【AI视野·今日NLP 自然语言处理论文速览 第四十四期】Fri, 29 Sep 2023
AI视野·今日CS.NLP 自然语言处理论文速览
Fri, 29 Sep 2023
Totally 45 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
| MindShift: Leveraging Large Language Models for Mental-States-Based Problematic Smartphone Use Intervention Authors Ruolan Wu, Chun Yu, Xiaole Pan, Yujia Liu, Ningning Zhang, Yue Fu, Yuhan Wang, Zhi Zheng, Li Chen, Qiaolei Jiang, Xuhai Xu, Yuanchun Shi 有问题的智能手机使用会对身心健康产生负面影响。尽管先前的研究范围很广,但现有的说服技术不够灵活,无法根据用户的身体环境和心理状态提供动态的说服内容。我们首先进行了绿野仙踪研究 N 12 和访谈研究 N 10,以总结有问题的智能手机使用无聊、压力和惯性背后的心理状态。这为我们设计四种说服策略提供了依据,即理解、安慰、唤起和搭建习惯。我们利用大型语言模型法学硕士来自动动态生成有效的说服内容。我们开发了 MindShift,这是一种新颖的法学硕士支持的有问题的智能手机使用干预技术。 MindShift 将用户当前的物理环境、心理状态、应用使用行为、用户目标习惯作为输入,并通过适当的说服策略生成高质量且灵活的说服内容。我们进行了为期 5 周的现场实验 N 25,以将 MindShift 与基线技术进行比较。结果显示,MindShift 将干预接受率显着提高了 17.8 ± 22.5,并将智能手机的使用频率降低了 12.1 ± 14.4。此外,用户的智能手机成瘾量表得分显着下降,自我效能感上升。 |
| Stress Testing Chain-of-Thought Prompting for Large Language Models Authors Aayush Mishra, Karan Thakkar 本报告探讨了思想链 CoT 提示在提高大型语言模型法学硕士多步推理能力方面的有效性。受先前引用 Min2022RethinkingWork 的研究的启发,我们分析了三种类型的 CoT 提示扰动,即 CoT 顺序、CoT 值和 CoT 算子对 GPT 3 在各种任务上的性能的影响。我们的研究结果表明,不正确的 CoT 提示会导致准确性指标表现不佳。 CoT 中的正确值对于预测正确答案至关重要。此外,与基于值的扰动相比,不正确的演示(其中 CoT 运算符或 CoT 顺序错误)不会对性能产生太大影响。 |
| Qwen Technical Report Authors Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, Tianhang Zhu 大型语言模型法学硕士彻底改变了人工智能领域,使以前被认为是人类独有的自然语言处理任务成为可能。在这项工作中,我们介绍了 Qwen,这是我们大型语言模型系列的第一部分。 Qwen 是一个综合性语言模型系列,包含具有不同参数数量的不同模型。它包括 Qwen(基本的预训练语言模型)和 Qwen Chat(通过人类对齐技术进行微调的聊天模型)。基础语言模型在众多下游任务中始终表现出卓越的性能,而聊天模型,特别是那些使用人类反馈 RLHF 强化学习训练的模型,具有很强的竞争力。聊天模型拥有用于创建代理应用程序的高级工具使用和规划功能,即使与执行复杂任务(例如使用代码解释器)的大型模型相比,也显示出令人印象深刻的性能。此外,我们还开发了编码专业模型 Code Qwen 和 Code Qwen Chat,以及基于数学的模型 Math Qwen Chat,这些模型都建立在基本语言模型的基础上。 |
| Unlikelihood Tuning on Negative Samples Amazingly Improves Zero-Shot Translation Authors Changtong Zan, Liang Ding, Li Shen, Yibin Lei, Yibing Zhan, Weifeng Liu, Dacheng Tao 零镜头翻译 ZST 通常基于多语言神经机器翻译模型,旨在在训练数据中未见过的语言对之间进行翻译。在推理过程中指导零样本语言映射的常见做法是故意插入源语言 ID 和目标语言 ID,例如英语的 EN 和德语的 DE。最近的研究表明,语言ID有时无法导航ZST任务,使其遭受脱靶问题,生成的翻译中存在非目标语言单词,因此很难将当前的多语言翻译模型应用于广泛的零范围镜头语言场景。为了了解语言 ID 的导航功能何时以及为何被削弱,我们比较了 ZST 方向 Off Target OFF 和 On Target ON 情况下的两种极端解码器输入情况。通过对比可视化这些使用教师强制的情况下的上下文单词表示 CWR,我们发现:1 当句子和 ID 匹配 ON 设置时,不同语言的 CWR 有效地分布在不同的区域;2 如果句子和 ID 不匹配 OFF设置中,不同语言的 CWR 分布是混乱的。我们的分析表明,尽管它们在理想的 ON 设置中运行良好,但当遇到偏离目标的标记时,语言 ID 会变得脆弱并失去导航能力,这种情况在推理过程中通常存在,但在训练场景中很少见。作为回应,我们对负 OFF 样本采用似然性调整来最小化它们的概率,以便语言 ID 可以在训练期间区分开启和关闭目标标记。 |
| GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond Authors Shen Zheng, Yuyu Zhang, Yijie Zhu, Chenguang Xi, Pengyang Gao, Xun Zhou, Kevin Chen Chuan Chang 随着大型语言模型法学硕士的快速发展,迫切需要一个全面的评估套件来评估其能力和局限性。现有的 LLM 排行榜经常引用其他论文中报告的分数,而没有一致的设置和提示,这可能会无意中鼓励挑选偏好的设置和提示以获得更好的结果。在这项工作中,我们介绍了 GPT Fathom,这是一个基于 OpenAI Evals 构建的开源且可重复的 LLM 评估套件。我们在 7 个能力类别的 20 个策划基准上系统地评估 10 个领先的法学硕士以及 OpenAI 的遗留模型,所有这些都在一致的设置下。我们对 OpenAI 早期模型的回顾性研究为从 GPT 3 到 GPT 4 的演进路径提供了宝贵的见解。目前,社区迫切想知道 GPT 3 如何逐步改进到 GPT 4,包括技术细节,例如添加代码数据是否可以改进 LLM 的性能。 |
| A Benchmark for Learning to Translate a New Language from One Grammar Book Authors Garrett Tanzer, Mirac Suzgun, Eline Visser, Dan Jurafsky, Luke Melas Kyriazi 大型语言模型法学硕士可以通过上下文学习或轻量级微调来实现令人印象深刻的壮举。人们很自然地想知道这些模型如何适应真正的新任务,但是如何找到在互联网规模的训练集中看不到的任务我们转向了一个因网络数据低资源语言的稀缺而受到明确推动和瓶颈的领域。在本文中,我们介绍了《One Book》中的 MTOB 机器翻译,这是学习在英语和卡拉芒语之间进行翻译的基准,卡拉芒语是一种使用人数少于 200 人的语言,因此使用数百页的现场语言学参考材料,在网络上几乎不存在。这个任务框架的新颖之处在于,它要求模型从一本人类可读的语法解释书中学习语言,而不是从大量挖掘的领域数据语料库中学习语言,这更类似于 L2 学习而不是 L1 习得。我们证明,使用当前法学硕士的基线很有希望,但低于人类的表现,在卡拉曼语到英语翻译上达到了 44.7 chrF,在英语到卡拉曼翻译上达到了 45.8 chrF,而从相同参考材料学习卡拉曼语的人则达到了 51.6 和 57.0 chrF 。 |
| Unsupervised Fact Verification by Language Model Distillation Authors Adri n Bazaga, Pietro Li , Gos Micklem 无监督事实验证旨在使用来自值得信赖的知识库的证据来验证主张,而无需任何类型的数据注释。为了应对这一挑战,算法必须为每个声明生成既具有语义意义又足够紧凑的特征,以便找到与源信息的语义对齐。与之前通过学习带注释的声明语料库及其相应标签来解决对齐问题的工作相比,我们提出了 SFAVEL 通过语言模型蒸馏进行自监督事实验证,这是一种新颖的无监督框架,利用预先训练的语言模型来提取自监督特征无需注释即可进行高质量的声明事实对齐。这是通过一种新颖的对比损失函数实现的,该函数鼓励特征获得高质量的主张和证据对齐,同时保留整个语料库的语义关系。 |
| KLoB: a Benchmark for Assessing Knowledge Locating Methods in Language Models Authors Yiming Ju, Zheng Zhang 最近,定位然后编辑范式已经成为改变语言模型中存储的事实知识的主要方法之一。然而,目前缺乏关于现有定位方法是否能够精确定位嵌入所需知识的确切参数的研究。此外,尽管许多研究者质疑事实知识局部性假设的有效性,但没有提供方法来检验该假设以进行更深入的讨论和研究。因此,我们引入了 KLoB,这是一个检查可靠知识定位方法应满足的三个基本属性的基准。 KLoB可以作为评估语言模型中现有定位方法的基准,并且可以为重新评估事实知识的局部性假设的有效性提供一种方法。 |
