11. 哈希冲突
上一节提到,通常情况下哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的。比如,输入空间为全体整数,输出空间为数组容量大小,则必然有多个整数映射至同一桶索引。
哈希冲突会导致查询结果错误,严重影响哈希表的可用性。为解决该问题,我们可以每当遇到哈希冲突就进行哈希表扩容,直至冲突消失为止。此方法简单粗暴且有效,但效率太低,因为哈希表扩容需要进行大量的数据搬运与哈希值计算。为了提升效率,我们可以采用以下策略。
- 改良哈希表数据结构,使得哈希表可以在出现哈希冲突时正常工作。
- 仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
哈希表的结构改良方法主要包括“链式地址”和“开放寻址”。
11.1 链式地址
在原始哈希表中,每个桶仅能存储一个键值对。链式地址(separate chaining)将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。下图展示了一个链式地址哈希表的例子。

基于链式地址实现的哈希表的操作方法发生了以下变化。
- 查询元素:输入
key,经过哈希函数得到桶索引,即可访问链表头节点,然后遍历链表并对比key以查找目标键值对。 - 添加元素:首先通过哈希函数访问链表头节点,然后将节点(键值对)添加到链表中。
- 删除元素:根据哈希函数的结果访问链表头部,接着遍历链表以查找目标节点并将其删除。
链式地址存在以下局限性。
- 占用空间增大,链表包含节点指针,它相比数组更加耗费内存空间。
- 查询效率降低,因为需要线性遍历链表来查找对应元素。
以下代码给出了链式地址哈希表的简单实现,需要注意两点。
- 使用列表(动态数组)代替链表,从而简化代码。在这种设定下,哈希表(数组)包含多个桶,每个桶都是一个列表。
- 以下实现包含哈希表扩容方法。当负载因子超过 2/3 时,我们将哈希表扩容至原先的 2 倍。
/* 链式地址哈希表 */ class HashMapChaining {private:int size; // 键值对数量int capacity; // 哈希表容量double loadThres; // 触发扩容的负载因子阈值int extendRatio; // 扩容倍数vector<vector<Pair *>> buckets; // 桶数组public:/* 构造方法 */HashMapChaining() : size(0), capacity(4), loadThres(2.0 / 3.0), extendRatio(2) {buckets.resize(capacity);}/* 析构方法 */~HashMapChaining() {for (auto &bucket : buckets) {for (Pair *pair : bucket) {// 释放内存delete pair;}}}/* 哈希函数 */int hashFunc(int key) {return key % capacity;}/* 负载因子 */double loadFactor() {return (double)size / (double)capacity;}/* 查询操作 */string get(int key) {int index = hashFunc(key);// 遍历桶,若找到 key 则返回对应 valfor (Pair *pair : buckets[index]) {if (pair->key == key) {return pair->val;}}// 若未找到 key 则返回空字符串return "";}/* 添加操作 */void put(int key, string val) {// 当负载因子超过阈值时,执行扩容if (loadFactor() > loadThres) {extend();}int index = hashFunc(key);// 遍历桶,若遇到指定 key ,则更新对应 val 并返回for (Pair *pair : buckets[index]) {if (pair->key == key) {pair->val = val;return;}}// 若无该 key ,则将键值对添加至尾部buckets[index].push_back(new Pair(key, val));size++;}/* 删除操作 */void remove(int key) {int index = hashFunc(key);auto &bucket = buckets[index];// 遍历桶,从中删除键值对for (int i = 0; i < bucket.size(); i++) {if (bucket[i]->key == key) {Pair *tmp = bucket[i];bucket.erase(bucket.begin() + i); // 从中删除键值对delete tmp; // 释放内存size--;return;}}}/* 扩容哈希表 */void extend() {// 暂存原哈希表vector<vector<Pair *>> bucketsTmp = buckets;// 初始化扩容后的新哈希表capacity *= extendRatio;buckets.clear();buckets.resize(capacity);size = 0;// 将键值对从原哈希表搬运至新哈希表for (auto &bucket : bucketsTmp) {for (Pair *pair : bucket) {put(pair->key, pair->val);// 释放内存delete pair;}}}/* 打印哈希表 */void print() {for (auto &bucket : buckets) {cout << "[";for (Pair *pair : bucket) {cout << pair->key << " -> " << pair->val << ", ";}cout << "]\n";}} };值得注意的是,当链表很长时,查询效率 O(n) 很差。此时可以将链表转换为“AVL 树”或“红黑树”,从而将查询操作的时间复杂度优化至 O(logn) 。
11.2 开放寻址
开放寻址(open addressing)不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测、多次哈希等。
下面以线性探测为例,介绍开放寻址哈希表的工作机制。
11.2.1 线性探测
线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同。
- 插入元素:通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 1 ),直至找到空桶,将元素插入其中。
- 查找元素:若发现哈希冲突,则使用相同步长向后线性遍历,直到找到对应元素,返回
value即可;如果遇到空桶,说明目标元素不在哈希表中,返回 None 。
下图展示了开放寻址(线性探测)哈希表的键值对分布。根据此哈希函数,最后两位相同的 key 都会被映射到相同的桶。而通过线性探测,它们被依次存储在该桶以及之下的桶中。

