强化学习(Reinforcement Learning)与策略梯度(Policy Gradient)
写在前面:本篇博文的内容来自李宏毅机器学习课程与自己的理解,同时还参考了一些其他博客(懒得放链接)。博文的内容主要用于自己学习与记录。
1 强化学习的基本框架
强化学习(Reinforcement Learning, RL)主要由智能体(Agent/Actor)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)组成。在这些成员中,需要训练的是智能体,他会根据不同的状态产生动作。具体过程见下图,智能体由环境得到Observation(状态),再根据Observation得到一个动作作用于环境产生一个新的环境,再根据之前的状态和动作会给出奖励(正奖励或者负奖励)。随后,智能体根据新的状态和奖励,按照一定的策略执行新的动作。智能体通过强化学习,可以知道自己在什么状态下,应该采取什么样的动作使得自身获得最大奖励。

2 强化学习基本步骤
2.1 步骤1:构建决策框架
对于智能体(后文都用Actor)模块,很容易想到构建一个用于分类任务的Neural Network,根据例如图像一类的输入,通过Neural Network的计算得到每个动作的概率,选最大概率的动作作为最终的动作。再根据最终的Reward进行反向传播更新权重,从而达到训练的效果。这是典型的Deep Learning(DL)做法。当然,在RL中确实是这么做的。

有了可训练的网络模型,就需要定义"Loss Function"用于训练。不同的是DL是为了使结果更加精准,需要尽可能的减小Loss,是一个“下山”的过程,而RL是为了尽可能的增大奖励,是一个“上山”的过程。奖励可以根据动作和状态计算,例如下图中击杀怪物后会获得一定量的分数。

让模型不断产生动作直到游戏结束,这就是一轮次(episode)(类似于DL中的epoch),那么我们可以把所有的奖励累加起来。一个简单的思路是可以利用奖励和去更新Neural Network的权重。

定义:一次episode的奖励总和为 R = ∑ t = 1 T r t R=\sum_{t=1}^{T}{r_t} R=∑t=1Trt ,总共进行 T T T 次动作, r t r_t rt 为第 t t t 次动作 a T a_T aT 产生的奖励。现在需要训练Neural Network使 R R R 最大化,这就需要一个优化策略。
2.2 Policy Gradient详解
怎么知道这个动作好还是不好呢?可以让Actor实际的去“玩”一下游戏。假设动作 π θ ( s ) \pi_\theta(s) πθ(s) 的参数是 θ \theta θ ,就让Actor π θ ( s ) \pi_\theta(s) πθ(s) 反复去玩这个游戏。那么经过不断“玩”,可以得到总得分为 R θ R_\theta Rθ 。就算是在同一个环境下采取相同的Action,得到的 R θ R_\theta Rθ 也会不相同,这是因为Actor具有一定的随机性。那么我们需要尽可能大的去增加总奖励的期望 R ˉ θ \bar R_\theta Rˉθ ,而不是某一次的结果增大。

定义:一次episode的所有状态、动作、奖励组成的向量叫 τ \tau τ ,其代表一次episode的过程,相关公式如下:
τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , . . . , s T , a T , r T } \tau = \{s1, a1, r1, s2, a2, r2, ..., s_T, a_T, r_T\} τ={s1,a1,r1,s2,a2,r2,...,sT,aT,rT}
R ( τ ) = ∑ n = 1 N r n R(\tau)=\sum_{n=1}^{N}r_n R(τ)=n=1∑Nrn
假设对于一个Actor,每一种过程 τ \tau τ 都可能被列举到,每一种 τ \tau τ 出现的概率取决于Actor的参数 θ \theta θ ,定义为 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ) 。那么 R ˉ θ \bar R_\theta Rˉθ 就等于每一次episode中的得分 R θ R_\theta Rθ 与该过程 τ \tau τ 出现的几率的乘积之和,见如下公式:
R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) \bar R_\theta=\sum_{\tau}{R(\tau)P(\tau|\theta)}\approx\frac{1}{N}\sum_{n=1}^N{R(\tau^n)} Rˉθ=τ∑R(τ)P(τ∣θ)≈N1n=1∑NR(τn)
但 τ \tau τ 的情况太复杂了,难以枚举所有情况,可以让 π θ \pi_\theta πθ sample N N N 次,得到 { τ 1 , τ 2 , . . . , τ N } \{\tau^1, \tau^2, ..., \tau^N\} {τ1,τ2,...,τN} 与所有的出现概率 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ) 。那么问题就变成了如下表达式:
θ ∗ = arg max θ R ˉ θ , R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) \theta^{*}=\arg \max _{\theta} \bar{R}_{\theta}, \bar{R}_{\theta}=\sum_{\tau}R(\tau)P(\tau|\theta) θ∗=argθmaxRˉθ,Rˉθ=τ∑R(τ)P(τ∣θ)
由前文中提到RL的训练过程是一个“上山”的过程,所以可以用Gradient Ascent。
2.2.1 Gradient Ascent
需要更新的权重为 θ \theta θ ,梯度的方向为 ∇ R ˉ θ \nabla \bar R_\theta ∇Rˉθ 。

