【高性能计算】TVM使用TE手动优化矩阵乘法算法解析与代码解读
引言
注:本文主要介绍、解释TVM的矩阵优化思想、代码,需要配合代码注释一起阅读。
矩阵乘法是计算密集型运算。为了获得良好的 CPU 性能,有两个重要的优化措施:
-
提高内存访问的高速缓存命中率。复杂的数值计算和热点内存(hot-spot memory)访问都可以通过高缓存命中率(high cache hit rate)来加速。这就要求我们将原内存(origin )访问模式转化为符合高速缓存策略的模式。
-
SIMD(单指令多数据),也被称为矢量处理单元。在每个周期中,SIMD 可以处理一小批数据,而不是处理一个单一的值。这就要求我们将循环体中的数据访问模式转化为统一模式,以便编译器后端可以将其降低到 SIMD。
1- 基于TVM和Numpy的基线实现
这是numpy 实现矩阵乘法的实现代码,作为实现比较的基础benchmark,他的速度并不会很慢,这是因为其本身就采用了加速矩阵数学计算的算法实现。
import tvm
import tvm.testing
from tvm import te
import numpy# The size of the matrix
# (M, K) x (K, N)
# You are free to try out different shapes, sometimes TVM optimization outperforms numpy with MKL.
M = 1024
K = 1024
N = 1024# The default tensor data type in tvm
dtype = "float32"# You will want to adjust the target to match any CPU vector extensions you
# might have. For example, if you're using using Intel AVX2 (Advanced Vector
# Extensions) ISA for SIMD, you can get the best performance by changing the
# following line to ``llvm -mcpu=core-avx2``, or specific type of CPU you use.
# Recall that you're using llvm, you can get this information from the command
# ``llc --version`` to get the CPU type, and you can check ``/proc/cpuinfo``
# for additional extensions that your processor might support.target = tvm.target.Target(target="llvm", host="llvm")
dev = tvm.device(target.kind.name, 0)# Random generated tensor for testing
a = tvm.nd.array(numpy.random.rand(M, K).astype(dtype), dev)
b = tvm.nd.array(numpy.random.rand(K, N).astype(dtype), dev)# Repeatedly perform a matrix multiplication to get a performance baseline
# for the default numpy implementation
np_repeat = 100
np_running_time = timeit.timeit( // 统计numpy.dot(a, b)计算耗时setup="import numpy\n""M = " + str(M) + "\n""K = " + str(K) + "\n""N = " + str(N) + "\n"'dtype = "float32"\n'"a = numpy.random.rand(M, K).astype(dtype)\n""b = numpy.random.rand(K, N).astype(dtype)\n",stmt="answer = numpy.dot(a, b)",number=np_repeat,
)
print("Numpy running time: %f" % (np_running_time / np_repeat))answer = numpy.dot(a.numpy(), b.numpy())
现在用 TVM TE 编写基本的矩阵乘法,并验证它产生的结果与 numpy 的实现相同。我们还写了一个函数,它将帮助衡量调度优化的性能。
# TVM Matrix Multiplication using TE
k = te.reduce_axis((0, K), "k") // 可以理解为约分轴,M*K * K*N = M*N,K轴维度消失啦
A = te.placeholder((M, K), name="A") // 一种tensor,通常用于计算图的Input节点使用,没有前序节点
B = te.placeholder((K, N), name="B")
C = te.compute((M, N), lambda x, y: te.sum(A[x, k] * B[k, y], axis=k), name="C") // 定义输出结果。第一个参数(M, N)表示输出矩阵的shape,lambda i:则可以理解为 for i: 0->n-1# Default schedule
s = te.create_schedule(C.op) // 从一个或多个 Tensor 的 Operation 进行创建
func = tvm.build(s, [A, B, C], target=target, name="mmult")c = tvm.nd.array(numpy.zeros((M, N), dtype=dtype), dev)
func(a, b, c)
tvm.testing.assert_allclose(c.numpy(), answer, rtol=1e-5)def evaluate_operation(s, vars, target, name, optimization, log):func = tvm.build(s, [A, B, C], target=target, name="mmult")assert funcc = tvm.nd.array(numpy.zeros((M, N), dtype=dtype), dev)func(a, b, c)tvm.testing.assert_allclose(c.numpy(), answer, rtol=1e-5)evaluator = func.time_evaluator(func.entry_name, dev, number=10)mean_time = evaluator(a, b, c).meanprint("%s: %f" % (optimization, mean_time))log.append((optimization, mean_time))log = []evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="none", log=log)
让我们来看看上述使用 TVM 低级函数的运算器和默认调度的中间表示。请注意这个实现基本上是矩阵乘法的原始实现,在 A 和 B 矩阵的索引上使用三个嵌套循环。
先来看看原始的矩阵乘法实现,他基本没有考虑cache连续的问题:
for(int x = 0; x < M; x++){for(int y = 0; y < N; y++){for(int k = 0; k < K; k++){C[x][y] += A[x][k] * B[k][y];}}
}
TVM的计算其实是将二维矩阵平铺为了一维数组进行计算,由于边界定义为了1024,这里的offset也是1024
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], [])} {for (x: int32, 0, 1024) { // 主要看这里,对应关系为 x->M y->N k->Kfor (y: int32, 0, 1024) {C[((x*1024) + y)] = 0f32for (k: int32, 0, 1024) {let cse_var_2: int32 = (x*1024)let cse_var_1: int32 = (cse_var_2 + y)C[cse_var_1] = (C[cse_var_1] + (A[(cse_var_2 + k)]*B[((k*1024) + y)]))}}}
