elasticsearch term match 查询
1. 准备数据
PUT h1/doc/1
{"name": "rose","gender": "female","age": 18,"tags": ["白", "漂亮", "高"]
}PUT h1/doc/2
{"name": "lila","gender": "female","age": 18,"tags": ["黑", "漂亮", "高"]
}PUT h1/doc/3
{"name": "john","gender": "male","age": 18,"tags": ["黑", "帅", "高"]
}
运行结果:
{"_index" : "h1","_type" : "doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
2. match 查询
2.1 match 按条件查询
# 查询性别是男性的结果
GET h1/doc/_search
{"query": {"match": {"gender": "male"}}
}
查询结果:
{"took" : 59,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 1,"max_score" : 0.2876821,"hits" : [{"_index" : "h1", # 索引"_type" : "doc", # 文档类型"_id" : "3", # 文档唯一 id"_score" : 0.2876821, # 打分机制打出来的分数"_source" : { # 查询结果"name" : "john","gender" : "male","age" : 18,"tags" : ["黑","帅","高"]}}]}
}
2.2 match_all 查询全部
# 查询 h1 中所有文档
GET h1/doc/_search
{"query": {"match_all": {}}
}
match_all的值为空,表示没有查询条件,那就是查询全部。就像select * from table_name 一样。
查询结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 3,"max_score" : 1.0,"hits" : [{"_index" : "h1","_type" : "doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "lila","gender" : "female","age" : 18,"tags" : ["黑","漂亮","高"]}},{"_index" : "h1","_type" : "doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "rose","gender" : "female","age" : 18,"tags" : ["白","漂亮","高"]}},{"_index" : "h1","_type" : "doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "john","gender" : "male","age" : 18,"tags" : ["黑","帅","高"]}}]}
}
2.3 match_phrase 短语查询
match 查询时散列映射,包含了我们希望搜索的字段和字符串,即只要文档中有我们希望的那个关键字,但也会带来一些问题。
es 会将文档中的内容进行拆分,对于英文来说可能没有太大的影响,但是中文短语就不太适用,一旦拆分就会失去原有的含义,比如以下:
1、准备数据:
PUT t1/doc/1
{"title": "中国是世界上人口最多的国家"
}PUT t1/doc/2
{"title": "美国是世界上军事实力最强大的国家"
}PUT t1/doc/3
{"title": "北京是中国的首都"
}
2、先使用 match 查询含有中国的文档:
GET t1/doc/_search
{"query": {"match": {"title": "中国"}}
}
查询结果:
{"took" : 5,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 3,"max_score" : 0.68324494,"hits" : [{"_index" : "t1","_type" : "doc","_id" : "1","_score" : 0.68324494,"_source" : {"title" : "中国是世界上人口最多的国家"}},{"_index" : "t1","_type" : "doc","_id" : "3","_score" : 0.5753642,"_source" : {"title" : "北京是中国的首都"}},{"_index" : "t1","_type" : "doc","_id" : "2","_score" : 0.39556286,"_source" : {"title" : "美国是世界上军事实力最强大的国家"}}]}
}
发现三篇文档都被返回,与我们的预期有偏差;这是因为 title 中的内容被拆分成一个个单独的字,而 id=2 的文档包含了 国 字也符合,所以也被返回了。es 自带的中文分词处理不太好用,后面可以使用 ik 中文分词器来处理。
3、match_phrase 查询短语
不过可以使用 match_phrase 来匹配短语,将上面的 match 换成 match_phrase 试试:
# 短语查询
GET t1/doc/_search
{"query": {"match_phrase": {"title": "中国"}}
}
查询结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 2,"max_score" : 0.5753642,"hits" : [{"_index" : "t1","_type" : "doc","_id" : "1","_score" : 0.5753642,"_source" : {"title" : "中国是世界上人口最多的国家"}},{"_index" : "t1","_type" : "doc","_id" : "3","_score" : 0.5753642,"_source" : {"title" : "北京是中国的首都"}}]}
}
4、slop 间隔查询
当我们要查询的短语,中间有别的词时,可以使用 slop 来跳过。比如上述要查询 中国世界,这个短语中间被 是 隔开了,这时可以使用 slop 来跳过,相当于正则中的中国.*?世界:
# 短语查询,查询中国世界,加 slop
GET t1/doc/_search
{"query": {"match_phrase": {"title": {"query": "中国世界","slop": 1}}}
}
查询结果:
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 1,"max_score" : 0.7445889,"hits" : [{"_index" : "t1","_type" : "doc","_id" : "1","_score" : 0.7445889,"_source" : {"title" : "中国是世界上人口最多的国家"}}]}
}
