pyflink学习笔记(一):table_apisql
具体定义请参考官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/overview/
本文主要针对实际使用中比较常用的api进行整理,大多数例子都是官网,如有歧义可与官方对照。
一、 创建 TableEnvironment
TableEnvironment 是 Table API 和 SQL 的核心概念。它负责:
在内部的 catalog 中注册 Table
注册外部的 catalog
加载可插拔模块
执行 SQL 查询
注册自定义函数 (scalar、table 或 aggregation)
DataStream 和 Table 之间的转换(面向 StreamTableEnvironment )
from pyflink.table import EnvironmentSettings, TableEnvironmentfrom pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
#创建流处理
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
#创建批处理
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
#用户可以从现有的 StreamExecutionEnvironment 创建一个 StreamTableEnvironment 与 DataStream API 互操作。
s_env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(s_env)TableEnvironment主要用来:
Table 管理:创建表、列举表、Table 和 DataStream 互转等。
自定义函数管理:自定义函数的注册、删除、列举等。 关于 Python 自定义函数的更多细节,请参考普通自定义函数 和向量化自定义函数章节的介绍。
执行 SQL 语句:更多细节可查阅SQL 查询章节的介绍。
作业配置管理:更多细节可查阅Python 配置章节的介绍。
Python 依赖管理:更多细节可查阅依赖管理章节的介绍。
作业提交:更多细节可查阅作业提交章节的介绍。
二、创建表
Table 是 Python Table API 的核心组件。Table 对象由一系列数据转换操作构成,但是它不包含数据本身。 相反,它描述了如何从数据源中读取数据,以及如何将最终结果写出到外部存储等。表可以被打印、优化并最终在集群中执行。 表也可以是有限流或无限流,以支持流式处理和批处理场景。
一个 Table 实例总是与一个特定的 TableEnvironment 相绑定。不支持在同一个查询中合并来自不同 TableEnvironments 的表,例如 join 或者 union 它们。
from pyflink.table import EnvironmentSettings, TableEnvironment# 创建 批 TableEnvironment
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)首先在上面创建了一个批处理的TableEnvironment。然后创建一张表。
在pyflink中,可从不同的数据类型中形成创建表,下面介绍几个比较常用的方法
1、from_elements
从元素集合创建表,集合中的元素必须长度相等,类型顺序相同
from_elements(elements: Iterable, schema: Union[pyflink.table.types.DataType, List[str]] = None, verify_schema: bool = True) → pyflink.table.table.Table参数:
elements- 创建表格的元素。
schema- 表的架构。
verify_schema- 是否根据架构验证元素。
例子如下:schema可以使用DataTypes 指定类型,也可以不指定,直接写列名,会自动识别。
#table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')],["a","b"])
#table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')],DataTypes.ROW([DataTypes.FIELD("a", DataTypes.INT()),DataTypes.FIELD("b", DataTypes.STRING())]))
table.execute().print()2、通过 pandas DataFrame 来创建表
from_pandas(pdf, schema=None, split_num=1)参数:
pdf- Pandas DataFrame 。
schema- 转换后的表的架构。
splits_num- 给定的 Pandas DataFrame 将被分割成的分割数。它决定了并行源任务的数量。如果未指定,将使用默认并行度。
pdf = pd.DataFrame(np.random.rand(10, 2))
table = table_env.from_pandas(pdf, ["a", "b"])
#table_env.from_pandas(pdf, [DataTypes.DOUBLE(), DataTypes.DOUBLE()])
# table_env.from_pandas(pdf, DataTypes.ROW(
# [DataTypes.FIELD("a", DataTypes.DOUBLE()), DataTypes.FIELD("b", DataTypes.DOUBLE())]))
table.execute().print()3、create_temporary_view
通过指定路径下已注册的表来创建一个表,例如通过 create_temporary_view 注册表。
from_path(path: str) → pyflink.table.table.Table参数:
path- 要扫描的表 API 对象的路径。
