【论文阅读】基于LevelDB的分布式数据库研究
基于LevelDB的分布式数据库研究
基于LevelDB的分布式数据库的研究与实现 - 中国知网 (cnki.net)
实现了什么?
基于键值型NoSQL数据库LevelDB,并与数据一致性算法Raft、 数据分片和负载均衡相结合,设计并实现基于LevelDB的分布式数据库。
主要工作包括:
1、修改Raft算法读取策略,将只允许从Leader读取修改为允许从Follower读 取,减轻Leader负担,在读负载远远大于写负载时增加读取吞吐量,减少请求平均延迟;增加预选举机制,在发起正式选举之前首先发起预选举,只有收到大多数的回复之后才正式发起选举。解决Raft算法在网络分区时可能出现的对已提交日志丢弃问题。
2、实现基于关键字区间分布的数据分布功能,为顺序读写提供友好地支持;实现负载均衡功能,通过分区拆分、分区迁移,动态地调整系统负载;添加中间层,
实现在单个存储实例上为多个用户提供逻辑独立的存储空间。
3、设计并实现原型系统DLevel。该系统具备基本的增删改查功能,
基本概念
CAP 与 BASE
CAP:数据一致性(Consistency)、服务可用性 (Availability)和分区容错性(Partition-tolerance)。
CAP理论正式成为分布式系统领域基本 定理,该定理指出对于分布式系统来说,下面三点不可能同时兼得:
- 一致性(Consistency):所有节点的数据在任何时刻都保持一致
- 可用性(Availability):对系统的读写请求总是能够成功完成
- 分区容错性(Partition tolerance):在节点宕机或者网络分区导致消息丢失时,系统仍能对外提供满足一致性和可用性的服务
BASE理论就是源于对分布式系统的实践总结,将强一致性降低为最终一致性。指Basically Available(基本可用)、Soft State(软状态)和Eventually Consistent (最终一致性)。
- 基本可用:分布式系统出现节点宕机或者网络分区的时候,允许损失一部分的一致性,来保证核心可用
- 软状态:相对于强一致性,必须保证多个节点的数据副本保 持一致而言,软状态允许允许系统不同节点间数据副本同步有一定的延 迟,允许数据副本处于不一致状态,不要求时时刻刻完全保持一致
- 最终一致性:虽然可能会存在不一致的时刻,但是经过一段时间的数据同步之后,系统中数据副本最终能够保持一致
LevelDB
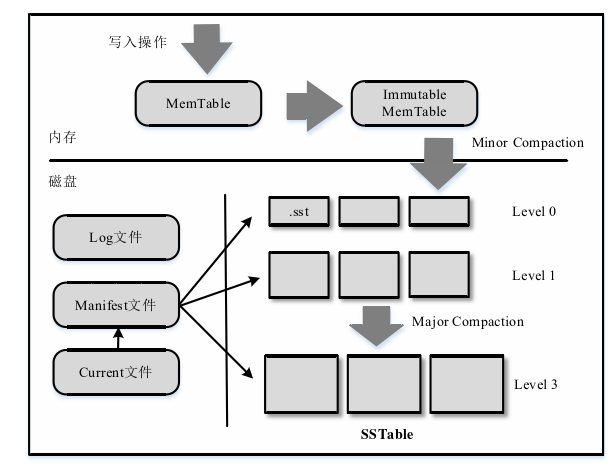
架构图
主要包含六个主要部分。内存中的Memtable 和Immutable Memtable,磁盘中的SSTable、Log文件、manifest文件和Current文 件。Memtable和Immutable Memtable都是基于Skiplist实现,区别在Immutable Memtable是不可变的Memtable。SSTable是主要保存KV数据的数据结构,将KV 数据对封装在一起,按照key有序保存。SSTable文件存储在磁盘中,按照层级存 储,从高层Level 0层一直向低层Level n扩展,低层Level n的SSTable数据来自 于高层Level n-1 SSTable的合并结果,每个层级内SSTable的start_key_与end_key_的
levelDB特点:
- LevelDB以机械磁盘作为主要存储介质,而非像Redis、Memcache等数据库,以内存作为主要存储介质
- LevelDB按照Key有序排列,支持自定义key比较方式
- Key和Value支持任意字节长度
- 支持快照,数据采用Snappy压缩算法自动压缩,支持前向和后向迭代器
- 支持原子批量操作,提供基本的操作接口Put、Get、Delete
RPC
RPC通常基于C/S 模式,Client在请求时携带预先定义的请求参数,调用Server端程序,Server在收 到客户端请求之后,解析请求参数,执行相应程序,返回client处理结果。
系统需求分析
设计目标
(1)具有LevelDB原生态的基本功能,提供包括Open、Close、Put、Get、 Delete、Scan等基本操作接口;
(2)通过数据分区算法将数据分布到多个存储集群中,提供远大于单机存储 容量的存储服务;
(3)通过Raft一致性算法来保证副本集内数据的强一致性,数据的写入成功
标志是成功写入到副本集中的大多数的成员。一旦数据写入成功,之后所有的客户
端都会看到最新的、一致的数据;
(4)在保证数据一致性的前提下,尽可能的提高系统的可用性,减少服务不 可用时间。
功能需求
(1)具备分布式KV数据库的基本功能
- 打开与关闭,Open(dbname)、Close(dbname)
- 数据写入Put(key, value),将key-value键值数据库写入数据库
- 数据查询Get(key),通过关键字key返回对应的value
- 数据删除Delete(key),删除关键字key对应的key-value键值对
- 获取指定范围内且数量小于limit的所有key-value数据Scan(start_key, end_key, std::map<std::string, std::string>, int limit)。
上述可以看出 这个系统是没有实现上层的KV到关系模型的转换 并且不支持SQL查询的。只是简单的KV操作
(2)支持副本集,通过数据复制来提高系统的可靠性,当有部分存储节点宕机时仍能保证系统的可用性;
(3)负载均衡,当数据分布不均衡时,通过分区的拆分和合并,分区的迁移 等方法来均衡系统中的数据分布;
(4)水平扩展,当存储容量需要扩展时,通过新增Storage Server Group来扩展系统的存储容量
三四基本暂时用不到,负载均衡和水平扩展是后面可能能加上的。
性能需求
- 可用性。当元数据管理节点 或者存储节点发生故障时,只要不是超过所在集群的半数节点,系统仍能保证服务 可用。
- 可靠性。本系统中通过数据复制将数据复制到大多数成员甚至所有成员, 当副本集内大多数节点存活时,数据就不会丢失。假设每个副本集节点损坏的概率p,副本集中节点数量为n。只有当副本集中所有节点都损坏时才会造成数据丢失, 因此本系统的可靠性为1-p^n。
- 可维护性
系统整体设计
架构图如下:
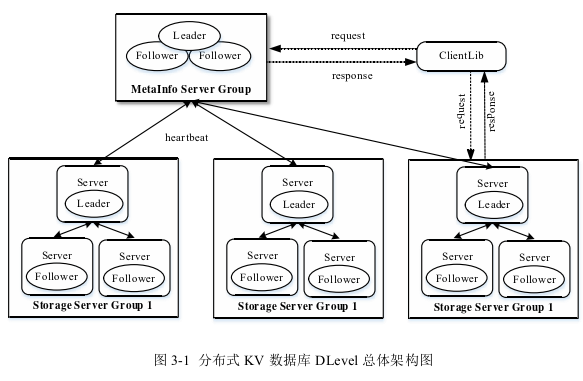
CS架构,服务器端主要由元数据管理模块MetaInfo Server Group,存储模块Storage Server Group组成,两者之间通过心跳交互。
客户端通过网络请求首先连接至元数据管理模块,返回具体 的存储模块信息之后,再向存储模块发起网络请求,存储模块完成对应的操作请求 之后返回客户端操作结果。
? 这样是不是就是被单模块限制了效率了? 还是说这个元数据管理模块是raft group 基本是只读的,然后每个成员都可以处理,所以效率还是分布式的效率?
