如何选择最适合你的LLM优化方法:全面微调、PEFT、提示工程和RAG对比分析
一、前言
自从ChatGPT问世以来,全球各地的企业都迫切希望利用大型语言模型(LLMs)来提升他们的产品和运营。虽然LLMs具有巨大的潜力,但存在一个问题:即使是最强大的预训练LLM也可能无法直接满足你的特定需求。其原因如下:
-
定制输出:你可能需要一个具有独特结构或风格的应用程序,例如可以评分并提供简洁反馈点评文章质量的工具。
-
缺少上下文:预训练LLM可能对于你应用程序中重要文件一无所知,例如针对某系列产品进行技术咨询的聊天机器人。如果这些产品的使用手册并未包含在LLM的训练数据中,那么它的准确性可能会受到影响。
-
专业词汇:某些领域、行业甚至特定企业通常具有独特的术语、概念和结构,而这些在一般预训练数据中并未得到充分体现。因此,预训练的LLM可能会在对财务数据、医学研究论文甚至公司会议记录进行总结或回答问题时面临挑战。
那么,你如何使LLM符合你的独特要求呢?你可能需要进行调整或“调优”。目前有四种主要的调优方法:
-
全面微调:使用任务特定数据调整LLM的所有参数。
-
参数高效精细调整(PEFT):修改选定参数以实现更高效的适应。
-
提示工程:改进模型输入以指导其输出。
-
RAG(检索增强生成):将提示工程与数据库查询结合,以获得丰富的上下文答案。
这些方法在所需专业知识、成本和适用性方面各有不同。本文将探讨每种方法,揭示它们的细微差异、成本和最佳使用案例。通过深入了解哪种方法最适合你的项目,你将能够更好地优化LLM。
二、全面微调
微调是我们用来进一步训练已经预训练过的 LLM 的过程,在一个较小、任务特定、带标签的数据集上进行。通过这种方式,我们调整一些模型参数以优化其对特定任务或一组任务的性能。在全面微调中,所有模型参数都被更新,使其类似于预训练——只不过它是在一个带标签且规模较小的数据集上进行。

2.1、全面微调的六个步骤
举例来说,假设我们想要构建一个工具,用于生成生物技术研究论文的摘要。对于全面微调,你需要经历以下步骤:
2.1.1、创建数据集
从生物技术的目标领域收集一套研究论文。确保每篇论文都附带其原始摘要。
将这个集合分割成训练、验证和测试集。
2.1.2、预处理数据
将每篇研究论文转换成模型可接受的格式。
将每篇处理过的论文内容与其相应的摘要配对,形成监督训练的输入-输出对。
2.1.3、配置模型
加载预训练的 LLM(例如,预训练版本的 GPT-4)。
根据初步测试或领域知识,决定微调的超参数,如学习率、批量大小和迭代次数。
2.1.4、训练模型
将处理过的内容作为输入提供给 LLM,并训练它生成相应的摘要作为输出。
监控模型在验证集上的性能,以防止过拟合,并决定何时停止训练或进行调整。
2.1.5、评估性能
一旦微调完成,评估模型在它之前未见过的测试集上的性能。
度量可能包括 BLEU 分数、ROUGE 分数,或者人类评估来衡量生成的摘要与原始摘要相比的质量和相关性。
2.1.6、迭代直到性能满意
根据评估结果,迭代上述步骤,可能需要收集更多数据、调整超参数,或尝试不同的模型配置以提高性能。
2.2、全面微调的优点
2.2.1、比从头开始训练需要更少的数据
即使是相对较小的任务特定数据集,全面微调也可以有效。预训练的 LLM 已经理解了通用语言结构。微调过程主要关注调整模型知识以适应新数据的特性。一个预训练的 LLM,最初在大约 1 万亿个标记上进行训练,并展示出稳健的通用性能,可以使用只有几百个例子(相当于几十万个标记)进行高效微调。
2.2.2、提高精度
通过在任务特定数据集上进行微调,LLM 可以把握该特定领域的细微差别。这在具有专业术语、概念或结构的领域尤其重要,如法律文件、医学文本或财务报告。因此,在面对特定领域或任务中未见过的例子时,模型可能会做出更高精度和相关性的预测或生成输出。
2.2.3、增加鲁棒性
微调使我们能够向模型展示更多例子,尤其是在领域特定数据集中边缘情况或不常见情况。这使得模型更好地处理各种输入而不产生错误输出。
2.3、全面微调的缺点
2.3.1、高计算成本
全面微调涉及更新大型模型的所有参数。对于拥有数十亿或数百亿参数的大规模 LLM 来说,训练需要大量计算能力。即使微调数据集相对较小,标记数量也可能非常大,并且计算成本高昂。
2.3.2、大量内存需求
使用大型模型可能需要专门硬件,如高端 GPU 或 TPU,具有显著内存容量。这对许多企业来说通常是不切实际的。
2.3.3、时间和专业知识密集型
当模型非常大时,你通常需要将计算分布在多个 GPU 和节点上。这需要适当的专业知识。根据模型和数据集的大小,微调可能需要几小时、几天,甚至几周。
三、参数高效微调
参数高效微调(PEFT)[1]使用技术进一步调整预训练模型,只更新其总参数的一小部分。在大量数据上预训练的大型语言模型已经学习了广泛的语言结构和知识。简而言之,它已经拥有了许多任务所需的大部分信息。考虑到范围较小,通常没有必要也不高效地调整整个模型。微调过程是在一小部分参数上进行的。
PEFT 方法在确定模型的哪些组件是可训练的方面各有不同。一些技术优先训练原始模型参数的选定部分。其他方法集成并训练较小的附加组件,如适配器层,而不修改原始结构。

