基于PyTorch搭建FasterRCNN实现目标检测
基于PyTorch搭建FasterRCNN实现目标检测
1. 图像分类 vs. 目标检测

图像分类是一个我们为输入图像分配类标签的问题。例如,给定猫的输入图像,图像分类算法的输出是标签“猫”。
在目标检测中,我们不仅对输入图像中存在的对象感兴趣。我们还对它们在输入图像中的位置感兴趣。从这个意义上说,目标检测超越了图像分类。
1.1 图像分类与目标检测:使用哪一个?
图像分类非常适合图像中只有一个对象的应用。可能有多个类(例如猫、狗等),但通常图像中只有该类的一个实例。
在大多数输入图像中有多个对象的应用中,我们需要找到对象的位置,然后对它们进行分类。在这种情况下,我们使用目标检测算法。
目标检测可能比图像分类慢数百倍。因此,在图像中对象的位置不重要的应用中,我们使用图像分类。
2. 目标检测
简单来说,目标检测是一个两步过程:
- 查找包含对象的边界框,使得每个边界框仅包含一个对象。
- 对每个边界框内的图像进行分类并为其分配标签。
在接下来的几节中,我们将介绍 Faster R-CNN 目标检测架构开发的步骤。
2.1 滑动窗口方法
大多数用于目标检测的经典计算机视觉技术(例如 HAAR 级联和 HOG + SVM)都使用滑动窗口方法来检测目标。
在这种方法中,滑动窗口在图像上移动。该滑动窗口内的所有像素都被裁剪掉并发送到图像分类器。
如果图像分类器识别出已知对象,则存储边界框和类标签。否则,将评估下一个窗口。
滑动窗口方法的计算量非常大。为了检测输入图像中的对象,需要在图像中的每个像素处评估不同尺度和纵横比的滑动窗口。
由于计算成本,仅当我们检测具有固定纵横比的单个对象类时才使用滑动窗口。例如,OpenCV 中基于 HOG + SVM 或 HAAR 的人脸检测器使用滑动窗口方法。有趣的是,著名的 Viola Jones 人脸检测使用滑动窗口。对于人脸检测器,复杂性是可控的,因为仅在不同尺度下评估方形边界框。
2.2 R-CNN目标检测
在基于 CNN 的方法赢得 2012 年 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 后,基于卷积神经网络 (CNN) 的图像分类器开始流行。
由于每个目标检测器的核心都有一个图像分类器,因此基于 CNN 的目标检测器的发明就变得不可避免。
有两个挑战需要克服:
- 与 HOG + SVM 或 HAAR 级联等传统技术相比,基于 CNN 的图像分类器的计算成本非常昂贵。
- 计算机视觉社区变得越来越雄心勃勃。人们希望构建一个多类对象检测器,除了能够处理不同的尺度之外,还可以处理不同的纵横比。
研究人员开始研究训练机器学习模型的新想法,该模型可以提出包含对象的边界框的位置。这些边界框称为区域提议或对象提议。
Ross Girshick 等人提出的第一个使用区域提议的方法被称为 R-CNN(具有 CNN 特征的区域的缩写)。
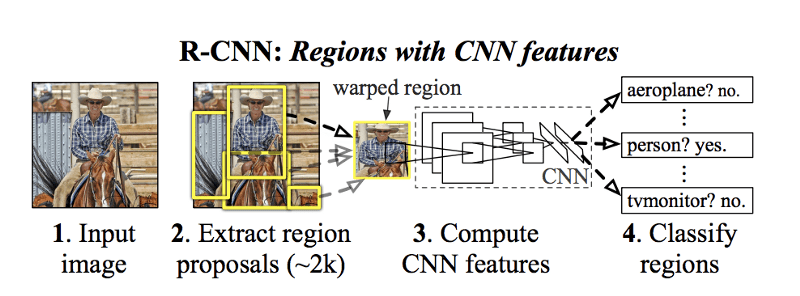
他们使用一种称为“选择性搜索”的算法来检测 2000 个区域提案,并在这 2000 个边界框上运行基于 CNN + SVM 的图像分类器。
当时 R-CNN 的精度是最先进的,但速度仍然很慢(GPU 上每张图像 18-20 秒)
2.3 Fast R-CNN目标检测
在 R-CNN 中,每个边界框由图像分类器独立分类。有 2000 个区域提案,图像分类器为每个区域提案计算一个特征图。这个过程是昂贵的。
在 Ross Girshick 的后续工作中,他提出了一种名为 Fast R-CNN 的方法,可以显着加快目标检测速度。
这个想法是为整个图像计算单个特征图,而不是为 2000 个区域提案计算 2000 个特征图。对于每个候选区域,感兴趣区域(RoI)池化层从特征图中提取固定长度的特征向量。每个特征向量随后用于两个目的:
- 将区域分类为某一类(例如狗、猫、背景)。
- 使用边界框回归器提高原始边界框的准确性。
2.4 Faster R-CNN目标检测
在 Fast R-CNN 中,尽管共享了对 2000 个区域提案进行分类的计算,但生成区域提案的算法部分并未与执行图像分类的部分共享任何计算。
在名为 Faster R-CNN 的后续工作中,主要见解是计算区域提议和图像分类这两个部分可以使用相同的特征图,从而共享计算负载。
卷积神经网络用于生成图像的特征图,同时用于训练区域提议网络和图像分类器。由于这种共享计算,目标检测的速度有了显着的提高。

