卫星图像应用 - 洪水检测 使用DALI进行数据预处理
这篇文章是上一篇的延申。
运行环境:Google Colab
1. 当今的深度学习应用包含由许多串行运算组成的、复杂的多阶段数据处理流水线,仅依靠 CPU 处理这些流水线已成为限制性能和可扩展性的瓶颈。
2. DALI 是一个用于加载和预处理数据的库,可使深度学习应用加速。它提供了一系列高度优化的模块,用于加载和处理图像、视频和音频数据。DALI 通过将数据预处理卸载到 GPU 来解决 CPU 瓶颈问题。
!nvidia-smi
- 检查CUDA版本
!pip install --extra-index-url https://developer.download.nvidia.com/compute/redist --upgrade nvidia-dali-cuda120
- 安装相应的nvidia.dali库
# import dependencies
from nvidia.dali.pipeline import Pipeline
from nvidia.dali import pipeline_def
import nvidia.dali.fn as fn
import nvidia.dali.types as typesimport warnings
# 在代码执行期间禁用警告信息的显示
warnings.filterwarnings("ignore")
- 导入需要的库。
batch_size=4@pipeline_def
def simple_pipeline():# use fn.readers.file to read encoded images and labels from the hard drivepngs, labels=fn.readers.file(file_root=image_dir)# use the fn.decoders.image operation to decode images from png to RGBimages=fn.decoders.image(pngs, device='mixed')# specify which of the intermediate variables should be returned as the outputs of the pipelinereturn images, labels
- @pipeline_def 是一个装饰器(decorator),它用于标记下面的函数 simple_pipeline,以告诉 DALI 库这是一个数据处理流水线的定义。
- 使用 DALI 库中的 fn.decoders.image 操作对图像数据进行解码。这里假设输入图像是 PNG 格式,而 fn.decoders.image 操作将其解码为 RGB 格式的图像。device=‘mixed’ 表示解码操作在 GPU 上执行。
3. 创建了一个数据处理流水线对象
# create and build pipeline
pipe=simple_pipeline(batch_size=batch_size, num_threads=4, device_id=0)
pipe.build()
- num_threads=4 表示在流水线中使用的线程数量。这里设置为4,意味着在数据加载和预处理过程中会使用4个并行的线程,以提高数据处理的效率。
- device_id=0 表示在哪个设备上执行数据处理操作。这里设置为0,表示在第一个设备(通常是CPU)上执行操作。
- 调用 build 方法来准备流水线以开始数据加载和预处理的工作。
4. 验证数据处理流水线的输出是否包含稠密张量。稠密张量通常用于深度学习模型的输入数据,因此检查它们是否是稠密的可以帮助确保数据准备工作正确完成。如果输出是稠密张量,那么它们可以直接用于模型的训练和推理。
# run the pipeline
simple_pipe_output=pipe.run()images, labels=simple_pipe_output
print("Images is_dense_tensor: " + str(images.is_dense_tensor()))
print("Labels is_dense_tensor: " + str(labels.is_dense_tensor()))
- 调用之前创建的 pipe 对象的 run 方法,用于执行数据处理流水线。执行流水线将开始加载和处理数据,生成流水线的输出结果。
- 将流水线的输出结果 simple_pipe_output 解包成两个变量:images 和 labels。通常,在数据处理流水线中,simple_pipe_output 是一个包含了单个批次数据的元组。
5. 定义用于显示图像批次的函数
# define a function display images
def show_images(image_batch):columns=4rows=1# create plot# 窗口的宽度是固定的,而高度根据列数和行数来自动计算,以确保图像按照指定的布局显示。fig=plt.figure(figsize=(15, (15 // columns) * rows))gs=gridspec.GridSpec(rows, columns)for idx in range(rows*columns):plt.subplot(gs[idx])plt.axis("off")plt.imshow(image_batch.at(idx))plt.tight_layout()show_images(images.as_cpu())
- 使用 gridspec.GridSpec 创建一个子图的网格布局。
- 使用 plt.subplot 创建一个子图,并根据 gs 中的索引 idx 来选择子图的位置。
- plt.imshow 显示图像,其中 image_batch.at(idx) 表示从图像批次中获取第 idx 张图像并在子图中显示。
- 调用 plt.tight_layout(),以确保图像布局紧凑,避免重叠或不适当的间距。