然而,线性探测容易产生“聚集现象”。具体来说,数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
值得注意的是,我们不能在开放寻址哈希表中直接删除元素。这是因为删除元素会在数组内产生一个空桶 None ,而当查询元素时,线性探测到该空桶就会返回,因此在该空桶之下的元素都无法再被访问到,程序可能误判这些元素不存在。
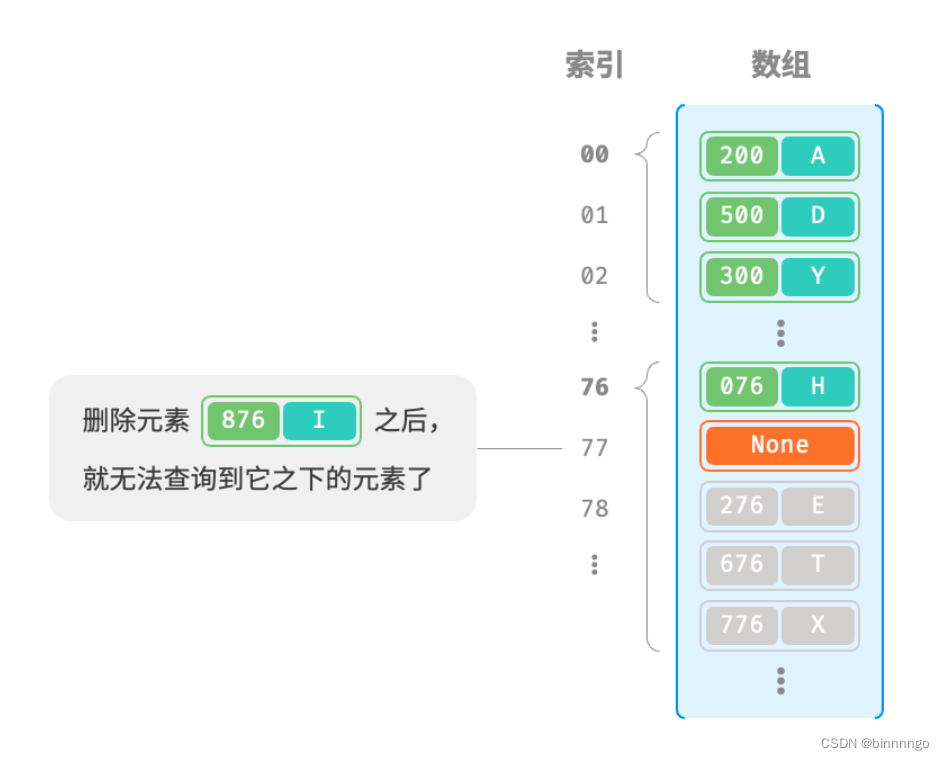
为了解决该问题,我们可以采用懒删除(lazy deletion)机制:它不直接从哈希表中移除元素,而是利用一个常量 TOMBSTONE 来标记这个桶。在该机制下,None 和 TOMBSTONE 都代表空桶,都可以放置键值对。但不同的是,线性探测到 TOMBSTONE 时应该继续遍历,因为其之下可能还存在键值对。
然而,懒删除可能会加速哈希表的性能退化。这是因为每次删除操作都会产生一个删除标记,随着 TOMBSTONE 的增加,搜索时间也会增加,因为线性探测可能需要跳过多个 TOMBSTONE 才能找到目标元素。
为此,考虑在线性探测中记录遇到的首个 TOMBSTONE 的索引,并将搜索到的目标元素与该 TOMBSTONE 交换位置。这样做的好处是当每次查询或添加元素时,元素会被移动至距离理想位置(探测起始点)更近的桶,从而优化查询效率。
以下代码实现了一个包含懒删除的开放寻址(线性探测)哈希表。为了更加充分地使用哈希表的空间,我们将哈希表看作一个“环形数组”,当越过数组尾部时,回到头部继续遍历。
/* 开放寻址哈希表 */
class HashMapOpenAddressing {private:int size; // 键值对数量int capacity = 4; // 哈希表容量const double loadThres = 2.0 / 3.0; // 触发扩容的负载因子阈值const int extendRatio = 2; // 扩容倍数vector<Pair *> buckets; // 桶数组Pair *TOMBSTONE = new Pair(-1, "-1"); // 删除标记public:/* 构造方法 */HashMapOpenAddressing() : size(0), buckets(capacity, nullptr) {}/* 析构方法 */~HashMapOpenAddressing() {for (Pair *pair : buckets) {if (pair != nullptr && pair != TOMBSTONE) {delete pair;}}delete TOMBSTONE;}/* 哈希函数 */int hashFunc(int key) {return key % capacity;}/* 负载因子 */double loadFactor() {return (double)size / capacity;}/* 搜索 key 对应的桶索引 */int findBucket(int key) {int index = hashFunc(key);int firstTombstone = -1;// 线性探测,当遇到空桶时跳出while (buckets[index] != nullptr) {// 若遇到 key ,返回对应桶索引if (buckets[index]->key == key) {// 若之前遇到了删除标记,则将键值对移动至该索引if (firstTombstone != -1) {buckets[firstTombstone] = buckets[index];buckets[index] = TOMBSTONE;return firstTombstone; // 返回移动后的桶索引}return index; // 返回桶索引}// 记录遇到的首个删除标记if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {firstTombstone = index;}// 计算桶索引,越过尾部返回头部index = (index + 1) % capacity;}// 若 key 不存在,则返回添加点的索引return firstTombstone == -1 ? index : firstTombstone;}/* 查询操作 */string get(int key) {// 搜索 key 对应的桶索引int index = findBucket(key);// 若找到键值对,则返回对应 valif (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {return buckets[index]->val;}// 