Day902.Memory存储引擎 -MySQL实战
Memory存储引擎
Hi,我是阿昌,今天学习记录的是关于Memory存储引擎的内容。
两个 group by 语句都用了 order by null,为什么使用内存临时表得到的语句结果里,0 这个值在最后一行;
而使用磁盘临时表得到的结果里,0 这个值在第一行?
一、内存表的数据组织结构
假设有以下的两张表 t1 和 t2,其中表 t1 使用 Memory 引擎, 表 t2 使用 InnoDB 引擎。
create table t1(id int primary key, c int) engine=Memory;
create table t2(id int primary key, c int) engine=innodb;
insert into t1 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
insert into t2 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
然后,分别执行 select * from t1 和 select * from t2。
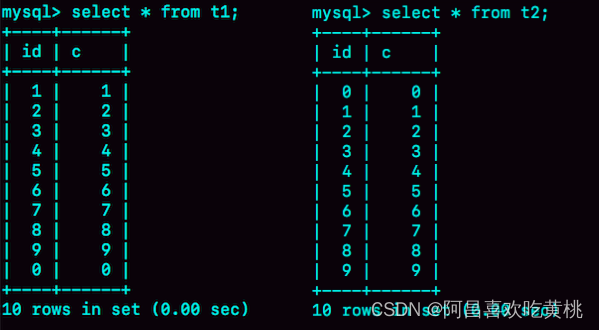
可以看到,内存表 t1 的返回结果里面 0 在最后一行,而 InnoDB 表 t2 的返回结果里 0 在第一行。
出现这个区别的原因,要从这两个引擎的主键索引的组织方式说起。
表 t2 用的是 InnoDB 引擎,它的主键索引 id 的组织方式:
InnoDB 表的数据就放在主键索引树上,主键索引是 B+ 树。
所以表 t2 的数据组织方式如下图所示:
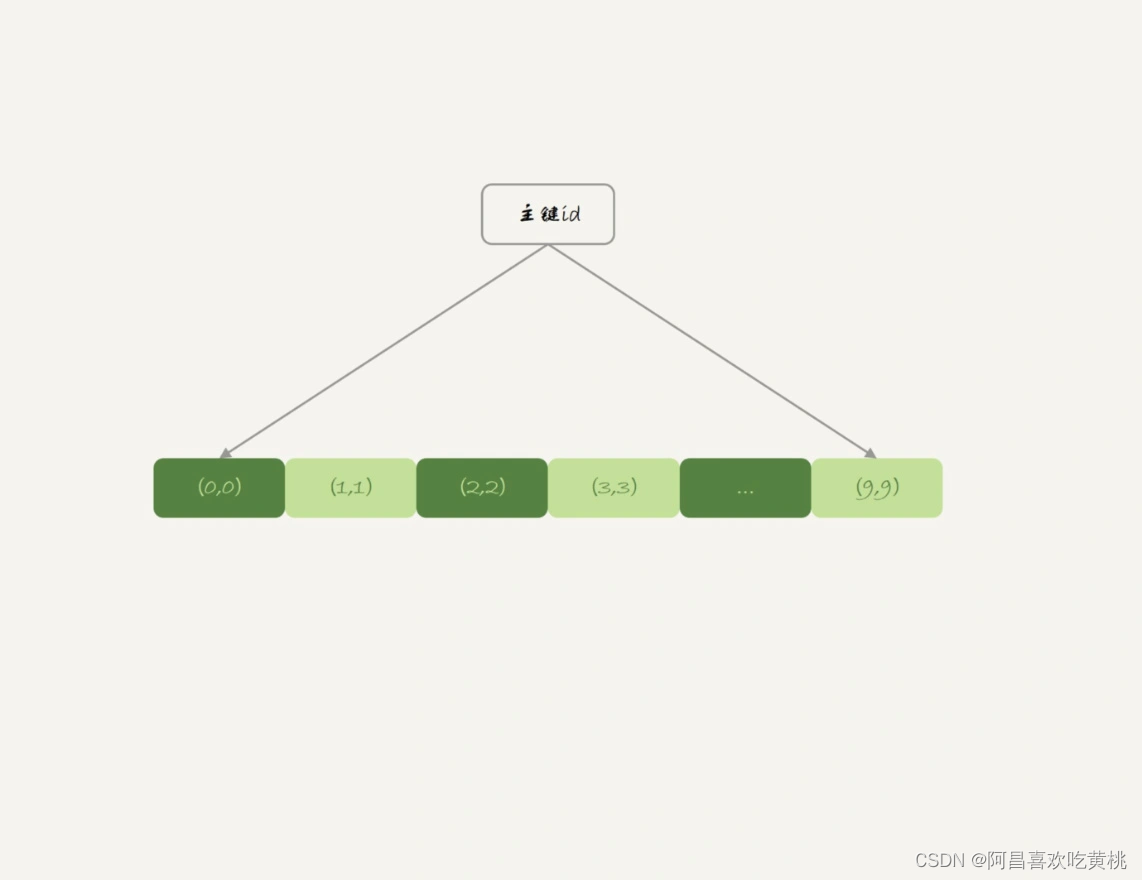
主键索引上的值是有序存储的。在执行 select * 的时候,就会按照叶子节点从左到右扫描,所以得到的结果里,0 就出现在第一行。
与 InnoDB 引擎不同,Memory 引擎的数据和索引是分开的。
来看一下表 t1 中的数据内容。
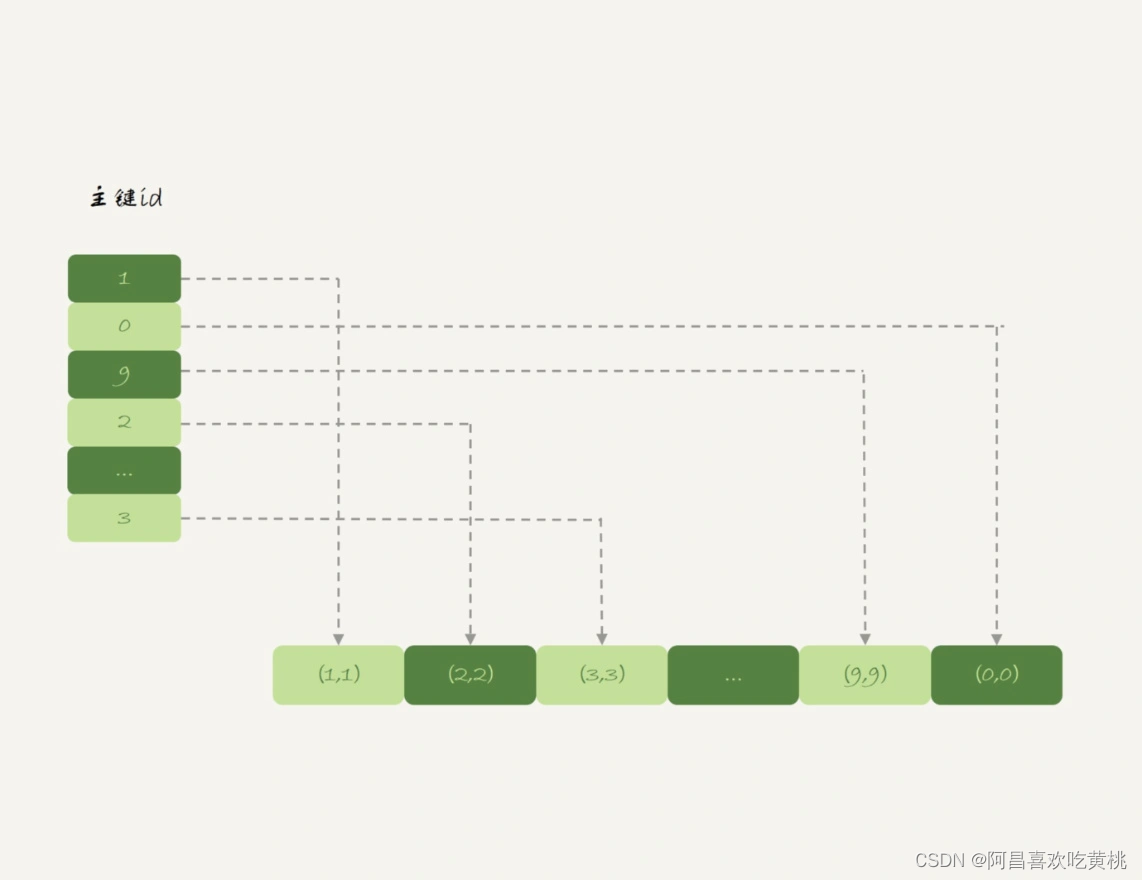
可以看到,内存表的数据部分以数组的方式单独存放,而主键 id 索引里,存的是每个数据的位置。