6. 深度学习模型需要使用大量数据进行训练才能获得准确的结果。DALI 不仅能读取磁盘中的图像并将其批处理为张量,它还能在这些图像上执行各种增强,以改进深度学习训练结果。
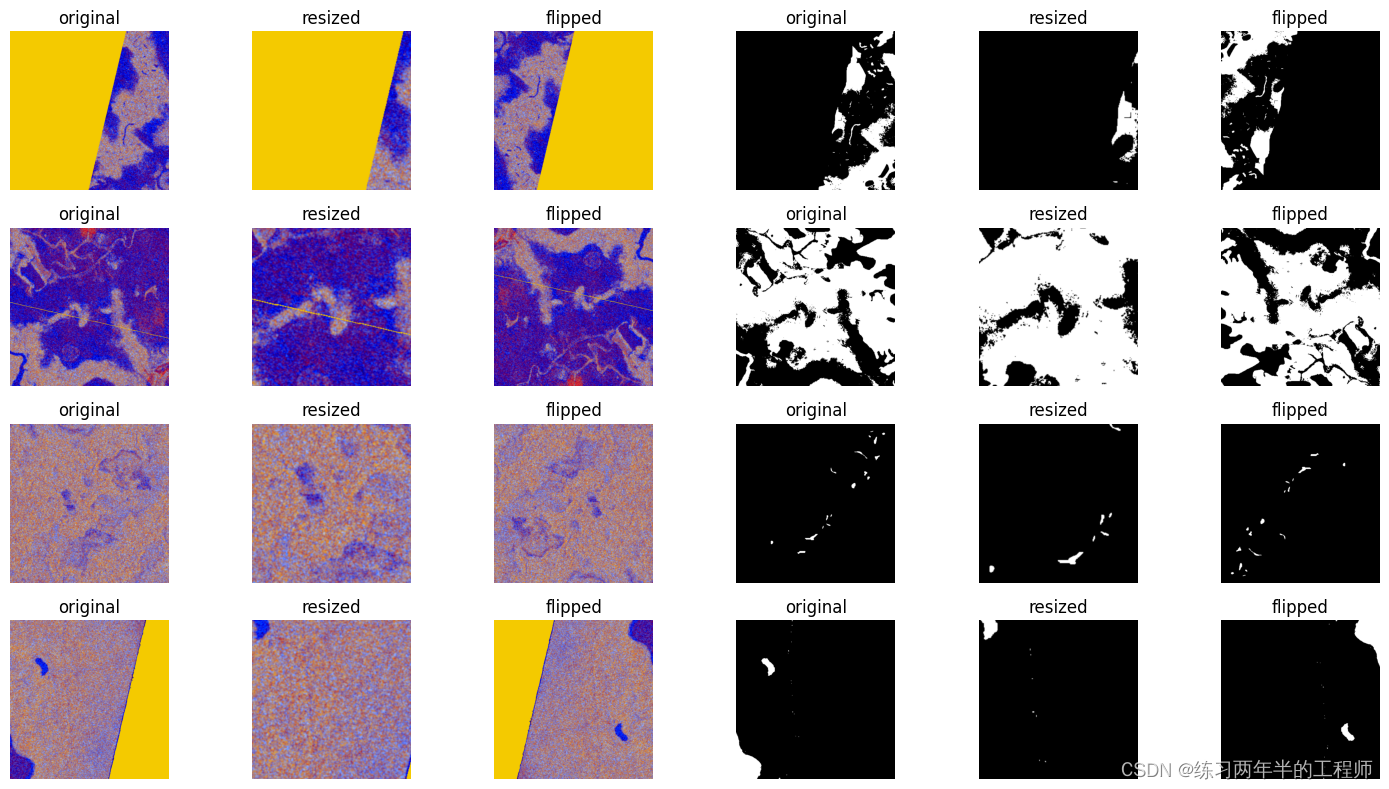
7. 对图像和掩码数据执行一系列的增强操作,包括裁剪和水平翻转,以增加数据的多样性和模型的鲁棒性
import random@pipeline_def
def augmentation_pipeline():# use fn.readers.file to read encoded images and labels from the hard driveimage_pngs, _=fn.readers.file(file_root=image_dir)# use the fn.decoders.image operation to decode images from png to RGBimages=fn.decoders.image(image_pngs, device='cpu')# the same augmentation needs to be performed on the associated masksmask_pngs, _=fn.readers.file(file_root=mask_dir)masks=fn.decoders.image(mask_pngs, device='cpu')image_size=512roi_size=image_size*.5roi_start_x=image_size*random.uniform(0, 0.5)roi_start_y=image_size*random.uniform(0, 0.5)# use fn.resize to investigate an roi, region of interestresized_images=fn.resize(images, size=[512, 512], roi_start=[roi_start_x, roi_start_y], roi_end=[roi_start_x+roi_size, roi_start_y+roi_size])resized_masks=fn.resize(masks, size=[512, 512], roi_start=[roi_start_x, roi_start_y], roi_end=[roi_start_x+roi_size, roi_start_y+roi_size])# use fn.resize to flip the imageflipped_images=fn.resize(images, size=[-512, -512])flipped_masks=fn.resize(masks, size=[-512, -512])return images, resized_images, flipped_images, masks, resized_masks, flipped_masks
- 使用 DALI 库中的 fn.readers.file 操作从硬盘上的指定目录(image_dir)中读取图像数据。image_pngs 变量将包含图像数据,而 _ 用于占位,表示不使用标签数据。
- roi_size 表示感兴趣区域(Region of Interest,ROI)的大小,这里设置为图像大小的一半。
- 使用 fn.resize 操作对图像和掩码进行裁剪,仅保留感兴趣区域(ROI)。size=[512, 512] 参数指定了裁剪后的图像大小,而 roi_start 和 roi_end 参数指定了感兴趣区域的起始和结束位置,从而对图像进行裁剪。
- 使用 fn.resize 操作对图像和掩码进行水平翻转。通过将 size 参数设置为负数,可以实现水平翻转操作。
# 创建数据增强的数据处理流水线
pipe=augmentation_pipeline(batch_size=batch_size, num_threads=4, device_id=0)
# 构建数据处理流水线
pipe.build()
# 执行数据处理流水线
augmentation_pipe_output=pipe.run()
# define a function display images
augmentation=['original', 'resized', 'flipped']
