webpack高级配置
摇树(tree shaking)
我主要是想说摇树失败的原因(tree shaking 失败的原因),先讲下摇树本身效果
什么是摇树?
举个例子
首先 webpack.config.js配置
const webpack = require("webpack");/*** @type {webpack.Configuration}*/
module.exports = {mode: "production"
};
在固定 a.js 用esm导出,b.js用commonjs导出不变动
// a.js
export function f1() {console.log("11111");
}
export function f2() {console.log("22222");
}// b.js
exports.f3 = function () {console.log("33333");
};
exports.f4 = function () {console.log("44444");
};
例子1:import a.js 和 require b.js
// index.js
import { f1 } from "./a";
import { f3 } from "./b";
console.log(f1);
console.log(f3);
打包结果:a.j 和 b.js 都摇树了,只输出了 f1 和 f3。所以导入用import,导出esm和commonjs都可以

例子2:import a.js 和 import b.js
// index.js
import { f1 } from "./a";
const { f3 } = require("./b");
console.log(f1);
console.log(f3);
打包结果:a.js 摇,b.js 没摇,输出了 f1 、f3、f4。所以导入用require不成功

结论:
摇树只能import,导出用esm和commonjs都可以
因为摇树发生在编译阶段,只支持esm的import,不支持commonjs的require,因为esm是编译时,commonjs是运行时
摇树失败的原因
三方面可能导致失败:
1、代码没用import引入
2、webpack配置没开启摇树
3、副作用(sideEffects)
4、babel配置preset-env没写 module:false 参数
代码没用import引入
这一点上面已经说明,必须用 import 导入,导出用 esm 或者 commonjs 都行
webpack配置没开启摇树
开启摇树两步:
1、usedExports设置true,标记无用代码,esm导出的没使用到的导出函数标记为unused harmony export f2,commonjs导出的没使用的导出函数赋值为__webpack_unused_export__
2、terser-webpack-plugin插件做代码压缩去除无用代码,根据一步两种标记,压缩代码会去除
const webpack = require("webpack");/*** @type {webpack.Configuration}*/
module.exports = {mode: "none",optimization:{usedExports:true}
};
mode: production模式下,默认开启摇树,不用做任何配置,由源码看出none和development不会开启摇树,需要手动加这两步,注意要设置minimize:true,或者放到plugins中
看webpack源码默认配置,参考 前端进阶面试题详细解答

副作用(sideEffects)
先来解释下什么是副作用:修改当前作用域之外的行为都叫副作用,比如在函数内部,修改dom,修改全局对象等等
这条主要是针对引入三方包,三方包package.json的sideEffects字段默认true表示有副作用,可以设置为false表示没有副作用,设置为数组列出有副作用的文件
在webpack.config.js设置sideEffects:true表示检查三方包的sideEffects字段,webpack在用userExports标记无用代码时,如果判断不出库中代码是否有副作用,就不会标记,则压缩的时候也没法清除,如果判断有副作用,则更不会标记清除
mode: production模式下,默认开启摇树,不用做任何配置,usedExports: true
const webpack = require("webpack");
const TerserPlugin = require("terser-webpack-plugin");/*** @type {webpack.Configuration}*/
module.exports = {mode: "none",optimization:{sideEffects:true,usedExports:true},plugins:[ new TerserPlugin() ]
};
babel配置preset-env没写 module:false 参数
在文章 我掌握的Babel配置 中详细讲解了 module: false 参数,简单说不设置false时,只针对babel相关的runtime包的引入会使用require,设置了false引入会使用import,就能让webpack去摇树,回到第一点上
module.exports = {presets: [ [ "@babel/preset-env", { modules: false }, ],]
};
拆包(splitChunks)
splitChunks是webpack配置下optimization下的配置,即优化。看单词理解意思就是拆分多个chunk。
什么是chunk
webpack的本质是把多个js模块合并到一个js中,即一个入口得到一个输出js文件(bundle.js)。
但是导致的问题是,如果这个bundle.js文件很大,那么浏览器请求的时候,导致请求时间很长,首屏长时间白屏。
所以优化手段就是把bundle.js文件拆分成多个小的js文件,同时请求,首屏当然就更快渲染显示。
所以入口文件,chunk文件,输出文件三者的关系从原来的一个入口文件对应一个chunk最后输出一个bundle文件改变为一个入口文件对应多个chunk最后输出多个bundle文件
三种方式获得chunk
-
1、入口文件可以生成chunk,入口文件即webpack配置的
entry选项; -
2、异步请求 import函数调用 或者 require.ensure 可以生成chunk;
如:import函数即我们在写vue-router时写的异步请求路由方式,这里webpackChunkName可以魔法定义chunk名,也可不写
import(/* webpackChunkName: "AboutPage" */'./view/about.vue')
- 3、webpack配置splitChunks手动拆分生成chunk,最后独立输出到js文件
splitChunks 配置
简单配置,把react相关包都单独提到一个文件
{optimization: {splitChunks: {chunks: "all", // initial、async和allcacheGroups: {react: {name: "react",test: /[\\/]react(\w)*[\\/]/i,priority: 10},lodash: {name: "lodash",test: /[\\/]lodash(\w)*[\\/]/i,priority: 20,minChunks:3},},},},
}
先来看下webpack默认的splitChunks参数

