竞赛选题 基于深度学习的人脸识别系统
前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的人脸识别系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
机器学习-人脸识别过程
基于传统图像处理和机器学习技术的人脸识别技术,其中的流程都是一样的。
机器学习-人脸识别系统都包括:
- 人脸检测
- 人脸对其
- 人脸特征向量化
- 人脸识别

人脸检测
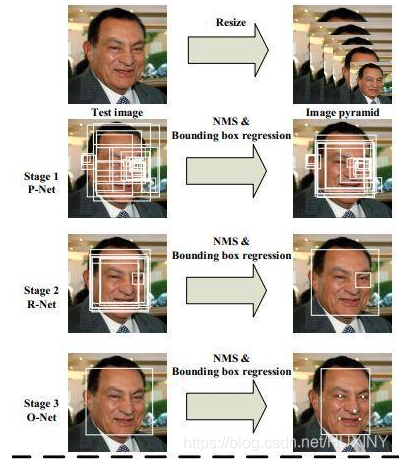
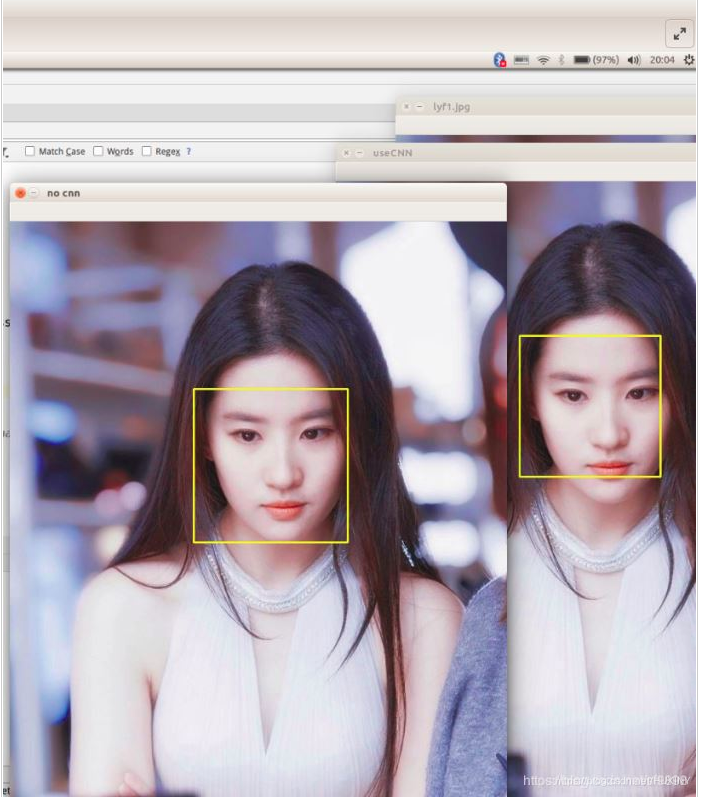
人脸检测用于确定人脸在图像中的大小和位置,即解决“人脸在哪里”的问题,把真正的人脸区域从图像中裁剪出来,便于后续的人脸特征分析和识别。下图是对一张图像的人脸检测结果:
人脸对其
同一个人在不同的图像序列中可能呈现出不同的姿态和表情,这种情况是不利于人脸识别的。
所以有必要将人脸图像都变换到一个统一的角度和姿态,这就是人脸对齐。
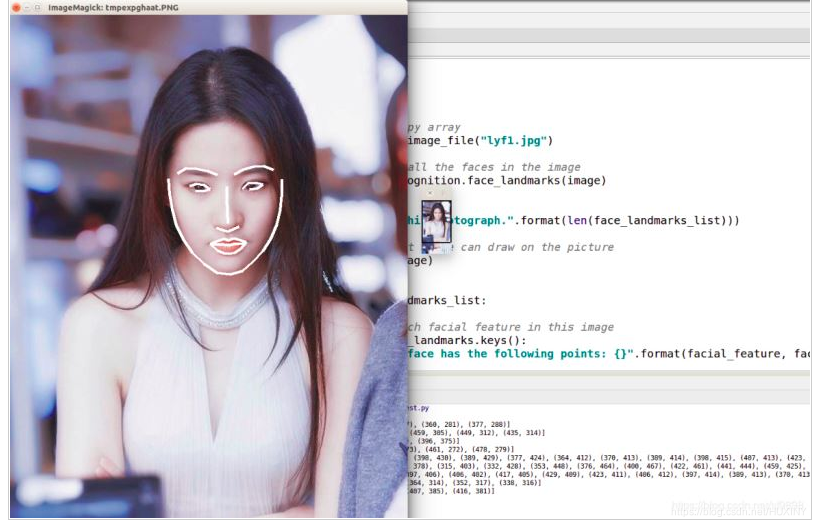
它的原理是找到人脸的若干个关键点(基准点,如眼角,鼻尖,嘴角等),然后利用这些对应的关键点通过相似变换(Similarity
Transform,旋转、缩放和平移)将人脸尽可能变换到标准人脸。
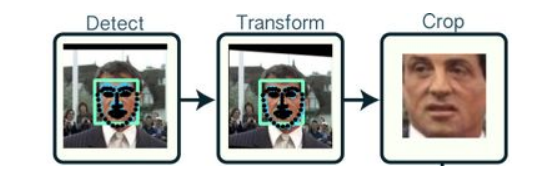
下图是一个典型的人脸图像对齐过程:
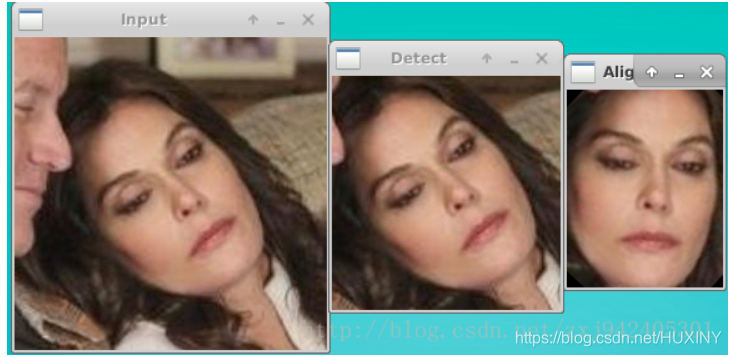
这幅图就更加直观了:
人脸特征向量化
这一步是将对齐后的人脸图像,组成一个特征向量,该特征向量用于描述这张人脸。
但由于,一幅人脸照片往往由比较多的像素构成,如果以每个像素作为1维特征,将得到一个维数非常高的特征向量, 计算将十分困难;而且这些像素之间通常具有相关性。
所以我们常常利用PCA技术对人脸描述向量进行降维处理,保留数据集中对方差贡献最大的人脸特征来达到简化数据集的目的
PCA人脸特征向量降维示例代码:
#coding:utf-8
from numpy import *
from numpy import linalg as la
import cv2
import osdef loadImageSet(add):FaceMat = mat(zeros((15,98*116)))j =0for i in os.listdir(add):if i.split('.')[1] == 'normal':try:img = cv2.imread(add+i,0)except:print 'load %s failed'%iFaceMat[j,:] = mat(img).flatten()j += 1return FaceMatdef ReconginitionVector(selecthr = 0.8):# step1: load the face image data ,get the matrix consists of all imageFaceMat = loadImageSet('D:\python/face recongnition\YALE\YALE\unpadded/').T# step2: average the FaceMatavgImg = mean(FaceMat,1)# step3: calculate the difference of avgimg and all image data(FaceMat)diffTrain = FaceMat-avgImg#step4: calculate eigenvector of covariance matrix (because covariance matrix will cause memory error)eigvals,eigVects = linalg.eig(mat(diffTrain.T*diffTrain))eigSortIndex = argsort(-eigvals)for i in xrange(shape(FaceMat)[1]):if (eigvals[eigSortIndex[:i]]/eigvals.sum()).sum() >= selecthr:eigSortIndex = eigSortIndex[:i]breakcovVects = diffTrain * eigVects[:,eigSortIndex] # covVects is the eigenvector of covariance matrix# avgImg 是均值图像,covVects是协方差矩阵的特征向量,diffTrain是偏差矩阵return avgImg,covVects,diffTraindef judgeFace(judgeImg,FaceVector,avgImg,diffTrain):diff = judgeImg.T - avgImgweiVec = FaceVector.T* diffres = 0resVal = inffor i in range(15):TrainVec = FaceVector.T*diffTrain[:,i]if (array(weiVec-TrainVec)**2).sum() < resVal:res = iresVal = (array(weiVec-TrainVec)**2).sum()return res+1if __name__ == '__main__':avgImg,FaceVector,diffTrain = ReconginitionVector(selecthr = 0.9)nameList = ['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15']characteristic = ['centerlight','glasses','happy','leftlight','noglasses','rightlight','sad','sleepy','surprised','wink']for c in characteristic:count = 0for i in range(len(nameList)):# 这里的loadname就是我们要识别的未知人脸图,我们通过15张未知人脸找出的对应训练人脸进行对比来求出正确率loadname = 'D:\python/face recongnition\YALE\YALE\unpadded\subject'+nameList[i]+'.'+c+'.pgm'judgeImg = cv2.imread(loadname,0)if judgeFace(mat(judgeImg).flatten(),FaceVector,avgImg,diffTrain) == int(nameList[i]):count += 1print 'accuracy of %s is %f'%(c, float(count)/len(nameList)) # 求出正确率
人脸识别
这一步的人脸识别,其实是对上一步人脸向量进行分类,使用各种分类算法。
比如:贝叶斯分类器,决策树,SVM等机器学习方法。
从而达到识别人脸的目的。
这里分享一个svm训练的人脸识别模型:
from __future__ import print_functionfrom time import timeimport loggingimport matplotlib.pyplot as pltfrom sklearn.cross_validation import train_test_splitfrom sklearn.datasets import fetch_lfw_peoplefrom sklearn.grid_search import GridSearchCVfrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.decomposition import RandomizedPCAfrom sklearn.svm import SVCprint(__doc__)# Display progress logs on stdoutlogging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')################################################################################ Download the data, if not already on disk and load it as numpy arrayslfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# introspect the images arrays to find the shapes (for plotting)n_samples, h, w = lfw_people.images.shape# for machine learning we use the 2 data directly (as relative pixel# positions info is ignored by this model)X = lfw_people.datan_features = X.shape[1]# the label to predict is the id of the persony = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]print("Total dataset size:")print("n_samples: %d" % n_samples)print("n_features: %d" % n_features)print("n_classes: %d" % n_classes)################################################################################ Split into a training set and a test set using a stratified k fold# split into a training and testing setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)################################################################################ Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled# dataset): unsupervised feature extraction / dimensionality reductionn_components = 80print("Extracting the top %d eigenfaces from %d faces"% (n_components, X_train.shape[0]))t0 = time()pca = RandomizedPCA(n_components=n_components, whiten=True).fit(X_train)print("done in %0.3fs" % (time() - t0))eigenfaces = pca.components_.reshape((n_components, h, w))print("Projecting the input data on the eigenfaces orthonormal basis")t0 = time()X_train_pca = pca.transform(X_train)X_test_pca = pca.transform(X_test)print("done in %0.3fs" % (time() - t0))################################################################################ Train a SVM classification modelprint("Fitting the classifier to the training set")t0 = time()param_grid = {'C': [1,10, 100, 500, 1e3, 5e3, 1e4, 5e4, 1e5],'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)clf = clf.fit(X_train_pca, y_train)print("done in %0.3fs" % (time() - t0))print("Best estimator found by grid search:")print(clf.best_estimator_)print(clf.best_estimator_.n_support_)################################################################################ Quantitative evaluation of the model quality on the test setprint("Predicting people's names on the test set")t0 = time()y_pred = clf.predict(X_test_pca)print("done in %0.3fs" % (time() - t0))print(classification_report(y_test, y_pred, target_names=target_names))print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))################################################################################ Qualitative evaluation of the predictions using matplotlibdef plot_gallery(images, titles, h, w, n_row=3, n_col=4):"""Helper function to plot a gallery of portraits"""plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)# Show the feature