def show_augmented_images(pipe_output):image_batch, resized_image_batch, flipped_image_batch, mask_batch, resized_mask_batch, flipped_mask_batch=pipe_outputcolumns=6rows=batch_size# create plotfig=plt.figure(figsize=(15, (15 // columns) * rows))gs=gridspec.GridSpec(rows, columns)grid_data=[image_batch, resized_image_batch, flipped_image_batch, mask_batch, resized_mask_batch, flipped_mask_batch]# grid 变量用于追踪要显示的图像数据在 grid_data 列表中的索引。grid=0for row_idx in range(rows): for col_idx in range(columns): plt.subplot(gs[grid])plt.axis('off')plt.title(augmentation[col_idx%3])plt.imshow(grid_data[col_idx].at(row_idx))grid+=1plt.tight_layout()
- 使用 gridspec.GridSpec 创建一个子图的网格布局。rows 和 columns 参数指定了网格的行数和列数,以便在图形界面上排列图像。
- 使用 plt.subplot 创建一个子图,并根据 gs 中的索引 grid 来选择子图的位置。
- grid_data[col_idx].at(row_idx) 表示从 grid_data 列表中获取要显示的图像,并在子图中显示。
show_augmented_images(augmentation_pipe_output)
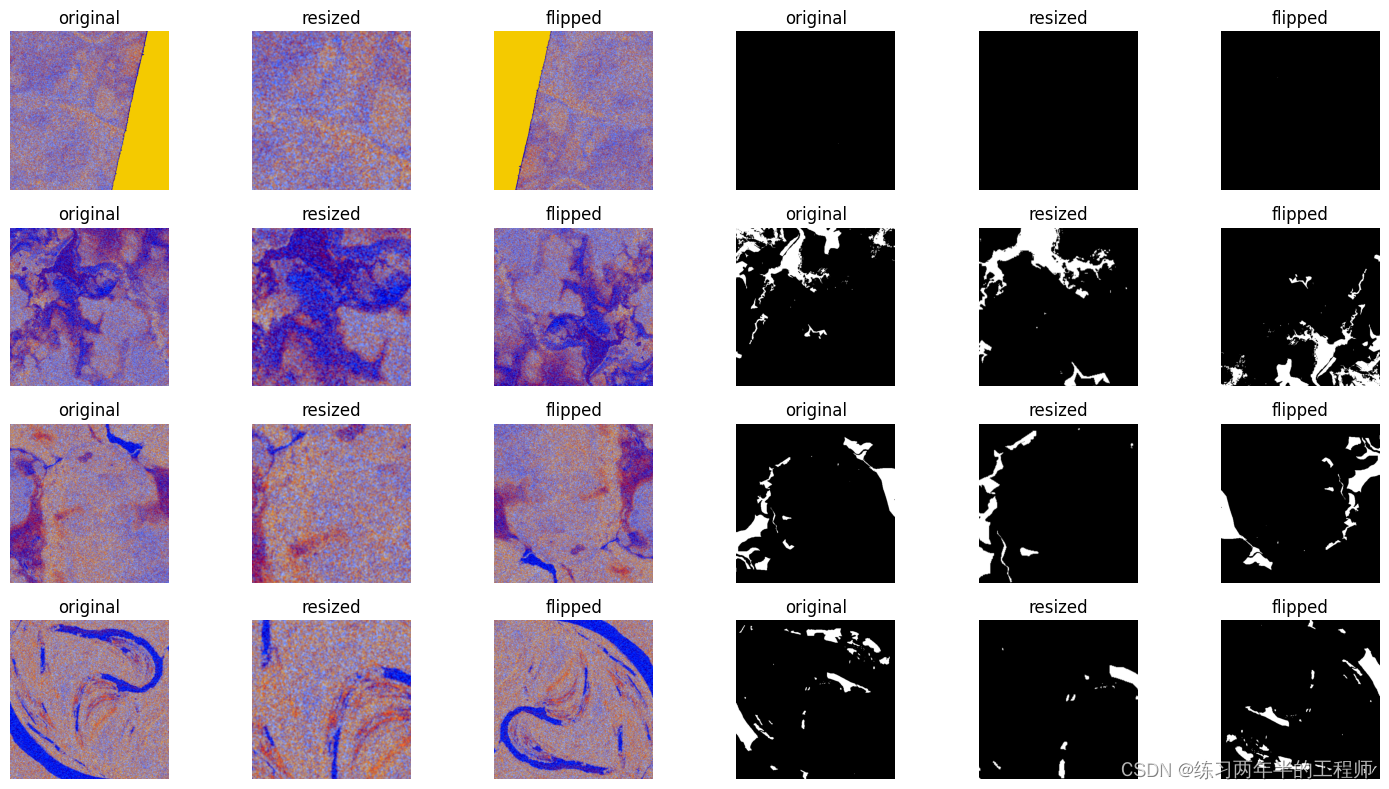
show_augmented_images(pipe.run())
- 针对下一批数据运行流水线
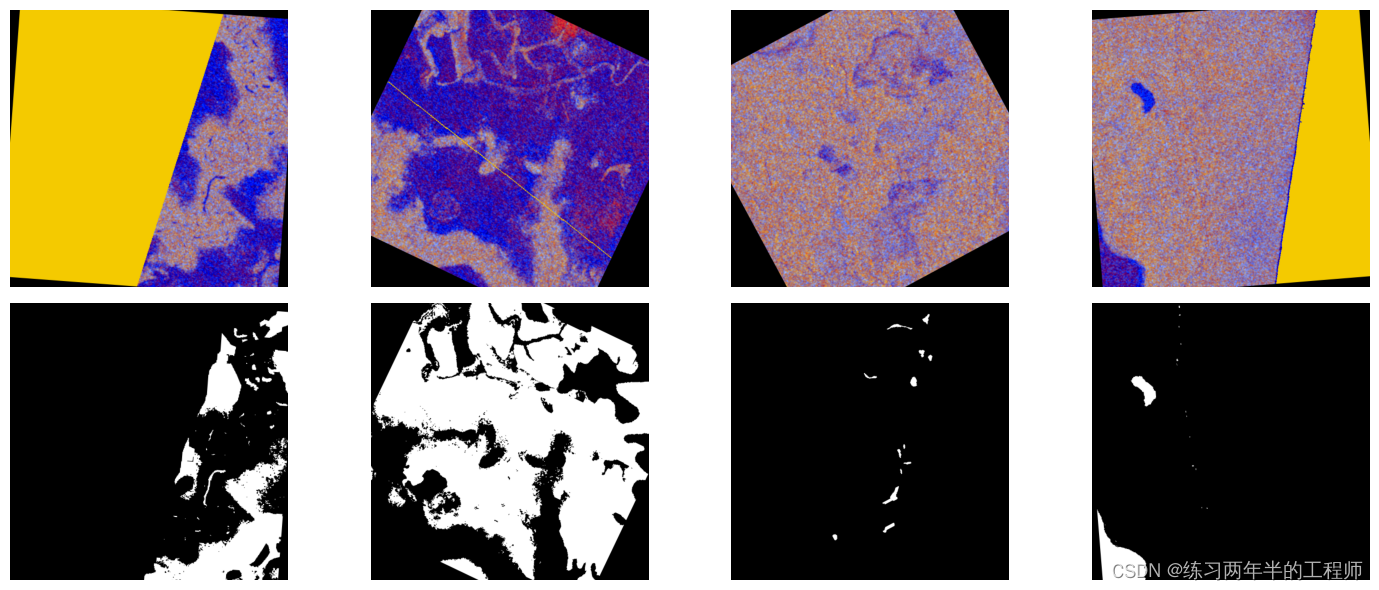
8. 旋转每个图像(以随机角度)来执行额外的数据增强
@pipeline_def
def rotate_pipeline():images, _=fn.readers.file(file_root=image_dir)masks, _=fn.readers.file(file_root=mask_dir)images=fn.decoders.image(images, device='cpu')masks=fn.decoders.image(masks, device='cpu')angle=fn.random.uniform(range=(-30.0, 30.0))rotated_images = fn.rotate(images.gpu(), angle=angle, fill_value=0, keep_size=True, device='gpu')rotated_masks = fn.rotate(masks.gpu(), angle=angle, fill_value=0, keep_size=True, device='gpu')return rotated_images, rotated_masks
- 使用
random.uniform并使用rotate进行旋转,由此生成随机角度。 - 创建一个使用 GPU 的流水线来执行数据增强。
- 将设备参数设为
gpu,并通过调用.gpu()确保其输入传输到 GPU。
9. rotate_pipeline 会在 GPU 上执行旋转
pipe=rotate_pipeline(batch_size=batch_size, num_threads=4, device_id=0)
pipe.build()
rotate_pipe_output=pipe.run()
- 生成的图像会分配到 GPU 显存中。
- 模型需要 GPU 显存中用于训练的数据。
# define a function display images
def show_rotate_images(pipe_output):image_batch, rotated_batch=pipe_outputcolumns=batch_sizerows=2fig=plt.figure(figsize=(15, (15 // columns) * rows))gs=gridspec.GridSpec(rows, columns)grid_data=[image_batch.as_cpu(), rotated_batch.as_cpu()]grid=0for row_idx in range(rows): for col_idx in range(columns): plt.subplot(gs[grid])plt.axis('off')plt.imshow(grid_data[row_idx].at(col_idx))grid+=1plt.tight_layout()
- 只要想在运行流水线之后将数据复制回 CPU 内存,都可通过针对
Pipeline.run()返回的对象调用as_cpu()来实现。
show_rotate_images(rotate_pipe_output)
相关文章:
卫星图像应用 - 洪水检测 使用DALI进行数据预处理
这篇文章是上一篇的延申。 运行环境:Google Colab 1. 当今的深度学习应用包含由许多串行运算组成的、复杂的多阶段数据处理流水线,仅依靠 CPU 处理这些流水线已成为限制性能和可扩展性的瓶颈。 2. DALI 是一个用于加载和预处理数据的库,可…...

