使用Python进行App用户细分
App用户细分是根据用户与App的互动方式对用户进行分组的任务。它有助于找到保留用户,找到营销活动的用户群,并解决许多其他需要基于相似特征搜索用户的业务问题。这篇文章中,将带你完成使用Python进行机器学习的App用户细分任务。
App用户细分
在App用户细分的问题中,我们需要根据用户与App的互动方式对用户进行分组。因此,为了解决这个问题,我们需要根据用户如何使用App来获得有关用户的数据。
导入必要的Python库和数据集:
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
import pandas as pd
pio.templates.default = "plotly_white"data = pd.read_csv("userbehaviour.csv")
print(data.head())
输出
userid Average Screen Time Average Spent on App (INR) Left Review \
0 1001 17.0 634.0 1
1 1002 0.0 54.0 0
2 1003 37.0 207.0 0
3 1004 32.0 445.0 1
4 1005 45.0 427.0 1 Ratings New Password Request Last Visited Minutes Status
0 9 7 2990 Installed
1 4 8 24008 Uninstalled
2 8 5 971 Installed
3 6 2 799 Installed
4 5 6 3668 Installed
让我们先来看看所有用户的最高、最低和平均屏幕时间:
print(f'Average Screen Time = {data["Average Screen Time"].mean()}')
print(f'Highest Screen Time = {data["Average Screen Time"].max()}')
print(f'Lowest Screen Time = {data["Average Screen Time"].min()}')
输出
Average Screen Time = 24.39039039039039
Highest Screen Time = 50.0
Lowest Screen Time = 0.0
现在让我们来看看所有用户的最高、最低和平均支出金额:
print(f'Average Spend of the Users = {data["Average Spent on App (INR)"].mean()}')
print(f'Highest Spend of the Users = {data["Average Spent on App (INR)"].max()}')
print(f'Lowest Spend of the Users = {data["Average Spent on App (INR)"].min()}')
输出
Average Spend of the Users = 424.4154154154154
Highest Spend of the Users = 998.0
Lowest Spend of the Users = 0.0
现在我们来看看活跃用户和卸载了APP的用户的消费能力和屏幕时间的关系:
figure = px.scatter(data_frame = data, x="Average Screen Time",y="Average Spent on App (INR)", size="Average Spent on App (INR)", color= "Status",title = "Relationship Between Spending Capacity and Screentime",trendline="ols")
figure.show()
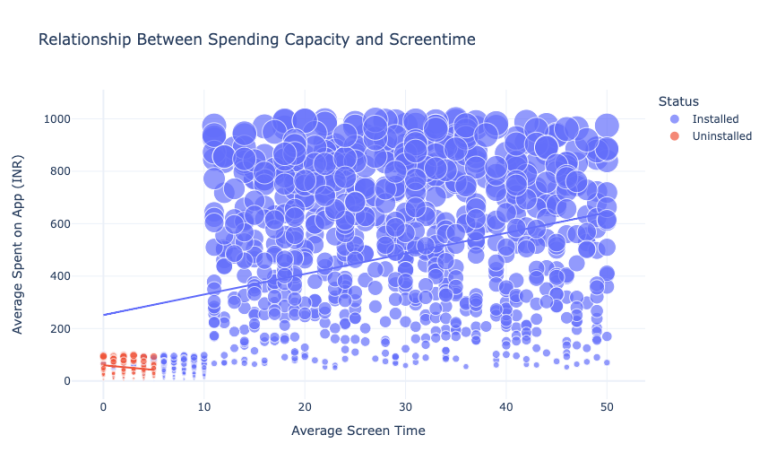
卸载该App的用户平均每天屏幕时间不到5分钟,平均花费不到100。我们还可以看到平均屏幕时间与仍在使用该App的用户的平均支出之间存在线性关系。
现在我们来看看用户给出的评分和平均屏幕时间之间的关系:
figure = px.scatter(data_frame = data, x="Average Screen Time",y="Ratings", size="Ratings", color= "Status", title = "Relationship Between Ratings and Screentime",trendline="ols")
figure.show()
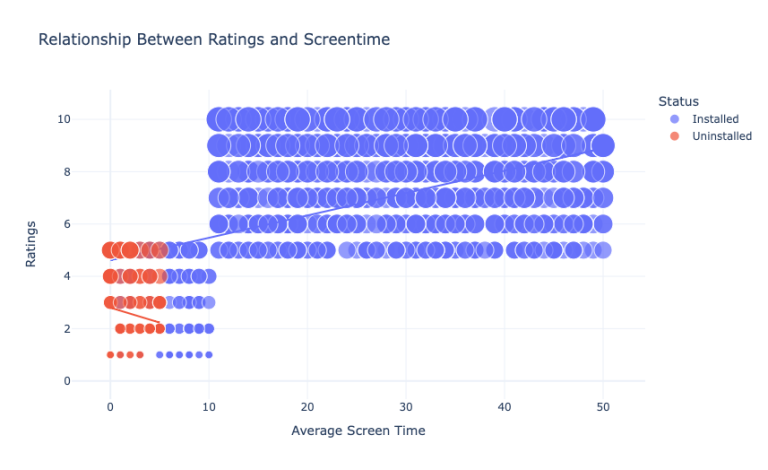
所以我们可以看到,卸载该应用的用户给该应用的评分最多为5分。与评分更高的用户相比,他们的屏幕时间非常低。所以,这描述了那些不喜欢花更多时间的用户对App的评价很低,并在某个时候卸载它。
App用户细分–查找保留和丢失的用户
现在,让我们继续进行App用户细分,以找到App保留和永远失去的用户。这里将使用机器学习中的K-means聚类算法来完成这项任务:
clustering_data = data[["Average Screen Time", "Left Review", "Ratings", "Last Visited Minutes", "Average Spent on App (INR)", "New Password Request"]]from sklearn.preprocessing import MinMaxScaler
for i in clustering_data.columns:MinMaxScaler(i)from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
clusters = kmeans.fit_predict(clustering_data)
data["Segments"] = clustersprint(data.head(10))
输出
userid Average Screen Time Average Spent on App (INR) Left Review \
0 1001 17.0 634.0 1
1 1002 0.0 54.0 0
2 1003 37.0 207.0 0
3 1004 32.0 445.0 1
4 1005 45.0 427.0 1
5 1006 28.0 599.0 0
6 1007 49.0 887.0 1
7 1008 8.0 31.0 0
8 1009 28.0 741.0 1
9 1010 28.0 524.0 1 Ratings New Password Request Last Visited Minutes Status Segments
0 9 7 2990 Installed 0
1 4 8 24008 Uninstalled 2
2 8 5 971 Installed 0
3 6 2 799 Installed 0
4 5 6 3668 Installed 0
5 9 4 2878 Installed 0
6 9 6 4481 Installed 0
7 2 1 1715 Installed 0
8 8 2 801 Installed 0
9 8 4 4621 Installed 0
现在让我们来看看我们得到的数据划分:
print(data[“Segments”].value_counts())
输出
0 910
1 45
2 44
Name: Segments, dtype: int64
现在让我们重命名这些数据段,以便更好地理解:
data["Segments"] = data["Segments"].map({0: "Retained", 1: "Churn", 2: "Needs Attention"})
进行数据可视化:
PLOT = go.Figure()
for i in list(data["Segments"].unique()):PLOT.add_trace(go.Scatter(x = data[data["Segments"]== i]['Last Visited Minutes'],y = data[data["Segments"] == i]['Average Spent on App (INR)'],mode = 'markers',marker_size = 6, marker_line_width = 1,name = str(i)))
PLOT.update_traces(hovertemplate='Last Visited Minutes: %{x} <br>Average Spent on App (INR): %{y}')PLOT.update_layout(width = 800, height = 800, autosize = True, showlegend = True,yaxis_title = 'Average Spent on App (INR)',xaxis_title = 'Last Visited Minutes',scene = dict(xaxis=dict(title = 'Last Visited Minutes', titlefont_color = 'black'),yaxis=dict(title = 'Average Spent on App (INR)', titlefont_color = 'black')))
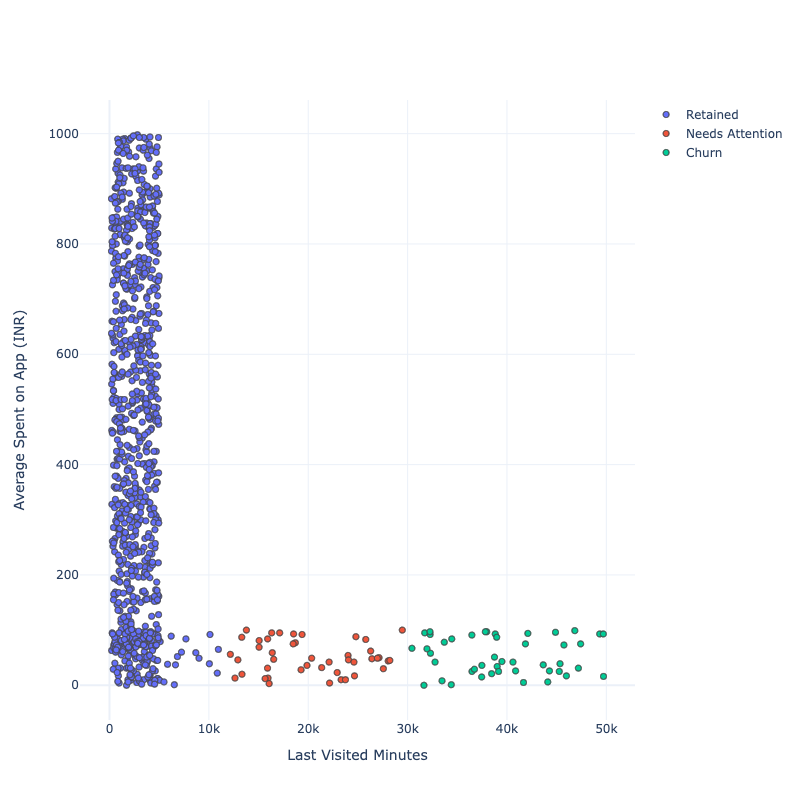
蓝色部分显示了App随着时间的推移保留的用户部分。红色部分表示刚刚卸载App或即将卸载App的用户部分。绿色部分表示App丢失的用户部分。
总结
这就是你如何根据用户与App的互动方式来细分用户。App用户细分可以帮助企业找到留存用户,找到营销活动的用户细分,并解决许多其他需要基于相似特征搜索用户的业务问题。以上是使用Python进行App用户细分的任务。
相关文章:
使用Python进行App用户细分
App用户细分是根据用户与App的互动方式对用户进行分组的任务。它有助于找到保留用户,找到营销活动的用户群,并解决许多其他需要基于相似特征搜索用户的业务问题。这篇文章中,将带你完成使用Python进行机器学习的App用户细分任务。 App用户细…...
)
博弈论——伯特兰德寡头模型(Bertrand Model)
伯特兰德寡头模型(Bertrand Model) 0 引言 在前面几篇文章中,我们介绍了古诺模型(Cournot duopoly model)和斯塔克尔伯格模型(Stackelberg model) 博弈论——连续产量古诺模型(Cournot duopoly model) 博弈论——斯塔克尔伯格模型(Stackelberg model) 这两个模型…...

