Lucene-MergePolicy详解
简介
该文章基于业务需求背景,因场景需求进行参数调优,下文会尽可能针对段合并策略(SegmentMergePolicy)的全参数进行说明。
主要介绍TieredMergePolicy,它是Lucene4以后的默认段的合并策略,之前采用的合并策略为LogMergePolicy,建议自行熟悉LogMergePolicy后再了解TieredMergePolicy,这样对于两种段合并策略的优缺点就一目了然,后续即可根据不同业务使用对应的策略,下面对两种策略的差异做一个简单总结:
- LogMergePolicy总是合并相邻的段文件,合并相邻的段文件(Adjacent Segment)描述的是对于IndexWriter提供的段集,LogMergePolicy会选取连续的部分(或全部)段集区间来生成一个待合并段集;
- TieredMergePolicy中会先对IndexWriter提供的段集进行排序,然后在排序后的段集中选取部分(可能不连续)段来生成一个待合并段集,即非相邻的段文件(Non-adjacent Segment)。
一句话描述:TieredMergePolicy:找出大小接近且最优的段集。下面对该概括进行详细分析。频繁且大量的段合并会造成进程CPU飙升。
TieredMergePolicy
TieredMergePolicy的一些参数
合并类型(MERGE_TYPE)
MERGE_TYPE中描述了IndexWriter在不同状态下调用合并策略的三种类型:
- NATURAL:IndexWriter对缩影执行变更操作后调用合并策略;
- FORCE_MERGE:IndexWriter需要需要将索引中包含所有的段集数量(total set of segments in the index)合并为指定数量;
- FORCE_MERGE_DELETES:IndexWriter需要将索引中包含所有的段中的被删除文件进行抹去(expunge)操作。
三中类型触发过程处理逻辑一致,下文仅对NATURAL进行介绍。
maxMergeAtOnce(可配置)
maxMergeAtOnce的缺省值为10,描述了在NATURAL类型下执行一次合并操作最多包含的段的个数(Maximum number of segments to be merged at a time during "normal" mergin)。
segsPerTier(可配置)
segsPerTier的默认值为10,描述了每一层(层级的概念类似LogMergePolicy,这里不做赘述)中需要包含segsPerTier个段才允许合并,例外情况就是当段集中包含的被删除的文档数量达到某个值(下文会介绍),就不用考虑segsPerTier中的段的个数。
mergeFactor
mergeFactor描述了执行一次合并操作最多包含的段的个数,该值计算方式如下:
final int mergeFactor = (int) Math.min(maxMergeAtOnce, segsPerTier);段大小(SegmentSize)
SegmentSize描述了一个段的大小,他是该段中除去被删除文档的索引信息的所有索引文件的大小的综合。
maxMergedSegmentBytes(可配置)
maxMergedSegmentBytes缺省值为5G,它有两个用途:
- 限制合并段集大小总量:待合并的段集大小总和不能超过该值;
- 限制大段(Segment with huge size)合并:该值的一半,即(maxMergedSegmentBytes / 2.0)用来描述某个段如果大小超过就不参与合并(限制大段还要同时满足被删除文档的条件,在下文会介绍)
另外值得一提的是,该值为内存杀手。内存有限的情况下,该值为必配项(5G的merge行为,在非受控堆外,将内存撑满)如下pmap图可见一般:


hitTooLarge
hitTooLarge是一个布尔值,当OneMerge中所有段的大小总和接近maxMergedSegmentBytes,hitTooLarge会被置为true,该值影响OneMerge的打分。
deletesPctAllowed(可配置)
deletesPctAllowed的默认值为33(百分比),自定义该值时允许的值域为[20,50],该值有两个用途:
- 限制大段合并:需要满足该段的SegmentSize≥(maxMergedSegmentBytes/2.0);并且满足段集中的被删除文档的索引信息大小占总索引文件大小的比例totalDelPct≤deletedPctAllowed或该段中被删除文档的索引信息大小占段中索引文件大小的比例segDelPct≤deletesPctAllowed,如下判断逻辑:
(SegmentSize > (maxMergedSegmentBytes / 2)) && (totalDelPct <= deletesPctAllowed || segDelPct <= deletesPctAllowed) - 计算allowedDelCount:计算公式如下,其中totalMaxDoc描述了段集中除去被删除文档的文档数量总和,allowedDelCount的介绍见下文:
int allowedDelCount = (int) (deletesPctAllowed * totalMaxDoc / 100);
allowedSegCount、allowedDelCount
- allowedSegCount:该值描述了段集内每个段的大小SegmentSize是否比较接近(segments of approximately equal size),根据当前索引大小来估算当前索引中"应该"有多少个段,如果实际的段个数小于估算值,那么说明索引中的段不满足差不多都相同(approximately equal size),那么就不会选出OneMerge(这里不赘述该名词含义,见LogMergePolicy)。allowedSegCount的最小值为segsPerTier,allowedSegCount的值越大,索引中会堆积更多的段,说明IndexWriter提交的段集(不包含大段)中最大的段的MaxSegmentSize跟最小的段MinSegmentSize相差越大,或者最小的段MinSegmentSize占段集总大小totalSegmentSize的占比特别低,一个原因在于有些flush()或者commit()的文档数相差太大,另一个原因是可配置参数floorSegmentBytes值设置的太小。
- allowedDelCount:描述了IndexWriter提交的段集(不包含大段)中包含的被删除文档数量,在NATURAL类型下,当某个段集中的成员个数不满足allowedSegCount时,但是如果该段集(不包含大段)中包含的被删除的文档数量大于allowedDelCount,那么该段集还可以继续参与剩余的合并策略的处理(因为执行段的合并的一个非常重要的目的就是"干掉"被删除的文档号),否则就该段集此次不生成一个oneMerge。
floorSegmentBytes(可配置,重要!!!)
floorSegmentBytes缺省值为2MB(2 * 1024 * 1024),该值描述了段的大小segmentSize小于floorSegmentBytes的段,他们的segmentSize都当做floorSegmentBytes。
(源码原文:Segments smaller than this are "rounded up" to this size, ie treated as equal (floor) size for merge selection)
使计算出来的allowedSegCount较小,这样能尽快的将小段(tiny Segment)合并,另外该值还会影响OneMerge的打分(下文会介绍)。设置了不合适的floorSegmentBytes后会发生以下的问题:
- floorSegmentBytes的值太小:导致allowedSegCount很大(allowedSegCount=n*segsPerTier+m 0≤m≤segsPerTier , n≥1),特别是段集中最小的段MinSegmentSize占段集总大小totalSegmentSize的占比特别低,最终使得索引中一段时间存在大量的小段,因为段集的总数小于等于allowedSegCount是不会参与段合并的(如果不满足allowedDelCount的条件)。源码中解释floorSegmentBytes的用途的原文为: This is to prevent frequent flushing of tiny segments from allowing a long tail in the index;
- floorSegmentBytes的值太大:导致allowedSegCount很小(最小值为segsPerTier),即较大的段合并可能更频繁,段越大,合并开销(合并时间,线程频繁占用)越大(在后面的文章中会介绍索引文件的合并)。
SegmentSize多小为小段(tiny Segment),这个定义取决于不同的业务,如果某个业务中认为小于TinySegmentSize的段都为小段,那么floorSegmentBytes的值大于TinySegmentSize即可。
段合并流程图
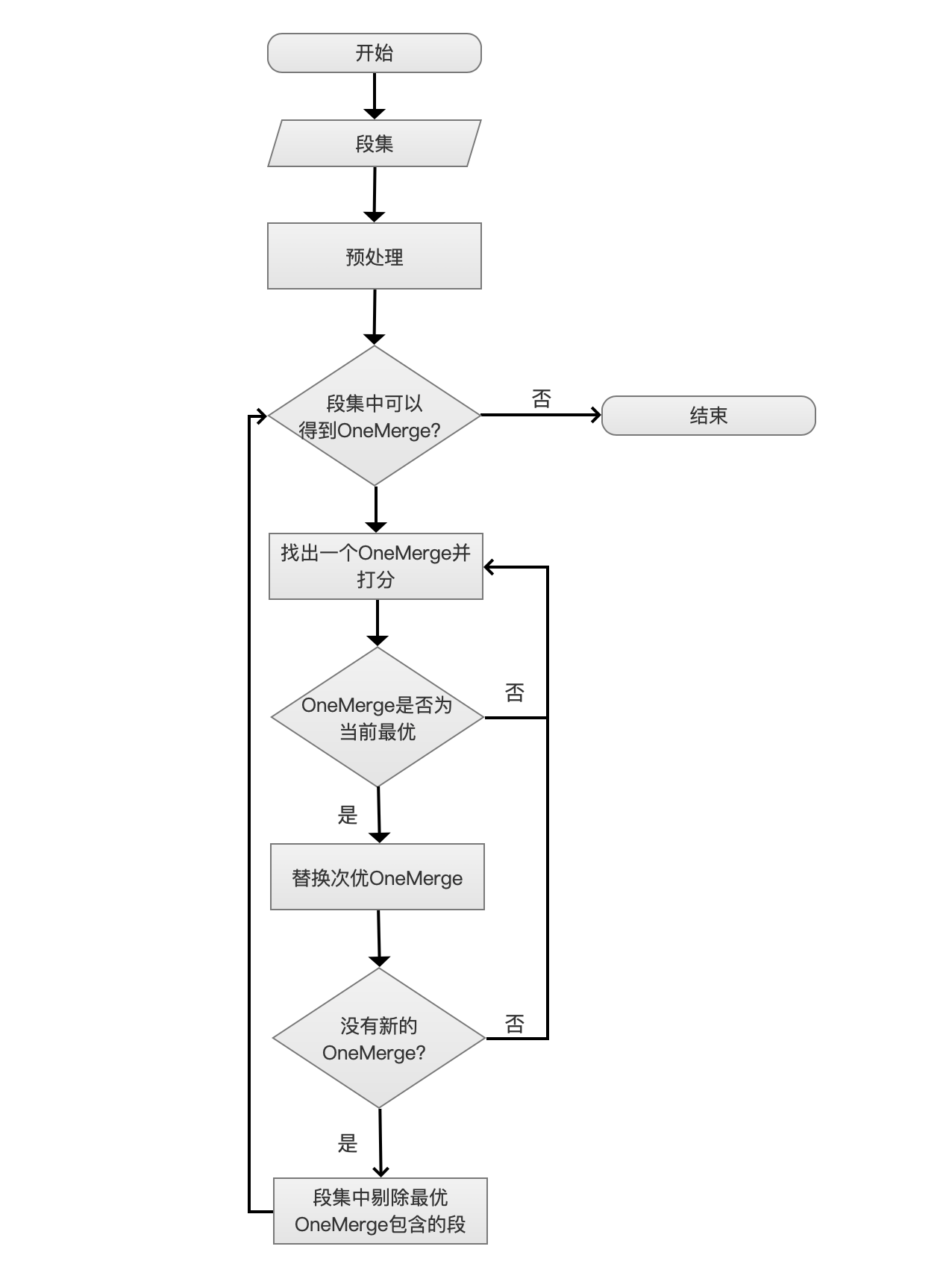
详细处理逻辑可以通过阅读Lucene源码得到(org.apache.lucene.index.TieredMergePolicy#findMerges),如下代码段为入口:
public MergeSpecification findMerges(MergeTrigger mergeTrigger, SegmentInfos infos, MergeContext mergeContext) throws IOException {final Set<SegmentCommitInfo> merging = mergeContext.getMergingSegments();// Compute total index bytes & print details about the indexlong totIndexBytes = 0;long minSegmentBytes = Long.MAX_VALUE;int totalDelDocs = 0;int totalMaxDoc = 0;long mergingBytes = 0;List<SegmentSizeAndDocs> sortedInfos = getSortedBySegmentSize(infos, mergeContext);Iterator<SegmentSizeAndDocs> iter = sortedInfos.iterator();while (iter.hasNext()) {SegmentSizeAndDocs segSizeDocs = iter.next();final long segBytes = segSizeDocs.sizeInBytes;if (verbose(mergeContext)) {String extra = merging.contains(segSizeDocs.segInfo) ? " [merging]" : "";if (segBytes >= maxMergedSegmentBytes) {extra += " [skip: too large]";} else if (segBytes < floorSegmentBytes) {extra += " [floored]";}message(" seg=" + segString(mergeContext, Collections.singleton(segSizeDocs.segInfo)) + " size=" + String.format(Locale.ROOT, "%.3f", segBytes / 1024 / 1024.) + " MB" + extra, mergeContext);}if (merging.contains(segSizeDocs.segInfo)) {mergingBytes += segSizeDocs.sizeInBytes;iter.remove();// if this segment is merging, then its deletes are being reclaimed already.// only count live docs in the total max doctotalMaxDoc += segSizeDocs.maxDoc - segSizeDocs.delCount;} else {totalDelDocs += segSizeDocs.delCount;totalMaxDoc += segSizeDocs.maxDoc;}minSegmentBytes = Math.min(segBytes, minSegmentBytes);totIndexBytes += segBytes;}assert totalMaxDoc >= 0;assert totalDelDocs >= 0;final double totalDelPct = 100 * (double) totalDelDocs / totalMaxDoc;int allowedDelCount = (int) (deletesPctAllowed * totalMaxDoc / 100);// If we have too-large segments, grace them out of the maximum segment count// If we're above certain thresholds of deleted docs, we can merge very large segments.int tooBigCount = 0;iter = sortedInfos.iterator();// remove large segments from consideration under two conditions.// 1> Overall percent deleted docs relatively small and this segment is larger than 50% maxSegSize// 2> overall percent deleted docs large and this segment is large and has few deleted docswhile (iter.hasNext()) {SegmentSizeAndDocs segSizeDocs = iter.next();double segDelPct = 100 * (double) segSizeDocs.delCount / (double) segSizeDocs.maxDoc;if (segSizeDocs.sizeInBytes > maxMergedSegmentBytes / 2 && (totalDelPct <= deletesPctAllowed || segDelPct <= deletesPctAllowed)) {iter.remove();tooBigCount++; // Just for reporting purposes.totIndexBytes -= segSizeDocs.sizeInBytes;allowedDelCount -= segSizeDocs.delCount;}}allowedDelCount = Math.max(0, allowedDelCount);final int mergeFactor = (int) Math.min(maxMergeAtOnce, segsPerTier);// Compute max allowed segments in the indexlong levelSize = Math.max(minSegmentBytes, floorSegmentBytes);long bytesLeft = totIndexBytes;double allowedSegCount = 0;while (true) {final double segCountLevel = bytesLeft / (double) levelSize;if (segCountLevel < segsPerTier || levelSize == maxMergedSegmentBytes) {allowedSegCount += Math.ceil(segCountLevel);break;}allowedSegCount += segsPerTier;bytesLeft -= segsPerTier * levelSize;levelSize = Math.min(maxMergedSegmentBytes, levelSize * mergeFactor);}// allowedSegCount may occasionally be less than segsPerTier// if segment sizes are below the floor sizeallowedSegCount = Math.max(allowedSegCount, segsPerTier);if (verbose(mergeContext) && tooBigCount > 0) {message(" allowedSegmentCount=" + allowedSegCount + " vs count=" + infos.size() +" (eligible count=" + sortedInfos.size() + ") tooBigCount= " + tooBigCount, mergeContext);}return doFindMerges(sortedInfos, maxMergedSegmentBytes, mergeFactor, (int) allowedSegCount, allowedDelCount, MERGE_TYPE.NATURAL,mergeContext, mergingBytes >= maxMergedSegmentBytes);
}相关文章:
Lucene-MergePolicy详解
简介 该文章基于业务需求背景,因场景需求进行参数调优,下文会尽可能针对段合并策略(SegmentMergePolicy)的全参数进行说明。 主要介绍TieredMergePolicy,它是Lucene4以后的默认段的合并策略,之前采用的合并…...