3. PyTorch实现目标检测
在本节中,我们将学习如何将 Faster R-CNN 目标检测器与 PyTorch 结合使用。我们将使用 torchvision 中包含的预训练模型。 PyTorch 中所有预训练模型的详细信息可以在 torchvision.models 中找到
3.1 输入和输出
我们将要使用的预训练 Faster R-CNN ResNet-50 模型期望输入图像张量采用 [n, c, h, w] 形式,最小尺寸为 800px,其中:
- n 是图像数量
- c 是通道数,对于 RGB 图像,其为 3
- h 是图像的高度
- w 是图像的宽度
模型将返回
- 边界框 [x0, y0, x1, y1] 形状为 (N,4) 的所有预测类别,其中 N 是模型预测的图像中存在的类别数量。
- 所有预测类别的标签。
- 每个预测标签的分数。
3.2 预训练模型
使用以下代码从 torchvision 下载预训练模型:
import torchvisionmodel = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()
定义PyTorch官方文档给出的类名
COCO_INSTANCE_CATEGORY_NAMES = ['__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
我们可以在列表中看到一些 N/A,因为后来的论文中删除了一些类。我们将使用 PyTorch 给出的列表。
3.3 模型预测
我们定义一个函数来获取图像路径并通过模型获得图像的预测。
from PIL import Image
from torchvision import transforms as Tdef get_prediction(img_path, threshold):"""get_predictionparameters:- img_path - path of the input image- threshold - threshold value for prediction score"""img = Image.open(img_path)transform = T.Compose([T.ToTensor()])img = transform(img)pred = model([img])pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]pred_boxes = [[(int(i[0]), int(i[1])), (int(i[2]), int(i[3]))] for i in list(pred[0]['boxes'].detach().numpy())]pred_score = list(pred[0]['scores'].detach().numpy())pred_t = [pred_score.index(x) for x in pred_score if x > threshold][-1]pred_boxes = pred_boxes[:pred_t + 1]pred_class = pred_class[:pred_t + 1]return pred_boxes, pred_class
- 从图像路径获取图像
- 使用 PyTorch 的 Transforms 将图像转换为图像张量
- 图像通过模型来获得预测
- 获得类、框坐标,但仅选择预测分数>阈值。
3.4 定义目标检测方法
接下来我们将定义一个方法来获取图像路径并获取输出图像。
import cv2
from matplotlib import pyplot as pltdef object_detection_api(img_path, threshold=0.5, rect_th=3, text_size=3, text_th=3):boxes, pred_cls = get_prediction(img_path, threshold)# Get predictionsimg = cv2.imread(img_path)# Read image with cv2img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# Convert to RGBfor i in range(len(boxes)):cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th)# Draw Rectangle with the coordinatescv2.putText(img,pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, (0,255,0),thickness=text_th)# Write the prediction classplt.figure(figsize=(20,30))# display the output imageplt.imshow(img)plt.xticks([])plt.yticks([])plt.show()
- 预测是从 get_prediction 方法获得的
- 对于每个预测,都会绘制边界框并写入文本
与opencv - 显示最终图像
3.5 运行测试






