使用Java Spring Boot构建高效的爬虫应用
本文将介绍如何使用Java Spring Boot框架来构建高效的爬虫应用程序。通过使用Spring Boot和相关的依赖库,我们可以轻松地编写爬虫代码,并实现对指定网站的数据抓取和处理。本文将详细介绍使用Spring Boot和Jsoup库进行爬虫开发的步骤,并提供一些实用的技巧和最佳实践。
一、介绍
爬虫是一种自动化程序,用于从互联网上获取数据。它可以访问并解析网页内容,提取感兴趣的信息,并将其存储或进一步处理。使用爬虫可以实现很多有用的功能,比如数据采集、信息监测、搜索引擎索引等。
Java是一种强大的编程语言,而Spring Boot是一个流行的Java开发框架,可以帮助我们快速构建可扩展的、高效的应用程序。结合Spring Boot和相关的库,我们可以编写出高效、可维护的爬虫应用程序。
二、准备工作
在开始编写爬虫代码之前,我们需要进行一些准备工作。首先,我们需要创建一个Spring Boot项目。可以使用Maven或Gradle构建工具来创建一个新的Spring Boot项目,然后将所需的依赖库添加到项目的配置文件中。
本文使用的依赖库是Jsoup,它是一个非常常用的Java HTML解析库,用于处理爬取到的网页内容。在项目的pom.xml文件中添加以下依赖:
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.13.1</version>
</dependency>
三、编写爬虫代码
- 创建一个Spring Boot应用程序,并在其中创建一个Controller类,用于处理用户的请求和响应。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/crawler")
public class CrawlerController {@GetMapping("/page")public String getPageContent() {try {String url = "http://example.com"; // 要爬取的网页URLDocument document = Jsoup.connect(url).get();String pageContent = document.html();return pageContent;} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在上述代码中,我们使用了Jsoup库来连接到指定的URL,并使用
get()方法获取页面内容。然后,我们可以将获取到的页面内容返回给用户。 -
在应用程序的主类中,使用
@SpringBootApplication注解来启动Spring Boot应用程序。
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class CrawlerApplication {public static void main(String[] args) {SpringApplication.run(CrawlerApplication.class, args);}
}
四、运行爬虫应用
现在,我们已经完成了爬虫应用的代码编写,可以通过运行Spring Boot应用来启动爬虫。
使用命令行工具进入项目的根目录,然后执行以下命令:
mvn spring-boot:run
或者,可以使用IDE来运行Spring Boot应用。
应用启动后,可以使用浏览器或其他工具发送GET请求到http://localhost:8080/crawler/page,即可获取到爬取到的网页内容。
五、案例
案例一:爬取天气数据
在这个案例中,我们将使用Java Spring Boot框架和Jsoup库来爬取天气数据。我们可以从指定的天气网站中获取实时的天气信息,并将其显示在我们的应用程序中。
-
创建一个新的Spring Boot应用程序,并添加所需的依赖库。
-
创建一个Controller类,在其中编写一个方法用于爬取天气数据。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/weather")
public class WeatherController {@GetMapping("/forecast")public String getWeatherForecast() {try {String url = "http://example.com/weather"; // 要爬取的天气网站URLDocument document = Jsoup.connect(url).get();Elements forecasts = document.select(".forecast-item"); // 获取天气预报的元素StringBuilder result = new StringBuilder();for (Element forecast : forecasts) {String date = forecast.select(".date").text(); // 获取日期String weather = forecast.select(".weather").text(); // 获取天气情况String temperature = forecast.select(".temperature").text(); // 获取温度result.append(date).append(": ").append(weather).append(", ").append(temperature).append("\n");}return result.toString();} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在应用程序的主类中启动Spring Boot应用程序。
-
运行应用程序,并在浏览器中访问
http://localhost:8080/weather/forecast,即可获取到天气预报信息。
案例二:爬取新闻头条
在这个案例中,我们将使用Java Spring Boot框架和Jsoup库来爬取新闻头条。我们可以从指定的新闻网站中获取最新的新闻标题和链接,并将其显示在我们的应用程序中。
-
创建一个新的Spring Boot应用程序,并添加所需的依赖库。