}
2-使用TVM调度原语tile分块优化cache阻塞
提高缓冲区命中率的一个重要技巧是阻塞,在这个过程中,你的内存访问结构是在一个块的内部有一个小的邻域,具有很高的内存定位性。在本教程中,我们选择一个 32 的块因子。这将导致一个块充满 32 * 32 * sizeof(float) 的内存区域。这相当于一个 4KB 的缓存大小,而 L1 缓存的参考缓存大小为 32KB。
对矩阵计算进行分块,以加速。分块可以进一步的提升B、C矩阵的空间局部性, 我们把C分成多个title,然后针对每一个title,A和B中对应的行tile和列tile也会切成相应大小的tile进行多个小矩阵乘法,最后加和到C的tile中,当我们把tile的大小限定到合适的范围内时,就可以把整个tile填充到cache内,分块的好处就体现在一个block内的计算小到可以被cache容纳,以充分利用cache快速的读写速度。
我们首先为 C 矩阵计算操作创建一个默认的调度,然后用指定的块因子对其应用一个 tile 调度原语,调度原语返回所产生的循环顺序,从最外层到最内层,作为一个向量 [x_outer, y_outer, x_inner, y_inner]。然后我们得到操作输出的还原轴,并使用 4 的因子对其进行分割操作。这个因子并不直接影响我们现在正在进行的阻塞优化,但在以后我们应用矢量化时将会很有用。
现在操作已经被阻塞了,我们可以重新调度计算的顺序,把较少操作放到计算的最外层循环中,帮助保证被阻止的数据仍然在缓存中。这样就完成了调度,我们可以建立并测试与原生的调度相比的性能。
bn = 32# Blocking by loop tiling
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4) // 分割# Hoist reduction domain outside the blocking loop
s[C].reorder(xo, yo, ko, ki, xi, yi)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="blocking", log=log)
通过重新安排计算顺序以利用缓存,你应该看到计算的性能有了明显的改善。现在,打印内部表示,并将其与原始表示进行比较。
print(tvm.lower(s, [A, B, C], simple_mode=True))
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], [])} {for (x.outer: int32, 0, 32) { // 外部32个分块for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) { // 内部32*32个浮点数for (y.inner.init: int32, 0, 32) {C[((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)) + y.inner.init)] = 0f32 // 32768为32*32*32,初始化该块内的数为0}}for (k.outer: int32, 0, 256) { // k轴分为4份,1024/4=256for (k.inner: int32, 0, 4) { // 这里的4主要用于后面的SIMD的使用for (x.inner: int32, 0, 32) {for (y.inner: int32, 0, 32) {let cse_var_3: int32 = (y.outer*32)let cse_var_2: int32 = ((x.outer*32768) + (x.inner*1024))let cse_var_1: int32 = ((cse_var_2 + cse_var_3) + y.inner)C[cse_var_1] = (C[cse_var_1] + (A[((cse_var_2 + (k.outer*4)) + k.inner)]*B[((((k.outer*4096) + (k.inner*1024)) + cse_var_3) + y.inner)])) // 其实这里B依然是cache不友好读取,即跳行读取,但可能是考虑到在一个定义的分块cache内}}}}}}
}
3-利用SIMD矢量化计算
另一个重要的优化技巧是矢量化。当内存访问模式是统一的,编译器可以检测到这种模式并将连续的内存传递给 SIMD 矢量处理器。在 TVM 中,我们可以使用 vectorize 接口来提示编译器这种模式,利用这一硬件特性。
- SIMD 的全称是 Single Instruction Multiple Data,中文名“单指令多数据”。顾名思义,一条指令处理多个数据。
在本教程中,我们选择对内循环的行数据进行矢量化,因为在我们之前的优化中,它已经是缓存友好的。
# Apply the vectorization optimization
s[C].vectorize(yi) // 对子块内的每一行进行SIMD计算evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="vectorization", log=log)# The generalized IR after vectorization
print(tvm.lower(s, [A, B, C], simple_mode=True))
vectorization: 0.257297
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], [])} {for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) {C[ramp((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (k.inner: int32, 0, 4) {for (x.inner: int32, 0, 32) { // 对于y.inner的每一行,使用128位SIMD计算,32*4,一次计算4位let cse_var_3: int32 = (y.outer*32)let cse_var_2: int32 = ((x.outer*32768) + (x.inner*1024))let cse_var_1: int32 = (cse_var_2 + cse_var_3)C[ramp(cse_var_1, 1, 32)] = (C[ramp(cse_var_1, 1, 32)] + (broadcast(A[((cse_var_2 + (k.outer*4)) + k.inner)], 32)*B[ramp((((k.outer*4096) + (k.inner*1024)) + cse_var_3), 1, 32)]))}}}}}
}
4-使用循环优化
如果我们看一下上面的 IR,我们可以看到内循环的行数据被矢量化,B 被转化为 分块B(这从内循环的 (float32x32*)B2 部分可以看出)。现在 B的分块 的遍历是顺序的。所以我们要看一下 A 的访问模式。在当前的计划中,A 是被逐列访问的,每次访问A的128位,这对缓冲区不友好。如果我们改变 ki 和内轴 xi 的嵌套循环顺序,A 矩阵的访问模式将对缓存更友好。
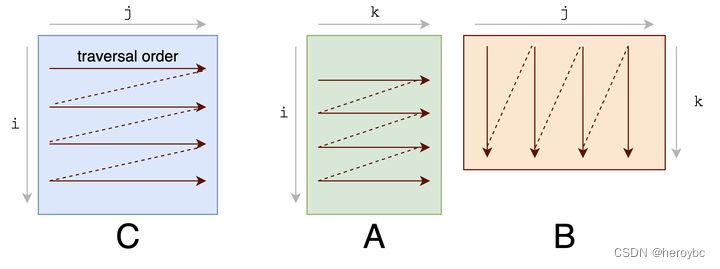
s = te.create_schedule(C.op)
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)# re-ordering
s[C].reorder(xo, yo, ko, xi, ki, yi) // 改变循环顺序
s[C].vectorize(yi)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="loop permutation", log=log
)# Again, print the new generalized IR
print(tvm.lower(s, [A, B, C], simple_mode=True))
loop permutation: 0.130006
