01Urllib
1.什么是互联网爬虫?
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
2.爬虫核心
1.爬取网页:爬取整个网页 包含了网页中所有得内容
2.解析数据:将网页中你得到的数据 进行解析
3.难点:爬虫和反爬虫之间的博弈
3.爬虫的用途?
- 数据分析/人工数据集
- 社交软件冷启动
- 舆情监控
- 竞争对手监控
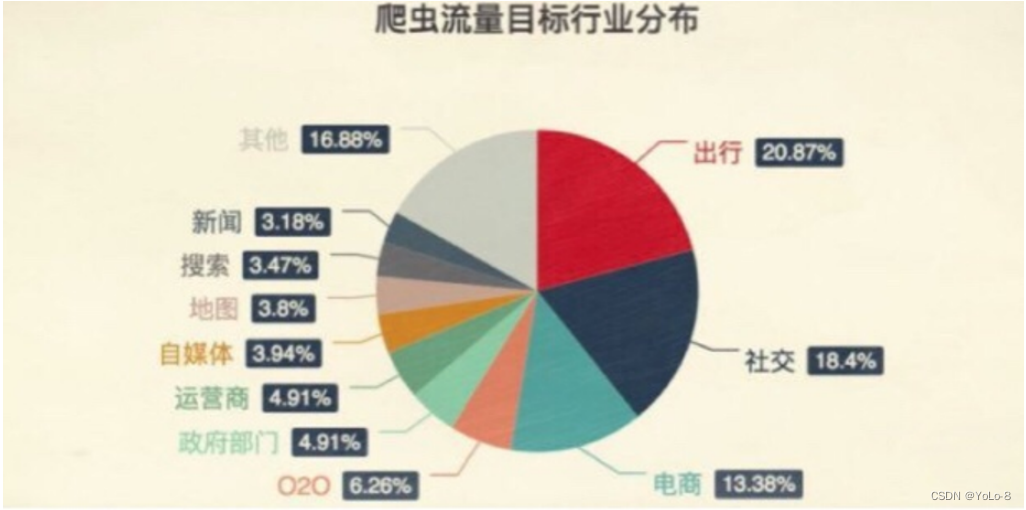
4.爬虫分类?
4.1通用爬虫
- 实例
百度、360、google、sougou等搜索引擎‐‐‐伯乐在线 - 功能
访问网页‐>抓取数据‐>数据存储‐>数据处理‐>提供检索服务 - robots协议
一个约定俗成的协议,添加robots.txt文件,来说明本网站哪些内容不可以被抓取,起不到限制作用
自己写的爬虫无需遵守 - 网站排名(SEO)
- 根据pagerank算法值进行排名(参考个网站流量、点击率等指标)
- 百度竞价排名
- 缺点
- 抓取的数据大多是无用的
- 不能根据用户的需求来精准获取数据
4.2聚焦爬虫
- 功能
根据需求,实现爬虫程序,抓取需要的数据 - 设计思路
- 确定要爬取的url
如何获取Url - 模拟浏览器通过http协议访问url,获取服务器返回的html代码
如何访问 - 解析html字符串(根据一定规则提取需要的数据)
如何解析
- 确定要爬取的url
5.反爬手段?
- User‐Agent:
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。 - 代理IP
西次代理
快代理
什么是高匿名、匿名和透明代理?它们有什么区别?
1. 使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
2. 使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
3. 使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。 - 验证码访问
打码平台
1. 云打码平台 - 动态加载网页 网站返回的是js数据 并不是网页的真实数据
selenium驱动真实的浏览器发送请求 - 数据加密
分析js代码
6.urllib库使用

7.请求对象的定制
UA介绍:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
语法:request = urllib.request.Request()
import urllib.requesturl = 'https://www.baidu.com'# url的组成
# https://www.baidu.com/s?wd=周杰伦# http/https www.baidu.com 80/443 s wd = 周杰伦 #
# 协议 主机 端口号 路径 参数 锚点
# http 80
# https 443
# mysql 3306
# oracle 1521
# redis 6379
# mongodb 27017headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}# 因为urlopen方法中不能存储字典 所以headers不能传递进去
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('utf8')print(content)- 扩展:编码的由来
‘’‘编码集的演变‐‐‐
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc‐kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。
现代操作系统和大多数编程语言都直接支持Unicode。’‘’
8.编解码
- get请求方式:
urllib.parse.quote()
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6# 需求 获取 https://www.baidu.com/s?wd=周杰伦的网页源码import urllib.request
import urllib.parseurl = 'https://www.baidu.com/s?wd='# 请求对象的定制为了解决反爬的第一种手段
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}# 将周杰伦三个字变成unicode编码的格式
# 我们需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦')url = url + name# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)# 获取响应的内容
content = response.read().decode('utf-8')# 打印数据
print(content)- get请求方式:
urllib.parse.urlencode()
# urlencode应用场景:多个参数的时候# https://www.baidu.com/s?wd=周杰伦&sex=男# import urllib.parse
#
# data = {
# 'wd':'周杰伦',
# 'sex':'男',
# 'location':'中国台湾省'
# }
#
# a = urllib.parse.urlencode(data)
# print(a)#获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7的网页源码import urllib.request
import urllib.parsebase_url = 'https://www.baidu.com/s?'data = {'wd':'周杰伦','sex':'男','location':'中国台湾省'
}new_data = urllib.parse.urlencode(data)# 请求资源路径
url = base_url + new_dataheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)# 获取网页源码的数据
content = response.read().decode('utf-8')# 打印数据
print(content)- post请求方式
# post请求---百度翻译import urllib.request
import urllib.parseurl = 'https://fanyi.baidu.com'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}data = {'kw':'spider'
}# post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')# post的请求的参数 是不会拼接在url的后面的 而是需要放在请求对象定制的参数中
# post请求的参数 必须要进行编码
request = urllib.request.Request(url=url,data=data,headers=headers)# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)print(response)
