Elasticsearch架构篇 - terms aggregation
terms aggregation
即词项分桶聚合。它是 Elasticsearch 最常用的聚合,类同于关系型数据库依据关键字段做 group。
-
size:返回的词项分桶数量,默认 10。阈值 65535。默认情况下,协调节点向每个分片请求 top size 数量的词项桶,并且在所有分片都响应后,将结果进行缩减并返回给客户端。如果实际词项桶的数量大于 size,则返回的词项桶可能会存在偏差并且不准确。
-
shard_size:每个分片返回的词项分桶数量,默认为 size * 1.5 + 10。shard_size 越大,结果越准确,但是最终计算结果的成本也越高(每个分片上的优先级队列会更大,并且节点与客户端之间的数据传输量也更大)。shard_size 不能比 size 小,否则 Elasticsearch 会覆盖该属性值,将其设置为和 size 一样的值。
-
min_doc_count:限制返回的词项分桶中对应文档的命中数量必须满足的最小值,默认 1。
-
shard_min_doc_count:限制每个分片返回的词项分桶中对应文档的命中数量必须满足的最小值,默认 0。必须小于 min_doc_count。建议为 min_doc_count / 分片数。
-
show_term_doc_count_error:显示词项分桶统计数据的错误信息,默认 false。用来显示聚合返回的每个词项的错误值,错误值表示文档计数在最差情况下的错误。这个错误值在决定 shard_size 参数值时非常有用。
-
order:指定排序规则。默认按照 doc_count 逆序排序。
-
missing:指定字段的值不存在时,给予文档的缺省值。默认会忽略。
修改返回的词项分桶的数量的阈值。
PUT _cluster/settings
{"transient": {"search.max_buckets": 10}
}
查询航班目的地最多的 Top 10 国家。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10}}}
}
结果输出如下:
{"took" : 38,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 10000,"relation" : "gte"},"max_score" : null,"hits" : [ ]},"aggregations" : {"DestCountry" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 3187,"buckets" : [{"key" : "IT","doc_count" : 2371},{"key" : "US","doc_count" : 1987},{"key" : "CN","doc_count" : 1096},{"key" : "CA","doc_count" : 944},{"key" : "JP","doc_count" : 774},{"key" : "RU","doc_count" : 739},{"key" : "CH","doc_count" : 691},{"key" : "GB","doc_count" : 449},{"key" : "AU","doc_count" : 416},{"key" : "PL","doc_count" : 405}]}}
}
词项分桶聚合返回的 doc_count 值是近似的。可以使用参考如下两个指标来判断 doc_count 值是否是准确的。
-
sum_other_doc_count:查询结果中没有出现的所有词项的文档总数。
-
doc_count_error_upper_bound:查询结果中没有出现的词项的最大可能文档数。它的值是所有分片返回的最后一个词项的文档数量的和。当
show_term_doc_count_error参数设置为 true,可以查看每个词项对应的文档数量的误差。这些误差只有当聚合结果按照文档数降序排序时才会被统计。此外,如果按照词项值本身排序、按照文档数升序或者按照子聚合结果排序都无法统计误差,doc_count_error_upper_bound 会返回 -1。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true}}}
}
结果输出如下:
{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 10000,"relation" : "gte"},"max_score" : null,"hits" : [ ]},"aggregations" : {"DestCountry" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 3187,"buckets" : [{"key" : "IT","doc_count" : 2371,"doc_count_error_upper_bound" : 0},{"key" : "US","doc_count" : 1987,"doc_count_error_upper_bound" : 0},{"key" : "CN","doc_count" : 1096,"doc_count_error_upper_bound" : 0},{"key" : "CA","doc_count" : 944,"doc_count_error_upper_bound" : 0},{"key" : "JP","doc_count" : 774,"doc_count_error_upper_bound" : 0},{"key" : "RU","doc_count" : 739,"doc_count_error_upper_bound" : 0},{"key" : "CH","doc_count" : 691,"doc_count_error_upper_bound" : 0},{"key" : "GB","doc_count" : 449,"doc_count_error_upper_bound" : 0},{"key" : "AU","doc_count" : 416,"doc_count_error_upper_bound" : 0},{"key" : "PL","doc_count" : 405,"doc_count_error_upper_bound" : 0}]}}