| Augmenting LLMs with Knowledge: A survey on hallucination prevention Authors Konstantinos Andriopoulos, Johan Pouwelse 大型预训练语言模型已经证明了它们在将事实知识存储在其参数内的能力,并在针对下游自然语言处理任务进行微调时取得了显着的结果。尽管如此,它们精确访问和操作知识的能力仍然受到限制,导致与特定任务架构相比,知识密集型任务的性能差异。此外,为模型决策提供来源和维护最新的世界知识的挑战仍然是开放的研究前沿。为了解决这些限制,将预训练模型与可微分访问机制集成到显式非参数内存成为一种有前景的解决方案。这项调查深入研究了语言模型领域,语言模型增强了利用外部知识源(包括外部知识库和搜索引擎)的能力。在遵循预测缺失标记的标准目标的同时,这些增强型语言模型利用各种可能非参数化的外部模块来增强其上下文处理能力,这与传统的语言建模范例不同。 |
| Prompt-and-Align: Prompt-Based Social Alignment for Few-Shot Fake News Detection Authors Jiaying Wu, Shen Li, Ailin Deng, Miao Xiong, Bryan Hooi 尽管自动假新闻检测取得了相当大的进步,但由于新闻的及时性,如何根据有限的事实检查有效预测新闻文章的真实性仍然是一个关键的悬而未决的问题。现有的方法通常遵循从头开始训练的范式,这从根本上受到大规模注释数据的可用性的限制。虽然表达性预训练语言模型 PLM 已经以预训练和微调的方式进行了调整,但预训练和下游目标之间的不一致也需要昂贵的特定任务监督。在本文中,我们提出了 Prompt and Align PA,这是一种基于提示的新型范式,用于少镜头假新闻检测,联合利用 PLM 中预先训练的知识和社交上下文拓扑。我们的方法通过将新闻文章包装在与任务相关的文本提示中来缓解标签稀缺性,然后由 PLM 处理以直接引出任务特定知识。为了在不引起额外训练开销的情况下补充 PLM 的社交背景,受到对用户准确性一致性的实证观察的启发,即社交用户倾向于消费相同准确性类型的新闻,我们进一步构建了新闻文章之间的新闻邻近图,以捕获准确性一致性共享读者群中的信号,并以置信度知情的方式沿图边缘对齐提示预测。 |
| A Comprehensive Survey of Document-level Relation Extraction (2016-2022) Authors Julien Delaunay, Thi Hong Hanh Tran, Carlos Emiliano Gonz lez Gallardo, Georgeta Bordea, Nicolas Sidere, Antoine Doucet 文档级关系提取 DocRE 是自然语言处理 NLP 的一个活跃研究领域,涉及识别和提取句子边界之外的实体之间的关系。与更传统的句子级关系提取相比,DocRE 提供了更广泛的分析上下文,并且更具挑战性,因为它涉及识别可能跨越多个句子或段落的关系。作为一种从非结构化大型文档(例如科学论文、法律合同或新闻文章)自动构建和填充知识库的可行解决方案,这项任务引起了越来越多的兴趣,以便更好地理解实体之间的关系。 |
| Human Feedback is not Gold Standard Authors Tom Hosking, Phil Blunsom, Max Bartolo 人类反馈已成为评估大型语言模型性能的事实上的标准,并且越来越多地被用作培训目标。然而,尚不清楚这个单一偏好分数捕获了生成输出的哪些属性。我们假设偏好分数是主观的并且容易出现不良偏差。我们批判性地分析人类反馈在培训和评估中的使用,以验证它是否完全捕获了一系列关键的错误标准。我们发现,虽然偏好分数具有相当好的覆盖范围,但它们未能代表真实性等重要方面。我们进一步假设偏好分数和错误注释都可能受到混杂因素的影响,并利用指令调整模型来生成沿着两个可能的混杂维度自信和复杂性变化的输出。我们发现输出的自信会扭曲事实错误的感知率,这表明人工注释并不是完全可靠的评估指标或训练目标。最后,我们提供了初步证据,表明使用人类反馈作为训练目标会不成比例地提高模型输出的自信。 |
| Augmenting transformers with recursively composed multi-grained representations Authors Xiang Hu, Qingyang Zhu, Kewei Tu, Wei Wu 我们提出了 ReCAT,一种递归组合增强 Transformer,它能够在学习和推理过程中显式地建模原始文本的分层句法结构,而无需依赖金树。沿着这条线的现有研究限制数据遵循分层树结构,因此缺乏跨跨通信。为了克服这个问题,我们提出了一种新颖的上下文内部外部 CIO 层,它通过自下而上和自上而下的传递来学习跨度的上下文表示,其中自下而上的传递通过组合低级跨度来形成高层跨度的表示,而自上而下的传递则形成高级跨度的表示。结合跨度内部和外部的信息。通过在 Transformer 中的嵌入层和注意力层之间堆叠多个 CIO 层,ReCAT 模型可以执行深度跨度内和深度跨度间交互,从而生成与其他跨度完全上下文相关的多粒度表示。而且,CIO层可以与Transformers联合预训练,使得ReCAT同时具有可扩展性、强大的性能和可解释性。我们对各种句子级别和跨度级别的任务进行了实验。评估结果表明,在自然语言推理任务上,ReCAT 在所有跨度级别任务和将递归网络与 Transformer 相结合的基线上都可以显着优于普通 Transformer 模型。 |
| At Which Training Stage Does Cocde Data Help LLMs Reasoning? Authors Yingwei Ma, Yue Liu, Yue Yu, Yuanliang Zhang, Yu Jiang, Changjian Wang, Shanshan Li 大型语言模型 法学硕士展现了卓越的推理能力,成为语言技术的基础。受到代码数据在训练LLM的巨大成功的启发,我们自然想知道在哪个训练阶段引入代码数据才能真正帮助LLM推理。为此,本文系统地探讨了不同阶段代码数据对LLM的影响。具体来说,我们分别介绍预训练阶段、指令调优阶段以及两者的代码数据。然后,通过五个领域的六个推理任务,全面、公正地评估法学硕士的推理能力。我们批判性地分析实验结果并提供具有见解的结论。首先,用代码和文本的混合方式预训练法学硕士可以显着增强法学硕士的一般推理能力,几乎不会对其他任务产生负迁移。此外,在指令调优阶段,代码数据赋予了法学硕士任务特定的推理能力。此外,代码和文本数据的动态混合策略有助于法学硕士在训练过程中逐步学习推理能力。 |
| LawBench: Benchmarking Legal Knowledge of Large Language Models Authors Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Songyang Zhang, Kai Chen, Zongwen Shen, Jidong Ge 大型语言模型LLM在各方面都展现了强大的能力。然而,当他们应用于高度专业化、安全的关键法律领域时,尚不清楚他们拥有多少法律知识以及是否能够可靠地执行法律相关任务。为了弥补这一差距,我们提出了综合评估基准LawBench。 LawBench经过精心设计,从三个认知层面对法学硕士的法律能力进行精准评估 1 法律知识记忆 法学硕士是否能够记住所需的法律概念、文章和事实 2 法律知识理解法学硕士是否能够理解法律文本中的实体、事件和关系 3法律知识应用法学硕士是否能够正确利用他们的法律知识并采取必要的推理步骤来解决现实的法律任务。 LawBench包含20个不同的任务,涵盖5种任务类型单标签分类SLC、多标签分类MLC、回归、提取和生成。我们对 LawBench 上的 51 名法学硕士进行了广泛的评估,其中包括 20 名多语言法学硕士、22 名中文法学硕士和 9 名法律专业法学硕士。结果表明,GPT 4 仍然是法律领域表现最好的法学硕士,远远超过其他课程。虽然对法律特定文本的法学硕士进行微调带来了一定的改进,但我们距离在法律任务中获得可用且可靠的法学硕士还有很长的路要走。 |
| UPB @ ACTI: Detecting Conspiracies using fine tuned Sentence Transformers Authors Andrei Paraschiv, Mihai Dascalu 阴谋论已成为网络言论的一个突出且令人担忧的方面,对信息完整性和社会信任构成挑战。因此,我们解决了 ACTI EVALITA 2023 共享任务提出的阴谋论检测问题。预训练的句子 Transformer 模型和数据增强技术的结合使我们在两个子任务的最终排行榜上都获得了第一名。 |
