ToolkenGPT:用大量工具增强LLM

深度学习自然语言处理 原创
作者:cola
用外部工具增强大型语言模型(LLM)已经成为解决复杂问题的一种方法。然而,用样例数据对LLM进行微调的传统方法,可能既昂贵又局限于一组预定义的工具。最近的上下文学习范式缓解了这一问题,但有限的上下文长度局限于少样本样例,导致不能完全挖掘工具的潜力。此外,当有许多工具可供选择时,上下文学习可能完全不起作用。因此本文提出了一种替代方法ToolkenGPT,它结合了双方的优势。
论文:
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings地址:
https://arxiv.org/abs/2305.11054
介绍
LLM已经成为各种现实世界应用程序的强大工具。随着这些模型的不断发展,人们对其与现实世界交互的潜力越来越感兴趣,并通过与其他工具集成来增强其功能,如计算器、数据库等。这些模型掌握和控制各种工具的能力不仅是其智能的标志,还标志着一条有希望的克服其部分基本弱点的道路。包括更新最新的世界知识,减少其幻觉,以及执行符号操作等。
然而,新工具的迅速出现,如高级软件库、新颖的API或特定领域的实用程序,为LLM的工具学习任务带来了额外的丰富和复杂性。这种不断的演变强调了赋予LLM快速适应和掌握大量新工具的能力的重要性。
表1展示了与LLM的工具集成的两种主要研究方法。第一种方法涉及微调以学习特定工具。虽然这种方法可以产生很好的结果,但它的计算成本很高,并且缺乏对新工具的适应性。第二种方法依赖于上下文学习,LLM通过提示中提供的上下文样例来学习如何使用工具。这种方法允许LLM处理新引入的工具。然而,上下文学习有其独特的局限性,使它不可能在上下文中使用大量的工具。此外,仅通过少量样本掌握新工具可能具有挑战性。 本文提出ToolkenGPT,一种使LLM能够掌握大量的工具,而不需要任何微调,同时允许LLM快速适应新工具。ToolkenGPT的关键思想是将每个工具表示为一个新token(“toolken”),以增加词汇表。具体来说,每个工具都与插入到LLM头部的嵌入相关联,就像常规的单词tokens嵌入一样。在生成过程中,一旦预测到toolken, LLM临时切换到特殊模式(通过提示)以产生工具要执行的输入参数,并将输出注入到生成中(参见图1)。这种方法为LLM提供了一种有效的方法,只需学习轻量级toolken嵌入即可掌握工具。
本文提出ToolkenGPT,一种使LLM能够掌握大量的工具,而不需要任何微调,同时允许LLM快速适应新工具。ToolkenGPT的关键思想是将每个工具表示为一个新token(“toolken”),以增加词汇表。具体来说,每个工具都与插入到LLM头部的嵌入相关联,就像常规的单词tokens嵌入一样。在生成过程中,一旦预测到toolken, LLM临时切换到特殊模式(通过提示)以产生工具要执行的输入参数,并将输出注入到生成中(参见图1)。这种方法为LLM提供了一种有效的方法,只需学习轻量级toolken嵌入即可掌握工具。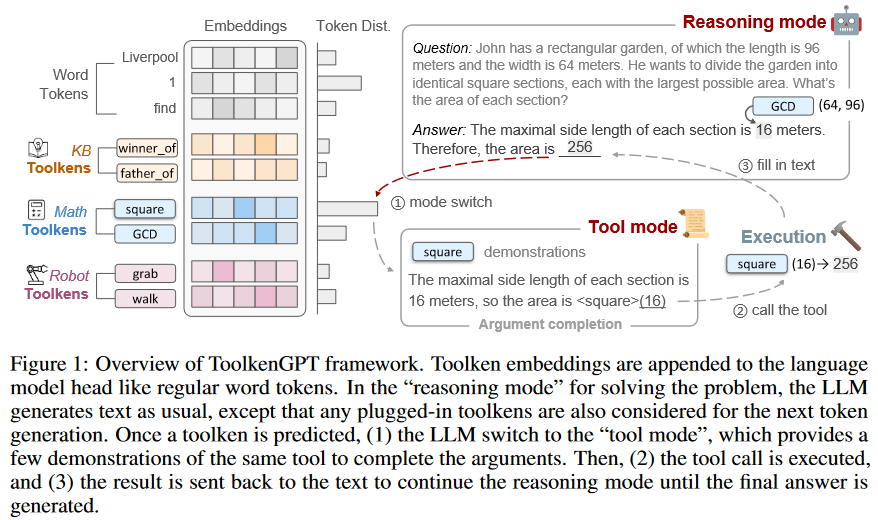 因此,ToolkenGPT结合了微调和上下文学习范式的优势,同时避免了它们的局限性:与只能容纳少量工具和少量样例的上下文学习相比,ToolkenGPT允许大量工具(通过简单地在词汇表中插入各自的工具),并可以使用广泛的样例数据来学习toolken嵌入;与微调相比,不仅需要最小的训练成本,而且还提供了一种方便的方法,通过扩展toolken词汇表来动态插入任意新工具。