faceplt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)plt.title(titles[i], size=12)plt.xticks(())plt.yticks(())# plot the result of the prediction on a portion of the test setdef title(y_pred, y_test, target_names, i):pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]return 'predicted: %s\ntrue: %s' % (pred_name, true_name)prediction_titles = [title(y_pred, y_test, target_names, i)for i in range(y_pred.shape[0])]plot_gallery(X_test, prediction_titles, h, w)# plot the gallery of the most significative eigenfaceseigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]plot_gallery(eigenfaces, eigenface_titles, h, w)plt.show()深度学习-人脸识别过程
不同于机器学习模型的人脸识别,深度学习将人脸特征向量化,以及人脸向量分类结合到了一起,通过神经网络算法一步到位。
深度学习-人脸识别系统都包括:
- 人脸检测
- 人脸对其
- 人脸识别
人脸检测
深度学习在图像分类中的巨大成功后很快被用于人脸检测的问题,起初解决该问题的思路大多是基于CNN网络的尺度不变性,对图片进行不同尺度的缩放,然后进行推理并直接对类别和位置信息进行预测。另外,由于对feature
map中的每一个点直接进行位置回归,得到的人脸框精度比较低,因此有人提出了基于多阶段分类器由粗到细的检测策略检测人脸,例如主要方法有Cascade CNN、
DenseBox和MTCNN等等。
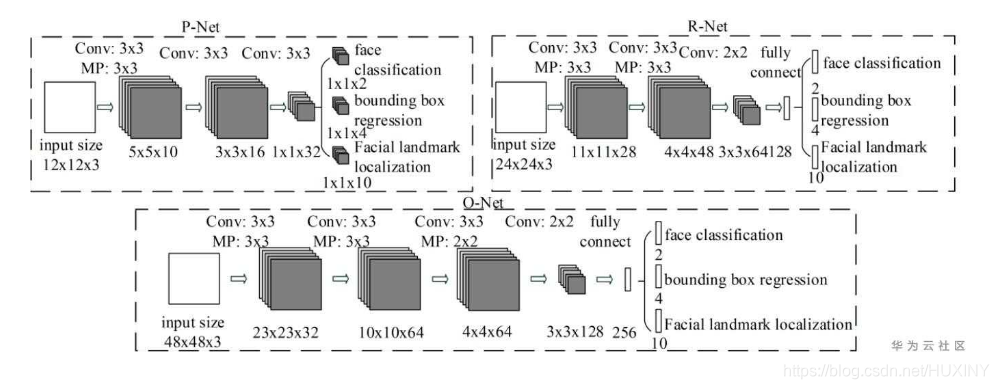
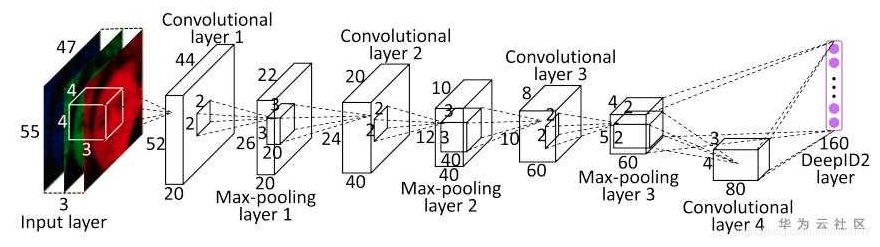
MTCNN是一个多任务的方法,第一次将人脸区域检测和人脸关键点检测放在了一起,与Cascade
CNN一样也是基于cascade的框架,但是整体思路更加的巧妙合理,MTCNN总体来说分为三个部分:PNet、RNet和ONet,网络结构如下图所示。
人脸识别
人脸识别问题本质是一个分类问题,即每一个人作为一类进行分类检测,但实际应用过程中会出现很多问题。第一,人脸类别很多,如果要识别一个城镇的所有人,那么分类类别就将近十万以上的类别,另外每一个人之间可获得的标注样本很少,会出现很多长尾数据。根据上述问题,要对传统的CNN分类网络进行修改。
我们知道深度卷积网络虽然作为一种黑盒模型,但是能够通过数据训练的方式去表征图片或者物体的特征。因此人脸识别算法可以通过卷积网络提取出大量的人脸特征向量,然后根据相似度判断与底库比较完成人脸的识别过程,因此算法网络能不能对不同的人脸生成不同的特征,对同一人脸生成相似的特征,将是这类embedding任务的重点,也就是怎么样能够最大化类间距离以及最小化类内距离。
Metric Larning
深度学习中最先应用metric
learning思想之一的便是DeepID2了。其中DeepID2最主要的改进是同一个网络同时训练verification和classification(有两个监督信号)。其中在verification
loss的特征层中引入了contrastive loss。
Contrastive
loss不仅考虑了相同类别的距离最小化,也同时考虑了不同类别的距离最大化,通过充分运用训练样本的label信息提升人脸识别的准确性。因此,该loss函数本质上使得同一个人的照片在特征空间距离足够近,不同人在特征空间里相距足够远直到超过某个阈值。(听起来和triplet
loss有点像)。
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 基于深度学习的人脸识别系统
前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的人脸识别系统 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/…...

idea Terminal 回退历史版本 Git指令 git reset
——————强制回滚历史版本—————— 一、idea Terminal 第一步:复制版本号 (右击项目–> Git --> Show History -->选中要回退的版本–>Copy Revision Number,直接复制;) 第二步:ide…...