2.4 match_phrase_prefix 最左前缀查询
场景:当我们要查询的词只能想起前几个字符时
# 最左前缀查询,查询名字为 rose 的文档
GET h1/doc/_search
{"query": {"match_phrase_prefix": {"name": "ro"}}
}
查询结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 1,"max_score" : 0.2876821,"hits" : [{"_index" : "h1","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"name" : "rose","gender" : "female","age" : 18,"tags" : ["白","漂亮","高"]}}]}
}
限制结果集
最左前缀查询很费性能,返回的是一个很大的集合,一般很少使用,使用的时候最好对结果集进行限制,max_expansions 参数可以设置最大的前缀扩展数量:
# 最左前缀查询
GET h1/doc/_search
{"query": {"match_phrase_prefix": {"gender": {"query": "fe","max_expansions": 1}}}
}
查询结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 2,"max_score" : 0.2876821,"hits" : [{"_index" : "h1","_type" : "doc","_id" : "2","_score" : 0.2876821,"_source" : {"name" : "lila","gender" : "female","age" : 18,"tags" : ["黑","漂亮","高"]}},{"_index" : "h1","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"name" : "rose","gender" : "female","age" : 18,"tags" : ["白","漂亮","高"]}}]}
}
2.5 multi_match 多字段查询
1、准备数据:
# 多字段查询
PUT t3/doc/1
{"title": "maggie is beautiful girl","desc": "beautiful girl you are beautiful so"
}PUT t3/doc/2
{"title": "beautiful beach","desc": "I like basking on the beach,and you? beautiful girl"
}
2、查询包含 beautiful 字段的文档:
GET t3/doc/_search
{"query": {"multi_match": {"query": "beautiful", # 要查询的词"fields": ["desc", "title"] # 要查询的字段}}
}
还可以当做 match_phrase和match_phrase_prefix使用,只需要指定type类型即可:
GET t3/doc/_search
{"query": {"multi_match": {"query": "gi","fields": ["title"],"type": "phrase_prefix"}}
}GET t3/doc/_search
{"query": {"multi_match": {"query": "girl","fields": ["title"],"type": "phrase"}}
}
3. term 查询
3.1 初始 es 的分析器
term 查询用于精确查询,但是不适用于 text 类型的字段查询。
在此之前我们先了解 es 的分析机制,默认的标准分析器会对文档进行:
- 删除大多数的标点符号
- 将文档拆分为单个词条,称为
token - 将
token转换为小写
最后保存到倒排序索引上,而倒排序索引用来查询,如 Beautiful girl 经过分析后是这样的:
POST _analyze
{"analyzer": "standard","text": "Beautiful girl"
}# 结果,转换为小写了
{"tokens" : [{"token" : "beautiful","start_offset" : 0,"end_offset" : 9,"type" : "<ALPHANUM>","position" : 0},{"token" : "girl","start_offset" : 10,"end_offset" : 14,"type" : "<ALPHANUM>","position" : 1}]
}
3.2 term 查询
1、准备数据:
# 创建索引,自定义 mapping,后面会讲到
PUT t4
{"mappings": {"doc":{"properties":{"t1":{"type": "text" # 定义字段类型为 text}}}}
}PUT t4/doc/1
{"t1": "Beautiful girl!"
}PUT t4/doc/2
{"t1": "sexy girl!"
}
2、match 查询:
GET t4/doc/_search
{"query": {"match": {"t1": "Beautiful girl!"}}
}
经过分析后,会得到 beautiful、girl 两个 token,然后再去 t4 索引上去查询,会返回两篇文档:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 2,"max_score" : 0.5753642,"hits" : [{"_index" : "t4","_type" : "doc","_id" : "1","_score" : 0.5753642,"_source" : {"title" : "Beautiful girl"}},{"_index" : "t4","_type" : "doc","_id" : "2","_score" : 0.2876821,"_source" : {"title" : "sex girl"}}]}
}
3、但是我们只想精确查询包含 Beautiful girl 的文档,这时就需要使用 term 来精确查询:
GET t4/doc/_search
{"query": {"term": {"title": "beautiful"}}
}
查询结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 1,"max_score" : 0.2876821,"hits" : [{"_index" : "t4","_type" : "doc","_id" : "1","_score" : 0.2876821,"_source" : {"title" : "Beautiful girl"}}]}
}
注意:
term查询不适用于类型是text的字段,可以使用match查询;另外Beautiful经过分析后变为beautiful,查询时使用Beautiful是查询不到的~
3.3 查询多个
精确查询多个字段:
GET t4/doc/_search
{"query": {"terms": {"title": ["beautiful", "sex"]}}
}
相关文章:

elasticsearch term match 查询
1. 准备数据 PUT h1/doc/1 {"name": "rose","gender": "female","age": 18,"tags": ["白", "漂亮", "高"] }PUT h1/doc/2 {"name": "lila","gender&quo…...
canal使用说明:MySQL、Redis实时数据同步
1. canal简介 canal是阿里开源的数据同步工具,基于bin log可以将数据库同步到其他各类数据库中,目标数据库支持mysql,postgresql,oracle,redis,MQ,ES等 canal分成服务端deployer和客户端adapter,我们可以部署多个,同时为了方便管…...

计算机视觉框架OpenMMLab开源学习(三):图像分类实战
前言:本篇主要偏向图像分类实战部分,使用MMclassification工具进行代码应用,最后对水果分类进行实战演示,本次环境和代码配置部分省略,具体内容建议参考前一篇文章:计算机视觉框架OpenMMLab开源学习&#x…...

awk命令
一.介绍 awk是专门为文本处理设计的编程语言,是一门数据驱动的编程语言。与sed类似,都是以数据驱动的行处理软件,主要用于数据扫描,过滤和汇总。数据可以来自于标准输入,管道或者文件。 二.语法 awk是一种处理文本文件…...

LocalDateTime获取时间的年、月、日、时、分、秒、纳秒
如何把String/Date转成LocalDateTime参考String、Date与LocalDate、LocalTime、LocalDateTime之间互转 String、Date、LocalDateTime、Calendar与时间戳之间互相转化参考String、Date、LocalDateTime、Calendar与时间戳之间互相转化 方法介绍 getYear() 获取日期的年 getMon…...
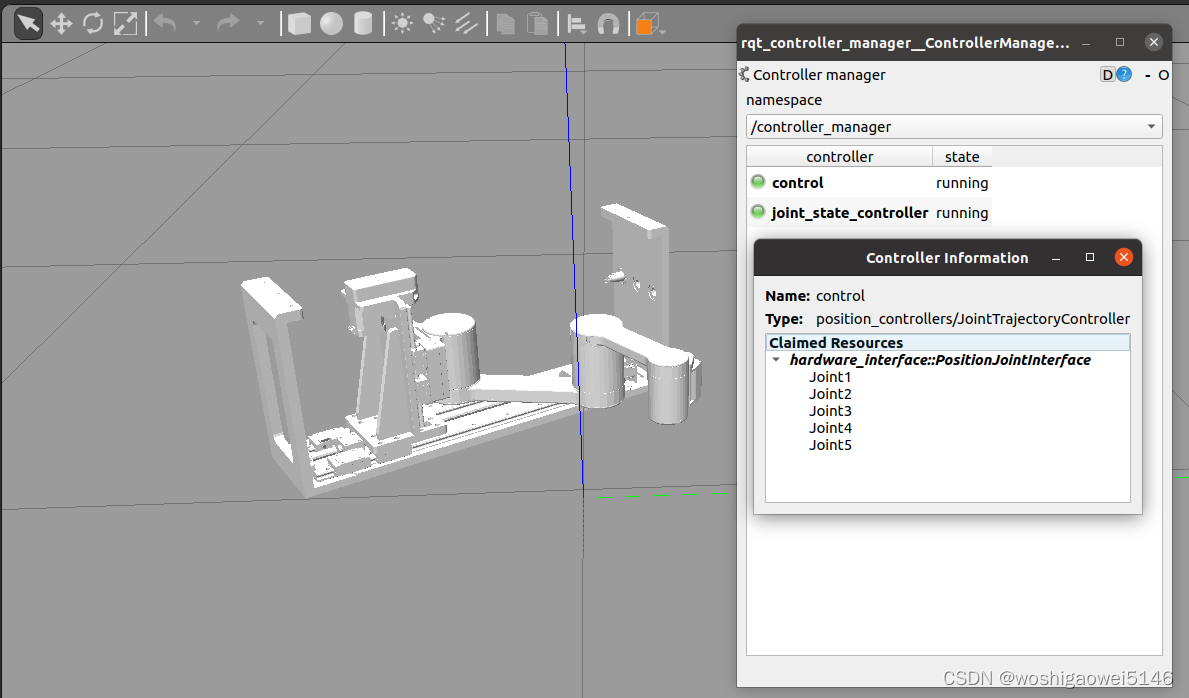
MoveIT Rviz和Gazebo联合仿真
文章目录环境安装概述ros_control框架ros_control数据流文件配置附加工具故障问题解决参考接前两篇:ROS MoveIT1(Noetic)安装总结 Solidworks导出为URDF用于MoveIT总结(带prismatic) MoveIT1 Assistant 总结 环境 Ubu…...
-DS18B20数码管显示温度)
ESP32S2(12K)-DS18B20数码管显示温度
一、物料清单: NODEMCU-32-S2 (ESP32-12K)四段数码管(共阴)DS18B20(VCC/DQ/GND)Arduino-IDE 2.0.3二、实现方法及效果图: 2.1 引用库 // #include <OneWire.h> //可以不引入,因为DallasTemperature.h中已经引入了OneWire.h #include <DallasTemperature.h>#…...