根据 R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) \bar{R}_{\theta}=\sum_{\tau}R(\tau)P(\tau|\theta) Rˉθ=∑τR(τ)P(τ∣θ) ,其中 R ( τ ) R(\tau) R(τ) 由于其有一定的随机性,只需要把 τ \tau τ 放进去根据 R ( ⋅ ) R(·) R(⋅) 得到结果,可以把其看成一个完全的“黑盒子”,不用考虑其可微性质。这样考虑的具体原因是 R ( τ ) R(\tau) R(τ) 本身是由环境打分得到的,环境是一个“黑盒子”。那么 ∇ R θ \nabla R_{\theta} ∇Rθ 为:
∇ R θ = ∑ τ R ( τ ) ∇ P ( τ ∣ θ ) = ∑ τ R ( τ ) P ( τ ∣ θ ) ∇ P ( τ ∣ θ ) P ( τ ∣ θ ) \nabla R_\theta = \sum_{\tau}{R(\tau)\nabla P(\tau|\theta)} = \sum_{\tau}{R(\tau)P(\tau|\theta)\frac{\nabla P(\tau|\theta)}{P(\tau|\theta)}} ∇Rθ=τ∑R(τ)∇P(τ∣θ)=τ∑R(τ)P(τ∣θ)P(τ∣θ)∇P(τ∣θ)
又由于:
d l o g ( f ( x ) ) d x = 1 f ( x ) d f ( x ) d x \frac{dlog(f(x))}{dx}=\frac{1}{f(x)} \frac{df(x)}{dx} dxdlog(f(x))=f(x)1dxdf(x)
∇ l o g ( f ( x ) ) = ∇ f ( x ) f ( x ) \nabla log(f(x))=\frac{\nabla f(x)}{f(x)} ∇log(f(x))=f(x)∇f(x)
那么 ∇ R θ \nabla R_\theta ∇Rθ 可以变为:
∇ R θ = ∑ τ R ( τ ) P ( τ ∣ θ ) ∇ l o g P ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ l o g P ( τ n ∣ θ ) \nabla R_\theta = \sum_{\tau}{R(\tau)P(\tau|\theta)\nabla log P(\tau|\theta)} \approx \frac{1}{N}\sum^{N}_{n=1}{R(\tau^n)\nabla log P(\tau^n|\theta)} ∇Rθ=τ∑R(τ)P(τ∣θ)∇logP(τ∣θ)≈N1n=1∑NR(τn)∇logP(τn∣θ)
其中 “玩” N N N 次游戏得到 { τ 1 , τ 2 , . . . , τ N } \{\tau^1, \tau^2, ..., \tau^N\} {τ1,τ2,...,τN} ,假设 N N N 足够大,表示概率的部分 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ) 就可以直接利用平均数去掉。现在的问题变成了如何计算 ∇ l o g P ( τ ∣ θ ) \nabla log P(\tau|\theta) ∇logP(τ∣θ) 。
我们可以把 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ) 展开:
P ( τ ∣ θ ) = p ( s 1 ) p ( a 1 ∣ s 1 , θ ) p ( r 1 , s 2 ∣ s 1 , a 1 ) p ( a 2 ∣ s 2 , θ ) p ( r 2 , s 3 ∣ s 2 , a 2 ) ⋯ = p ( s 1 ) ∏ t = 1 T p ( a t ∣ s t , θ ) p ( r t , s t + 1 ∣ s t , a t ) P(\tau|\theta)= p\left(s_{1}\right) p\left(a_{1} \mid s_{1}, \theta\right) p\left(r_{1}, s_{2} \mid s_{1}, a_{1}\right) p\left(a_{2} \mid s_{2}, \theta\right) p\left(r_{2}, s_{3} \mid s_{2}, a_{2}\right) \cdots =p(s_1)\prod^{T}_{t=1}{p(a_t|s_t, \theta)p(r_t, s_{t+1}|s_t, a_t)} P(τ∣θ)=p(s1)p(a1∣s1,θ)p(r1,s2∣s1,a1)p(a2∣s2,θ)p(r2,s3∣s2,a2)⋯=p(s1)t=1∏Tp(at∣st,θ)p(rt,st+1∣st,at)
其实这是一个用于描述马尔科夫决策过程的公式,其中每个状态和行动都有相应的概率分布。其中 p ( s 1 ) p(s_1) p(s1) 与 p ( r t , s t + 1 ∣ s t , a t ) p(r_t, s_{t+1}|s_t, a_t) p(rt,st+1∣st,at) 跟 π θ \pi_\theta πθ 是没关系的, p ( a t ∣ s t , θ ) p(a_t|s_t, \theta) p(at∣st,θ) 受 π θ \pi_\theta πθ 控制,后者的解释可以见下图。

