揭秘关于TFRcord的五脏六腑
揭秘关于TFRcord的五脏六腑
前言:本篇文章将演示如何创建、解析和使用tf.Example消息,以及如何在.tfrecord文件之间对tf.Example消息进行序列化、写入和读取。
教程讲解使用的都是结构化数据,文章最后还会演示如果将图片写成.tfrecord文件,这在同个数据集用于不同模型情景之下非常有用。
官网文档是从讲原理,然后再展现示例。我觉得这种方式很容易劝退小白,因为原理晦涩难懂。这里先展示示例,然后再肢解示例,先总体再细分的思想
希望能让读者更容易理解和接受
一、如何将标量输入值变成协议消息
这里先不解释什么是协议消息,先看示例,后解释
# todo 导入相应工具包
import tensorflow as tfimport numpy as np
import IPython.display as display# todo 为了讲解,模拟生成一些数据
# 这里准备生成10000个元素
n_observations = int(1e4)# 随机生成10000个True和False布尔值
feature0 = np.random.choice([False, True], n_observations)# 随机生成10000个0-5的整数
feature1 = np.random.randint(0, 5, n_observations)# 随机生成10000个值是以下字符串的字符串
strings = np.array([b'cat', b'dog', b'chicken', b'horse', b'goat'])
feature2 = strings[feature1]# 随机生成10000个01正太分布数据,数据是浮点型
feature3 = np.random.randn(n_observations)# todo 下面分别演示将字符串类型标量、浮点型标量、整数型标量转换成协议消息
# todo 这些方法可以复制过去直接使用
def _bytes_feature(value):"""输入string / byte类型数据,返回bytes_list类型的协议消息"""if isinstance(value, type(tf.constant(0))):value = value.numpy() # BytesList won't unpack a string from an EagerTensor.return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) # 先记住这个写法,这个写法是TF官网推荐的写法def _float_feature(value):"""输入float / double类型数据,返回float_list类型的协议消息"""return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))def _int64_feature(value):"""输入bool / enum / int / uint.类型数据,返回int64_list类型的协议消息"""return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))# todo 通过调用上面的方法可以做到将相应类型的标量转换成协议消息了
print(_bytes_feature(b'test_string')) # 字符串
print(_bytes_feature(u'test_bytes'.encode('utf-8'))) # 二进制bytesprint(_float_feature(np.exp(1))) # 浮点型,自然数eprint(_int64_feature(True)) # 布尔型
print(_int64_feature(1)) # 整型
结果如下。结果展示的就是协议消息的“样子”,协议消息就是长这样,协议消息对应的值就是value里面的值
bytes_list {value: "test_string"
}bytes_list {value: "test_bytes"
}float_list {value: 2.7182817459106445
}int64_list {value: 1
}int64_list {value: 1
}
二、如何将协议消息变成二进制字符串
接着上面代码的延续,先不解释什么是二进制字符串,读者先阅读一遍代码的注释
# todo 将浮点型标量转成协议消息
feature = _float_feature(np.exp(1))# todo 使用方法SerializeToString(),将协议消息变成二进制字符串
string_010 = feature.SerializeToString()print(string_010) # 结果是: b'\x12\x06\n\x04T\xf8-@'"""
b'\x12\x06\n\x04T\xf8-@'
就是二进制字符串的样子
你可以简单把它理解成字符串
"""
三、如何将协议消息变成字典协议消息
字典型的协议消息如下,读者先看一遍代码的注释,再进行理解一遍
# todo 构建不同类型的协议消息
bytes_fea = _bytes_feature(b'test_string') # 字符串协议消息float_fea = _float_feature(np.exp(1)) # 浮点型协议消息int64_fea = _int64_feature(1) # 整数型协议消息# todo 将协议消息变成字典型协议消息
dict_fea = {'featrue0':bytes_fea,'featrue1':float_fea,'featrue2':int64_fea,
}
"""
说明:
dict_fea就是字典型协议消息,其中字典的key可以顺便自己命名,而字典的value就是协议消息
"""
字典型协议消息就是字典的value就是协议消息的字典
四、如何将字典协议消息变成二进制字符串
做法就是将字典协议消息转成特征消息,因为特征消息是协议消息的一种,所以可以将特征消息根据方法SerializeToString()变成二进制字符串
# todo 构建不同类型的协议消息
bytes_fea = _bytes_feature(b'test_string') # 字符串协议消息float_fea = _float_feature(np.exp(1)) # 浮点型协议消息int64_fea = _int64_feature(1) # 整数型协议消息# todo 将协议消息变成字典型协议消息
dict_fea = {'featrue0':bytes_fea,'featrue1':float_fea,'featrue2':int64_fea,
}# todo 将协议消息变成特征消息,代码就是这么写的,读者根据官网推荐这些写法这么写即可
example_proto = tf.train.Example(features=tf.train.Features(feature=dict_fea))# todo 将特征消息转成二进制字符串
bytes_string = example_proto.SerializeToString()
print(bytes_string)
结果如下。显示的就是字典协议消息的二进制字符串
b'\nF\n\x1b\n\x08featrue0\x12\x0f\n\r\n\x0btest_string\n\x14\n\x08featrue1\x12\x08\x12\x06\n\x04T\xf8-@\n\x11\n\x08featrue2\x12\x05\x1a\x03\n\x01\x01'
