MySQL---单表查询、多表查询
一、单表查询
素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等
CREATE TABLE `worker` (
`部门号` int(11) NOT NULL,
`职工号` int(11) NOT NULL,
`工作时间` date NOT NULL,
`工资` float(8,2) NOT NULL,
`政治面貌` varchar(10) NOT NULL DEFAULT '群众',
`姓名` varchar(20) NOT NULL,
`出生日期` date NOT NULL,
PRIMARY KEY (`职工号`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
1、显示所有职工的基本信息。
2、查询所有职工所属部门的部门号,不显示重复的部门号。
3、求出所有职工的人数。
4、列出最高工和最低工资。
5、列出职工的平均工资和总工资。
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
7、显示所有女职工的年龄。
8、列出所有姓刘的职工的职工号、姓名和出生日期。
9、列出1960年以前出生的职工的姓名、参加工作日期。
10、列出工资在1000-2000之间的所有职工姓名。
11、列出所有陈姓和李姓的职工姓名。
12、列出所有部门号为2和3的职工号、姓名、党员否。
13、将职工表worker中的职工按出生的先后顺序排序。
14、显示工资最高的前3名职工的职工号和姓名。
15、求出各部门党员的人数。
16、统计各部门的工资和平均工资
17、列出总人数大于4的号和总人数。
mysql> CREATE TABLE `worker` (-> `部门号` int(11) NOT NULL,-> `职工号` int(11) NOT NULL,-> `工作时间` date NOT NULL,-> `工资` float(8,2) NOT NULL,-> `政治面貌` varchar(10) NOT NULL DEFAULT '群众',-> `姓名` varchar(20) NOT NULL,-> `出生日期` date NOT NULL,-> PRIMARY KEY (`职工号`)-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
Query OK, 0 rows affected (0.01 sec)mysql> desc worker;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| 部门号 | int(11) | NO | | NULL | |
| 职工号 | int(11) | NO | PRI | NULL | |
| 工作时间 | date | NO | | NULL | |
| 工资 | float(8,2) | NO | | NULL | |
| 政治面貌 | varchar(10) | NO | | 群众 | |
| 姓名 | varchar(20) | NO | | NULL | |
| 出生日期 | date | NO | | NULL | |
+--------------+-------------+------+-----+---------+-------+
7 rows in set (0.00 sec)mysql> INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (101, 1001, '2015-5-4', 3500.00, '群众', '张三', '1990-7-1');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日 期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日 期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30');
INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日 期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2');
Query OK, 1 row affected (0.03 sec)mysql> INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (101, 1002, '2017-2-6', 3200.00, '团员', '李四', '1997-2-8');
Query OK, 1 row affected (0.00 sec)mysql> INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1003, '2011-1-4', 8500.00, '党员', '王亮', '1983-6-8');
Query OK, 1 row affected (0.00 sec)mysql> INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1004, '2016-10-10', 5500.00, '群众', '赵六', '1994-9-5');
Query OK, 1 row affected (0.01 sec)mysql> INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1005, '2014-4-1', 4800.00, '党员', '钱七', '1992-12-30');
Query OK, 1 row affected (0.00 sec)mysql> INSERT INTO `worker` (`部门号`, `职工号`, `工作时间`, `工资`, `政治面貌`, `姓名`, `出生日期`) VALUES (102, 1006, '2017-5-5', 4500.00, '党员', '孙八', '1996-9-2');
Query OK, 1 row affected (0.00 sec)mysql>
1、显示所有职工的基本信息。
mysql> select * from worker;
+-----------+-----------+--------------+---------+--------------+--------+--------------+
| 部门号 | 职工号 | 工作时间 | 工资 | 政治面貌 | 姓名 | 出生日期 |
+-----------+-----------+--------------+---------+--------------+--------+--------------+
| 101 | 1001 | 2015-05-04 | 3500.00 | 群众 | 张三 | 1990-07-01 |
| 101 | 1002 | 2017-02-06 | 3200.00 | 团员 | 李四 | 1997-02-08 |
| 102 | 1003 | 2011-01-04 | 8500.00 | 党员 | 王亮 | 1983-06-08 |
| 102 | 1004 | 2016-10-10 | 5500.00 | 群众 | 赵六 | 1994-09-05 |
| 102 | 1005 | 2014-04-01 | 4800.00 | 党员 | 钱七 | 1992-12-30 |
| 102 | 1006 | 2017-05-05 | 4500.00 | 党员 | 孙八 | 1996-09-02 |
+-----------+-----------+--------------+---------+--------------+--------+--------------+
6 rows in set (0.00 sec)mysql>
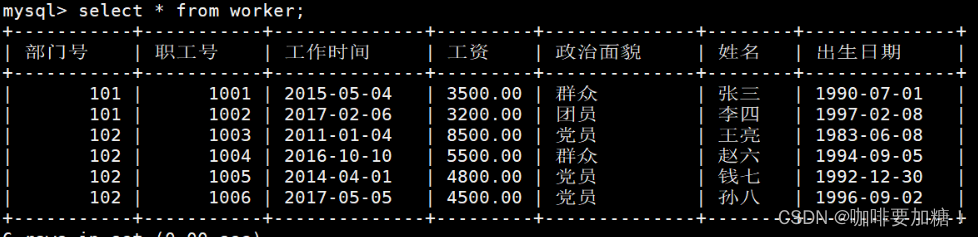
2、查询所有职工所属部门的部门号,不显示重复的部门号。
mysql> select distinct 部门号 from worker;
+-----------+
| 部门号 |
+-----------+
| 101 |
| 102 |
+-----------+
2 rows in set (0.00 sec)mysql>