四、LoRA
LoRA[2],即大型语言模型的低秩适应,于 2023 年初引入。此后,它已经成为最常用的 PEFT 方法,帮助公司和研究人员降低他们的微调成本。使用重参数化,这种技术通过执行低秩近似来缩小可训练参数的集合。
例如,如果我们有一个 100,000 x 100,000 的权重矩阵,那么对于全面微调,我们需要更新 10,000,000,000 个参数。使用 LoRA,我们可以通过使用包含微调期间更新的选定参数的低秩矩阵来捕获所有或大部分关键信息。
为了得到这个低秩矩阵,我们可以将原始权重矩阵重新参数化为两个矩阵 A 和 B,每个都是低秩 r。我们的新低秩矩阵然后被认为是 A 和 B 的乘积。如果 r = 2,我们最终更新 (100,000 x 2) + (100,000 x 2) = 400,000 个参数而不是 10,000,000。通过更新更少数量的参数,我们减少了微调所需的计算和内存需求。以下来自 LoRA 原始论文的图形说明了这种技术。
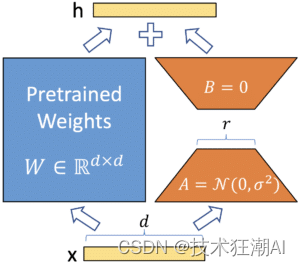
图1:LoRA重新参数化只训练A和B。(图片来源:https://arxiv.org/abs/2106.09685)
以下是 LoRA 的一些优点:
-
任务切换效率 - 创建模型的不同版本以适应特定任务变得更容易。你可以简单地存储预训练权重的单个副本,并构建许多小 LoRA 模块。当你从任务切换到任务时,你只替换矩阵 A 和 B,并保留 LLM。这显著减少了存储需求。
-
需要更少的 GPU - LoRA 将 GPU 内存需求减少了最多 3 倍,因为我们不计算/重新训练大多数参数。
-
高精度 - 在各种评估基准上,LoRA 的性能被证明几乎等同于全面微调 - 而且只需要一部分成本。
因为它是如此新颖,LoRA 在你需要对多个任务进行模型微调的情况下的有效性仍未经测试。在这种情况下,预训练 LLM 需要顺序地对每个任务进行微调,并且尚待观察 LoRA 是否能保持全面微调的精度。
五、PEFT 相比全面微调的优势
5.1、更高效和更快的训练
更少的参数调整意味着更少的计算,这直接转化为需要更少的计算能力和内存资源的更快的训练会话。这使得在资源紧张的情况下进行微调变得更加实用。
5.2、保留预训练的知识
在广泛数据集上进行大量预训练使模型具有宝贵的通用知识和能力。使用 PEFT,我们确保在将模型适应新任务时,这个宝库不会丢失,因为我们保留了大部分或所有的原始模型权重。
PEFT 是否是全面微调的有效替代方案取决于使用案例和选择的特定 PEFT 技术。在 PEFT 中,你训练的参数数量比全面微调少得多,如果任务“足够困难”,训练参数数量的差异将会显现。
六、提示工程
到目前为止讨论的方法涉及在新数据集和任务上训练模型参数,使用所有预训练权重(如全面微调)或一组独立权重(如 LoRA)。相比之下,提示工程根本不涉及训练网络权重。它是设计和精炼模型输入以引导和影响你想要的输出类型的过程。