相关文章:
基于PyTorch搭建FasterRCNN实现目标检测
基于PyTorch搭建FasterRCNN实现目标检测 1. 图像分类 vs. 目标检测 图像分类是一个我们为输入图像分配类标签的问题。例如,给定猫的输入图像,图像分类算法的输出是标签“猫”。 在目标检测中,我们不仅对输入图像中存在的对象感兴趣。我们还…...
线性表应用(非递减合并、分解链表、删除线性表)
将两个非递减的有序链表合并为一个非递增的有序链表。要求结果链表仍使用原来两个链表的存储空间,不另外占用其它的存储空间。表中允许有重复的数据。 #include<iostream> using namespace std; typedef struct list {int data;list* next; }list,*linklist;…...
【C++面向对象侯捷下】1.导读
文章目录 来源:我的百度网盘 百科全书 专家书籍 C标准库 C编译器...
Ubuntu22.04 vnc远程黑屏
一、原因 原因是Ubuntu22.04使用的gnome启用了Wayland。vnc、teamviewer、向日葵、todesk等均无法使用或者远程黑屏等。 简单的说vnc、teamviewer、向日葵、todesk等均基于xorg实现(xorg太流行),并不兼容Wayland,所以vnc无法正常…...

【1区TOP】Elsevier旗下CCF推荐,仅3个月左右录用!
01 期刊简介 CCF推荐人工智能类SCIE&EI 【期刊概况】IF:8.0-9.0,JCR1区,中科院2区TOP; 【版面类型】正刊; 【检索情况】SCIE&EI双检,CCF推荐; 【数据库收录年份】1992年ÿ…...

CentOS下安装Python3
一、电脑有网络: 1、直接使用yum包管理安装: yum是CentOS的默认包管理器,在安装软件时非常方便。要安装Python3,可以使用以下命令: sudo yum install python3等待安装完成后,查看python3是否安装完成 //不…...

微信小程序底部安全区域高度获取
CSS 属性 safe-area-inset-bottom safe-area-inset-bottom 就是安全区的高度 padding-bottom:env(safe-area-inset-bottom); wx.getSystemInfoSync() wx.getSystemInfoSync()可以获取系统信息 let system wx.getSystemInfoSync() let bottomSafe system.screenHeight -…...
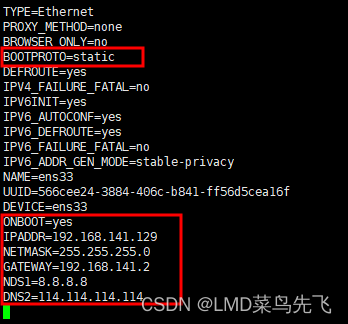
虚拟机部署linux网络连接配置
1、虚拟机安装linux后,配置网络访问 虚拟机网络设置为NAT模式 linux网络配置好IP,主要是以下网络配置 2、linux没有ifconfig命令,ifconfig命令是在net-tools.x86_64包里 yum install net-tools.x86_64安装...
)
2591. 将钱分给最多的儿童(Java)
给你一个整数 money ,表示你总共有的钱数(单位为美元)和另一个整数 children ,表示你要将钱分配给多少个儿童。 你需要按照如下规则分配: 所有的钱都必须被分配。 每个儿童至少获得 1 美元。 没有人获得 4 美元。 请你…...

c++23中的新功能之十五类tuple类型的完全支持
一、std::tuple和std::pair 在传统的C里一直有一个问题让开发者不爽,就是无法返回多个值。一般来说,返回多个都建议采用封装的模式,比如弄一个结构体或者类啥的。这样做一定时没有问题的,但对于一些只返回一些简单值并且只在偶尔…...

iPhone15线下购买,苹果零售店前门店排长队
今年的苹果新品发布会于北京时间 9 月 13 日凌晨举行,并于 9 月 15 日(周五)开启订购,9 月 22 日(周五)起正式发售。 据多位网友反馈,首批苹果 iPhone15 系列手机、Apple Watch Ultra 2 / Seri…...

