Day898.Join语句执行流程 -MySQL实战
Join语句执行流程
Hi,我是阿昌,今天学习记录的是关于Join语句执行流程的内容。
在实际生产中,关于 join 语句使用的问题,一般会集中在以下两类:
- 不让使用 join,使用 join 有什么问题呢?
- 如果有两个大小不同的表做 join,应该用哪个表做驱动表呢?
创建两个表 t1 和 t2 来说明。
CREATE TABLE `t2` (`id` int(11) NOT NULL,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `a` (`a`)
) ENGINE=InnoDB;drop procedure idata;
delimiter ;;
create procedure idata()
begindeclare i int;set i=1;while(i<=1000)doinsert into t2 values(i, i, i);set i=i+1;end while;
end;;
delimiter ;
call idata();create table t1 like t2;
insert into t1 (select * from t2 where id<=100)
可以看到,这两个表都有一个主键索引 id 和一个索引 a,字段 b 上无索引。
存储过程 idata() 往表 t2 里插入了 1000 行数据,在表 t1 里插入的是 100 行数据。
一、Index Nested-Loop Join
如果直接使用 join 语句,MySQL 优化器可能会选择表 t1 或 t2 作为驱动表,这样会影响分析 SQL 语句的执行过程。
所以,为了便于分析执行过程中的性能问题,改用 straight_join 让 MySQL 使用固定的连接方式执行查询,这样优化器只会按照指定的方式去 join。
来看一下这个语句:
select * from t1 straight_join t2 on (t1.a=t2.a);
在这个语句里,t1 是驱动表,t2 是被驱动表。
现在,来看一下这条语句的 explain 结果。

可以看到,在这条语句里,被驱动表 t2 的字段 a 上有索引,join 过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表 t1 中读入一行数据 R;
- 从数据行 R 中,取出 a 字段到表 t2 里去查找;
- 取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
- 重复执行步骤 1 到 3,直到表 t1 的末尾循环结束。
这个过程是先遍历表 t1,然后根据从表 t1 中取出的每行数据中的 a 值,去表 t2 中查找满足条件的记录。
在形式上,这个过程就跟写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以称之为“Index Nested-Loop Join”,简称 NLJ。它对应的流程图如下所示:

在这个流程里:
- 对驱动表 t1 做了全表扫描,这个过程需要扫描 100 行;
- 而对于每一行 R,根据 a 字段去表 t2 查找,走的是树搜索过程。由于构造的数据都是一一对应的,因此每次的搜索过程都只扫描一行,也是总共扫描 100 行;
- 所以,整个执行流程,总扫描行数是 200。
能不能使用 join?
假设不使用 join,那就只能用单表查询。
看看上面这条语句的需求,用单表查询怎么实现。
- 执行select * from t1,查出表 t1 的所有数据,这里有 100 行;
- 循环遍历这 100 行数据:
- 从每一行 R 取出字段 a 的值 $R.a;
- 执行select * from t2 where a=$R.a;
- 把返回的结果和 R 构成结果集的一行。
可以看到,在这个查询过程,也是扫描了 200 行,但是总共执行了 101 条语句,比直接 join 多了 100 次交互。
除此之外,客户端还要自己拼接 SQL 语句和结果。
显然,这么做还不如直接 join 好。
怎么选择驱动表?
在这个 join 语句执行过程中,==驱动表是走全表扫描,而被驱动表是走树搜索。==假设被驱动表的行数是 M。
每次在被驱动表查一行数据,要先搜索索引 a,再搜索主键索引。
每次搜索一棵树近似复杂度是以 2 为底的 M 的对数,记为 log2M,所以在被驱动表上查一行的时间复杂度是 2*log2M。
假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上匹配一次。
因此整个执行过程,近似复杂度是 N + N*2*log2M。
显然,N 对扫描行数的影响更大,因此应该让小表来做驱动表。
如果没觉得这个影响有那么“显然”, 可以这么理解:
N 扩大 1000 倍的话,扫描行数就会扩大 1000 倍;
而 M 扩大 1000 倍,扫描行数扩大不到 10 倍。
小结一下,通过上面的分析得到了两个结论:
- 使用 join 语句,性能比强行拆成多个单表执行 SQL 语句的性能要好;
- 如果使用 join 语句的话,需要让小表做驱动表。
但是,需要注意,这个结论的前提是“可以使用被驱动表的索引”。
二、Simple Nested-Loop Join
再看看被驱动表用不上索引的情况。
现在,把 SQL 语句改成这样:
select * from t1 straight_join t2 on (t1.a=t2.b);
由于表 t2 的字段 b 上没有索引,因此再用图 2 的执行流程时,每次到 t2 去匹配的时候,就要做一次全表扫描。
你可以先设想一下这个问题,继续使用图 2 的算法,是不是可以得到正确的结果呢?
如果只看结果的话,这个算法是正确的,而且这个算法也有一个名字,叫做“Simple Nested-Loop Join”。
但是,这样算来,这个 SQL 请求就要扫描表 t2 多达 100 次,总共扫描 100*1000=10 万行。
这还只是两个小表,如果 t1 和 t2 都是 10 万行的表(当然了,这也还是属于小表的范围),就要扫描 100 亿行,这个算法看上去太“笨重”了。
三、Block Nested-Loop Join
当然,MySQL 也没有使用这个 Simple Nested-Loop Join 算法,而是使用了另一个叫作“Block Nested-Loop Join”的算法,简称 BNL。
这时候,被驱动表上没有可用的索引,算法的流程是这样的:
- 把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
- 扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
这个过程的流程图如下:
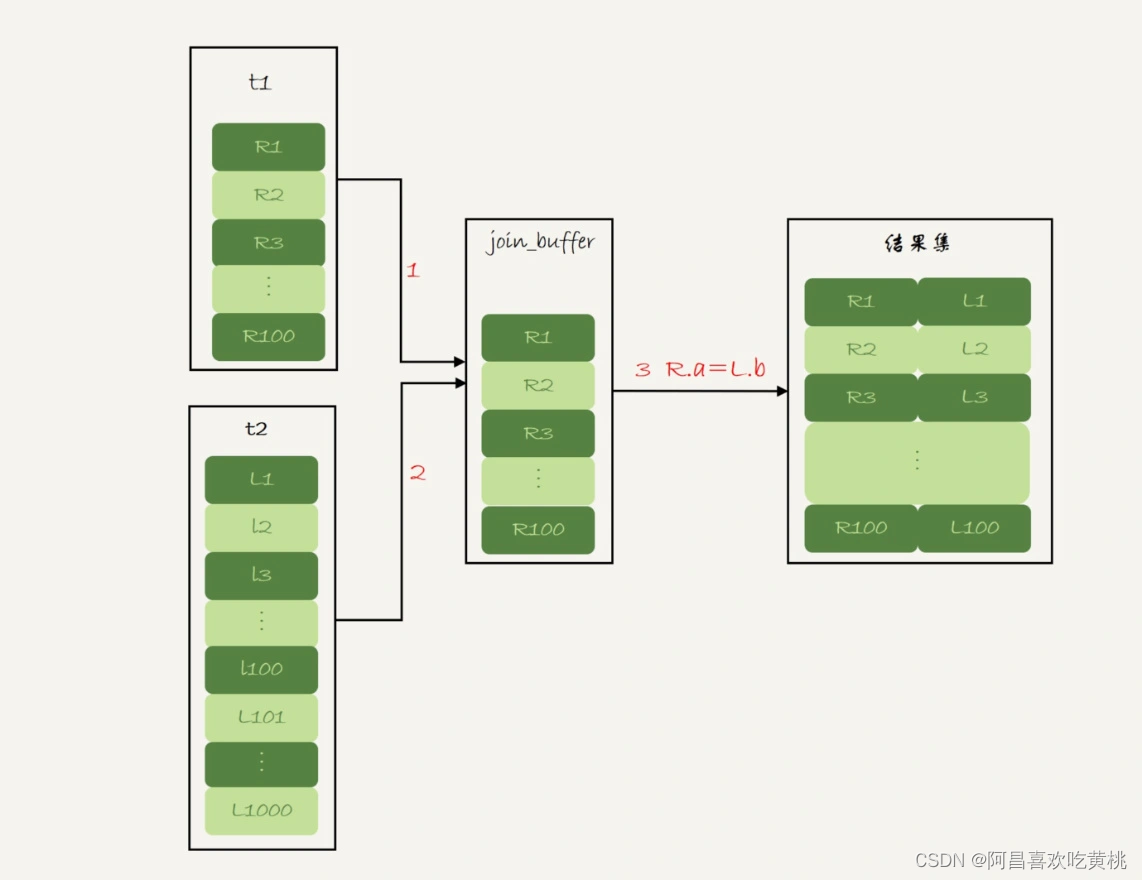
对应地,这条 SQL 语句的 explain 结果如下所示:

可以看到,在这个过程中,对表 t1 和 t2 都做了一次全表扫描,因此总的扫描行数是 1100。
由于 join_buffer 是以无序数组的方式组织的,因此对表 t2 中的每一行,都要做 100 次判断,总共需要在内存中做的判断次数是:100*1000=10 万次。
前面我们说过,如果使用 Simple Nested-Loop Join 算法进行查询,扫描行数也是 10 万行。因此,从时间复杂度上来说,这两个算法是一样的。但是,Block Nested-Loop Join 算法的这 10 万次判断是内存操作,速度上会快很多,性能也更好。
在这种情况下,应该选择哪个表做驱动表。
假设小表的行数是 N,大表的行数是 M,那么在这个算法里:
- 两个表都做一次全表扫描,所以总的扫描行数是 M+N;
- 内存中的判断次数是 M*N。
可以看到,调换这两个算式中的 M 和 N 没差别,因此这时候选择大表还是小表做驱动表,执行耗时是一样的。
这个例子里表 t1 才 100 行,要是表 t1 是一个大表,join_buffer 放不下怎么办呢?
join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。如果放不下表 t1 的所有数据话,策略很简单,就是分段放。
join_buffer_size 改成 1200,再执行:
select * from t1 straight_join t2 on (t1.a=t2.b);
执行过程就变成了:
- 扫描表 t1,顺序读取数据行放入 join_buffer 中,放完第 88 行 join_buffer 满了,继续第 2 步;
- 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
- 清空 join_buffer;
- 继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中,继续执行第 2 步。
执行流程图也就变成这样:
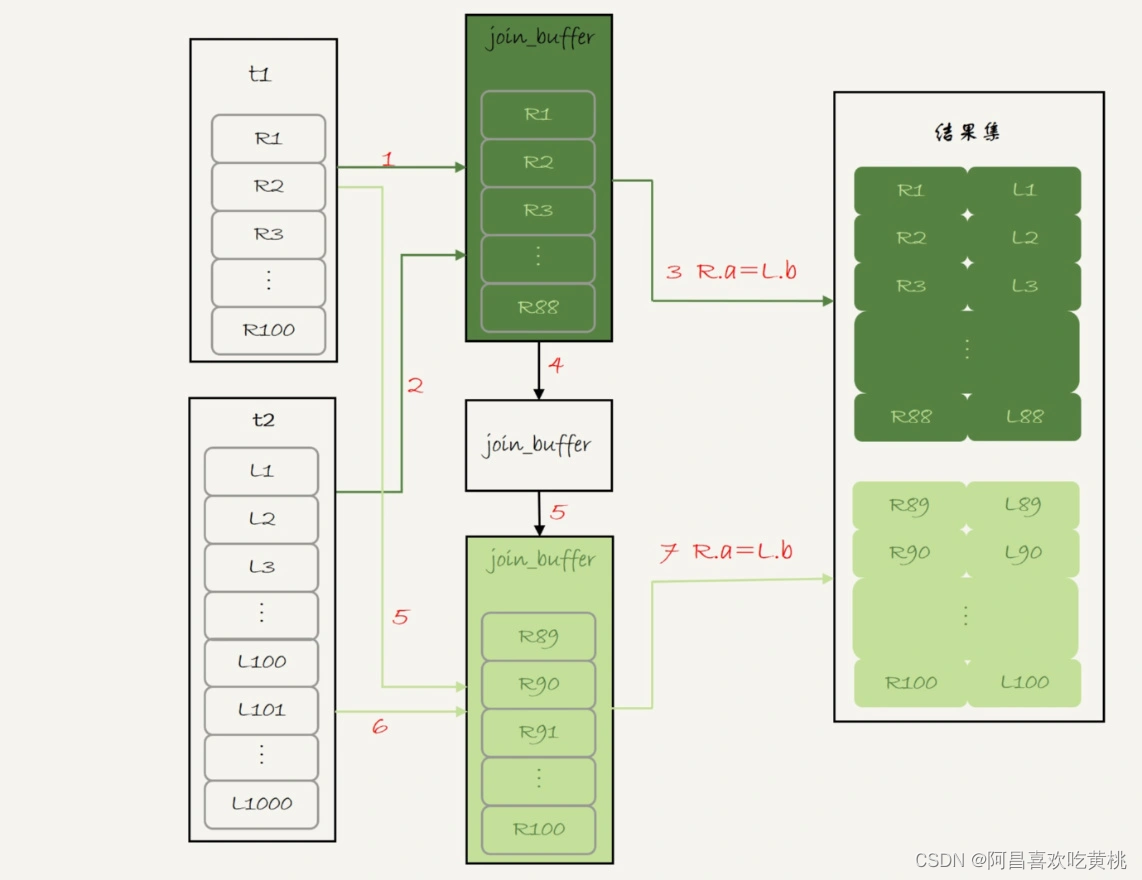
图中的步骤 4 和 5,表示清空 join_buffer 再复用。
这个流程才体现出了这个算法名字中“Block”的由来,表示“分块去 join”。
可以看到,这时候由于表 t1 被分成了两次放入 join_buffer 中,导致表 t2 会被扫描两次。
虽然分成两次放入 join_buffer,但是判断等值条件的次数还是不变的,依然是 (88+12)*1000=10 万次。
在这种情况下驱动表的选择问题。
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。
注意,这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为λ*N,显然λ的取值范围是 (0,1)。
所以,在这个算法的执行过程中:
- 扫描行数是 N+λNM;
- 内存判断 N*M 次。
显然,内存判断次数是不受选择哪个表作为驱动表影响的。
而考虑到扫描行数,在 M 和 N 大小确定的情况下,N 小一些,整个算式的结果会更小。所以结论是,应该让小表当驱动表。
在 N+λNM 这个式子里,λ才是影响扫描行数的关键因素,这个值越小越好。
刚刚我们说了 N 越大,分段数 K 越大。那么,N 固定的时候,什么参数会影响 K 的大小呢?(也就是λ的大小)答案是 join_buffer_size。
join_buffer_size 越大,一次可以放入的行越多,分成的段数也就越少,对被驱动表的全表扫描次数就越少。
如果你的 join 语句很慢,就把 join_buffer_size 改大。
第一个问题:能不能使用 join 语句?
- 如果可以使用 Index Nested-Loop Join 算法,也就是说可以用上被驱动表上的索引,其实是没问题的;
