论文笔记(整理):轨迹相似度顶会论文中使用的数据集
0 汇总
| 数据类型 | 数据名称 | 数据处理 |
| 出租车数据 | 波尔图 | 原始数据:2013年7月到2014年6月,170万条数据 |
| ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 过滤位于城市(或国家)区域之外的轨迹 过滤包含少于20个点或超过200个点的轨迹 | ||
| CIKM 2022 Efficient Trajectory Similarity Computation with Contrastive Learning 为两个数据集设置相同的采样率,即15秒 | ||
| CIKM 2022 Aries: Accurate Metric-based Representation Learning for Fast Top-k Trajectory Similarity Query 根据位置和时间戳,在三个月内选择了一个相对集中的轨迹集,数量为100𝑘 | ||
| KDD2022 TrajGAT: A Graph-based Long-term Dependency Modeling Approach for Trajectory Similarity Computation 2019 ICDE Computing Trajectory Similarity in Linear Time: A Generic Seed-Guided Neural Metric Learning Approach 选择城市中心区域的轨迹,并移除少于10条记录的轨迹 ——>超过60W条轨迹 | ||
| CIKM 2023 Can Adversarial Training benefit Trajectory Representation? An Investigation on Robustness for Trajectory Similarity ICDE 2018 Deep Representation Learning for Trajectory Similarity Computation
| ||
| ICDE 2022 TMN: Trajectory Matching Networks for Predicting Similarity ICDE 2021 T3S: Effective Representation Learning for Trajectory Similarity Computation 没有多少处理 | ||
| 哈尔滨 | ICDE 2018 Deep Representation Learning for Trajectory Similarity Computation 8个月内13000辆出租车的轨迹。 选择了长度至少为30,且连续采样点之间的时间间隔少于20秒的轨迹。 这产生了150万条轨迹 | |
| 西安 | 2018年10月的前两周 ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 过滤位于城市(或国家)区域之外的轨迹 过滤包含少于20个点或超过200个点的轨迹 |
| 数据类型 | 数据名称 | 数据处理 |
| 出租车数据 | 德国 | ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 2006年到2013年间 过滤位于城市(或国家)区域之外的轨迹 过滤包含少于20个点或超过200个点的轨迹 |
| 罗马 | KDD 2022 Spatio-Temporal Trajectory Similarity Learning in Road Networks 移除了少于10个采样点的轨迹 45157条轨迹 | |
| 北京(T-drive) | AAAI 2023 GRLSTM: Trajectory Similarity Computation with Graph-Based Residual LSTM 从10,357辆出租车中收集的 使用空间相似函数通过GPS坐标在北京道路网络上创建基准真值 | |
| KDD 2022 Spatio-Temporal Trajectory Similarity Learning in Road Networks 移除了少于10个采样点的轨迹 | ||
| KDD 2021 A Graph-based Approach for Trajectory Similarity Computation in Spatial Networks 按小时分割这些轨迹,然后我们总共可以得到5,621,428条轨迹。 通过过滤异常值,这些轨迹的平均长度为25。 | ||
| 新加坡 | 15,054辆出租车的轨迹 对于每辆出租车,GPS信息在整整一个月内以半分钟到三分钟的采样率持续收集 | |
| 人流mobility数据 | 北京( Geolife) | 2007年4月到2012年8月收集的17621条轨迹 |
| Sigspatial 2022 TSNE: trajectory similarity network embedding 选择了城市中心区域的轨迹,并将该区域离散化为200m×200m的网格单元。 移除了所有点太稀疏(少于10个点的轨迹),并在Geolife中获得了10,504条轨迹 | ||
