尚硅谷Flink(三)时间、窗口

1
🎰🎲🕹️
🎰时间、窗口
🎲窗口
🕹️是啥
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
在Flink中,窗口其实并不是一个“框”,应该把窗口理解成一个“桶”。在Flink中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。

Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭
事实上“触发计算”和“窗口关闭”两个行为也可以分开
🕹️分类
窗口本身是截取有界数据的一种方式,所以窗口一个非常重要的信息其实就是“怎样截取数据”。换句话说,就是以什么标准来开始和结束数据的截取,我们把它叫作窗口的“驱动类型”。
1)时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。(2)计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。每个窗口截取数据的个数,就是窗口的大小。基本思路是“人齐发车”。

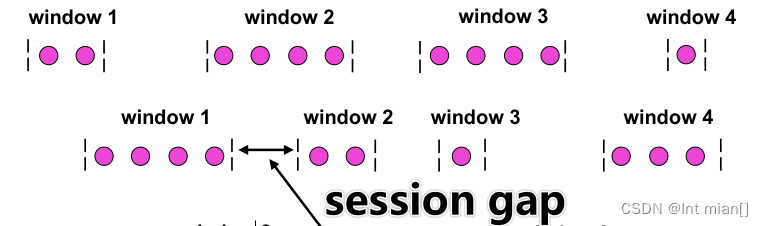
根据分配数据的规则,窗口的具体实现可以分为 4 类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)
- 滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。这是最简单的窗口形式,每个数据都会被分配到一个窗口,而且只会属于一个窗口。比如我们可以定义一个长度为1小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为10的滚动计数窗口,就会每10个数进行一次统计。
滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)。
- 滑动窗口的大小也是固定的。但是窗口之间并不是首尾相接的,而是可以“错开”一定的位置。定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(window slide),它其实就代表了窗口计算的频率。窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。
- 会话窗口,是基于“会话”(session)来来对数据进行分组的。会话窗口只能基于时间来定义。会话窗口中,最重要的参数就是会话的超时时间,也就是两个会话窗口之间的最大距离。如果相邻两个数据到来的时间间隔(Gap)小于指定的大小(size),那说明还在保持会话,它们就属于同一个窗口;如果gap大于size,那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。
- “全局窗口”,这种窗口全局有效,会把相同key的所有数据都分配到同一个窗口中。这种窗口没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger)。

🕹️api
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流KeyedStream 来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调用窗口算子之前,是否有 keyBy 操作。
(1)按键分区窗口(Keyed Windows)
经过按键分区 keyBy 操作后,数据流会按照key 被分为多条逻辑流(logical streams),这就是KeyedStream。基于KeyedStream 进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基于每个 key 进行单独的处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。
stream.keyBy(...) .window(...)
(2)非按键分区(Non-Keyed Windows)
如果没有进行 keyBy,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了1。
stream.windowAll(...)
注意:对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,windowAll
本身就是一个非并行的操作。
stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不只.aggregate()一种
🕹️窗口分配器
// 窗口分配器 指定用什么窗口 时间、计数————滚动、滑动、会话KS.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));KS.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)));KS.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)));KS.window(GlobalWindows.create());KS.countWindow(5); // 窗口数据长度5KS.countWindow(5, 2); // 滑动🕹️窗口函数
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么, 其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。