若键值对不存在,则返回空字符串return "";}/* 添加操作 */void put(int key, string val) {// 当负载因子超过阈值时,执行扩容if (loadFactor() > loadThres) {extend();}// 搜索 key 对应的桶索引int index = findBucket(key);// 若找到键值对,则覆盖 val 并返回if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {buckets[index]->val = val;return;}// 若键值对不存在,则添加该键值对buckets[index] = new Pair(key, val);size++;}/* 删除操作 */void remove(int key) {// 搜索 key 对应的桶索引int index = findBucket(key);// 若找到键值对,则用删除标记覆盖它if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {delete buckets[index];buckets[index] = TOMBSTONE;size--;}}/* 扩容哈希表 */void extend() {// 暂存原哈希表vector<Pair *> bucketsTmp = buckets;// 初始化扩容后的新哈希表capacity *= extendRatio;buckets = vector<Pair *>(capacity, nullptr);size = 0;// 将键值对从原哈希表搬运至新哈希表for (Pair *pair : bucketsTmp) {if (pair != nullptr && pair != TOMBSTONE) {put(pair->key, pair->val);delete pair;}}}/* 打印哈希表 */void print() {for (Pair *pair : buckets) {if (pair == nullptr) {cout << "nullptr" << endl;} else if (pair == TOMBSTONE) {cout << "TOMBSTONE" << endl;} else {cout << pair->key << " -> " << pair->val << endl;}}}
};
11.2.2 平方探测
平方探测与线性探测类似,都是开放寻址的常见策略之一。当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过“探测次数的平方”的步数,即 1,4,9,… 步。
平方探测主要具有以下优势。
- 平方探测通过跳过平方的距离,试图缓解线性探测的聚集效应。
- 平方探测会跳过更大的距离来寻找空位置,有助于数据分布得更加均匀。
然而,平方探测也并不是完美的。
- 仍然存在聚集现象,即某些位置比其他位置更容易被占用。
- 由于平方的增长,平方探测可能不会探测整个哈希表,这意味着即使哈希表中有空桶,平方探测也可能无法访问到它。
11.2.3 多次哈希
顾名思义,多次哈希方法使用多个哈希函数 f1(x)、f2(x)、f3(x)、… 进行探测。
- 插入元素:若哈希函数 f1(x) 出现冲突,则尝试 f2(x) ,以此类推,直到找到空桶后插入元素。
- 查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;若遇到空桶或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回 None 。
与线性探测相比,多次哈希方法不易产生聚集,但多个哈希函数会带来额外的计算量。
11.3 编程语言的选择
各个编程语言采取了不同的哈希表实现策略,以下举几个例子。
- Python 采用开放寻址。字典 dict 使用伪随机数进行探测。
- Java 采用链式地址。自 JDK 1.8 以来,当 HashMap 内数组长度达到 64 且链表长度达到 8 时,链表会转换为红黑树以提升查找性能。
- Go 采用链式地址。Go 规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶。当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。
相关文章:
11. 哈希冲突
上一节提到,通常情况下哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的。比如,输入空间为全体整数,输出空间为数组容量大小,则必然有多个整数映射至同一桶索引。 哈希冲突会导致查询结果错误&#…...