- 如果使用 Block Nested-Loop Join 算法,扫描行数就会过多。尤其是在大表上的 join 操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种 join 尽量不要用。
所以在判断要不要使用 join 语句时,就是看 explain 结果里面,Extra 字段里面有没有出现“Block Nested Loop”字样。
第二个问题是:如果要使用 join,应该选择大表做驱动表还是选择小表做驱动表?
- 如果是 Index Nested-Loop Join 算法,应该选择小表做驱动表;
- 如果是 Block Nested-Loop Join 算法:
- 在 join_buffer_size 足够大的时候,是一样的;
- 在 join_buffer_size 不够大的时候(这种情况更常见),应该选择小表做驱动表。
所以,这个问题的结论就是,总是应该使用小表做驱动表。
当然了,这里我需要说明下,什么叫作“小表”。
如果我在语句的 where 条件加上 t2.id<=50 这个限定条件,再来看下这两条语句:
select * from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=50;
select * from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=50;
注意,为了让两条语句的被驱动表都用不上索引,所以 join 字段都使用了没有索引的字段 b。
但如果是用第二个语句的话,join_buffer 只需要放入 t2 的前 50 行,显然是更好的。
所以这里,“t2 的前 50 行”是那个相对小的表,也就是“小表”。
再来看另外一组例子:
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;
这个例子里,表 t1 和 t2 都是只有 100 行参加 join。
但是,这两条语句每次查询放入 join_buffer 中的数据是不一样的:
- 表 t1 只查字段 b,因此如果把 t1 放到 join_buffer 中,则 join_buffer 中只需要放入 b 的值;
- 表 t2 需要查所有的字段,因此如果把表 t2 放到 join_buffer 中的话,就需要放入三个字段 id、a 和 b。
应该选择表 t1 作为驱动表。也就是说在这个例子里,“只需要一列参与 join 的表 t1”是那个相对小的表。
所以,更准确地说,在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
四、总结
- 如果可以使用被驱动表的索引,join 语句还是有其优势的;
- 不能使用被驱动表的索引,只能使用 Block Nested-Loop Join 算法,这样的语句就尽量不要使用;
- 在使用 join 的时候,应该让小表做驱动表。
使用 Block Nested-Loop Join 算法,可能会因为 join_buffer 不够大,需要对被驱动表做多次全表扫描。如果被驱动表是一个大表,并且是一个冷数据表,除了查询过程中可能会导致 IO 压力大以外,觉得对这个 MySQL 服务还有什么更严重的影响吗?
如果被驱动表是一个大表(因为不论用BNL还是ILJ算法) 都是优先让被参与join的总的字段量较大的一张表作为一个被驱动表。
但是由于关联的时候被驱动表的数据会频繁被走索引数, 所以根据MYSQL 的LRU算法 其实冷数据也会被提到链表的前部 ,造成冷数据的前移,其余业务数据被淘汰。 造成内存命中率降低。 请求响应变慢,业务可能造成阻塞。
相关文章:
Day898.Join语句执行流程 -MySQL实战
Join语句执行流程 Hi,我是阿昌,今天学习记录的是关于Join语句执行流程的内容。 在实际生产中,关于 join 语句使用的问题,一般会集中在以下两类: 不让使用 join,使用 join 有什么问题呢?如果有…...

