【Python百宝箱】漫游Python数据可视化宇宙:pyspark、dash、streamlit、matplotlib、seaborn全景式导览
Python数据可视化大比拼:从大数据处理到交互式Web应用
前言
在当今数字时代,数据可视化是解释和传达信息的不可或缺的工具之一。本文将深入探讨Python中流行的数据可视化库,从大数据处理到交互式Web应用,为读者提供全面的了解和比较。
本文将带领读者穿越Python数据可视化的世界,从分布式计算的pyspark到交互式Web应用的dash和streamlit,再到经典的matplotlib和seaborn,每个工具都有其独特的魅力。通过深入研究它们的特性和应用场景,读者将更好地掌握数据可视化的艺术,为自己的项目赋能。
文章目录
- Python数据可视化大比拼:从大数据处理到交互式Web应用
- 前言
- 1. **`pyspark`**
- 1.1 Apache Spark的概述
- 1.2 `pyspark`介绍
- 1.3 `pyspark`的核心概念
- 1.3.1 Resilient Distributed Datasets (RDDs)
- 1.3.2 DataFrame
- 1.3.3 Spark任务
- 1.4 `pyspark`的应用领域
- 1.4.1 大数据处理
- 1.4.2 机器学习
- 1.4.3 流处理
- 1.5 总结
- 2. **`dash`**
- 2.1 `dash`概述
- 2.2 `dash`特点
- 2.3 `dash`的核心组件
- 2.3.1 `dash_html_components`
- 2.3.2 `dash_core_components`
- 2.4 `dash`的应用场景
- 2.4.1 数据可视化
- 2.4.2 仪表板开发
- 3. **`streamlit`**
- 3.1 `streamlit`概述
- 3.2 `streamlit`特点
- 3.3 `streamlit`应用场景
- 3.3.1 数据可视化
- 3.3.2 交互式组件
- 3.4 总结
- 4. **`matplotlib`**
- 4.1 `matplotlib`概述
- 4.2 `matplotlib`特点
- 4.3 `matplotlib`进阶用法
- 4.3.1 子图和多图
- 4.3.2 散点图和柱状图
- 4.4 总结
- 5. **`seaborn`**
- 5.1 `seaborn`概述
- 5.2 `seaborn`特点
- 5.3 `seaborn` 进阶用法
- 5.3.1 分布图
- 5.3.2 热力图
- 5.4 `seaborn` 进阶用法
- 5.4.1 美化图表风格
- 5.4.2 进一步定制图表
- 5.5 `seaborn` 应用场景
- 5.5.1 数据探索
- 5.5.2 多子图布局
- 5.6 总结
- 6. **`plotly`**
- 6.1 `plotly`概述
- 6.2 `plotly`特点
- 6.3 `plotly` 进阶用法
- 6.3.1 交互式地图
- 6.3.2 3D图表
- 6.4 `plotly` 应用场景
- 6.4.1 数据探索与展示
- 6.4.2 Web应用开发
- 6.5 总结
- 7. **`bokeh`**
- 7.1 `bokeh`概述
- 7.2 `bokeh`特点
- 7.3 `bokeh` 进阶用法
- 7.3.1 高级绘图工具
- 7.3.2 嵌入到Jupyter Notebooks
- 7.4 `bokeh` 应用场景
- 7.4.1 大规模数据可视化
- 7.4.2 Jupyter Notebooks中的交互式可视化
- 7.5 总结
- 总结
1. pyspark
1.1 Apache Spark的概述
Apache Spark是一个强大的开源分布式计算系统,旨在高效地处理大规模数据集。Spark提供了多个API,包括Spark SQL、Spark Streaming和MLlib,使用户能够进行复杂的数据处理和分析操作。其核心思想是通过弹性分布式数据集(Resilient Distributed Datasets,简称RDDs)来实现高容错性和性能。
1.2 pyspark介绍
pyspark是Apache Spark的Python API,为开发人员提供了使用Python语言进行大规模数据处理的能力。下面是一个简单的pyspark示例:
from pyspark.sql import SparkSession# 创建Spark会话
spark = SparkSession.builder.appName("example").getOrCreate()# 创建一个DataFrame
data = [("Alice", 1), ("Bob", 2), ("Charlie", 3)]
df = spark.createDataFrame(data, ["Name", "Value"])# 展示DataFrame内容
df.show()
这个例子中,我们首先创建了一个Spark会话,然后使用createDataFrame方法构建了一个简单的DataFrame,最后使用show方法展示DataFrame的内容。
1.3 pyspark的核心概念
1.3.1 Resilient Distributed Datasets (RDDs)
RDD是Spark的基本数据结构,代表可并行操作的不可变元素集合。让我们看一个简单的RDD示例:
# 创建一个RDD
rdd = spark.sparkContext.parallelize([1, 2, 3, 4, 5])# 执行转换操作
squared_rdd = rdd.map(lambda x: x**2)# 执行动作操作
result = squared_rdd.collect()# 打印结果
print(result)
在这个例子中,我们创建了一个RDD,对其执行了一个平方转换操作,并最终使用collect方法将结果收集并打印。
1.3.2 DataFrame
DataFrame是一个以命名列方式组织的分布式数据集。以下是一个简单的DataFrame示例:
# 创建一个DataFrame
data = [("Alice", 1), ("Bob", 2), ("Charlie", 3)]
df = spark.createDataFrame(data, ["Name", "Value"])# 执行操作
filtered_df = df.filter(df["Value"] > 1)# 展示结果
filtered_df.show()
在这个例子中,我们创建了一个DataFrame,然后使用filter方法过滤出“Value”列大于1的行。
1.3.3 Spark任务
Spark任务是由RDD和DataFrame上的转换和动作组成的操作序列。以下是一个任务的示例:
# 创建一个RDD
rdd = spark.sparkContext.parallelize([1, 2, 3, 4, 5])# 执行转换和动作操作
