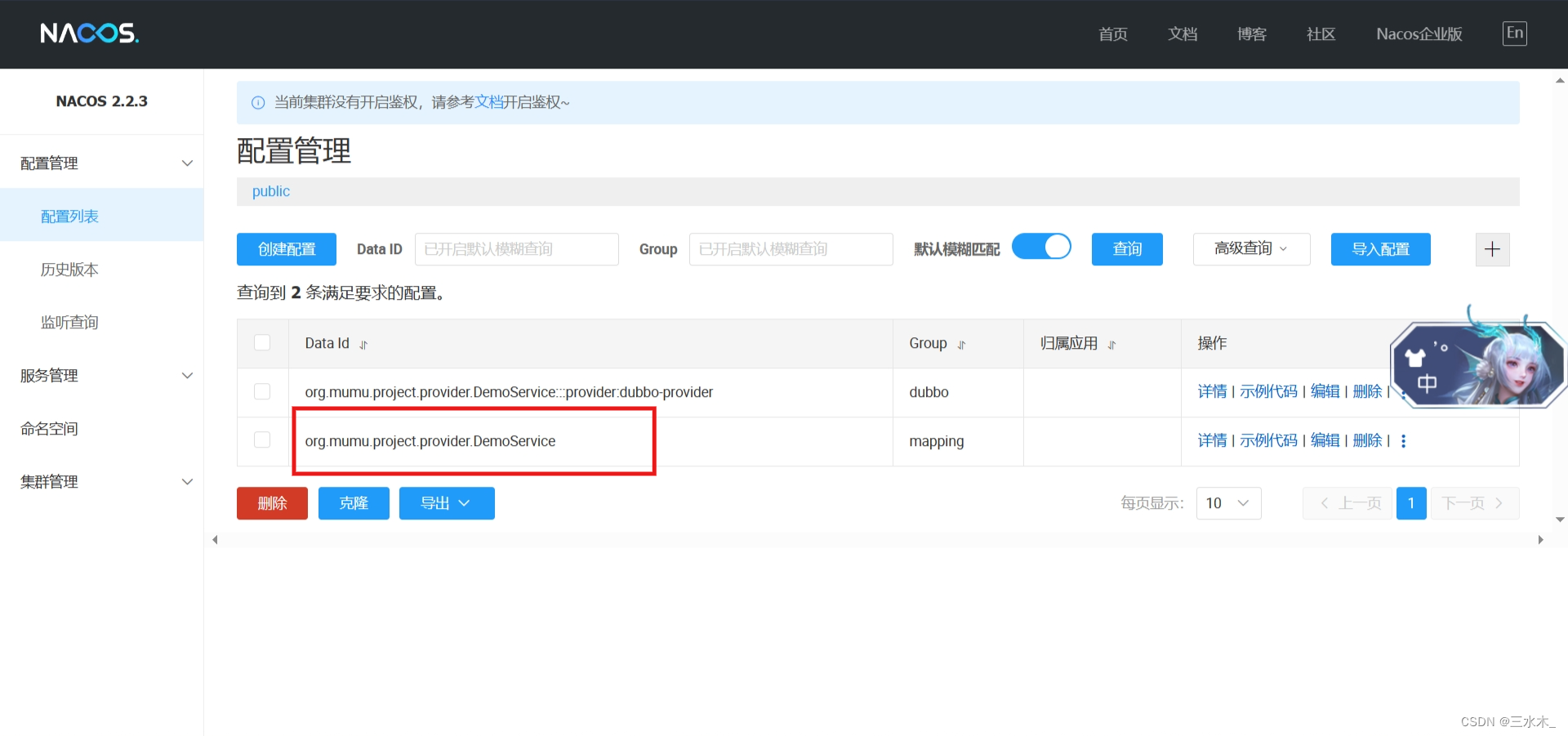
nacos+Dubbo整合快速入门
官网:Nacos Spring Boot 快速开始 下载下载链接启动:进入bin目录,startup.cmd -m standalone引入依赖 <dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo</artifactId><version>3.0.9…...
QT实现钟表
1、 头文件 #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QPaintEvent> //绘制事件类 #include <QDebug> //信息调试类 #include <QPainter> //画家类 #include <QTimerEve…...
准备我们心爱的IDEA写Jsp
JSP学习 一、准备我们心爱的IDEA new一个项目:New Project --> Next -->Next -->Finsh 二、配置好服务器Tomcat-9.0.30 1.> 在WEB-INF下创建一个Lib包 将jsp-api.jar复制进去,并使其生效 未生效前: 生效过程: 2.>…...
