Elasticsearch:索引数据是如何完成的

在我在之前的文章 “Elasticsearch:彻底理解 Elasticsearch 数据操作” 文章中,我详细地描述了如何索引数据到 Elasticsearch 中。在今天的文章中,我想更进一步来描述这个流程。
Elasticsearch® 是一个非常强大和灵活的分布式数据系统,接受数十亿个文档并为其建立索引,使它们可以近乎实时地用于搜索、聚合和分析。 本文将介绍如何做到这一点,重点介绍基本的新数据插入和从请求一直到磁盘的数据流。
索引是一个相对简单的高级过程,包括:
- 通过 API 到达数据
- 路由到正确的索引、分片和节点
- 映射、规范化和分析
- 存储在内存和磁盘上
- 使其可供搜索
然而,实际过程要复杂得多,尤其是考虑到集群及其数据的分布式特性、涉及的高数据速率以及同时进行的所有事情的并行特性。 此外,这一切都必须尽可能可靠和可扩展。 这就是 Elasticsearch 的神奇之处。
让我们更详细地看一下这些步骤。充分了解这个过程对于我们如何优化 Elasticsearch 集群及操作以提高其索引数据的速度非常重要。

API 请求和分批
当数据通过索引 API 到达时,Elasticsearch 首先了解要索引的传入数据。 Logstash、Beats 甚至 cURL 等客户端将数据发送到集群的节点进行处理。 他们一次可以发送一个文档,但通常使用批量 API 批量发送数据,以减少开销并加快处理速度。 批次只是在一个 API 调用中发送的一组文档,不需要相关,即它们可以包含发往多个不同索引的数据。

摄取数据可以发送到任何节点。 然而,更大的集群通常使用专用协调节点(更多用于搜索而不是摄取),甚至专用摄取节点,它们可以运行数据管道来预处理数据。 数据到达的任何节点都将成为该批次的协调节点,并将数据路由到正确的位置,即使实际摄取工作是在保存目标索引数据的数据节点上执行的。
管道和数据流
数据最常到达单个标准索引,但也可以路由到数据流(data stream)或摄取管道(ingest pipeline)。 数据流是 X-Pack 的一项功能,最常用于处理时间序列数据,例如指标和日志,并且基本上解析为该摄取过程的实际支持索引。 管道是处理器的集合,用于在索引之前处理文档数据。
如果请求或批处理包含管道并且协调节点不是摄取节点,则它似乎会首先路由到摄取节点,然后继续到主节点。 目前尚不清楚协调器或摄取节点是否将其发送到主节点(primary node,即 primary shard 所在的节点),但可能是协调节点,即摄取节点运行管道后,然后将文档返回到协调器节点以进行下一步,也即下面将要讲到的 Routing。
路由 - Routing
一旦数据到达协调节点,每个文档都必须路由到正确的索引、分片和节点以进行摄取。 由于批量请求可能包含许多索引的数据,并且单个索引的多个文档可能会转到不同的分片,因此路由步骤是针对每个文档运行的,并且对于将每个文档都送到正确的位置非常重要。 此过程启动 “协调阶段”。
每个文档的第一步是协调节点使用提供的索引、别名、数据流等来确定文档将要到达的实际目标索引。 如果索引不存在,将创建它,然后该过程可以继续。 请注意,Elasticsearch 在执行任何索引之前会尝试首先创建批量请求所需的所有索引。
协调节点知道目标索引后,它会运行一个路由过程来为文档选择索引的分片。 路由可能会变得复杂,默认情况下由文档 ID 驱动,默认情况下它由协调节点自动生成。
如果你愿意,客户端可以指定自己的 ID,还可以控制用于路由的字段,例如时间戳、用户、源设备等,作为集群策略,将相关(且可快速查询)的数据共同定位在一个单一的分片。 此外,索引可以具有将文档强制到特定分片的自定义路由。 但一般来说,每个文档都会随机分布在其目标索引的分片中。