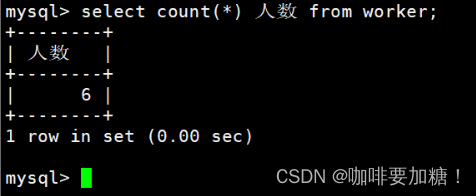
3、求出所有职工的人数。
mysql> select count(*) from worker;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)mysql>
4、列出最高工和最低工资。
mysql> select max(工资),min(工资) from worker;
+-------------+-------------+
| max(工资) | min(工资) |
+-------------+-------------+
| 8500.00 | 3200.00 |
+-------------+-------------+
1 row in set (0.00 sec)mysql>

5、列出职工的平均工资和总工资。
mysql> select sum(工资),avg(工资) from worker;
+-------------+-------------+
| sum(工资) | avg(工资) |
+-------------+-------------+
| 30000.00 | 5000.000000 |
+-------------+-------------+
1 row in set (0.00 sec)mysql>
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
mysql> create table worktime select 职工号,姓名,工作时间 from worker;
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from worktime;
+-----------+--------+--------------+
| 职工号 | 姓名 | 工作时间 |
+-----------+--------+--------------+
| 1001 | 张三 | 2015-05-04 |
| 1002 | 李四 | 2017-02-06 |
| 1003 | 王亮 | 2011-01-04 |
| 1004 | 赵六 | 2016-10-10 |
| 1005 | 钱七 | 2014-04-01 |
| 1006 | 孙八 | 2017-05-05 |
+-----------+--------+--------------+
6 rows in set (0.00 sec)mysql>

7、显示所有女职工的年龄。
mysql> select 2019 - year(出生日期) as 年龄 from worker;
+--------+
| 年龄 |
+--------+
| 29 |
| 22 |
| 36 |
| 25 |
| 27 |
| 23 |
+--------+
6 rows in set (0.00 sec)mysql>
8、列出所有姓刘的职工的职工号、姓名和出生日期。
mysql> select 职工号,姓名,出生日期 from worker-> where 姓名 like '王%';
+-----------+--------+--------------+
| 职工号 | 姓名 | 出生日期 |
+-----------+--------+--------------+
| 1003 | 王亮 | 1983-06-08 |
+-----------+--------+--------------+
1 row in set (0.00 sec)mysql>
9、列出1990年以前出生的职工的姓名、参加工作日期。
mysql> select 姓名,工作时间 from worker where 出生日期 < '1990-01-01';
+--------+--------------+
| 姓名 | 工作时间 |
+--------+--------------+
| 王亮 | 2011-01-04 |
+--------+--------------+
1 row in set (0.00 sec)mysql
10、列出工资在1000-2000之间的所有职工姓名。
mysql> select 姓名 from worker where 工资 between 1000 and 2000;
+--------+
| 姓名 |
+--------+
| 赵六 |
+--------+
1 row in set (0.00 sec)mysql>
11、列出所有陈姓和李姓的职工姓名。
mysql> select 姓名 from worker where 姓名 like '张%' or 姓名 like '李%';
+--------+
| 姓名 |
+--------+
| 张三 |
| 李四 |
+--------+
2 rows in set (0.00 sec)mysql>

