Golang 处理parquet文件实战教程
Parquet是Apache基金会支持的项目,是面向列存储二进制文件格式。支持不同类型的压缩方式,广泛用于数据科学和大数据环境,如Hadoop生态。
本文主要介绍Go如何生成和处理parquet文件。
创建结构体
首先创建struct,用于表示要处理的数据:
type user struct {ID string `parquet:"name=id, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`FirstName string `parquet:"name=firstname, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`LastName string `parquet:"name=lastname, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Email string `parquet:"name=email, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Phone string `parquet:"name=phone, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Blog string `parquet:"name=blog, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Username string `parquet:"name=username, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Score float64 `parquet:"name=score, type=DOUBLE"`CreatedAt time.Time //wont be saved in the parquet file
}
这里要提醒的是tag,用于说明struct中每个字段在生成parquet过程中如何被处理。
parquet-go包可以处理parquet数据,更多的tag可以参考其官网。
生成parquet文件
下面现给出生成parquet文件的代码,然后分别进行说明:
package mainimport ("fmt""log""time""github.com/bxcodec/faker/v3""github.com/xitongsys/parquet-go-source/local""github.com/xitongsys/parquet-go/parquet""github.com/xitongsys/parquet-go/reader""github.com/xitongsys/parquet-go/writer"
)type user struct {ID string `parquet:"name=id, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`FirstName string `parquet:"name=firstname, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`LastName string `parquet:"name=lastname, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Email string `parquet:"name=email, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Phone string `parquet:"name=phone, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Blog string `parquet:"name=blog, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Username string `parquet:"name=username, type=BYTE_ARRAY, encoding=PLAIN_DICTIONARY"`Score float64 `parquet:"name=score, type=DOUBLE"`CreatedAt time.Time //wont be saved in the parquet file
}const recordNumber = 10000func main() {var data []*user//create fake datafor i := 0; i < recordNumber; i++ {u := &user{ID: faker.UUIDDigit(),FirstName: faker.FirstName(),LastName: faker.LastName(),Email: faker.Email(),Phone: faker.Phonenumber(),Blog: faker.URL(),Username: faker.Username(),Score: float64(i),CreatedAt: time.Now(),}data = append(data, u)}err := generateParquet(data)if err != nil {log.Fatal(err)}}func generateParquet(data []*user) error {log.Println("generating parquet file")fw, err := local.NewLocalFileWriter("output.parquet")if err != nil {return err}//parameters: writer, type of struct, sizepw, err := writer.NewParquetWriter(fw, new(user), int64(len(data)))if err != nil {return err}//compression typepw.CompressionType = parquet.CompressionCodec_GZIPdefer fw.Close()for _, d := range data {if err = pw.Write(d); err != nil {return err}}if err = pw.WriteStop(); err != nil {return err}return nil
}
定义结构体上面已经说明,但需要提醒的是类型与文档保持一致:
| Primitive Type | Go Type |
|---|---|
| BOOLEAN | bool |
| INT32 | int32 |