路由过程的结果将是目标分片及其分片 ID,但我们必须记住,分片可能有副本。 如果有副本,协调节点也会将它们包含在路由列表中,因此结果是该文档的所有分片的列表:主分片和副本。 协调节点然后查找这些分片的节点 ID,以了解将文档路由到何处以进行索引。
索引阶段 - indexing stage
一旦协调节点知道文档的目标主分片和该分片的节点,文档将被发送到该节点以进行主索引,作为 “初级阶段” 的一部分。 主分片验证请求,然后在本地索引它们,这也验证了映射、字段等。 下面更详细地描述了该过程。
如果主节点索引成功,主分片节点(不是协调节点)将文档并行发送到所有 “in-sync” “active” 副本,即 “Replica Stage”。 主分片节点等待所有副本完成索引,然后将结果返回给等待的协调节点。 一旦批处理中的所有文档都被索引(或失败),协调器就会将结果返回给原始 API 调用者,即客户端。
每个文档都由其每个主分片和副本分片分别索引。
必须了解每个文档都由它将存在的每个分片分别索引,并且所有这些都必须在给定文档被 “索引” 之前完成。 因此,如果一个索引的副本数为 3,这意味着每个文档都将转到四个分片(主分片和三个副本),并分别由这些分片索引,所有分片都在不同的节点上。
![]()
Elasticsearch 中没有真正的预处理或中央索引,并且集群完成的 “工作” 随着给定索引的副本数量线性增加。 这通常是大多数索引延迟发生的地方,因为它只能像最慢的节点和分片一样慢地完成。
协调器节点尽可能多地并行化一批文档。 它并行地将文档发送到它们的路由主分片,但似乎只对每个主分片排队一个请求。 因此,如果批次有 10 个文档用于单个索引和单个分片,这些将全部按顺序处理,一次处理一个,但是如果批次有 10 个文档用于两个索引,每个索引有 5 个分片并且路由结果为一个每个分片的文档,所有 10 个将并行完成。 这是额外的主分片加速处理的一种方式。
分片级索引
一旦文档到达拥有它将驻留的分片的给定节点,实际的文档索引就完成了。 第一步是将文档写入 translog 以获得持久副本,以防在此之后节点崩溃。
Translog 是 Elasticsearch 的一项功能,提供了 Lucene 自身无法做到的持久性,并且是可靠系统的关键。 如果节点在实际索引完成之前崩溃,则在重新启动时 Elasticsearch 会将文档重播到索引过程中以确保它得到处理。更多关于 translog 的描述清阅读文章 “Elasticsearch:Elasticsearch 中的 refresh 和 flush 操作指南”。

实际的索引过程有几个步骤:
- 在 Elasticsearch 中映射文档字段
- 在 Lucene 中分析
- 添加到 Lucene 中的倒排索引
首先,节点通过索引模板映射文档的字段,该模板指定如何处理每个字段,例如类型,但也包括分析器和其他选项。 由于每个文档都可以有不同的字段和数据,所以这个映射步骤是必不可少的,也是经常发生错误的地方,因为字段类型不匹配、超出范围等。 这项工作是在 Elasticsearch 级别完成的,因为 Lucene 没有模板或映射的概念。 Lucene 文档只是一组字段,每个字段都有名称、类型和值。
其次,文档被传递给 Lucene,后者将对其进行 “分析”。 实际上,这意味着在其上运行配置的分析器,每个分析器可以有几个步骤和组件,包括标记化和过滤,它们一起可以做很多强大的事情。有关分析器方面的知识,请阅读文章 “Elasticsearch: analyzer”。
