【数据挖掘】2、数据预处理
文章目录
- 一、数据预处理的意义
- 1.1 缺失数据
- 1.1.1 原因
- 1.1.2 方案
- 1.1.3 离群点分析
- 1.2 重复数据
- 1.2.1 原因
- 1.2.2 去重的方案
- 1.3 数据转换
- 1.4 数据描述
- 二、数据预处理方法
- 2.1 特征选择 Feature Selection
- 2.2 特征提取 Feature Extraction
- 2.2.1 PCA 主成分分析
- 2.2.2 LDA 线性判别分析
数据预处理分为数据清洗、转换、描述、选择、提起五部分:

一、数据预处理的意义
数据预处理的意义:因为真实世界的问题,脏数据的预处理才是最大的挑战。脏数据主要包括如下方面:
- 不完整:缺失
- 噪声:错误的数据
- 不一致
- 冗余:我们只需真实有用的部分
- 其他
- 数据类型

- 数据类型
1.1 缺失数据
1.1.1 原因
可能有很多原因:
- 设备故障
- 并未提供数据(例如调查问卷的被访人)
- 不适用、无意义(可能并无物理意义,比如一张宽表:既有学生、又有教师,那么学生并无收入(只有教师才有),则此表格设计的并不合理)

1.1.2 方案
数据缺失的应对方案:其实是一门艺术
- 忽略:
- 不处理有问题的列或行(当然只有这部分数据较少才可以)
- 填充:
- 重新采集
- 利用领域知识去猜:(比如一个人住了 18 年的房子,那推测为住房,而不是租房形式)
- 用固定值 or 均值、众数等

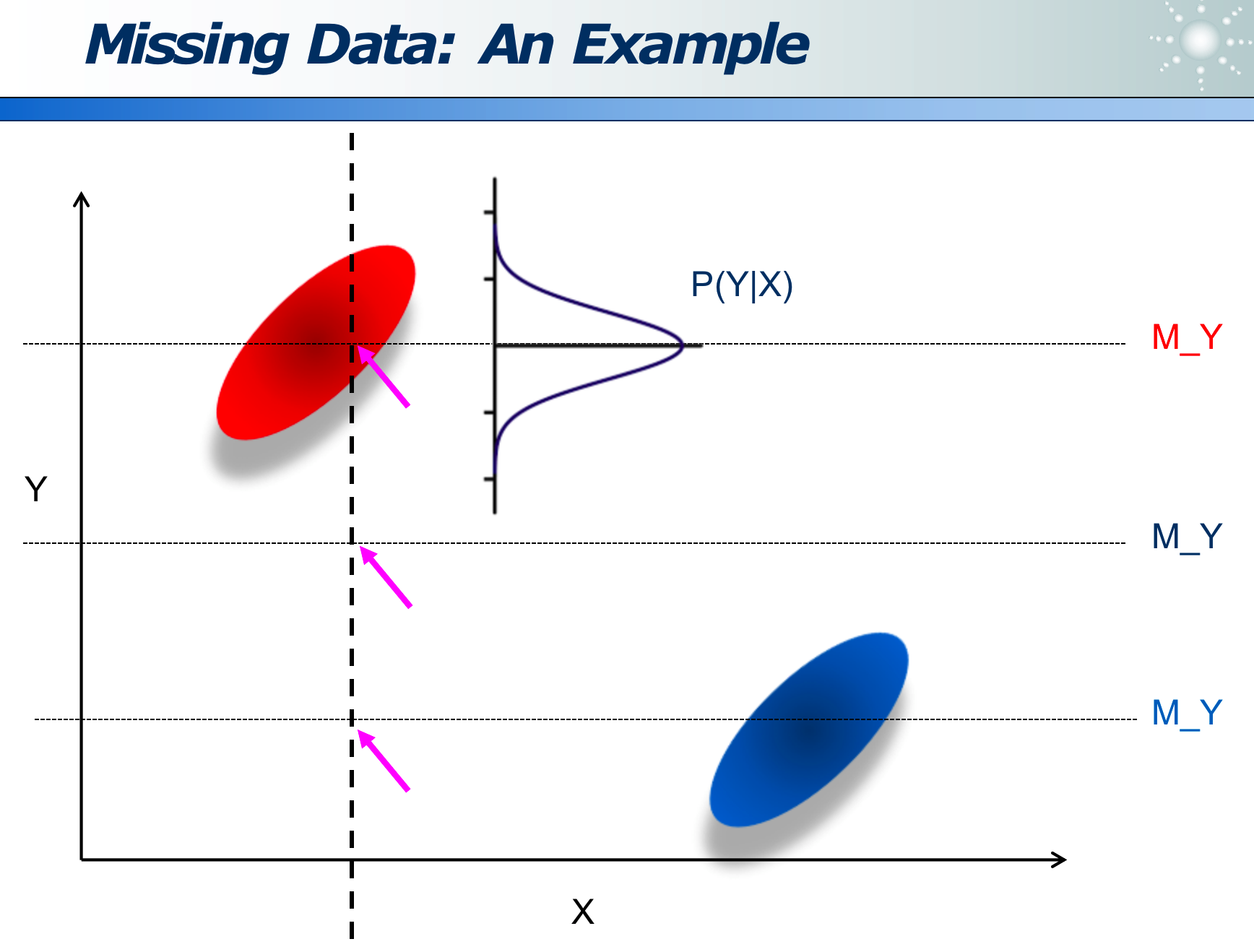
可以在均值基础上,做高斯分布,来让填充的数据即具备随机性,又基于一个基点分布:
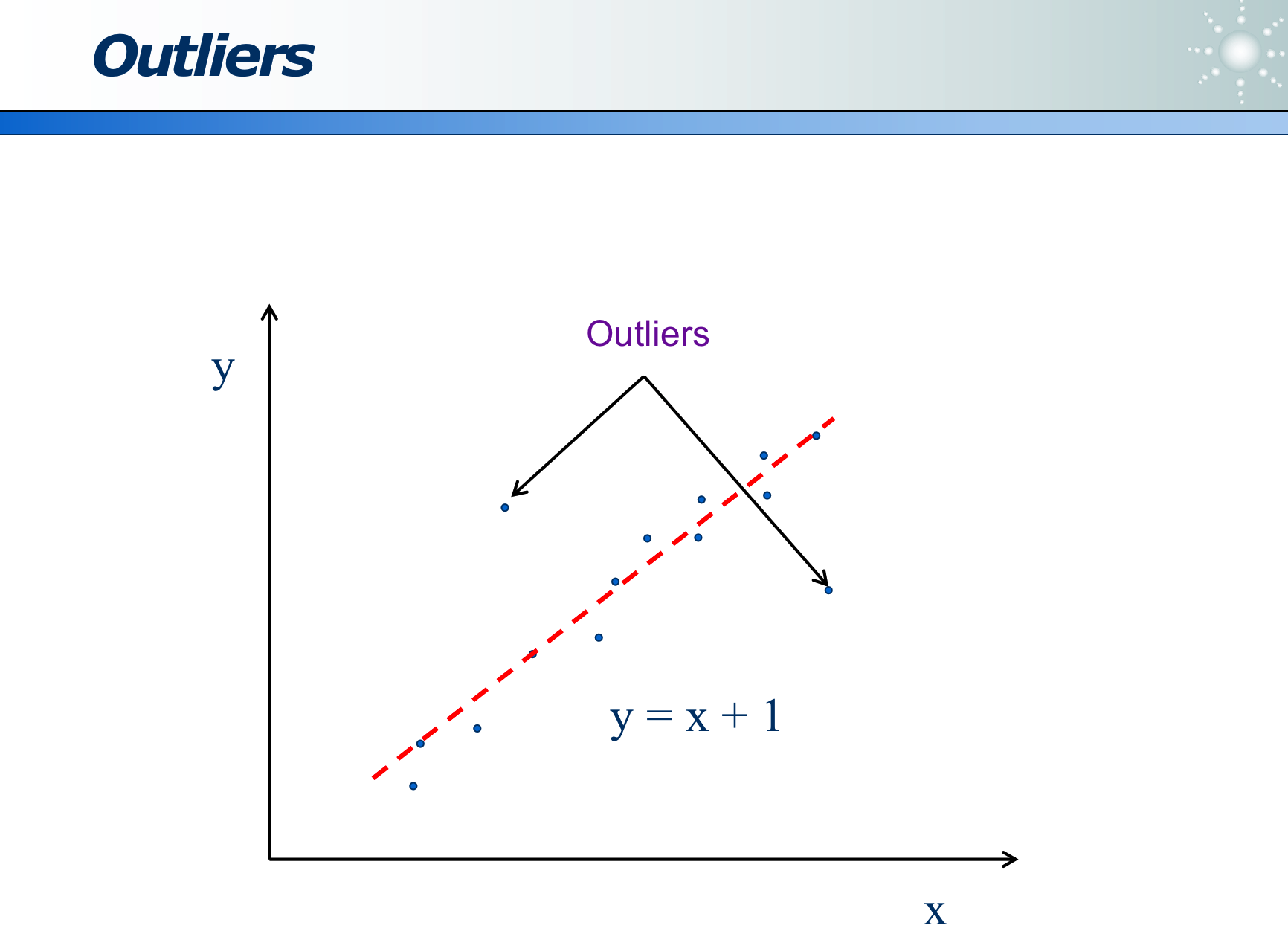
Outliers 异常值:是指数据明显出错了
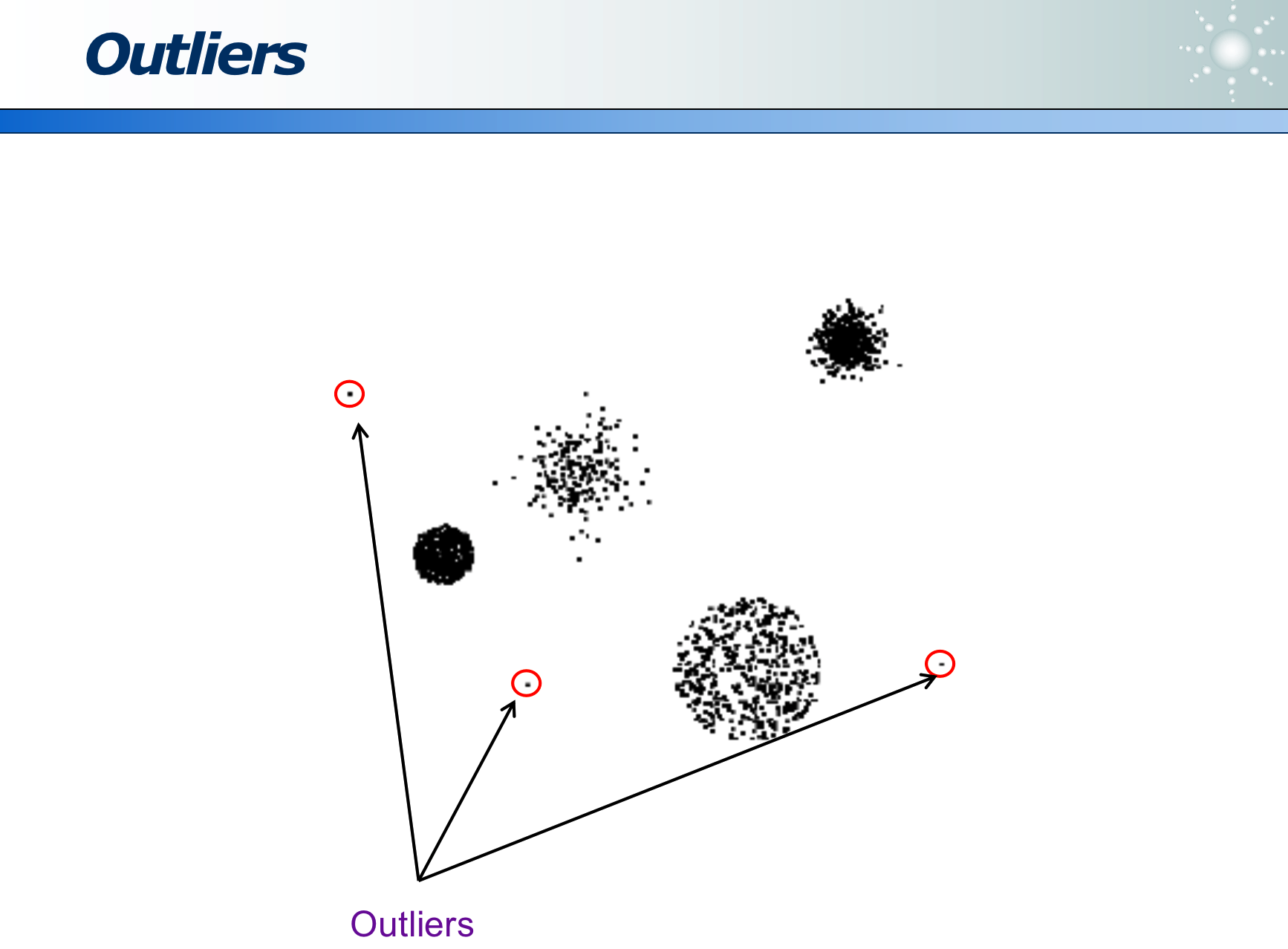
而 Anomaly 指数据是正确的,只是它和众数有别:例如下图中的黄衣服人也是正常的样本,只是他没有和别人聚在一堆而已:

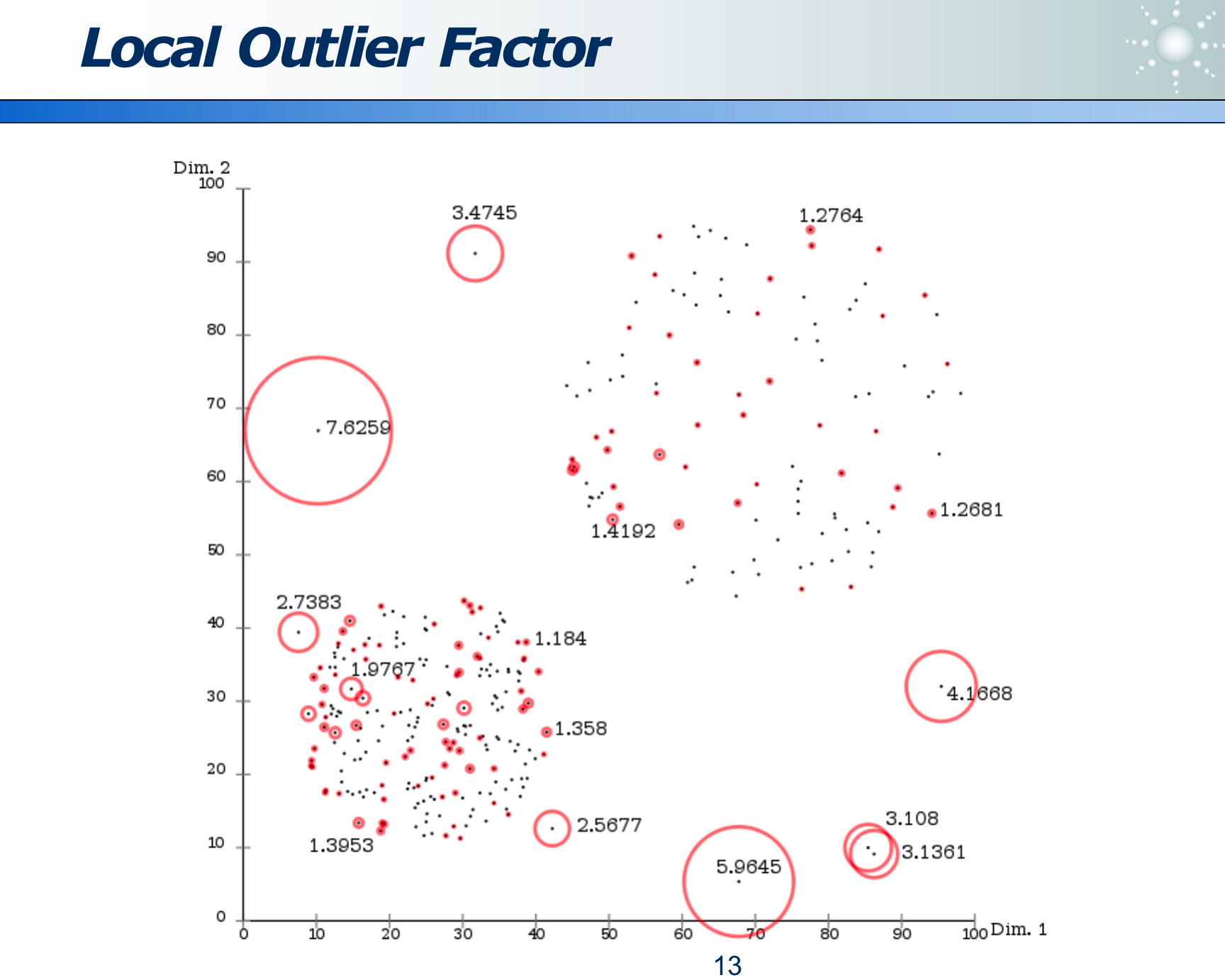
1.1.3 离群点分析
因为离群点是相对概念,所以不能只用绝对距离distance(A, B),而应用相对距离lrd(A)。