# # 获取响应的数据
# content = response.read().decode('utf-8')
#
# # 字符串--》json对象
#
# import json
#
# obj = json.loads(content)
# print(obj)# post请求方式的参数 必须编码 data = urllib.parse.urlencode(data)
# 编码之后 必须调用encode方法 data = urllib.parse.urlencode(data).encode('utf-8')
# 参数是放在请求对象定制的方法中 request = urllib.request.Request(url=url,data=data,headers=headers)总结:post和get区别?
get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
案例练习:百度详细翻译
import urllib.request
import urllib.parseurl = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'headers = {# 'Accept': '*/*',# 'Accept-Encoding': 'gzip, deflate, br',# 'Accept-Language': 'zh-CN,zh;q=0.9',# 'Connection': 'keep-alive',# 'Content-Length': '135',# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Cookie': 'BIDUPSID=DAA8F9F0BD801A2929D96D69CF7EBF50; PSTM=1597202227; BAIDUID=DAA8F9F0BD801A29B2813502000BF8E9:SL=0:NR=10:FG=1; __yjs_duid=1_c19765bd685fa6fa12c2853fc392f8db1618999058029; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=R2bEZvTjFCNHQxdUV-cTZ-MzZrSGxhbUYwSkRkUWk2SkxxS3E2M2lqaFRLUlJoRVFBQUFBJCQAAAAAAAAAAAEAAAA3e~BTveK-9sHLZGF5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFOc7GBTnOxgaW; BDUSS_BFESS=R2bEZvTjFCNHQxdUV-cTZ-MzZrSGxhbUYwSkRkUWk2SkxxS3E2M2lqaFRLUlJoRVFBQUFBJCQAAAAAAAAAAAEAAAA3e~BTveK-9sHLZGF5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFOc7GBTnOxgaW; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=DAA8F9F0BD801A29B2813502000BF8E9:SL=0:NR=10:FG=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=2; H_PS_PSSID=34435_31660_34405_34004_34073_34092_26350_34426_34323_22158_34390; delPer=1; BA_HECTOR=8185a12020018421b61gi6ka20q; BCLID=10943521300863382545; BDSFRCVID=boDOJexroG0YyvRHKn7hh7zlD_weG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK0mOTHv8F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tR3aQ5rtKRTffjrnhPF3-44vXP6-hnjy3bRkX4Q4Wpv_Mnndjn6SQh4Wbttf5q3RymJ42-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvD-ug3-7qqU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIE3-oJqC8hMIt43f; BCLID_BFESS=10943521300863382545; BDSFRCVID_BFESS=boDOJexroG0YyvRHKn7hh7zlD_weG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK0mOTHv8F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR3aQ5rtKRTffjrnhPF3-44vXP6-hnjy3bRkX4Q4Wpv_Mnndjn6SQh4Wbttf5q3RymJ42-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvD-ug3-7qqU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIE3-oJqC8hMIt43f; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1629701482,1629702031,1629702343,1629704515; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1629704515; __yjs_st=2_MDBkZDdkNzg4YzYyZGU2NTM5NzBjZmQ0OTZiMWRmZGUxM2QwYzkwZTc2NTZmMmIxNDJkYzk4NzU1ZDUzN2U3Yjc4ZTJmYjE1YTUzMTljYWFkMWUwYmVmZGEzNmZjN2FlY2M3NDAzOThhZTY5NzI0MjVkMmQ0NWU3MWE1YTJmNGE5NDBhYjVlOWY3MTFiMWNjYTVhYWI0YThlMDVjODBkNWU2NjMwMzY2MjFhZDNkMzVhNGMzMGZkMWY2NjU5YzkxMDk3NTEzODJiZWUyMjEyYTk5YzY4ODUyYzNjZTJjMGM5MzhhMWE5YjU3NTM3NWZiOWQxNmU3MDVkODExYzFjN183XzliY2RhYjgz; ab_sr=1.0.1_ZTc2ZDFkMTU5ZTM0ZTM4MWVlNDU2MGEzYTM4MzZiY2I2MDIxNzY1Nzc1OWZjZGNiZWRhYjU5ZjYwZmNjMTE2ZjIzNmQxMTdiMzIzYTgzZjVjMTY0ZjM1YjMwZTdjMjhiNDRmN2QzMjMwNWRhZmUxYTJjZjZhNTViMGM2ODFlYjE5YTlmMWRjZDAwZGFmMDY4ZTFlNGJiZjU5YzE1MGIxN2FiYTU3NDgzZmI4MDdhMDM5NTQ0MjQxNDBiNzdhMDdl',# 'Host': 'fanyi.baidu.com',# 'Origin': 'https://fanyi.baidu.com',# 'Referer': 'https://fanyi.baidu.com/?aldtype=16047',# 'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',# 'sec-ch-ua-mobile': '?0',# 'Sec-Fetch-Dest': 'empty',# 'Sec-Fetch-Mode': 'cors',# 'Sec-Fetch-Site': 'same-origin',# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',# 'X-Requested-With': 'XMLHttpRequest',
}data = {'from': 'en','to': 'zh','query': 'love','transtype': 'realtime','simple_means_flag': '3','sign': '198772.518981','token': '5483bfa652979b41f9c90d91f3de875d','domain': 'common',
}
# post请求的参数 必须进行编码 并且要调用encode方法
data = urllib.parse.urlencode(data).encode('utf-8')# 请求对象的定制
request = urllib.request.Request(url = url,data = data,headers = headers)# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)# 获取响应的数据
content = response.read().decode('utf-8')import jsonobj = json.loads(content)
print(obj)
9.ajax的get请求
案例:豆瓣电影
- 请求豆瓣电影的第一页