-
创建一个Controller类,在其中编写一个方法用于爬取新闻头条。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/news")
public class NewsController {@GetMapping("/headlines")public String getNewsHeadlines() {try {String url = "http://example.com/news"; // 要爬取的新闻网站URLDocument document = Jsoup.connect(url).get();Elements headlines = document.select(".headline"); // 获取新闻标题的元素StringBuilder result = new StringBuilder();for (Element headline : headlines) {String title = headline.text(); // 获取新闻标题String link = headline.attr("href"); // 获取新闻链接result.append(title).append(": ").append(link).append("\n");}return result.toString();} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在应用程序的主类中启动Spring Boot应用程序。
-
运行应用程序,并在浏览器中访问
http://localhost:8080/news/headlines,即可获取到新闻头条信息。
案例三:爬取电影排行榜
在这个案例中,我们将使用Java Spring Boot框架和Jsoup库来爬取电影排行榜。我们可以从指定的电影网站中获取最新的电影排名、评分和简介,并将其显示在我们的应用程序中。
-
创建一个新的Spring Boot应用程序,并添加所需的依赖库。
-
创建一个Controller类,在其中编写一个方法用于爬取电影排行榜。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/movies")
public class MovieController {@GetMapping("/top")public String getTopMovies() {try {String url = "http://example.com/movies"; // 要爬取的电影网站URLDocument document = Jsoup.connect(url).get();Elements movies = document.select(".movie"); // 获取电影排行榜的元素StringBuilder result = new StringBuilder();for (Element movie : movies) {String rank = movie.select(".rank").text(); // 获取排名String title = movie.select(".title").text(); // 获取电影标题String rating = movie.select(".rating").text(); // 获取评分String description = movie.select(".description").text(); // 获取简介result.append(rank).append(". ").append(title).append(", Rating: ").append(rating).append("\n").append("Description: ").append(description).append("\n\n");}return result.toString();} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在应用程序的主类中启动Spring Boot应用程序。
-
运行应用程序,并在浏览器中访问
http://localhost:8080/movies/top,即可获取到电影排行榜信息。
这些案例只是展示了使用Java Spring Boot和Jsoup库进行爬虫开发的基本原理和方法。根据实际需求,我们可以根据网站的HTML结构和数据格式进行进一步的解析和处理。
六、注意事项
在编写和使用爬虫代码时,我们需要遵守网站的服务条款和法律规定。尊重网站的隐私权和使用规则是非常重要的。另外,为了避免给网站带来过多的负担,我们应该设置合理的爬取频率,并避免过于频繁的请求。
七、总结
本文介绍了如何使用Java Spring Boot框架来构建高效的爬虫应用程序。通过结合Spring Boot和Jsoup库,我们可以轻松地编写爬虫代码,并实现对指定网站的数据抓取和处理。同时,我们也提到了一些注意事项,以确保合法性和避免给网站带来过多的负担。
爬虫是一个非常有用的工具,可以帮助我们自动化获取互联网上的数据。当然,在使用爬虫时,我们也要遵守相关的法律和道德规范,确保使用爬虫的合法性和合理性。希望本文对于想要使用Java Spring Boot构建爬虫应用的开发者有所帮助。
相关文章:

使用Java Spring Boot构建高效的爬虫应用
本文将介绍如何使用Java Spring Boot框架来构建高效的爬虫应用程序。通过使用Spring Boot和相关的依赖库,我们可以轻松地编写爬虫代码,并实现对指定网站的数据抓取和处理。本文将详细介绍使用Spring Boot和Jsoup库进行爬虫开发的步骤,并提供一…...
归并排序与非比较排序详解
W...Y的主页 😊 代码仓库分享 💕 🍔前言: 上篇博客我们讲解了非常重要的快速排序,相信大家已经学会了。最后我们再学习一种特殊的排序手法——归并排序。话不多说我们直接上菜。 目录 归并排序 基本思想 递归思路…...
第85步 时间序列建模实战:CNN回归建模
基于WIN10的64位系统演示 一、写在前面 这一期,我们介绍CNN回归。 同样,这里使用这个数据: 《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndrome i…...