看图production和非production模式下有参数不一样,下面这些参数表示自动拆包的条件:
- chunks
重要:拆包的范围,默认async,只针对异步请求的,即上面第二条的import函数调用的chunk里面;initial表示只针对初始化入口entry的;all表示最大包含async + entry
- cacheGroups
重要:自定义拆包规则,name是chunk名,test正则包名,priority优先级(因为同一个包可能符合多个拆包规则,会处理给优先级高的);看图可知,默认会有两个包规则,defaultVendors规则表示node_modules会拆到一个chunk包,default规则表示只有被两个即以上chunk引用就要拆到一个chunk包
- minChunks
拆分前必须共享模块的最小 chunks 数,可以不用修改
- maxAsyncRequests
浏览器发送异步请求时,最大不超过30个请求,即上面第二条的import函数调用,可以不用修改
- maxInitialRequests
浏览器请求入口entry时,最大不超过30个,可以不用修改
热更新
我们主要是说明热更新的 module.hot.accept()
先来了解一下热更新怎么配置的?
热更新配置
装包
npm i -D webpack-dev-server html-webpack-plugin
webpack.config.js
const webpack = require("webpack");
const HtmlWebpackPlugin = require('html-webpack-plugin');/*** @type {webpack.Configuration}*/
module.exports = {mode: "development",devServer: {port: 3000,open: true,hot: true,},plugins: [ new HtmlWebpackPlugin(), ]
};
package.json
"scripts": {"serve": "webpack serve",
},
结论
到此热更新配置完成,正常写代码,但是发现问题了,此时更新页面是整个刷新页面的,并不是局部刷新,怎么回事呢,原来需要在每个文件中最后加上module.hot.accept()才会触发局部更新,accept可以接受两个参数,依赖和回调
exports.f3 = function () {console.log("33333");
};
exports.f4 = function () {console.log("44444");
};
if (module.hot) {module.hot.accept();
}
随即产生了另一个疑问,这太麻烦了吧,每个文件文件都需要去加module.hot.accept(),但是我们在实际写下项目的时候怎么没有写这句呢?
原因是不论css、vue、react的loader都帮我们自动加了这句。
css有style-loader,react有react-hot-loader,vue有vue-loader。
对于jsx文件,有vue-jsx-hot-loader
{test:/\.jsx?$/,use:['babel-loader','vue-jsx-hot-loader']
}
按需加载
一段时间以来,我一直把tree shaking和按需加载混为一谈,其实应该分开理解,这里我主要是想说第三方包的按需加载,比如使用element-ui、lodash、vant
tree shaking的前提是使用import导入,但是按需加载并不需要
还有一个点需要注意:如果是我们封装的库,如组件库,导出格式根据文件类型不同,如是js文件可以为 commonjs + es5、esm + es5;如是vue或react文件,esm/commonjs + es6/es5 任意都行,因为我们用babel-loader时会排除node_modules目录不编译,vue-loader等会去编译vue文件
使用babel插件
npm install babel-plugin-component -D
babel.config.js
module.exports = {presets: [["@babel/preset-env",{useBuiltIns: "usage",corejs: 2,modules: false,},],],plugins: [["@babel/plugin-transform-runtime"],["babel-plugin-import",{libraryName: "vant",libraryDirectory: "es",style: true,},"vant",],["babel-plugin-import",{libraryName: "antd",style: true, // or 'css'},],["babel-plugin-import",{"libraryName": "lodash","libraryDirectory": "","camel2DashComponentName": false, // default: true},"lodash",],["babel-plugin-component",{libraryName: "element-ui",styleLibraryName: "theme-chalk",},"element-ui",],],
};
完毕!
相关文章:
webpack高级配置
摇树(tree shaking) 我主要是想说摇树失败的原因(tree shaking 失败的原因),先讲下摇树本身效果 什么是摇树? 举个例子 首先 webpack.config.js配置 const webpack require("webpack");/**…...
jQuery 事件
jQuery 事件 Date: February 28, 2023 Sum: jQuery事件注册、处理、对象 目标: 能够说出4种常见的注册事件 能够说出 on 绑定事件的优势 能够说出 jQuery 事件委派的优点以及方式 能够说出绑定事件与解绑事件 jQuery 事件注册 单个时间注册 语法:…...

【批处理脚本】-2.3-解析地址命令arp
"><--点击返回「批处理BAT从入门到精通」总目录--> 共2页精讲(列举了所有arp的用法,图文并茂,通俗易懂) 目录 1 arp命令解析 1.1 询问当前协议数据,显示当前 ARP 项...