result = rdd.map(lambda x: x**2).filter(lambda x: x > 5).collect()# 打印结果
print(result)
在这个例子中,我们对RDD执行了平方和过滤操作,并最终使用collect方法将结果收集并打印。
1.4 pyspark的应用领域
1.4.1 大数据处理
pyspark可用于高效处理大规模数据集,执行复杂的数据转换和分析操作。以下是一个简单的大数据处理示例:
# 读取大规模数据集
big_data = spark.read.csv("big_data.csv", header=True, inferSchema=True)# 执行复杂的数据转换操作
result = big_data.groupBy("Category").agg({"Value": "avg"})# 展示结果
result.show()
在这个例子中,我们使用pyspark读取了一个大规模的CSV文件,并对其进行了复杂的聚合操作。
1.4.2 机器学习
pyspark结合Spark的MLlib库,可用于在大规模数据集上进行机器学习模型的训练和评估。以下是一个简单的机器学习示例:
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression# 创建一个DataFrame
data = [(1.0, 2.0, 3.0), (4.0, 5.0, 6.0), (7.0, 8.0, 9.0)]
df = spark.createDataFrame(data, ["feature1", "feature2", "label"])# 创建特征向量
assembler = VectorAssembler(inputCols=["feature1", "feature2"], outputCol="features")
assembled_df = assembler.transform(df)# 创建线性回归模型
lr = LinearRegression(featuresCol="features", labelCol="label")# 创建一个机器学习管道
pipeline = Pipeline(stages=[assembler, lr])# 训练模型
model = pipeline.fit(assembled_df)# 进行预测
predictions = model.transform(assembled_df)# 展示预测结果
predictions.show()
在这个例子中,我们创建了一个包含特征和标签的DataFrame,使用了线性回归模型进行训练和预测。
1.4.3 流处理
pyspark的Spark Streaming模块支持实时数据处理和流式计算。以下是一个简单的流处理示例:
from pyspark.streaming import StreamingContext# 创建StreamingContext
ssc = StreamingContext(spark.sparkContext, batchDuration=1)# 创建一个DStream
lines = ssc.socketTextStream("localhost", 9999)# 执行实时数据处理操作
word_counts = lines.flatMap(lambda line: line.split()) \.map(lambda word: (word, 1)) \.reduceByKey(lambda x, y: x + y)# 打印每个批次的单词计数
word_counts.pprint()# 启动流处理
ssc.start()# 等待流处理结束
ssc.awaitTermination()
在这个示例中,我们创建了一个StreamingContext,连接到本地端口9999的数据流,并执行了实时的单词计数操作。这个流处理应用将每个批次的单词计数打印出来。
1.5 总结
pyspark作为Apache Spark的Python API,提供了丰富的工具和框架,适用于大规模数据处理、机器学习和实时数据处理等多个应用领域。了解pyspark的核心概念和应用场景,可以帮助开发人员更有效地利用其强大的功能进行数据处理和分析。在接下来的章节中,我们将深入探讨pyspark的高级功能、最佳实践和实际案例应用。
2. dash
2.1 dash概述
dash是一个基于Python的Web应用程序框架,专注于构建交互式数据可视化界面和仪表板。其核心特点包括简单易用的API和强大的扩展性,使得开发人员能够快速创建美观且功能丰富的Web应用。
2.2 dash特点
dash的特点使其成为数据科学家和开发人员的首选:
- 组件丰富: 提供了丰富的组件,包括图表、表格、下拉框等,方便用户构建多样化的交互界面。
- 纯Python: 完全使用Python语言进行开发,无需HTML、CSS或JavaScript的深入了解,降低了学习成本。
- 交互逻辑简单: 可以通过简单的Python代码实现复杂的交互逻辑,无需繁琐的前端开发。
下面是一个简单的dash应用程序示例:
import dash
import dash_core_components as dcc
import dash_html_components as htmlapp = dash.Dash(__name__)app.layout = html.Div(children=[html.H1("Hello Dash"),dcc.Graph(id='example-graph',figure={'data': [{'x': [1, 2, 3], 'y': [4, 1, 2], 'type': 'bar', 'name': 'SF'},{'x': [1, 2, 3], 'y': [2, 4, 5], 'type': 'bar', 'name': u'Montréal'},],'layout': {'title': 'Dash Data Visualization'}})
])if __name__ == '__main__':app.run_server(debug=True)
在这个例子中,我们创建了一个简单的dash应用,包含一个标题为"Hello Dash"的html.H1元素和一个柱状图。整个布局由html.Div组成,其中包含了这两个子组件。
2.3 dash的核心组件
2.3.1 dash_html_components
dash_html_components包含用于构建HTML元素的类。这些类使开发人员能够以声明性的方式构建Web应用的用户界面(UI)。以下是一个简单的例子,展示如何使用html.Div和html.H1创建一个包含标题的页面段落:
import dash
import dash_html_components as htmlapp = dash.Dash(__name__)app.layout = html.Div(children=[html.H1("Welcome to Dash"),html.Div("This is a simple Dash web application.")