主键 id 是 hash 索引,可以看到索引上的 key 并不是有序的。
在内存表 t1 中,当我执行 select * 的时候,走的是全表扫描,也就是顺序扫描这个数组。
因此,0 就是最后一个被读到,并放入结果集的数据。
可见,InnoDB 和 Memory 引擎的数据组织方式是不同的:
- InnoDB 引擎把数据放在主键索引上,其他索引上保存的是主键 id。这种方式,称之为索引组织表(Index Organizied Table)。
- 而
Memory 引擎采用的是把数据单独存放,索引上保存数据位置的数据组织形式,称之为堆组织表(Heap Organizied Table)。
从中可以看出,这两个引擎的一些典型不同:
- InnoDB 表的数据总是有序存放的,而内存表的数据就是按照写入顺序存放的;
- 当数据文件有空洞的时候,InnoDB 表在插入新数据的时候,为了保证数据有序性,只能在固定的位置写入新值,而内存表找到空位就可以插入新值;
- 数据位置发生变化的时候,InnoDB 表只需要修改主键索引,而内存表需要修改所有索引;
- InnoDB 表用主键索引查询时需要走一次索引查找,用普通索引查询的时候,需要走两次索引查找。而内存表没有这个区别,所有索引的“地位”都是相同的。InnoDB 支持变长数据类型,不同记录的长度可能不同;
- 内存表不支持 Blob 和 Text 字段,并且即使定义了 varchar(N),实际也当作 char(N),也就是固定长度字符串来存储,因此内存表的每行数据长度相同。
由于内存表的这些特性,每个数据行被删除以后,空出的这个位置都可以被接下来要插入的数据复用。
比如,如果要在表 t1 中执行:
delete from t1 where id=5;
insert into t1 values(10,10);
select * from t1;
就会看到返回结果里,id=10 这一行出现在 id=4 之后,也就是原来 id=5 这行数据的位置。
需要指出的是,表 t1 的这个主键索引是哈希索引,因此如果执行范围查询,比如
select * from t1 where id<5;
是用不上主键索引的,需要走全表扫描。
二、hash 索引和 B-Tree 索引
那如果要让内存表支持范围扫描,应该怎么办呢 ?