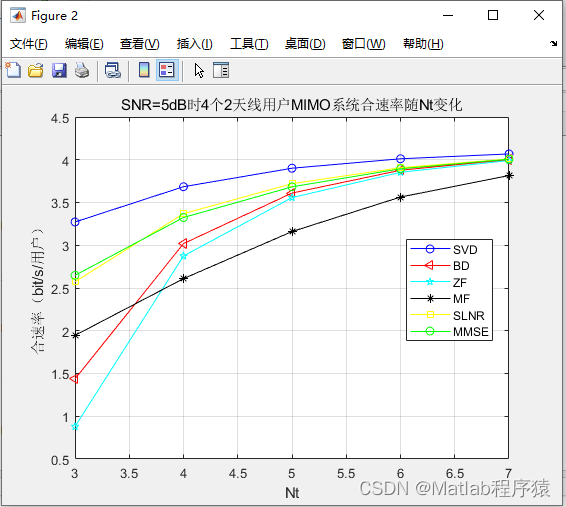
【MATLAB源码-第36期】matlab基于BD,SVD,ZF,MMSE,MF,SLNR预编码的MIMO系统误码率分析。
1、算法描述 1. MIMO (多输入多输出):这是一个无线通信系统中使用的技术,其中有多个发送和接收天线。通过同时发送和接收多个数据流,MIMO可以增加数据速率和系统容量,同时提高信号的可靠性。 2. BD (块对角化):这是一…...

Uniapp 新手专用 抖音登录 获取用户头像、名称、openid、unionid、anonymous_openid、session_key
TC-dylogin 一定请选择 源码授权版 教程 第一步 将代码拷贝至您所需要的页面 该代码位置:pages/index.vue 第二步 修改appid和secret 第三步 获取appid和secret 获取appid和secret链接 注意事项 为了安全,我将默认的自己的appid和secret在云函数中删…...

openssl引擎开发踩坑小记
前言 在开发openssl引擎过程中,引擎莫名其妙的加载不上,错误如下图: 大概意思就是加载引擎动态库时失败了。 在网上一顿搜索后,也没找到想要的答案。 原因 许多引擎都是基于第三方动态库开发的,引擎本身在开发时&a…...
ubuntu 设置x11vnc服务
Ubuntu 18.04 设置x11vnc服务 自带的vino-server也可以用但是不好用,在ubuntu论坛上看见推荐的x11vnc(ubuntu关于vnc的帮助页面),使用设置一下,结果发现有一些坑需要填,所以写下来方便下次使用 转载请说明…...

物理备份xtrabackup
物理备份: 直接复制数据库文件,适用于大型数据库环境,不受存储引擎的限制,但不能恢复到不同的MySQL版本。 1.完全备份-----完整备份: 每次都将所有数据(不管自第一次备份以来有没有修改过)&am…...