linux栈溢出定位
一、编译选项定位堆栈溢出 来源:堆栈溢出检测机制 - SkrSky - 博客园 1、栈溢出可能打印 unhandled level 1 translation fault (11) at 0x7f8d0347, esr 0x92000005 2、栈溢出保护机制 gcc提供了栈保护机制stack-protector(编译选项-fstack-protec…...

CSS基础:选择器和声明样式
CSS概念 CSS(Cascading Style Sheets)层叠样式表,又叫级联样式表,简称样式表 CSS用于HTML文档中元素样式的定义 使用css让网页具有美观一致的页面 语法 CSS 规则由两个主要的部分构成:选择器和声明样式 选择器通常…...
VS中安装gismo库
文章目录前言一、下载安装paraview直接下载压缩包安装就可以了解压后按步骤安装即可二、gismo库的安装gismo库网址第一种方法:第二种方法第三种方法:用Cmake软件直接安装首先下载cmake软件[网址](https://cmake.org/download/)安装gismo库三、gismo库的使…...
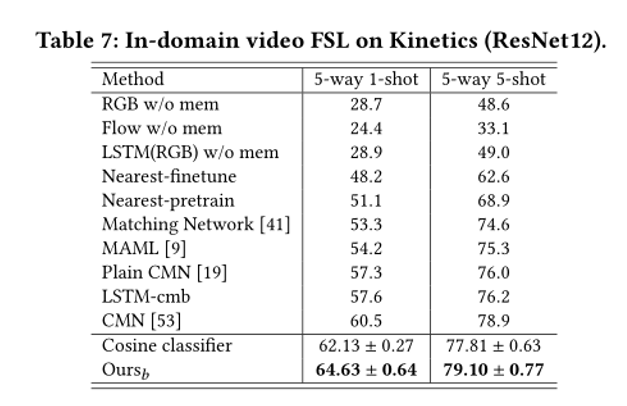
元学习方法解决CDFSL以及两篇SOTA论文讲解
来源:投稿 作者:橡皮 编辑:学姐 带你学习跨域小样本系列1-简介篇 跨域小样本系列2-常用数据集与任务设定详解 跨域小样本系列3:元学习方法解决CDFSL以及两篇SOTA论文讲解(本篇) 跨域小样本系列4…...
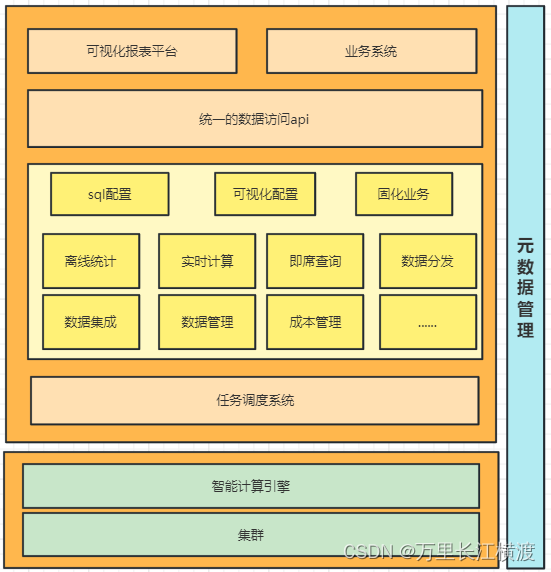
大数据之------------数据中台
一、什么是数据中台 **数据中台是指通过数据技术,对海量数据进行采集、计算、存储、加工,同时统一标准和口径。**数据中台的目标是让数据持续用起来,通过数据中台提供的工具、方法和运行机制,把数据变为一种服务能力,…...

Python 中 字符串是什么?
字符串是 Python 中最常用的数据类型。我们可以使用引号 ( ’ 或 " ) 来创建字符串。 创建字符串很简单,只要为变量分配一个值即可。例如: var1 ‘Hello World!’ var2 “Python Runoob” Python 访问字符串中的值 Python 不支持单字符类型&…...

