YOLOv7改进:GAMAttention注意力机制
1.背景介绍
为了提高各种计算机视觉任务的性能,人们研究了各种注意机制。然而,以往的方法忽略了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局调度机制,通过减少信息缩减和放大全局交互表示来提高深度神经网络的性能。我们沿着卷积空间注意子模块引入了用于通道注意的多层感知器3D置换。
论文题目:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
论文地址:https://paperswithcode.com/paper/global-attention-mechanism-retain-information

GAMAttention注意力机制原理图
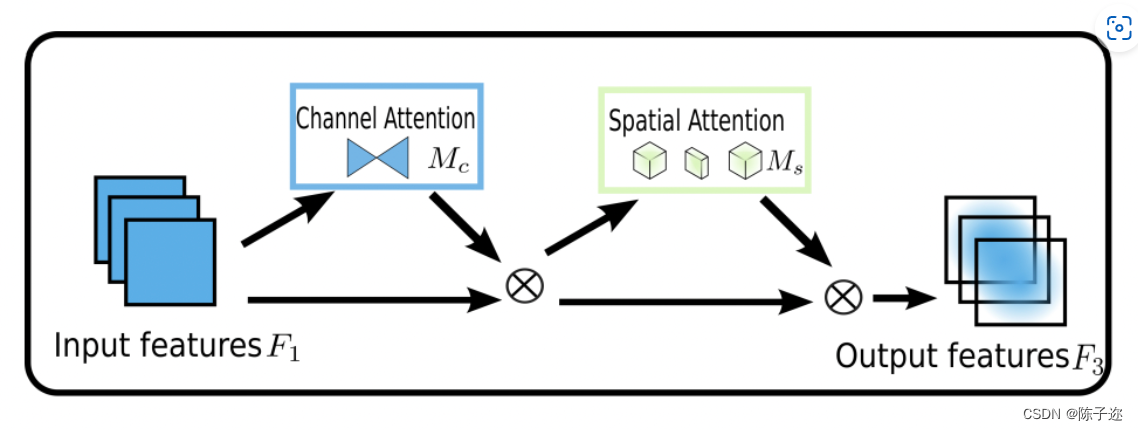
对于ImageNet-1K,我们将图像预处理为224×224(He et al.[2016])。我们包括ResNet18和ResNet50(He et al.[2016]),以验证不同网络深度的方法推广。对于ResNet50,我们将其与群卷积进行了比较,以防止参数显著增加。我们将起始学习率设置为0.1,并每隔30个阶段降低一次。我们总共使用90个训练时段。在空间注意子模块中,我们将第一个块的第一步从1切换到2,以匹配特征的大小。为了进行公平比较,CBAM保留了其他设置,包括在空间注意子模块中使用最大池。3 MobileNet V2是用于图像分类的最高效的轻量级模型之一。我们对MobileNet V2使用相同的ResNet设置,只是使用了0.045的初始学习率和4×10的权重衰减−5.对ImageNet-1K的评估如表所示。它表明GAM可以稳定地提高不同神经架构的性能。尤其是对于ResNet18,GAM以更少的参数和更好的效率优于ABN。
相关实验结果
对ImageNet-1K的评估如表2所示,它表明GAM可以稳定地提高不同神经体系结构的性能。特别是,对于ResNet18,GAM的性能优于ABN,参数更少,效率更高。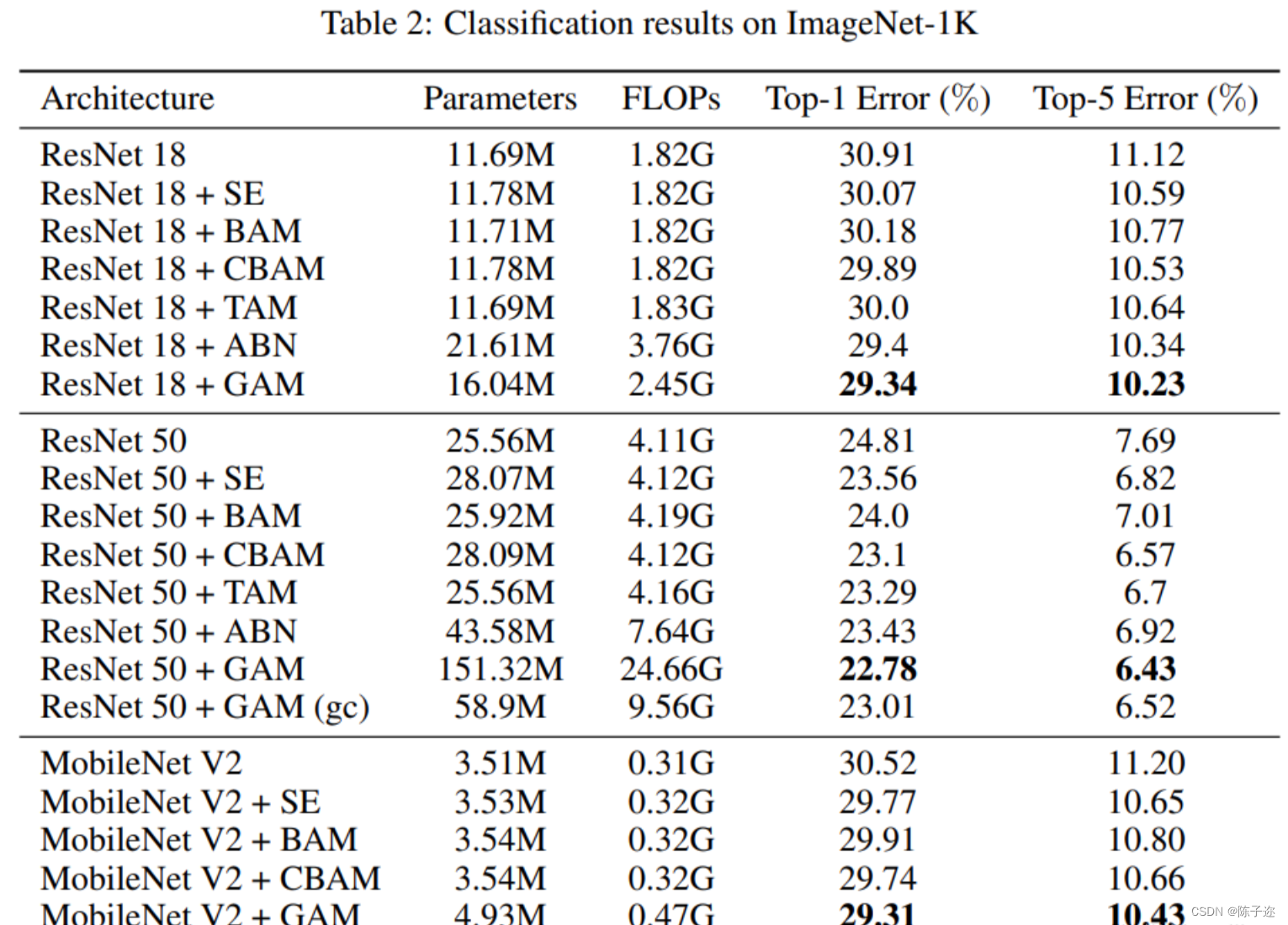
为了更好地理解空间注意和通道注意分别对消融的贡献,我们通过开启和关闭一种方式进行了消融研究。例如,ch表示空间注意力被关闭,而频道注意力被打开。SP表示通道关注已关闭,空间关注已打开。结果如表3所示。我们可以在两个开关实验中观察到性能的提高。结果表明,空间关注度和通道关注度对性能增益均有贡献。请注意,它们的组合进一步提高了性能。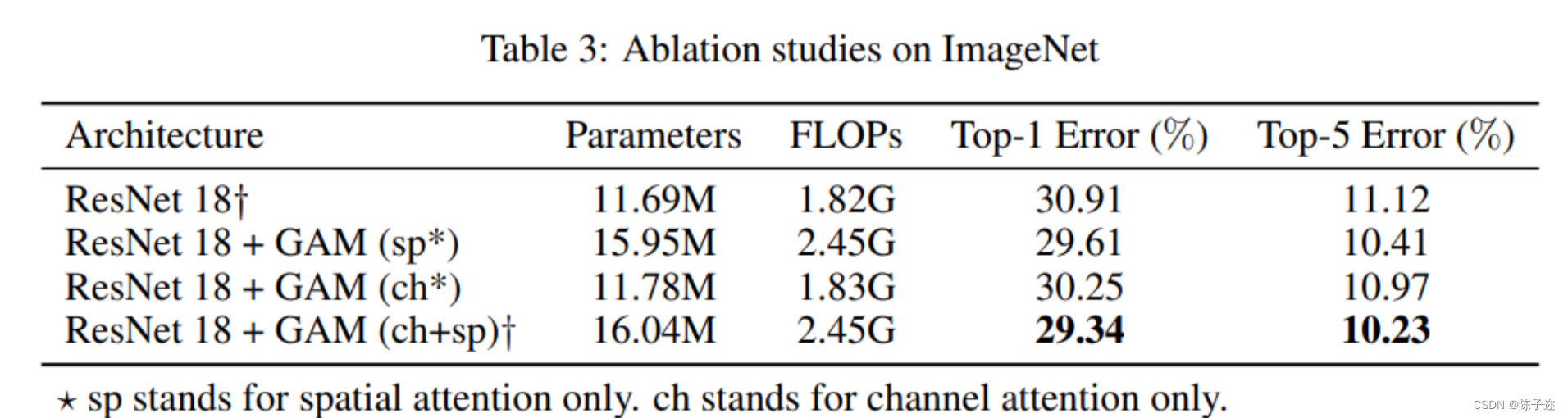
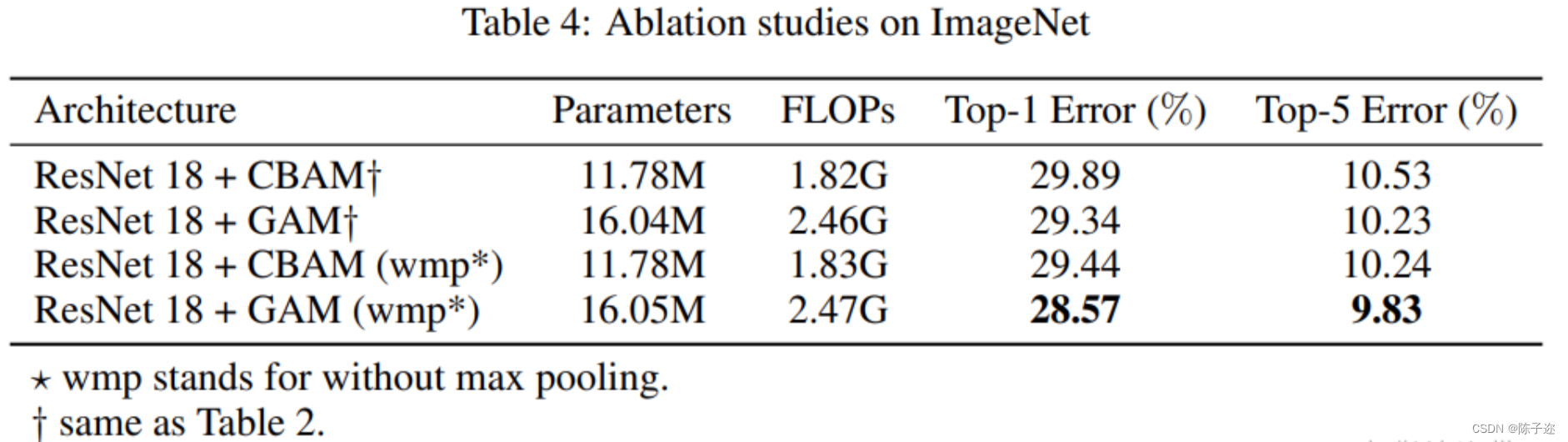
将GAM与CBAM在使用和不使用ResNet18最大池化的情况下进行比较。表4显示了结果。可以观察到,在这两种情况下,我们的方法都优于CBAM。
2.YOLOv7改进方法
2.1增加以下GAMAttention.yaml文件
# YOLOv7 🚀, GPL-3.0 license
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone by yoloair
