【数据结构与算法】——第八章:排序
文章目录
- 1、基本概念
- 1.1 什么是排序
- 1.2 排序算法的稳定性
- 1.3 排序算法的分类
- 1.4 内排序的方法
- 2、插入排序
- 2.1 直接插入排序
- 2.2 直接插入排序
- 2.3 希尔排序
- 3、交换排序
- 3.1 冒泡排序
- 3.2 快速排序
- 4、选择排序
- 4.1 简单选择排序
- 4.2 树形选择排序
- 4.3 堆排序
- 4.4 二路归并排序
- 5、基数排序
- 5.1 链式基数排序
- 6、各种内部排序方法的比较
============================ 【说明】 ===================================================
大家好,本专栏是 数据结构与算法, 该科目是计算机类专业必修课之一,比较重要也比较基础,有想从事算法研究的同学,这些内容是专/本科、甚至硕士期间较为基础的内容,适用范围较广:大学专业课学习、考研复习等。
通过自己的理解进行整理,希望大家积极交流、探讨,多给意见。后面也会给大家更新其他一些知识。若有侵权,联系删除!共同维护网络知识权利!
1、基本概念
1.1 什么是排序
给定一个记录集合( r1,r2,…,rn),其相应的关键码分别为(k1,k2,…,kn),排序是将这些记录排成顺序为(rs1,rs2,…,rsn)的一个序列,使得相应的关键码满足ks1≤ks2≤…≤ksn(非降序或升序)或ks1≥ks2≥…≥ksn(非升序或降序)。
1.2 排序算法的稳定性
若对任意的数据元素序列,使用某个排序方法,对它按关键码进行排序:
(1) 若相同关键码元素间的位置关系,排序前与排序后保持一致,称此排序方法是稳定的;
(2) 不能保持一致的排序方法则称为不稳定的;
1.3 排序算法的分类
(1) 内排序和外排序
按照参加排序的数据元素(记录)是否全部放置在内存中可把排序分为内排序和外排序:
内排序:指待排序列完全存放在内存中所进行的排序过程,适合不太大的元素序列。
外排序:指排序过程中还需访问外存储器,足够大的元素序列,因不能完全放入内存,只能使用外排序。
(2) 单键排序和多键排序
按照排序所依据的关键码的个数可以把排序分为单键排序和多键排序。
单键排序:根据一个关键码进行的排序。
多键排序:根据多个关键码进行的排序。
(3) 基于比较和不基于比较
按照排序的方法是否建立在关键码比较的基础上可以把排序分为:
基于比较:主要是通过关键码之间的比较和记录的移动这两种操作来实现的排序。
不基于比较:根据待排序数据的特点所采取的其它方法,通常是没有大量的关键码之间的比较和记录的移动操作的排序。
1.4 内排序的方法
内部排序的过程是一个逐步扩大记录的有序序列长度的过程。
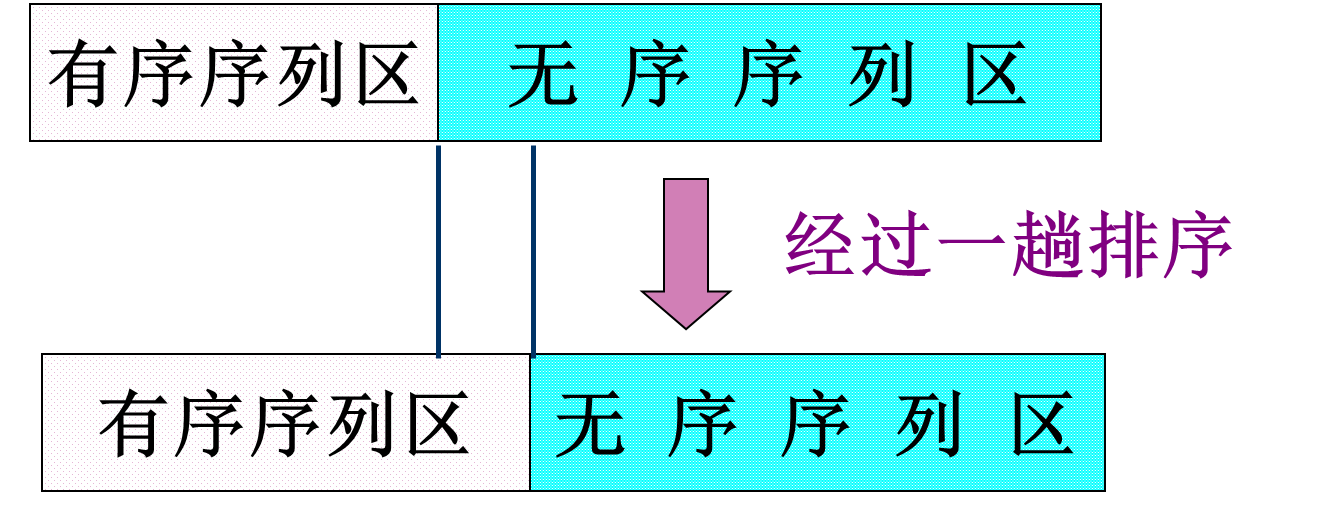
内排序有如下几大类:

下面对各种排序算法做个详细介绍:
2、插入排序
2.1 直接插入排序
算法思想:仅有一个记录的表总是有序的,因此,对于n个记录的表,可从第二个记录开始直到第n个记录,逐个向有序表中进行插入操作,从而得到n个记录按关键码有序的表。
步骤:
(1) 从第一个元素开始,该元素可以认为已经被排序;
(2) 取出下一个元素,在已经排序的元素序列中从后向前扫描;
(3) 如果该元素(已排序)大于新元素,将该元素移到下一位置;
(4) 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
(5) 将新元素插入到该位置后;
(6) 重复步骤2~5。
算法分析:
空间效率:仅用了一个辅助单元O(1)。
时间效率:
最好情况下:初始序列是顺序的
最坏情况下:初始序列是逆序的
平均情况下:初始序列是无序的
稳定性:是一种稳定的排序方法。

