Tune-A-Video论文阅读
论文链接:Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
文章目录
- 摘要
- 引言
- 相关工作
- 文生图扩散模型
- 文本到视频生成模型
- 文本驱动的视频编辑
- 从单个视频生成
- 方法
- 前提
- DDPMs
- LDMs
- 网络膨胀
- 微调和推理
- 模型微调
- 基于DDIM inversion的结构引导
- Tune-A-Video的应用
- 对象编辑
- 背景变化
- 风格转移
- 个性化可控生成
- 实验
- 实现细节
- Baseline对比
- 数据集
- Baselines
- 定性结果
- 定量结果
- 自动指标
- 用户研究
- 消融实验
- 局限性和未来的工作
- 结论

摘要
为了复制文本到图像 (T2I) 生成的成功,最近的工作使用大规模视频数据集来训练文本到视频 (T2V) 生成器。尽管他们的结果很有希望,但这种范式的计算成本很高。本工作提出了一种新的 T2V 生成设置——One-Shot Video Tuning,仅需要一个文本-视频对。本文中模型为了进一步学习连续运动,引入了Tune-A-Video,它涉及定制的时空注意机制和有效的一次性调整策略。本文做出两个关键观察:1)T2I 模型可以生成仍然代表动词术语的图像; 2)扩展 T2I 模型以生成多个图像同时表现出令人惊讶的良好内容一致性。在推理时,使用 DDIM 反转来为采样提供结构指导。广泛的定性和定量实验表明本文方法在各种应用中具有显着的能力。
引言
大规模多模态数据集Laion由从互联网上抓取的数十亿个文本图像对组成,在文本到图像(T2I)生成方面取得了突破。为了在 Text-toVideo (T2V) 生成中复制这种成功,最近的工作将空间域的 T2I 生成模型扩展到时空域。这些模型通常采用在大规模文本视频数据集(例如 WebVid-10M)上进行训练的标准范式。尽管这种范式为 T2V 生成产生了有希望的结果,但它需要对大型硬件加速器进行大量训练,这既昂贵又耗时。
人类能够通过利用现有知识和提供给它们的信息来创建新概念、想法或事物的能力。例如,当呈现带有“一只男子滑雪在雪上滑雪”文本描述的视频时,可以想象熊猫在雪上滑雪,借鉴了对熊猫看起来像什么的知识。由于使用大规模图像文本数据预训练的 T2I 模型已经捕获了开放域概念的知识,因此出现了一个直观的问题:它们能否从单个视频示例(如人类)中推断出其他新颖的视频?因此引入了一种新的 T2V 生成设置,即 One-Shot Video Tuning,其中仅使用单个文本-视频对来训练 T2V 生成器。生成器有望从输入视频中捕获基本的运动信息,并合成带有编辑提示的新视频。
直观地说,成功生成视频的关键在于保持一致物体的连续运动。因此,本文对最先进的T2I扩散模型进行了以下观察,相应地激发了方法。(1) 关于运动:T2I模型能够生成与文本对齐的图像,包括动词术语。例如,给定文本提示“一个人在海滩上跑步”,T2I模型生成一个人跑步(不是走路或跳跃)的快照,尽管不一定以连续的方式(图2的第一行)。这证明T2I模型可以通过跨模态注意来正确地关注静态运动生成的动词。(2)关于一致的对象:简单地将T2I模型中的空间自注意从一张图像扩展到多张图像,就可以产生跨帧的一致内容。同样的例子,当用扩展的时空注意力并行生成连续的帧时,虽然运动仍然不是连续的,但在结果序列中可以观察到同一个人和同一海滩(图2第二行)。这意味着 T2I 模型中自注意力层仅由空间相似性而不是像素位置驱动。