五、关于TFRecord文件各种疑问
-
什么是TFRecord文件
TFRecord 格式是一种用于存储二进制字符串记录序列的简单格式。
-
为什么要用TFRecord文件
通过tfrecord文件建立的数据管道Dataset对象读数的性能更好
-
TFRecord格式详细信息
TFRecord 文件包含一系列记录。该文件只能按顺序读取。
每条记录包含一个字节字符串(用于数据有效负载),外加数据长度,以及用于完整性检查的 CRC32C(使用 Castagnoli 多项式的 32 位 CRC)哈希值。
每条记录会存储为以下格式:
uint64 length uint32 masked_crc32_of_length byte data[length] uint32 masked_crc32_of_data将记录连接起来以生成文件。此处对 CRC 进行了说明,且 CRC 的掩码为:
masked_crc = ((crc >> 15) | (crc << 17)) + 0xa282ead8ul注:不需要在 TFRecord 文件中使用
tf.Example。tf.Example只是将字典序列化为字节字符串的一种方法。文本行、编码的图像数据,或序列化的张量(使用tf.io.serialize_tensor,或在加载时使用tf.io.parse_tensor)。有关更多选项,请参阅tf.io模块。
六、TFRecord文件如何存储数据
TFRecord文件存储的是二进制字符串,二进制字符串由协议消息或者是字典协议消息生成,协议消息又由标量或者是向量生成。
所以TFRecord存储的二进制字符串相当于存储了真实的数据
之所以要通过协议消息、字典协议消息来存储这些数据,是因为这样子可以提高数据的复用率和使用效率
七、将numpy数据存储成TFRecord格式文件
读者可以直接阅读代码的注释.从上往下阅读即可,不需要觉得很难
# todo 导入相应工具包
import tensorflow as tfimport numpy as np
import IPython.display as display# todo 为了讲解,模拟生成一些数据
# 这里准备生成10000个元素
n_observations = int(1e4)# 随机生成10000个True和False布尔值
feature0 = np.random.choice([False, True], n_observations)# 随机生成10000个0-5的整数
feature1 = np.random.randint(0, 5, n_observations)# 随机生成10000个值是以下字符串的字符串
strings = np.array([b'cat', b'dog', b'chicken', b'horse', b'goat'])
feature2 = strings[feature1]# 随机生成10000个01正太分布数据,数据是浮点型
feature3 = np.random.randn(n_observations)# todo 下面分别演示将字符串类型标量、浮点型标量、整数型标量转换成协议消息
# todo 这些方法可以复制过去直接使用
def _bytes_feature(value):"""输入string / byte类型数据,返回bytes_list类型的协议消息"""if isinstance(value, type(tf.constant(0))):value = value.numpy() # BytesList won't unpack a string from an EagerTensor.return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) # 先记住这个写法,这个写法是TF官网推荐的写法def _float_feature(value):"""输入float / double类型数据,返回float_list类型的协议消息"""return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))def _int64_feature(value):"""输入bool / enum / int / uint.类型数据,返回int64_list类型的协议消息"""return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))def serialize_example(feature0, feature1, feature2, feature3):"""输入标量,转成字典协议消息,转成特征消息,转成二进制字符串"""# 构建字典协议消息feature = {'feature0': _int64_feature(feature0),'feature1': _int64_feature(feature1),'feature2': _bytes_feature(feature2),'feature3': _float_feature(feature3),}# Create a Features message using tf.train.Example.example_proto = tf.train.Example(features=tf.train.Features(feature=feature))return example_proto.SerializeToString()# todo 将二进制字符串写进tfrecord文件中
filename = './test.tfrecord'
with tf.io.TFRecordWriter(filename) as writer: # 构建一个写入对象的上下文for i in range(n_observations): # 循环写入example = serialize_example(feature0[i], feature1[i], feature2[i], feature3[i])writer.write(example)
<ipython-input-62-e109c8c4da87>:38: DeprecationWarning: In future, it will be an error for 'np.bool_' scalars to be interpreted as an indexreturn tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
从上面可以看出来,上面的代码需要循环写入数据,速度比较慢,下面介绍一种速度更加快速的写入方法
八、通过Dataset将numpy数据存储成TFRecord格式文件
过程代码解释了原理,并且这些代码都可以进行复用,请读者认真消化
# todo 导入相应工具包
import tensorflow as tfimport numpy as np
import IPython.display as display# todo 为了讲解,模拟生成一些数据
# 这里准备生成10000个元素
n_observations = int(1e4)# 随机生成10000个True和False布尔值
feature0 = np.random.choice([False, True], n_observations)# 随机生成10000个0-5的整数
feature1 = np.random.randint(0, 5, n_observations)# 随机生成10000个值是以下字符串的字符串