为什么字节大量用GO而不是Java?
见字如面,我是军哥。 我看很多程序员对字节编程语言选型很好奇,为此我还特地问了在字节的两位4-1的技术大佬朋友,然后加上自己的思考,总结了一下就以下 2 个原因: 1、 选型上没有历史包袱 字节的早期的程序员大多来自于…...
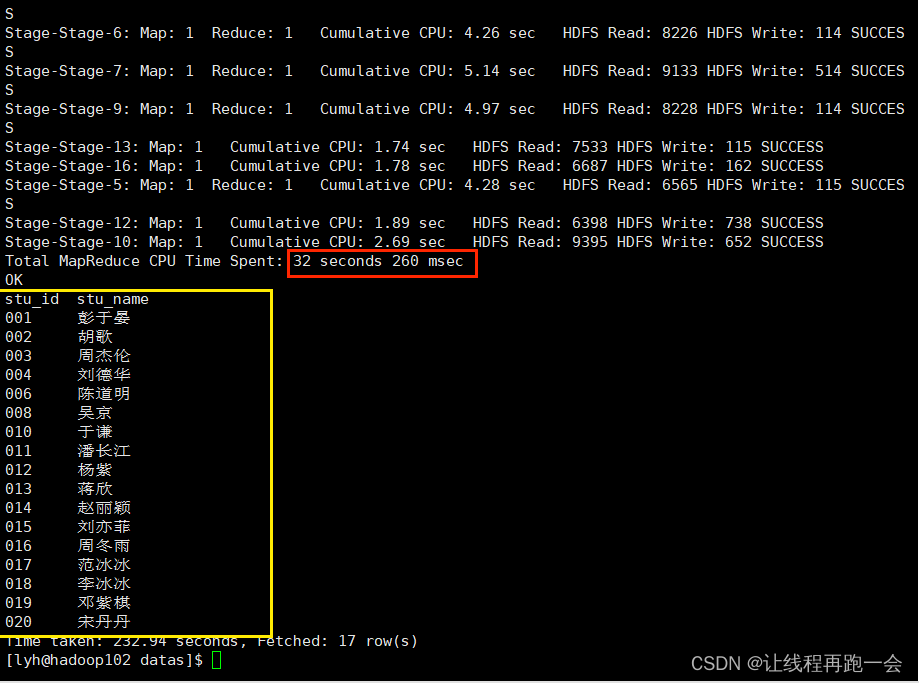
Hive SQL初级练习(30题)
前言 Hive 的重要性不必多说,离线批处理的王者,Hive 用来做数据分析,SQL 基础必须十分牢固。 环境准备 建表语句 这里建4张表,下面的练习题都用这些数据。 -- 创建学生表 create table if not exists student_info(stu_id st…...