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], [])} {for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) {C[ramp((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.inner: int32, 0, 32) {for (k.inner: int32, 0, 4) { // 调换了这里的顺序let cse_var_3: int32 = (y.outer*32)let cse_var_2: int32 = ((x.outer*32768) + (x.inner*1024))let cse_var_1: int32 = (cse_var_2 + cse_var_3)C[ramp(cse_var_1, 1, 32)] = (C[ramp(cse_var_1, 1, 32)] + (broadcast(A[((cse_var_2 + (k.outer*4)) + k.inner)], 32)*B[ramp((((k.outer*4096) + (k.inner*1024)) + cse_var_3), 1, 32)]))}}}}}
}
5-使用数组打包
另一个重要的技巧是数组打包。这个技巧是对数组的存储维度进行重新排序,将某些维度上的连续访问模式转换为扁平化后的顺序模式。
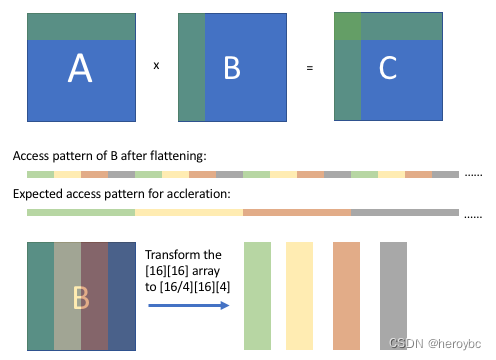
正如上图所示,在阻塞计算后,我们可以观察到 B 的数组访问模式(扁平化后),它是有规律的,但是不连续的。我们期望经过一些转换后,我们可以得到一个连续的访问模式。通过将 [16][16] 数组重新排序为 [16/4][16][4] 数组,当从打包的数组中抓取相应的值时,B 的访问模式将是连续的。
为了实现这一目标,将不得不从新的默认调度开始,考虑到 B 的新包装,值得花点时间来评论一下。TE 是编写优化运算符的强大而富有表现力的语言,但它往往需要对你所编写的底层算法、数据结构和硬件目标有一些了解。在本教程的后面,我们将讨论一些让 TVM 承担这一负担的选项。无论如何,让我们继续编写新的优化调度。
这里的本质相当于改变了B的按列读取,改为按行读取,即cache友好。
// 必须重写算法。对计算方式进行重新定义。
packedB = te.compute((N / bn, K, bn), lambda x, y, z: B[y, x * bn + z], name="packedB")
C = te.compute((M, N),lambda x, y: te.sum(A[x, k] * packedB[y // bn, k, tvm.tir.indexmod(y, bn)], axis=k), // TIR 的全称是 Tensor IR, tvm.tir.indexmod 为计算y/bn的余数name="C",
)s = te.create_schedule(C.op)xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
(k,) = s[C].op.reduce_axis
ko, ki = s[C].split(k, factor=4)s[C].reorder(xo, yo, ko, xi, ki, yi)
s[C].vectorize(yi)x, y, z = s[packedB].op.axis
s[packedB].vectorize(z) // 执行向量操作的指令。vectorize 是并发思路在CPU里的最细粒度实现。
s[packedB].parallel(x)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="array packing", log=log)# Here is the generated IR after array packing.
print(tvm.lower(s, [A, B, C], simple_mode=True))
array packing: 0.140257
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], [])} {allocate(packedB: Pointer(global float32x32), float32x32, [32768]), storage_scope = global {for (x: int32, 0, 32) "parallel" {for (y: int32, 0, 1024) {packedB_1: Buffer(packedB, float32x32, [32768], [])[((x*1024) + y)] = B[ramp(((y*1024) + (x*32)), 1, 32)]}}for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.inner.init: int32, 0, 32) {C[ramp((((x.outer*32768) + (x.inner.init*1024)) + (y.outer*32)), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.inner: int32, 0, 32) {for (k.inner: int32, 0, 4) {let cse_var_3: int32 = ((x.outer*32768) + (x.inner*1024))let cse_var_2: int32 = (k.outer*4)let cse_var_1: int32 = (cse_var_3 + (y.outer*32))C[ramp(cse_var_1, 1, 32)] = (C[ramp(cse_var_1, 1, 32)] + (broadcast(A[((cse_var_3 + cse_var_2) + k.inner)], 32)*packedB_1[(((y.outer*1024) + cse_var_2) + k.inner)]))}}}}}}
}
6-通过缓存优化块的写入
到目前为止,我们所有的优化都集中在有效地访问和计算 A 和 B 矩阵的数据以计算 C 矩阵上。在阻塞优化之后,运算器将逐块地将结果写入 C,而且访问模式不是顺序的。我们可以通过使用一个顺序缓存数组来解决这个问题,使用 cache_write、compute_at 和 unroll 的组合来保存块结果,并在所有块结果准备好后写入 C。
cache_write和cache_read对应,是先在shared memory中存放计算结果,最后将结果写回到global memory。当然在真实的场景中,我们往往是会将结果先放着register中,最后写回。
s = te.create_schedule(C.op)# Allocate write cache
CC = s.cache_write(C, "global")xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)# Write cache is computed at yo
s[CC].compute_at(s[C], yo) // 默认情况下,TVM将在函数的最外层或根计算张量。compute_at指定应在另一个运算符的第一个计算轴上计算一个张量。应该是为了方便后续的在xo维度上进行并行计算。# New inner axes
xc, yc = s[CC].op.axis(k,) = s[CC].op.reduce_axis
ko, ki = s[CC].split(k, factor=4)
s[CC].reorder(ko, xc, ki, yc)
s[CC].unroll(ki) // 循环展开
s[CC].vectorize(yc)x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="block caching", log=log)# Here is the generated IR after write cache blocking.
print(tvm.lower(s, [A, B, C], simple_mode=True))