12、列出所有部门号为2和3的职工号、姓名、党员否。
mysql> select 职工号,姓名,政治面貌 from worker where 部门号 like '%2' and 政治面貌 like '党员';
+-----------+--------+--------------+
| 职工号 | 姓名 | 政治面貌 |
+-----------+--------+--------------+
| 1003 | 王亮 | 党员 |
| 1005 | 钱七 | 党员 |
| 1006 | 孙八 | 党员 |
+-----------+--------+--------------+
3 rows in set (0.00 sec)mysql>
13、将职工表worker中的职工按出生的先后顺序排序。
mysql> select 姓名 from worker order by 出生日期;
+--------+
| 姓名 |
+--------+
| 王亮 |
| 张三 |
| 钱七 |
| 赵六 |
| 孙八 |
| 李四 |
+--------+
6 rows in set (0.00 sec)mysql>

14、显示工资最高的前3名职工的职工号和姓名。
mysql> select 职工号,姓名 from worker order by 工资 desc limit 3;
+-----------+--------+
| 职工号 | 姓名 |
+-----------+--------+
| 1003 | 王亮 |
| 1004 | 赵六 |
| 1005 | 钱七 |
+-----------+--------+
3 rows in set (0.00 sec)mysql>

15、求出各部门党员的人数。
mysql> select 部门号,count(*) from worker where 政治面貌='党员' group by 部门号;
+-----------+----------+
| 部门号 | count(*) |
+-----------+----------+
| 102 | 3 |
+-----------+----------+
1 row in set (0.00 sec)mysql>

16、统计各部门的工资和平均工资
mysql> select 部门号,sum(工资),avg(工资) from worker group by 部门号 ;
+-----------+-------------+-------------+
| 部门号 | sum(工资) | avg(工资) |
+-----------+-------------+-------------+
| 101 | 6700.00 | 3350.000000 |
| 102 | 23300.00 | 5825.000000 |
+-----------+-------------+-------------+
2 rows in set (0.00 sec)mysql>

17、列出总人数大于4的部门号和总人数。
mysql> select 部门号,count(*) from worker-> group by 部门号-> having count(*) > 3;
+-----------+----------+
| 部门号 | count(*) |
+-----------+----------+
| 102 | 4 |
+-----------+----------+
1 row in set (0.00 sec)mysql>
二、多表查询
1.创建student和score表
CREATE TABLE student (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR(20) NOT NULL ,
sex VARCHAR(4) ,
birth YEAR,
department VARCHAR(20) ,
address VARCHAR(50)
);
创建score表。SQL代码如下:
CREATE TABLE score (
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);
2.为student表和score表增加记录
向student表插入记录的INSERT语句如下:
INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区');
INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
向score表插入记录的INSERT语句如下:
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);1.查询student表的所有记录
2.查询student表的第2条到4条记录
3.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
4.从student表中查询计算机系和英语系的学生的信息
5.从student表中查询年龄18~22岁的学生信息
6.从student表中查询每个院系有多少人
7.从score表中查询每个科目的最高分
8.查询李四的考试科目(c_name)和考试成绩(grade)
9.用连接的方式查询所有学生的信息和考试信息
10.计算每个学生的总成绩
11.计算每个考试科目的平均成绩
12.查询计算机成绩低于95的学生信息
13.查询同时参加计算机和英语考试的学生的信息
14.将计算机考试成绩按从高到低进行排序
15.从student表和score表中查询出学生的学号,然后合并查询结果
16.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
17.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
1.查询student表的所有记录
select * from student;
2.查询student表的第2条到4条记录
select * from student limit 1,3;
3.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
select id,name,department from student;
4.从student表中查询计算机系和英语系的学生的信息
select * from student where department='计算机系' or department='英语系';
5.从student表中查询年龄28~32岁的学生信息
select * from student where (2022-birth+1) between 28 and 32;
6.从student表中查询每个院系有多少人
select department,count(3) 人数 from student group by department;
7.从score表中查询每个科目的最高分
select c_name,max(grade) from score group by c_name;
8.查询李四的考试科目(c_name)和考试成绩(grade)
select c.c_name,c.grade from student d,score c where d.id=c.stu_id and d.name='李四';
9.用连接的方式查询所有学生的信息和考试信息
select d.id,name,sex,birth,department,address,c_name,grade from student d,score c where d.id = c.stu_id
10.计算每个学生的总成绩
select d.id,name,sum(grade) from student d,score c where d.id=c.stu_id group by id;
11.计算每个考试科目的平均成绩
select c_name,avg(grade) from score group by c_name;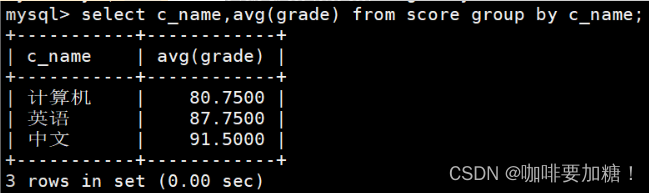
12.查询计算机成绩低于95的学生信息
select * from student where id in (select stu_id from score where c_name ='计算机' and grade < 95);
13.查询同时参加计算机和英语考试的学生的信息
select * from student where id = any(select stu_id from score where stu_id in ( select stu_id from score where c_name = '计算机') and c_name = '英语');