strings = np.array([b'cat', b'dog', b'chicken', b'horse', b'goat'])
feature2 = strings[feature1]# 随机生成10000个01正太分布数据,数据是浮点型
feature3 = np.random.randn(n_observations)# todo 下面分别演示将字符串类型标量、浮点型标量、整数型标量转换成协议消息
# todo 这些方法可以复制过去直接使用
def _bytes_feature(value):"""输入string / byte类型数据,返回bytes_list类型的协议消息"""if isinstance(value, type(tf.constant(0))):value = value.numpy() # BytesList won't unpack a string from an EagerTensor.return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) # 先记住这个写法,这个写法是TF官网推荐的写法def _float_feature(value):"""输入float / double类型数据,返回float_list类型的协议消息"""return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))def _int64_feature(value):"""输入bool / enum / int / uint.类型数据,返回int64_list类型的协议消息"""return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))def serialize_example(feature0, feature1, feature2, feature3):"""输入标量,转成字典协议消息,转成特征消息,转成二进制字符串"""# 构建字典协议消息feature = {'feature0': _int64_feature(feature0),'feature1': _int64_feature(feature1),'feature2': _bytes_feature(feature2),'feature3': _float_feature(feature3),}# Create a Features message using tf.train.Example.example_proto = tf.train.Example(features=tf.train.Features(feature=feature))return example_proto.SerializeToString()# todo 构建Dataset对象
features_dataset = tf.data.Dataset.from_tensor_slices((feature0, feature1, feature2, feature3))def tf_serialize_example(f0,f1,f2,f3):tf_string = tf.py_function( # py_function函数将python函数转成可以通过tf计算图进行运算的函数,提升速度的关键就是在此serialize_example,(f0,f1,f2,f3), # 传到函数serialize_example的参数tf.string) # 指定函数serialize_example返回值的类型return tf.reshape(tf_string, ()) # 返回结果# todo 构建一个生成器
def generator():for features in features_dataset:yield serialize_example(*features)if True:# todo 通过map函数将函数tf_serialize_example作用到features_dataset对象中的每个元素中,生成一个新的Dataset对象serialized_features_dataset = features_dataset.map(tf_serialize_example)
else:# todo 也可以直接通过生成器构建需要的Dataset对象serialized_features_dataset = tf.data.Dataset.from_generator(generator, # 可调用的生成器函数output_types=tf.string, # 输出数据的类型output_shapes=() # 输出数据的形状)# todo 通过Dataset对象,将数据存储成TFRecord格式文件
filename = 'test.tfrecord'
writer = tf.data.experimental.TFRecordWriter(filename)
writer.write(serialized_features_dataset)
九、通过Dataset对象读取TFRecord格式文件
过程代码解释了原理,并且这些代码都可以进行复用,请读者认真消化。定义特征描述,这个非常重要,主要是定义了特征描述的形状和类型
# 将TFRecord文件读成Dataset对象
filenames = [filename]
raw_dataset = tf.data.TFRecordDataset(filenames)# todo 定义特征描述,这个非常重要,格式如下,主要是定义了特征描述的形状和类型
feature_description = {'feature0': tf.io.FixedLenFeature([], tf.int64, default_value=0),'feature1': tf.io.FixedLenFeature([], tf.int64, default_value=0),'feature2': tf.io.FixedLenFeature([], tf.string, default_value=''),'feature3': tf.io.FixedLenFeature([], tf.float32, default_value=0.0),
}def _parse_function(example_proto):# 将二进制字符串转成实际的存储数据return tf.io.parse_single_example(example_proto, feature_description)# 运用map函数将函数_parse_function作用到Dataset对象的每个元素里面
parsed_dataset = raw_dataset.map(_parse_function)# parsed_dataset对象的每个元素就是真实的存储数据
for parsed_record in parsed_dataset.take(10):print(repr(parsed_record))break
结果如下
{'feature0': <tf.Tensor: shape=(), dtype=int64, numpy=1>, 'feature1': <tf.Tensor: shape=(), dtype=int64, numpy=2>, 'feature2': <tf.Tensor: shape=(), dtype=string, numpy=b'chicken'>, 'feature3': <tf.Tensor: shape=(), dtype=float32, numpy=-0.10460473>}
10、欢迎关注,下期讲解使用TFRecord文件读取和写入图像数据
相关文章:

揭秘关于TFRcord的五脏六腑
揭秘关于TFRcord的五脏六腑 前言:本篇文章将演示如何创建、解析和使用tf.Example消息,以及如何在.tfrecord文件之间对tf.Example消息进行序列化、写入和读取。 教程讲解使用的都是结构化数据,文章最后还会演示如果将图片写成.tfrecord文件&am…...

【Shell学习笔记】3.Shell 传递参数及数组
前言 本章介绍Shell的传递参数和数组。 Shell 传递参数 我们可以在执行 Shell 脚本时,向脚本传递参数,脚本内获取参数的格式为:$n。n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,…...

【终结Bug】ModuleNotFoundError: No module named ‘cv2’
解决方案: 打开 cmd键入 pip install opencv_python -i https://pypi.tuna.tsinghua.edu.cn/simple...
SQL Server2008详细安装步骤(保姆式教程)
安装包下载 链接:https://pan.baidu.com/s/1Rjx4DHJBeCW2asC_4Kzo6Q?pwdchui 提取码:chui 安装过程 1.解压后使用管理员身份打开安装程序 2.选择全新安装或向现有安装添加新功能 3.确认 4.输入产品密钥(上方网盘安装包里有࿰…...

Linux常用操作
Linux常用操作 前言常用命令:一些操作命令:前言 本文是笔者在使用cadence的过程中,操作linux的笔记,仅记录个人常用,持续更新 常用命令: (1)高频:会了这几个就能在文件…...

Golang 处理parquet文件实战教程
Parquet是Apache基金会支持的项目,是面向列存储二进制文件格式。支持不同类型的压缩方式,广泛用于数据科学和大数据环境,如Hadoop生态。 本文主要介绍Go如何生成和处理parquet文件。 创建结构体 首先创建struct,用于表示要处理…...
腾讯TIM实现即时通信 v3+ts实践
目录 初始化sdk 功能描述 初始化 准备 SDKAppID 调用初始化接口 监听事件 发送消息 创建消息 创建文本消息 登录登出 功能描述 登录 登出 销毁 登录设置 获取会话列表 功能描述 获取会话列表 获取全量的会话列表 历史消息 功能描述 拉取消息列表 分页拉取…...
)
华为OD机试 - 回文字符串(Java JS Python)
题目描述 如果一个字符串正读和反渎都一样(大小写敏感),则称它为一个「回文串」,例如: leVel是一个「回文串」,因为它的正读和反读都是leVel;同理a也是「回文串」art不是一个「回文串」,因为它的反读tra与正读不同Level不是一个「回文串」,因为它的反读leveL与正读不…...

