TTS | 2019~2023年最新增强/生成情绪的语音合成调研(20231211更新版)
本博客主要是 增强/生成情绪的语音合成调研,论文按照时间顺序排列,且有些论文为期刊会议论文,有的是arxiv论文,在本文中,标识如下:
【🔊ICML 】【✨Interspeech 】【🫧ICASSP】
2019.09.30_Determination of representative emotional style of speech based on k-means algorithm
论文地址:Determination of representative emotional style of speech based on k-means algorithm (jask.or.kr)
将GST引入端到端的语音合成模型中,GST-Tacotron 框架如下
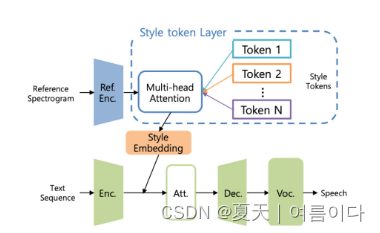
添加情感表示的框架
[✨Interspeech 2021]2021.04.03_Reinforcement Learning for Emotional Text-to-Speech Synthesis with Improved Emotion Discriminability
论文地址:2104.01408.pdf (arxiv.org)
近年来,情感文本到语音合成 (ETTS) 取得了很大进展。然而,生成的声音通常无法通过其预期的情感类别在感知上识别。为了解决这个问题,我们提出了一种新的ETTS交互式训练范式,表示为i-ETTS,它试图通过与语音情感识别(SER)模型的交互来直接提高情感的可判别性。此外,我们制定了强化学习的迭代训练策略,以确保i-ETTS优化的质量。实验结果表明,所提出的i-ETTS通过更准确地呈现语音风格,优于最先进的基线。据我们所知,这是情感文本到语音合成中强化学习的首次研究。
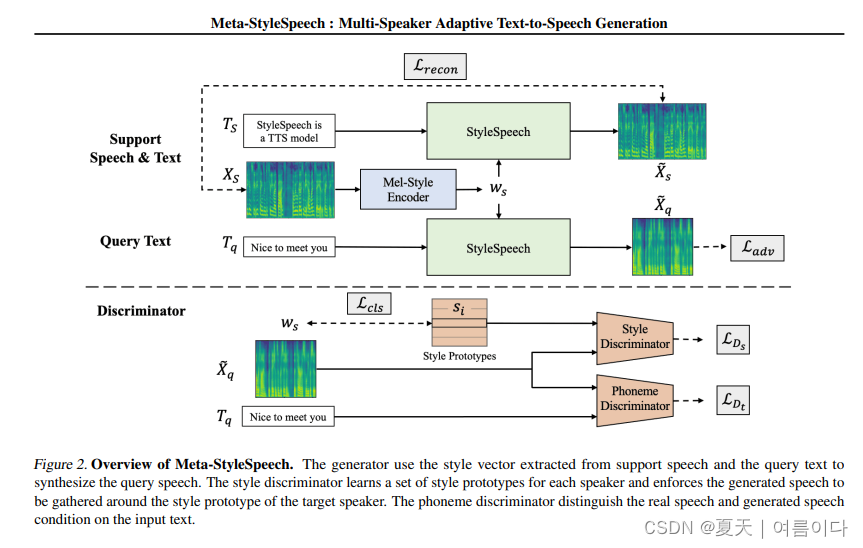
[ 🔊ICML 2021 ]2021.06.06_Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
论文地址:Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation (arxiv.org)
随着神经文本转语音 (TTS) 模型的快速发展,个性化语音生成现在对许多应用的需求量很大。为了实现实际适用性,TTS 模型应该仅使用来自给定说话者的几个音频样本来生成高质量的语音,这些样本的长度也很短。然而,现有方法要么需要对模型进行微调,要么在不进行微调的情况下实现低适应质量。在这项工作中,我们提出了一种新的TTS模型StyleSpeech,它不仅可以合成高质量的语音,还可以有效地适应新的说话者。具体来说,我们提出了风格自适应层归一化(SALN),它根据从参考语音音频中提取的风格来对齐文本输入的增益和偏置。借助 SALN,我们的模型可以有效地合成目标说话人的语音,即使是从单个语音音频中也是如此。此外,为了增强 StyleSpeech 对新说话者语音的适应能力,我们通过引入两个使用风格原型训练的判别器并执行情景训练,将其扩展到 Meta-StyleSpeech。实验结果表明,我们的模型生成高质量的语音,通过单个短时(1-3秒)语音音频准确地跟随说话者的声音,性能明显优于基线。
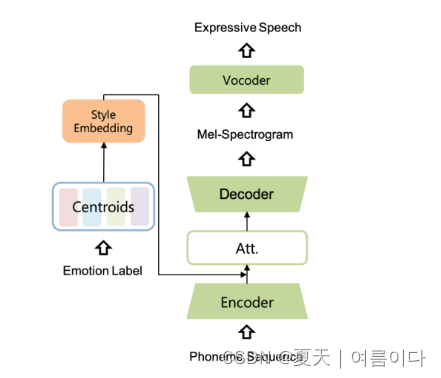
[ ✨Interspeech 2021]2021.06.17_EMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model
论文地址:2106.09317.pdf (arxiv.org)