# 临时表
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table_env.create_temporary_view('source_table', table)
new_table = table_env.from_path('source_table')
new_table.execute().print()#读取表 - 从已注册的目录中读取表
table_env.execute_sql("""CREATE TABLE random_source (id BIGINT, data TINYINT ) WITH ('connector' = 'datagen','fields.id.kind'='sequence','fields.id.start'='1','fields.id.end'='3','fields.data.kind'='sequence','fields.data.start'='4','fields.data.end'='6')
""")
table = table_env.from_path("random_source")
table.execute().print()create_temporary_view : 将一个 `Table` 对象注册为一张临时表,类似于 SQL 的临时表。
create_temporary_view(view_path, table)参数:
view_path - 注册视图的路径。
table_or_data_stream :用于创建视图的表或数据流。
table_env.execute_sql("""CREATE TABLE table_sink (id BIGINT, data VARCHAR ) WITH ('connector' = 'print')
""")# 将 Table API 表转换成 SQL 中的视图
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table_env.create_temporary_view('table_api_table', table)# 将 Table API 表的数据写入结果表
table_env.execute_sql("INSERT INTO table_sink SELECT * FROM table_api_table").wait()4、execute_sql
执行指定的语句并返回执行结果。 执行语句可以是 DDL/DML/DQL/SHOW/DESCRIBE/EXPLAIN/USE。
注意,对于 "INSERT INTO" 语句,这是一个异步操作,通常在向远程集群提交作业时才需要使用。
execute_sql(stmt str) 参数:
str- sql 语句
table_env.execute_sql("INSERT INTO table_sink SELECT * FROM table_api_table").wait()5、sql_query(query)
执行一条 SQL 查询,并将查询的结果作为一个 `Table` 对象.
sql_query(query) 参数:
query- sql 语句
table_env.sql_query("SELECT * FROM %s" % table)6、create_statemente_set
用来执行多条sql语句,可以通过该方法编写multi_sink的作业。
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table_env.create_temporary_view("simple_source", table)
table_env.execute_sql("""CREATE TABLE first_sink_table (id BIGINT, data VARCHAR ) WITH ('connector' = 'print')
""")
table_env.execute_sql("""CREATE TABLE second_sink_table (id BIGINT, data VARCHAR) WITH ('connector' = 'print')
""")# 创建 statement set
statement_set = table_env.create_statement_set()# 将 "table" 的数据写入 "first_sink_table"
statement_set.add_insert("first_sink_table", table)# 通过一条 sql 插入语句将数据从 "simple_source" 写入到 "second_sink_table"
statement_set.add_insert_sql("INSERT INTO second_sink_table SELECT * FROM simple_source")# 执行 statement set
statement_set.execute().wait()7> +I(1,Hi)
7> +I(1,Hi)
7> +I(2,Hello)
7> +I(2,Hello)
7、get_schema
获取schema信息
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
# 默认情况下,“id” 列的类型是 64 位整型
print('By default the type of the "id" column is %s.' % table.get_schema().get_field_data_type("id"))from pyflink.table import DataTypestable = table_env.from_elements([(1, 'Hi'), (2, 'Hello')],DataTypes.ROW([DataTypes.FIELD("id", DataTypes.TINYINT()),DataTypes.FIELD("data", DataTypes.STRING())]))
# 现在 “id” 列的类型是 8 位整型
print(table.get_schema())By default the type of the "id" column is BIGINT.