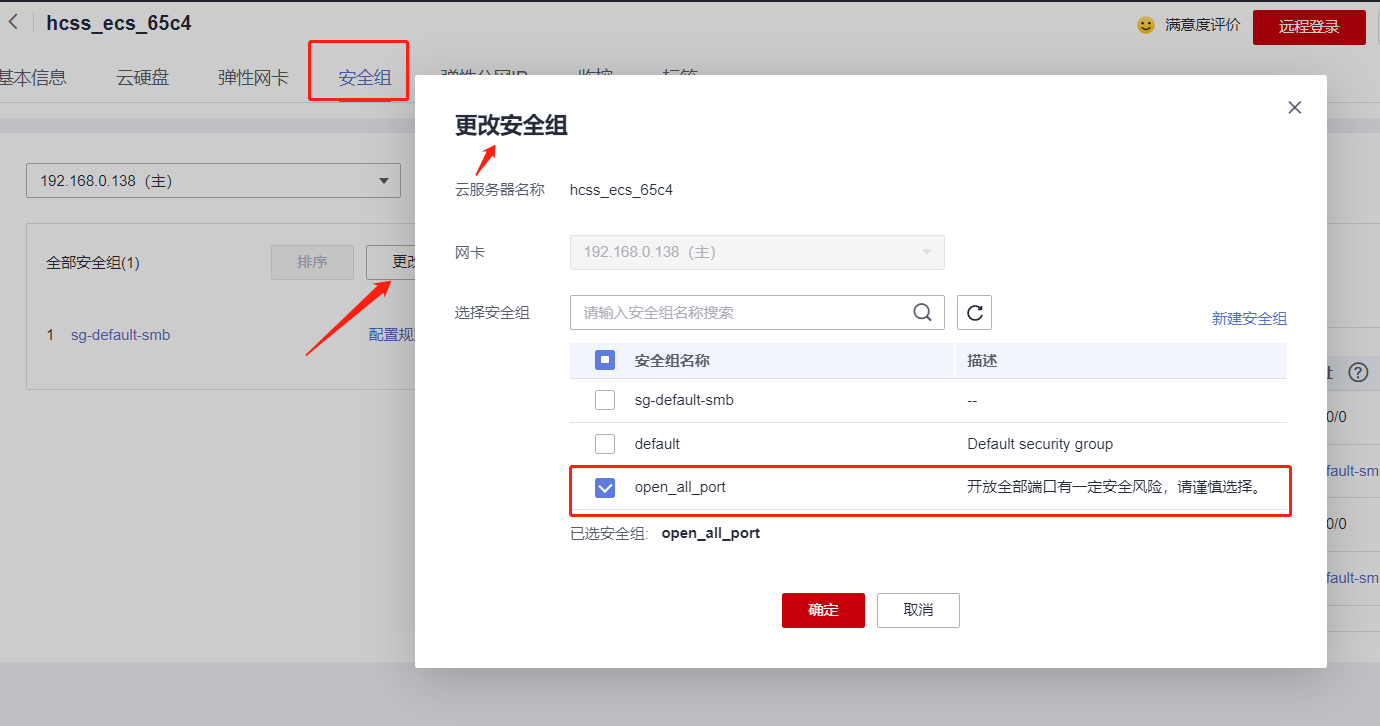
华为云云耀云服务器L实例评测|华为云上安装监控服务Prometheus三件套安装
文章目录 华为云云耀云服务器L实例评测|华为云上试用监控服务Prometheus一、监控服务Prometheus三件套介绍二、华为云主机准备三、Prometheus安装四、Grafana安装五、alertmanager安装六、三个服务的启停管理1. Prometheus、Alertmanager 和 Grafana 启动顺序2. 使用…...

C语言基础知识点(八)联合体和大小端模式
以下程序的输出是() union myun {struct { int x, y, z;} u;int k; } a; int main() {a.u.x 4;a.u.y 5;a.u.z 6;a.k 0;printf("%d\n", a.u.x); } 小端模式 数据的低位放在低地址空间,数据的高位放在高地址空间 简记ÿ…...

一个线程运行时发生异常会怎样?
如果一个线程在运行时发生异常而没有被捕获(即未被适当的异常处理代码处理),则会导致以下几种情况之一: 线程终止:线程会立即终止其执行,并将异常信息打印到标准错误输出(System.err)。这通常包括异常的类型、堆栈跟踪信息以及异常消息。 ThreadDeath 异常:在某些情况…...

