改进 YOLO V5 的密集行人检测算法研究(论文研读)——目标检测
改进 YOLO V5 的密集行人检测算法研究(2021.08)
- 摘 要:
- 1 YOLO V5
- 2 SENet 通道注意力机制
- 3 改进的 YOLO V5 模型
- 3.1 训练数据处理改进
- 3.2 YOLO V5 网络改进
- 3.3 损失函数改进
- 3.3.1 使用 CIoU
- 3.3.2 非极大值抑制改进
- 4 研究方案与结果分析
- 4.1 实验平台与数据集
- 4.2 网络训练
- 4.3 模型评价与对比
- 4.4 检测效果对比
- 5 结语
摘 要:
- 针对在人员密集区或相互拥挤场景下进行的行人目标检测时,因行人遮挡或人像交叠所导致的跟踪目标丢失、检测识别率低的问题,提出了一种融合注意力机制的改进 YOLO V5 算法。 通过引入注意力机制来深入挖掘特征通道间关系和特征图空间信息,进一步增强了对行人目标可视区域的特征提取。为提高模型的收敛能力,利用 CIoU、 DIoU_NMS代替YOLO V5 的原有损失函数优化 anchor 的回归预测,降低了网络的训练难度,提升了遮挡情况下的 检测率; 同时, 结合数据增强及标签平滑算法进一步提高了特征模型的泛化能力和分类器性能。 相比于一般的 YOLOV5算法,论文所提出的改进算法在人员密集区或相互拥挤场景下进行行人检测时,具有更高的准确率和更低 的漏检率,同时保持了原有算法的实时性。
- 关键词: 行人检测;拥挤场景;YOLO V5;注意力机制
- 行人检测在辅助驾驶系统、车辆监控系统和预警防护系统等多个领域扮演着重要角色,是目标检测领域中的一个重要的基础研究课题[1],可以为商场和景区等人流密度较大的公共场所以及智能安防领域提供有效的信息支撑[2]。
- 随着人工智能产业的高速发展与计算机硬件计算能力的提升,国内外学者已经开展了基于深度学习的研究行人检测方案,并且取得了一些的效果[3]。
- 而目前的行人检测算法在实际大规模拥挤场景应用过程中,始终存在着由于行人交叠、遮挡而导致的漏检率较高的问题,此类问题依然困扰着很多研究者,也是目前行人检测面临的巨大挑战[4]。
- 许多学者基于深度学习理论提出了不同措施以提高算法的性能。 2019 年,Wojke 等人[5]提出了 Deep Sort算法,运用一个残差网络结构来提取目标的外观信息,用匈牙利算法将外观特征向量的余弦距离与运动信息关联起来,然而其跟踪效果依赖目标检测器的精确度和特征区分程度,跟踪速度与目标检测速度密切相关。
- 2019 年,徐诚极等人[6]使用注意力机制改进了 YOLO V3,提出了Attention-YOLO 算法,有效提高了检测准确率,但是其短板在于对小范围的不连续的信息上的表现并不准确。 2021 年,周大可等人[7]以 RetinaNet 作为基础框架,在回归和分类支路分别添加空间注意力和通道注意力子网络,提出一种结合双重注意力机制的遮挡感知行人检测算法,有效提高了行人检测算法在严重遮挡情况下的性能,降低遮挡对检测造成的影响,但由于双重注意力机制子网络带来了附加的计算量,因此检测帧率只有 11.8 fps。 沈军宇等人[8]基于 YOLO 算法进行端到端训练,快速检测实时视频中目标的数量,根据预先设置的阈值触发截图与保存视频功能,实现鱼群高效地检测与跟踪,系统鲁棒性强,对数据处理与存储效率较高,但是并未针对视频中的鱼群由于数量较多,处于密集状态的这一特殊情况进行考虑,在进行密集鱼群的检测计数时会有较高的漏检率。