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], [])} {allocate(packedB: Pointer(global float32x32), float32x32, [32768]), storage_scope = global;allocate(C.global: Pointer(global float32), float32, [1024]), storage_scope = global {for (x: int32, 0, 32) "parallel" {for (y: int32, 0, 1024) {packedB_1: Buffer(packedB, float32x32, [32768], [])[((x*1024) + y)] = B[ramp(((y*1024) + (x*32)), 1, 32)]}}for (x.outer: int32, 0, 32) {for (y.outer: int32, 0, 32) {for (x.c.init: int32, 0, 32) {C.global_1: Buffer(C.global, float32, [1024], [])[ramp((x.c.init*32), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.c: int32, 0, 32) {let cse_var_4: int32 = (k.outer*4)let cse_var_3: int32 = (x.c*32)let cse_var_2: int32 = ((y.outer*1024) + cse_var_4)let cse_var_1: int32 = (((x.outer*32768) + (x.c*1024)) + cse_var_4){C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[cse_var_1], 32)*packedB_1[cse_var_2]))C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[(cse_var_1 + 1)], 32)*packedB_1[(cse_var_2 + 1)]))C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[(cse_var_1 + 2)], 32)*packedB_1[(cse_var_2 + 2)]))C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[(cse_var_1 + 3)], 32)*packedB_1[(cse_var_2 + 3)]))}}}for (x.inner: int32, 0, 32) {for (y.inner: int32, 0, 32) {C[((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)) + y.inner)] = C.global_1[((x.inner*32) + y.inner)]}}}}}
}
7-并行化
到目前为止,我们的计算只被设计为使用单核。几乎所有的现代处理器都有多个内核,计算可以从并行运行的计算中获益。最后的优化是利用线程级并行化的优势。
# parallel
s[C].parallel(xo)x, y, z = s[packedB].op.axis
s[packedB].vectorize(z)
s[packedB].parallel(x)evaluate_operation(s, [A, B, C], target=target, name="mmult", optimization="parallelization", log=log
)# Here is the generated IR after parallelization.
print(tvm.lower(s, [A, B, C], simple_mode=True))
parallelization: 0.026403
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}buffers = {A: Buffer(A_2: Pointer(float32), float32, [1048576], []),B: Buffer(B_2: Pointer(float32), float32, [1048576], []),C: Buffer(C_2: Pointer(float32), float32, [1048576], [])}buffer_map = {A_1: A, B_1: B, C_1: C}preflattened_buffer_map = {A_1: A_3: Buffer(A_2, float32, [1024, 1024], []), B_1: B_3: Buffer(B_2, float32, [1024, 1024], []), C_1: C_3: Buffer(C_2, float32, [1024, 1024], [])} {allocate(packedB: Pointer(global float32x32), float32x32, [32768]), storage_scope = global {for (x: int32, 0, 32) "parallel" {for (y: int32, 0, 1024) {packedB_1: Buffer(packedB, float32x32, [32768], [])[((x*1024) + y)] = B[ramp(((y*1024) + (x*32)), 1, 32)]}}for (x.outer: int32, 0, 32) "parallel" {allocate(C.global: Pointer(global float32), float32, [1024]), storage_scope = global;for (y.outer: int32, 0, 32) {for (x.c.init: int32, 0, 32) {C.global_1: Buffer(C.global, float32, [1024], [])[ramp((x.c.init*32), 1, 32)] = broadcast(0f32, 32)}for (k.outer: int32, 0, 256) {for (x.c: int32, 0, 32) {let cse_var_4: int32 = (k.outer*4)let cse_var_3: int32 = (x.c*32)let cse_var_2: int32 = ((y.outer*1024) + cse_var_4)let cse_var_1: int32 = (((x.outer*32768) + (x.c*1024)) + cse_var_4){C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[cse_var_1], 32)*packedB_1[cse_var_2]))C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[(cse_var_1 + 1)], 32)*packedB_1[(cse_var_2 + 1)]))C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[(cse_var_1 + 2)], 32)*packedB_1[(cse_var_2 + 2)]))C.global_1[ramp(cse_var_3, 1, 32)] = (C.global_1[ramp(cse_var_3, 1, 32)] + (broadcast(A[(cse_var_1 + 3)], 32)*packedB_1[(cse_var_2 + 3)]))}}}for (x.inner: int32, 0, 32) {for (y.inner: int32, 0, 32) {C[((((x.outer*32768) + (x.inner*1024)) + (y.outer*32)) + y.inner)] = C.global_1[((x.inner*32) + y.inner)]}}}}}
}
总结
如前所述,如何使用 TE 和调度原语进行优化,可能需要对底层架构和算法有一些了解。然而,TE 的设计是作为更复杂的算法的基础,可以搜索潜在的优化。
本教程提供了一个 TVM 张量表达(TE)工作流程的演练,使用了一个矢量添加和一个矩阵乘法的例子。一般的工作流程是:
- 通过一系列的操作来描述你的计算。
- 描述我们要如何计算使用调度原语。
- 编译到我们想要的目标函数。
- 可以选择保存该函数以便以后加载。
参考资料
- TVM官方教程:https://daobook.github.io/tvm/docs/tutorial/tensor_expr_get_started.html
相关文章:
【高性能计算】TVM使用TE手动优化矩阵乘法算法解析与代码解读
引言 注:本文主要介绍、解释TVM的矩阵优化思想、代码,需要配合代码注释一起阅读。 矩阵乘法是计算密集型运算。为了获得良好的 CPU 性能,有两个重要的优化措施: 提高内存访问的高速缓存命中率。复杂的数值计算和热点内存&#x…...

