【强化学习】12 —— 策略梯度(REINFORCE )
文章目录
- 前言
- 策略梯度
- 基于策略的强化学习的优缺点
- Example:Aliased Gridworld
- 策略目标函数
- 策略优化
- 策略梯度
- 利用有限差分计算策略梯度
- 得分函数和似然比
- 策略梯度定理
- 蒙特卡洛策略梯度(Monte-Carlo Policy Gradient)
- Puck World Example
- Softmax随机策略
- 代码实践
- 结果
- 参考
前言
之前在【强化学习】09——价值和策略近似逼近方法中讨论过使用参数 θ \theta θ来近似价值函数 V V V或状态价值函数 Q Q Q V θ ( s ) ≈ V π ( s ) Q θ ( s , a ) ≈ Q π ( s , a ) \begin{aligned}V_\theta(s)&\approx V^\pi(s)\\Q_\theta(s,a)&\approx Q^\pi(s,a)\end{aligned} Vθ(s)Qθ(s,a)≈Vπ(s)≈Qπ(s,a)之后,再通过价值函数推导出相应的策略(比如利用 ϵ \epsilon ϵ-贪婪策略)。
本节将主要讨论直接参数化策略的方法 π θ ( s , a ) \pi_{\theta}(s,a) πθ(s,a)。策略可以是确定性的—— a = π θ ( s ) a=\pi_{\theta}(s) a=πθ(s),也可以是随机的—— π θ ( s , a ) = P [ a ∣ s , θ ] \pi_\theta(s,a)=\mathbb{P}[a\mid s,\theta] πθ(s,a)=P[a∣s,θ]。通过参数化策略可以将可见的已知状态泛化到未知的状态上。在本节中我们主要讨论的是模型无关的强化学习。
强化学习算法主要可以分为基于价值函数(Value-Based)的、基于策略的(Policy-Based)以及基于Actor-Critic(后文会进行介绍)框架的。

三者区别如下表所示:
| Methods | Value | Policy |
|---|---|---|
| Value Based | 学习到的价值函数 | 隐式的策略,如 ϵ \epsilon ϵ-贪婪策略 |
| Policy Based | 没有价值函数 | 学习到的策略 |
| Actor-Critic | 学习到的价值函数 | 学习到的策略 |
策略梯度
基于策略的强化学习的优缺点
优点
- 具有更好的收敛性质
- 在高维度或连续的动作空间中更有效
- 这是最重要的因素:基于值函数的方法,通常需要取最大值
- 能够学习出随机策略
缺点
- 通常会收敛到局部最优而非全局最优(基于值函数的方法也可能出现)
- 评估一个策略通常不够高效并具有较大的方差(variance)
Example:Aliased Gridworld

- 智能体无法区分灰色部分的格子
- 移动方向N, E, S, W

对于一个确定性的策略,可能会出现以下情况:
- 在灰色区域同时向W方向移动
- 或在灰色区域同时向E方向移动
因此,就无法抵达终点,获得奖励。基于价值函数的策略是近于确定性的策略(greedy or ϵ \epsilon ϵ-greedy),因此会在上面的区域经过很长的时间才可能获得奖励。

对于随机性的策略,在灰色区域向W或E方向移动的概率五五开。 π θ ( wall to N and S, move E ) = 0.5 π θ ( wall to N and S, move W ) = 0.5 \begin{aligned}\pi_\theta(\text{wall to N and S, move E})&=0.5\\\pi_\theta(\text{wall to N and S, move W})&=0.5\end{aligned} πθ(wall to N and S, move E)πθ(wall to N and S, move W)=0.5=0.5随机性的策略很有可能在几步内达到目标状态。基于策略的方法可以学习到最优的随机性策略。
策略目标函数
目标:给定策略 π θ ( s , a ) \pi_{\theta}(s,a) πθ(s,a),找到最优的 θ \theta θ。以下为几种衡量策略 π θ ( s , a ) \pi_{\theta}(s,a) πθ(s,a)质量的方法:
- 在离散episodic的环境中使用起始价值(start value): J 1 ( θ ) = V π θ ( s 1 ) = E π θ [ v 1 ] J_1(\theta)=V^{\pi_\theta}(s_1)=\mathbb{E}_{\pi_\theta}\left[v_1\right] J1(θ)=Vπθ(s1)=Eπθ[v1]
- 在连续 continuing的环境中使用平均价值(average value): J a v V ( θ ) = ∑ s d π θ ( s ) V π θ ( s ) J_{avV}(\theta)=\sum_sd^{\pi_\theta}(s)V^{\pi_\theta}(s) JavV(θ)=s∑dπθ(s)Vπθ(s)
- 或者是每步的平均奖励average reward per time-step: J a v R ( θ ) = ∑ s d π θ ( s ) ∑ a π θ ( s , a ) R s a J_{avR}(\theta)=\sum_sd^{\pi_\theta}(s)\sum_a\pi_\theta(s,a)R_s^a JavR(θ)=s∑dπθ(s)a∑πθ(s,a)Rsa
- π θ \pi_{\theta} πθ服从 d π θ ( s ) d^{\pi_\theta}(s) dπθ(s)分布
策略优化
基于策略的强化学习本质是一个优化问题,对于目标函数 J ( θ ) J({\theta}) J(θ),找到合适的 θ \theta θ,使得目标函数最大化。
- 未使用梯度的方法
- Hill climbing
- Simplex / amoeba / Nelder Mead
- Genetic algorithms
- 使用梯度的方法
- Gradient descent
- Conjugate gradient
- Quasi-newton
在本节中,主要讨论基于梯度下降的方法。
策略梯度