实际上,内存表也是支持 B-Tree 索引的。在 id 列上创建一个 B-Tree 索引,SQL 语句可以这么写:
alter table t1 add index a_btree_index using btree (id);
这时,表 t1 的数据组织形式就变成了这样:

这跟 InnoDB 的 b+ 树索引组织形式类似。
作为对比,可以看一下这下面这两个语句的输出:
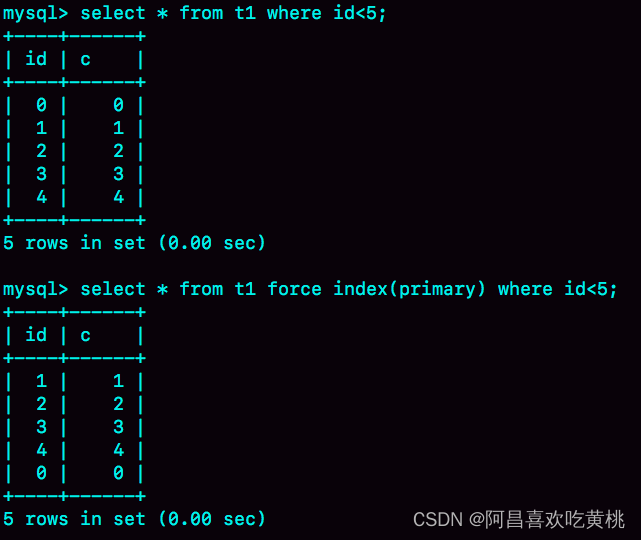
可以看到,执行 select * from t1 where id<5 的时候,优化器会选择 B-Tree 索引,所以返回结果是 0 到 4。
使用 force index 强行使用主键 id 这个索引,id=0 这一行就在结果集的最末尾了。
内存表的优势是速度快,其中的一个原因就是 Memory 引擎支持 hash 索引。
当然,更重要的原因是,内存表的所有数据都保存在内存,而内存的读写速度总是比磁盘快。
为什么不建议在生产环境上使用内存表。这里的原因主要包括两个方面:
- 锁粒度问题;
- 数据持久化问题。
三、内存表的锁
我们先来说说内存表的锁粒度问题。内存表不支持行锁,只支持表锁。
因此,一张表只要有更新,就会堵住其他所有在这个表上的读写操作。
需要注意的是,这里的表锁跟之前介绍过的 MDL 锁不同,但都是表级的锁。
模拟一下内存表的表级锁。

在这个执行序列里,session A 的 update 语句要执行 50 秒,在这个语句执行期间 session B 的查询会进入锁等待状态。
session C 的 show processlist 结果输出如下:

跟行锁比起来,表锁对并发访问的支持不够好。
所以,内存表的锁粒度问题,决定了它在处理并发事务的时候,性能也不会太好。
四、数据持久性问题
数据放在内存中,是内存表的优势,但也是一个劣势。
因为,数据库重启的时候,所有的内存表都会被清空。
如果数据库异常重启,内存表被清空也就清空了,不会有什么问题啊。
但是,在高可用架构下,内存表的这个特点简直可以当做 bug 来看待了。
为什么这么说呢?先看看 M-S 架构下,使用内存表存在的问题。