| INT64 | int64 |
| INT96(deprecated) | string |
| FLOAT | float32 |
| DOUBLE | float64 |
| BYTE_ARRAY | string |
| FIXED_LEN_BYTE_ARRAY | string |
接着就是使用faker包生成模拟数据。然后调用err := generateParquet(data)方法。该方法大概逻辑为:
- 首先准备输出文件,然后基于本地输出文件构造pw,用于写parquet数据:
fw, err := local.NewLocalFileWriter("output.parquet")if err != nil {return err}//parameters: writer, type of struct, sizepw, err := writer.NewParquetWriter(fw, new(user), int64(len(data)))if err != nil {return err}//compression typepw.CompressionType = parquet.CompressionCodec_GZIPdefer fw.Close()
然后设置压缩类型,并通过defer操作确保关闭文件。下面开始写数据:
for _, d := range data {if err = pw.Write(d); err != nil {return err}}if err = pw.WriteStop(); err != nil {return err}return nil
循环写数据,最后调用pw.WriteStop()停止写。 成功写文件后,下面介绍如何读取parquet文件。
读取parquet文件
首先介绍如何一次性读取文件,主要用于读取较小的文件:
func readParquet() ([]*user, error) {fr, err := local.NewLocalFileReader("output.parquet")if err != nil {return nil, err}pr, err := reader.NewParquetReader(fr, new(user), recordNumber)if err != nil {return nil, err}u := make([]*user, recordNumber)if err = pr.Read(&u); err != nil {return nil, err}pr.ReadStop()fr.Close()return u, nil
}
大概流程如下:首先定义本地文件,然后构造pr用于读取parquet文件:
fr, err := local.NewLocalFileReader("output.parquet")if err != nil {return nil, err}pr, err := reader.NewParquetReader(fr, new(user), recordNumber)if err != nil {return nil, err}
然后定义目标内容容器u,一次性读取数据:
u := make([]*user, recordNumber)if err = pr.Read(&u); err != nil {return nil, err}pr.ReadStop()fr.Close()
但一次性大量记录加载至内存可能有问题。这是官方文档提示:
If the parquet file is very big (even the size of parquet file is small, the uncompressed size may be very large), please don’t read all rows at one time, which may induce the OOM. You can read a small portion of the data at a time like a stream-oriented file.
大意是不要一次读取文件至内存,可能造成OOM。实际应用中应该分页读取,下面通过代码进行说明:
func readPartialParquet(pageSize, page int) ([]*user, error) {fr, err := local.NewLocalFileReader("output.parquet")if err != nil {return nil, err}defer func() {_ = fr.Close()}()pr, err := reader.NewParquetReader(fr, new(user), int64(pageSize))if err != nil {return nil, err}defer pr.ReadStop()//num := pr.GetNumRows()pr.SkipRows(int64(pageSize * page))u := make([]*user, pageSize)if err = pr.Read(&u); err != nil {return nil, err}return u, nil
}
与上面函数差异不大,首先函数包括两个参数,用于指定页大小和页数,关键代码是跳过一定记录:
pr.SkipRows(int64(pageSize * page))
根据这个方法可以获得总行数,pr.GetNumRows(),然后结合页大小计算总页数,最后循环可以实现分页查询。
计算列平均值
既然使用了Parquet列存储格式,下面演示下如何计算Score列的平均值。
func calcScoreAVG() (float64, error) {fr, err := local.NewLocalFileReader("output.parquet")if err != nil {return 0.0, err}pr, err := reader.NewParquetColumnReader(fr, recordNumber)if err != nil {return 0.0, err}num := int(pr.GetNumRows())data, _, _, err := pr.ReadColumnByPath("parquet_go_root\u0001score", num)if err != nil {return 0.0, err}var result float64for _, i := range data {result += i.(float64)}return (result / float64(num)), nil
}
首先打开文件,然后调用pr.GetNumRows()方法获取总行数。然后基于路径指定列,其中parquet_go_root为根路径,因为前面使用字节数组,这里分割符变为\u0001,完整路径为:parquet_go_root\u0001score。
相关文章:

Golang 处理parquet文件实战教程
Parquet是Apache基金会支持的项目,是面向列存储二进制文件格式。支持不同类型的压缩方式,广泛用于数据科学和大数据环境,如Hadoop生态。 本文主要介绍Go如何生成和处理parquet文件。 创建结构体 首先创建struct,用于表示要处理…...
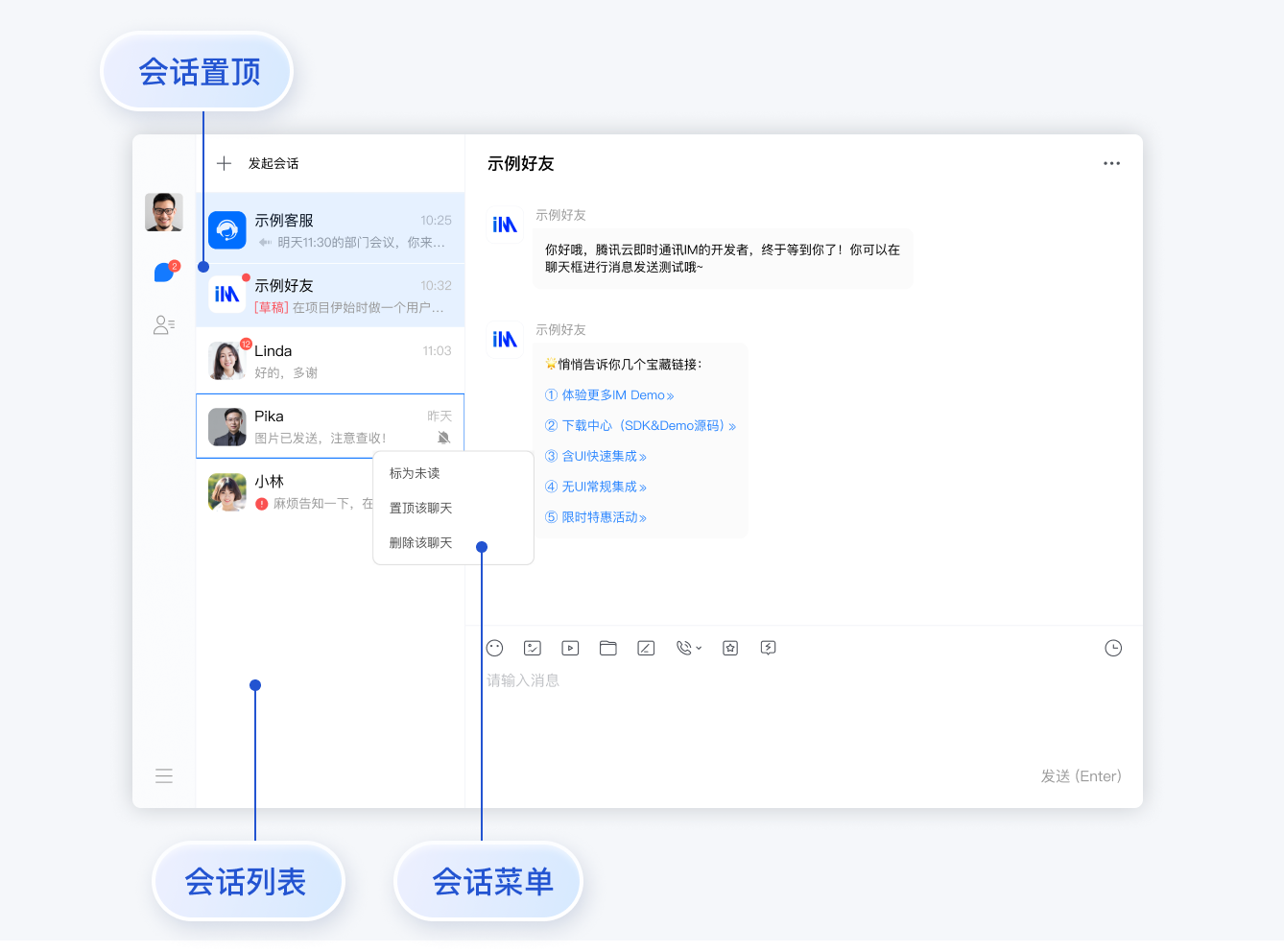
腾讯TIM实现即时通信 v3+ts实践
目录 初始化sdk 功能描述 初始化 准备 SDKAppID 调用初始化接口 监听事件 发送消息 创建消息 创建文本消息 登录登出 功能描述 登录 登出 销毁 登录设置 获取会话列表 功能描述 获取会话列表 获取全量的会话列表 历史消息 功能描述 拉取消息列表 分页拉取…...
)
华为OD机试 - 回文字符串(Java JS Python)
题目描述 如果一个字符串正读和反渎都一样(大小写敏感),则称它为一个「回文串」,例如: leVel是一个「回文串」,因为它的正读和反读都是leVel;同理a也是「回文串」art不是一个「回文串」,因为它的反读tra与正读不同Level不是一个「回文串」,因为它的反读leveL与正读不…...