ChatGPT商业前景如何?人工智能未来会如何发展?
ChatGPT不仅在互联网和多个行业引发人们的关注,在投资界还掀起了机构对人工智能领域的投资热潮。人工智能聊天程序ChatGPT在去年11月亮相之后,在推出仅两个月后,今年1月份的月活用户已达到了1亿,成为史上增长最快的消费者应用程序…...
代码随想录第十六天(347、194、195、94)
347. 前 K 个高频元素 答案 思路: 1、首先,用到了每个值对应的出现次数,想到要用哈希map存放 2、还需要将出现频率从大到小进行排序,找出前k个元素 3、时间复杂度应该比O(nlogn)小 如果想用快速排序&…...

< elementUI组件样式及功能补全: 实现点击steps组件跳转对应步骤 >
文章目录👉 前言👉 一、效果演示👉 二、点击steps跳转效果实现👉 三、实现案例往期内容 💨👉 前言 在 Vue elementUi 开发中,elementUI中steps步骤条组件只提供了change方法,并未提…...

【学习笔记】互联网金融:芝麻信用分的建模过程
学习资料: 数据分析学习随记 | 互联网金融行业2C授信模型(芝麻信用) 1. 背景 互联网金融的本质是风控。 1.1 数据分析师的角色 数据分析师在金融行业基本上有两种角色: 1.1.1 数据建模师 偏算法,但要很懂业务。要求对算法的理解较深&am…...

Linux C/C++或者嵌入式开发到底有没有35岁危机?
一个读者问了一个问题: 我现在25岁,双非一本本科。在深圳上班,做嵌入式开发,打算走Linux C/C开发,工资目前一般。读了前辈写的很多博客之后,觉得很棒。我现在有一些疑问。 1.最近互联网裁员很厉害嘛&#x…...
国内领先的十大API接口排行
应用程序编程接口API即(Application Programming Interface),现在众多企业的应用系统中常用的开放接口,对接相应的系统、软件功能,简化专业化的程序开发。 一、百度API 百度API超市开通1136个数据服务接口。 网址&a…...

【Linux】Kickstart 配置U盘自动化安装Linux系统
文章目录前言一、刻录USB二、配置以BIOS方式启动引导2.1 引导文件配置2.2 KS文件配置三、以EFI方式启动引导3.1 引导文件3.2 KS文件四、 总结前言 之前安装系统,例如在VMware虚拟机中或物理服务器中,都是根据图形界面上的指示进行下一步这类的操作。 现…...