2.2 直接插入排序
算法思想:设在顺序表中有一 个对象序列 V[0], V[1], …, V[n-1]。其中, V[0], V[1], …, V[i-1] 是已经排好序的对象。在插入V[i] 时, 利用折半查找法寻找V[i] 的插入位置。
步骤:
折半插入排序与直接插入排序算法原理相同。只是,在向已排序的数据中插入数据时,采用来折半查找(二分查找)。先取已经排序的序列的中间元素,与待插入的数据进行比较,如果中间元素的值大于待插入的数据,那么待插入的数据属于数组的前半部分,否则属于后半部分。依次类推,不断缩小范围,确定要插入的位置。
Step1: 顺序表中前j-1个记录有序,将第j个记录插入。令low=1;high=j-1;r[0]=r[j];
Step2: 若low>high,得到插入位置,转Step5;
Step3: 若low≤high,则取有序子表的中点m=(low+high)/2;
Step4: 若r[0].key<r[m].key,则插入位置在低半区,令high=m-1;否则插入位置在高半区,令low=m+1;转Step2;
Step5: high+1即为待插入位置,从j-1到high+1的记录,逐个后移,r[high+1]=r[0];放置待插入记录。
案例:
(1) 待排序数据:2,1,6,7,4
取第一个元素作为有序表,剩余的元素作为无序表;其中有序表:2;无序表:1,6,7,4
(2) 第一次比较,从无序表中取出第一个数 1,与中间值2比较,1<2,1插到2的前面,得到:有序表:1,2;无序表:6,7,4
(3) 第二次比较,从无序表中取出第一个数 6,与中间值1比较,6>1,要放在1的后面,再与后半区(有序表:2)的中间值2比较,6>2,6插入到2的后面,得到: 有序表:1,2,6;无序表:7,4
(4) 第三次比较,从无序表中取出第一个数 7,与中间值2比较,7>2,7放在2后面,再与后半区(有序表:6)的中间值6比较,7>6,7放在6后面,得到:有序表:1,2,6,7;无序表:4
(5) 第四次比较,从无序表中取出第一个数 4,与中间值2比较,4>2,4放在2后面,再与后半区(有序表:6,7)的中间值6比较,4<6,4放在6前面,最终得到:1,2,4,6,7
算法分析:
时间复杂度:O(n2n^2n2)。
空间复杂度:O(1)。
稳定性:是一种稳定的排序方法。
2.3 希尔排序
算法思想:先将整个待排记录分割成若干个子序列,在子序列中分别进行直接插入排序,待整个序列基本有序的时候,再对全体序列进行一次直接插入排序。
步骤:
Step1: 选择一个步长序列t1,t2,…,tk,其中 ti>tj,tk=1;
Step2: 按步长序列个数k,对序列进行k趟排序;
Step3: 每趟排序,根据对应的步长ti,将待排序列分割成若干长度为m的子序列,分别对各子表进行直接插入排序。仅步长因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度。
案例:

算法分析:
时间复杂度:由于希尔排序是依赖于增量的选取,它的时间复杂度是在O(nlog2n)-O(n2n^2n2)之间。
空间复杂度:在希尔排序的过程中只需要一个辅助空间用于暂存当前待插入的记录,因此,希尔排序的空间复杂度为O(1)。
稳定性:希尔排序方法是一种不稳定的排序方法。
3、交换排序
3.1 冒泡排序
算法思想:对n个记录的表,第一趟冒泡得到一个关键码最大的记录r[n],第二趟冒泡对n-1个记录的表,再得到一个关键码最大的记录r[n-1],如此重复,直到n个记录按关键码有序的表。
步骤:
(1) 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
(2) 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
(3) 针对所有的元素重复以上的步骤,除了最后一个;
(4) 重复步骤1~3,直到排序完成。
一趟冒泡方法:
Step1: i=1; //设置从第一个记录开始进行两两比较
Step2: 若i≥j,一趟冒泡结束。
Step3: 比较r[i].key与r[i+1].key,若 r[i].key≤r[i+1].key,不交换,转Step5;
Step4: 当r[i].key>r[i+1].key时, r[0]=r[i];r[i]=r[i+1];r[i+1]=r[0]; // 将r[i]与r[i+1]交换
Step5: i=i+1;对下两个记录进行两两比较,转Step2;
算法分析:
空间复杂度:冒泡排序的空间复杂度为O(1)。
时间复杂度:总共要进行n-1趟冒泡,对j个记录的表进行一趟冒泡需要j-1次关键码比较。 冒泡排序的时间复杂度为O(n2n^2n2)。
稳定性:冒泡排序是一种稳定的排序方法。
3.2 快速排序
算法思想:找一个记录,以它的关键字作为“枢轴”,凡其关键字小于枢轴的记录均移动至该记录之前,反之,凡关键字大于枢轴的记录均移动至该记录之后。致使一趟排序之后,记录的无序序列R[s…t]将分割成两部分:R[s..i-1]和R[i+1..t],且R[j].key≤ R[i].key ≤ R[j].key (s≤j≤i-1) 枢轴 (i+1≤j≤t)。
步骤:
Step1: 如果待排子序列中元素的个数大于1,则以L.r[low]作为枢轴,进行一次划分;否则排序结束。
Step2: 对枢轴左半子序列重复Step1;
Step3: 对枢轴右半子序列重复Step1;
案例:
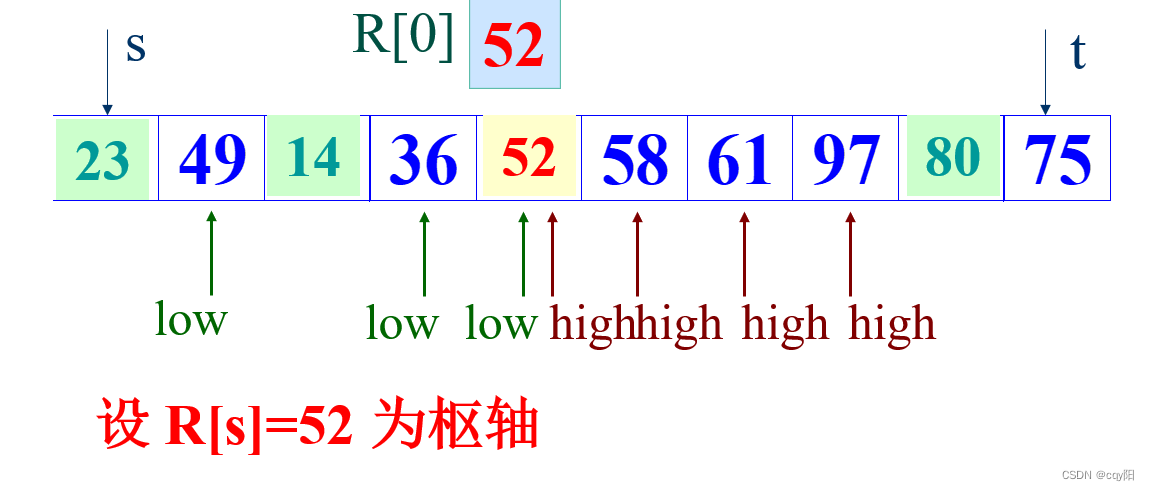
算法分析:
空间复杂度:快速排序是递归的,递归调用层次数与其二叉树的深度一致。因而,存储开销在理想情况下为O(log2n);在最坏情况下,为O(n)。
时间复杂度:最好情况下为O(nlog2n) ,最坏情况,快速排序蜕化为冒泡排序。
稳定性:快速排序是一个不稳定的排序方法。
4、选择排序
4.1 简单选择排序
