数据集划分——train_test_split函数使用说明
当我们拿到数据集时,首先需要对数据集进行划分训练集和测试集,sklearn提供了相应的函数供我们使用
一、讲解
快速随机划分数据集,可自定义比例进行划分训练集和测试集
二、官网API
官网API
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
导包:from sklearn.model_selection import train_test_split
为了方便说明,这里以一个具体的案例进行分析
织物起球等级评定,已知织物起球个数N、织物起球总面积S、织物起球最大面积Max_s、织物起球平均面积Aver_s、对比度C、光学体积V这六个特征参数来确定最终的织物起球等级Grade
说白了:六个特征(N、S、Max_s、Aver_s、C、V),来确定最终的等级(Grade)
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
参数:
①*arrays
传入因变量和自变量
这里的因变量为六个特征(N、S、Max_s、Aver_s、C、V)
自变量为最终评定的等级(Grade)
具体官网详情如下:
②test_size
若给该参数传入float浮点数,则范围为[0.0,1.0],表示测试集的比例
若给该参数传入int整型数,则表示测试集样本的具体数量
若为None,则设置为train_size参数的补数形式
若该test_size参数和train_size参数的值均为None,则该test_size设置为0.25,按float浮点型对待
具体官网详情如下:

③train_size
若给该参数传入float浮点数,则范围为[0.0,1.0],表示训练集的比例
若给该参数传入int整型数,则表示训练集样本的具体数量
若为None,则设置为test_size参数的补数形式
该参数跟test_size类似
具体官网详情如下:

④random_state
随机种子random_state,如果要是为了对比,需要控制变量的话,这里的随机种子最好设置为同一个整型数
具体官网详情如下:

⑤shuffle
是否在分割前对数据进行洗牌
如果 shuffle=False 则 stratify 必须为 None
具体官网详情如下:

⑥stratify
如果不是 “None”,数据将以分层方式分割,并以此作为类别标签
具体官网详情如下:

返回值:
splitting
返回一个包含训练和测试分割之后的列表
具体官网详情如下:

三、项目实战
①导包
若导入过程报错,pip安装即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
②加载数据集
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
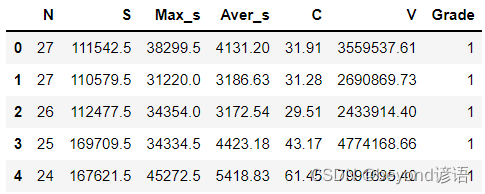
通过pandas读入文本数据集,展示前五行数据
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
③划分数据集
前六列是自变量X,最后一列是因变量Y
参数:
test_size:测试集数据所占比例,这里是0.25,表示测试集占总数据集的25%
train_size:训练集数据所占比例,这里是0.75,表示训练集占总数据集的75%
random_state:随机种子,为了控制变量
shuffle:是否将数据进行打乱
因为我这里的数据集共48个,训练集0.75,测试集0.25,即训练集36个,测试集12个
返回值:
依此返回四个list,分别为训练集的自变量、测试集的自变量、训练集的因变量和测试集的因变量,分别通过X_train, X_test, y_train, y_test进行接收
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
根据返回的四个list的shape可以看到数据集已经成功按自定义需求划分
⑤完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_splitfiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
相关文章:
数据集划分——train_test_split函数使用说明
当我们拿到数据集时,首先需要对数据集进行划分训练集和测试集,sklearn提供了相应的函数供我们使用 一、讲解 快速随机划分数据集,可自定义比例进行划分训练集和测试集 二、官网API 官网API sklearn.model_selection.train_test_split(*a…...