OJ刷题Day1 · 一维数组的动态和 · 将数字变成 0 的操作次数 · 最富有的客户资产总量 · Fizz Buzz · 链表的中间结点 · 赎金信
一、一维数组的动态和二、将数字变成 0 的操作次数三、最富有的客户资产总量四、Fizz Buzz五、链表的中间结点六、赎金信一、一维数组的动态和 给你一个数组 nums 。数组「动态和」的计算公式为:runningSum[i] sum(nums[0]…nums[i]) 。 请返回 nums 的动态和。 示…...

【数据结构】栈——必做题
逆波兰表达式后缀表达式的出现是为了方便计算机处理,它的运算符是按照一定的顺序出现,所以求值过程中并不需要使用括号来指定运算顺序,也不需要考虑运算符号(比如加减乘除)的优先级。先介绍中简单的人工转化方法&#…...
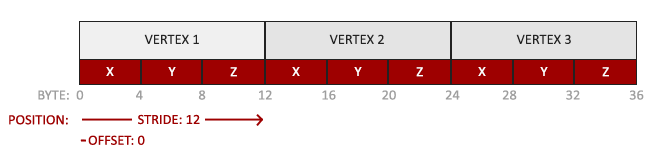
LearnOpenGL 笔记 - 入门 04 你好,三角形
系列文章目录 LearnOpenGL 笔记 - 入门 01 OpenGLLearnOpenGL 笔记 - 入门 02 创建窗口LearnOpenGL 笔记 - 入门 03 你好,窗口 文章目录系列文章目录前言你好,三角形顶点输入顶点着色器(Vertex Shader)编译着色器片段着色器&…...
keepalived+mysql高可用
一.设置mysql同步信息两节点安装msyql略#配置节点11.配置权限允许远程访问mysql -u root -p grant all on *.* to root% identified by Root1212# with grant option; flush privileges;2.修改my.cnf#作为主节点配置(节点1)#作为主节点配置 server-id 1 …...
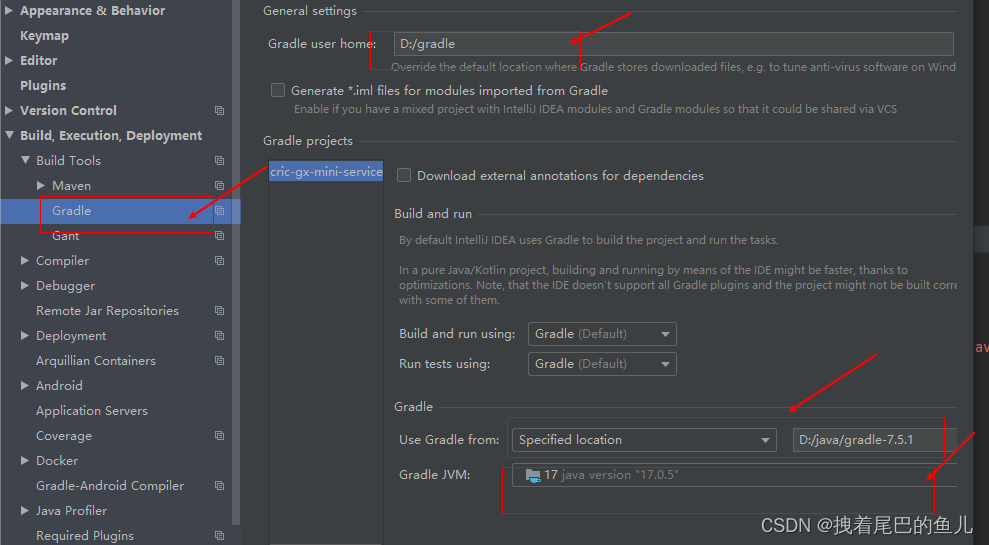
JAVA工具篇--1 Idea中 Gradle的使用
前言: 既然我们已经使用Maven 来完成对项目的构建,为什么还要使用Gradle 进行项目的构建;gradle和maven都可以作为java程序的构建工具,但两者还是有很大的不同之处的:1.可扩展性,gradle比较灵活,…...

弄懂自定义 Hooks 不难,改变开发认知有点不习惯
前言 我之前总结逻辑重用的时候,就一直在思考一个问题。 对于逻辑复用,render props 和 高阶组件都可以实现,同样官方说 Hooks 也可以实现,且还是在不增加额外的组件的情况下。 但是我在项目代码中,没有找到自定义 …...
Java面向对象基础
文章目录面向对象类注意事项内存机制构造器this关键字封装javabean格式成员变量和局部变量区别static静态关键字使用成员方法使用场景内存机制注意事项static应用:工具类static应用:代码块静态代码块实例代码块(用的比较少)static…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...