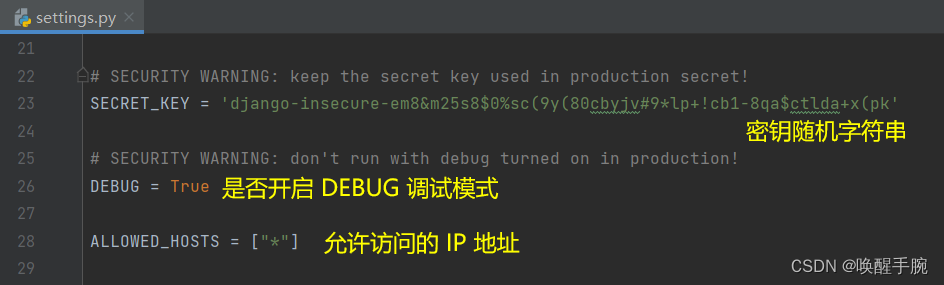
将近 5 万字讲解 Python Django 框架详细知识点(更新中)
Django 框架基本概述 Django 是一个开源的 Web 应用后端框架,由 Python 编写。它采用了 MVC 的软件设计模式,即模型(Model)、视图(View)和控制器(Controller)。在 Django 框架中&am…...
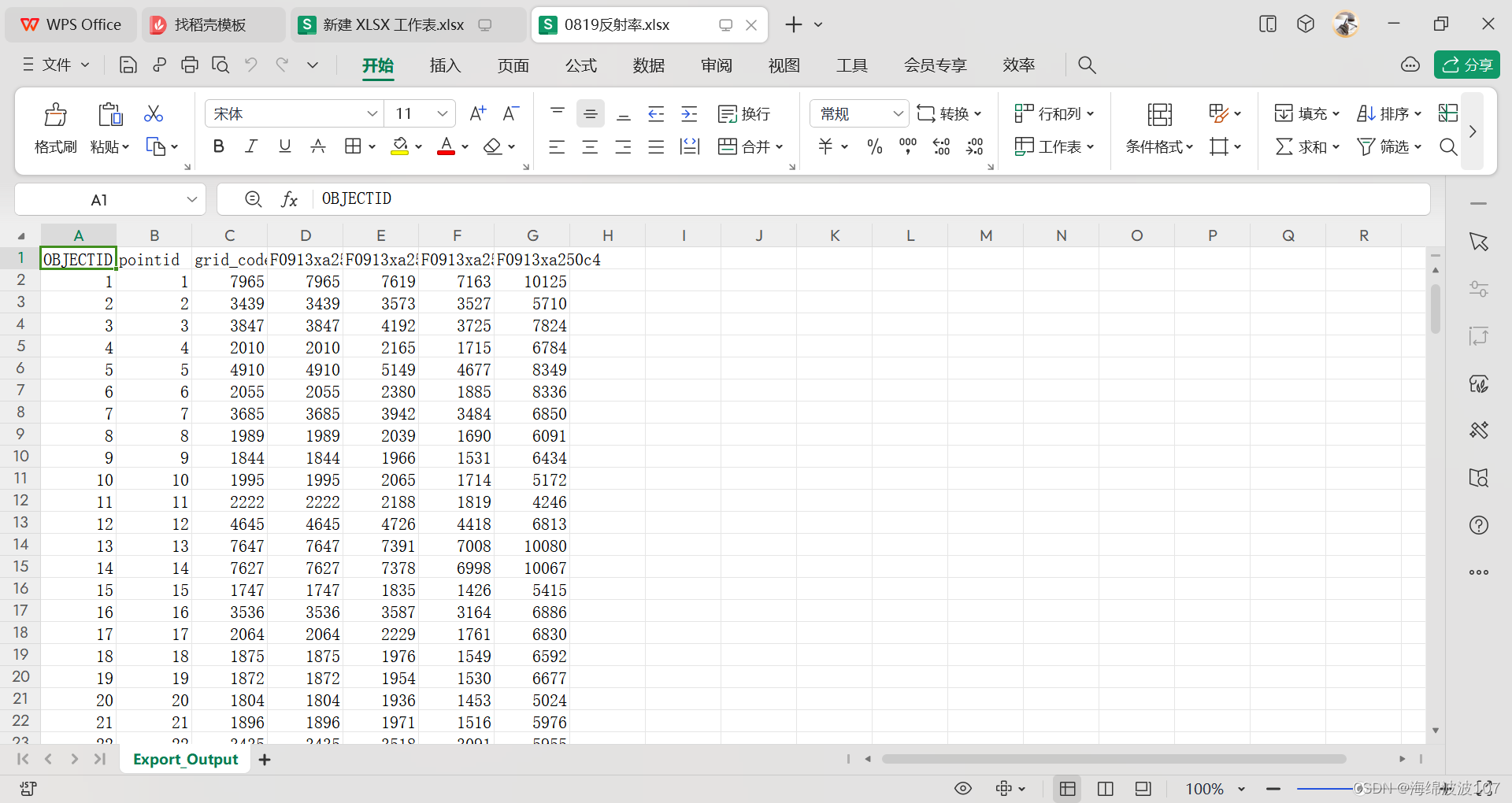
Arcgis提取每个像元的多波段反射率值
Arcgis提取每个像元的多波段反射率值 数据预处理 数据预处理阶段需要对遥感图像进行编辑传感器参数、辐射定标、大气校正、正射校正,具体流程见该文章 裁剪研究区 对于ENVI处理得到的tiff影像,虽然是经过裁剪了,但是还存在黑色的背景值&a…...
)
JavaScript面试题整理(一)
数据类型篇 1、JavaScript有哪些数据类型,它们的区别是什么? 基本数据类型:number、string、boolean、undefined、NaN、BigInt、Symbol 引入数据类型:Object NaN是JS中的特殊值,表示非数字,NaN不是数字…...