改进 YOLO V5 的密集行人检测算法研究(论文研读)——目标检测
改进 YOLO V5 的密集行人检测算法研究(2021.08)摘 要:1 YOLO V52 SENet 通道注意力机制3 改进的 YOLO V5 模型3.1 训练数据处理改进3.2 YOLO V5 网络改进3.3 损失函数改进3.3.1 使用 CIoU3.3.2 非极大值抑制改进4 研究方案与结果分析4.1 实验…...
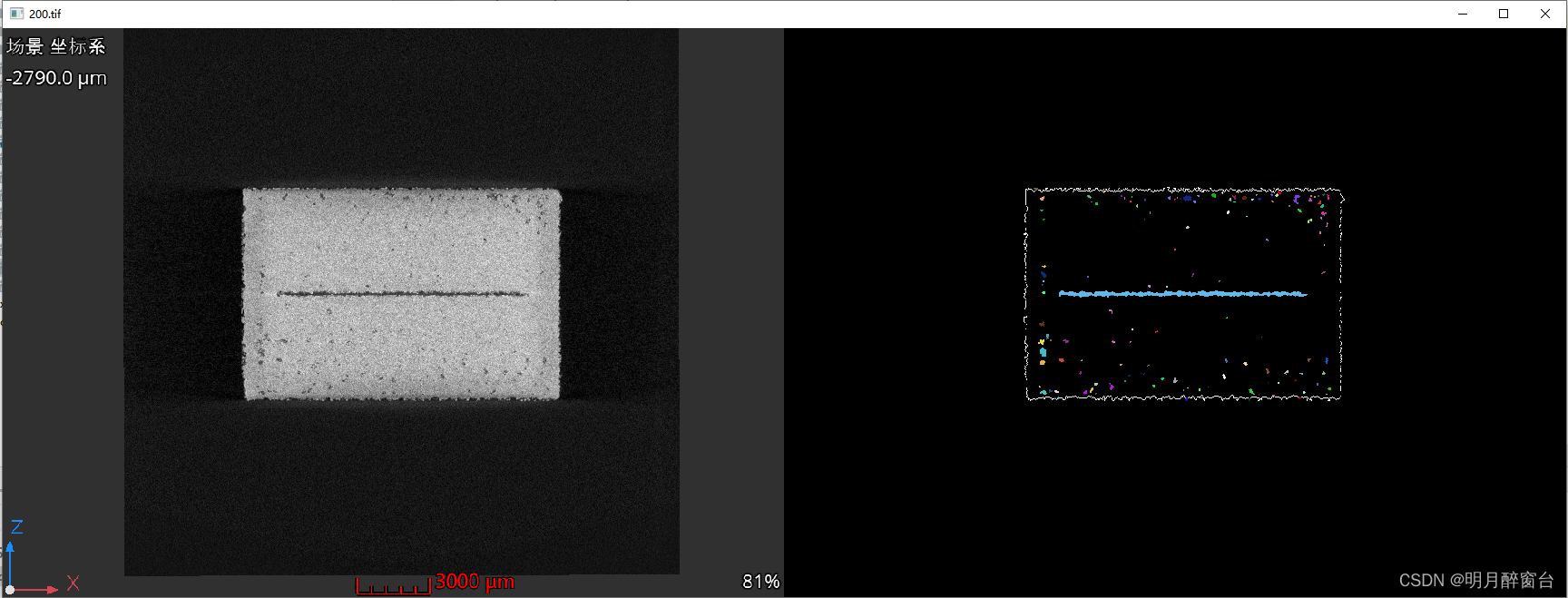
Python - Opencv应用实例之CT图像检测边缘和内部缺陷
Python - Opencv应用实例之CT图像检测边缘和内部缺陷 将传统图像处理处理算法应用于CT图像的边缘检测和缺陷检测,想要实现效果如下: 关于图像处理算法,主要涉及的有:灰度、阈值化、边缘或角点等特征提取、灰度相似度变换,主要偏向于一些2D的几何变换、涉及图像矩阵的一些统…...
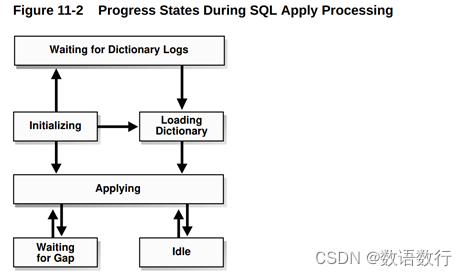
管理逻辑备数据库(Logical Standby Database)
1. SQL Apply架构概述 SQL Apply使用一组后台进程来应用来自主数据库的更改到逻辑备数据库。 在日志挖掘和应用处理中涉及到的不同的进程和它们的功能如下: 在日志挖掘过程中: 1)READER进程从归档redo日志文件或备redo日志文件中读取redo记…...

