推荐算法—widedeep原理知识总结代码实现
wide&deep原理知识总结代码实现
- 1. Wide&Deep 模型的结构
- 1.1 模型的记忆能力
- 1.2 模型的泛化能力
- 2. Wide&Deep 模型的应用场景
- 3. Wide&Deep 模型的代码实现
- 3.1 tensorflow实现
- 3.2 pytorch实现
今天,总结一个在业界有着巨大影响力的推荐模型,Google 的 Wide&Deep。可以说,只要掌握了 Wide&Deep,就抓住了深度推荐模型这几年发展的一个主要方向。
1. Wide&Deep 模型的结构

上图就是 Wide&Deep 模型的结构图,它是由左侧的 Wide 部分和右侧的 Deep 部分组成的。Wide 部分的结构很简单,就是把输入层直接连接到输出层,中间没有做任何处理。Deep 层的结构稍复杂,就是常见的Embedding+MLP 的模型结构。
Wide 部分的主要作用是让模型具有较强的“记忆能力”(Memorization),而 Deep 部分的主要作用是让模型具有“泛化能力”(Generalization),因为只有这样的结构特点,才能让模型兼具逻辑回归和深度神经网络的优点,也就是既能快速处理和记忆大量历史行为特征,又具有强大的表达能力,这就是 Google 提出这个模型的动机。
1.1 模型的记忆能力
所谓的 “记忆能力”,可以被宽泛地理解为模型直接学习历史数据中物品或者特征的“共现频率”,并且把它们直接作为推荐依据的能力。
就像我们在电影推荐中可以发现一系列的规则,比如,看了 A 电影的用户经常喜欢看电影 B,这种“因为 A 所以 B”式的规则,非常直接也非常有价值。
1.2 模型的泛化能力
“泛化能力”指的是模型对于新鲜样本、以及从未出现过的特征组合的预测能力。
看一个例子:假设,我们知道 25 岁的男性用户喜欢看电影 A,35 岁的女性用户也喜欢看电影 A。如果我们想让一个只有记忆能力的模型回答,“35 岁的男性喜不喜欢看电影 A”这样的问题,这个模型就会“说”,我从来没学过这样的知识啊,没法回答你。这就体现出泛化能力的重要性了。模型有了很强的泛化能力之后,才能够对一些非常稀疏的,甚至从未出现过的情况作出尽量“靠谱”的预测。
事实上,矩阵分解就是为了解决协同过滤“泛化能力”不强而诞生的。因为协同过滤只会“死板”地使用用户的原始行为特征,而矩阵分解因为生成了用户和物品的隐向量,所以就可以计算任意两个用户和物品之间的相似度了。这就是泛化能力强的另一个例子。
2. Wide&Deep 模型的应用场景
Wide&Deep 模型是由 Google 的应用商店团队 Google Play 提出的,在 Google Play 为用户推荐 APP 这样的应用场景下,Wide&Deep 模型的推荐目标就显而易见了,就是应该尽量推荐那些用户可能喜欢,愿意安装的应用。那具体到 Wide&Deep 模型中,Google Play 团队是如何为 Wide 部分和 Deep 部分挑选特征的呢?
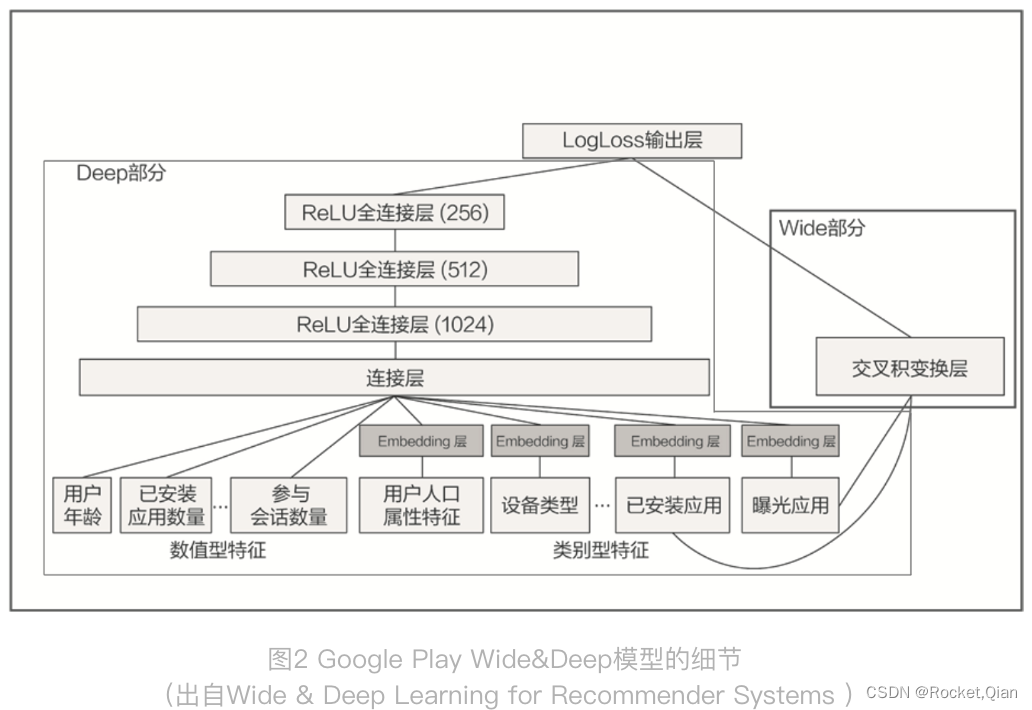
先从右边 Wide 部分的特征看起,只利用了两个特征的交叉,这两个特征是“已安装应用”和“当前曝光应用”。这样一来,Wide 部分想学到的知识就非常直观,就是希望记忆好“如果 A 所以 B”这样的简单规则。在 Google Play 的场景下,就是希望记住“如果用户已经安装了应用 A,是否会安装 B”这样的规则。
再来看看左边的 Deep 部分,就是一个非常典型的 Embedding+MLP 结构。其中的输入特征很多,有用户年龄、属性特征、设备类型,还有已安装应用的 Embedding 等。把这些特征一股脑地放进多层神经网络里面去学习之后,它们互相之间会发生多重的交叉组合,这最终会让模型具备很强的泛化能力。
总的来说,Wide&Deep 通过组合 Wide 部分的线性模型和 Deep 部分的深度网络,取各自所长,就能得到一个综合能力更强的组合模型。
3. Wide&Deep 模型的代码实现
3.1 tensorflow实现
# wide and deep model architecture
# deep part for all input features
deep = tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns)(inputs)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
# wide part for cross feature
wide = tf.keras.layers.DenseFeatures(crossed_feature)(inputs)
both = tf.keras.layers.concatenate([deep, wide])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(both)