APP测试的7大注意点。
1. 运行 1) App安装完成后的试运行,可正常打开软件。 2) App打开测试,是否有加载状态进度提示。 3) App⻚面间的切换是否流畅,逻辑是否正确。 4) 注册 同表单编辑⻚面 用户名密码⻓度 …...
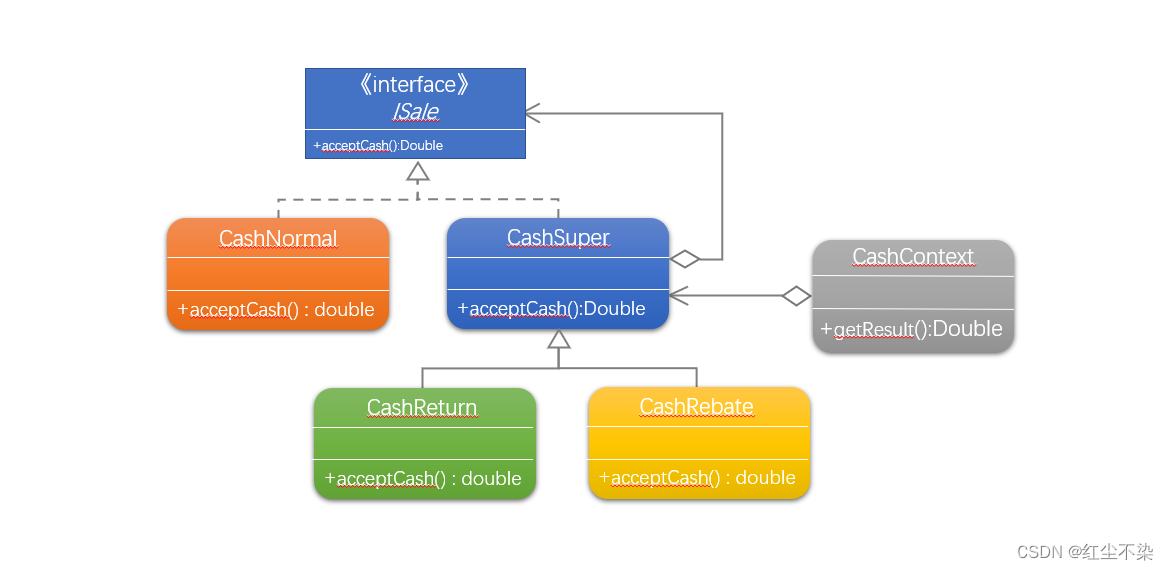
设计模式-第4章(装饰模式)
装饰模式装饰模型装饰模式示例商场收银程序(简单工厂策略装饰模式实现)装饰模式总结装饰模型 装饰模式(Decorator),动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更为…...

【算法设计-分治】快速幂与龟速乘
文章目录1. 快速幂2. 龟速乘3. 快速幂取模4. 龟速乘取模5. 快速幂取模优化1. 快速幂 算法原理: 计算 311: 311 (35)2 x 335 (32)2 x 332 3 x 3仅需计算 3 次,而非 11 次 计算 310: 310 (35)235 (32)2 x 332 3 x 3仅需计算…...

基于新一代kaldi项目的语音识别应用实例
本文是由郭理勇在第二届SH语音技术研讨会和第七届Kaldi技术交流会上对新一代kaldi项目在学术及“部署”两个方面报告的内容上的整理。如果有误,欢迎指正。 文字整理丨李泱泽 编辑丨语音小管家 喜报:新一代Kaldi团队三篇论文均被语音顶会ICASSP-2023接…...
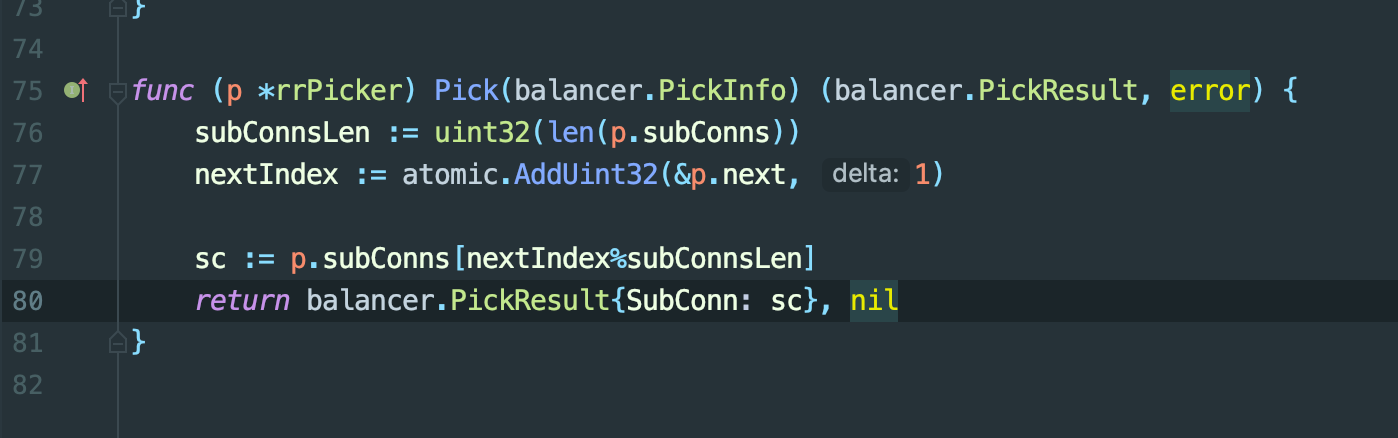
【GO】31.grpc 客户端负载均衡源码分析
这篇文章是记录自己查看客户端grpc负载均衡源码的过程,并没有太详细的讲解,参考价值不大,可以直接跳过,主要给自己看的。一.主要接口:Balancer Resolver1.Balancer定义Resolver定义具体位置为1.grpc源码对解析器(resol…...