那么 LOF(A) 则正比于 lrd(B) / lrd(A)
- 其中
lrd(A)指:待分析的A点,距离其近邻 B 的均值。 - 其中
lrd(B)指:待分析A点 的 近邻点 B,距离其近邻们的均值。 - 若二者之商越大,则说明 A 越「相对」离群。
例如下图是离群点分析的结果:其红色圆圈越大(红圈内的数字即为 LOF 值)则说明越离群
1.2 重复数据
1.2.1 原因
不同数据源汇总时,都包含同一个人的信息,需要汇总。
- 其中各数据源的数据格式不同:比如有的表叫 id,有的表叫 no。
- 数据的内容不同,但可能表示的含义相同:比如快递地址写广东省深圳市某小区,和写深圳市某小区,的含义是相同的。
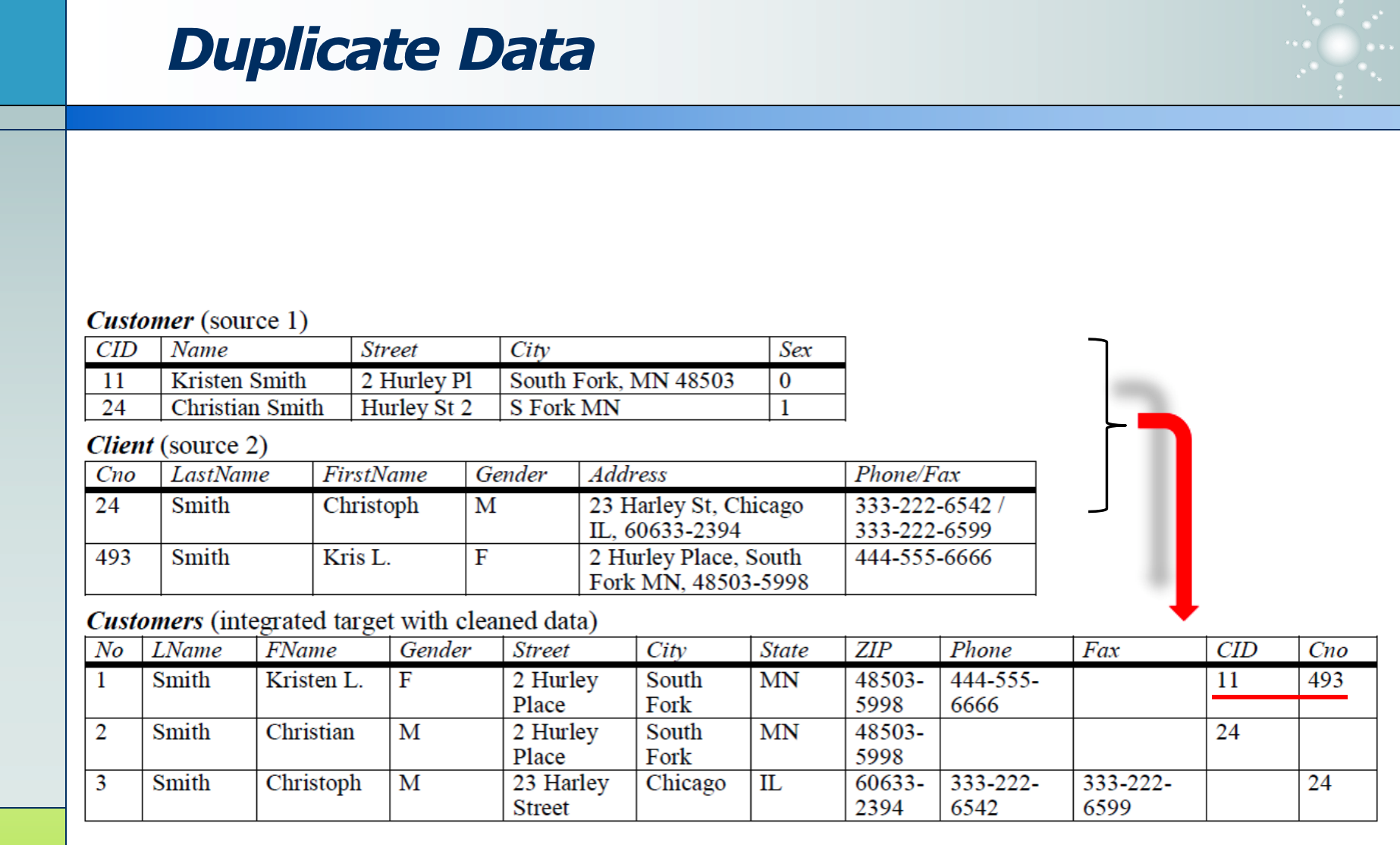
1.2.2 去重的方案
因为大数据,不可能在所有数据范围内去重。因此一般采用局部去重。
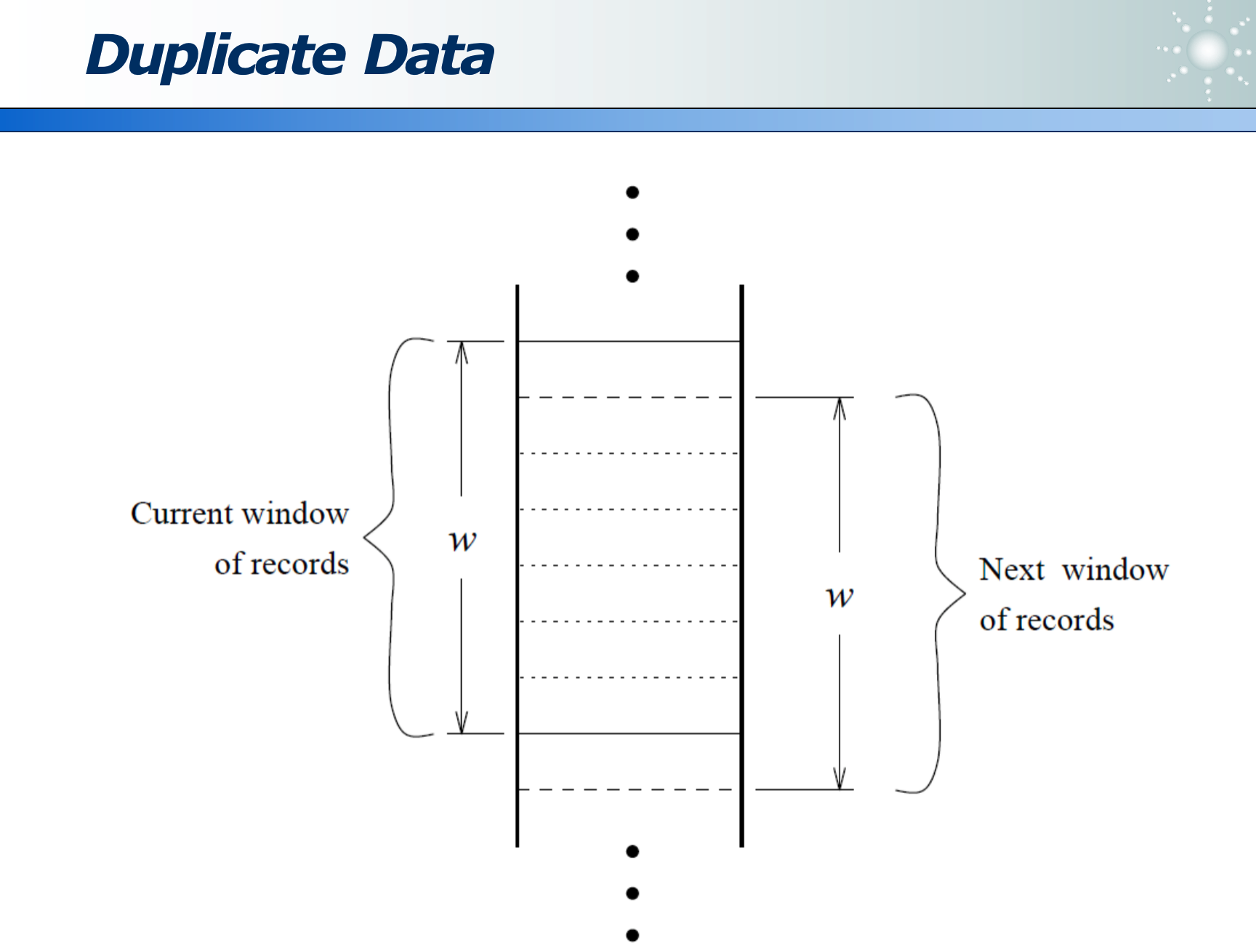
- 如果业务决定重复的数据通常相邻,则可用滑动窗口实现(在滑窗内去重):即在一定程度去重,又提升了计算性能。
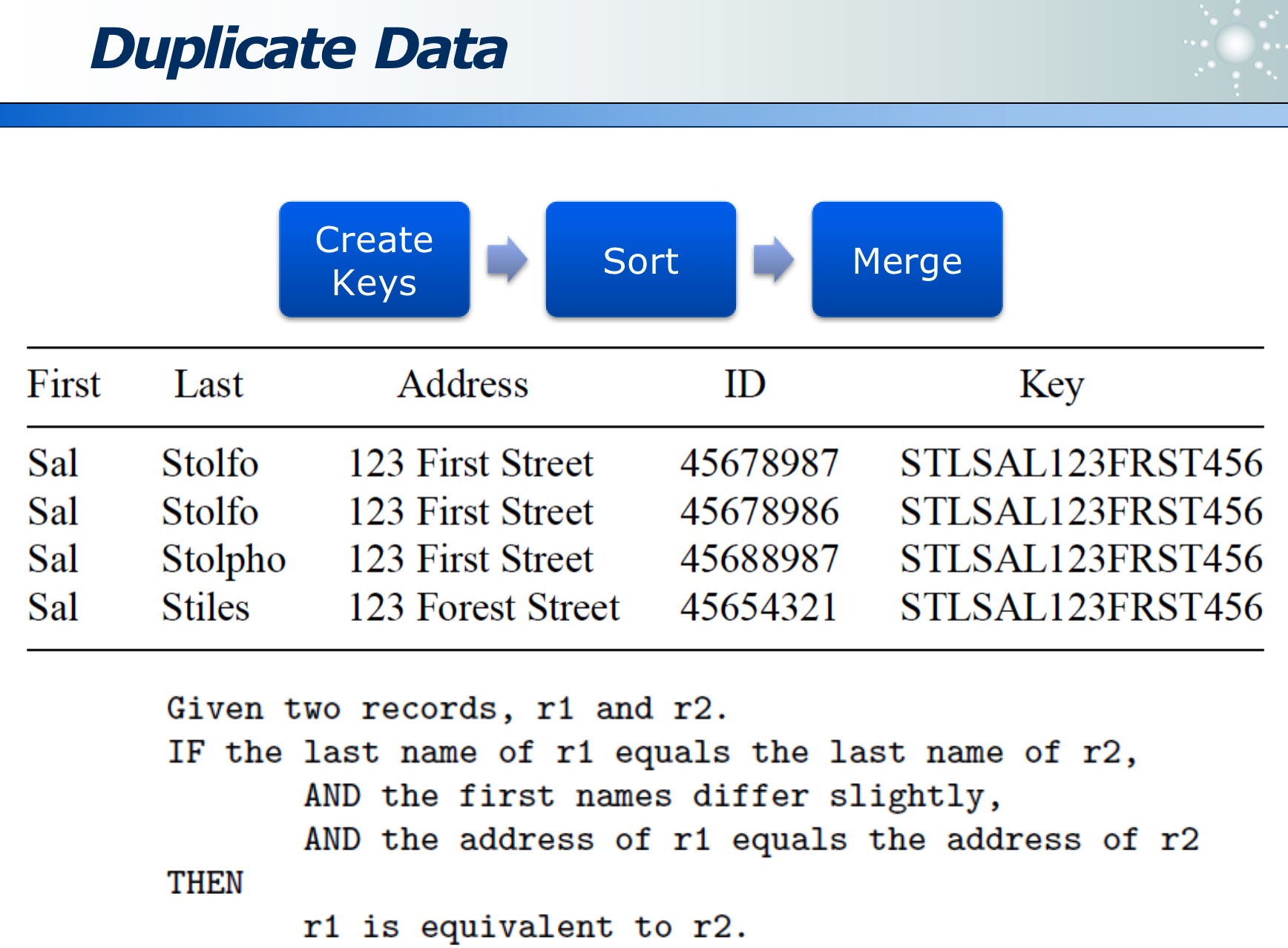
可以根据领域知识,定义一种规则:来识别出原本相同,但被错记录的数据。比如若名字相同,姓不同,地址相同的人,认为是同一个人。
1.3 数据转换


数据的编码:影响数据问题的复杂度

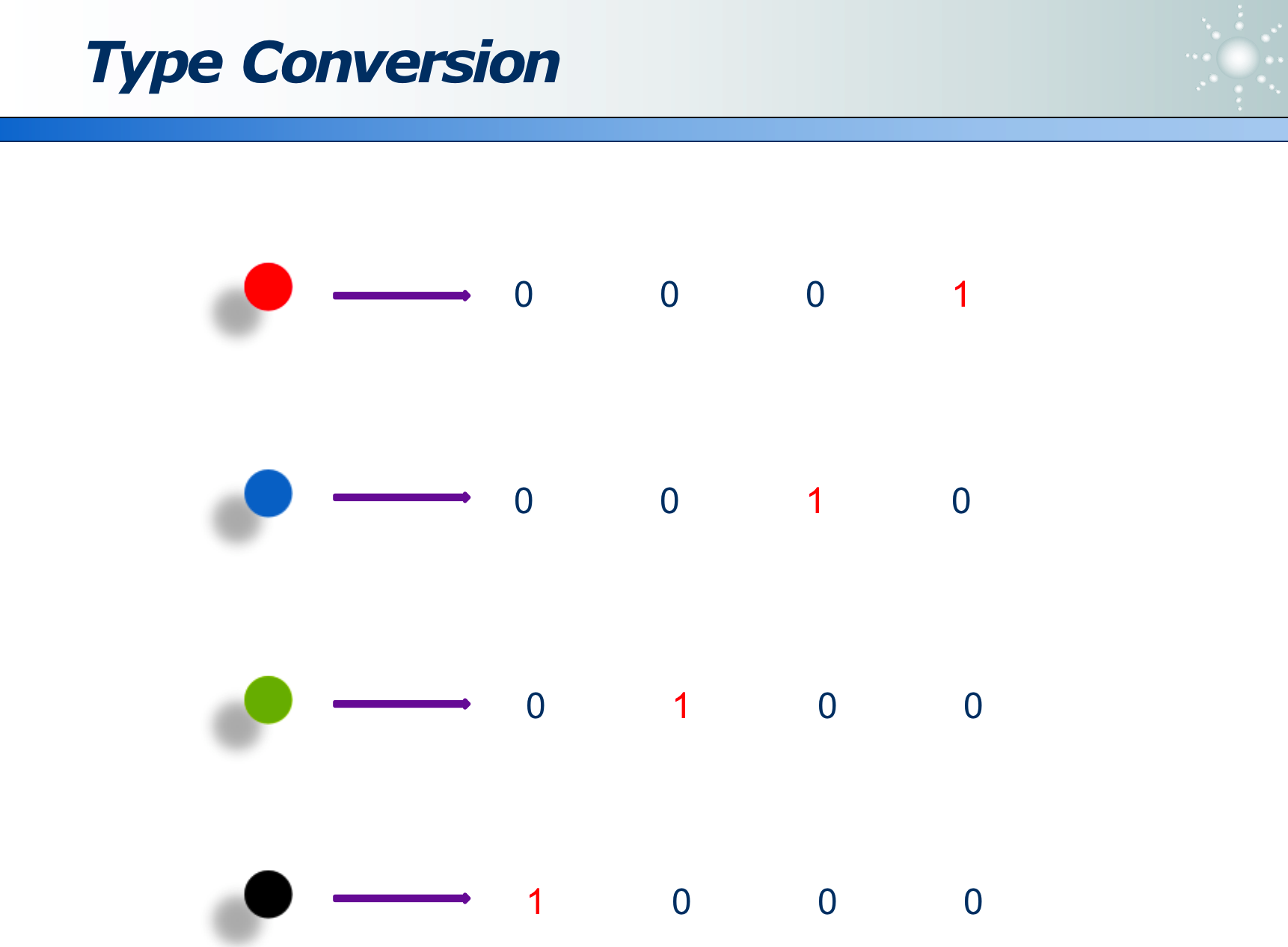
可以用位来标识不同数据:
数据采样:通过采样频率,可以降低数据量

不平衡数据:当两类数据占比差别很大时,整体准确率并不能很好地度量,应用各自的准确率。(例如 99%人健康,1%的人生病,模型需要预测出生病的人)
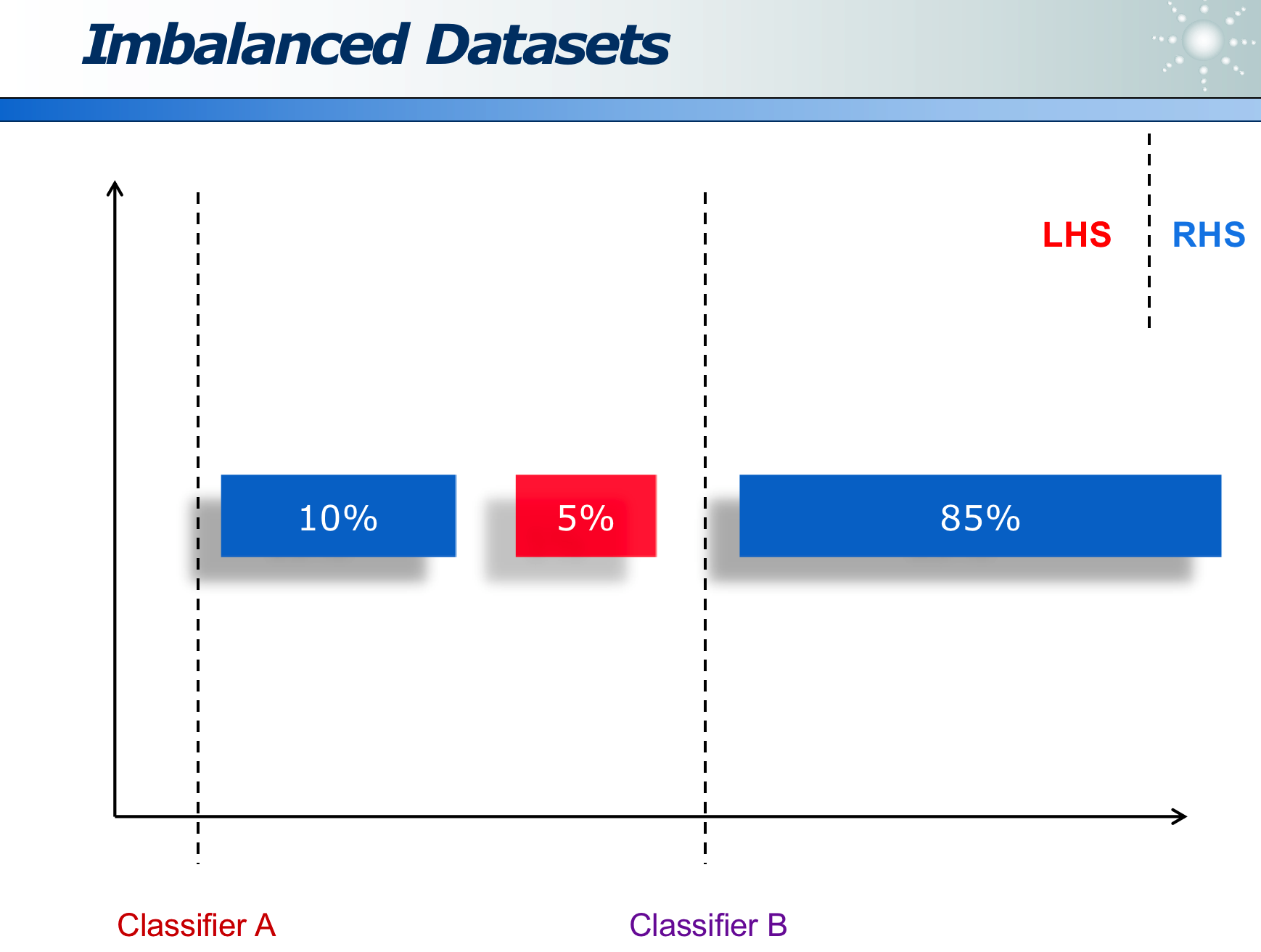
G-mean 方法:

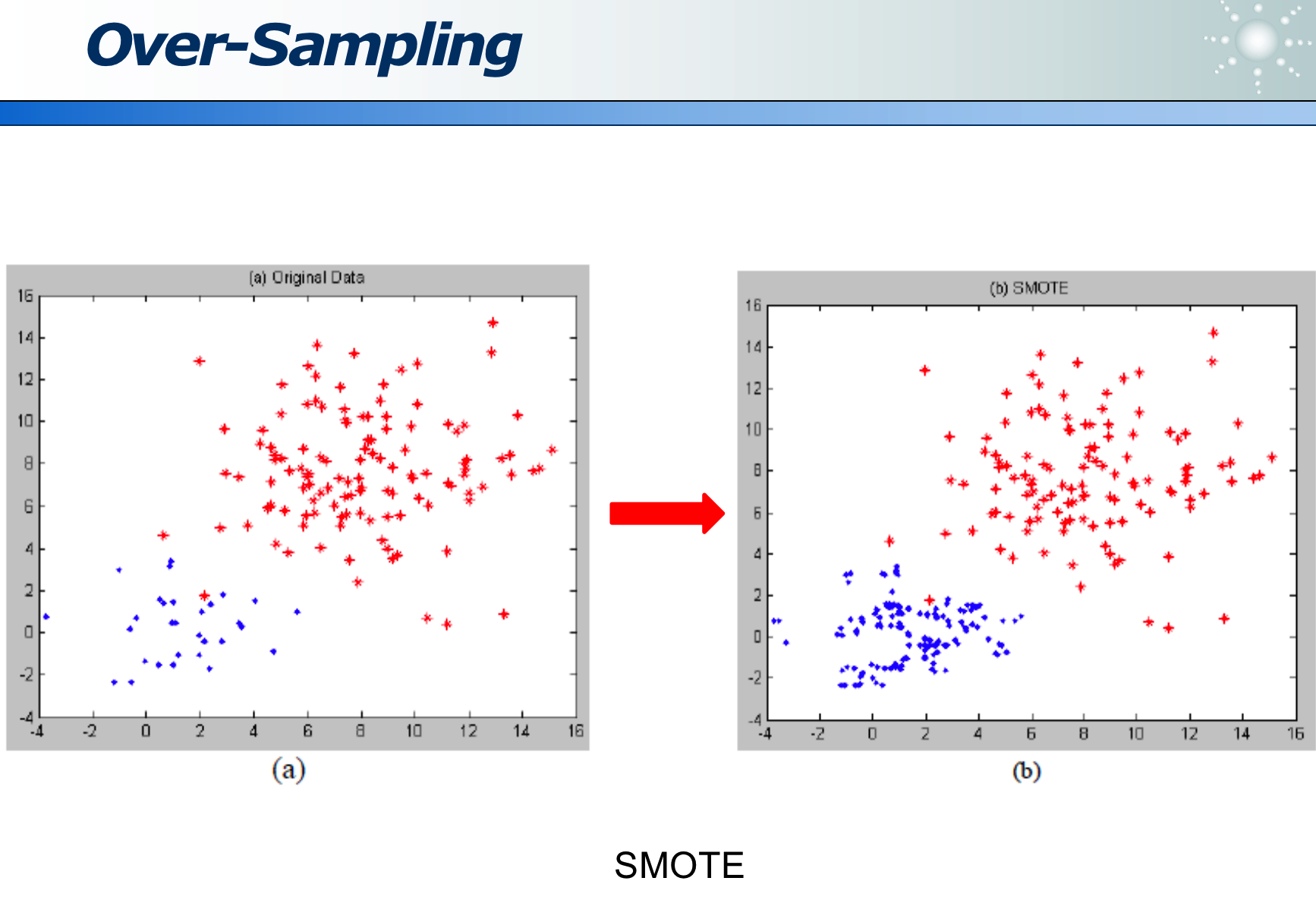
采样不均衡:可以有针对性的,对数据量少的类(如下图的蓝色点),多采样。
边缘采样:边缘点的价值更大

归一化:

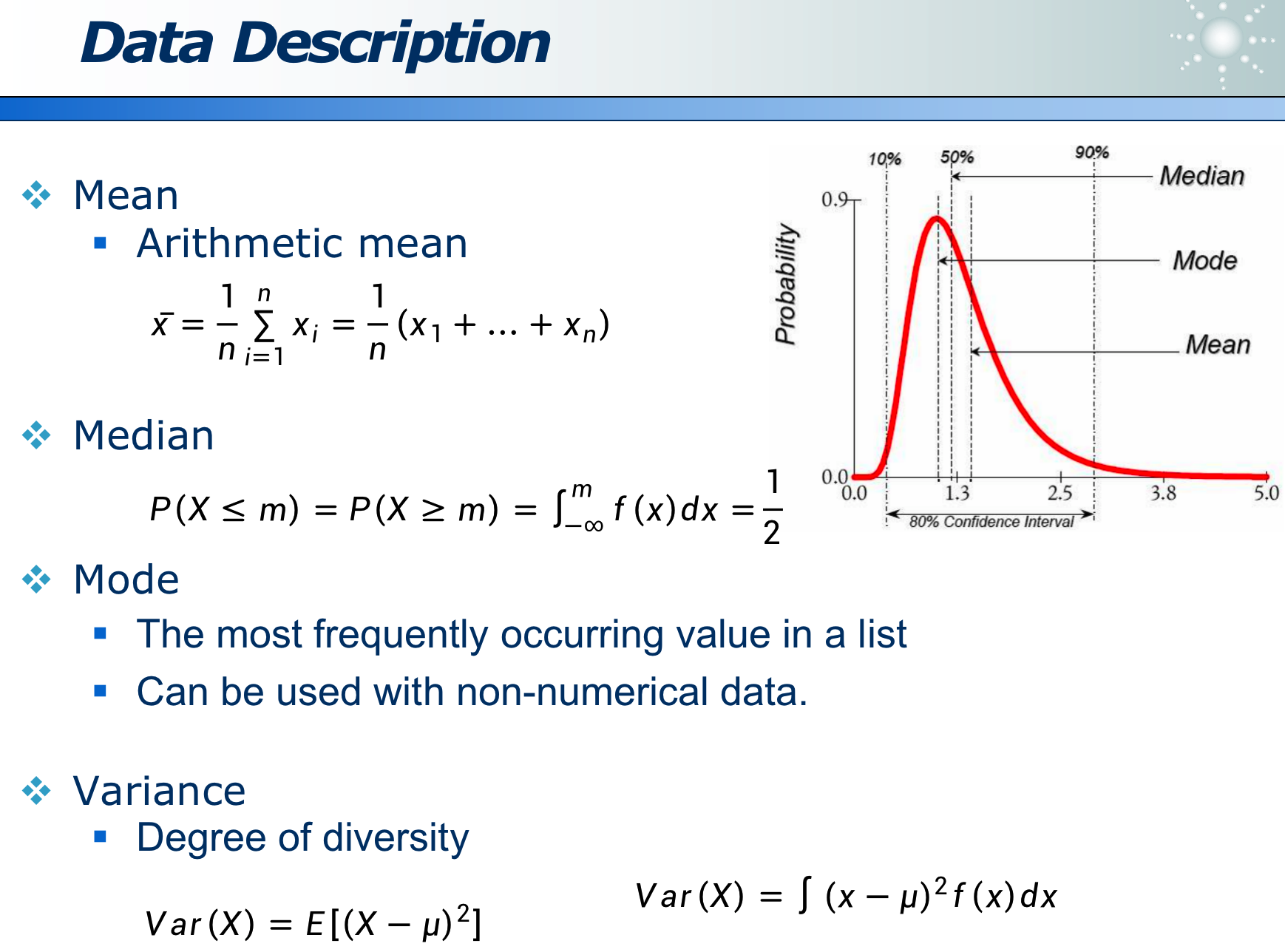
1.4 数据描述
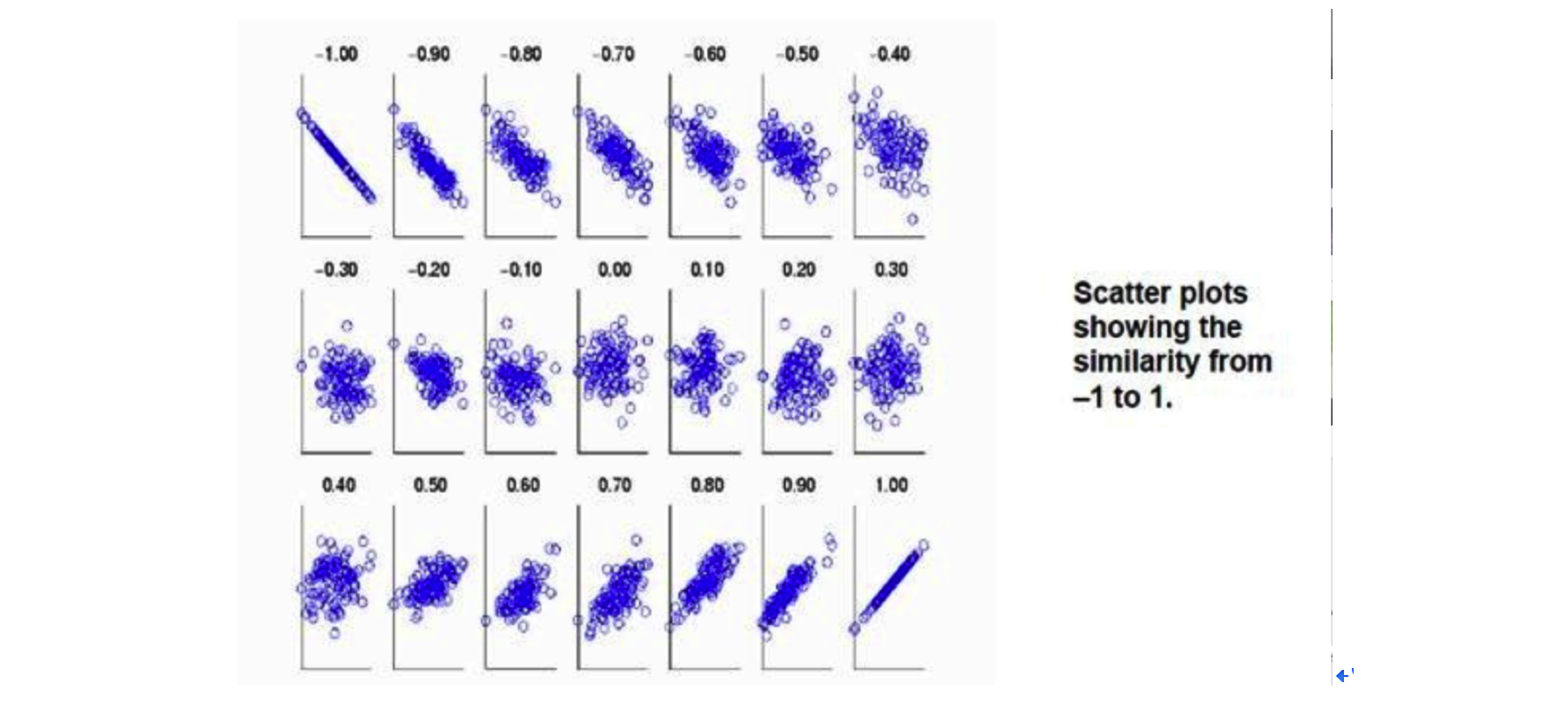
相关性可用「皮尔森相关系数」衡量,其分子为 「A 与 B 的协方差」,分母为「A的方差 乘以 B的方差」
- ra,b > 0:正相关:即 a 越大则 b 越大,即 a 与 b 的协方差为正
- ra,b = 0:没有「线性」相关性
- ra,b > 0:负相关:即 a 越大则 b 越小,即 a 与 b 的协方差为负

要理解 Pearson 相关系数,首先要理解协方差(Covariance)。协方差表示两个变量 X,Y 间相互关系的数字特征,其计算公式为:
协方差公式如下:
Cov(X,Y)=1n−1Σ1n(Xi−X‾)(Yi−Y‾)Cov(X,Y)=\frac{1}{n-1}\Sigma_1^n \ (X_i-\overline X)(Y_i-\overline Y)Cov(X,Y)=n−11Σ1n (Xi−X)(Yi−Y)
当 Y = X 时,即与方差相同。当变量 X,Y 的变化趋势一致时,Pearson 相关系数为正数。当变量 X,Y 的变化趋势相反时,Pearson 相关系数为负数。
Pearson 相关系数如下:
COR(X,Y)=Σ1n(Xi−X‾)(Yi−Y‾)Σ1n(Xi−X‾)2Σ1n(Yi−Y‾)2COR(X, Y) = \frac{\Sigma_1^n(X_i-\overline X)(Y_i-\overline Y)}{\sqrt{\Sigma_1^n(X_i-\overline X)^2\Sigma_1^n(Y_i-\overline Y)^2}}COR(X,Y)=Σ1n(Xi−X)2Σ1n(Yi−Y)2Σ1n(Xi−X)(Yi−Y)
由公式可知,Pearson 相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但其数值上受量纲的影响很大,不能简单地从协方差的数值大小给出变量相关程度的判断。为了消除这种量纲的影响,于是就有了相关系数的概念。
当两个变量的方差都不为零时,相关系数才有意义,相关系数的取值范围为[-1,1]。
计算方式为cor = corr(Matrix,'type','Pearson'),其中Matrix 参数即为需要计算的矩阵。
数据相关性描述:Person 卡方检定,其值越大则相关性越大(如下图为 507.93 较大,说明有较大相关性)