model = tf.keras.Model(inputs, output_layer)
Deep 部分,它是输入层加两层 128 维隐层的结构,它的输入是类别型 Embedding 向量和数值型特征。
Wide 部分直接把输入特征连接到了输出层就可以了。但是,这里要重点关注一下 Wide 部分所用的特征 crossed_feature。
movie_feature = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
rated_movie_feature = tf.feature_column.categorical_column_with_identity(key='userRatedMovie1', num_buckets=1001)
crossed_feature = tf.feature_column.crossed_column([movie_feature, rated_movie_feature], 10000)
在 Deep 部分和 Wide 部分都构建完后,要使用 concatenate layer 把两部分连接起来,形成一个完整的特征向量,输入到最终的 sigmoid 神经元中,产生推荐分数。
3.2 pytorch实现
#Wide部分
class LR_Layer(nn.Module):def __init__(self,enc_dict):super(LR_Layer, self).__init__()self.enc_dict = enc_dictself.emb_layer = EmbeddingLayer(enc_dict=self.enc_dict,embedding_dim=1)self.dnn_input_dim = get_dnn_input_dim(self.enc_dict, 1)self.fc = nn.Linear(self.dnn_input_dim,1)def forward(self,data):sparse_emb = self.emb_layer(data)sparse_emb = torch.stack(sparse_emb,dim=1).flatten(1) #[batch,num_sparse*emb]dense_input = get_linear_input(self.enc_dict, data) #[batch,num_dense]dnn_input = torch.cat((sparse_emb, dense_input), dim=1) # [batch,num_sparse*emb + num_dense]out = self.fc(dnn_input)return out
#DNN部分
class MLP_Layer(nn.Module):def __init__(self,input_dim,output_dim=None,hidden_units=[],hidden_activations="ReLU",final_activation=None,dropout_rates=0,batch_norm=False,use_bias=True):super(MLP_Layer, self).__init__()dense_layers = []if not isinstance(dropout_rates, list):dropout_rates = [dropout_rates] * len(hidden_units)if not isinstance(hidden_activations, list):hidden_activations = [hidden_activations] * len(hidden_units)hidden_activations = [set_activation(x) for x in hidden_activations]hidden_units = [input_dim] + hidden_unitsfor idx in range(len(hidden_units) - 1):dense_layers.append(nn.Linear(hidden_units[idx], hidden_units[idx + 1], bias=use_bias))if batch_norm:dense_layers.append(nn.BatchNorm1d(hidden_units[idx + 1]))if hidden_activations[idx]:dense_layers.append(hidden_activations[idx])if dropout_rates[idx] > 0:dense_layers.append(nn.Dropout(p=dropout_rates[idx]))if output_dim is not None:dense_layers.append(nn.Linear(hidden_units[-1], output_dim, bias=use_bias))if final_activation is not None:dense_layers.append(set_activation(final_activation))self.dnn = nn.Sequential(*dense_layers) # * used to unpack listdef forward(self, inputs):return self.dnn(inputs)