Vue3如何优雅的加载大量图片?
前端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 表妹一键制作自己的五星红旗国庆头像,超好看 最近开发了一个功能,页面首页会加载大量的图片,初次进入页面时ÿ…...
Go语言开发环境搭建指南:快速上手构建高效的Go开发环境
Go 官网:https://go.dev/dl/ Go 语言中文网:https://studygolang.com/dl 下载 Go 的语言包 进入官方网站 Go 官网 或 Go 语言中文网: 选择下载对应操作系统的安装包: 等待下载完成: 安装 Go 的语言包 双击运行上…...
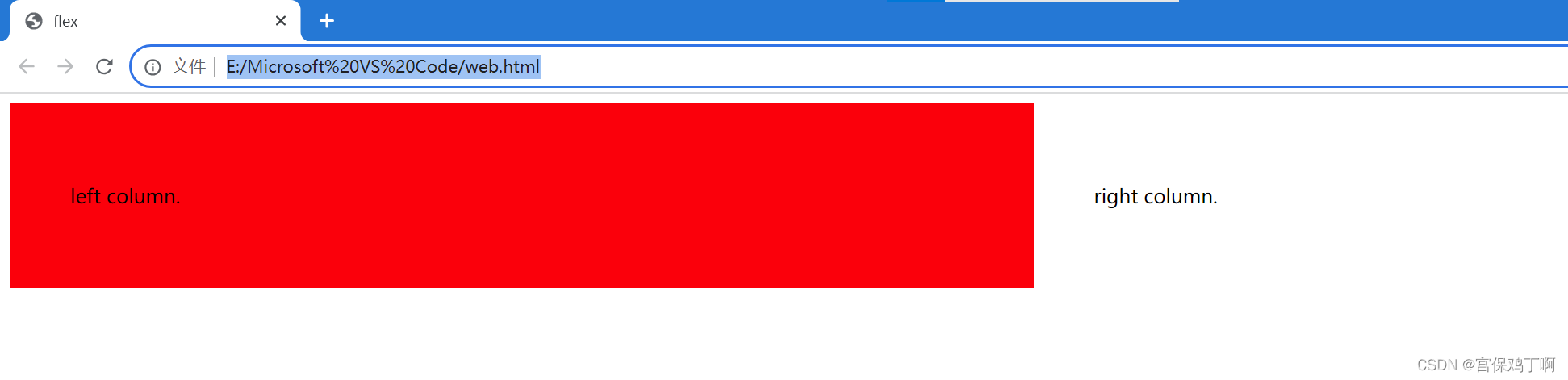
flex布局与float布局
float布局 俩栏 三栏 flex布局...

【C语言】字符函数和字符串函数(含模拟)
前言: 在做OJ题或阅读代码时或多或少会遇到一些字符函数和字符串函数, 如果不认识或不熟悉就会造成不便, 本篇文章主要是为了这方面而存在, 此篇介绍各个字符串的功能与使用方法, 下一篇会讲解如何模拟这些函数 重点&a…...
基于YOLOv8模型的条形码二维码检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的条形码二维码检测系统可用于日常生活中检测与定位条形码与二维码目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测…...

2023/09/22 制作demo期间心得
A*的估价函数:例如A->C,会计算A到B的距离B到C的距离作为成本,雕刻不会导致全局路线的重新计算,凸多边形是一个内部为凸集的简单多边形。 简单多边形的下列性质与其凸性等价:1、所有内角小于等于180度。 2、任意两个…...
高阶数据结构——图
图 图的基本概念 图的基本概念 图是由顶点集合和边的集合组成的一种数据结构,记作 G ( V , E ) G(V, E)G(V,E) 。 有向图和无向图: 在有向图中,顶点对 < x , y >是有序的,顶点对 < x , y > 称为顶点 x 到顶点 y 的…...

高性能AC算法多关键词匹配文本功能Java实现
直接上测试结果: 1000000数据集。 1000000关键词(匹配词) 装载消耗时间:20869 毫秒 匹配消耗时间:6599 毫秒 代码和测试案例: package com.baian.tggroupmessagematchkeyword.ac;import lombok.Data;im…...
如何在没有第三方.NET库源码的情况,调试第三库代码?
大家好,我是沙漠尽头的狼。 本方首发于Dotnet9,介绍使用dnSpy调试第三方.NET库源码,行文目录: 安装dnSpy编写示例程序调试示例程序调试.NET库原生方法总结 1. 安装dnSpy dnSpy是一款功能强大的.NET程序反编译工具,…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...