算法思想:第一趟,从n个记录中找出关键码最小的记录与第一个记录交换;第二趟,从第二个记录开始的n-1个记录中再选出关键码最小的记录与第二个记录交换;如此,第i趟,则从第i个记录开始的n-i+1个记录中选出关键码最小的记录与第i个记录交换,直到整个序列按关键码有序。
步骤:
Step1: 从L.key[i]~ 从L.key[length]记录中选择一个关键字值最小的记录,将其下标保存至min中;
Step2: 若L.key[i]≥L.key[min];则交换这两个记录;否则转Step3;
Step3: i=i+1,若i≤L.length,则转Step1;否则排序结束。
算法分析:
时间复杂度:从算法中可看出,简单选择排序移动记录的次数较少,但关键码的比较次数依然是,算法的时间复杂度仍是O(n2n^2n2)。
空间复杂度:简单选择排序算法只需要一个辅助空间来作为交换记录用的暂存单元。因此,它的空间复杂度O(1)。
稳定性:简单选择排序是一种不稳定的排序方法。
4.2 树形选择排序
步骤:
Step1:从最底层叶子结点开始,按层一一进行兄弟间的比赛,关键字值较大者上升为子树根结点,直到树的顶层为止;
Step2:将树的根结点输出,把底层叶子中值相同的结点值改为0;如果输出的结点总数小于初始时树的叶子结点总数,则重复Step1;否则结束排序。
案例:
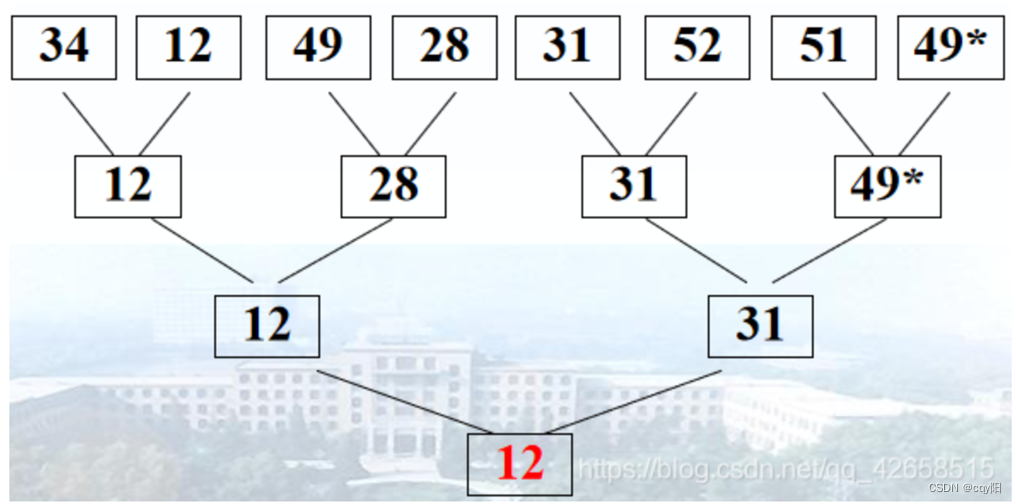
首先对n个记录的关键字两两进行比较,然后在n/2个较小者之间再进行两两比较,如此重复,直至选出最小关键字的记录。整个过程可用一个含有n个叶结点的二叉树表示;
选出最小记录后,将树中的该最小记录修改为∞,然后从该叶子结点所在子树开始,修改到达树根的路径上的结点;
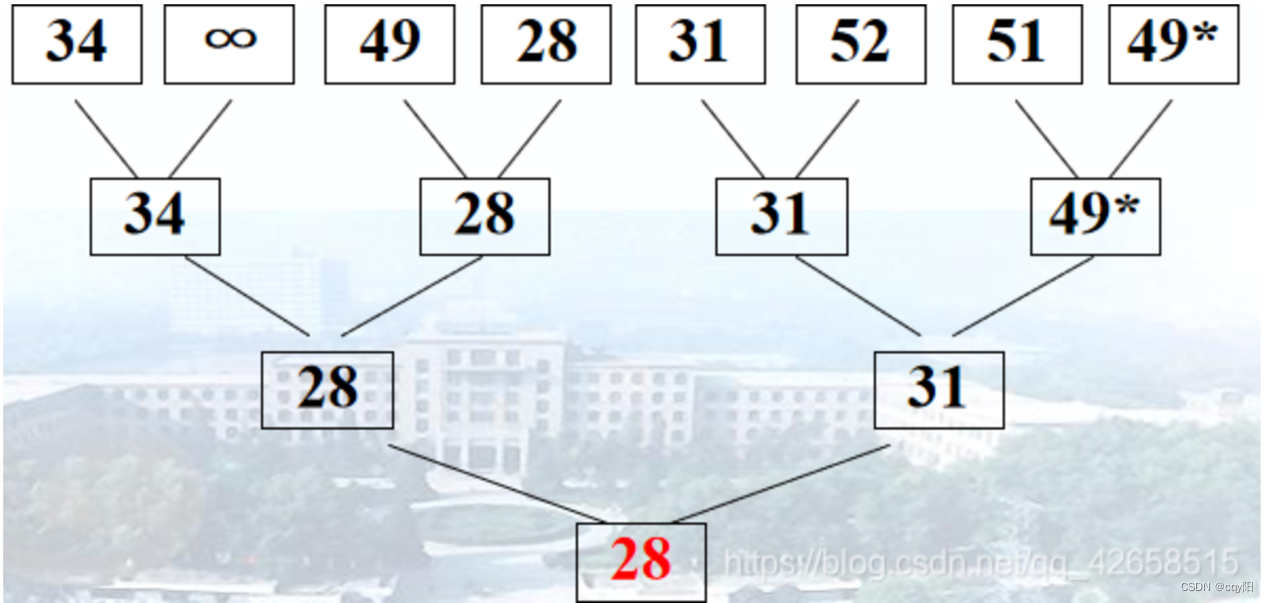
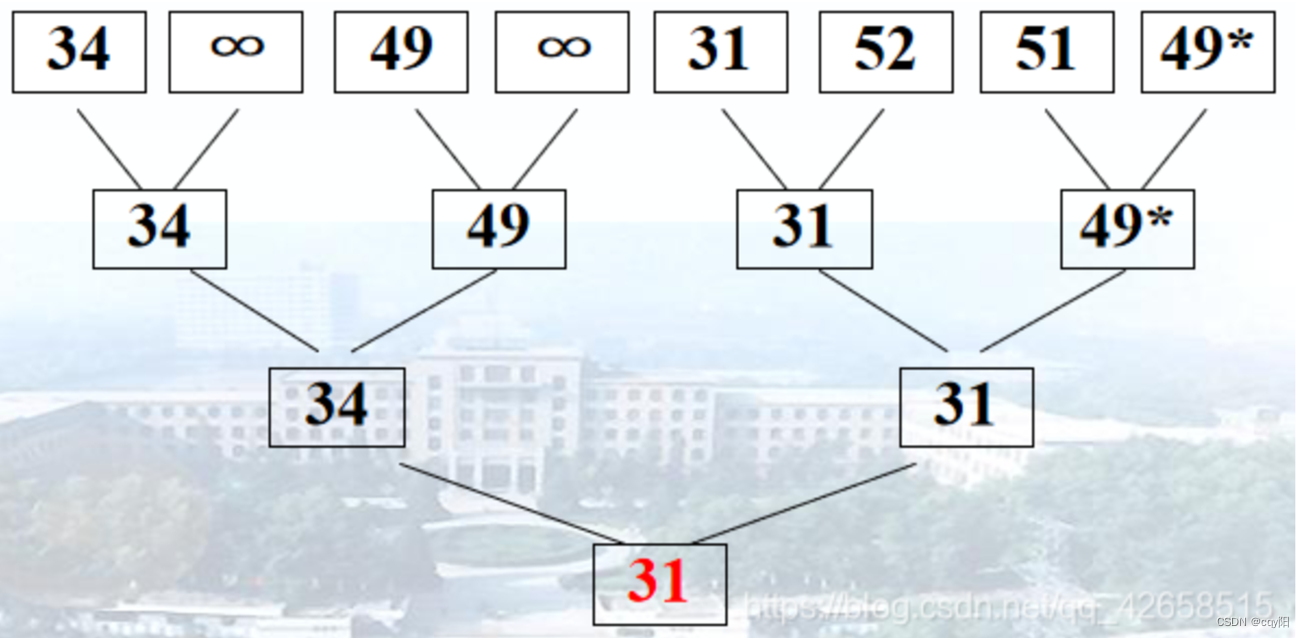
算法分析
时间复杂度:除了最大关键字之外,每选择一个次大的关键字只需要进行log2n次比较,因此,它的时间复杂度为O(nlogn)。
空间复杂度:需要附加n个辅助空间用来保存排序的结果,还要n-1个辅助空间作为排序过程中使用。因此,它的空间复杂度O(n)。
稳定性:树形选择排序是一种不稳定的排序方法。这是因为在比较的过程中是跳跃式进行的。
4.3 堆排序
定义:
第一种定义方式:
设有n个元素的序列 {k1,k2,…,kn},当且仅当满足下述关系之一时,称之为堆。
第二种定义方式:
堆是具有下列性质的完全二叉树:每个结点的值都小于或等于其左右孩子结点的值(称为小根堆或小顶堆);或者每个结点的值都大于或等于其左右孩子结点的值(称为大根堆或大顶堆)。
算法思想:设有n个元素,将其按关键码排序。首先将这n个元素按关键码建成堆,将堆顶元素输出,得到n个元素中关键码最小(或最大)的元素。然后,再对剩下的n-1个元素建成堆,输出堆顶元素,得到n个元素中关键码次小(或次大)的元素。如此反复,便得到一个按关键码有序的序列。称这个过程为堆排序。
堆排序需解决的两个问题:
1.怎样建堆:如何将n个元素的序列按关键码建成堆;
2. 怎样调整:输出堆顶元素后,怎样调整剩余n-1个元素,使其按关键码成为一个新堆。