}
排序
默认按照 doc_count 逆序排序。不推荐按照 doc_count 升序排序或者在子聚合中排序,这会增加统计文档数量的错误。但是如果在单一分片或者聚合使用的字段在索引时用做路由键,这两种情况下却是准确的。
_count:按照数量排序,默认的排序方式。
_key:按照词项排序。
_term: 按照词项排序。
按照文档数量的升序排序。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true,"order": {"_count": "asc"}}}}
}
按照 key 的字母顺序升序排序。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true,"order": {"_key": "asc"}}}}
}
查询航班飞行最短的 Top 10 国家。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"order": {"min_FlightTimeMin": "desc"}},"aggs": {"min_FlightTimeMin": {"min": {"field": "FlightTimeMin"}}}}}
}
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"order": {"stats_FlightTimeMin.max": "desc"}},"aggs": {"stats_FlightTimeMin": {"stats": {"field": "FlightTimeMin"}}}}}
}
词项嵌套分桶
嵌套深度建议不要超过三层。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true},"aggs": {"OriginCountry": {"terms": {"field": "OriginCountry","size": 10}}}}}
}
脚本方式
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"script": {"source": """doc['DestCountry'].value + "-DEMO";""","lang": "painless"},"size": 10}}}
}
结果输出如下:
{"took" : 56,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 10000,"relation" : "gte"},"max_score" : null,"hits" : [ ]},"aggregations" : {"DestCountry" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 3187,"buckets" : [{"key" : "IT-DEMO","doc_count" : 2371},{"key" : "US-DEMO","doc_count" : 1987},{"key" : "CN-DEMO","doc_count" : 1096},{"key" : "CA-DEMO","doc_count" : 944},{"key" : "JP-DEMO","doc_count" : 774},{"key" : "RU-DEMO","doc_count" : 739},{"key" : "CH-DEMO","doc_count" : 691},{"key" : "GB-DEMO","doc_count" : 449},{"key" : "AU-DEMO","doc_count" : 416},{"key" : "PL-DEMO","doc_count" : 405}]}}
}
词项分桶键值过滤
支持精确键值过滤与模糊匹配方式(通过正则表达式)过滤。个人发现 Elasticsearch 7.14 版本模糊匹配方式实际操作中不生效。
- include:包括指定的词项分桶值。
- exclude:不包括指定的词项分桶值。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true,"include": ["US", "IT", "CN"]}}}
}
结果输出如下:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 10000,"relation" : "gte"},"max_score" : null,"hits" : [ ]},"aggregations" : {"DestCountry" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "IT","doc_count" : 2371,"doc_count_error_upper_bound" : 0},{"key" : "US","doc_count" : 1987,"doc_count_error_upper_bound" : 0},{"key" : "CN","doc_count" : 1096,"doc_count_error_upper_bound" : 0}]}}
}
词项分桶分区聚合
很多时候需要统计的分桶数量太多,导致一次运行很慢。可以借助分区机制,在客户端进行合并。对所有可能的分桶进行分区。
partition:分区编号。从 0 开始。