| CIKM 2023 Can Adversarial Training benefit Trajectory Representation? An Investigation on Robustness for Trajectory Similarity
| ||
| 2019 ICDE Computing Trajectory Similarity in Linear Time: A Generic Seed-Guided Neural Metric Learning Approach 过滤掉位于稀疏区域的轨迹,保留城市中心区域的轨迹 移除了少于10条记录的轨迹 大约8,000条轨迹 |
1 2023
1.1 ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention
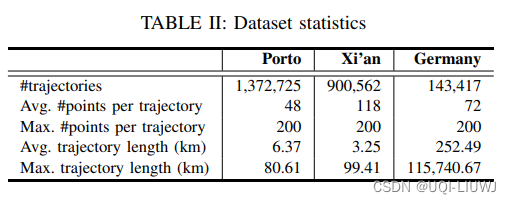
使用了三个真实世界的轨迹数据集:
(1)Porto ——2013年7月到2014年6月间,葡萄牙波尔图的170万条出租车轨迹;
(2)西安——2018年10月的前两周内,中国西安的210万条网约车轨迹(滴滴)
(3)德国 ——2006年到2013年间,170.7千条用户提交的轨迹。(openStreetMap)
- 过滤位于城市(或国家)区域之外的轨迹,
- 过滤包含少于20个点或超过200个点的轨迹
预处理后的数据集在表II中进行了总结。
1.2 AAAI 2023 GRLSTM: Trajectory Similarity Computation with Graph-Based Residual LSTM
- 北京的轨迹来自T-drive项目的出租车轨迹。
- 这些出租车轨迹是在几天内通过出租车id,GPS坐标和时间戳从10,357辆出租车中收集的
- 按小时划分这些轨迹,并丢弃短长度的轨迹
- 使用空间相似函数(Shang et al. 2017b)通过GPS坐标在北京道路网络上创建基准真值
- T-Drive trajectory data sample - Microsoft Research
- 纽约的轨迹从NYC Open Data - (cityofnewyork.us)获取
- 使用相同的预处理方法来处理这些轨迹并获得基准真值
- 对于这两个数据集,我们将这些数据随机分为训练集,验证集和测试集,比例为[0.2,0.1,0.7]
2 2022
2.1 CIKM 2022 Efficient Trajectory Similarity Computation with Contrastive Learning

为两个数据集设置相同的采样率,即15秒。
根据轨迹的开始时间戳将每个数据集划分为训练集和测试集,其中前100万条轨迹用于训练,其余的用于测试
2.2 CIKM 2022 Aries: Accurate Metric-based Representation Learning for Fast Top-k Trajectory Similarity Query
波尔图数据集:从2013年到2014年,有超过四百辆出租车的170万辆车轨迹。
我们根据它们的位置和时间戳,在三个月内选择了一个相对集中的轨迹集,数量为100𝑘。
然后我们删除少于50个点的记录,并将整个区域划分为1500×1500大小的网格。
经过预处理,我们在波尔图获得了79,362条轨迹。
2.3 CIKM 2023 Can Adversarial Training benefit Trajectory Representation? An Investigation on Robustness for Trajectory Similarity
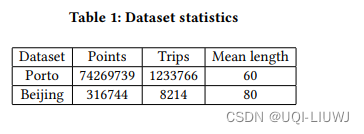
- 波尔图的数据集——从2013年7月到2014年6月的12个月期间的170万条出租车轨迹
- 删除了长度少于30的轨迹
- 最终剩下120万条轨迹
- 北京数据集(Geolife)
- 2007年4月到2012年8月收集的17621条轨迹
- 也选择了那些至少满足长度为30的轨迹,并且在连续采样点之间的时间间隔小于20秒
- 这样的操作产生了8214条轨迹
- 对于波尔图数据集,训练数据由800,000条轨迹组成,其余的用于测试数据。
- 对于Geolife数据集,前4928条轨迹用于训练数据,其余的用于测试数据。
2.4 Sigspatial 2022 TSNE: trajectory similarity network embedding
Geolife ——由182个用户从2007年到2012年在中国北京收集的17,621条轨迹组成。
选择了城市中心区域的轨迹,并将该区域离散化为200m×200m的网格单元。
移除了所有点太稀疏(少于10个点的轨迹),并在Geolife中获得了10,504条轨迹。
2.5 KDD 2022 Spatio-Temporal Trajectory Similarity Learning in Road Networks
- 北京包含了从2008年2月2日到2008年2月8日在中国北京收集的1500万个出租车轨迹点。
- 罗马包含了367,052条来自意大利罗马的出租车轨迹,覆盖了30多天。
- 首先将所有轨迹映射匹配到来自OpenStreetMap的相应道路网络。
- 这样,原始GPS轨迹数据就转换成了按时间顺序排列的顶点序列。
- 进一步,获取了来自城市地区的轨迹,并移除了少于10个采样点的轨迹。
- 这个预处理得到了在北京的348,210条轨迹和在罗马的45,157条轨迹。