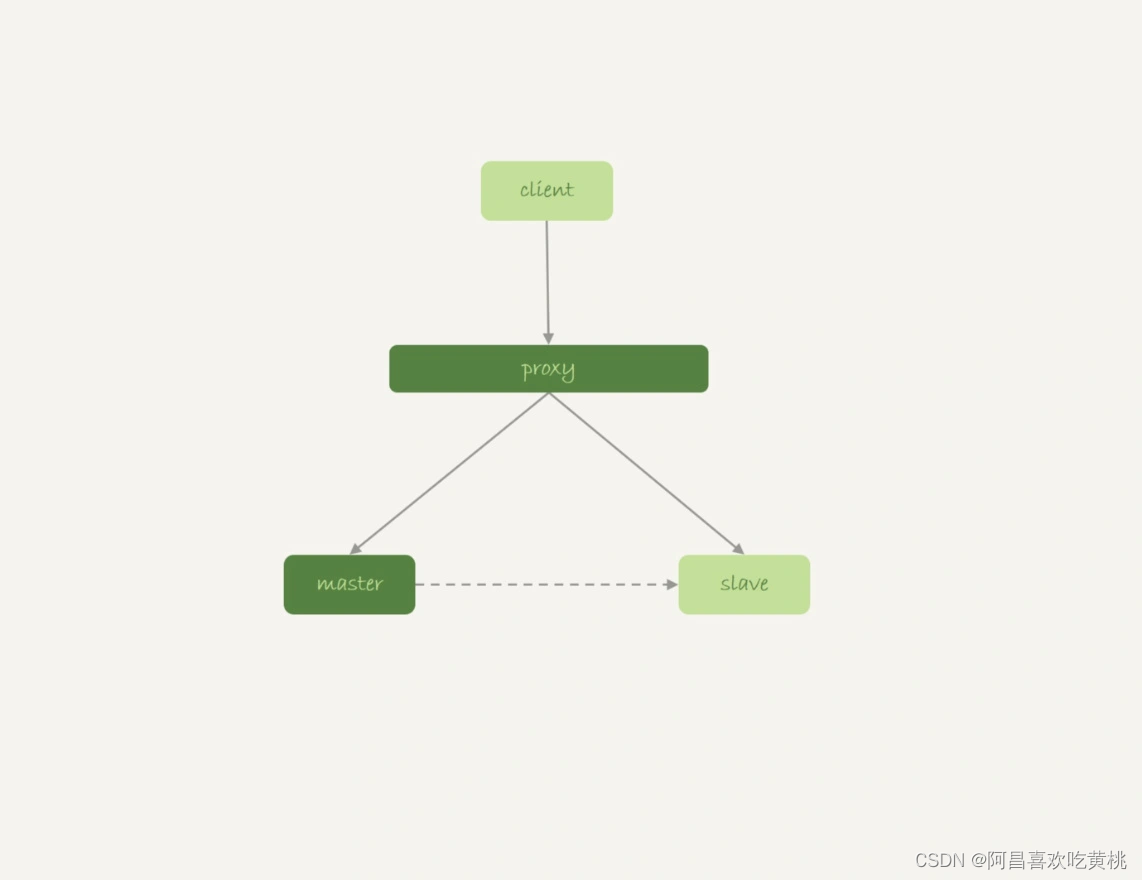
来看一下下面这个时序:
- 业务正常访问主库;
- 备库硬件升级,备库重启,内存表 t1 内容被清空;
- 备库重启后,客户端发送一条 update 语句,修改表 t1 的数据行,这时备库应用线程就会报错“找不到要更新的行”。
这样就会导致主备同步停止。当然,如果这时候发生主备切换的话,客户端会看到,表 t1 的数据“丢失”了。
在图 8 中这种有 proxy 的架构里,大家默认主备切换的逻辑是由数据库系统自己维护的。
这样对客户端来说,就是“网络断开,重连之后,发现内存表数据丢失了”。
可能说这还好啊,毕竟主备发生切换,连接会断开,业务端能够感知到异常。
但是,接下来内存表的这个特性就会让使用现象显得更“诡异”了。
由于 MySQL 知道重启之后,内存表的数据会丢失。
所以,担心主库重启之后,出现主备不一致,MySQL 在实现上做了这样一件事儿:
在数据库重启之后,往 binlog 里面写入一行 DELETE FROM t1。
如果使用是如图 9 所示的双 M 结构的话:
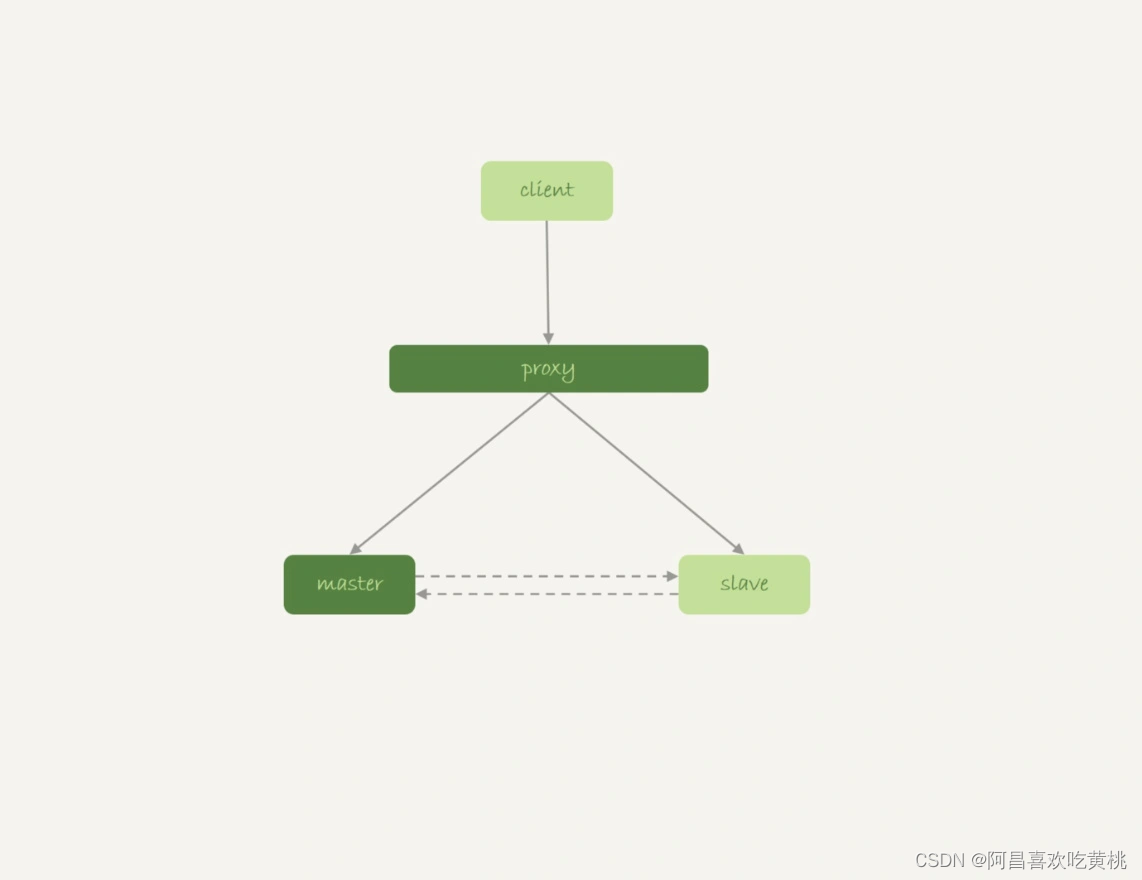
在备库重启的时候,备库 binlog 里的 delete 语句就会传到主库,然后把主库内存表的内容删除。这样你在使用的时候就会发现,主库的内存表数据突然被清空了。
基于上面的分析,内存表并不适合在生产环境上作为普通数据表使用。
但是内存表执行速度快呀。
这个问题,其实可以这么分析:
- 如果你的表更新量大,那么并发度是一个很重要的参考指标,InnoDB 支持行锁,并发度比内存表好;能放到内存表的数据量都不大。
- 如果你考虑的是读的性能,一个读 QPS 很高并且数据量不大的表,即使是使用 InnoDB,数据也是都会缓存在 InnoDB Buffer Pool 里的。因此,使用 InnoDB 表的读性能也不会差。
所以,建议你把普通内存表都用 InnoDB 表来代替。
但是,有一个场景却是例外的。
在数据量可控,不会耗费过多内存的情况下,可以考虑使用内存表。
内存临时表刚好可以无视内存表的两个不足,主要是下面的三个原因:
