如何设计一个高效的应用缓冲区【一个动态扩容的buffer类】
文章目录
- 前言
- 一、为什么需要设计应用层缓冲区
- 必须要有 output buffer
- 目的
- 问题
- output buffer的解决方案:
- 必须要有 input buffer
- 总结
- 二、设计要点
- 三、buffer设计思路
- 基础函数
- 关于iovec与readv
- readfd
- 如何实现动态扩容
- 问题
前言
在上一个博客,我们介绍到什么是缓冲区出发,然后也分析了epoll 两个模式使用阻塞与非阻塞缓冲区的区别。
epoll与socket缓冲区的恩恩怨怨
本文介绍如何设计一个合理的内部逻辑稳定的读写缓冲区。基于Muduo库的设计思想。
一、为什么需要设计应用层缓冲区
基于Muduo库的应用缓冲区源码以及陈硕大神的博客进行实现与总结。
大多数的网络模型是非阻塞IO模型,即每次send() 不一定全发完,没发完的数据要用一个容器进行接收,所以必须要实现应用层缓冲区.
如果是水平触发,那么套接字会一直处于可读状态,io多路复用函数会一直认为这个套接字被激活,也就是说如果第一次触发后没有将tcp缓冲区中的数据全部读出,那么下次进行到poll函数时会立即返回,因为套接字一直是可读的。这会导致了busy loop问题。
如果是边缘触发,那么就只会触发一次,即使第一次触发没有将所有数据都读走,下次进行到poll也不会再触发套接字的可读状态,直到下次又有一批数据送至tcp缓冲区中,才会再次触发可读。所以有可能存在漏读数据的问题,万一不会再有数据到来呢,此时tcp缓冲区中仍然有数据,而应用程序却不知道。
这样一来,应用层的缓冲是必须的,每个 TCP socket 都要有 stateful 的 input buffer 和 output buffer。
必须要有 output buffer
目的
网络库需要为每个TCP连接配置输出缓冲区,以便处理数据的发送和缓冲,并且需要根据套接字的可写状态进行相应的处理和调度。这样可以实现高效的数据发送和事件处理,使程序能够快速返回事件循环,提高整体的性能和响应能力。
问题
程序想通过 TCP 连接发送 100k 字节的数据,但是在 write() 调用中,操作系统只接受了 80k 字节(受 TCP advertised window 的控制,细节见 TCPv1),你肯定不想在原地等待,因为不知道会等多久(取决于对方什么时候接受数据,然后滑动 TCP 窗口)。程序应该尽快交出控制权,返回 event loop。在这种情况下,剩余的 20k 字节数据怎么办?
output buffer的解决方案:
1、对于应用程序而言,它只管生成数据,它不应该关心到底数据是一次性发送还是分成几次发送,这些应该由网络库来操心,程序只要调用 TcpConnection::send() 就行了,网络库会负责到底。网络库应该接管这剩余的 20k 字节数据,把它保存在该 TCP connection 的 output buffer 里,然后注册 POLLOUT 事件,一旦 socket 变得可写就立刻发送数据。当然,这第二次 write() 也不一定能完全写入 20k 字节,如果还有剩余,网络库应该继续关注 POLLOUT 事件;如果写完了 20k 字节,网络库应该停止关注 POLLOUT,以免造成 busy loop。
2、如果在发送过程中,输出缓冲区仍然有待发送的数据,而程序又要写入新的数据,网络库应该将新的数据追加到输出缓冲区的末尾,等待下次套接字可写时再发送。这样可以避免频繁的写入操作导致的性能下降。
3、如果程序想要关闭连接时,但输出缓冲区中仍有待发送的数据,网络库不能立即关闭连接。相反,它应该等待数据发送完毕后再关闭连接,以确保数据不会丢失。
必须要有 input buffer
TcpConnection必须要有input buffer TCP是一个无边界的字节流协议,接收方必须要处理“收到的数据尚不构成一条完整的消息”和“一次收到两条消息的数据”等等情况。一个常见的场景是,发送方send了两条10k字节的消息(共20k),接收方收到数据的情况可能是:
一次性收到20k数据
分两次收到,第一次5k,第二次15k
分三次收到,第一次6k,第二次8k,第三次6k
等等任何可能
以上情况俗称“粘包”问题。
网络库在处理“socket可读”事件的时候,必须一次性把socket中数据读完(从操作系统buffer搬到应用层buffer),否则会反复触发POLLIN事件,造成busy loop。
如何处理?
接收到数据,存在input buffer,通知上层的应用程序,OnMessage(buffer)回调,根据应用层协议判定是否是一个完整的包,进行codec解码,如果不是一条完整的消息,不会取走数据,也不会进行相应的处理。如果是一条完整的消息,将取走这条消息,并进行相应的处理。如何处理就是上层应用程序的职责了。
总结