数据结构:树和二叉树之-堆排列 (万字详解)
目录 树概念及结构 1.1树的概念 1.2树的表示 编辑2.二叉树概念及结构 2.1概念 2.2数据结构中的二叉树:编辑 2.3特殊的二叉树: 编辑 2.4 二叉树的存储结构 2.4.1 顺序存储: 2.4.2 链式存储: 二叉树的实现及大小堆…...

爬虫入门基础:深入解析HTTP协议的工作过程
目录 一、HTTP协议简介 二、HTTP协议的工作过程 三、请求方法与常见用途 四、请求头与常见字段 五、状态码与常见含义 六、进阶话题和注意事项 总结 在如今这个数字化时代,互联网已经成为我们获取信息、交流和娱乐的主要渠道。而在互联网中,HTTP协…...
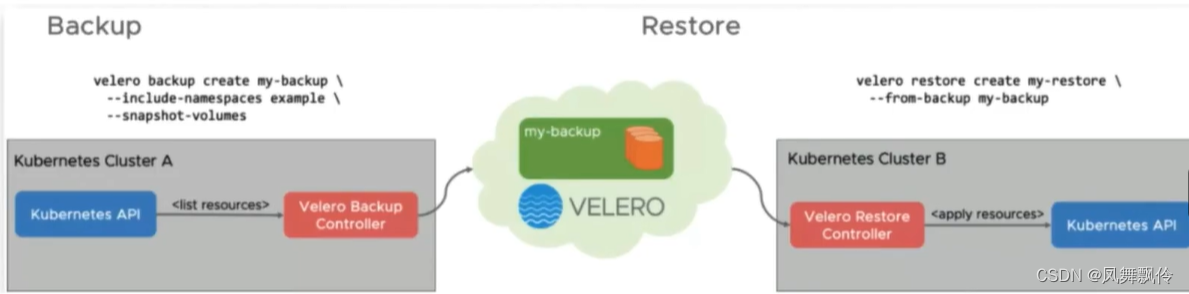
k8备份与恢复-Velero
简介 Velero 是一款可以安全的备份、恢复和迁移 Kubernetes 集群资源和持久卷等资源的备份恢复软件。 Velero 实现的 kubernetes 资源备份能力,可以轻松实现 Kubernetes 集群的数据备份和恢复、复制 kubernetes 集群资源到其他kubernetes 集群或者快速复制生产环境…...