num_partitions:分区数量。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true,"include": {"partition": 2,"num_partitions": 5}}}}
}
个人在实际操作中,发现每次调整 partition的值,返回的桶的数量可能会不同。比如partition设置为2,结果返回8个桶;parition设置为1,结果返回6个桶,
词项分桶统计收集模型
- collect_mode:词项分桶统计收集模型。
- depth_first:(默认值)深度优先。适用于分桶数据量小的,分桶比较固定的,建议 10000 以内。
- breadth_first:广度优先。适用于分桶数据量大的。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true,"collect_mode": "depth_first"}}}
}
词项分桶存储选择
- execution_hint:词项分桶临时存储设置。
- map:使用 map 结构。适用于少量分桶的聚合统计。
- global_ordinals:(默认值)使用全局序号结构。适用于大量分桶的聚合统计。
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"DestCountry": {"terms": {"field": "DestCountry","size": 10,"show_term_doc_count_error": true,"execution_hint": "map"}}}
}
提前加载全局序号
Elasticsearch 在使用全局序号时,第一次需要从 doc_values 读取所有值来构建全局序号。可以设置提前加载到内存中,避免查询响应慢。
- eager_global_ordinals:设置 true,提前加载并构建全局序号。
PUT my-index-000001/_mapping
{"properties": {"tags": {"type": "keyword","eager_global_ordinals": true}}
}
指标聚合进行子聚合
stats 指标聚合作为子聚合。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"aggs": {"city_name": {"terms": {"field": "geoip.city_name","size": 10},"aggs": {"taxful_total_price": {"stats": {"field": "taxful_total_price"}}}}}
}
top_hits 指标聚合作为子聚合。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"aggs": {"aggs_customer_id": {"terms": {"field": "customer_id","size": 10},"aggs": {"top_hits": {"top_hits": {"size": 2, "_source": {"includes": ["customer_id", "order_date", "products"]},"sort": [{"order_date": {"order": "desc"}} ]}}}}}
}
top_metrics 指标聚合作为子聚合。
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"aggs_customer_id": {"terms": {"field": "customer_id","size": 2},"aggs": {"top_metrics_total_price": {"top_metrics": {"metrics": {"field": "taxful_total_price"},"sort": {"order_date": "desc"},"size": 1}}}}}
}
相关文章:

Elasticsearch架构篇 - terms aggregation
terms aggregation 即词项分桶聚合。它是 Elasticsearch 最常用的聚合,类同于关系型数据库依据关键字段做 group。 size:返回的词项分桶数量,默认 10。阈值 65535。默认情况下,协调节点向每个分片请求 top size 数量的词项桶&…...

MySQL 的体系结构、引擎与索引
MySQL的引擎与体系结构 体系结构 连接层 最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限 服务层 第二层架构主要完成大多数的核心服务功能,如SQL…...

数字IC设计需要学什么?
看到不少同学在网上提问数字IC设计如何入门,在学习过程中面临着各种各样的问题,比如书本知识艰涩难懂,有知识问题难解决,网络资源少,质量参差不齐。那么数字IC设计到底需要学什么呢? 首先来看看数字IC设计…...

五分钟搞懂POM设计模式
今天,我们来聊聊Web UI自动化测试中的POM设计模式。 为什么要用POM设计模式 前期,我们学会了使用PythonSelenium编写Web UI自动化测试线性脚本 线性脚本(以快递100网站登录举栗): import timefrom selenium import …...

面试 | 递归乘法【细节决定成败】
不用[ * ]如何使两数相乘❓一、题目明细二、思路罗列 & 代码解析1、野蛮A * B【不符合题意】2、sizeof【可借鉴】解析3、简易递归【推荐】① 解析(递归展开图)② 时间复杂度分析4、移位<<运算【有挑战性💪】① 思路顺理② 算法图解…...
【Linux】环境变量与进程优先级
文章目录🎪 进程优先级🚀1.孤儿进程🚀2.优先级查看🚀3.优先级修改🎪 环境变量🚀1.常见环境变量🚀2.环境变量获取🚀3.main中的命令行参数🎪 进程优先级 每个进程都有相应…...
