【Classical Network】EfficientNetV2
原文地址
原文代码
pytorch实现1
pytorch实现2
详细讲解
文章目录
- EfficientNet中存在的问题
- NAS 搜索
- EfficientNetV2 网络结构
- code
EfficientNet中存在的问题
- 训练图像尺寸大时,训练速度非常慢。train size = 512, batch = 24时,V100 out of memory
- 在网络浅层中使用Depthwise convolutions速度会很慢。因此将原本EfficientNet中的
conv1x1 and depthwise conv3x3 (MBConv)替换成conv3x3 (Fused-MBCon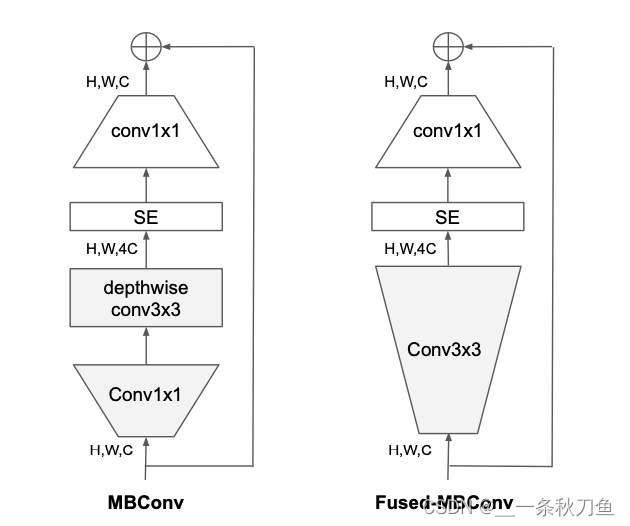 v)。但如果将所有的conv1x1 and depthwise conv3x3都替换成conv3x3后,会明显增加参数数量,降低训练速度,因此使用NAS技术去搜索两者的最佳组合。
- 同等放大每个stage是次优的,因为每个stage对网络的训练速度以及参数量贡献不同。
NAS 搜索
与EfficientNet相同,但这次的NAS搜索采用了联合优化策略,联合了accuracy, parameter efficiency, training efficiency三个标准。设计空间包括
- convolutional operation types {MBConv, Fused-MBConv}
- number of layers
- kernel size {3x3, 5x5}
- expansion ration {1,4,6}
同时随机采样1000个models,并且对每个models进行了10个epochs的训练。搜索奖励结合了模型准确率A,标准训练一个step所需要的时间S,和参数量P, A⋅S−0.07⋅P−0.05A \cdot S^{-0.07} \cdot P^{-0.05} A⋅S−0.07⋅P−0.05
EfficientNetV2 网络结构
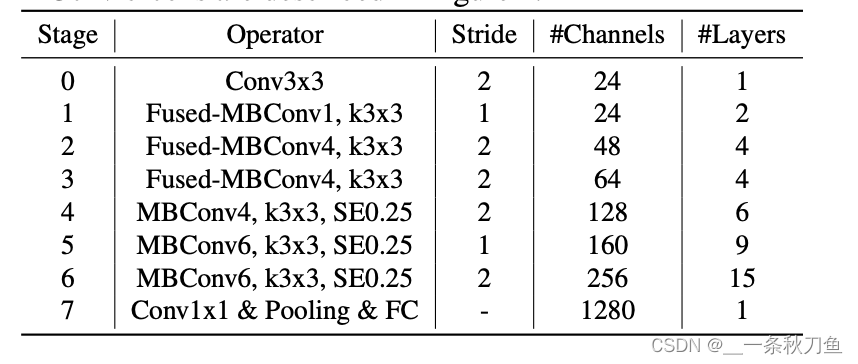
与EfficientNet相比,EfficientNetV2有以下区别:
- 在浅层网络中大量运用了
MBConv和新加入的fused-MBConv - 使用了较小的expansion ratio,可以达到较小的内存访问开销
- 偏向于
kernel3x3,但这需要增加层数来弥补小kernel感受野的不足 - 移除了last stride-1 stage,但是这是由于NAS搜索出来的,所以是作者的猜测可能是在参数量和访存开销的优化。
code
# 使用的是https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/master/pytorch_classification/Test11_efficientnetV2/model.py 中的代码!from collections import OrderedDict
from functools import partial
from typing import Callable, Optionalimport torch.nn as nn
import torch
from torch import Tensordef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdfThis function is taken from the rwightman.It can be seen here:https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py#L140"""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf"""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class ConvBNAct(nn.Module):def __init__(self,in_planes: int,out_planes: int,kernel_size: int = 3,stride: int = 1,groups: int = 1,norm_layer: Optional[Callable[..., nn.Module]] = None,activation_layer: Optional[Callable[..., nn.Module]] = None):super(ConvBNAct, self).__init__()padding = (kernel_size - 1) // 2if norm_layer is None:norm_layer = nn.BatchNorm2dif activation_layer is None:activation_layer = nn.SiLU # alias Swish (torch>=1.7)self.conv = nn.Conv2d(in_channels=in_planes,out_channels=out_planes,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bias=False)self.bn = norm_layer(out_planes)self.act = activation_layer()def forward(self, x):result = self.conv(x)result = self.bn(result)result = self.act(result)return resultclass SqueezeExcite(nn.Module):def __init__(self,input_c: int, # block input channelexpand_c: int, # block expand channelse_ratio: float = 0.25):super(SqueezeExcite, self).__init__()squeeze_c = int(input_c * se_ratio)self.conv_reduce = nn.Conv2d(expand_c, squeeze_c, 1)self.act1 = nn.SiLU() # alias Swishself.conv_expand = nn.Conv2d(squeeze_c, expand_c, 1)self.act2 = nn.Sigmoid()def forward(self, x: Tensor) -> Tensor:scale = x.mean((2, 3), keepdim=True)scale = self.conv_reduce(scale)scale = self.act1(scale)scale = self.conv_expand(scale)scale = self.act2(scale)return scale * xclass MBConv(nn.Module):def __init__(self,kernel_size: int,input_c: int,out_c: int,expand_ratio: int,stride: int,se_ratio: float,drop_rate: float,norm_layer: Callable[..., nn.Module]):super(MBConv, self).