消息中间件的概念
中间件(middleware)是基础软件的一大类,属于可复用的软件范畴。中间件在操作系统软件,网络和数据库之上,应用软件之下,总的作用是为处于自己上层的应用软件提供运行于开发的环境,帮助用户灵活、高效的开发和集成复杂的…...

窃密恶意软件Raccoon最新样本Stealer v2分析
Raccoon 是一个恶意软件家族,2019 年来一直在地下犯罪论坛中以恶意软件即服务的身份进行售卖。2022 年 7 月,该恶意软件家族发布了 C 语言编写的新版本 Raccoon Stealer v2,打破了以往使用 C 开发的传统。 Raccoon 是一个信息窃密恶意软件&a…...
足球俱乐部管理系统
技术:Java、JSP等摘要:网站是一种主要的渠道。人们通过互联网快速、准确的发布信息、获取信息。而足球俱乐部是足球职业化、专业化的一个标志,是足球运动员以足球谋生时,所被聘用的机构,应运时代发展,规模、…...
)
2023上半年数学建模竞赛汇总(比赛时间、难易程度、含金量、竞赛官网)
1、美国大学生数学建模竞赛等级:国家级是否可跨校:否竞赛开始时间:2月17日~2月21日综合难度:⭐⭐⭐⭐ 竞赛含金量:⭐⭐⭐⭐⭐竞赛官网:https://www.comap.com/2、MathorCup高校数学建模挑战赛---大数据竞赛…...