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 [-1, 1, CNeB, [128]], [-1, 1, Conv, [256, 3, 2]], [-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], [-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]],[-1, 1, CNeB, [1024]],[-1, 1, Conv, [256, 3, 1]],]# yolov7 head by yoloair
head:[[-1, 1, SPPCSPC, [512]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[31, 1, Conv, [256, 1, 1]],[[-1, -2], 1, Concat, [1]],[-1, 1, C3C2, [128]],[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[18, 1, Conv, [128, 1, 1]],[[-1, -2], 1, Concat, [1]],[-1, 1, C3C2, [128]],[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, GAMAttention, [128]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 44], 1, Concat, [1]],[-1, 1, C3C2, [256]], [-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]], [[-1, -3, 39], 1, Concat, [1]],[-1, 3, C3C2, [512]],# 检测头 -----------------------------[49, 1, RepConv, [256, 3, 1]],[55, 1, RepConv, [512, 3, 1]],[61, 1, RepConv, [1024, 3, 1]],[[62,63,64], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
2.2common.py配置
./models/common.py文件增加以下模块
import numpy as np
import torch
from torch import nn
from torch.nn import initclass GAMAttention(nn.Module):#https://paperswithcode.com/paper/global-attention-mechanism-retain-informationdef __init__(self, c1, c2, group=True,rate=4):super(GAMAttention, self).__init__()self.channel_attention = nn.Sequential(nn.Linear(c1, int(c1 / rate)),nn.ReLU(inplace=True),nn.Linear(int(c1 / rate), c1))self.spatial_attention = nn.Sequential(nn.Conv2d(c1, c1//rate, kernel_size=7, padding=3,groups=rate)if group else nn.Conv2d(c1, int(c1 / rate), kernel_size=7, padding=3), nn.BatchNorm2d(int(c1 /rate)),nn.ReLU(inplace=True),nn.Conv2d(c1//rate, c2, kernel_size=7, padding=3,groups=rate) if group else nn.Conv2d(int(c1 / rate), c2, kernel_size=7, padding=3), nn.BatchNorm2d(c2))def forward(self, x):b, c, h, w = x.shapex_permute = x.permute(0, 2, 3, 1).view(b, -1, c)x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)x_channel_att = x_att_permute.permute(0, 3, 1, 2)x = x * x_channel_attx_spatial_att = self.spatial_attention(x).sigmoid()x_spatial_att=channel_shuffle(x_spatial_att,4) #last shuffle out = x * x_spatial_attreturn out def channel_shuffle(x, groups=2):B, C, H, W = x.size()out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()out=out.view(B, C, H, W) return out
2.3yolo.py配置
在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要新增以下代码
elif m is GAMAttention:c1, c2 = ch[f], args[0]if c2 != no:c2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]
修改完成
相关文章:
YOLOv7改进:GAMAttention注意力机制
1.背景介绍 为了提高各种计算机视觉任务的性能,人们研究了各种注意机制。然而,以往的方法忽略了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局调度机制,通过减少信息缩减和放大全局交互表示来提高深…...