元数据管理模块 负责分区信息的管理、请求路由、负载均衡
存储模块:负责KV数据的读写请求,每个raft group中包括一 个主副本节点和多个从副本节点。存储模块由多个storage server group组成,每个 group负责特定分区的读写请求。
DLevel还包括集群管理模块,主要借助Zookeeper实现,存储模块和元 数据管理模块在启动时,在Zookeeper指定目录下创建znode,如果节点出现故障, 不能与Zookeeper进行心跳联系,Zookeeper就会产生相应的报告信息,以此用于集群管理。
关于zookeeper,这个文章是参考了:[22] Ti KV. https://github.com/tikv/tikv. [23] Pegasus. https://github.com/XiaoMi/pegasus. [44] FoundationDB. https://www.foundationdb.org/.
服务端
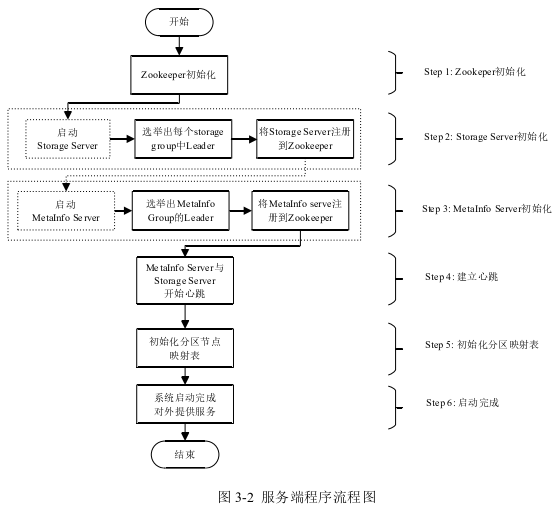
step 1:首先启动Zookeeper,便于Storage Server和Metainfo Server注册;
step 2:Storage Server初始化,因为Storage Server集群包括多个group,每个 group内部启动时通过Raft算法选举出当前group内的Leader,然后每个Storage Server在Zookeeper中创建各自znode节点。 // 怎么知道哪个是一个group呢?
Step 3:Metainfo Server初始化,Metainfo Server作为系统中心节点,一般配置 三个节点,通过raft算法进行管理。group选举出Leader, 然后每个Metainfo Server 在Zookeeper中创建各自znode节点。
Step 4:Storage Server和Metainfo Server启动成功之后,双方建立心跳连接,在心跳中Storage Server附带自身状态信息上传值Metainfo Server,用于Metainfo Server管理集群,进行负载均衡。
Step 5:Metainfo Server初始化分区节点映射关系表。
Step 6:完成启动,系统对外提供服务。
存储模块
改造成为分布式版本首先需要添加网络通信模块,本文通过RPC实现网络通信。本文通过一致性算法Raft实现副本集。
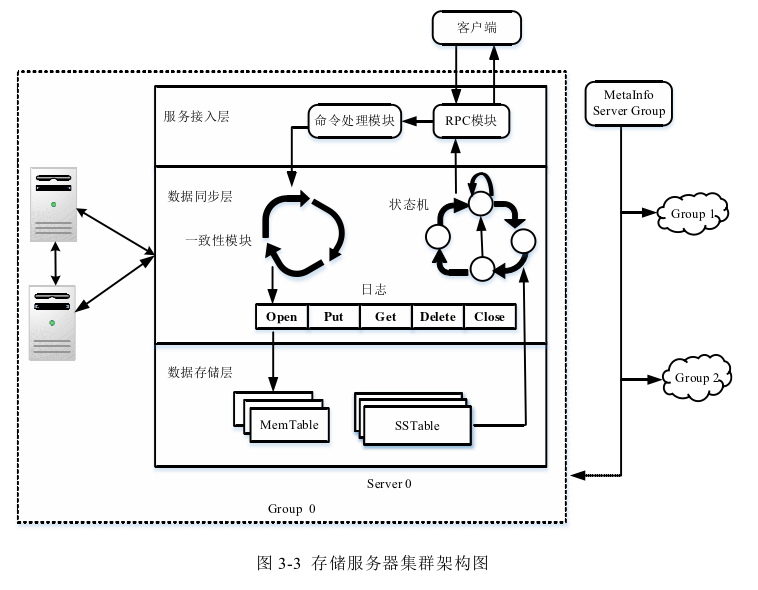
服务接入层主要由RPC模块和命令处理模块组成,存储节点的服务接入层同时可能收到多个客 户端的请求,因此接入层需要具备一定的并发处理能力。服务接入层首先对来自客 户端的消息后做简单的处理,如消息格式的合法性验证、消息内容的规范性验证等,然后交给数据同步层。