分词化将每个字段中的数据拆分为分词,例如在空格上分隔单词和过滤包括除了基本过滤之外的广泛内容,以小写文本,删除停用词和通过词干归一化(即改变单词到他们的 “正常” 版本,例如 dogs 变成 dog,watched 变成 watch 等)
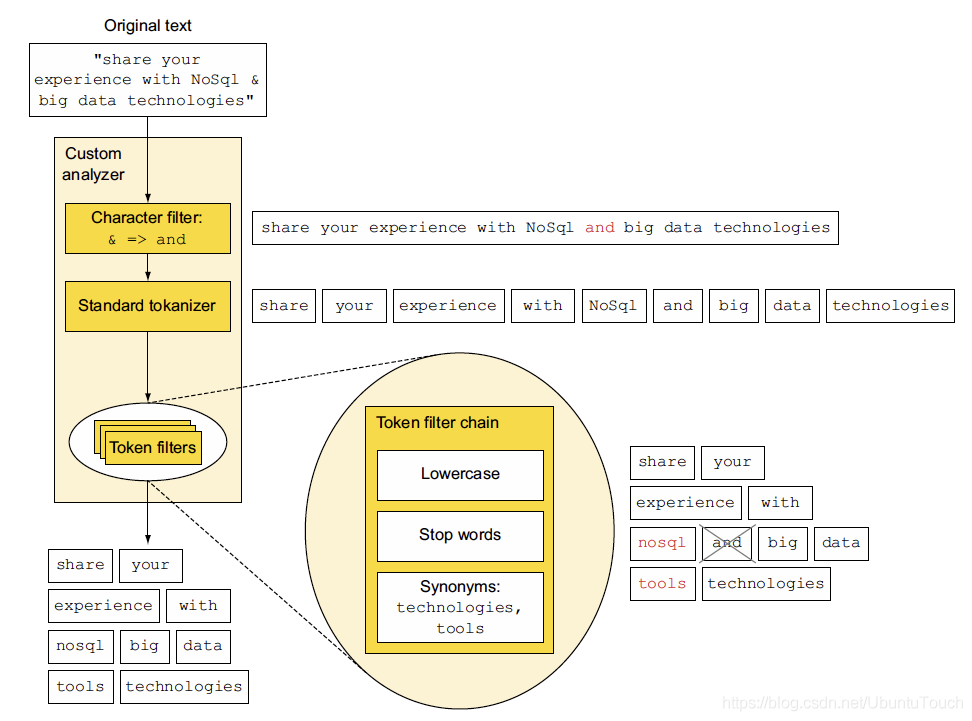
最后,Lucene 获取结果并为此文档构建存储记录。 这通常包括文档中的每个字段,以及可用于重新索引等的特殊字段,例如 _source 和 _all 等。 以及最重要的倒排索引本身。
Lucene 将所有这些写入内存中的段缓冲区,然后成功返回协调节点。 在所有副本分片上完成此操作后,从协调器节点或客户端的角度来看,该文档的索引基本上已完成。
获取磁盘上的文档数据并可搜索
刚刚建立索引的文档只在内存中的临时多文档段中,还没有在磁盘上,也不能用于搜索。 两个独立的进程在幕后运行以实现这两件事。
索引数据尚未在磁盘上,也不可搜索。
第一个过程是 “refreshing” 以使数据可用于搜索。 刷新间隔按索引设置,默认为 1 秒。 许多用户将此设置得更高,例如 30-60 秒,因为这是一项昂贵的操作,并且每秒执行一次会降低整体索引吞吐量。 请注意,不经常搜索的索引在搜索之前不会自动刷新,以提高批量索引速度。有关 refresh 操作的描述,请阅读文章 “Elasticsearch:Elasticsearch 中的 refresh 和 flush 操作指南”。
在刷新间隔,内存缓冲区的段被合并并写入文件系统上的单个新段,并且数据可用于搜索。 但是,虽然这个段现在存在于文件系统上,但它主要在文件缓存中,实际上可能不在磁盘上,如果此时出现崩溃,这就是一个问题。 数据可用,但不安全,但如果发生崩溃,translog 仍然存在并会被回放,文档会重新被索引。
为了使数据在磁盘上安全,有一个单独的 Elasticsearch 刷新过程执行 Lucene 提交,合并和 fsyncs 上述段,确保它们确实在磁盘上。 完成后,Elasticsearch 会截断传输日志,因为数据现在安全地保存在磁盘上,不会在崩溃中丢失。 Elasticsearch 根据传输日志大小(默认最大值为 512MB)安排这些刷新,以帮助保持合理的恢复时间。
本质上,translog 维护所有新文档更改的可靠性,以及 Elasticsearch 刷新/Lucene 提交之间的可靠性。 请注意,translog 有其自己的可靠性设置,包括每 5 秒 fsync 到磁盘的默认值。
Elasticsearch 还单独运行后台线程以尽可能继续合并段,使用分层合并策略尝试最小化段(segment)数(因为它们是按顺序搜索的),同时不会降低整体实时索引和搜索性能。 这与上述所有过程都是分开的。
总体结果是,在任何给定时间,任何特定的可用索引都由磁盘上一组大小不同的永久段和文件缓存中的一些新段组成。 加上仅在内存中的索引但尚未可用的段,等待刷新间隔。
问题
Elasticsearch 索引是一个很好但很复杂的分布式过程,它平衡了高性能、数据可靠性和强大的功能。 虽然它运作良好,但事情可能而且确实会出错。 有些问题出在文档本身,而另一些则出在集群方面。
集群级问题通常与分片丢失或过程中的移动有关。 正常的流程是从协调器节点到主节点再到副本节点,但是如果主节点在这个过程中发生变化,或者副本丢失了怎么办? 尽管尝试保存文档有各种复杂的重试、超时和路由过程,当然,它们可能会失败,此时客户端必须重试。