因此,ToolkenGPT结合了微调和上下文学习范式的优势,同时避免了它们的局限性:与只能容纳少量工具和少量样例的上下文学习相比,ToolkenGPT允许大量工具(通过简单地在词汇表中插入各自的工具),并可以使用广泛的样例数据来学习toolken嵌入;与微调相比,不仅需要最小的训练成本,而且还提供了一种方便的方法,通过扩展toolken词汇表来动态插入任意新工具。
ToolkenGPT掌握大量工具
首先介绍一下工具使用语言建模的背景和符号表示。通常,LLMs对单词标记序列为,其中每个单词token来自LLM的词汇,即,表示第步之前的部分词token序列。在实践中,通常设置序列的前缀(称为提示),以引导LLM生成所需的内容。进一步深入,下一个token的分布被预测为,其中是当前上下文的最后一个隐藏状态,是单词token的嵌入矩阵(也称为语言模型头)。
给定工具集,我们的目标是使LLM能够调用这些工具的子集来解决复杂的问题。所提出的灵活公式允许工具通过返回一些可以帮助LLM进行文本生成(例如计算)或影响现实世界环境(例如机器人动作)的结果来发挥作用。要在生成过程中调用工具,LLM首先需要选择工具,然后输入参数。在图1所示的运行示例中,在答案生成过程(“Reasoning model”)中,选择数学运算符square作为工具,并在“工具模式”中生成一个操作数16作为参数。一旦外部工具收到调用,它就会执行工具并返回结果256,返回Reasoning model。
框架概览
ToolkenGPT的核心思想是明确地将工具制定为token。每个工具集被参数化为一个工具集嵌入向量,我们将一组工具集嵌入表示为一个矩阵,即。假设我们已经训练了toolken嵌入,如图1所示,LLM默认处于推理模式,以生成下一个token。该框架允许LLM统一考虑单词token和工具token。具体来说,工具嵌入矩阵与连接。因此,LLM预测下一个token的概率如下: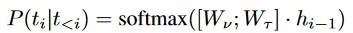 其中下一个token可以是词token,也可以是工具集,即,且[;]是拼接操作。我们将工具表述为toolken嵌入,自然允许通过扩展toolken嵌入矩阵来快速适应新工具。要执行工具,一旦其toolken被预测为下一个令牌(如图1中的“mode switch”所示),LLM将切换到“tool mode”,其目的是为工具生成参数。
其中下一个token可以是词token,也可以是工具集,即,且[;]是拼接操作。我们将工具表述为toolken嵌入,自然允许通过扩展toolken嵌入矩阵来快速适应新工具。要执行工具,一旦其toolken被预测为下一个令牌(如图1中的“mode switch”所示),LLM将切换到“tool mode”,其目的是为工具生成参数。