])if __name__ == '__main__':app.run_server(debug=True)
在这个例子中,html.Div用于创建一个HTML div 元素,而html.H1用于创建一个HTML h1 元素。这样,我们可以以声明性的方式构建页面结构。
2.3.2 dash_core_components
dash_core_components包含用于构建交互性组件的类。其中,dcc.Graph是一个常用的组件,用于创建数据图表。以下是一个简单的例子,展示如何使用dcc.Graph创建一个简单的条形图:
import dash
import dash_core_components as dcc
import dash_html_components as htmlapp = dash.Dash(__name__)app.layout = html.Div(children=[html.H1("Graph Example"),dcc.Graph(id='example-graph',figure={'data': [{'x': [1, 2, 3], 'y': [4, 1, 2], 'type': 'bar', 'name': 'SF'},{'x': [1, 2, 3], 'y': [2, 4, 5], 'type': 'bar', 'name': u'Montréal'},],'layout': {'title': 'Dash Data Visualization'}})
])if __name__ == '__main__':app.run_server(debug=True)
在这个例子中,dcc.Graph用于创建一个图表,通过figure参数指定图表的数据和布局。
2.4 dash的应用场景
2.4.1 数据可视化
dash为开发人员提供了强大的数据可视化工具,可以通过结合类似于plotly的库创建各种类型的图表,包括线图、散点图、热力图等。以下是一个简单的例子,展示了如何使用plotly.express库创建散点图:
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.express as px
import pandas as pdapp = dash.Dash(__name__)# 生成示例数据
df = pd.DataFrame({'Category': ['A', 'B', 'C', 'D'],'Values': [4, 7, 1, 8]
})# 数据可视化示例 - 散点图
scatter_fig = px.scatter(df, x='Category', y='Values', title='Scatter Plot')# 仪表板布局
app.layout = html.Div(children=[html.H1("数据可视化示例"),# 数据可视化组件dcc.Graph(id='scatter-plot',figure=scatter_fig)
])if __name__ == '__main__':app.run_server(debug=True)
在这个例子中,我们使用plotly.express创建了一个简单的散点图,展示了dash在数据可视化方面的应用。
2.4.2 仪表板开发
dash是仪表板开发的理想选择,通过使用各种dash_core_components,例如dcc.Dropdown、dcc.Input等,用户可以轻松创建具有各种交互式元素的仪表板。以下是一个包含下拉框和输入框的仪表板示例:
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.express as px
import pandas as pdapp = dash.Dash(__name__)# 生成示例数据
df = pd.DataFrame({'Category': ['A', 'B', 'C', 'D'],'Values': [4, 7, 1, 8]
})# 数据可视化示例 - 散点图
scatter_fig = px.scatter(df, x='Category', y='Values', title='Scatter Plot')# 仪表板布局
app.layout = html.Div(children=[html.H1("仪表板示例"),# 数据可视化组件dcc.Graph(id='scatter-plot',figure=scatter_fig),# 仪表板开发组件html.Label('选择一个类别:'),dcc.Dropdown(id='category-dropdown',options=[{'label': category, 'value': category} for category in df['Category']],value='A'),html.Label('输入一个数值:'),dcc.Input(id='value-input',type='number',value=df.loc[0, 'Values'])
])if __name__ == '__main__':app.run_server(debug=True)
这个示例展示了如何在仪表板中添加下拉框和输入框,并通过这些交互式元素实时更新散点图,突显了dash在仪表板开发方面的强大功能。#### 2.5 总结
dash是一个强大的Python库,用于构建交互式Web应用程序,特别适用于数据可视化和仪表板开发。通过灵活的组件和简单的Python代码,开发人员能够轻松创建具有丰富交互性的Web界面。在接下来的章节中,我们将深入了解dash的更多功能和最佳实践,以便更好地利用其在数据科学和Web开发领域的优势。
3. streamlit
3.1 streamlit概述
streamlit是一个用于快速创建数据应用的库,它简化了数据应用的搭建过程。通过一个简单的Python脚本,用户可以创建交互式的Web应用程序,展示数据可视化、机器学习模型等。
3.2 streamlit特点
streamlit的主要特点包括:
- 零配置:通过一个脚本即可创建应用。
- 实时预览:支持实时预览应用效果。
- 高度自定义:提供丰富的界面元素和布局选项。
下面是一个简单的streamlit应用程序示例:
import streamlit as st
import pandas as pd# 创建一个DataFrame
data = {"Name": ["Alice", "Bob", "Charlie"], "Value": [1, 2, 3]}
df = pd.DataFrame(data)# 创建streamlit应用
st.title("Streamlit Example")
st.write("This is a simple Streamlit app.")# 展示DataFrame内容
st.dataframe(df)
3.3 streamlit应用场景
3.3.1 数据可视化
streamlit提供了简便而强大的工具,使得数据可视化变得十分容易。通过与plotly、matplotlib等库的结合,用户可以轻松创建各种图表,并将其嵌入到streamlit应用中。以下是一个展示简单散点图的streamlit应用:
import streamlit as st
import pandas as pd
import plotly.express as px# 创建一个DataFrame
data = {"Name": ["Alice", "Bob", "Charlie"], "Value": [1, 2, 3]}
df = pd.DataFrame(data)# 创建散点图