2.6 KDD2022 TrajGAT: A Graph-based Long-term Dependency Modeling Approach for Trajectory Similarity Computation
- 西安的出租车轨迹
- 从2007年到2010年的17,621条人类移动轨迹
- 波尔图
- 从2013年到2014年的超过170万条出租车轨迹
- 预处理:选择城市中心区域的轨迹,并移除少于10条记录的轨迹
- 处理后,我们获得了西安数据集的7641条轨迹和波尔图数据集的超过600,000条轨迹
2.7 ICDE 2022 TraSS: Efficient Trajectory Similarity Search Based on Key-Value Data Stores
(1)TDrive ,包含了两周内北京的321,387条出租车轨迹(752MB)
(2)Lorry,包含了广州的4,394,397条JD物流卡车轨迹(136GB)
(3)合成,为了验证TraSS的可扩展性,我们使用了由Lorry数据集复制7次生成的五个合成数据集
2.8 ICDE 2022 TMN: Trajectory Matching Networks for Predicting Similarity
• Geolife 由中国北京的182名用户收集,它包含了广泛的人类户外运动,这些运动是用户的GPS位置。总共,Geolife中有17,612条轨迹。
• Porto 包含了超过170万辆车的路线轨迹,主要由葡萄牙波尔图的442辆出租车收集。
遵循之前的工作,过滤掉位于稀疏区域的轨迹,保留城市中心区域的轨迹用于训练和测试。
也移除了少于10条记录的轨迹。
- 这是因为计算较长序列的相似性更为困难和耗时。
- 此外,轨迹数据集通常以许多GPS错误和其他问题为特征,如果受到影响,短轨迹会严重受到这些错误的影响
经过预处理后,Geolife数据集中有大约8,000条轨迹,Porto数据集中有600,000条轨迹
2.9 ICDE 2022 Continuous Trajectory Similarity Search for Online Outlier Detection
1)北京(Geolife)
该数据集保留了182名用户在三年多的时间里的所有旅行记录,包括多种交通方式(步行、驾驶和乘坐公共交通)。
轨迹每1-5秒采样一次,两个相邻点之间的平均速度为5.73 m/s。
北京的道路网络有65,129个节点和85,322条边。
2)新加坡。
该数据集追踪了新加坡的15,054辆出租车的轨迹。
对于每辆出租车,GPS信息在整整一个月内以半分钟到三分钟的采样率持续收集。
它在两个相邻点之间的平均距离远高于GeoLife。
新加坡的道路网络包含20,801个节点和42,309条边。
这是一个私有数据

3)波尔图。
该数据集包含了442辆出租车在波尔图市,葡萄牙一整年(从2013年7月1日到2014年6月30日)的轨迹。
其道路网络具有最细的粒度,有100,484个节点和129,303条边。
3 2021
3.1 ICDE 2021 REPOSE: Distributed Top-k Trajectory Similarity Search with Local Reference Point Tries
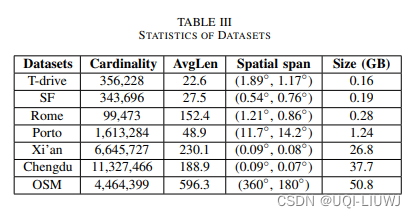
我们在3种类型的数据集上进行实验。
1)小规模和小空间跨度:旧金山(SF),波尔图(Porto),罗马(Rome),T-drive [33]。
2)大规模和小空间跨度:成都和西安。
3)大规模和大空间跨度:OSM。
数据集统计信息显示在表III中。
在预处理阶段,我们删除长度小于10的轨迹,并将长度大于1000的轨迹分割成多条轨迹。我们均匀且随机地选择100条轨迹作为查询集。
1http://sigspatial2017.sigspatial.org/giscup2017/home 2https://www.kaggle.com/c/pkdd-15-predict-taxiservice-trajectory-i 3http://crawdad.org/roma/taxi/20140717 4https://gaia.didichuxing.com 5https://www.openstreetmap.org
3.2 ICDE 2021 T3S: Effective Representation Learning for Trajectory Similarity Computation
我们的实验使用了以下两个数据集:
• Geolife [17] 是一个基于GPS的轨迹数据集,由2007年4月至2012年8月在中国北京的182名用户收集。该数据集包含17,621条轨迹,并记录了广泛的人类户外活动。
• Porto [18] 是一个包含超过170万辆车路线轨迹的数据集,由葡萄牙波尔图的442辆出租车收集。该数据集用作评估交通监测模型的基准。
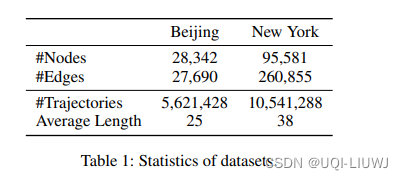
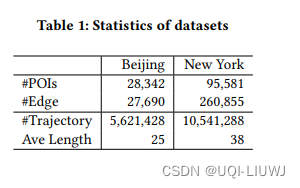
3.3 KDD 2021 A Graph-based Approach for Trajectory Similarity Computation in Spatial Networks
使用来自不同城市的两个空间网络。一个是来自北京市的,即北京道路网络(BRN)。另一个是来自纽约市的,即纽约道路网络(NRN)。
