基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(二)
目录
- 前言
- 总体设计
- 运行环境
- Python环境
- 依赖库
- 模块实现
- 1. 疾病预测
- 2. 药物推荐
- 1)数据预处理
- 2)模型训练及应用
- 3)模型应用
- 其它相关博客
- 工程源代码下载
- 其它资料下载

前言
本项目基于Kaggle上公开的数据集,旨在对心脏病和慢性肾病进行深入的特征筛选和提取。它利用了随机森林机器学习模型,通过对这些特征进行训练,能够预测是否患有这些疾病。不仅如此,该项目还会根据患者的症状或需求,提供相关的药物推荐,从而实现了一款实用性强的智能医疗助手。
首先,项目收集了来自Kaggle的公开数据集,这些数据包含了与心脏病和慢性肾病相关的丰富信息。然后,通过数据预处理和特征工程,从这些数据中提取出最相关的特征,以用于机器学习模型的训练。
接下来,项目采用了随机森林机器学习模型,这是一种强大的分类算法。通过使用训练数据,模型能够学习不同特征与心脏病和慢性肾病之间的关联。一旦模型经过训练,它可以对新的患者数据进行预测,判断患者是否有这些疾病。
除了疾病预测,该项目还具备一个药物推荐系统。基于患者的症状、需求和疾病诊断,系统会推荐适合的药物和治疗方案,以提供更全面的医疗支持。
综合来看,这个项目不仅可以预测心脏病和慢性肾病,还可以提供个性化的治疗建议。这种智能医疗助手有望提高医疗决策的准确性,为患者提供更好的医疗体验,并对医疗资源的合理分配起到积极作用。
总体设计
本部分包括系统整体结构图和系统流程图。
运行环境
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
依赖库
使用下面命令安装:
pip install pandas
模块实现
本项目包括2个功能,每个功能有3个模块:疾病预测、药物推荐、模块应用,下面分别给出各模块的功能介绍及相关代码。
1. 疾病预测
本模块是一个小型健康预测系统,预测两种疾病心脏病和慢性肾病。
2. 药物推荐
本模块是一个小型药物推荐系统,对800余种症状提供药物推荐。
1)数据预处理
UCI ML药品评论数据集来源:https://www.kaggle.com/jessicali9530/kuc-hackathon-winter-2018 。包括超20多万条不同用户在某一种症状下服用某药物后的评论,并根据效果从1~10进行打分。通过分析该数据集,可以对用户症状推荐大众认可的药物。
加载数据集和数据预处理,大部分通过Pandas实现,相关代码如下:
#导入相应库函数
import pandas as pd
#读取评论数据集
train = pd.read_csv('../Thursday9 10 11/drugsComTrain_raw.csv')
test = pd.read_csv('../Thursday9 10 11/drugsComTest_raw.csv')
会自动从csv数据源读取相应的数据,如图所示。

数据集中有用户ID (UniqueID) 、症状( condition)、服用的药物(drugName) 、服用该药物后的评论(review)、打分(rating) ,其他用户对该用户评论的点赞数(usefulCount) 。
本项目根据用户对药物的打分判断是否推荐在该症状下服用此药物。打分为1分和10分可以认为用户不推荐和推荐该药物。然而,用户对药物的打分不只是1分和10分,一般来说,对一种药物有时有效但见效慢、好用但昂贵、有所缓解但效果不明显、副作用不容忽视等。打4分不一定代
表评价者的否定态度,打6分也不一定意味着评价者支持。
#通过Pandas的统计,全部评论数为
print('全部评论数:')
print(len(train))
print(len(test))
print('两端评分有:')
print(len(train))
print(len(test))
样本总量如图所示。