APP测试的7大注意点。
1. 运行 1) App安装完成后的试运行,可正常打开软件。 2) App打开测试,是否有加载状态进度提示。 3) App⻚面间的切换是否流畅,逻辑是否正确。 4) 注册 同表单编辑⻚面 用户名密码⻓度 …...
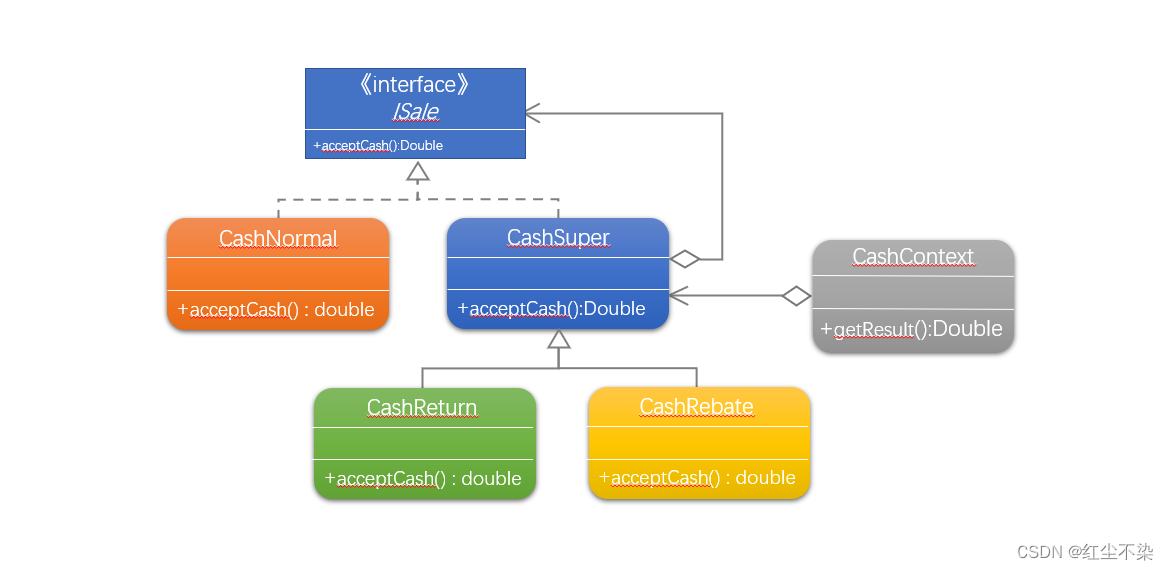
设计模式-第4章(装饰模式)
装饰模式装饰模型装饰模式示例商场收银程序(简单工厂策略装饰模式实现)装饰模式总结装饰模型 装饰模式(Decorator),动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更为…...