【C++】构造函数(初始化列表)、explicit、 Static成员、友元、内部类、匿名对象
构造函数(初始化列表)前提构造函数体赋值初始化列表explicit关键字static成员概念特性(重要)有元友元函数友元类内部类匿名对象构造函数(初始化列表) 前提 前面 六个默认成员对象中我们已经学过什么是构造…...
再来看看几个最常见和最基本的索引使用规则)
(六十)再来看看几个最常见和最基本的索引使用规则
今天我们来讲一下最常见和最基本的几个索引使用规则,也就是说,当我们建立好一个联合索引之后,我们的SQL语句要怎么写,才能让他的查询使用到我们建立好的索引呢? 下面就一起来看看,还是用之前的例子来说明。…...

机器学习与目标检测作业(数组相加:形状需要满足哪些条件)
机器学习与目标检测(数组相加:形状需要满足哪些条件)机器学习与目标检测(数组相加:形状需要满足哪些条件)一、形状相同1.1、形状相同示例程序二、符合广播机制2.1、符合广播机制的描述2.2、符合广播机制的示例程序机器学习与目标检…...
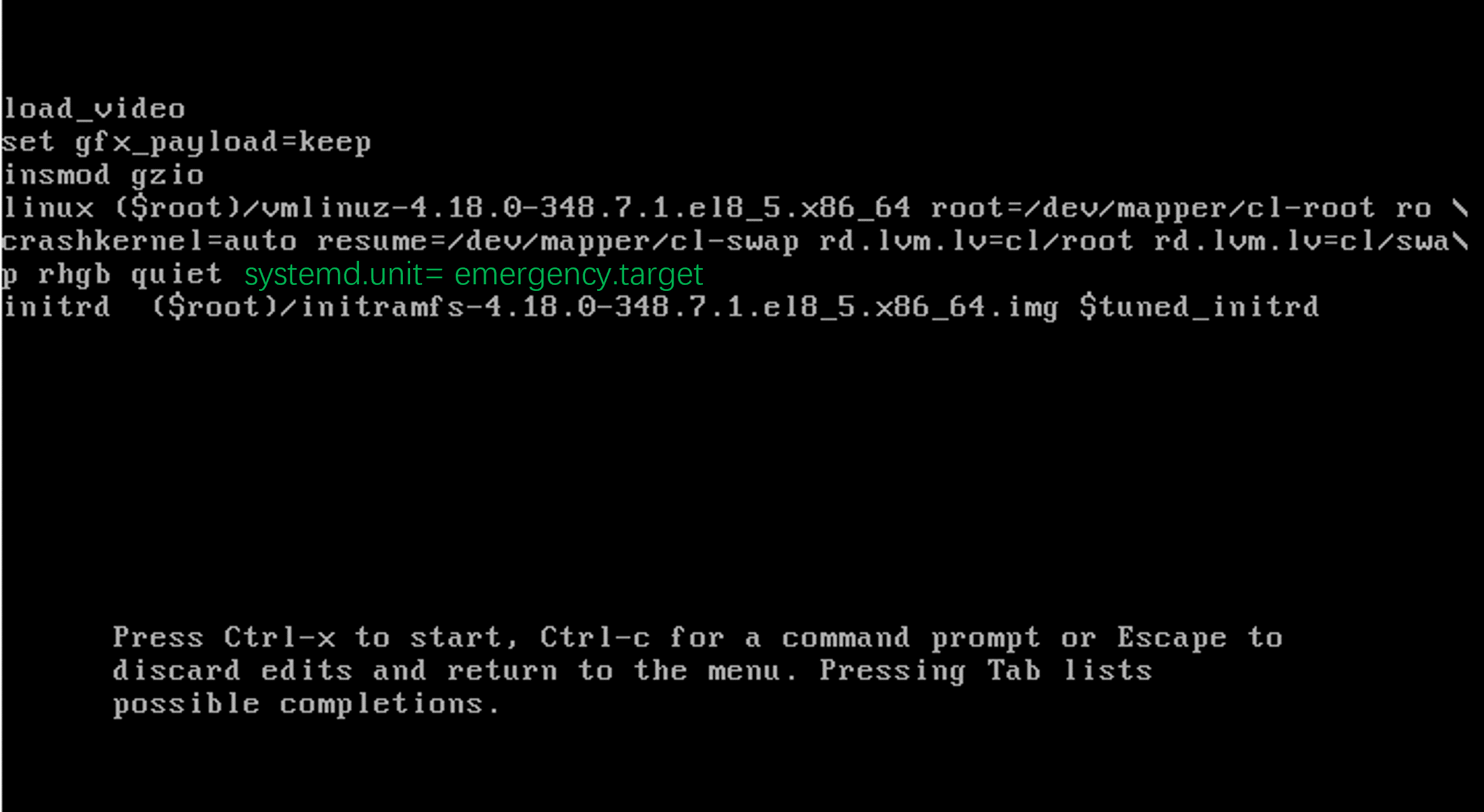
CentOS救援模式(Rescue Mode)及紧急模式(Emergency Mode)
当CentOS操作系统崩溃,无法正常启动时,可以通过救援模式或者紧急模式进行系统登录。启动CentOS, 当出现下面界面时,按e进入编辑界面。在编辑界面里,加入参数:systemd.unitrescue.target ,然后Ctrl-X启动进入…...
从面试官角度告诉你高级性能测试工程师面试必问的十大问题