__init__()if stride not in [1, 2]:raise ValueError("illegal stride value.")self.has_shortcut = (stride == 1 and input_c == out_c)activation_layer = nn.SiLU # alias Swishexpanded_c = input_c * expand_ratio# 在EfficientNetV2中,MBConv中不存在expansion=1的情况所以conv_pw肯定存在assert expand_ratio != 1# Point-wise expansionself.expand_conv = ConvBNAct(input_c,expanded_c,kernel_size=1,norm_layer=norm_layer,activation_layer=activation_layer)# Depth-wise convolutionself.dwconv = ConvBNAct(expanded_c,expanded_c,kernel_size=kernel_size,stride=stride,groups=expanded_c,norm_layer=norm_layer,activation_layer=activation_layer)self.se = SqueezeExcite(input_c, expanded_c, se_ratio) if se_ratio > 0 else nn.Identity()# Point-wise linear projectionself.project_conv = ConvBNAct(expanded_c,out_planes=out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity) # 注意这里没有激活函数,所有传入Identityself.out_channels = out_c# 只有在使用shortcut连接时才使用dropout层self.drop_rate = drop_rateif self.has_shortcut and drop_rate > 0:self.dropout = DropPath(drop_rate)def forward(self, x: Tensor) -> Tensor:result = self.expand_conv(x)result = self.dwconv(result)result = self.se(result)result = self.project_conv(result)if self.has_shortcut:if self.drop_rate > 0:result = self.dropout(result)result += xreturn resultclass FusedMBConv(nn.Module):def __init__(self,kernel_size: int,input_c: int,out_c: int,expand_ratio: int,stride: int,se_ratio: float,drop_rate: float,norm_layer: Callable[..., nn.Module]):super(FusedMBConv, self).__init__()assert stride in [1, 2]assert se_ratio == 0self.has_shortcut = stride == 1 and input_c == out_cself.drop_rate = drop_rateself.has_expansion = expand_ratio != 1activation_layer = nn.SiLU # alias Swishexpanded_c = input_c * expand_ratio# 只有当expand ratio不等于1时才有expand convif self.has_expansion:# Expansion convolutionself.expand_conv = ConvBNAct(input_c,expanded_c,kernel_size=kernel_size,stride=stride,norm_layer=norm_layer,activation_layer=activation_layer)self.project_conv = ConvBNAct(expanded_c,out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity) # 注意没有激活函数else:# 当只有project_conv时的情况self.project_conv = ConvBNAct(input_c,out_c,kernel_size=kernel_size,stride=stride,norm_layer=norm_layer,activation_layer=activation_layer) # 注意有激活函数self.out_channels = out_c# 只有在使用shortcut连接时才使用dropout层self.drop_rate = drop_rateif self.has_shortcut and drop_rate > 0:self.dropout = DropPath(drop_rate)def forward(self, x: Tensor) -> Tensor:if self.has_expansion:result = self.expand_conv(x)result = self.project_conv(result)else:result = self.project_conv(x)if self.has_shortcut:if self.drop_rate > 0:result = self.dropout(result)result += xreturn resultclass EfficientNetV2(nn.Module):def __init__(self,model_cnf: list,num_classes: int = 1000,num_features: int = 1280,dropout_rate: float = 0.2,drop_connect_rate: float = 0.2):super(EfficientNetV2, self).