在BRN数据集中,有28,342个兴趣点和27,690条边;在NRN数据集中,有95,581个兴趣点和260,855条边。
对于BRN中的轨迹,我们使用来自T-drive项目的出租车行驶数据。BRN中的出租车轨迹是按出租车id收集的,一条轨迹的时间范围可能持续几天。因此,我们按小时分割这些轨迹,然后我们总共可以得到5,621,428条轨迹。通过过滤异常值,这些轨迹的平均长度为25。
对于NRN中的轨迹,我们使用来自纽约的出租车行驶数据。在原始数据集中,有697,622,444次行程,我们随机抽样其中的一部分来生成轨迹数据集。经过预处理后,我们的实验中有10,541,288条轨迹,它们的平均长度为38。详细信息总结在表1中。
对于这两个轨迹数据集,我们都以20%、10%和70%的比例随机分割它们为训练集、评估集和测试集。
4 2020
4.1 IJCAI 2020 Trajectory Similarity Learning with Auxiliary Supervision and Optimal Matching
ECML/PKDD 15: Taxi Trajectory Prediction (I) | Kaggle
4.2 2020 ICDE Parallel Semantic Trajectory Similarity Join
- 纽约轨迹数据(NTD)和北京轨迹数据(BTD)。
- NTD包含一张道路网络和1000万辆出租车行程。每个出租车行程都是一个起点-终点对。
- 将从源到目的地的最短路径视为一次行程的轨迹。
- 此外,使用了一个真实的POI数据集,其中包含了纽约市的19,969个POI。
- 每个POI都有一个带有纬度和经度的空间坐标和一个文本描述。
- 因为POI可能不匹配轨迹点,我们将每个POI映射到道路网络中最近的节点,并将POI视为语义轨迹中的一个对象。
- 在BTD中——T-drive
- BTD中的原始轨迹非常长,因为每条轨迹都包含了特定时间段内的所有行程,这可能是几天。
- 我们将这些轨迹划分为半小时的子轨迹。目的是创建具有现实长度和持续时间的行程。
- 为了用文本描述增强每个轨迹点,我们从包含200万条推文的真实推文集合中随机选择一条推文,并将推文的文本描述与轨迹点关联起来。
https://publish.illinois.edu/dbwork/open-data/
5 更早
5.1 ICDE 2018 Deep Representation Learning for Trajectory Similarity Computation
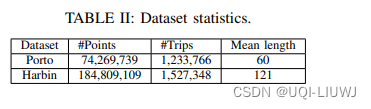
第一个数据集在葡萄牙的波尔图市收集,持续19个月,包含170万条轨迹。每辆出租车每15秒报告一次其位置。我们移除了长度少于30的轨迹,得到了120万条轨迹。
第二个数据集包含了在中国哈尔滨市收集的8个月内13000辆出租车的轨迹。我们选择了长度至少为30,且连续采样点之间的时间间隔少于20秒的轨迹。这产生了150万条轨迹。
我们根据轨迹的开始时间戳将两个集合划分为训练数据和测试数据。对于这两个集合,前80万条轨迹用于训练,其余的轨迹用于测试。
5.2 2019 ICDE Computing Trajectory Similarity in Linear Time: A Generic Seed-Guided Neural Metric Learning Approach
第一个数据集[33],被称为Geolife,包含了从2007年到2010年的17,621条人类移动轨迹。
第二个数据集[23]包含了从2013年到2014年的超过170万条出租车轨迹。
为了减小M的维度,我们选择了城市中心区域的轨迹,并将该区域离散化为50m × 50m的网格单元。
然后,我们删除了记录少于10条的轨迹。经过这样的预处理,我们在Geolife中获得了8203条轨迹,在波尔图中获得了601,071条轨迹。
相关文章:
论文笔记(整理):轨迹相似度顶会论文中使用的数据集
0 汇总 数据类型数据名称数据处理出租车数据波尔图 原始数据:2013年7月到2014年6月,170万条数据 ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 过滤位于城市(或国家)区域之外的轨迹 过…...

Python实现单例模式
使用函数装饰器 def singleton(cls):_instance {}def inner():if cls not in _instance:_instance[cls] cls()return _instance[cls]return innersingleton class Demo(object):def __init__(self):passdef test():b1 Demo()b2 Demo()print(b1, b2)使用类装饰器 class si…...

spark相关网站
Spark的五种JOIN策略解析 https://www.cnblogs.com/jmx-bigdata/p/14021183.html 万字详解整个数据仓库建设体系(好文值得收藏) https://mp.weixin.qq.com/s?__bizMzg2MzU2MDYzOA&mid2247484692&idx1&snf624672e62ba6cd4cc69bdb6db28756a&…...