Non-blocking IO 的核心思想是避免阻塞在 read() 或 write() 或其他 IO 系统调用上,这样可以最大限度地复用 thread-of-control,让一个线程能服务于多个 socket 连接。IO 线程只能阻塞在 IO-multiplexing 函数上,如 select()/poll()/epoll_wait()。这样一来,应用层的缓冲是必须的,每个 TCP socket 都要有 stateful 的 input buffer 和 output buffer。muduo库都是带缓冲的I/O,不会自己去read()或write()某个socket,只会操作TcpConnection的input buffer和output buffer。更确切的说,是在OnMessage()回调里读取input buffer;调用TcpConnection::send()来间接操作output buffer,一般不会直接操作output buffer。
所以,设计应用层自己的缓冲区是很有必要的,也就是由应用程序来管理缓冲区问题
二、设计要点
陈硕大神的总结如下:
应用缓冲区对外表现为一块连续的内存(char, len),以方便客户代码的编写。其 size() 可以自动增长,以适应不同大小的消息。它不是一个 fixed size array (即 char buf[8192])。内部以 vector of char 来保存数据,并提供相应的访问函数。*
要点
1、应用层缓冲区通常很大,也可以初始很小,但可以通过动态调整改变大小(vector)
2、当用户想要调用write/send写入数据给对端,如果数据可以全部写入,那么写入就好了。如果写入了部分数据或者根本一点数据都写不进去,此时表明内核缓冲区已满,为了不阻塞当前线程,应用层写缓冲区会接管这些数据,等到内核缓冲区可以写入的时候自动帮用户写入。
3、当有数据到达内核缓冲区,应用层的读缓冲区会自动将这些数据读到自己那里,当用户调用read/recv想要读取数据时,应用层读缓冲区将已经从内核缓冲区取出的数据返回给用户,实际上就是用户从应用层读缓冲区读取数据
4、应用层缓冲区对用户而言是隐藏的,用户可能根本不知道有应用层缓冲区的存在,只需读/取数据,而且也不会阻塞当前线程
三、buffer设计思路
/*1-----2---3-------4------51是begin2是kCheapPrepend 表示8字节头部3是prependableBytes也就是readerIndex_ 4是writerIndex_5是buffer_.size()1-2是 头部信息大小2-3是 已经读过来的 缓冲区 空闲的prependableBytes() - kCheapPrepend3-4是 readableBytes 要读的空间 也就是writerIndex_ - readerIndex_4-5是 writableBytes 可写的空间 也就是是buffer_.size() - writerIndex_prependableBytes() - kCheapPrepend 就是已经读了的 ,空闲出来的
加上可以写的,就是中共能够写入的,如果不够就要resize
如果够那么 就需要挪一下 ,把已经读的了与可以写的拼在一起
*/
muduo应用层缓冲区的设计采用std::vector数据结构,一方面内存是连续的方便管理,另一方面,vector自带的增长模式足以应对动态调整大小的任务
缓冲区Buffer的定义如下,只列出了一些重要部分
主要就是利用两个指针readerIndex,writerIndex分别记录着缓冲区中数据的起点和终点,写入数据的时候追加到writeIndex后面,读出数据时从readerIndex开始读。在readerIndex前面预留了几个字节大小的空间,方便日后为数据追加头部信息。缓冲区在使用的过程中会动态调整readerIndex和writerIndex的位置,初始缓冲区为空,readerIndex == writerIndex。
Muduo Buffer 的 size() 是自适应的,它一开始的初始值是 1k,如果程序里边经常收发 10k 的数据,那么用几次之后它的 size() 会自动增长到 10k,然后就保持不变。这样一方面避免浪费内存(有的程序可能只需要 4k 的缓冲),另一方面避免反复分配内存。当然,客户代码可以手动 shrink() buffer size()。
以下是别人的总结
-
1.相比之下,采用vector连续内存更容易管理,同时利用std::vector自带的内存 -
增长方式,可以减少扩充的次数(capacity和size一般不同) -
2.记录缓冲区数据起始位置和结束位置,写入时写到已有数据的后面,读出时从 -
数据起始位置读出 -
3.起始/结束位置如上图的readerIndex/writeIndex,其中readerIndex为缓冲区 -
数据的起始索引下标,writeIndex为结束位置下标。采用下标而不是迭代器的 -