__init__()for cnf in model_cnf:assert len(cnf) == 8norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)stem_filter_num = model_cnf[0][4]self.stem = ConvBNAct(3,stem_filter_num,kernel_size=3,stride=2,norm_layer=norm_layer) # 激活函数默认是SiLUtotal_blocks = sum([i[0] for i in model_cnf])block_id = 0blocks = []for cnf in model_cnf:repeats = cnf[0]op = FusedMBConv if cnf[-2] == 0 else MBConvfor i in range(repeats):blocks.append(op(kernel_size=cnf[1],input_c=cnf[4] if i == 0 else cnf[5],out_c=cnf[5],expand_ratio=cnf[3],stride=cnf[2] if i == 0 else 1,se_ratio=cnf[-1],drop_rate=drop_connect_rate * block_id / total_blocks,norm_layer=norm_layer))block_id += 1self.blocks = nn.Sequential(*blocks)head_input_c = model_cnf[-1][-3]head = OrderedDict()head.update({"project_conv": ConvBNAct(head_input_c,num_features,kernel_size=1,norm_layer=norm_layer)}) # 激活函数默认是SiLUhead.update({"avgpool": nn.AdaptiveAvgPool2d(1)})head.update({"flatten": nn.Flatten()})if dropout_rate > 0:head.update({"dropout": nn.Dropout(p=dropout_rate, inplace=True)})head.update({"classifier": nn.Linear(num_features, num_classes)})self.head = nn.Sequential(head)# initial weightsfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.BatchNorm2d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.zeros_(m.bias)def forward(self, x: Tensor) -> Tensor:x = self.stem(x)x = self.blocks(x)x = self.head(x)return xdef efficientnetv2_s(num_classes: int = 1000):"""EfficientNetV2https://arxiv.org/abs/2104.00298"""# train_size: 300, eval_size: 384# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config = [[2, 3, 1, 1, 24, 24, 0, 0],[4, 3, 2, 4, 24, 48, 0, 0],[4, 3, 2, 4, 48, 64, 0, 0],[6, 3, 2, 4, 64, 128, 1, 0.25],[9, 3, 1, 6, 128, 160, 1, 0.25],[15, 3, 2, 6, 160, 256, 1, 0.25]]model = EfficientNetV2(model_cnf=model_config,num_classes=num_classes,dropout_rate=0.2)return modeldef efficientnetv2_m(num_classes: int = 1000):"""EfficientNetV2https://arxiv.org/abs/2104.00298"""# train_size: 384, eval_size: 480# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config = [[3, 3, 1, 1, 24, 24, 0, 0],[5, 3, 2, 4, 24, 48, 0, 0],[5, 3, 2, 4, 48, 80, 0, 0],[7, 3, 2, 4, 80, 160, 1, 0.25],[14, 3, 1, 6, 160, 176, 1, 0.25],[18, 3, 2, 6, 176, 304, 1, 0.25],[5, 3, 1, 6, 304, 512, 1, 0.25]]model = EfficientNetV2(model_cnf=model_config,num_classes=num_classes,dropout_rate=0.3)return modeldef efficientnetv2_l(num_classes: int = 1000):"""EfficientNetV2https://arxiv.org/abs/2104.00298"""# train_size: 384, eval_size: 480# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config = [[4, 3, 1, 1, 32, 32, 0, 0],[7, 3, 2, 4, 32, 64, 0, 0],[7, 3, 2, 4, 64, 96, 0, 0],[10, 3, 2, 4, 96, 192, 1, 0.25],[19, 3, 1, 6, 192, 224, 1, 0.25],[25, 3, 2, 6, 224, 384, 1, 0.25],[7, 3, 1, 6, 384, 640, 1, 0.25]]model = EfficientNetV2(model_cnf=model_config,num_classes=num_classes,dropout_rate=0.4)return modelfrom torchsummary import summary
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = efficientnetv2_l()
model = model.to(device)
summary(model, (3,256,256))
使用torchsummary输出结果:
================================================================
Total params: 118,515,272
Trainable params: 118,515,272
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 1576.33
Params size (MB): 452.10
Estimated Total Size (MB): 2029.18
----------------------------------------------------------------
相关文章:
【Classical Network】EfficientNetV2
原文地址 原文代码 pytorch实现1 pytorch实现2 详细讲解 文章目录EfficientNet中存在的问题NAS 搜索EfficientNetV2 网络结构codeEfficientNet中存在的问题 训练图像尺寸大时,训练速度非常慢。train size 512, batch 24时,V100 out of memory在网络浅…...

索引类型FULLTEXT、NORMAL、SPATIAL、UNIQUE的区别
SQL索引的创建及使用请移步另一篇文章 (188条消息) SQL索引的创建及使用_sql索引的建立与使用_t梧桐树t的博客-CSDN博客 索引的种类 NORMAL 表示普通索引,大多数情况下都可以使用 UNIQUE 表示唯一索引,不允许重复的索引,如果该字段信息…...