增量聚合Reduce
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);KeyedStream<WaterSensor, String> KS = stream.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] list = s.split(",");return new WaterSensor(list[0], Long.valueOf(list[1]), Integer.valueOf(list[2]));}}).keyBy(value -> value.id);// 窗口分配器 指定用什么窗口 时间、计数————滚动、滑动、会话WindowedStream<WaterSensor, String, TimeWindow> window = KS.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));window.reduce(new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor t1, WaterSensor t2) throws Exception {System.out.println("reduce, t1: t2 = "+t1+": "+t2);return new WaterSensor(t1.getId(), t1.getTs(), t1.getVc()+t2.getVc());}}).print();env.execute();}Aggregate
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合 状态的类型、输出结果的类型都必须和输入数据类型一样。
AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:
输入类型 (IN)、累加器类型(ACC)和输出类型(OUT)。输入类型 IN 就是输入流中元素的数据类型;累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型OUT当然就是最终计算结果 的类型了。
接口中有四个方法:
⚫ createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚 合任务只会调用一次。
⚫ add():将输入的元素添加到累加器中。
⚫ getResult():从累加器中提取聚合的输出结果。
⚫ merge():合并两个累加器,并将合并后的状态作为一个累加器返回
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);KeyedStream<WaterSensor, String> KS = stream.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] list = s.split(",");return new WaterSensor(list[0], Long.valueOf(list[1]), Integer.valueOf(list[2]));}}).keyBy(value -> value.id);// 窗口分配器 指定用什么窗口 时间、计数————滚动、滑动、会话WindowedStream<WaterSensor, String, TimeWindow> window = KS.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));// 类型形参:// <IN> – The type of the values that are aggregated (input values)// <ACC> – The type of the accumulator (intermediate aggregate state).// <OUT> – The type of the aggregated resultSingleOutputStreamOperator<String> aggregate = window.aggregate(new AggregateFunction<WaterSensor, Integer, String>() {@Overridepublic Integer createAccumulator() {System.out.println("createAccumulator()");return 0;}@Overridepublic Integer add(WaterSensor value, Integer accumulator) {System.out.println("add");return value.getVc() + accumulator;}@Overridepublic String getResult(Integer accumulator) {return "getResult " + accumulator.toString();}@Overridepublic Integer merge(Integer a, Integer b) {// 会话窗口才用得到System.out.println("用不到的merge");return null;}});aggregate.print();env.execute();}
全窗口函数
有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意 义了;另外,输出的结果有可能要包含上下文中的一些信息(比如窗口的起始时间),这是增 量聚合函数做不到的。
全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口 要输出结果的时候再取出数据进行计算。WindowFunction 和 ProcessWindowFunction。
1)窗口函数(WindowFunction)
WindowFunction 字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们 可以基于 WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类。不过 WindowFunction 能提供的上下文信息较少,也没有更高级的功能。事实上,它的作 用可以被ProcessWindowFunction 全覆盖,所以之后可能会逐渐弃用。
2)处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最 底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction 还可以获取到 一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以 访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富,其 实就是一个增强版的 WindowFunction。 事实上,ProcessWindowFunction 是 Flink 底层 API——处理函数(process function)中的 一员,关于处理函数我们会在后续章节展开讲解。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);KeyedStream<WaterSensor, String> KS = stream.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] list = s.split(",");return new WaterSensor(list[0], Long.valueOf(list[1]), Integer.valueOf(list[2]));}}).keyBy(value -> value.id);WindowedStream<WaterSensor, String, TimeWindow> window = KS.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));/*** 类型形参:* <IN> – The type of the input value.* <OUT> – The type of the output value.* <KEY> – The type of the key.* <W> – The type of Window that this window function can be applied on.*/SingleOutputStreamOperator<String> process = window.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {/**** @param s The key 分组的key* @param context The context in which the window is being evaluated.* @param elements The elements in the window being evaluated.* @param out A collector for emitting elements.* @throws Exception*/@Overridepublic void process(String s, ProcessWindowFunction<WaterSensor, String, String, TimeWindow>.Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {// 上下文可以拿到的东西long start = context.window().getStart();long end = context.window().getEnd();String StartTime = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");String EndTime = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect(s + "窗口[" + StartTime + "———" + EndTime + "] 有 " + count + " 条数据");}});process.print();/*** 16> s1窗口[2023-10-16 10:33:30.000———2023-10-16 10:33:35.000] 有 1 条数据* 16> s1窗口[2023-10-16 10:33:40.000———2023-10-16 10:33:45.000] 有 3 条数据* 16> s1窗口[2023-10-16 10:33:50.000———2023-10-16 10:33:55.000] 有 6 条数据* 16> s1窗口[2023-10-16 10:33:55.000———2023-10-16 10:34:00.000] 有 7 条数据*/env.execute();}agg、pro合体
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);KeyedStream<WaterSensor, String> KS = stream.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] list = s.split(",");return new WaterSensor(list[0], Long.valueOf(list[1]), Integer.valueOf(list[2]));}}).keyBy(value -> value.id);WindowedStream<WaterSensor, String, TimeWindow> window = KS.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));SingleOutputStreamOperator<String> process = window.aggregate(new MyAgg(), new MyProcess());process.print();env.execute();}public static class MyAgg implements AggregateFunction<WaterSensor, Integer, String>{@Overridepublic Integer createAccumulator() {System.out.println("createAccumulator()");return 0;}@Overridepublic Integer add(WaterSensor value, Integer accumulator) {System.out.println("add");return value.getVc() + accumulator;}@Overridepublic String getResult(Integer accumulator) {return "getResult " + accumulator.toString();}@Overridepublic Integer merge(Integer a, Integer b) {// 会话窗口才用得到System.out.println("用不到的merge");return null;}}public static class MyProcess extends ProcessWindowFunction<String, String, String, TimeWindow> {@Overridepublic void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) throws Exception {// 上下文可以拿到的东西long start = context.window().getStart();long end = context.window().getEnd();String StartTime = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");String EndTime = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect(s + "窗口[" + StartTime + "———" + EndTime + "] 有 " + count + " 条数据"+elements.toString());}}🕹️触发器、移除器*
上述已经默认实现
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗 口函数,所以可以认为是计算得到结果并输出的过程。
基于WindowedStream调用.trigger()方法,就可以传入一个自定义的窗口触发器(Trigger)。
stream.keyBy(...) .window(...) .trigger(new MyTrigger())
移除器主要用来定义移除某些数据的逻辑。基于 WindowedStream 调用.evictor()方法,就 可以传入一个自定义的移除器(Evictor)。Evictor是一个接口,不同的窗口类型都有各自预实 现的移除器。
stream.keyBy(...) .window(...).evictor(new MyEvictor())
🎲时间语义(瞎起名)