14.将计算机考试成绩按从高到低进行排序
select stu_id, grade from score where c_name= '计算机' order by grade desc;
15.从student表和score表中查询出学生的学号,然后合并查询结果
select id from student union select stu_id from score;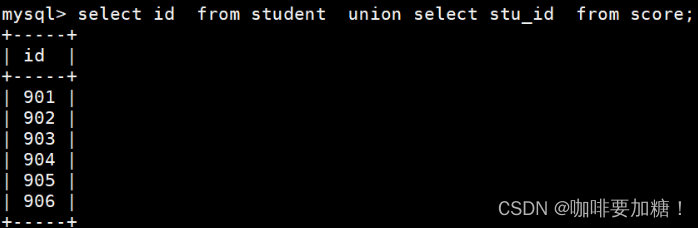
16.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
select student.id, name,sex,birth,department, address, c_name,grade from student, score where student.id=score.stu_id and (name like '张%' or name like '王%') ;
17.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
select student.id, name,sex,birth,department, address, c_name,grade from student, score where student.id=score.stu_id and address like '湖南%' ;

相关文章:
MySQL---单表查询、多表查询
一、单表查询 素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等 CREATE TABLE worker ( 部门号 int(11) NOT NULL, 职工号 int(11) NOT NULL, 工作时间 date NOT NULL, 工资 float(8,2) NOT NULL, 政治面貌 v…...
3年自动化测试这水平?我还不如去招应届生
公司前段缺人,也面了不少测试,结果竟然没有一个合适的。一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但平均水平很让人失望。看简历很多都是3年工作经验,但面试…...

5 个自定义 React Hooks 将改变你的代码
昨天完成我的每日文章(是的,我每天都会发布一篇关于前端开发的新文章,所以如果你想要每天的代码丸,请务必关注 😉),我去编码了一点......我开始为我正在构建的副项目编写一些自定义挂钩…...

Java学习笔记-03(API阶段)
前言 目前我们看到的是Java基础部分的一个新的部分API,这是个啥,又能做啥呢? 其实可以概括成一句话:帮助我们站在巨人的肩膀上,实现更加高效的开发,那么我们来一探究竟吧~ API API(Application Programming Interface,应用程序接口)是一些预…...
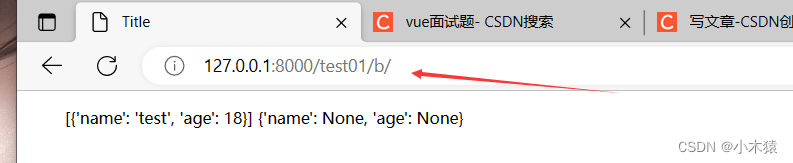
Django自定义模板标签的使用详解
目录 1.创建子应用:python manage.py startapp test01 2.进行相关的配置 3.在新建的test01文件下创建urls.py(此处名称可变但注意上图) 4.在test01文件下创建名称为templatetags的文件夹 5.templatetags文件下继续创建几个py文件如下图编辑 6.views视图函数…...

洗地机怎么选?洗地机品牌排行榜
洗地机的出现不仅能高效的清洁地面还能节省我们做家务的时间,对于上班族、有宠物的家庭以及宝妈来说简直不要太方便;目前市面上的洗地机有分有线款和无线款,无线款会比有线款操作更加方便;洗地机怎么选,其实洗地机的清洁能力主要是看吸力大小…...

CSS的元素显示模式
😊博主页面:鱿年年 👉博主推荐专栏:《WEB前端》👈 💓博主格言:追风赶月莫停留,平芜尽处是春山❤️ 目录 前言 一、什么是元素显示模式 1.1块元素 1.2行内元素 1.3行内块元素…...