6.1、基础提示
像 GPT4 这样的超大型 LLM 被调整以遵循指令,可以根据它们在训练过程中看到的多样化模式从很少的例子中进行概括,并展示基本推理能力。提示工程利用这些能力来引出模型的期望响应。
6.1.1、零样本提示
在零样本提示中,我们在用户查询前添加某个指令,而不向模型提供任何直接示例。
想象一下你正在使用大型语言模型开发一个技术支持聊天机器人。为了确保模型专注于提供技术解决方案而不需要先前的例子,你可以在所有用户输入前添加一个特定指令:
提示:
根据以下用户关注点提供技术支持解决方案。用户关注点:我的电脑无法开机。
解决方案:通过在用户查询(“我的电脑无法开机”)前添加指令,我们给模型提供了期望答案的上下文。这是一种即使没有明确的技术解决方案示例也能适应其输出以进行技术支持的方式。
6.1.2、少样本提示
少样本提示中,我们在用户查询前添加几个示例。这些示例本质上是样本输入和期望模型输出的配对。
想象一下你正在创建一个使用语言模型将菜肴分类为“低脂”或“高脂”的健康应用程序。为了定向模型,几个示例被添加到用户查询之前:
根据其脂肪含量对以下菜肴进行分类:烤鸡、柠檬、香草。回应:低脂
根据其脂肪含量对以下菜肴进行分类:用浓奶油和黄油做的马克和奶酪。回应:高脂
根据其脂肪含量对以下菜肴进行分类:橄榄油烤牛油果吐司
回应:根据提示中的示例,足够大且训练良好的 LLM 将可靠地回应:“高脂”。
少射提示是一种使模型采用某种响应格式的好方法。回到我们的技术支持应用示例,如果我们希望模型的响应符合某种结构或长度限制,我们可以通过少射提示来实现。
6.1.3、链式思考引导
链式思考引导通过指导模型进行中间步骤来进行详细问题解决。配合少数示例引导可以提升需要深度分析才能得出答案任务的表现。
在这个组合里面,最大数减去最小数得到一个偶数:5、8、9。
答案:9 减去 5 等于 4。所以答案是 True。
在这个组合里面,最大数减去最小数得到一个偶数:10、15、20。
答案:20 减去 10 等于 10。所以答案是 True。
在这个组合里面,最大数减去最小数得到一个偶数:7、12、15。
答案:实际上,链式思考引导也可以和零示例引导配合使用,以提升需要逐步分析的任务的表现。回到我们的技术支持应用示例,如果我们想提升模型的表现,我们可以要求它逐步分解解决方案。
根据以下用户问题逐步分解技术支持解决方案。用户问题:我的电脑无法开机。
解决方案:对于各种应用,基本的引导工程对于大型语言模型来说可以提供“足够好”的准确性。它提供了一种经济的适应方法,因为它快速且不涉及大量计算能力。但是缺点是它对于需要额外背景知识的用例来说,简单地不够准确或稳健。
七、检索增强生成(RAG)
由 Meta 研究人员引入的检索增强生成(RAG)[3]是一种强大的技术,它将引导工程与从外部数据源检索上下文相结合,以提高语言模型的性能和相关性。通过在模型上附加额外信息,它允许更准确和上下文感知的响应。
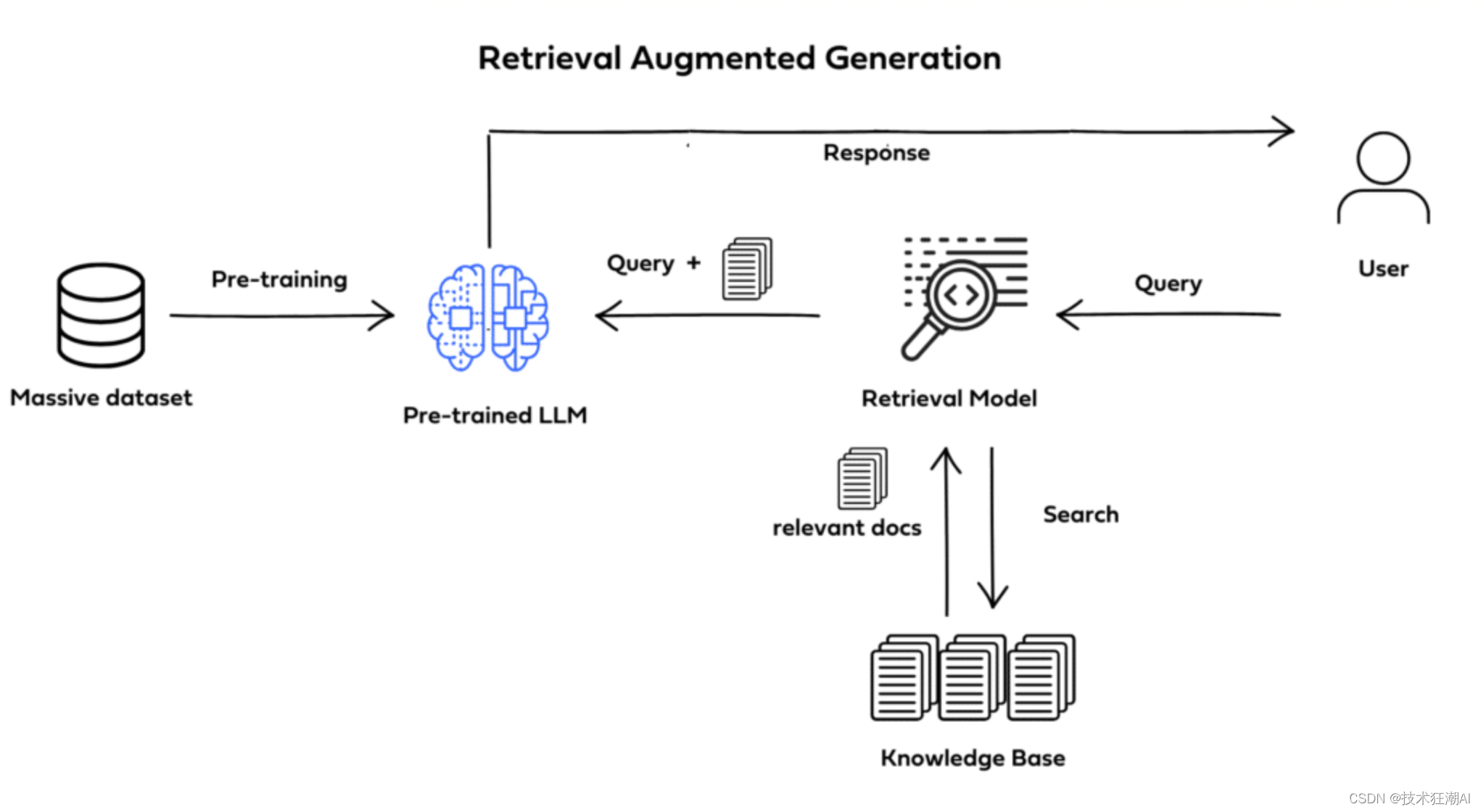
7.1、RAG 是如何工作的?
RAG 本质上将信息检索机制与文本生成模型相结合。信息检索组件有助于从数据库中拉取相关的上下文信息,并且文本生成模型使用这个添加的上下文来产生更准确和“知识丰富”的响应。以下是它的工作方式:
-
向量数据库:实施 RAG 包括嵌入内部数据集,从中创建向量,并将它们存储在向量数据库中。
-
用户查询:RAG 从提示中获取用户查询,这是一个需要回答或完成的自然语言问题或陈述。
-
检索组件:一旦接收到用户查询,检索组件扫描向量数据库以识别与查询语义相似的信息块。然后使用这些相关片段为 LLM 提供额外上下文,使其能够生成更准确和上下文感知的响应。
-
串联:将检索到的文档与原始查询串联成一个提供生成响应所需额外上下文的提示。
-
文本生成:将包含串联查询和检索文档的提示馈送到 LLM 以产生最终输出。
7.2、RAG 使用案例
当应用程序需要 LLM 基于特定于应用程序上下文的大量文档来生成响应时,RAG 尤其有用。这些应用程序可以包括各种熟悉的任务。例如,一个技术支持聊天机器人,它从公司的说明书和技术文档中获取信息以回答客户问题,以及一个内部问答应用程序,它可以访问企业的内部文档,并根据这些文档提供答案。
当应用程序需要使用最新的信息和文档(这些文档不是 LLM 的训练集的一部分)时,RAG 也很有用。一些例子可能是新闻数据库或搜索与新治疗方法相关的医学研究的应用程序。
