Lecture6 逻辑斯蒂回归(Logistic Regression)
目录
1 常用数据集
1.1 MNIST数据集
1.2 CIFAR-10数据集
2 课堂内容
2.1 回归任务和分类任务的区别
2.2 为什么使用逻辑斯蒂回归
2.3 什么是逻辑斯蒂回归
2.4 Sigmoid函数和饱和函数的概念
2.5 逻辑斯蒂回归模型
2.6 逻辑斯蒂回归损失函数
2.6.1 二分类损失函数
2.6.2 小批量二分类损失函数
3 代码实现
1 常用数据集
1.1 MNIST数据集
MNIST是一个手写数字图像数据集,主要用于训练和测试机器学习模型。它由60,000个训练图像和10,000个测试图像组成,每个图像都是28x28像素的灰度图像,表示一个手写数字。MNIST数据集已成为许多机器学习算法的基准数据集之一,尤其是用于图像分类任务和数字识别任务。

下载方式
import torchvision
train_set = torchvision.datasets.MNIST(root='../dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='../dataset/mnist', train=False, download=True)这段代码中,包括两个参数:root和train,download为可选参数。root指定数据集下载的根目录,train指定要加载的数据集类型,train=True表示加载训练集,train=False表示加载测试集。download=True表示如果本地不存在则进行该数据集的下载,最后将训练集和测试集分别保存在train_set和test_set两个变量中。
1.2 CIFAR-10数据集