建堆方法:
(1) 先把待排序序列构造成一棵完全二叉树;
(2) 然后从下往上,自右而左进行筛选,最终得到堆。
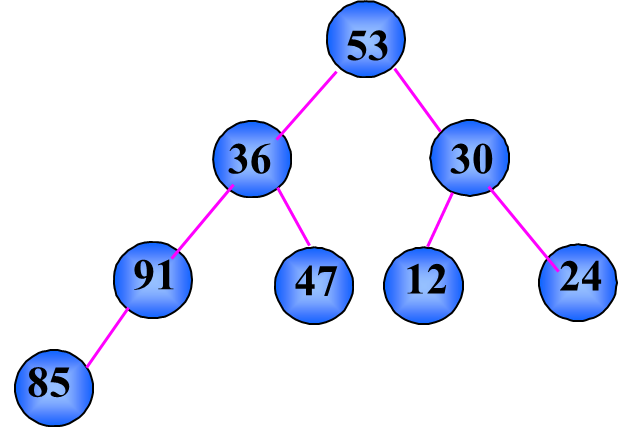
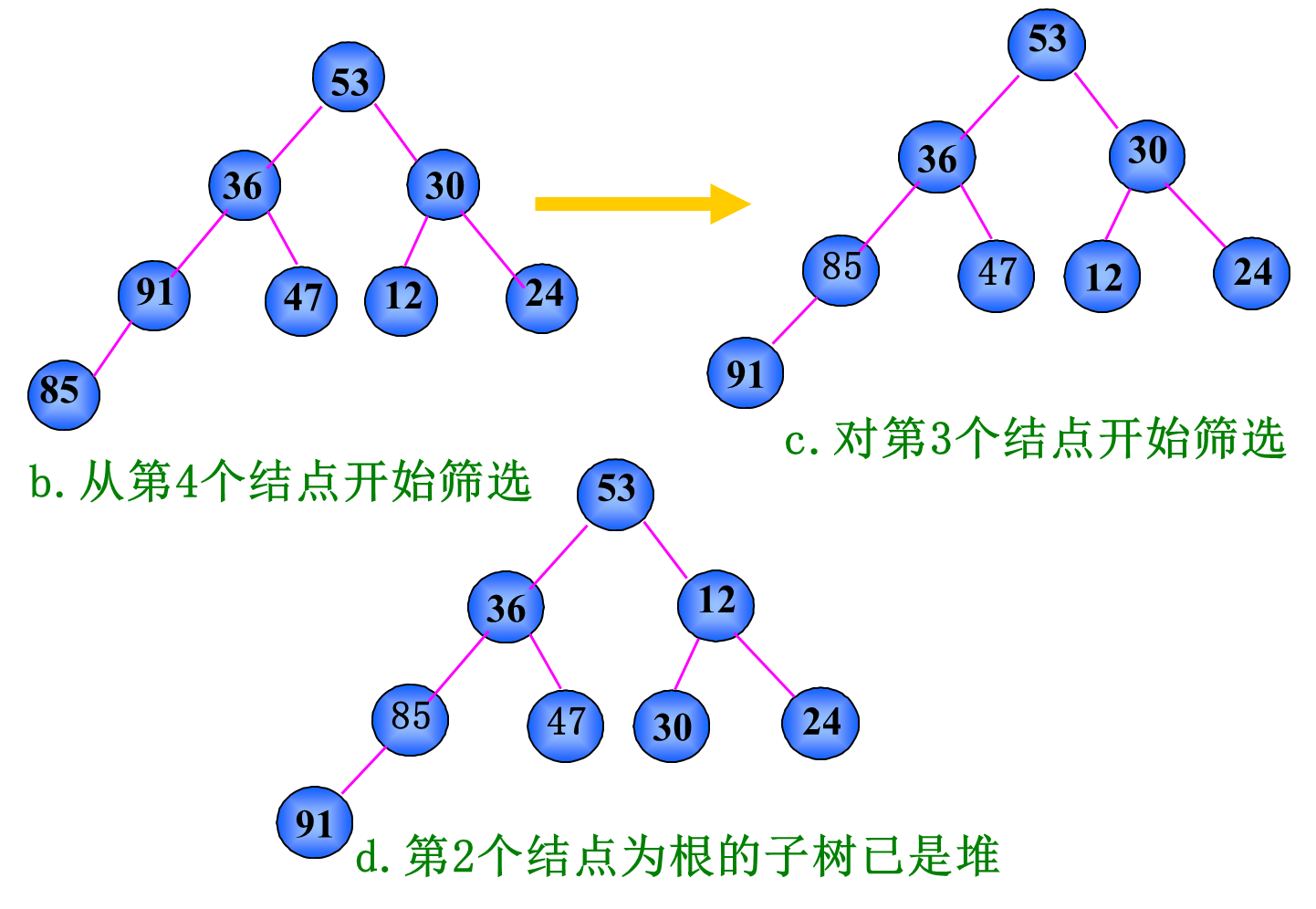
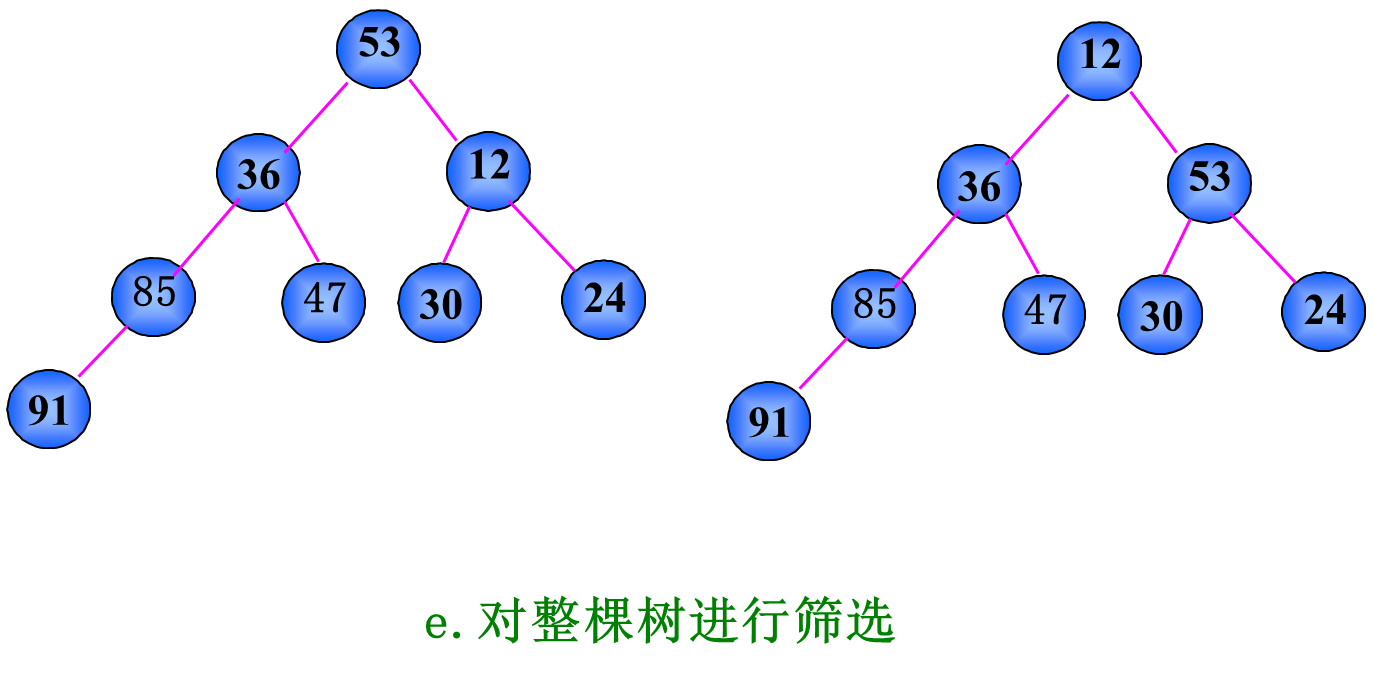
步骤:
Step1: i=1,对顺序表L[1…L.lengh-i+1]中的建大顶堆;
Step2: 将堆顶元素和L[L.lengh-i+1]交换;
Step3: i=i+1,若i<L.lengh,则将L[1…L.lengh-i+1]调整;使之成为新的大顶堆;转Step2;否则排序结束。
算法分析:
时间复杂度:在建好堆后,排序过程中的筛选次数不超过 O(nlog2n),而建堆时的比较次数不超过4n次,因此堆排序最坏情况下,时间复杂度也为O(nlog2n)。
空间复杂度:堆排序中,只需要一个用来交换的暂存单元,因此它的空间复杂度为O(1)。
算法的稳定性:由于记录的比较和交换是跳跃式进行的,因此,堆排序是一种不稳定的排序方法。
4.4 二路归并排序
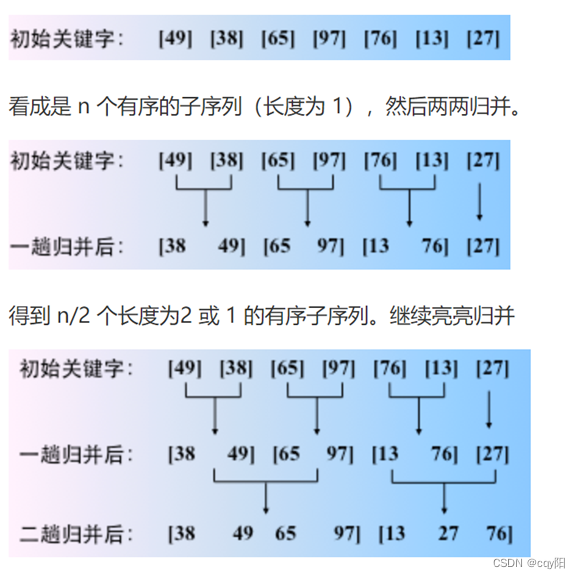
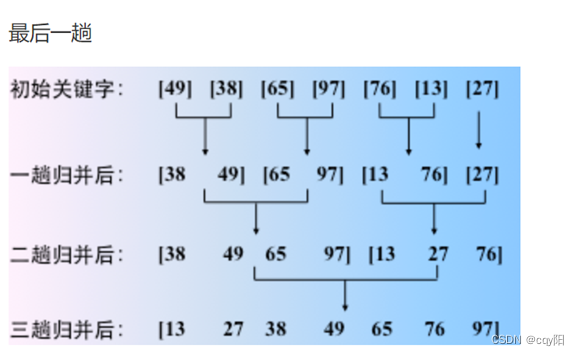
算法思想:归并排序的基本思想是基于将两个或两个以上的有序子序列 “归并” 为一个有序序列。
步骤:
Step1: 设置两个子表的起始下标及辅助数组的起始下标:i=u;j=v;k=u;
Step2: 若i>v 或 j>t,则比较选取结束转Step4;
Step3: 选取r[i]和r[j]中关键码较小的存入辅助数组rf。如果 r[i].key<r[j].key,则rf[k]=r[i]; i++; k++;否则,rf[k]=r[j]; j++; k++。 转Step2;
Step4: 将尚未处理完的子表中元素存入rf:
Step5: 合并结束。
递归算法操作步骤:
Step1: 将待排序的记录序列分为两个相等的子序列,分别将这两个子序列进行排序;
Step2: 调用一次归并算法Merge,将这两个有序子序列合并成一个含有全部记录的有序序列。
案例:
算法分析:
时间复杂度:归并过程对应由叶向根生成一棵二叉树的过程,所以归并趟数约等于二叉树的高度-1,即log2n,每趟归并需移动记录n次,故时间复杂度为O(nlog2n)。
空间复杂度:需要一个与表等长的辅助元素数组空间,所以空间复杂度为O(n)。
稳定性:由一次归并算法中的if语句可知,二路归并算法是一种稳定的算法。
5、基数排序
基数排序是一种借助“多关键字排序”的思想来实现“单关键字排序”的内部排序算法。
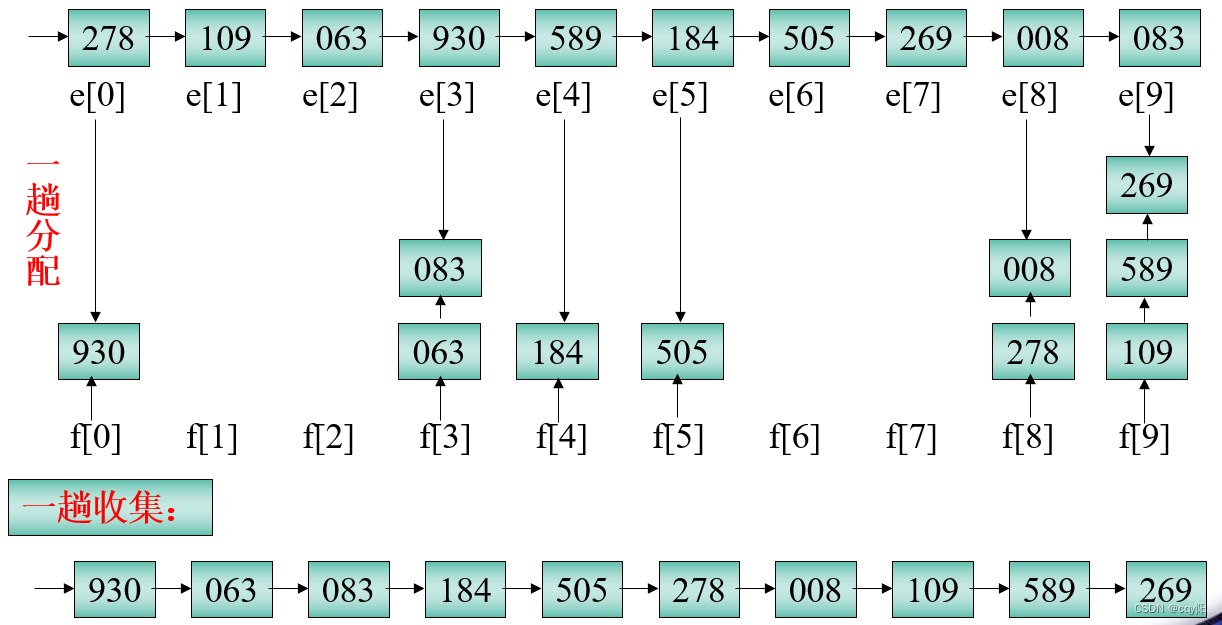
5.1 链式基数排序
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
案例:
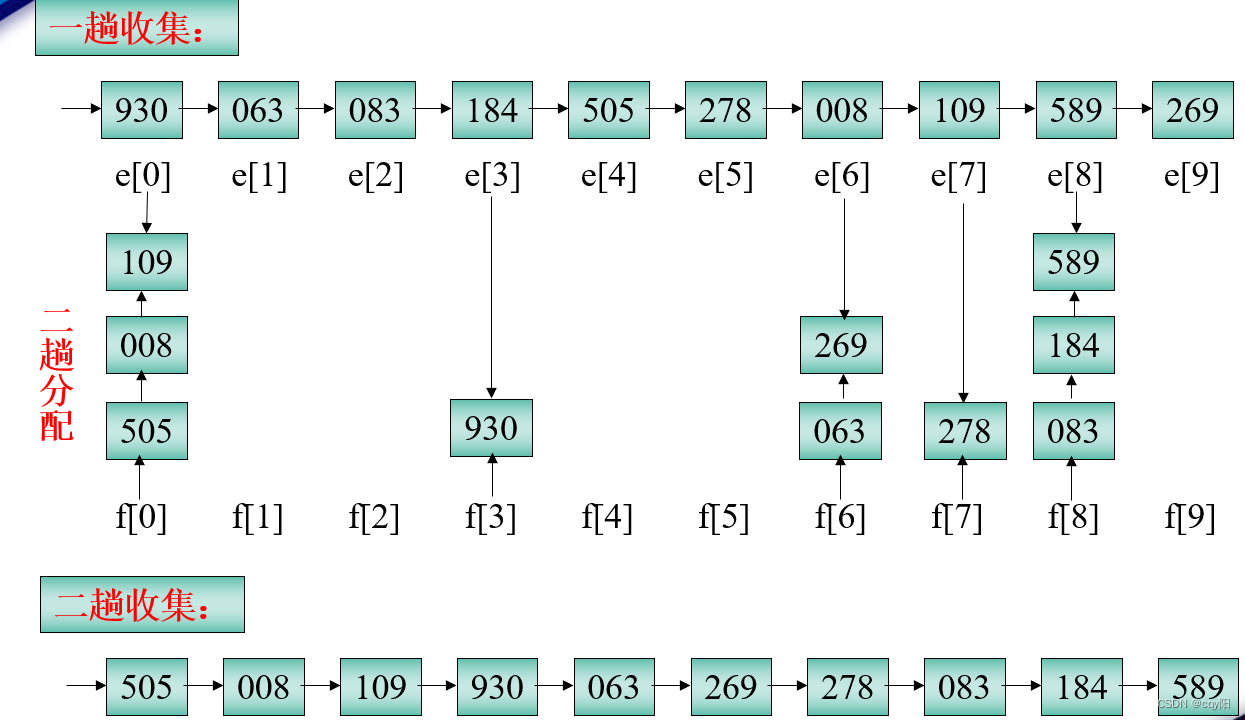