其中一些,例如副本超时或失败,将导致该分片被声明为不同步和无效,将索引状态更改为黄色并安排副本重建。 其他的,比如网络分区,会导致主节点本身被声明为无效,当它试图与副本对话时会发现这一点。 总的来说,这是一个复杂但强大的系统。
相关文章:
Elasticsearch:索引数据是如何完成的
在我在之前的文章 “Elasticsearch:彻底理解 Elasticsearch 数据操作” 文章中,我详细地描述了如何索引数据到 Elasticsearch 中。在今天的文章中,我想更进一步来描述这个流程。 Elasticsearch 是一个非常强大和灵活的分布式数据系统&#x…...

处理器管理
处理器状态处理器管理是操作系统中重要组成部分,负责管理、调度和分配计算机系统的重要资源——处理器,并控制程序执行由于处理器管理是操作系统最核心的部分,无论是应用程序还是系统程序,最终都要在处理器上执行以实现其功能&…...
第五)
跟着我从零开始入门FPGA(一周入门系列)第五
5、同步和异步设计 前面已有铺垫,同步就是与时钟同步。 同步就是走正步,一二一,该迈哪个脚就迈那个脚,跑的快的要等着跑的慢的。 异步就是搞赛跑,各显神通,尽最大力量去跑,谁跑得快,…...

【第42天】Arrays.sort 与 Collections.sort 应用 | 整形数组与集合的排序
本文已收录于专栏🌸《Java入门一百练》🌸学习指引序、专栏前言一.sort函数二、【例题1】1、题目描述2、解题思路3、模板代码4、代码解析二、【例题1】1、题目描述2、解题思路3、模板代码4、代码解析三、推荐专栏序、专栏前言 本专栏开启,目的…...

LeetCode第334场周赛
2023.2.26LeetCode第334场周赛 A. 左右元素和的差值 思路 前缀和后缀和 代码 class Solution { public:vector<int> leftRigthDifference(vector<int>& nums) {int n nums.size();vector<int> l(n), r(n), ans(n);for (int i 1; i < n; i )l[…...
:PatchMatchNet配置及代码主要运行流程)
基于深度学习的三维重建网络PatchMatchNet(三):PatchMatchNet配置及代码主要运行流程
目录 1.PatchMatchNet环境配置 2. PatchMatchNet的大致执行流程(eval.py) 2.1 深度图的保存...

【一天一门编程语言】设计一门编程语言,给出基础语法代码示例,SDK设计。
文章目录设计一门编程语言,给出基础语法代码示例,SDK设计。一、编程语言设计1.1 语言名称1.2 数据类型1.3 基本运算符1.4 控制语句二、SDK设计2.1 基础库2.2 第三方库三、例子用 Mango 这门语言实现斐波那契数列。基础语法代码示例SDK 设计使用 Mango 语…...

ubuntu 下 python 安装 venv
ubuntu 下 python 安装 venv1.首先,确保您的系统已安装 Python3 和 pip3,如果没有安装,可以使用以下命令安装:2. 接着,安装 virtualenv 包,使用以下命令:3.创建 Python 虚拟环境,使用…...

HTML#1快速入门
一. 简介HTML是一门语言, 所有的网页都是用HTML编写的HTML(Hyper Text Markup Language): 超文本(超越了文本限制,除了文字信息还可以定义图片,音频,视频等)标记语言(有标签构成的语言)W3C标准: 网页主要由三部分组成(1) 结构: HTML(2) 表现: CSS(3) 行为: JavaScript二. 快速入…...