那么 l o g P ( τ ∣ θ ) logP(\tau|\theta) logP(τ∣θ) 可以变成如下:
l o g P ( τ ∣ θ ) = l o g p ( s 1 ) + ∑ t = 1 T l o g p ( a t ∣ s t , θ ) + l o g p ( r t , s t + 1 ∣ s t , a t ) logP(\tau|\theta) = logp(s_1)+\sum_{t=1}^{T}logp(a_t|s_t, \theta) + logp(r_t, s_{t+1}|s_t, a_t) logP(τ∣θ)=logp(s1)+t=1∑Tlogp(at∣st,θ)+logp(rt,st+1∣st,at)
则 ∇ l o g P ( τ ∣ θ ) \nabla log P(\tau|\theta) ∇logP(τ∣θ) 跟 π θ \pi_\theta πθ 不相干的项直接可以去掉了,变成如下式子:
∇ l o g P ( τ ∣ θ ) = ∑ t = 1 T ∇ l o g p ( a t ∣ s t , θ ) \nabla logP(\tau|\theta)=\sum_{t=1}^{T}\nabla logp(a_t|s_t, \theta) ∇logP(τ∣θ)=t=1∑T∇logp(at∣st,θ)
那么可以把这个式子往回带,就可以得到 ∇ R ˉ θ \nabla \bar R_\theta ∇Rˉθ (注意这里的 T T T 变成了 T n T_n Tn ,这是因为对于不同的 τ \tau τ 产生动作序列的次数不一样,所以需要添加下标 n n n 与 不同轮次的 τ \tau τ 对应):
∇ R ˉ θ ≈ 1 N ∑ n = 1 N R ( τ n ) ∇ l o g P ( τ n ∣ θ ) = 1 N ∑ n = 1 N R ( τ θ ) ∑ t = 1 T n ∇ l o g p ( a t n ∣ s t n , θ ) = 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ θ ) ∇ l o g p ( a t n ∣ s t n , θ ) \nabla \bar R_\theta \approx \frac{1}{N} \sum_{n=1}^{N}{R(\tau^n) \nabla log P(\tau^n|\theta)} = \frac{1}{N} \sum_{n=1}^{N}{R(\tau^\theta) \sum_{t=1}^{T_n}{\nabla log p(a_t^n|s_t^n, \theta)}} = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n}{R(\tau^\theta){\nabla log p(a_t^n|s_t^n, \theta)}} ∇Rˉθ≈N1n=1∑NR(τn)∇logP(τn∣θ)=N1n=1∑NR(τθ)t=1∑Tn∇logp(atn∣stn,θ)=N1n=1∑Nt=1∑TnR(τθ)∇logp(atn∣stn,θ)
这个式子的含义是,假设在sample的一个 θ \theta θ 里面, s t n s_t^n stn 这个State下采取了 a t n a_t^n atn 这个动作的概率,取log再计算梯度,与那一次 τ \tau τ 的总奖励相乘。进一步理解,如果在某一次 τ n \tau^n τn 时,机器在看到状态 s t n s_t^n stn 时,采取了一个动作 a t n a_t^n atn ,然后总的奖励是正的,那么机器就会自己去增加看到这个场景下做出该行动的概率。

值得注意的是,如果把梯度里的 R ( τ n ) R(\tau^n) R(τn) 替换成 r t n r_t^n rtn 后,也就是将第 n n n 次 τ n \tau^n τn 的总奖励换成第 n n n 次 τ n \tau^n τn 在 t t t 时刻在状态 s t n s_t^n stn 下采取动作 a t n a_t^n atn 得到的奖励,那么就会丢失其他动作的期望贡献,最后训练出来的模型只会在原地开火。这里还能这么理解(个人理解),如果换成 r t n r_t^n rtn ,由于sample的随机性,可以不用考虑 1 N ∑ n = 1 N \frac{1}{N}\sum_{n=1}^{N} N1∑n=1N 这一层。那么 ∇ R ˉ θ \nabla \bar R_\theta ∇Rˉθ 可以写成:
∇ R ˉ θ = g ( ∑ t = 1 T r t ∇ l o g p ( a t ∣ s t , θ ) ) \nabla \bar R_\theta = g(\sum_{t=1}^{T}r_t \nabla log p(a_t|s_t, \theta)) ∇Rˉθ=g(t=1∑Trt∇logp(at∣st,θ))
此时的 r t r_t rt 与 a t , s t a_t, s_t at,st 唯一对应,那么梯度在每个时刻只关注了一个动作的奖励与概率~~,很容易陷入局部最优~~,导致训练出来的模型在某一特定环境下只会侧重一个动作。由Actor在不同连续的 s t s_t st 下产生的一系列动作是有一定的关联性的~~,类似于NLP上下文特征或者音频里的时域特征~~,所以不能只考虑某一 a t , s t a_t, s_t at,st 下单独的 r t r_t rt。这就有点类似于分类任务的损失函数。
有了梯度,就可以根据Gradient Ascent更新Actor网络的权重,公式如下:
θ n e w ← θ o l d + η ∇ R ˉ θ o l d \theta^{new} ← \theta^{old} + \eta \nabla \bar R_{\theta^{old}} θnew←θold+η∇Rˉθold
下面我们再看看更新模型的过程,如下图,即生成一组训练数据,更新一次 θ \theta θ ,值得注意的是每一组训练数据只能用一次。