简单的提示工程无法处理这些情况,因为 LLM 的上下文窗口有限。目前,对于大多数用例,你无法将整个文档集馈送到 LLM 的提示中。
7.3、RAG 的优点
RAG 有许多明显的优点:
最小化幻觉 - 当模型做出“最佳猜测”假设,本质上填补了它“不知道”的内容时,输出可能是错误的或纯粹的胡说八道。与简单的提示工程相比,RAG 产生的结果更准确,幻觉的机会更低。
易于适应新数据 - RAG 可以在事实可能随时间演变的情况下进行适应,使其对生成需要最新信息的响应非常有用。
可解释 - 使用 RAG,可以确定 LLM 答案的来源。对答案来源进行追溯对于内部监控、质量保证或处理客户纠纷可能是有益的。
成本有效 - 与在特定任务数据集上对整个模型进行微调相比,你可以使用 RAG 获得相当的结果,这涉及到更少的标记数据和计算资源。
7.4、RAG 的潜在限制
RAG 旨在通过从外部文档中提取上下文来增强 LLM 的信息检索能力。然而,在某些使用案例中,额外的上下文还不够。如果一个预训练的 LLM 在总结财务数据或从患者的医疗文档中提取见解方面遇到困难,很难看出以单个文档形式提供额外上下文如何有所帮助。在这种情况下,微调更有可能产生期望的输出。
八、选择最佳的调整策略
在综合评估了 LLM 适应性的四种方法后,让我们在四个重要指标上进行比较:复杂性、成本、准确性和灵活性。
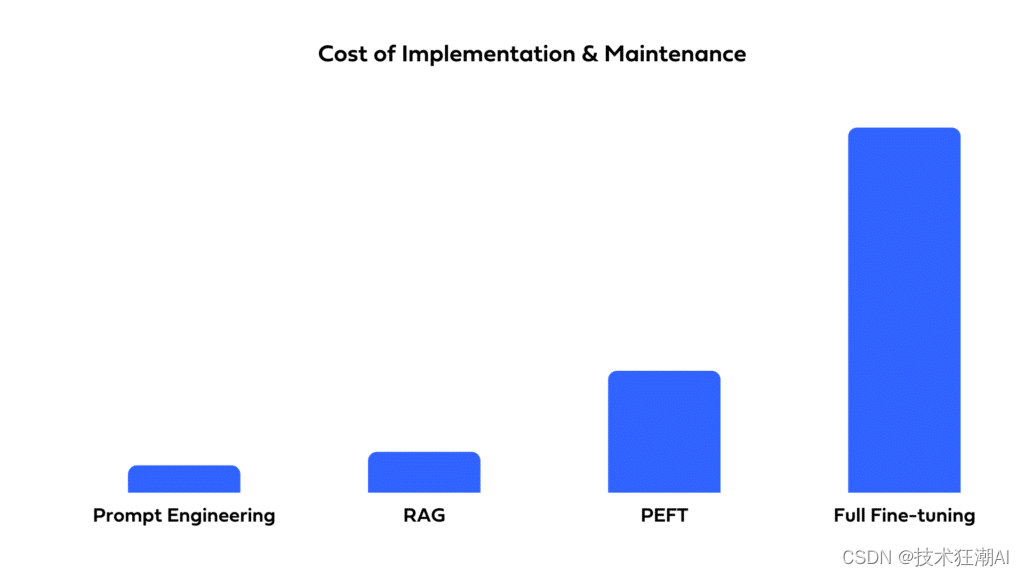
8.1、成本
在衡量一种方法的成本时,有意义的是考虑其初始实施成本以及维护解决方案的成本。鉴于此,让我们比较一下我们四种方法的成本。
提示工程 - 提示工程是四种方法中成本最低的。它归结为编写和测试提示,以找到馈送到预训练 LLM 时能够提供良好结果的提示。它也可能涉及更新提示,如果预训练模型本身被更新或替换。当使用像 OpenAI 的 GPT4 这样的商业模型时,这可能会定期发生。
RAG - 实施 RAG 的成本可能高于提示工程。这是因为需要多个组件:嵌入模型、向量存储、向量存储检索器和预训练 LLM。
PEFT:PEFT 的成本往往高于 RAG。这是因为微调,即使是高效的微调,都需要大量的计算能力、时间和 ML 专业知识。此外,要维护这种方法,你需要定期进行微调以将新的相关数据纳入模型。
全面微调 - 这种方法的成本明显高于 PEFT,因为它需要更多的计算能力和时间。
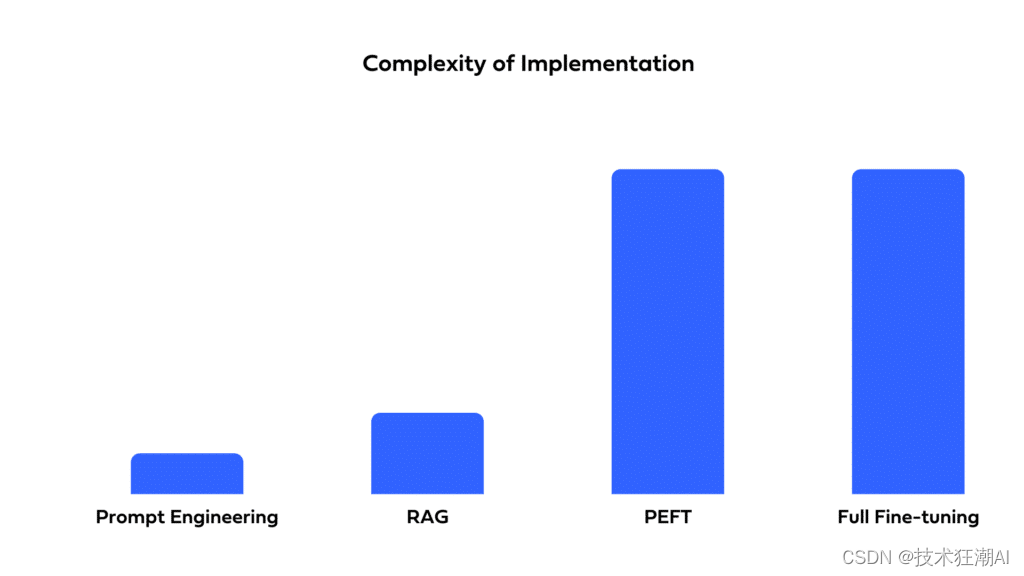
8.2、实施的复杂性
从相对简单的提示工程到更复杂的 RAG 和高级调优方法,复杂性可以显著变化。以下是每种方法所涉及的快速概述:
提示工程 - 这种方法的实施复杂性相对较低。它几乎不需要编程。要起草一个好的提示并进行实验,提示工程师需要良好的语言技能、领域专业知识和熟悉少数学习方法。
RAG - 这种方法的实施复杂性高于提示工程。要实施这个解决方案,你需要编码和架构技能。根据选择的 RAG 组件,复杂性可能会非常高。
PEFT 和全面微调 - 这些方法是最复杂的实施。它们需要对深度学习和 NLP 有深入的理解,并且需要数据科学专业知识来通过调整脚本改变模型的权重。你还需要考虑诸如训练数据、学习率、损失函数等因素。
8.3、准确性
评估 LLM 适应性的不同方法的准确性可能很复杂,特别是因为准确性通常取决于一系列不同的指标。这些指标的重要性可能会根据特定用例而变化。某些应用程序可能优先考虑特定领域的行话。其他人可能优先考虑将模型的响应追溯到特定来源的能力。为了找到最适合你需求的最准确的方法,必须确定你的应用程序的相关准确性指标,并根据这些特定标准比较方法。
让我们看一下一些准确性指标。
8.3.1、特定领域术语
微调可以有效地向 LLM 提供特定领域术语。虽然 RAG 在数据检索方面很熟练,但它可能无法像微调模型那样捕获特定领域的模式、词汇和细微差别。对于寻求强烈领域亲和力的任务,微调是首选。
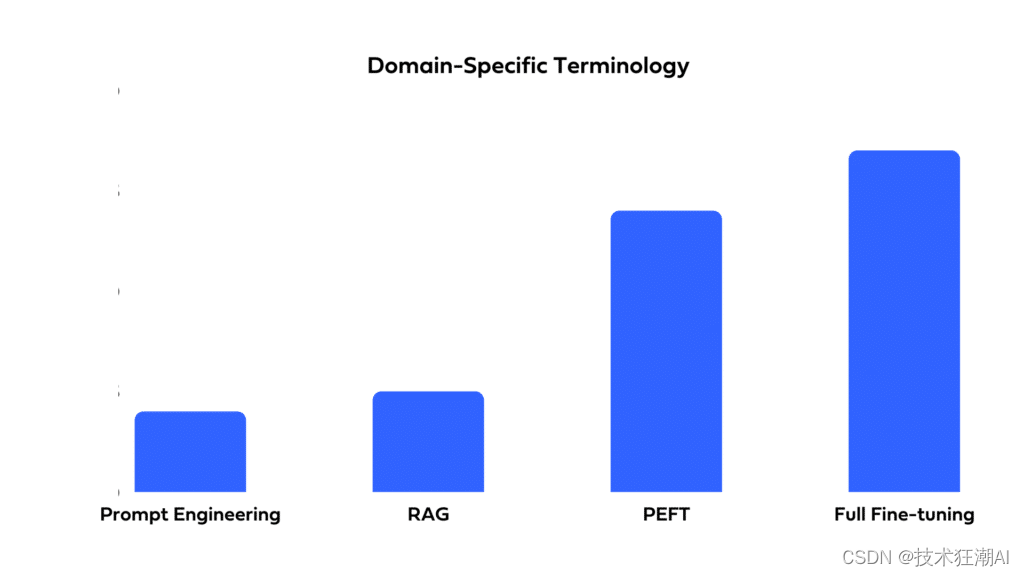
8.3.2、最新响应
微调后的 LLM 成为其训练数据集的固定快照,并且需要定期重新训练以适应正在演变的数据。这使得专门微调(全面和 PEFT)成为需要响应与动态信息池同步的应用程序的较少可行方法。相比之下,RAG 的外部查询可以确保更新响应,使其成为具有动态数据环境的理想选择。