# get请求
# 获取豆瓣电影的第一页的数据 并且保存起来import urllib.requesturl = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}# (1) 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)# (2)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')# (3) 数据下载到本地
# open方法默认情况下使用的是gbk的编码 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8
# encoding = 'utf-8'
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)with open('douban1.json','w',encoding='utf-8') as fp:fp.write(content)
- 请求豆瓣电影的前十页
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=0&limit=20# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=20&limit=20# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=40&limit=20# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=60&limit=20# page 1 2 3 4
# start 0 20 40 60# start (page - 1)*20# 下载豆瓣电影前10页的数据
# (1) 请求对象的定制
# (2) 获取响应的数据
# (3) 下载数据import urllib.parse
import urllib.requestdef create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'data = {'start':(page - 1) * 20,'limit':20}data = urllib.parse.urlencode(data)url = base_url + dataheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}request = urllib.request.Request(url=url,headers=headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef down_load(page,content):with open('douban_' + str(page) + '.json','w',encoding='utf-8')as fp:fp.write(content)# 程序的入口
if __name__ == '__main__':start_page = int(input('请输入起始的页码'))end_page = int(input('请输入结束的页面'))for page in range(start_page,end_page+1):
# 每一页都有自己的请求对象的定制request = create_request(page)
# 获取响应的数据content = get_content(request)
# 下载down_load(page,content)10.ajax的post请求
案例:KFC官网
# 1页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10# 2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10import urllib.request
import urllib.parsedef create_request(page):base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'data = {'cname': '北京','pid':'','pageIndex': page,'pageSize': '10'}data = urllib.parse.urlencode(data).encode('utf-8')headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}request = urllib.request.Request(url=base_url,headers=headers,data=data)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef down_load(page,content):with open('kfc_' + str(page) + '.json','w',encoding='utf-8')as fp:fp.write(content)if __name__ == '__main__':start_page = int(input('请输入起始页码'))end_page = int(input('请输入结束页码'))for page in range(start_page,end_page+1):# 请求对象的定制request = create_request(page)# 获取网页源码content = get_content(request)# 下载down_load(page,content)11.URLError\HTTPError
简介:
1. HTTPError类是URLError类的子类
2. 导入的包urllib.error.HTTPError urllib.error.URLError
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出
了问题。
4.通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try‐except进行捕获异常,异常有两类,URLError\HTTPError
import urllib.request
import urllib.error# url = 'https://blog.csdn.net/sulixu/article/details/1198189491'url = 'http://www.doudan1111.com'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}try:request = urllib.request.Request(url = url, headers = headers)response = urllib.request.urlopen(request)content = response.read().decode('utf-8')print(content)
except urllib.error.HTTPError:print('系统正在升级。。。')
except urllib.error.URLError:print('我都说了 系统正在升级。。。')12.cookie登录
使用案例:
1.weibo登陆
作业:qq空间的爬取
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
# 个人信息页面是utf-8 但是还报错了编码错误 因为并没有进入到个人信息页面 而是跳转到了登陆页面
# 那么登陆页面不是utf-8 所以报错# 什么情况下访问不成功?
# 因为请求头的信息不够 所以访问不成功import urllib.requesturl = 'https://weibo.cn/6451491586/info'headers = {
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6451491586/info',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
# cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面
'cookie': '_T_WM=24c44910ba98d188fced94ba0da5960e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFxxfgNNUmXi4YiaYZKr_J_5NHD95QcSh-pSh.pSKncWs4DqcjiqgSXIgvVPcpD; SUB=_2A25MKKG_DeRhGeBK7lMV-S_JwzqIHXVv0s_3rDV6PUJbktCOLXL2kW1NR6e0UHkCGcyvxTYyKB2OV9aloJJ7mUNz; SSOLoginState=1630327279',
# referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链
'referer': 'https://weibo.cn/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')# 将数据保存到本地
with open('weibo.html','w',encoding='utf-8')as fp:fp.write(content)
13.Handler处理器
为什么要学习handler?