基于Python开发的火车票分析助手(源码+可执行程序+程序配置说明书+程序使用说明书)
一、项目简介 本项目是一套基于Python开发的火车票分析助手,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Python学习者。 包含:项目源码、项目文档等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,…...

旺店通·企业奇门与金蝶云星空对接集成订单查询连通销售订单新增(旺店通销售-金蝶销售订单-小红书)
旺店通企业奇门与金蝶云星空对接集成订单查询连通销售订单新增(旺店通销售-金蝶销售订单-小红书) 接通系统:旺店通企业奇门 慧策最先以旺店通ERP切入商家核心管理痛点——订单管理,之后围绕电商经营管理中的核心管理诉求,先后布局流量获取、会…...
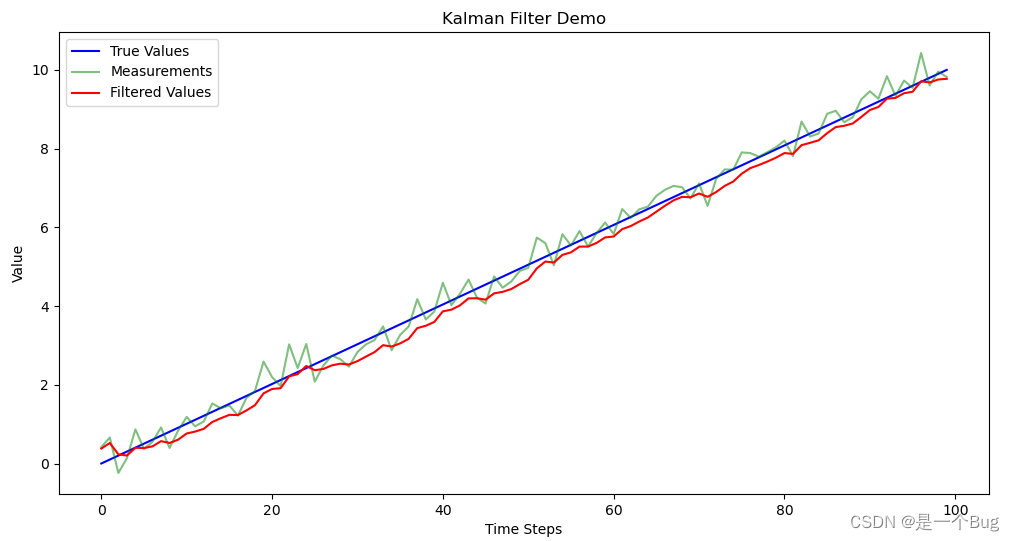
卡尔曼滤波应用在数据处理方面的应用
卡尔曼滤波应用到交通领域 滤波器介绍核心思想核心公式一维卡尔曼滤波器示例导入所需的库 滤波器介绍 卡尔曼滤波器是一种用于估计系统状态的数学方法,它以卡尔曼核心思想为基础,广泛应用于估计动态系统的状态和滤除测量中的噪声。以下是卡尔曼滤波器的核…...

PROFIBUS主站转ETHERCAT协议网关
产品介绍 JM-DPM-ECT是自主研发的一款PROFIBUS-DP主站功能的通讯网关。该产品主要功能是将各种PROFIBUS-DP从站接入到ETHERCAT网络中。 本网关连接到PROFIBUS总线中作为主站使用,连接到ETHERCAT总线中作为从站使用。 产品参数 技术参数 ◆ PROFIBUS-DP/V0 协议符…...