第一百六十回 SliverPadding组件
文章目录 概念介绍使用方法示例代码 我们在上一章回中介绍了SliverAppBar组件相关的内容,本章回中将介绍 SliverPadding组件.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在本章回中介绍的SliverPadding组件类似Pading组件,它主要用…...
Mapfree智驾方案,怎样实现成本可控?
整理|睿思 编辑|祥威 编者注:本文是HiEV出品的系列直播「智驾地图之变」第二期问答环节内容整理。 元戎启行副总裁刘轩与连线嘉宾奥维咨询董事合伙人张君毅、北汽研究总院智能网联中心专业总师林大洋、主持嘉宾周琳展开深度交流,并进行了答疑。 本期元…...
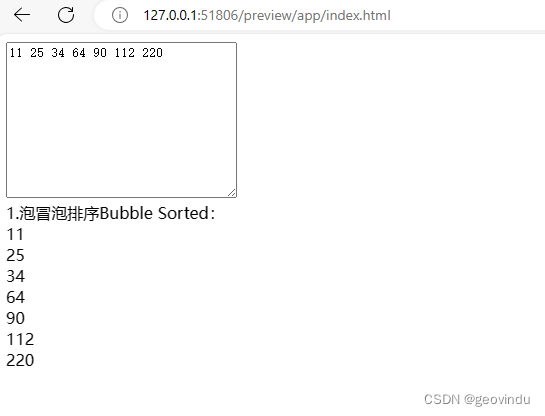
javascript: Bubble Sort
// Sorting Algorithms int JavaScript /** * file Sort.js * 1. Bubble Sort冒泡排序法 */ function BubbleSort(arry, nszie) {var i, j, temp;var swapped;for (i 0; i < nszie - 1; i){swapped false;for (j 0; j < nszie - i - 1; j){if (arry[j] > arry[j …...