urllib.request.urlopen(url)
不能定制请求头
urllib.request.Request(url,headers,data)
可以定制请求头
Handler
定制更高级的请求头(随着业务逻辑的复杂 请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)
# 需求 使用handler来访问百度 获取网页源码import urllib.requesturl = 'http://www.baidu.com'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}request = urllib.request.Request(url = url,headers = headers)# handler build_opener open# (1)获取hanlder对象
handler = urllib.request.HTTPHandler()# (2)获取opener对象
opener = urllib.request.build_opener(handler)# (3) 调用open方法
response = opener.open(request)content = response.read().decode('utf-8')print(content)
14.代理服务器

import urllib.requesturl = 'http://www.baidu.com/s?wd=ip'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}# 请求对象的定制
request = urllib.request.Request(url = url,headers= headers)# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)proxies = {'http':'118.24.219.151:16817'
}
# handler build_opener open
handler = urllib.request.ProxyHandler(proxies = proxies)opener = urllib.request.build_opener(handler)response = opener.open(request)# 获取响应的信息
content = response.read().decode('utf-8')# 保存
with open('daili.html','w',encoding='utf-8')as fp:fp.write(content)扩展:
- 代理池
import urllib.requestproxies_pool = [{'http':'118.24.219.151:16817'},{'http':'118.24.219.151:16817'},
]import randomproxies = random.choice(proxies_pool)url = 'http://www.baidu.com/s?wd=ip'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}request = urllib.request.Request(url = url,headers=headers)handler = urllib.request.ProxyHandler(proxies=proxies)opener = urllib.request.build_opener(handler)response = opener.open(request)content = response.read().decode('utf-8')with open('daili.html','w',encoding='utf-8')as fp:fp.write(content)
- 快代理
相关文章:
01Urllib
1.什么是互联网爬虫? 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据 解释1:通过一个程序,根据Url(http://www.…...

python爬取酷我音乐 根据歌名进行爬取
# _*_ coding:utf-8 _*_ # 开发工具:PyCharm # 公众号:小宇教程import urllib.parse from urllib.request import urlopen import json import time import sys import osdef Time_1...

【深度学习】吴恩达课程笔记(五)——超参数调试、batch norm、Softmax 回归
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 【吴恩达课程笔记专栏】 【深度学习】吴恩达课程笔记(一)——深度学习概论、神经网络基础 【深度学习】吴恩达课程笔记(二)——浅层神经网络、深层神经网络 【深度学习】吴恩达课程笔记(三)——参数VS超参数、深度…...
腾讯云轻量级服务器和云服务器什么区别?轻量服务器是干什么用的
随着互联网的迅速发展,服务器成为了许多人必备的工具。然而,面对众多的服务器选择,我们常常会陷入纠结之中。在这篇文章中,我们将探讨轻量服务器和标准云服务器的区别,帮助您选择最适合自己需求的服务器。 腾讯云双十…...

解决:虚拟机远程连接失败
问题 使用FinalShell远程连接虚拟机的时候连接不上 发现 虚拟机用的VMware,Linux发行版是CentOs 7,发现在虚拟机中使用ping www.baidu.com是成功的,但是使用FinalShell远程连接不上虚拟机,本地网络也ping不通虚拟机,…...
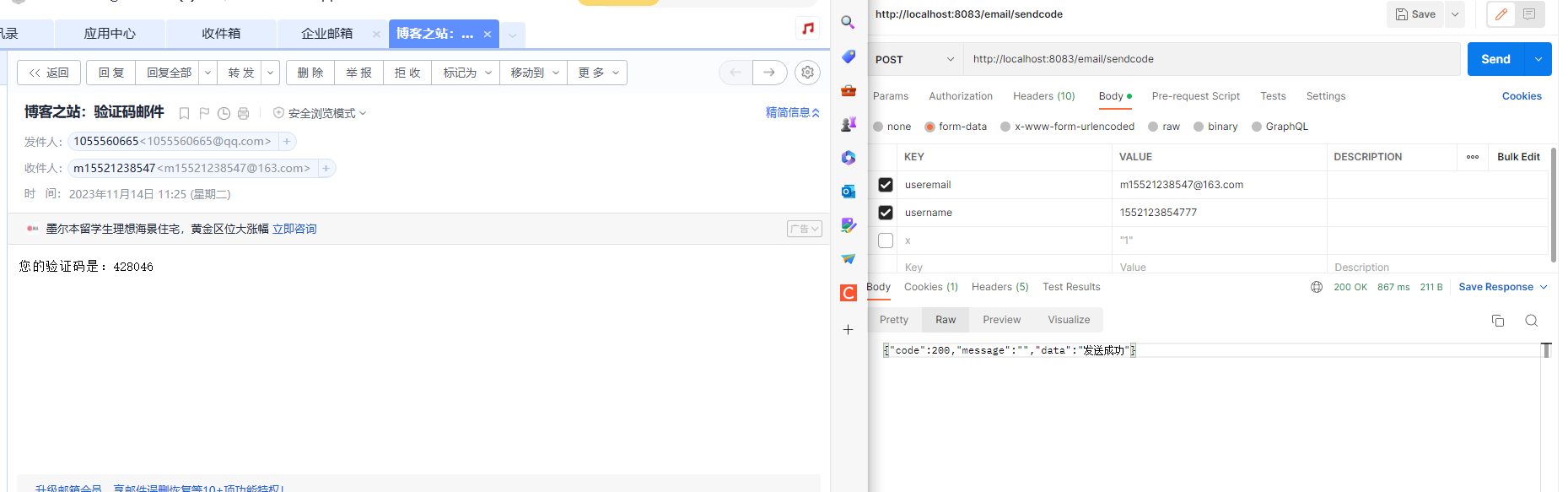
SpringBoot项目集成发邮件功能
1:引入依赖2:配置设置3:授权码获取:4:核心代码5:postman模拟验证6:安全注意 1:引入依赖 <dependency><groupId>org.apache.commons</groupId><artifactId>c…...