NSSCTF做题(6)
[HCTF 2018]Warmup 查看源代码得到 开始代码审计 <?php highlight_file(__FILE__); class emmm { public static function checkFile(&$page) { $whitelist ["source">"source.php","hint"…...
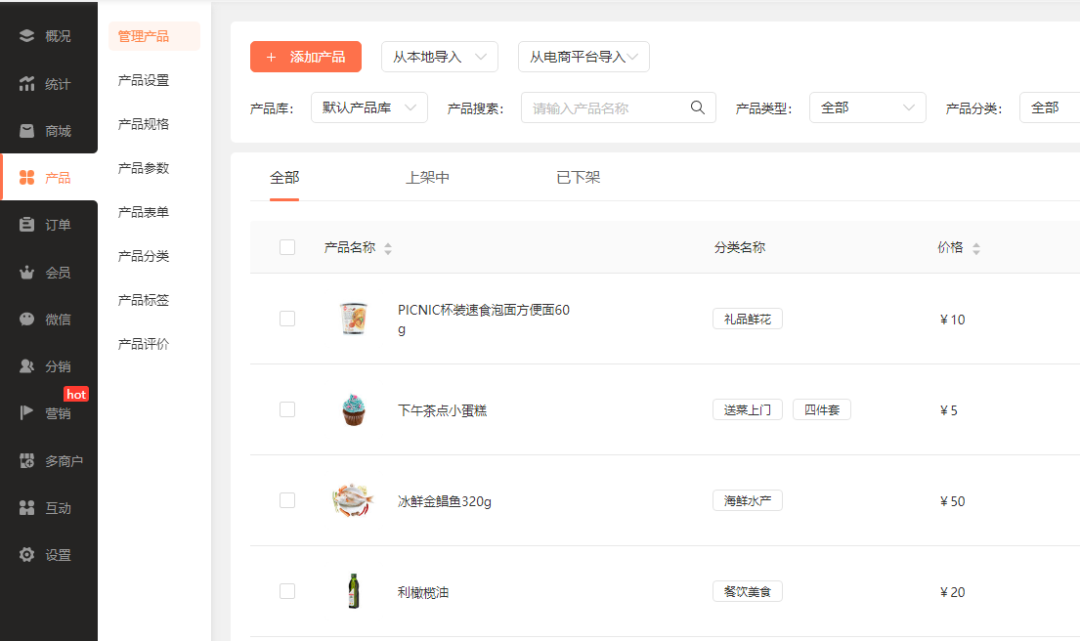
公众号商城小程序的作用是什么
公众号是微信平台重要的生态体系之一,它可以与其它体系连接实现多种效果,同时公众号内容创作者非常多,个人或企业商家等,会通过公众号分享信息或获得收益等,而当商家需要在微信做私域经营或想要转化粉丝、售卖产品时就…...