最近,人们对神经语音合成的兴趣越来越大。虽然深度神经网络在文本转语音(TTS)任务中取得了最先进的结果,但由于高质量情感语音数据集的稀缺性和先进的情感TTS模型的缺乏,如何生成更具情感性和表现力的语音正成为研究人员面临的新挑战。在本文中,我们首先简要介绍并公开发布了一个普通话情感语音数据集,该数据集包含9,724个样本,其中包含音频文件及其情感人工标记注释。之后,我们提出了一种简单而有效的情感语音合成架构,称为EMSpeech。与那些需要额外参考音频作为输入的模型不同,我们的模型可以仅从输入文本中预测情感标签,并根据情感嵌入生成更具表现力的语音。在实验阶段,我们首先通过情绪分类任务来验证数据集的有效性。然后,我们在提议的数据集上训练我们的模型,并进行一系列主观评估。最后,通过在情感语音合成任务中表现出可比的性能,我们成功地证明了所提模型的能力。
[ ✨Interspeech 2021]2021.11.Emotional Prosody Control for Speech Generation
论文地址:2111.04730.pdf (arxiv.org)
机器生成的语音的特点是其有限或不自然的情绪变化。当前的文本转语音系统生成具有平坦情感的语音、从预定义集合中选择的情感、从训练数据中的韵律序列中学习的平均变化或从源风格传输的平均变化。我们提出了一种文本到语音(TTS)系统,用户可以从连续且有意义的情感空间(Arousal-Valence space)中选择生成语音的情感。所提出的TTS系统可以从任何说话者的文本中生成语音,并可以很好地控制情绪。我们表明,该系统可以处理训练期间看不见的情绪,并且可以根据他/她的语音样本扩展到以前看不见的说话者。我们的工作将最先进的 FastSpeech2 骨干网的视野扩展到多扬声器设置,并为其提供令人垂涎的连续(和可解释)情感控制,而不会对合成语音的质量造成任何可观察到的下降。
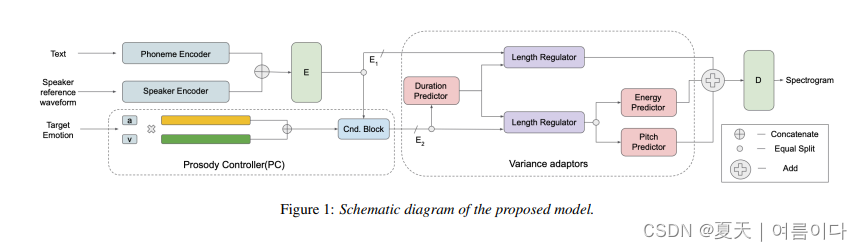
[ 🫧ICASSP2023 ]2022.11.17_ Grad-StyleSpeech: Any-speaker Adaptive Text-to-Speech Synthesis with Diffusion Models
论文地址:[2211.09383] Grad-StyleSpeech: Any-speaker Adaptive Text-to-Speech Synthesis with Diffusion Models (arxiv.org)
论文代码:WelkinYang/GradTTS: Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech" (github.com)
Demo:
近年来,由于神经生成建模的进步,文本转语音 (TTS) 合成技术取得了重大进展。然而,现有的任何说话人自适应TTS方法在模仿目标说话人的风格方面都取得了不理想的性能,因为它们在模仿目标说话人的风格方面精度不理想。在这项工作中,我们提出了 Grad-StyleSpeech,这是一个基于扩散模型的任意说话人自适应 TTS 框架,该模型可以生成高度自然的语音,与目标说话人的声音具有极高的相似性,给定几秒钟的参考语音。在英语基准测试中,Grad-StyleSpeech 明显优于最近的说话人自适应 TTS 基线。音频示例可在此 https URL 中找到。
2022.11.26_CONTEXTUAL EXPRESSIVE TEXT-TO-SPEECH
论文地址:2211.14548.pdf (arxiv.org)
代码未开源
富有表现力的文本转语音 (TTS) 的目标是以高表现力合成具有所需内容、韵律、情感或音色的自然语音。以前的大多数研究都试图从给定的风格和情绪标签中生成语音,通过将风格和情绪分类为固定数量的预定义类别来过度简化问题。在本文中,我们引入了一种新的任务设置,即上下文TTS(CTTS)。CTTS的主要思想是,一个人说话的方式取决于她所处的特定语境,其中语境通常可以表示为文本。因此,在CTTS任务中,我们建议利用这样的上下文来指导语音合成过程,而不是依赖风格和情感的明确标签。为了完成这项任务,我们构建了一个合成数据集并开发了一个有效的框架。实验表明,我们的框架可以在合成数据集和真实场景中基于给定的上下文生成高质量的表达语音。