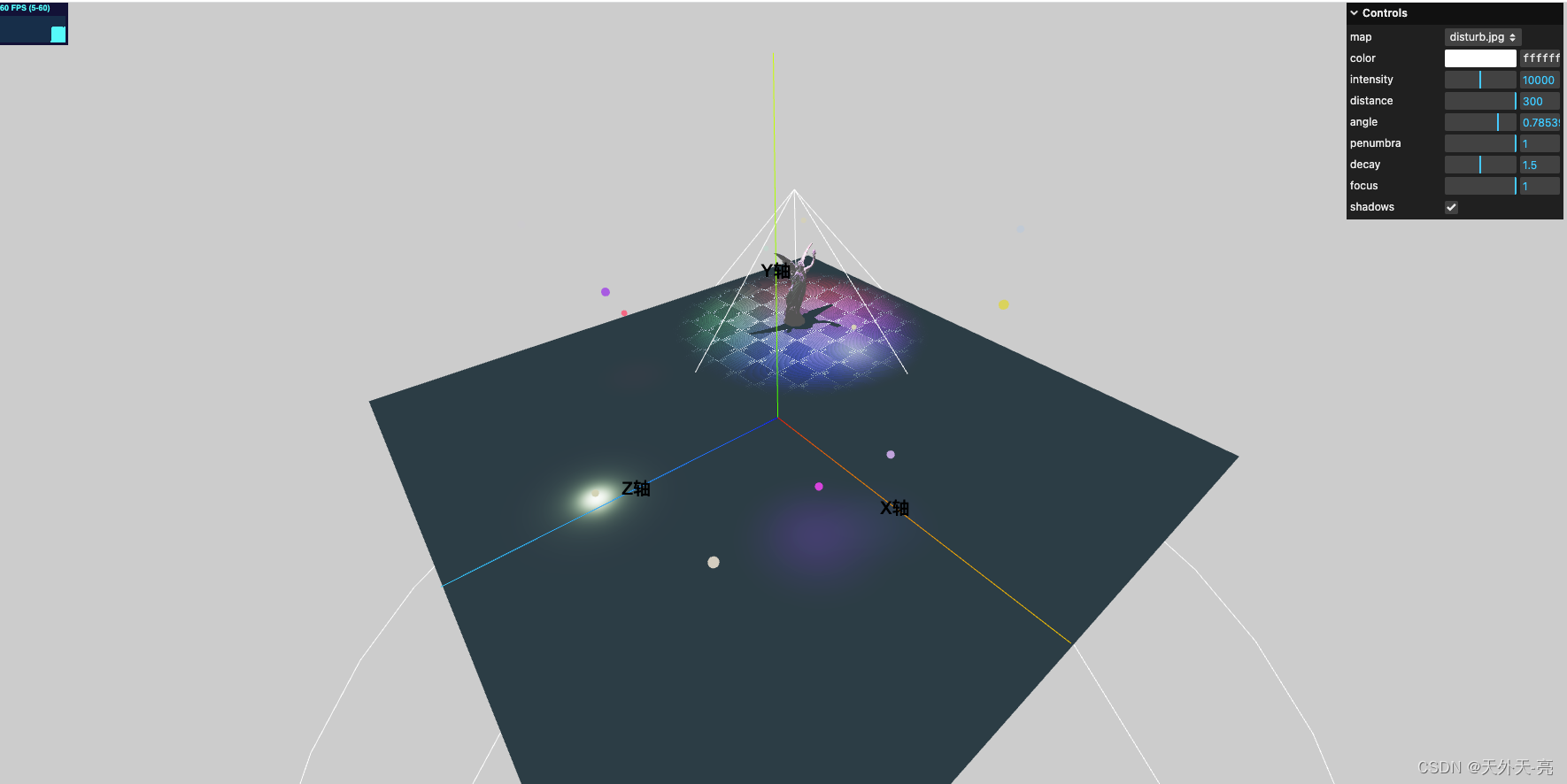
ThreeJS-3D教学四-光源
three模拟的真实3D环境,一个非常炫酷的功能便是对光源的操控,之前教学一中已经简单的描述了多种光源,这次咱们就详细的讲下一些最常见的光源: AmbientLight 该灯光在全局范围内平等地照亮场景中的所有对象。 该灯光不能用于投射阴…...

Linux 回收内存到底怎么计算anon/file回收比例,只是swappiness这么简单?
概述 Linux内核为了区分冷热内存,将page以链表的形式保存,主要分为5个链表,除去evictable,我们主要关注另外四个链表:active file/inactive file,active anon和inactive anon链表,可以看到这主要分为两类,file和anon page,内存紧张的时候,内核开始从inactive tail定…...

软件测试中的测试工具和自动化测试
1. 测试工具 测试工具也分为不同人员使用的 开发人员:测试框架,编写测试用例;各类线上dump分析工具如windgb;开发时的集成IDE工具如Visual Studio,idea等等 面向不同测试需求的测试工具 软件测试是软件开发生命周期…...