| Social Media Fashion Knowledge Extraction as Captioning Authors Yifei Yuan, Wenxuan Zhang, Yang Deng, Wai Lam 社交媒体在推动时尚产业发展方面发挥着重要作用,每天都会产生大量与时尚相关的帖子。为了从帖子中获取丰富的时尚信息,我们研究了社交媒体时尚知识提取的任务。时尚知识通常由场合、人物属性和时尚商品信息组成,可以有效地表示为一组元组。以往的时尚知识提取研究大多基于时尚产品图像,没有考虑社交媒体帖子中丰富的文本信息。现有的社交媒体时尚知识提取工作是基于分类的,需要提前手动确定一组时尚知识类别。在我们的工作中,我们建议将任务作为字幕问题来捕获多模态帖子信息的相互作用。具体来说,我们通过句子转换方法将时尚知识元组转换为自然语言标题。然后,我们的框架旨在直接从社交媒体帖子生成基于句子的时尚知识。受到预训练模型巨大成功的启发,我们基于多模态预训练生成模型构建模型,并设计了几个辅助任务来增强知识提取。由于没有可以直接借用到我们的任务的现有数据集,我们引入了一个由社交媒体帖子和手动时尚知识注释组成的数据集。 |
| On the Challenges of Fully Incremental Neural Dependency Parsing Authors Ana Ezquerro, Carlos G mez Rodr guez, David Vilares 自从 BiLSTM 和基于 Transformer 的双向编码器的普及以来,最先进的句法解析器缺乏增量性,需要访问整个句子并偏离人类语言处理。本文探讨了现代架构的完全增量依赖解析是否具有竞争力。我们构建的解析器将严格从左到右的神经编码器与完全增量序列标记和基于转换的解码器相结合。 |
| Spider4SPARQL: A Complex Benchmark for Evaluating Knowledge Graph Question Answering Systems Authors Catherine Kosten, Philippe Cudr Mauroux, Kurt Stockinger 随着最近大型语言模型法学硕士数量和可用性的激增,为评估知识图问答 KBQA 系统提供大型且现实的基准变得越来越重要。到目前为止,大多数基准测试都依赖于基于模式的 SPARQL 查询生成方法。随后的自然语言自然语言问题生成是通过众包或其他自动化方法进行的,例如基于规则的释义或自然语言问题模板。 |
| Analyzing Political Figures in Real-Time: Leveraging YouTube Metadata for Sentiment Analysis Authors Danendra Athallariq Harya Putra, Arief Purnama Muharram 使用 YouTube 视频元数据中的大数据进行情绪分析,可以分析代表政党的各种政治人物的公众意见。这是可能的,因为 YouTube 已经成为人们表达自己的平台之一,包括他们对各种政治人物的看法。由此产生的情绪分析可有助于政治高管了解公众情绪并制定适当且有效的政治策略。本研究旨在构建一个利用 YouTube 视频元数据的情感分析系统。情感分析系统是使用 Apache Kafka、Apache PySpark 和用于大数据处理的 Hadoop、用于深度学习处理的 TensorFlow 和用于在服务器上部署的 FastAPI 构建的。本研究中使用的 YouTube 视频元数据是视频描述。情绪分析模型是使用LSTM算法构建的,并产生两种类型的情绪:积极情绪和消极情绪。 |
| Controllable Text Generation with Residual Memory Transformer Authors Hanqing Zhang, Sun Si, Haiming Wu, Dawei Song 大规模因果语言模型 CLM,例如 GPT3 和 ChatGPT,在文本生成方面取得了巨大成功。然而,在平衡灵活性、控制粒度和生成效率的同时控制 CLM 的生成过程仍然是一个开放的挑战。在本文中,我们通过设计一个非侵入式、轻量级的控制插件来伴随任意时间步长的 CLM 生成,为可控文本生成 CTG 提供了一种新的替代方案。所提出的控制插件,即 Residual Memory Transformer RMT ,具有编码器解码器设置,可以接受任何类型的控制条件,并通过残差学习范式与 CLM 配合,以实现更灵活、通用和高效的 CTG。以自动和人工评估的形式对各种控制任务进行了广泛的实验。 |
| Marathi-English Code-mixed Text Generation Authors Dhiraj Amin, Sharvari Govilkar, Sagar Kulkarni, Yash Shashikant Lalit, Arshi Ajaz Khwaja, Daries Xavier, Sahil Girijashankar Gupta 代码混合,即混合不同语言的语言元素以形成有意义的句子,在多语言环境中很常见,产生像印度英语和明式英语这样的混合语言。马拉地语是印度第三大语言,为了精确和正式,通常会融入英语。开发代码混合语言系统(例如 Marathi English Minglish )面临资源限制。本研究介绍了马拉地语英语代码混合文本生成算法,并使用代码混合指数 CMI 和代码混合程度 DCM 指标进行评估。在 2987 个代码混合问题中,它的平均 CMI 为 0.2,平均 DCM 为 7.4,表明代码混合句子有效且易于理解。 |
| Using Weak Supervision and Data Augmentation in Question Answering Authors Chumki Basu, Himanshu Garg, Allen McIntosh, Sezai Sablak, John R. Wullert II COVID 19 大流行的爆发凸显了获取生物医学文献以及时回答特定疾病问题的必要性。在大流行初期,我们面临的最大挑战之一是缺乏有关 COVID 19 的同行评审生物医学文章,这些文章可用于训练问答 QA 的机器学习模型。在本文中,我们探讨了弱监督和数据增强在训练深度神经网络 QA 模型中的作用。首先,我们研究使用信息检索算法 BM25 从学术论文的结构化摘要自动生成的标签是否提供弱监督信号来训练提取式 QA 模型。 |
| Large Language Model Soft Ideologization via AI-Self-Consciousness Authors Xiaotian Zhou, Qian Wang, Xiaofeng Wang, Haixu Tang, Xiaozhong Liu 大型语言模型法学硕士已经在大量自然语言任务中展示了人类水平的表现。然而,很少有研究从意识形态的角度解决法学硕士的威胁和脆弱性,特别是当它们越来越多地被部署在敏感领域(例如选举和教育)时。在这项研究中,我们通过使用人工智能自我意识来探索 GPT 软意识形态化的影响。通过利用GPT自我对话,人工智能可以被赋予理解预期意识形态的愿景,并随后生成用于LLM意识形态注入的微调数据。 |
| The Trickle-down Impact of Reward (In-)consistency on RLHF Authors Lingfeng Shen, Sihao Chen, Linfeng Song, Lifeng Jin, Baolin Peng, Haitao Mi, Daniel Khashabi, Dong Yu 人类反馈强化学习 RLHF 中的标准实践涉及针对奖励模型 RM 进行优化,该模型本身经过训练以反映人类对理想世代的偏好。 |
| AE-GPT: Using Large Language Models to Extract Adverse Events from Surveillance Reports-A Use Case with Influenza Vaccine Adverse Events Authors Yiming Li, Jianfu Li, Jianping He, Cui Tao 尽管疫苗有助于全球健康、减轻传染病和大流行病的爆发,但它们有时也会导致不良事件 AE。最近,大型语言模型法学硕士在有效识别和分类临床报告中的 AE 方面表现出了良好的前景。本研究利用 1990 年至 2016 年疫苗不良事件报告系统 VAERS 的数据,特别关注 AE,以评估法学硕士提取 AE 的能力。使用流感疫苗作为用例评估了各种流行的 LLM,包括 GPT 2、GPT 3 变体、GPT 4 和 Llama 2。经过微调的 GPT 3.5 模型 AE GPT 脱颖而出,严格比赛的平均微 F1 分数为 0.704,宽松比赛的平均微 F1 分数为 0.816。 |
| The Confidence-Competence Gap in Large Language Models: A Cognitive Study Authors Aniket Kumar Singh, Suman Devkota, Bishal Lamichhane, Uttam Dhakal, Chandra Dhakal 大型语言模型法学硕士因其在不同领域的表现而受到普遍关注。我们在这里的研究探索了法学硕士的认知能力和信心动态。我们深入了解他们的自我评估信心与实际表现之间的一致性。我们通过不同的调查问卷和现实世界场景来利用这些模型,并提取法学硕士如何对他们的回答表现出信心。我们的研究结果揭示了一些有趣的例子,即使模型回答错误,也表现出很高的置信度。这让人想起人类心理学中观察到的邓宁克鲁格效应。相反,在某些情况下,模型的置信度较低,而正确答案则揭示了潜在的低估偏差。我们的结果强调需要更深入地了解他们的认知过程。 |