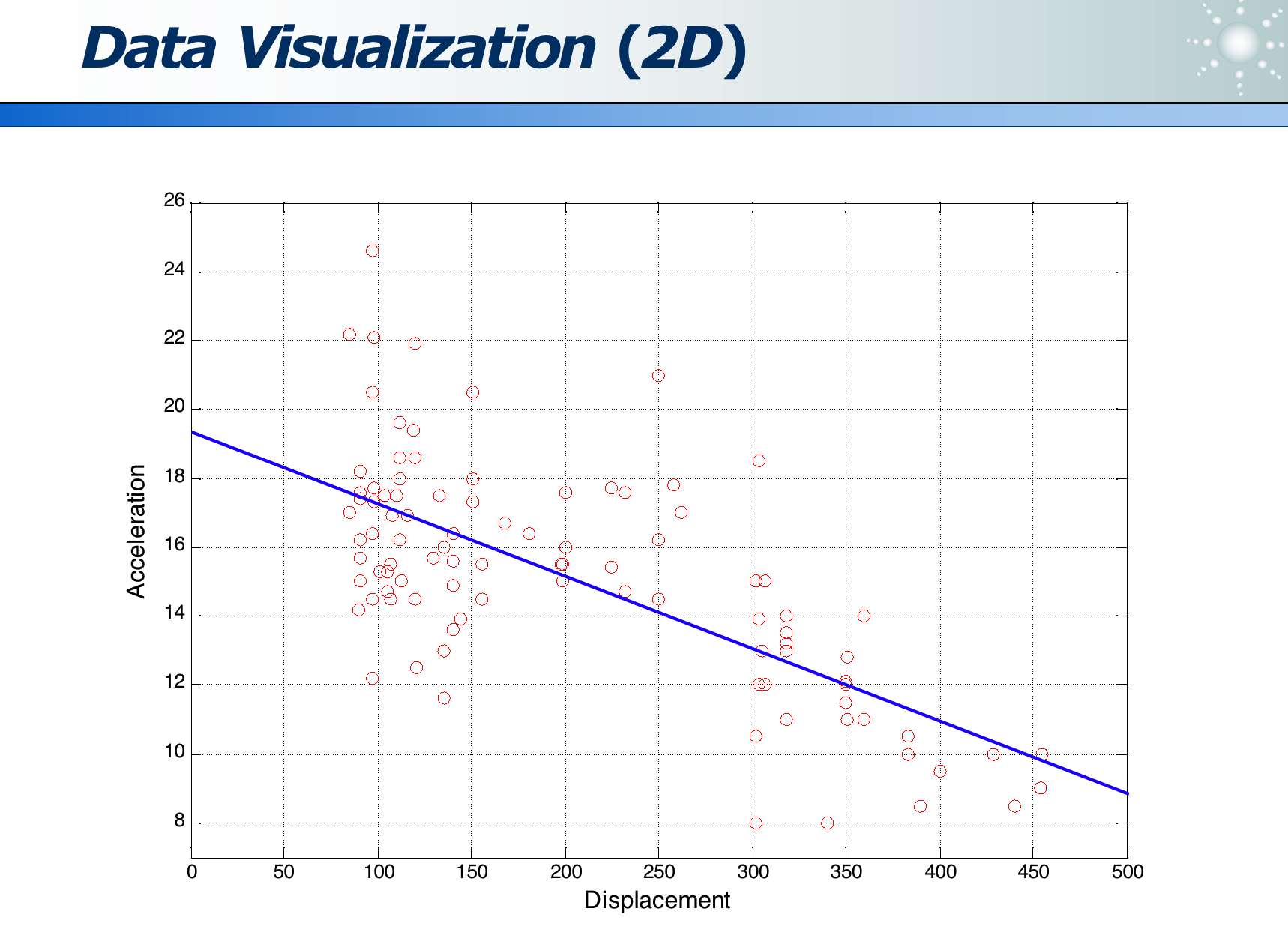
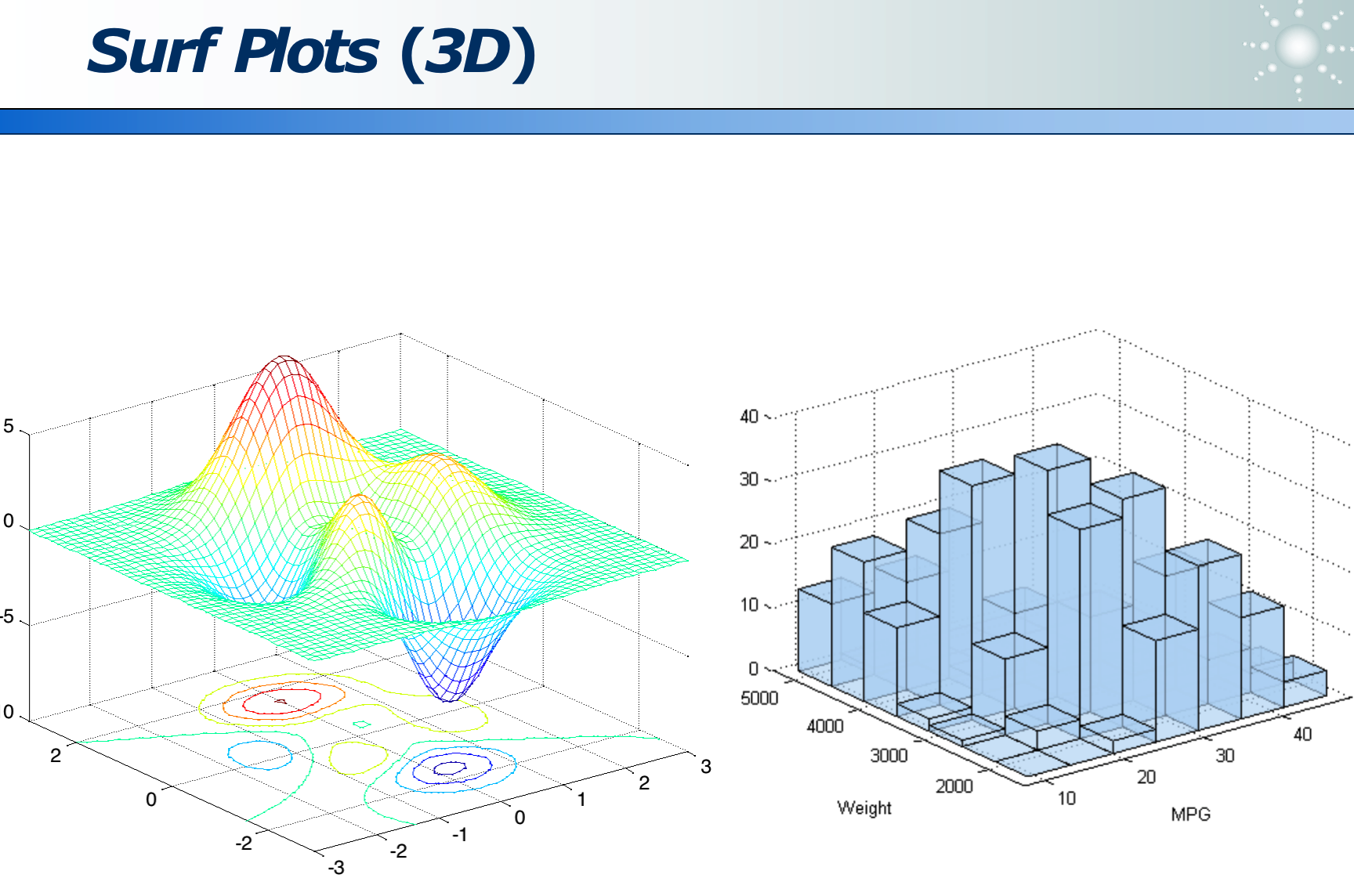
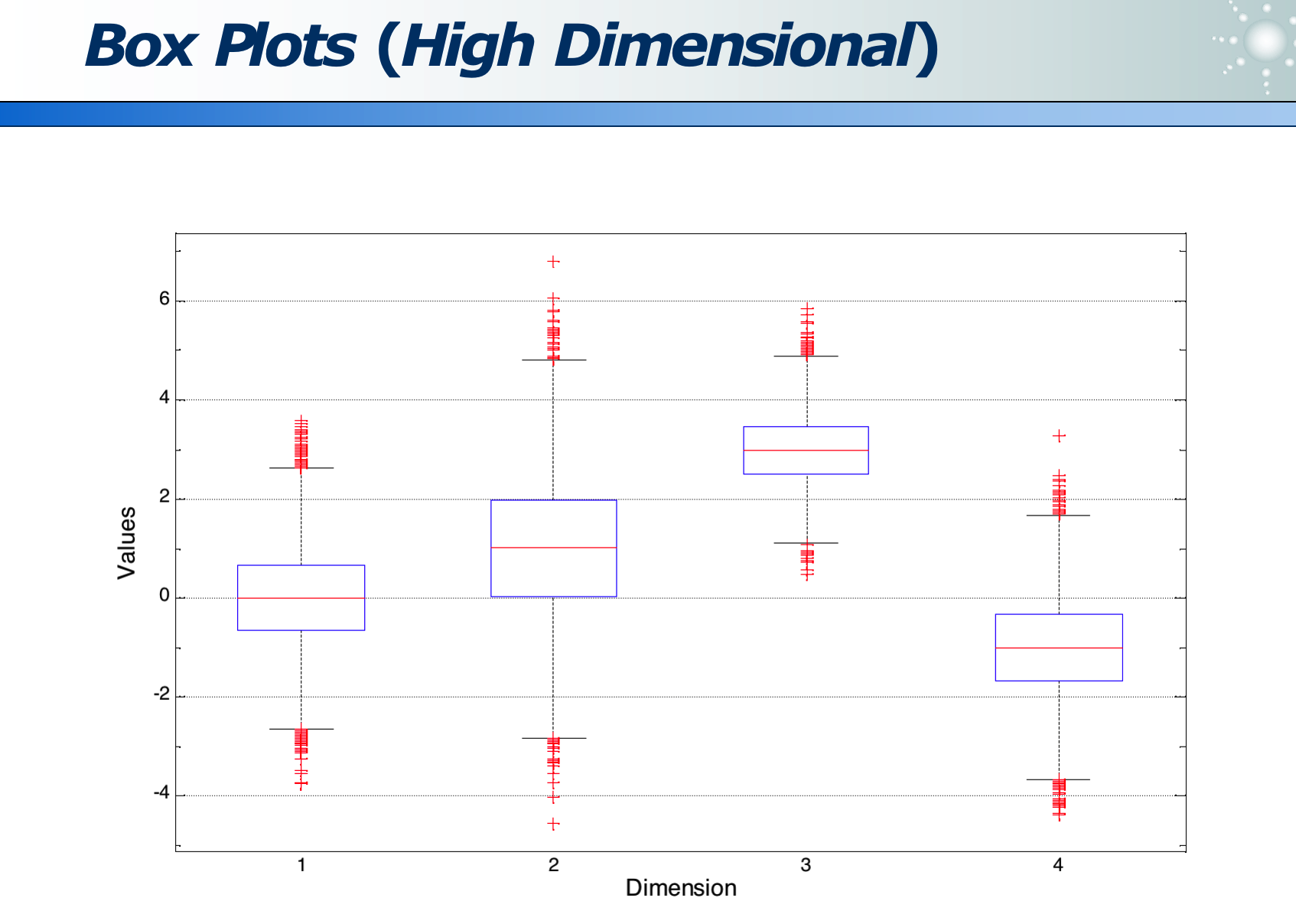
数据可视化:
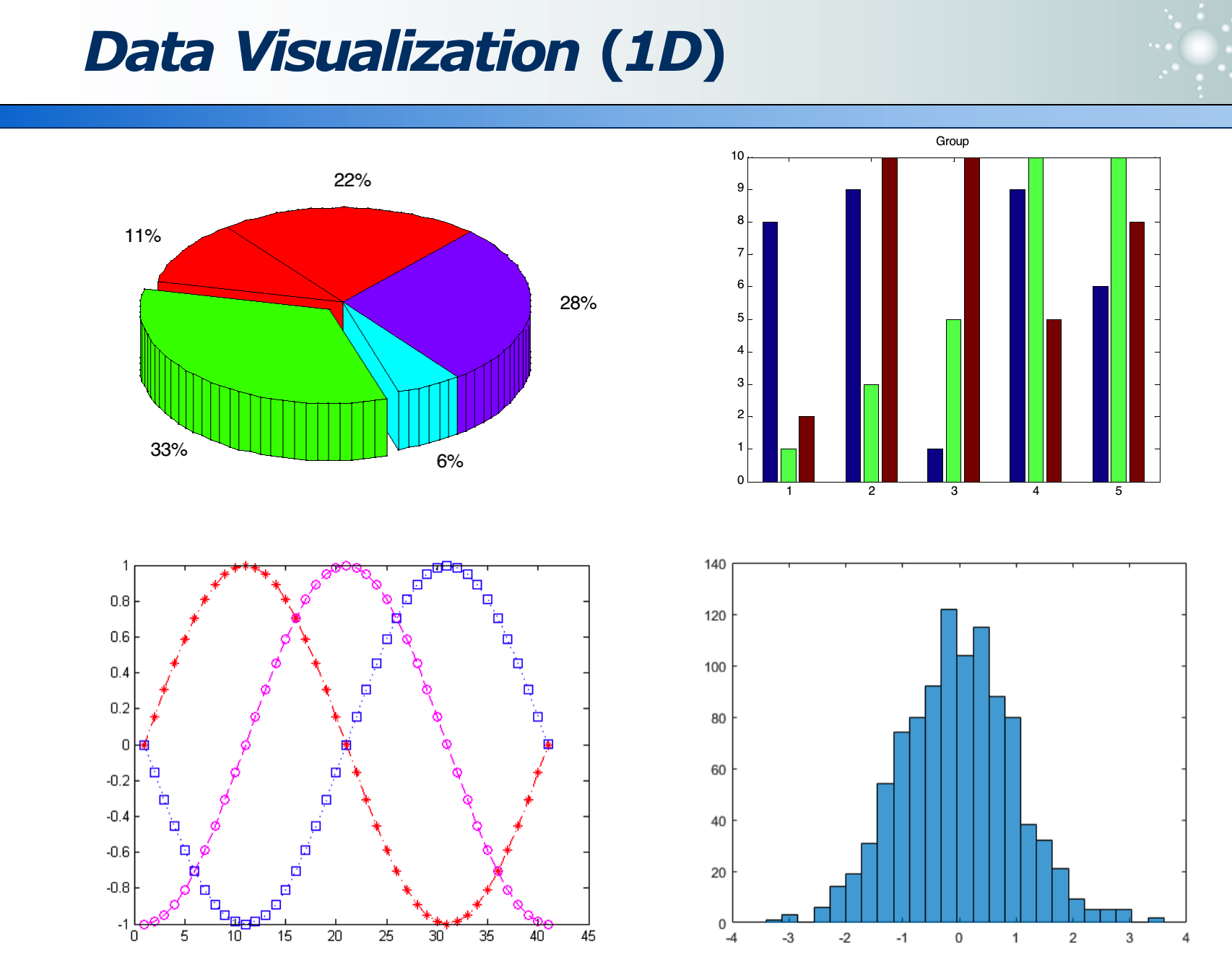
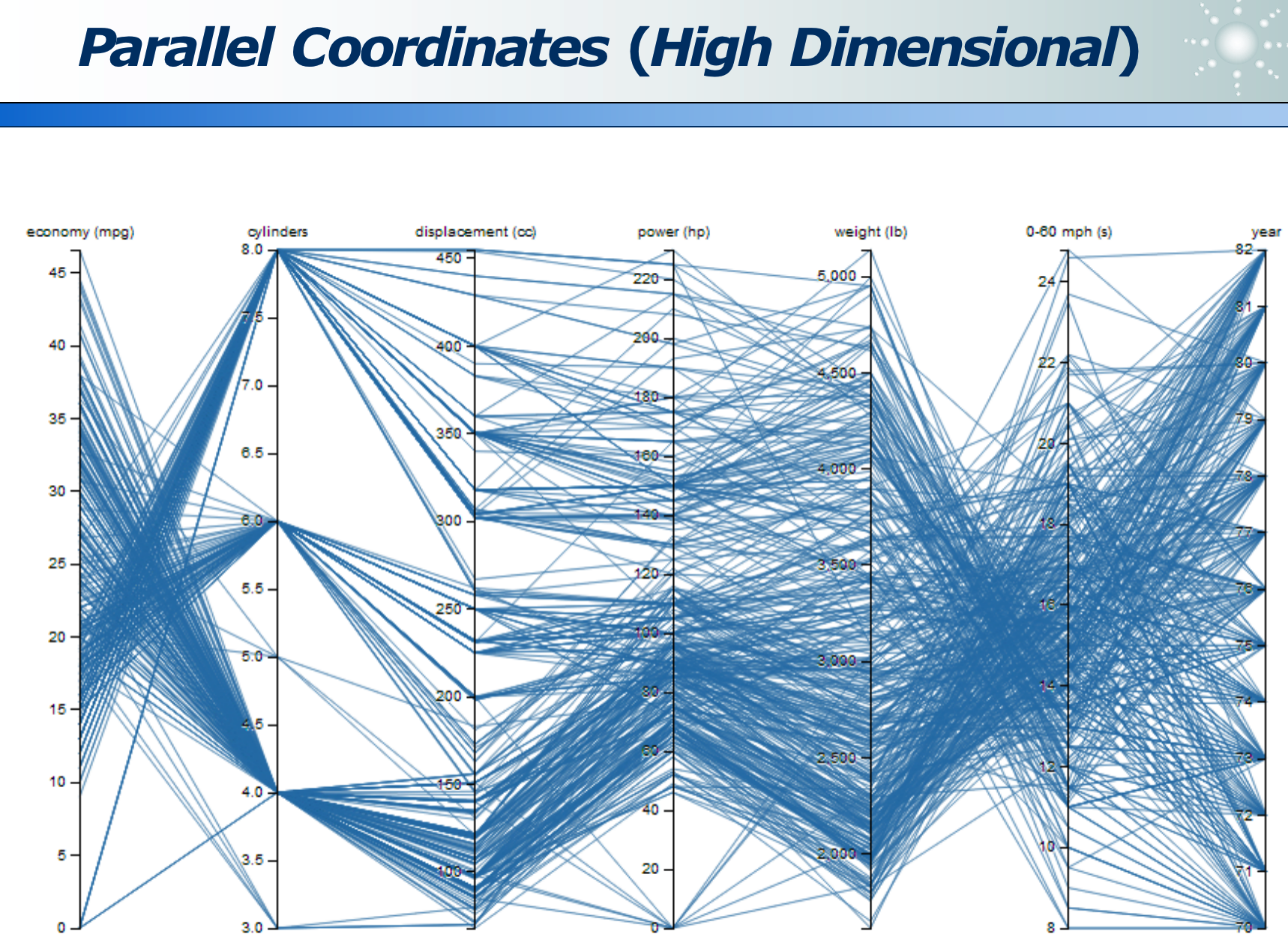
高维数据:各维度的分布
高维数据:各位数据的关系
CiteSpace 是文献可视化的软件:下图为文章的引用次数
Gephi 软件可以可视化各维度数据,是开源的:
二、数据预处理方法
2.1 特征选择 Feature Selection
收集到大量的特征,需要选择好的、有代表性的特征,这个过程称为特征选择。
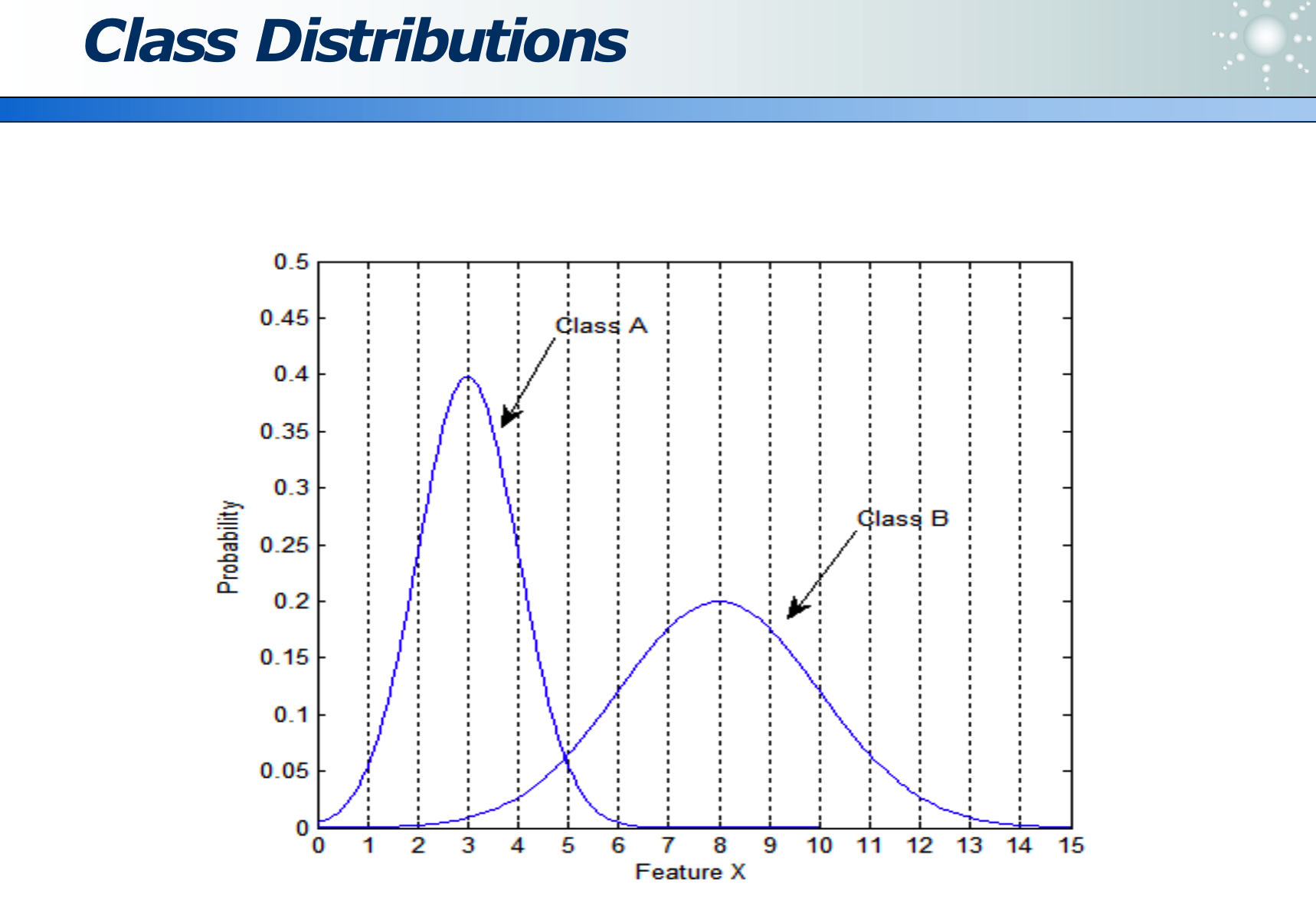