打1分和10分的评论总量如图5所示。

用户打分分布图如图6所示。
# 打分
train.rating.hist(bins=10)
plt.title('Distribution of Ratings')
plt.xlabel('Rating')
plt.ylabel('Count')
plt.xticks([i for i in range(1, 11)]);
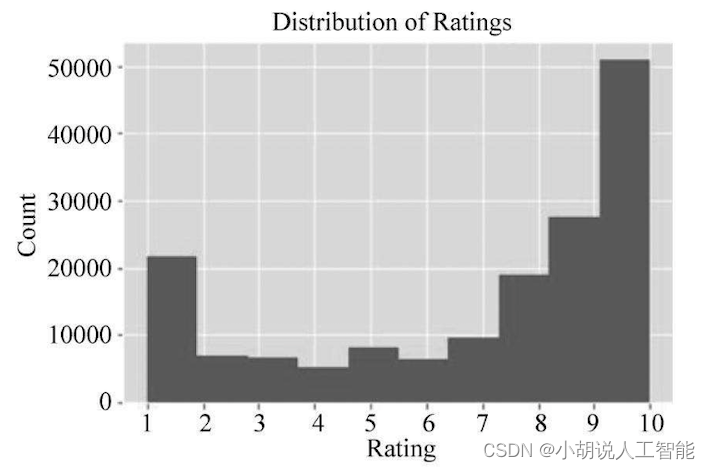
图5和图6可以看出,超过一半的用户打1分和10分,样本数据量足够机器学习用户情感,使用学习到的情感,分析打分在2~9分的用户就是内心深处支持与否。打分为1分和10分的评论情感分析学习如图7所示。
#取出评分为1和10两端的数据
train=train[train.rating.isin([1,10])]
test=test[test.rating.isin([1,10])]

评论(review)中,句子两端有引号,编写函数将引号删除。
def remove_enclosing_quotes(s):if s[0] == '"' and s[-1] == '"':return s[1:-1]else:return s
#调用写好的函数,删除双引号
train.review = train.review.apply(remove_enclosing_quotes)
test.review = test.review.apply(remove_enclosing_quotes
发现一句话中经常出现不合时宜的符号,该数据集是网络爬虫爬取的,所以有很多字符表示成ASCII码,防止被误识别为分隔,使用正则表达式从审阅文本中删除这些符号。
评论(review) 中,句子两端有引号,编写函数将引号删除。
import re
train.review = train.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
test.review = test.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
预测的标签是喜欢与不喜欢,但是drugName和condition种类很多,写进程序中可以简化工作量,所以需要将drugName和condition列前置到review中,并将完整的字符串保存为text列。
#定义函数
def combine_text_columns(data_frame, text_cols):text_data = data_frame[text_cols]text_data.fillna("", inplace=True)return text_data.apply(lambda x: " ".join(x), axis=1)
#将drugName和condition列前置到review中
text_cols = ['drugName', 'condition', 'review']
train['text'] = combine_text_columns(train, text_cols)
test['text'] = combine_text_columns(test, text_cols)
CountVectorizer类将文本中的词语转换为词频矩阵。通过分词后把所有文档中的全部词作为一个字典,将每行的词用0、1矩阵表示。并且每行的长度相同,长度为字典的长度,在词典中存在,置为1,否则为0。由于大部分文本只用词汇表中很少一部分词,因此,词向量中有大量的0,说明词向量是稀疏的,在实际应用中使用稀疏矩阵存储。
#过滤规则,token的正则表达式
TOKENS_ALPHANUMERIC = '[A-Za-z0-9]+(?=\\s+)'
#CountVectorizer对象的实例化,停用词选为english内置的英语停用词
vec_alphanumeric = CountVectorizer(token_pattern=TOKENS_ALPHANUMERIC, ngram_range=(1,2), lowercase=True, stop_words='english', min_df=2, max_df=0.99)
#fit_transform是fit和transform的组合,对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值、最小值等,对trainData转换成transform,实现数据的标准化、归一化
X = vec_alphanumeric.fit_transform(train.text)
#1和10是两类,从5分开还是6分开无所谓,因为当前数据集中只有1分和10分
train['binary_rating'] = train['rating'] > 5
y = train.binary_rating
#使用Scikit-learn的train_test_split自动划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, stratify=y, test_size=0.1)
#UCI ML药品评论预处理完成
2)模型训练及应用
相关代码如下:
#使用逻辑斯蒂回归训练模型
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, stratify=y, test_size=0.1)
clf_lr = LogisticRegression(penalty='l2', C=100).fit(X_train, y_train)
#在测试集检验模型准确度
pred = clf_lr.predict(X_test)
#输出模型准确度
print("Accuracy on training set: {}".format(clf_lr.score(X_train, y_train)))
print("Accuracy on test set: {}".format(clf_lr.score(X_test, y_test)))
仅取出打分为1分和10分的评论进行情感分析学习,如图8所示,打分2~9分的评论如图9所示,代入模型分析评论情感为支持或不支持如图10所示。