| Forgetting Private Textual Sequences in Language Models via Leave-One-Out Ensemble Authors Zhe Liu, Ozlem Kalinli 最近的研究表明,语言模型倾向于记住训练语料库中罕见或独特的标记序列。部署模型后,从业者可能会被要求根据个人要求从模型中删除任何个人信息。每当个人想要行使被遗忘的权利时,重新训练底层模型在计算上是昂贵的。我们采用了师生框架,并提出了一种新颖的留一法集成方法来忘记需要从模型中遗忘的目标文本序列。在我们的方法中,针对要删除的每个目标序列,对多个教师进行不相交集的训练,我们排除在包含该序列的集上训练的教师,并汇总剩余教师的预测,以在微调期间提供监督。 |
| Effective Long-Context Scaling of Foundation Models Authors Wenhan Xiong, Jingyu Liu, Igor Molybog, Hejia Zhang, Prajjwal Bhargava, Rui Hou, Louis Martin, Rashi Rungta, Karthik Abinav Sankararaman, Barlas Oguz, Madian Khabsa, Han Fang, Yashar Mehdad, Sharan Narang, Kshitiz Malik, Angela Fan, Shruti Bhosale, Sergey Edunov, Mike Lewis, Sinong Wang, Hao Ma 我们提出了一系列长上下文 LLM,支持最多 32,768 个令牌的有效上下文窗口。我们的模型系列是通过 Llama 2 的持续预训练构建的,具有更长的训练序列和长文本上采样的数据集。我们对语言建模、综合上下文探测任务和广泛的研究基准进行广泛的评估。在研究基准上,我们的模型在大多数常规任务上实现了一致的改进,并且在长上下文任务上比 Llama 2 有了显着改进。值得注意的是,通过不需要人工注释的长指令数据的成本有效的指令调整过程,70B 变体已经可以超越 gpt在一组长上下文任务上的整体性能为 3.5 Turbo 16k s。除了这些结果之外,我们还对我们方法的各个组成部分进行了深入分析。我们深入研究 Llama 的位置编码并讨论其在建模长依赖关系方面的局限性。我们还研究了预训练过程中各种设计选择的影响,包括数据混合和序列长度的训练课程,我们的消融实验表明,预训练数据集中拥有丰富的长文本并不是实现强大性能的关键,我们根据经验 |
| MedEdit: Model Editing for Medical Question Answering with External Knowledge Bases Authors Yucheng Shi, Shaochen Xu, Zhengliang Liu, Tianming Liu, Xiang Li, Ninghao Liu 大型语言模型法学硕士虽然在一般领域很强大,但在特定领域的任务(例如医学问答 QA)上通常表现不佳。此外,它们往往充当黑匣子,因此很难改变它们的行为。为了解决这个问题,我们的研究深入研究了上下文学习中的模型编辑,旨在提高法学硕士的反应,而无需进行微调或再培训。具体来说,我们提出了一种全面的检索策略,从外部知识库中提取医学事实,然后将它们合并到法学硕士的查询提示中。我们使用 MedQA SMILE 数据集重点关注医学 QA,评估不同检索模型的影响以及向法学硕士提供的事实数量。值得注意的是,我们编辑的 Vicuna 模型的准确度从 44.46 提高到 48.54。 |
| Unsupervised Pre-Training for Vietnamese Automatic Speech Recognition in the HYKIST Project Authors Khai Le Duc 在当今互联互通的全球,移居国外越来越普遍,无论是出于就业、难民安置还是其他原因。当地人和移民之间的语言困难是日常生活中的一个常见问题,尤其是在医疗领域。这可能会使患者和医生在病历收集期间或在急诊室中难以沟通,从而影响患者护理。 |
| A Survey on Image-text Multimodal Models Authors Ruifeng Guo, Jingxuan Wei, Linzhuang Sun, Bihui Yu, Guiyong Chang, Dawei Liu, Sibo Zhang, Zhengbing Yao, Mingjun Xu, Liping Bu 在人工智能不断发展的格局中,视觉和文本信息的融合已成为一个关键前沿,导致图像文本多模态模型的出现。本文全面回顾了图像文本多模态模型的演变和现状,探讨了它们的应用价值、挑战和潜在的研究轨迹。首先,我们重新审视这些模型的基本概念和发展里程碑,引入一种新颖的分类,根据它们的引入时间和随后对学科的影响,将它们的演变分为三个不同的阶段。此外,根据任务的重要性和学术界的普遍性,我们提出将与图像文本多模态模型相关的任务分为五种主要类型,阐明每个类别的最新进展和关键技术。尽管这些模型取得了显着的成就,但仍然存在许多挑战和问题。本文深入探讨了图像文本多模态模型的固有挑战和局限性,促进了对前瞻性研究方向的探索。我们的目标是对图像文本多模态模型的当前研究前景进行详尽的概述,并为未来的学术努力提供有价值的参考。 |
| Demystifying CLIP Data Authors Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po Yao Huang, Russell Howes, Vasu Sharma, Shang Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer 对比语言图像预训练 CLIP 是一种在计算机视觉领域拥有先进研究和应用的方法,为现代识别系统和生成模型提供了动力。我们相信 CLIP 成功的主要因素是它的数据,而不是模型架构或预训练目标。然而,CLIP 仅提供有关其数据及其收集方式的非常有限的信息,从而导致了旨在通过使用其模型参数进行过滤来重现 CLIP 数据的工作。在这项工作中,我们打算揭示 CLIP 的数据管理方法,并为了向社区开放,引入元数据管理语言图像预训练 MetaCLIP。 MetaCLIP 采用原始数据池和源自 CLIP 概念的元数据,并在元数据分布上生成平衡的子集。我们的实验研究严格隔离模型和训练设置,仅关注数据。 MetaCLIP 应用于具有 400M 图像文本数据对的 CommonCrawl,在多个标准基准测试中优于 CLIP 的数据。在零样本 ImageNet 分类中,MetaCLIP 达到了 70.8 的准确率,超过了 ViT B 模型上 CLIP 的 68.3。扩展到 1B 数据,同时保持相同的训练预算,达到 72.4 。我们的观察结果适用于各种模型尺寸,例如 ViT H 达到 80.5,没有任何附加功能。 |
| Toloka Visual Question Answering Benchmark Authors Dmitry Ustalov, Nikita Pavlichenko, Sergey Koshelev, Daniil Likhobaba, Alisa Smirnova 在本文中,我们提出了 Toloka Visual Question Answering,这是一个新的众包数据集,可以将机器学习系统的性能与人类在基础视觉问答任务中的专业水平进行比较。在此任务中,给定图像和文本问题,必须在正确响应该问题的对象周围绘制边界框。每个图像问题对都包含答案,每个图像只有一个正确答案。我们的数据集包含 45,199 对英语图像和问题,提供真实边界框,分为训练子集和两个测试子集。除了描述数据集并在 CC BY 许可下发布之外,我们还对开源零样本基线模型进行了一系列实验,并在 WSDM Cup 上组织了多阶段竞赛,吸引了全球 48 名参与者。 |
| Transformer-VQ: Linear-Time Transformers via Vector Quantization Authors Lucas D. Lingle 我们介绍 Transformer VQ,这是一种仅解码器的变压器,在线性时间内计算基于 softmax 的密集自注意力。 Transformer VQ 的高效注意力是通过矢量量化密钥和新颖的缓存机制实现的。在大规模实验中,Transformer VQ 在质量上表现出很强的竞争力,在 Enwik8 0.99 bpb 、 PG 19 26.6 ppl 和 ImageNet64 3.16 bpb 上取得了强劲的结果。 |
| Intrinsic Language-Guided Exploration for Complex Long-Horizon Robotic Manipulation Tasks Authors Eleftherios Triantafyllidis, Filippos Christianos, Zhibin Li 当前的强化学习算法在稀疏和复杂的环境中举步维艰,尤其是在需要大量不同序列的长范围操作任务中。在这项工作中,我们提出了大型语言模型 IGE LLM 框架的本质引导探索。通过利用法学硕士作为辅助内在奖励,IGE 法学硕士指导强化学习的探索过程,以解决复杂的长视野和稀疏奖励的机器人操作任务。我们在充满探索挑战的环境以及受到探索和长期视野挑战的复杂机器人操作任务中评估我们的框架和相关的内在学习方法。结果表明,IGE LLM i 比相关内在方法和在决策中直接使用 LLM 表现出明显更高的性能,ii 可以组合并补充现有的学习方法,突出其模块化性,iii 对不同的内在缩放参数相当不敏感,iv 保持鲁棒性 |
| DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models Authors Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, Yu Qiao 自动驾驶的最新进展依赖于数据驱动的方法,这些方法被广泛采用,但面临着数据集偏差、过度拟合和不可解释性等挑战。从人类驾驶的知识驱动本质中汲取灵感,我们探索了如何将类似的功能注入自动驾驶系统的问题,并总结了一个集成交互环境、驾驶员代理和记忆组件的范例来解决这个问题。利用具有涌现能力的大型语言模型,我们提出了DiLu框架,该框架结合了推理和反射模块,使系统能够基于常识知识进行决策并不断发展。大量的实验证明了DiLu具有积累经验的能力,并且在泛化能力上比基于强化学习的方法具有显着的优势。此外,DiLu能够直接从现实世界的数据集中获取经验,这凸显了其部署在实际自动驾驶系统上的潜力。 |
| Self-supervised Cross-view Representation Reconstruction for Change Captioning Authors Yunbin Tu, Liang Li, Li Su, Zheng Jun Zha, Chenggang Yan, Qingming Huang 更改字幕旨在描述一对相似图像之间的差异。其关键挑战是如何在视点变化引起的伪变化下学习稳定的差异表示。在本文中,我们通过提出一种自监督交叉视图表示重建 SCORER 网络来解决这个问题。具体来说,我们首先设计一个多头标记明智匹配来模拟来自相似不同图像的交叉视图特征之间的关系。然后,通过最大化两个相似图像的交叉视图对比对齐,SCORER 以自我监督的方式学习两个视图不变图像表示。在此基础上,我们通过交叉注意力重建未变化对象的表示,从而学习用于字幕生成的稳定差异表示。此外,我们设计了一种跨模态反向推理来提高字幕的质量。该模块对带有标题和之前表示的幻觉表示进行反向建模。通过将其推近后表示,我们强制标题以自我监督的方式提供有关差异的信息。大量的实验表明我们的方法在四个数据集上取得了最先进的结果。 |
| Language models in molecular discovery Authors Nikita Janakarajan, Tim Erdmann, Sarath Swaminathan, Teodoro Laino, Jannis Born 语言模型(尤其是基于 Transformer 的架构)的成功已经渗透到其他领域,从而产生了对小分子、蛋白质或聚合物进行操作的科学语言模型。在化学领域,语言模型有助于加速分子发现周期,早期药物发现中令人鼓舞的最新发现就证明了这一点。在这里,我们回顾了语言模型在分子发现中的作用,强调了它们在从头药物设计、性质预测和反应化学方面的优势。我们强调有价值的开源软件资产,从而降低科学语言建模领域的进入壁垒。最后,我们勾勒出未来分子设计的愿景,它将聊天机器人界面与计算化学工具的访问结合起来。 |
| Brand Network Booster: A New System for Improving Brand Connectivity Authors J. Cancellieri, W. Didimo, A. Fronzetti Colladon, F. Montecchiani 本文提出了一种新的决策支持系统,用于深入分析语义网络,可以为更好地探索品牌形象和改善其连通性提供见解。在网络分析方面,我们表明,这一目标是通过解决最大介数改进问题的扩展版本来实现的,其中包括考虑对抗性节点、受限预算和加权网络的可能性,其中可以通过添加链路或增加现有连接的权重。我们通过两个案例研究展示了这个新系统,并讨论了其性能。 |
| TPE: Towards Better Compositional Reasoning over Conceptual Tools with Multi-persona Collaboration Authors Hongru Wang, Huimin Wang, Lingzhi Wang, Minda Hu, Rui Wang, Boyang Xue, Hongyuan Lu, Fei Mi, Kam Fai Wong 大型语言模型法学硕士在规划各种功能工具(例如计算器和检索器)的使用方面表现出了卓越的性能,特别是在问答任务中。在本文中,我们以对话系统背景下的概念工具为中心,扩展了这些工具的定义。概念工具指定了有助于系统或研究性思维的认知概念。这些概念工具在实践中发挥着重要作用,例如在一个回合中动态应用多种心理或辅导策略来组成有用的反应。为了利用这些概念工具进一步增强法学硕士的推理和规划能力,我们引入了多人协作框架 Think Plan Execute TPE 。该框架将响应生成过程解耦为三个不同的角色:思考者、计划者和执行者。具体来说,思考者分析对话上下文中表现出的内部状态,例如用户的情绪和偏好,以制定全局指南。然后,规划器生成可执行计划来调用不同的概念工具,例如源或策略,而执行器将所有中间结果编译成连贯的响应。这种结构化方法不仅增强了响应的可解释性和可控性,而且减少了令牌冗余。我们证明了 TPE 在各种对话响应生成任务中的有效性,包括多源 FoCus 和多策略交互 CIMA 和 PsyQA。这揭示了它处理现实世界对话交互的潜力,这些对话交互需要更复杂的工具学习,而不仅仅是功能性工具。 |
| AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model Authors Seungwhan Moon, Andrea Madotto, Zhaojiang Lin, Tushar Nagarajan, Matt Smith, Shashank Jain, Chun Fu Yeh, Prakash Murugesan, Peyman Heidari, Yue Liu, Kavya Srinet, Babak Damavandi, Anuj Kumar 我们提出了任何模态增强语言模型 AnyMAL,这是一个统一模型,可以对不同的输入模态信号(即文本、图像、视频、音频、IMU 运动传感器)进行推理,并生成文本响应。 AnyMAL 继承了包括 LLaMA 2 70B 在内的最先进的 LLM 强大的基于文本的推理能力,并通过预训练的对齐器模块将模态特定信号转换到联合文本空间。为了进一步加强多模态法学硕士的能力,我们使用手动收集的多模态指令集对模型进行微调,以涵盖简单问答之外的各种主题和任务。 |
| Towards Best Practices of Activation Patching in Language Models: Metrics and Methods Authors Fred Zhang, Neel Nanda 机械可解释性旨在理解机器学习模型的内部机制,其中识别重要模型组件的本地化是关键步骤。激活补丁,也称为因果追踪或交换干预,是这项任务的标准技术 Vig et al., 2020,但文献中包含许多变体,在超参数或方法的选择上几乎没有达成共识。在这项工作中,我们系统地研究了激活修补中方法细节的影响,包括评估指标和损坏方法。在语言模型中的本地化和电路发现的几种设置中,我们发现改变这些超参数可能会导致不同的可解释性结果。在经验观察的支持下,我们给出了概念性论证,说明为什么某些指标或方法可能是首选。 |
| Targeted Image Data Augmentation Increases Basic Skills Captioning Robustness Authors Valentin Barriere, Felipe del Rio, Andres Carvallo De Ferari, Carlos Aspillaga, Eugenio Herrera Berg, Cristian Buc Calderon 人工神经网络通常难以推广到上下文之外的示例。造成这种限制的原因之一是数据集仅包含有关世界潜在相关结构的部分信息。在这项工作中,我们提出了 TIDA 有针对性的图像编辑数据增强,这是一种有针对性的数据增强方法,专注于通过使用文本到图像生成模型填充相关结构差距来改进模型的类人能力,例如性别识别。更具体地说,TIDA 识别描述图像的标题中的特定技能(例如图像中特定性别的存在),更改标题(例如从女人到男人),然后使用文本到图像模型来编辑图像以匹配小说标题例如,在保持上下文相同的情况下将女性独特地改变为男性。基于 Flickr30K 基准测试,我们表明,与原始数据集相比,与性别、颜色和计数能力相关的 TIDA 增强数据集在多个图像字幕指标中具有更好的性能。此外,除了依赖经典的 BLEU 指标之外,我们还以不同的方式对模型相对于基线的改进进行了细粒度分析。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com
相关文章:
【AI视野·今日NLP 自然语言处理论文速览 第四十四期】Fri, 29 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 29 Sep 2023 Totally 45 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers MindShift: Leveraging Large Language Models for Mental-States-Based Problematic Smartphone Use Interve…...