CIFAR-10是一个常用的图像分类数据集,由10个不同类别的60000个32x32彩色图像组成。这些类别包括:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。数据集被分为训练集和测试集,其中训练集包含50000个图像,测试集包含10000个图像。CIFAR-10数据集被广泛用于计算机视觉和深度学习研究领域,特别是用于图像分类算法的开发和测试。
import torchvision
train_set = torchvision.datasets.CIFAR10(…)
test_set = torchvision.datasets.CIFAR10(…)2 课堂内容
2.1 回归任务和分类任务的区别
回归任务和分类任务是机器学习中两个重要的任务类型,其主要区别在于预测目标的不同。分类任务的目标是将输入数据分到预定义的类别中。例如,手写数字分类任务中,目标是将手写数字图像分到0-9十个数字中的一个类别中。回归任务的目标是预测连续的数值。例如,房价预测任务中,目标是预测房屋的售价,这是一个连续的数值。
因此,回归任务和分类任务的主要区别在于预测目标的类型:分类任务的目标是预测一个离散的类别,而回归任务的目标是预测一个连续的数值。
2.2 为什么使用逻辑斯蒂回归
对于分类问题,由于值是离散的,所以用逻辑斯蒂回归(logistic regression)。二分类问题中,我们需要求得结果 是 输入数据 所属的类别。例如下图,结果要么通过要么不通过,属于典型的二分类(binary classification)问题。
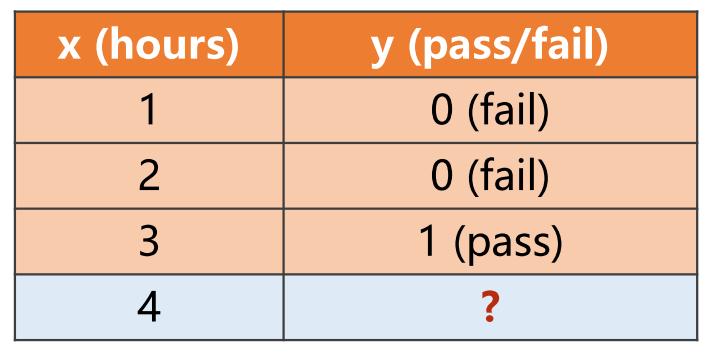
二分类问题是机器学习中最常见的问题之一,应用广泛,例如判断一封邮件是否是垃圾邮件、判断一个人是否患有某种疾病等。
2.3 什么是逻辑斯蒂回归
在二分类问题中,我们衡量输入的数据运算过后的所属类别的方法,一般是通过概率来表示,我们得到对应类别的概率值,哪个概率值大,就认为它是属于哪个类别。
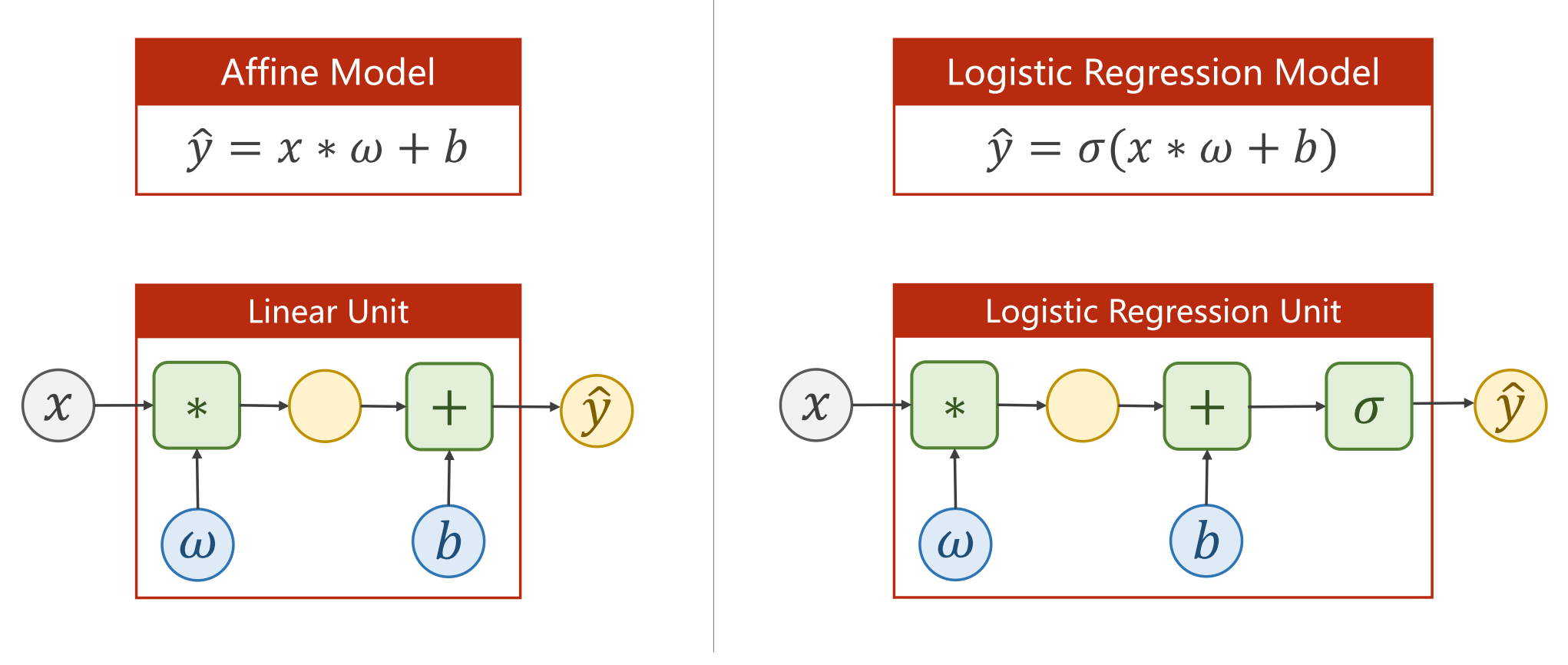
Logistic回归是一种用于二分类问题的线性分类模型。它的基本思想是,将输入特征和对应的类别之间的关系建模为一个线性函数,并通过Sigmoid函数将其映射到[0,1]的区间上,以得到对应于正例的概率,所以可以说sigmoid函数的作用是使数据映射到[0,1]区间上。
2.4 Sigmoid函数和饱和函数的概念
在数学中,饱和函数(Saturated Function)是一类函数,当输入值接近正或负无穷时,函数的输出值趋向于一个有限的上下限。饱和函数通常用于神经网络的激活函数,例如Sigmoid函数
当输入值x的绝对值很大时,Sigmoid函数的输出值会趋近于0或1,因此称为“饱和函数”。