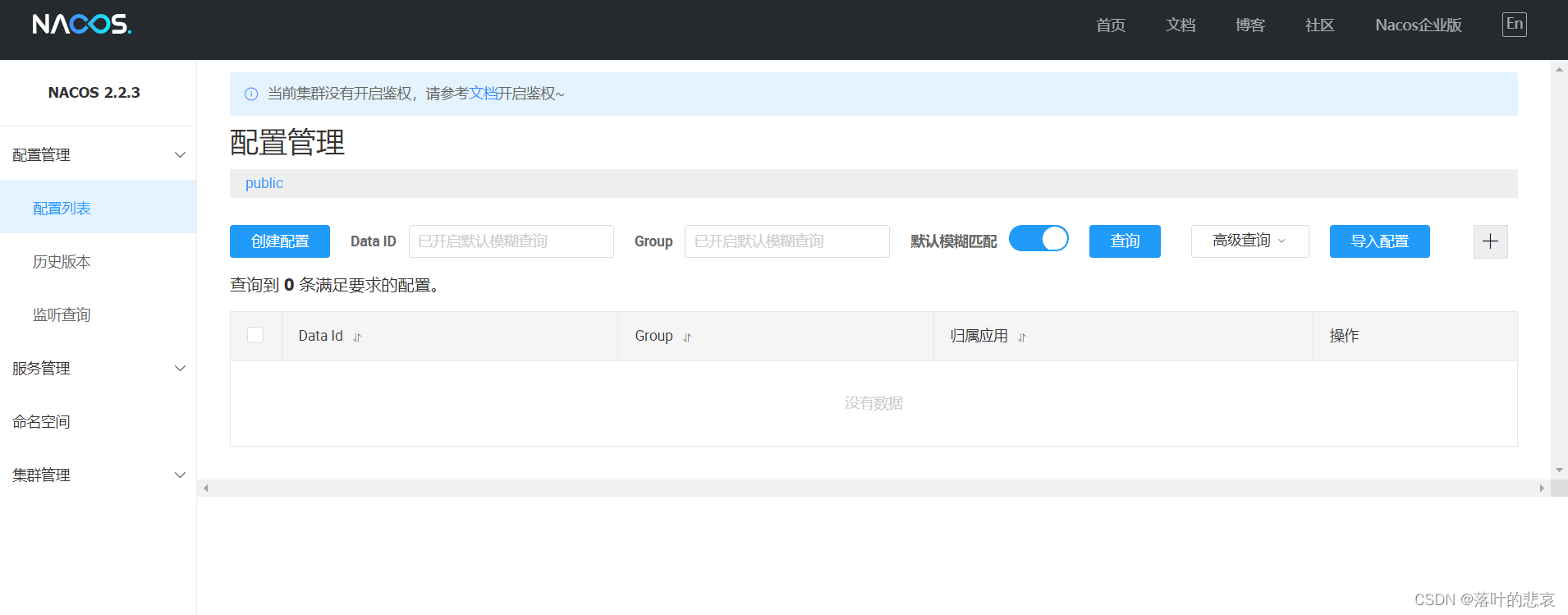
1.springcloudalibaba nacos2.2.3部署
前言 nacos是springcloudalibaba体系的注册中心,演示如何搭建最新稳定版本的linux搭建。 前置条件,安装好jdk1.8 一、二进制压缩包下载 1.1 下载压缩包 nacos下载 点击下载下载后得到二进制包如下 nacos-2.2.3.tar.gz二、安装步骤 2.1.解压二进制…...
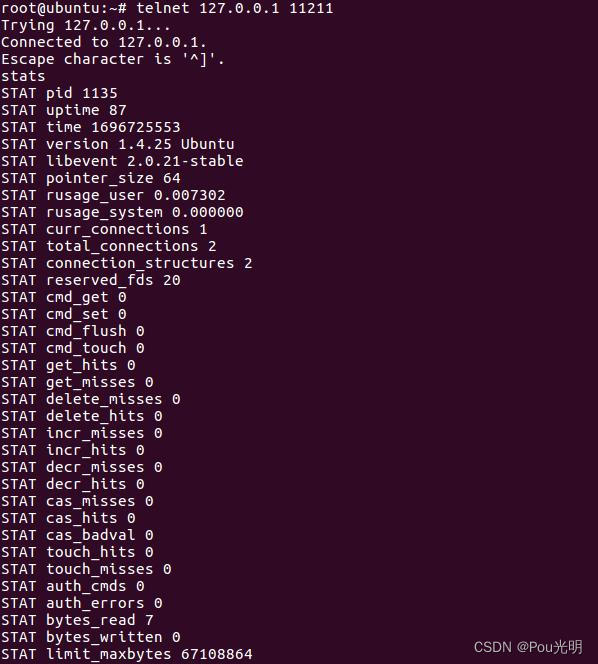
Linux 查看是否安装memcached
telnet 127.0.0.1 11211这样的命令连接上memcache,然后直接输入stats就可以得到memcache服务器的版本 安装memcached : sudo apt-get install memcached...
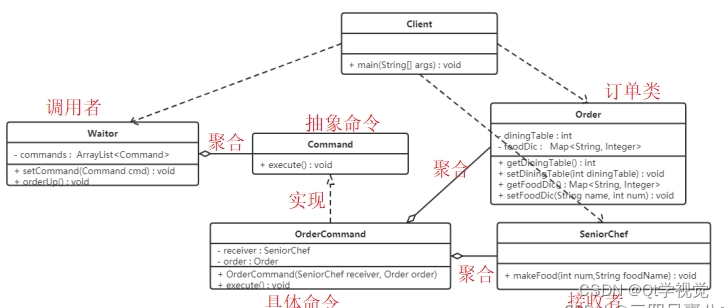
设计模式14、命令模式 Command
解释说明:命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传递给调用对象。调用对象寻找可以处理该命令的合适对象,并把该命令传给相应的对象&…...

【Go】excelize库实现excel导入导出封装(一),自定义导出样式、隔行背景色、自适应行高、动态导出指定列、动态更改表头
前言 最近在学go操作excel,毕竟在web开发里,操作excel是非常非常常见的。这里我选择用 excelize 库来实现操作excel。 为了方便和通用,我们需要把导入导出进行封装,这样以后就可以很方便的拿来用,或者进行扩展。 我参…...