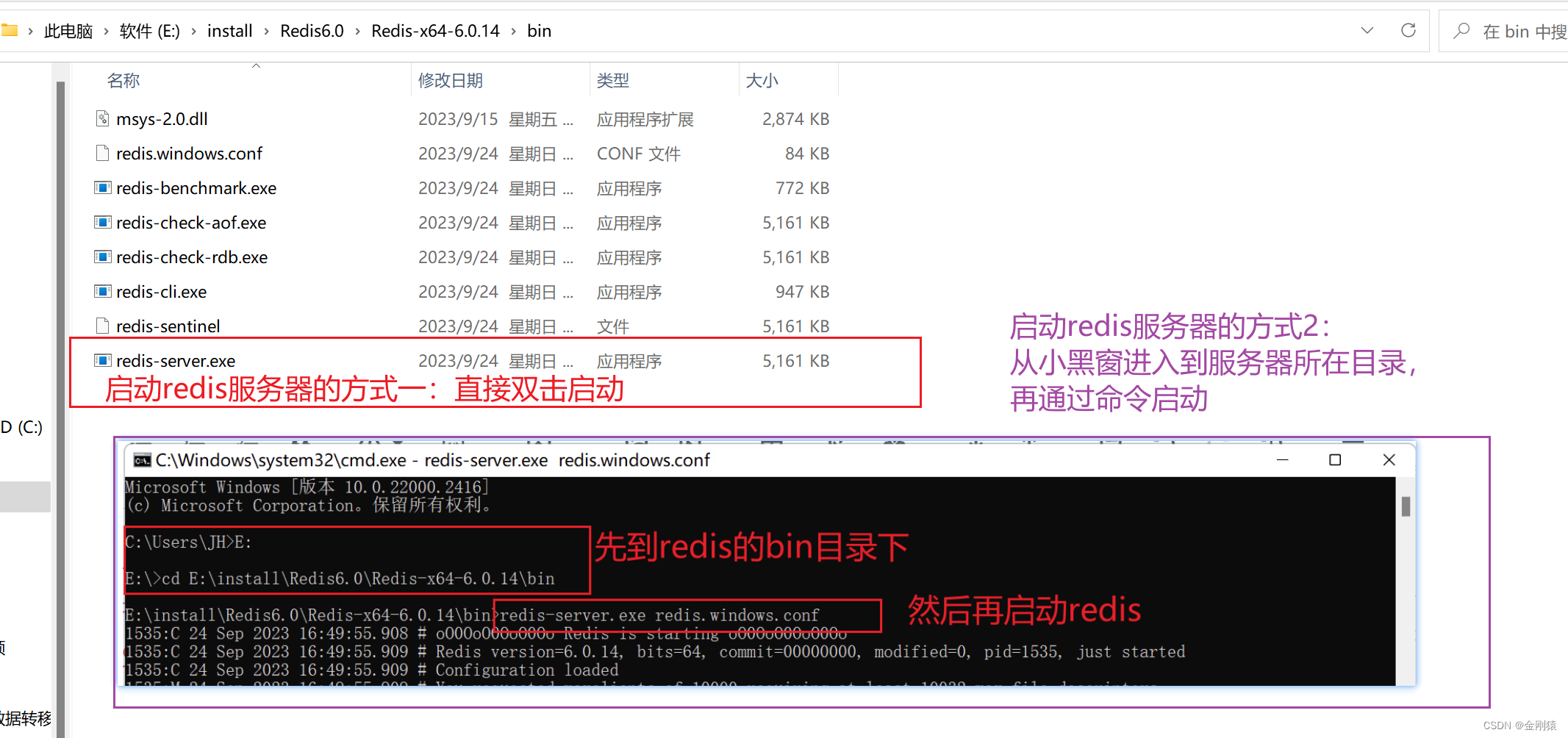
83、SpringBoot --- 下载和安装 MSYS2、 Redis
启动redis服务器: 打开小黑窗: C:\Users\JH>e: E:>cd E:\install\Redis6.0\Redis-x64-6.0.14\bin E:\install\Redis6.0\Redis-x64-6.0.14\bin>redis-server.exe redis.windows.conf 启动redis客户端: 小黑窗:redis-cli …...

用css画一个半圆弧(以小程序为例)
一、html结构 圆弧的html结构是 两个块级元素嵌套。 <View classNamewrap><View className"inner">{/* 图标下的内容 */}</View></View>二、css样式:原理是两个半圆叠在一起,就是一个半圆弧。那么,如何画一…...

redis介绍
一、简介 Redis 与其他 key - value 缓存产品有以下三个特点: Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。 Redis不仅仅支持简单的key-value类型的数据,同时还提供list,…...