【python学习笔记】:PHP7 Null合并运算符
在PHP7,一个新的功能,空合并运算符(??)已被引入。它被用来代替三元运算并与 isset()函数功能结合一起使用。如果它存在并且它不是空的,空合并运算符返回它的第一个操作数;否则返回第二个操作数。 示例 <?php// fetch the value of $_…...
数据结构与算法——3.时间复杂度分析1(概述)
前面我们已经介绍了,研究算法的最终目的是如何花费更少的时间,如何占用更少的内存去完成相同的需求,并且也通过案例演示了不同算法之间时间耗费和空间耗费上的差异,但我们并不能将时间占用和空间占用量化。因此,接下来…...
FPGA学习之日常工作复位电路
最近一个多月没有写博客了,然后最近工作中也遇到一个复位信号的问题。问题是这样的,关于外部复位信号,之前我们的处理方式都是通过PLL产生的Lock信号作为内部的复位信号。但是由于换到A54上面没有IP核,所以只有不用PLL,…...
)
【洛谷 P1177】【模板】快速排序 题解(快速排序+指针)
【模板】快速排序 题目描述 利用快速排序算法将读入的 NNN 个数从小到大排序后输出。 快速排序是信息学竞赛的必备算法之一。对于快速排序不是很了解的同学可以自行上网查询相关资料,掌握后独立完成。(C 选手请不要试图使用 STL,虽然你可以…...
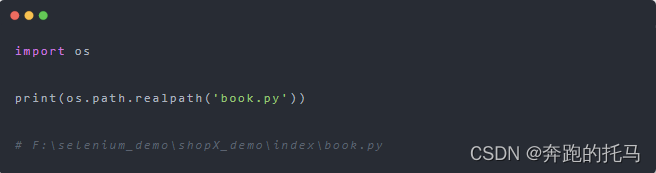
Pthon--自动化实用技巧篇--文件目录处理
为什么要讲这一篇,主要是因为这个在自动化测试框架或者脚本的编写的时候会用到,还是比较方便的。看上述两个函数。getcwd()、chdir()。使用 os.getcwd() 函数获得当前工作目录。使用 os.chdir()函数改变当前工作目录。所以在用chdir()函数的时候别忘记指…...