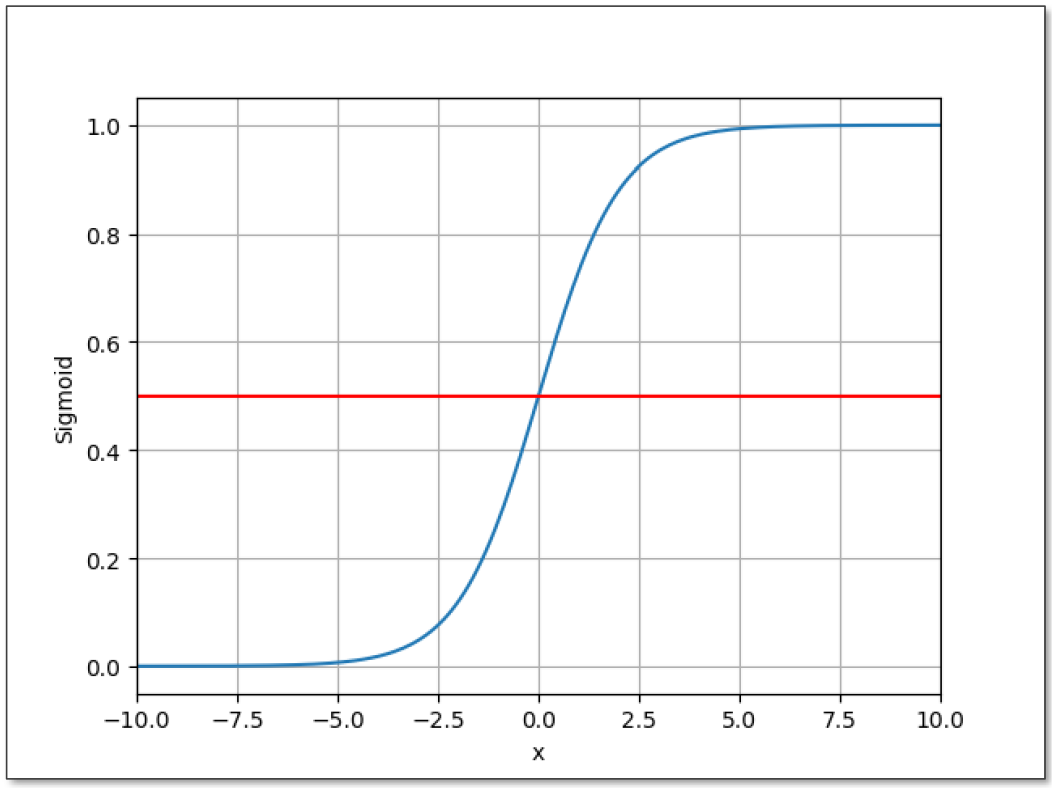
Sigmoid 函数在输入为负无穷时,输出为 0,在输入为正无穷时,输出为 1,因此可以将预测结果解释为概率值,并进行阈值分类。
在神经网络中,饱和函数作为激活函数具有平滑、可导的性质,并能够将输出值限制在一定范围内,使神经网络的训练更加稳定。但是,由于饱和函数在梯度计算时可能会出现梯度消失的问题,因此在深度神经网络中,更常使用一些非饱和函数作为激活函数,例如ReLU函数。
常见的Sigmoid函数还有:
2.5 逻辑斯蒂回归模型
添加完logistic函数后的模型相较于普通的线性回归模型的变化:
2.6 逻辑斯蒂回归损失函数
2.6.1 二分类交叉熵损失函数
二分类交叉熵损失函数(Binary Cross Entropy, BCE)较线性回归的损失函数也发生了些许变化,主要是引入了交叉熵(Cross Entropy)这个概念。交叉熵是在给定一组真实标签和一组预测标签的情况下,衡量这两组标签之间的差异的一种方法。
二分类交叉熵是指特定于二元分类任务而设计的交叉熵损失函数。对于二元分类问题,二分类交叉熵损失函数可以表示为:
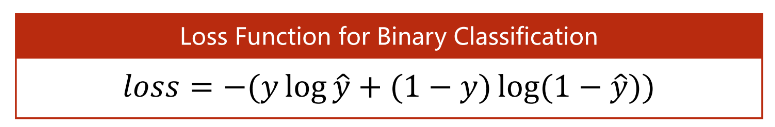
其中,y表示样本的真实标签(0或1),表示样本的预测标签(取值范围为[0, 1])。
交叉熵损失函数的基本思想是:将真实标签和预测标签的概率分布进行比较,计算它们之间的差距,用来衡量预测标签和真实标签之间的相似度。当预测标签与真实标签越相似时,损失函数的值越小,反之,损失函数的值越大。
对于二分类问题而言,交叉熵损失函数可以解释为:如果样本的真实标签为1,那么我们希望模型预测标签的值越接近1越好;如果样本的真实标签为0,那么我们希望模型预测标签
的值越接近0越好。因此,交叉熵损失函数可以作为衡量二分类模型预测效果的重要指标。
BCE和MSE的区别?
BCE主要应用于二元分类问题,它的损失函数形式简单,可以直接衡量模型对于每个样本预测出的概率值和真实标签之间的差距。而 MSE 更适合用于回归问题,它可以衡量模型对于每个样本预测出的数值和真实值之间的差距。
2.6.2 小批量二分类损失函数
在实际应用中,我们通常需要对大规模数据集进行训练。如果使用全量数据计算梯度,会占用过多的内存和计算资源,从而导致训练速度缓慢或者无法完成训练。而使用小批量的BCELoss,可以将数据集分批次读入内存,逐个小批量地计算损失函数,进而计算梯度,从而加快训练速度,同时还能够有效降低内存使用和计算复杂度。