【Spring篇】使用注解进行开发
🎊专栏【Spring】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 🥰欢迎并且感谢大家指出小吉的问题 文章目录 🌺原代码(无注解)🎄加上注解⭐两个注…...
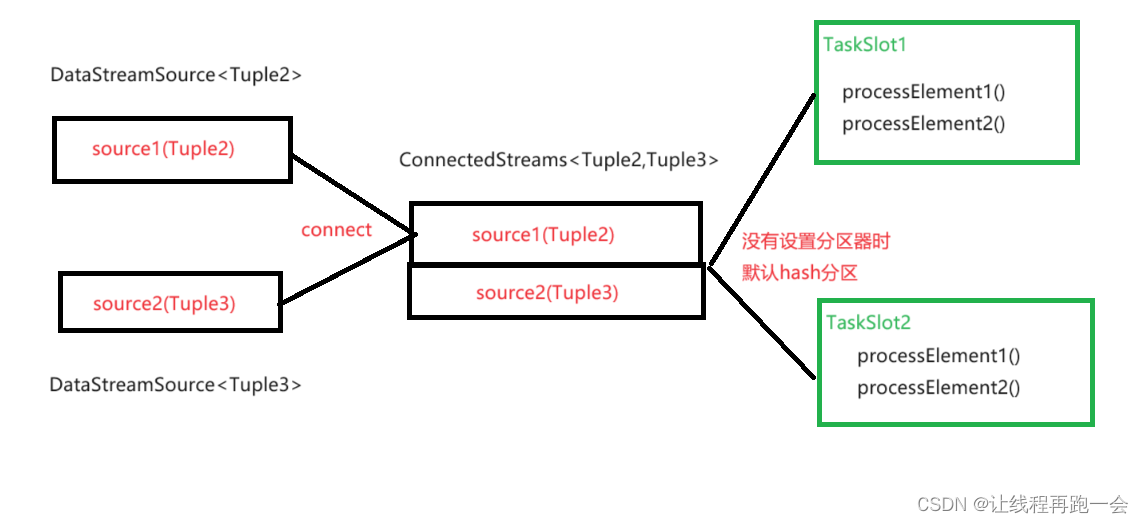
Flink(六)【DataFrame 转换算子(下)】
前言 今天学习剩下的转换算子:分区、分流、合流。 每天出来自学是一件孤独又充实的事情,希望多年以后回望自己的大学生活,不会因为自己的懒惰与懈怠而悔恨。 回答之所以起到了作用,原因是他们自己很努力。 …...
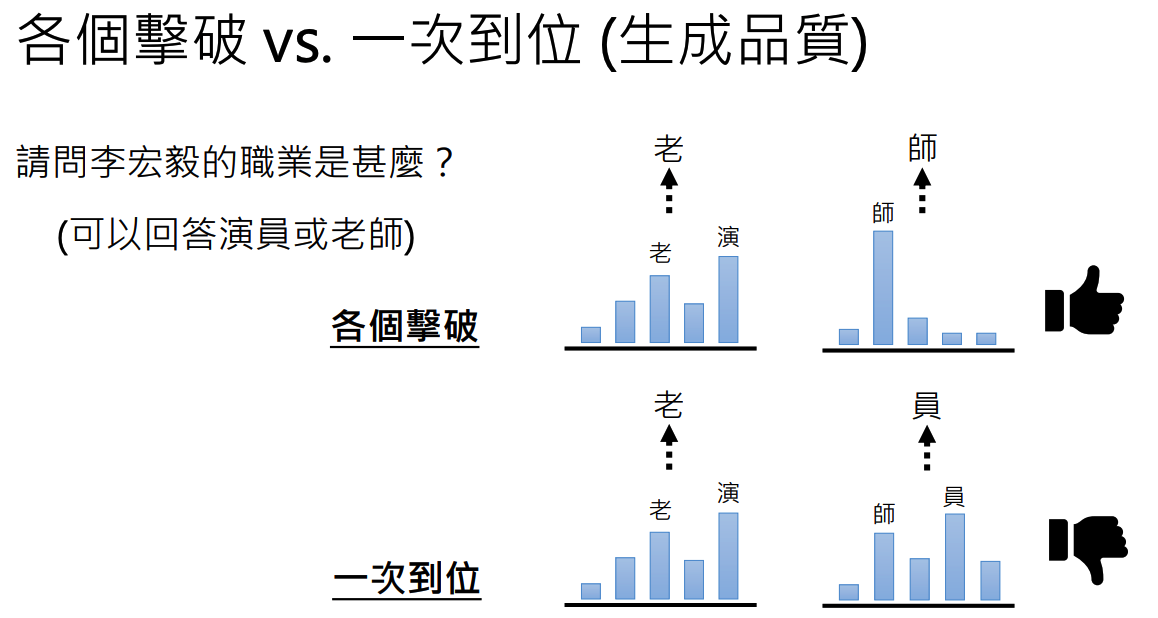
【2023春李宏毅机器学习】生成式学习的两种策略
文章目录 1 各个击破2 一步到位3 两种策略的对比 生成式学习的两种策略:各个击破、一步到位 对于文本生成:把每一个生成的元素称为token,中文当中token指的是字,英文中的token指的是word piece。比如对于unbreakable,他…...