- 临时表不会被其他线程访问,没有并发性的问题;
- 临时表重启后也是需要删除的,清空数据这个问题不存在;
- 备库的临时表也不会影响主库的用户线程。
再看一下Join语句优化的例子,当时建议的是创建一个 InnoDB 临时表,使用的语句序列是:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
这里使用内存临时表的效果更好,原因有三个:
- 相比于 InnoDB 表,使用内存表不需要写磁盘,往表 temp_t 的写数据的
速度更快; - 索引 b 使用 hash 索引,查找的速度比 B-Tree 索引快;
- 临时表数据只有 2000 行,
占用的内存有限。
因此,将临时表 temp_t 改成内存临时表,并且在字段 b 上创建一个 hash 索引。
create temporary table temp_t(id int primary key, a int, b int, index (b))engine=memory;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);
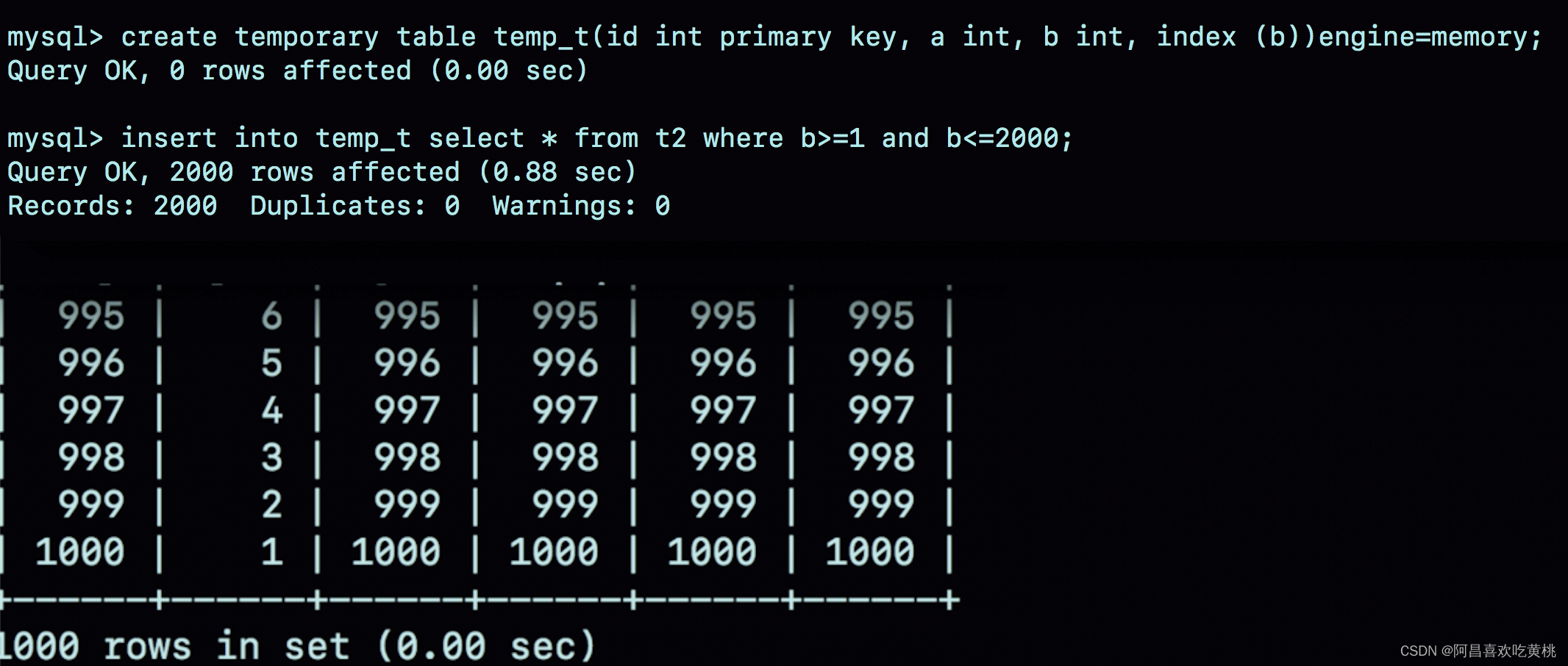
可以看到,不论是导入数据的时间,还是执行 join 的时间,使用内存临时表的速度都比使用 InnoDB 临时表要更快一些。
五、总结
由于重启会丢数据,如果一个备库重启,会导致主备同步线程停止;如果主库跟这个备库是双 M 架构,还可能导致主库的内存表数据被删掉。
因此,在生产上,不建议你使用普通内存表。如果是 DBA,可以在建表的审核系统中增加这类规则,要求业务改用 InnoDB 表。InnoDB 表性能还不错,而且数据安全也有保障。而内存表由于不支持行锁,更新语句会阻塞查询,性能也未必就如想象中那么好。
基于内存表的特性,还分析了它的一个适用场景,就是内存临时表。
内存表支持 hash 索引,这个特性利用起来,对复杂查询的加速效果还是很不错的。
假设刚刚接手的一个数据库上,真的发现了一个内存表。
备库重启之后肯定是会导致备库的内存表数据被清空,进而导致主备同步停止。