- SENet(通道注意力机制,Squeeze-and-Excitation Networks)是一种将各个通道之间的特征进行通道卷积来改善模型的表达能力,注重各类通道特征关系的网络结构。 将 SENet 应用在公共大规模场景拥挤情况下的行人检测上,可以增强重要特征的通道权重,从而提高检测的效果。
- 针对上述学者研究中的问题与不足,笔者在文献[6-8]研究的基础上提出一种融合注意力机制的改进YOLO V5 的密集行人检测算法。 该算法利用 SENet 融合网络特征对融合的特征图采用自适应调整的方式更新不同特征通道的权重,提高网络特征提取和特征融合的能力,并通过数据增强、标签平滑的方式提高模型的泛化能力,丰富行人的样本特征,以及利用 CIoU、DIoU_NMS 参数对 YOLO V5 原有的损失函数进行改进,提升算法的检测准确率和降低漏检率。
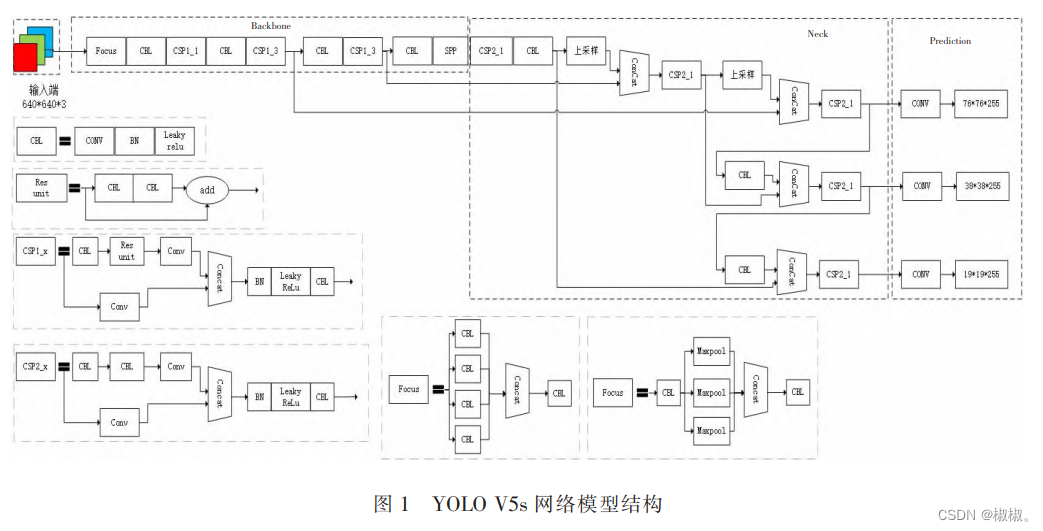
1 YOLO V5
- YOLO V5 由 Ultralytics LLC 公司于 2020 年 5 月提出,按照网络深度和特征图宽度大小分为 YOLOV5s、YOLO V5m、YOLO V5l、YOLO V5x。 文中采用了 YOLO V5s 作为使用模型,其网络模型结构如图 1 所示。从网络结构图中可看出,YOLO V5s 模型主要分为 4 个部分,分别为 Input、Backbone、Neck 和 Prediction。
2 SENet 通道注意力机制
- SENet(通道注意力机制)最早见于 2017 年,由国内自动驾驶公司 Momenta的胡杰团队[9]在《Squeezeand-Excitation Networks》一文中提出。通道注意力机制通过研究特征图的各个通道之间的相关性,计算了各个通道的重要性得分,并且作为分配给各个通道的不同权重,以此凸显出包含重要特征信息的相关通道 表达[10]。
- SENet主要由压缩(Squeeze)和激励(Excitation)两部分组成,其网络结构如图 2 所示[11]。
-
3 改进的 YOLO V5 模型
3.1 训练数据处理改进
- 在大多数应用场景中,训练模型使用的原始数据集并不能满足理想的训练需要,而获取更多的数据集也会增加训练的成本和带来更多的工作量,所以更好的处理方式是进行适当的数据预处理,数据预处理包括数据增强和标签平滑处理两个部分。
- 应用数据增强进行数据预处理的主要目的是:通过数据增强的方式扩充训练集图片,可以让用于训练的数据集样本更加多样,降低各方面的额外因素对识别的影响。而图像中添加随机噪声,也可以有效提高模型的泛化能力和鲁棒性[12]。 在实际应用过程中使用次数较多的单样本数据增强方法包括对图像进行缩放并进行长和宽的扭曲、对图像进行翻转的几何变换类数据增强,以及在图像上添加噪声和修改对比度、亮度等的颜色变换类数据增强。 文中实验过程中所采用的数据增强方法在原有的传统增强方法基础上增加了噪声图片随机裁剪-拼接法,即将多个待检测图像添加噪声后,再从每一张图片中截取一部分,合成一张图片进行整体检测。这种方式能够同时有效提升微小扰动和大量扰动条件下模型的检测准确性。标签平滑处理(label smooth)其本质是一种正则化处理,能够减少过拟合训练的可能性,使得模型对测试集预测的概率分布更接近真实的分布情况,从而提升分类器性能[13]。 文中实验过程中采用的标签平滑方法为随机增加训练集中的错误标注,并在训练过程中使其拥有负的学习率,由此促使模型的分类结果更快地向正确的分类结果靠近。