将发现实现为一种简单而有效的方法,称为 Tune-A-Video。该方法基于最先进的 T2I 模型在时空维度上的简单膨胀。然而,在时空中使用完全注意不可避免地会导致计算的二次增长。因此,生成帧增加的视频是不可行的。此外,采用一种简单的微调策略来更新所有参数可能会危及 T2I 模型的预先存在的知识,并阻碍生成具有新概念的视频的生成。为了解决这些问题,引入了一种稀疏时空注意力机制,它只访问第一个和前一个视频帧,以及一个高效的调整策略,仅更新注意力块中的投影矩阵。根据经验,这些设计在所有帧中保持一致的对象,但缺乏连续的运动。因此,在推理时,进一步通过DDIM反演从输入视频中寻找结构指导,即DDIM采样的反向过程。使用倒置的潜在作为初始噪声,生成具有平滑运动的时间相干视频。值得注意的是,本论文方法本质上与现有的个性化和条件预训练的 T2I 模型兼容,例如 DreamBooth 和 T2I-Adapter ,提供了一个个性化可控的用户界面。
图1展示了Tune-A-Video在文本驱动的视频生成的广泛应用中的显著结果。通过广泛的定性和定量实验将本论文方法与最先进的基线进行比较,证明了它的优越性。主要贡献如下:
- 为 T2V 生成引入了 One-Shot Video Tuning 的新设置,消除了使用大规模视频数据集进行训练的负担
- 提出了 Tune-A-Video,这是第一个使用预训练的 T2I 模型生成 T2V 的框架
- 提出了有效的注意力调整和结构反演,显着提高了时间一致性
- 通过广泛的实验证明了提出方法的有效性
相关工作
本文工作涉及多个领域交叉;从文本提示生成图像/视频的扩散模型和方法,对真实图像/视频的文本驱动编辑,以及在单个视频上训练的生成模型。在此简要概述了每个领域的关键成就,强调了其与本文方法的联系和区别。
文生图扩散模型
文本到图像(T2I)的生成已经得到了广泛的研究,在过去的几年里,许多模型都是基于Transformers。几个T2I生成模型最近采用了扩散模型。GLIDE在扩散模型中提出了无分类器引导来提高图像质量,而DALLE-2则利用CLIP特征空间改进了文本-图像对齐。Imagen使用级联扩散模型进行高清视频生成,随后的工作如VQ-diffusion和Latent Diffusion Models (LDMs)在自动编码器的潜在空间中运行,以提高训练效率。本文方法建立在LDMs的基础上,通过将2D模型膨胀到潜在空间中的时空域。
文本到视频生成模型
虽然 T2I 生成方面取得了重大进展,但由于高质量、大规模的文本视频数据集的稀缺以及建模时间一致性和连贯性的固有复杂性,从文本中生成视频仍然落后。早期的工作主要集中在生成简单域中的视频,例如移动数字或特定的人类行为。最近,GODIVA是第一个利用2D VQ-VAE和稀疏注意力来生成 T2V 的模型,这允许更现实的场景。N̈UWA通过多任务学习方法为各种生成任务提供统一的表示,扩展了GODIVA。为了进一步增强 T2V 生成性能,CogVideo通过在预训练的 T2I 模型 CogView2 之上合并额外的时间注意模块来开发的。
为了复制T2I扩散模型的成功,Video diffusion models(VDM)使用了一个时空分解的U-Net,进行图像和视频数据的联合训练。Imagen Video使用级联扩散模型和 v 预测参数化改进了 VDM,以生成高清视频。Make-A-Video 和 MagicVideo 具有相似的动机,旨在将 T2I 生成的进展转移到 T2V 生成。尽管目前的T2V生成模型已经显示出令人印象深刻的结果,但它们的成功在很大程度上依赖于使用大量视频数据进行训练。相比之下,本文提出了一个新的T2V生成框架,通过在一个文本视频对上有效地调整预训练的T2I扩散模型。
文本驱动的视频编辑
最近基于扩散的图像编辑模型可以处理视频中的每个单独帧,但由于模型中缺乏时间意识,这会在帧之间产生不一致。Text2Live 允许使用文本提示进行一些基于文本的视频编辑,但由于其依赖于分层神经图谱,难以准确反映预期的编辑。此外,生成神经图谱通常需要大约 10 小时,而本文方法只需要每个视频 10 分钟的训练,只需 1 分钟就可以对视频进行采样。两个当前工作,Dreamix 和 Gen-1,都利用视频扩散模型 (VDM) 进行视频编辑。尽管VDMs取得了令人印象深刻的结果,但值得注意的是,VDMs的计算要求很高,需要大规模的字幕图像和视频进行训练。此外,他们的训练数据和预训练模型无法公开访问。
从单个视频生成
Single-video GANs为输入视频生成具有相似外观和动态的新视频。然而,这些基于 GAN 的方法在计算时间上受到限制(例如,HPVAE-GAN 在 13 帧的短视频上训练需要 8 天),因此在某种程度上是不切实际的且不可扩展。Patch - nearest-neighbour方法在提高视频生成质量的同时,将计算费用降低了几个数量级。然而,它们在泛化方面是有限的,因此只能处理需要“复制”输入视频部分的任务。最近,SinFusion将扩散模型应用于单视频任务,并使自回归视频生成具有改进的运动泛化能力;然而,它仍然无法产生包含新颖语义上下文的视频。
方法
设 V = { v i ∣ i ∈ [ 1 , m ] } V=\{v_{i}|i \in [1,m]\} V={vi∣i∈[1,m]}是有 m m m帧的视频, P P P是描述 V V V的原始提示词。本文目标是基于编辑过的 P ∗ P^{*} P∗生成你新视频 V ∗ V^{*} V∗。例如,考虑一个视频和原始提示“"a man is skiing”,并假设用户想要改变衣服的颜色,将牛仔帽子融入滑雪者,甚至用Spider Man替换滑雪者,同时保留原始视频的运动。用户可以通过进一步描述滑雪者的外观或用另一个词替换它来直接修改原始提示。
一个直观的解决方案是在大规模视频数据集上训练一个 T2V 模型,但它的计算成本很高。本文提出了一种新的设置,称为 One Shot Video Tuning,它使用公开可用的 T2I 模型和单个文本-视频对来实现相同的目标。

前提
DDPMs
DDPMs是经过训练以重新创建固定前向马尔可夫链 x 1 , . . . , x N x_{1},...,x_{N} x1,...,xN的潜在生成模型。给定数据分布 x 0 ∼ q ( x 0 ) x_{0} \sim q(x_{0}) x0∼q(x0),马尔可夫转换 q ( x t ∣ x t − 1 ) q(x_{t}|x_{t−1}) q(xt∣xt−1)定义为方差调度 β t ∈ ( 0 , 1 ) β_{t} ∈ (0,1) βt∈(0,1)的高斯分布,即

通过贝叶斯规则和马尔可夫性质,可以明确地将条件概率 q ( x t ∣ x 0 ) q(x_{t}|x_{0}) q(xt∣x0)和 q ( x t − 1 ∣ x t , x 0 ) q(x_{t−1}|x_{t,} x_{0}) q(xt−1∣xt,x0)表示为:

为了生成马尔可夫链 x 1 , . . . , x N x_{1},...,x_{N} x1,...,xN,DDPM利用先验分布 p ( x T ) = N ( x T ; 0 , I ) p(x_{T})=N (x_{T};0, I) p(xT)=N(xT;0,I)的反向过程和高斯转换