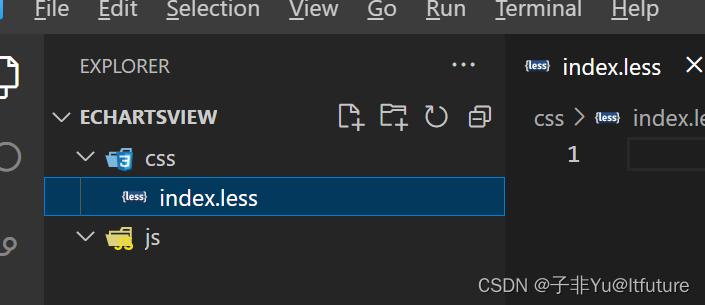
【VsCode】vscode创建文件夹有小图标显示和配置
效果 步骤 刚安装软件后, 开始工作目录下是没有小图标显示的。 如下图操作,安装vscode-icons 插件,重新加载即可 创建文件夹,显示图标如下:...

celery分布式异步任务队列-4.4.7
文章目录 celery介绍兼容性简单使用安装使用方式 功能介绍常用案例获取任务的返回值任务中使用logging定义任务基类 任务回调函数No result will be storedResult will be stored任务的追踪、失败重试 python setup.py installln -s /run/shm /dev/shmOptional configuration, …...

解决M2苹果芯片Mac无法安装python=3.7的虚拟环境
问题描述 conda无法安装python3.7的虚拟环境: conda create -n py37 python3.7出现错误 (base) ➜ AzurLaneAutoScript git:(master) conda create -n alas python3.7.6 -y Collecting package metadata (current_repodata.json): done Solving environment: fa…...
Sound/播放提示音, Haptics/触觉反馈, LocalNotification/本地通知 的使用
1. Sound 播放提示音 1.1 音频文件: tada.mp3, badum.mp3 1.2 文件位置截图: 1.3 实现 import AVKit/// 音频管理器 class SoundManager{// 单例对象 Singletonstatic let instance SoundManager()// 音频播放var player: AVAudioPlayer?enum SoundOption: Stri…...

Oracle实现主键字段自增
Oracle实现主键自增有4种方式: Identity Columns新特性自增(Oracle版本≥12c)创建自增序列,创建表时,给主键字段默认使用自增序列创建自增序列,使用触发器使主键自增创建自增序列,插入语句&…...
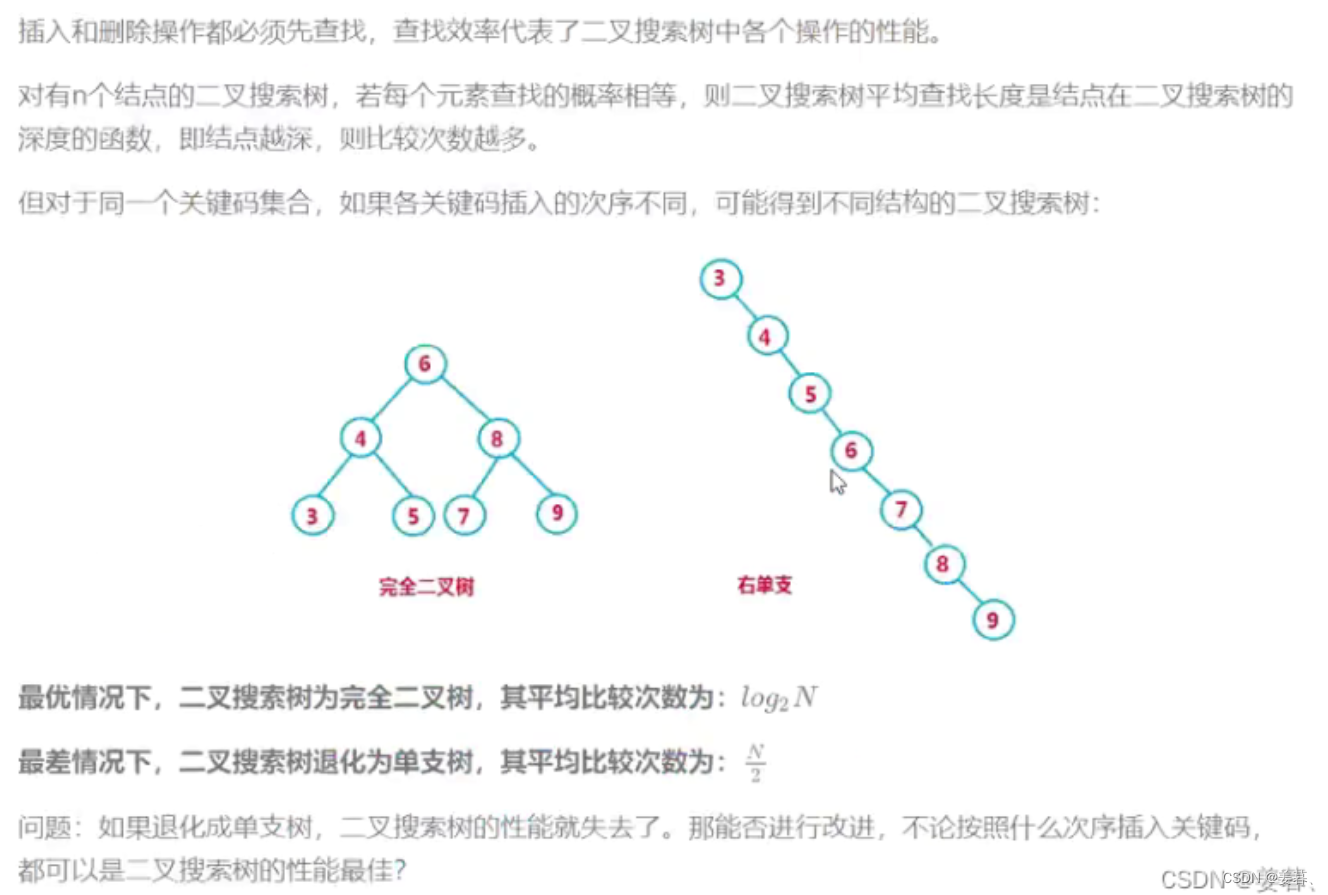
【C++数据结构】二叉树搜索树【完整版】
目录 一、二叉搜索树的定义 二、二叉搜索树的实现: 1、树节点的创建--BSTreeNode 2、二叉搜索树的基本框架--BSTree 3、插入节点--Insert 4、中序遍历--InOrder 5、 查找--Find 6、 删除--erase 完整代码: 三、二叉搜索树的应用 1、key的模型 &a…...

TouchGFX之字体缓存
使用二进制字体需要将整个字体加载到存储器。 在某些情况下,如果字体很大,如大字号中文字体,则这样做可能不可取。 字体缓存使应用能够从外部存储器只能加载显示字符串所需的字母。 这意味着整个字体无需保存到在可寻址闪存或RAM上ÿ…...