目录 1、介绍下最近做过的项目,背景、预期指标、系统架构、场景设计及遇到的性能问题,定位分析及优化; 2、项目处于什么阶段适合性能测试介入,原因是什么? 3、性能测试场景设计要考虑哪些因素? 4、对于一…...
通过知识库深度了解用户的心理
自助服务知识库的价值是毋庸置疑的,如果执行得当,可以帮助减少客户服务团队的工作量,仅仅编写内容和发布是不够的,需要知道知识库对客户来说是否有用,需要了解客户获得的反馈,如果你正确的使用知识库软件&a…...
HiveSQL一天一个小技巧:如何将分组内数据填充完整?
0 需求1 需求分析需求分析:需求中需要求出分组中按成绩排名取倒数第二的值作为新字段,且分组内没有倒数第二条的时候取当前值。如果本题只是求分组内排序后倒数第二,则很简单,使用row_number()函数即可求出,但是本题问…...
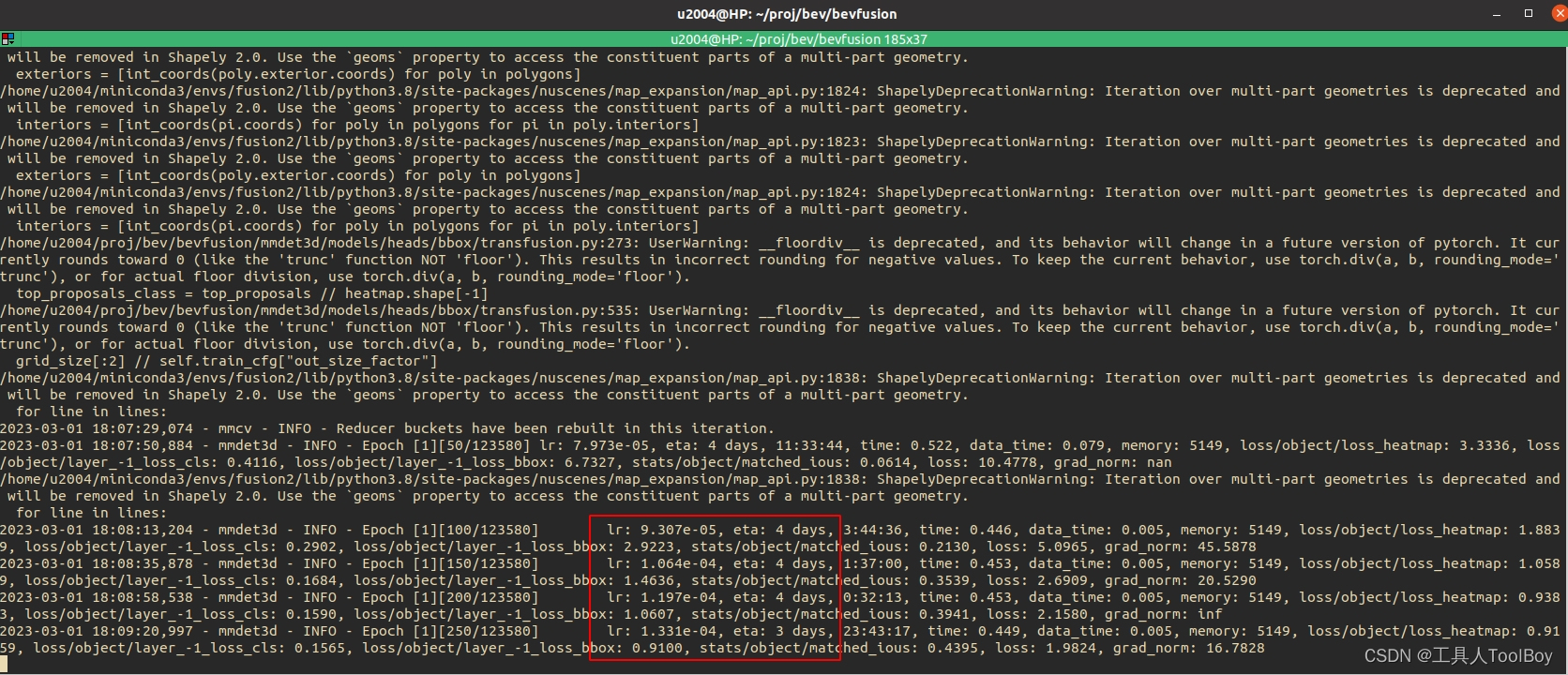
【亲测可用】BEV Fusion (MIT) 环境配置
CUDA环境 首先我们需要打上对应版本的显卡驱动: 接下来下载CUDA包和CUDNN包: wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run sudo sh cuda_11.6.2_510.47.03_linux.runwget htt…...
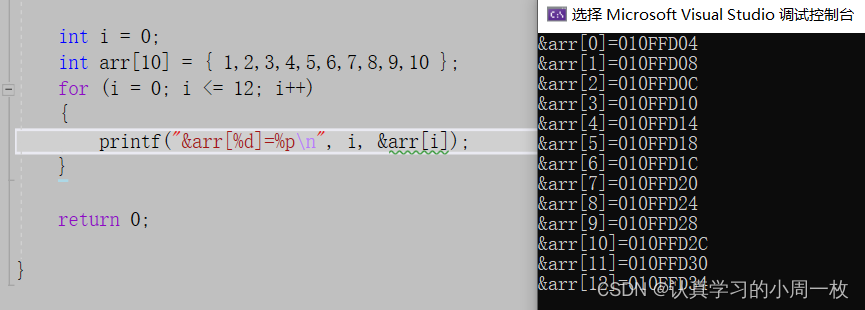
【调试方法】基于vs环境下的实用调试技巧
前言: 对万千程序猿来说,在这个世界上如果有比写程序更痛苦的事情,那一定是亲手找出自己编写的程序中的bug(漏洞)。作为新手在我们日常写代码中,经常会出现报错的情况(好的程序员只是比我们见过…...