想招到实干派程序员?你需要这种面试法
技术招聘中最痛的点其实是不精准。技术面试官或CTO们常常会向我们吐槽: “我经常在想,能不能把我们项目中的代码打印出来,作为候选人的面试题的一部分?” “能不能把一个Bug带上环境,让候选人来试试怎么解决…...

cesium常见操作:鼠标点击获取对象
目录 一、viewer.scene.pick(获取Cartesian2) 二、 viewer.scene.pickPosition(获取Cartesian3) 三、viewer.scene.drillPick(穿透拾取,获取所有对象) 四、viewer.scene.globe.pick…...
【玩转c++】git的安装和使用以及可视化处理
本期主题:git的安装和使用(windows环境)博客主页:小峰同学分享小编的在Linux中学习到的知识和遇到的问题 小编的能力有限,出现错误希望大家不吝赐1.两个工具介绍第一个工具git,链接gitee或者github等代码托…...

第三阶段02-Mybatis框架
Mybatis框架 Mybatis框架是目前最流行的数据持久层框架, 使用Mybatis框架可以帮助程序员自动生成JDBC代码, 程序员只需要通过注解或xml配置文件提供需要执行的SQL语句,以及对象和表的映射关系, Mybatis框架会根据此映射关系和SQL自动生成出JDBC代码,从而提高开发效率 Mybatis框…...

基于超像素的多视觉特征图像分割算法研究
0.引言 背景: 经典聚类算法:Kmeans、FCM 现有问题: 1)现有算法大都是基于单一的视觉特征而设计的,eg:基于颜色特征的分割。 2)没有考虑像素周围的空间信息;分割结果:多噪…...

mysql的三大日志
摘自https://blog.csdn.net/chuige2013/article/details/123027580 一. 初步认识 binlog二进制日志 redolog undolog 二. binlog binlog记录写入行操作 作用 1)、主从复制:在Master端开启binlog,然后将binlog发送到各个Slave端,S…...

API接口及社区电子商务化的解释
API是应用程序的开发接口,在开发程序的时候,我们有些功能可能不需要从到到位去研发,我们可以拿现有的开发出来的功能模块来使用,而这个功能模块,就叫做库(libary)。比如说:要实现数据传输的安全,…...

[蓝帽杯 2021]One Pointer PHP
知识点:php 数组整型溢出,open_basedir 绕过分析 利用数组整型溢出绕过,因为PHP 会对溢出的数字处理为 float 类型。 <?php include "user.php"; if($userunserialize($_COOKIE["data"])){$count[$user->count]…...
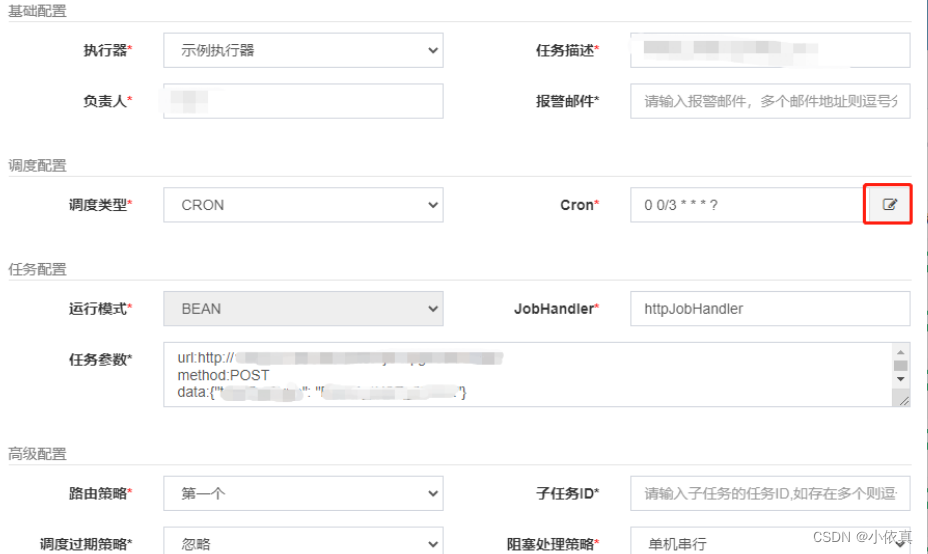
【JAVA】xxl-job服务搭建
xxl-job服务搭建 1.下载xxl-job项目 https://github.com/xuxueli/xxl-job 2.数据库表创建 3.修改配置 注意:这是两个项目,一个是xxl-job前台,一个是xxl-job执行器,找到这两个项目得配置文件,修改配置。 配置文件地址…...