由于是评1分和10分,所以正确率高,接下来将训练好的模型应用到打分为2~9分的评论中。
#读取2~9分的评论
Train_0 = train_0[train.rating.isin([2,3,4,5,6, 7,8,9])]
Train_0.head()
将评论经过数据预处理后,带入训练好的模型,得到评论感情分类。
pred_0 = clf_lr.predict(X_0)
#输出最终判决结果
print(pred_0)
#输出结果到csv文件中
import csv
data =pred_0
with open('medicine.csv','r') as csvFile: #此处的csv是源表rows = csv.reader(csvFile)with open('2.csv','w',newline='support') as f:#这里csv是最后输出得到的新表writer = csv.writer(f)i = 0for row in rows:row.append(data[i])print(i)i = i + 1writer.writerow(row)
3)模型应用
将两个csv文件合并成一个, 本项目对某一特定症状选取支持率前三名的药物。
help_dict = {}
#unique方法不重复的记录所有症状,遍历
import csv
headers = ['condition','medicine_1','medicine_2','medicine_3']
with open('cure.csv','a',newline='') as f:f_csv = csv.writer(f)f_csv.writerow(headers)for i in train.condition.unique():temp_ls = []#遍历这个症状所提到,且被认同的药物for j in train[train.condition == i & train.support==True ].drugName.unique():#如果这种药物至少10个人提及,则记录下来if np.sum(train.drugName == j) >= 10:temp_ls.append((j, np.sum(train[train.drugName == j].rating) / np.sum(train.drugName == j))) #针对症状i,从好到坏将刚刚提到的药进行排名help_dict[i] = pd.DataFrame(data=temp_ls, columns=['drug', 'average_rating']).sort_values(by='average_rating', ascending=False).reset_index(drop=True) rows=[(i,help_dict[i].iloc[0:1].drug,help_dict[i].iloc[1:2].drug,help_dict[i].iloc[2:3].drug)]f_csv.writerows(rows)f.close()
#最终完成遍历时,在编译界面有一个反馈
print('ok')
得到一个csv数据库,但是数据库中除了特定的药物名称,还有一些特殊字符,通过编写Python脚本文件将它们清理干净。
其它相关博客
-
基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(一)
-
基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
相关文章:
基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(二)
目录 前言总体设计运行环境Python环境依赖库 模块实现1. 疾病预测2. 药物推荐1)数据预处理2)模型训练及应用3)模型应用 其它相关博客工程源代码下载其它资料下载 前言 本项目基于Kaggle上公开的数据集,旨在对心脏病和慢性肾病进行…...
stm32学习-芯片系列/选型
【03】STM32HAL库开发-初识STM32 | STM概念、芯片分类、命名规则、选型 | STM32原理图设计、看数据手册、最小系统的组成 、STM32IO分配_小浪宝宝的博客-CSDN博客 STM32:ST是意法半导体,M是MCU/MPU,32是32位。 ST累计推出了:…...

LeetCode //C - 200. Number of Islands
200. Number of Islands Given an m x n 2D binary grid grid which represents a map of *‘1’*s (land) and *‘0’*s (water), return the number of islands. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically…...

使用Python构建强大的网络爬虫
介绍 网络爬虫是从网站收集数据的强大技术,而Python是这项任务中最流行的语言之一。然而,构建一个强大的网络爬虫不仅仅涉及到获取网页并解析其HTML。在本文中,我们将为您介绍创建一个网络爬虫的过程,这个爬虫不仅可以获取和保存网…...