root
|-- id: TINYINT
|-- data: STRING
三、创建TableDescriptor
用来定义表的scheam
例子:
from pyflink.table import EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes# create a stream TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)table_env.create_temporary_table('random_source',TableDescriptor.for_connector('datagen').schema(Schema.new_builder().column('id', DataTypes.BIGINT()).column('data', DataTypes.TINYINT()).build()).option('fields.id.kind', 'sequence').option('fields.id.start', '1').option('fields.id.end', '3').option('fields.data.kind', 'sequence').option('fields.data.start', '4').option('fields.data.end', '6').build())table = table_env.from_path("random_source")
table.execute().print()+----+----------------------+--------+
| op | id | data |
+----+----------------------+--------+
| +I | 1 | 4 |
| +I | 2 | 5 |
| +I | 3 | 6 |
+----+----------------------+--------+for_connector:使用给定的连接器为表创建一个新的构建器
参数:
当前仅有部分 connector 的实现包含在 Flink 官方提供的发行包中,好比 FileSystem,DataGen、Print、BlackHole 等,大部分 connector 的实现当前没有包含在 Flink 官方提供的发行包中,好比 Kafka、ES 等。针对没有包含在 Flink 官方提供的发行包中的 connector,若是须要在 PyFlink 做业中使用,用户须要显式地指定相应 FAT JAR.
具体直接看阿里云的flink文档:https://help.aliyun.com/document_detail/176688.html
四、在 Catalog 中创建表
表可以是临时的,并与单个 Flink 会话(session)的生命周期相关,也可以是永久的,并且在多个 Flink 会话和群集(cluster)中可见。
永久表需要 catalog(例如 Hive Metastore)以维护表的元数据。一旦永久表被创建,它将对任何连接到 catalog 的 Flink 会话可见且持续存在,直至被明确删除。
通过 SQL DDL 创建的表和视图, 例如 “create table …” 和 “create view …",都存储在 catalog 中。
你可以通过 SQL 直接访问 catalog 中的表。
如果你要用 Table API 来使用 catalog 中的表,可以使用 “from_path” 方法来创建 Table API 对象:
# 准备 catalog
# 将 Table API 表注册到 catalog 中
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table_env.create_temporary_view('source_table', table)# 从 catalog 中获取 Table API 表
new_table = table_env.from_path('source_table')
new_table.execute().print()+----+----------------------+--------------------------------+
| op | id | data |
+----+----------------------+--------------------------------+
| +I | 1 | Hi |
| +I | 2 | Hello |
+----+----------------------+--------------------------------+五、Table API-DML语法
from pyflink.table import EnvironmentSettings, TableEnvironment
from pyflink.table.expressions import col
from pyflink.table.expressions import concat# 通过 batch table environment 来执行查询
env_settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)orders = table_env.from_elements([('Jack', 'FRANCE', 10), ('Rose', 'ENGLAND', 30), ('Jack', 'FRANCE', 20)],['name', 'country', 'revenue'])1.查询-select
# 查询两列
revenue = orders.select(col("name"), col("country").alias('country'))
# 查询全部列
revenue1 = orders .select(col("*")) revenue.execute().print()
table_result = revenue.execute()
print(type(table_result ))+--------------------------------+--------------------------------+
| name | country |
+--------------------------------+--------------------------------+
| Jack | FRANCE |
| Rose | ENGLAND |
| Jack | FRANCE |
| Bob | CH |
| Bob | CH |
| YU | CH |
+--------------------------------+--------------------------------<class 'pyflink.table.table_result.TableResult'>
说下返回值,通过打印可以知道revenue.execute()返回值类型是TableResult,这个类型不能直接通过for循环遍历。
需要调用collect()方法,然后在遍历。
for res_row in table_result.collect():for rr in res_row:print(rr)对于 SELECT 操作,除非已收集所有结果数据,否则作业不会完成,所以除非是有界或是批处理,那么不建议使用for循环遍历数据。
#所以建立使用with循环
with table_result.collect() as results:for result in results:2.过滤-where
等同filter,和 SQL 的 WHERE 子句类似。 过滤掉未验证通过过滤谓词的行。
--javascripttypescriptbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
result = orders.where(col("name") == 'Jack')
#或
result = orders.filter(col("name") == 'Jack')
#打印