8.3.3、透明度和可解释性
对于某些应用程序,理解模型的决策制定过程至关重要。虽然微调更像一个“黑箱”,使其推理模糊不清,但 RAG 提供了更清晰的洞察力。它的两步过程确定了它检索到的文档,增强了用户信任和理解

8.3.4、幻觉
预训练 LLM 有时会编造出缺失于其训练数据或提供输入中的答案。微调可以通过将 LLM 集中在特定领域数据上来减少这些幻觉。然而,不熟悉的查询仍然可能导致 LLM 编造出一个捏造出来的答案。RAG 通过将 LLM 的响应锚定在检索到的文档中来减少幻觉。初始检索步骤本质上进行事实检查,而随后生成受限于检索数据的上下文。对于避免幻觉至关重要的任务,推荐使用 RAG。
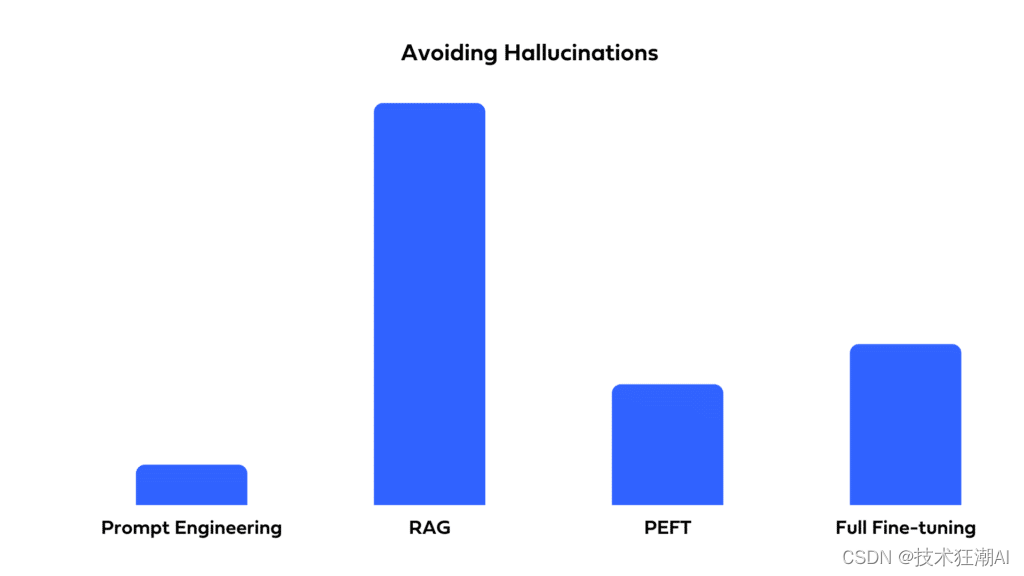
我们看到,对于解释性、最新响应和避免幻觉至关重要的情况,RAG 是优秀的。全面微调和 PEFT 对于将大部分权重放在特定领域风格和词汇上的用例是明确的赢家。但是如果你的用例需要两者呢?在这种情况下,你可能想考虑一种混合方法,同时使用微调和 RAG。
8.4、灵活性
提示工程:提示工程具有非常高的灵活性,因为你只需要根据 FM 和用例的变化来更改提示模板。
RAG:当架构发生变化时,RAG 具有最高程度的灵活性。你可以独立更改嵌入模型、向量存储和 LLM,对其他组件的影响最小到中等。它还可以灵活地在流程中添加更多组件,例如复杂的授权,而不会影响其他组件。
PEFT:微调对变化的灵活性相当低,因为数据和输入的任何变化都需要另一个微调周期,这可能非常复杂且耗时。此外,使相同的微调模型适应不同的用例需要付出很大的努力,因为相同的模型权重/参数可能在其他领域表现不佳,而不是在其所调整的领域。
全面微调: 从头开始的培训对变化的灵活性最差。由于在这种情况下模型是从头开始构建的,因此对模型执行更新会触发另一个重新训练周期。可以说,我们也可以微调模型,而不是从头开始重新训练,但准确性会有所不同。
九、LLM 优化的关键因素和策略分析
确定优化LLM去适应你需求的最佳方法,不仅需要考虑预算和专业能力的限制,更重要的是分析应用的具体需求。
-
LLM 预测准确度在你这里哪些方面最重要?防止它产生虚构信息,还是提升它的创造力更关键?
-
LLM的预测准确度在不同的应用场景中可能有不同的重要性,需要根据具体情况进行权衡。一些场景可能更加关注防止虚构信息的产生,而另一些场景则更注重提升LLM的创造力。
-
LLM 如何及时获得最新数据进行更新也很重要。你可以通过提示设计来做一些简单更新,比如利率变化,还是需要依靠知识引导生成模型来处理信息更新的频率和复杂度更高?
-
LLM的更新方式需要根据具体情况进行选择。一些简单的更新可以通过提示设计等方式实现,而对于更新频率和复杂度更高的情况,则需要依靠知识引导生成模型来处理。
-
单一的优化策略是否足以满足需求,还是结合多种策略会更好?单一的优化策略可能无法满足所有需求,需要结合多种策略进行优化。例如,可以结合数据增强、模型融合等策略来提升LLM的性能。
现在你已经了解需要检查的问题点,下面就是根据实际情况进行分析,找到最优的适应LLM的方法了。
十、References
[1]. PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware (https://huggingface.co/blog/peft)
[2]. LoRA: Low-Rank Adaptation of Large Language Models (https://arxiv.org/abs/2106.09685)
[3]. Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models
(https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/)
相关文章:
如何选择最适合你的LLM优化方法:全面微调、PEFT、提示工程和RAG对比分析
一、前言 自从ChatGPT问世以来,全球各地的企业都迫切希望利用大型语言模型(LLMs)来提升他们的产品和运营。虽然LLMs具有巨大的潜力,但存在一个问题:即使是最强大的预训练LLM也可能无法直接满足你的特定需求。其原因如…...
)
Jenkins实现CI/CD发布(Ansible/jenkins共享库/gitlab)
Jenkins实现多环境发布 1. 需求介绍 本人负责公司前端业务模块,由于前端模块较多,所以在编写jenkinsfile时会出现很多项目使用的大部分代码相同的情况,为解决这种问题,采用了jenkins的共享库方式优化,并且jenkins要支持…...