数据同步层主要由分布式一致性算法Raft组成,用于将接入层接收的请求同 步到group副本集中。数据同步层主要由一致性模块、状态机和日志模块组成。先将数据接入层处理的消息经由一致性模块同步到副本集中的所有节点,通常是 由领导者将自身数据同步到追随者。数据同步时的数据一般都是序列化之后的操 作日志,然后再交由日志模块,解析提取出具体的客户端请求。副本集中的每个节 点拥有相同的日志序列,再加上状态机,所有节点最初处于相同的状态,应用相同 的操作序列之后,之后也处于相同的状态,从而实现一致性状态机。数据同步层通过Raft算法保证数据的强一致性
数据存储层主要由LevelDB存储引擎组成。
元数据管理模块
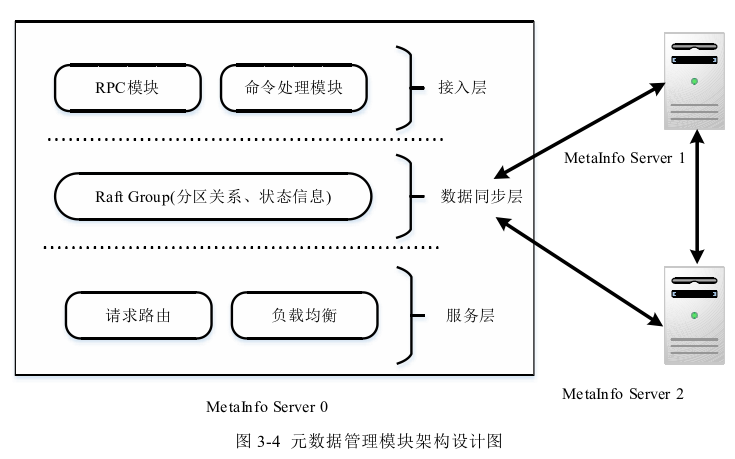
总体上为一个Raft集群,由三个MetaInfo Server组成,每个MetaInfo Server内部大致分为三层,分别是接入层、数据同步层和服务层,服务层主要完成请求路由和负载均衡两个主要功能。
元数据集群存储分区与存储节点的映射关系表, 客户端请求到达元数据管理集群之后,通过查找映射关系表,返回客户端具体的存 储集群。
数据同步模块
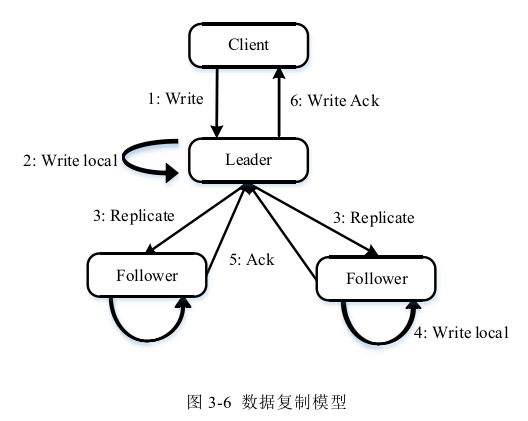
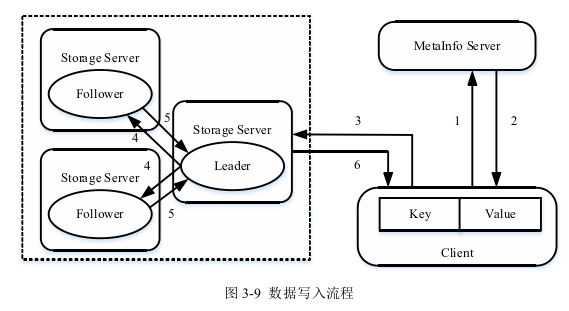
Client首先向Leader发起写入请求,Leader将写入操作序列日志写入到本地, 然后Leader再向Follower进行转发,Follower写入本地后向Leader返回确认信 息,Leader收到来自大多数Follower的确认信息就向client返回确认。
配置管理模块
每个集群都拥有多个节点,且同一集群中的多个节点运行相同的 服务,存在一些相同的配置。
对于同一个集群中如 果要修改这些参数,则必须同时修改多个节点中的参数,在分布式环境下非常容易出问题。本系统主要借助Zookeeper来完成集群配置管理。Zookeeper是一种分布 式协调服务,通过提供简单的架构和API解决了分布式环境中协调和管理服务,方便程序开发。
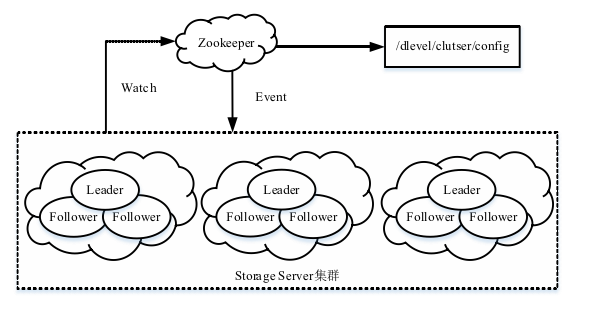
这里就是用zookeeper来管理元数据?
watch 节点 当节点发生变动时, 元数据管理集群会收到变动事件,从而感知到存储集群的变化,随即进行相应的应 对策略。
客户端模块
针对我们的需求,用户交互模块加上sql、事务即可。
缓存模块来缓存路由表,只要路由表没有发生变更,就不用每次都经过元数据管理路由。当发生路由表变更时,元数据管理集群向client发送请求,更新 路由表。
也就是说 给某个节点发请求,可以不用再查询元数据,而是根据缓存直接路由。
读写流程
写入

读取
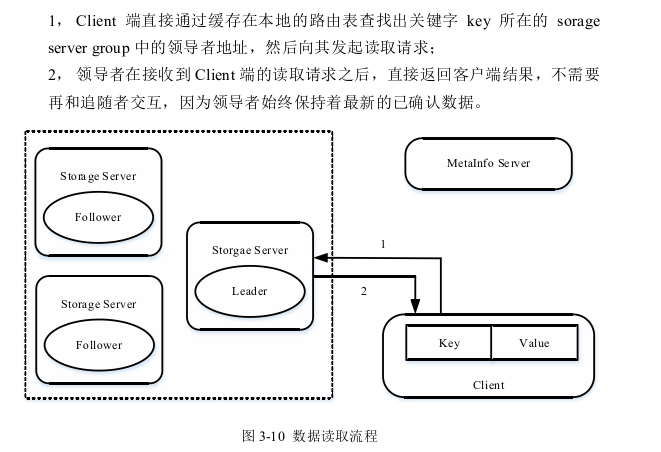
总结一下:在我们的架构设计中,也可以采用CS架构,在客户端的启动过程中就与元数据管理器进行交互,缓存路由,但是这个表大不大呢? 然后根据这个缓存的内容直接读取;
如果是我们有上层的查询的话,客户端要不要进行粗粒度的查询处理呢? 不进行的发给服务器,然后那缓存的就白缓存了?