算法分析:
时间效率:设待排序列为n个记录,d个关键码,关键码的取值范围为radix,则进行链式基数排序的时间复杂度为O(d(n+radix)) 。
空间效率:需要2*radix个指向队列的辅助空间,以及用于静态链表的n个指针。
稳定性:在基数排序的过程中,并没有交换记录的前后位置,因此该排序方法是一种稳定的排序方法。
6、各种内部排序方法的比较

相关文章:
【数据结构与算法】——第八章:排序
文章目录1、基本概念1.1 什么是排序1.2 排序算法的稳定性1.3 排序算法的分类1.4 内排序的方法2、插入排序2.1 直接插入排序2.2 直接插入排序2.3 希尔排序3、交换排序3.1 冒泡排序3.2 快速排序4、选择排序4.1 简单选择排序4.2 树形选择排序4.3 堆排序4.4 二路归并排序5、基数排序…...

在linux中web服务器的搭建与配置
以下涉及到的linux命令大全查阅 https://www.runoob.com/linux/linux-command-manual.htmlvim命令查阅 https://www.runoob.com/linux/linux-vim.htmlscp命令https://www.runoob.com/linux/linux-comm-scp.html首先要有一个请求的服务地址用ssh 进入到linux系统中ssh 请求的服务…...
《Python机器学习》基础代码2
👂 逝年 - 夏小虎 - 单曲 - 网易云音乐 目录 👊Matplotlib综合应用:空气质量监测数据的图形化展示 🌼1,AQI时序变化特点 🌼2,AQI分布特征 相关性分析 🌼3,优化图形…...

如何基于MLServer构建Python机器学习服务
文章目录前言一、数据集二、训练 Scikit-learn 模型三、基于MLSever构建Scikit-learn服务四、测试模型五、训练 XGBoost 模型六、服务多个模型七、测试多个模型的准确性总结参考前言 在过去我们训练模型,往往通过编写flask代码或者容器化我们的模型并在docker中运行…...

9.1 IGMPv1实验
9.4.1 IGMPv1 实验目的 熟悉IGMPv1的应用场景掌握IGMPv1的配置方法实验拓扑 实验拓扑如图9-7所示: 图9-7:IGMPv1 实验步骤 (1)配置IP地址 MCS1的配置 MCS1的IP地址配置如图9-8所示: 图9-8:MCS1的配置 …...