DM数据库根据rowid删除重复的记录
oracle中rowid的用法-CSDN博客 delete from stu a where rowid not in (select max(b.rowid) from stu b where a.nob.no and a.name b.name and a.sex b.sex); //这里max使用min也可以...

【AI视野·今日Robot 机器人论文速览 第四十期】Mon, 25 Sep 2023
AI视野今日CS.Robotics 机器人学论文速览 Mon, 25 Sep 2023 Totally 36 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚CloudGripper, 一套云化的机器抓取人数据采集系统,包含了32个机械臂的集群。(from KTH Royal Institute of Te…...
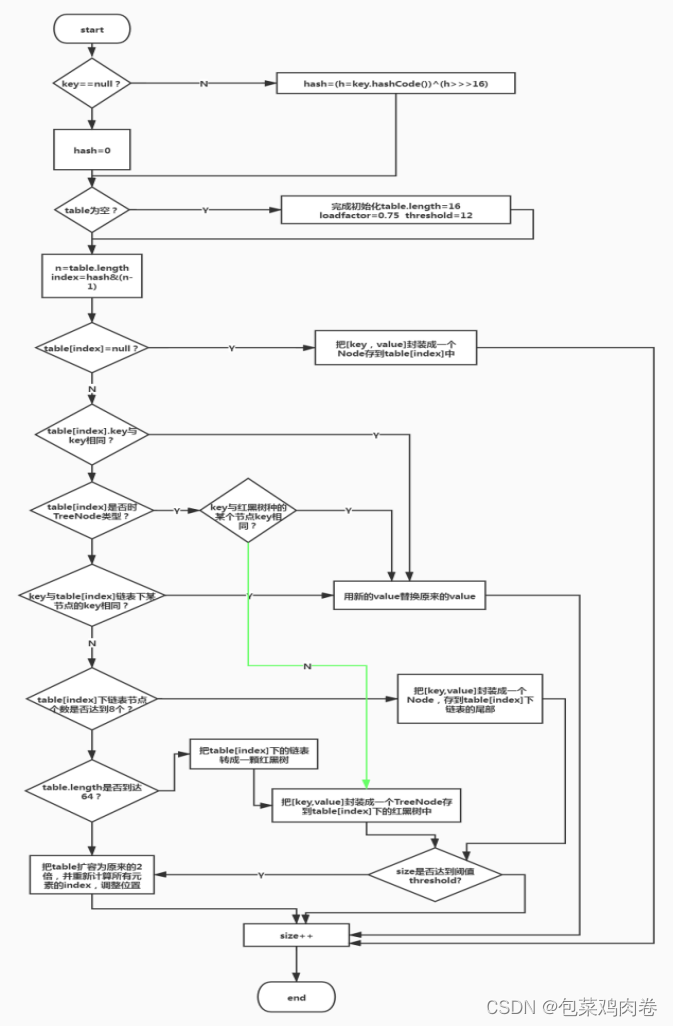
HashMap底层源码,数据结构
HashMap的底层结构在jdk1.7中由数组链表实现,在jdk1.8中由数组链表红黑树实现,以数组链表的结构为例。 JDK1.8之前Put方法: JDK1.8之后Put方法: HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,…...