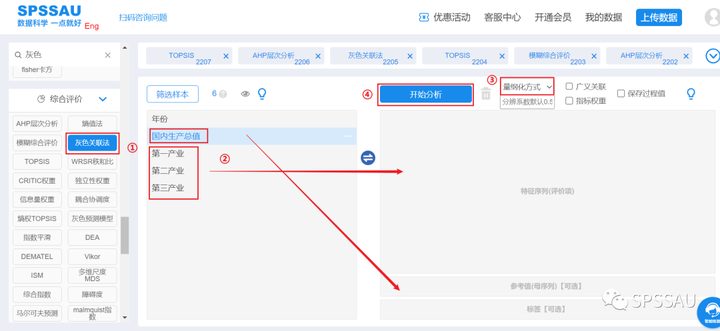
数学建模常用模型
作为数学建模的编程手还掌握一些各类模型常用算法,数学建模评价类模型、分类模型、预测类模型比较常用的方法总结如下: 接下来对这些比较典型的模型进行详细进行介绍说明。 一、评价模型 在数学建模中,评价模型是比较基础的模型之一&#x…...
Linux 基本语句_5_创建静态库|动态库
静态库 创建主函数:main.c 应用函数:add.c、sub.c、mul.c 创建calc.h文件作为头文件 生成可执行文件*.o文件 gcc -c add.c -o add.o ....包装*.o文件为静态库 ar -rc libmymath.a add.o sub.o mul.o编译静态库并指明创建静态库的位置 sudo gcc mai…...
【每日一题】2703. 返回传递的参数的长度
2703. 返回传递的参数的长度 - 力扣(LeetCode) 请你编写一个函数 argumentsLength,返回传递给该函数的参数数量。 示例 1: 输入:args [5] 输出:1 解释: argumentsLength(5); // 1只传递了一个值…...
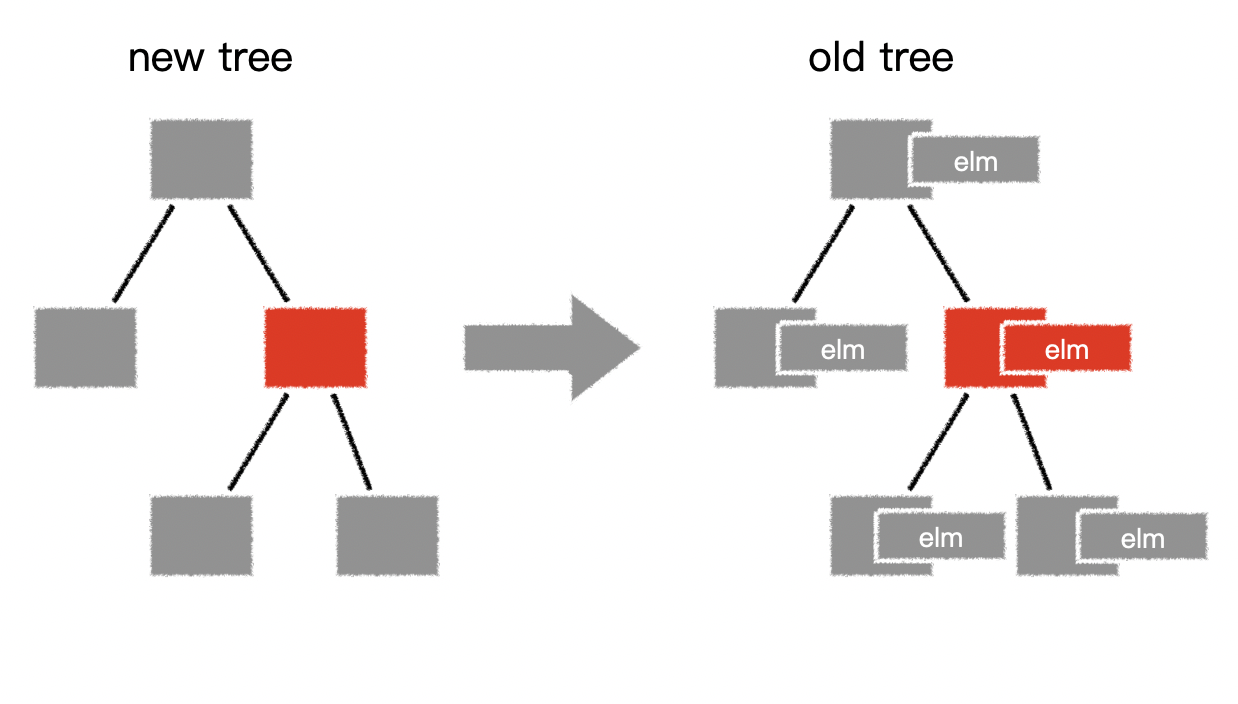
虚拟DOM详解
面试题:请你阐述一下对vue虚拟dom的理解 什么是虚拟dom? 虚拟dom本质上就是一个普通的JS对象,用于描述视图的界面结构 在vue中,每个组件都有一个render函数,每个render函数都会返回一个虚拟dom树,这也就意味…...