系统实现
存储模块
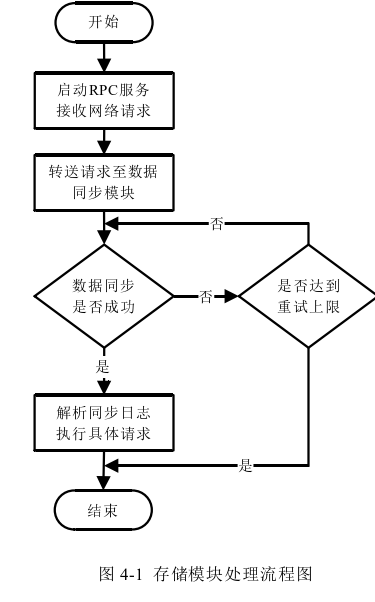
数据同步模块实现
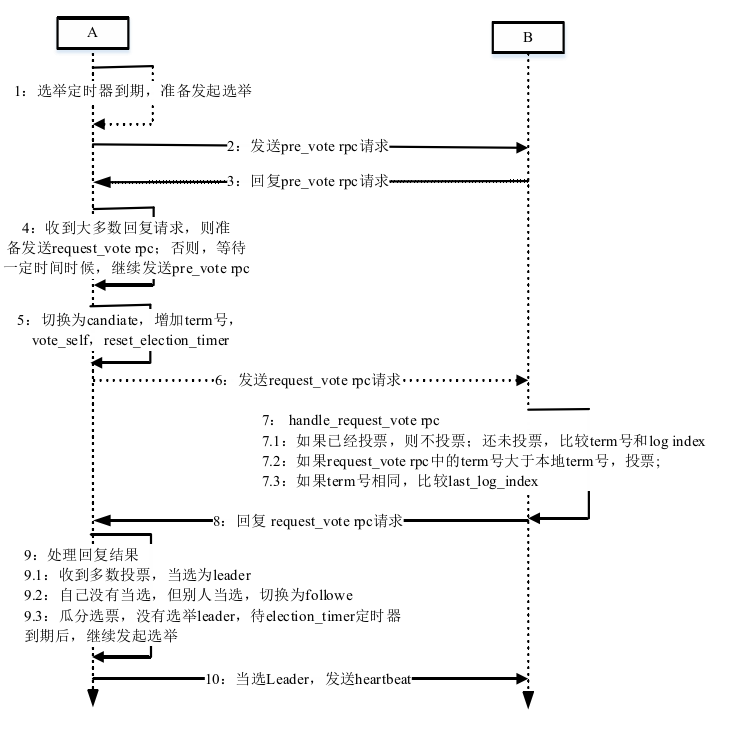
Leader选举
为了解决网络分区所带来的错误,使用预选举来感知集群网络状况,直到收到大多数节点的回复,才开始真正的选举。
类图如下:
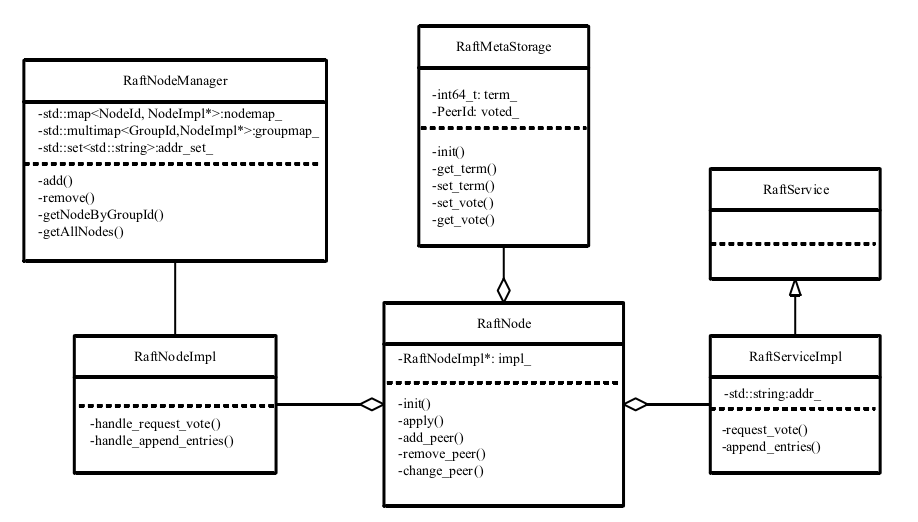
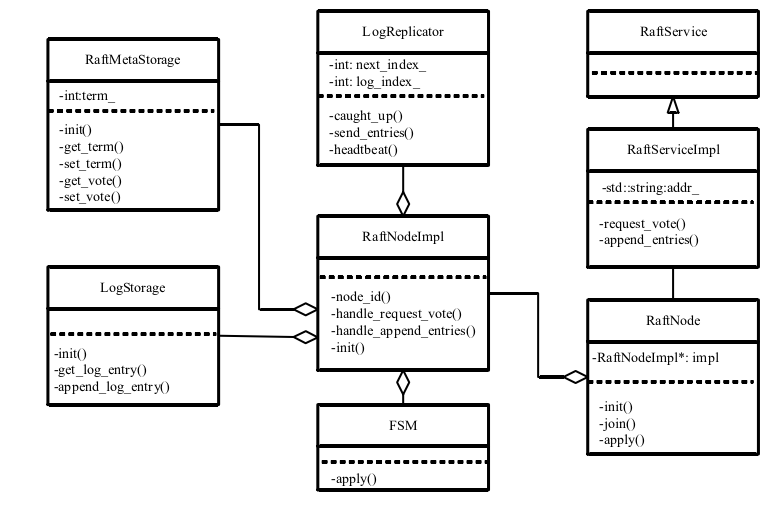
主要包括RaftNode类、RaftNodeManger类、RaftService类三个类。
RaftNode类是对Raft算法中节点的封装描述,定义节点的行为。包括节点初 始化init、节点启动start和终止shutdown和join、处理leader选举中的请求服务 handler_request_vote、处理raft group成员添加和移除的add_peer和remove_peer、 重置选举时间reset_election_timeout等。
RaftService类是由定义的protobuf文件raft.proto经过protoc编译自动生成的, raft.proto文件主要定义request_vote和append_entries两个主要rpc服务的接口, 其发送的参数数据格式与返回数据格式。
具体的内容图4-12所示: request_vote rpc请求参数包括节点server_id,当前term号,最后一条日志 last_log_term及最后一条日志下标last_log_index;回复参数包括当前term号以及 是否投票。pre_vote参数与request_vote参数相同,pre_vote rpc用于探测当前集群 中节点之间的网络状况,防止网络分区时处于小部分分区的节点,持续发起Leader 选举造成term号的交替增加,最后分区合并时小部分分区的节点当选Leader,从 而对网络分区期间提交的日志进行丢弃和覆盖。
RaftNode的 具体实现在RaftNodeImpl类中完成,RaftNode类中通过成员变量RaftNodeImpl* impl_来调用具体的实现,使得类的实现与类本身解耦,同时达到类的内容实现对于类的使用者透明。
RaftService类是由定义的protobuf文件raft.proto经过protoc编译自动生成的, raft.proto文件主要定义request_vote和append_entries两个主要rpc服务的接口,其发送的参数数据格式与返回数据格式如下:

ppend_entries rpc请求参数包括节点server_id,当前term号,上一条日志号 prev_log_term,上一条日志下标prev_log_index,当前请求中待复制的日志entries, 注意这里是列表形式,可以一次性提交复制多条日志,最后是系统已提交的日志
RaftNodeManage类对RaftNode进行管理,通过std:map记录group中的 RaftNode的信息,负责Group中Node的添加、移除及获取当前Group的成员信 息等。