个人博客系统测试报告
个人博客系统测试报告 一.项目背景二.项目功能三.测试用例3.1 功能测试3.2 自动化测试(部分测试)3.2.1登陆页面3.2.2博客详情页3.2.3博客编辑页3.2.4个人列表页3.2.5测试结果 3.3 性能测试 一.项目背景 当学习完一项技能后,我们总会习惯通过博…...
高效搜索,提升编程效率
一、搜索效率 1.1魔法上网 网址: 一个很变态但可以让你快速学会计算机的方法…………_哔哩哔哩_bilibili 谷歌镜像: https://search.fuyeor.com/zh-cn/Google 谷歌学术: https://link.zhihu.com/?targethttps%3A//scholar.lanfanshu.cn/…...
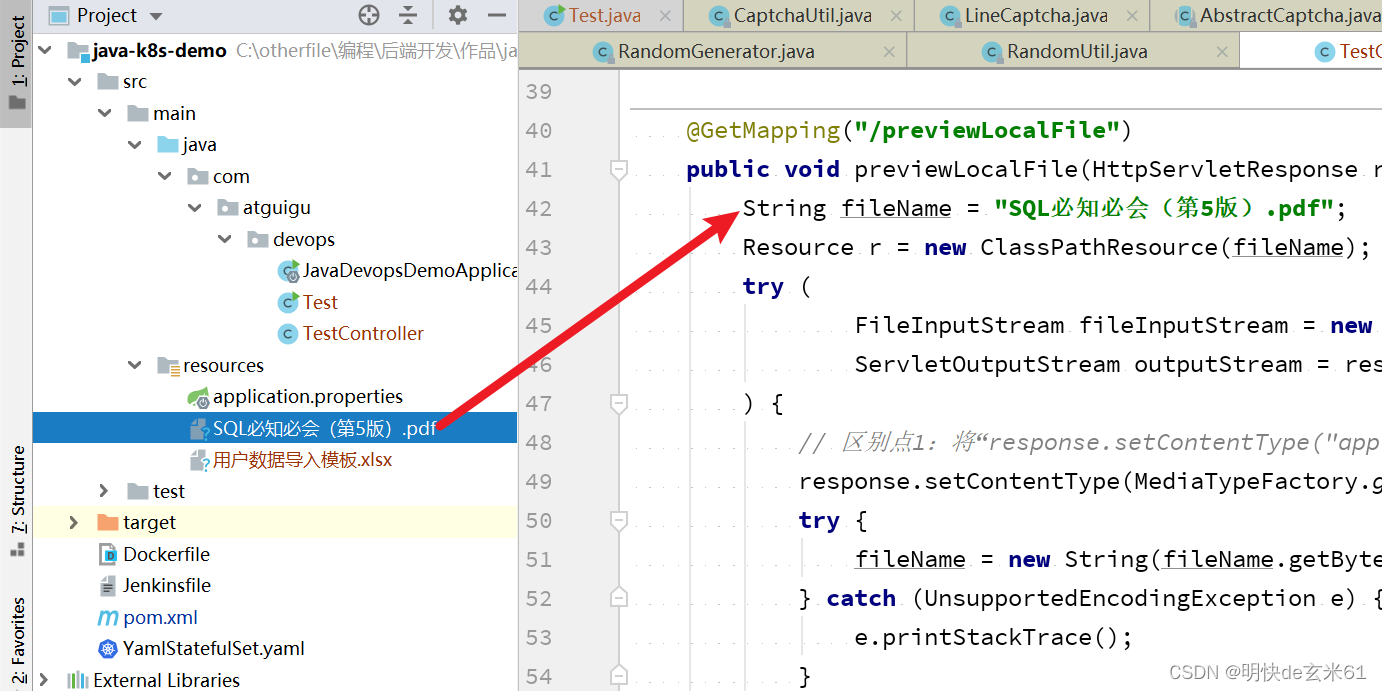
Java编程技巧:文件上传、下载、预览
目录 1、上传文件1.1、代码1.2、postman测试截图 2、下载resources目录中的模板文件2.1、项目结构2.2、代码2.3、使用场景 3、预览文件3.1、项目结构3.2、代码3.3、使用场景 1、上传文件 1.1、代码 PostMapping("/uploadFile") public String uploadFile(Multipart…...

【蓝桥杯选拔赛真题63】Scratch云朵降雨 少儿编程scratch图形化编程 蓝桥杯选拔赛真题解析
目录 scratch云朵降雨 一、题目要求 编程实现 二、案例分析 1、角色分析...