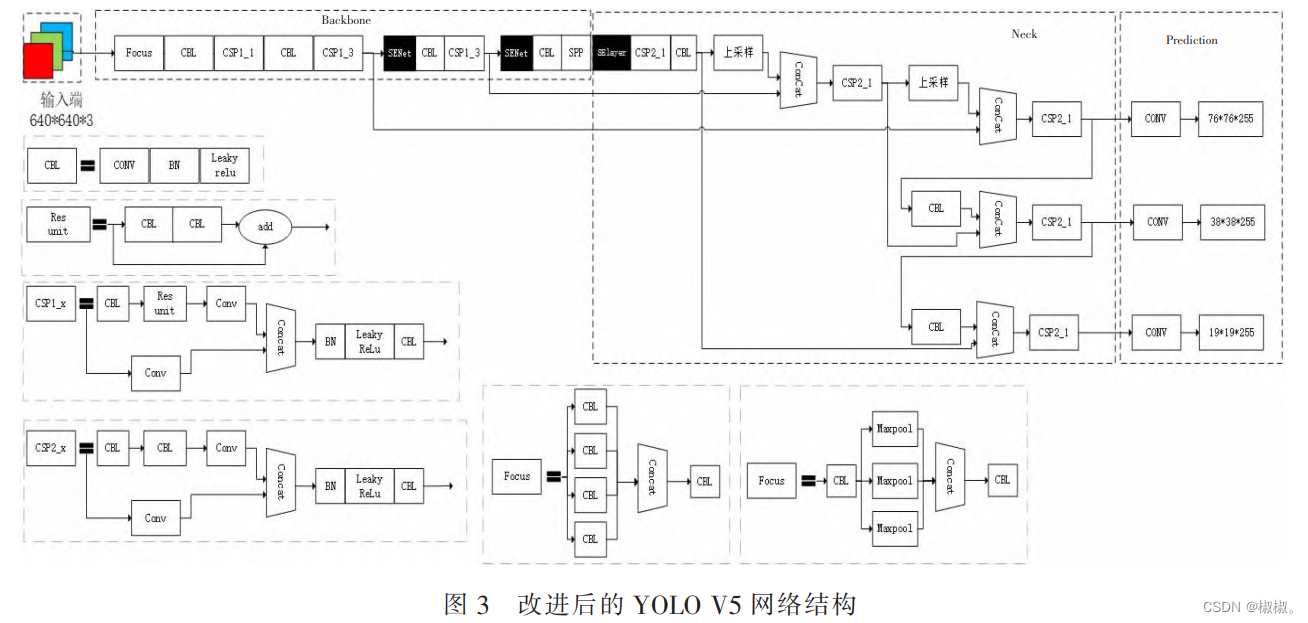
3.2 YOLO V5 网络改进
- 为了进一步提升密集场景的行人检测效果,文中提出了一种改进的 YOLO V5 算法,引入通道注意力机制 SELayer 改进 YOLO V5 的骨干网络,提升特征图不同通道间目标信息的相关性表述。 将 SELayer 加入后的 YOLO V5 网络结构如图 3所示(图中黑色方框为加入的 SENet 结构)。
- 从文中扩充后的拥挤行人数据集中随机抽取了如图 4(a)、图 4(d)2 张图片。 利用原始 YOLO V5 算法与增加了 SENet 后的
YOLO V5 算法进行检测,检测结果分别如图 4(b)、图 4(e)与图 4(c)、图 4(f)所示。
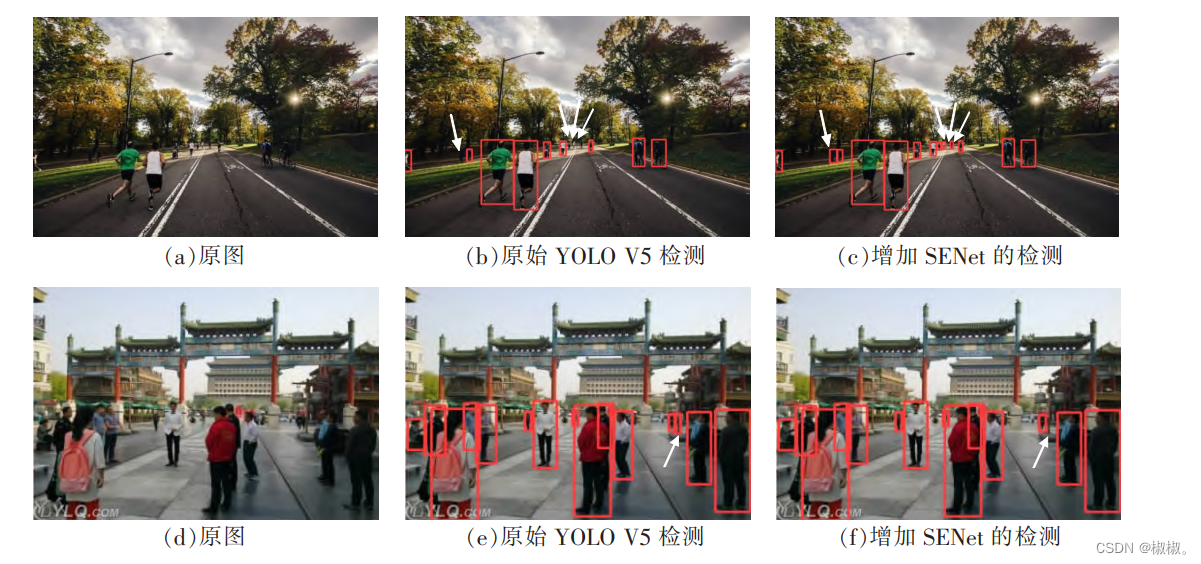

- 在图 4(a)与背景差别不大的被遮挡目标和中间部分的由于距离较远的小尺度目标检测中,仅增加了SENet 后的改进算法对其进行了正确标注,如图 4(c)的白色箭头指向所示,而传统 YOLO V5 算法的检测结果图 4(b)中并未对其标注,如图 4(b)中白色箭头指向所示;对于图 4(d)存在相似物体的行人检测,原始YOLO V5 算法的检测结果图 4(e)出现了错误标注的情况,而增加了 SENet 的 YOLO V5 算法并未受到相似物体的干扰,其检测结果如图 4(f)所示。 从图 4 的实验结果可以看出,SENet 模块的引入,有效地滤除了密集行人检测中的背景干扰,降低了误检率,提高了检测精度。
3.3 损失函数改进
3.3.1 使用 CIoU
- 在对画面中的目标进行检测时,因视场内存在不止一个目标,算法将生成不止一个预测框,因此需要使用非极大值抑制方法删除多余的预测框,选择最接近真实框的预测框[14]。在 YOLO V5 中采用 GIoU_Loss 作为损失函数,其原理见公式(1)[15]。 GIoU 加了相交尺度的衡量方式,有效解决了边界框不重合时问题。 但当预测框和目标框出现互相包含关系,或者宽和高对齐的情况时,GIoU 就会在回归的过程中,逐渐退化为 IoU,从而无法评估相对位置,容易出现迭代次数增加和检测速度减慢的情况,且存在发散的风险[16]。

- 针对上述问题,Zheng 等人[16]将不同目标框中心点之间的中心距离一同考虑进去,提出了回归更加稳定、 收敛更快更难发散的Distance-IoU(DIoU) Loss。 但是在进行实际目标检测时,还需要将边框的高宽比的 一致性列入考虑范围。为此,文中在文献[16]的基础上,将边框的高宽比的一致性列入考虑范围,引入 CIoU_Loss 作为损失函数对 YOLO V5算法进行改进。 相比于 DIoU,CIoU_Loss 的收敛速度更快,回归的效果 也更好。
- CIoU_Loss 的惩罚项定义如下:
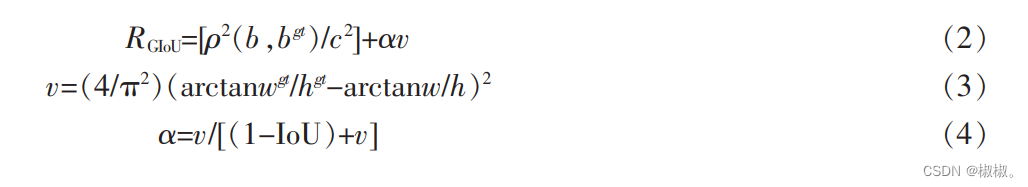
CIoU_Loss 的最终定义如下

- 在上述公式中,α 为一个正的权衡参数,v 为衡量长宽比的一致性。 上述损失函数中,检测框和目标框的 中心点用 b,bgt表示,其欧式距离为 ρ。 c 为覆盖检测框和目标框之间的最小矩形的斜距。