软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用
软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用 一、摘要二、正文三、总结一、摘要 近年来,在应用需求的强大驱动下,我国通信业有了长足的进步。现有通信行业中的许多企业单位,如电信公司或移动集团,其信息系统的主要特征之一是对线路的…...
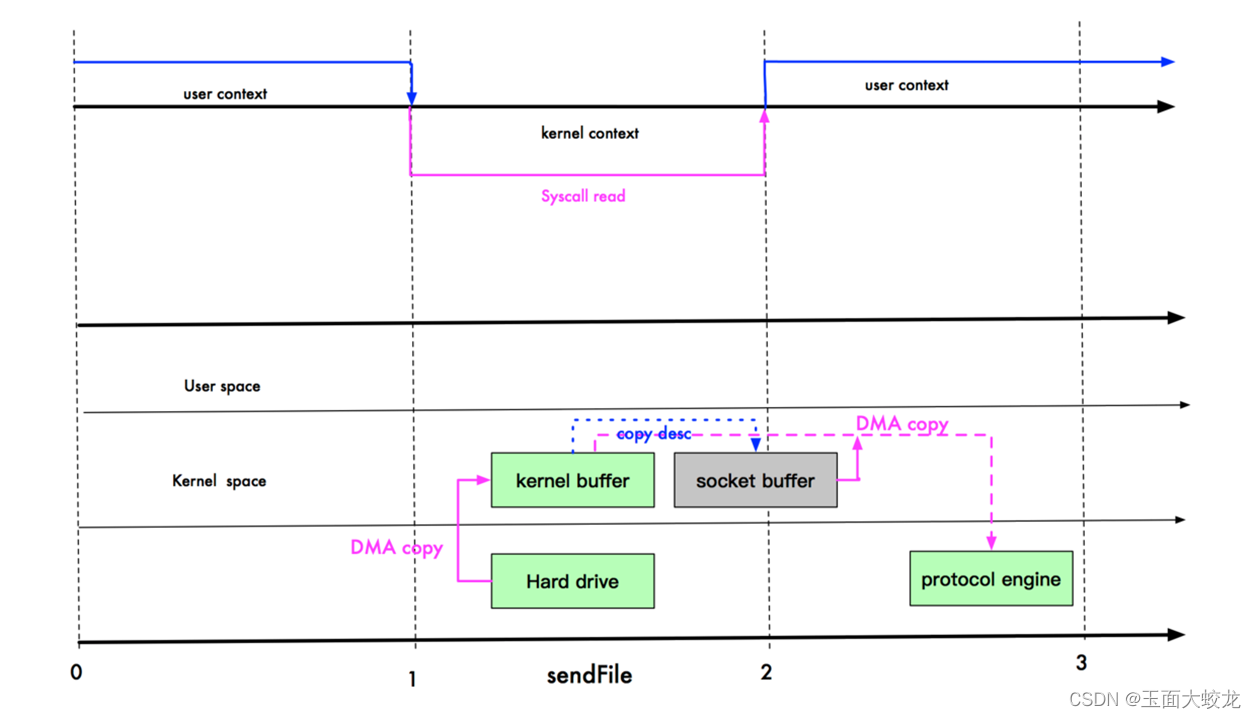
NIO与零拷贝
目录 一、零拷贝的基本介绍 二、传统IO数据读写的劣势 三、mmap优化 四、sendFile优化 五、 mmap 和 sendFile 的区别 六、零拷贝实战 6.1 传统IO 6.2 NIO中的零拷贝 6.3 运行结果 一、零拷贝的基本介绍 零拷贝是网络编程的关键,很多性能优化都离不开。 在…...
)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分) 前言 Problem:1151 LCA in a Binary Tree (30 分) Tags:树的遍历 并查集 LCA Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1151 LCA in a Binary Tree (30 分…...

Android 获取手机语言环境 区分简体和繁体,香港,澳门,台湾繁体
安卓和IOS 系统语言都是准守:ISO 639 ISO 代码表IOS:plus.os.language ios正常,安卓下简体和繁体语言,都是zh安卓获取系统语言方法:Locale.getDefault().language手机切换到繁体(台湾,香港&…...

一文搞懂Python时间序列
Python时间序列1. datetime模块1.1 datetime对象1.2 字符串和datatime的相互转换2. 时间序列基础3. 重采样及频率转换4. 时间序列可视化5. 窗口函数5.1 移动窗口函数5.2 指数加权函数5.3 二元移动窗口函数时间序列(Time Series)是一种重要的结构化数据形…...
GeoServer发布数据进阶
GeoServer发布数据进阶 GeoServer介绍 GeoServer是用于共享地理空间数据的开源服务器。 它专为交互操作性而设计,使用开放标准发布来自任何主要空间数据源的数据。 GeoServer实现了行业标准的 OGC 协议,例如网络要素服务 (WFS)…...
Docker离线部署
Docker离线部署 目录 1、需求说明 2、下载docker安装包 3、上传docker安装包 4、解压docker安装包 5、解压的docker文件夹全部移动至/usr/bin目录 6、将docker注册为系统服务 7、重启生效 8、设置开机自启 9、查看docker版本信息 1、需求说明 大部份公司为了服务安全…...
《数据库系统概论》学习笔记——第七章 数据库设计
教材为数据库系统概论第五版(王珊) 这一章概念比较多。最重点就是7.4节。 7.1 数据库设计概述 数据库设计定义: 数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构&#x…...

【Datawhale图机器学习】半监督节点分类:标签传播和消息传递
半监督节点分类:标签传播和消息传递 半监督节点分类问题的常见解决方法: 特征工程图嵌入表示学习标签传播图神经网络 基于“物以类聚,人以群分”的Homophily假设,讲解了Label Propagation、Relational Classificationÿ…...
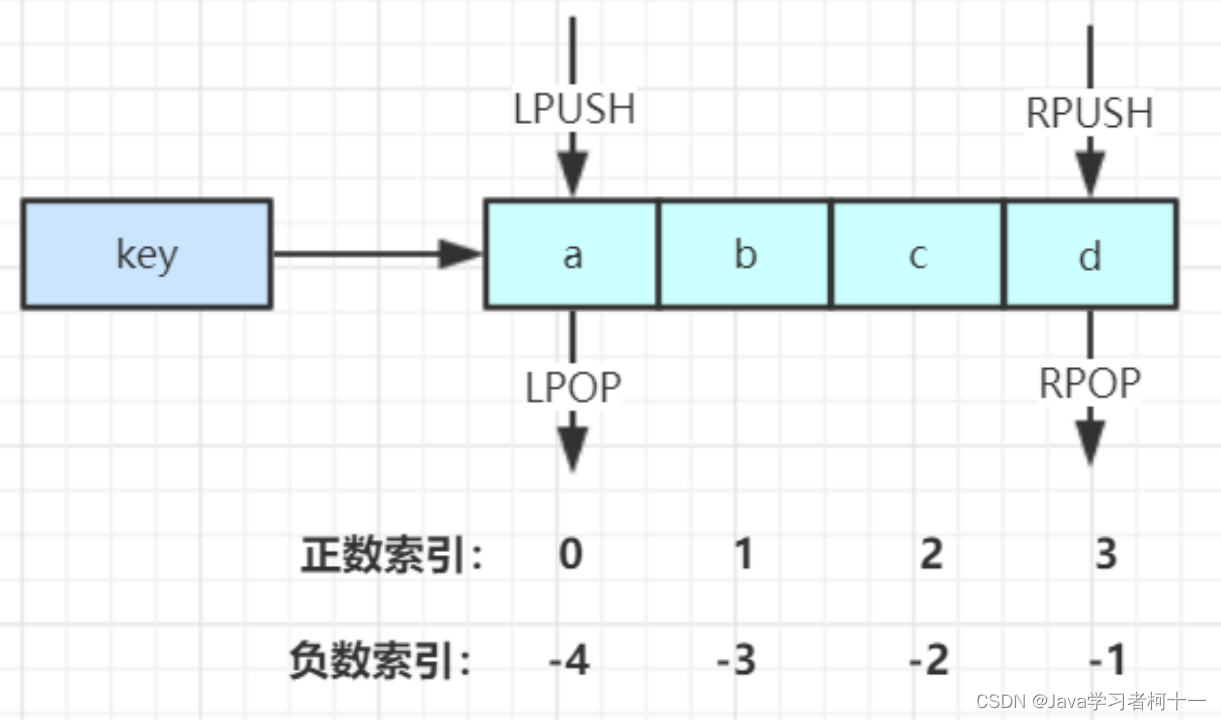
【分布式缓存学习篇】Redis数据结构
一、Redis的数据结构 二、String 数据结构 2.1 字符串常用操作 //存入字符串键值对 SET key value //批量存储字符串键值对 MSET key value [key value ...] //存入一个不存在的字符串键值对 SETNX key value //获取一个字符串键值 GET ke…...