[ ✨Interspeech 2021]2021.12.07_Multi-speaker Emotional Text-to-speech Synthesizer
论文代码:2112.03557.pdf (arxiv.org)
我们提出了一种方法来训练我们的多说话人情感文本到语音合成器,它可以表达 10 个说话者的 7 种不同情绪的语音。在学习之前,将删除音频样本中的所有静音。这导致我们的模型可以快速学习。应用课程学习来有效地训练我们的模型。我们的模型首先使用大型单说话人中立数据集进行训练,然后使用所有说话人的中性语音进行训练。最后,我们的模型使用来自所有说话者的情感语音数据集进行训练。在每个阶段,每个说话者-情感对的训练样本以小批量出现的概率相等。通过这个过程,我们的模型可以合成所有目标说话者和情绪的语音。我们的合成音频集可在我们的网页上找到。
[ ✨Interspeech 2022 ]2022.07.13_Text-driven Emotional Style Control and Cross-speaker Style Transfer in Neural TTS
论文地址:2207.06000.pdf (arxiv.org)
近年来,富有表现力的文本转语音功能已显示出改进的性能。然而,合成语音的风格控制往往局限于离散的情感类别,需要目标说话人在目标风格中记录的训练数据。在许多实际情况下,用户可能没有记录目标情绪的参考语音,但仍然有兴趣通过输入所需情感风格的文本描述来控制语音风格。在本文中,我们提出了一种基于文本的接口,用于多说话人TTS中的情感风格控制和跨说话人风格迁移。我们提出了一种双模态风格编码器,该编码器使用预训练的语言模型对文本描述嵌入和语音风格嵌入之间的语义关系进行建模。为了进一步改善在不相交的多风格数据集上的交叉说话人风格迁移,我们提出了一种新的风格损失。实验结果表明,我们的模型即使在看不见的风格下也能产生高质量的表达性语音。
2022.12.28_Speech Synthesis with Mixed Emotions
论文地址:2208.05890.pdf (arxiv.org)
情感语音合成旨在合成具有各种情感效果的人声。目前的研究主要集中在模仿属于特定情绪类型的平均风格上。在本文中,我们试图在运行时生成具有混合情绪的语音。我们提出了一种新的公式来测量不同情绪的语音样本之间的相对差异。然后,我们将我们的公式合并到序列的情感文本到语音框架中。在训练过程中,该框架不仅明确表征了情绪风格,还通过量化与其他情绪的差异来探索情绪的序数性质。在运行时,我们通过手动定义情感属性向量来控制模型以产生所需的情感混合。客观和主观评价验证了拟议框架的有效性。据我们所知,这项研究是第一个关于建模、综合和评估言语中混合情绪的研究。
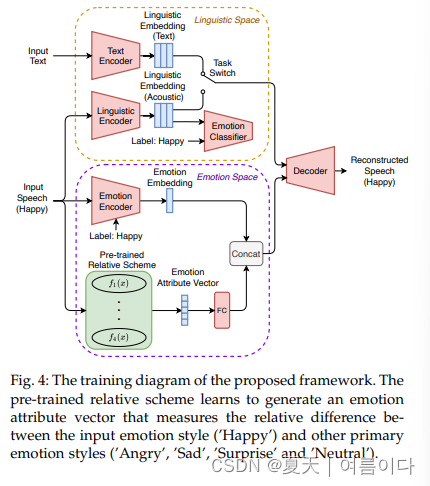
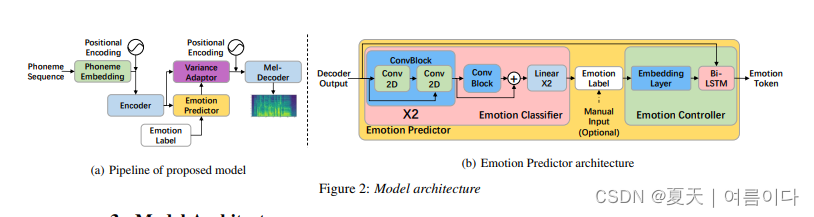
[ 🫧ICASSP 2023 ]2023.03.02_Fine-grained Emotional Control of Text-To-Speech: Learning To Rank Inter- And Intra-Class Emotion Intensities
论文地址:2303.01508.pdf (arxiv.org)
Demo:https: //wshijun1991.github.io/ICASSP2023_DEMO
最先进的文本转语音 (TTS) 模型能够产生高质量的语音。然而,生成的语音在情感表达中通常是中性的,而人们往往希望对单词或音素进行细粒度的情感控制。尽管仍然具有挑战性,但最近提出了第一个TTS模型,该模型能够通过手动分配情绪强度来控制语音。不幸的是,由于忽略了班级内的距离,强度差异往往无法识别。在本文中,我们提出了一种细粒度的可控情绪TTS,它同时考虑了类间和类内的距离,并能够合成具有可识别强度差异的语音。我们的主观和客观实验表明,我们的模型在可控性、情感表达性和自然性方面超过了两个最先进的可控TTS模型。