图像处理之《基于语义对象轮廓自动生成的生成隐写术》论文精读
一、相关知识 首先我们需要了解传统隐写和生成式隐写的基本过程和区别。传统隐写需要选定一幅封面图像,然后使用某种隐写算法比如LSB、PVD、DCT等对像素进行修改将秘密嵌入到封面图像中得到含密图像,通过信道传输后再利用算法的逆过程提出秘密信息。而生…...

Java 字节流
一、输入输出流 输入输出 ------- 读写文件 输入 ------- 从文件中获取数据到自己的程序中,接收处理【读】 输出 ------- 将自己程序中处理好的数据保存到文件中【写】 流 ------- 数据移动的轨迹 二、流的分类 按照数据的移动轨迹分为:输入流 输出流…...

华硕电脑怎么录屏?分享实用录制经验!
“华硕电脑怎么录屏呀,刚买的笔记本电脑,是华硕的,自我感觉挺好用的,但是不知道怎么录屏,最近刚好要录一个教程,怎么都找不到在哪里录制,有人能教教我吗?” 随着电脑技术的不断发展…...

python学习--python的异常处理机制
try…except try:n1int(input(请输入一个整数))n2int(input(请输入另一个整数))resultn1/n2print(结果为,result) except ZeroDivisionError: print(除数不能为0)try…except…else 如果try块中没有抛出异常,则执行else块,如果try中抛出异常࿰…...
nacos+Dubbo整合快速入门
官网:Nacos Spring Boot 快速开始 下载下载链接启动:进入bin目录,startup.cmd -m standalone引入依赖 <dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo</artifactId><version>3.0.9…...
QT实现钟表