2.2.2 如何损失函数进一步优化
假设所有的 R ( τ n ) R(\tau^n) R(τn) 都是正值。假设在某一个状态下,采取 a , b , c a, b, c a,b,c 三个动作的概率如下,但 a , c a, c a,c 的奖励更高,那么理想状态下经过训练 a , c a, c a,c 出现的概率会增高, b b b 出现的概率会降低。但实际上我们是sample的,假设没有采集到 a a a 动作这种情况,那么经过训练后 a a a 出现的概率会降低。这时,我们需要引入一个baseline,即可以对 R ( τ n ) R(\tau^n) R(τn) 减去一个 b b b ,从而使奖励有好有坏,不然都是正值无法区分,通常可以将 b b b 值设置为与 R ( τ n ) R(\tau^n) R(τn) 的期望接近的值,即 E [ R ( τ n ) ] E[R(\tau^n)] E[R(τn)]。

还有很多方法能缓解这一问题,例如为不同的动作分配不同的权重,即好的动作给正分,差的动作给负分,再将 R ( τ n ) R(\tau^n) R(τn) 替换成所有动作的权重和,这种做法的本质就是改变了原本奖励的计算。

随着时间的推移,状态-动作的组合会越来越多,那么前面的组合对距离过远的组合的影响就会越来越小,可以用添加一个衰减因子 γ \gamma γ ,这种方法叫Advantage function,见下图。

相关文章:
强化学习(Reinforcement Learning)与策略梯度(Policy Gradient)
写在前面:本篇博文的内容来自李宏毅机器学习课程与自己的理解,同时还参考了一些其他博客(懒得放链接)。博文的内容主要用于自己学习与记录。 1 强化学习的基本框架 强化学习(Reinforcement Learning, RL)主要由智能体(Agent/Actor)、环境(Environment)、…...

JUC之ForkJoin并行处理框架
ForkJoin并行处理框架 Fork/Join 它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。 类似于mapreduce 其实,在Java 8中引入的并行流计算,内部就是采用的ForkJoinPool来实现…...

【牛客面试必刷TOP101】Day8.BM33 二叉树的镜像和BM36 判断是不是平衡二叉树
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:牛客面试必刷TOP101 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!&…...
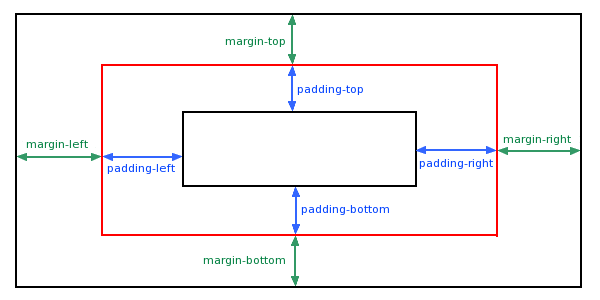
CSS padding(填充)
CSS padding(填充)是一个简写属性,定义元素边框与元素内容之间的空间,即上下左右的内边距。 padding(填充) 当元素的 padding(填充)内边距被清除时,所释放的区域将会受到…...
C语言达到什么水平才能从事单片机工作
C语言达到什么水平才能从事单片机工作 从事单片机工作需要具备一定的C语言编程水平。以下是几个关键要点:基本C语言知识: 掌握C语言的基本语法、数据类型、运算符、流控制语句和函数等基本概念。最近很多小伙伴找我,说想要一些C语言学习资料&…...