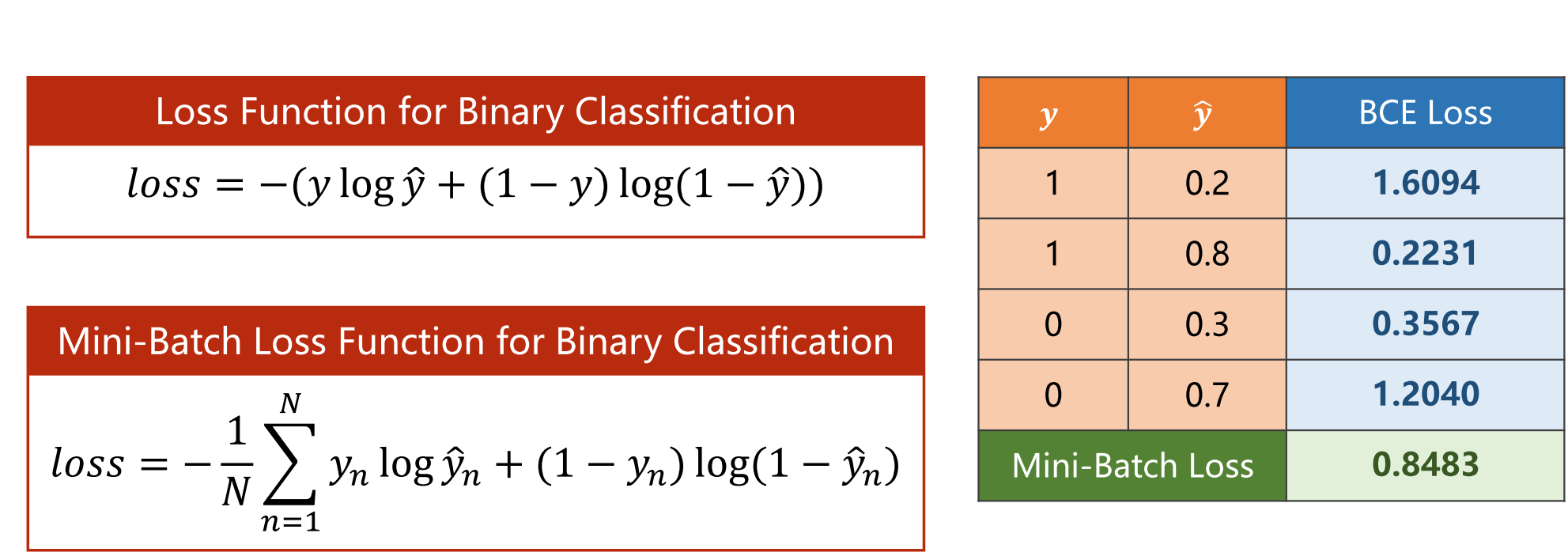
如果模型的预测值越接近真实值,交叉熵的损失就越小。因此,通过最小化交叉熵损失,我们可以训练一个能够准确分类数据的模型。
3 代码实现
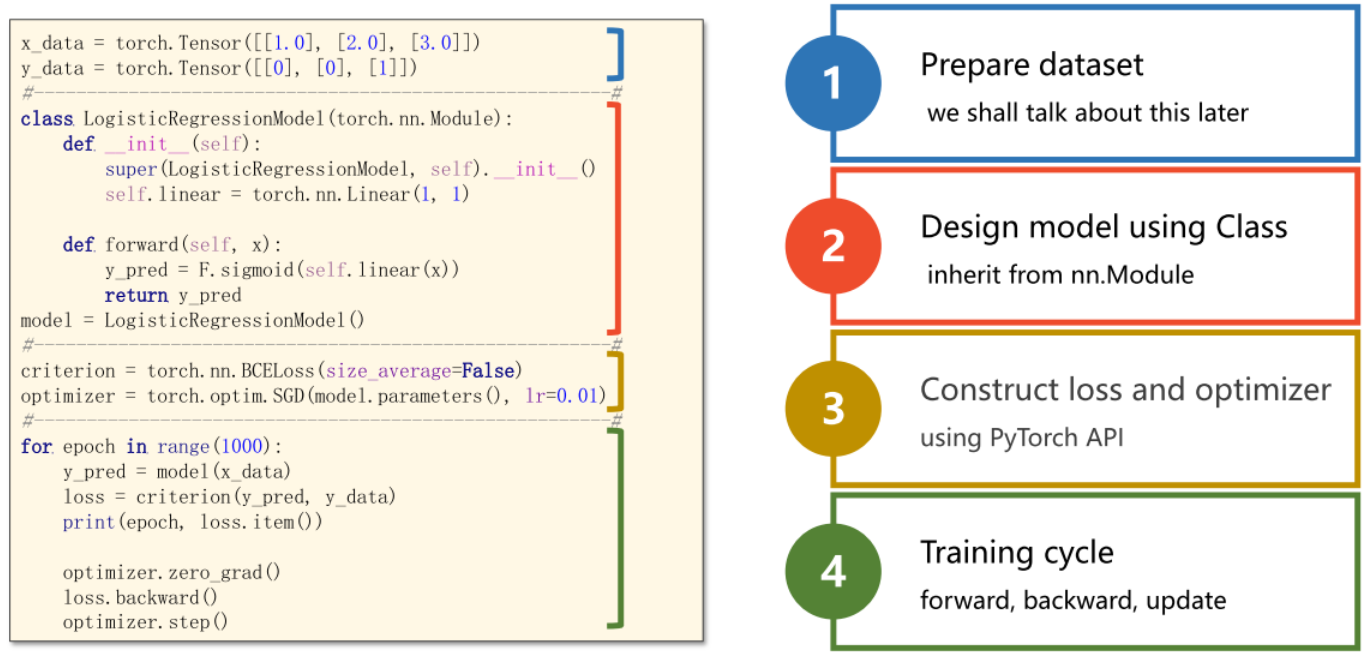
1、这段代码定义了一个 logistic 回归模型类 LogisticRegressionModel,继承了 Module 类。该模型使用单个线性层(Linear)来预测输入 x 的输出。
class LogisticRegressionModel(torch.nn.Module):def __init__(self):super(LogisticRegressionModel, self).__init__()self.linear = torch.nn.Linear(1, 1)def forward(self, x):y_pred = F.sigmoid(self.linear(x)) # sigmoid 函数将输入值压缩到 [0,1] 的区间内,可以将线性层的输出转换为概率值,用于二分类问题的预测。return y_pred2、定义一个二分类交叉熵损失函数对象,并将其赋值给变量criterion:
criterion = torch.nn.BCELoss (size_average=False)在PyTorch中,torch.nn.BCELoss是二分类交叉熵损失函数的实现,它用于度量模型输出与真实标签之间的差异,其返回值即为模型的损失值。size_average参数表示是否对每个batch的损失值求平均,默认为True,如果设为False,则不求平均,返回的是每个batch的总和。因为我们一般在训练神经网络时,采用小批量梯度下降法,因此需要对每个小批量的损失值求平均。
输出图像
import numpy as np
import matplotlib.pyplot as plt'''这里使用NumPy的linspace函数在0到10之间生成了200个等间距的数字,
并将其转换为PyTorch张量,方便后续计算。'''
x = np.linspace(0, 10, 200)
x_t = torch.Tensor(x).view((200, 1))y_t = model(x_t)'''这里使用PyTorch张量的data属性将其转换为NumPy数组,