选举流程如下,在发送request_vote rpc之前,首先发送pre_vote rpc探测当前集群中的网络状况。当收到 pre_vote rpc的大多数回复之后,才开始Raft算法伪代码中描述的选举流程。
日志复制
日志复制模块的类图如图。日志复制模块相关的类主要LogStorage类、LogReplicator类、LogReplicatorGroup类和FSM类。
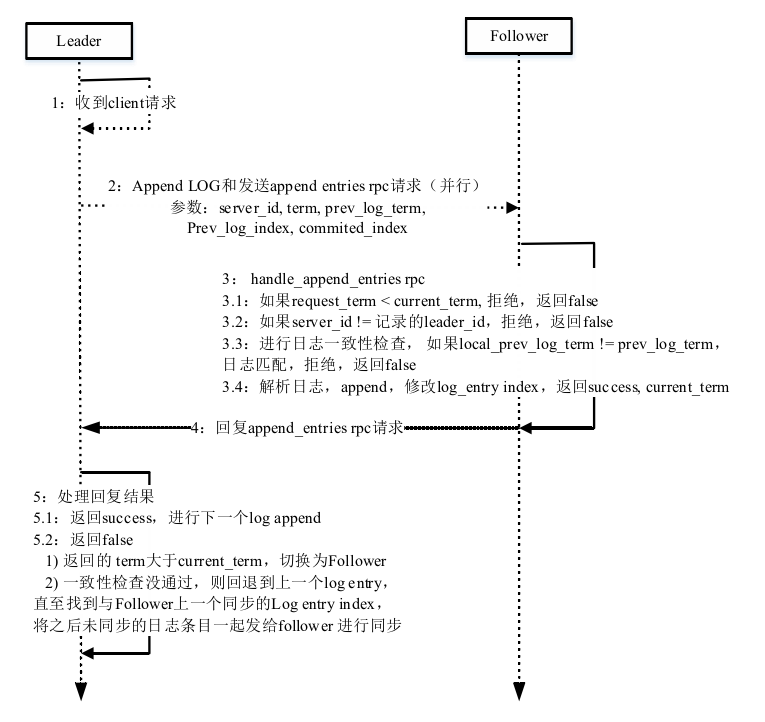
LogStorage类主要负责存储日志,主要包括添加单条日志append_log_entry和 批量添加日志append_log_entries、与Leader同步日志match_log,去除与Leader不 一致的log entry,获取尚未同步的log entry等。
LogReplicator类是Leader在日志复制时为每个Follower创建该类具体实例来 管理日志复制,负责记录的主要数据如目前已经同步的日志条目log_index_、下一 个待同步的日志条目next_index_、日志同步的timeout_、已同步的日志条目等等。 LogReplicator类的主要行为包括开始与Follower同步start、停止与Follower同步、 stop和join、检查与Follower日志一致性并强制同步catch_up、保持心跳等。
FSM类主要实现状态机,用于接收每个raft node上执行的事件。当Leader确 定日志已经同步到大多数节点时,便将操作apply到状态机中。一旦提交到状态机 之后,便表示该日志已经commit。
日志同步的具体流程
提高性能的措施:
- 主要采用日志批量提交(batch),对于Leader一次收集一定size的client的 请求然后批量发送给Follower。但这种方式需要考虑size大小限制
- Leader可以将LOG发送给Follower和Append到本地并行处理
读取模式
Raft算法中标准的读写只能经由Leader完成,Follower不能对外提供任何读写 请求,如果有客户端连接到Follower之后,会将请求转至Leader。Leader始终具有最新的已提交日志记录,这种设计保证每次都能读取都能读取到最新的数据,但对于读请求来说,如果允许从Follower读取,则会一定程度上减轻Leader的负担,增加读取的效率,但关键在于如何保证读取尽可能新的数据。
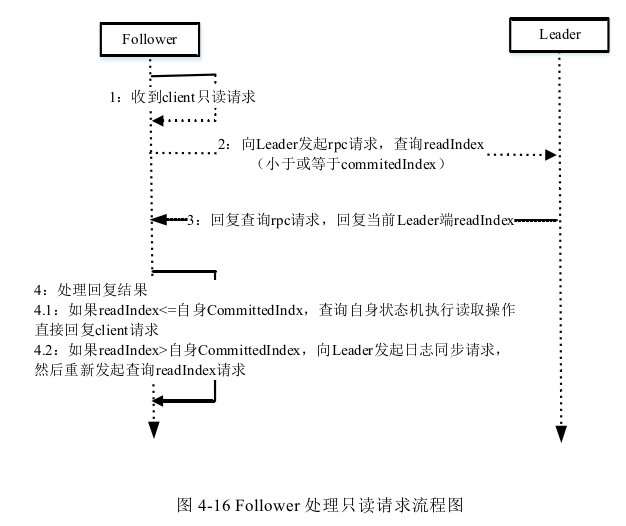
读取模式
Raft算法中标准的读写只能经由Leader完成,Follower不能对外提供任何读写 请求,如果有客户端连接到Follower之后,会将请求转至Leader。Leader始终具有最新的已提交日志记录,这种设计保证每次都能读取都能读取到最新的数据,但对于读请求来说,如果允许从Follower读取,则会一定程度上减轻Leader的负担,增加读取的效率,但关键在于如何保证读取尽可能新的数据。
相关文章:
【论文阅读】基于LevelDB的分布式数据库研究
基于LevelDB的分布式数据库研究 基于LevelDB的分布式数据库的研究与实现 - 中国知网 (cnki.net) 实现了什么? 基于键值型NoSQL数据库LevelDB,并与数据一致性算法Raft、 数据分片和负载均衡相结合,设计并实现基于LevelDB的分布式数据库。 主要…...