2.1.秩模型
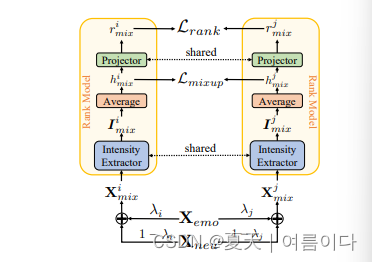
Xemo是非自然情绪分类的样本,Xneu是自然的,
2.2.TTS模型
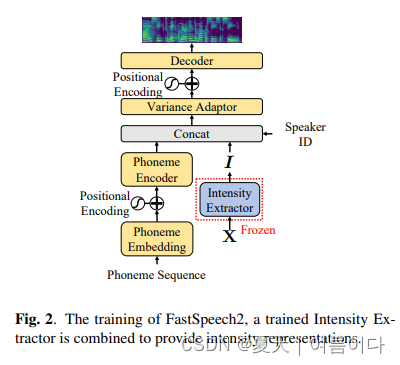
使用fastspeech2的结构
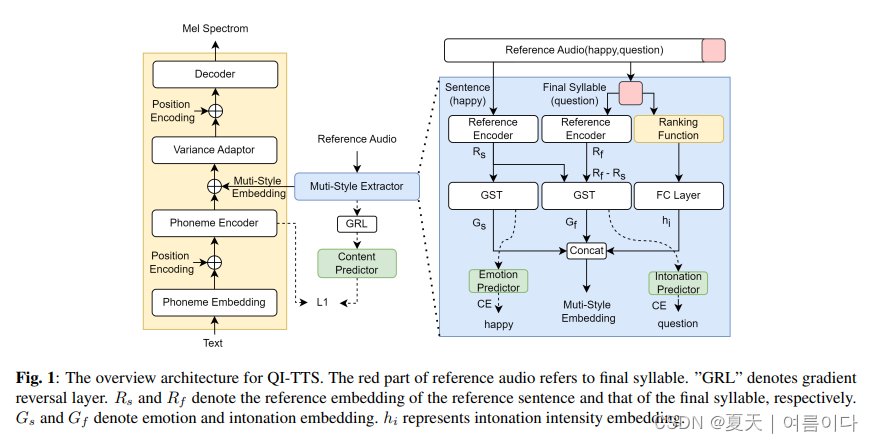
[ 🫧ICASSP 2023 ]2023.03.14_QI-TTS: Questioning Intonation Control for Emotional Speech Synthesis
论文地址:2303.07682.pdf (arxiv.org)
最近的表达性文本转语音 (TTS) 模型侧重于合成情感语音,但忽略了一些细粒度的风格,例如语调。在本文中,我们提出了QI-TTS,旨在更好地传递和控制语调,以进一步传递说话者的提问意图,同时从参考语音中传递情感。我们提出了一个多样式提取器,从两个不同的层次提取样式嵌入。句子级别代表情感,而最后一个音节级别代表语调。对于细粒度的语调控制,我们使用相对属性来表示音节级别的语调强度。实验验证了QI-TTS在改善情感语音合成中语调表现力的有效性。
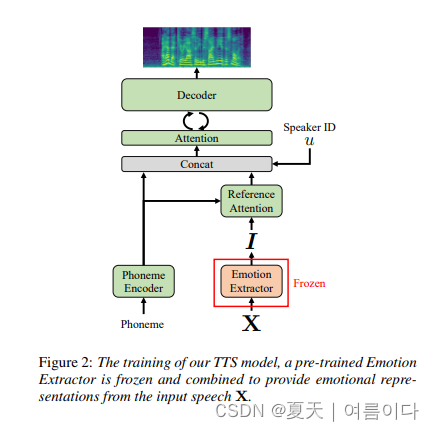
[ 🫧ICASSP 2023 ]2023.03.15_Cross-speaker Emotion Transfer by Manipulating Speech Style Latents
论文地址:[2303.08329] Cross-speaker Emotion Transfer by Manipulating Speech Style Latents (arxiv.org)
近年来,情感文本转语音取得了长足的进步。但是,它需要大量的标记数据,不容易访问。即使可以获取情感语音数据集,在控制情感强度方面仍然存在局限性。在这项工作中,我们提出了一种在潜在风格空间中使用向量算术进行交叉说话者情感传递和操纵的新方法。通过仅利用少数标记样本,我们从阅读式语音中生成情感语音,而不会丢失说话者身份。此外,使用标量值可以很容易地控制情绪强度,为用户提供了一种直观的方式来操纵语音。实验结果表明,所提方法在表现力、自然性和可控性方面具有较好的性能,保留了说话人的身份。
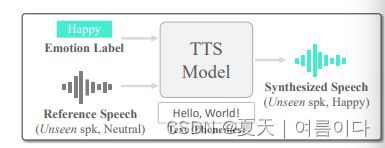
2023.05.23_ZET-Speech: Zero-shot adaptive Emotion-controllable Text-to-Speech Synthesis with Diffusion and Style-based Models
论文地址:[2305.13831] ZET-Speech: Zero-shot adaptive Emotion-controllable Text-to-Speech Synthesis with Diffusion and Style-based Models (arxiv.org)
代码地址:ZET-Speech/ZET-Speech-Demo: ZET-Speech: Zero-shot adaptive Emotion-controllable Text-to-Speech Synthesis with Diffusion and Style-based Models (TTS) (github.com)
Demo:ZET-Speech
情感文本转语音 (TTS) 是开发需要自然和情感语音的系统(例如类人对话代理)中的一项重要任务。然而,现有方法的目的只是在培训期间为看到的说话者产生情感 TTS,而没有考虑对看不见的说话者的泛化。在本文中,我们提出了 ZET-Speech,这是一种零样本自适应情绪可控 TTS 模型,允许用户仅使用简短的中性语音片段和目标情绪标签来合成任何说话者的情感语音。具体而言,为了实现零样本自适应TTS模型来合成情感语音,我们提出了基于扩散模型的领域对抗学习和引导方法。实验结果表明,ZET-Speech成功地将自然和情感语音与看得见和看不见的说话者所需的情感相结合。示例位于此 https URL。