同样的,对于目标函数 J ( θ ) J({\theta}) J(θ),策略梯度算法需要通过不断提升策略的梯度以找到 J ( θ ) J({\theta}) J(θ)的局部最大值, Δ θ = α ∇ θ J ( θ ) \Delta\theta=\alpha\nabla_\theta J(\theta) Δθ=α∇θJ(θ)。其中 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ)为策略梯度 ∇ θ J ( θ ) = ( ∂ J ( θ ) ∂ θ 1 ⋮ ∂ J ( θ ) ∂ θ n ) \nabla_\theta J(\theta)=\begin{pmatrix}\frac{\partial J(\theta)}{\partial\theta_1}\\\vdots\\\frac{\partial J(\theta)}{\partial\theta_n}\end{pmatrix} ∇θJ(θ)= ∂θ1∂J(θ)⋮∂θn∂J(θ)
利用有限差分计算策略梯度
- 对于维度 k ∈ [ 1 , n ] k\in[1,n] k∈[1,n]
- 估计滴 k k k维上目标函数 J ( θ ) J({\theta}) J(θ)对 θ \theta θ的偏微分
- 引入偏移量 ϵ u k \epsilon u_k ϵuk,用差分近似微分。其中 u k u_k uk是单位向量,第 k k k个分量中为1,其他分量中为0. ∂ J ( θ ) ∂ θ k ≈ J ( θ + ϵ u k ) − J ( θ ) ϵ \frac{\partial J(\theta)}{\partial\theta_k}\approx\frac{J(\theta+\epsilon u_k)-J(\theta)}\epsilon ∂θk∂J(θ)≈ϵJ(θ+ϵuk)−J(θ)
- 简单、噪声大、效率低,但有时有效
- 适用于任意策略,即使策略不可微分
得分函数和似然比
似然比(Likelihood ratios)利用下列特性 ∇ θ π θ ( s , a ) = π θ ( s , a ) ∇ θ π θ ( s , a ) π θ ( s , a ) = π θ ( s , a ) ∇ θ log π θ ( s , a ) \begin{aligned} \nabla_\theta\pi_\theta(s,a)& =\pi_\theta(s,a)\frac{\nabla_\theta\pi_\theta(s,a)}{\pi_\theta(s,a)} \\ &=\pi_\theta(s,a)\nabla_\theta\log\pi_\theta(s,a) \end{aligned} ∇θπθ(s,a)=πθ(s,a)πθ(s,a)∇θπθ(s,a)=πθ(s,a)∇θlogπθ(s,a)其中, ∇ θ log π θ ( s , a ) \nabla_\theta\log\pi_\theta(s,a) ∇θlogπθ(s,a)是得分函数(score function)
考虑一个简单的单步马尔可夫决策过程
- 起始状态为𝑠~𝑑(𝑠)
- 决策过程在进行一步决策后结束,获得奖励值为 r = R s , a r=\mathcal R_{s,a} r=Rs,a
所以策略的价值期望可以写成 J ( θ ) = E π θ [ r ] = ∑ s ∈ S d ( s ) ∑ a ∈ A π θ ( s , a ) R s , a ∇ θ J ( θ ) = ∑ s ∈ S d ( s ) ∑ a ∈ A ∇ θ π θ ( s , a ) = ∑ s ∈ S d ( s ) ∑ a ∈ A π θ ( s , a ) ∇ θ log π θ ( s , a ) R s , a = E π θ [ ∇ θ log π θ ( s , a ) r ] \begin{aligned} J(\theta)& =\mathbb{E}_{\pi_\theta}\left[r\right] \\ &=\sum_{s\in\mathcal{S}}d(s)\sum_{a\in\mathcal{A}}\pi_\theta(s,a)\mathcal{R}_{s,a} \\ \nabla_\theta J(\theta)&=\sum_{s\in\mathcal{S}}d(s)\sum_{a\in\mathcal{A}}\nabla_\theta\pi_\theta(s,a)\\& =\sum_{s\in\mathcal{S}}d(s)\sum_{a\in\mathcal{A}}\color{red}\pi_\theta(s,a)\nabla_\theta\log\pi_\theta(s,a)\mathcal{R}_{s,a} \\ &=\mathbb{E}_{\pi_\theta}\left[\nabla_\theta\log\pi_\theta(s,a)r\right] \end{aligned} J(θ)∇θJ(θ)=Eπθ[r]=s∈S∑d(s)a∈A∑πθ(s,a)Rs,a=s∈S∑d(s)a∈A∑∇θπθ(s,a)=s∈S∑d(s)a∈A∑πθ(s,a)∇θlogπθ(s,a)Rs,a=Eπθ[∇θlogπθ(s,a)r]
这一结果可以通过从 d ( s ) d(s) d(s)中采样状态 s s s和从 π θ π_θ πθ中采样动作𝑎来近似估计
策略梯度定理
策略梯度定理把似然比的推导过程泛化到多步马尔可夫决策过程.用长期的价值函数 Q π θ ( s , a ) Q^{\pi_\theta}(s,a) Qπθ(s,a)代替前面的瞬时奖励 r = R s , a r=\mathcal R_{s,a} r=Rs,a。策略梯度定理涉及起始状态目标函数 J 1 J_1 J1,平均奖励目标函数 J a v R J_{avR} JavR ,和平均价值目标函数 J a v V J_{avV} JavV.
定理
对任意可微的策略 π θ ( s , a ) \pi_{\theta}(s,a) πθ(s,a),任意策略的目标函数 J 1 , J a v R , J a v V J_1,J_{avR},J_{avV} J1,JavR,JavV,其策略梯度是 ∇ θ J ( θ ) = E π θ [ ∇ θ log π θ ( s , a ) Q π θ ( s , a ) ] \nabla_\theta J(\theta)=\color{red}{\mathbb{E}_{\pi_\theta}\left[\nabla_\theta\log\pi_\theta(s,a)\right.Q^{\pi_\theta}(s,a)}] ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)Qπθ(s,a)]这种形式也是 ∂ J ( θ ) ∂ θ = E π θ [ ∂ l o g π θ ( a ∣ s ) ∂ θ Q π θ ( s , a ) ] \frac{\partial J(\theta)}{\partial\theta}=\mathbb{E}_{\pi_\theta}\left[\frac{\partial\mathrm{log}\pi_\theta(a|s)}{\partial\theta}Q^{\pi_\theta}(s,a)\right] ∂θ∂J(θ)=Eπθ[∂θ∂logπθ(a∣s)Qπθ(s,a)]
详细证明过程请参考:
- Rich Sutton’s Reinforcement Learning: An Introduction (2nd Edition)第13章
- 动手学强化学习策略梯度的附录
蒙特卡洛策略梯度(Monte-Carlo Policy Gradient)
- 利用随机梯度上升更新参数
- 利用策略梯度定理
- 利用累计奖励值 G t G_t Gt作为 Q π θ ( s , a ) Q^{\pi_\theta}(s,a) Qπθ(s,a)的无偏采样 Δ θ t = α ∂ log π θ ( a t ∣ s t ) ∂ θ G t \Delta\theta_t=\alpha\frac{\partial\log\pi_\theta(a_t|s_t)}{\partial\theta}G_t Δθt=α∂θ∂logπθ(at∣st)Gt
REINFORCE算法伪代码