Java架构师理解SAAS和多租户
目录 1 云服务的三种模式1.1 IaaS(基础设施即服务)1.2 PaaS(平台即服务)1.3 SaaS(软件即服务)1.4 区别与联系2 SaaS的概述2.1 Saas详解2.2 应用领域与行业前景2.3 Saas与传统软件对比3 多租户SaaS平台的数据库方案3.1 多租户是什么3.2 需求分析3.3 多租户的数据库方案分析…...
关于Java线程池相关面试题
【更多面试资料请加微信号:suns45】 https://flowus.cn/share/f6cd2cbe-627a-435f-a6e5-1395333f92e8 【FlowUs 息流】📣suns-Java资料 访问密码:【请加微信号:suns45】 ————线程相关的面试题———— 0:创建线…...
ExcelBDD Python指南
在Python里面支持BDD Excel BDD Tool Specification By ExcelBDD Method This tool is to get BDD test data from an excel file, its requirement specification is below The Essential of this approach is obtaining multiple sets of test data, so when combined with…...

基于深度学习的驾驶员疲劳监测系统的设计与实现
点击以下链接获取源码: https://download.csdn.net/download/qq_64505944/88421622?spm1001.2014.3001.5503 基于深度学习的驾驶员疲劳监测系统的设计与实现 1 绪论 在21世纪,各国的经济飞速发展,人民越来越富裕,道路上的汽车也逐…...
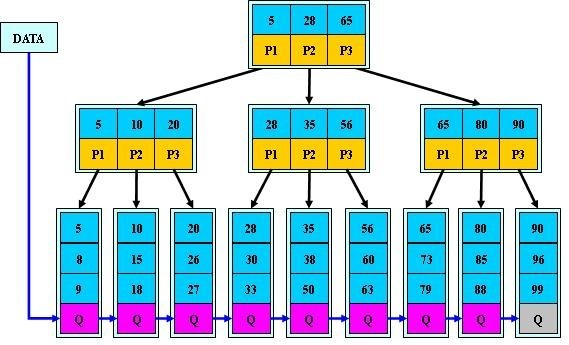
B树、B+树详解
B树 前言 首先,为什么要总结B树、B树的知识呢?最近在学习数据库索引调优相关知识,数据库系统普遍采用B-/Tree作为索引结构(例如mysql的InnoDB引擎使用的B树),理解不透彻B树,则无法理解数据…...
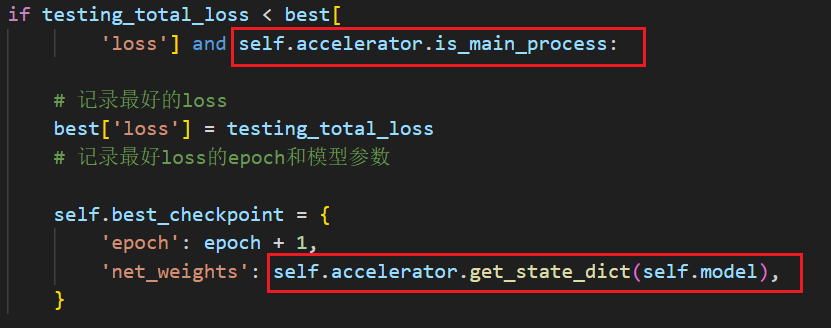
使用hugging face开源库accelerate进行多GPU(单机多卡)训练卡死问题
目录 问题描述及配置网上资料查找1.tqdm问题2.dataloader问题3.model(input)写法问题4.环境变量问题 我的卡死问题解决方法 问题描述及配置 在使用hugging face开源库accelerate进行多GPU训练(单机多卡)的时候,经常出现如下报错 [E Process…...
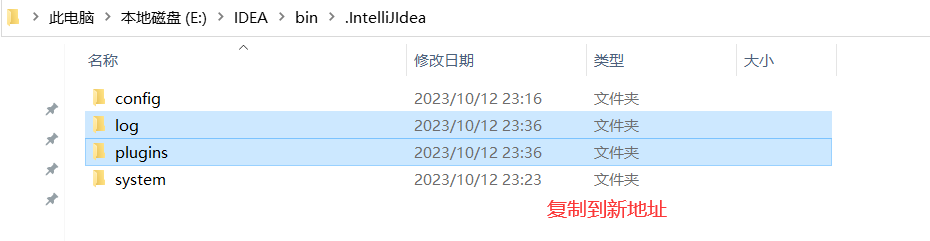
IDEA 修改插件安装位置
不说假话,一定要看到最后,不然你以为我为什么要自己总结!!! IDEA 修改插件安装位置 前言步骤 前言 IDEA 默认的配置文件均安装在C盘,使用时间长会生成很多文件,这些文件会占用挤兑C盘空间&…...