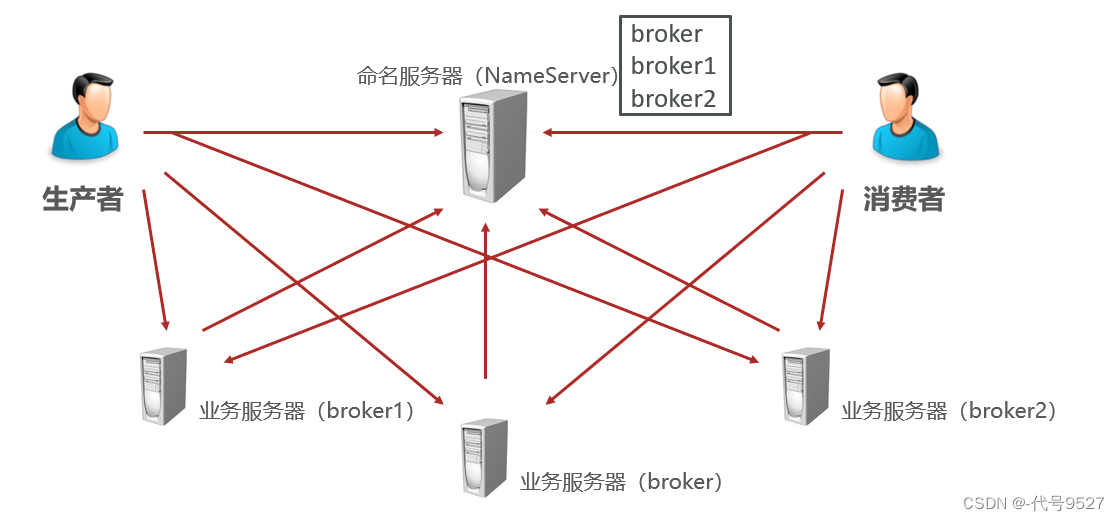
【开发篇】二十、SpringBoot整合RocketMQ
文章目录 1、整合2、消息的生产3、消费4、发送异步消息5、补充:安装RocketMQ 1、整合 首先导入起步依赖,RocketMQ的starter不是Spring维护的,这一点从starter的命名可以看出来(不是spring-boot-starter-xxx,而是xxx-s…...

OpenCV实现求解单目相机位姿
单目相机通过对极约束来求解相机运动的位姿。参考了ORBSLAM中单目实现的代码,这里用opencv来实现最简单的位姿估计. mLeftImg cv::imread(lImg, cv::IMREAD_GRAYSCALE); mRightImg cv::imread(rImg, cv::IMREAD_GRAYSCALE); cv::Ptr<ORB> OrbLeftExtractor …...

深入解析PostgreSQL:命令和语法详解及使用指南
文章目录 摘要引言基本操作安装与配置连接和退出 数据库操作创建数据库删除数据库切换数据库 表操作创建表删除表插入数据查询数据更新数据删除数据 索引和约束创建索引创建约束 用户管理创建用户授权用户修改用户密码 备份和恢复备份数据库恢复数据库 高级特性结语参考文献 摘…...

Elasticsearch数据搜索原理
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个…...