【MySQL Shell】8.9.1 在 InnoDB ClusterSet 中隔离集群
在发生紧急故障切换后,如果 ClusterSet 的各个部分之间存在事务集不同的风险,则必须保护集群不受写入流量或所有流量的影响。 如果发生网络分区,则有可能出现脑裂的情况,即实例失去同步,无法正确通信以定义同步状态。…...
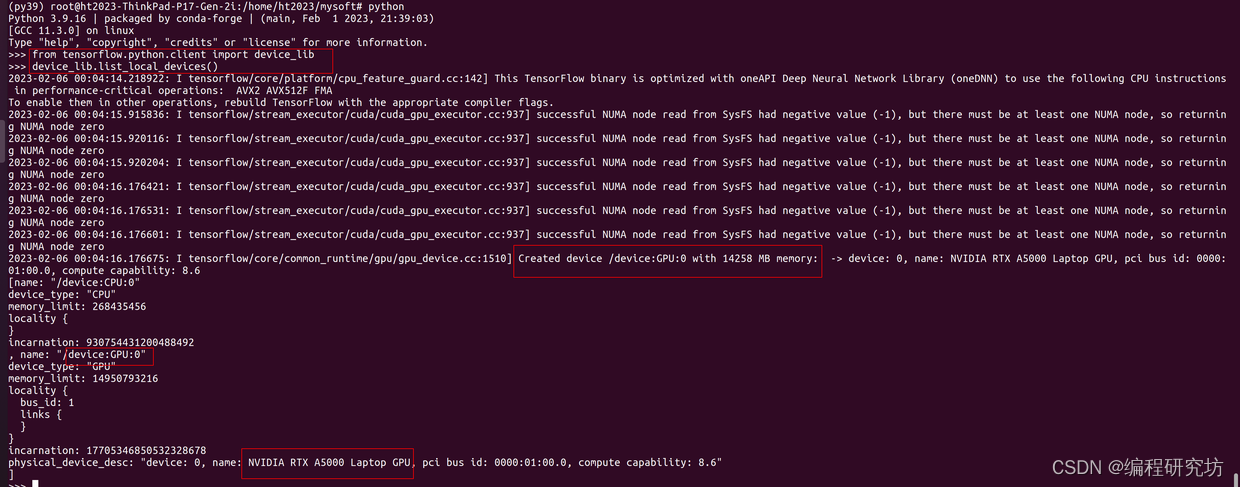
Ubuntu20.04+cuda11.2+cudnn8.1+Anaconda3安装tensorflow-GPU环境,亲测可用
(1)安装nvidia显卡驱动注意Ubuntu20.04和Ubuntu16.04版本的安装方法不同,安装驱动前一定要更新软件列表和安装必要软件、依赖(必须)sudo apt-get update #更新软件列表sudo apt-get install gsudo apt-get install gccsudo apt-get install make查看GP…...
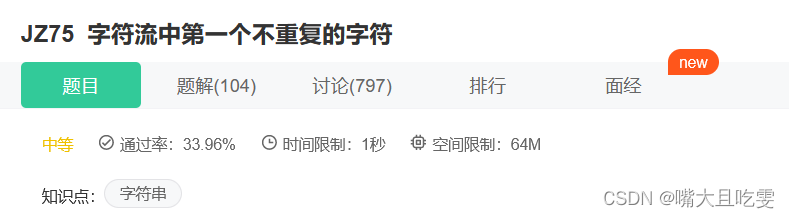
剑指Offer 第27天 JZ75 字符流中第一个不重复的字符
字符流中第一个不重复的字符_牛客题霸_牛客网 描述 请实现一个函数用来找出字符流中第一个只出现一次的字符。例如,当从字符流中只读出前两个字符 "go" 时,第一个只出现一次的字符是 "g" 。当从该字符流中读出前六个字符 “google&…...
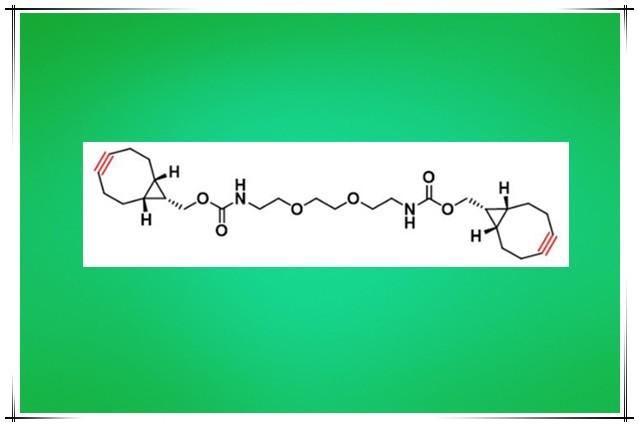
科研试剂供应1476737-97-9,Bis-PEG2-endo-BCN可发生点击反应
●外观以及性质:Bis-PEG2-endo-BCN一般为白色固体,BCN其为点击试剂,点击化学(Click chemistry),又译为“链接化学”、“动态组合化学” (Dynamic Combinatorial Chemistry)、“速配接…...