1、 头文件 #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QPaintEvent> //绘制事件类 #include <QDebug> //信息调试类 #include <QPainter> //画家类 #include <QTimerEve…...
准备我们心爱的IDEA写Jsp
JSP学习 一、准备我们心爱的IDEA new一个项目:New Project --> Next -->Next -->Finsh 二、配置好服务器Tomcat-9.0.30 1.> 在WEB-INF下创建一个Lib包 将jsp-api.jar复制进去,并使其生效 未生效前: 生效过程: 2.>…...
将近 5 万字讲解 Python Django 框架详细知识点(更新中)
Django 框架基本概述 Django 是一个开源的 Web 应用后端框架,由 Python 编写。它采用了 MVC 的软件设计模式,即模型(Model)、视图(View)和控制器(Controller)。在 Django 框架中&am…...
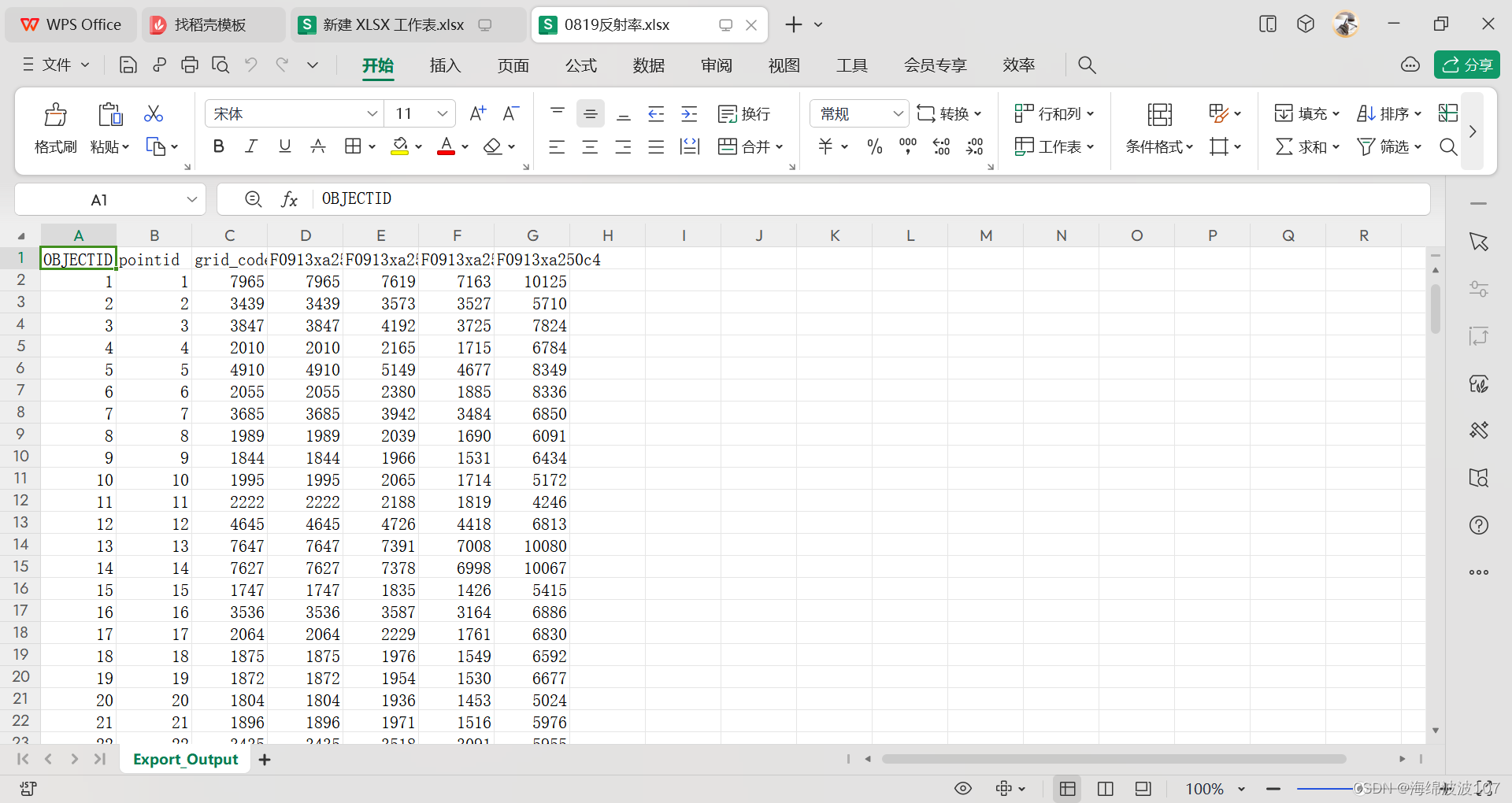
Arcgis提取每个像元的多波段反射率值
Arcgis提取每个像元的多波段反射率值 数据预处理 数据预处理阶段需要对遥感图像进行编辑传感器参数、辐射定标、大气校正、正射校正,具体流程见该文章 裁剪研究区 对于ENVI处理得到的tiff影像,虽然是经过裁剪了,但是还存在黑色的背景值&a…...
)
JavaScript面试题整理(一)
数据类型篇 1、JavaScript有哪些数据类型,它们的区别是什么? 基本数据类型:number、string、boolean、undefined、NaN、BigInt、Symbol 引入数据类型:Object NaN是JS中的特殊值,表示非数字,NaN不是数字…...