result .execute().print()+--------------------------------+--------------------------------+-------------+-------------------------+
| name | country | revenue | r_time |
+--------------------------------+--------------------------------+-------------+-------------------------+
| Jack | FRANCE | 10 | 2023-02-23 11:11:33.081 |
| Jack | FRANCE | 20 | 2023-02-24 07:11:33.081 |
+--------------------------------+--------------------------------+-------------+-------------------------+3.列操作
--javascripttypescriptbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
#添加列,add_columns但是如果该列存在则直接报错
#concat 合并
result = orders.add_columns(concat(col("name"), 'sunny').alias('desc'))
result .execute().print()+--------------------------------+--------------------------------+-------------+-------------------------+--------------------------------+
| name | country | revenue | r_time | desc |
+--------------------------------+--------------------------------+-------------+-------------------------+--------------------------------+
| Jack | FRANCE | 10 | 2023-02-23 11:11:33.081 | Jacksunny |
| Rose | ENGLAND | 30 | 2023-02-23 21:11:33.081 | Rosesunny |
| Jack | FRANCE | 20 | 2023-02-24 07:11:33.081 | Jacksunny |
| Bob | CH | 40 | 2023-02-24 17:11:33.081 | Bobsunny |
| Bob | CH | 50 | 2023-02-24 17:11:33.081 | Bobsunny |
| YU | CH | 100 | 2023-02-23 14:11:33.081 | YUsunny |
+--------------------------------+--------------------------------+-------------+-------------------------+--------------------------------+#add_or_replace_columns:执行字段添加操作。 如果添加的列名称和已存在的列名称相同,则已存在的字段将被替换。 此外,如果添加的字段里面有重复的字段名,则会使用最后一个字段。
result = orders.add_or_replace_columns(concat(col("name"), 'sunny').alias('desc')).select(col("name"),col("desc"))
result.execute().print()+--------------------------------+--------------------------------+
| name | desc |
+--------------------------------+--------------------------------+
| Jack | Jacksunny |
| Rose | Rosesunny |
| Jack | Jacksunny |
| Bob | Bobsunny |
| Bob | Bobsunny |
| YU | YUsunny |
+--------------------------------+--------------------------------+#删除列,如果删除多个,则用逗号隔开,drop_columns(col("a"),col("b"))
result = orders.drop_columns(col("name"))
result.execute().print()+--------------------------------+-------------+-------------------------+
| country | revenue | r_time |
+--------------------------------+-------------+-------------------------+
| FRANCE | 10 | 2023-02-23 11:11:33.081 |
| ENGLAND | 30 | 2023-02-23 21:11:33.081 |
| FRANCE | 20 | 2023-02-24 07:11:33.081 |
| CH | 40 | 2023-02-24 17:11:33.081 |
| CH | 50 | 2023-02-24 17:11:33.081 |
| CH | 100 | 2023-02-23 14:11:33.081 |
+--------------------------------+-------------+-------------------------+#修改列名
result = orders.rename_columns(col("name").alias('name1'), col("country").alias('country2'))
result.execute().print()+--------------------------------+--------------------------------+-------------+-------------------------+
| name1 | country2 | revenue | r_time |
+--------------------------------+--------------------------------+-------------+-------------------------+
| Jack | FRANCE | 10 | 2023-02-23 11:11:33.081 |
| Rose | ENGLAND | 30 | 2023-02-23 21:11:33.081 |
| Jack | FRANCE | 20 | 2023-02-24 07:11:33.081 |
| Bob | CH | 40 | 2023-02-24 17:11:33.081 |
| Bob | CH | 50 | 2023-02-24 17:11:33.081 |
| YU | CH | 100 | 2023-02-23 14:11:33.081 |
+--------------------------------+--------------------------------+-------------+-------------------------+4.聚合计算-Aggregations
4.1 group_by
# 计算所有来自法国客户的收入
# 使用group_by 来进行分组计算
#对于流失计算,因为数据是无界的,计算出的结果是可能是无限长的,取决查询或聚合的字段,所以当是流式时,请提供空闲状态保留时间。