#Wide&Deep
class WDL(nn.Module):def __init__(self,embedding_dim=40,hidden_units=[64, 64, 64],loss_fun = 'torch.nn.BCELoss()',enc_dict=None):super(WDL, self).__init__()self.embedding_dim = embedding_dimself.hidden_units = hidden_unitsself.loss_fun = eval(loss_fun)
# self.loss_fun = torch.nn.BCELoss()self.enc_dict = enc_dictself.embedding_layer = EmbeddingLayer(enc_dict=self.enc_dict, embedding_dim=self.embedding_dim)#Wide部分self.lr = LR_Layer(enc_dict=self.enc_dict)# Deep部分self.dnn_input_dim = get_dnn_input_dim(self.enc_dict, self.embedding_dim) # num_sprase*emb + num_denseself.dnn = MLP_Layer(input_dim=self.dnn_input_dim, output_dim=1, hidden_units=self.hidden_units,hidden_activations='relu', dropout_rates=0)def forward(self,data):#Widewide_logit = self.lr(data) #Batch,1#Deepsparse_emb = self.embedding_layer(data)sparse_emb = torch.stack(sparse_emb,dim=1).flatten(1) #[Batch,num_sparse_fea*embedding_dim]dense_input = get_linear_input(self.enc_dict, data)dnn_input = torch.cat((sparse_emb, dense_input), dim=1)#[Batch,num_sparse_fea*embedding_dim+num_dense]deep_logit = self.dnn(dnn_input)#Wide+Deepy_pred = (wide_logit+deep_logit).sigmoid()
# return y_pred#输出loss = self.loss_fun(y_pred.squeeze(-1),data['label'])output_dict = {'pred':y_pred,'loss':loss}return output_dict
最后,有个问题,什么样的特征应该放进wide,什么样的特征应该放进deep部分呢?
相关文章:
推荐算法—widedeep原理知识总结代码实现
wide&deep原理知识总结代码实现1. Wide&Deep 模型的结构1.1 模型的记忆能力1.2 模型的泛化能力2. Wide&Deep 模型的应用场景3. Wide&Deep 模型的代码实现3.1 tensorflow实现3.2 pytorch实现今天,总结一个在业界有着巨大影响力的推荐模型,…...
PHP面向对象03:命名空间
PHP面向对象03:命名空间一、命名空间基础二、子空间三、命名空间访问1. 非限定名称2. 限定名称3. 完全限定名称四、全局空间五、命名空间应用六、命名空间引入一、命名空间基础 namespace,是指人为的将内存进行分隔,让不同内存区域的同名结构…...
Elasticsearch:使用 pipelines 路由文档到想要的 Elasticsearch 索引中去
路由文件 当应用程序需要向 Elasticsearch 添加文档时,它们首先要知道目标索引是什么。在很多的应用案例中,特别是针对时序数据,我们想把每个月的数据写入到一个特定的索引中。一方面便于管理索引,另外一方面在将来搜索的时候可以…...