到底是以那种时间作为衡量标准,就是所谓的“时间语义”。
在实际应用中,事件时间语义(真正产生的时间)会更为常见。一般情况下,业务日志数据中都会记录数据生成的时间戳(timestamp),它就可以作为事件时间的判断基础。
从 Flink1.12版本开始,Flink已经将事件时间作为默认的时间语义了。
🎲水位线
在窗口的处理过程中,我 们 可以基于数据的时间戳,自定义 一 个“逻辑时钟”。这个时钟的时间不会自动流逝;它的时间进 展,就是靠着新到数据的时间戳 来推动的

这样的好处在于,计算的过程可以完全不依赖处理时间(系统时间),不论什么时候进行统计 处理,得到的结果都是正确的。而一般实时流处理的场景中,事件时间可以基本与处理时间保持同 步,只是略微有一点延迟,同时保证了窗口计算的正确性。
在 Flink 中,用来衡量事件时间进展的标记,就被称作“水位线”(Watermark)。
具体实现上,水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点, 主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某 个数据到来之后;这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
1)有序流中的水位线
理想状态(数据量小),数据应该按照生成的先后顺序进入流中,每条数据产生一个水位线;

实际应用中,如果当前数据量非常大,且同时涌来的数据时间差会非常小(比如几毫秒),往 往对处理计算也没什么影响。所以为了提高效率,一般会每隔一段时间生成一个水位线。

2)乱序流中的水位线
😅乱序 + 数据量小:在分布式系统中,数据在节点间传输,会因为网络传输延迟的不确定性,导致顺序发生改变,这就是 所谓的“乱序数据”。

情况是数据乱序,也就是说,只有数据的时间戳比当前时钟大,才能推动时钟前进,这时才插入水位线。
😅乱序 + 数据量大:如果考虑到大量数据同时到来的处理效率,我们同样可以周期性地生成水位线。这时 只需要保存一下之前所有数据中的最大时间戳,需要插入水位线时,就直接以它作为时间戳生成新的水位 线。