这时,最好的做法是将它修改成 InnoDB 引擎表。
假设当时的业务场景暂时不允许修改引擎,可以加上什么自动化逻辑,来避免主备同步停止呢?
在备库上设置跳过主库内存表的同步,避免因为同步主库内存表的错误而影响了其他表的同步进度。
相关文章:
Day902.Memory存储引擎 -MySQL实战
Memory存储引擎 Hi,我是阿昌,今天学习记录的是关于Memory存储引擎的内容。 两个 group by 语句都用了 order by null,为什么使用内存临时表得到的语句结果里,0 这个值在最后一行; 而使用磁盘临时表得到的结果里&…...
Linux(Centos)安装RabbitMQ+延时插件+开机自启动
安装目录1:前言1.1 系统环境1.2:安装版本1.3 简介2:安装2.1:安装前准备:2.2:安装Erlang2.3:安装RabbitMQ2.3:延迟依赖插件安装1:前言 1.1 系统环境 操作系统版本&#…...
)
最近是遇到了CKPT(BLOCKED)
半夜被电话吵醒,数据库不可用了,无法交易。 远程登录查看,这个时候就没有所谓的安全不安全了,都可以远程了。 onstat - 数据库处于CKPT(REQ) CKPT:BLOCKED状态 onstat -l 发现所有的逻辑日志都是U------状态ÿ…...
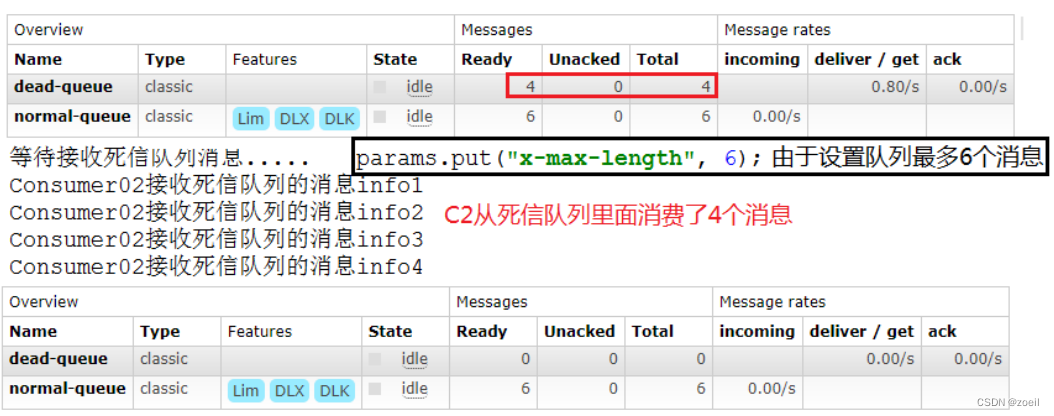
RabbitMQ死信队列
目录 一、概念 二、出现死信的原因 三、实战 (一)代码架构图 (二)消息被拒 (三)消息TTL过期 (四)队列达到最大长度 一、概念 先从概念解释上搞清楚这个定义,死信&…...

Word控件Spire.Doc 【书签】教程(1):在C#/VB.NET:在 Word 中插入书签
Spire.Doc for .NET是一款专门对 Word 文档进行操作的 .NET 类库。在于帮助开发人员无需安装 Microsoft Word情况下,轻松快捷高效地创建、编辑、转换和打印 Microsoft Word 文档。拥有近10年专业开发经验Spire系列办公文档开发工具,专注于创建、编辑、转…...