前端开发常用的18个JavaScript框架和库
JavaScript 可以说是最流行的编程语言之一,也是Web 开发人员必须学习的 3 种语言之一,JavaScript 几乎可以做任何事情,更可以在包括物联网在内的多个平台和设备上运行。在WebGL库和SVG/Canvas元素的支持下,JavaScript变得惊人的强…...

理解、总结重点知识
一、常见的数据结构 1、数组结构 数组结构: 存储区间连续、内存占用严重、空间复杂度大 优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快)缺点:插入和删除数据效率低&a…...

记一次从文件备份泄露到主机上线
前言 记录下某个测试项目中,通过一个文件备份泄露到主机上线的过程。 文件备份泄露 对于测试的第一项当然是弱口令,bp跑了一通词典,无果。目录又爆破了一通,发现一个web.rar可通,赶紧下载看看,如下图所示…...

8年测开经验面试28K公司后,吐血整理出1000道高频面试题和答案
1、python的数据类型有哪些 答:Python基本数据类型一般分为:数字、字符串、列表、元组、字典、集合这六种基本数据类型。 浮点型、复数类型、布尔型(布尔型就是只有两个值的整型)、这几种数字类型。列表、元组、字符串都是序列。 2、列表和元组的区别 答…...

Linux 基础知识之权限管理
目录一、权限的认识二、用户切换三、文件权限1.三类文件访问者2.文件权限类型3.文件访问权限4.文件权限值表示一、权限的认识 权限是对用户所能进行的操作的限制,如果不对用户作出限制,那么碰到恶意用户,就会损害其他用户的利益。 Linux是多用…...

百度LAC分词
对应数据的链接放这里了 import pandas as pd from util.logger import Log import os from util.data_dir import root_dir from LAC import LAC os_file_name os.path.split(os.path.realpath(__file__))[-1]# 加载LAC模型 lac LAC(mode"lac") # 载入自定义词典 …...

软件测试面试题 —— 整理与解析(1)
😏作者简介:博主是一位测试管理者,同时也是一名对外企业兼职讲师。 📡主页地址:🌎【Austin_zhai】🌏 🙆目的与景愿:旨在于能帮助更多的测试行业人员提升软硬技能…...

深入浅出C++ ——红黑树模拟实现STL中的set与map
文章目录一、红黑树二、用泛型红黑树模拟实现set三、用泛型红黑树模拟实现map一、红黑树 红黑树作为set和map的底层容器,既要实现插入key又要实现插入pair,所以做了稍许的改动,使其成为一颗泛型结构的红黑树,通过不同的实例化参数…...