CSS中去掉li前面的圆点方法
1. 引言 在网页开发中,我们经常会使用无序列表(<ul>)来展示一系列的项目。默认情况下,每个列表项(<li>)前面都会有一个圆点作为标记。然而,在某些情况下,我们可能希望去…...

Python:获取当前目录下所有文件夹名称及文件夹下所有文件名称
获取当前目录下所有文件夹名称 def get_group_list(folder_path):group_list []for root, dirs, files in os.walk(folder_path):for dir in dirs:group_list.append(dir)return group_list获取文件夹下所有文件名称 def get_file_list(folder_path, group_name):file_list …...
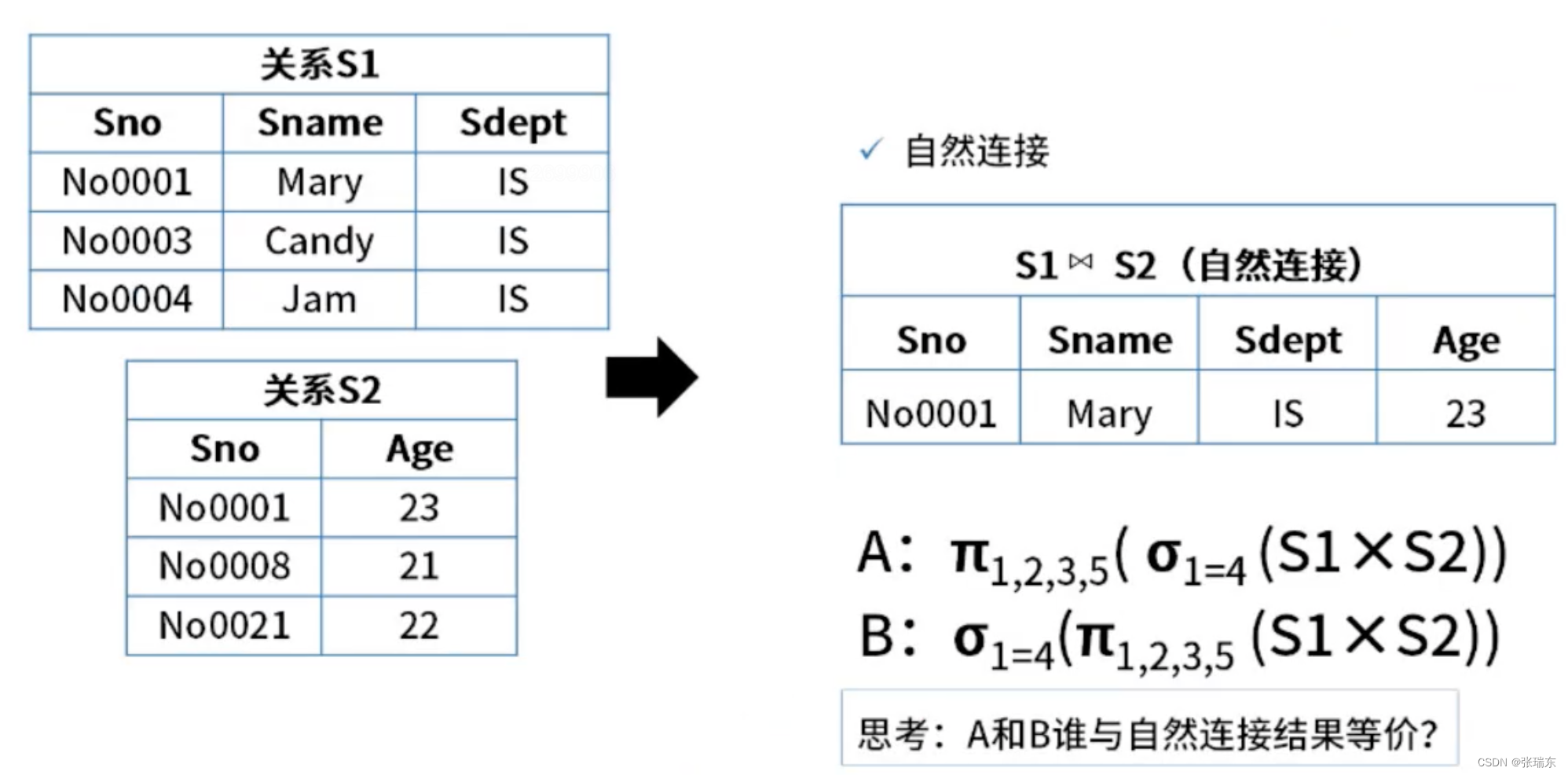
系统架构设计师-数据库系统(1)
目录 一、数据库模式 1、集中式数据库 2、分布式数据库 二、数据库设计过程 1、E-R模型 2、概念结构设计 3、逻辑结构设计 三、关系代数 1、并交差 2、投影和选择 3、笛卡尔积 4、自然连接 一、数据库模式 1、集中式数据库 三级模式: (1)外…...