😅我们无法正确处理“迟到”的数据。为了让窗口能够正确收集到迟到的数据,我们也可 以等上一段时间,比如2秒;也就是用当前已有数据的最大时间戳减去2秒,就是要插入的水位线的时间戳。 这样的话,9秒的数据到来之后,事件时钟不会直接推进到9秒,而是进展到了7秒;必须等到11秒的数据到来 之后,事件时钟才会进展到9秒,这时迟到数据也都已收集齐,0~9秒的窗口就可以正确计算结果了
🕹️生成水位线原则
完美的水位线是“绝对正确”的,也就是一个水位线一旦出现,就表示这个时间之前的 数据已经全部到齐、之后再也不会出现了。不过如果要保证绝对正确,就必须等足够长的时间,这会带来更高的延迟。
如果我们对准确性完全不考虑、一味地追求处理速度,可以直接使用处理时间语义, 这在理论上可以得到最低的延迟。
所以 Flink中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把 控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略。
🕹️内置水位线
对于有序流,主要特点就是时间戳单调增长,所以永远不会出现迟到数据的问题。这是 周期性生成水位线的最简单的场景,直接调用 WatermarkStrategy.forMonotonousTimestamps() 方法就可以实现
注意并行度输出
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);SingleOutputStreamOperator<WaterSensor> DS = stream.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] list = s.split(",");return new WaterSensor(list[0], Long.valueOf(list[1]), Integer.valueOf(list[2]));}});// TODO 1.定义Watermark策略WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy// 1.1 指定watermark生成:升序的watermark,没有等待时间.<WaterSensor>forMonotonousTimestamps()// 1.2 指定 时间戳分配器,从数据中提取.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {@Overridepublic long extractTimestamp(WaterSensor element, long recordTimestamp) {// 返回的时间戳,要 毫秒System.out.println("数据=" + element + ",recordTs=" + recordTimestamp);return element.getTs() * 1000L;}});// TODO 2. 指定 watermark策略SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = DS.assignTimestampsAndWatermarks(watermarkStrategy);sensorDSwithWatermark.keyBy(sensor -> sensor.getId())// TODO 3.使用 事件时间语义 的窗口.window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {long startTs = context.window().getStart();long endTs = context.window().getEnd();String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}}).print();env.execute();/*** 数据=WaterSensor{id='s1', ts=1, vc=1},recordTs=-9223372036854775808* 数据=WaterSensor{id='s1', ts=2, vc=1},recordTs=-9223372036854775808* 数据=WaterSensor{id='s1', ts=3, vc=1},recordTs=-9223372036854775808* 数据=WaterSensor{id='s1', ts=4, vc=1},recordTs=-9223372036854775808* 数据=WaterSensor{id='s1', ts=5, vc=1},recordTs=-9223372036854775808* key=s1的窗口[1970-01-01 08:00:00.000,1970-01-01 08:00:05.000)包含4条数据===>[WaterSensor{id='s1', ts=1, vc=1}, WaterSensor{id='s1', ts=2, vc=1}, WaterSensor{id='s1', ts=3, vc=1}, WaterSensor{id='s1', ts=4, vc=1}]* 数据=WaterSensor{id='s1', ts=6, vc=1},recordTs=-9223372036854775808* 数据=WaterSensor{id='s1', ts=7, vc=1},recordTs=-9223372036854775808* 数据=WaterSensor{id='s1', ts=9, vc=1},recordTs=-9223372036854775808* 数据=WaterSensor{id='s1', ts=10, vc=1},recordTs=-9223372036854775808* key=s1的窗口[1970-01-01 08:00:05.000,1970-01-01 08:00:10.000)包含4条数据===>[WaterSensor{id='s1', ts=5, vc=1}, WaterSensor{id='s1', ts=6, vc=1}, WaterSensor{id='s1', ts=7, vc=1}, WaterSensor{id='s1', ts=9, vc=1}]*/}由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间。这时生成 水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前 时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy. forBoundedOutOfOrderness()方法就 可以实现。这个方法需要传入一个 maxOutOfOrderness 参数,表示“最大乱序程度”,它表示 数据流中乱序数据时间戳的最大差值;如果我们能确定乱序程度,那么设置对应时间长度的 延迟,就可以等到所有的乱序数据了。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);SingleOutputStreamOperator<WaterSensor> DS = stream.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] list = s.split(",");return new WaterSensor(list[0], Long.valueOf(list[1]), Integer.valueOf(list[2]));}});// TODO 1.定义Watermark策略WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy// 1.1 指定watermark生成:乱的watermark,没有等待时间.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))// 1.2 指定 时间戳分配器,从数据中提取.withTimestampAssigner((element, recordTimestamp) -> {// 返回的时间戳,要 毫秒System.out.println("数据=" + element + ",recordTs=" + recordTimestamp);return element.getTs() * 1000L;});// TODO 2. 指定 watermark策略SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = DS.assignTimestampsAndWatermarks(watermarkStrategy);sensorDSwithWatermark.keyBy(sensor -> sensor.getId())// TODO 3.使用 事件时间语义 的窗口.window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {long startTs = context.window().getStart();long endTs = context.window().getEnd();String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}}).print();env.execute();}周期性水位生成器
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);SingleOutputStreamOperator<WaterSensor> DS = stream.map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String s) throws Exception {String[] list = s.split(",");return new WaterSensor(list[0], Long.valueOf(list[1]), Integer.valueOf(list[2]));}});// TODO 1.定义Watermark策略WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy// 1.1 指定watermark生成:乱的watermark,没有等待时间.<WaterSensor>forGenerator(new WatermarkStrategy<WaterSensor>() {@Overridepublic WatermarkGenerator<WaterSensor> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {return new MyWaterStrategy<>(3000L);}})// 1.2 指定 时间戳分配器,从数据中提取.withTimestampAssigner((element, recordTimestamp) -> {// 返回的时间戳,要 毫秒System.out.println("数据=" + element + ",recordTs=" + recordTimestamp);return element.getTs() * 1000L;});// TODO 2. 指定 watermark策略SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = DS.assignTimestampsAndWatermarks(watermarkStrategy);sensorDSwithWatermark.keyBy(sensor -> sensor.getId())// TODO 3.使用 事件时间语义 的窗口.window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {@Overridepublic void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {long startTs = context.window().getStart();long endTs = context.window().getEnd();String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");long count = elements.spliterator().estimateSize();out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());}}).print();env.execute();}public static class MyWaterStrategy<T> implements WatermarkGenerator<T> {private long delay;private long maxTs;public MyWaterStrategy(long delay) {this.delay = delay;this.maxTs = Long.MIN_VALUE+this.delay+1;}@Overridepublic void onEvent(T event, long eventTimestamp, WatermarkOutput output) {maxTs = Math.max(maxTs, eventTimestamp);}@Overridepublic void onPeriodicEmit(WatermarkOutput output) {output.emitWatermark(new Watermark(maxTs- delay -1));}}🕹️并行,水位线传递