单目标应用:蜣螂优化算法DBO优化RBF神经网络实现数据预测(提供MATLAB代码)
一、RBF神经网络 1988年,Broomhead和Lowc根据生物神经元具有局部响应这一特点,将RBF引入神经网络设计中,产生了RBF(Radical Basis Function)。1989年,Jackson论证了RBF神经网络对非线性连续函数的一致逼近性能。 RBF的基本思想是…...
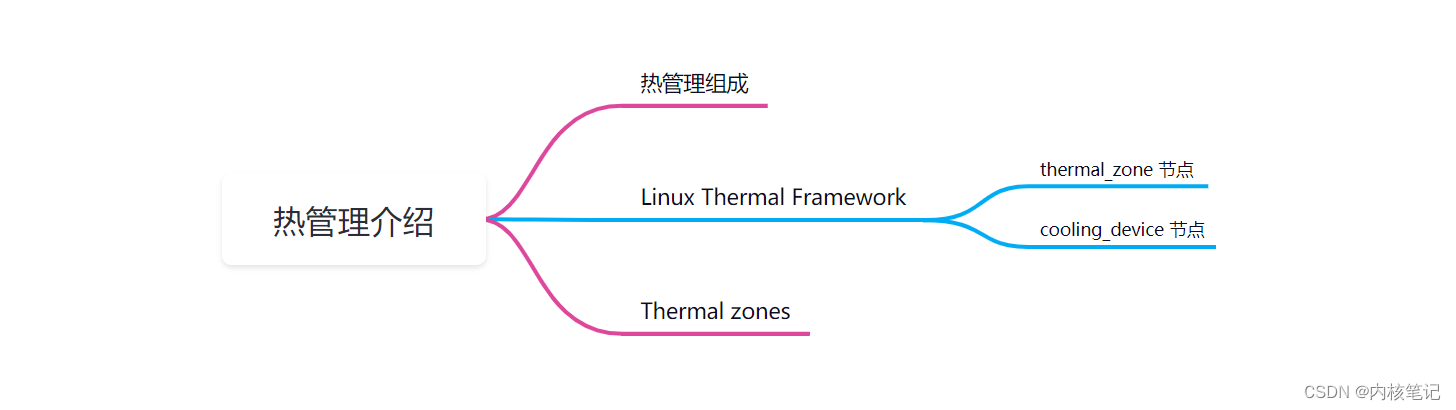
MTK平台开发入门到精通(Thermal篇)热管理介绍
文章目录 一、热管理组成二、Linux Thermal Framework2.1、thermal_zone 节点2.2、cooling_device 节点三、Thermal zones沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍MTK平台的热管理机制,热管理机制是为了防止模组在高温下工作导致硬件损坏而存在的…...
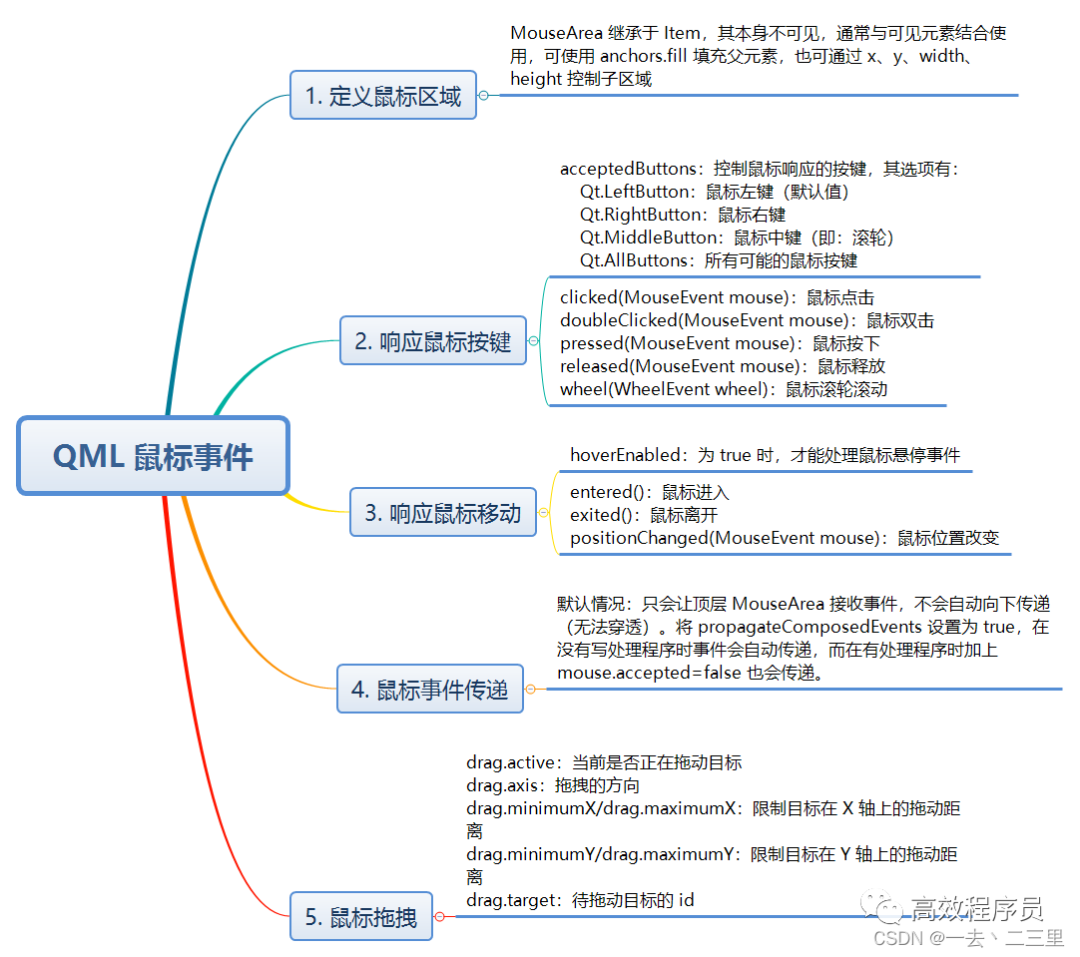
最好的 QML 教程,让你的代码飞起来!