Docker的相关知识介绍以及mac环境的安装
一、什么是Docker 大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题: 依赖关系复杂,容易出现兼容性问题开发、测试、生产环境有差异 Docker就是来解决这些问题的。Docker是一个快速交付应用、运行应用的技术&#x…...
Android设计支持库
本文所有的代码均存于 https://github.com/MADMAX110/BitsandPizzas 设计支持库(Design Support Library)是 Google 在 2015 年的 I/O 大会上发布的全新 Material Design 支持库,在这个 support 库里面主要包含了 8 个新的 Material Design …...

【Java 基础篇】Java实现文件搜索详解
文件搜索是计算机应用中的一个常见任务,它允许用户查找特定文件或目录,以便更轻松地管理文件系统中的内容。在Java中,您可以使用各种方法来实现文件搜索。本文将详细介绍如何使用Java编写文件搜索功能,以及一些相关的内容。 文件…...
会C++还需要再去学Python吗?
提到的C、数据结构与算法、操作系统、计算机网络和数据库技术等确实是计算机科学中非常重要的基础知识领域,对于软件开发和计算机工程师来说,它们是必备的核心知识。掌握这些知识对于开发高性能、可靠和安全的应用程序非常重要。Python作为一种脚本语言&…...
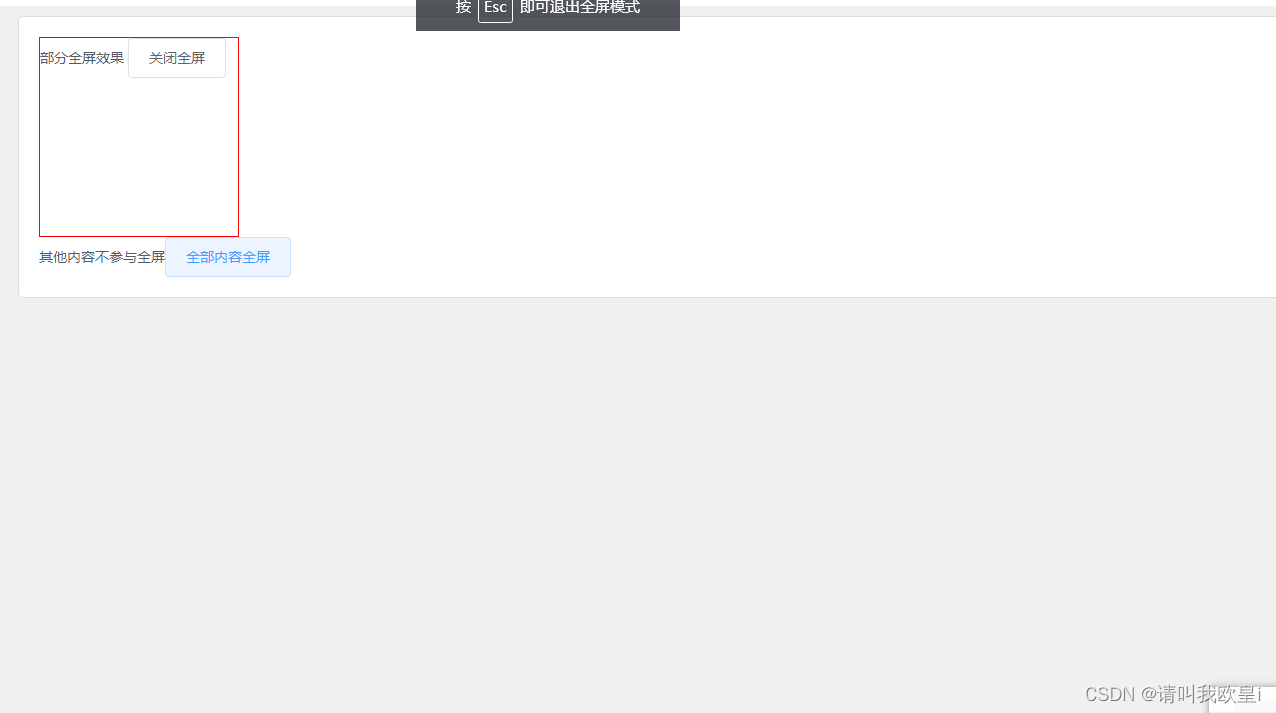
vue部分/所有内容全屏切换展示
需求:就是把一个页面的某一部分内容点击全屏操作按钮后全屏展示,并非所有内容全屏,所有内容的话那肯定就所有全屏展示啊,可以做切换 1.部分全屏代码 element.requestFullscreen();这个就是全屏的代码了,注意前面的ele…...