revenue = orders \.select(col("name"), col("country"), col("revenue")) \.where(col("country") == 'FRANCE') \.group_by(col("name")) \.select(col("name"), orders.revenue.sum.alias('rev_sum'))revenue.execute().print()+--------------------------------+-------------+
| name | rev_sum |
+--------------------------------+-------------+
| Jack | 30 |
+--------------------------------+-------------+4.2窗口函数 - Tumble
滚动窗口将行分配给固定长度的非重叠连续窗口。例如,一个 5 分钟的滚动窗口以 5 分钟的间隔对行进行分组。滚动窗口可以定义在事件时间、处理时间或行数上。
#生成测试数据
orders = table_env.from_elements(
[
('Jack', 'FRANCE', 10, datetime.now()+timedelta(hours=2)),
('Rose', 'ENGLAND', 30, datetime.now()+timedelta(hours=12)),
('Jack', 'FRANCE', 20, datetime.now()+timedelta(hours=22)),
('Bob', 'CH', 40, datetime.now()+timedelta(hours=32)),
('Bob', 'CH', 50, datetime.now()+timedelta(hours=32)),
('YU', 'CH', 100, datetime.now()+timedelta(hours=5))
],
DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("country", DataTypes.STRING()),
DataTypes.FIELD("revenue", DataTypes.INT()),
DataTypes.FIELD("r_time", DataTypes.TIMESTAMP(3))]))#设置窗口函数
win_fun= Tumble.over(lit(1).hours).on(col('r_time')).alias("w")over | 将窗口的长度定义为时间或行计数间隔。 |
on | 要对数据进行分组(时间间隔)或排序(行计数)的时间属性。批处理查询支持任意 Long 或 Timestamp 类型的属性。流处理查询仅支持声明的事件时间或处理时间属性。 |
alias | 指定窗口的别名。别名用于在 group_by() 子句中引用窗口,并可以在 select() 子句中选择如窗口开始、结束或行时间戳的窗口属性。 |
#使用窗口函数
result = orders.window(win_fun) \.group_by(col('name'), col('w')) \.select(col('name'), col('w').start, col('w').end, col('revenue').sum.alias('d')).order_by("d")
result.execute().print()+--------------------------------+-------------------------+-------------------------+-------------+
| name | EXPR$0 | EXPR$1 | d |
+--------------------------------+-------------------------+-------------------------+-------------+
| Jack | 2023-02-22 19:00:00.000 | 2023-02-22 20:00:00.000 | 10 |
| Jack | 2023-02-23 15:00:00.000 | 2023-02-23 16:00:00.000 | 20 |
| Rose | 2023-02-23 05:00:00.000 | 2023-02-23 06:00:00.000 | 30 |
| Bob | 2023-02-24 01:00:00.000 | 2023-02-24 02:00:00.000 | 90 |
| YU | 2023-02-22 22:00:00.000 | 2023-02-22 23:00:00.000 | 100 |
+--------------------------------+-------------------------+-------------------------+-------------+4.3窗口函数 - Over Window
和 SQL 的 OVER 子句类似 PS:暂时没有测试数据,参考sql即可
Over.partition_by(col("a")) \ .order_by(col("rowtime")) \ .preceding(expr.UNBOUNDED_RANGE) \ .alias("w")order_by 需是time 属性才可以排序
4.4Distinct Aggregation
和 SQL DISTINCT 聚合子句类似,例如 COUNT(DISTINCT a)。
#去重后相加
group_by_distinct_result = orders.group_by(col("name")) \.select(col("name"), col("revenue").sum.distinct.alias('d'))
group_by_distinct_result .execute().print()+--------------------------------+-------------+
| name | d |
+--------------------------------+-------------+
| Jack | 30 |
| Bob | 90 |
| YU | 100 |
| Rose | 30 |
+--------------------------------+-------------+也可以直接Distinct,筛选完全相同的行数据。
orders1 = table_env.from_elements([('Jack', 'FRANCE', 10),('Jack', 'FRANCE', 10)],DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("country", DataTypes.STRING()),DataTypes.FIELD("revenue", DataTypes.INT())]))
result = orders1.distinct()
result .execute().print()+--------------------------------+--------------------------------+-------------+
| name | country | revenue |
+--------------------------------+--------------------------------+-------------+
| Jack | FRANCE | 10 |
+--------------------------------+--------------------------------+-------------+相关文章:
:table_apisql)
pyflink学习笔记(一):table_apisql
具体定义请参考官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/overview/本文主要针对实际使用中比较常用的api进行整理,大多数例子都是官网,如有歧义可与官方对照。一、 创建 TableEnvironmentTab…...