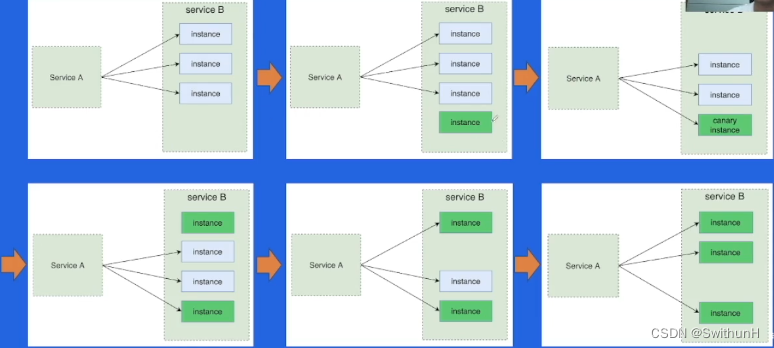
微服务框架-学习笔记
1 微服务架构介绍 1.1 系统架构演变历史 单体架构垂直应用架构:按照业务线垂直划分分布式架构:抽出业务无关的公共模块SOA架构:面向服务微服务架构:彻底的服务化1.2 微服务架构概览 1.3 微服务架构核心要素 服务治理࿱…...

实验心理学笔记01:引论
原视频链接: https://www.bilibili.com/video/BV1Qt41137Kv 目录 一、实验心理学:定义、内容及简要历史回顾 二、实验心理学和普通心理学、认知心理学的区别 三、实验方法与非实验方法 四、实验范式 五、实验中的各种变量 六、The science of psy…...

预备3-如何学习编程
如何学习编程 我说说曾经学习编程踩得坑 纠结字面上的意思 如纠结一个关键词的名称如何来 为什么叫这个名称... 只是一个简单的名称,该名称代表某一想象/行为,就好比你为啥叫张三, 千万别去深究这些...做笔记的时间比敲代码的时间还多 做笔记的原因是,自己总结归纳所学的知识, …...

操作系统权限提升(十七)之绕过UAC提权-Windows令牌概述和令牌窃取攻击
系列文章 操作系统权限提升(十二)之绕过UAC提权-Windows UAC概述 操作系统权限提升(十三)之绕过UAC提权-MSF和CS绕过UAC提权 操作系统权限提升(十四)之绕过UAC提权-基于白名单AutoElevate绕过UAC提权 操作系统权限提升(十五)之绕过UAC提权-基于白名单DLL劫持绕过UAC提权 操作系…...
)
【时间之外】系统管人,能行?(冷眼旁观连载之二)
上次写了在用的工具系统和痛点,基本情况都交待清楚了,春节假期很快就过去了。这次继续按照之前观察计划,谈谈对这些工具使用情况的感受,学而时习之,算是抛砖引玉,也算是个人对这项工作的总结和体会。 目录…...
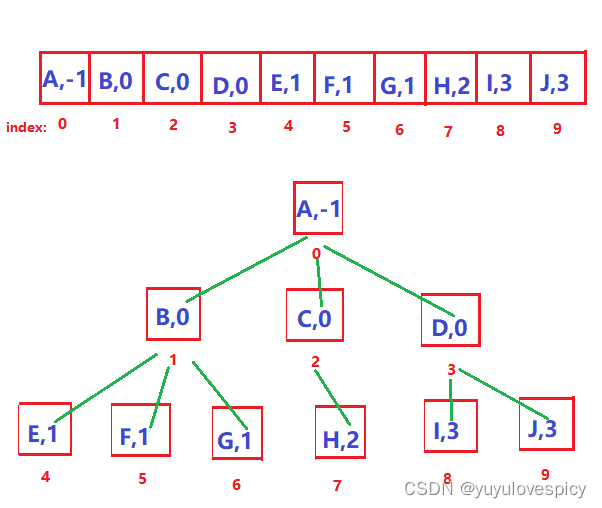
【数据结构必会基础】关于树,你所必须知道的亿些概念
目录 1.什么是树 1.1浅显的理解树 1.2 数据结构中树的概念 2.树的各种结构概念 2.1 节点的度 2.2 根节点/叶节点/分支节点 2.3 父节点/子节点 2.4祖先节点/子孙节点 2.5兄弟节点 2.6树的度 2.7节点的层次 2.8森林 3. 如何用代码表示一棵树 3.1链式结构 3.1.1 树节…...
)
设计模式的应用(已在大型项目中使用)
说明:开发语言:在本文中,使用的是C# 一、目录 •1 、单例模式 •2 、简单工厂模式 •3 、代理模式 •4 、观察者模式 •5 、外观模式 •6 、享元模式 •7 、命令模式 •8 、状态模式 •9 、发布订阅模式...

Git的相关用法
1.全局设置自己的git提交用户名和邮箱git config --global user.name 张三 git config --global user.email zsgmail.com即所有的提交都会用这个姓名和邮箱。如果不知道自己配置的是什么,可以查询下git config --global user.name git config --global user.email 或…...
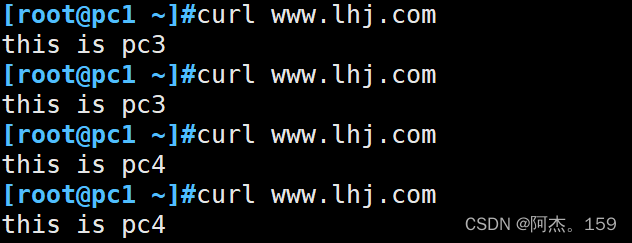
Linux服务:Nginx反向代理与负载均衡
目录 一、Nginx反向代理 1、什么是代理 2、实现反向代理实验 ①实验拓扑 ②实验目的 ③实验过程 二、反向代理负载均衡 1、反向代理负载均衡调度算法 ①轮询算法 ②加权轮询算法 ③最小连接数算法 ④ip、url 哈希算法 ⑤响应时间fair算法 2、实现反向代理负载均…...