- 如图 5 所示, 利用 Opencv+numpy绘制了不同尺寸和长宽比的两个矩形框模拟算法的预测框和实际框 之间的交并情况,并利用公式(1)得到 GIoU,利用公式(2)-(5)计算得到CIoU,计算结果如图 5(b)、图 5(a) 所示。从图 5 中 CIoU 与 GIoU 的计算结果可以看出,由于此时 GIoU损失退化,导致在预测框 bbox 和 ground truth bbox 包含的时候优化变得非常困难,特别是在水平和垂直方向收敛难,而 CIoU 仍可以使回归更快。
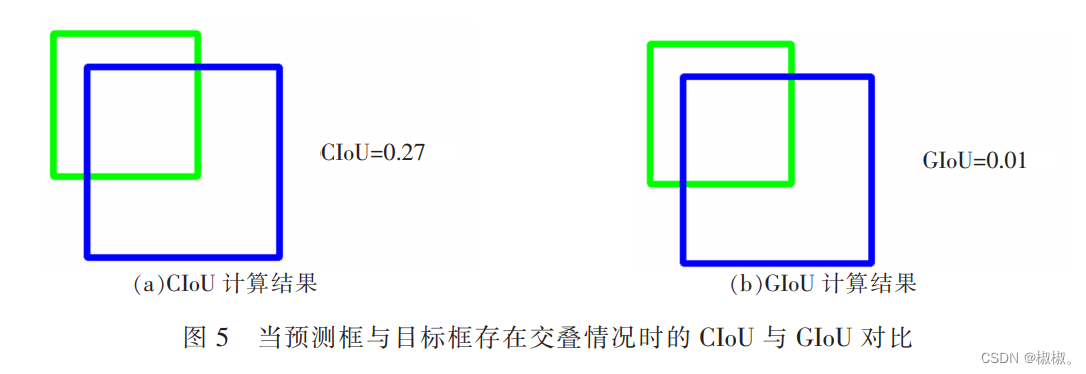
- 因此,文中利用 CIoU 来代替原始 YOLO V5 算法中的 GIoU 进行 anchor 的回归,实现真实框和预测框无重合时的梯度回传,提高模型收敛能力。 当边界框与真实框上下或左右相邻时,CIoU 能够优化不相交的边界框,保留位置更准确的边界框,提高模型对目标位置预测的精确度,使其通过非极大值抑制筛选得到的结果 更加合理。 同时,使用 CIoU能够降低模型的训练难度,提高检测的准确率。
3.3.2 非极大值抑制改进
- 在原始 YOLO V5 算法目标检测预测结果处理阶段,针对出现的众多目标框的筛选,采用加权 NMS 操作,获得最优目标框。 但是加权 NMS 只考虑两个目标框的重叠区域面积,容易出现定位与得分不一致的 问题[16]。 在抑制准则中,不仅应考虑重叠区域,还应该考虑两个 box 之间的中心点间距,DIoU_NMS 则同时考 虑了这两点。因此,文中使用 DIoU_NMS 进行评判,使得效果更符合实际。对于score 最高的预测 box M,可以 将 DIoU_NMS 的 si 更新公式正式定义为:

- 其中通过同时考虑 IoU 和两个 box 的中心点之间的距离来删除 box Bi,M 为当前得分最高预测框,Bi 表示与M 相交的第 i
个预测框,si 是分类得分,ε 是 NMS 阈值。 - 如图 6 所示,分别利用 LCIoU+加权 NMS 与 LCIoU+DIoU_NMS 同时对图6(a)的行人进行检测,CIoU+加权NMS 的检测结果如图 6(b)所示,出现了由于目标框重叠导致的漏检率增大,而在 LCIoU+DIoU_NMS 的检测结果图 6(c)中,图 6(b)中未能框选出的目标得到了正确的标注,检测率高于图 6(b),如图 6(b)与图 6(c)中的白色箭头指向所示。 实验表明,利用 DIoU_NMS 来代替原始 YOLO V5 的加权 NMS,有效提升了由于行人密 集导致的遮挡情况的检测率。

注:图中方框为预测框。 图 6(a)为文中扩充后的拥挤行人数据集(不在训练集)中随机抽取出的图片,画面中存在多个行人目标且不同行人目标之间存在由于拥挤引起的遮挡、交叠情况;图 6(b)为原始 YOLO V5 利用 CIoU+加权 NMS 的检测结果;图 6(c)为在原始 YOLO V5 的基础上利用 CIoU+DIoU_NMS 的检测结果。 白色箭头指向的部分为加权 NMS 时漏检的部分,以及修改为 DIoU_NMS 后能够正确标注出来的部分

4 研究方案与结果分析
4.1 实验平台与数据集
- 文中进行模型训练与验证测试的硬件平台 CPU 为 Core(TM) i5-10400F CPU @ 2.90 GHz,内存 16 GB,选用的 GPU 是 RTX 2060S 8 GB,在 Windows 10 操作系统上运行。 根据 YOLO 系列算法训练集格式要求,笔者从野外密集行人检测的 WiderPerson 数据集与旷世发布的 CrowdHuman 数据集中各随机选择了 8 000 张与 5000 张图片,并将数据集标注格式全部转化为 VOC 格式, 同时使用上文中提到的数据增强的方法对数据集进行扩容,最终得到数据集共 20000 张,按照 8∶2 的比例 区分训练集、测试集。