scatter_fig = px.scatter(df, x='Name', y='Value', title='Scatter Plot')# 创建streamlit应用
st.title("Streamlit Data Visualization")
st.write("This app displays a scatter plot.")# 展示散点图
st.plotly_chart(scatter_fig)
这个示例中,我们使用了plotly.express创建了一个简单的散点图,并通过st.plotly_chart将其嵌入到streamlit应用中。
3.3.2 交互式组件
streamlit支持各种交互式组件,使用户能够通过简单的方式添加用户界面元素。下面的例子展示了如何使用streamlit的slider组件创建一个交互式的图表,用户可以通过滑动条选择数据范围:
import streamlit as st
import pandas as pd
import plotly.express as px# 创建一个DataFrame
data = {"Name": ["Alice", "Bob", "Charlie"], "Value": [1, 2, 3]}
df = pd.DataFrame(data)# 创建streamlit应用
st.title("Interactive Streamlit App")
st.write("Use the slider to select data range.")# 添加滑动条组件
selected_range = st.slider("Select a range:", min_value=1, max_value=3, value=(1, 3))# 根据滑动条选择数据
selected_data = df.loc[selected_range[0]-1:selected_range[1]-1, :]# 展示选择的数据
st.dataframe(selected_data)
在这个例子中,我们使用了st.slider创建了一个滑动条,用户可以通过调整滑块选择数据的范围。
3.4 总结
streamlit是一个强大而易用的数据应用创建工具,通过简单的Python脚本即可实现数据可视化和交互式应用的开发。在接下来的章节中,我们将更加深
4. matplotlib
4.1 matplotlib概述
matplotlib是一个用于绘制图表的Python库,支持各种静态和交互式图形的创建。它被广泛应用于科学计算、数据可视化和绘图任务。
4.2 matplotlib特点
matplotlib的主要特点包括:
- 支持多种图表类型,如折线图、散点图、柱状图等。
- 可以定制图表的各个元素,如标题、轴标签等。
- 与Jupyter Notebooks等环境无缝集成。
下面是一个简单的matplotlib示例:
import matplotlib.pyplot as plt
import numpy as np# 生成示例数据
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x)# 绘制折线图
plt.plot(x, y)
plt.title("Simple Plot with Matplotlib")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.show()
4.3 matplotlib进阶用法
4.3.1 子图和多图
matplotlib允许创建多个子图或多个图形,以更灵活地展示数据。以下是一个展示子图和多图的示例:
import matplotlib.pyplot as plt
import numpy as np# 生成示例数据
x = np.linspace(0, 2 * np.pi, 100)
y1 = np.sin(x)
y2 = np.cos(x)# 创建子图
plt.figure(figsize=(10, 4))# 子图1
plt.subplot(1, 2, 1)
plt.plot(x, y1, color='blue')
plt.title('Sin Function')# 子图2
plt.subplot(1, 2, 2)
plt.plot(x, y2, color='green')
plt.title('Cos Function')plt.show()
在这个例子中,我们使用plt.subplot创建了一个包含两个子图的图形。第一个子图绘制了正弦函数,第二个子图绘制了余弦函数。
4.3.2 散点图和柱状图
matplotlib支持绘制各种类型的图表。以下是一个展示散点图和柱状图的示例:
import matplotlib.pyplot as plt
import numpy as np# 生成示例数据
x = np.random.rand(50)
y = np.random.rand(50)# 绘制散点图
plt.figure(figsize=(10, 4))plt.subplot(1, 2, 1)
plt.scatter(x, y, color='red', marker='o')
plt.title('Scatter Plot')# 生成示例数据
data = {'Category A': 30, 'Category B': 20, 'Category C': 25, 'Category D': 15}
categories = list(data.keys())
values = list(data.values())# 绘制柱状图
plt.subplot(1, 2, 2)
plt.bar(categories, values, color='orange')
plt.title('Bar Chart')plt.show()
这个例子中,左侧子图是一个散点图,右侧子图是一个柱状图。
4.4 总结
matplotlib是一个功能强大且灵活的绘图库,适用于各种科学计算和数据可视化任务。它提供了丰富的功能,允许用户创建各种类型的图表,并通过定制实现专业的图形展示。在接下来的实践中,你可以根据具体需求进一步学习和应用matplotlib。
5. seaborn
5.1 seaborn概述
seaborn是建立在matplotlib之上的数据可视化库,旨在简化统计数据可视化的过程。它提供了高级接口,使得绘制各种统计图表变得更加轻松。
5.2 seaborn特点
seaborn的主要特点包括:
- 提供简单的API用于绘制常见的统计图表,如箱线图、热力图等。
- 支持数据集探索和分析的可视化。
- 集成了各种配色方案,使图表更具美感。
下面是一个简单的seaborn示例:
import seaborn as snsimport matplotlib.pyplot as plt# 生成示例数据data = sns.load_dataset("iris")# 绘制箱线图sns.boxplot(x="species", y="sepal_length", data=data)plt.title("Boxplot with Seaborn")plt.xlabel("Species")plt.ylabel("Sepal Length")plt.show()
5.3 seaborn 进阶用法
5.3.1 分布图
seaborn提供了绘制分布图的函数,用于展示单变量或双变量的分布情况。以下是一个展示单变量分布的例子:
import seaborn as sns
import matplotlib.pyplot as plt# 生成示例数据
data = sns.load_dataset("tips")# 绘制单变量分布图
sns.histplot(data["total_bill"], kde=True, color="skyblue")