数据结构与算法——2.算法概述
这篇文章,我们来讲一下算法的概述,大致理解一下什么是算法。 目录 1.定义 2.生活实例 3.算法目标 4.实际案例 4.1案例一 4.2案例二 5.小结 1.定义 官方解释: 算法是指解题方案的准确而完整的描述,是一系列解决问题的清…...

BPMN2.0是什么,BPMN能解决企业流程管理中哪些问题?
一、前言: 在任何行业和企业中,一定存在着各式各样的流程,请假流程、报销流程、入职流程、离职流程、出差流程、合同审批流程、出入库流程等等…… 无论是管理者、技术人员还是业务人员,每天肯定也在使用各种流程,但…...

Java线程池的基本工作原理及案例
一、线程池的优点 线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。 主要特点:线程复用;控制最大并发数;管理线程…...
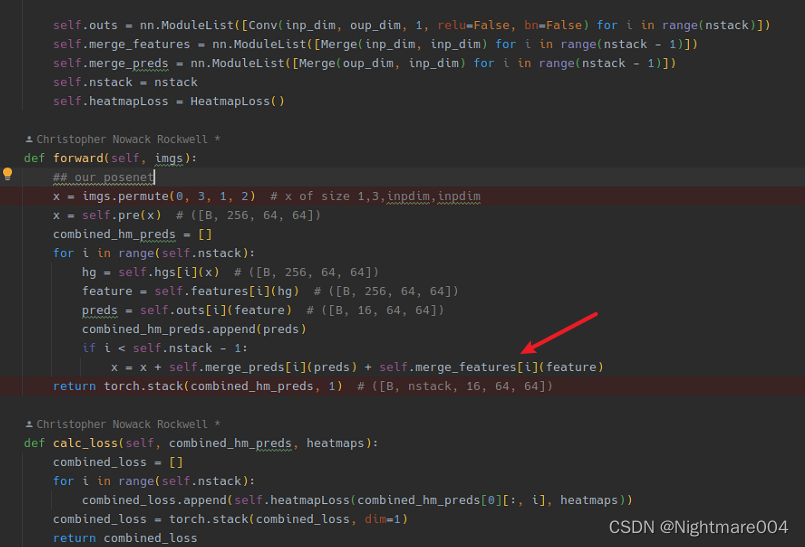
Stacked hourglass networks for human pose estimation代码学习
Stacked hourglass networks for human pose estimation https://github.com/princeton-vl/pytorch_stacked_hourglass 这是一个用于人体姿态估计的模型,只能检测单个人 作者通过重复的bottom-up(高分辨率->低分辨率)和top-down࿰…...
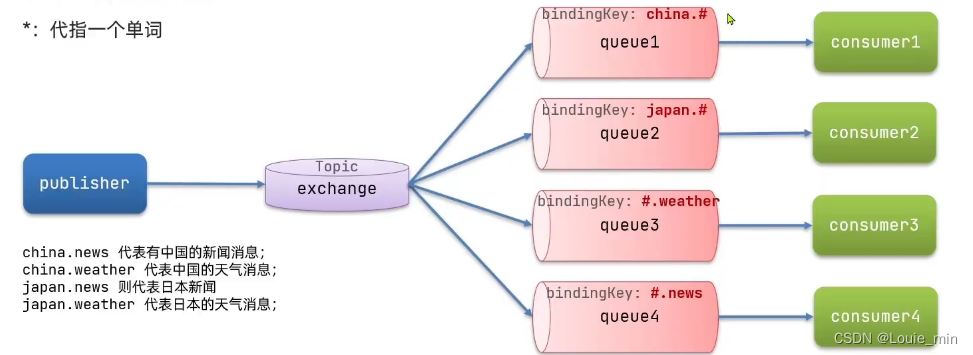
SpringCloud(五)MQ消息队列
MQ概念常见消息模型helloworld案例实现实现spring AMQP发送消息实现spring AMQP接收消息工作消息队列实现发布订阅模型Fanout Exchange实现DirectExchange实现TopicExchange实现DirectExchange 和FanoutExchange的差异DirectExchange 和TopicExchange的差异基于RabbitListener注…...

SQL语法基础汇总
三年前的存稿 默认端口号 3306 超级用户名 root 登录 mysql -uroot -p / mysql -uroot -proot 退出 exit / quit 服务器版本 SELECT VERSION(); 当前日期 SELECT NOW(); 当前用户 SELECT USER(); 备份 mysqldump -uroot -p 数据库名称 > 保存的路径 还原 create database1-…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...
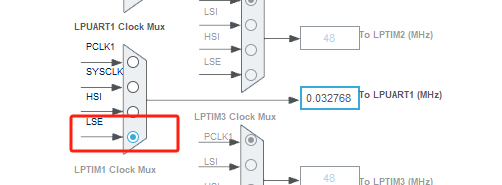
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...