Puck World Example

- 连续的动作对冰球施加较小的力
- 冰球接近目标可以得到奖励
- 目标位置每30秒重置一次
- 使用蒙特卡洛策略梯度方法训练策略
Softmax随机策略
对于具体策略的设计,通常使用Softmax随机策略。Softmax策略是一种非常常用的随机策略 π θ ( a ∣ s ) = e f θ ( s , a ) ∑ a ′ e f θ ( s , a ′ ) \pi_\theta(a|s)=\frac{e^{f_\theta(s,a)}}{\sum_{a^{\prime}}e^{f_\theta(s,a^{\prime})}} πθ(a∣s)=∑a′efθ(s,a′)efθ(s,a)式中, f θ ( s , a ) f_\theta(s,a) fθ(s,a)是用𝜃参数化的状态-动作对得分函数,可以预先定义。其对数似然的梯度是 ∂ log π θ ( a ∣ s ) ∂ θ = ∂ f θ ( s , a ) ∂ θ − 1 ∑ a ′ e f θ ( s , a ′ ) ∑ a ′ ′ e f θ ( s , a ′ ′ ) ∂ f θ ( s , a ′ ′ ) ∂ θ = ∂ f θ ( s , a ) ∂ θ − E a ′ ∼ π θ ( a ′ ∣ s ) [ ∂ f θ ( s , a ′ ) ∂ θ ] \begin{gathered} \frac{\partial\text{log}\pi_\theta(a|s)}{\partial\theta} \begin{aligned}=\frac{\partial f_\theta(s,a)}{\partial\theta}-\frac{1}{\sum_{a^{\prime}}e^{f_\theta(s,a^{\prime})}}\sum_{a^{\prime\prime}}e^{f_\theta(s,a^{\prime\prime})}\frac{\partial f_\theta(s,a^{\prime\prime})}{\partial\theta}\end{aligned} \\ =\frac{\partial f_\theta(s,a)}{\partial\theta}-\mathbb{E}_{a^{\prime}\sim\pi_\theta(a^{\prime}|s)}\left[\frac{\partial f_\theta(s,a^{\prime})}{\partial\theta}\right] \end{gathered} ∂θ∂logπθ(a∣s)=∂θ∂fθ(s,a)−∑a′efθ(s,a′)1a′′∑efθ(s,a′′)∂θ∂fθ(s,a′′)=∂θ∂fθ(s,a)−Ea′∼πθ(a′∣s)[∂θ∂fθ(s,a′)]
举线性得分函数为例,则有 f θ ( s , a ) = θ T x ( s , a ) ∂ log π θ ( a ∣ s ) ∂ θ = ∂ f θ ( s , a ) ∂ θ − E a ′ ∼ π θ ( a ′ ∣ s ) [ ∂ f θ ( s , a ′ ) ∂ θ ] = x ( s , a ) − E a ′ ∼ π θ ( a ′ ∣ s ) [ x ( s , a ′ ) ] \begin{aligned} &f_{\theta}(s,a)=\theta^{\mathrm{T}}x(s,a) \\ \frac{\partial\text{log}\pi_\theta(a|s)}{\partial\theta}& =\frac{\partial f_{\theta}(s,a)}{\partial\theta}-\mathbb{E}_{a^{\prime}\sim\pi_{\theta}(a^{\prime}|s)}\left[\frac{\partial f_{\theta}(s,a^{\prime})}{\partial\theta}\right] \\ &=x(s,a)-\mathbb{E}_{a^{\prime}\sim\pi_{\theta}(a^{\prime}|s)}[x(s,a^{\prime})] \end{aligned} ∂θ∂logπθ(a∣s)fθ(s,a)=θTx(s,a)=∂θ∂fθ(s,a)−Ea′∼πθ(a′∣s)[∂θ∂fθ(s,a′)]=x(s,a)−Ea′∼πθ(a′∣s)[x(s,a′)]
代码实践
class PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, action_dim)def forward(self, x):x = F.relu(self.fc1(x))return F.softmax(self.fc2(x), dim=1)class REINFORCE:def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,device, numOfEpisodes, env):self.policy_net = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr=learning_rate)self.gamma = gammaself.device = deviceself.env = envself.numOfEpisodes = numOfEpisodes# 根据动作概率分布随机采样def takeAction(self, state):state = torch.tensor(np.array([state]), dtype=torch.float).to(self.device)action_probs = self.policy_net(state)action_dist = torch.distributions.Categorical(action_probs)action = action_dist.sample()return action.item()def update(self, transition_dict):reward_list = transition_dict['rewards']state_list = transition_dict['states']action_list = transition_dict['actions']G = 0self.optimizer.zero_grad()for i in reversed(range(len(reward_list))):reward = reward_list[i]state = torch.tensor(np.array([state_list[i]]), dtype=torch.float).to(self.device)action = torch.tensor(np.array([action_list[i]]), dtype=torch.int64).view(-1, 1).to(self.device)log_prob = torch.log(self.policy_net(state).gather(1, action))G = self.gamma * G + rewardloss = -log_prob * G # 每一步的损失函数loss.backward() # 反向传播计算梯度self.optimizer.step() # 梯度下降def REINFORCERun(self):returnList = []for i in range(10):with tqdm(total=int(self.numOfEpisodes / 10), desc='Iteration %d' % i) as pbar:for episode in range(int(self.numOfEpisodes / 10)):# initialize statestate, info = self.env.reset()terminated = Falsetruncated = FalseepisodeReward = 0transition_dict = {'states': [],'actions': [],'next_states': [],'rewards': [],'terminateds': [],'truncateds':[]}# Loop for each step of episode:while (not terminated) or (not truncated):action = self.takeAction(state)next_state, reward, terminated, truncated, info = self.env.step(action)if terminated or truncated:breaktransition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['terminateds'].append(terminated)transition_dict['truncateds'].append(truncated)state = next_stateepisodeReward += rewardself.update(transition_dict)returnList.append(episodeReward)if (episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报pbar.set_postfix({'episode':'%d' % (self.numOfEpisodes / 10 * i + episode + 1),'return':'%.3f' % np.mean(returnList[-10:])})pbar.update(1)return returnList
结果