训练可学习参数 θ θ θ,以保证生成的逆过程接近正过程。
为此,DDPM通过最大化负对数似然的变分下界来遵循变分推理原理,该下界在给定高斯分布之间的KL散度的情况下具有封闭形式。根据经验,这些模型可以解释为一系列加权去噪自编码器 ϵ θ ( x t , t ) \epsilon_{θ}(x_{t}, t) ϵθ(xt,t),这些自编码器经过训练以预测其输入 x t x_{t} xt的去噪变体。目标可以简化为 E x , ϵ ∼ N ( 0 , 1 ) , t [ ‖ ϵ − ϵ θ ( x t , t ) ‖ 2 2 ] E_{x,\epsilon \sim N (0,1),t}[‖\epsilon −\epsilon_{θ}(x_{t}, t)‖^{2}_{2}] Ex,ϵ∼N(0,1),t[‖ϵ−ϵθ(xt,t)‖22]。
LDMs
LDMs是DDPMs的新变体,它在自编码器的潜在空间中工作。LDMs由两个关键组件组成。首先,在大量图像集合上使用逐块损失训练自编码器,其中编码器 E E E学习将图像 x x x压缩为潜在表示 z = E ( x ) z = E(x) z=E(x),解码器 D D D学习将潜在重构回像素空间,使 D ( E ( x ) ) ≈ x D(E(x))≈x D(E(x))≈x。第二个组件是DDPM,它经过训练以去除添加到采样数据中的噪声。对于文本引导的LDM,目标如下:
E z , ϵ ∼ N ( 0 , 1 ) , t , c [ ‖ ϵ − ϵ θ ( z t , t , c ) ‖ 2 2 ] E{z,\epsilon \sim N (0,1),t,c}[‖\epsilon −\epsilon_{θ}(z_{t},t,c)‖^{2}_{2}] Ez,ϵ∼N(0,1),t,c[‖ϵ−ϵθ(zt,t,c)‖22]
其中 c = ψ ( P ∗ ) c = ψ(P^{∗}) c=ψ(P∗)是文本条件 P ∗ P^{∗} P∗的嵌入。
网络膨胀
T2I扩散模型(如LDM)通常采用U-Net,这是一种基于空间下采样传递的神经网络体系结构,然后是具有跳过连接的上采样传递。它由堆叠的2D残差块和transformer块组成。每个transformer块由一个空间自注意力层、一个交叉注意力层和一个前馈网络 (FFN) 组成。空间自注意力利用特征图中的像素位置进行相似的相关性,而交叉注意力考虑像素和条件输入(如文本)之间的对应关系。形式上,给定视频帧 v i v_{i} vi的潜在表示 z v i z_{v_{i}} zvi,空间自注意机制实现 A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d ) ⋅ V Attention(Q, K, V) = Softmax(\frac{QK^{T}}{\sqrt d})·V Attention(Q,K,V)=Softmax(dQKT)⋅V, Q = W Q z v i , K = W K z v i , V = W V z v i Q = W^{Q}z_{v_{i}} , K = W^{K}z_{v_{i}} , V = W^{V}z_{v_{i}} Q=WQzvi,K=WKzvi,V=WVzvi,其中 W Q , W K , W V W^{Q},W^{K},W^{V} WQ,WK,WV分别是将输入投影到查询、键和值的可学习矩阵, d d d是键和查询特征的输出维度。
本文将2D LDM扩展到时空域。与 VDM 类似,本文将 2D 卷积层膨胀为伪 3D 卷积层,3 × 3 内核被替换为 1 × 3 × 3 内核,并在每个transformer中附加时间自注意力层以进行时间建模。为了增强时间一致性,进一步将空间自注意机制扩展到时空域。时空注意 (ST-Attn) 机制还有其他选择,包括完全注意和因果注意,这也捕获了时空一致性。然而,由于计算复杂度高,这种直接的选择在生成具有增加帧的视频方面实际上是不可行的。具体来说,给定 m m m帧和每帧 N N N个序列,完全注意和因果注意的复杂度都是 O ( ( m N ) 2 ) O((mN)^{2}) O((mN)2)。如果需要生成 m m m值较大的长视频,这是负担不起的。本文建议使用稀疏版本的因果注意机制,在帧 z v i z_{v_{i}} zvi和前两帧 z v 1 z_{v_{1}} zv1和 z v i − 1 z_{v_{i−1}} zvi−1之间计算注意矩阵,保持在 O ( 2 m ( N ) 2 ) O(2m(N)^{2}) O(2m(N)2)的低计算复杂度。具体来说,从帧 z v i z_{v_{i}} zvi中导出查询特征,从第一帧 z v 1 z_{v_{1}} zv1和前帧 z v i − 1 z_{v_{i−1}} zvi−1中导出键值特征,并通过 Q = W Q z v i , K = W K [ z v 1 , z v i − 1 ] , V = W V [ z v 1 , z v i − 1 ] Q = W^{Q}z_{v_{i}}, K = W^{K} [z_{v_{1}},z_{v_{i−1}}],V = W^{V} [z_{v_{1}},z_{v_{i−1}}] Q=WQzvi,K=WK[zv1,zvi−1],V=WV[zv1,zvi−1]实现 A t t e n t i o n ( Q , K , V ) Attention(Q, K, V) Attention(Q,K,V),其中[,]表示连接操作。请注意,投影矩阵 W Q , W K , W V W^{Q}, W^{K},W^{V} WQ,WK,WV在空间和时间之间共享。如图五所示,将帧 z v i z_{v_{i}} zvi、前一帧 z v i − 1 z_{v_{i−1}} zvi−1和 z v 1 z_{v_{1}} zv1的潜在特征投影到 Q , K , V Q,K,V Q,K,V中。输出是这些值的加权和,根据查询和关键特征之间的相似性进行加权。突出显示更新的参数 W Q W^{Q} WQ。
微调和推理
模型微调
在给定的输入视频上微调网络以进行时间建模。时空注意(ST-Attn)旨在通过查询前一帧中的相关位置来建模时间一致性。本文建议固定参数 W K , W V W^{K},W^{V} WK,WV,并且只更新 ST-Attn 层中的 W Q W^{Q} WQ。相反,在整个时间自注意(T-Attn)层被添加时对其进行微调。此外,提出通过更新交叉关注(Cross-Attn)中的查询投影来改进文本视频对齐。在实践中,与完全调优相比,对注意力块进行微调计算效率更高,同时保留了预先训练的T2I扩散模型的原始性质。在标准LDM中使用相同的训练目标。图 4 说明了带有突出显示可训练参数的微调过程。