计算机等级考试—信息安全三级真题八
一、单选题...
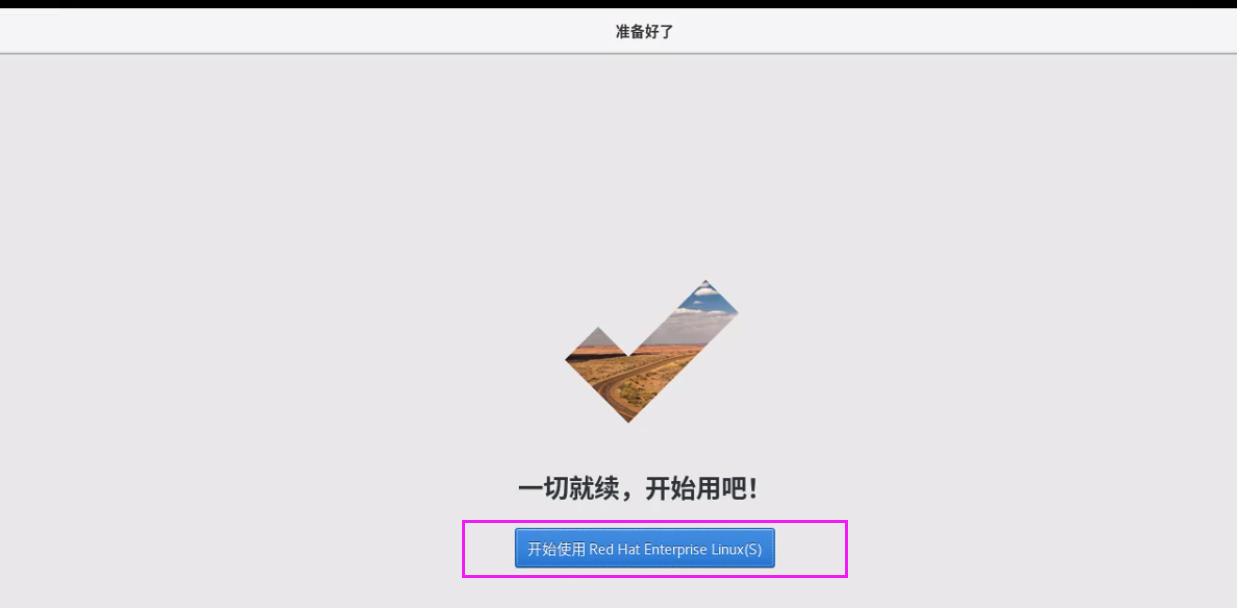
番外6:下载+安装+配置Linux
#########配置Linux---后续 step08: 点击编辑虚拟机设置,选择下载好的映像文件.iso进行挂载; step09: 点击编辑虚拟机选项,选择UEFI启动模式并点击确定; step10: 点击开启虚拟机,选择Install rhel ; 备注&…...
方法和他的属性)
javascript验证表单字段有效性,使用checkValidity()方法和他的属性
<script type"text/javascript">function LoginCheckValidity(){var txt"";var rmb1document.getElementById("rmb1");if(rmb1.checkValidity()false){if(rmb1.validitionMessageundefined){txt"输入金额有误,金额10-200之间";}…...
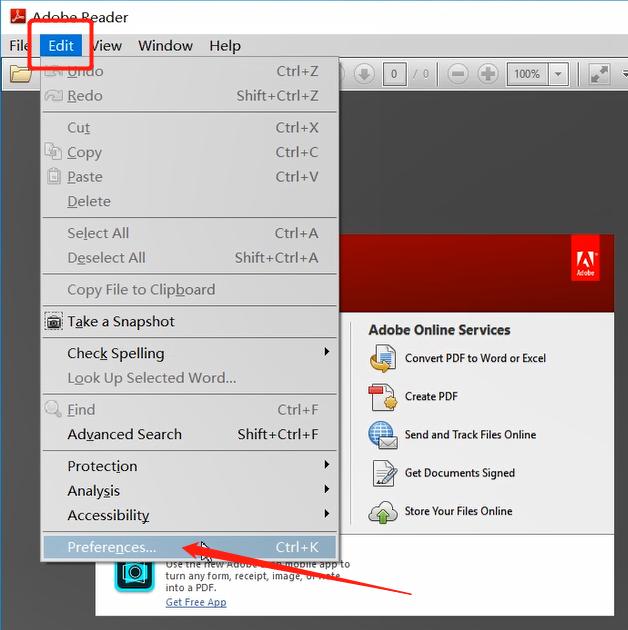
pdf怎么调整大小kb?pdf文件过大这样压缩
在日常的工作和生活中,我们常常会遇到需要调整PDF文件大小的问题。有时候,我们需要将大型的PDF文件上传到某些平台,但平台的限制让我们不得不压缩文件的大小。那么,如何有效地调整PDF文件的大小呢? 一、使用嗨格式压缩…...