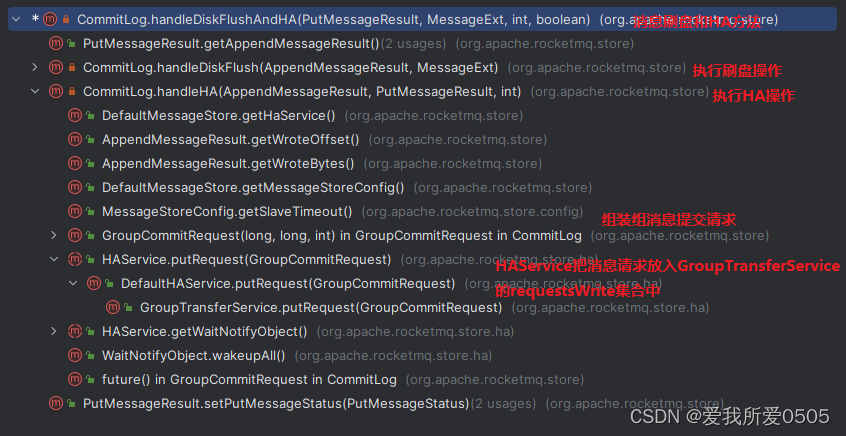
RocketMQ5.0.0的Broker主从同步机制
目录 一、主从同步工作原理 1. 主从配置 2. 启动HA 二、主从同步实现机制 1. 从Broker发送连接事件 2. 主Broker接收连接事件 3. 从Broker反馈复制进度 4. ReadSocketService线程读取从Broker复制进度 5. WriteSocketService传输同步消息 6. GroupTransferService线程…...

深度学习论文: EdgeYOLO: An Edge-Real-Time Object Detector及其PyTorch实现
深度学习论文: EdgeYOLO: An Edge-Real-Time Object Detector及其PyTorch实现 EdgeYOLO: An Edge-Real-Time Object Detector PDF: https://arxiv.org/pdf/2302.07483.pdf PyTorch代码: https://github.com/shanglianlm0525/CvPytorch PyTorch代码: https://github.com/shangli…...

如何做好APP性能测试?
随着智能化生活的推进,我们生活中不可避免的要用到很多程序app。有的APP性能使用感很好,用户都愿意下载使用,而有的APP总是出现卡顿或网络延迟的情况,那必然就降低了用户的好感。所以APP性能测试对于软件开发方来说至关重要&#…...
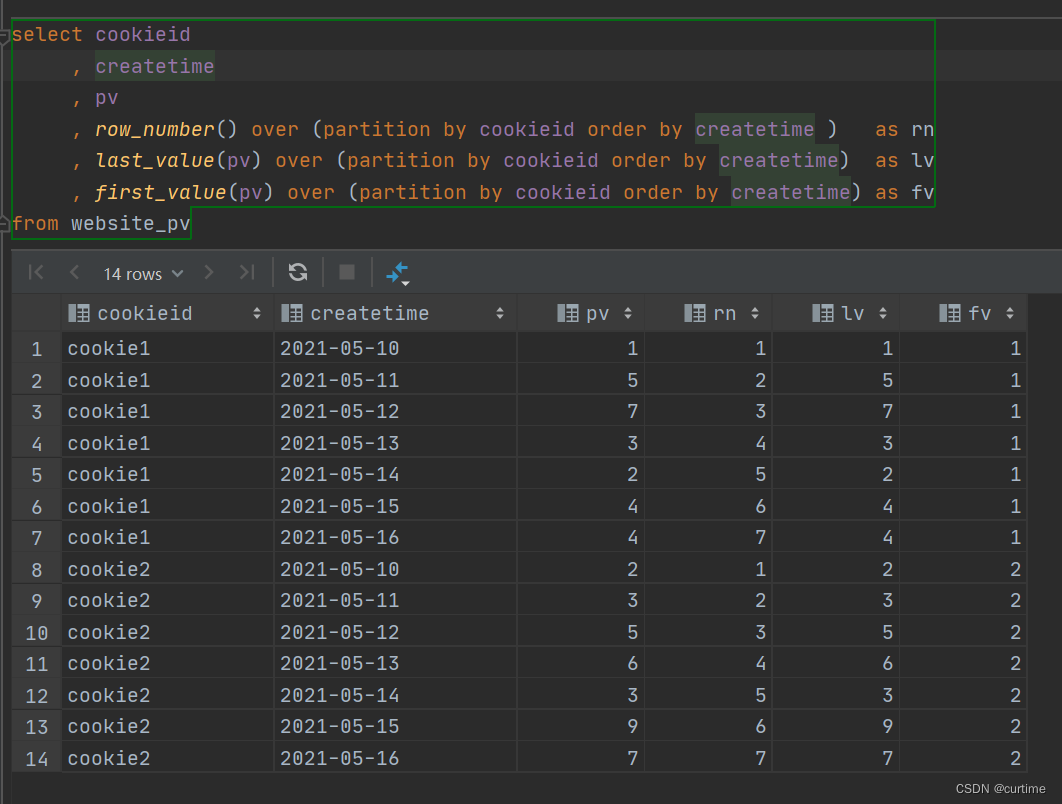
Hive窗口函数
概述 窗口函数(window functions)也叫开窗函数、OLAP函数。 如果函数具有over子句,则它是窗口函数 窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过group by 子句组合的 常规聚合会隐藏正在聚合的各个…...