可以看到,随着收集到的轨迹越来越多,REINFORCE 算法有效地学习到了最优策略。不过,相比于前面的 DQN 算法,REINFORCE 算法使用了更多的序列,这是因为 REINFORCE 算法是一个在线策略算法,之前收集到的轨迹数据不会被再次利用。此外,REINFORCE 算法的性能也有一定程度的波动,这主要是因为每条采样轨迹的回报值波动比较大,这也是 REINFORCE 算法主要的不足。
REINFORCE 算法是策略梯度乃至强化学习的典型代表,智能体根据当前策略直接和环境交互,通过采样得到的轨迹数据直接计算出策略参数的梯度,进而更新当前策略,使其向最大化策略期望回报的目标靠近。这种学习方式是典型的从交互中学习,并且其优化的目标(即策略期望回报)正是最终所使用策略的性能,这比基于价值的强化学习算法的优化目标(一般是时序差分误差的最小化)要更加直接。 REINFORCE 算法理论上是能保证局部最优的,它实际上是借助蒙特卡洛方法采样轨迹来估计动作价值,这种做法的一大优点是可以得到无偏的梯度。但是,正是因为使用了蒙特卡洛方法,REINFORCE 算法的梯度估计的方差很大,可能会造成一定程度上的不稳定,这也是后面将介绍的 Actor-Critic 算法要解决的问题。
参考
[1] 伯禹AI
[2] https://www.davidsilver.uk/teaching/
[3] 动手学强化学习
[4] Reinforcement Learning
相关文章:
【强化学习】12 —— 策略梯度(REINFORCE )
文章目录 前言策略梯度基于策略的强化学习的优缺点Example:Aliased Gridworld策略目标函数策略优化策略梯度利用有限差分计算策略梯度得分函数和似然比策略梯度定理蒙特卡洛策略梯度(Monte-Carlo Policy Gradient)Puck World Example Softmax随机策略 代…...

Kubernetes Taint(污点) 和 Toleration(容忍)
Author:rab 目录 前言一、Taint(污点)1.1 概述1.2 查看节点 Taint1.3 标记节点 Taint1.4 删除节点 Taint 二、Toleration(容忍) 前言 Kubernetes 中的污点(Taint)和容忍(Toleration…...

使用cv::FileStorage时出错 Can‘t open file: yaml‘ in read mode
1. 使用说明 在做的一个c工程项目,想加一个配置文件,我发现主要有两种主流的方式, (1)opencv有cv::FileStorage这样的一个函数可以使用。 (2)也可以使用cpp-yaml GitHub - jbeder/yaml-cpp: …...

代码之困:那些让你苦笑不得的bug
在编写代码的过程中,我们常常会遇到各种各样的bug。有的时候,我们花费了大量的时间和精力去寻找问题的根源,但却找不到任何线索。然而,令人哭笑不得的是,有时候这些问题的解决方案却是如此简单,以至于我们不…...

【C语言初学者周冲刺计划】2.2用选择法对10个整数从小到大排序
目录 1解题思路: 2代码如下: 3运行结果: 4总结: 1解题思路: 首先利用一维数组和循环语句输入10个整数,然后利用双循环的嵌套进行比较大小,最后输出结果; 2代码如下: #include&…...

c++系列——智能指针
1.智能指针的使用及原理 1.1 RAII RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内 存、文件句柄、网络连接、互斥量等等)的简单技术。 在对象构造时获取资源,接着控制对资…...

力扣日记10.30-【栈与队列篇】滑动窗口最大值
力扣日记:【栈与队列篇】滑动窗口最大值 日期:2023.10.30 参考:代码随想录、力扣 239. 滑动窗口最大值 题目描述 难度:困难 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只…...