plt.title("Distribution Plot with Seaborn")
plt.xlabel("Total Bill")
plt.ylabel("Frequency")
plt.show()
在这个例子中,我们使用了histplot函数绘制了total_bill这一变量的分布图,并通过kde=True添加了核密度估计。
5.3.2 热力图
热力图是一种有效的可视化工具,用于展示两个维度之间的关系。seaborn的heatmap函数使得绘制热力图变得简单:
import seaborn as sns
import matplotlib.pyplot as plt# 生成示例数据
data = sns.load_dataset("flights")# 转换数据格式
flights_data = data.pivot_table(index='month', columns='year', values='passengers')# 绘制热力图
sns.heatmap(flights_data, cmap="YlGnBu", annot=True, fmt="d", linewidths=.5)
plt.title("Heatmap with Seaborn")
plt.xlabel("Year")
plt.ylabel("Month")
plt.show()
在这个例子中,我们使用了heatmap函数绘制了乘客数量随时间变化的热力图,通过颜色深浅表示数值大小,annot=True在每个方格中显示具体数值。
5.4 seaborn 进阶用法
5.4.1 美化图表风格
seaborn内置了不同的图表风格,用户可以根据需求选择不同的主题。以下是一个展示如何美化图表风格的例子:
import seaborn as sns
import matplotlib.pyplot as plt# 生成示例数据
data = sns.load_dataset("tips")# 设置图表风格
sns.set_style("whitegrid")# 绘制单变量分布图
sns.histplot(data["total_bill"], kde=True, color="skyblue")
plt.title("Styled Distribution Plot with Seaborn")
plt.xlabel("Total Bill")
plt.ylabel("Frequency")
plt.show()
在这个例子中,我们使用了sns.set_style("whitegrid")来设置图表风格为白色网格。
5.4.2 进一步定制图表
seaborn允许用户通过多种参数定制图表,以满足个性化需求。以下是一个展示如何调整图表颜色和元素的例子:
import seaborn as sns
import matplotlib.pyplot as plt# 生成示例数据
data = sns.load_dataset("tips")# 绘制散点图
sns.scatterplot(x="total_bill", y="tip", hue="time", style="time", data=data, palette="Set2", markers=["o", "D"])
plt.title("Customized Scatter Plot with Seaborn")
plt.xlabel("Total Bill")
plt.ylabel("Tip")
plt.show()
在这个例子中,我们使用了hue参数表示时间,style参数让同一时间内的点使用不同的标记,palette参数设置颜色主题,markers参数设置不同时间的标记形状。
5.5 seaborn 应用场景
5.5.1 数据探索
seaborn常用于数据集的初步探索,通过绘制直观的图表帮助用户了解数据的分布和关系。以下是一个简单的数据探索例子:
import seaborn as sns
import matplotlib.pyplot as plt# 生成示例数据
data = sns.load_dataset("iris")# 绘制成对关系图
sns.pairplot(data, hue="species")
plt.suptitle("Pairplot for Iris Dataset")
plt.show()
这个例子中,我们使用pairplot函数绘制了鸢尾花数据集中不同物种的成对关系图。
5.5.2 多子图布局
seaborn支持在单个图中创建多个子图,从而更灵活地展示数据的多个方面。以下是一个展示多子图布局的例子:
import seaborn as sns
import matplotlib.pyplot as plt# 生成示例数据
data = sns.load_dataset("tips")# 创建多子图布局
fig, axes = plt.subplots(2, 2, figsize=(10, 8))# 绘制不同图表
sns.histplot(data["total_bill"], kde=True, color="skyblue", ax=axes[0, 0])
sns.scatterplot(x="total_bill", y="tip", data=data, hue="time", ax=axes[0, 1])
sns.boxplot(x="day", y="total_bill", data=data, ax=axes[1, 0])
sns.barplot(x="sex", y="total_bill", data=data, ax=axes[1, 1])plt.suptitle("Multiple Plots with Seaborn")
plt.tight_layout()
plt.show()
在这个例子中,我们使用subplots创建了一个2x2的子图布局,并在每个子图中绘制了不同类型的图表。
5.6 总结
seaborn是一个功能强大而灵活的数据可视化库,通过简单而强大的API,使用户能够轻松创建各种统计图表。在实践中,根据数据的特性选择适当的seaborn函数和参数,可以更好地理解和呈现数据的关系、分布和趋势。通过进阶用法的学习,用户可以更灵活地定制图表风格,实现更复杂的数据可视化需求。
6. plotly
6.1 plotly概述
plotly是一个交互式图表库,支持在Web应用程序中创建动态图表。它提供了丰富的可视化功能和定制选项,可以用于展示复杂的数据集和模型输出。
6.2 plotly特点
plotly的主要特点包括:
- 支持绘制交互式图表,如散点图、地图、3D图等。
- 可嵌入到Dash应用程序中,实现更丰富的Web应用。
- 提供API和图形编辑器,方便用户创建和定制图表。
下面是一个简单的plotly示例:
import plotly.express as px# 生成示例数据
data = px.data.iris()# 绘制散点图
fig = px.scatter(data, x="sepal_width", y="sepal_length", color="species", size="petal_length")
fig.update_layout(title="Scatter Plot with Plotly")
fig.show()
6.3 plotly 进阶用法
6.3.1 交互式地图
plotly支持绘制交互式地图,用户可以通过鼠标交互查看不同地理位置的数据。以下是一个展示交互式地图的例子:
import plotly.express as px# 生成示例数据
data = px.data.gapminder().query("year == 2007")# 绘制交互式地图