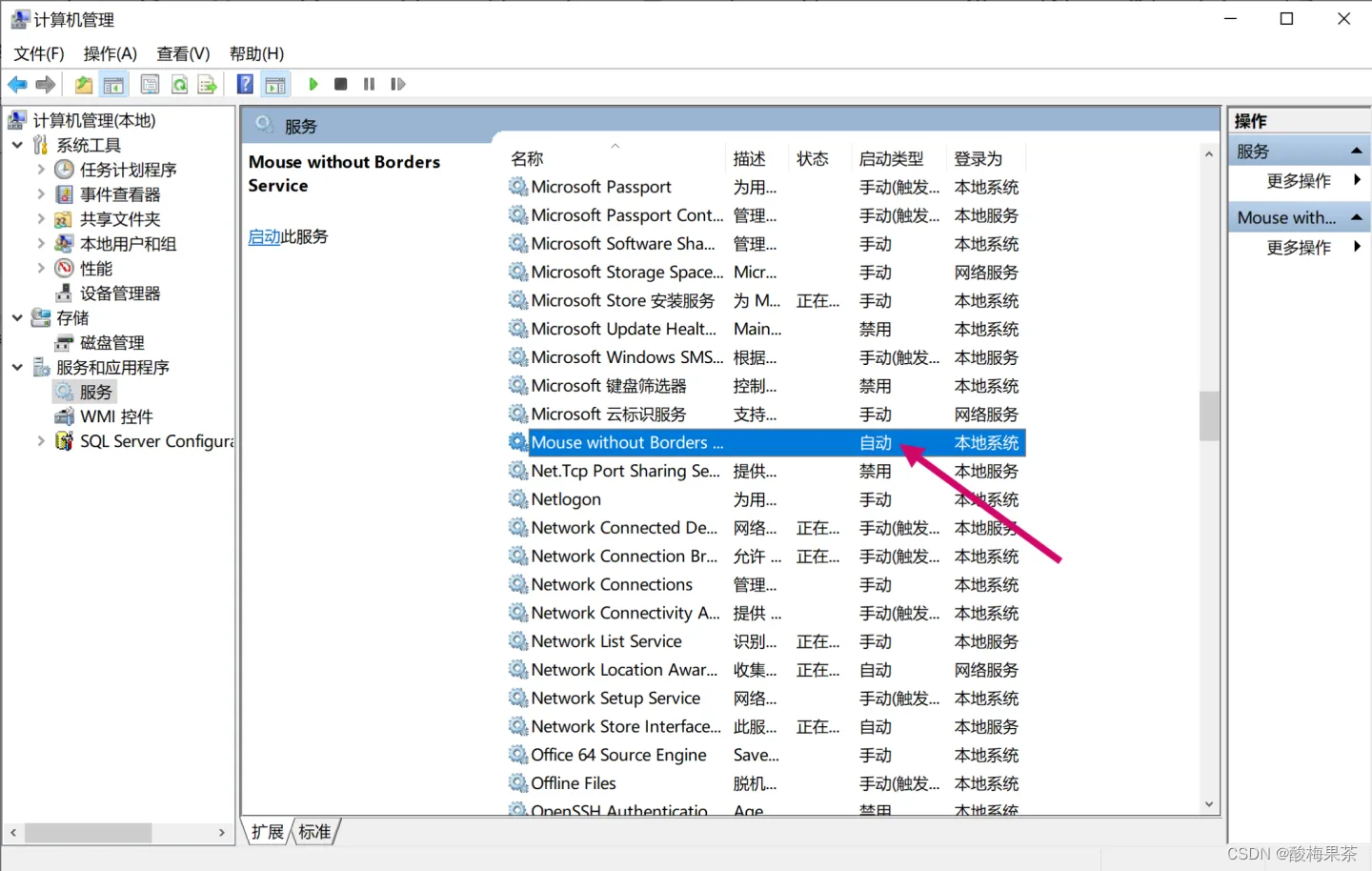
windows系统关闭软件开机自启的常用两种方法
win10中安装软件时经常会默认开机自启动,本文主要介绍两种关闭软件开机自启动方法。 方法1 通过任务管理器设置 1.在任务管理器中禁用开机自启动:打开任务管理器,右键已启动的软件,选择禁用。 方法2 通过windows服务控制开机自启…...
巧用@Conditional注解根据配置文件注入不同的bean对象
项目中使用了mq,kafka两种消息队列进行发送数据,为了避免硬编码,在项目中通过不同的配置文件自动识别具体消息队列策略。这里整理两种实施方案,仅供参考! 方案一:创建一个工具类,然后根据配置文…...
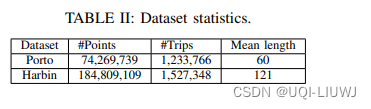
论文笔记(整理):轨迹相似度顶会论文中使用的数据集
0 汇总 数据类型数据名称数据处理出租车数据波尔图 原始数据:2013年7月到2014年6月,170万条数据 ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 过滤位于城市(或国家)区域之外的轨迹 过…...

Python实现单例模式
使用函数装饰器 def singleton(cls):_instance {}def inner():if cls not in _instance:_instance[cls] cls()return _instance[cls]return innersingleton class Demo(object):def __init__(self):passdef test():b1 Demo()b2 Demo()print(b1, b2)使用类装饰器 class si…...

spark相关网站
Spark的五种JOIN策略解析 https://www.cnblogs.com/jmx-bigdata/p/14021183.html 万字详解整个数据仓库建设体系(好文值得收藏) https://mp.weixin.qq.com/s?__bizMzg2MzU2MDYzOA&mid2247484692&idx1&snf624672e62ba6cd4cc69bdb6db28756a&…...
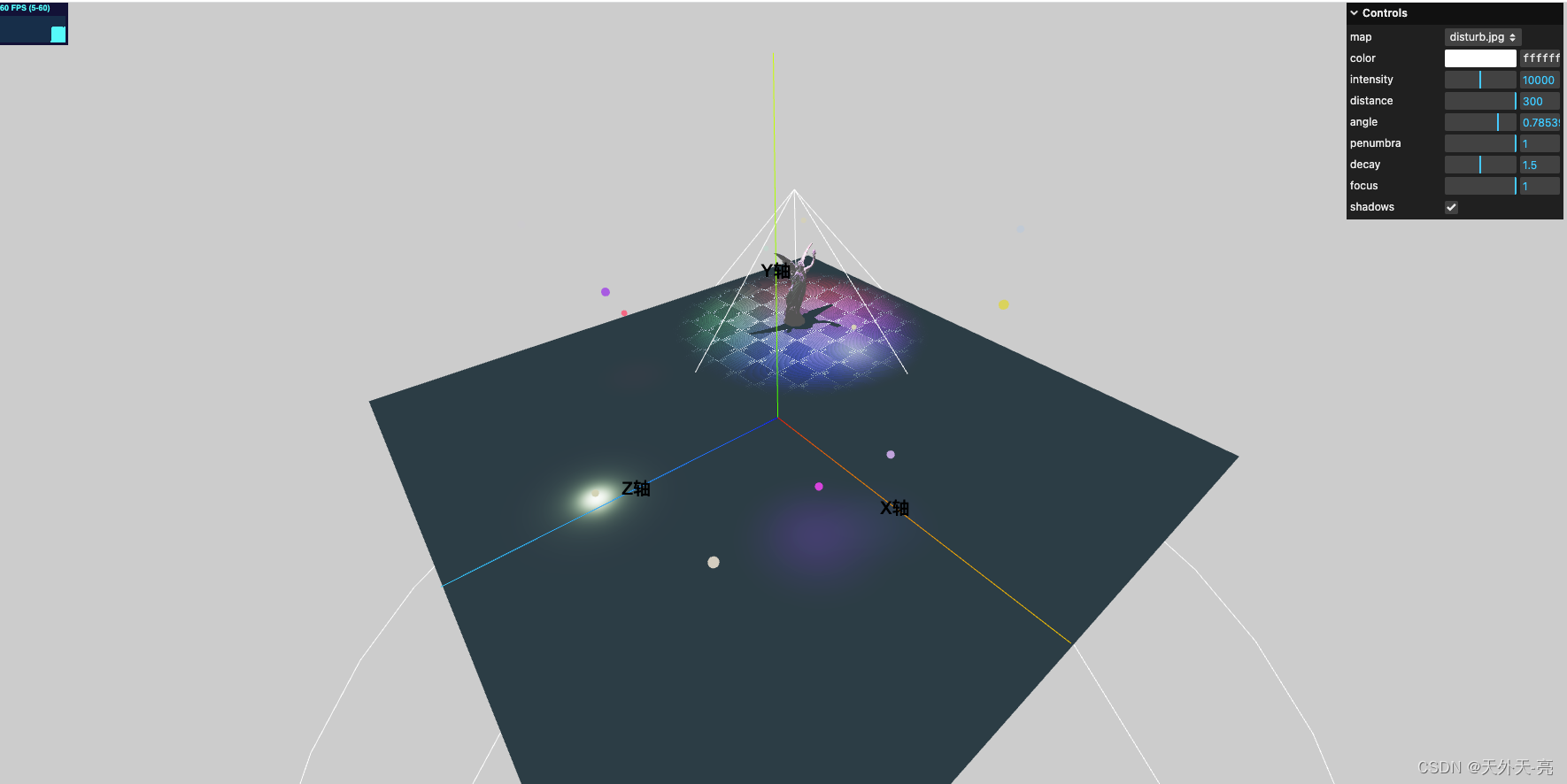
ThreeJS-3D教学四-光源
three模拟的真实3D环境,一个非常炫酷的功能便是对光源的操控,之前教学一中已经简单的描述了多种光源,这次咱们就详细的讲下一些最常见的光源: AmbientLight 该灯光在全局范围内平等地照亮场景中的所有对象。 该灯光不能用于投射阴…...

Linux 回收内存到底怎么计算anon/file回收比例,只是swappiness这么简单?
概述 Linux内核为了区分冷热内存,将page以链表的形式保存,主要分为5个链表,除去evictable,我们主要关注另外四个链表:active file/inactive file,active anon和inactive anon链表,可以看到这主要分为两类,file和anon page,内存紧张的时候,内核开始从inactive tail定…...