Pytorch中关于forward函数的理解与用法
目录 前言1. 问题所示2. 原理分析2.1 forward函数理解2.2 forward函数用法 前言 深入深度学习框架的代码,发现forward函数没有被显示调用 但代码确重写了forward函数,于是好奇是不是python的魔术方法作用 1. 问题所示 代码如下所示: cla…...
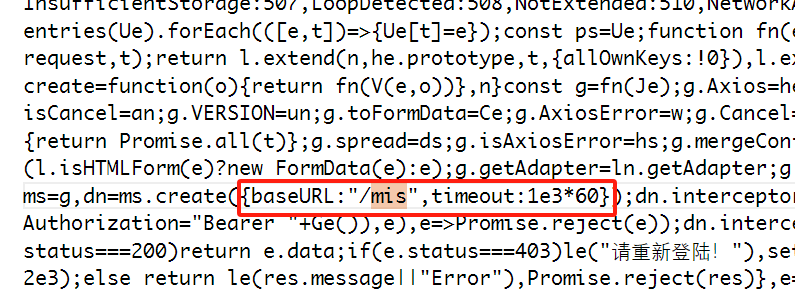
vite跨域proxy设置与开发、生产环境的接口配置,接口在生产环境下,还能使用proxy代理地址吗
文章目录 vite的proxy开发环境设置如果后端没有提供可以替换的/mis等可替换的后缀的处理办法接口如何区分.env.development开发和.env.production生产环境接口在生产环境下,还能使用proxy代理地址吗? vite的proxy开发环境设置 环境: vite 4…...
【嵌入式】使用MultiButton开源库驱动按键并控制多级界面切换
目录 一 背景说明 二 参考资料 三 MultiButton开源库移植 四 设计实现--驱动按键 五 设计实现--界面处理 一 背景说明 需要做一个通过不同按键控制多级界面切换以及界面动作的程序。 查阅相关资料,发现网上大多数的应用都比较繁琐,且对于多级界面的…...

【数据结构】树的概念理解和性质推导(保姆级详解,小白必看系列)
目录 一、前言 🍎 为什么要学习非线性结构 ---- 树(Tree) 💦 线性结构的优缺点 💦 优化方案 ----- 树(Tree) 💦 树的讲解流程 二、树的概念及结构 🍐 树的概念 &…...
融合之力:数字孪生、人工智能和数据分析的创新驱动
数字孪生、人工智能(AI)和数据分析是当今科技领域中的三个重要概念,它们之间存在着紧密的关联和互动,共同推动了许多领域的创新和发展。 一、概念 数字孪生是一种数字化的模拟技术,它通过复制现实世界中的物理实体、…...

Spring的注解开发-Spring配置类的开发
Bean配置类的注解开发 Component等注解替代了<bean>标签,但像<import>、<context:componentScan>等非<bean>标签怎样去使用注解去替代呢?定义一个配置类替代原有的xml配置文件,<bean>标签以外的标签ÿ…...
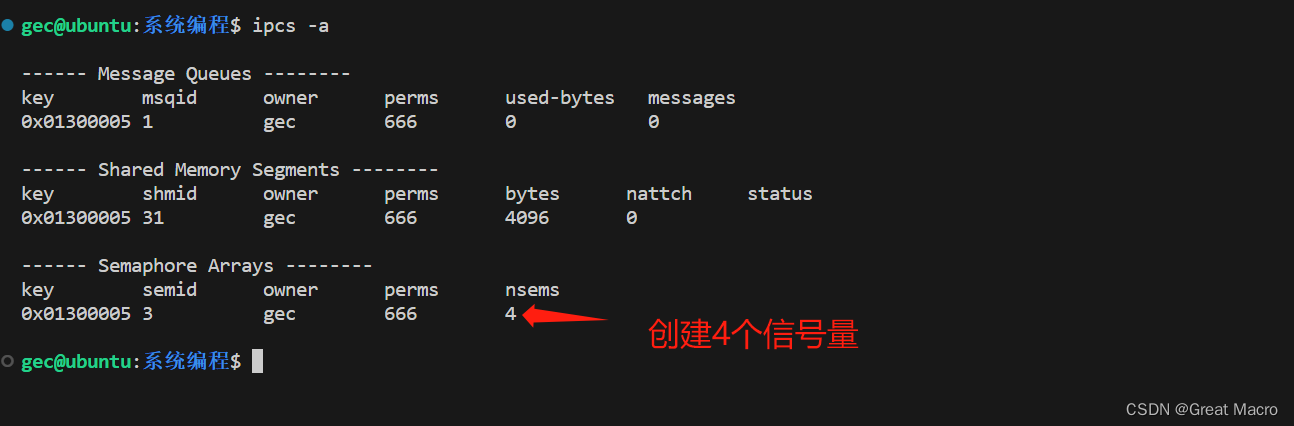
Linux系统编程系列之进程间通信-信号量组
一、什么是信号量组 信号量组是信号量的一种, 是system-V三种IPC对象之一,是进程间通信的一种方式。 二、信号量组的特性 信号量组不是用来传输数据的,而是作为“旗语”,用来协调各进程或者线程工作的。信号量组可以一次性在其内…...