使用navicat查看类型颜色
问题描述: 最近遇到一个mongodb的数据问题。 在date日期数据中,混入了string类型的数据,导致查询视图报错: $add only supports numeric or date types解决办法: 使用类型颜色工具。 找到在last_modified_date字段中…...

iOS 中,Atomic 修饰 NSString、 NSArray,也会线程不安全
众所周知,基础类型如 int、float 的变量被 atomic 修饰后就具有原子性,则线程安全。 然而有些情况,atomic 修饰后不一定是线程安全的。 atomic 修饰 NSString,NSArray 的时候,只是保障首地址(数组名&…...

2023医药微信公众号排名榜top100汇总合集
相信每个医药人都或多或少关注了几个医药微信公众号,便于日常了解到最新的医药新闻包括治疗技术、药物研发、研究成果、医学进展、临床试验进展、市场动向等前沿动态。 笔者也不列外,大大小小的公众号收集了有上百个,本着方便查看的目的&…...

基于YOLO算法的单目相机2D测量(工件尺寸和物体尺寸)三
1.简介 1.1 2D测量技术 基于单目相机的2D测量技术在许多领域中具有重要的背景和意义。 工业制造:在工业制造过程中,精确测量是确保产品质量和一致性的关键。基于单目相机的2D测量技术可以用于检测和测量零件尺寸、位置、形状等参数,进而实…...

Cython编译文件出错
报错信息: (rpc) stuamax:~/segment/dss_crf$ python setup.py install Compiling pydensecrf/eigen.pyx because it changed. Compiling pydensecrf/densecrf.pyx because it changed. [1/2] Cythonizing pydensecrf/densecrf.pyx /home/stu/anaconda3/envs/rpc/l…...

WPF 用户控件依赖注入赋值
前言 我一直想组件化得去开发WPF,因为我觉得将复杂问题简单化是最好的 如何组件化开发 主窗口引用 <Window x:Class"WpfApp1.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.…...
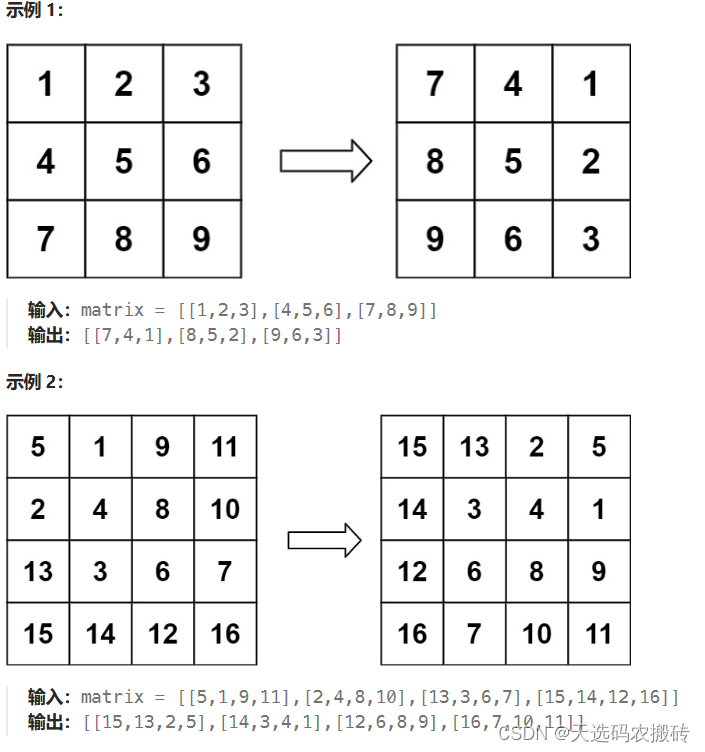
leetcode-48.旋转图像
1. 题目 leetcode题目链接 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 2. 编程 矩阵转置: 遍历矩阵&#x…...
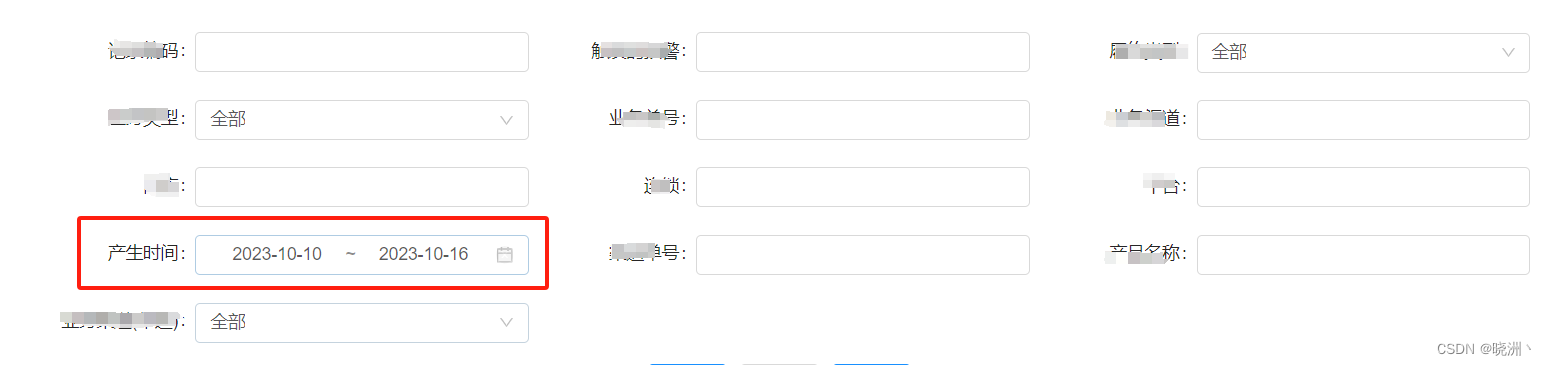
antd的RangePicker设置默认值,默认近七天(andt+react)
import moment from "moment";state {initData:[moment().startOf(day).subtract(6, d), moment().endOf(day)], }<FormItem label"产生时间" {...tailItemLayout}>{getFieldDecorator("produceTime", {initialValue: initData})(<Ran…...
大数据可视化模块竞赛Vue项目文件结构与注意事项
1.vue项目src目录下只有两个文件夹与两个js文件,如图所示: 2.asseets目录存放包或其他外部资料 注意 :echarts采用的是引用外部文件导入 let echarts = require(@/assets/echarts.min.js) 3.components目录存放绘制页面的vue文件(我这里示例创建了一个newPage.vue)…...
户外运动盛行,运动品牌如何利用软文推广脱颖而出?
全民健康意识的提升和城市居民对亲近自然的渴望带来户外运动的盛行,这也使运动品牌的市场保持强劲发展势头,那么在激烈的市场竞争中,运动品牌应该如何脱颖而出呢?下面就让媒介盒子告诉你! 一、 分享户外运动干货 用户…...