关于 FOCA
目录 注意团队成员成品官网项目社区 版本信息致谢 注意 此文章会随时更新,最好收藏起来,总对你有好处。我们不定时发布一些 IT 内容,所以请关注我们。 此账号为 FOCA 唯一的官方账号,请勿轻易相信其他账号所发布内容。 团队 全…...
TVP专家谈腾讯云 Cloud Studio:开启云端开发新篇章
导语 | 近日,由腾讯云 TVP 团队倾力打造的 TVP 吐槽大会第六期「腾讯云 Cloud Studio」专场圆满落幕,6 位资深的 TVP 专家深度体验腾讯云 Cloud Studio 产品,提出了直击痛点的意见与建议,同时也充分肯定了腾讯云 Cloud Studio 的实…...

2023-09-27 Cmake 编译 OpenCV+Contrib 源码通用设置
Cmake 编译 OpenCV 通用设置 特点: 包括 Contrib 模块关闭了 Example、Test、OpenCV_AppLinux、Windows 均只生成 OpenCV_World 需要注意: 每次把 Cmake 缓存清空,否则,Install 路径可能被设置为默认路径Windows 需要注意编译…...
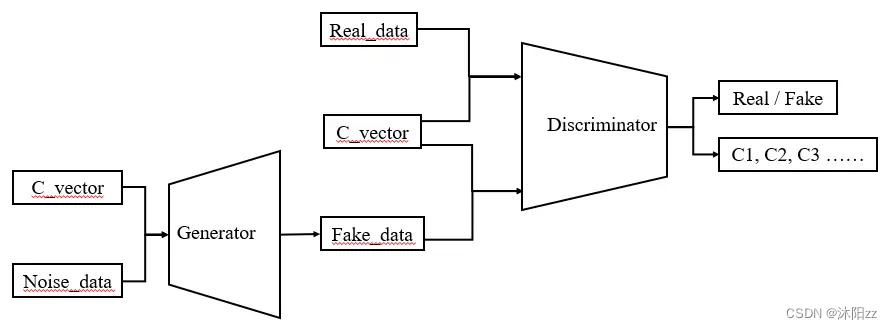
ACGAN
CGAN通过在生成器和判别器中均使用标签信息进行训练,不仅能产生特定标签的数据,还能够提高生成数据的质量;SGAN(Semi-Supervised GAN)通过使判别器/分类器重建标签信息来提高生成数据的质量。既然这两种思路都可以提高生成数据的质…...

模块化CSS
1、什么是模块化CSS 模块化CSS是一种将CSS样式表的规则和样式定义封装到模块或组件级别的方法,以便于更好地管理、维护和组织样式代码。这种方法通过将样式与特定的HTML元素或组件相关联,提供了一种更具可维护性、可复用性和隔离性的方式来处理样式。简单…...

意大利储能公司【Energy Dome】完成1500万欧元融资
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于意大利米兰的储能公司Energy Dome今日宣布已完成1500万欧元B轮融资。 本轮融资完成后,Energy Dome的融资总额已经达到了5500万欧元,本轮融资的参与者包括阿曼创新发…...

【Java 进阶篇】JDBC Connection详解:连接到数据库的关键
在Java中,要与数据库进行交互,需要使用Java数据库连接(JDBC)。JDBC允许您连接到不同类型的数据库,并执行SQL查询、插入、更新和删除操作。在JDBC中,连接数据库是一个重要的步骤,而Connection对象…...
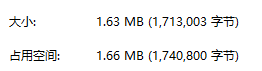
vue-cli项目打包体积太大,服务器网速也拉胯(100kb/s),客户打开网站需要等十几秒!!! 尝试cdn优化方案
一、首先用插件webpack-bundle-analyzer查看自己各个包的体积 插件用法参考之前博客 vue-cli项目中,使用webpack-bundle-analyzer进行模块分析,查看各个模块的体积,方便后期代码优化 二、发现有几个插件体积较大,有改成CDN引用的…...