软件测试中的测试工具和自动化测试
1. 测试工具 测试工具也分为不同人员使用的 开发人员:测试框架,编写测试用例;各类线上dump分析工具如windgb;开发时的集成IDE工具如Visual Studio,idea等等 面向不同测试需求的测试工具 软件测试是软件开发生命周期…...
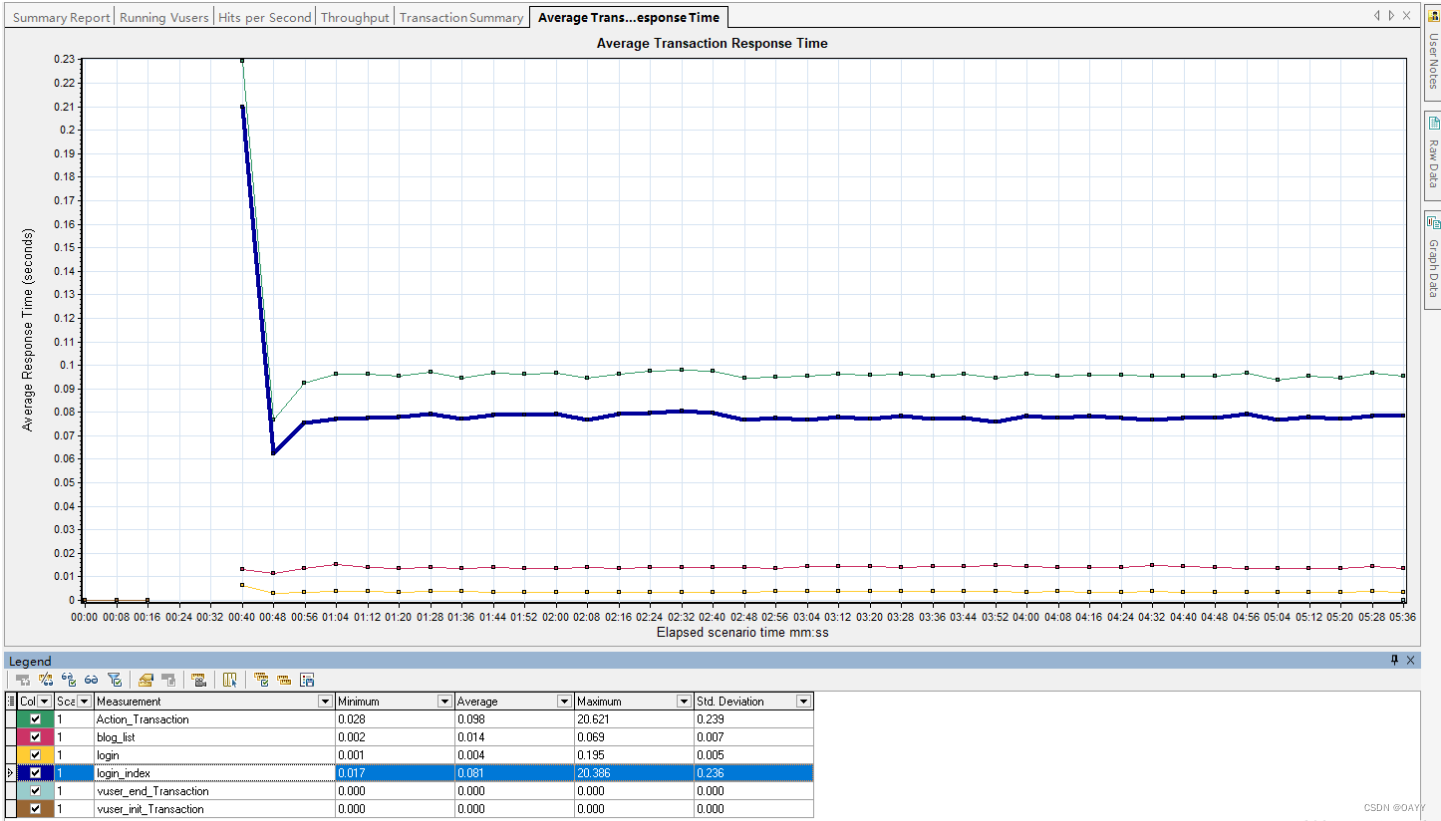
个人博客系统测试报告
个人博客系统测试报告 一.项目背景二.项目功能三.测试用例3.1 功能测试3.2 自动化测试(部分测试)3.2.1登陆页面3.2.2博客详情页3.2.3博客编辑页3.2.4个人列表页3.2.5测试结果 3.3 性能测试 一.项目背景 当学习完一项技能后,我们总会习惯通过博…...
高效搜索,提升编程效率
一、搜索效率 1.1魔法上网 网址: 一个很变态但可以让你快速学会计算机的方法…………_哔哩哔哩_bilibili 谷歌镜像: https://search.fuyeor.com/zh-cn/Google 谷歌学术: https://link.zhihu.com/?targethttps%3A//scholar.lanfanshu.cn/…...
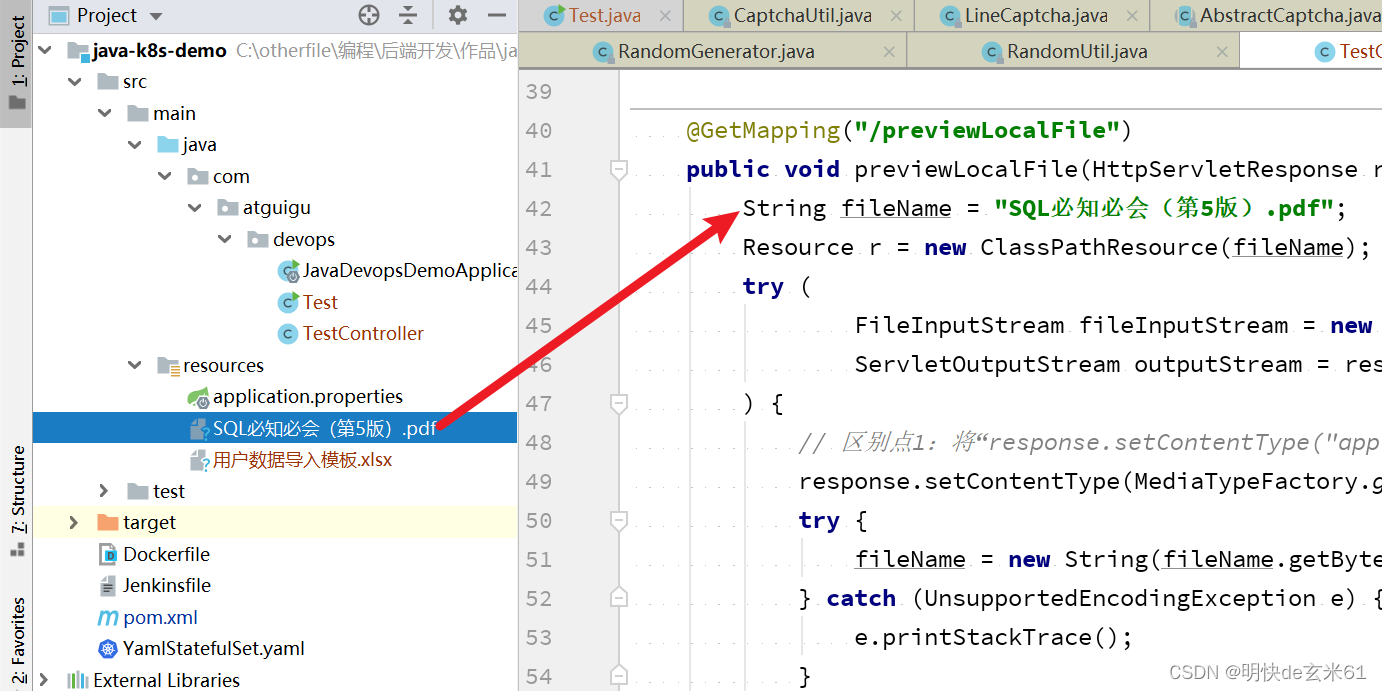
Java编程技巧:文件上传、下载、预览
目录 1、上传文件1.1、代码1.2、postman测试截图 2、下载resources目录中的模板文件2.1、项目结构2.2、代码2.3、使用场景 3、预览文件3.1、项目结构3.2、代码3.3、使用场景 1、上传文件 1.1、代码 PostMapping("/uploadFile") public String uploadFile(Multipart…...

【蓝桥杯选拔赛真题63】Scratch云朵降雨 少儿编程scratch图形化编程 蓝桥杯选拔赛真题解析
目录 scratch云朵降雨 一、题目要求 编程实现 二、案例分析 1、角色分析...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...