数据结构:树和二叉树之-堆排列 (万字详解)
目录 树概念及结构 1.1树的概念 1.2树的表示 编辑2.二叉树概念及结构 2.1概念 2.2数据结构中的二叉树:编辑 2.3特殊的二叉树: 编辑 2.4 二叉树的存储结构 2.4.1 顺序存储: 2.4.2 链式存储: 二叉树的实现及大小堆…...

爬虫入门基础:深入解析HTTP协议的工作过程
目录 一、HTTP协议简介 二、HTTP协议的工作过程 三、请求方法与常见用途 四、请求头与常见字段 五、状态码与常见含义 六、进阶话题和注意事项 总结 在如今这个数字化时代,互联网已经成为我们获取信息、交流和娱乐的主要渠道。而在互联网中,HTTP协…...
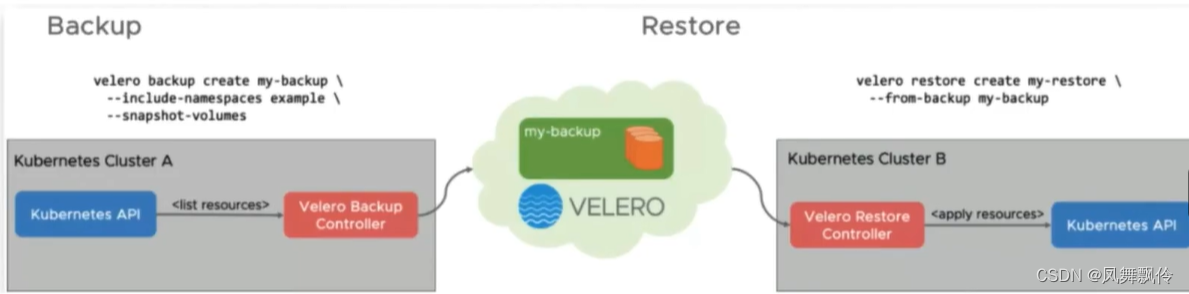
k8备份与恢复-Velero
简介 Velero 是一款可以安全的备份、恢复和迁移 Kubernetes 集群资源和持久卷等资源的备份恢复软件。 Velero 实现的 kubernetes 资源备份能力,可以轻松实现 Kubernetes 集群的数据备份和恢复、复制 kubernetes 集群资源到其他kubernetes 集群或者快速复制生产环境…...

基于Python开发的火车票分析助手(源码+可执行程序+程序配置说明书+程序使用说明书)
一、项目简介 本项目是一套基于Python开发的火车票分析助手,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Python学习者。 包含:项目源码、项目文档等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,…...

旺店通·企业奇门与金蝶云星空对接集成订单查询连通销售订单新增(旺店通销售-金蝶销售订单-小红书)
旺店通企业奇门与金蝶云星空对接集成订单查询连通销售订单新增(旺店通销售-金蝶销售订单-小红书) 接通系统:旺店通企业奇门 慧策最先以旺店通ERP切入商家核心管理痛点——订单管理,之后围绕电商经营管理中的核心管理诉求,先后布局流量获取、会…...
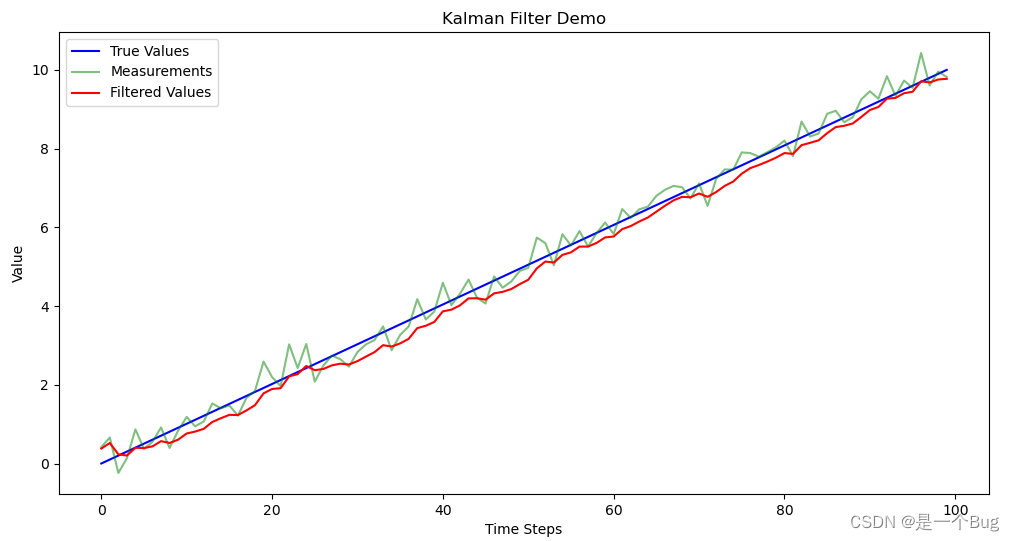
卡尔曼滤波应用在数据处理方面的应用
卡尔曼滤波应用到交通领域 滤波器介绍核心思想核心公式一维卡尔曼滤波器示例导入所需的库 滤波器介绍 卡尔曼滤波器是一种用于估计系统状态的数学方法,它以卡尔曼核心思想为基础,广泛应用于估计动态系统的状态和滤除测量中的噪声。以下是卡尔曼滤波器的核…...