4.2 网络训练
- 文中利用 Python 语言应用 Pytorch 深度学习框架对 YOLO V5 网络模型进行结构搭建与编写程序,并且在训练过程中应用随机梯度下降算法 ( stochastic gradient descent,SGD[17])作为优化算法,对训练过程中的参数进行优化[18]。 训练过程中设置动量为 0.7,权重衰减 0.000 2,初始学习率设定为 0.01,每训练 10 次后学 习率衰减0.01,总的训练次数为 300 次。
4.3 模型评价与对比
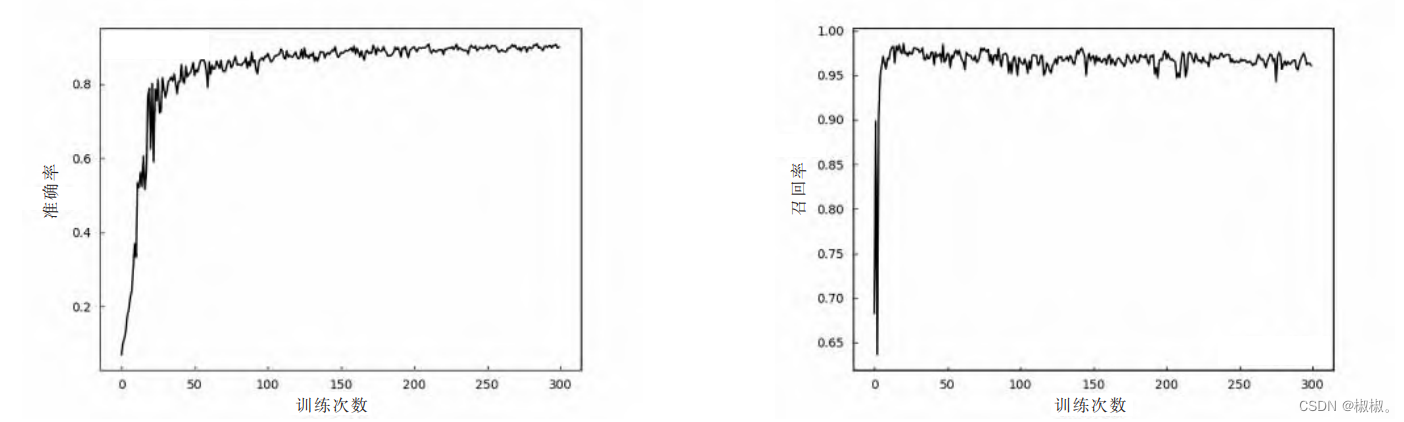
- 文中在进行模型训练时,将准确率、召回率、平均精度均值以及调和均值作为评估指标[19]。 利用准确率和召回率作为判别行人检测识别效果的标准,但两者为负相关关系[20]。 平均精度均值与调和均值是同时考虑准确率和召回率的量化指标,它们的数值越大,则识别效果越好[21]。
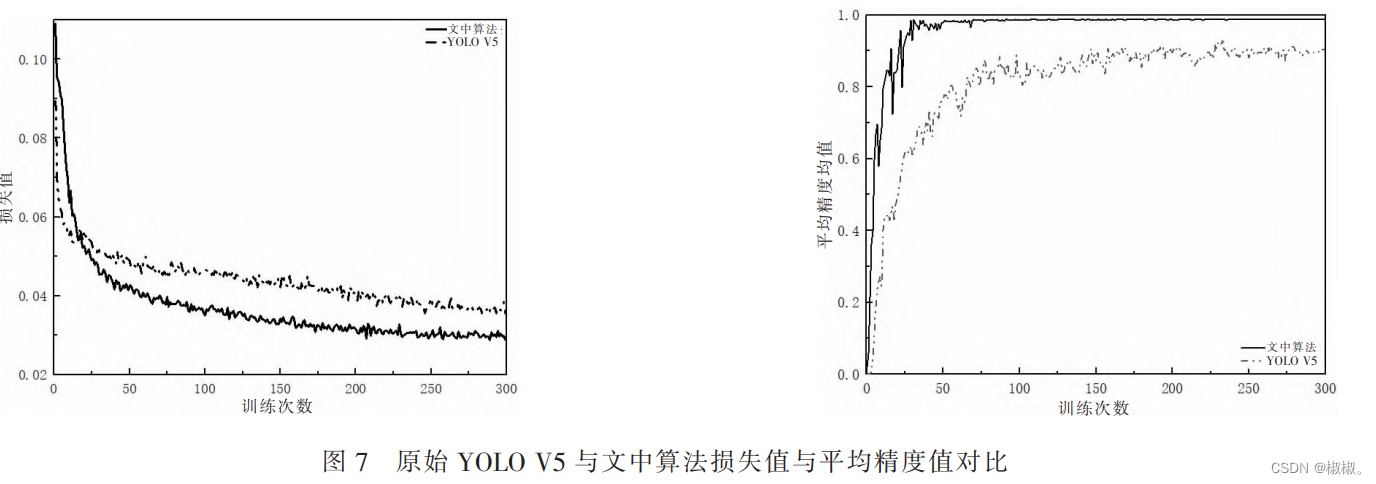
- 为了验证修改后网络的有效性,文中比较了原始 YOLO V5 网络与改进后的 YOLO V5 网络在同一数据集中训练时间及实际检测效果。 在同一数据集中分别训练 300 次,训练中的损失值与 mAP 的收敛曲线对比如图 7 所示,准确率变化与召回率曲线如图 8 所示。 迭代完成后损失值大约为 0.021 76,mAP 最终的收敛值在 0.976 4,绘制 Loss、mAP 曲线后对参数的收敛情况进行对比分析可得,文中提出的基于 YOLO V5 的改进模型训练结果相比于原始 YOLO V5 模型准确率更高、Loss 更低。


4.4 检测效果对比
- 训练结束后利用得到的权重参数模型对待检测目标样本进行检测,同时标出检测的对象位置,结果如图 9 所示,左中右三幅图依次为原图、文中改进算法检测图与原始 YOLO V5 检测图。 在光线明亮、遮挡较少的正常情况的图 9(a)的检测对比实验中,原始 YOLO V5 能框选出图 9(a)中的大 部分行人目标,但仍然是出现了漏检率较高的情况,如图9(c)所示;在光线正常、不同目标之间存在相互遮 挡的图 9(d)检测对比中,原始 YOLO V5 的漏检率与文中算法均存在漏检情况,但从图 9(e)、图 9(f)中的框 选结果可以看出,原始 YOLO V5算法的漏检率更高;在对比度较低情况下的图 9(g)检测对比实验中,由于拍摄图片角度与距离原因,行人与阴影部分的重叠区域较大,且行人目标也较前两个实验的目标更小,原始 YOLO V5的在该次实验中的漏检率进一步增加,如图 9(i)所示,而文中的改进算法依旧能够将图片中的行 人框选出来,如图9(h)所示,虽然也出现了漏检情况,但从检测结果可以看出,文中算法的鲁棒性比原始 YOLO V5 算法更好。
-
- 注:图中方框为预测框,person 为类别,数字为置信度。 图 9(a)、图 9(d)、图 9(g)为文中在 widerperson 与CrowdHuman 基础上利用数据增 强的方法扩充后的拥挤行人数据集(不在训练集)中随机抽取出来的三张图片。 图9(a)是光线明亮、遮挡较少的正常情况的图片,图 9(d)是光 线正常但不同目标之间的遮挡较多的图片,图9(g)是由于拍摄距离较远目标较小且目标与背景之间对比度较低情况下的图片。 图 9(b)、 图 9(e)、图9(h)为利用文中改进算法检测的结果;图 9(c)、图 9(f)、图 9(i)为原始 YOLO V5 算法检测结果 图 9正常情况、存在遮挡、对比度较低情况下的对比实验结果。