Android13 adb 无法连接?
Android13 adb 无法连接? 文章目录 Android13 adb 无法连接?一、前言二、替换adbGoogle 官网对adb的介绍:Google 提供的adb tools的下载: 三、总结1、adb connect 连接后显示offline2、输入adb devices 报错:版本不匹配导致3、adb常用命令4…...

Ubuntu 20.04 调整交换分区大小
Ubuntu 调整交换分区大小 一、系统情况二、去除旧的交换分区文件三、配置并启用交换分区四、查看swap文件大小 一、系统情况 Ubuntu :Ubuntu 20.04.6 LTS 交换分区位置: cat /proc/swaps二、去除旧的交换分区文件 去掉旧的交换分区有两个步骤&#x…...
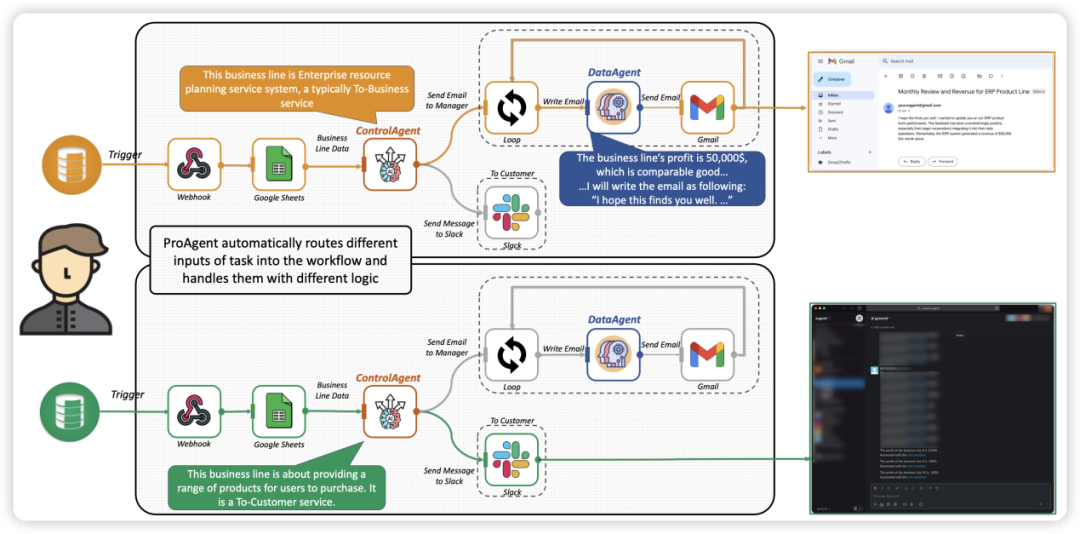
将Agent技术的灵活性引入RPA,清华等发布自动化智能体ProAgent
近日,来自清华大学的研究人员联合面壁智能、中国人民大学、MIT、CMU 等机构共同发布了新一代流程自动化范式 “智能体流程自动化” Agentic Process Automation(APA),结合大模型智能体帮助人类进行工作流构建,并让智能…...

高济健康:数字化科技创新与新零售碰撞 助推医疗产业优化升级
近日,第六届中国国际进口博览会在上海圆满落幕,首次亮相的高济健康作为一家专注大健康领域的疾病和健康管理公司,在本届进博会上向业内外展示了围绕“15分钟步行健康生活圈”构建进行的全域数字化升级成果。高济健康通过数字化科技创新与新零…...

SystemVerilog学习 (5)——接口
一、概述 验证一个设计需要经过几个步骤: 生成输入激励捕获输出响应决定对错和衡量进度 但是,我们首先需要一个合适的测试平台,并将它连接到设计上。 测试平台包裹着设计,发送激励并且捕获设计的输出。测试平台组成了设计周围的“真实世界”,…...