JavaScript高级 Iterator Generator
1. Iterator 1. JavaScript迭代器协议 在JavaScript中,迭代器也是一个具体的对象,这个对象需要符合迭代器协议(iterator protocol): ◼ 迭代器协议定义了产生一系列值(无论是有限还是无限个)…...

数字IC手撕代码--乐鑫科技(次小值与次小值出现的次数)
前言:本专栏旨在记录高频笔面试手撕代码题,以备数字前端秋招,本专栏所有文章提供原理分析、代码及波形,所有代码均经过本人验证。目录如下:1.数字IC手撕代码-分频器(任意偶数分频)2.数字IC手撕代…...

JavaScript DOM和BOM
目录 查找html元素 1.通过id 2.通过标签名 3.通过类名 DOM 1.创建动态的HTML内容 2.修改元素内容 3.改变HTML属性 4.改变css样式 DOM事件 DOM节点 1.添加HTML元素 2.删除HTML元素 浏览器对象 1.Window对象 2.Screen对象 3.History对象 4.Location对象 5.Navi…...
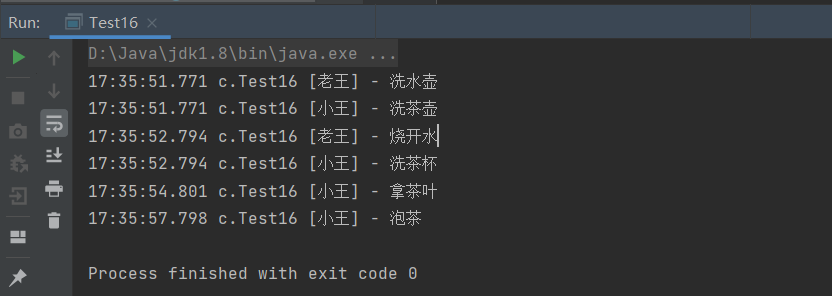
JUC并发编程(二)
一、过时方法 一些不推荐使用的方法已经过时,容易破坏同步代码块,使对象的锁得不到释放,进而造成线程死锁 二、守护线程 默认情况下,Java 进程需要等待所有线程都运行结束,才会结束。有一种特殊的线程叫做守护线程…...

Python控制CANoe使能TestCase
前面介绍了多种CANoe配置下的dbc文件添加,常见的配置我们能够常用的就是testcase的使能和环境变量的设置,针对于环境变量的问题,我们下次再进行详聊,今天主要聊一下测试脚本的使能。在做这块之前,我们第一步就需要了解我们的测试脚本的层级是都包含有哪些? 一、测试脚本结…...
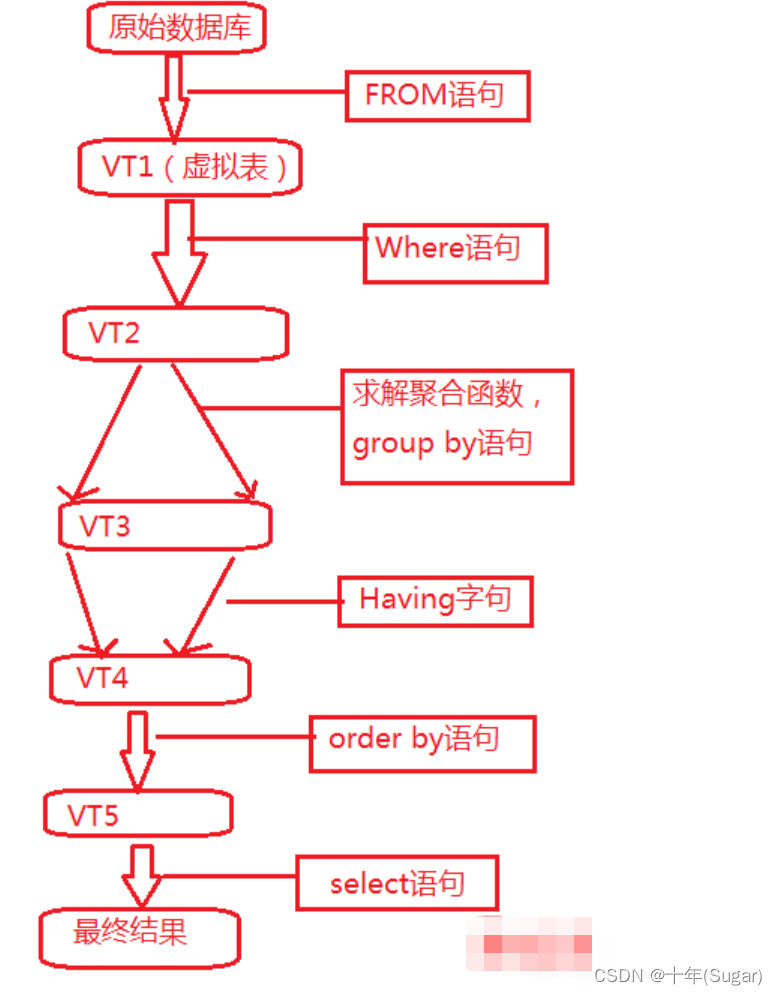
sql的执行顺序
一.前言 在我们世家开发中,我们少不了和数据库打交道, 我们的持久层是与数据库打交道的, 少不了要用sql语句来请求数据库的数据, 前台(前端页面)请求到-->控制器(接口层)-->service(业务层)-->mapper或dao(持久层) 简图: 在持久层我们的sql是怎么执行的, 它的执行顺…...

java 8 中的实用技巧
1 判断2个对象是否相等Objects.equals(a, b)(1) 比较时, 若a 和 b 都是null, 则返回 true, 如果a 和 b 其中一个是null, 另一个不是null, 则返回false。注意:不会抛出空指针异常。(2) a 和 b 如果都是空值字符串:"", 则 a.equals(b…...