论文架构
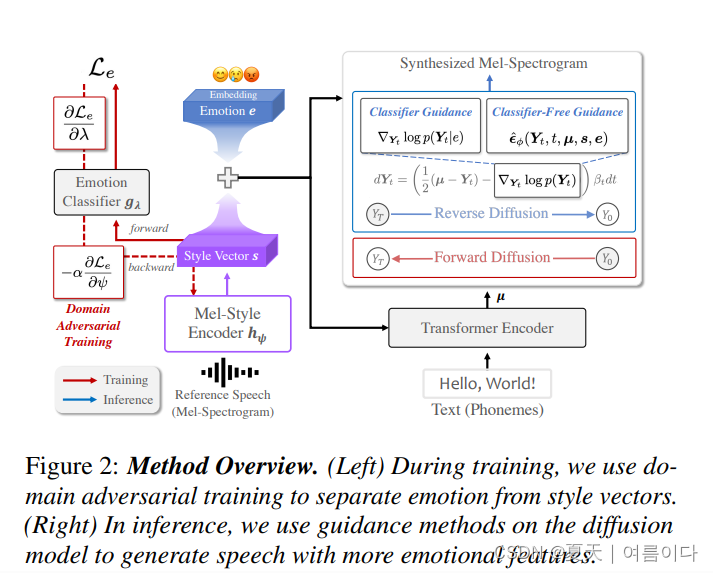
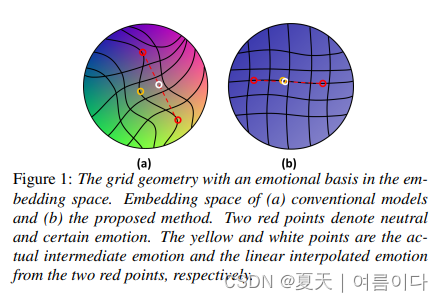
2023.05.29.v2_Semi-supervised learning for continuous emotional intensity controllable speech synthesis with disentangled representations
论文地址:Submitted to INTERSPEECH (arxiv.org)
最近的文本转语音模型已经达到了生成类似于人类所说的自然语音的水平。但在表现力方面仍然存在局限性。现有的情感语音合成模型在情感潜在空间中使用具有缩放参数的插值特征表现出可控性。然而,由于情绪、说话者等特征的纠缠,现有模型产生的情感潜在空间难以控制持续的情感强度。在本文中,我们提出了一种使用半监督学习来控制情绪连续强度的新方法。该模型使用从语音信息的音素级序列生成的伪标签来学习中等强度的情绪。根据所提出的模型构建的嵌入空间满足了具有情感基础的均匀网格几何形状。实验结果表明,所提方法在可控性和自然性方面具有较好的优点。
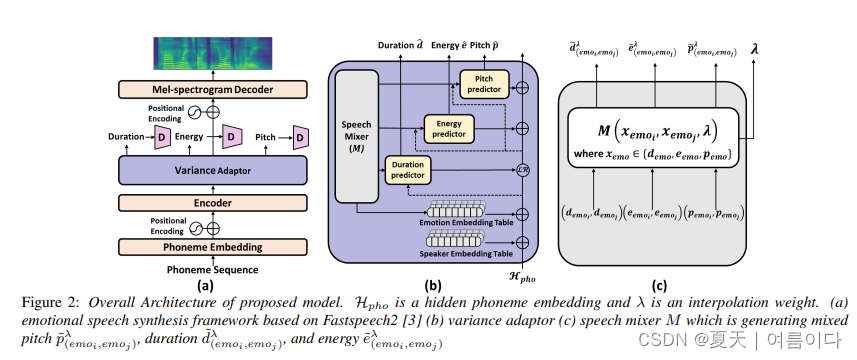
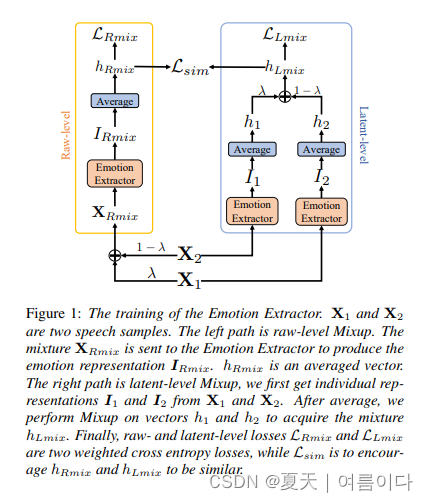
[ ✨Interspeech 2023 ]2023.06.09_Learning Emotional Representations from Imbalanced Speech Data for Speech Emotion Recognition and Emotional Text-to-Speech
论文地址:Submitted to INTERSPEECH (arxiv.org)
有效的言语情感表征在言语情感识别 (SER) 和情感文本转语音 (TTS) 任务中起着关键作用。然而,与中性风格语音相比,情感语音样本的获取更加困难和昂贵,这导致了一个大多数相关作品不幸忽略的问题:数据集不平衡。模型可能会过度拟合大多数中性类,并且无法产生稳健有效的情感表征。在本文中,我们提出了一个情感提取器来解决这个问题。我们使用增强方法来训练模型,并使其能够从不平衡的数据集中提取有效且可推广的情感表征。我们的实证结果表明:(1)对于SER任务,所提出的Emotion Extractor在三个不平衡数据集上都超过了最先进的基线;(2)我们的情感提取器生成的表征有利于TTS模型,并使其能够合成更具表现力的语音。
2023.06.28_EmoSpeech: Guiding FastSpeech2 Towards Emotional Text to Speech
论文地址:Submitted to SSW (arxiv.org)
最先进的语音合成模型试图尽可能接近人声。因此,情绪建模是文本转语音 (TTS) 研究的重要组成部分。在我们的工作中,我们选择了 FastSpeech2 作为起点,并提出了一系列用于合成情感语音的修改。根据自动和人工评估,我们的模型 EmoSpeech 在生成语音的 MOS 分数和情感识别准确性方面都超过了现有模型。我们为构成 EmoSpeech 的 FastSpeech2 架构的每个扩展提供了详细的消融研究。文本中情感的不均匀分布对于更好的综合语音和语调感知至关重要。我们的模型包括一个调节机制,通过允许情绪以不同的强度水平影响每部手机来有效地处理这个问题。人工评估表明,所提出的修改生成的音频具有更高的 MOS 和情感表现力。
论文使用了:
- 用离散标签表示一个或多个情绪
- 有参考语音的情感状态
- 目标情绪状态作为表单条件数据的上下文
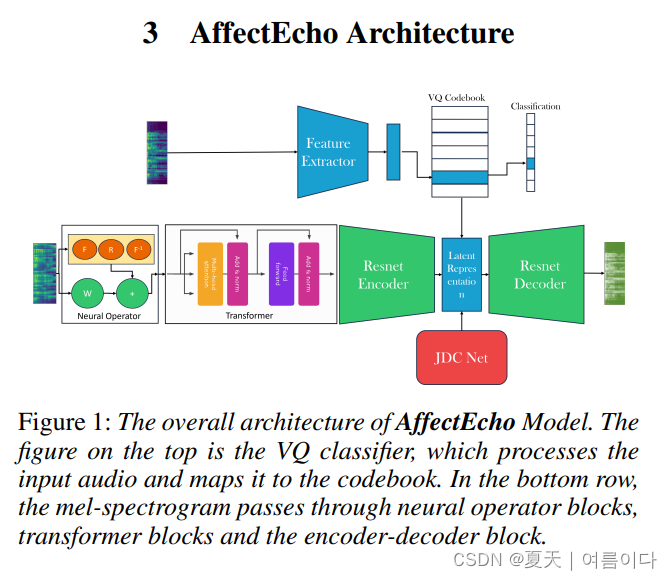