centos 6使用yum安装软件
1. 执行以下命令,查看当前操作系统 CentOS 版本。 cat /etc/centos-release返回结果如下图所示,则说明当前操作系统版本为 CentOS 6.9。 2. 执行以下命令,编辑 CentOS-Base.repo 和CentOS-Epel.repo文件。 vim /etc/yum.repos.d/CentOS-Bas…...
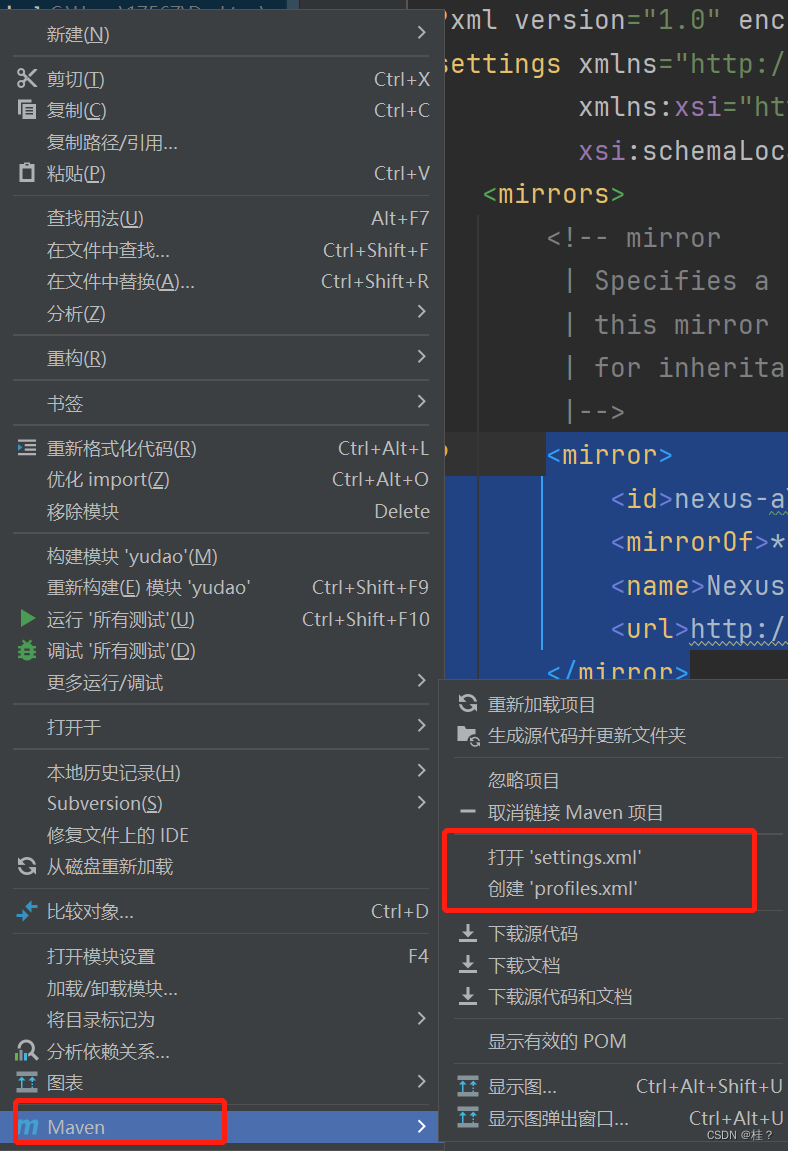
maven无法下载时的解决方法——笔记
右键项目然后点击创建setting.xml(因为现在创建了,所以没显示了,可以直接点击打开setting.xml) 然后添加 <mirror><id>nexus-aliyun</id><mirrorOf>*,!jeecg,!jeecg-snapshots</mirrorOf><name…...