自学大数据的第一天
默认跳过基础部分,直接搞集群的部分,期间用到的linux基础默认大伙都会了(不会的话可以现用现查) Hadoop集群搭建 集群特点: 1,逻辑上分离~集群之间没有依赖,互不影响 2,某些进程往往部署在一台服务器上,但是属于不同的集群 3,MapReduce 是计算框架,代码层面的处理逻辑 集群的…...
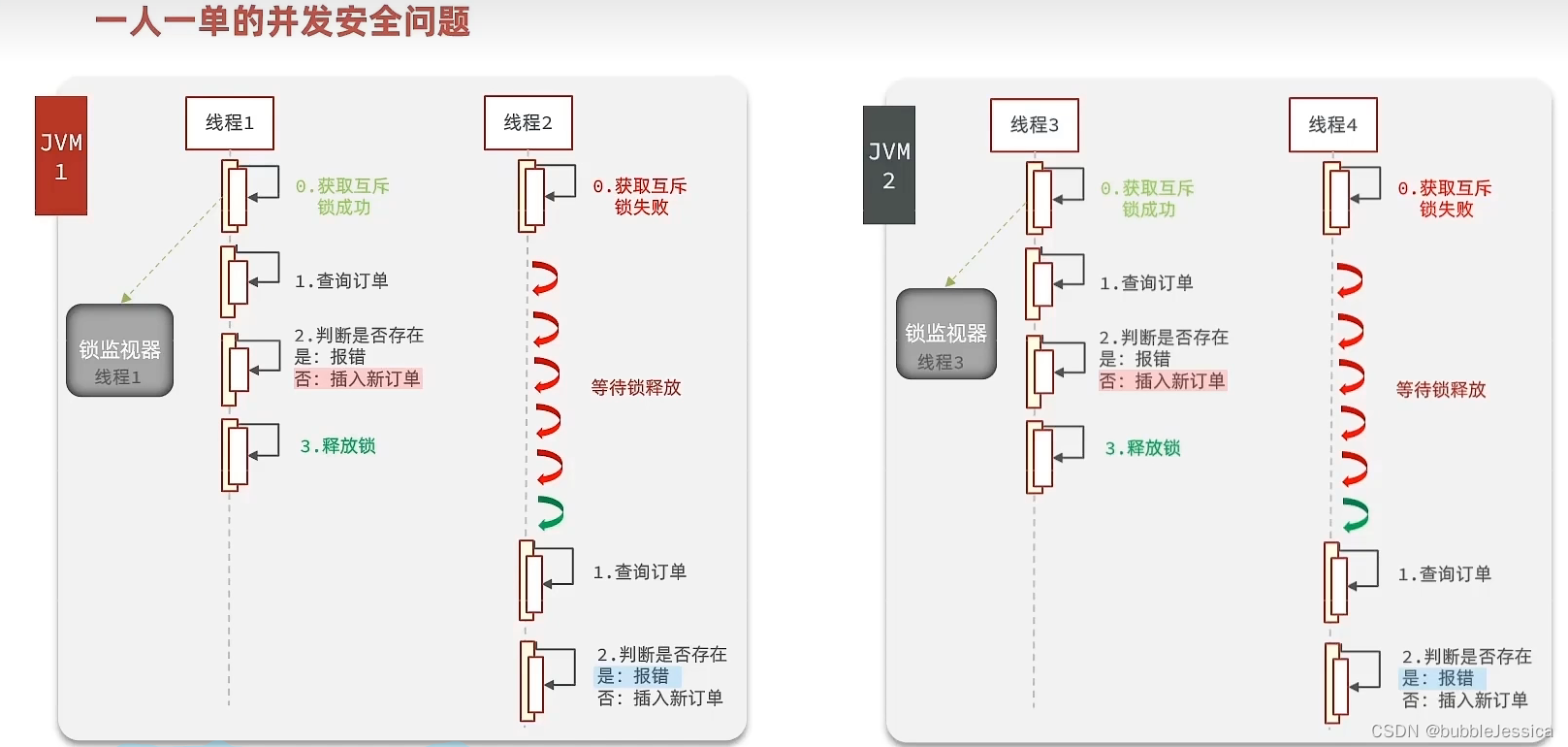
redis秒杀
redis优惠券秒杀 为什么订单表订单ID不采用自增长? id规律性太明显,容易被用户猜测到(比如第一天下订单id10,第二天下订单id100,在昨天的1天内只卖出90商品)受单表数据量限制(订单数据量大&am…...

JS学习第3天——Web APIs之DOM(什么是DOM,相关API【创建、增删改查、属性操作、事件操作API】)
目录一、Web APIs介绍1、API2、Web API二、DOM1、DOM树2、获取元素3、事件基础4、操作元素属性5、节点(node)操作三、DOM操作总结(创建、增删改查、属性操作、事件操作API)1、创建2、增3、删4、改5、查6、属性操作7、事件操作四、…...

【MySQL】增删改操作(基础篇)
目录 1、新增操作(Create) 1.1 单行数据 全列插入 1.2 多行数据 全列插入 1.3 单行数据 指定列插入 2、修改操作(Update) 3、删除操作(Delete) 1、新增操作(Create) 如何给一张表新增数据呢? 新增(Create),在我们数据库中,用 ins…...
STM32—DMA
什么是DMA? DMA(Direct Memory Access,直接存储器访问) 提供在外设与内存、存储器和存储器、外设与外设之间的高速数据传输使用。它允许不同速度的硬件装置来沟通,而不需要依赖于CPU,在这个时间中,CPU对于内存的工作来…...

C语言刷题(3)——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容还是做几道题噢,好好复习一下之前的知识点,现在,就让我们开始复习吧 牛客网在线编程_编程学习|练习题_数据结构|系统设计题库 倒置字符串_牛客题霸_牛客网 BC40 竞选社长 BC41 你是天才…...
搭建Vue工程
搭建Vue工程 localhost 127.0.0.1 域名 IP 192.168.0.28 联网IP 最后都会渲染到一个页面里面,有多少个页面就有多少个页面模板。 vue里面改webpack配置 vue.config.js 配置参考 | Vue CLI /assets /api* 开发的时候用到的请求后台地址 和 项目真实部署上线的时候 请…...