【算法设计-分治】快速幂与龟速乘
文章目录1. 快速幂2. 龟速乘3. 快速幂取模4. 龟速乘取模5. 快速幂取模优化1. 快速幂 算法原理: 计算 311: 311 (35)2 x 335 (32)2 x 332 3 x 3仅需计算 3 次,而非 11 次 计算 310: 310 (35)235 (32)2 x 332 3 x 3仅需计算…...

基于新一代kaldi项目的语音识别应用实例
本文是由郭理勇在第二届SH语音技术研讨会和第七届Kaldi技术交流会上对新一代kaldi项目在学术及“部署”两个方面报告的内容上的整理。如果有误,欢迎指正。 文字整理丨李泱泽 编辑丨语音小管家 喜报:新一代Kaldi团队三篇论文均被语音顶会ICASSP-2023接…...
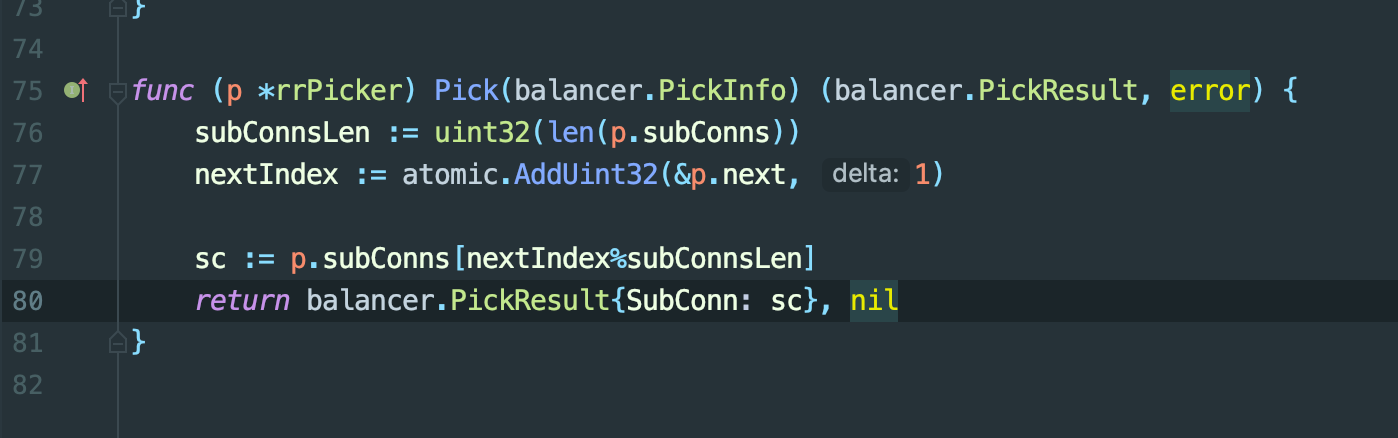
【GO】31.grpc 客户端负载均衡源码分析
这篇文章是记录自己查看客户端grpc负载均衡源码的过程,并没有太详细的讲解,参考价值不大,可以直接跳过,主要给自己看的。一.主要接口:Balancer Resolver1.Balancer定义Resolver定义具体位置为1.grpc源码对解析器(resol…...

PTA L1-058 6翻了(详解)
前言:内容包括:题目,代码实现,大致思路,代码解读 题目: “666”是一种网络用语,大概是表示某人很厉害、我们很佩服的意思。最近又衍生出另一个数字“9”,意思是“6翻了”࿰…...

【Origin科研绘图】如何快速绘制一个折线图 ||【前端特效】爱心篇 之 幸好有你 || 泰坦尼克号——乘客生存与否 预测 || PyCharm使用介绍
🎯作者主页:追光者♂ 🌸个人简介:在读计算机专业硕士研究生、CSDN-人工智能领域新星创作者🏆、2022年CSDN博客之星人工智能领域TOP4🌟、阿里云社区专家博主🏅 【无限进步,一起追光!】 🍎欢迎点赞👍 收藏⭐ 留言📝 🌿本篇,首先是:基于科研绘图工具O…...

一文解读电压放大器(电压放大器原理)
关于电压放大器的科普知识,之前讲过很多,今天为大家汇总一篇文章来详细的讲解电压放大器,希望大家对于电压放大器能有更清晰的认识。电压放大器是什么:电压放大器是一种常用的电子器件,它的主要作用是把输入信号的振幅…...
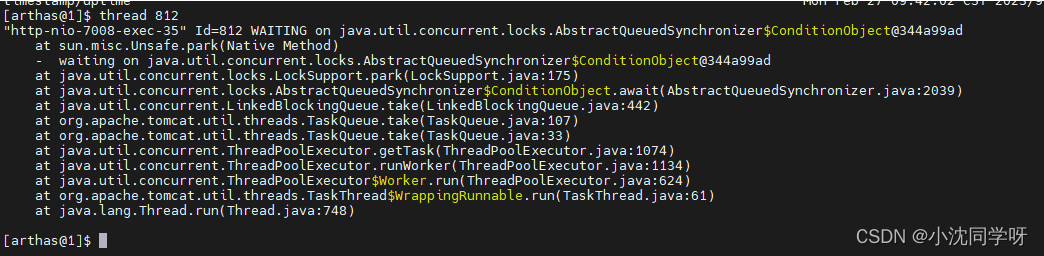
线上监控诊断神器arthas
目录 什么是arthas 常用命令列表 1、dashboard仪表盘 2、heapdump dumpJAVA堆栈快照 3、jvm 4、thread 5、memory 官方文档 安装使用 1、云安装arthas 2、获取需要监控进程ID 3、运行arthas 4、进入仪表盘 5、其他命令使用查看官方文档 什么是arthas arthas是阿…...