自动化测试框架设计
大数据时代,多数的web或app产品都会使用第三方或自己开发相应的数据系统,进行用户行为数据或其它信息数据的收集,在这个过程中,埋点是比较重要的一环。 埋点收集的数据一般有以下作用: 驱动决策:ABtest、漏…...
【虚拟仿真】Unity3D中实现鼠标的单击、双击、拖动的不同状态判断
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 这篇文章分享一下虚拟仿真项目中经常碰到鼠标事件控制代码。 …...
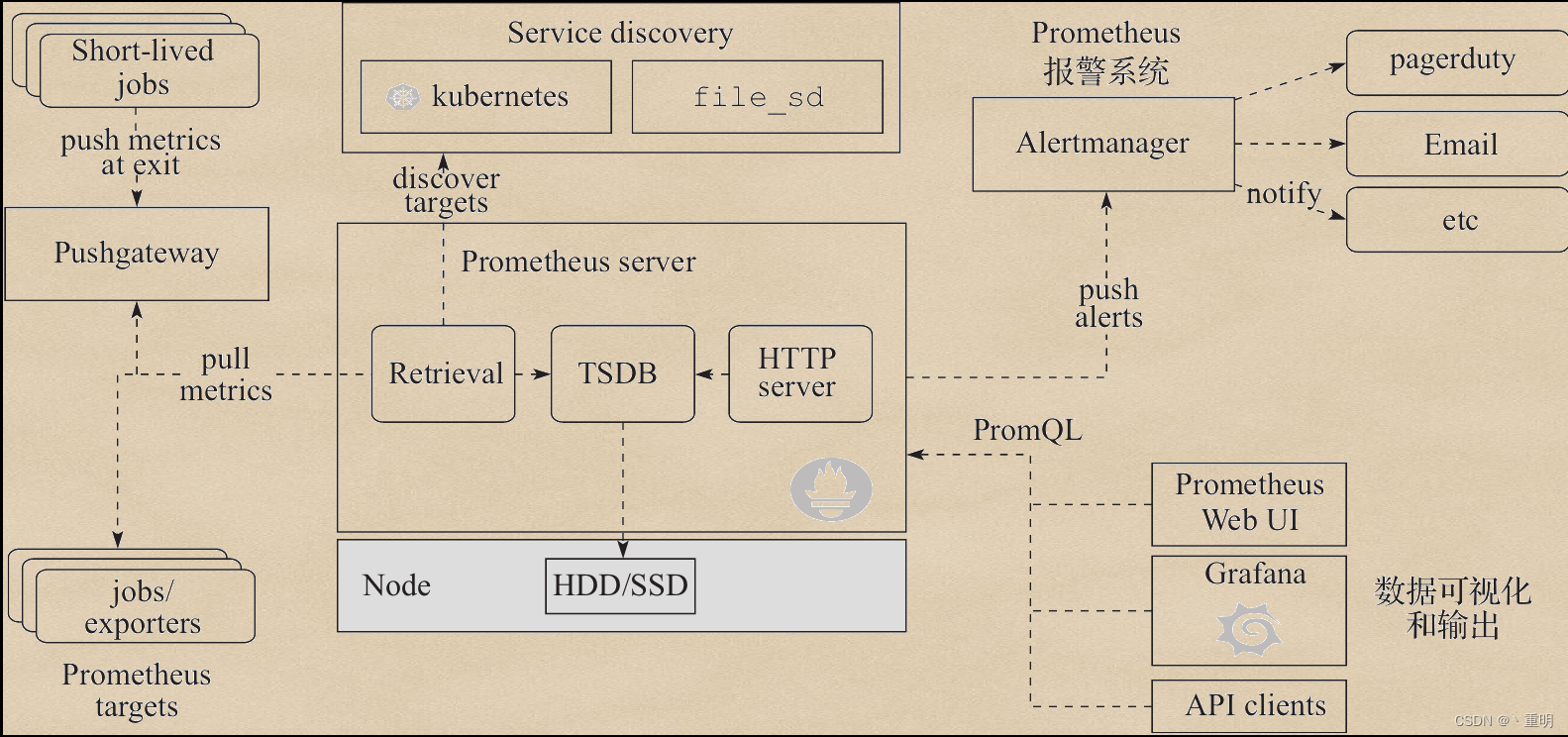
【2023】Prometheus-相关知识点(面试点)
目录1.Prometheus1.1.什么是Prometheus1.2.Prometheus的工作流程1.3.Prometheus的组件有哪些1.4.Prometheus有什么特点1.5.Metric的几种类型?分别是什么?1.6.Prometheus的优点和缺点1.7.Prometheus怎么采集数据1.8.Prometheus怎么获取采集对象1.9.Promet…...
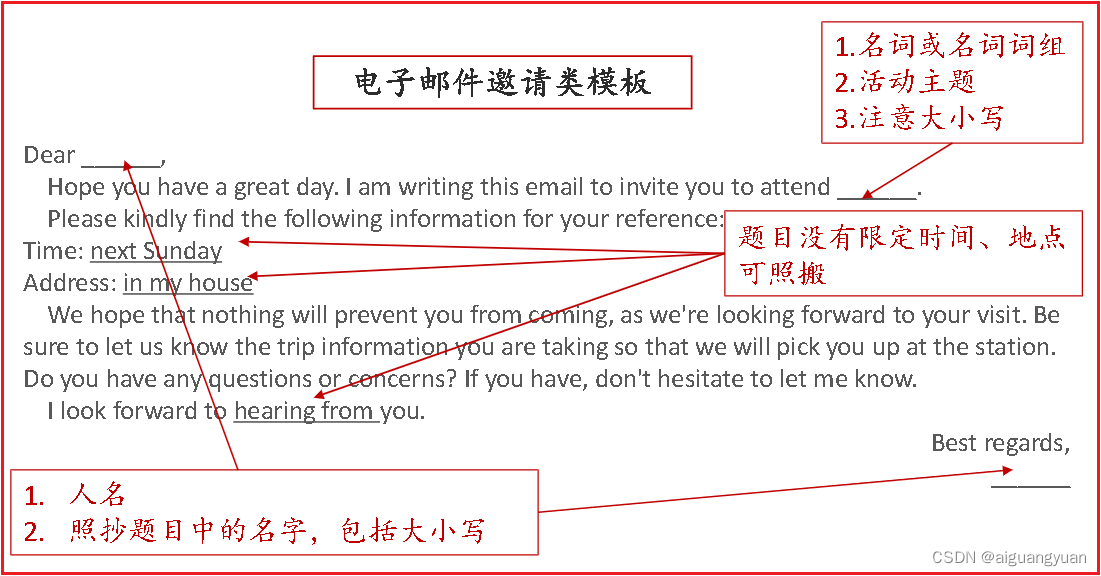
英语二-电子邮件邀请短文写作
1. 邮件模板 Dear 邀请人, Hope you have a great day. I am writing this email to invite you to attend 主题. Please kindly find the following information for your reference: Time: 时间 Address: 地点 We hope that nothing will prevent you from coming, as…...