并使用matplotlib库的plot函数绘制出曲线。'''
y = y_t.data.numpy()
plt.plot(x, y)plt.plot([0, 10], [0.5, 0.5], c='r') # 这里绘制了红色的水平分界线,表示y值为0.5时的x轴取值范围
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()完整代码
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
#-------------------------------------------------------#
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
#-------------------------------------------------------#
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#-------------------------------------------------------#
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()使用逻辑斯蒂回归处理二分类问题的整个过程:
官方文档链接:https://pytorch.org/docs/stable/nn.html?highlight=bceloss#torch.nn.BCELoss
相关文章:
Lecture6 逻辑斯蒂回归(Logistic Regression)
目录 1 常用数据集 1.1 MNIST数据集 1.2 CIFAR-10数据集 2 课堂内容 2.1 回归任务和分类任务的区别 2.2 为什么使用逻辑斯蒂回归 2.3 什么是逻辑斯蒂回归 2.4 Sigmoid函数和饱和函数的概念 2.5 逻辑斯蒂回归模型 2.6 逻辑斯蒂回归损失函数 2.6.1 二分类损失函数 2.…...
File类及IO流说明
目录 1.File类说明 (1)构造方法创建文件 (2)创建功能 (3)File类的判断和获取功能 (4)文件删除功能 2.I/O流说明 (1).分类 3.字节流写数据 (1)说明 (2)字节流写数据的三种方式 (3)写入时实现换行和追加写入 (4)异常处理中加入finally实现资源的释放 4.字节流读数据 …...