:在默认构造函数内部使用带参数的构造函数)
C++学习笔记(1):在默认构造函数内部使用带参数的构造函数
题目以下代码的输出是不是0:#include <unordered_map> #include <iostream>using namespace std;struct CLS{int i;CLS(int i_) :i(i_){}CLS(){CLS(0);} };int main(){CLS obj;std::cout << obj.i << endl;return 0; }结果-858993460为什么…...
设计模式源码案例)
Android面试题_安卓面经(23/30)设计模式源码案例
系列专栏: 《150道安卓常见面试题全解析》 安卓专栏目录见帖子 : 安卓面经_anroid面经_150道安卓基础面试题全解析 安卓系统Framework面经专栏:《Android系统Framework面试题解析大全》 安卓系统Framework面经目录详情:Android系统面经_Framework开发面经_150道面试题答案解…...

Dubbo性能调优参数以及原理
Dubbo作为一个服务治理框架,功能相对来说比较完善,性能也挺不错。但很多同学在使用dubbo的时候,只是简单的参考官方说明进行配置和应用,并没有过多的去思考一些关键参数的意义,最终做出来的效果总是差强人意,接下来我们…...
)
vue3全家桶之vuex和pinia持久化存储基础(二)
一.vuex数据持久化存储 这里使用的是vuex4.1.0版本,和之前的vuex3一样,数据持久化存储方案也使用 vuex-persistedstate,版本是最新的安装版本,当前可下载依赖包版本4.1.0,接下来在vue3项中安装和使用: 安装vuex-persistedstate npm i vuex-persisteds…...
LAMP架构与搭建论坛
目录 1、LAMP架构简述 2、各组件作用 3、构建LAMP平台 1.编译安装Apache httpd服务 2.编译安装mysql 3.编译安装php 4.搭建一个论坛 1、LAMP架构简述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整台系统和相关软件,能够提供动…...

代码随想录 || 回溯算法93 78 90
Day2493.复原IP地址力扣题目链接给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 . 分隔。例如&#…...
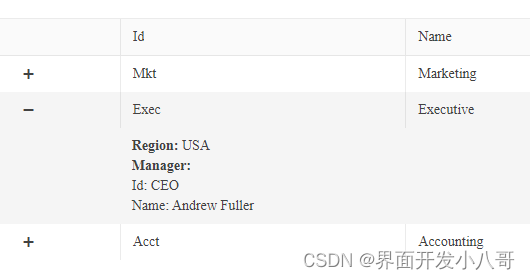
界面组件Kendo UI for Angular——让网格数据信息显示更全面
Kendo UI致力于新的开发,来满足不断变化的需求,通过React框架的Kendo UI JavaScript封装来支持React Javascript框架。Kendo UI for Angular是专用于Angular开发的专业级Angular组件,telerik致力于提供纯粹的高性能Angular UI组件,…...