毕业设计 基于STM32单片机生理监控心率脉搏TFT彩屏波形曲线设计
基于STM32单片机生理监控心率脉搏TFT彩屏波形曲线设计1、项目简介1.1 系统构成1.2 系统功能2、部分电路设计2.1 STM32F103C8T6核心系统电路设计2.2心率检测电路设计2.3 TFT2.4寸彩屏电路设计3、部分代码展示3.1 ADC初始化3.2 获取ADC采样值3.3 LCD引脚初始化3.3 在LCD指定位置显…...

5分钟搞定ECharts Tooltip显示问题:从滚动条到完美适配屏幕的保姆级教程
5分钟搞定ECharts Tooltip显示问题:从滚动条到完美适配屏幕的保姆级教程 第一次用ECharts做数据可视化时,Tooltip的显示问题简直让人抓狂——要么内容太长出现滚动条,要么直接冲出屏幕边界。作为过来人,我整理了这份实战指南&…...

ICEM高效建模技巧:从快捷键到多点创建模式
1. ICEM快捷键:让你的建模效率翻倍 刚开始用ICEM建模那会儿,我总被繁琐的鼠标操作折磨得够呛。直到有天发现隔壁工位的同事建模速度比我快三倍,偷师学艺才知道——原来快捷键才是真正的生产力神器。这里分享几个我每天必用的核心快捷键组合&a…...

bat批处理命令
一、 什么是 .bat 文件?.bat 文件是一个文本文件,里面包含了一系列 CMD(命令提示符) 命令。当你双击这个文件时,系统会按顺序逐条执行里面的命令。二、 如何开始?创建文件:新建一个文本文件&…...

MedGemma与Ray集成:分布式医学AI训练
MedGemma与Ray集成:分布式医学AI训练 1. 引言 医学AI模型训练正面临着一个关键挑战:随着模型参数量的增加和医学数据集的扩大,单机训练已经无法满足需求。一张高分辨率CT影像可能达到GB级别,而完整的医学影像数据集往往需要TB级…...

LiTmall:如何用Spring Boot + Vue + 微信小程序构建高效开源电商系统?
LiTmall:如何用Spring Boot Vue 微信小程序构建高效开源电商系统? 【免费下载链接】litemall linlinjava/litemall: LiTmall 是一个基于Spring Boot MyBatis的轻量级Java商城系统,适合中小型电商项目作为基础框架,便于快速搭建…...

当柔性车间遇上强化学习:从传统规则到DRL的调度进化史
柔性车间调度的智能革命:深度强化学习如何重塑制造业决策 在当今快节奏、定制化需求激增的制造业环境中,传统的生产调度方法正面临前所未有的挑战。想象一下,一个典型的电子设备制造车间:数百种不同规格的订单不断涌入,…...

Buildah多平台容器构建终极指南:使用QEMU跨架构构建Docker镜像
Buildah多平台容器构建终极指南:使用QEMU跨架构构建Docker镜像 【免费下载链接】buildah A tool that facilitates building OCI images. 项目地址: https://gitcode.com/gh_mirrors/bu/buildah Buildah作为专业的OCI镜像构建工具,为开发者提供了…...

手把手教你搭建轻量级Gitea代码托管平台:Windows本地部署实战
1. 为什么选择Gitea作为本地代码托管平台 作为一个长期在Windows环境下开发的程序员,我深知一个轻量级代码托管平台的重要性。以前我也用过Gitblit这类工具,但随着项目复杂度提升,越来越需要一个更现代的解决方案。Gitea就像是为个人开发者量…...

手把手教你修复conda的HTTP 404错误:从错误日志分析到快速解决
深度解析Conda的HTTP 404错误:从日志分析到高效修复 当你满怀期待地输入conda create -n myenv python3.9准备创建新环境时,终端却无情地抛出一堆红色错误信息,最扎眼的就是那个requests.exceptions.HTTPError: 404 Client Error。这种突如其…...

Swagger2配置避坑指南:为什么你的Docket分组设置会导致api-docs 404?
Swagger2配置避坑指南:为什么你的Docket分组设置会导致api-docs 404? 在RESTful API开发中,Swagger2作为API文档生成工具被广泛使用。但许多开发者在配置过程中都遇到过这样的问题:明明能正常访问swagger-ui.html页面,…...