Zabbix 构建监控告警平台(一)--部署安装
监控对象监控收集信息方式Zabbix 部署 1.监控对象 源代码: *.html *.jsp *.php *.py 数据库: MySQL,MariaDB,Oracle,SQL Server,DB2 应用软件:Nginx,Apache,PHP,Tomcat agent 集群: LVS,Keepalived,HAproxy…...
【nodejs】nodejs入门核心知识(命令行使用、内置模块、node 模块化开发)
💻 nodejs入门核心知识(命令行使用、内置模块、node 模块化开发) 🏠专栏:JavaScript 👀个人主页:繁星学编程🍁 🧑个人简介:一个不断提高自我的平凡人🚀 🔊分享…...
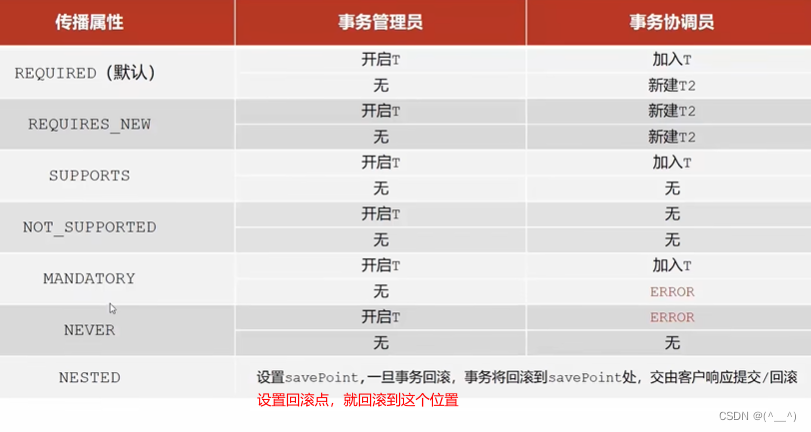
5. Spring 事务
文章目录1. Spring 事务简介2. Spring 事务角色3. Spring 事务属性3.1 事务配置3.2 案例:转账业务追加日志3.3 事务传播行为1. Spring 事务简介 Spring 事务作用:在数据层或业务层保障一系列的数据库操作同成功、同失败。 数据层有事务我们可以理解&am…...
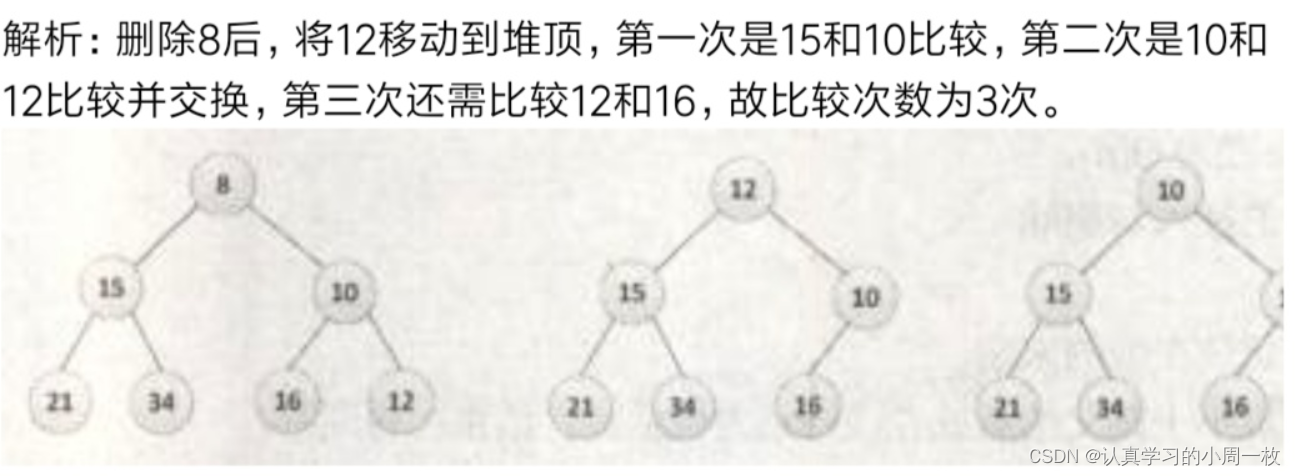
【堆】数据结构堆的实现(万字详解)