PTA L1-058 6翻了(详解)
前言:内容包括:题目,代码实现,大致思路,代码解读 题目: “666”是一种网络用语,大概是表示某人很厉害、我们很佩服的意思。最近又衍生出另一个数字“9”,意思是“6翻了”࿰…...

【Origin科研绘图】如何快速绘制一个折线图 ||【前端特效】爱心篇 之 幸好有你 || 泰坦尼克号——乘客生存与否 预测 || PyCharm使用介绍
🎯作者主页:追光者♂ 🌸个人简介:在读计算机专业硕士研究生、CSDN-人工智能领域新星创作者🏆、2022年CSDN博客之星人工智能领域TOP4🌟、阿里云社区专家博主🏅 【无限进步,一起追光!】 🍎欢迎点赞👍 收藏⭐ 留言📝 🌿本篇,首先是:基于科研绘图工具O…...

一文解读电压放大器(电压放大器原理)
关于电压放大器的科普知识,之前讲过很多,今天为大家汇总一篇文章来详细的讲解电压放大器,希望大家对于电压放大器能有更清晰的认识。电压放大器是什么:电压放大器是一种常用的电子器件,它的主要作用是把输入信号的振幅…...
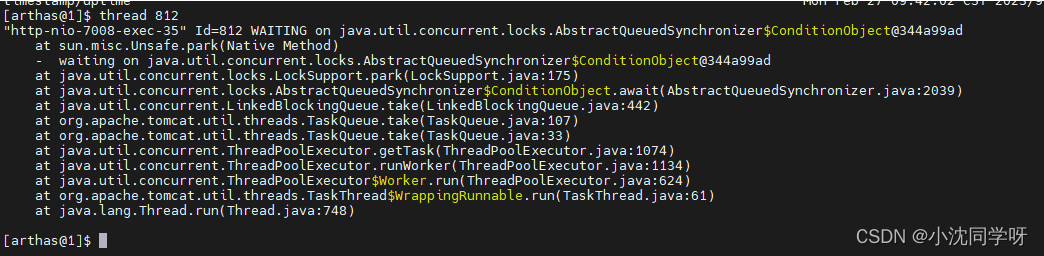
线上监控诊断神器arthas
目录 什么是arthas 常用命令列表 1、dashboard仪表盘 2、heapdump dumpJAVA堆栈快照 3、jvm 4、thread 5、memory 官方文档 安装使用 1、云安装arthas 2、获取需要监控进程ID 3、运行arthas 4、进入仪表盘 5、其他命令使用查看官方文档 什么是arthas arthas是阿…...

@Import注解的原理
此注解是springboot自动注入的关键注解,所以拿出来单独分析一下。 启动类的run方法跟进去最终找到refresh方法; 这里直接看这个org.springframework.context.support.AbstractApplicationContext#refresh方法即可,它下面有一个方法 invoke…...
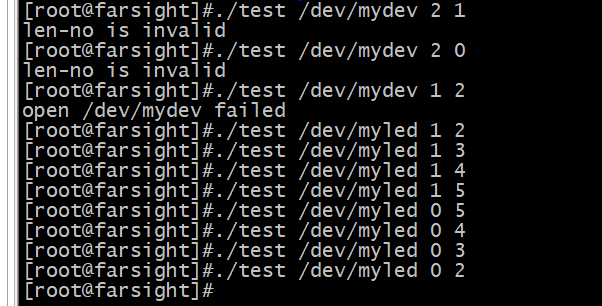
平台总线开发(id和设备树匹配)
目录 一、ID匹配之框架代码 二、ID匹配之led驱动 三、设备树匹配 四、设备树匹配之led驱动 五、一个编写驱动用的宏 一、ID匹配之框架代码 id匹配(可想象成八字匹配):一个驱动可以对应多个设备 ------优先级次低 注意事项…...