2023.08.16_AffectEcho: Speaker Independent and Language-Agnostic Emotion and Affect Transfer for Speech Synthesis
论文地址:2308.08577.pdf (arxiv.org)
情感是一种情感特征,包括效价、唤醒和强度,是实现真实对话的关键属性。虽然现有的文本转语音 (TTS) 和语音转语音系统依赖于强度嵌入向量和全局风格标记来捕获情感,但这些模型将情感表示为风格的组成部分,或者在离散类别中表示它们。我们提出了 AffectEcho,一种情绪翻译模型,它使用矢量量化代码本在具有五个影响强度级别的量化空间中对情绪进行建模,以捕捉同一情绪中复杂的细微差别和细微差异。量化的情感嵌入是从口语样本中隐式派生的,无需使用单热向量或显式强度嵌入。实验结果表明,我们的方法在控制生成语音的情绪方面是有效的,同时保留了每个说话者独特的身份、风格和情感节奏。我们展示了从双语(英语和中文)语音语料库中学习到的量化情感嵌入的语言独立情感建模能力,以及从参考语音到目标语音的情感迁移任务。我们在定性和定量指标上都取得了最先进的结果。
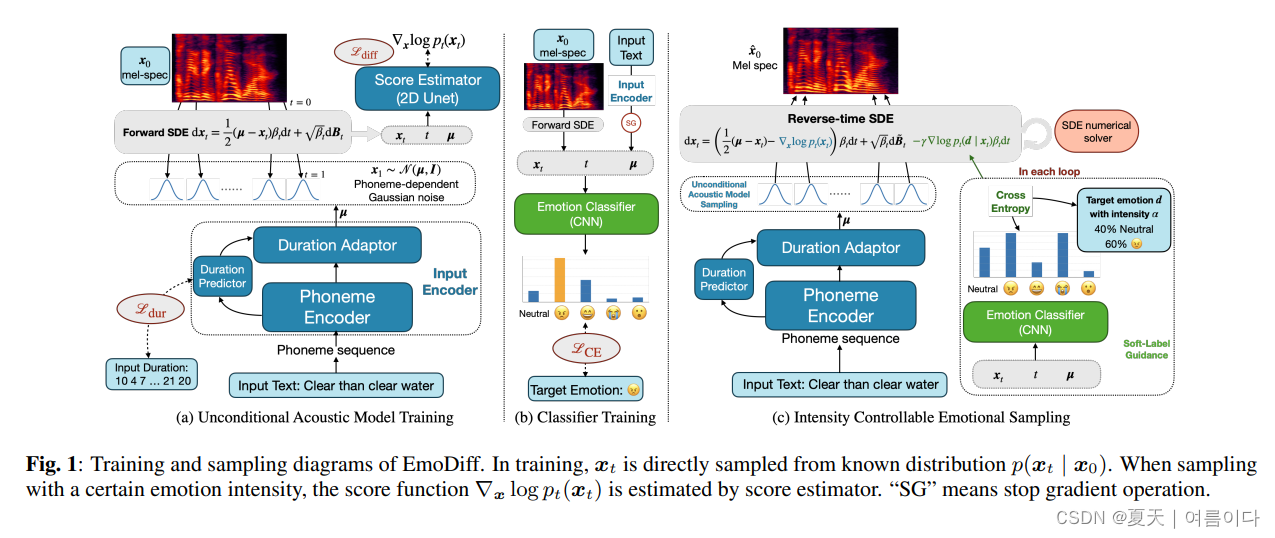
2023.11.16_EMODIFF: INTENSITY CONTROLLABLE EMOTIONAL TEXT-TO-SPEECH WITH SOFT-LABEL GUIDANCE
论文地址:2211.09496.pdf (arxiv.org)
尽管当前的神经文本转语音 (TTS) 模型能够生成高质量的语音,但强度可控的情感 TTS 仍然是一项具有挑战性的任务。大多数现有方法需要外部优化才能进行强度计算,从而导致结果欠佳或质量下降。在本文中,我们提出了EmoDiff,这是一种基于扩散的TTS模型,其中情绪强度可以通过源自分类器引导的软标签引导技术来操纵。具体来说,EmoDiff 不是使用指定情绪的 one-hot 向量进行引导,而是使用软标签进行引导,其中指定情绪和 \textit{Neutral} 的值设置为α和1−α分别。这α这里代表情绪强度,可以从 0 到 1 中选择。我们的实验表明,EmoDiff 可以在保持高语音质量的同时精确控制情绪强度。此外,通过反向去噪过程中的采样,可以产生具有特定情感强度的多样化语音。
参考文献
【1】 Emotional Speech Synthesis | Papers With Code
【2】keonlee9420/StyleSpeech: PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation (github.com) 【3】arxiv-sanity (arxiv-sanity-lite.com)
相关文章:
TTS | 2019~2023年最新增强/生成情绪的语音合成调研(20231211更新版)
本博客主要是 增强/生成情绪的语音合成调研,论文按照时间顺序排列,且有些论文为期刊会议论文,有的是arxiv论文,在本文中,标识如下: 【🔊ICML 】【✨Interspeech 】【🫧ICASSP】 20…...

搜狗输入法v模式 | 爱莉希雅皮肤
搜狗输入法v模式 | 爱莉希雅皮肤 前言爱莉希雅皮肤v模式 前言 搜狗输入法有v模式,v模式是一个转换和计算的功能组合。拥有数字转换、日期转换、算式计算、函数计算等功能。本文介绍如何使用v模式,并附赠一个爱莉希雅的皮肤,可通过百度网盘下…...

2023年阿里云云栖大会-核心PPT资料下载
一、峰会简介 历经14届的云栖大会,是云计算产业的建设者、推动者、见证者。2023云栖大会以“科技、国际、年轻”为基调,以“计算,为了无法计算的价值”为主题,发挥科技平台汇聚作用,与云计算全产业链上下游的先锋代表…...

JavaScript实战:制作一个待办事项列表应用
JavaScript实战:制作一个待办事项列表应用 引言 在本教程中,我们将一步步创建一个简单的待办事项列表应用,这不仅会帮助你学习基本的JavaScript编程概念,还会教会你如何处理事件以及操作DOM。这个项目是面向初学者的,…...