原因是删除(erase)数据时迭代器可能失效 -
4.开头部分(readerIndex以前)是预留空间,通常只有几个字节的大小,可以用来 -
写入数据的长度,解决粘包问题 -
5.读出和写入数据时会动态调整readerIndex/writeIndex,如果没有数据,二者 -
相等
基础函数
成员变量
static const size_t kCheapPrepend = 8; //默认预留8个字节static const size_t kInitialSize = 1024; //初始大小
private:std::vector<char> buffer_; //vector用于替代固定数组size_t readerIndex_; //读位置size_t writerIndex_; //写位置Buffer获取各个长度的方法:
//可读大小size_t readableBytes() const{ return writerIndex_ - readerIndex_; }
//可写大小size_t writableBytes() const{ return buffer_.size() - writerIndex_; }
//预留大小size_t prependableBytes() const{ return readerIndex_; }
获取可读下标:
//读的下标const char* peek() const{ return begin() + readerIndex_;
返回缓冲区中可读数据的起始地址
const char* peek() const{return begin() + readerIndex_;}
把onMessage函数上报的Buffer数据,转成string类型的数据返回
// 把onMessage函数上报的Buffer数据,转成string类型的数据返回std::string retrieveAllAsString(){// 应用缓存区可读取长度writerIndex_ - readerIndex_数据的长度return retrieveAsString(readableBytes());}std::string retrieveAsString(size_t len){// 可读数据的 地址以及长度 构造出ret,把readable的数据全部读取std::string result(peek(), len);// 上面一句把缓冲区中可读的数据,已经读取出来,这里肯定要对缓冲区进行复位操作retrieve(len);return result;}
关于iovec与readv
引用博客
使用read()将数据读到不连续的内存,要经过多次的调用read。如果要从文件中读一片连续的数据至进程的不同区域,有两种方案:
①使用read()一次将它们读至一个较大的缓冲区中,然后将它们分成若干部分复制到不同的区域;
②调用r©adO若干次分批将它们读至不同区域。同样,如果想将程序中不同区域的数据块连续地写至文件,也必须进行类似的处理。
缺点:执行系统调用必然使得性能降低。
UNIX提供了另外两个函数—readv()它们只需一次系统调用就可以实现多个缓冲区之间传送数据,免除了多次系统调用或复制数据的开销。readv()称为散布读,即将文件中若干连续的数据块读入内存分散的缓冲区中。
这里为什么要用readv
因为我们预先不知道内核缓冲区的数据大小, 在某些情况下,应用缓冲区可能无法存储全部的读取数据,需要额外的缓冲区进行存储。通过使用栈上的内存空间extrabuf,存储额外的读取数据。
这样就带来了另外一个问题,可能需要把内核缓冲区的数据保存到这个两个不同的内存区域中。
通过一次 readv 函数调用读入内存分散的缓冲区中。就能大大提高数据读取效率。
主要是为了解决,应用缓冲区内存不够的情况下保证只是进行一次系统调用。
readfd
用户自定义缓冲区Buffer是有大小限制的,我们一开始不知道TCP接收缓冲区中的数据量有多少,如果一次性读出来会不会导致Buffer装不下而溢出。所以在readFd( )函数中会在栈上创建一个临时空间extrabuf,然后使用readv的分散读特性,将TCP缓冲区中的数据先拷贝到Buffer中,如果Buffer容量不够,就把剩余的数据都拷贝到extrabuf中,然后再调整Buffer的容量(动态扩容),再把extrabuf的数据拷贝到Buffer中。当这个函数结束后,extrabuf也会被释放。另外extrabuf是在栈上开辟的空间,速度比在堆上开辟还要快。
ssize_t Buffer::readFd(int fd, int* saveErrno)