而当一个任务接收到多个上游并行任务传递来的水位线时,应该以 最小的那个作为当前任务的事件时钟。
在多个上游并行任务中,如果有其中一个没有数据,由于当前 Task 是以最小的那个作为 当前任务的事件时钟,就会导致当前 Task 的水位线无法推进,就可能导致窗口无法触发。这 时候可以设置空闲等待。
.withIdleness(Duration.ofSecond(3))
迟到数据处理:
Flink的窗口,也允许迟到数据。当触发了窗口计算后,会先计算当前的结果,但是此时 并不会关闭窗口。
以后每来一条迟到数据,就触发一次这条数据所在窗口计算(增量计算)。直到 wartermark 超过了窗口结束时间+推迟时间,此时窗口会真正关闭。
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
允许迟到只能运用在 event time 上
🎲时间的合流
可以发现,根据某个 key 合并两条流,与关系型数据库中表的 join 操作非常相近。事实 上,Flink 中两条流的 connect 操作,就可以通过 keyBy 指定键进行分组后合并,实现了类似 于 SQL 中的 join 操作;另外 connect 支持处理函数,可以使用自定义实现各种需求,其实已 经能够处理双流 join 的大多数场景。
不过处理函数是底层接口,所以尽管 connect能做的事情多,但在一些具体应用场景下还 是显得太过抽象了。比如,如果我们希望统计固定时间内两条流数据的匹配情况,那就需要 自定义来实现——其实这完全可以用窗口(window)来表示。为了更方便地实现基于时间的 合流操作,Flink 的 DataStrema API 提供了内置的 join 算子。
🕹️窗口联结(Window Join)
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODOSingleOutputStreamOperator<Tuple2<String, Integer>> DS1 = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 2),Tuple2.of("b", 7),Tuple2.of("b", 5),Tuple2.of("c", 3)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> (value.f1 * 1000L)));SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> DS2 = env.fromElements(Tuple3.of("a", 1, 1),Tuple3.of("a", 8, 1),Tuple3.of("b", 8, 1),Tuple3.of("b", 5, 1),Tuple3.of("c", 3, 1)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));DataStream<String> join = DS1.join(DS2).where(x -> x.f0)// ds1的keyBy.equalTo(x -> x.f0)// ds2的keyBy.window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(new JoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/**** @param first The element from first input.* @param second The element from second input.* @return* @throws Exception*/@Overridepublic String join(Tuple2<String, Integer> first, Tuple3<String, Integer, Integer> second) throws Exception {return first + "-------" + second;}});join.print();env.execute();}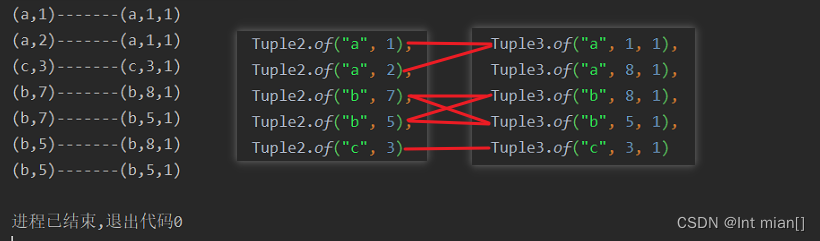
🕹️间隔联结(Interval Join)
Flink 提供了一种叫作“间隔联结”(interval join)的合流操作。 顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间 隔,看这期间是否有来自另一条流的数据匹配。
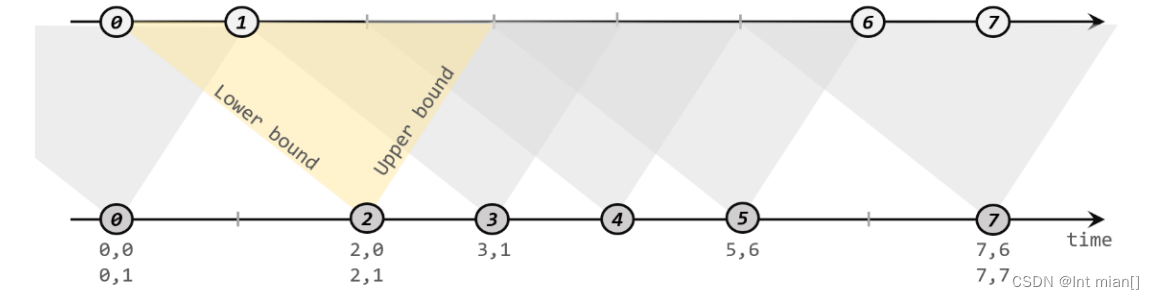
案例需求:在电商网站中,某些用户行为往往会有短时间内的强关联。我们这里举一个 例子,我们有两条流,一条是下订单的流,一条是浏览数据的流。我们可以针对同一个用户, 来做这样一个联结。也就是使用一个用户的下订单的事件和这个用户的最近十分钟的浏览据进行一个联结查询。
相关文章:
尚硅谷Flink(三)时间、窗口
1 🎰🎲🕹️ 🎰时间、窗口 🎲窗口 🕹️是啥 Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就…...

MPLS基础
1. MPLS原理与配置 MPLS基础 (1)MPLS概念 MPLS位于TCP/IP协议栈中的数据链路层和网络层之间,可以向所有网络层提供服务。 通过在数据链路层和网络层之间增加额外的MPLS头部,基于MPLS头部实现数据快速转发。 本课程仅介绍MPLS在…...

react+antd+Table实现表格初始化勾选某条数据,分页切换保留上一页勾选的数据
加上rowKey这个属性 <Table rowKey{record > record.id} // 加上rowKey这个属性rowSelection{rowSelection}columns{columns}dataSource{tableList}pagination{paginationProps} />...

Linux shell编程学习笔记13:文件测试运算
Linux Shell 脚本编程和其他编程语言一样,支持算数、关系、布尔、逻辑、字符串、文件测试等多种运算。前面几节我们依次研究了 Linux shell编程 中的 字符串运算、算术运算、关系运算、布尔运算 和 逻辑运算,今天我们来研究 Linux shell编程中的文件测…...