下图是指:身高的分布,其中 Class A 是女生身高分布曲线,Class B 是男生身高分布曲线:
下图是抽烟的数据集:其中 60% 不抽烟,40% 抽烟。不抽烟的人由 60% 女 + 40% 男构成。抽烟的人由 5% 女 + 95% 男构成。
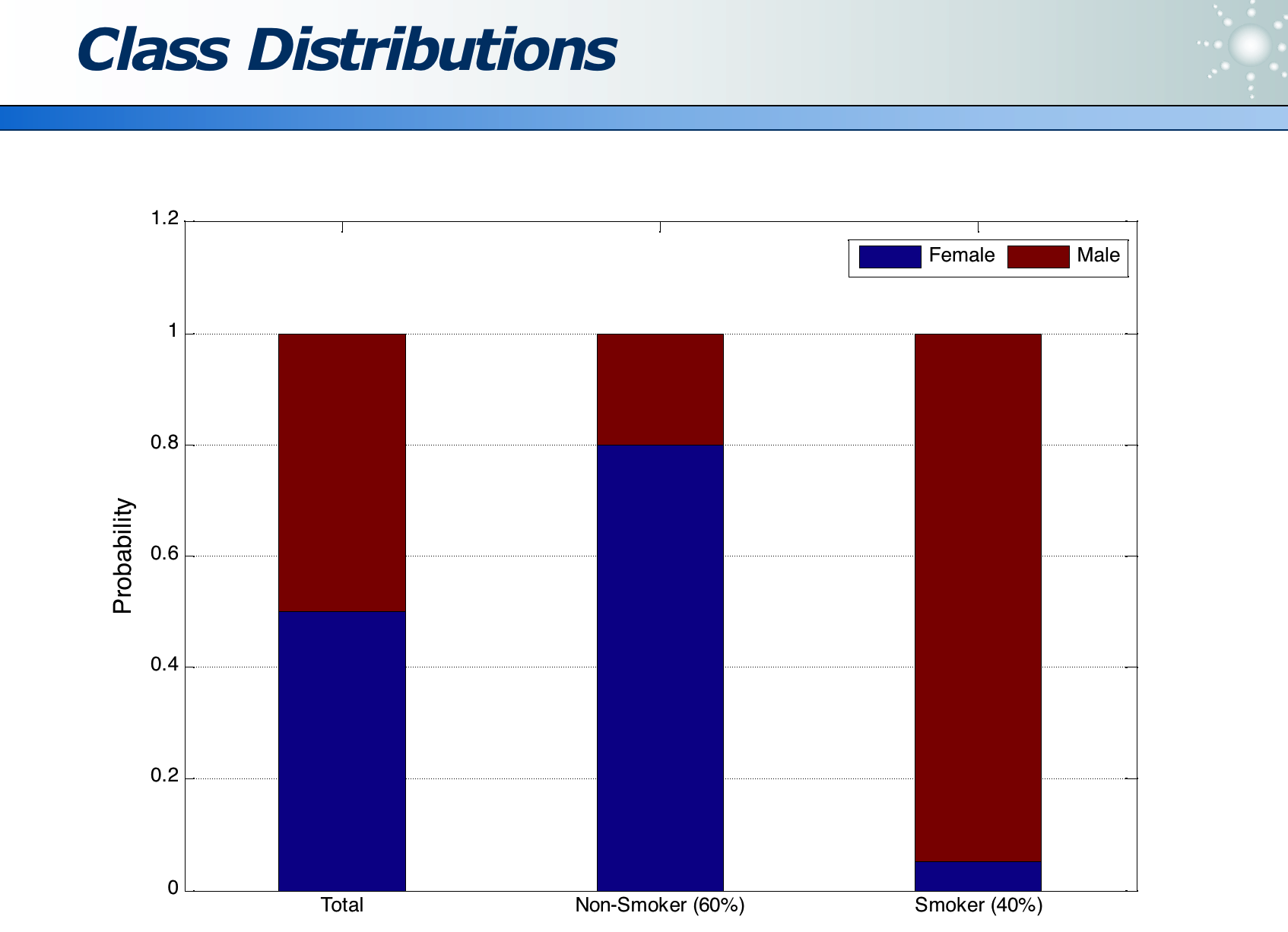
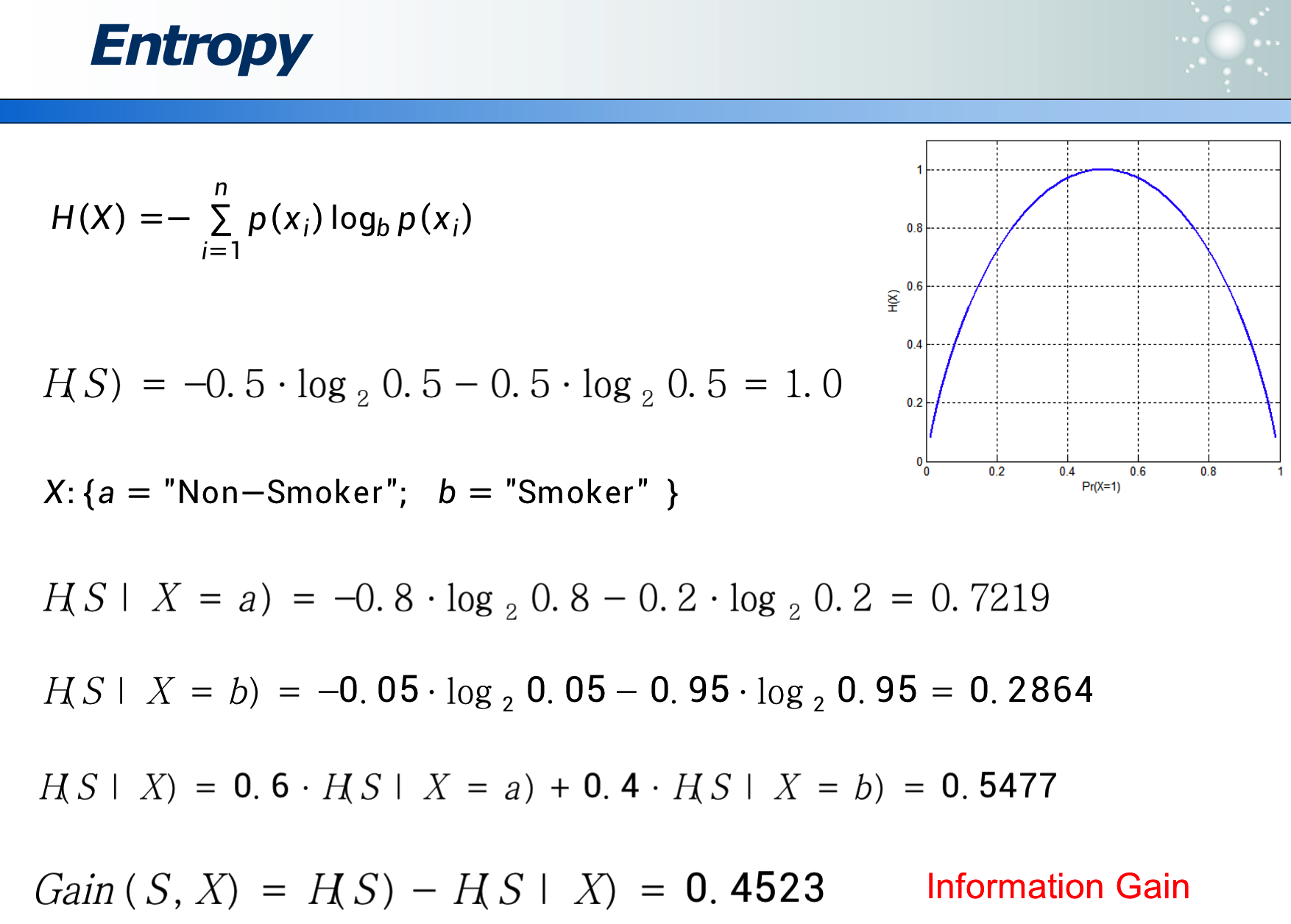
熵:可以量化属性的区分度
- 1 就是最大的熵,表示最不确定。
- 属性整体的效能是 0.5477
- 此属性的信息增益(Information Gain)是 1 - 0.5477 = 0.4523,表示此属性的价值。此值越大,说明此属性的效力越高(因为将原来最不确定性的熵降低的幅度最大)。
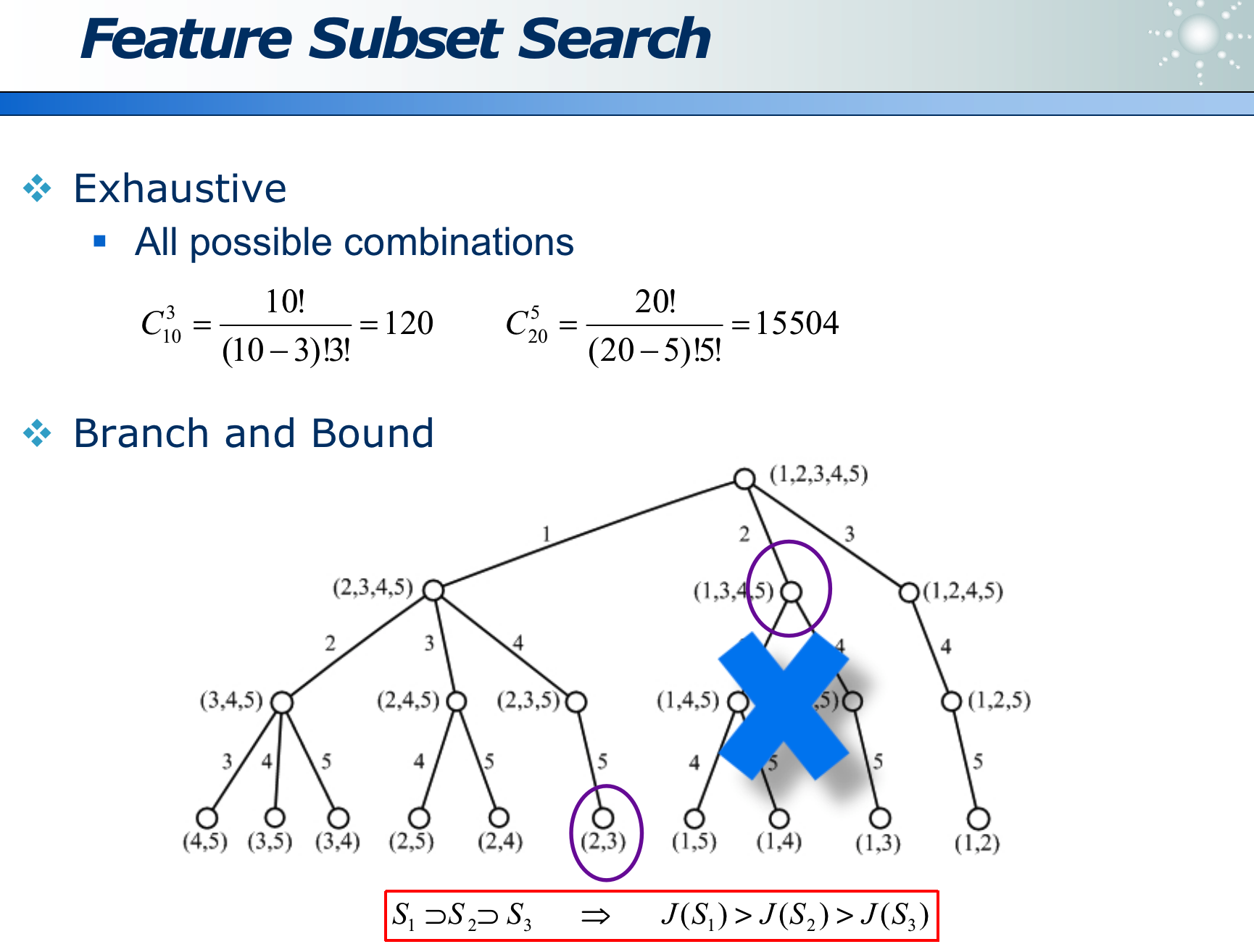
利用熵,在各种属性里搜索,最好的属性。
- 利用 Branch and Bound 可以剪枝