{/*在某些情况下,应用缓冲区可能无法存储全部的读取数据,需要额外的缓冲区进行存储。通过使用栈上的内存空间extrabuf,存储额外的读取数据。需要将文件(套接字)接收缓冲中的数据读入不同位置时,可以不必多次调用 read 函数,而是通过一次 readv 函数调用就能大大提高数据读取效率。*/char extrabuf[65536] = {0}; // 栈上的内存空间 64Kstruct iovec vec[2];// 这是Buffer底层缓冲区剩余的可写空间大小const size_t writable = writableBytes();vec[0].iov_base = begin() + writerIndex_;vec[0].iov_len = writable;vec[1].iov_base = extrabuf;vec[1].iov_len = sizeof extrabuf;// 保证缓冲区刚刚好 能够一次性读完const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;const ssize_t n = ::readv(fd, vec, iovcnt);if (n < 0){*saveErrno = errno;}else if (n <= writable) // Buffer的可写缓冲区已经够存储读出来的数据了{writerIndex_ += n;}else // extrabuf里面也写入了数据 {// writerIndex_开始写 n - writable大小的数据writerIndex_ = buffer_.size();append(extrabuf, n - writable); }return n;
}
readFd巧妙的设计,可以让用户一次性把所有TCP接收缓冲区的所有数据全部都读出来并放到用户自定义的缓冲区Buffer中。
如何实现动态扩容
上面介绍到了,如果用户自定义的缓冲区Buffer内存不够,需要把extrabuf中的数据加入到我们的应用缓冲区中去,这个时候我们的应用缓冲区就需要动态扩容了。主要是通过两种方式,一种是直接扩容,一种是内部腾挪的方式
在追加函数中 想要确保有足够的空间ensureWriteableBytes。
// 把[data, data+len]内存上的数据,添加到writable缓冲区当中void append(const char *data, size_t len){// 追加到 beginWrite 后面 也就是 3-4是 readableBytes 要读的空间// 然后writerIndex_ 往后面挪ensureWriteableBytes(len);std::copy(data, data+len, beginWrite());writerIndex_ += len;}
如果writableBytes可写入的空间小雨将要存入数据的带下就需要makeSpace扩容
// 可写部分 是buffer_.size() - writerIndex_ // 要写 len 这么长,需要对比一下可写缓存区的 长度// 如果太小要扩容void ensureWriteableBytes(size_t len){if (writableBytes() < len){makeSpace(len); // 扩容函数}}
prependableBytes() - kCheapPrepend 就是已经读了的 ,空闲出来的加上可以写的,就是总共能够写入的,如果不够就要resize
如果够那么 就需要挪一下 ,把已经读的了与可以写的拼在一起。
void makeSpace(size_t len){if (writableBytes() + prependableBytes() - kCheapPrepend< len ){// 腾不出这个大小 ,就要resizebuffer_.resize(writerIndex_ + len);}else{size_t readalbe = readableBytes();std::copy(begin() + readerIndex_, begin() + writerIndex_,begin() + kCheapPrepend);readerIndex_ = kCheapPrepend;writerIndex_ = readerIndex_ + readalbe;}}
问题
为什么不在Buffer构造时就开辟足够大的缓冲区
1.每个tcp连接都有输入/输出缓冲区,如果连接过多则内存消耗会很大
2.防止客户端与服务器端数据交互比较少,造成缓冲区的浪费
3.当缓冲区大小不足时,利用vector内存增长的优势,扩充缓冲区
为什么不在读数据之前判断一下应用层缓冲区是否可以容纳内核缓冲区的全部数据
1.采用这种方式就会调用一次recv,传入MSG_PEEK,即recv(sockfd, extrabuf, sizeof(extrabuf), MSG_PEEK)可根据返回值判断缓冲区还有多少数据没有接收,然后再调用一次recv从内核冲读取数据
2.但是这样会执行两次系统调用,得不偿失,尽量使用一次系统调用就将所有数据读出,这就需要一个很大的空间
相关文章:

如何设计一个高效的应用缓冲区【一个动态扩容的buffer类】
文章目录 前言一、为什么需要设计应用层缓冲区必须要有 output buffer目的问题output buffer的解决方案: 必须要有 input buffer总结 二、设计要点三、buffer设计思路基础函数关于iovec与readv readfd如何实现动态扩容 问题 前言 在上一个博客,我们介绍…...

图像处理初学者导引---OpenCV 方法演示项目
OpenCV 方法演示项目 项目地址:https://github.com/WangQvQ/opencv-tutorial 项目简介 这个开源项目是一个用于演示 OpenCV 方法的工具,旨在帮助初学者快速理解和掌握 OpenCV 图像处理技术。通过这个项目,你可以轻松地对图像进行各种处理&a…...
管道-匿名管道
一、管道介绍 管道(Pipe)是一种在UNIX和类UNIX系统中用于进程间通信的机制。它允许一个进程的输出直接成为另一个进程的输入,从而实现数据的流动。管道是一种轻量级的通信方式,用于协调不同进程的工作。 1. 创建和使用管道&#…...

【JavaEE基础学习打卡08】JSP之初次认识say hello!
目录 前言一、JSP技术初识1.动态页面2.JSP是什么3.JSP特点有哪些 二、JSP运行环境配置1.JDK安装2.Tomcat安装 三、编写JSP1.我的第一个JSP2.JSP执行过程3.在IDEA中开发JSP 总结 前言 📜 本系列教程适用于JavaWeb初学者、爱好者,小白白。我们的天赋并不高…...