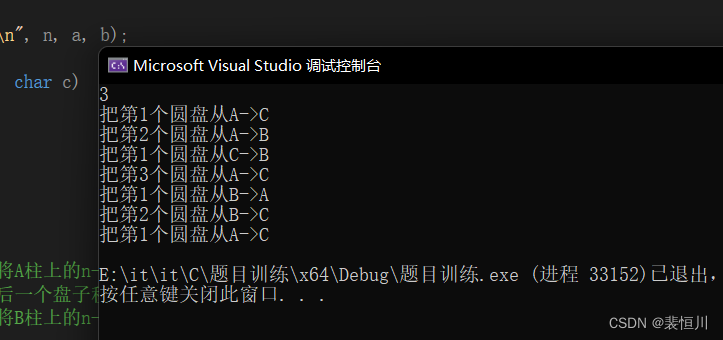
C语言汉诺塔问题【图文详解】
汉诺塔1. 什么是汉诺塔2. 有关汉诺塔的有趣故事3. 利用动画来演示汉诺塔4. 如何用C语言实现汉诺塔1. 什么是汉诺塔 源于印度古老传说的益智玩具 汉诺塔(Tower of Hanoi),又称河内塔,是一个源于印度古老传说的益智玩具。大梵天创造…...
1、RocketMQ概述
文章目录1 MQ概述1.1 MQ简介1.2 MQ用途1.3 常见MQ产品1.4 MQ常见协议2 RocketMQ概述2.1 RocketMQ简介2.2 RocketMQ发展历程尚硅谷RocketMQ教程-讲师:Reythor雷(老雷) 我们缺乏的不是知识,而是学而不厌的态度 1 MQ概述 1.1 MQ简介…...
)
【POJ 3352】Road Construction 题解(Tarjan算法求边双连通分量缩点)
描述 现在几乎是夏天,这意味着几乎是夏天的施工时间!今年,负责偏远岛热带岛屿天堂道路的好心人希望修复和升级岛上各个旅游景点之间的各种道路。 道路本身也很有趣。由于岛上的奇怪风俗,道路的安排使得它们不会在交叉路口相遇&…...
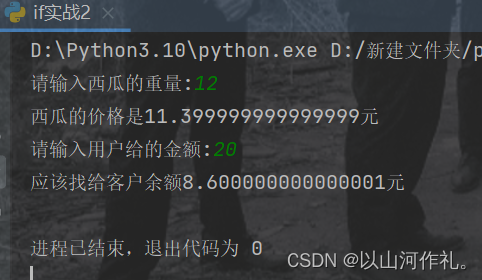
Python—单分支结构
(1)if分支语句 Python中if语句的语法结构: if <条件表达式>: 满足条件运行的代码1 满足条件运行的代码2 代码示例: age 12 if age > 18:print(去上网)if 1 1 2 and :print(我满足条件了)if 1 …...
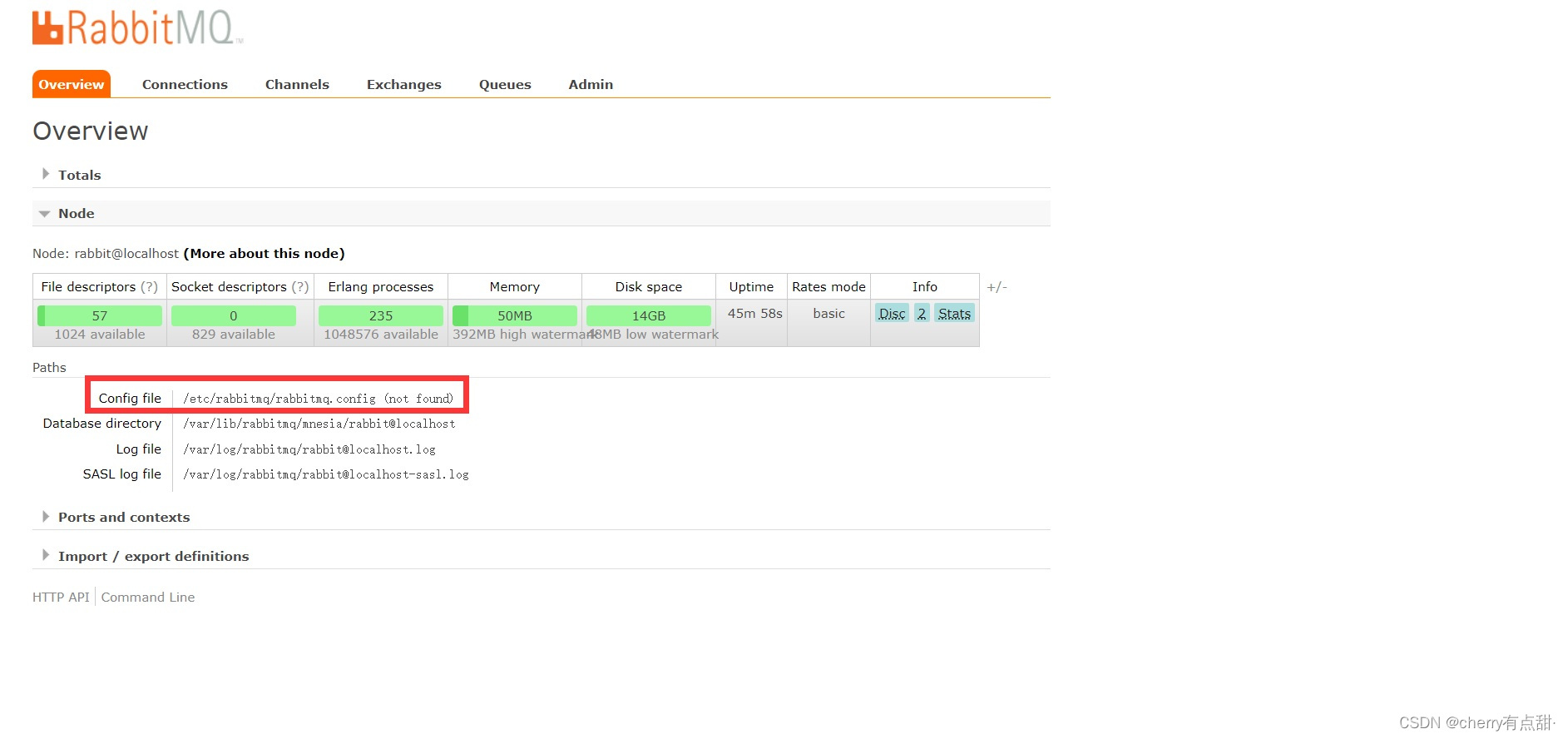
rabbitmq添加用户,虚拟机步,设置rabbitmq配置文件
第一步,登录后台控制页面 http://ip:15672第二步,添加用户和权限 重点:选择Admin和Users 第三步,添加虚拟机 点击侧边的Virtual Hosts 第四步将虚拟机和用户搭配 注意新建好后,在虚拟机列表中,点击虚拟机…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...