稳定、可控、高可用:运维最应该加持哪些技术 buff?
如何保障开发需求高效交付,系统高峰扛得住、长期平稳,是项目组中的每位技术人必须面对的问题。 本文大纲 1、强稳定性Buff 2、风控服务实时性Buff 3、高资源利用率Buff 1.强稳定性Buff 强稳定性背后有三大挑战,其一是应对发布变更引起故障问…...
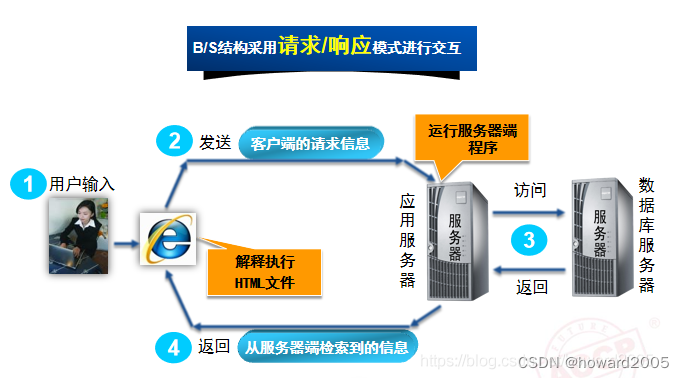
动态网站开发讲课笔记02:Java Web概述
文章目录零、本讲学习目标一、 XML基础(一)XML概述1、XML2、XML与HTML的比较(二)XML语法1、XML文档的声明2、XML元素的定义3、XML属性的定义4、XML注释的定义5、XML文件示例(三)DTD约束1、什么是XML约束2、…...
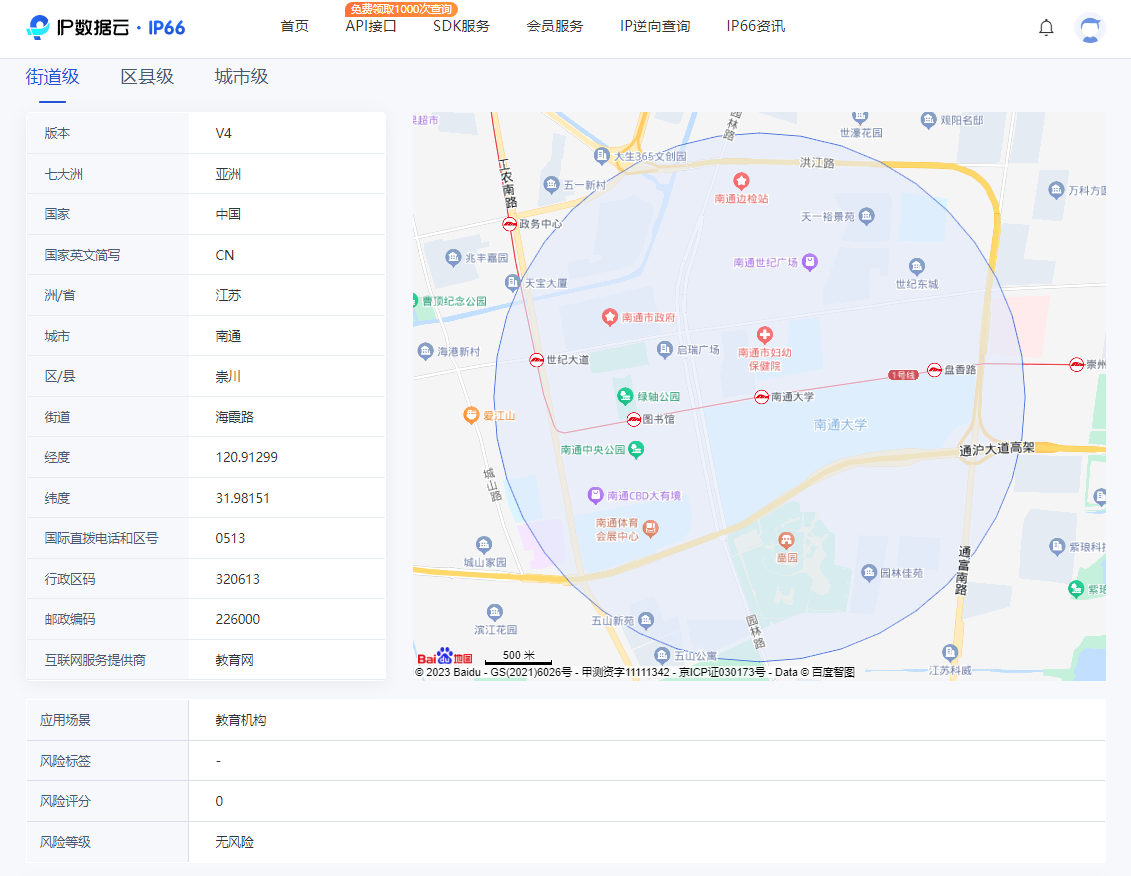
如何保护 IP 地址的隐私问题
是不是只有运营商才能查到某个人的住址信息呢?在大数据时代的今天,各种互联网应用收集了大量的数据信息,它们其实也可以根据这些信息,推断出某个人的大致地址位置。例如百度地图会一直用 App SDK 以及网页的方式记录 IP 和地址位置…...