4面百度软件测试工程师的面试经验总结
没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2023年7月,我有幸成为了百度的一名测试工程师,从外包辞职了历经1000…...
textarea文本框回车enter的时候自动提交表单,根据内容自动高度
切图网近期一个bootstrap5仿chatgpt页面的项目遇到的,textarea文本框回车enter的时候自动提交表单,根据内容自动高度,代码如下,亲测可用。 <textarea placeholder"Message ChatGPT…" name"" rows"&q…...
dubbo框架技术文档-《spring-boot整合dubbo框架搭建+配置文件》框架的本地基础搭建
阿丹: 目前流行的微服务更多的就是dubbo和springcould微服务。之前阿丹没有出过dubbo相关的文章,因为之前接触springcould的微服务概念比较多一点,但是相对于springcould来说,springcould服务之间的调用是大多是使用了nacos&#…...
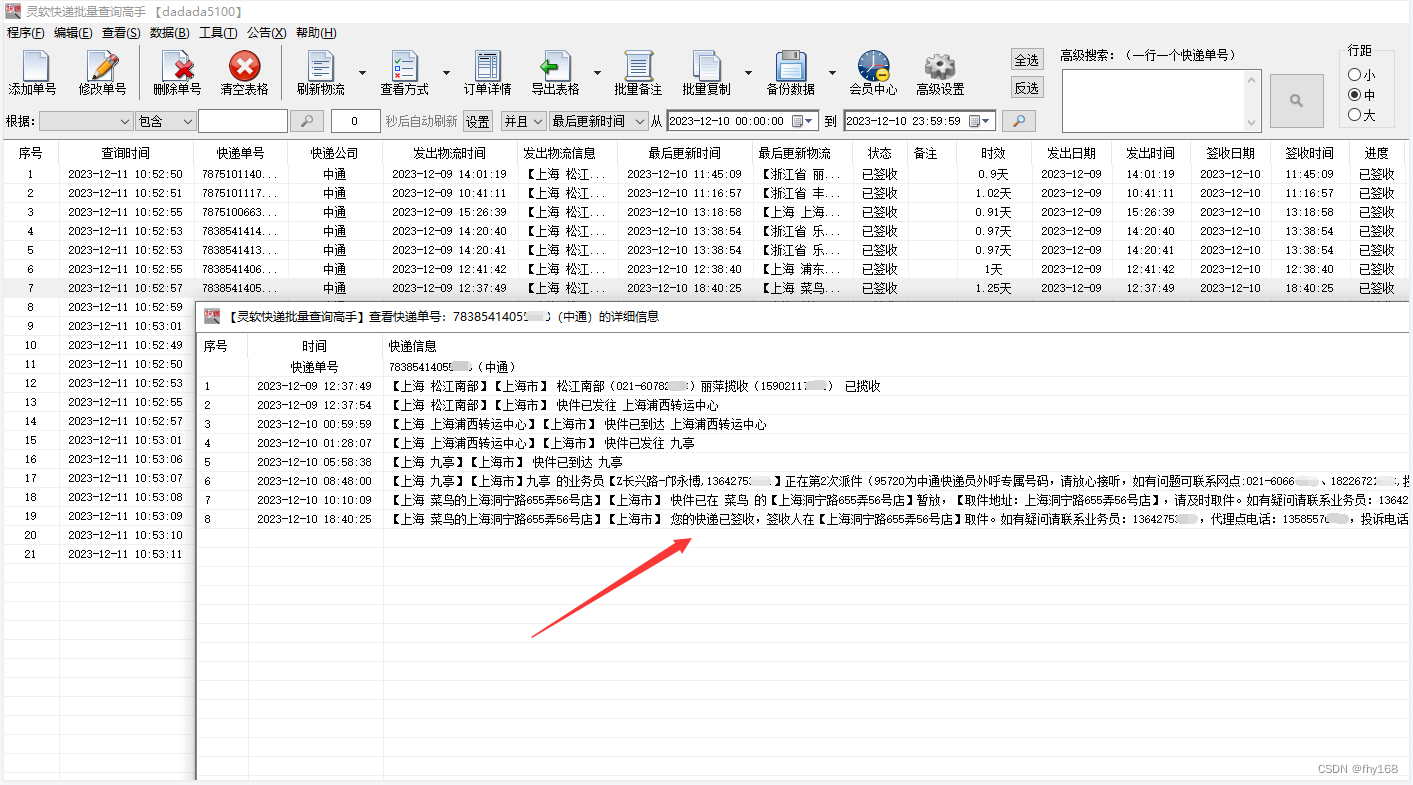
中通快递单号查询入口,将指定某天签收的单号筛选出来
批量查询中通快递单号的物流信息,将指定某天签收的单号筛选出来。 所需工具: 一个【快递批量查询高手】软件 中通快递单号若干 操作步骤: 步骤1:运行【快递批量查询高手】软件,并登录 步骤2:点击主界面左…...