element ui this.$msgbox 自定义组件
this.$msgbox({title: "选择", message: (<com1figs{this.figs} on-selected{this.new_selected}></com1>),showCancelButton: false,showConfirmButton: false,}); 运行报错 Syntax Error: Unexpected token (89:20) 参考: https://gith…...
尚硅谷Flink(四)处理函数
目录 🦍处理函数 🐒基本处理函数 🐒按键分区处理函数(KeyedProcessFunction) 🐵定时器(Timer)和定时服务(TimerService) // 1、事件时间的案例 // 2、处理…...
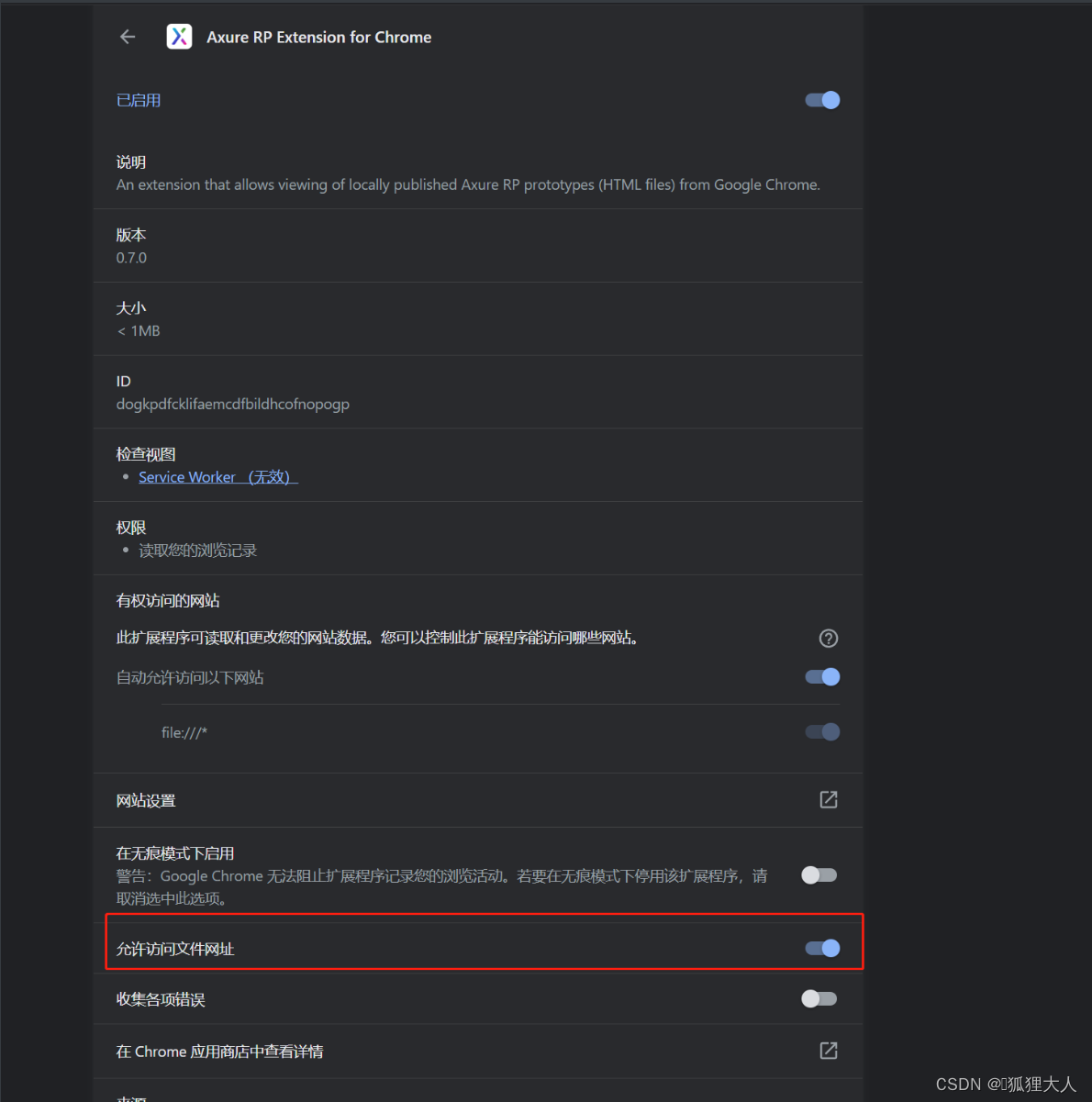
AXURE RP EXTENSION For Chrome 安装
在浏览器上输入地址:chrome://extensions/ 打开图片中这个选项,至此你就能通过index.html访问...
-3)
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
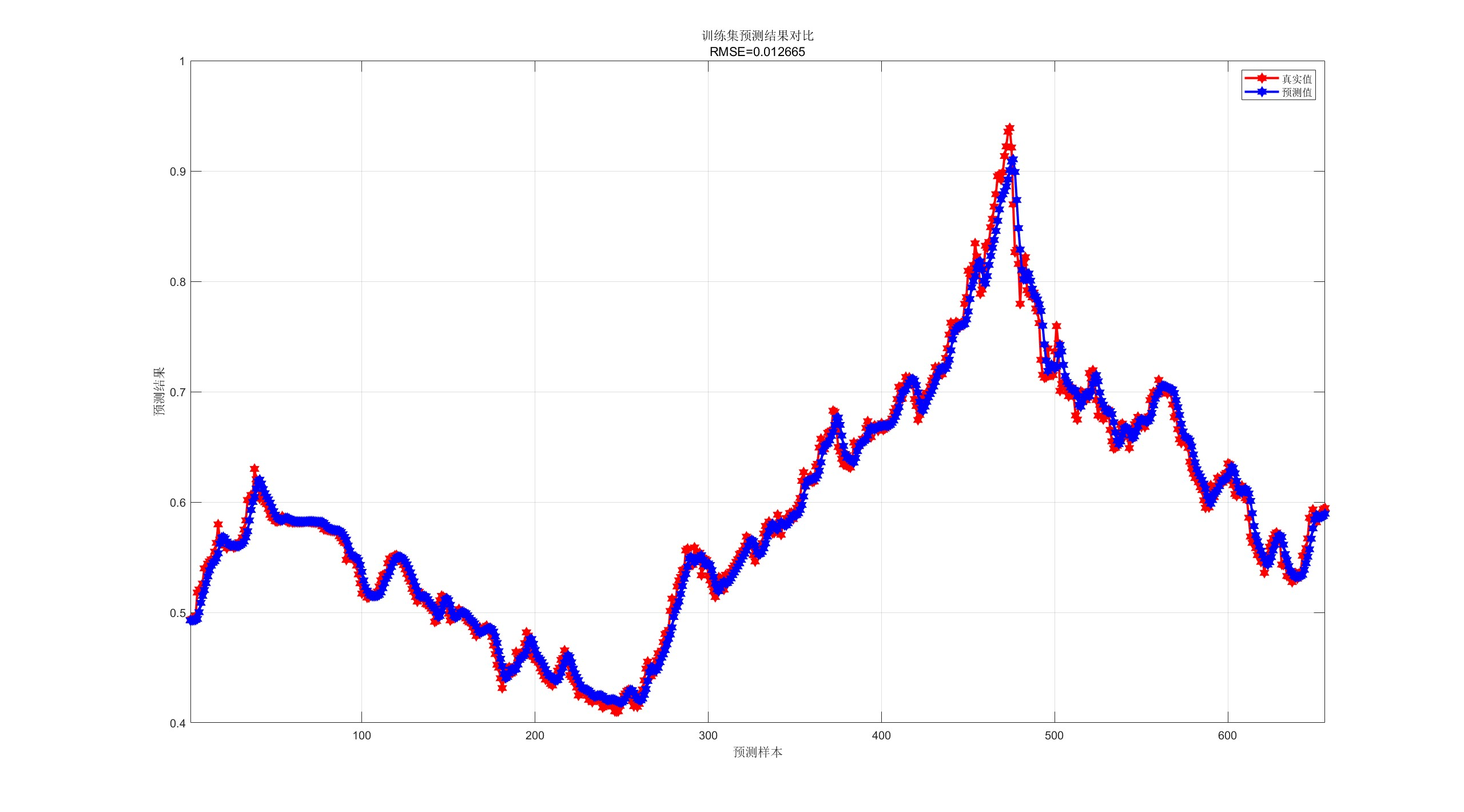
【CNN-GRU预测】基于卷积神经网络-门控循环单元的单维时间序列预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
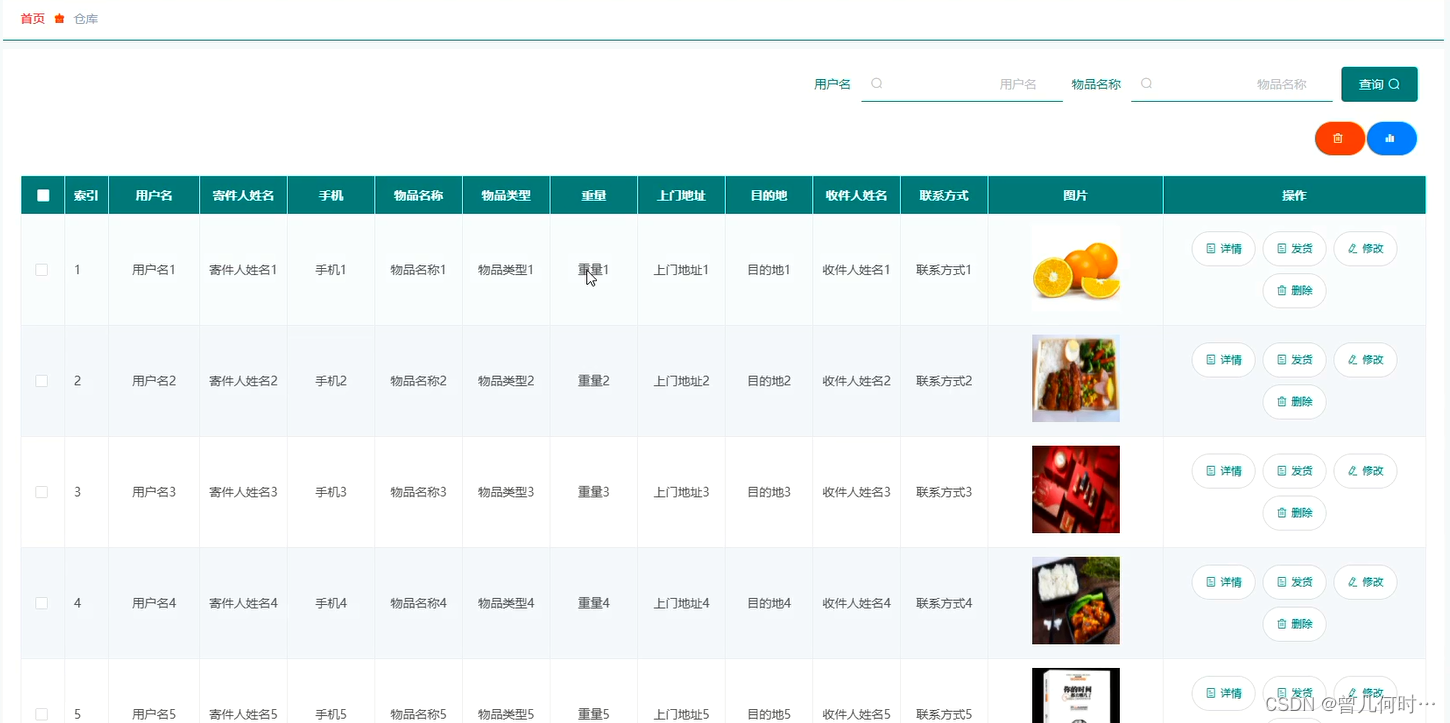
计算机毕业设计--基于SSM+Vue的物流管理系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