想必大家都知道,亮哥一直深耕于 CSDN,坚持了好很多年,目前为止,原创已经 500 多篇了,一路走来相当不易。当然了,中间有段时间比较忙,没怎么更新。就拿 QML 来说,最早的一篇文章还是 …...
——stack容器的基础理论知识)
笔记(六)——stack容器的基础理论知识
stack是堆栈容器,元素遵循先进后出的顺序。头文件:#include<stack>一、stack容器的对象构造方法stack采用模板类实现默认构造例如stack<T> vecT;#include<iostream> #include<stack> using namespace std; int main(…...
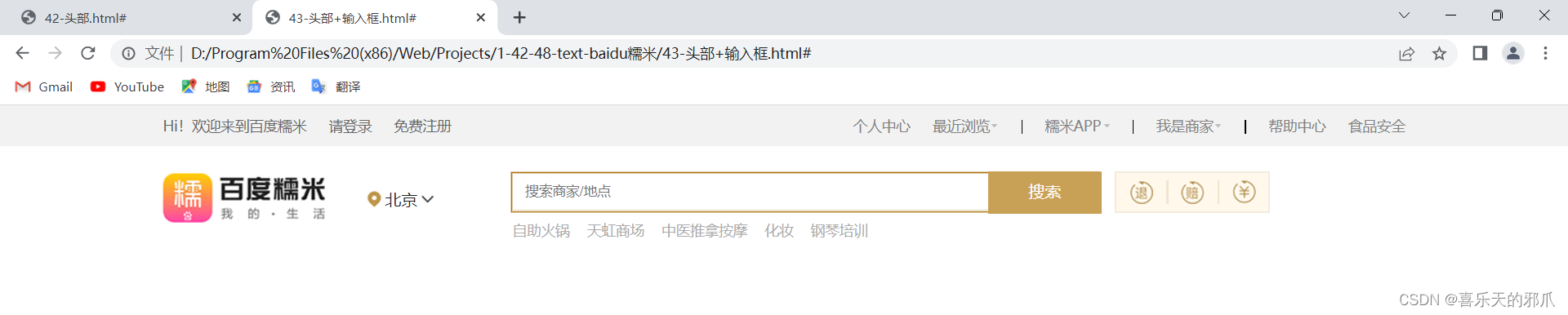
Web前端学习:四 - 练习
三九–四一:百度页面制作 1、左右居中: text-align: center; 2、去掉li默认的状态 list-style: none; li中有的有点,有的有序,此代码去掉默认状态 3、伪类:hovar 一般显示为color: #0f0e0f, 当鼠标接触时…...