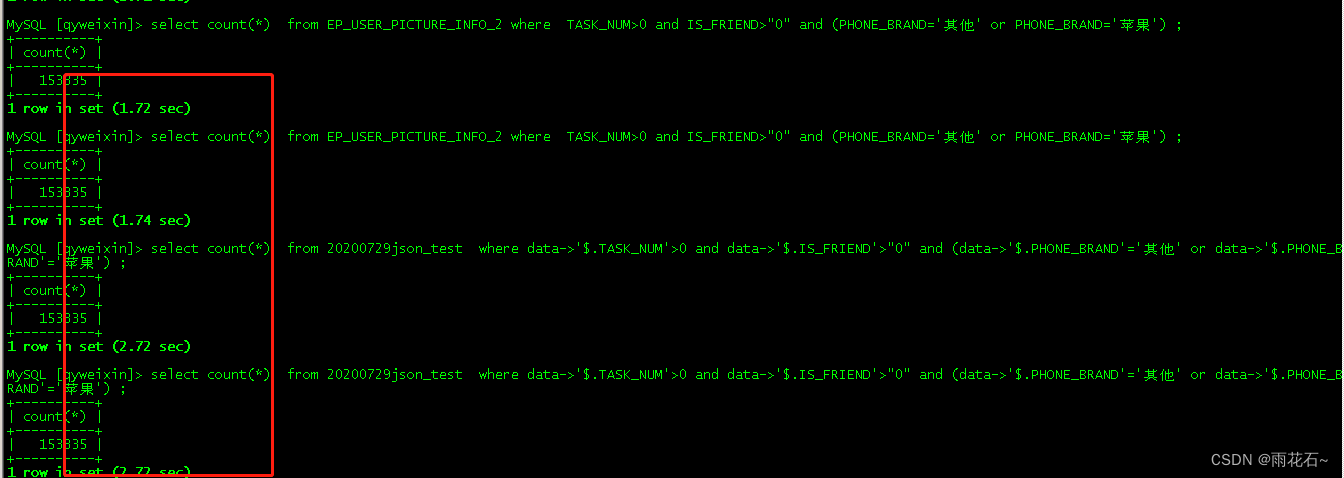
MySQL-含json字段表和与不含json字段表查询性能对比
含json字段表和与不含json字段表查询性能对比 说明: EP_USER_PICTURE_INFO_2:不含json字段表 20200729json_test:含有json字段表 其中20200729json_test 标准ID、MANAGER_NO、PHONE_NO 为非json字段 data为json字段 2个表中MANAGER_NO、PHONE_NO都创建了各自的索引 测试…...

如何用Docker快速搭建本地开发环境
📢 声明: 🍄 大家好,我是风筝 🌍 作者主页:【古时的风筝CSDN主页】。 ⚠️ 本文目的为个人学习记录及知识分享。如果有什么不正确、不严谨的地方请及时指正,不胜感激。 直达博主:「…...

SpringDataJPA基础
简介 Spring Data为数据访问层提供了熟悉且一致的Spring编程模版,对于每种持久性存储,业务代码通常需要提供不同存储库提供对不同CURD持久化操作。Spring Data为这些持久性存储以及特定实现提供了通用的接口和模版。其目的是统一简化对不同类型持久性存储…...
程序员如何成为自由的独立开发者?
你是不是那个整天坐在电脑前敲代码的程序员朋友?作为程序员,你是否也曾思考过如何成为一名独立开发者?思考过究竟如何踏上这段充满挑战和创造的旅程? 现在这个数码时代,技术不断演进,越来越多的程序员朋友…...

Ant Design Vue(v1.7.8)a-table组件的插槽功能
本案例中,编写了一个名为stockAdd的vue(v2.5.17)自定义组件,使用a-table组件的插槽功能,创建了一个可编辑的数据表格: 表格用于添加采购的物品,点“新增物品”按键,表格添加一行&…...

笔记69:Conv1d 和 Conv2d 之间的区别
笔记地址:D:\work_file\(4)DeepLearning_Learning\03_个人笔记\4. Transformer 网络变体 a a a a a a a a a a a...
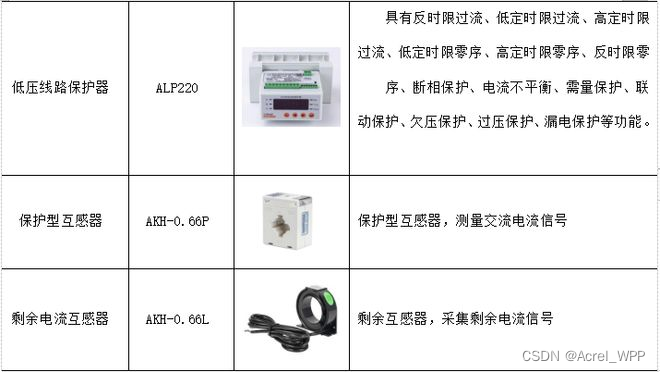
关于马达保护器 的选型 你知道吗
一、智能马达保护器的介绍 在有色冶炼中,根据工艺需求和客户需求,智能电动机保护器的主要应用模式有保护模式、端子控制模式、全通信模式和半通信模式。 4.1保护模式 在保护模式下,智能电动机保护器只利用其自身的保护功能和测量功能&#…...

springboot(ssm高校竞赛管理系统 在线竞赛平台 Java系统
springboot(ssm高校竞赛管理系统 在线竞赛平台 Java系统 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0) 数…...
SDXL使用animateDiff和hotshot-xl进行文生视频
截至2023.12.8号,目前市面上有两款适用于SDXL的文生视频开源工具,分别是AnimateDiff和hotshot-xl。 一、工具下载链接 (1)AnimateDiff的webui版本的git链接: GitHub - continue-revolution/sd-webui-animatediff: A…...

【高数:3 无穷小与无穷大】
【高数:3 无穷小与无穷大】 1 无穷小与无穷大2 极限运算法则3 极限存在原则4 趋于无穷小的比较 参考书籍:毕文斌, 毛悦悦. Python漫游数学王国[M]. 北京:清华大学出版社,2022. 1 无穷小与无穷大 无穷大在sympy中用两个字母o表示无…...

C语言预读取技术 __builtin_prefetch
__builtin_prefetch 是一个编译器内置函数,用于在编译时向编译器发出指令,要求在执行期间预取内存数据。它通常用于提高程序的性能,特别是对于那些需要频繁访问内存的情况。 __builtin_prefetch 函数的语法如下:c __builtin_prefe…...
自动驾驶学习笔记(十三)——感知基础
#Apollo开发者# 学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往: 《自动驾驶新人之旅》免费课程—> 传送门 《Apollo Beta宣讲和线下沙龙》免费报名—>传送门 文章目录 前言 传感器 测距原理 坐标系 标定 同…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...