基于DDIM inversion的结构引导
微调注意力层对于确保所有帧之间的空间一致性至关重要。然而,它并没有提供对像素偏移的太多控制,导致循环中停滞的视频。为了解决这个问题,推理阶段合并了来自源视频的结构指导。具体来说,通过没有文本条件的DDIM inersion得到源视频 V V V的潜在噪声。该噪声作为DDIM采样的起点,由编辑后的提示 T ∗ T^{*} T∗指导。输出视频 V ∗ V^{*} V∗则由以下公式给出:
V ∗ = D ( D D I M − s a m p ( D D I M − i n v ( E ( V ) ) , T ∗ ) ) ) . V^{*} = D(DDIM-samp(DDIM-inv (E(V)), T^{*}))). V∗=D(DDIM−samp(DDIM−inv(E(V)),T∗))).
Tune-A-Video的应用
以下展示了几个用于文本驱动视频生成和编辑的Tune-A-Video应用程序。
对象编辑
本文方法的主要应用之一是通过编辑文本提示来修改对象。这允许轻松替换、添加或删除对象。图 6 显示了一些示例,将“a man”替换为“Spider Man”或“Wonder Woman”、“a rabbit”替换为“a cat”或“a puppy”,甚至将“a watermelon”换成“a cheeseburger”,只需修改相应的单词。可以通过进一步描述提示中的对象,例如“a cowboy hat”或“"sunglasses”。删除一个对象可以通过删除相应的短语实现——例如 watermelon。

背景变化
本文方法还允许用户更改视频背景(即对象所在的位置),同时保留对象运动的一致性。例如,可以通过添加新的位置/时间描述,将图6中滑雪人的背景修改为“on the beach”或“at sunset”,并通过替换现有的位置描述,将图7中的乡村道路视图更改为海景。

风格转移
由于预训练的 T2I 模型的开放域知识,本文方法将视频转移到各种难以仅从视频数据中学习的样式中。例如,通过将全局样式描述符附加到提示中,将真实世界的视频转换为漫画风格(图 6)或 Van Gogh 风格(图 10)。
个性化可控生成
本文方法可以很容易地与个性化的 T2I 模型(例如,DreamBooth,它以 3-5 张图像作为输入并返回个性化的 T2I 模型)集成,通过直接对它们进行微调。例如,可以使用为“Modern Disney Style”或“Mr Potato Head”个性化的 DreamBooth 来创建特定风格或主题的视频(图 11)。本文方法还可以与T2I-Adapter和ControlNet等条件T2I模型集成,以不需要额外的训练成本对生成的视频进行不同的控制。例如,可以使用一系列人体姿势作为控制来进一步编辑运动(如图 1 中的跳舞)。注意,可以使用现成的姿势估计模型从真实世界的视频中自动检测到人体姿势序列。本文方法与个性化和有条件的T2I模型的兼容性为用户创造他们想要的视频内容提供了更多的可能性。
实验
实现细节
开发基于潜在扩散模型(即稳定扩散)和公开预训练权重。从输入视频中采样32个分辨率为512 × 512的均匀帧,并使用本文方法对模型进行500步的微调,学习率为 3 × 1 0 − 5 3 × 10^{−5} 3×10−5,batch size为1。在推理方面,实验中使用无分类器引导的DDIM采样器。对于单个视频,微调大约需要10分钟,在NVIDIA A100 GPU上采样大约需要1分钟。
Baseline对比
数据集
为了评估本文方法,使用了42个来自DAVIS数据集的代表性视频。使用现成的字幕模型自动生成视频片段,并在应用程序中手动设计140个编辑提示。有关基准测试的更多详细信息,请参见附录A 。
Baselines
将本文呢方法与三个基线进行比较:
- CogVideo:在540万个字幕视频数据集上训练的T2V模型,能够以zeor-shot的方式直接从文本提示生成视频
- Plug-and-Play:一个尖端的图像编辑模型,可以单独编辑视频的每一帧
- Text2LIVE:最近的一种文本引导视频编辑方法,使用分层神经图谱
定性结果
图7中给出了本文方法与几个baselines的比较。观察到,虽然CogVideo可以生成反映文本中一般概念的视频,但输出的视频质量差异很大,并且不能将视频作为输入。另一方面,Plug-andPlay 成功地单独编辑每个视频帧,但由于忽略了时间上下文,缺乏帧一致性(如Porsche car 的外观跨帧不一致)。Text2LIVE 虽然能够产生时间平滑的视频,但很难准确地表示编辑过的提示(如Porsche car 仍然出现在原始 jeep car 的形状中)。这可能是因为它依赖于分层神经图谱,这限制了其编辑能力。相比之下,本文方法生成时间连贯的视频,以保留输入视频的结构信息,并与编辑过的单词和细节很好地对齐。
定量结果
通过自动度量和用户研究来根据基线量化本文方法,并在表1中报告框架一致性和文本可信度。

自动指标
对于帧一致性,在输出视频的所有帧上计算CLIP图像嵌入,并报告所有视频帧对之间的平均余弦相似度。为了衡量文本的可信度,计算输出视频的所有帧和相应的编辑提示之间的平均CLIP分数。研究结果表明,CogVideo产生一致的视频帧,但难以表示文本描述,而Plug-and-Play实现了高文本忠实度,但未能生成一致的内容。相比之下,本文方法在两个指标上都优于基线。
用户研究
对于帧一致性,以随机顺序展示了本文方法和基线生成的两个视频,并要求评估者“which one has better temporal consistency?”。对于文本忠实度,还展示了文本描述并询问评估者“which video better aligns with the textual description?”。招募了 5 名参与者来注释每个示例,并对最终结果使用多数票。附录B中提供了更多详细信息。观察到 CogVideo 和 Plug-and-Play 由于框架和框架文本不一致而不太受欢迎,而本文方法从两个方面实现了更高的用户偏好。
消融实验
本文进行了消融研究,以评估在 Tune-A-Video 中时空注意力 (ST-Attn) 机制、DDIM 反转和微调的重要性。每个设计都被单独消融以分析其影响。图 8 所示的结果表明,w/o ST-Attn 的模型表现出显着的内容差异(与滑雪者的服装颜色无关)。相比之下,w/o 反演模型保持一致的内容,但不能复制输入视频中的运动(即滑雪)。由于 ST-Attn 和反演,w/o 微调的模型仍然足以跨帧保持一致的内容。然而,连续帧中的运动并不平滑,导致视频闪烁。结果表明,所有的关键设计都有助于本文方法的生成结果。

局限性和未来的工作
图 9 显示了当输入视频包含多个对象并显示遮挡时本文方法的失败例子。这可能是因为 T2I 模型在处理多个对象和对象交互方面的固有限制。一个潜在的解决方案是使用额外的条件信息,例如深度,使模型能够区分不同的对象及其交互。这条研究途径留作未来的工作。