在Ubuntu 18.04上搞定GAMMA遥感软件:从依赖库到加密狗驱动的保姆级避坑记录
在Ubuntu 18.04上搞定GAMMA遥感软件:从依赖库到加密狗驱动的保姆级避坑记录 如果你正在Ubuntu 18.04上尝试安装GAMMA遥感软件,那么这篇文章就是为你准备的。作为一名遥感领域的科研人员,我深知GAMMA软件在InSAR处理中的重要性,也体…...

嵌入式轻量级状态机库:零依赖、确定性FSM实现
1. 项目概述SimpleStateProcessor 是一个轻量级、零依赖的有限状态机(Finite State Machine, FSM)处理器库,专为资源受限的嵌入式系统设计。其核心目标并非提供图灵完备的复杂状态建模能力,而是以极小的内存开销(典型R…...

嵌入式LED控制库Blink:极简GPIO翻转与实时性设计
1. 项目概述“Blink”并非一个功能繁复的通用驱动库,而是一个高度凝练、面向嵌入式底层开发本质的LED控制抽象层。其核心价值不在于封装多少高级特性,而在于以最小代码体积、最短执行路径、最可控时序,完成嵌入式系统中最基础也最关键的物理层…...
)
CSP-J/S初赛必看:5个高频考点+避坑指南(附真题解析)
CSP-J/S初赛高频考点深度解析与避坑指南 参加CSP-J/S竞赛的初中生们常常在初赛阶段遇到一些看似简单却容易失分的"陷阱题"。本文将从历年真题中提炼出5个最易出错的知识点,通过典型错题分析帮助考生避开常见误区,掌握解题关键技巧。 1. 递归调…...
)
SpringBoot 2.x 集成 MQTT 踩坑实录:从配置文件报错到消息成功收发(EMQX 4.4.1 Docker版)
SpringBoot 2.x 集成 MQTT 实战避坑指南:EMQX 4.4.1 Docker 部署全解析 在物联网和消息中间件领域,MQTT协议凭借其轻量级、低带宽消耗和高效发布/订阅模式,已成为设备互联的首选方案。本文将带您深入SpringBoot 2.x与EMQX 4.4.1(D…...

Realistic Vision V5.1摄影级效果实测:RAW模式下噪点控制与动态范围表现
Realistic Vision V5.1摄影级效果实测:RAW模式下噪点控制与动态范围表现 1. 引言:当AI摄影棚遇上“RAW模式” 想象一下,你有一台顶级的单反相机,但每次拍照前,都需要手动调整几十个参数——光圈、快门、ISO、白平衡、…...

Vite项目实战:利用Autoprefixer优化跨浏览器CSS兼容性
1. 为什么你的CSS在不同浏览器上表现不一致? 每次写完漂亮的CSS样式,打开Chrome一看效果完美,结果同事用Safari打开却发现布局错乱?这种场景前端开发者应该都不陌生。浏览器兼容性问题就像牛皮癣一样困扰着我们,特别是…...

sdut-软件测试-软件测试概述1
1. 单选题 某网上购物软件,与京东、淘宝等现有主流系统操作流程一致,符合最终用户的使用习惯和操作模式,主要目的是为了改善 ISO/IEC 9126 质量模型中的( C )质量特性。 A. 功能性B. 可靠性C. 易用性D. 可维护性E.…...

光电经纬仪与AI:能捕获隐身战机的“最后一瞥”吗?
引言 在现代防空体系中,光电经纬仪作为一种高精度光学测量设备,一直扮演着“记录者”与“验证者”的角色。它能够以极高的精度测量空中目标的轨迹,并记录下清晰的光学图像。然而,当面对像F-35这样的第五代隐身战机时,…...

Claude Code + OpenSpec 正在加速 AICoding 落地:从模型博弈到工程化的范式转移
引言:AI 编程的黄金时代与隐忧 过去两年,AI 编程工具如雨后春笋般涌现。从 GitHub Copilot 到 Cursor,从 ChatGPT 到 Claude,开发者们已经习惯了用自然语言生成代码、调试 Bug、甚至重构整个模块。根据 Stack Overflow 2025 年调查,超过 80% 的开发者每周至少使用一次 AI…...