@Import注解的原理
此注解是springboot自动注入的关键注解,所以拿出来单独分析一下。 启动类的run方法跟进去最终找到refresh方法; 这里直接看这个org.springframework.context.support.AbstractApplicationContext#refresh方法即可,它下面有一个方法 invoke…...
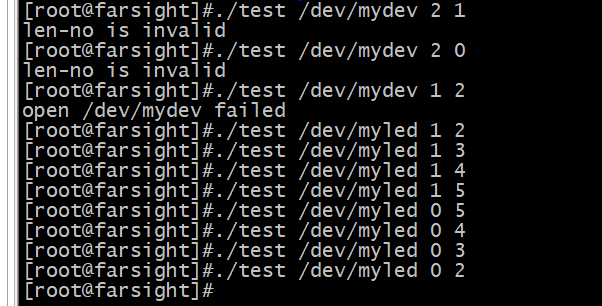
平台总线开发(id和设备树匹配)
目录 一、ID匹配之框架代码 二、ID匹配之led驱动 三、设备树匹配 四、设备树匹配之led驱动 五、一个编写驱动用的宏 一、ID匹配之框架代码 id匹配(可想象成八字匹配):一个驱动可以对应多个设备 ------优先级次低 注意事项…...

TS泛型,原来就这?
一、泛型是什么?有什么作用? 当我们定义一个变量不确定类型的时候有两种解决方式: 使用any 使用any定义时存在的问题:虽然知道传入值的类型但是无法获取函数返回值的类型;另外也失去了ts类型保护的优势 使用泛型 泛型…...
关于算法学习和刷题的建议
大家好,我是方圆。最近花时间学了学算法,应该算是我接触Java以来第一次真正的学习它,这篇帖子我会说一些我对算法学习的理解,当然这仅仅是浅浅的入算法的门,如果想深挖或者是有基础的人想提升自己,我觉得这…...
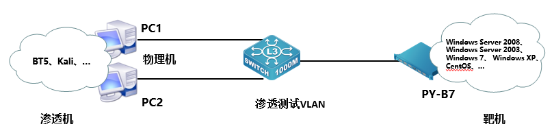
2023年“网络安全”赛项浙江省金华市选拔赛 任务书
2023年“网络安全”赛项浙江省金华市选拔赛 任务书 任务书 一、竞赛时间 共计3小时。 二、竞赛阶段 竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 第一阶段单兵模式系统渗透测试 任务一 Windows操作系统渗透测试 任务二 Linux操作系统渗透测试 任务三 网页渗透 任务四 Linux系统…...

http协议简介
http 1.简介 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。1960年美国人Ted Nelson构思了一种通过计算机处…...

CSDN 第三十一期竞赛题解
第二次参加 总分77.5,主要是在最后一题数据有误,花费了巨量时间… 参加的另一次比赛最后一道题目也出现了一点问题,有点遗憾。 题解 T1:最优利润值 你在读的经营课程上,老师布置了一道作业。在一家公司的日常运营中&…...
)
EM_ASM系列宏定义(emscripten)
2.5 EM_ASM系列宏很多编译器支持在C/C代码直接嵌入汇编代码,Emscripten采用类似的方式,提供了一组以“EM_ASM”为前缀的宏,用于以内联的方式在C/C代码中直接嵌入JavaScript代码。2.5.1 EM_ASMEM_ASM使用很简单,只需要将欲执行的Ja…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...