结论
本文介绍了一个名为 One-Shot Video Tuning 的 T2V 生成新任务。该任务涉及仅使用单个文本-视频对和预训练的 T2I 模型训练 T2V 生成器。提出了 Tune-A-Video,这是一个简单而有效的文本驱动视频生成和编辑框架。为了生成连续的视频,本文提出了一种有效的调优策略和结构反演,能够生成时间连贯的视频。大量实验表明,本文方法在广泛的应用中取得了显著的效果。
相关文章:
Tune-A-Video论文阅读
论文链接:Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation 文章目录 摘要引言相关工作文生图扩散模型文本到视频生成模型文本驱动的视频编辑从单个视频生成 方法前提DDPMsLDMs 网络膨胀微调和推理模型微调基于DDIM inversio…...

Dataset和DataLoader用法
Dataset和DataLoader用法 在d2l中有简洁的加载固定数据的方式,如下 d2l.load_data_fashion_mnist() # 源码 Signature: d2l.load_data_fashion_mnist(batch_size, resizeNone) Source: def load_data_fashion_mnist(batch_size, resizeNone):"""…...
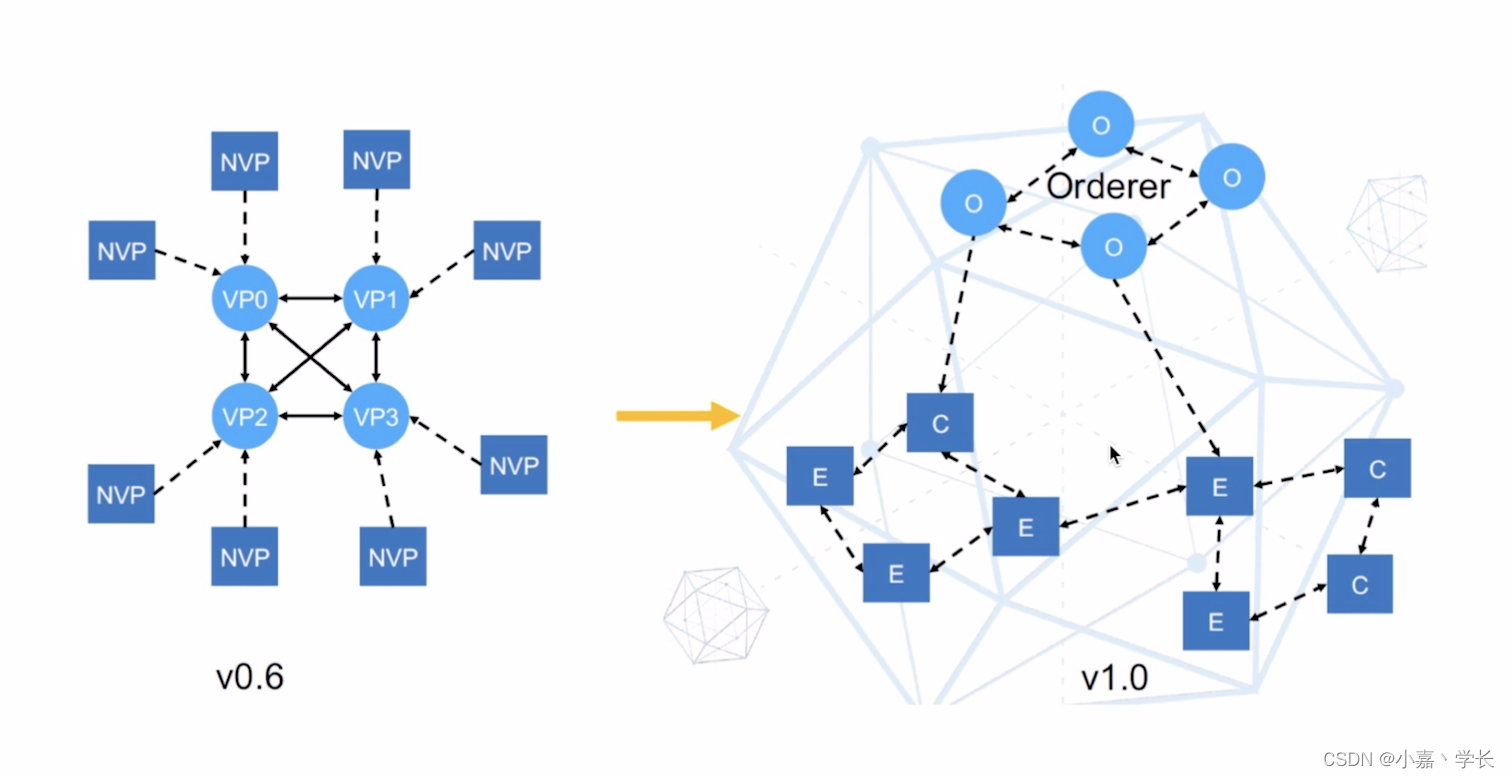
【跟小嘉学习区块链】二、Hyperledger Fabric 架构详解
系列文章目录 【跟小嘉学习区块链】一、区块链基础知识与关键技术解析 【跟小嘉学习区块链】一、区块链基础知识与关键技术解析 文章目录 系列文章目录[TOC](文章目录) 前言一、Hyperledger 社区1.1、Hyperledger(面向企业的分布式账本)1.2、Hyperledger社区组织结构 二、Hype…...