具体来说,LLM暂停生成并将当前生成的上下文附加到另一个提示符。工具模式下的提示由预测工具的上下文样例组成,展示如何通过引用特殊语法[tool]中的工具调用来生成工具参数。然后LLM可以在样例中遵循模式来完成当前工具调用的参数。与之前完全依赖上下文学习进行工具学习的方法相比,所提出框架只将完成论证的简单工作留给上下文学习。此外,对于单个指定工具的样例,将有丰富的上下文空间。最后,将参数发送到指定的工具执行,并将返回值发送回推理模式下的文本。
学习工具嵌入
该框架冻结了原始LLM的参数,并使用工具嵌入引入了最小的额外训练开销。该嵌入矩阵包含唯一需要优化的参数,但与其他有效的LLM微调方法不同,它不需要梯度流过LLM参数的主体,从而导致非常稳定和高效的训练。因此,toolken嵌入的微调与LLM推理使用了几乎相同的GPU内存。每当添加新工具时,toolken嵌入可以方便地扩展,然后,在涉及新工具的工具样例数据上的后续训练逐渐细化其嵌入。此外,与只将少数示例消化为训练信号的上下文学习方法不同,ToolkenGPT能够从大规模样例中调整工具嵌入。
本文主要关注通过工具样例学习工具嵌入,它可以是域内训练数据,也可以是LLM生成的合成数据。我们首先描述训练数据的格式和训练目标,并使用图1中的相同示例来展示如何将其用于训练。例如"the area is 256 square feet …"可以标记为token序列s=("the","area","is","2","5","6","square ","feet",…)。为了表明何时预测工具集,我们需要一个混合了词token和工具集的平行序列,即s'=(“the”,“area”,“is”,“[square]”,“[N/a]”,“[N/a]”,“square”,“feet”,…)。在s中(“2”,“5”,“6”)的子序列是返回的工具结果应该填充的地方,我们选择s'中对应的第一个token作为工具调用的工具,以下token填充[N/A],表示在损失计算中被忽略。因此,给定一个由配对序列D={(s,s')}组成的数据集,ToolkenGPT的训练目标为: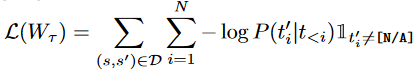
其中在公式1中定义了,是指示函数,表示我们在训练期间忽略[N/A]标记。因此,我们的训练过程在很大程度上与推理模式中的推理一致。
获取配对数据的方法主要有两种。首先,一些数据集与自然语言序列一起提供了基准事实工具调用。为了将数据用于监督学习,我们对其进行预处理,以获得训练所需的成对数据,如上文所述。其次,探索了用LLM合成工具样例,分享了与自指导类似的想法。对这个过程的直观解释是将LLM中的知识提取到新的工具嵌入中。具体来说,我们可以用工具文档和一些具有特殊语法指示工具调用的样例来提示LLM,例如,The capital of U.S. is <capital> ("U.S.")="Washington D.C."。在此基础上,LLM可以生成一些新的用例,这些用例利用给定的工具并使用相同的语法引用工具调用。然后,我们可以轻松地定位工具调用,并将数据处理为用于训练的成对数据。
实验
作者将ToolkenGPT应用于三个不同的应用:用于数值推理的算术工具、用于基于知识的问答的数据库API、用于具具计划生成的机器人动作。重点关注方法如何准确地调用工具,以及它们如何成功地解决任务。实验表明,ToolkenGPT可以有效地掌握大量工具,同时利用它们来解决复杂问题,性能有所提高,始终优于先进的提示技术。