牛客网SQL160
国庆期间每类视频点赞量和转发量_牛客题霸_牛客网 select * from ( select tag,dt, sum(单日点赞量)over(partition by tag order by dt rows between 6 preceding and 0 following), max(单日转发量)over(partition by tag order by dt rows between 6 preceding and 0 follo…...
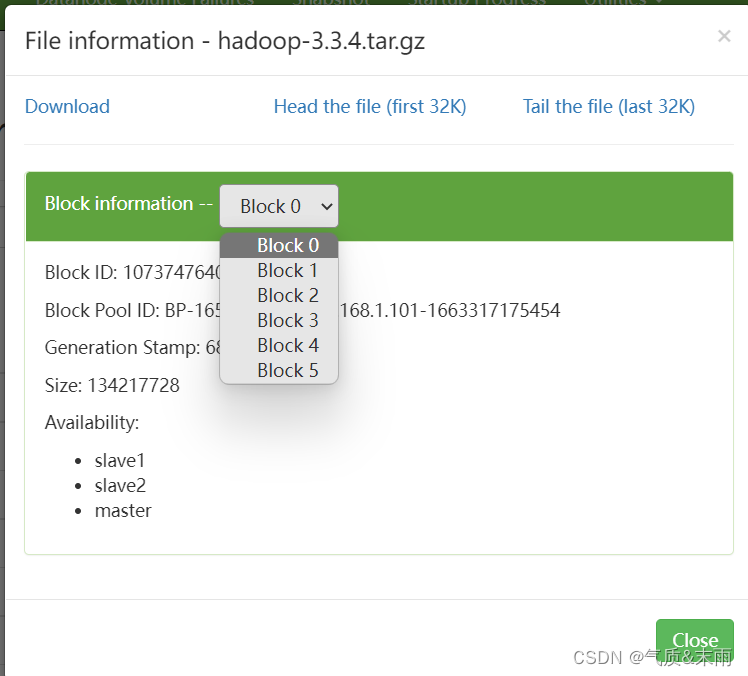
HDFS Java API 操作
文章目录 HDFS Java API操作零、启动hadoop一、HDFS常见类接口与方法1、hdfs 常见类与接口2、FileSystem 的常用方法 二、Java 创建Hadoop项目1、创建文件夹2、打开Java IDEA1) 新建项目2) 选择Maven 三、配置环境1、添加相关依赖2、创建日志属性文件 四、Java API操作1、在HDF…...
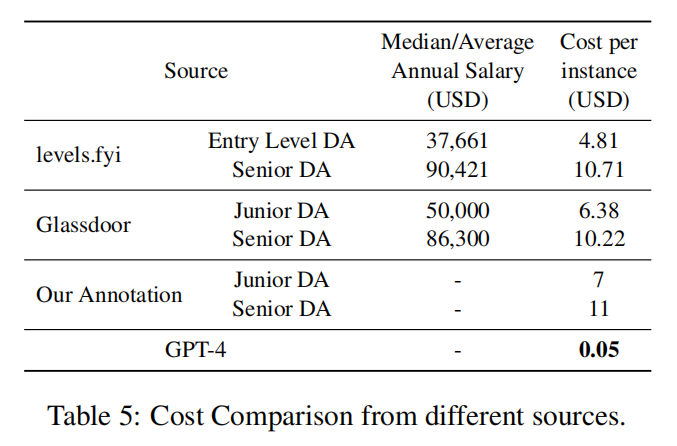
论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】
文章目录 论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】背景:数据分析师工作范围基于GPT-4的端到端数据分析框架将GPT-4作为数据分析师的框架的流程图 实验分析评估指标表1:GPT-4性能表现表2&…...
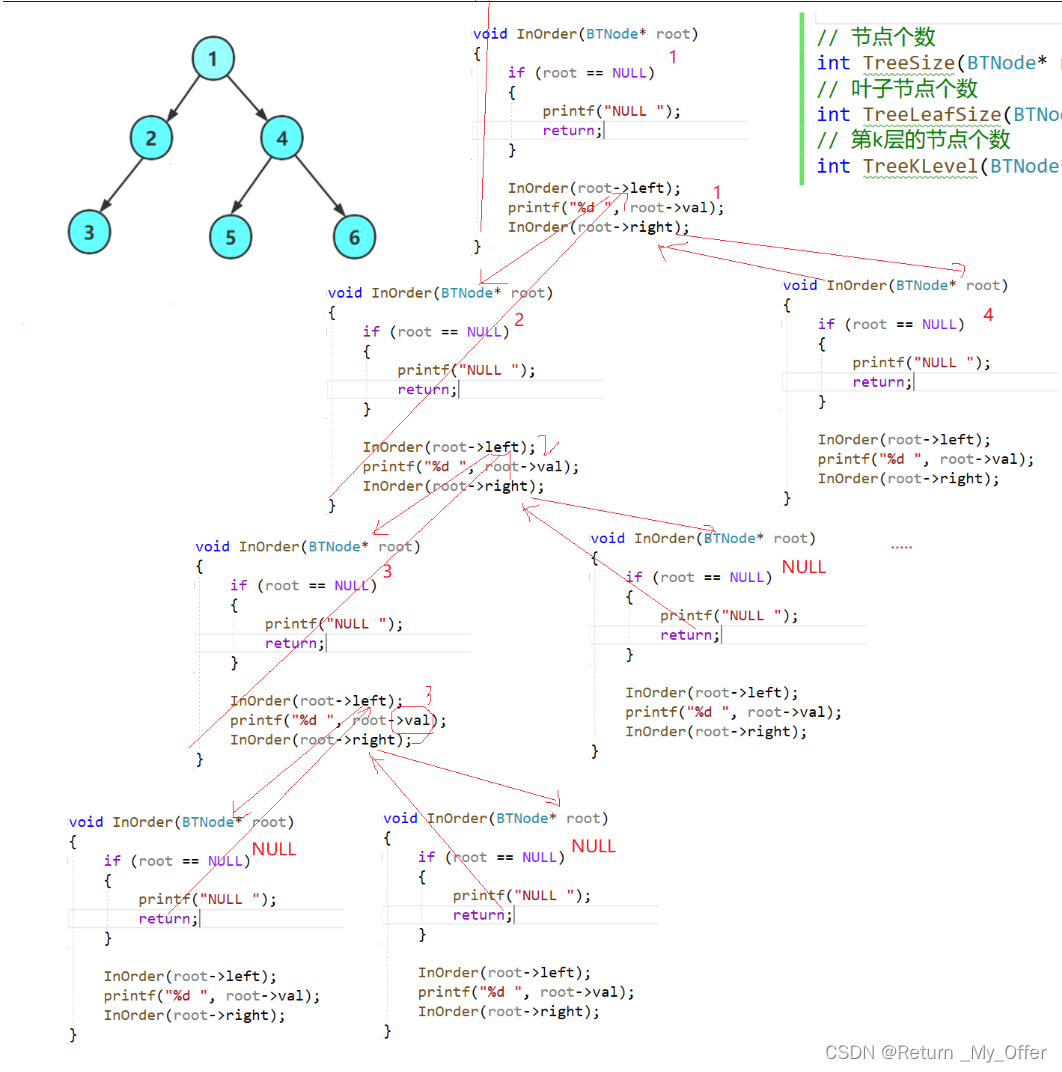
【数据结构】:二叉树与堆排序的实现
1.树概念及结构(了解) 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的有一个特殊的结点&#…...