springboot下spring方式实现Websocket并设置session时间
概述 springboot实现websocket有4种方式 servlet,spring,netty,stomp 使用下来spring方式是最简单的. springboot版本:3.1.2 jdk:17 当前依赖版本 <dependency><groupId>org.springframework.boot<…...
LeetCode算法二叉树—相同的树
目录 100. 相同的树 - 力扣(LeetCode) 代码: 运行结果: 给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是…...
搭建Flink集群、集群HA高可用以及配置历史服务器
Flink集群搭建 Flink集群搭建集群规划下载并解压安装包修改集群配置分发安装目录启动集群访问Web UI Flink集群HA高可用概述集群规划配置flink配置master、workers配置ZK分发安装目录启动HA集群测试 Flink参数配置配置历史服务器概述配置启动、停止历史服务器提交一个Job任务查…...
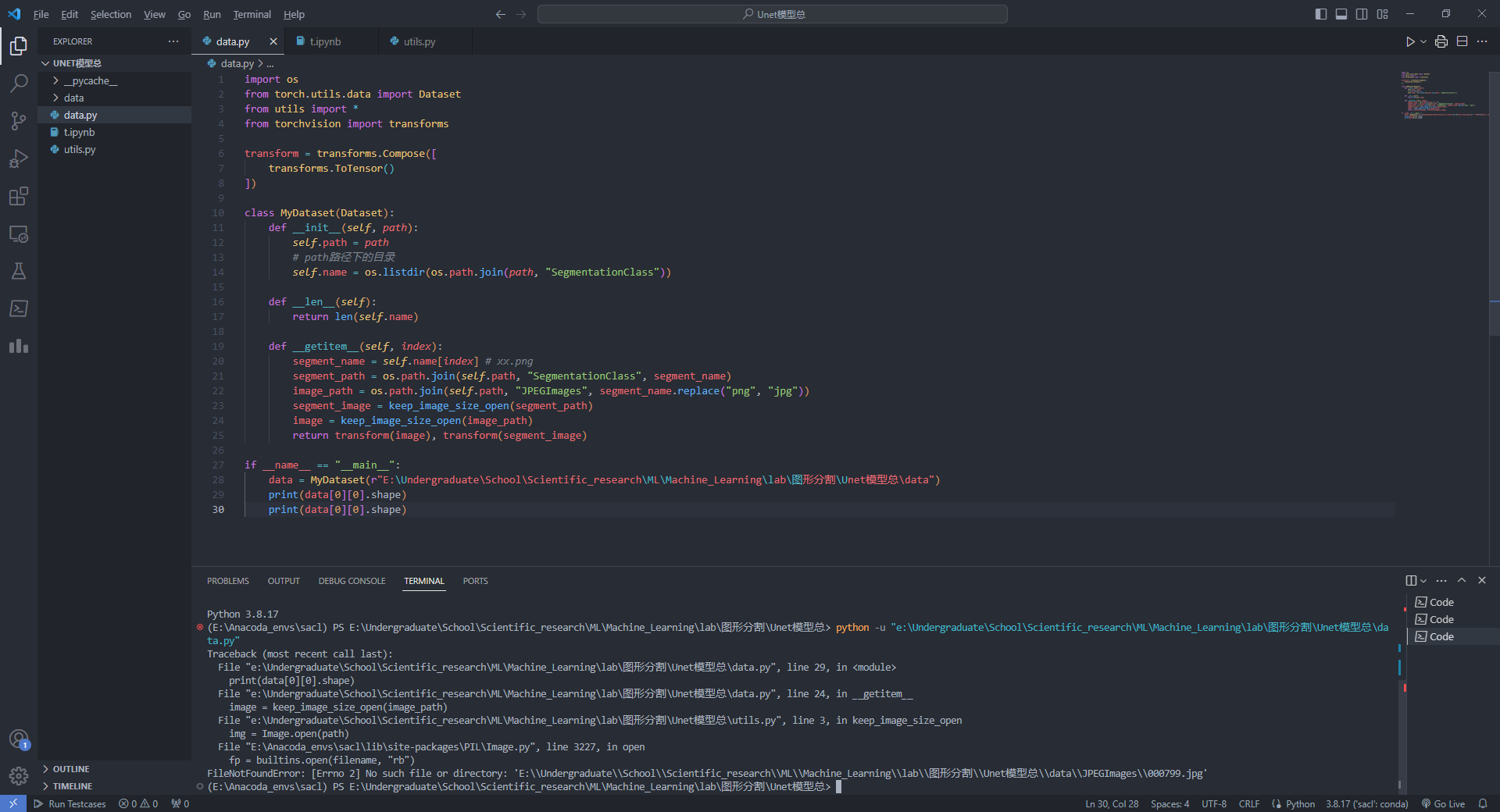
vscode终端中打不开conda虚拟包管理
今天,想着将之前鸽的Unet网络模型给实现一下,结果发现,在vscode中运行python脚本,显示没有这包,没有那包。但是在其他的ipynb中是有的,感觉很奇怪。我检查了一下python版本,发现不是我深度学习的…...

【音视频】MP4封装格式
基本概念 使用MP4box.js查看MP4内部组成结构 整体结构 数据索引(moov)数据流包(mdat) 各个包的位置,大小,信息,时间戳,编码方式等全在数据索引 数据流包只有纯二进制码流数据 数据…...