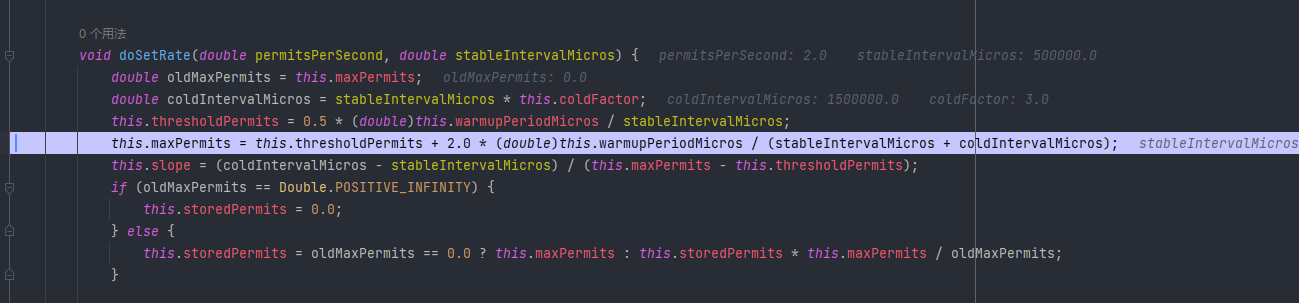
高并发系统设计之限流
本文已收录至Github,推荐阅读 👉 Java随想录 文章目录限流算法计数器算法滑动窗口漏桶算法令牌桶算法限流算法实现Guava RateLimiter实现限流令牌预分配预热限流Nginx 限流limit_connlimit_req黑白名单限流这篇文章来讲讲限流,在高并发系统中…...
)
ZCMU--5286: Rose的字符串(C语言)
Description 一天Rose同学想得到一个仅由01组成的字符串S,Jack同学为了让Rose同学开心,于是打算去商店购买另一个也仅由01组成的字符串T。而商店的字符串价格由它的长度决定,比如字符串011售价3元,001011售价6元,商店…...

MAC下搭建hadoop
一:简介 Hadoop是一个用Java开发的开源框架,它允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。它的设计是从单个服务器扩展到数千个机器,每个都提供本地计算和存储。特别适合写一次,读多次的场景。 Hado…...
Python如何实现自动登录和下单的脚本,请看selenium的表演
前言 学python对selenium应该不陌生吧 Selenium 是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一。Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驱动…...
)
华为OD机试真题Python实现【关联子串】真题+解题思路+代码(20222023)
关联子串 题目 给定两个字符串str1和str2 如果字符串str1中的字符,经过排列组合后的字符串中 只要有一个是str2的子串 则认为str1是str2的关联子串 若不是关联子串则返回-1 示例一: 输入: str1="abc",str2="efghicaibii" 输出: -1 预制条件: 输入的…...
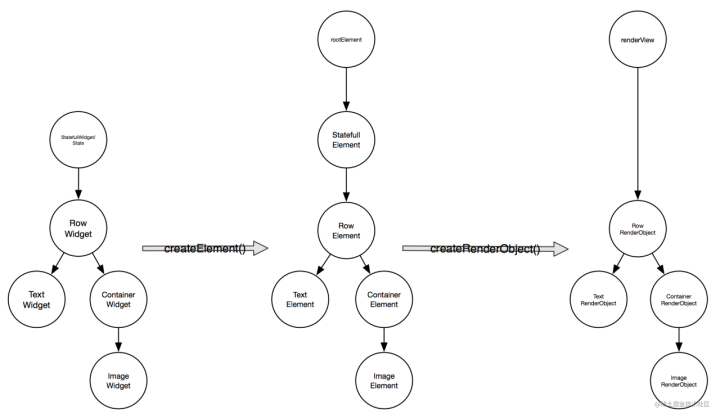
Flutter+【三棵树】
定义 在Flutter中和Widgets一起协同工作的还有另外两个伙伴:Elements和RenderObjects;由于它们都是有着树形结构,所以经常会称它们为三棵树。 这三棵树分别是:Widget、Element、RenderObject Widget树:寄存烘托内容…...