fig = px.scatter_geo(data, locations="iso_alpha", size="pop", hover_name="country", projection="natural earth")
fig.update_layout(title="Interactive Map with Plotly")
fig.show()
在这个例子中,我们使用了scatter_geo函数创建了一个交互式地图,展示了2007年各国人口的分布情况。
6.3.2 3D图表
plotly还支持绘制3D图表,使用户能够更全面地呈现数据的关系。以下是一个展示3D散点图的例子:
import plotly.express as px# 生成示例数据
data = px.data.iris()# 绘制3D散点图
fig = px.scatter_3d(data, x='sepal_width', y='sepal_length', z='petal_length', color='species')
fig.update_layout(title="3D Scatter Plot with Plotly")
fig.show()
这个例子中,我们使用了scatter_3d函数创建了一个3D散点图,展示了鸢尾花不同属性之间的关系。
6.4 plotly 应用场景
6.4.1 数据探索与展示
plotly适用于数据的探索与展示,特别是在需要交互式查看数据关系、趋势或地理分布时。通过plotly的各种图表类型,用户可以更灵活地呈现复杂的数据集。
6.4.2 Web应用开发
plotly图表可以嵌入到Web应用程序中,尤其是与Dash框架结合使用,可以创建丰富的数据可视化Web应用。这对于需要实时更新和交互的应用场景非常有用。
6.5 总结
plotly是一个强大的交互式图表库,适用于展示复杂的数据集和模型输出。通过简单的API和丰富的可视化功能,用户可以创建各种交互式图表,满足不同的数据可视化需求。plotly在数据探索、Web应用开发等场景中都有广泛的应用。
7. bokeh
7.1 bokeh概述
bokeh是一个用于创建交互式可视化的Python库,特别适用于大规模数据集的高性能可视化。它支持在Web应用程序中实现动态图表和数据可视化。
7.2 bokeh特点
bokeh的主要特点包括:
- 提供高性能的绘图工具,适用于大规模数据。
- 支持交互式工具,如缩放、平移等。
- 可以嵌入到Jupyter Notebooks中,与其他库集成。
下面是一个简单的bokeh示例:
from bokeh.plotting import figure, show
from bokeh.models import ColumnDataSource# 生成示例数据
x = [1, 2, 3, 4, 5]
y = [2, 5, 8, 2, 7]# 创建ColumnDataSource
source = ColumnDataSource(data=dict(x=x, y=y))# 绘制折线图
p = figure(title="Line Plot with Bokeh", x_axis_label='X-axis', y_axis_label='Y-axis')
p.line('x', 'y', source=source, line_width=2)show(p)
7.3 bokeh 进阶用法
7.3.1 高级绘图工具
bokeh提供了丰富的高级绘图工具,用户可以通过这些工具实现更复杂的可视化效果。以下是一个展示如何使用HoverTool添加悬停提示的例子:
from bokeh.plotting import figure, show
from bokeh.models import ColumnDataSource, HoverTool# 生成示例数据
x = [1, 2, 3, 4, 5]
y = [2, 5, 8, 2, 7]
labels = ['A', 'B', 'C', 'D', 'E']# 创建ColumnDataSource
source = ColumnDataSource(data=dict(x=x, y=y, labels=labels))# 创建HoverTool
hover = HoverTool(tooltips=[("Label", "@labels"), ("Value", "@y")])# 绘制带悬停提示的折线图
p = figure(title="Line Plot with HoverTool", x_axis_label='X-axis', y_axis_label='Y-axis', tools=[hover])
p.line('x', 'y', source=source, line_width=2)show(p)
在这个例子中,我们使用了HoverTool工具,悬停在图表上时会显示相关的标签和数值。
7.3.2 嵌入到Jupyter Notebooks
bokeh可以方便地嵌入到Jupyter Notebooks中,使得在Notebook中进行交互式可视化变得简单。以下是一个在Jupyter Notebooks中使用bokeh的例子:
from bokeh.plotting import figure, output_notebook, show# 生成示例数据
x = [1, 2, 3, 4, 5]
y = [2, 5, 8, 2, 7]# 绘制折线图
p = figure(title="Line Plot in Jupyter with Bokeh", x_axis_label='X-axis', y_axis_label='Y-axis')
p.line(x, y, line_width=2)# 在Notebook中显示图表
output_notebook()
show(p)
这个例子中,我们使用了output_notebook函数将图表嵌入到Jupyter Notebooks中,并通过show函数显示图表。
7.4 bokeh 应用场景
7.4.1 大规模数据可视化
bokeh在处理大规模数据集时表现出色,其高性能的绘图工具和交互式特性使得用户能够在Web应用程序中实现动态的、高度可视化的数据呈现。
7.4.2 Jupyter Notebooks中的交互式可视化
由于bokeh可以轻松嵌入到Jupyter Notebooks中,它成为数据科学家和分析师在Notebook中进行交互式可视化的理想选择。
7.5 总结
bokeh是一个强大的交互式可视化库,适用于大规模数据集的高性能可视化。通过简单的API和丰富的高级绘图工具,用户可以创建各种复杂的可视化效果。bokeh在大规模数据可视化和Jupyter Notebooks中的交互式可视化方面具有广泛的应用。
总结
通过上述示例,展示了使用pyspark进行大规模数据处理,dash和streamlit构建交互式Web应用程序,以及matplotlib、seaborn、plotly和bokeh等库用于数据可视化的强大功能。这些工具使得在Python环境中进行大数据处理和可视化变得更加便捷和灵活。
数据可视化的选择不仅仅取决于需求,还取决于工具的适用性和开发者的偏好。从大数据处理到构建交互式Web应用,本文全面覆盖了多个工具的优劣势,帮助读者在各种场景下做出明智的选择。
相关文章:

【Python百宝箱】漫游Python数据可视化宇宙:pyspark、dash、streamlit、matplotlib、seaborn全景式导览
Python数据可视化大比拼:从大数据处理到交互式Web应用 前言 在当今数字时代,数据可视化是解释和传达信息的不可或缺的工具之一。本文将深入探讨Python中流行的数据可视化库,从大数据处理到交互式Web应用,为读者提供全面的了解和…...