数理推理
探索四个基本算术函数(+、−、×、÷)的可用性。此外,为了对更复杂数学问题中的工具处理能力进行基准测试,包括更多可用的工具,即扩展的函数集,并创建一组合成数据。结果表明,通过仅在合成数据上进行训练,ToolkenGPT显著优于基线。
数据集
为全面评估工具学习在数值推理方面的能力,策划了两个新的测试数据集:
GSM8K-XL:现有GSM8K数据集的增强版本。GSM8K是一个包含不同语言的小学数学应用题的数据集,涉及使用4种基本算术运算(+、−、×、÷)进行一系列计算,以得到最终答案。在测试集中,我们放大数字以增加LLMs的计算难度,这导致了GSM8K-XL数据集,具有568个具有更大数字的测试用例。
FuncQA:该数据集需要至少13个运算符(如power、sqrt、lcm)来解决,在没有外部计算器的情况下,人类和LLM都具有挑战性。将FuncQA分为两个子集:68个只需一次操作即可求解的单跳问题(one-hop question, FuncQAone)和60个需要少量推理步骤的多跳问题(multi-hop question, FuncQAmulti)。
对比方法
我们为每个可用的数学运算符训练toolken嵌入。在推理过程中,用4-shot思维链的例子来提示LLM。为了进行比较,对以下基线进行了评估:
使用ChatGPT作为基础LLM。这个基线衡量了LLM用其自身的推理和计算能力回答复杂数值推理问题的能力。
思维链(chain -of- thought, CoT)是一种更先进的提示技术。在这种方法中,精心设计了一系列相互关联的提示,以指导LLM一步步地推理过程。示例中的推理链与我们在ToolkenGPT中使用的推理链相同,但没有可用的函数。
ReAct通过促使LLM以交错的方式生成语言推理轨迹和工具调用,将推理和工具相结合。具体来说,不仅仅是提供推理链,还引入了特殊的语法来调用操作符。一旦在推理过程中检测到语法,就会调用该工具来计算结果。
结果分析
表2显示了所有方法在GSM8K-XL和FuncQA数据集上的性能。在GSM8K-XL数据集上,使用CoT的零样本ChatGPT和少样本学习在没有工具帮助的情况下很难计算大量的数字,而ReAct和ToolkenGPT设法以较大的幅度持续提高准确性。这两个方法都可以在必要时调用正确的工具,因为工具集只有4个基本操作符。
然而,对于FuncQAone和FuncQAmulti数据集,随着工具数量的增加,学习调用适用的工具变得具有挑战性。在ReAct中,尽管所有的工具都列在提示符的开头,但在有限的上下文中包括每个工具的样例是不可行的。因此,ReAct很容易受到缺少工具调用、错误的工具调用和预测错误的参数的影响,特别是对于没有在上下文中样例的工具。ToolkenGPT在单跳和多跳场景中都优于所有基线,当有许多工具时,显示出卓越的工具学习能力。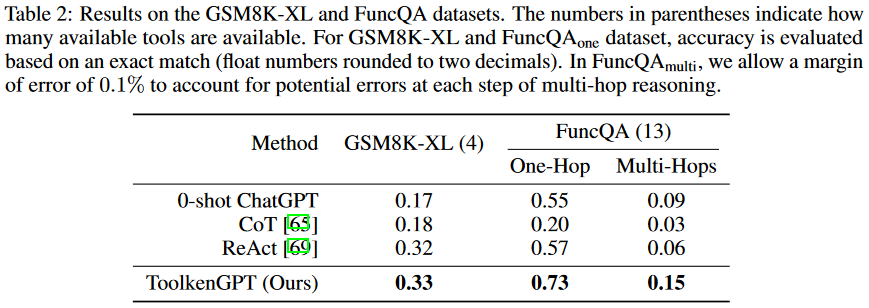
基于知识的问答
由于有限的知识限制,LLM经常犯事实错误和幻觉。让它们能够访问知识库(KBs)是一个有希望的研究方向,以减少它们的幻觉。我们将对知识库的访问表述为查询数据库的API。因此,每个关系查询都可以被视为一个工具,其输入参数是主题实体,输出是相应的尾部实体。