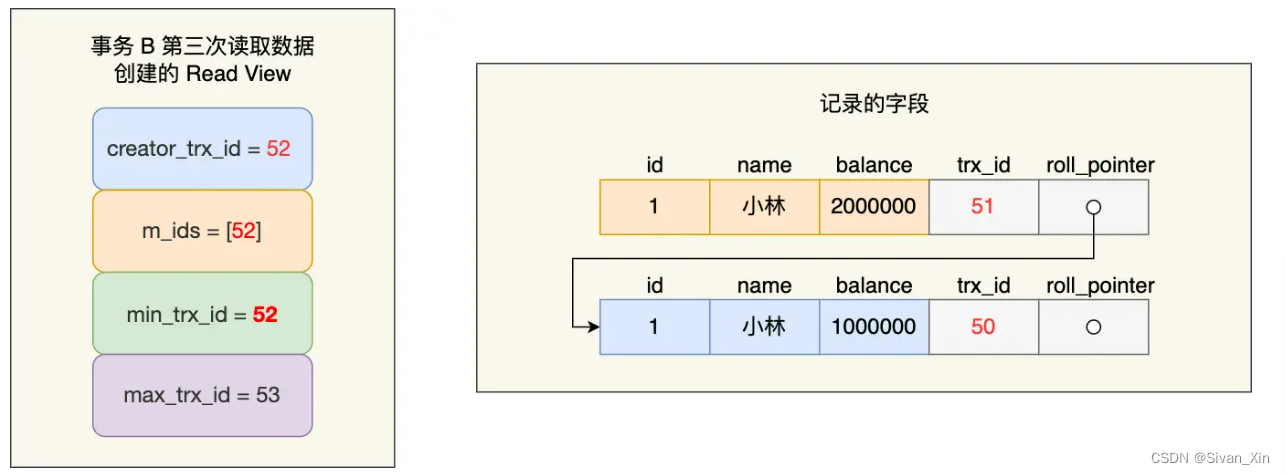
【MySQL】事务隔离级别是怎么实现的?
事务隔离级别是怎么实现的? 四种隔离级别具体的实现方式 对于「读未提交」:直接读取最新的数据就好。对于「串行化」:通过加读写锁的方式来避免并行访问。对于「读提交」和「可重复读」:通过 Read View 来实现,主要区…...
JSP网上书店系统用myeclipse定制开发mysql数据库B/S模式java编程计算机网页
一、源码特点 JSP 网上书店系统 是一套完善的系统源码,对理解JSP java 编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。研究的基本内容是基于网上书店系 统,使用JSP作为页面开发工具。Web服务的运…...

配置 Haproxy 负载均衡群集
配置 haproxy 负载均衡群集 🏆荣誉认证:51CTO博客专家博主、TOP红人、明日之星;阿里云开发者社区专家博主、技术博主、星级博主。 💻微信公众号:微笑的段嘉许 📌本文由微笑的段嘉许原创! &#…...