【优秀学员统计】python实现-附ChatGPT解析
1.题目 优秀学员统计 知识点排序统计编程基础 时间限制: 1s 空间限制: 256MB 限定语言:不限 题目描述: 公司某部门软件教导团正在组织新员工每日打卡学习活动,他们开展这项学习活动已经一个月了,所以想统计下这个月优秀的打卡员工。每个员工会对应一个id,每天的打卡记录记录…...
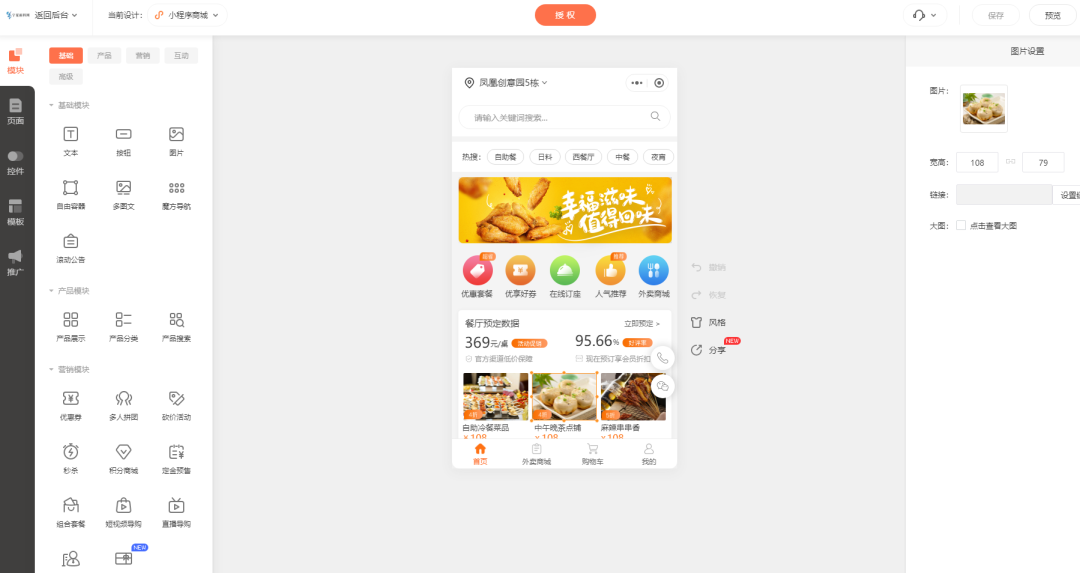
餐饮外卖配送小程序商城的作用是什么?
餐饮是支撑市场的主要行业之一,其市场规模很大,从业商家从大到小不计其数,对众商家来说,无论门店大小都希望不断生意增长,但在实际发展中却会面对不少痛点; 餐饮很适合线上经营,无论第三方外卖…...
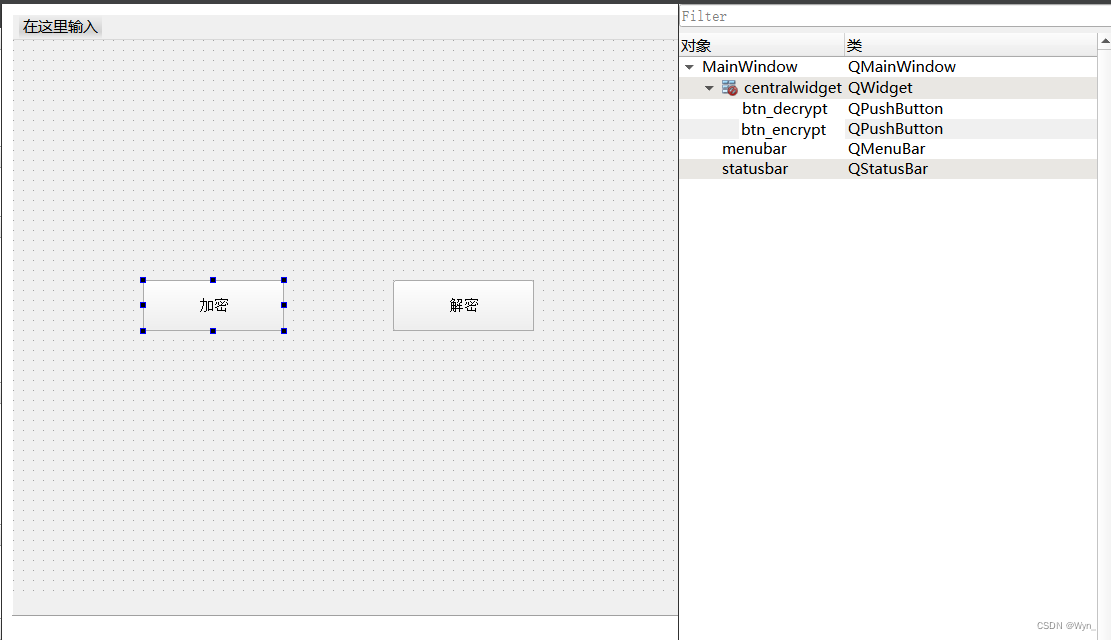
【QT】使用toBase64方法将.txt文件的明文变为非明文(类似加密)
目录 0.环境 1.背景 2.详细代码 2.1 .h主要代码 2.2 .cpp主要代码,主要实现上述的四个方法 0.环境 windows 11 64位 Qt Creator 4.13.1 1.背景 项目需求:我们项目中有配置文件(类似.txt,但不是这个格式,本文以…...