docker与宿主机共享内存通信
docker与宿主机共享内存通信 docker中的进程要与宿主机使用共享内存通信,需要在启动容器的时候指定“–ipchost”选项。然后再编写相应的共享内存的程序,一个跑在宿主机上,另一个跑在docker上面。 宿主机程序准备 shm_data.h #ifndef _SH…...
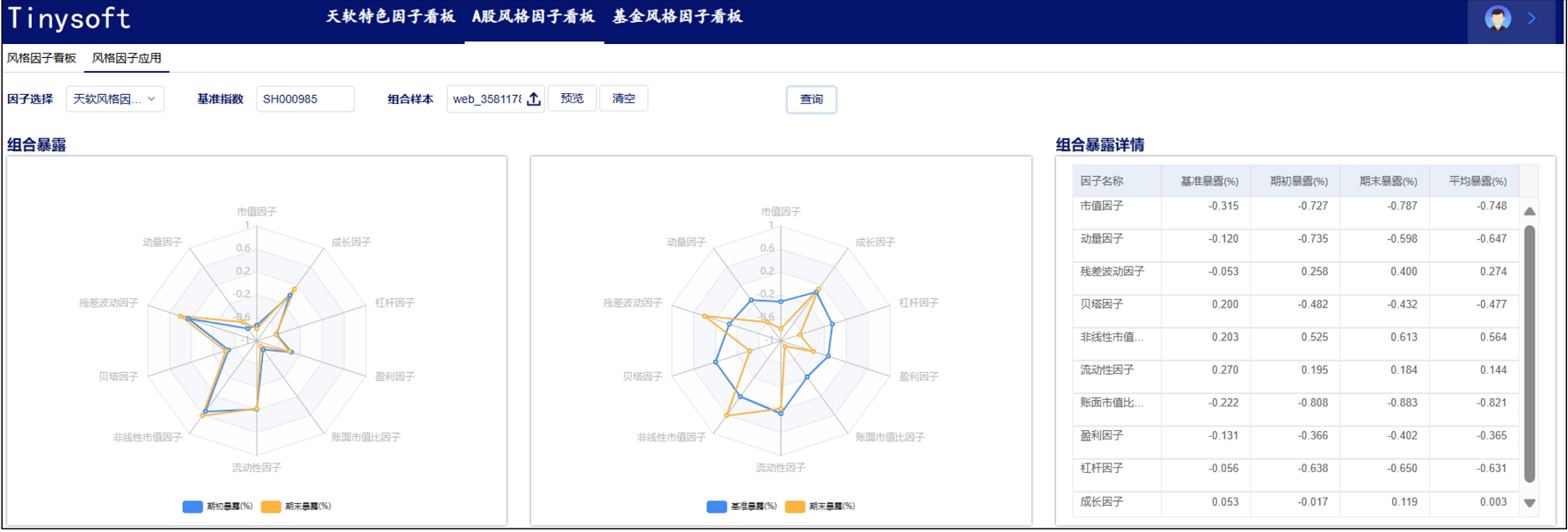
A股风格因子看板 (2023.10 第13期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴露等。 今日为该因子跟踪第13期,指数组合数据截止日2023-09-30,要点如下 近1年A股风格因子检验统…...

ORB-SLAM3算法2之EuRoc、TUM和KITTI开源数据集运行ORB-SLAM3生成轨迹并用evo工具评估轨迹
文章目录 0 引言1 数据和真值1.1 TUM1.2 EuRoc1.3 KITTI2 ORB-SLAM3的EuRoc示例2.1 纯单目的示例2.2 纯单目的轨迹评估2.3 纯双目的示例2.4 纯双目的轨迹评估2.5 单目和IMU的示例2.6 单目和IMU的轨迹评估2.7 双目和IMU的示例2.8 双目和IMU的轨迹评估2.9 前四种的评估结果对比3 …...

【蓝桥杯选拔赛真题07】C++小球自由落体 青少年组蓝桥杯C++选拔赛真题 STEMA比赛真题解析
目录 C/C++小球自由落体 一、题目要求 1、编程实现 2、输入输出 二、算法分析...