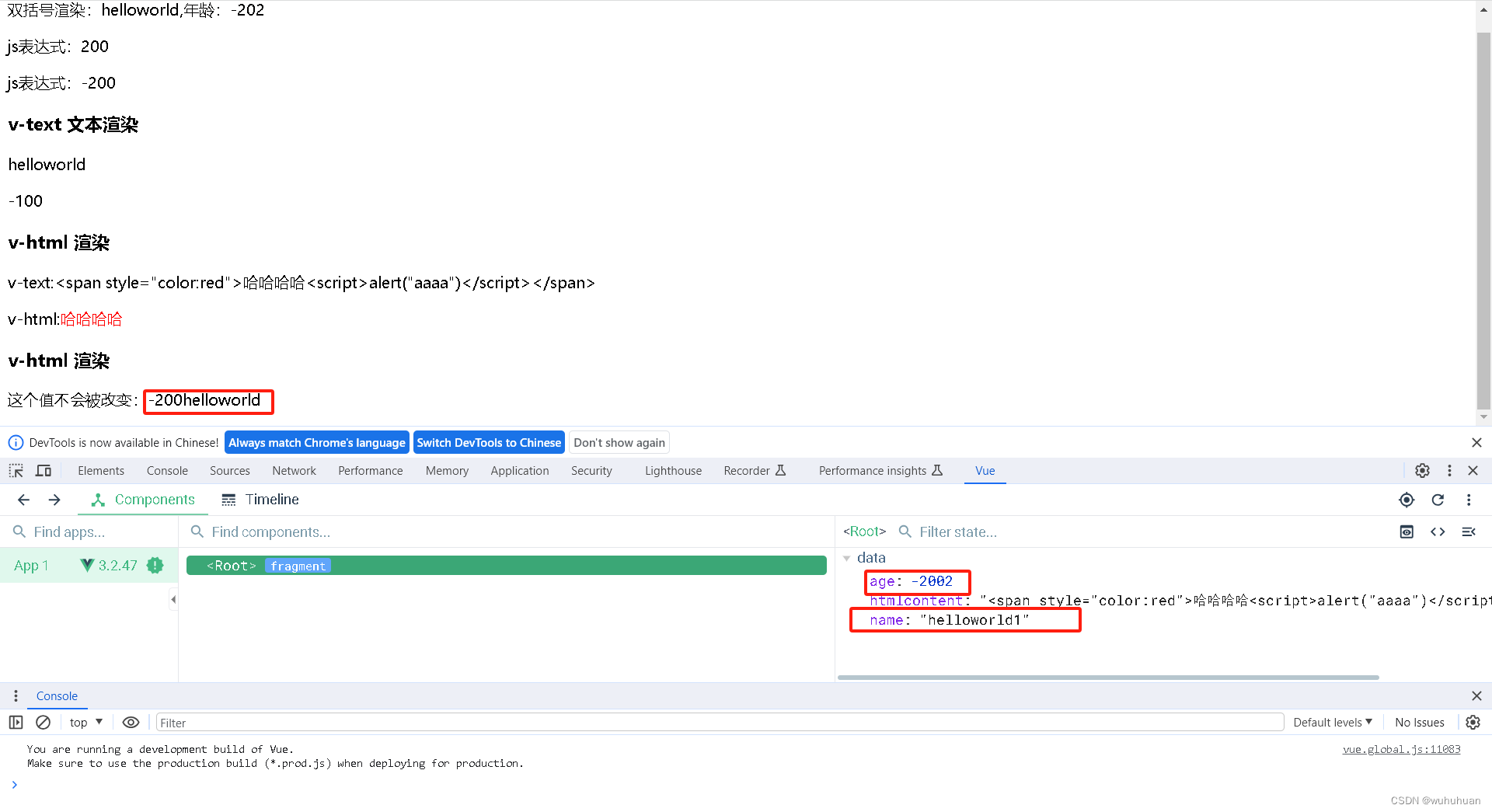
vue模版语法-{{}}/v-text/v-html/v-once
一、{{}}双括号:用于文本渲染 1、 {{变量名}}:data中返回对象的变量名 2、{{js表达式}}:可以直接进行js表达式处理 3、注意:双大括号中不要写等式书写 二、v-text 指令,用于文本渲染 1、为了解决双大括号渲染数据出现闪烁问题 三、v-cloak …...

前端埋点上传
没事看看: 从用户行为到数据:数据采集全景解析 | 人人都是产品经理 搭建前端监控,采集用户行为的 N 种姿势-前端监控设备 创业公司做数据分析(三)用户行为数据采集系统-CSDN博客...
)
第11章 Redis(一)
11.1 谈谈你对Redis的理解 难度:★★★ 重点:★★ 白话解析 对Redis的理解无非从三个方面去说一说:背景,是什么,特性。 背景:数据直接存磁盘太慢了,虽然MySQL用到了BufferPool等缓存,但是为了保证数据不丢失,MySQL采用的RedoLog依然要直接写磁盘。所以,数据的存储就…...

freertos信号量之二值信号量
freertos信号量之二值信号量 简介例程 简介 FreeRTOS的二值信号量(Binary Semaphore)是用于实现进程间同步和临界资源保护的重要工具。以下是一些二值信号量的常用函数及其说明: 1)xSemaphoreCreateBinary() 创建一个二值信号量…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...