GPT4 Plugins 插件 WebPilot 生成抖音文案
1. 生成抖音文案 1.1. 准备1篇优秀的抖音文案范例 1.2. Promept公式 你是一个有1000万粉丝的抖音主播, 请模仿下面的抖音脚本文案,重新改与一篇文章改写成2分钟的抖音视频脚本, 要求前一部分是十分有争议性的内容,并且能够引发…...
通过核密度分析工具建模,基于arcgis js api 4.27 加载gp服务
一、通过arcmap10.2建模,其中包含三个参数 注意input属性,选择数据类型为要素类: 二、建模之后,加载数据,执行模型,无错误的话,找到执行结果,进行发布gp服务 注意,发布g…...
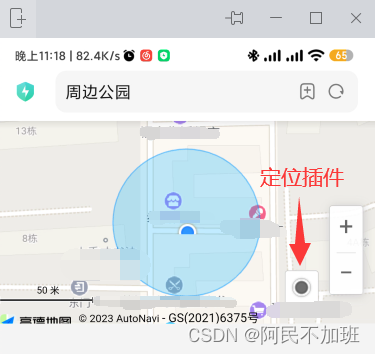
【vue2高德地图api】02-npm引入插件,在页面中展示效果
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、安装高德地图二、在main.js中配置需要配置2个key值以及1个密钥 三、在页面中使用3.1 新建路由3.2新建vue页面3.2-1 index.vue3.2…...