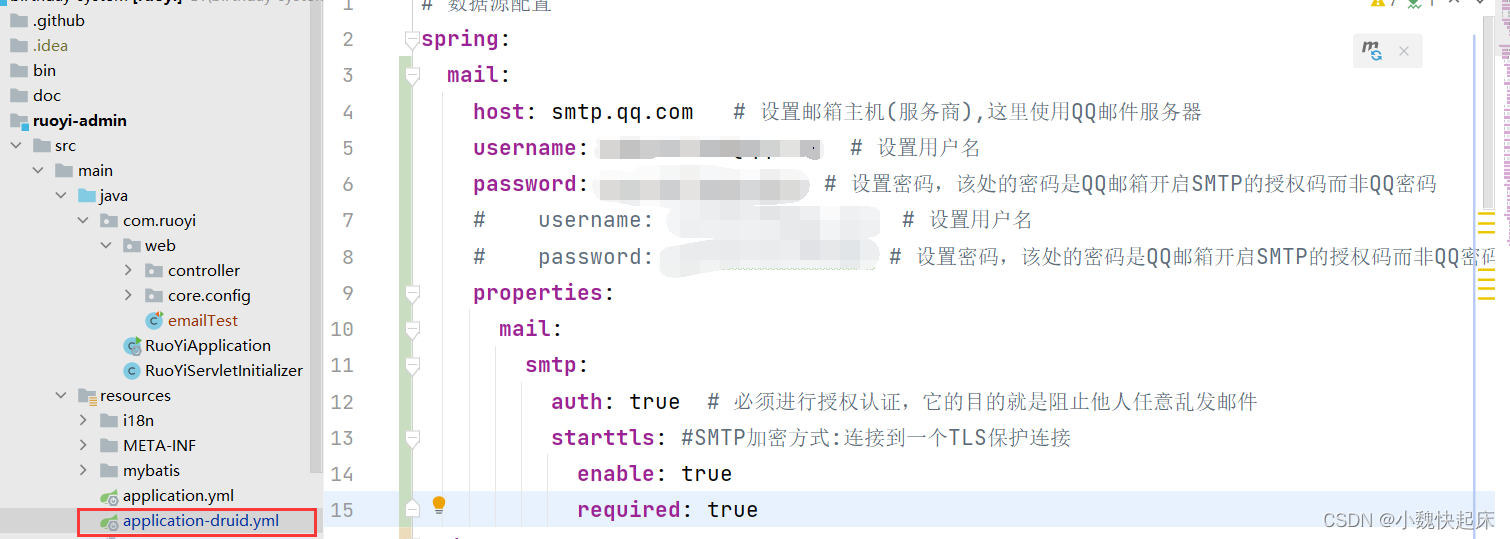
若依系统【SpringBoot】如何集成qq邮件发送【超详细,建议收藏】
若依系统的部署博主就不在这儿阐述了,默认大家的电脑已经部署好了若依系统,这里直接开始集成邮件系统,首先我们得需要对qq邮箱进行配置;一套学不会你来打我😀; 一、开启我们的qq邮箱发送邮件的配置 1、先进…...
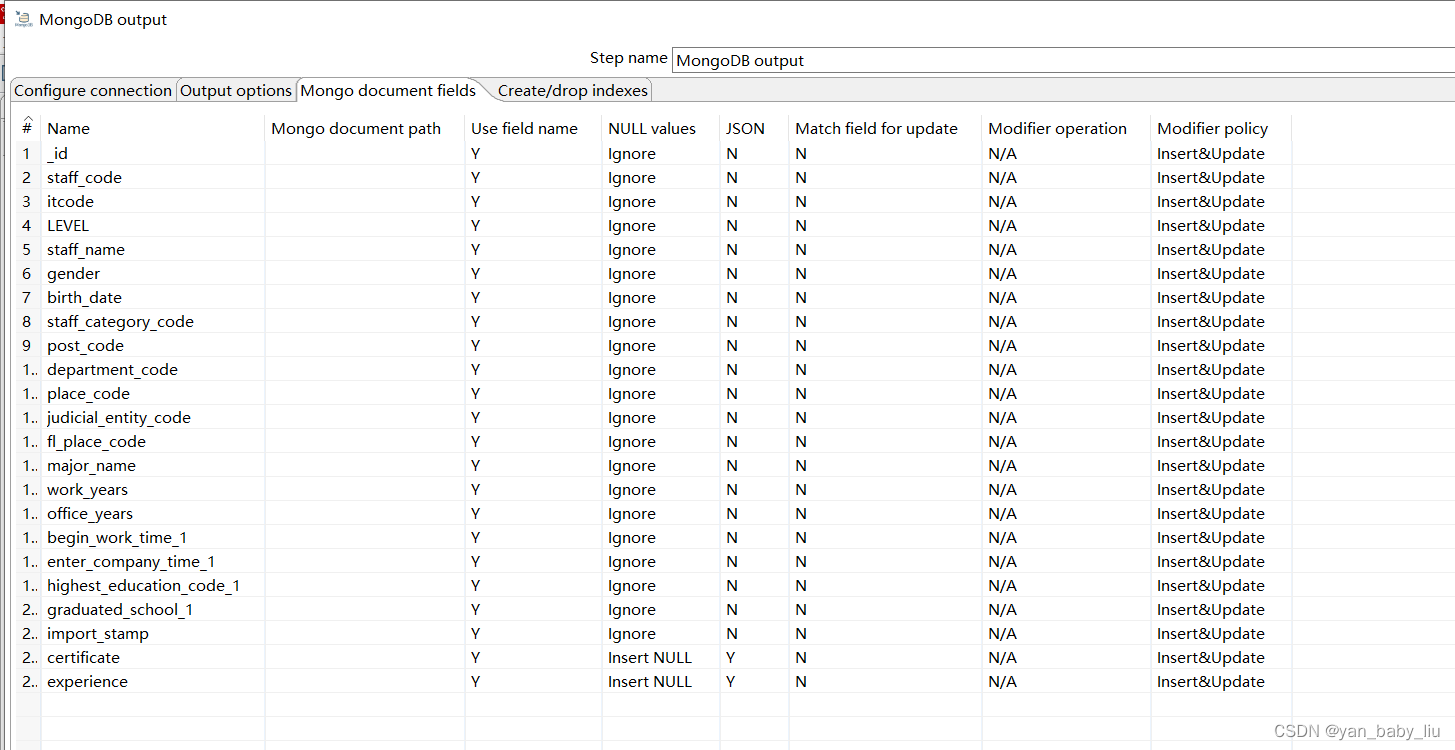
kettle使用--1.mysql多表关联导入mongoDB
文章目录1. 初步体验:csv 转为excelKettle概念配置mysql链接mysql 一对多关联查询结果保存到mongodb中1. 初步体验:csv 转为excel Windows环境下安装pdi-ce-8.0.0.0-28.zip ,解压后执行lib下的Spoon.bat 将csv输入拖入 双击拖进去的csv&…...
)
2023年CDGA考试-第10章-参考数据和主数据(含答案)