前言: 在上一期中我们讲到了树以及二叉树的基本的概念,有了之前的认识,今天我们将来具体实现一种二叉树的存储结构“堆”!!! 目录1.二叉树顺序结构介绍2.堆的概念及结构3.调整算法3.1向上调整算法3.1.1算法…...
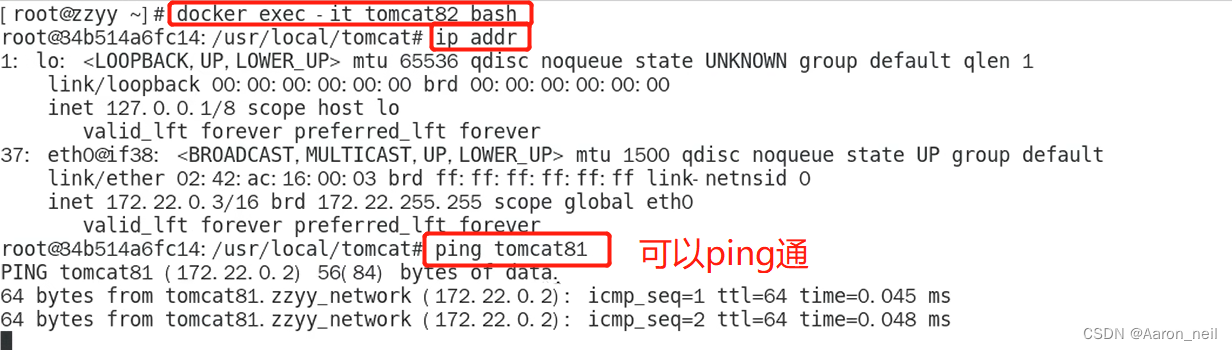
Docker进阶 - 9. docker network 之自定义网络
1. 运行两个tomcat实例,并进入容器内部 docker run -d -p 8081:8080 --name tomcat81 billygoo/tomcat8-jdk8 docker exec -it tomcat81 bashdocker run -d -p 8082:8080 --name tomcat82 billygoo/tomcat8-idk8 docker exec -it tomcat82 bash2. ping一下各自的ip…...
springcloud-工程创建(IDEA)
文章目录介绍springcloud 常用组件1.创建父工程2.删除父工程的src目录3.修改父工程的pom文件4 springcloud 版本依赖5.创建子模块6 子项目下创建启动类介绍 Spring Cloud 是一个基于 Spring Boot 实现的云应用开发工具,它为开发中的配置管理、服务发现、断路器、智…...
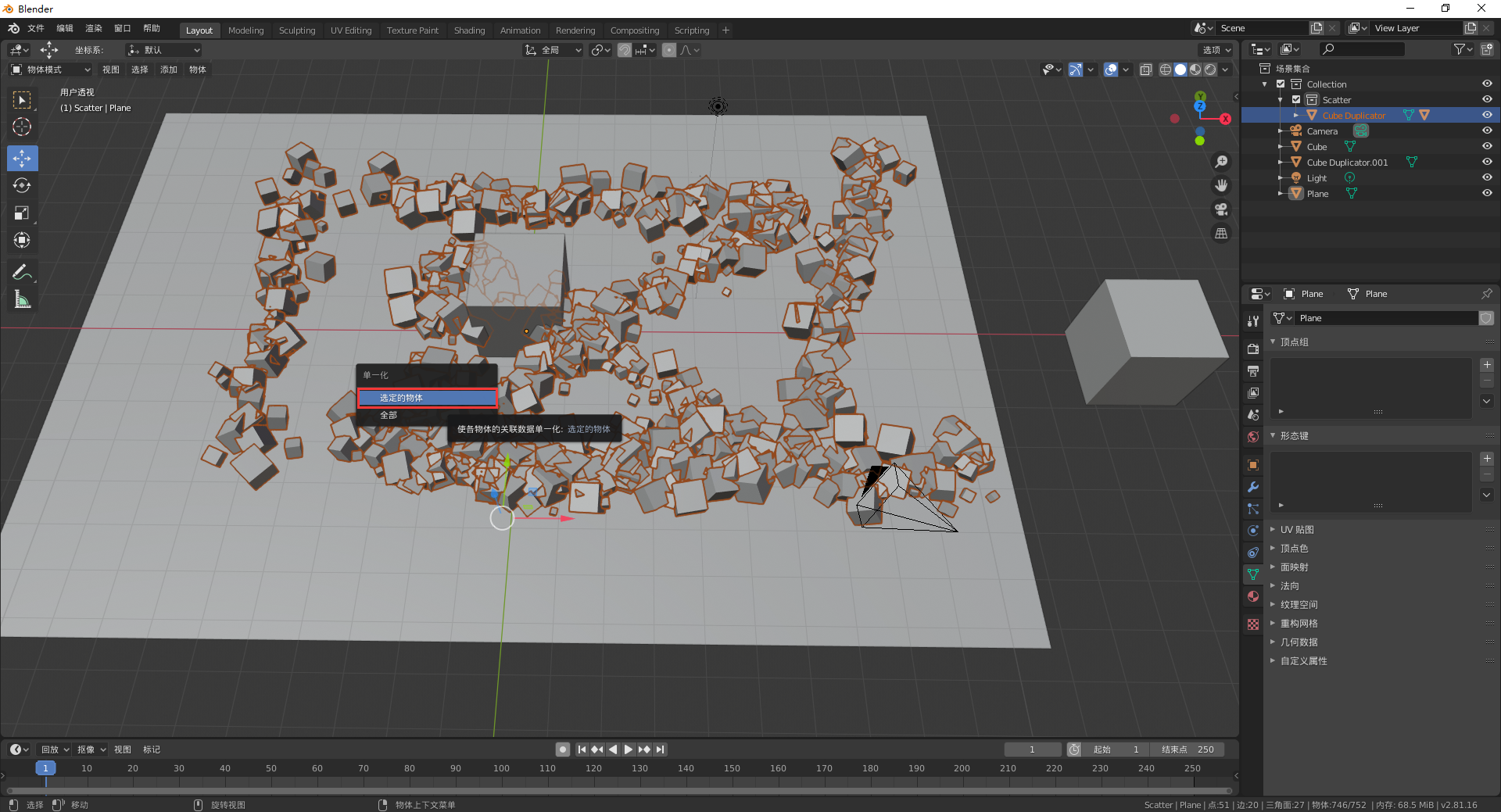
Blender——物体的随机分布