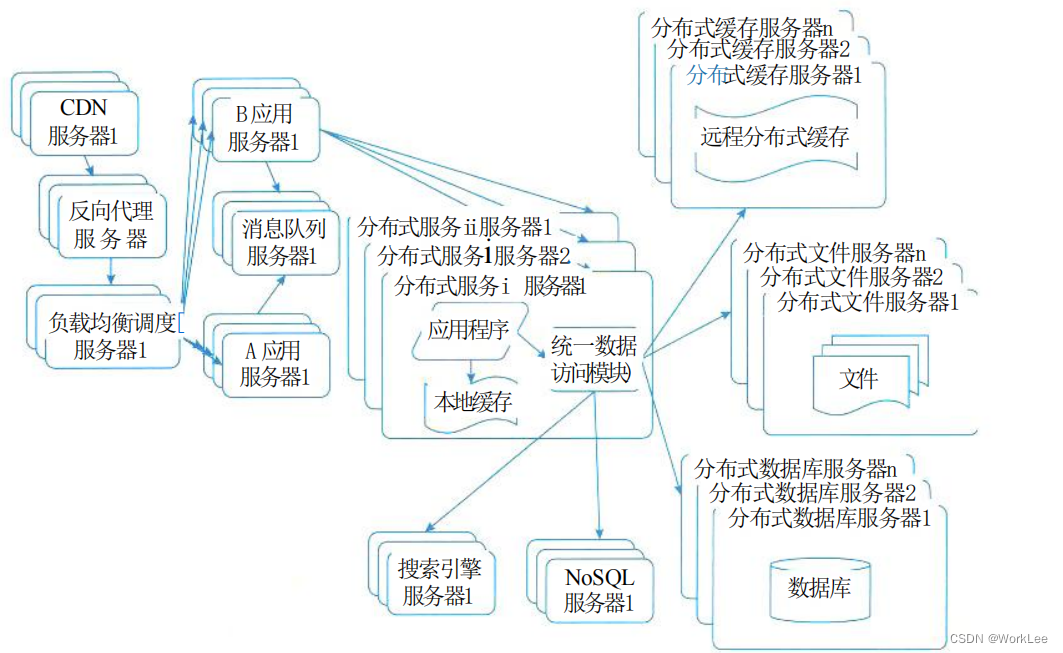
【新版】系统架构设计师 - 软件架构的演化与维护
个人总结,仅供参考,欢迎加好友一起讨论 文章目录 架构 - 软件架构的演化与维护考点摘要软件架构演化和定义面向对象软件架构演化对象演化消息演化复合片段演化约束演化 软件架构演化方式静态演化动态演化 软件架构演化原则软件架构演化评估方法大型网站架…...

安卓循环遍历计时器
计时器循环遍历 计时器的使用 我习惯两种方式如下: 第一种使用 handler: 1,初始化 声明 public static final int REGULAR_TIME 1000; //1秒 时间间隔private Handler mUiHandler;private int index0;Runnable runnable new Runnable()…...
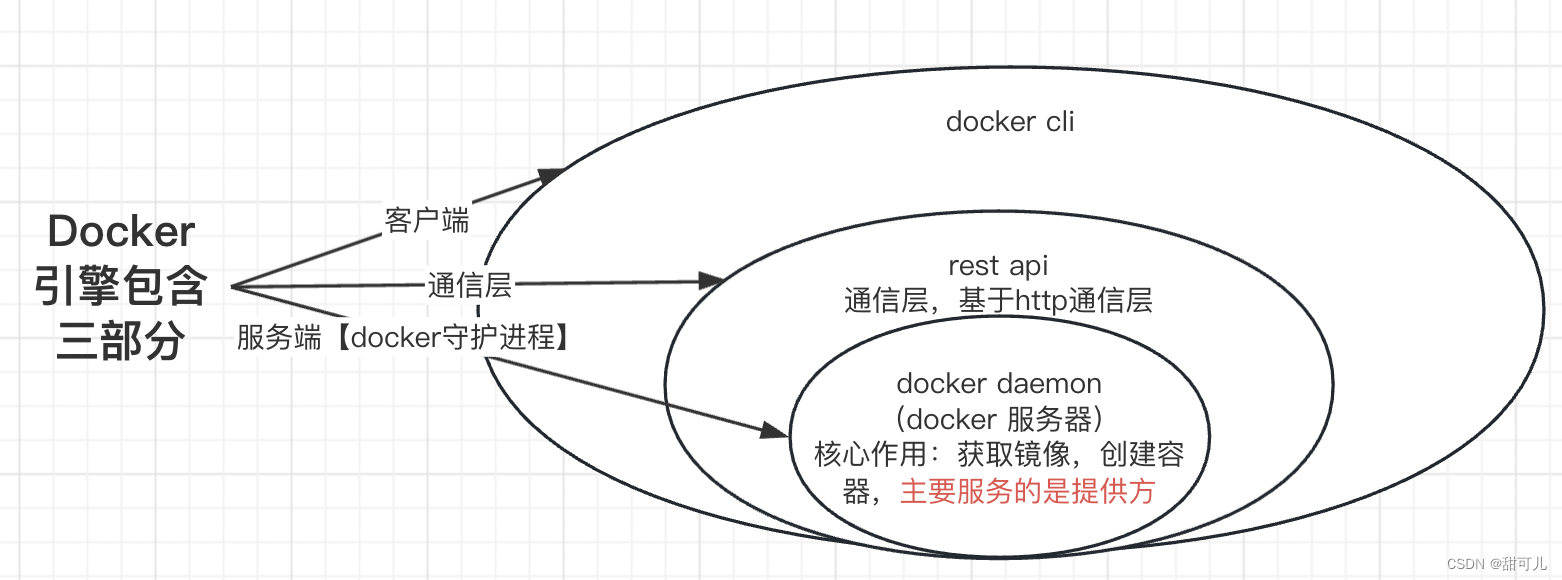
Docker-基本了解
Docker-基本了解 一、基本概念1、镜像2、容器 二、执行流程三、体系结构 一、基本概念 Docker是容器化平台,提供应用打包,部署与运行应用的容器化平台,应用程序通过docker engine(Docker 引擎获取可用资源)࿰…...