期中考成绩一键私发
作为一名教师,期中考试后最繁忙的事情之一就是发布成绩。每个学生都希望尽快知道自己的成绩,而作为老师,我们需要一种更高效、更方便的方式来完成这项任务。今天,我就来给大家介绍一种成绩查询系统,让我们一起告别繁琐…...
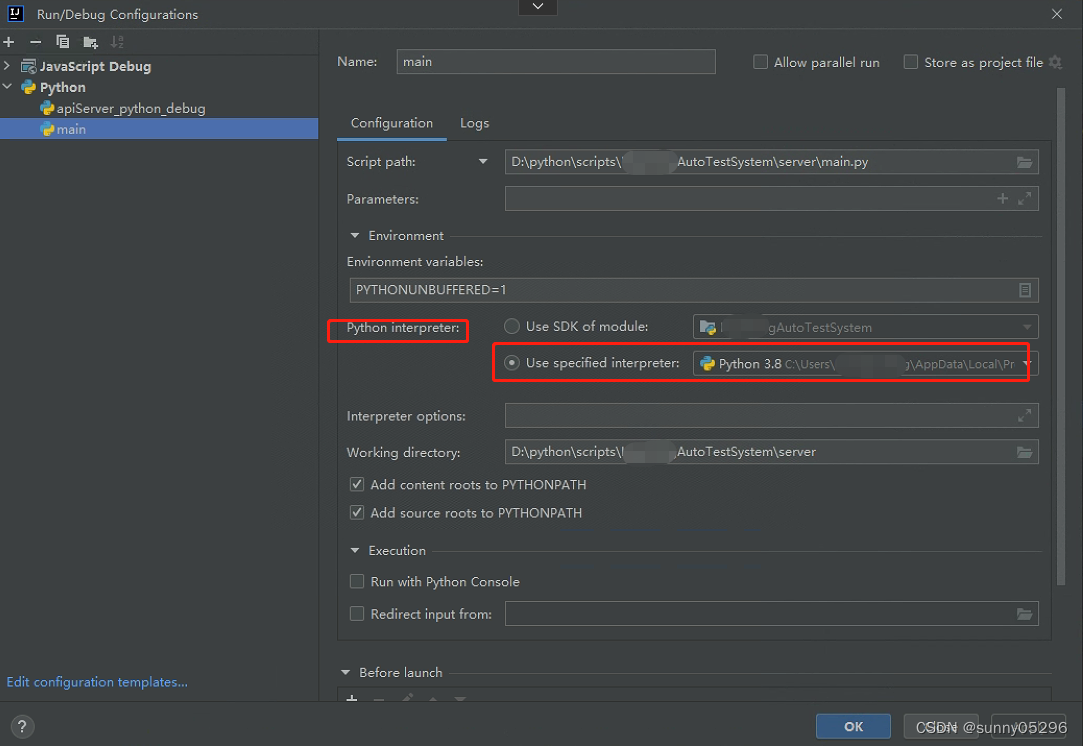
idea中Run/Debug Python项目报错 Argument for @NotNull parameter ‘module‘ of ...
idea中Run/Debug Python项目报错 Argument for NotNull parameter module of ... idea中运行Python项目main.py时报错: Error running main: Argument for NotNull parameter module of com/intellij/openapi/roots/ModuleRootManager.getInstance must not be nu…...
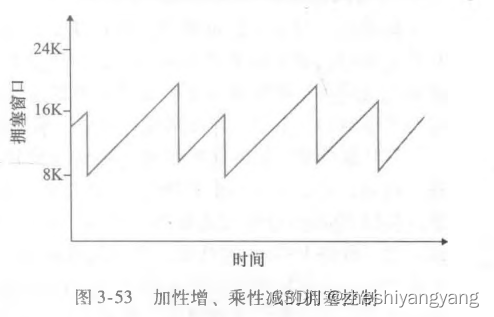
计算机网络第3章-TCP协议(2)
TCP拥塞控制 TCP拥塞控制的三种方式: 慢启动、拥塞避免、快速恢复 慢启动 当一条TCP连接开始时,cwnd的值是一个很小的MSS值,这使得初始发送速率大约为MSS/RTT。 在慢启动状态,cwnd的值以1个MSS开始并且每当传输的报文段首次被…...
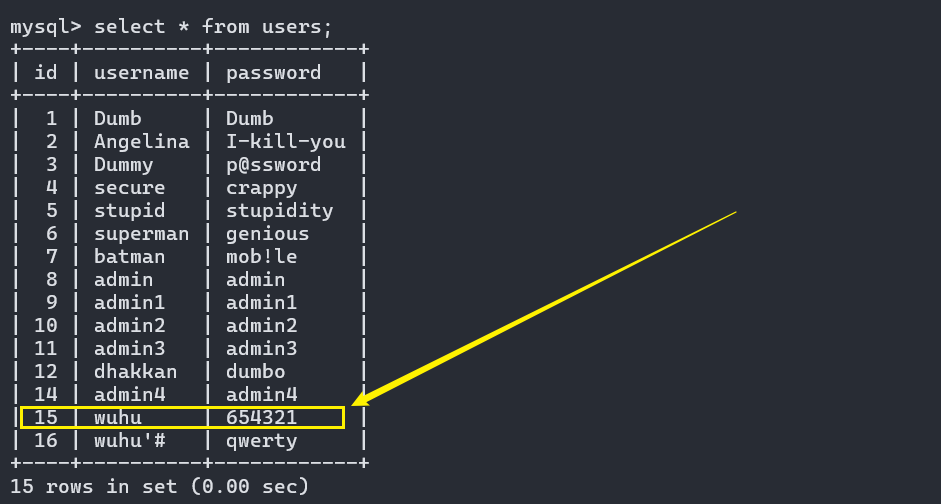
SQL注入——二次注入漏洞
文章目录 SQL注入——二次注入漏洞1. 二次注入原理2. 二次注入需要具备的两个条件3. 二次注入实例4. 总结 SQL注入——二次注入漏洞 1. 二次注入原理 在第一次插入恶意数据的时候,只是对其中的特殊字符进行了转义,在写入数据库的时候还是原来的字符&am…...
【c++|opencv】二、灰度变换和空间滤波---1.灰度变换、对数变换、伽马变换
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 灰度变换、对数变换、伽马变换 1. 灰度变换 #include <iostream> #include <opencv2/opencv.hpp>using namespace std; using namespace c…...
)
【vue3】子传父-事件总线-mitt(子组件派发事件,父组件接收事件和传递的参数)
安装库:cnpm install mitt 封装 eventbus.ts: src->utils->eventbus.ts //eventbus.tsimport mitt from mittconst emitter mitt()export default emitter使用 B2.vue: //B2.vue <template><div class"aa">…...