企业数字档案馆室建设指南
数字化时代,企业数字化转型已经成为当下各行业发展的必然趋势。企业数字化转型不仅仅是IT系统的升级,也包括企业内部各种文件、档案、合同等信息的数字化管理。因此,建设数字档案馆室也变得尤为重要。本篇文章将为您介绍企业数字档案馆室建设…...

JavaScript中处理时间差
ES6版本 function countdown(endTime, includeSeconds true) {// 获取当前时间let now new Date();// 将传入的结束时间字符串转换为日期对象let endDateTime new Date(endTime);// 检查传入的时间字符串是否只包含日期(不包含时分秒)if (endTime.tr…...
Multidimensional Scaling(MDS多维缩放)算法及其应用
在这篇博客中,我将与大家分享在流形分析领域的一个非常重要的方法,即多维缩放MDS。整体来说,该方法提供了一种将内蕴距离映射到显性欧氏空间的计算,为非刚性形状分析提供了一种解决方案。当初就是因为读了Bronstein的相关工作【1】…...

单片机_RTOS_架构
一. RTOS的概念 // 经典单片机程序 void main() {while (1){喂一口饭();回一个信息();} } ------------------------------------------------------ // RTOS程序 喂饭() {while (1){喂一口饭();} }回信息() {while (1){回一个信息();} }void main() {create_task(喂饭);cr…...

Golang rsa 验证
一下代码用于rsa 签名的验签, 签名可以用其他语言产生。也可以用golang生成。 package mainimport ("crypto""crypto/rsa""crypto/sha256""crypto/x509""encoding/pem""errors""fmt" )fun…...

网络安全威胁——跨站脚本攻击
跨站脚本攻击 1. 定义2. 跨站脚本攻击如何工作3. 跨站脚本攻击类型4. 如何防止跨站脚本攻击 1. 定义 跨站脚本攻击(Cross-site Scripting,通常称为XSS),是一种典型的Web程序漏洞利用攻击,在线论坛、博客、留言板等共享…...
Java利用UDP实现简单的双人聊天
一、创建新项目 首先创建一个新的项目,并命名。 二、实现代码 import java.awt.*; import java.awt.event.*; import javax.swing.*; import java.net.*; import java.io.IOException; import java.lang.String; public class liaotian extends JFrame{ pri…...

HBase整合Phoenix
文章目录 一、简介1、Phoenix定义2、Phoenix架构 二、安装Phoenix1、安装 三、Phoenix操作1、Phoenix 数据映射2、Phoenix Shell操作3、Phoenix JDBC操作3.1 胖客户端3.2 瘦客户端 四、Phoenix二级索引1、为什么需要二级索引2、全局索引(global index)3、…...

C# 委托/事件/lambda
概念 委托 定义委托编译器会自动生成一个类派生自System.MulticastDelegate 这个类包含4个方法:一个构造器、Invoke、BeginInvoke、EndInvoke。 调用委托的时候实际上执行的是 Invoke方法。 MulticastDelegate类有三个重要字段: _targetÿ…...

13款趣味性不错(炫酷)的前端动画特效及源码(预览获取)分享(附源码)
文字激光打印特效 基于canvas实现的动画特效,你既可以设置初始的打印文字也可以在下方输入文字可实现激光字体打印,精简易用。 预览获取 核心代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8&q…...
C# 友元程序集
1.友元程序集 使用友元程序集可以将internal成员提供给其他的友元程序集访问。 程序集FriendTest1.dll [assembly:InternalsVisibleTo("FriendTest2")] namespace FriendTest1 {internal class Friend{string name;public string Name > name;public Friend(str…...
CRM系统的数据分析和报表功能对企业重要吗?
竞争日益激烈,企业需要更加高效地管理客户关系,以获取更多的商机。为此,许多企业选择使用CRM系统。在CRM中,数据分析功能扮演着重要的角色。下面就来详细说说,CRM系统数据分析与报表功能对企业来说重要吗? …...

【单体架构事务失效解决方式之___代理对象加锁】
单体架构__用户限买 一个id一单的多线程事务失效问题解决 背景介绍:有一种情况,我们在使用Synchronized的时候出现失效情况。 经过排查,是因为使用了this.当前对象,他现在使用的是目标对象加锁失效,使用代理对象加锁就…...

面试被问到 HTTP和HTTPS的区别有哪些?你该如何回答~
HTTP和HTTPS的区别有哪些,主要从以下几个方面来说: 1.安全性 HTTP和HTTPS是两种不同的协议,它们之间最主要的区别在于安全性。HTTP协议以明文方式发送内容,不提供任何方式的数据加密,容易被攻击者截取信息。 HTTPS则在…...