纯css手写switch
CSS 手写switch 纯css手写switchcss变量 纯css手写switch 思路: switch需要的元素有:开关背景、开关按钮。点击按钮后,背景色变化,按钮颜色变化,呈现开关打开状态。 利用typecheckbox,来实现switch效果(修…...

PyTorch 深度学习之处理多维特征的输入Multiple Dimension Input(六)
1.Multiple Dimension Logistic Regression Model 1.1 Mini-Batch (N samples) 8D->1D 8D->2D 8D->6D 1.2 Neural Network 学习能力太好也不行(学习到的是数据集中的噪声),最好的是要泛化能力,超参数尝试 Example, Arti…...

LeetCode【438】找到字符串中所有字母异位词
题目: 注意:下面代码勉强通过,每次都对窗口内字符排序。然后比较字符串。 代码: public List<Integer> findAnagrams(String s, String p) {int start 0, end p.length() - 1;List<Integer> result new ArrayL…...
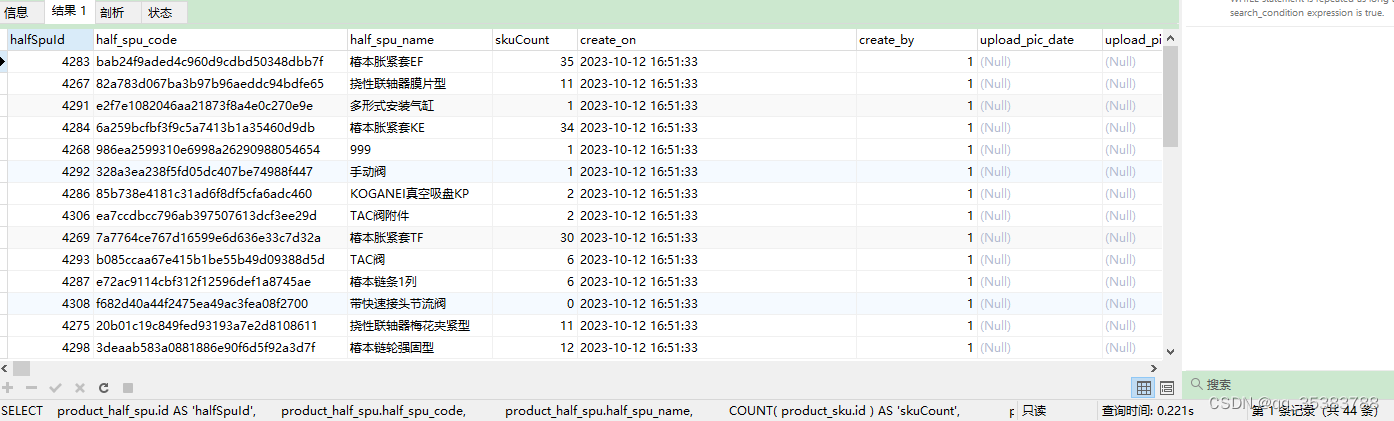
关于LEFT JOIN的一次理解
先看一段例子: SELECTproduct_half_spu.id AS halfSpuId,product_half_spu.half_spu_code,product_half_spu.half_spu_name,COUNT( product_sku.id ) AS skuCount,product_half_spu.create_on,product_half_spu.create_by,product_half_spu.upload_pic_date,produc…...