-
为统计分析各种算法的性能,在上文提到的软硬件环境下利用文中扩充后的拥挤行人数据集将 SSD、原 始 YOLO V5以及文中改进算法进行训练和测试。 IoU 设定为 0.5,它是 VOC 数据集的测试标准,也是常用指 标[22]。文中以这一指标进行准确率对比,各算法的实验结果见表 1。
-
实验表明,相比原始 YOLO V5 算法,文中改进算法 mAP 提升了 10.5%,精准率提升接近 16%,漏检率降 低了接近10%,同时保持了原始 YOLO V5 算法的高帧率。 改进后的模型对行人检测较为精准,在多目标、行人相互遮挡的情况下也可以很好地进行检测,有效地避免了漏检的问题,整体表现良好,目标定位准确,识别 率较高。
5 结语
- 笔者针对公共场景下的行人检测问题,研究了当下主流的 YOLO V5 算法,并在原始 YOLO V5 算法的基础上进行了以下改进:(1)引入SENet 对原始 YOLO V5网络进行改进,对融合的特征图进行自适应的调整;(2)通过引入数据增强、标签平滑的方式对原有数据集数据进行拓展得到大量新的训练数据,有效提升模型训练集大小,快速提升目标检测效果;(3)引入CIoU、DIoU_NMS 参数,提高网络特征提取和特征融合的能力,同时提升算法的检测准确率和检测速度。
- 与原算法相比,在文中扩充后的拥挤行人数据集上,笔者提出基于 YOLO V5 的改进算法检测的准确率和漏检率明显优于原始 YOLO V5 算法,同时保持了原有算法的实 时性,mAP 达到了 0.976 4,帧率达到了 140fps,满足公共大规模拥挤场景下进行行人检测时的速度与精度 的要求。
相关文章:
改进 YOLO V5 的密集行人检测算法研究(论文研读)——目标检测
改进 YOLO V5 的密集行人检测算法研究(2021.08)摘 要:1 YOLO V52 SENet 通道注意力机制3 改进的 YOLO V5 模型3.1 训练数据处理改进3.2 YOLO V5 网络改进3.3 损失函数改进3.3.1 使用 CIoU3.3.2 非极大值抑制改进4 研究方案与结果分析4.1 实验…...
Python - Opencv应用实例之CT图像检测边缘和内部缺陷
Python - Opencv应用实例之CT图像检测边缘和内部缺陷 将传统图像处理处理算法应用于CT图像的边缘检测和缺陷检测,想要实现效果如下: 关于图像处理算法,主要涉及的有:灰度、阈值化、边缘或角点等特征提取、灰度相似度变换,主要偏向于一些2D的几何变换、涉及图像矩阵的一些统…...
管理逻辑备数据库(Logical Standby Database)
1. SQL Apply架构概述 SQL Apply使用一组后台进程来应用来自主数据库的更改到逻辑备数据库。 在日志挖掘和应用处理中涉及到的不同的进程和它们的功能如下: 在日志挖掘过程中: 1)READER进程从归档redo日志文件或备redo日志文件中读取redo记…...

【C++】构造函数(初始化列表)、explicit、 Static成员、友元、内部类、匿名对象
构造函数(初始化列表)前提构造函数体赋值初始化列表explicit关键字static成员概念特性(重要)有元友元函数友元类内部类匿名对象构造函数(初始化列表) 前提 前面 六个默认成员对象中我们已经学过什么是构造…...