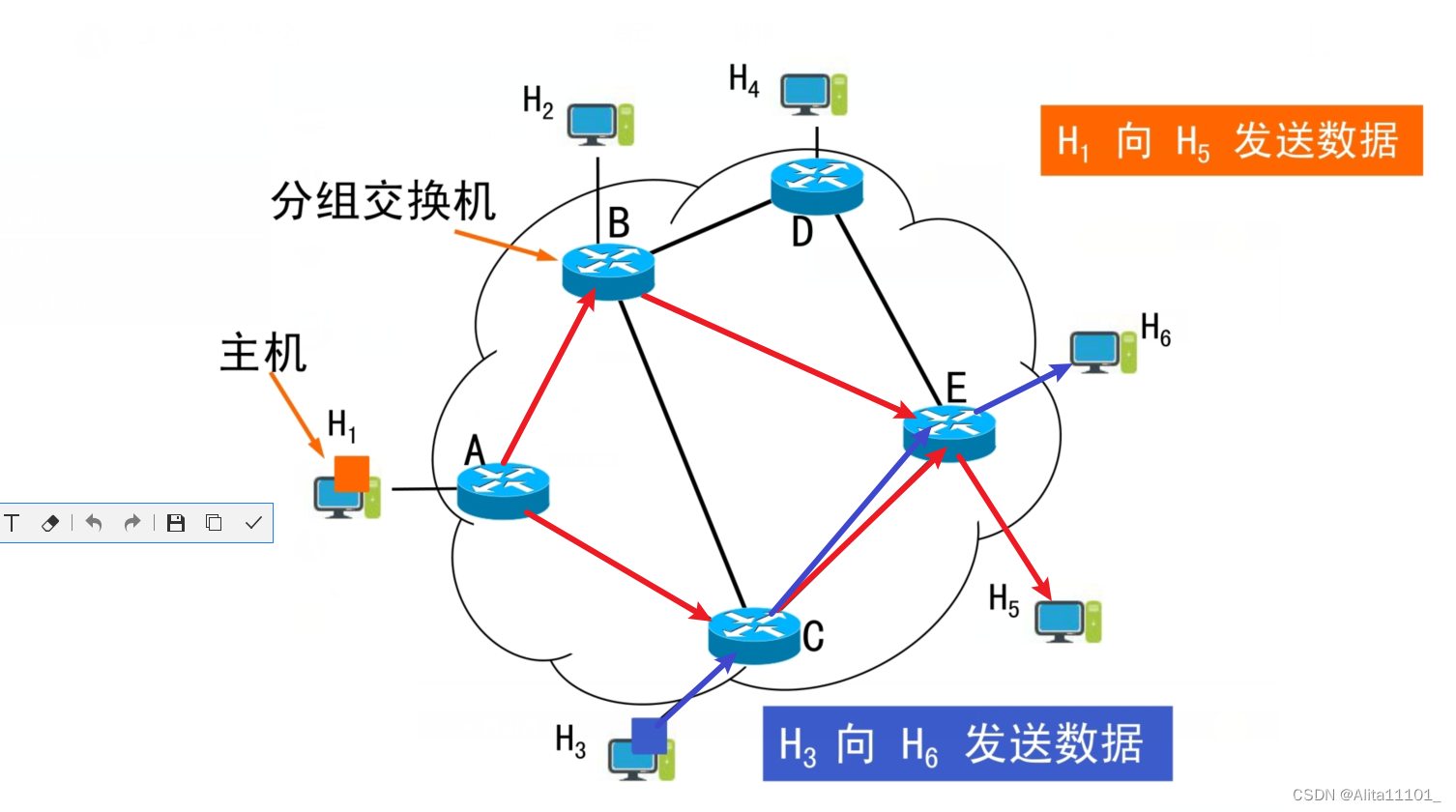
计算机网络笔记 | 第一章:计算机网络概述(1.1-1.4小节知识点整理)
从专栏将讲述有关于计算机网络相关知识点,如果有想学习Java的小伙伴可以点击下方连接查看专栏,还有JavaEE部分 本专栏地址(持续更新中):🔥计算机网络 MyBatis:✍️MyBatis Java入门篇࿱…...

Flutter3引用原生播放器-Android篇
接上篇:Flutter3引用原生播放器-IOS(Swift)篇 安卓端原生播放器的接入思路与ios基本一致,所以本篇就不废话了,直接上代码: 创建插件VideoViewPlugin实现FlutterPlugin: package io.flutter.plugins.videoplayer;imp…...