Linux配置命令
一:HCSA-VM-Linux安装虚拟机后的基础命令 1.代码命令 1.查看本机IP地址: ip addr 或者 ip a [foxbogon ~]$ ip addre [foxbogon ~]$ ip a 1:<Loopback,U,LOWER-UP> 为环回2网卡 2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP&g…...
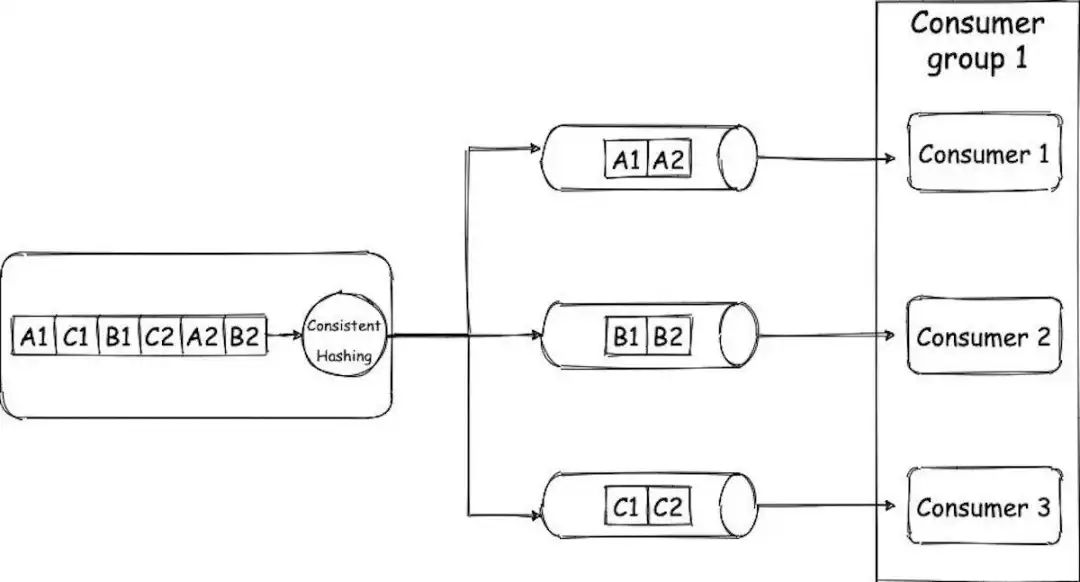
Kafka:介绍和内部工作原理
展示Kafka工作方式的简单架构。 什么是Kafka?为什么我们要使用它?它是消息队列吗? 它是一个分布式流处理平台或分布式提交日志。 Kafka通常用于实时流数据管道,即在系统之间传输数据,构建不断流动的数据转换系统和构…...

在 EMR Serverless 上使用 Delta Lake
本文是一份开箱即用的全自动测试脚本,用于在 EMR Serverless 上提交一个 Delta Lake 作业。本文完全遵循《最佳实践:如何优雅地提交一个 Amazon EMR Serverless 作业?》 一文给出的标准和规范! 1. 导出环境相关变量 注意&#x…...
)
Stream流的使用详解(持续更新)
1. 对比两List集合数据某些字段一样的情况下取值: 一般简单方式我们会使用双重for循环来处理判断数据取值(如下代码所示),但是数据量越大的情况下代码效率则越低,并且现在很多公司都会限制for循环层数所以更推荐strea…...

golang工程——gRpc 拦截器及原理
oauth2认证与拦截器 类似java spring中的拦截器。gRpc也有拦截器的说法,拦截器可作用于客户端请求,服务端请求。对请求进行拦截,进行业务上的一些封装校验等,类似一个中间件的作用 拦截器类型 一元请求拦截器流式请求拦截器链式…...
Python接口自动化之unittest单元测试
以下主要介绍unittest特性、运行流程及实际案例。 一、单元测试三连问 1、什么是单元测试? 按照阶段来分,一般就是单元测试,集成测试,系统测试,验收测试。单元测试是对单个模块、单个类或者单个函数进行测试。 将访…...
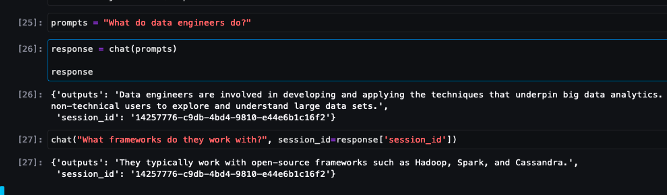
在亚马逊云科技Amazon SageMaker上部署构建聊天机器人的开源大语言模型
开源大型语言模型(LLM)已经变得流行起来,研究人员、开发人员和组织都可以使用这些模型来促进创新和实验。这促进了开源社区开展合作,从而为LLM的开发和改进做出贡献。开源LLM提供了模型架构、训练过程和训练数据的透明度ÿ…...