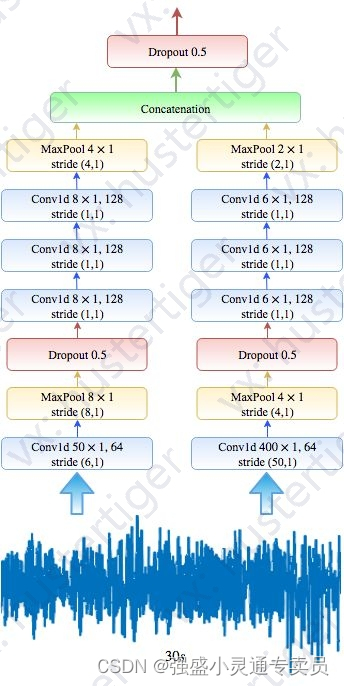
使用序列到序列深度学习方法自动睡眠阶段评分
深度学习方法,用于使用单通道脑电图进行自动睡眠阶段评分。 def build_firstPart_model(input_var,keep_prob_0.5):# List to store the output of each CNNsoutput_conns []######### CNNs with small filter size at the first layer ########## Convolutionnetw…...
【算法】排序——选择排序和交换排序(快速排序)
主页点击直达:个人主页 我的小仓库:代码仓库 C语言偷着笑:C语言专栏 数据结构挨打小记:初阶数据结构专栏 Linux被操作记:Linux专栏 LeetCode刷题掉发记:LeetCode刷题 算法头疼记:算法专栏…...
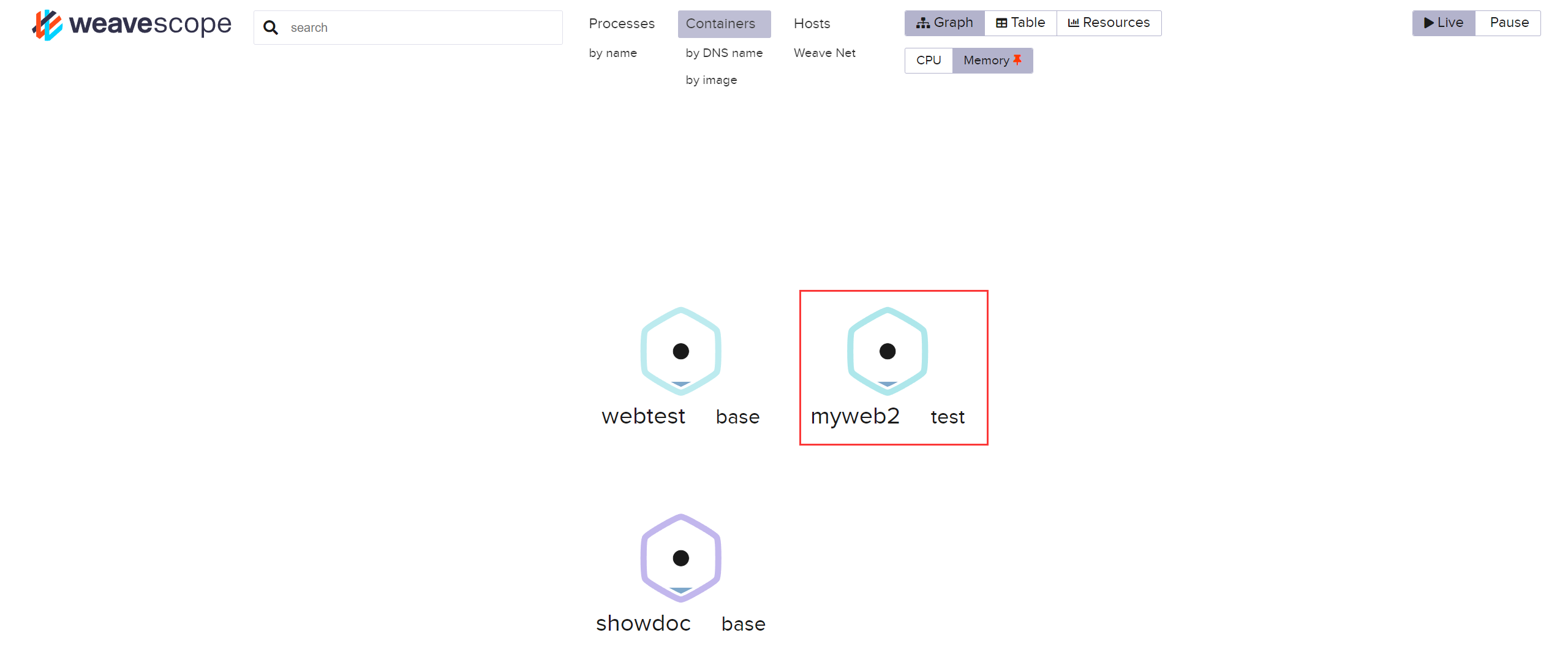
Docker 容器监控 - Weave Scope
Author:rab 目录 前言一、环境二、部署三、监控3.1 容器监控 - 单 Host3.2 容器监控 - 多 Host 总结 前言 Docker 容器的监控方式有很多,如 cAdvisor、Prometheus 等。今天我们来看看其另一种监控方式 —— Weave Scope,此监控方法似乎用的人…...