再来看看几个最常见和最基本的索引使用规则)
(六十)再来看看几个最常见和最基本的索引使用规则
今天我们来讲一下最常见和最基本的几个索引使用规则,也就是说,当我们建立好一个联合索引之后,我们的SQL语句要怎么写,才能让他的查询使用到我们建立好的索引呢? 下面就一起来看看,还是用之前的例子来说明。…...

机器学习与目标检测作业(数组相加:形状需要满足哪些条件)
机器学习与目标检测(数组相加:形状需要满足哪些条件)机器学习与目标检测(数组相加:形状需要满足哪些条件)一、形状相同1.1、形状相同示例程序二、符合广播机制2.1、符合广播机制的描述2.2、符合广播机制的示例程序机器学习与目标检…...
CentOS救援模式(Rescue Mode)及紧急模式(Emergency Mode)
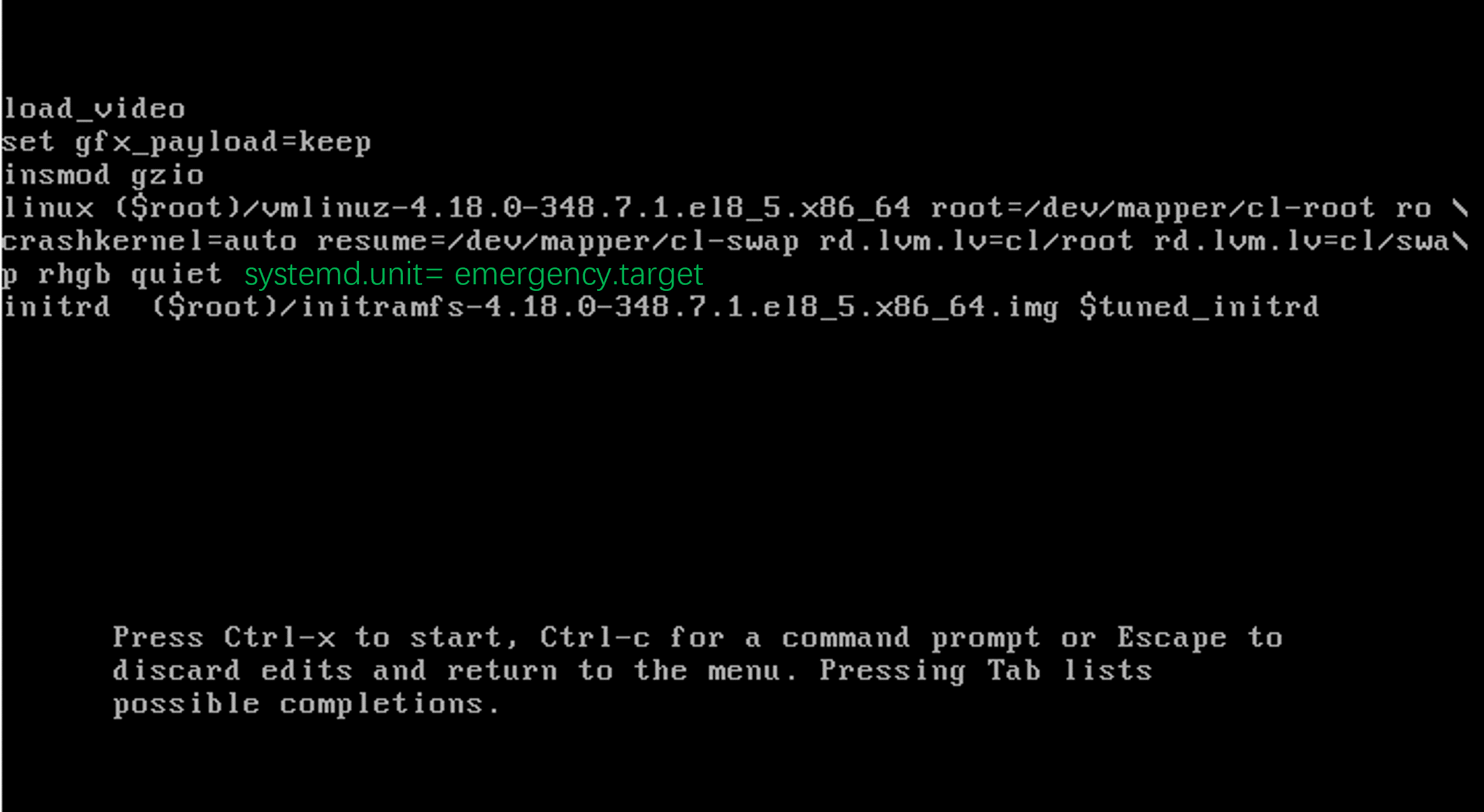
当CentOS操作系统崩溃,无法正常启动时,可以通过救援模式或者紧急模式进行系统登录。启动CentOS, 当出现下面界面时,按e进入编辑界面。在编辑界面里,加入参数:systemd.unitrescue.target ,然后Ctrl-X启动进入…...
从面试官角度告诉你高级性能测试工程师面试必问的十大问题
目录 1、介绍下最近做过的项目,背景、预期指标、系统架构、场景设计及遇到的性能问题,定位分析及优化; 2、项目处于什么阶段适合性能测试介入,原因是什么? 3、性能测试场景设计要考虑哪些因素? 4、对于一…...
通过知识库深度了解用户的心理
自助服务知识库的价值是毋庸置疑的,如果执行得当,可以帮助减少客户服务团队的工作量,仅仅编写内容和发布是不够的,需要知道知识库对客户来说是否有用,需要了解客户获得的反馈,如果你正确的使用知识库软件&a…...
HiveSQL一天一个小技巧:如何将分组内数据填充完整?
0 需求1 需求分析需求分析:需求中需要求出分组中按成绩排名取倒数第二的值作为新字段,且分组内没有倒数第二条的时候取当前值。如果本题只是求分组内排序后倒数第二,则很简单,使用row_number()函数即可求出,但是本题问…...