TS泛型,原来就这?
一、泛型是什么?有什么作用? 当我们定义一个变量不确定类型的时候有两种解决方式: 使用any 使用any定义时存在的问题:虽然知道传入值的类型但是无法获取函数返回值的类型;另外也失去了ts类型保护的优势 使用泛型 泛型…...

SQL刷题_牛客_SQL热题
SQL201 查找入职员工时间排名倒数第三的员工所有信息【简单】 SQL201 查找入职员工时间排名倒数第三的员工所有信息 窗口函数其他方法 # 怎么算倒数第三 如果倒数第123都是同一个日期,那算谁? # 从运行结果倒推看,日期需要去重 select *…...

CAD 学习笔记
1.平移视图:按住鼠标滚轮,拖动视图2.缩放视图:滚动鼠标滚轮3.三维围绕:按住键盘shift键,再按住鼠标滚轮拖动4.恢复平面 :左上角选择俯视或者输入“PLAN”空格两下5.选择图形:点选、框选…...
)
伺服电机控制四台丝杆升降机联动的3种方案对比(附真实案例)
伺服电机控制四台丝杆升降机联动的3种方案对比(附真实案例) 在工业自动化领域,多轴同步控制一直是精密制造的核心挑战之一。想象一下汽车生产线上的车身焊接工位,或是造船厂里数十吨重的分段组装平台,四台丝杆升降机需…...

卡证检测矫正模型在复杂网络环境下的自适应传输优化
卡证检测矫正模型在复杂网络环境下的自适应传输优化 1. 引言 想象一下这个场景:你正在银行网点办理业务,柜员用手机或平板对你的身份证进行拍照识别。网络信号时好时坏,图片上传缓慢,识别结果迟迟出不来,后面排队的人…...
)
安防开发者必看:如何用视频中间件统一接入大华/海康设备(含Ehome/主动注册协议对比)
安防开发者必看:如何用视频中间件统一接入大华/海康设备(含Ehome/主动注册协议对比) 在智慧城市建设和连锁门店管理等场景中,安防设备的多品牌混合组网已成为常态。作为开发者,我们常常需要同时对接大华、海康等不同厂…...

StructBERT中文句子相似度实测:200字符长句、中英混排处理效果展示
StructBERT中文句子相似度实测:200字符长句、中英混排处理效果展示 1. 工具概述与核心能力 StructBERT是由百度研发的预训练语言模型,在中文自然语言处理任务中表现出色。本次实测的StructBERT文本相似度计算工具基于该模型实现,专门用于评…...

WHAT - 好用的低代码平台
文章目录一、国际主流低代码平台(偏技术/企业级)Microsoft Power AppsOutSystemsMendixAppianZoho Creator二、国内低代码平台(更接地气)钉钉宜搭简道云用友 YonBuilder金蝶云苍穹网易 CodeWave奥哲云枢其他TinyEngine2026 年关键…...

2026高职统计与大数据分析毕业缺少实战经验怎么办?
提升高职统计与大数据分析专业实战经验的策略对于2026年高职统计与大数据分析专业的毕业生而言,缺乏实战经验是常见的职业发展障碍。通过系统化的学习、证书考取、项目实践等方式可以有效弥补这一短板。以下是具体方法:考取行业权威证书(如CD…...

CNKI-download:知网文献批量下载与信息采集终极指南
CNKI-download:知网文献批量下载与信息采集终极指南 【免费下载链接】CNKI-download :frog: 知网(CNKI)文献下载及文献速览爬虫 项目地址: https://gitcode.com/gh_mirrors/cn/CNKI-download CNKI-download是一款基于Python开发的知网文献自动化获取工具&am…...

Qwen3-14b_int4_awqChainlit二次开发:集成RAG模块实现私有知识库问答增强
Qwen3-14b_int4_awq Chainlit二次开发:集成RAG模块实现私有知识库问答增强 1. 项目概述 Qwen3-14b_int4_awq是基于Qwen3-14b模型的int4 AWQ量化版本,通过AngelSlim技术进行压缩优化,专门用于高效文本生成任务。本文将详细介绍如何在这个模型…...