Spring Boot集成redis集群拓扑动态刷新
项目场景: Spring Boot集成Redis集群,使用lettuce连接Cluster集群实例。 问题描述 redis其中一个节点挂了之后,springboot集成redis集群配置信息没有及时刷新,出现读取操作报错。 java.lang.IllegalArgumentException: Connec…...

COCI2022-2023#1 Neboderi
P9032 [COCI2022-2023#1] Neboderi 题目大意 有一个长度为 n n n的序列 h i h_i hi,你需要从中选择一个长度大于等于 k k k的子区间 [ l , r ] [l,r] [l,r],使得 g ( h l h l 1 ⋯ h r ) g\times (h_lh_{l1}\cdotsh_r) g(hlhl1⋯hr)最小&…...

由于找不到d3dx9_43.dll无法继续执行此代码怎么解决?全面解析d3dx9_43.dll
在使用计算机过程中,我们可能会遇到各种各样的问题。其中之一就是d3dx9_43.dll文件丢失的问题。这个问题通常会出现在运行某些应用程序或游戏时,导致程序无法正常启动或运行。那么,如何解决这个问题呢?小编将为您提供一些解决方案…...

Linux--网络编程-字节序
进程间的通信: 管道、消息队列、共享内存、信号、信号量。 特点:都依赖于linux内核。 缺陷:无法多机通信。 一、网络编程: 1、地址:基于网络,ip地址端口号。 端口号作用: 一台拥有ip地址的主机…...
python实现http/https拦截
python实现http拦截 前言:为什么要使用http拦截一、技术调研二、技术选择三、使用方法前言:为什么要使用http拦截 大多数爬虫玩家会直接选择API请求数据,但是有的网站需要解决扫码登录、Cookie校验、数字签名等,这种方法实现时间长,难度高。需求里面不需要高并发,有没有…...
农产品团购配送商城小程序的作用是什么
农产品覆盖稻麦油蛋等多种细分类目,各地区经营商家众多,随着人们生活品质提升,对食物的要求也在提升,绿色无污染无激素的农产品往往受到不少人喜爱,而在销售中,也有不少人选择自建商城线上经营。 通过【雨…...

使用van-dialog二次封装微信小程序模态框
由于微信小程序的wx.showModal不支持富文本内容,无法实现更灵活的展示效果,故需要进行二次封装 实现思路:使用van-dialog以及微信小程序的rich-text实现 代码如下: // index.wxml <van-dialoguse-slottitle"提示"s…...
生鲜蔬果同城配送社区团购小程序商城的作用是什么
生鲜蔬果行业作为市场主要支撑之一,从业商家众多的同时消费者也从不缺,尤其对中高城市,生鲜蔬果除了传统线下超市、市场经营外,线上更是受到大量消费者信任,而很多商家也是自建了生鲜蔬果商城多场景生意经营。 那么通…...
Unity实现设计模式——状态模式
Unity实现设计模式——状态模式 状态模式最核心的设计思路就是将对象的状态抽象出一个接口,然后根据它的不同状态封装其行为,这样就可以实现状态和行为的绑定,最终实现对象和状态的有效解耦。 在实际开发中一般用到FSM有限状态机的实现&…...

差分数组的应用技巧
前缀和技巧 针对的算法场景是不需要对原始数组进行修改的情况下,频繁查询某个区间的累加和。 差分数组 主要适用场景是频繁对原始数组的某个区间的元素进行增减。 相关题目 1094. 拼车 1109. 航班预订统计 370. 区间加法 # 1094. 拼车 class Solution:def carPool…...
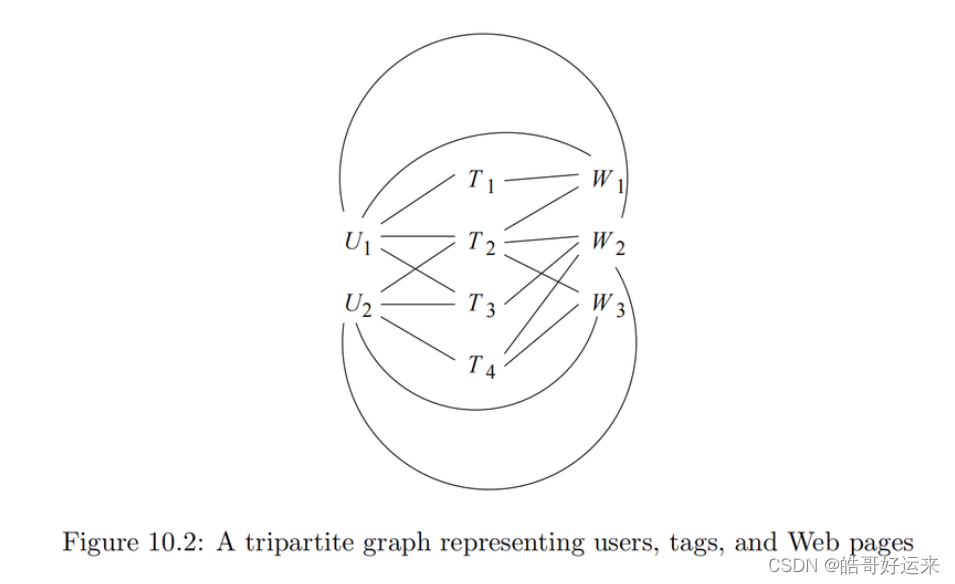
斯坦福数据挖掘教程·第三版》读书笔记(英文版)Chapter 10 Mining Social-Network Graphs
来源:《斯坦福数据挖掘教程第三版》对应的公开英文书和PPT。 Chapter 10 Mining Social-Network Graphs The essential characteristics of a social network are: There is a collection of entities that participate in the network. Typically, these entiti…...