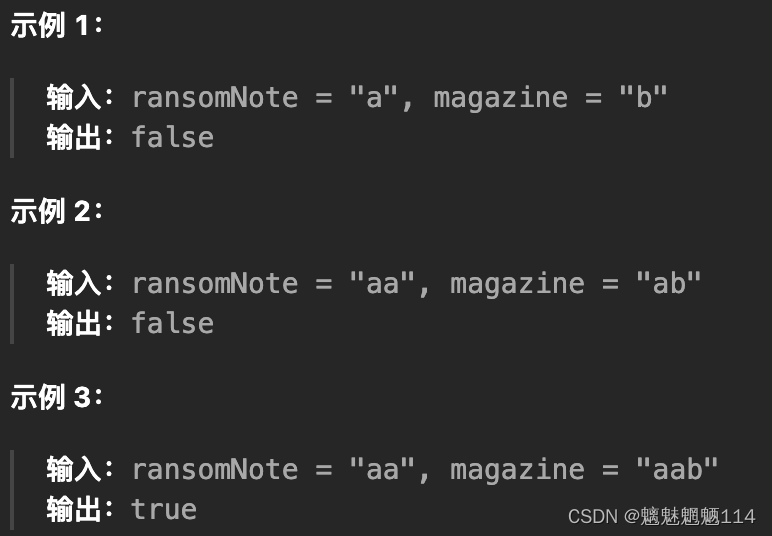
Leetcode383. 赎金信
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。 如果可以,返回 true ;否则返回 false 。 magazine 中的每…...

overleaf杂谈-Springer文献格式问题
目录 overleaf写作问题记录1.Latex中的%问题(文本变成灰色)2.Springer文献格式问题2.1 新建reference.bib2.2 谷歌学术搜索文章并引用2.3 复制BibTex2.4 复制进reference.bib2.5 在sn-article.tex的\end{document}前添加语句2.6 引用文献2.7 Springer模板…...

No148.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

BASH shell脚本篇4——函数
这篇文章介绍下BASH shell中的函数。之前有介绍过shell的其它命令,请参考: BASH shell脚本篇1——基本命令 BASH shell脚本篇2——条件命令 BASH shell脚本篇3——字符串处理 函数是代码重用的最重要方式。Bash函数可以定义为一组命令,在b…...

VisualStudio配置OpenCV环境
VS2022配置OpenCV环境 记录一下Windows上VS配置OpenCV环境的过程。(VS2022 OpenCV4.8) 一、下载OpenCV 从官网或者镜像网站下载Windows版OpenCV。4.8版本的文件为opencv-4.8.0-windows.exe 双击解压到自定义目录,我这边是:E:…...

C++手写NMS
文章目录 前言一、NMS是什么?二、代码展示三、代码实现思路总结 前言 目标检测模型推理后,一般都需要进行NMS操作进行多余框去重,板端部署一般不用opencv自带的NMS,所以记录下手写NMS的代码。 一、NMS是什么? 非极大…...

第9讲:VUE中监听器WATCH使用详解
目录 监听器介绍 监听普通属性 监听对象属性 监听路由属性监听器watch 监听器:它是侦听属性值或者计算属性的变化,一旦发生变化可以在函数中进行相应的操作,从而达到change事件监听的效果!监听器是一个对象,以 key-value 的形式表示。key 是需要监听的表达式,value 是对…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...