GCC 编译器套件说明
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录GCC 简述GCC 主要…...
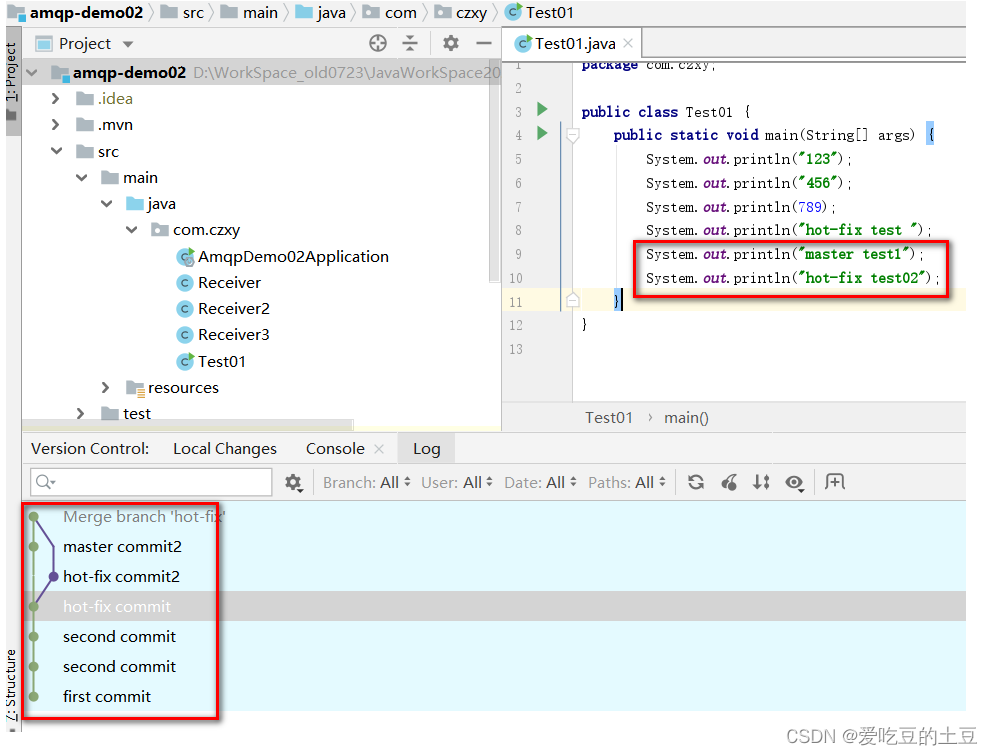
IDEA集成Git
1:IDEA集合Git1.1:配置Git忽略文件-IDEA特定文件问题 1:为什么要忽略他们?答: 与项目的实际功能无关, 不参与服务器上部署运行。把它们忽略掉能够屏蔽 IDE 工具之间的差异。问题 2:怎么忽略?1&a…...

算法流程图
里程计定位: 优:定位信息连续,无离散的跳跃 缺:存在累计误差,不利于长距或长期定位 传感器定位: 优:比里程计定位更精准 缺:会出现跳变情况,且传感器定位在标志物较少的环…...