【Spring MVC】这一篇,带你从入门到进阶
目录 1、什么是MVC? 2、什么是 Spring MVC 3、如何学好 Spring MVC? 3.1、如何创建 Spring MVC 项目 3.1.1、使用Spring Initializr创建(推荐) 3.2、将 Spring 程序与用户(浏览器)联通 3.3、基础注解…...
InstallAware Multi-Platform updated
InstallAware Multi-Platform updated 原生ARM:为您的内置设置、IDE和整个工具链添加了Apple macOS和Linux ARM构建。 本地化:引擎内多语言感知,可再分发工具,具有资产隔离功能,使您的IP保持安全。 模板:将…...
Spring Batch 高级篇-多线程步骤
目录 引言 概念 案例 转视频版 引言 接着上篇:Spring Batch ItemWriter组件,了解Spring Batch ItemWriter处理组件后,接下来一起学习一下Spring Batch 高级功能-多线程步骤 概念 默认的情况下,步骤基本上在单线程中执行&…...

关于iframe一些通讯的记录(可适用工作流审批)
一.知识点(1).我们可以通过postMessage(发送方)和onmessage(接收方)这两个HTML5的方法, 来解决跨页面通信问题,或者通过iframe嵌套的不同页面之间的通信a.父页面代码如下<div v-if"src" class"iframe"><iframeref"iframe"id…...

JavaWeb
1、静态Web html、css 2、动态Web 提供给所有人看的数据始终会发生变化。技术栈:Servlet/JSP,ASP,PHP。 Web应用程序:可以提供浏览器访问的程序。 1、这个统一的web资源会被放在同一个文件夹下,web应用程序-->Tom…...

ip段192.168.1.0/24和192.168.0.0/16
192.168.1.0/24192.168.1.1 ~ 192.168.1.254前24位为网络前缀,后8位代表主机号。如下1100 0000,1010 1000,0000 0001,0000 0000192.168.0.0/16192.168.0.1 ~ 192.168.255.254前16位为网络前缀,后16位代表主机号。如下1…...

《爆肝整理》保姆级系列教程python接口自动化(二十二)--unittest执行顺序隐藏的坑(详解)
简介 大多数的初学者在使用 unittest 框架时候,不清楚用例的执行顺序到底是怎样的。对测试类里面的类和方法分不清楚,不知道什么时候执行,什么时候不执行。虽然或许通过代码实现了,也是稀里糊涂的一知半解,这样还好&am…...
、XML注入集合属性)】)
【第二章 IOC操作bean管理(XML注入其他类型属性(字面量,外部bean,内部bean,级联赋值)、XML注入集合属性)】
第二章 IOC操作bean管理(XML注入其他类型属性(字面量,外部bean,内部bean,级联赋值)、XML注入集合属性) 1.IOC操作bean管理(XML注入其他类型属性) (1…...

Kotlin-枚举和印章
kotlin-枚举 枚举也是一个对象,枚举对象的定义需要使用enum关键字 枚举对象可以定义函数 假设定义一个星期枚举对象。就是一下写法 enum class Week {星期一,星期二,星期三,星期四,星期五,星期六,星期日;//打印星期几fun printWeek(){println("这是星期枚举对…...
_linux (TCP协议通讯流程)
文章目录TCP协议通讯流程TCP 和 UDP 对比TCP协议通讯流程 下图是基于TCP协议的客户端/服务器程序的一般流程: 服务器初始化: 调用socket, 创建文件描述符;调用bind, 将当前的文件描述符和ip/port绑定在一起;如果这个端口已经被其他进程占用了, 就会bind失 败;调用listen, 声…...

PMP考试详解,新考纲有什么变化?
一,为什么优先考虑PMP持证人员? PMP证书在我国大型企业、跨国企业、央企/国企等单位的招聘中都比较重视,特别是在许多项目投标环节中,明确标明需要有PMP持证人员,才能在投标、竞标中代表公司有资格承担项目。 除此之…...

C++学习笔记-日期和时间
C中可以使用的日期时间API主要分为两类: C-style 日期时间库,位于头文件中。这是原先<time.h>头文件的C版本。 chrono库:C 11中新增API,增加了时间点,时长和时钟等相关接口。 在C11之前,C编程只能使…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...