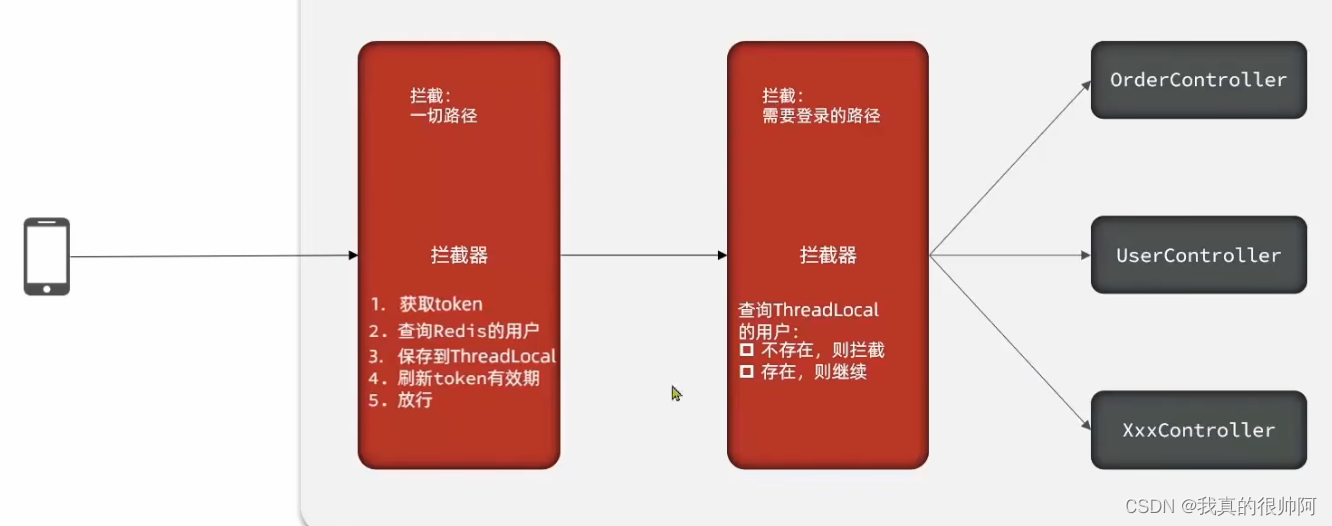
点评项目——短信登陆模块
2023.12.6 短信登陆如果基于session来实现,会存在session共享问题:多台Tomcat不能共享session存储空间,这会导致当请求切换到不同服务器时出现数据丢失的问题。 早期的解决办法是让session提供一个数据拷贝的功能,即让各个Tomcat的…...

2023亚太地区五岳杯量子计算挑战赛
计算电源网 (CPN)布局优化 1. 介绍 计算能力网络 (CPN)是一种基于业务需求分配和调度计算资源的新型信息基础设施,计算资源通常由终端用户、边缘服务器和云服务器组成。该网络旨在满足各种计算任务的需求。根据计算需求的空间分…...

Python 模块的使用方法
Python 模块是一种组织和封装代码的方式,允许你将相关的功能和变量放在一个单独的文件中,以便在其他程序中重复使用。在Python中,模块是一种可执行的Python脚本,其文件扩展名为 .py。这里,我将详细讲解Python模块的使用…...
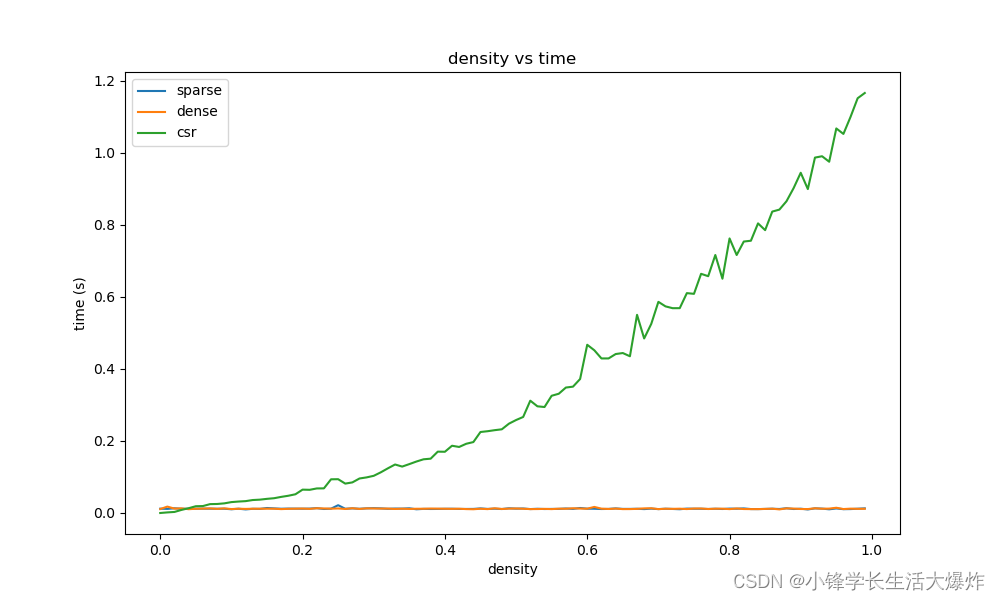
【知识】稀疏矩阵是否比密集矩阵更高效?
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 问题提出 有些地方说,稀疏图比密集图的计算效率更高,真的吗? 原因猜想 这里的效率高,应该是有前提的:当使用稀疏矩阵的存储格式(如CSR)时,计…...

代码随想Day24 | 回溯法模板、77. 组合
理论基础 回溯法和递归不可分割,回溯法是一种穷举的方法,通常需要剪枝来降低复杂度。回溯法有一个选择并退回的过程,可以抽象为树结构,回溯法的模板如下: void backtracking(参数) {if (终止条件) {存放结果;return;}…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...