【亲测可用】BEV Fusion (MIT) 环境配置
CUDA环境 首先我们需要打上对应版本的显卡驱动: 接下来下载CUDA包和CUDNN包: wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run sudo sh cuda_11.6.2_510.47.03_linux.runwget htt…...
【调试方法】基于vs环境下的实用调试技巧
前言: 对万千程序猿来说,在这个世界上如果有比写程序更痛苦的事情,那一定是亲手找出自己编写的程序中的bug(漏洞)。作为新手在我们日常写代码中,经常会出现报错的情况(好的程序员只是比我们见过…...

单目标应用:蜣螂优化算法DBO优化RBF神经网络实现数据预测(提供MATLAB代码)
一、RBF神经网络 1988年,Broomhead和Lowc根据生物神经元具有局部响应这一特点,将RBF引入神经网络设计中,产生了RBF(Radical Basis Function)。1989年,Jackson论证了RBF神经网络对非线性连续函数的一致逼近性能。 RBF的基本思想是…...
MTK平台开发入门到精通(Thermal篇)热管理介绍
文章目录 一、热管理组成二、Linux Thermal Framework2.1、thermal_zone 节点2.2、cooling_device 节点三、Thermal zones沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍MTK平台的热管理机制,热管理机制是为了防止模组在高温下工作导致硬件损坏而存在的…...
最好的 QML 教程,让你的代码飞起来!
想必大家都知道,亮哥一直深耕于 CSDN,坚持了好很多年,目前为止,原创已经 500 多篇了,一路走来相当不易。当然了,中间有段时间比较忙,没怎么更新。就拿 QML 来说,最早的一篇文章还是 …...
——stack容器的基础理论知识)
笔记(六)——stack容器的基础理论知识
stack是堆栈容器,元素遵循先进后出的顺序。头文件:#include<stack>一、stack容器的对象构造方法stack采用模板类实现默认构造例如stack<T> vecT;#include<iostream> #include<stack> using namespace std; int main(…...
Web前端学习:四 - 练习
三九–四一:百度页面制作 1、左右居中: text-align: center; 2、去掉li默认的状态 list-style: none; li中有的有点,有的有序,此代码去掉默认状态 3、伪类:hovar 一般显示为color: #0f0e0f, 当鼠标接触时…...
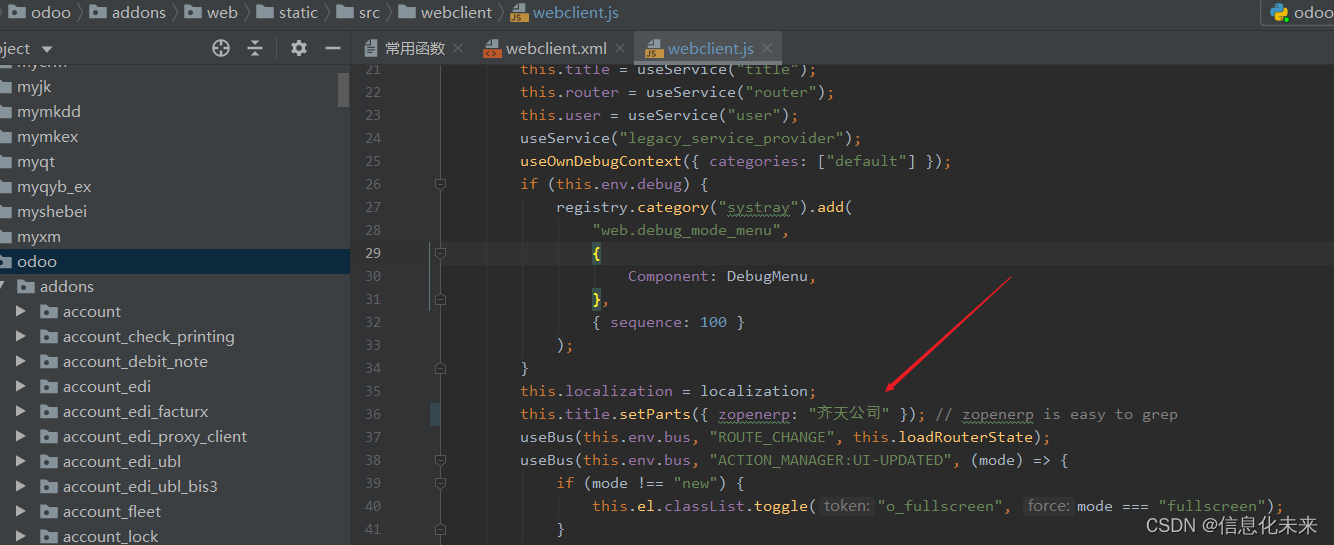
odoo15 标题栏自定义
odoo15 标题栏自定义 如何显示为自定义呢 效果如下: 代码分析: export class WebClient extends Component {setup() {this.menuService = useService("menu");this.actionService = useService("action");this.title = useService("title&…...

视觉SLAM十四讲 ch3 (三维空间刚体运动)笔记
本讲目标 ●理解三维空间的刚体运动描述方式:旋转矩阵、变换矩阵、四元数和欧拉角。 ●学握Eigen库的矩阵、几何模块使用方法。 旋转矩阵、变换矩阵 向量外积 向量外积(又称叉积或向量积)是一种重要的向量运算,它表示两个向量所形成的平行…...

问题解决:java.net.SocketTimeoutException: Read timed out
简单了解Sockets Sockets:两个计算机应用程序之间逻辑链接的一个端点,是应用程序用来通过网络发送和接收数据的逻辑接口 是IP地址和端口号的组合每个Socket都被分配了一个用于标识服务的特定端口号基于连接的服务使用基于tcp的流Sockets Java为客户端…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...