如何快速一次性通过pmp考试?
我们就从三个方向进行了解 1.PMP考试难不难? 2.PMP如何备考? 3.考试过程中需要注意什么? 一,PMP考试难不难? 首先关注的问题是,PMP考试难吗?我想全球55%的通过率和学会这边93.9%的通过率&a…...

1-Linux 保存kernel panic信息到flash
在系统运行过程中,如果内核发生了panic,那么开发人员需要通过内核报错日志来进行定位问题。但是很多时候出现问题的时候没有接调试串口,而报错日志是在内存里面的,重启后就丢失了。所以需要一种方法,可以在系统发生crash时&#x…...

linux基本功系列-top命令实战
文章目录一. top命令介绍二. 语法格式及常用选项三. 参考案例3.1 显示进程信息3.2 显示完整的进程命令3.3 以批处理的形式展示3.4 设置信息更新频次3.5 显示指定进程号的信息3.6 top面板中常用参数3.7 其他用法四. top的相关说明4.1 交互命令介绍4.2 top面板每行信息的含义4.2.…...

6.5 拓展:如何实现 Web API 版本控制,同时兼容无版本控制的原始接口?
第6章 构建 RESTful 服务 6.1 RESTful 简介 6.2 构建 RESTful 应用接口 6.3 使用 Swagger 生成 Web API 文档 6.4 实战:实现 Web API 版本控制 6.5 拓展:如何实现 Web API 版本控制,同时兼容无版本控制的原始接口? 6.5 拓展&#…...

Springboot依赖注入Bean的三种方式,final+构造器注入Bean
文章目录Springboot依赖注入Bean的方式一、Field 注入/属性注入二、set注入三、构造器注入Springboot依赖注入Bean的方式 一、Field 注入/属性注入 Autowired注解的一大使用场景就是Field Injection。 Controller public class UserController {Autowiredprivate UserServic…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...