数据的加解密
文章目录 分类特点业务的使用补充 分类 对称加密算法非对称加密算法 特点 对称加密算法 : 加密效率高 !加密和解密都使用同一款密钥 但是有一个问题 : 密钥如何从服务端发给客户端? (假如你直接先将密钥发给对方,要是在过程中被黑客技术破解了,那后面的消息也就泄漏了) (后…...

【Spring】更简单的读取和存储对象
更简单的读取和存储对象 一. 存储 Bean 对象1. 前置工作:配置扫描路径2. 添加注解存储 Bean 对象Controller(控制器存储)Service(服务存储)Repository(仓库存储)Component(组件存储&…...
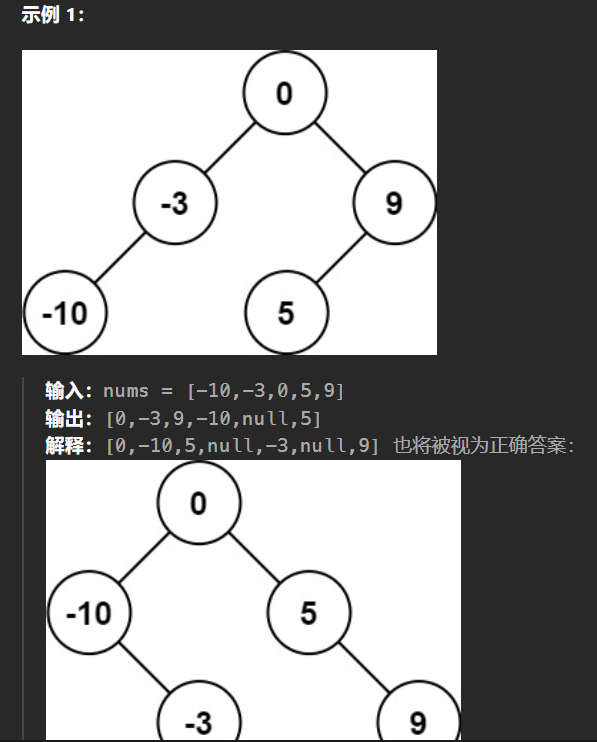
【LeetCode热题100】--108.将有序数组转换为二叉搜索树
108.将有序数组转换为二叉搜索树 给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。 高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。 二叉搜索树的中序遍历是升序…...