12.04 二叉树中等题
513. 找树左下角的值 给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。 假设二叉树中至少有一个节点。 示例 1: 输入: root [2,1,3] 输出: 1 思路:找到最低层中最左侧的节点值,比较适合层序遍历,返回最…...

Redis的安装
本文采用原生的方式安装Redis,Redis的版本为5.0.5 安装 下载 下载网站:https://download.redis.io/releases/ wget http://download.redis.io/releases/redis-5.0.5.tar.gz解压 tar -zxvf redis-5.0.5.tar.gz进入redis目录 cd redis-5.0.5执行编译…...
JDK安装太麻烦?一篇文章搞定
JDK是 Java 语言的软件开发工具包,主要用于移动设备、嵌入式设备上的java应用程序。JDK是整个java开发的核心,它包含了JAVA的运行环境(JVMJava系统类库)和JAVA工具。 JDK包含的基本组件包括: javac – 编译器…...

漫谈HBuilderX App-Jenkins热更新构建
漫谈Uniapp App热更新包-Jenkins CI/CD打包工具链的搭建 零、写在前面 HBuilderX是DCloud旗下的IDE产品,目前只提供了Windows和Mac版本使用。本项目组在开发阶段经常需要向测试环境提交热更新包,使用Jenkins进行CD是非常有必要的一步。尽管HBuilderX提…...

技术前沿丨Teranode如何实现无限扩容
发表时间:2023年9月15日 BSV区块链协会的技术团队目前正在努力开发Teranode,这是一款比特币节点软件,其最终目标是实现比特币的无限扩容。然而,正如BSV区块链协会网络基础设施负责人Jake Jones在2023年6月举行的伦敦区块链大会…...

世岩清上:如何制作年终工作汇报宣传片
年终工作汇报宣传片是一种以视觉和口头语言为主要表现形式的宣传手段,旨在向领导、同事、客户等展示一年来的工作成果和亮点。以下是制作年终工作汇报宣传片的几个关键步骤: 明确目的和受众:在制作宣传片前,要明确宣传片的目的和受…...
练习十一:简单卷积器的设计
简单卷积器的设计 1,任务目的:2,明确设计任务2.1,目前这部分代码两个文件没找到,见第5、6节,待解决中。 ,卷积器的设计,RTL:con1.v4,前仿真和后仿真,测试信号…...
外包干了4年,技术退步太明显了。。。。。
先说一下自己的情况,本科生生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年国庆,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...

微服务实战系列之EhCache
前言 书接前文,继续深耕。上一篇博主对Redis进行了入门级介绍,大体知道了Redis可以干什么以及怎么使用它。 今日博主继续带着大家学习如何使用EhCache,这是一款基于Java的缓存框架。 微服务实战系列之Redis微服务实战系列之Cache微服务实战…...

SpringBoot:SpringMVC(上)
文章目录 前言一、SpringMVC是什么?1.1 MVC的定义:1.2 MVC 和 Spring MVC 的关系 二、Spring MVC 创建和连接2.1创建springmvc2.2接下来,创建⼀个 UserController 类,实现⽤户到 Spring 程序的互联互通,具体实现代码如…...

一文搞懂Go语言中包导入
一文搞懂Go语言中包导入 定义包 在go语言中,定义包的关键字为package,如package main等,在go语言中有一个约定俗成的标准,那就是包名与目录名把持一致。 //service目录下 package servicepackage utils 可以看到,我…...
)
Vue2学习笔记(事件处理)
一、基本使用 1.使用v-on:xxx 或 xxx 绑定事件,其中xxx是事件名;2.事件的回调需要配置在methods对象中,最终会在vm上;3.methods中配置的函数,不要用箭头函数!否则this就不是vm了;4.methods中配…...