Vue路由的使用及node.js下载安装和环境搭建
目录 一、Vue路由 1.1 简介 ( 1 ) 特点 ( 2 ) 作用 1.2 实例 ( 1 ) 引入 ( 2 ) 组件 ( 3 ) 关系 ( 4 ) 路由 ( 5 ) 事件 ( 6 ) 锚点 二、nodeJS 2.1 下载 2.2 安装 2.3 环境搭建 新增 添加 测试 配置 运行 一、Vue路由 1.1 简介 Vue路由是Vue.…...
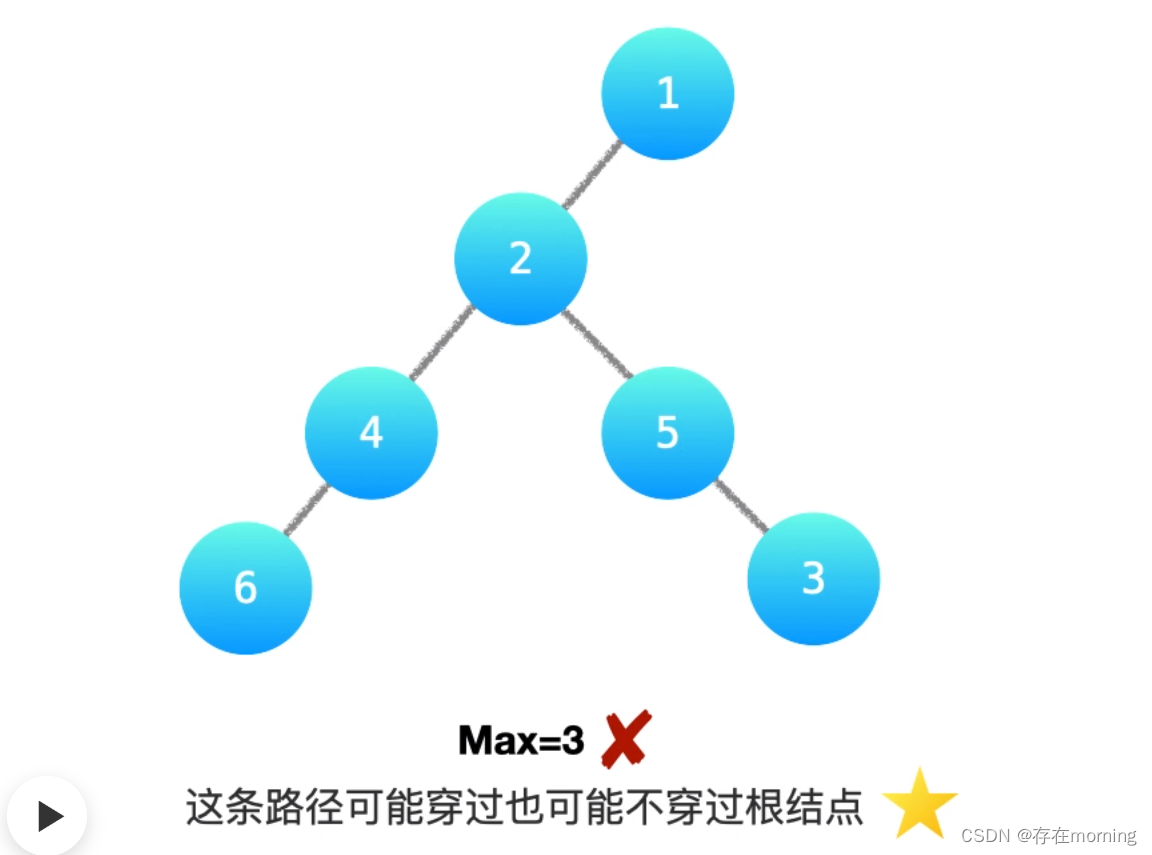
【算法训练-二叉树 三】【最大深度与直径】求二叉树的最大深度、求二叉树的直径
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【求二叉树的直径】,使用【二叉树】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件…...
)
VINS_Fusion轨迹评估实战:如何用evo工具搞定MH_01_easy数据集测试(附完整代码修改指南)
VINS_Fusion轨迹精度评估全流程:从数据准备到evo工具深度解析 1. 环境配置与工具准备 在开始评估VINS_Fusion的轨迹精度之前,我们需要确保开发环境已经正确配置。以下是必要的准备工作: 基础环境要求: Ubuntu 18.04/20.04 LTS&…...