环境-使用vagrant快速创建linux虚拟机
1.下载软件 虚拟机 Oracle VM VirtualBox 镜像 Vagrant by HashiCorp (vagrantup.com) 如果下载慢,可以复制下载链接,使用迅雷下载 2.安装 根据提示点击下一步即可,建议安装到空间较大的非系统盘。 打开 window cmd 窗口,…...
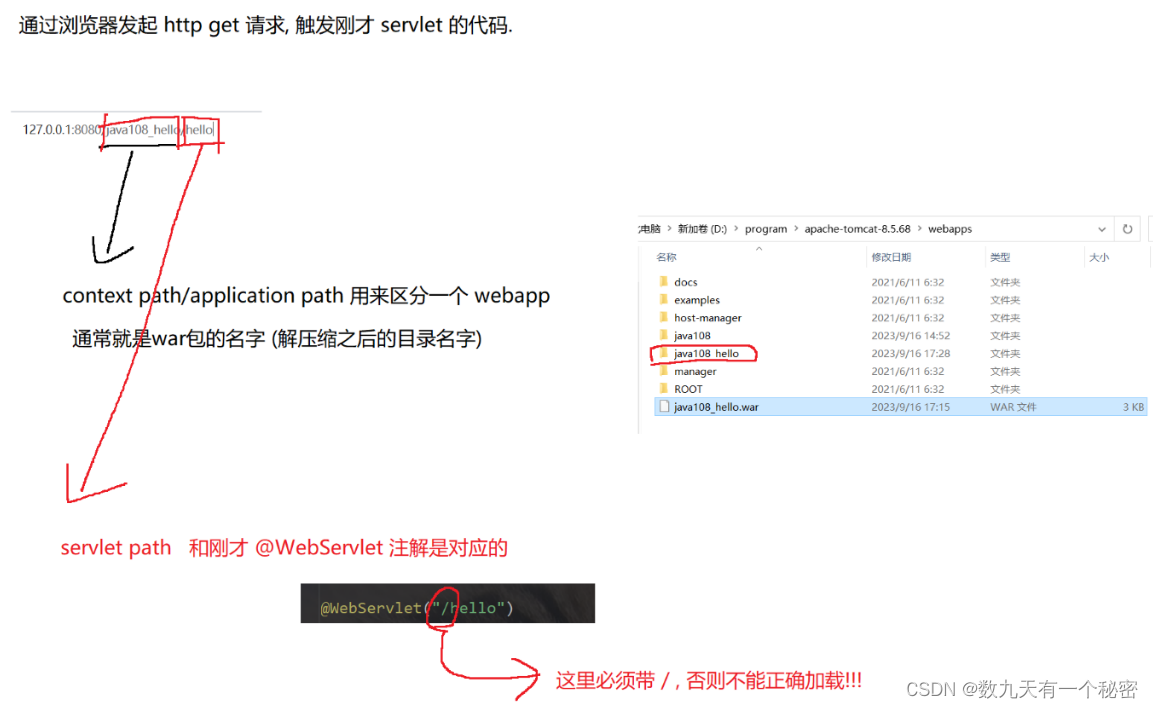
10.1网站编写(Tomcat和servlet基础)
一.Tomcat: 1.Tomcat是java写的,运行时需要依赖jre,所以要装jdk. 2.建议配置好环境变量. 3.默认端口号8080(业务端口)可能会被占用,建议改一下(本人改成了9999). 4.另一个默认端口是8005(管理端口). 二Servlet基础(编写一个hello world代码): 整体分为7个步骤,分别是创建…...
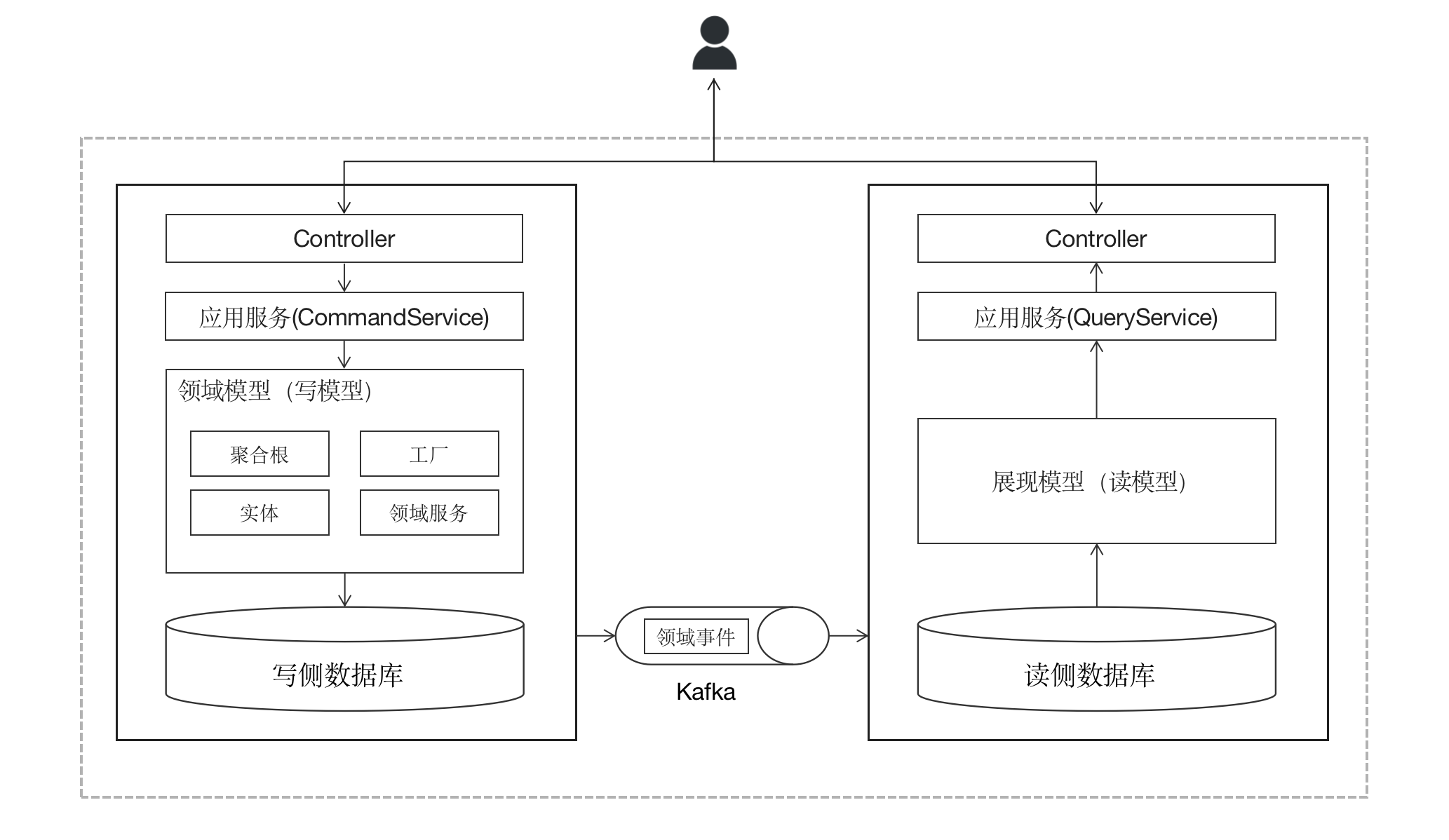
10CQRS
本系列包含以下文章: DDD入门DDD概念大白话战略设计代码工程结构请求处理流程聚合根与资源库实体与值对象应用服务与领域服务领域事件CQRS(本文) 案例项目介绍 # 既然DDD是“领域”驱动,那么我们便不能抛开业务而只讲技术&…...