ai智能语音电销机器人怎么选?
智能语音电销机器人哪家好?如何选择一款智能语音电销机器人?这几年生活中人工智能的普及越来越广泛,就如智能语音机器人在生活当中的应用还是比较方便的,有许多行业都会选择这类的智能语音系统来把工作效率提高上去,随…...

NumPy基础及取值操作
目录 第1关:ndarray对象 相关知识 怎样安装NumPy 什么是ndarray对象 如何实例化ndarray对象 使用array函数实例化ndarray对象 使用zeros,ones,empty函数实例化ndarray对象 代码文件 第2关:形状操作 相关知识 怎样改变n…...

vue webpack/vite的区别
Vue.js 可以与不同的构建工具一起使用,其中两个主要的工具是 Webpack 和 Vite。以下是 Vue.js 与 Webpack 和 Vite 之间的一些主要区别: Vue.js 与 Webpack: 成熟度: Webpack 是一个成熟的构建工具,已经存在多年&…...
多线程下的单例设计模式(新手必看!!!)
在项目中为了避免创建大量的对象,频繁出现gc的问题,单例设计模式闪亮登场。 一、饿汉式 1.1饿汉式 顾名思义就是我们比较饿,每次想吃的时候,都提前为我们创建好。其实我记了好久也没分清楚饿汉式和懒汉式的区别。这里给出我的一…...

JDK 21的新特性总结和分析
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

【VR】【Unity】白马VR课堂系列-VR开发核心基础03-项目准备-VR项目设置
【内容】 详细说明 在设置Camera Rig前,我们需要针对VR游戏做一些特别的Project设置。 点击Edit菜单,Project Settings,选中最下方的XR Plugin Management,在右边面板点击Install。 安装完成后,我们需要选中相应安卓平台下的Pico VR套件,关于怎么安装PICO VR插件,请参…...
Windows服务器安装php+mysql环境的经验分享
php mysql环境 下载IIS Php Mysql环境集成包,集成包下载地址: 1、Windows Server 2008 一键安装Web环境包 x64 适用64位操作系统服务器:下载地址:链接: https://pan.baidu.com/s/1MMOOLGll4D7Eb5tBrdTQZw 提取码: btnx 2、Windows Server 2008 一键安装Web环境包 32 适…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...