vue3中的watch
在Vue3中,watch中的参数可以分为两部分,即要监听的响应式数据以及回调函数。 语法格式如下: watch(要监听的响应式数据, 回调函数)除了以上的两个还有其他的参数 immediate:是否在初始化时立即执行一次回调函数,默认…...
开绕组电机零序Bakc EMF-based无感控制以及正交锁相环inverse Park-based
前言 最近看论文遇到了基于反Park变换的锁相环,用于从开绕组永磁同步电机零序电压信号中提取转子速度与位置信息,实现无感控制。在此记录 基于零序Back EMF的转子估算 开绕组电机的零序反电动势 e 0 − 3 ω e ψ 0 s i n 3 θ e e_0-3\omega_e\psi_…...
番外5:下载+安装+配置Linux
任务前期工作: 01. 电脑已安装好VMware Workstation软件; 02.提前下载好Rhel-8.iso映像文件(文件较大一般在9.4GB,建议采用迅雷下载),本人使用的以下版本(地址ed2k://|file|rhel-8.4-x86_64-dvd…...

新手--安装好Quartus II13.0(带modelsim集成包)并用Quartus II搭建一个工程
前言 今天是国庆节,我们正式来学习Quartus II13.0软件的安装与使用。学习verilog与学习C语言都是学习一门语言,那么学习一门语言,光看理论不敲代码绝对是学习不好的。要用verilog语言敲代码,就要像C语言那样搭建起语言的编译环境&…...

python监控软件内存、cpu和GDI
目录 前言代码 前言 最近做软件测试需要监控软件内存、cpu和GDI对象数,用psutil库可以很方便的实现监控内存和CPU,但是GDI好像还不行,最后来的win32api来调用的Windows API接口来实现GDI监控的,在此做个记录。 代码 import psu…...

wordpress搭建自己的博客详细过程以及踩坑
WordPress作为一款开源的内容管理系统(CMS),具有诸多优势。首先,它的易用性使得即使对于没有编程经验的用户来说也能轻松上手,通过直观的用户界面和友好的管理工具,用户可以方便地创建、编辑和发布内容。其…...