Redis学习笔记(下):持久化RDB、AOF+主从复制(薪火相传,反客为主,一主多从,哨兵模式)+Redis集群
十一、持久化RDB和AOF 持久化:将数据存入硬盘 11.1 RDB(Redis Database) RDB:在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。 备份…...

【智能家居项目】裸机版本——设备子系统(LED Display 风扇)
🐱作者:一只大喵咪1201 🐱专栏:《智能家居项目》 🔥格言:你只管努力,剩下的交给时间! 输入子系统中目前仅实现了按键输入,剩下的网络输入和标准输入在以后会逐步实现&am…...

[Linux]记录plasma-wayland下无法找到HDMI接口显示器的问题解决方案
内核:Linux 6.5.5-arch1-1 Plasma 版本:5.27.8 窗口系统:Wayland 1 问题 在前些时候置入了一块显示器,接口较多,有 HDMI 接口,type-C 接口。在 X11 中可以找到外接显示器,但是卡顿明显…...

【计算机网络】高级IO之select
文章目录 1. 什么是IO?什么是高效 IO? 2. IO的五种模型五种IO模型的概念理解同步IO与异步IO整体理解 3. 阻塞IO4. 非阻塞IOsetnonblock函数为什么非阻塞IO会读取错误?对错误码的进一步判断检测数据没有就绪时,返回做一些其他事情完整代码myt…...

如何设计一个高效的应用缓冲区【一个动态扩容的buffer类】
文章目录 前言一、为什么需要设计应用层缓冲区必须要有 output buffer目的问题output buffer的解决方案: 必须要有 input buffer总结 二、设计要点三、buffer设计思路基础函数关于iovec与readv readfd如何实现动态扩容 问题 前言 在上一个博客,我们介绍…...