Java Spring Boot 开发框架
Spring Boot是一种基于Java编程语言的开发框架,它的目标是简化Java应用程序的开发过程。Spring Boot提供了一种快速、易于使用的方式来创建独立的、生产级别的Java应用程序。本文将介绍Spring Boot的特性、优势以及如何使用它来开发高效、可靠的应用程序。 一、简介…...

Pytorch学习记录-1-张量
1. 张量 (Tensor): 数学中指的是多维数组; torch.Tensor data: 被封装的 Tensor dtype: 张量的数据类型 shape: 张量的形状 device: 张量所在的设备,GPU/CPU requires_grad: 指示是否需要计算梯度 grad: data 的梯度 grad_fn: 创建 Tensor 的 Functio…...
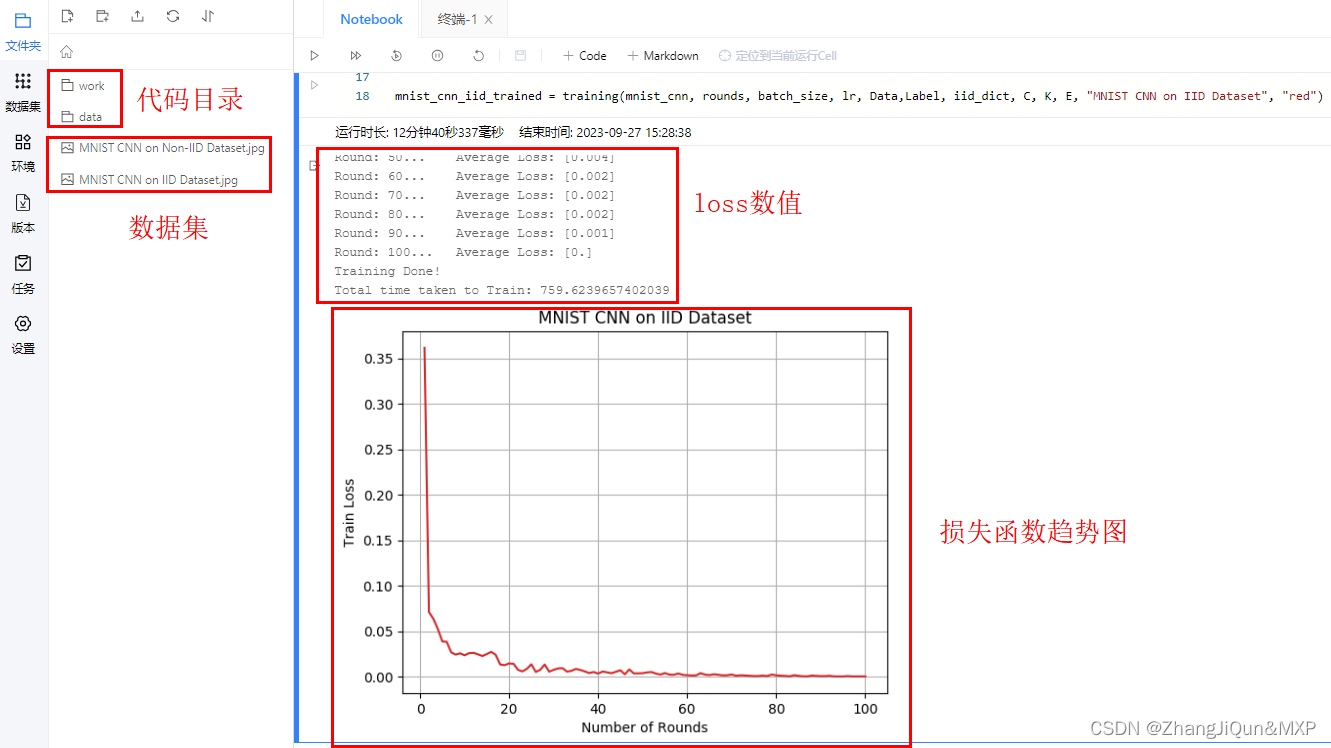
paddle2.3-基于联邦学习实现FedAVg算法-CNN
目录 1. 联邦学习介绍 2. 实验流程 3. 数据加载 4. 模型构建 5. 数据采样函数 6. 模型训练 1. 联邦学习介绍 联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备&#…...