DFS:842. 排列数字
给定一个整数 nn,将数字 1∼n1∼n 排成一排,将会有很多种排列方法。 现在,请你按照字典序将所有的排列方法输出。 输入格式 共一行,包含一个整数 nn。 输出格式 按字典序输出所有排列方案,每个方案占一行。 数据…...

pytorch之nn.Conv1d详解
自然语言处理中一个句子序列,一维的,所以使用Conv1d...

在Jetson Orin NX上为PyTorch 2.0编译TorchVision 0.15:一份完整的避坑与问题解决记录
在Jetson Orin NX上为PyTorch 2.0编译TorchVision 0.15:一份完整的避坑与问题解决记录 Jetson Orin NX作为英伟达新一代边缘计算设备,凭借其强大的AI算力和紧凑的尺寸,成为众多开发者的首选。然而,当我们需要在ARM架构上为特定版本…...
)
告别Cline!用Roo Code在VSCode里打造你的专属AI编程搭档(附扫雷游戏实战)
从Cline到Roo Code:VSCode智能编程助手的进化实战 如果你曾经使用过Cline这类AI编程助手,可能会对它们提供的代码补全和简单问答功能感到满意。但当项目复杂度上升时,这些基础功能往往显得力不从心。这就是为什么越来越多的开发者开始转向Roo…...

Go语言中的包管理
Go语言中的包管理 1. 包管理的基本概念 包管理是Go语言开发中的重要部分,它负责管理项目的依赖关系。Go语言的包管理经历了几个阶段: GOPATH模式vendor模式Go Modules模式(当前推荐) 2. Go Modules简介 Go Modules是Go 1.11引入的…...

复合材料仿真这活儿,玩的就是“套娃“艺术——微观纤维排排坐,细观铺层叠叠乐,宏观冲击看效果。今天咱们就手把手整点硬核操作,捎带唠唠代码里的门道
abaqus多尺度复合材料力学性能仿真模拟 1.建立六角分布的纤维束微观单胞模型,应用最大应力或最大应变准则考虑相应损伤 2.在细观层次上采用hashin准则考虑纤维束和基体的损伤演化 3,做层合板的低速冲击模拟,引入相应损伤准则微观篇࿱…...

KMS_VL_ALL_AIO:Windows和Office智能激活的革命性解决方案
KMS_VL_ALL_AIO:Windows和Office智能激活的革命性解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题烦恼吗?KMS_VL_ALL_AIO是一款创…...

YimMenu:GTA V体验增强工具的全方位应用指南
YimMenu:GTA V体验增强工具的全方位应用指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

Mysql 06: 表与字段别名全解——让 SQL 更简洁、可读性拉满
在 MySQL 中,为表和字段取别名(Alias) 是 SQL 开发的基础必备技能,既能大幅简化 SQL 代码、避免字段名冲突,又能让查询结果更易读,是多表连接、复杂查询的核心优化技巧。本文围绕「表别名」和「字段别名」两…...

茉莉花插件:5分钟快速上手Zotero中文文献智能管理终极指南
茉莉花插件:5分钟快速上手Zotero中文文献智能管理终极指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为处理…...

Phi-3-mini-128k-instruct效果对比:在Reasoning-Over-Code基准中超越Claude-3-Haiku
Phi-3-mini-128k-instruct效果对比:在Reasoning-Over-Code基准中超越Claude-3-Haiku 1. 模型简介 Phi-3-Mini-128K-Instruct是一个38亿参数的轻量级开放模型,属于Phi-3系列的最新成员。这个模型通过Phi-3数据集进行训练,该数据集包含合成数…...

WuliArt Qwen-Image Turbo多场景:跨境电商多语言Prompt适配与本地化出图
WuliArt Qwen-Image Turbo多场景:跨境电商多语言Prompt适配与本地化出图 1. 项目概述 WuliArt Qwen-Image Turbo是一款专为个人GPU环境优化的高性能文生图系统。这个项目基于阿里通义千问的Qwen-Image-2512模型作为核心底座,并深度融合了专门开发的Wul…...