DAZ To UMA⭐一.DAZ简单使用教程
文章目录 🟥 DAZ快捷键🟧 DAZ界面介绍 🟥 DAZ快捷键 移动物体:ctrlalt鼠标左键 旋转物体:ctrlalt鼠标右键 导入模型:双击左侧模型UI 🟧 DAZ界面介绍 Files:显示全部文件 Products:显示全部产品 Figures:安装的全部人物 Wardrobe…...
)
面试题 —— Java集合篇(23题)
文章目录 1.Java中常见集合有哪些 ?2. 说说你对Java集合是怎么理解的?3.请你说一下List,Set,Map三者的特点是 ?4.在实际开发过程中如何更好的选择集合 ?5. ArrayList和Vector区别 ?6. ArrayList…...

SpringBoot2.7.14整合Swagger3.0的详细步骤及容易踩坑的地方
🧑💻作者名称:DaenCode 🎤作者简介:啥技术都喜欢捣鼓捣鼓,喜欢分享技术、经验、生活。 😎人生感悟:尝尽人生百味,方知世间冷暖。 📖所属专栏:Sp…...

题解:ABC321D - Set Menu
题解:ABC321D - Set Menu 题目 链接:Atcoder。 链接:洛谷。 难度 算法难度:B。 思维难度:C。 调码难度:B。 综合评价:见洛谷链接。 算法 枚举二分查找。 思路 先对b升序排序&#x…...

什么是Progressive Web App(PWA)?它们有哪些特点?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 渐进式Web App简介⭐ PWAs的主要特点⭐ 总结⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入…...
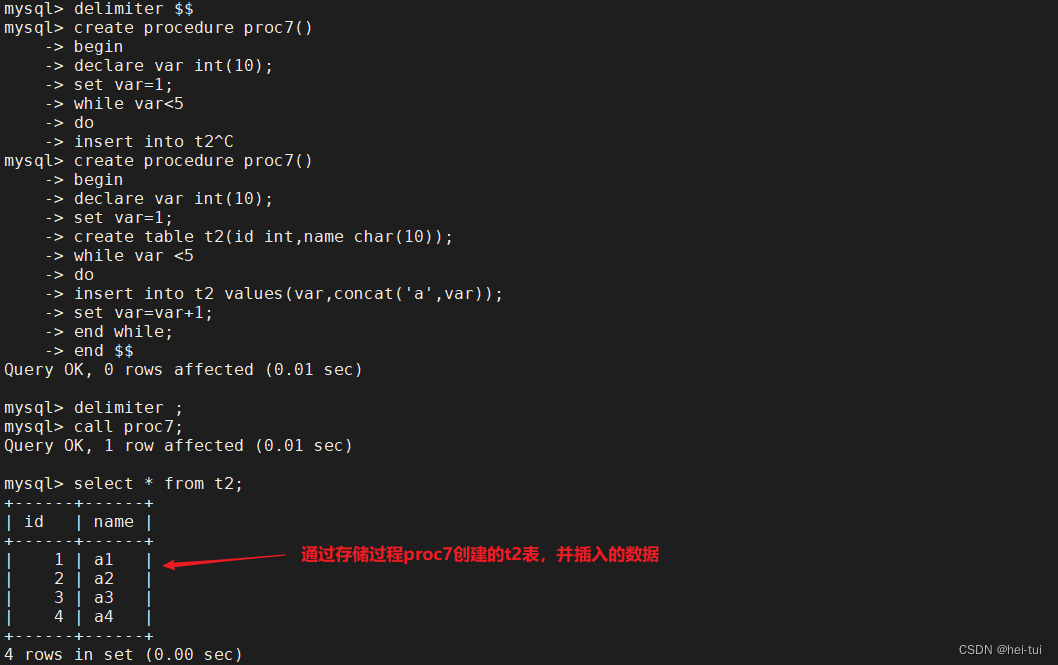
MySQL的高级SQL语句
目录 一、高级SQL语句 1、select 查询表中一个或多个字段的数据 2、distinct 不显示重复的数据记录 3、where 有条件查询 4、and与or 且与或 5、in 显示在某个范围值内 的字段的信息 6、between 显示两个值范围内的数据记录 7、order by 对字…...

基于人脸5个关键点的人脸对齐(人脸纠正)
摘要:人脸检测模型输出人脸目标框坐标和5个人脸关键点,在进行人脸比对前,需要对检测得到的人脸框进行对齐(纠正),本文将通过5个人脸关键点信息对人脸就行对齐(纠正)。 一、输入图像…...

vue3中两个el-select下拉框选项相互影响
vue3中两个el-select下拉框选项相互影响 1、开发需求2、代码2.1 定义hooks文件2.2 在组件中使用 1、开发需求 如图所示,在项目开发过程中,遇到这样一个需求,常规时段中选中的月份在高峰时段中是禁止选择的状态,反之亦然。 2、代…...
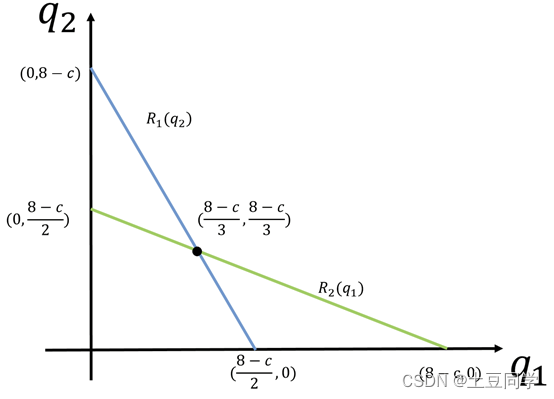
博弈论——反应函数
反应函数 1 引言 谢老师的《经济博弈论》书中对反应函数并没有给出一般笼统的定义,而是将其应用与古诺模型并给出了相关解释:反应函数是指在无限策略的古诺博弈模型中,博弈方的策略有无限多种,因此各个博弈方的最佳对策也有无限…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...