【51单片机】10-蜂鸣器
1.蜂鸣器的原理 这里的“源”不是指电源。而是指震荡源。 也就是说,有源蜂鸣器内部带震荡源,所以只要一通电就会叫。 而无源内部不带震荡源,所以如果用直流信号无法令其鸣叫。必须用2K~5K的方波去驱动它。 有源蜂鸣器往往比无源的贵ÿ…...

26377-2010 逆反射测量仪 知识梳理
声明 本文是学习GB-T 26377-2010 逆反射测量仪. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了逆反射测量仪的术语和定义、结构与分类、技术要求、计量学特性、试验方法、检验规 则以及标志、包装、运输与贮存。 本标准适用于…...
css实现渐变电量效果柱状图
我们通常的做法就是用echarts来实现 比如 echarts象形柱图实现电量效果柱状图 接着我们实现进阶版,增加渐变效果 echarts分割柱形图实现渐变电量效果柱状图 接着是又在渐变的基础上,增加了背景色块的填充 echarts实现渐变电量效果柱状图 其实思路是一…...
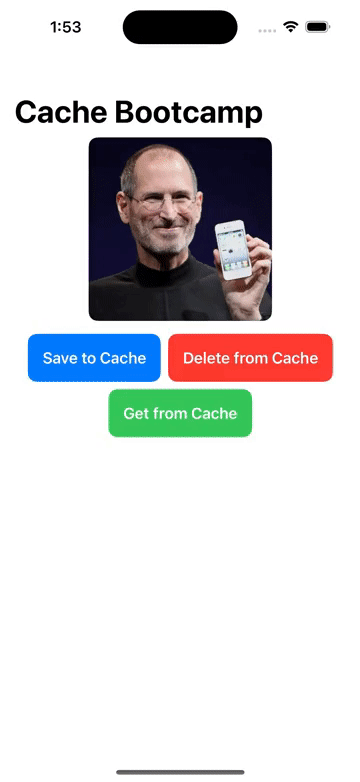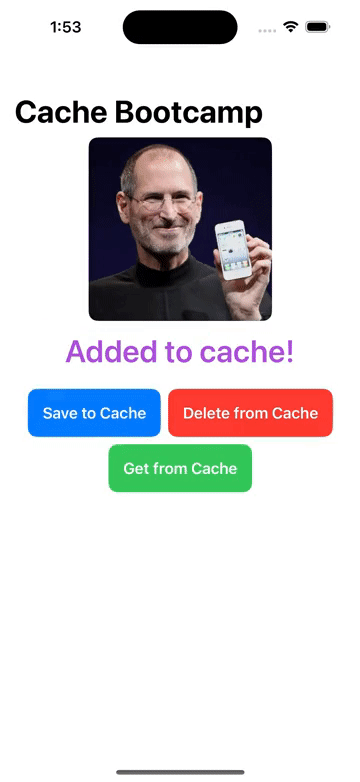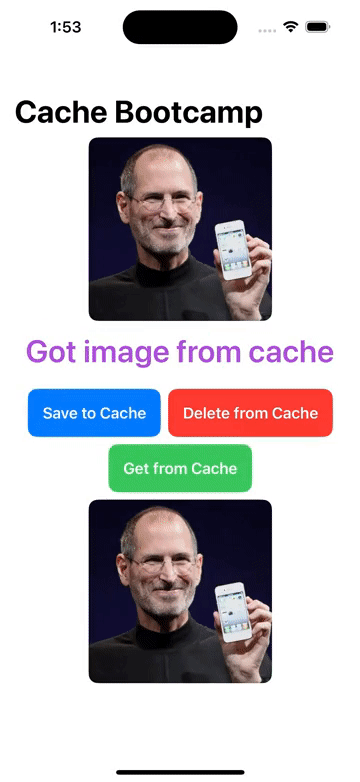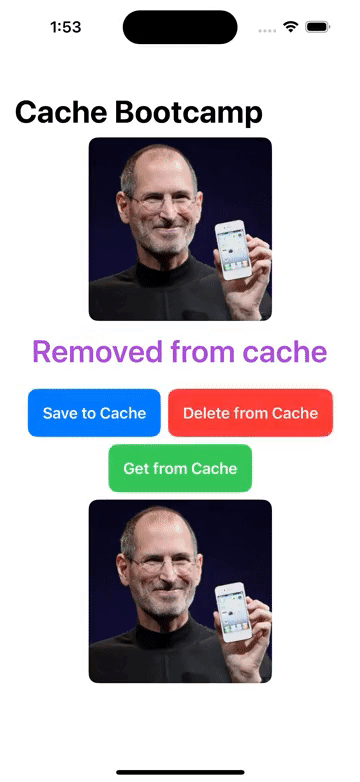
FileManager/本地文件增删改查, Cache/图像缓存处理 的操作
1. FileManager 本地文件管理器,增删改查文件 1.1 实现 // 本地文件管理器 class LocalFileManager{// 单例模式static let instance LocalFileManager()let folderName "MyApp_Images"init() {createFolderIfNeeded()}// 创建特定应用的文件夹func cr…...