问题描述将正方体随机分布在平面上。问题解决点击编辑-->偏好设置。在【插件】中的【物体】类型中勾选【Object: Scatter Objects】。右下的活动工具与工作区设置中就会出现【物体散列】的模块,可以调节各参数。选中正方体,按着Shift,选中…...
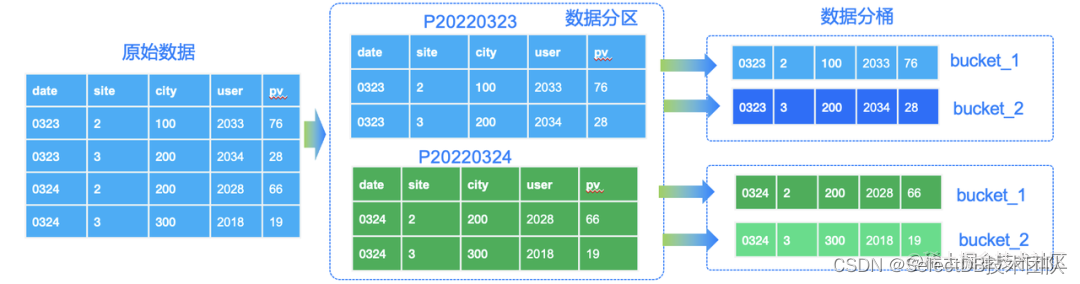
一文教你玩转 Apache Doris 分区分桶新功能
数据分片(Sharding)是分布式数据库分而治之 (Divide And Conquer) 这一设计思想的体现。过去的单机数据库在大数据量下往往面临存储和 IO 的限制,而分布式数据库则通过数据划分的规则,将数据打散分布至不同的机器或节点上…...

Spring JdbcTemplate 和 事务
JdbcTemplate概述 JdbcTemplate是spring框架中提供的一个对象,是对原始繁琐的Jdbc API对象的简单封装。spring框架为我们提供了很多的操作模板类。例如:操作关系型数据的JdbcTemplate和,操作nosql数据库的RedisTemplate,操作消息…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

前端中slice和splic的区别
1. slice slice 用于从数组中提取一部分元素,返回一个新的数组。 特点: 不修改原数组:slice 不会改变原数组,而是返回一个新的数组。提取数组的部分:slice 会根据指定的开始索引和结束索引提取数组的一部分。不包含…...