2.2 特征提取 Feature Extraction
特征提取:是指对特征做一定转换,如下图将像素点转变为像素点的差值,来分割边缘。

2.2.1 PCA 主成分分析
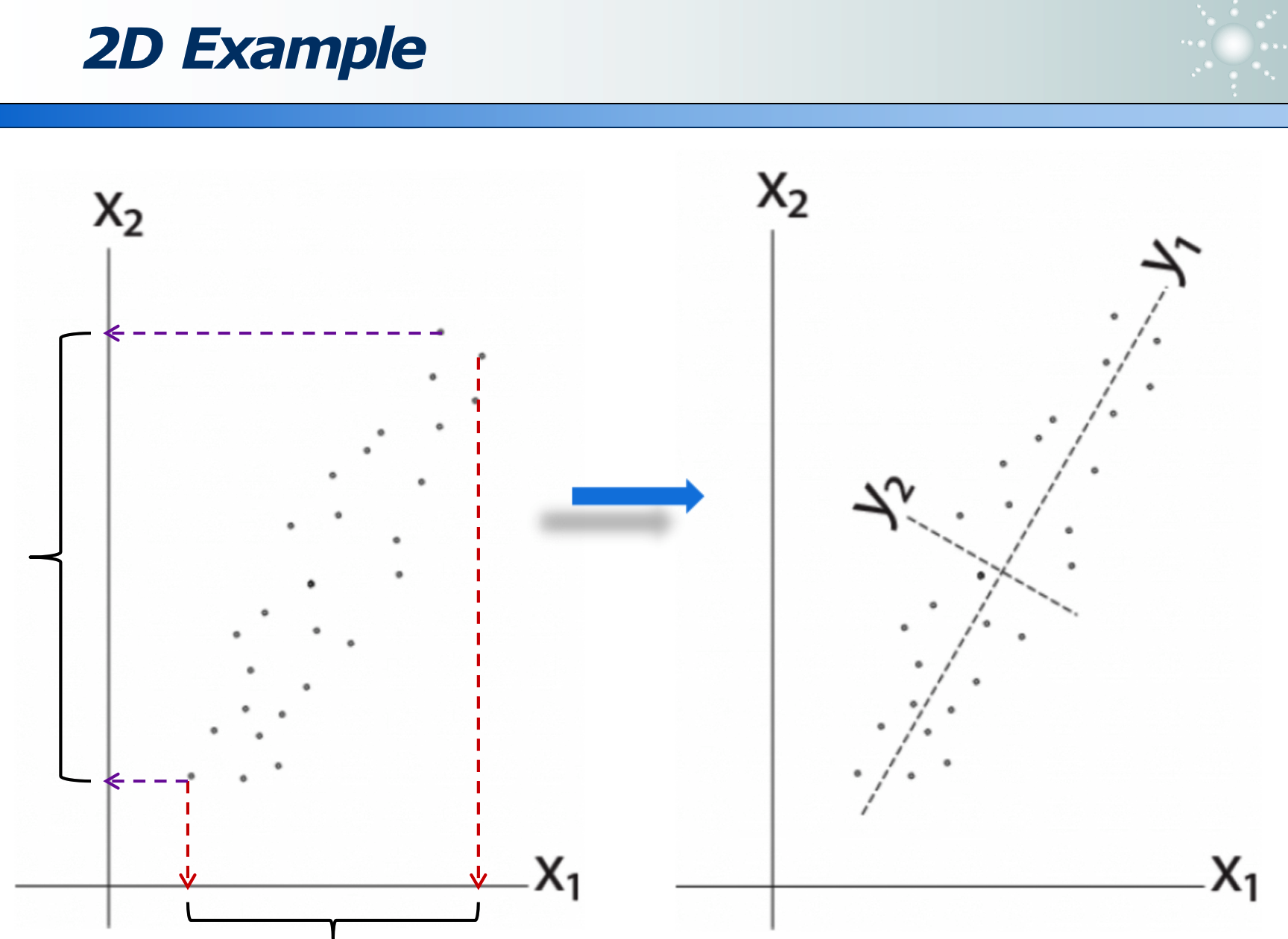
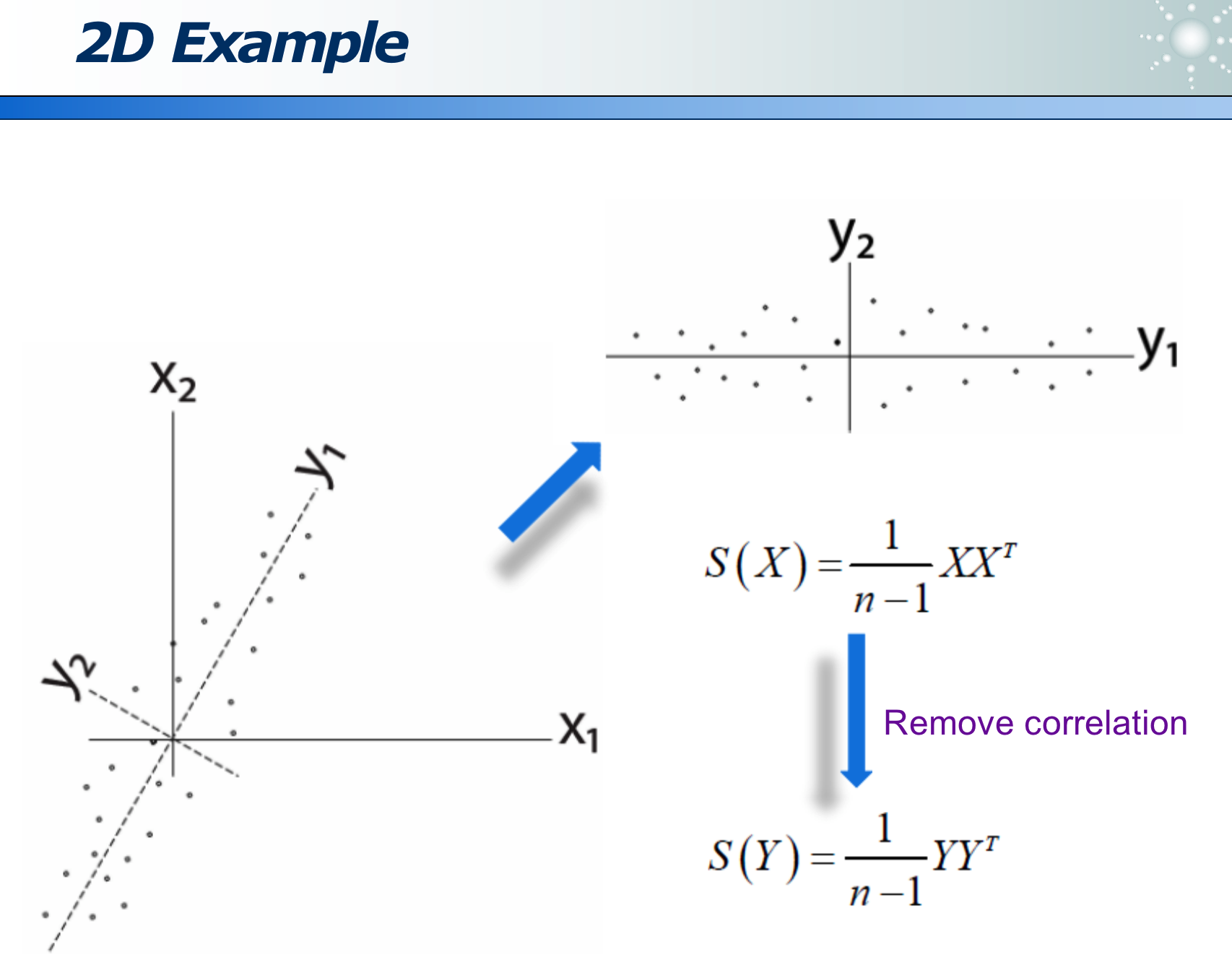
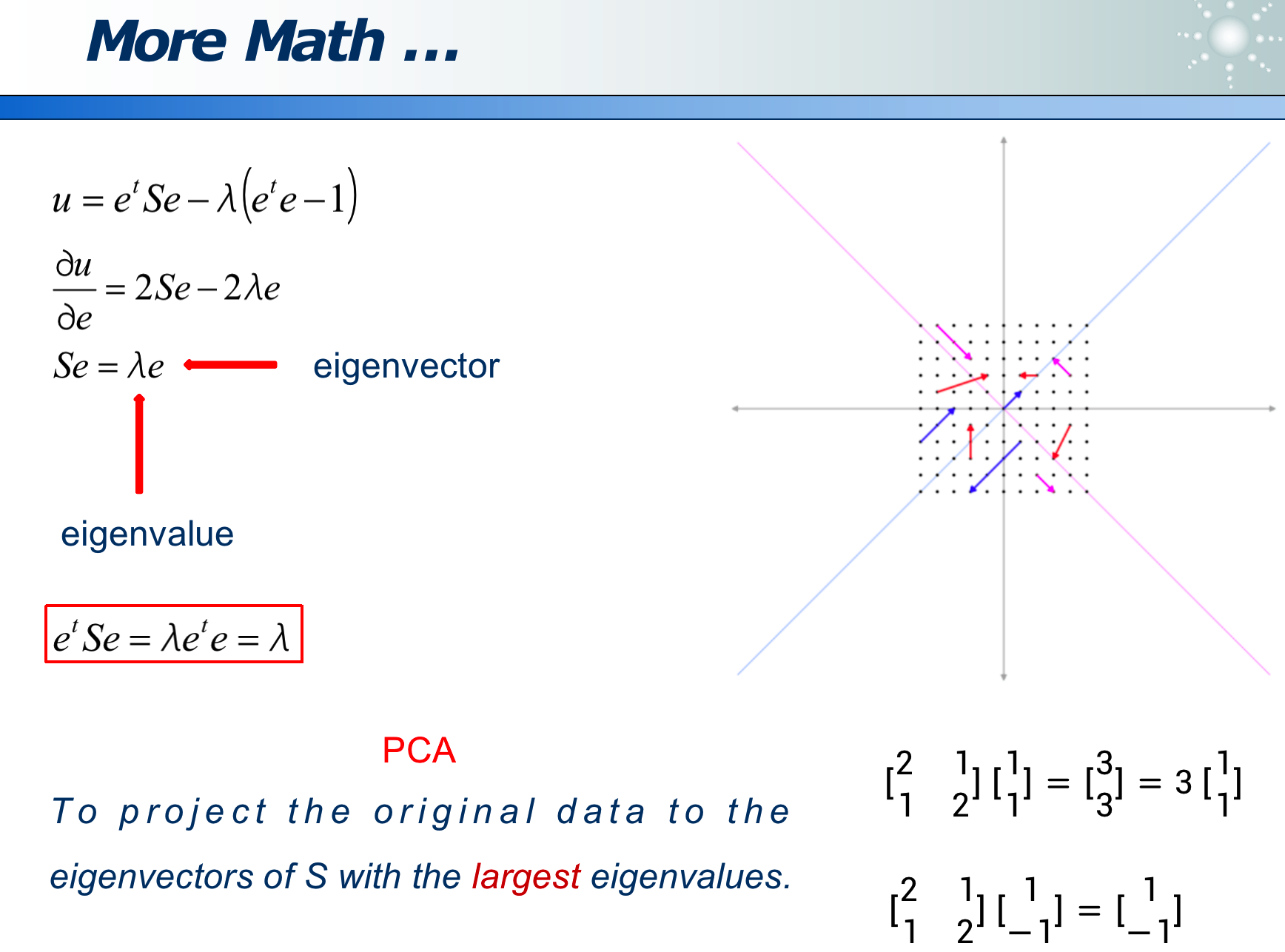
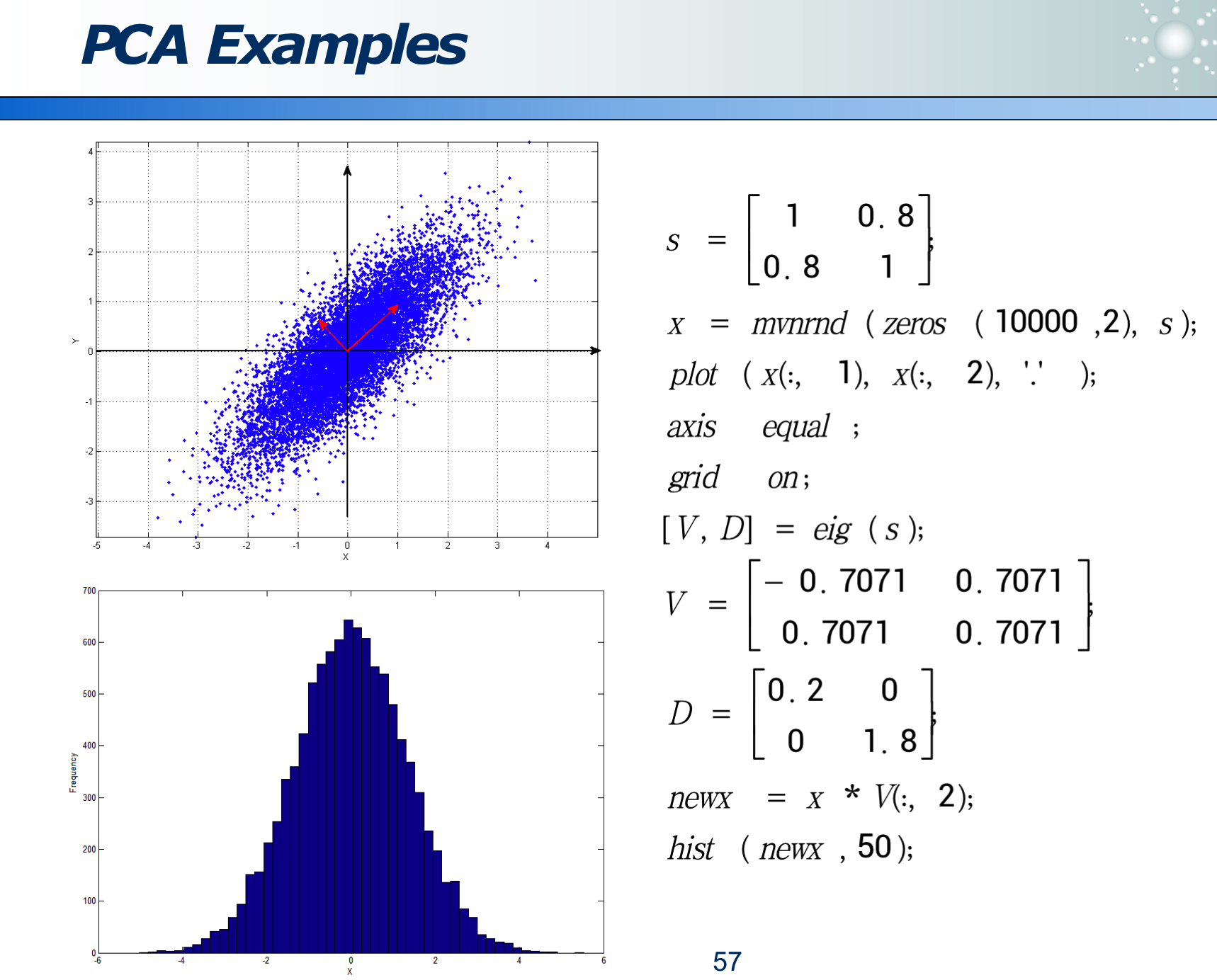
事物从不同角度看,不同的映射方法,信息损失程度不同:

如果某属性区分度越大,则此属性越重要。
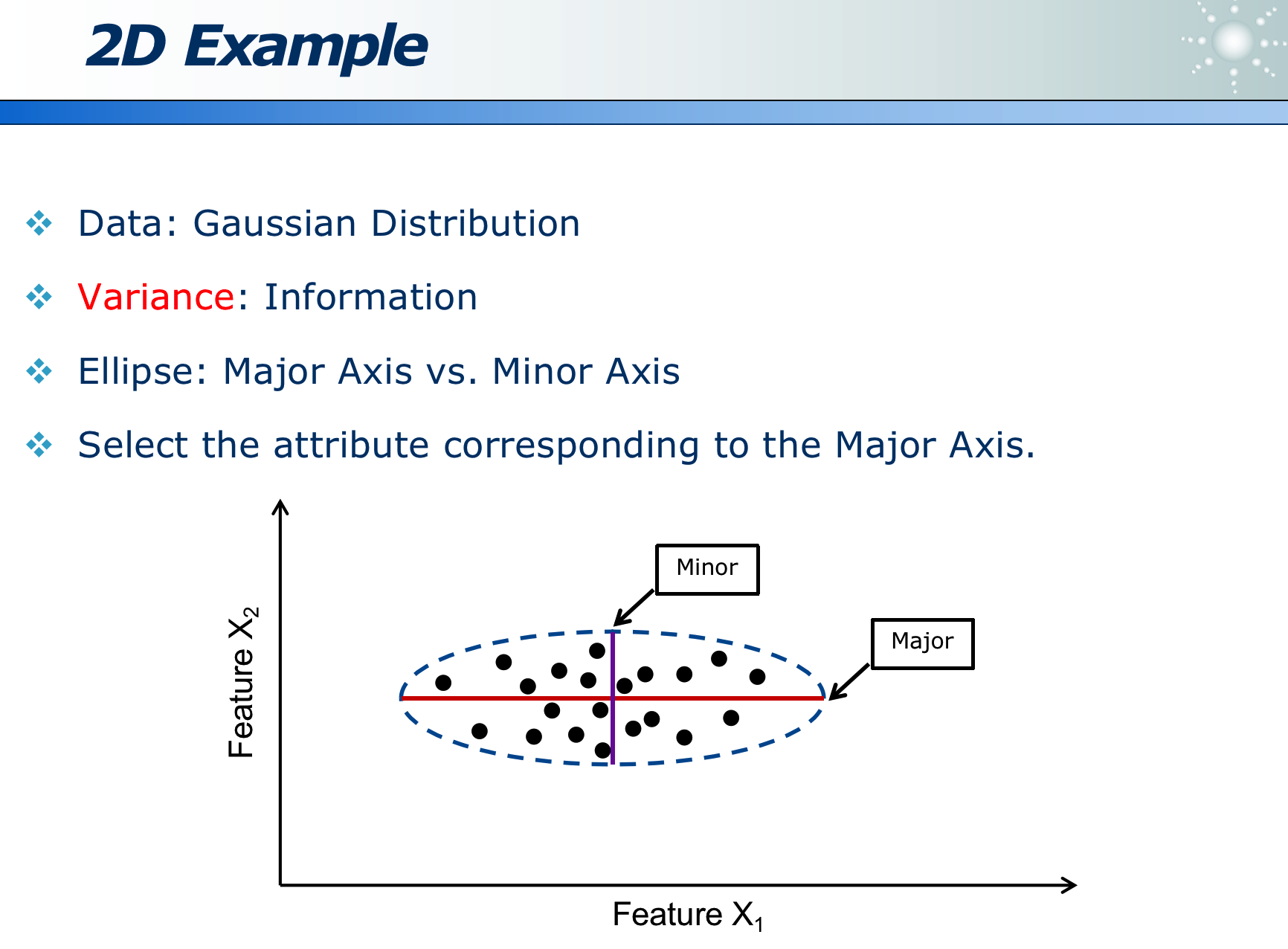
可以经过变换来消除 correlation,使更容易选特征:




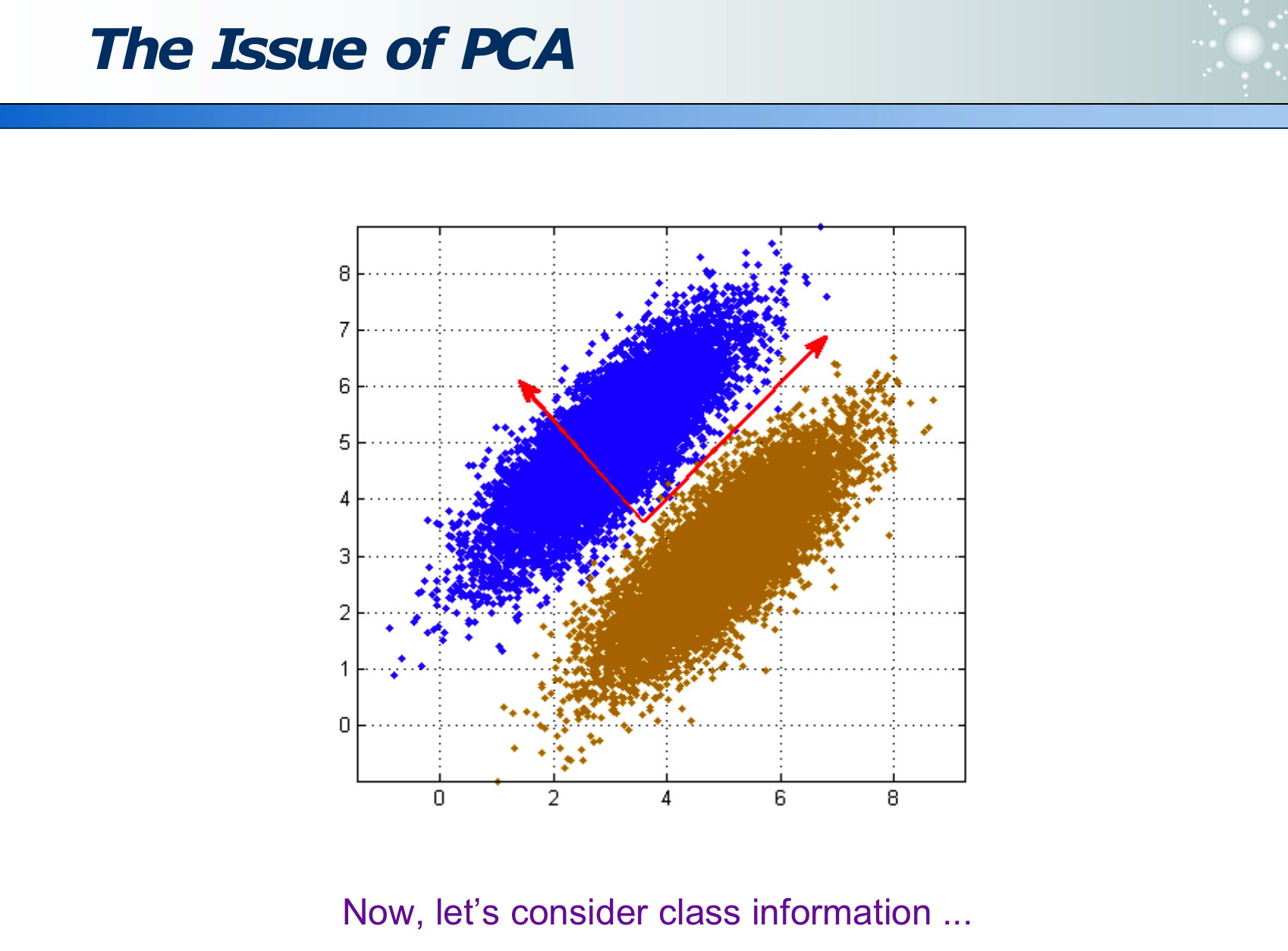
2.2.2 LDA 线性判别分析
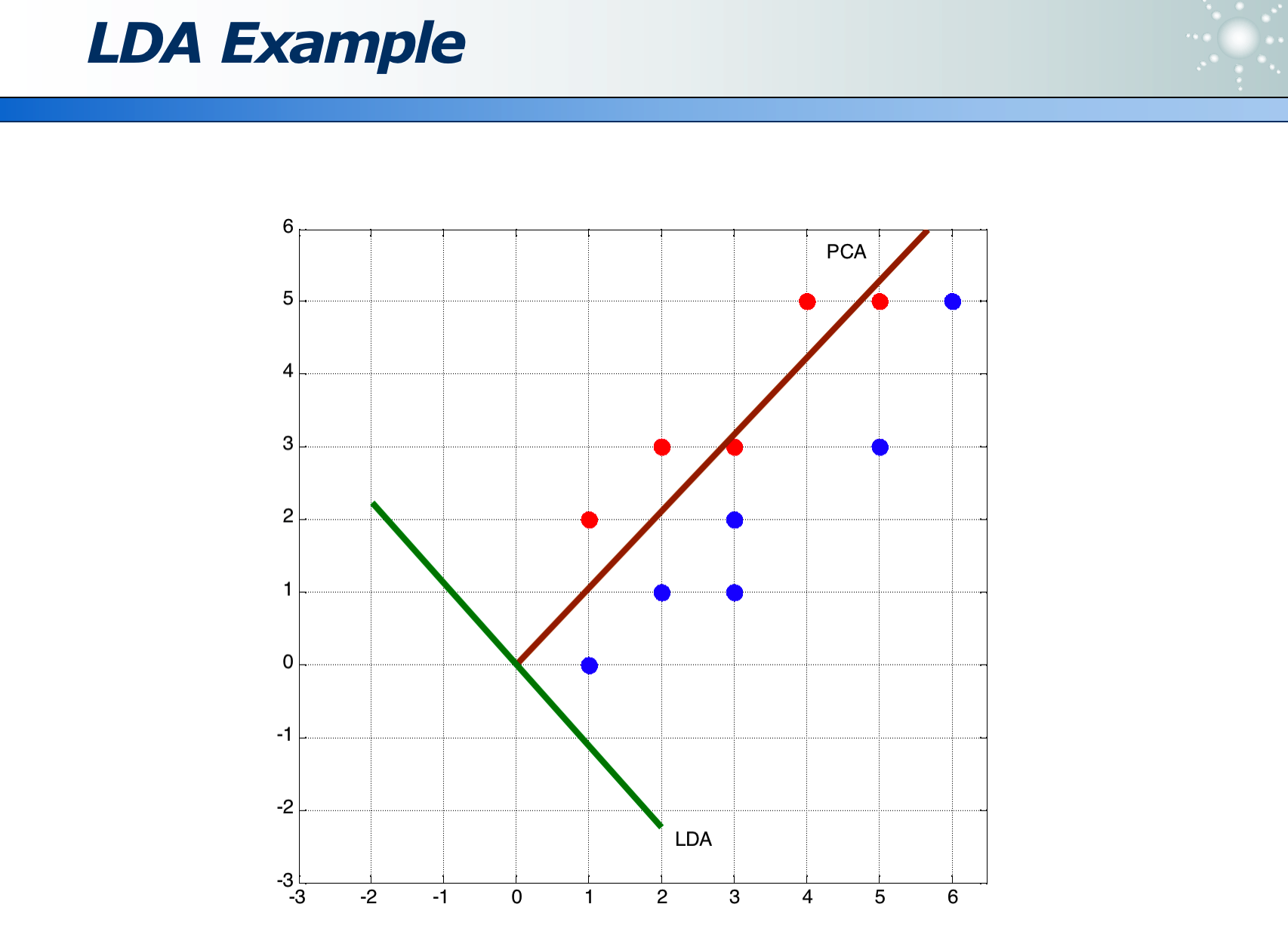
PCA 虽然计算量不大,但如果投影方向选错,会丢失类别信息,使得无法区分主成分:
- 如下图如果延着长的红色箭头投影,则蓝黄两类在投影线上无法区分
- 如下图如果延着短的红色箭头投影,则蓝黄两类在投影线上可以区分
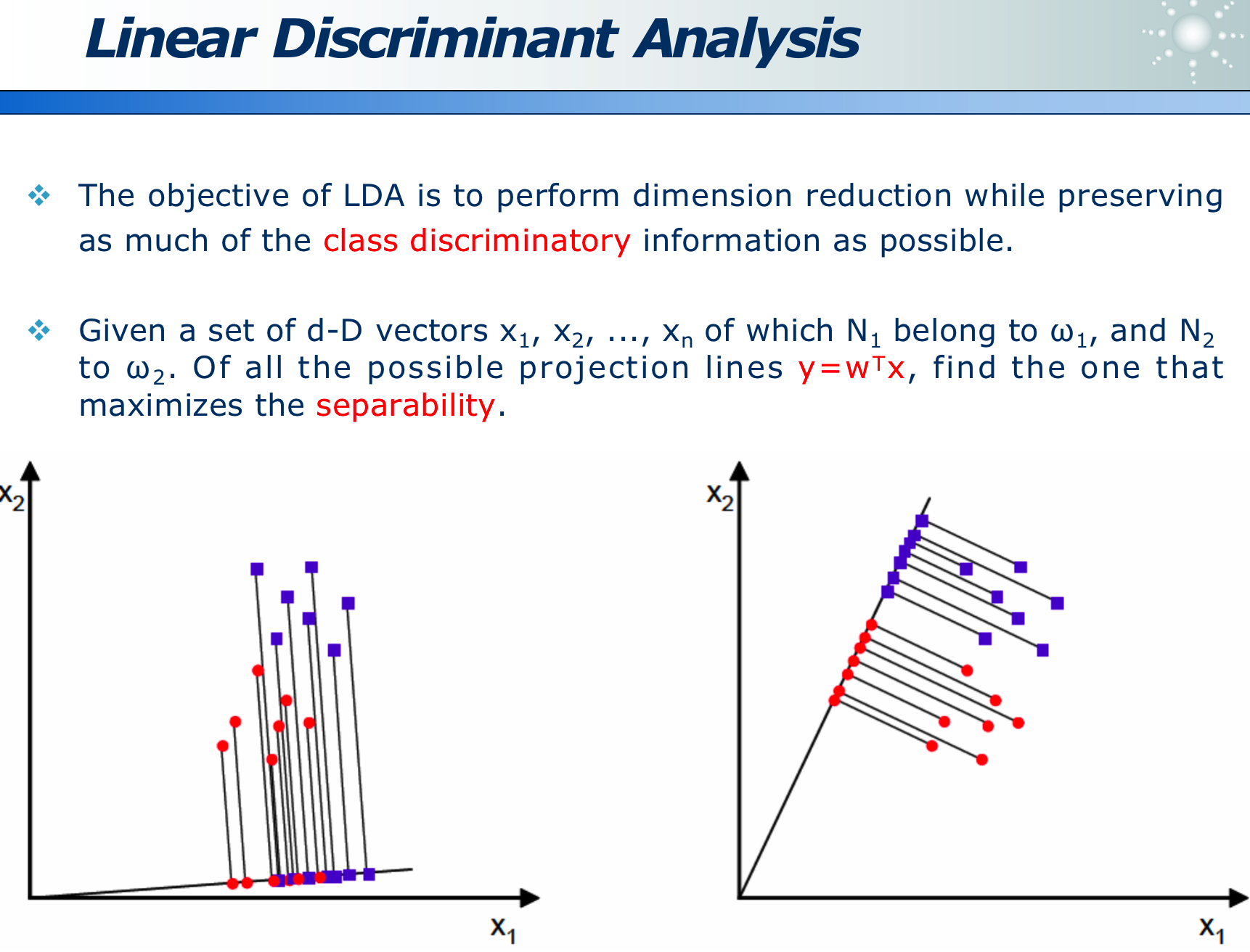
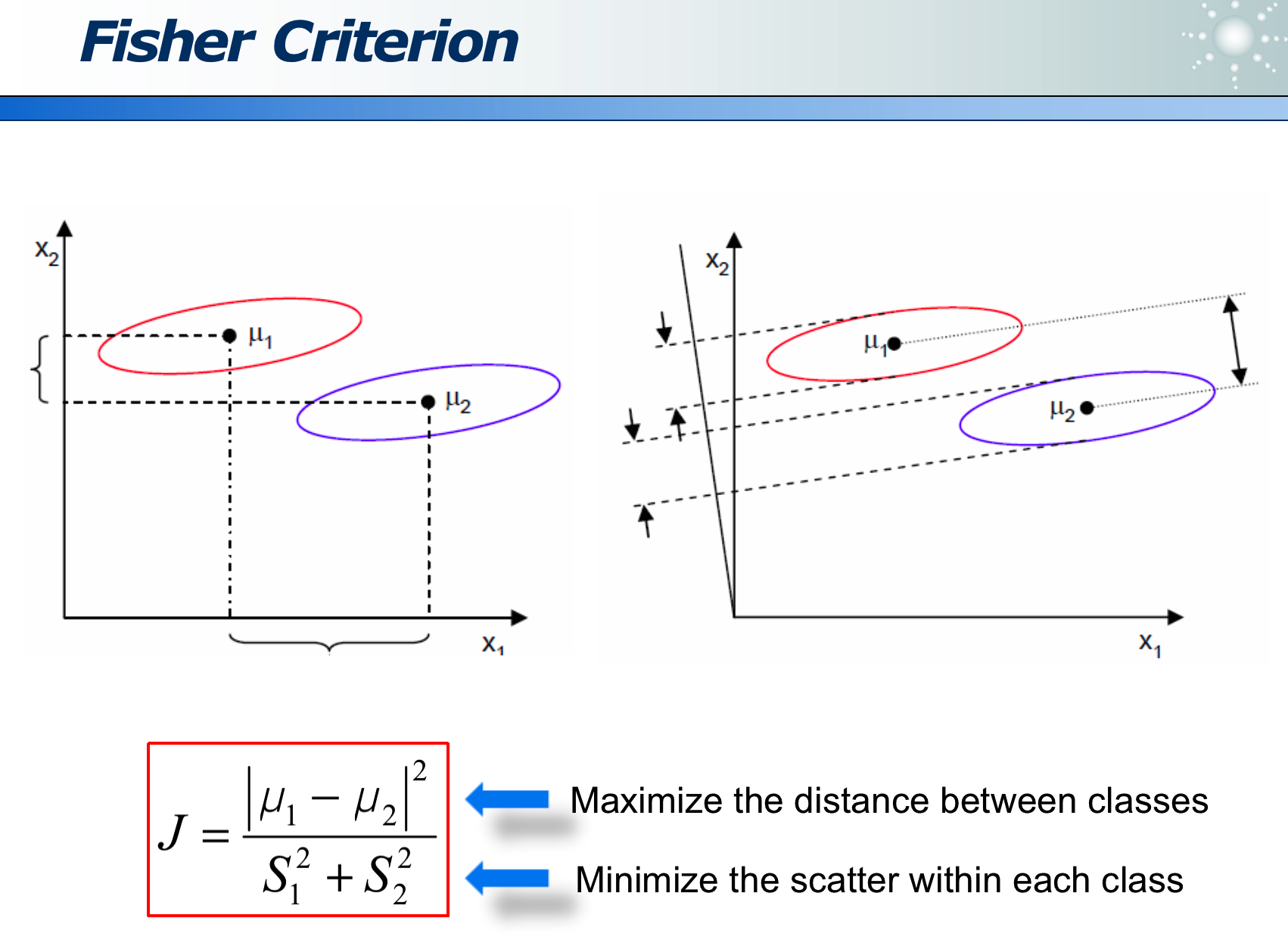
LDA 的目的就是,在维度收缩时,尽量保留「类间区分度」信息,如下图,x 为原始数据, w 即为方向,降为数据 y,左图区分度小,而右图区分度大即效果好。
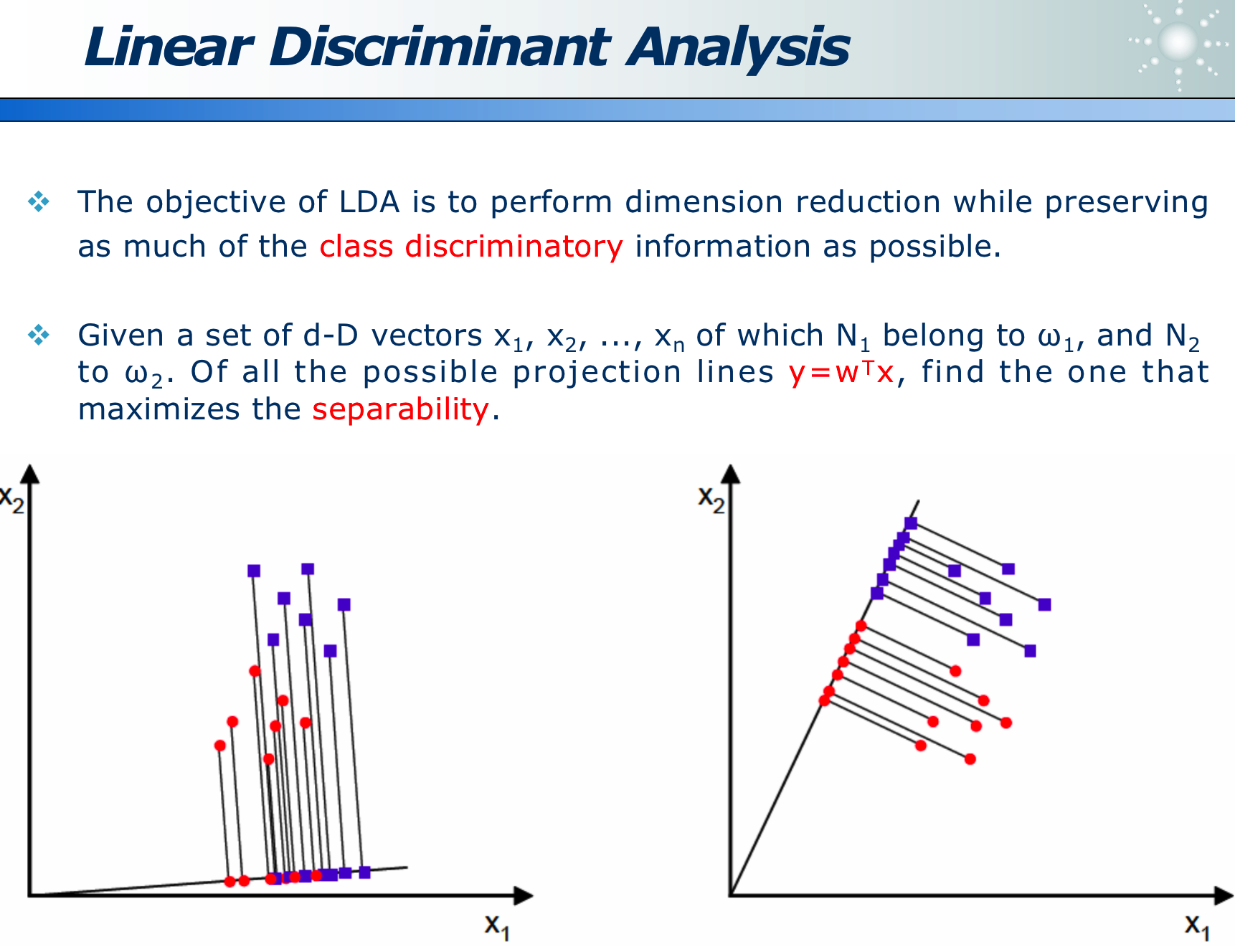
类间距离大,而类内距离小:
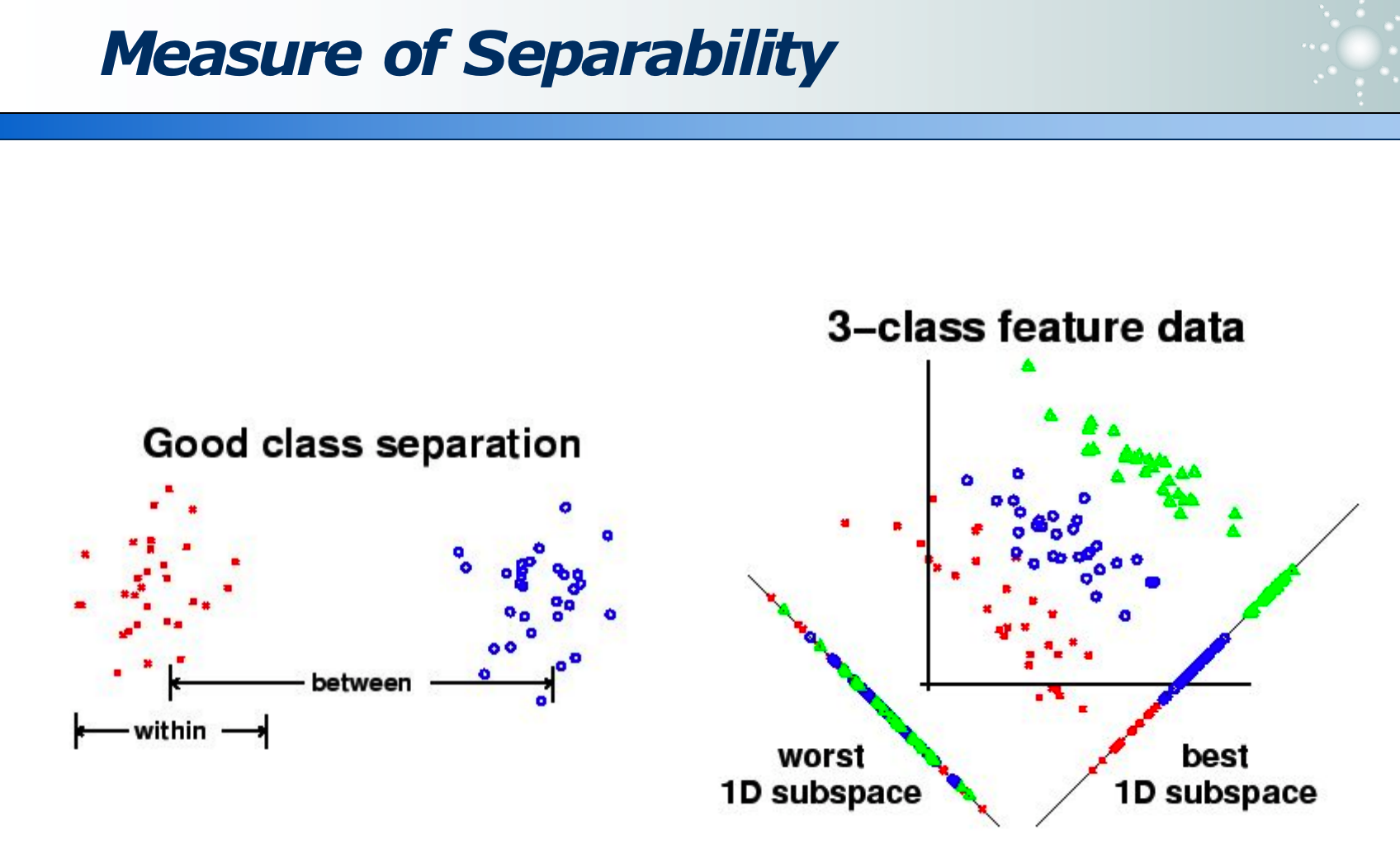
投影评价的准则是JJJ最大化:J=∣μ1−μ2∣2S12+S22J=\frac{\left|\mu_1-\mu_2\right|^2}{S_1^2+S_2^2}J=S12+S22∣μ1−μ2∣2
其中分子是「类间距离」越大越好,分母是「类内距离」越小越好:






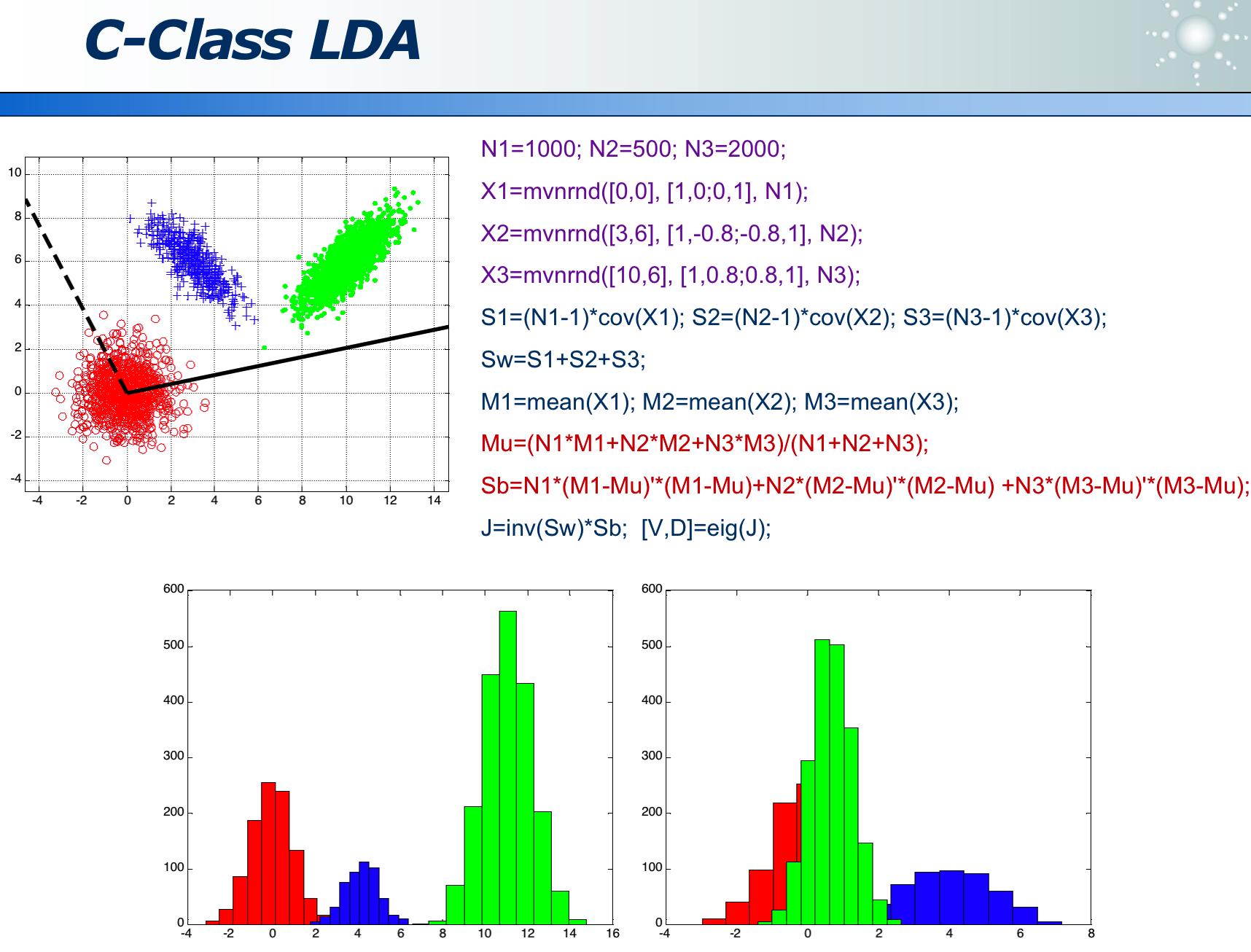
多类分类问题:



相关文章:
【数据挖掘】2、数据预处理
文章目录一、数据预处理的意义1.1 缺失数据1.1.1 原因1.1.2 方案1.1.3 离群点分析1.2 重复数据1.2.1 原因1.2.2 去重的方案1.3 数据转换1.4 数据描述二、数据预处理方法2.1 特征选择 Feature Selection2.2 特征提取 Feature Extraction2.2.1 PCA 主成分分析2.2.2 LDA 线性判别分…...
大白话在数据库里,哪些操作会导致在表级别加锁呢?)
(四十六)大白话在数据库里,哪些操作会导致在表级别加锁呢?
之前我们已经给大家讲解了数据库里的行锁的概念,其实还是比较简单,容易理解的,因为在讲解锁这个概念之前,对于多事务并发以及隔离,我们已经深入讲解过了,所以大家应该很容易在脑子里有一个多事务并发执行的…...
)
【Android源码面试宝典】MMKV从使用到原理分析(二)
上一章节,我们从使用入手,进行了MMKV的简单讲解,我们通过分析简单的运行时日志,从中大概猜到了一些MMKV的代码内部流程,同时,我们也提出了若干的疑问?还是那句话,带着目标(问题)去阅读一篇源码,那么往往收获的知识,更加深入&扎实。 本节,我们一起来从源码层次…...

如何使用ADFSRelay分析和研究针对ADFS的NTLM中继攻击
关于ADFSRelay ADFSRelay是一款功能强大的概念验证工具,可以帮助广大研究人员分析和研究针对ADFS的NTLM中继攻击。 ADFSRelay这款工具由NTLMParse和ADFSRelay这两个实用程序组成。其中,NTLMParse用于解码base64编码的NTLM消息,并打印有关消…...
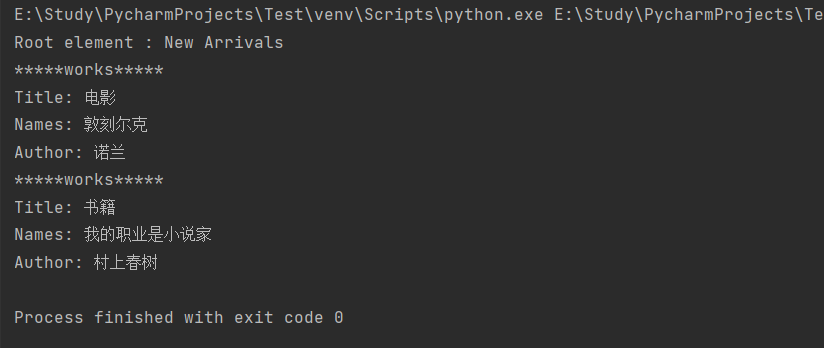
【Python学习笔记】第二十二节 Python XML 解析
一、什么是XMLXML即ExtentsibleMarkup Language(可扩展标记语言),是用来定义其它语言的一种元语言。XML 被设计用来传输和存储数据。XML 是一套定义语义标记的规则,它没有标签集(tagset),也没有语法规则(grammatical rule)。任何XML文档对任何…...

5分钟轻松拿下Java枚举
文章目录一、枚举(Enum)1.1 枚举概述1.2 定义枚举类型1.2.1 静态常量案例1.2.2 枚举案例1.2.3 枚举与switch1.3 枚举的用法1.3.1 枚举类的成员1.3.2 枚举类的构造方法1)枚举的无参构造方法2)枚举的有参构造方法1.3.3 枚举中的抽象方法1.4 Enum 类1.4.1 E…...

华为OD机试【独家】提供C语言题解 - 最小传递延迟
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明最小…...

【Web前端】关于JS数组方法的一些理解
一、具备栈特性的方法unshift(...items: T[]) : number将一个或多个元素添加到数组的开头,并返回该数组的新长度。shift(): T | undefined从数组中删除第一个元素,并返回该元素的值。此方法更改数组的长度。二、具备队列特性的方法push(...items: T[]): …...

多智能体集群协同控制笔记(1):线性无领航多智能体系统的一致性
对于连续时间高阶线性多智能体系统的状态方程为: x˙i(t)Axi(t)Bui(t),i1,2..N\dot {\mathbf{x}}_i(t)A\mathbf{x}_i(t)B\mathbf{u}_i(t),i1,2..N x˙i(t)Axi(t)Bui(t),i1,2..N 下标iii代表第iii个智能体,ui(t)∈Rq1\mathbf{u}_i(t)\in R^{q \time…...

hadoop-Yarn资源调度器【尚硅谷】
大数据学习笔记 Yarn资源调度器 Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行与操作系统之上的应用程序。 (也就是负责MapTask、ReduceTask等任…...

聊聊如何避免多个jar通过maven打包成一个jar,多个同名配置文件发生覆盖问题
前言 不知道大家在开发的过程中,有没有遇到这种场景,外部的项目想访问内部nexus私仓的jar,因为私仓不对外开放,导致外部的项目没法下载到私仓的jar,导致项目因缺少jar而无法运行。 通常遇到这种场景,常用…...

Flume 使用小案例
案例一:采集文件内容上传到HDFS 1)把Agent的配置保存到flume的conf目录下的 file-to-hdfs.conf 文件中 # Name the components on this agent a1.sources r1 a1.sinks k1 a1.channels c1 # Describe/configure the source a1.sources.r1.type spoo…...

DLO-SLAM代码阅读
文章目录DLO-SLAM点评代码解析OdomNode代码结构主函数 main激光回调函数 icpCB初始化 initializeDLO重力对齐 gravityAlign点云预处理 preprocessPoints关键帧指标 computeMetrics设定关键帧阈值setAdaptiveParams初始化目标数据 initializeInputTarget设置源数据 setInputSour…...
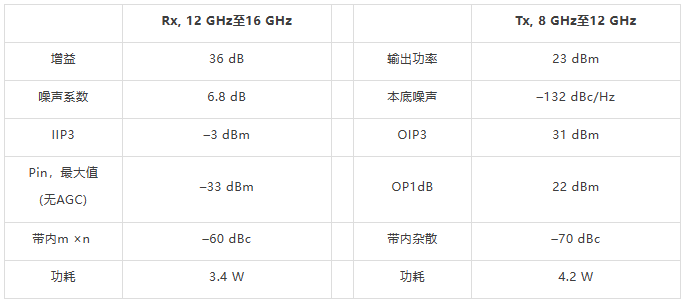
X和Ku波段小尺寸无线电设计
卫星通信、雷达和信号情报(SIGINT)领域的许多航空航天和防务电子系统早就要求使用一部分或全部X和Ku频段。随着这些应用转向更加便携的平台,如无人机(UAV)和手持式无线电等,开发在X和Ku波段工作,同时仍然保持极高性能水平的新型小尺寸、低功耗…...

推荐算法 - 汇总
本文主要对推荐算法整体知识点做汇总,做到总体的理解;深入理解需要再看专业的材料。推荐算法的意义推荐根据用户兴趣和行为特点,向用户推荐所需的信息或商品,帮助用户在海量信息中快速发现真正所需的商品,提高用户黏性…...
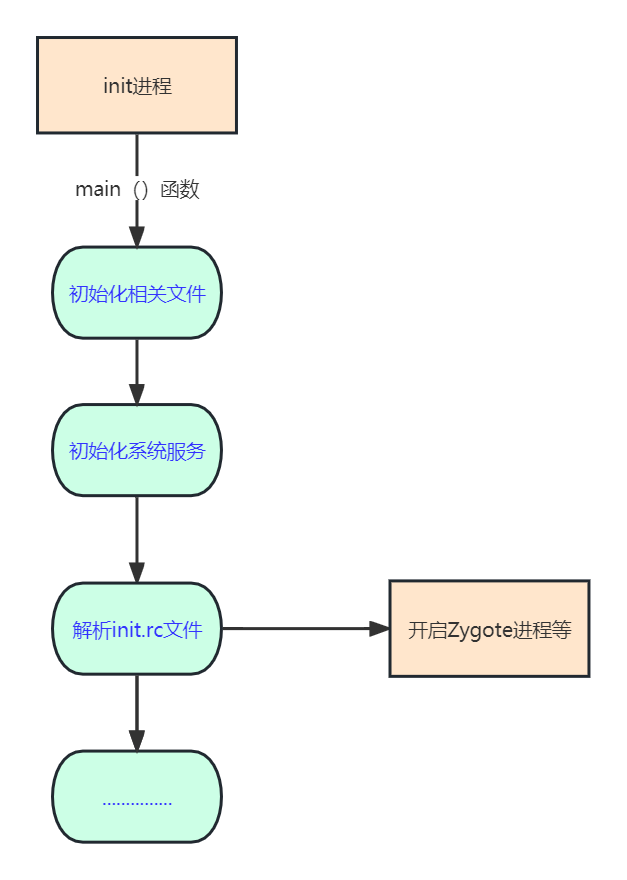
Android 系统的启动流程
前言:从开机的那一刻,到开机完成后launcher将所有应用进行图标展示的这个过程,大概会有哪一些操作?执行了哪些代码?作为Android开发工程师的我们,有必要好好的梳理一遍。既然要梳理Android系统的启动流程&a…...

自学5个月Java找到了9K的工作,我的方式值得大家借鉴 第二部分
我的学习心得,我认为能不能自学成功的要素有两点。 第一点就是自身的问题,虽然想要转行学习Java的人很多,但是非常强烈的想要转行学好的人是小部分。而大部分人只是抱着试试的心态来学习Java,这是完全不可能的。所以能不能学成Jav…...

Vue 3 第五章:reactive全家桶
文章目录1. reactive1.1. reactive函数创建一个响应式对象1.2. 修改reactive创建的响应式对象的属性2. readOnly2.1. 使用 readonly 函数创建一个只读的响应式对象2.2. 如何修改嵌套在只读响应式对象中的对象?3. shallowReactive3.1. 使用 shallowReactive 函数创建一个浅层响…...

【联机对战】微信小程序联机游戏开发流程详解
现有一个微信小程序叫中国象棋项目,棋盘类的单机游戏看着有缺少了什么,现在给补上了,加个联机对战的功能,增加了可玩性,对新手来说,实现联机游戏还是有难度的,那要怎么实现的呢,接下…...

优化基于axios接口管理的骚操作
优化基于axios接口管理的骚操作! 本文针对中大型的后台项目的接口模块优化,在不影响项目正常运行的前提下,增量更新。 强化功能 1.接口文件写法简化(接口模块半自动化生成) 2.任务调度、Loading调度(接口层…...

对抗消息消失:RevokeMsgPatcher的创新防护方案
对抗消息消失:RevokeMsgPatcher的创新防护方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHu…...

WebLaTex:革新学术写作体验的云端LaTeX解决方案
WebLaTex:革新学术写作体验的云端LaTeX解决方案 【免费下载链接】WebLaTex A complete alternative for Overleaf with VSCode Web Git Integration Copilot Grammar & Spell Checker Live Collaboration Support. Based on GitHub Codespace and Dev cont…...

用快马AI十分钟搭建班级宠物园应用下载页,快速验证教育产品原型
最近在帮小学老师朋友设计一个班级宠物园应用,想快速验证这个教育产品的可行性。传统开发流程太耗时,于是尝试用InsCode(快马)平台的AI生成功能,十分钟就搭出了可交互的下载页原型。分享下具体实现思路: 需求拆解与框架搭建 先明确…...

如何实现重组抗体的精准定制?
一、重组抗体定制与传统抗体制备有何本质区别?重组抗体定制是通过基因工程技术在体外构建并表达目标抗体的创新方法。与传统杂交瘤技术相比,重组抗体技术具有多方面的显著优势。首先,其生产完全不依赖于动物免疫系统,而是通过人工…...

MATLAB科研绘图:如何用title/legend/grid on让你的论文图表通过审稿人‘火眼金睛’?
MATLAB科研绘图:学术图表标注的审稿人级优化指南 科研图表是论文的"门面",审稿人往往在30秒内就能通过图表质量判断研究的严谨性。我曾参与多个顶级期刊的图表评审工作,发现90%的退稿图表问题都出在标注细节上——不是数据不好&…...
中lumapi模块导入失败的完整指南)
解决Lumerical(FDTD)中lumapi模块导入失败的完整指南
1. 为什么会出现lumapi导入失败的问题 第一次遇到import lumapi报错的时候,我也是一头雾水。明明按照官方文档安装了Lumerical软件和lumopt扩展包,怎么Python就找不到这个模块呢?后来经过多次实践和排查,发现这个问题在Windows系统…...

Django React Redux Base:终极全栈开发模板完全指南
Django React Redux Base:终极全栈开发模板完全指南 【免费下载链接】django-react-redux-base Seedstars Labs Base Django React Redux Project 项目地址: https://gitcode.com/gh_mirrors/dj/django-react-redux-base 想要快速构建现代化Web应用却苦于复杂…...

如何将网页转化为可编辑设计稿?3大核心场景与实现方案
如何将网页转化为可编辑设计稿?3大核心场景与实现方案 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html 你是否曾遇到过看到优秀网页设计却无法直接复用的困境ÿ…...

Neeshck-Z-lmage_LYX_v2应用落地:国风插画师本地AI绘画工作流搭建
Neeshck-Z-lmage_LYX_v2应用落地:国风插画师本地AI绘画工作流搭建 想成为一名国风插画师,但苦于绘画技巧需要长期积累?或者,你已经是一位创作者,却常常被灵感枯竭和重复性工作所困扰?今天,我将…...

Stable Diffusion 3.5 FP8镜像:简化部署流程,提升使用体验
Stable Diffusion 3.5 FP8镜像:简化部署流程,提升使用体验 1. 镜像概述 Stable Diffusion 3.5 (SD 3.5) 是由 Stability AI 推出的新一代文本到图像生成模型,相比 3.0 版本,它在图像质量、运行速度和硬件效率方面都有显著提升。…...