图像处理初学者导引---OpenCV 方法演示项目
OpenCV 方法演示项目 项目地址:https://github.com/WangQvQ/opencv-tutorial 项目简介 这个开源项目是一个用于演示 OpenCV 方法的工具,旨在帮助初学者快速理解和掌握 OpenCV 图像处理技术。通过这个项目,你可以轻松地对图像进行各种处理&a…...
管道-匿名管道
一、管道介绍 管道(Pipe)是一种在UNIX和类UNIX系统中用于进程间通信的机制。它允许一个进程的输出直接成为另一个进程的输入,从而实现数据的流动。管道是一种轻量级的通信方式,用于协调不同进程的工作。 1. 创建和使用管道&#…...

【JavaEE基础学习打卡08】JSP之初次认识say hello!
目录 前言一、JSP技术初识1.动态页面2.JSP是什么3.JSP特点有哪些 二、JSP运行环境配置1.JDK安装2.Tomcat安装 三、编写JSP1.我的第一个JSP2.JSP执行过程3.在IDEA中开发JSP 总结 前言 📜 本系列教程适用于JavaWeb初学者、爱好者,小白白。我们的天赋并不高…...
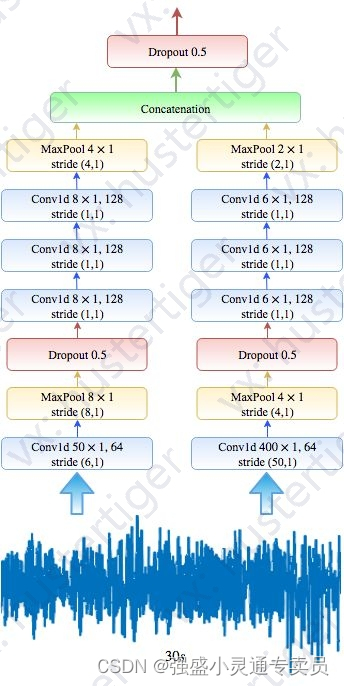
使用序列到序列深度学习方法自动睡眠阶段评分
深度学习方法,用于使用单通道脑电图进行自动睡眠阶段评分。 def build_firstPart_model(input_var,keep_prob_0.5):# List to store the output of each CNNsoutput_conns []######### CNNs with small filter size at the first layer ########## Convolutionnetw…...
【算法】排序——选择排序和交换排序(快速排序)
主页点击直达:个人主页 我的小仓库:代码仓库 C语言偷着笑:C语言专栏 数据结构挨打小记:初阶数据结构专栏 Linux被操作记:Linux专栏 LeetCode刷题掉发记:LeetCode刷题 算法头疼记:算法专栏…...
Docker 容器监控 - Weave Scope
Author:rab 目录 前言一、环境二、部署三、监控3.1 容器监控 - 单 Host3.2 容器监控 - 多 Host 总结 前言 Docker 容器的监控方式有很多,如 cAdvisor、Prometheus 等。今天我们来看看其另一种监控方式 —— Weave Scope,此监控方法似乎用的人…...

Spring Boot集成redis集群拓扑动态刷新
项目场景: Spring Boot集成Redis集群,使用lettuce连接Cluster集群实例。 问题描述 redis其中一个节点挂了之后,springboot集成redis集群配置信息没有及时刷新,出现读取操作报错。 java.lang.IllegalArgumentException: Connec…...

COCI2022-2023#1 Neboderi
P9032 [COCI2022-2023#1] Neboderi 题目大意 有一个长度为 n n n的序列 h i h_i hi,你需要从中选择一个长度大于等于 k k k的子区间 [ l , r ] [l,r] [l,r],使得 g ( h l h l 1 ⋯ h r ) g\times (h_lh_{l1}\cdotsh_r) g(hlhl1⋯hr)最小&…...

由于找不到d3dx9_43.dll无法继续执行此代码怎么解决?全面解析d3dx9_43.dll
在使用计算机过程中,我们可能会遇到各种各样的问题。其中之一就是d3dx9_43.dll文件丢失的问题。这个问题通常会出现在运行某些应用程序或游戏时,导致程序无法正常启动或运行。那么,如何解决这个问题呢?小编将为您提供一些解决方案…...