2024年孝感市建筑类中级职称申报资料私企VS国企
2024年孝感市建筑类中级职称申报资料私企VS国企 民营企业中级职称申报跟事业单位或者是国企申报中级职称流程不一样么?实际上流程基本都是相同的,就是提交纸质版资料有点不一样。 孝感市建筑类中级职称申报基本流程 1.参加建筑类中级职称水平能力测试。 …...

OpenResty安装
OpenResty 是一个基于 Nginx 的 Web 平台,它将 Nginx 和 Lua 脚本语言结合起来,提供了更强大的 Web 应用开发和部署能力。OpenResty 仓库是 OpenResty 项目的官方仓库,包含了 OpenResty 的源代码、文档、示例等资源。 OpenResty 仓库地址是&…...
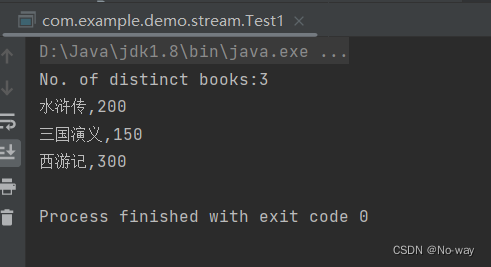
通过stream对list集合中对象的多个字段进行去重
记录下通过stream流对list集合中对象的多个字段进行去重! 举个栗子,对象book,我们要通过姓名和价格这两个字段的值进行去重,该这么做呢? distinct()返回由该流的不同元素组成的流。distinct&am…...
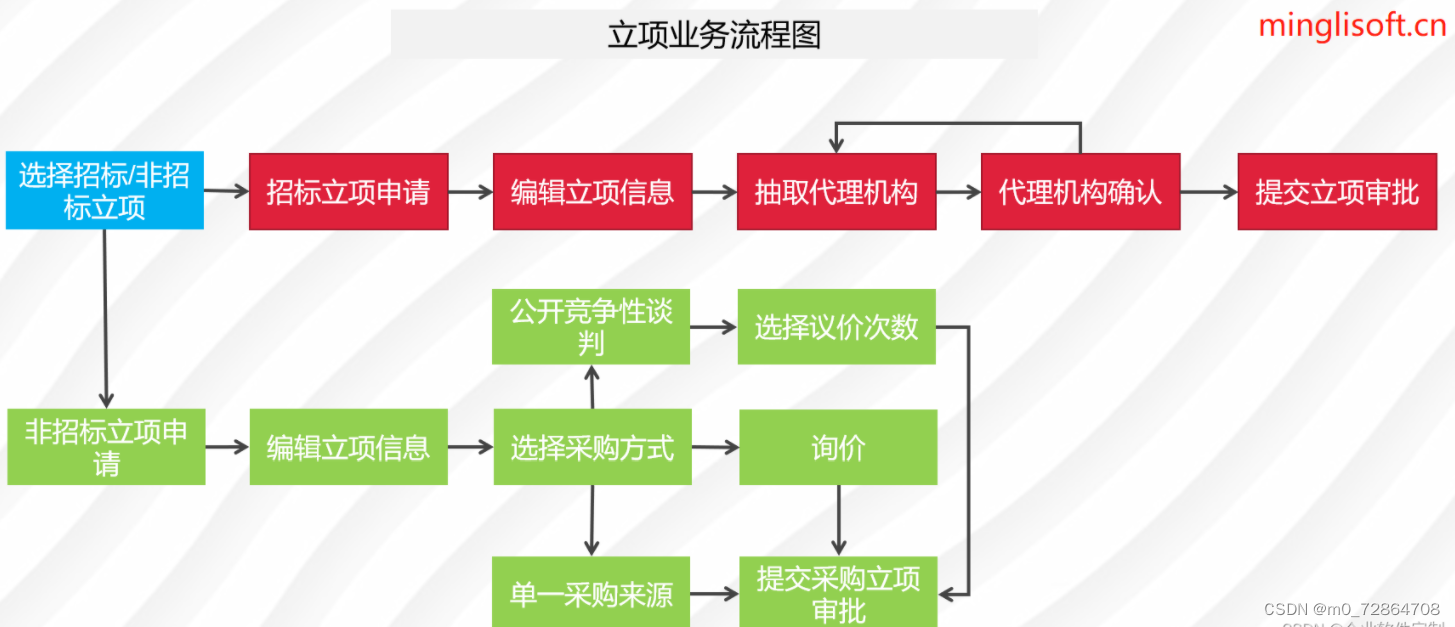
招投标系统软件源码,招投标全流程在线化管理
功能描述 1、门户管理:所有用户可在门户页面查看所有的公告信息及相关的通知信息。主要板块包含:招标公告、非招标公告、系统通知、政策法规。 2、立项管理:企业用户可对需要采购的项目进行立项申请,并提交审批,查看所…...

css设置文本溢出隐藏...
在CSS中,文本溢出可以使用text-overflow属性来处理,下面分别介绍单行文本溢出和多行文本溢出的处理方法1: 单行文本溢出。需要使用text-overflow: ellipsis;来显示省略号。需要注意的是,为了兼容部分浏览器,还需要设置…...