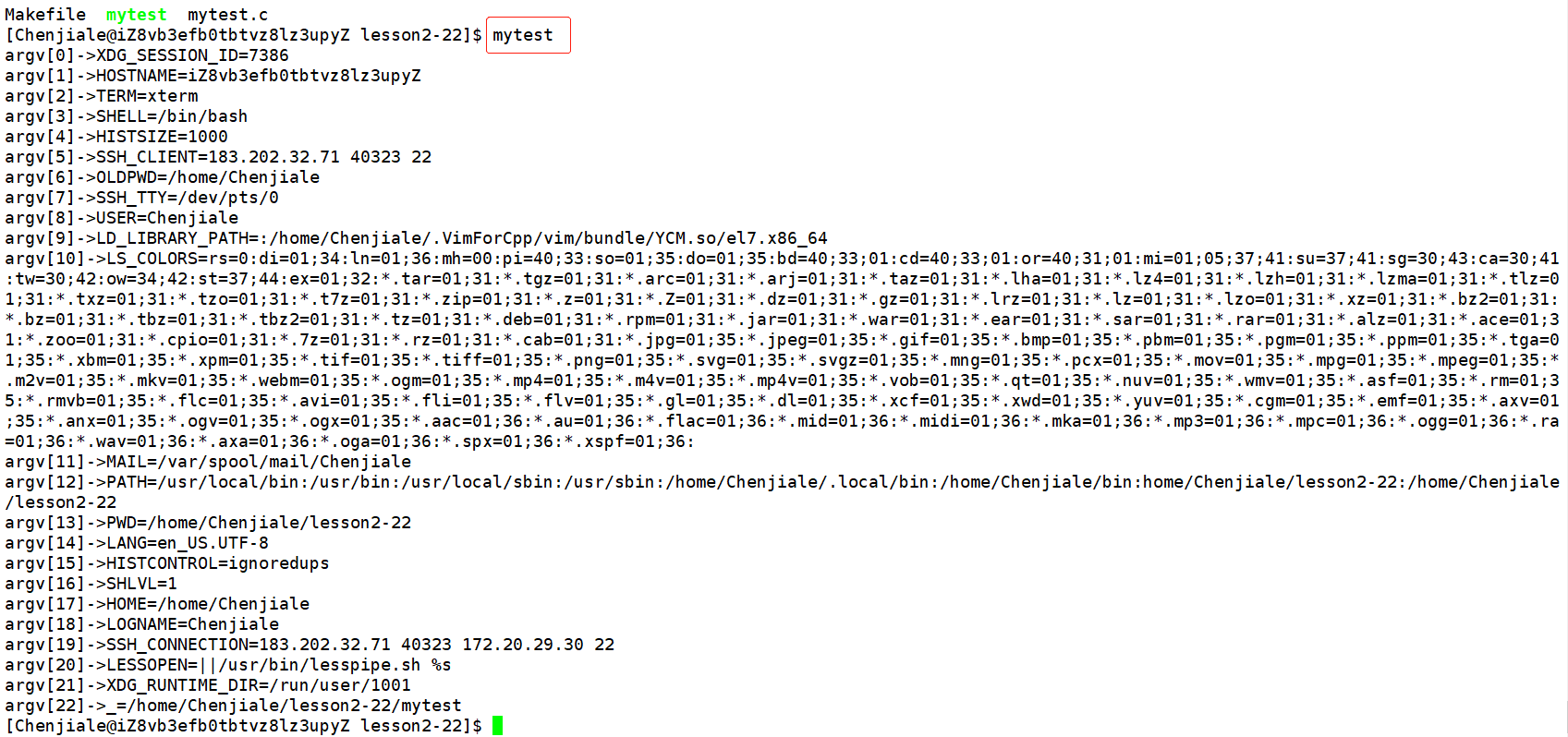
【Linux】进程状态|优先级|进程切换|环境变量
文章目录1. 运行队列和运行状态2. 进程状态3. 两种特殊的进程僵尸进程孤儿进程4. 进程优先级5. 进程切换进程特性进程切换6. 环境变量的基本概念7. PATH环境变量8. 设置和获取环境变量9. 命令行参数1. 运行队列和运行状态 💕 运行队列: 进程是如何在CP…...