优秀的网络安全工程师应该有哪些能力?
网络安全工程师是一个各行各业都需要的职业,工作内容属性决定了它不会只在某一方面专精,需要掌握网络维护、设计、部署、运维、网络安全等技能。目前稍有经验的薪资在10K-30K之间,全国的网络安全工程师还处于一个供不应求的状态,因…...

[C++11] auto初始值类型推导
背景:旧标准的auto 在旧标准中,auto代表“具有自动存储期的 局部变量” auto int i 0; //具有自动存储期的局部变量 //C98/03,可以默认写成int i0; static int j 0; //静态类型的定义方法实际上,我们很少使用auto,…...

【Java】List集合去重的方式
List集合去重的方式方式一:利用TreeSet集合特性排序去重(有序)方式二:利用HashSet的特性去重(无序)方式三:利用LinkedHashSet去重(有序)方式四:迭代器去重&am…...
每个人都应该知道的5个NLP代码库
在本文中,将详细介绍目前常用的Python NLP库。内容译自网络。这些软件包可处理多种NLP任务,例如词性(POS)标注,依存分析,文档分类,主题建模等等。NLP库的基本目标是简化文本预处理。目前有许多工…...
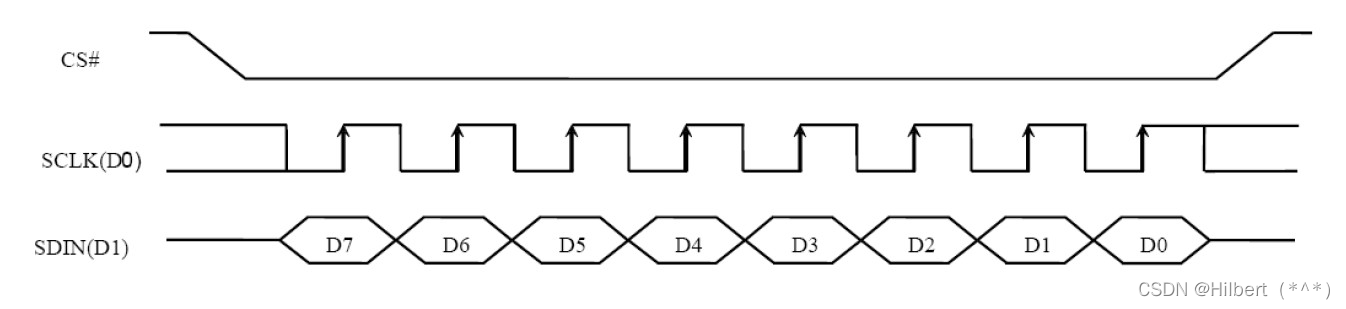
SPI协议介绍
SPI协议介绍 文章目录SPI协议介绍一、 SPI硬件知识1.1 硬件连线1.2 SPI控制器内部结构二、 SPI协议2.1 传输示例2.2 SPI模式致谢一、 SPI硬件知识 1.1 硬件连线 引脚含义如下: 引脚含义DO(MOSI)Master Output, Slave Input,SPI主控用来发出数据&#x…...

MySQL数据库中索引的优点及缺点
一、索引的优点 1)创建索引可以大幅提高系统性能,帮助用户提高查询的速度; 2)通过索引的唯一性,可以保证数据库表中的每一行数据的唯一性; 3)可以加速表与表之间的链接; 4&#…...
sort函数总结(基础篇))
(q)sort函数总结(基础篇)
1.sort函数 介绍:这是一个C的函数,包含于algorithm头文件中。 基本格式: sort(起始地址(常为变量名),排序终止的地址(变量名加上排序长度),自定义的比较函数) 重点&a…...

【数据库】MongoDB数据库详解
目录 一,数据库管理系统 1, 什么是数据库 2,什么是数据库管理系统 二, NoSQL 是什么 1,NoSQL 简介 2,NoSQL数据库 3,NoSQL 与 RDBMS 对比 三,MongoDB简介 1, MongoDB 是什…...

【linux】进程间通信——system V
system V一、system V介绍二 、共享内存2.1 共享内存的原理2.2 共享内存接口2.2.1 创建共享内存shmget2.2.2 查看IPC资源2.2.3 共享内存的控制shmctl2.2.4 共享内存的关联shmat2.2.5 共享内存的去关联shmdt2.3 进程间通信2.4 共享内存的特性2.5 共享内存的大小三、消息队列3.1 …...