vue中使用富文本编辑器
vue中使用富文本编辑器(wangEditor) wangEditor官网地址:https://www.wangeditor.com/ 使用示例 <template><div class"app-container"><div class"box"><div class"editor-tool">&l…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
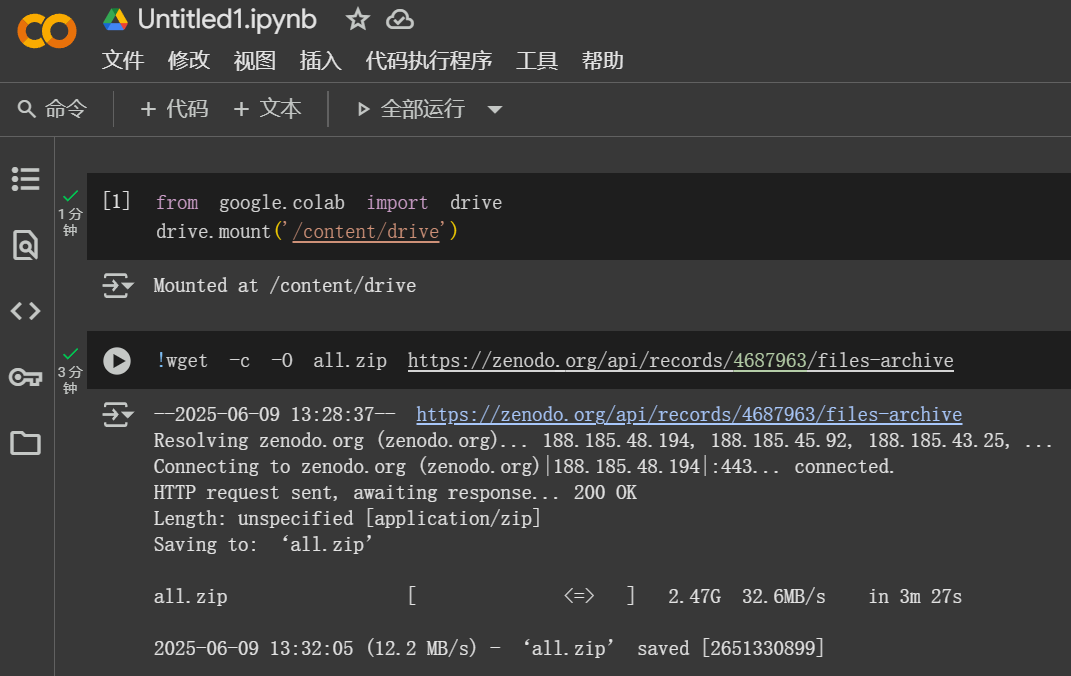
在Zenodo下载文件 用到googlecolab googledrive
方法:Figshare/Zenodo上的数据/文件下载不下来?尝试利用Google Colab :https://zhuanlan.zhihu.com/p/1898503078782674027 参考: 通过Colab&谷歌云下载Figshare数据,超级实用!!࿰…...
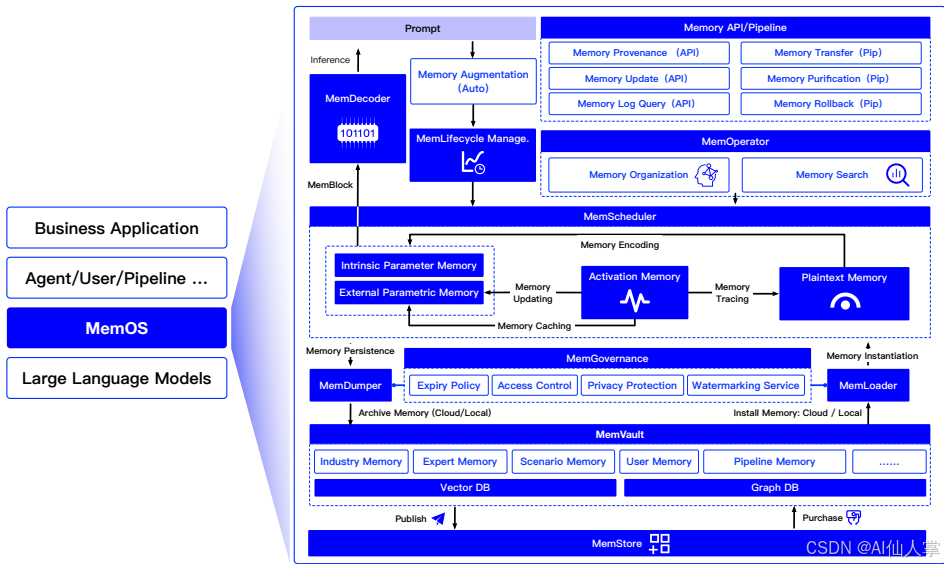
【阅读笔记】MemOS: 大语言模型内存增强生成操作系统
核心速览 研究背景 研究问题:这篇文章要解决的问题是当前大型语言模型(LLMs)在处理内存方面的局限性。LLMs虽然在语言感知和生成方面表现出色,但缺乏统一的、结构化的内存架构。现有的方法如检索增强生成(RA…...