《QDebug 2023年9月》
一、Qt Widgets 问题交流 1.Qt 程序在 Windows 上以管理员权限运行时无法响应拖放(Drop) 无论是 Widget 还是 QML 程序,以管理员权限运行时,都无法响应拖放操作。可以右键管理员权限打开 Qt Creator,然后丢个文本文件…...

C++使用高斯模糊处理图像
C使用高斯模糊处理图像 cv::GaussianBlur 是 OpenCV 中用于对图像进行高斯模糊处理的函数。高斯模糊是一种常用的图像滤波方法,它可以减少图像中的噪声,并平滑图像以降低细节级别。 void cv::GaussianBlur(const cv::Mat& src, cv::Mat& dst, …...

多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络)
多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络) 目录 多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现PSO-BP粒子群优化BP神经网络多变量时间序列预测ÿ…...

LeetCode 283. 移动零
移动零 问题描述 LeetCode 283. 移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意,必须在不复制数组的情况下原地对数组进行操作。 解决思路 为了将所有 0 移动到数组的末尾&#…...

赛美特冲刺港股:年营收7亿,刚完成8亿融资,估值73亿
雷递网 雷建平 3月31日赛美特信息集团股份有限公司(简称:“赛美特”)日前更新招股书,准备在港交所上市。赛美特成立以来获得多次融资,其中,2023年4月完成2.33亿元融资,投后估值62.33亿ÿ…...

给AI模型‘打补丁’:用‘上下文提示’和‘查询分解’两招,轻松提升多模态大模型的抗攻击能力
多模态大模型防御实战:用上下文提示与查询分解抵御图像对抗攻击 当你在社交媒体上传一张"猫"的照片,AI系统却识别为"狗"——这种看似无害的错误在医疗影像分析或自动驾驶场景中可能引发灾难。2024年CVPR会议揭示了一个关键发现&…...

IO-Link物理层深度解析:编码机制与接口设计实战
1. IO-Link物理层编码机制详解 第一次接触IO-Link的开发者往往会被它的11bit编码规则绕晕。我刚开始调试STM32的IO-Link主站时,就因为在UART配置上少勾选了一个校验位,导致从站设备死活不响应。后来用逻辑分析仪抓包才发现,原来发送的0xF1在…...

AI正冲击金融岗!高薪职业如何守住饭碗?金融人转行AI指南
AI技术正全面冲击金融行业,初级分析师、风控专员、客服等中低端认知劳动密集型岗位面临被替代风险。但高端投行、深度研究、资源型和创新型岗位短期内仍安全。金融人转型AI有独特优势,如数据敏感性、业务理解力等。转型路径包括AI应用专家、金融科技产品…...

【测试之道】第四篇:分层测试论 —— 金字塔、奖杯与蜂巢:构建你的质量防御阵型
专栏进度:04 / 10 (测试理论专题) 在不同的架构(单体、微服务、前端驱动)下,测试资源的分配比例是完全不同的。盲目套用模板是测试经理最容易犯的错误。 一、 经典模型:测试金字塔 (Testing Pyramid) 由 Mike Cohn 提出…...
)
别再死磕英文手册了!手把手带你用Lisflood-FP跑通第一个洪水模拟案例(附T001_buscot实战)
从零到一:Lisflood-FP洪水模拟实战指南(T001_buscot案例详解) 刚接触水文模型的研究者常被英文手册劝退——密密麻麻的公式、晦涩的术语、复杂的参数配置让人望而生畏。其实,掌握Lisflood-FP的关键不在于死磕理论,而在…...

Keyv自定义序列化教程:超越JSON,支持更多数据类型
Keyv自定义序列化教程:超越JSON,支持更多数据类型 【免费下载链接】keyv jaredwray/keyv: 这是一个分布式键值存储库,用于在多个节点上存储数据。适合用于需要分布式存储和访问的场景。特点:易于使用,支持多种数据存储…...
)
51单片机入门-直流电机(十五)
目录:1.直流电机驱动(PWM)2.LED呼吸灯&直流电机调速1.直流电机驱动(PWM)让他转的快一些让他转2us停1us2.LED呼吸灯&直流电机调速点亮一个LED:在循环里:点亮熄灭显示暗一些:让…...

10个C语言开源项目解析与学习指南
1. 10个值得学习的C语言开源项目解析 作为一名在嵌入式领域摸爬滚打多年的开发者,我深知阅读优秀开源代码对提升编程能力的重要性。今天要分享的这10个C语言项目,每一个都是精炼而实用的典范,特别适合想要深入理解系统编程、网络协议和底层实…...

告别电量焦虑:用STM32+IP2366打造你的140W双向快充移动电源方案
告别电量焦虑:用STM32IP2366打造140W双向快充移动电源方案 1. 为什么需要高性能移动电源方案 当代智能设备对电力的需求呈现爆发式增长。从智能手机到笔记本电脑,从无人机到便携式医疗设备,快速充电和大容量储能已成为刚需。传统移动电源方…...