【小尘送书-第八期】《小团队管理:如何轻松带出1+1>2的团队》
大家好,我是小尘,欢迎你的关注!大家可以一起交流学习!欢迎大家在CSDN后台私信我!一起讨论学习,讨论如何找到满意的工作! 👨💻博主主页:小尘要自信 …...
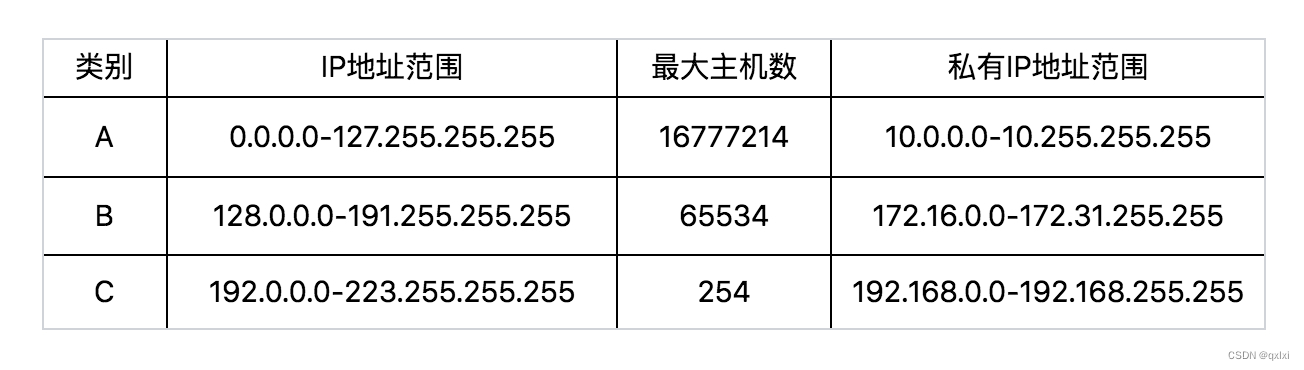
【网络协议】聊聊ifconfig
我们知道在linux是ifconfig查看ip地址,但是ip addr也可以查看 IP 地址是一个网卡在网络世界的通讯地址,相当于我们现实世界的门牌号码。 从IP地址的划分来看,C类地址只可以容纳254个,而B类6W多,那么又没有一种折中的…...

python项目之AI动物识别工具的设计与实现(django)
项目介绍: 💕💕作者:落落 💕💕个人简介:混迹java圈十余年,擅长Java、小程序、Python等。 💕💕各类成品java毕设 。javaweb,ssm,spring…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...
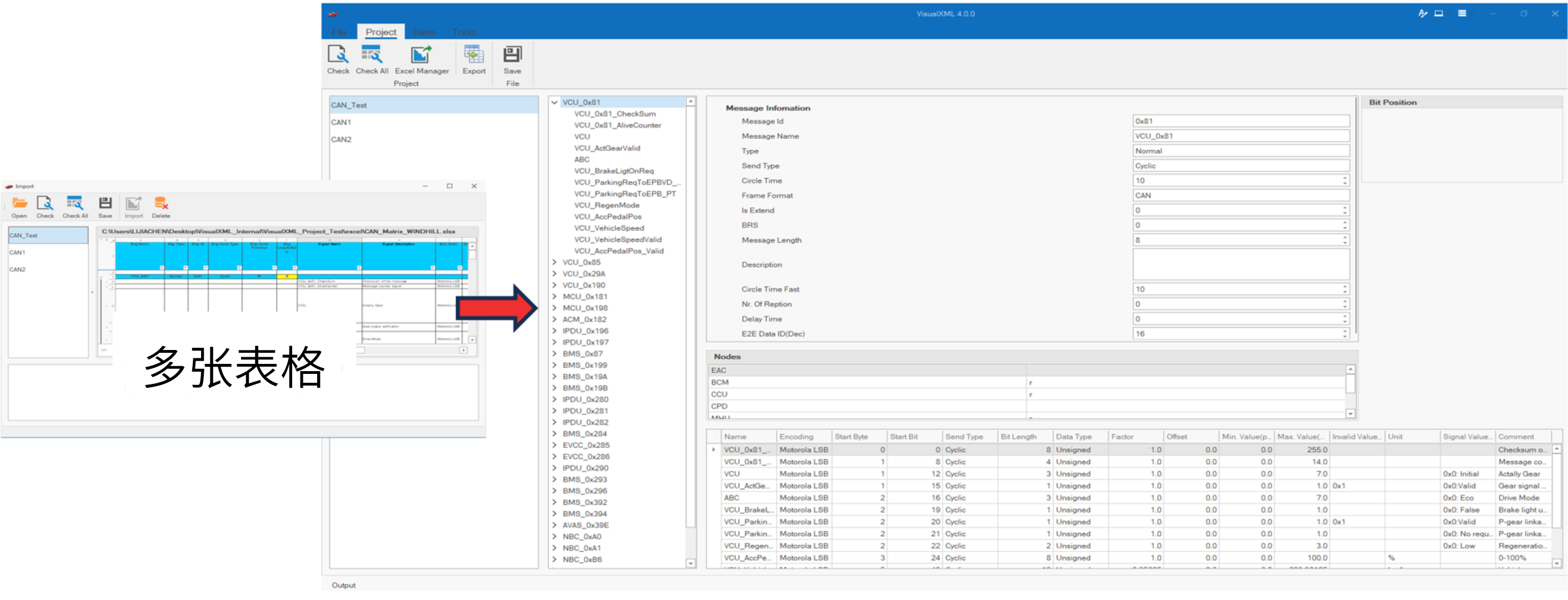
VisualXML全新升级 | 新增数据库编辑功能
VisualXML是一个功能强大的网络总线设计工具,专注于简化汽车电子系统中复杂的网络数据设计操作。它支持多种主流总线网络格式的数据编辑(如DBC、LDF、ARXML、HEX等),并能够基于Excel表格的方式生成和转换多种数据库文件。由此&…...