【跟着ChatGPT学深度学习】ChatGPT带我入门NLP
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

RGB888与RGB565颜色
颜色名称RGB888原色RGB565还原色英RGB888[Hex]RGB888_R[Hex]RGB888_G[Hex]RGB888_B[Hex]RGB565[Hex]RGB565_R[Hex]RGB565_G[Hex]RGB565_B[Hex]黑色Black0x0000000000000x0000000昏灰Dimgray0x6969696969690x6B4DD1AD灰色Gray0x8080808080800x8410102010暗灰Dark Gray0xA9A9A9A9…...

常见的域名后缀有哪些?不同域名后缀的含义是什么?
域名发展至今,已演变出各种各样的域名后缀,导致很多网站管理人员在注册域名时不知该如何选择。下面,中科三方针对常见域名后缀种类,以及不同域名后缀的含义做下简单介绍。 什么是域名后缀? 域名是由一串由点分隔开的…...
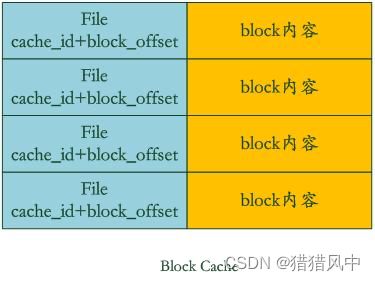
LevelDB架构介绍以及读、写和压缩流程
LevelDB 基本介绍 是一个key/value存储,key值根据用户指定的comparator排序。 特性 keys 和 values 是任意的字节数组。数据按 key 值排序存储。调用者可以提供一个自定义的比较函数来重写排序顺序。提供基本的 Put(key,value),Get(key),…...

华为OD机试模拟题 用 C++ 实现 - 快递货车(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明快递货车题目输入输出示例一输入输出Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD 清单…...

机器学习中的1-Lipschitz函数:为什么GANs和正则化都爱用它?
机器学习中的1-Lipschitz函数:为什么GANs和正则化都爱用它? 在深度学习领域,我们常常会遇到模型训练不稳定的问题——梯度爆炸、模式崩溃、过拟合等现象屡见不鲜。而一个来自数学分析的古老概念,正悄然成为解决这些难题的利器。1-…...

使用Matlab调用DeOldify服务进行图像分析研究
使用Matlab调用DeOldify服务进行图像分析研究 1. 引言 如果你是一位从事图像处理或历史影像研究的科研人员,可能遇到过这样的困扰:手头有一批珍贵的黑白老照片或灰度图像,你想分析其中的色彩信息,或者想基于颜色进行更精细的区域…...

Cogito-V1-Preview-Llama-3B创意编程:生成抽象艺术或算法的文字描述
Cogito-V1-Preview-Llama-3B创意编程:生成抽象艺术或算法的文字描述 最近在玩一个挺有意思的模型,叫Cogito-V1-Preview-Llama-3B。名字有点长,但功能很特别。它不是用来写代码或者回答问题的,而是专门干一件“翻译”的活儿——把…...

国风美学生成模型v1.0长卷生成:AI再现《清明上河图》般的风俗长卷
国风美学生成模型v1.0长卷生成:AI再现《清明上河图》般的风俗长卷 最近试用了国风美学生成模型v1.0,它有个功能让我特别着迷:生成超宽幅的长卷图像。这听起来就很有挑战性,毕竟要在一张图里讲一个完整的故事,还得保持…...

手把手教学:基于PyTorch 2.9镜像,5分钟搞定云端Jupyter开发环境
手把手教学:基于PyTorch 2.9镜像,5分钟搞定云端Jupyter开发环境 1. 为什么选择PyTorch 2.9云端开发环境? 1.1 本地开发环境的常见痛点 作为一名AI开发者,你是否经常遇到这样的困扰:好不容易配置好的本地环境&#x…...

从零到一:CTF Misc与Web实战解题的通用思维框架
1. CTF解题的通用思维框架 第一次接触CTF比赛时,面对五花八门的Misc和Web题目,很多人会陷入"工具依赖症"——疯狂收集各种神器却不知如何下手。经过多年实战,我发现真正的高手都有一套可复用的解题思维框架。这个框架不依赖特定工具…...

ILRepack:.NET程序集整合的现代解决方案
ILRepack:.NET程序集整合的现代解决方案 【免费下载链接】il-repack Open-source alternative to ILMerge 项目地址: https://gitcode.com/gh_mirrors/il/il-repack 在.NET应用开发过程中,随着项目规模扩大,程序集数量往往会不断增加。…...

如何打造终极便携编程环境:VSCode便携版完全指南
如何打造终极便携编程环境:VSCode便携版完全指南 【免费下载链接】VSCode-Portable VSCode 便携版 VSCode Portable 项目地址: https://gitcode.com/gh_mirrors/vsc/VSCode-Portable 还在为每次换电脑都要重新配置开发环境而烦恼吗?VSCode便携版就…...

Linux内核链表遍历:list_for_each_entry_safe宏的5个实战技巧
Linux内核链表遍历:list_for_each_entry_safe宏的5个实战技巧 在Linux内核开发中,链表是最基础也是最常用的数据结构之一。不同于用户空间的链表实现,内核链表采用了一种独特的侵入式设计,通过struct list_head将链表节点嵌入到业…...

Win7虚拟机下UltraISO找不到虚拟光驱?3步搞定镜像加载问题
Win7虚拟机下UltraISO虚拟光驱识别难题的深度解决方案 在虚拟化技术广泛应用的今天,许多开发者依然需要在Windows 7虚拟机环境中处理ISO镜像文件。UltraISO作为老牌光盘映像工具,其虚拟光驱功能在物理机上表现稳定,但在VMware虚拟机环境中却常…...