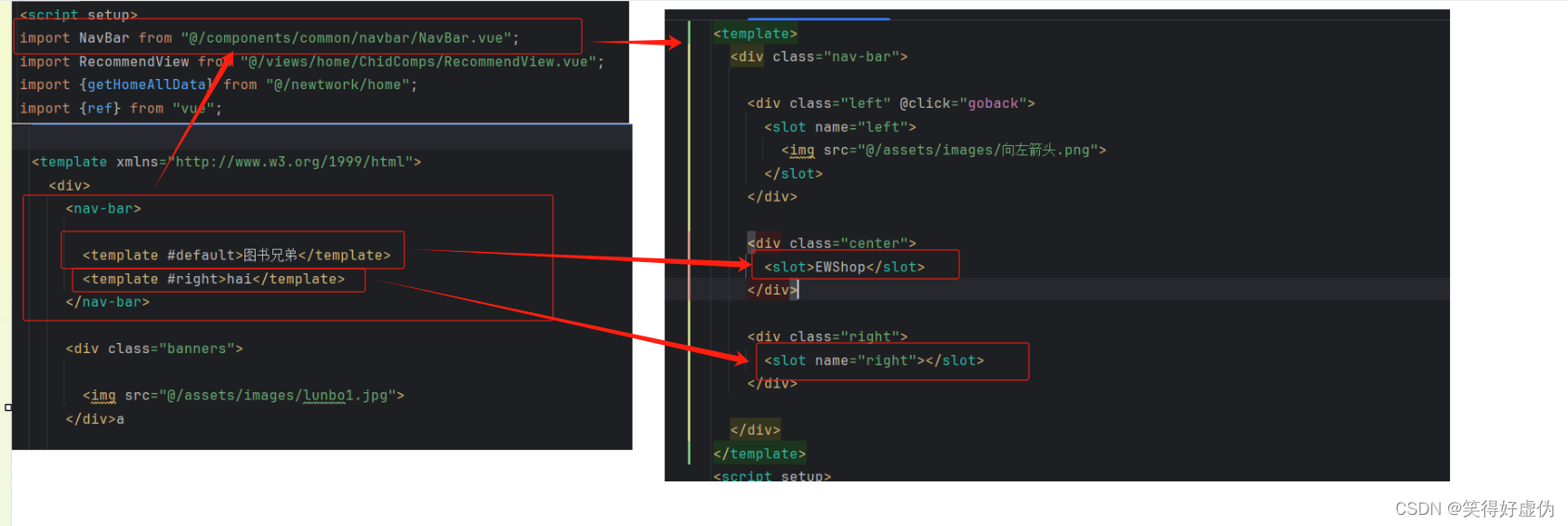
vue3插槽的使用
什么是插槽 Vue 3 插槽(Slots)是一个强大的工具,用于在组件之间传递内容和逻辑。通过使用插槽,我们可以将子组件中的内容插入到父组件中的特定位置。本篇文章将总结 Vue 3 插槽的基本用法、特点以及使用场景。 基本用法 插槽分为…...

IPTABLES问题:DNAT下如何解决内网访问内部服务器问题
这个问题,困扰了我几年了,今天终于得到解决。 问题是这样的,在局域网内部有一台服务器,通过IPTABLES的网关提供对外服务,做过IPTABLES网关的人都知道,这很容易做到,只要在网关机器上写一个DNAT…...
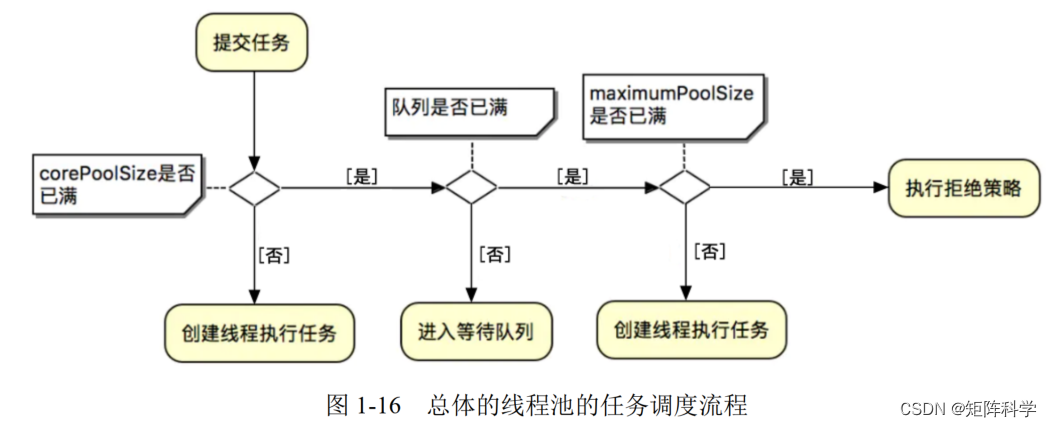
异步任务线程池——最优雅的方式创建异步任务
对于刚刚从校园出来的菜鸡选手很容易写出自以为没问题的屎山代码,可是当上线后就会立即暴露出问题,这说到底还是基础不够扎实!只会背八股文,却不理解,面试头头是道,一旦落地就啥也不是。此处,抛…...

uniapp 跨页面传值及跨页面方法调用
uniapp 跨页面传值及跨页面方法调用 1、跨页面传值 使用全局方法监听uni.$emit、uni.$on、uni.$off 发布、监听、移除 methods: {addFun(){let data [1]uni.navigateBack({ // 返回上一页delta: 1})uni.$emit(successFun,{data}) // 传值} }监听页 onLoad() {uni.$on(succ…...