科研党收藏!9个降AIGC工具:全行业通用测评与推荐
在科研论文写作过程中,AI生成内容的痕迹往往成为查重率攀升的“隐形杀手”。如何在保持学术严谨性的同时有效降低AIGC率,已成为众多研究者亟需解决的问题。随着技术的发展,各类AI降重工具应运而生,它们不仅能够精准识别并去除AI痕…...
)
保姆级教程:Windows下GDC-client下载TCGA数据的完整配置流程(含环境变量与配置文件修改)
Windows平台TCGA数据下载全流程:从环境配置到实战避坑指南 在生物信息学研究中,TCGA数据库无疑是癌症基因组学的宝库。但对于刚入门的研究者来说,获取这些数据往往成为第一道门槛。本文将彻底解决Windows用户在使用GDC-client工具时的各种&qu…...

LightOnOCR-2-1B GPU优化实践:vLLM推理引擎配置与显存占用压测报告
LightOnOCR-2-1B GPU优化实践:vLLM推理引擎配置与显存占用压测报告 你是不是也遇到过这样的烦恼?部署一个OCR模型,明明看着参数不大,但一跑起来,显存就蹭蹭往上涨,甚至直接爆掉。或者,服务启动…...

深入理解Vue中.native修饰符在Element UI组件事件绑定的应用
1. 为什么el-card上的click事件会失效? 第一次在Element UI的el-card组件上绑定click事件时,你可能遇到过点击毫无反应的情况。这其实不是代码写错了,而是Vue事件系统的一个特性在"作怪"。Element UI的组件本质上都是Vue自定义组件…...

造相-Z-Image效果对比:Z-Image在中文语义理解准确率上超越SDXL实测
造相-Z-Image效果对比:Z-Image在中文语义理解准确率上超越SDXL实测 最近在折腾本地文生图,发现了一个挺有意思的现象。我用的是基于通义千问官方Z-Image模型定制的“造相-Z-Image”引擎,专门为我的RTX 4090显卡做了优化。本来只是想试试它的…...

【deepseek】SYCL™ 2020 Specification 简介
SYCL™ 2020 Specification 简介 SYCL 2020 是由 Khronos Group 发布的异构计算标准,它是 SYCL(发音为 “sickle”)规范的最新主要版本。SYCL 是一种基于标准 C 的编程模型,旨在简化在各种硬件加速器(如 CPU、GPU、FPG…...

开关电源设计实战:Buck、Boost、Buck-Boost三大拓扑公式详解与选型指南
开关电源设计实战:Buck、Boost、Buck-Boost三大拓扑公式详解与选型指南 刚入行电源设计那会儿,我最头疼的就是面对各种拓扑结构的选择。Buck、Boost、Buck-Boost这三种基础拓扑看似简单,但实际设计中总会在参数计算和器件选型上栽跟头。记得第…...

Meixiong Niannian画图引擎CFG引导实验:从3.0到12.0的画质变化图谱
Meixiong Niannian画图引擎CFG引导实验:从3.0到12.0的画质变化图谱 1. 引言:为什么CFG系数如此重要? 如果你用过AI画图工具,一定遇到过这样的困惑:明明描述词写得很好,为什么生成的图片要么太“放飞自我”…...
)
PCIe Gen4眼图测试实战:如何用示波器快速定位信号完整性问题(附避坑指南)
PCIe Gen4眼图测试实战:示波器操作与信号完整性诊断全解析 当PCIe Gen4的信号速率突破16GT/s大关时,硬件工程师的工作台上总少不了一台高性能示波器。记得去年参与某企业级SSD项目时,我们团队连续三周被一个诡异的眼图闭合问题困扰——每次系…...