Linux--网络编程-字节序
进程间的通信: 管道、消息队列、共享内存、信号、信号量。 特点:都依赖于linux内核。 缺陷:无法多机通信。 一、网络编程: 1、地址:基于网络,ip地址端口号。 端口号作用: 一台拥有ip地址的主机…...
python实现http/https拦截
python实现http拦截 前言:为什么要使用http拦截一、技术调研二、技术选择三、使用方法前言:为什么要使用http拦截 大多数爬虫玩家会直接选择API请求数据,但是有的网站需要解决扫码登录、Cookie校验、数字签名等,这种方法实现时间长,难度高。需求里面不需要高并发,有没有…...

从水果摊到芯片验证:用SystemVerilog队列模拟真实场景的3种方法
从水果摊到芯片验证:用SystemVerilog队列模拟真实场景的3种方法 当你在水果摊前看到摊主熟练地整理货架时,可能不会想到这场景与芯片验证工程师的工作有何关联。但实际上,管理水果库存和构建高效验证环境有着惊人的相似之处——都需要处理动态…...

维科技术2025年亏损收窄至1.02亿!钠电池爬坡期后的业绩拐点已现?
维科技术2025年亏损收窄至1.02亿!钠电池爬坡期后的业绩拐点已现? 2025年,维科技术交出"减亏成绩单",全年净亏损1.02亿元,较上年同期收窄64.5%,营收14.18亿元虽同比下滑7.2%,但第四季…...
)
【MicroPython编程-ESP32篇:设备驱动】-8x8LED点阵驱动(基于Max7219+SPI)
8x8LED点阵驱动(基于Max7219+SPI) 文章目录 8x8LED点阵驱动(基于Max7219+SPI) 1、Max7219 LED驱动器介绍 2、软件准备 3、硬件准备 4、代码实现 4.1 MAX7219传感器驱动 4.2 主程序 1、Max7219 LED驱动器介绍 MAX7219/MAX7221是一款紧凑型串行输入/输出共阴极显示驱动器,可将微…...

GEOS库在Windows环境下的编译与配置实战指南
1. GEOS库简介与Windows编译必要性 GEOS(Geometry Engine - Open Source)是一个强大的C空间计算库,它完整实现了OGC简单要素规范的空间谓词和空间操作功能。简单来说,它就是地理信息系统领域的"瑞士军刀",能…...

从游戏UI到数据可视化:Circle packing问题的7个实际应用案例
从游戏UI到数据可视化:Circle packing问题的7个实际应用案例 在数字时代,高效的空间利用和视觉呈现成为产品设计的关键竞争力。Circle packing(圆形填充)算法作为一种优雅的数学解决方案,正在悄然改变多个行业的布局逻…...

计算机毕业设计springboot基于Vue.js的企业资产管理系统 基于SpringBoot与Vue.js的企业固定资产全生命周期管理平台 采用前后端分离架构的企业设备资产数字化运营系统
计算机毕业设计springboot基于Vue.js的企业资产管理系统(配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着企业规模的扩张与业务复杂度的提升,传统手工记录模式已难…...

springboot基于Java的旅游攻略分享平台
第一章 平台开发背景与SpringBoot适配性 当前旅游攻略领域面临诸多痛点:旅行者获取攻略多依赖旅游平台官方推荐,内容同质化严重,缺乏真实、个性化的本地体验分享;攻略创作者发布内容需在多个平台切换,数据分散且收益难…...

PPOCRLabel进行多语言语种的自动标注
需求需要标注法语。PPOCRLabel默认标注中文/英文。如果需要标注其他语种,需要修改代码。在PPOCRLabel.py中MainWindow的__init__中进行修改:self.lang "fr" # 加入法语标志params {"use_doc_orientation_classify": False,&qu…...

10大功能让Ctool成为开发者必备的集成化效率工具
10大功能让Ctool成为开发者必备的集成化效率工具 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool Ctool(GitHub 加速计划)是一款面向程序…...
)
NT3H1101W0FHKH 中文规格书开放获取(完整中英对照/能量采集NFC标签IC)
项目说明: 已完成NXP NT3H1101W0FHKH 能量采集NFC标签IC官方数据手册的完整汉化,主要特性:页数:65页(中文版)/130页(双语版)格式:完美保留原版排版、状态图、表格与公式文…...