nuiapp保存canvas绘图
要保存一个 Canvas 绘图,可以使用以下步骤: 获取 Canvas 元素和其绘图上下文: var canvas document.getElementById("myCanvas"); var ctx canvas.getContext("2d");使用 Canvas 绘图 API 绘制图形。 使用 toDataUR…...
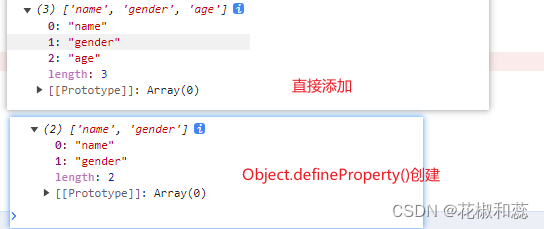
Object.defineProperty()方法详解,了解vue2的数据代理
假期第一篇,对于基础的知识点,我感觉自己还是很薄弱的。 趁着假期,再去复习一遍 Object.defineProperty(),对于这个方法,更多的还是停留在面试的时候,面试官问你vue2和vue3区别的时候,不免要提一提这个方法…...

Linux 磁盘管理
Linux 系统的磁盘管理直接关系到整个系统的性能表现。磁盘管理常用三个命令为: df、du 和 fdisk。 df df(英文全称:disk free)。df 命令用于显示磁盘空间的使用情况,包括文件系统的挂载点、总容量、已用空间、可用空间…...

大数据与人工智能的未来已来
大数据与人工智能的定义 大数据: 大数据指的是规模庞大、复杂性高、多样性丰富的数据集合。这些数据通常无法通过传统的数据库管理工具来捕获、存储、管理和处理。大数据的特点包括"3V": 大量(Volume):大数…...

【AI视野·今日Robot 机器人论文速览 第四十一期】Tue, 26 Sep 2023
AI视野今日CS.Robotics 机器人学论文速览 Tue, 26 Sep 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers Extreme Parkour with Legged Robots Authors Xuxin Cheng, Kexin Shi, Ananye Agarwal, Deepak Pathak人类可以通过以高度动态…...
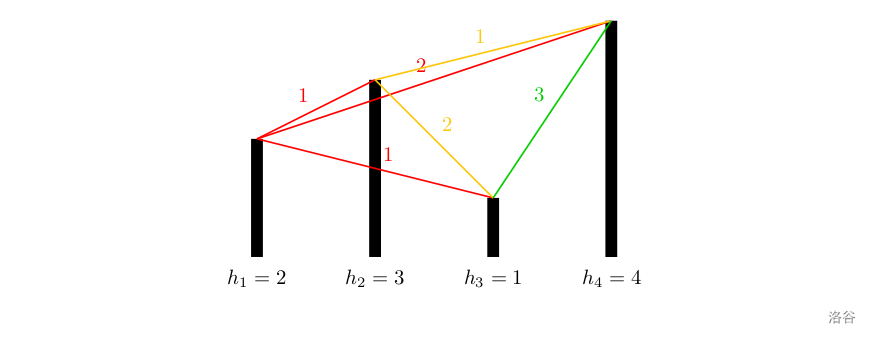
[NOIP2012 提高组] 开车旅行
[NOIP2012 提高组] 开车旅行 题目描述 小 A \text{A} A 和小 B \text{B} B 决定利用假期外出旅行,他们将想去的城市从 $1 $ 到 n n n 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同,记城市 …...

数据库设计流程---以案例熟悉
案例名字:宠物商店系统 课程来源:点击跳转 信息->概念模型->数据模型->数据库结构模型 将现实世界中的信息转换为信息世界的概念模型(E-R模型) 业务逻辑 构建 E-R 图 确定三个实体:用户、商品、订单...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...
32单片机——基本定时器
STM32F103有众多的定时器,其中包括2个基本定时器(TIM6和TIM7)、4个通用定时器(TIM2~TIM5)、2个高级控制定时器(TIM1和TIM8),这些定时器彼此完全独立,不共享任何资源 1、定…...