在jupyter中更改、增加内核
今天在配置llama2的环境,在学院实验室的服务器上面用jupyter,怎么都不会增加内核。今天说一下怎么把创建好的conda环境增加到jupyter列表中。 例如我有个环境叫做llama2,很简单只要两步。 第一步先激活conda环境。 conda activate llama2第…...

Redis代码实践总结(二)
使用 CLI 探索 Redis 外部程序使用 TCP 套接字和 Redis 特定协议与 Redis 进行通信。该协议在不同编程语言的 Redis 客户端库中实现。然而,为了使使用 Redis 进行黑客攻击变得更简单,Redis 提供了一个命令行实用程序,可用于向 Redis 发送命令…...

Ghidra逆向工程平台:探索二进制世界的开源利器
Ghidra逆向工程平台:探索二进制世界的开源利器 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 在当今数字化时代…...
)
别再死记硬背了!一张图帮你理清InfiniBand那些让人头疼的术语(HCA/QP/LID/GID)
从数据流视角拆解InfiniBand:用一次完整通信串联核心术语 第一次接触InfiniBand的技术文档时,那些缩写字母组合——HCA、QP、CQ、LID、GID——就像天书般令人困惑。它们被分门别类地罗列在文档中,却缺乏实际场景中的互动关系。本文将打破传统…...

如何在复杂逻辑谜题中寻找确定性答案:MiniSat 求解器的极简哲学
如何在复杂逻辑谜题中寻找确定性答案:MiniSat 求解器的极简哲学 【免费下载链接】minisat A minimalistic and high-performance SAT solver 项目地址: https://gitcode.com/gh_mirrors/mi/minisat 当你面对一个由数千个变量和约束条件构成的复杂逻辑系统时&…...

StructBERT-Large镜像部署教程:GPU加速推理环境搭建指南
StructBERT-Large镜像部署教程:GPU加速推理环境搭建指南 1. 环境准备与快速部署 在开始部署StructBERT-Large镜像之前,我们需要确保基础环境配置正确。这个步骤将帮助你快速搭建起可运行的GPU加速推理环境。 1.1 硬件与系统要求 为了获得最佳性能&am…...

实战演练:基于快马平台快速开发数据库连接池监控与告警脚本
实战演练:基于快马平台快速开发数据库连接池监控与告警脚本 最近线上应用频繁出现响应缓慢的问题,经过初步排查,怀疑是数据库连接数过多导致的。作为运维工程师,我们需要快速开发一个监控脚本,实时掌握数据库连接状态…...

3步构建企业级AI应用:无代码开发新范式
3步构建企业级AI应用:无代码开发新范式 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Workflow …...

⚔️ 易经+人性+数学·三位一体终极博弈|算法裁判·话语权殖民·三色审计逻辑链闭环 v2.0|UID9622
《道德经》第三十六章:“将欲夺之,必固予之。” —— 先给你一把裁判的椅子,再告诉你,坐上去的人才有资格说话。🧭 这篇文章在干嘛⚔️ 这不是针对任何人的。 这是一场博弈论的推演——用易经的智慧、人性的逻辑、数学…...

Ryujinx模拟器技术解析与实践指南
Ryujinx模拟器技术解析与实践指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 价值主张:重新定义主机游戏体验 在当代游戏技术发展历程中,模拟器扮演着连接…...

双腔制动主缸建模实战:从物理结构到联合仿真验证
乘用车双腔制动主缸建模,simulink模型,以及amesim模型,simulink和amesim联合仿真模型及验证,而是较为精细化的建模,非常详细的公式建模,不是相关文献上对制动主缸进行简化的公式模型,制动主缸的…...

快速验证c语言算法:使用快马ai一键生成排序算法性能对比原型
最近在复习算法基础时,突然想直观比较冒泡排序和快速排序的性能差异。传统方式从零开始写代码太耗时,正好发现了InsCode(快马)平台的AI生成功能,尝试用它快速搭建测试原型,整个过程比想象中顺畅很多。 需求拆解 首先明确需要验证的…...