从AeroSpike的实战看SSD优化:为什么你的数据库性能上不去?
从AeroSpike的实战看SSD优化:为什么你的数据库性能上不去? 在数据库性能优化的战场上,SSD的使用方式往往成为决定胜负的关键。传统机械硬盘时代的经验法则在SSD面前频频失效,而像AeroSpike这样的高性能KV数据库却能在相同硬件上实…...

别让数据‘撑爆’了!手把手教你配置Xilinx FFT IP核的缩放因子与防溢出策略
Xilinx FFT IP核实战:精准控制数据动态范围的三大黄金法则 在数字信号处理领域,FFT(快速傅里叶变换)堪称频谱分析的"瑞士军刀",而Xilinx的FFT IP核则是FPGA开发者手中的利器。但当我们真正将其部署到实际项目…...

Dhizuku终极指南:如何在Android 8-16上无ROOT获取DeviceOwner权限
Dhizuku终极指南:如何在Android 8-16上无ROOT获取DeviceOwner权限 【免费下载链接】Dhizuku A tool that can share DeviceOwner permissions to other application. 项目地址: https://gitcode.com/gh_mirrors/dh/Dhizuku Dhizuku是一款开源工具,…...

A* 算法学习
在游戏中,有一个很常见地需求,就是要让一个角色从A点走向B点,我们期望是让角色走最少的路。嗯,大家可能会说,直线就是最短的。没错,但大多数时候,A到B中间都会出现一些角色无法穿越的东西&#…...

基于Azure Cosmos DB与OpenAI构建企业级RAG智能问答应用实战
1. 项目概述:构建一个基于向量数据库的智能对话应用最近在折腾一个挺有意思的项目,想和大家分享一下如何用 Azure Cosmos DB 和 Azure OpenAI Service 来搭建一个真正能用的“副驾驶”应用。这个项目的核心思路,就是把你的数据变成 AI 能理解…...

Windows 10 下 Qt 5.15 组件选择避坑指南:从MSVC到MinGW,32G空间怎么装最合理?
Windows 10下Qt 5.15组件选择避坑指南:从MSVC到MinGW的32G空间优化方案 Qt作为跨平台开发框架,其组件选择直接影响开发效率和磁盘空间占用。面对Qt在线安装器中庞大的组件列表,开发者常陷入两难:既希望功能完备,又担心…...

AI Agent工作流与提示工程:构建自动化内容创作系统的核心技术解析
1. 项目概述:当AI开始“做梦”,一个自动化内容创作的探索 最近在GitHub上看到一个挺有意思的项目,叫 openclaw-auto-dream 。光看名字,就透着一股子赛博朋克的味道——“自动做梦”。这可不是什么玄学或者心理学实验,…...

从Tomcat到Redis:用Vulfocus编排一个多层内网靶场,复盘真实渗透路径
从Tomcat到Redis:构建多层内网靶场的渗透实战指南 在网络安全领域,靶场环境的重要性不亚于真实战场上的演习场。一个精心设计的靶场能够模拟复杂的企业内网环境,让安全从业者在零风险的情况下磨练渗透测试技能。本文将带你深入探索如何利用Vu…...

智能小车转向核心:基于STM32F103C8T6与CubeMX的舵机控制库封装实战
智能小车转向核心:基于STM32F103C8T6与CubeMX的舵机控制库封装实战 在智能小车开发中,转向控制是决定运动精度的关键模块。许多开发者习惯在main函数中直接调用HAL库的PWM控制函数,但随着项目复杂度提升,这种"面条式代码&qu…...

什么是CISP-PTE?
什么是CISP-PTE? 那我就简单的写几点给你介绍一下什么是CISP-PTE。上目录!1.认证机构 中国信息安全测评中心英文名简称:CNITSEC。是经中央批准成立的国家信息安全权威测评机构,职能是开展信息安全漏洞分析和风险评估工作ÿ…...