【杂记】java 大集合进行拆分
日常中需要对一个大的集合进行拆分成多个小集合,其主要思路为: 设置需要拆分多少个小集合 A大集合里面有多少条数据 B计算出每个集合里面有多个条数据 CB/A计算出看是否存在余数 DB%A采用集合(List.subList())的方法对大集合进行拆分,循环A变进行集合拆…...

select...for update 锁表了?
在MySQL中,事务A中使用select...for update where id1锁住了,某一条数据,事务还没提交,此时,事务B中去用select ... where id1查询那条数据,会阻塞等待吗? select...for update在MySQL中&#…...
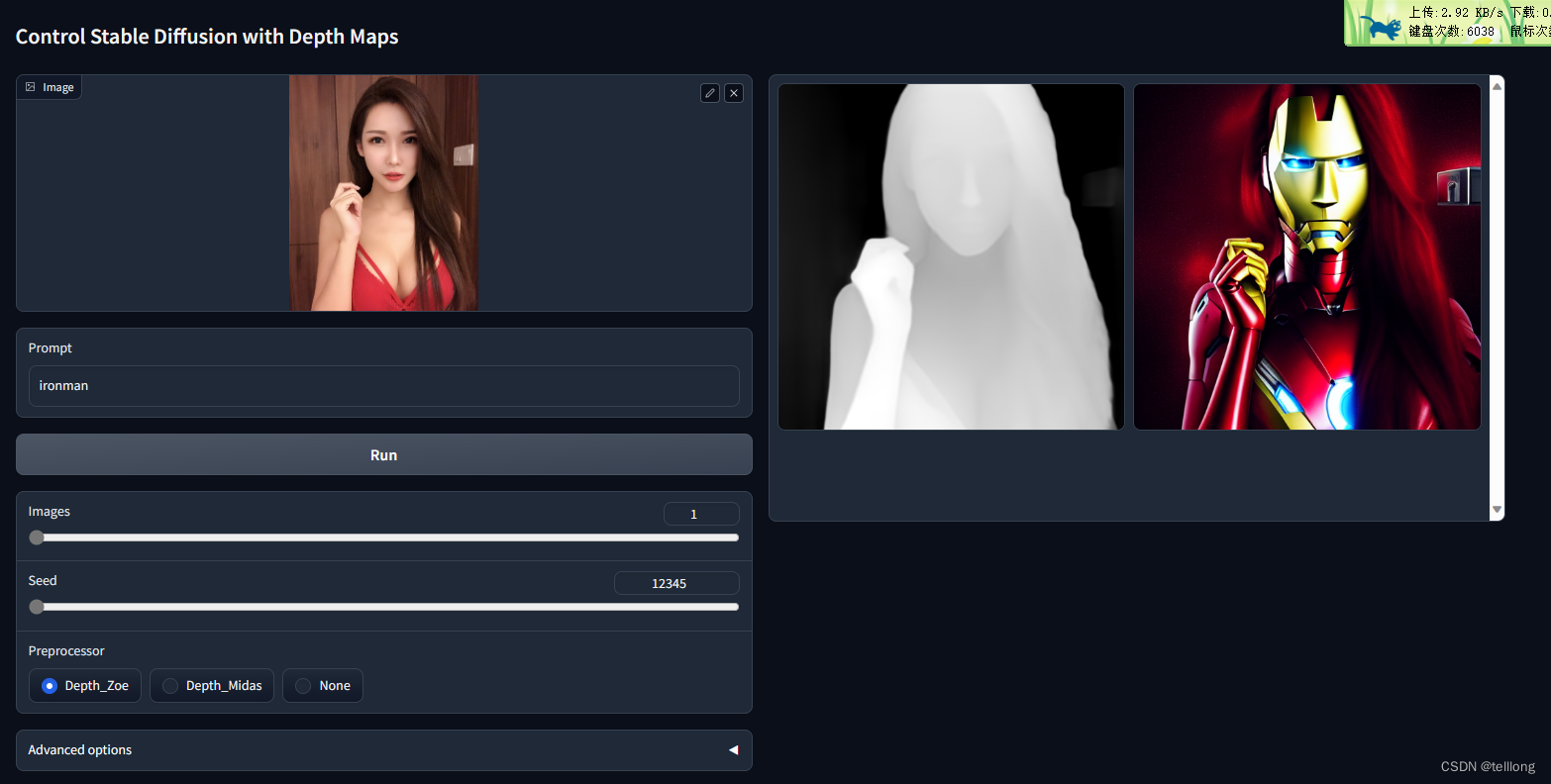
使用ControlNet生成视频(Pose2Pose)
目录 ControlNet 介绍 ControlNet 14种模型分别是用来做什么的 ControlNet 运行环境搭建 用到的相关模型地址 ControlNet 介绍 ControlNet 是一种用于控制扩散模型的神经网络结构,可以通过添加额外的条件来实现对图像生成的控制。它通过将神经网络块的权重复制到…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...