OpenClaw人人养虾:转录清洁
Transcript Hygiene(转录清洁)是对 OpenClaw 对话历史记录进行清理、脱敏和维护的实践。良好的转录清洁习惯有助于保障数据安全、节省存储空间并满足合规要求。为什么需要转录清洁对话转录中可能包含:风险类型示例个人身份信息(PI…...
)
新加坡求职股权激励介绍(股票期权Stock Options / ESOP、行权价Strike Price、限制性股票RSU、Phantom Shares虚拟股权)
文章目录新加坡求职必看:一文搞懂公司股权激励(股票小白入门)一、什么是股权激励?二、常见的三种股权形式(重点)1️⃣ 股票期权(Stock Options / ESOP)2️⃣ 限制性股票(…...

终极指南:如何用RL4CO快速解决复杂组合优化问题
终极指南:如何用RL4CO快速解决复杂组合优化问题 【免费下载链接】rl4co A PyTorch library for all things Reinforcement Learning (RL) for Combinatorial Optimization (CO) 项目地址: https://gitcode.com/gh_mirrors/rl/rl4co 你是否曾为物流配送路线规…...
)
手把手教你用TigerVNC在Ubuntu上搭建‘云电脑’实验室(支持多人同时在线)
从零构建Ubuntu云端实验室:TigerVNC多用户远程桌面实战指南 想象一下这样的场景:你的学生团队分布在不同城市,却需要共享同一套开发环境;或是线上教学时,每个学员都能获得独立的Linux桌面进行实操练习。传统方案需要为…...

从蓝牙到UWB:手把手拆解CCC R3标准如何实现车辆‘厘米级’安全定位
从蓝牙到UWB:手把手拆解CCC R3标准如何实现车辆‘厘米级’安全定位 当你的手机靠近车门时,车辆自动解锁;坐进驾驶舱的瞬间,引擎悄然启动——这种科幻电影般的体验,正通过CCC R3标准中的UWB定位技术走进现实。与传统方…...

Qwen3-0.6B-FP8效果展示:用非思维模式生成抖音爆款短视频口播文案脚本
Qwen3-0.6B-FP8效果展示:用非思维模式生成抖音爆款短视频口播文案脚本 最近在短视频平台刷到不少爆款视频,发现它们的口播文案都很有特点:节奏快、情绪足、有记忆点。作为一个技术爱好者,我就在想,能不能用AI来批量生…...

YOLO12作品集:高清标注、实时推理,展示AI视觉的无限可能
YOLO12作品集:高清标注、实时推理,展示AI视觉的无限可能 1. 模型概述 1.1 YOLO12核心架构 YOLO12作为2025年最新发布的目标检测模型,由美国纽约州立大学布法罗分校和中国科学院大学联合研发。该模型创新性地采用了注意力为中心架构&#x…...

企业知识库构建新方案:StructBERT中文句向量工具在智能客服问答对匹配中的落地实践
企业知识库构建新方案:StructBERT中文句向量工具在智能客服问答对匹配中的落地实践 1. 项目背景与价值 在智能客服系统中,用户提问的方式千变万化,但核心意图往往相同。传统的关键词匹配方法经常遇到这样的问题:用户问"怎么…...

Nanbeige 4.1-3B WebUI应用实践:AI学习伙伴/日语练习助手/轻量内容创作工具
Nanbeige 4.1-3B WebUI应用实践:AI学习伙伴/日语练习助手/轻量内容创作工具 1. 引言:一个不一样的AI对话界面 如果你用过一些AI对话工具,可能会觉得界面都差不多:左边是聊天记录,右边是输入框,头像方方正…...

从鸢尾花到你的数据:手把手教你用R语言为任意二分类模型绘制ROC曲线
从零到专业:用R语言打造高精度二分类模型评估体系 在数据科学领域,模型评估从来都不是可有可无的装饰品。想象一下,你花费数周时间构建的预测模型,在关键时刻却给出了完全相反的判断——医疗诊断误判生死,金融风控错放…...