计算机网络的基本组成
计算机网络是由多个计算机、服务器、网络设备(如路由器、交换机、集线器等)通过各种通信线路(如有线、无线、光纤等)和协议(如TCP/IP、HTTP、FTP等)互相连接组成的复杂系统,它们能够在物理层、数…...
【数据结构趣味多】Map和Set
1.概念及场景 Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。 在此之前,我还接触过直接查询O(N)和二分查询O(logN),这两个查询有很多不足之出,直接查询的速率太低,而二分查…...

Redis 之企业级解决方案
文章目录一、缓存预热二、缓存雪崩三、缓存击穿四、缓存穿透五、性能指标监控5.1 监控指标5.2 监控方式🍌benchmark🍌monitor🍌slowlog提示:以下是本篇文章正文内容,Redis系列学习将会持续更新 一、缓存预热 1.1 现象…...
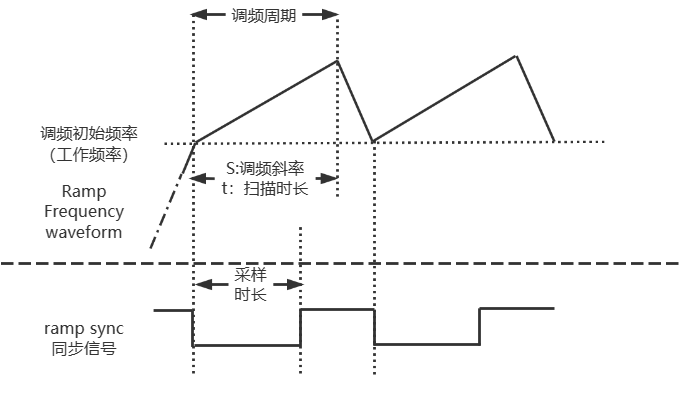
雷达实战之射频前端配置说明
在无线通信领域,射频系统主要分为射频前端,以及基带。从发射通路来看,基带完成语音等原始信息通过AD转化等手段转化成基带信号,然后经过调制生成包含跟多有效信息,且适合信道传输的信号,最后通过射频前端将信号发射出去…...

Android SDK删除内置的触宝输入法
问题 Android 8.1.0, 展锐平台。 过CTA认证,内置的触宝输入法会连接网络,且默认就获取到访问网络的权限,没有弹请求窗口访问用户,会导致过不了认证。 预置应用触宝输入法Go版连网未明示(开启后࿰…...

[202002][Spring 实战][第5版][张卫滨][译]
[202002][Spring 实战][第5版][张卫滨][译] habuma/spring-in-action-5-samples: Home for example code from Spring in Action 5. https://github.com/habuma/spring-in-action-5-samples 第 1 部分 Spring 基础 第 1 章 Spring 起步 1.1 什么是 Spring 1.2 初始化 Spr…...

H5视频上传与播放
背景 需求场景: 后台管理系统: (1)配置中支持上传视频、上传成功后封面缩略图展示,点击后自动播放视频; (2)配置中支持上传多个文件; 前台系统: &#…...
通过OpenAI来做机械智能故障诊断-测试(1)
通过OpenAI来做机械智能故障诊断 1. 注册使用2. 使用案例1-介绍故障诊断流程2.1 对话内容2.2 对话小结3. 使用案例2-写一段轴承故障诊断的代码3.1 对话内容3.2 对话小结4. 对话加载Paderborn轴承故障数据集并划分4.1 加载轴承故障数据集并划分第一次测试4.2 第二次加载数据集自…...

ASE40N50SH-ASEMI高压MOS管ASE40N50SH
编辑-Z ASE40N50SH在TO-247封装里的静态漏极源导通电阻(RDS(ON))为100mΩ,是一款N沟道高压MOS管。ASE40N50SH的最大脉冲正向电流ISM为160A,零栅极电压漏极电流(IDSS)为1uA,其工作时耐温度范围为-55~150摄氏度。ASE40N…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...