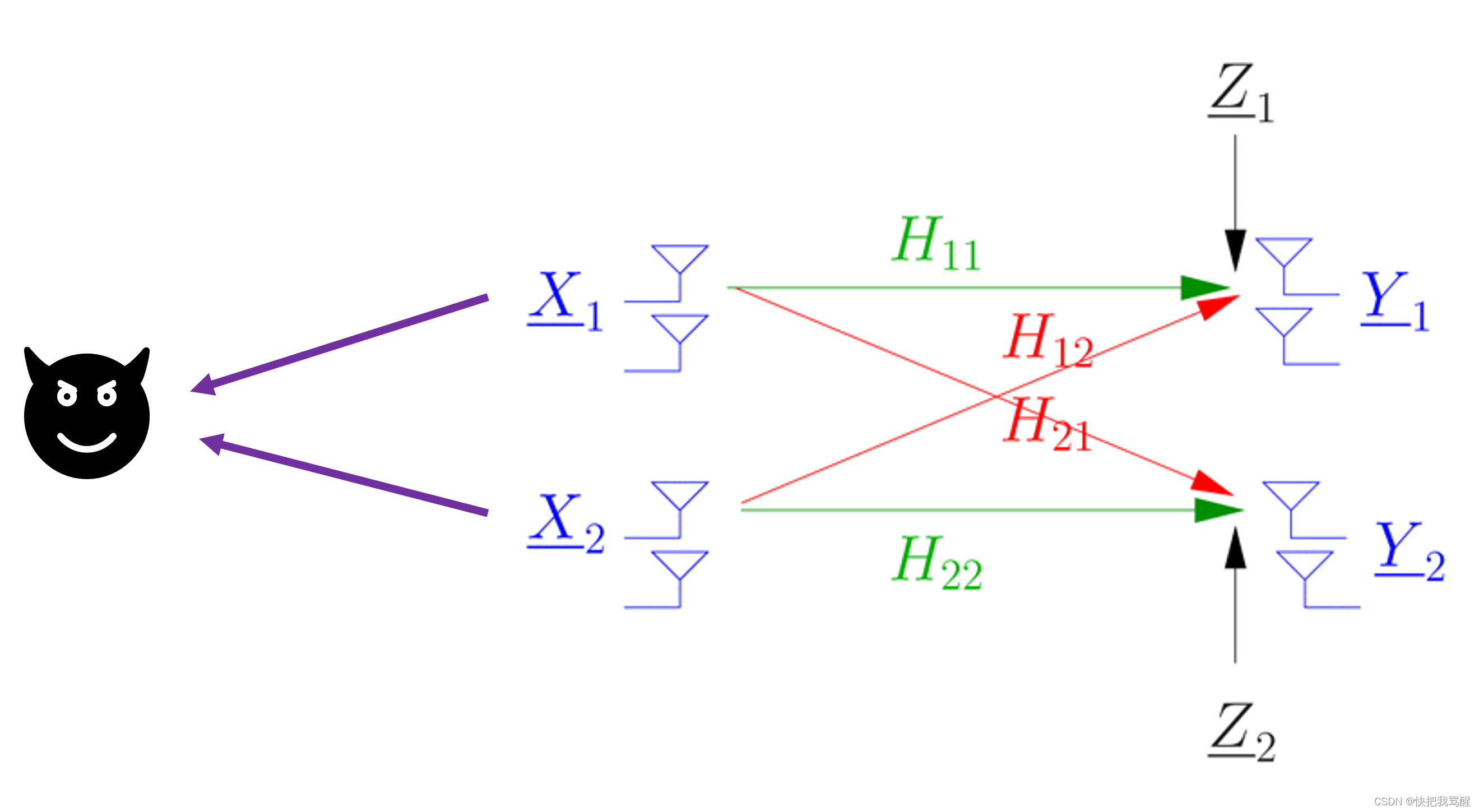
无线物理层安全大作业
这个标题很帅 Beamforming Optimization for Physical Layer Security in MISO Wireless NetworksProblem Stateme Beamforming Optimization for Physical Layer Security in MISO W…...
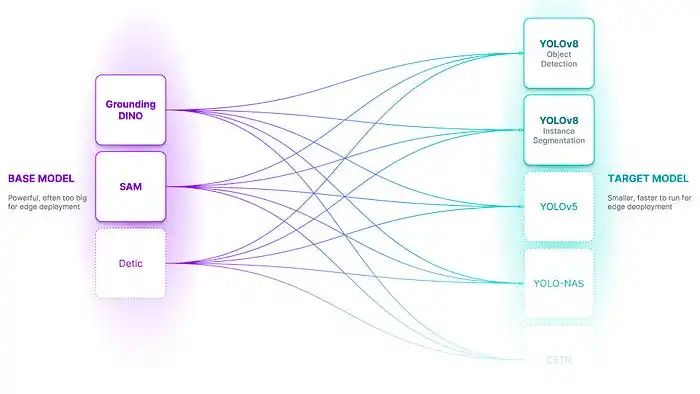
目标检测标注工具AutoDistill
引言 在快速发展的机器学习领域,有一个方面一直保持不变:繁琐和耗时的数据标注任务。无论是用于图像分类、目标检测还是语义分割,长期以来人工标记的数据集一直是监督学习的基础。 然而,由于一个创新性的工具 AutoDistill&#x…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...