2023年CDGA考试-第10章-参考数据和主数据(含答案) 单选题 1.实现主数据中心环境的三种基本方法中不包括哪种? A.参考目录 B.注册表 C.交易中心 D.混合模式 答案 A 2.参考数据还具有很多区别于其他主数据 (例如,企业结构数据和交易结构数据)的特征。以下哪项目描述错误的…...

2023年,什么行业更有发展前景?
关于有前景有发展的行业推荐,小课今天还是推荐咱们IT互联网行业。 很多人会说现在懂电脑的那么多,这个行业都饱和了,很多学电脑的找不到工作都改行了。但事实是现在每个行各业都需要互联网,需要懂电脑的技术人才,尤其是在云计算、大数据到来…...
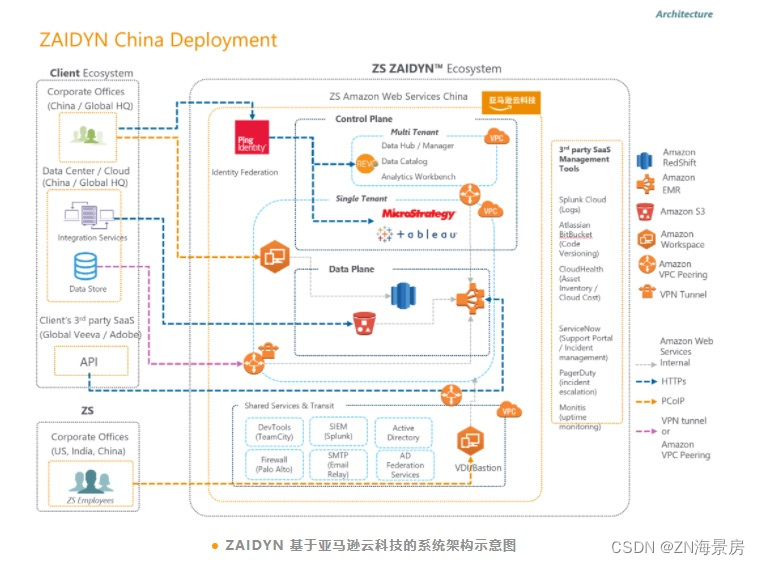
致盛咨询携手亚马逊云科技进一步开拓中国市场
作为医疗保健领域的咨询公司,ZS需要保证服务可靠性、敏捷性和安全性的同时,获得经济效益。亚马逊云科技丰富的云服务产品简化了ZS基础架构的搭建,为ZS节省了大量的人力与资金成本。同时,缩短了ZS扩展基础设施的周转时间࿰…...