Java中安装JDK环境–javac命令无效
Java中安装JDK环境–javac命令无效 一,安装JDK1.8 阿里云盘地址推荐 我们可以选择安装地址,这个地址是我们用来配置环境变量的,唯一注意的是这个,其他的都是默认下一步。直至安装完成,jdk下载地址https://www.oracl…...

递推问题
递推:在面对一个大任务的时候,有时候我们可以将大任务划分为小任务,再将小任务划分为更小的任务......,直到遇到初始情况,最后由初始情况一直往前推进,最后解决大任务,这就是递推的思想。递推问…...

js中强制类型转换Number、parseInt、parseFloat、Boolean、String、toString的使用
文章目录一、Number() 转换为整数二、Number.parseInt() 将字符串转换为整数三、Number.parseFloat() 将字符串转换为浮点数四、Boolean() 转换为布尔值五、String() 转换为字符串六、.toString() 转换为字符串最近在巩固 js 的基础知识,今天复习到了 js 中的数据类…...
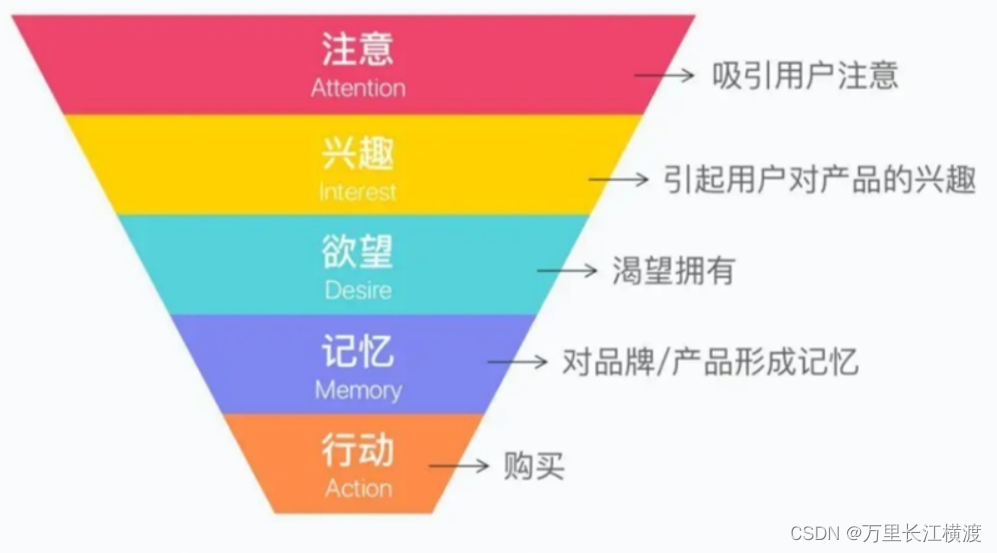
漏斗分析法
一什么是漏斗分析? 漏斗分析是数据领域最常见的一种“程式化”数据分析方法,它能够科学地评估一种业务过程,从起点到终点,各个阶段的转化情况。通过可以量化的数据分析,帮助业务找到有问题的业务环节,并进…...
)
pycharm入门快捷操作(部分)
altenter:提示意图动作shift两次或者crtlshifta:查找框(查找动作、类、项目等)crtlw:一次一个字符、两次整个字符串(if条件下选择整个判断体)、三次整个句子、四次整个引用ctrlshiftw࿱…...

宣布 Databricks 支持 Amazon Graviton2,性价比提高3倍
今天,我们很高兴地宣布 Databricks 对基于 Amazon Graviton2 的亚马逊弹性计算云(Amazon EC2)实例的支持的公开预览。Graviton 处理器由亚马逊云科技进行定制设计和优化,为运行在 Amazon EC2 上的云工作负载提供最佳性价比。当与高…...