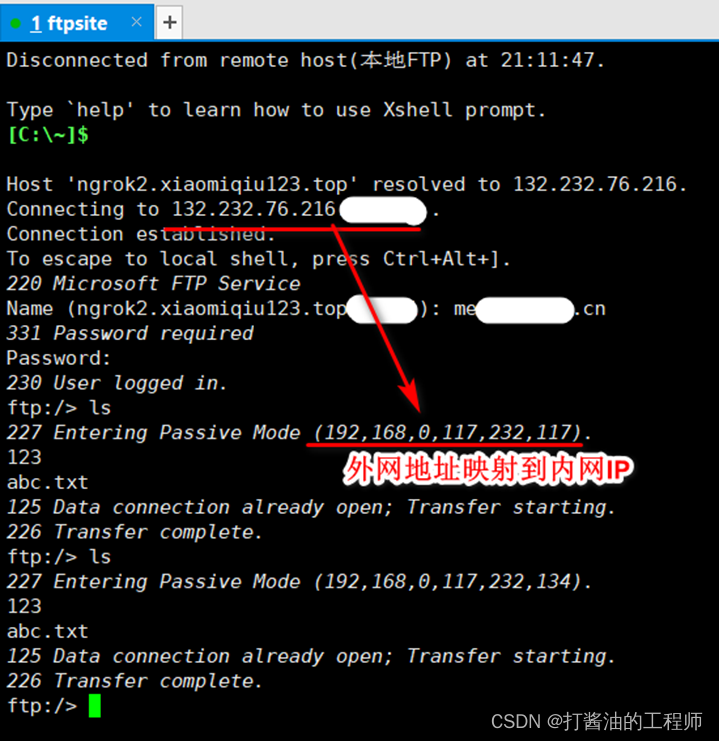
合宙Air780E|FTP|内网穿透|命令测试|LuatOS-SOC接口|官方demo|学习(18):FTP命令及应用
1、FTP服务器准备 本机为win11系统,利用IIS搭建FTP服务器。 搭建方式可参考博文:windows系统搭建FTP服务器教程 windows系统搭建FTP服务器教程_程序员路遥的博客-CSDN博客_windows服务器安装ftp 设置完成后,测试FTP(已正常访问…...
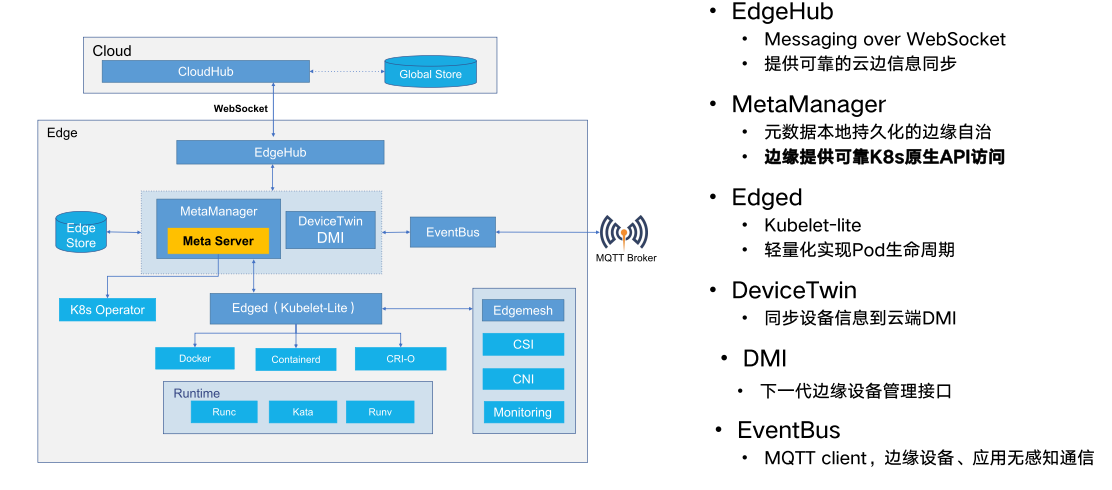
大规模 IoT 边缘容器集群管理的几种架构-4-Kubeedge
前文回顾 大规模 IoT 边缘容器集群管理的几种架构-0-边缘容器及架构简介大规模 IoT 边缘容器集群管理的几种架构-1-RancherK3s大规模 IoT 边缘容器集群管理的几种架构-2-HashiCorp 解决方案 Nomad大规模 IoT 边缘容器集群管理的几种架构-3-Portainer 📚️Reference…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...