)
ts之 命名空间 namespace、三斜线指令、声明文件(declare 声明ts的变量函数第三方模块等 )
目录ts之 命名空间 namespacets之 命名空间 namespacets之 三斜线指令 ( 引入其他.ts文件 )app.tsindex.tsts之 声明文件 d.ts - declare01:declare声明express第三方模块typings 为代码或者第三方模块 编写声明文件index.ts02:de…...
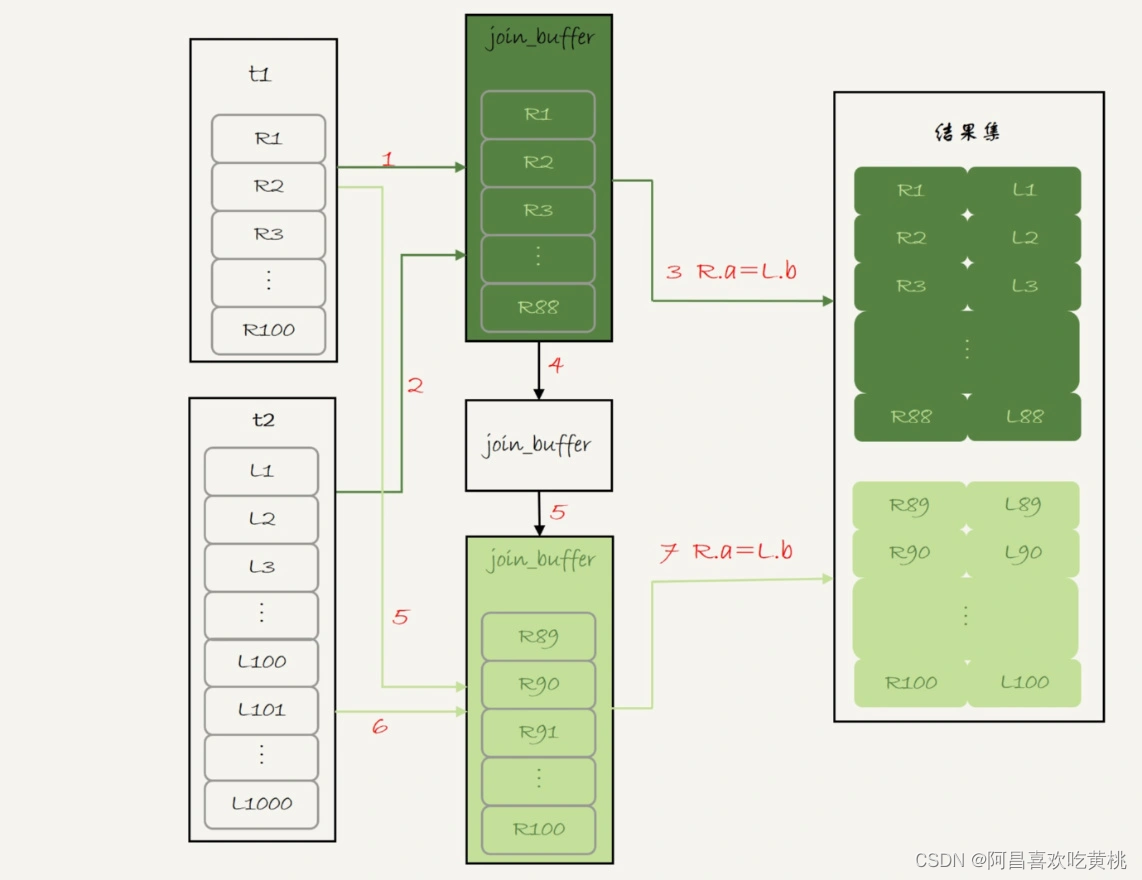
Day898.Join语句执行流程 -MySQL实战
Join语句执行流程 Hi,我是阿昌,今天学习记录的是关于Join语句执行流程的内容。 在实际生产中,关于 join 语句使用的问题,一般会集中在以下两类: 不让使用 join,使用 join 有什么问题呢?如果有…...

ChatGPT商业前景如何?人工智能未来会如何发展?
ChatGPT不仅在互联网和多个行业引发人们的关注,在投资界还掀起了机构对人工智能领域的投资热潮。人工智能聊天程序ChatGPT在去年11月亮相之后,在推出仅两个月后,今年1月份的月活用户已达到了1亿,成为史上增长最快的消费者应用程序…...
代码随想录第十六天(347、194、195、94)
347. 前 K 个高频元素 答案 思路: 1、首先,用到了每个值对应的出现次数,想到要用哈希map存放 2、还需要将出现频率从大到小进行排序,找出前k个元素 3、时间复杂度应该比O(nlogn)小 如果想用快速排序&…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]
报错信息:libc.so.6: cannot open shared object file: No such file or directory: #ls, ln, sudo...命令都不能用 error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory重启后报错信息&…...