18_FreeRTOS任务通知
目录 任务通知的简介 任务通知值的更新方式 任务通知的优势 任务通知的劣势 任务通知值和通知状态 发送通知相关API函数 接收通知相关API函数 任务通知模拟信号量实验 任务通知模拟消息邮箱实验 任务通知模拟事件标志组实验 任务通知的简介 任务通知:用来通知任务的…...

【华为OD机试模拟题】用 C++ 实现 - 整理扑克牌(2023.Q1)
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...
mysql lesson1
常用命令 1:exit 退出mysql 2:uroot pENTER键,再输入密码,不被别人看见 3:完美卸载:双击安装包,手动删除program file中的mysql,手动删除Programedate里的mysql 4:use mysql 使用数据库 5:…...
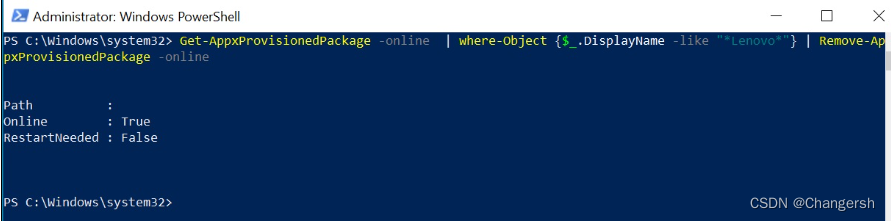
联想笔记本无法下载 Lenovo Vantage
状况 在 Microsoft Store 下载时发生错误,可能是如下代码:0x80070005, 0x80073D05, or 0x80070017. 解决方法 1.在“开始”菜单搜索栏中输入PowerShell 2.当Windows PowerShell出现在“开始”菜单中,右键点击此图标,然后选择以…...

功能性材料深入超级赛道,赋能多行业迭代升级
中国国际胶粘剂及密封剂展览会深耕胶粘剂、密封剂和胶粘带行业26年,是行业认可的、优质的贸易与技术交流平台。展会连接了十几个行业的买家和卖家,包括汽车、电子、新能源、轨道交通、工业等重要领域,为客户提供封装、粘合、散热、装配制造等…...

【项目精选】jsp企业快信系统(论文+视频+源码)
点击下载源码 计算机网络的出现到现在已经经历了翻天覆地的重大改变。因特网也从最早的供科学家交流心得的简单的文本浏览器发展成为了商务和信息的中心。到了今天,互联网已经成为了大量应用的首选平台,人们已经渐渐习惯了网络交易,渐渐对网络…...

通信算法之112:载波同步及comm.CarrierSynchronizer
1. 2. 载波同步是基于锁相环技术使本地获取和载波同频同相的参考信号,用来解调信号。载波同步就是对本地参考信号进行频率和相位偏差的补偿,进而实现本地参考信号和载波信号同频同相。 载波同步只适用于单载波调制系统,载波同步算法对于BPSK、…...
)
【C. Build Permutation】(整数理论、构造、思维)
链接 理论基础 结论:在区间[n,2n]上,至少存在一个完全平方数。结论:在区间[n,2n]上,至少存在一个完全平方数。结论:在区间[n,2n]上,至少存在一个完全平方数。 构造⌈n⌉2构造\lceil \sqrt{n}\rceil^2构造⌈…...
)
前端面试题:事件循环(Eventloop)
什么是事件循环?如何理解事件循环?事件循环原理如何描述?事件循环涉及了很多知识点,想要彻底掌握JS事件循环原理必须要掌握以下知识点:同步任务、异步任务、宏任务、微任务、任务队列、执行栈、js运行机制、EventLoop。 1.事件循…...

jmeter接口自动化测试框架
接口测试可以分为两部分: 一是线上接口(生产环境)自动化测试,需要自动定时执行,每5分钟自动执行一次,相当于每5分钟就检查一遍线上的接口是否正常,有异常能够及时发现,不至于影响用…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...