【2023第十二届“认证杯”数学中国数学建模国际赛】A题 太阳黑子预报完整解题思路
A题 太阳黑子预报 题目任务思路分析第一问第二问第三问 题目 太阳黑子是太阳光球上的一种现象,表现为比周围区域更暗的临时斑点。它们是由于磁通量集中而导致表面温度降低的区域,磁通量的集中抑制了对流。太阳黑子出现在活跃区域内,通常成对…...
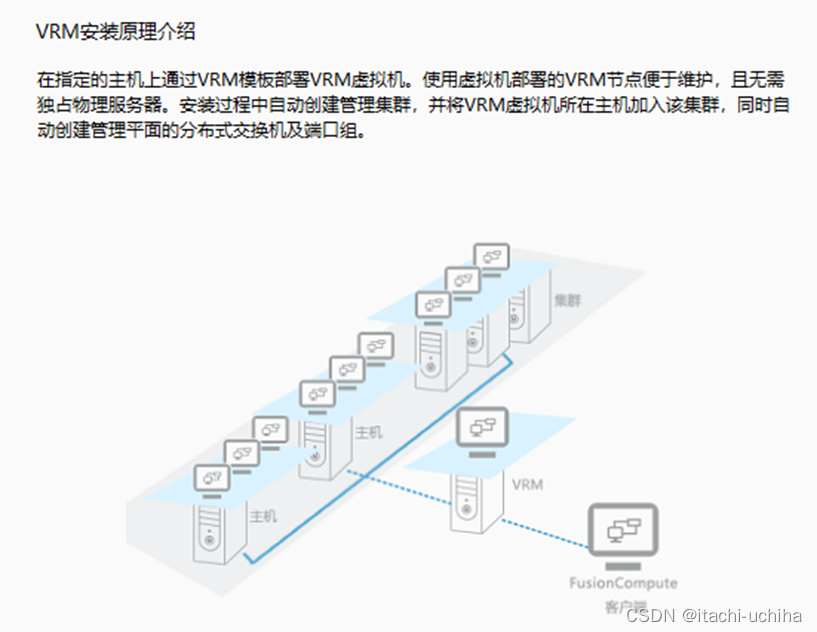
Huawei FusionSphere FusionCompte FusionManager
什么是FusionSphere FusionSphere 解决方案不独立发布软件,由各配套部件发布,请参 《FusionSphere_V100R005C10U1_版本配套表_01》。 目前我们主要讨论FusionManager和FusionCompute两个组件。 什么是FusionCompte FusionCompute是华为提供的虚拟化软…...
GSLB是什么?谈谈对该技术的一点理解
GSLB是什么?它又称为全局负载均衡,是主流的负载均衡类型之一。众所周知,负载均衡位于服务器的前面,负责将客户端请求路由到所有能够满足这些请求的服务器,同时最大限度地提高速度和资源利用率,并确保无任何…...

【接口测试】POST请求提交数据的三种方式及Postman实现
1. 什么是POST请求? POST请求是HTPP协议中一种常用的请求方法,它的使用场景是向客户端向服务器提交数据,比如登录、注册、添加等场景。另一种常用的请求方法是GET,它的使用场景是向服务器获取数据。 2. POST请求提交数据的常见编…...
SpringBoot系列之集成Jedis教程
SpringBoot系列之集成Jedis教程,Jedis是老牌的redis客户端框架,提供了比较齐全的redis使用命令,是一款开源的Java 客户端框架,本文使用Jedis3.1.0加上Springboot2.0,配合spring-boot-starter-data-redis使用࿰…...

centos用什么命令可查看版本号
概述 查版本号的命令:1、“cat /etc/redhat-release”,可输出centos版本号;2、“cat /proc/version”、“uname -a”或“uname -r”,可输出内核版本号。 本教程操作环境:centos7.9.2009系统。 查看centos版本 [roo…...

大数据之Redis
NoSQL SQL数据库泛指关系型数据库NoSQL不拘泥于关系型数据的设计范式,放弃了通用的技术标准,为某一特定领域场景而设计 NoSQL的特点 不遵循SQL标准不支持ACID远超SQL的性能 NoSQL的适用场景 对数据高并发的读写海量数据的读写对数据高可扩展性的 N…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...