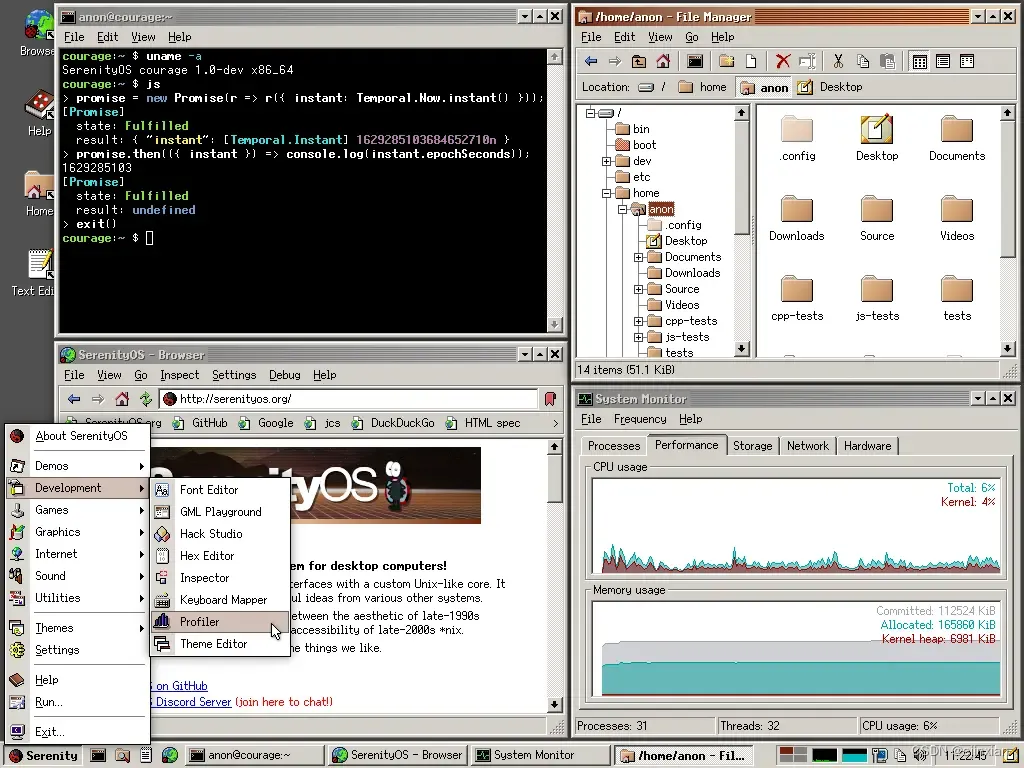
SerenityOS 操作系统类 Unix 操作系统
创建于2018年的SerenityOS是一个类似Unix的操作系统,但是带有图形化界面,适合X86台式计算机,,其界面类似90 年代的Win98/NT。几乎由一个人完成额操作系统。这几天其Web浏览器通过了 Acid3 浏览器。 Kernel features 具有抢占式多…...
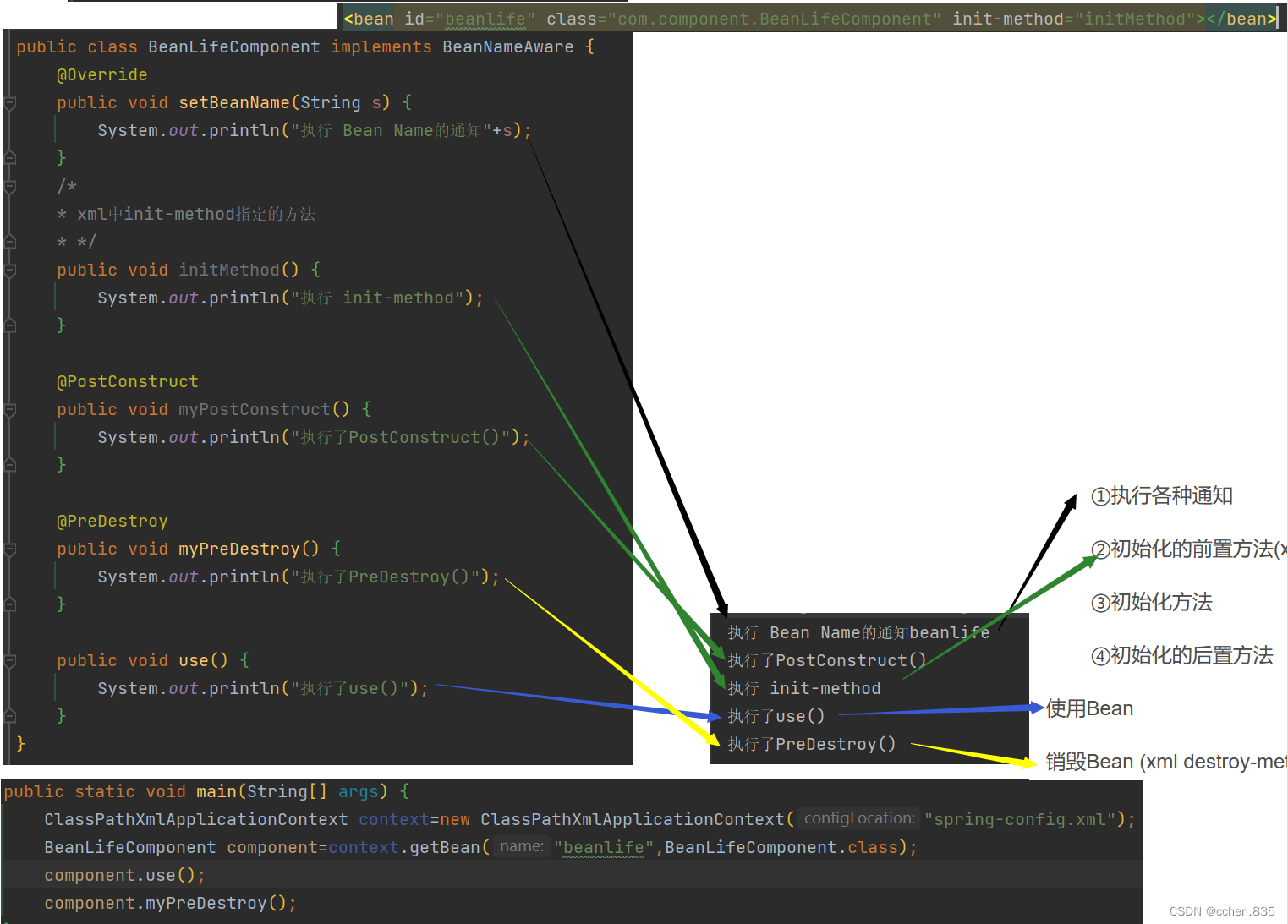
Bean作用域和生命周期
目录 Bean作用域的例子 作用域定义 Bean的六种作用域 设置作用域 Spring的执行过程和Bean的生命周期 Spring的主要执行流程 Bean的生命周期 在上篇博客中我们使用Spring存储和获取Bean,因此Bean是Spring中最重要的资源,今天这篇博客就深入了解Bean对象 Bean作用域的例子 …...
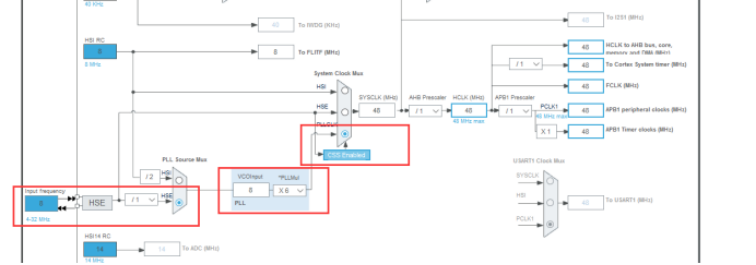
STM32笔记
目录 1.1. 预备阶段 1.2. 单片机介绍 2. 初识STM32 2.1. STM32 1.1. 预备阶段 1.2. 单片机介绍 1.2.1. 单片机是什么 单片微型计算机(Single Chip Microcomputer)简称为单片机(Microcontrollers),也称为微控制单元(Microcontroller Uni…...
【论文阅读】基于LevelDB的分布式数据库研究
基于LevelDB的分布式数据库研究 基于LevelDB的分布式数据库的研究与实现 - 中国知网 (cnki.net) 实现了什么? 基于键值型NoSQL数据库LevelDB,并与数据一致性算法Raft、 数据分片和负载均衡相结合,设计并实现基于LevelDB的分布式数据库。 主要…...

JavaScript高级 Iterator Generator
1. Iterator 1. JavaScript迭代器协议 在JavaScript中,迭代器也是一个具体的对象,这个对象需要符合迭代器协议(iterator protocol): ◼ 迭代器协议定义了产生一系列值(无论是有限还是无限个)…...

数字IC手撕代码--乐鑫科技(次小值与次小值出现的次数)
前言:本专栏旨在记录高频笔面试手撕代码题,以备数字前端秋招,本专栏所有文章提供原理分析、代码及波形,所有代码均经过本人验证。目录如下:1.数字IC手撕代码-分频器(任意偶数分频)2.数字IC手撕代…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...