8.gec6818开发板通过并发多线程实现电子相册 智能家居 小游戏三合一完整项目
并发 前面编写的程序都是从mian函数开始,从上往下执行,称为顺序执行 假设一个程序需要I输入 C计算 P输出,以顺序执行三个上述程序,则其执行过程如下: 程序内部的语句是一条一条的执行,如果要运行多个程序…...

角度回归——角度编码方式
文章目录 1.为什么研究角度的编码方式?1.1 角度本身具有周期性1.2 深度学习的损失函数因为角度本身的周期性,在周期性的点上可能产生很大的Loss,造成训练不稳定1.3 那么如何处理边界问题呢:(以θ的边界问题为例&#x…...

【C# Programming】值类型、良构类型
值类型 1、值类型 值类型的变量直接包含值。换言之, 变量引用的位置就是值内存中实际存储的位置。 2、引用类型 引用类型的变量存储的是对一个对象实例的引用(通常为内存地址)。 复制引用类型的值时,复制的只是引用。这个引用非常小…...
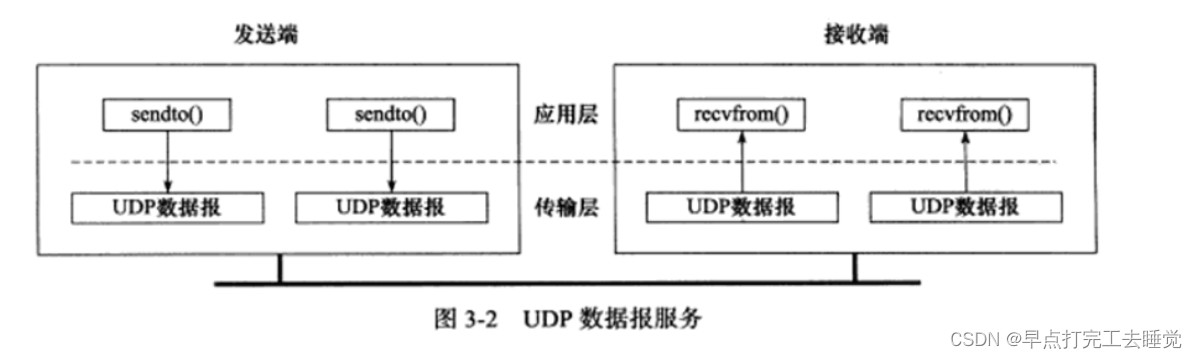
Linux Day18 TCP_UDP协议及相关知识
一、网络基础概念 1.1 网络 网络是由若干结点和连接这些结点的链路组成,网络中的结点可以是计算机,交换机、 路由器等设备。 1.2 互联网 把多个网络连接起来就构成了互联网。目前最大的互联网就是因特网。 网络设备有:交换机、路由器、…...

【Java 基础篇】Java网络编程实时数据流处理
在现代计算机应用程序中,处理实时数据流是一项关键任务。这种数据流可以是来自传感器、网络、文件或其他源头的数据,需要即时处理并做出相应的决策。Java提供了强大的网络编程工具和库,可以用于处理实时数据流。本文将详细介绍如何使用Java进…...

Oracle 和 mysql 增加字段SQL
在Oracle和MySQL中,可以使用ALTER TABLE语句来增加字段。下面是分别是两种数据库增加字段的SQL示例: 在Oracle中增加字段的SQL示例: ALTER TABLE 表名ADD (新字段名 数据类型);例如,如果要在名为"employees"的表中添加…...

【脚本】 【Linux】循环执行命令
loop.sh #!/bin/bashif [ "" "$1" ]; thenecho 用法: ./loop.sh 命令内容 时间间隔(毫秒) 循环次数(小于0表示无限循环)echo 示例: ./loop.sh "ps -ef" 1000 10exit 0 fiinterval1000 if [ "" ! "$2" ]; thenif echo &quo…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...