数据集
KAMEL是一个基于Wikidata的问答数据集。参照ToolFormer采用KAMEL来评估KB查询工具的使用情况。KAMEL包含了来自Wikidata的243个关系的知识,每个关系都与一个问题模板相关联,以便将Wikidata中的一个事实转换为一个问题。这个数据集总共有234个工具。为了分析不同数量工具的性能,我们从原始测试集中抽样创建了四个子集。每个子集由与不同数量关系相关的问题组成,分别对应于30、60、100和234。每个子集的大小是500。
对比方法
我们设置了两个不同的框架:
ToolkenGPT(sup):从KAMEL的训练集中每个关系采样200个示例,并通过监督学习训练toolken嵌入。该设置表示有足够的域内训练数据可用的真实场景。
ToolkenGPT(syn):假设域内训练数据不可用,使用每个关系的文本描述与ChatGPT合成训练数据,使用潜在的工具winner_of(NOBEL PEACE PRIZE IN 2020)→UNITED NATIONS WORLD FOOD PROGRAMME。平均使用40个示例来训练每个toolken嵌入。
本文提出以下比较基线:
提示:用LLM的内部知识回答问题。我们在" question:[QUESTION]\nThe answer is"提示符中构建每个问题,并让LLM继续这个句子。
上下文学习(ICL):在提出问题之前,我们列出所有可用工具的工具样例和描述。样例以特定的语法显示,以便LLM可以以类似的风格生成以进行解析。
上下文学习(desc):所有可用工具的描述将在上下文中提供,但它们的样例并不直接显示。相反,我们展示了测试子集中不包含的工具的样例。
所有方法的基本模型都是LLaMA-13B。
结果分析
我们在图2中展示了涉及不同数量关系的4个测试集上的实验结果。ToolkenGPT(sup)取得了最高的结果,表明在有大量域内训练数据时,学习toolken嵌入是一种有效的方法。相反,即使上下文学习也会在上下文中看到域内训练数据,但它仍然不清楚要调用哪些工具。此外,当要使用的工具超过30个时,上下文长度限制会导致性能急剧下降。多工具场景中的失败揭示了上下文学习范式的根本局限性。ToolkenGPT(syn)在所有子集中也优于所有其他基线。
合成训练数据通常与数据集具有非常不同的表达风格,但仍然有助于LLM理解这些关系。这一成功反映了该框架的灵活性,即使在没有域内训练数据可用的情况下也可以应用。上下文学习(desc)在这项任务中通常失败,因为LLM很难记忆在上下文中显示的文本描述并将其映射到关系标识符。该结果证实了LLM在使用不熟悉的工具时存在困难这一猜想。基于这种观察,我们有理由推测,LLM主要是从它们的标识符中回忆工具,而不是真正从它们的描述中学习使用工具。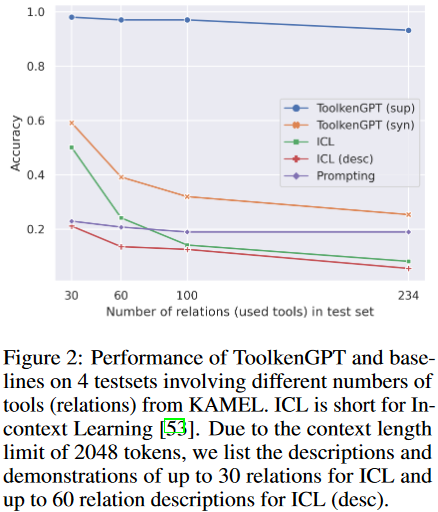
具身计划生成
最近,有许多研究尝试利用LLM作为具身智能体的控制器。我们也探索了所提出框架如何应用于具身智能体的计划生成。与之前提示LLM的方法相比,ToolkenGPT可以通过学习智能体动作和对象的toolken嵌入来更好地理解环境。
数据集
VirtualHome:一个典型家庭活动的仿真平台,活动程序知识库由许多可在VirtualHome中执行的任务和计划组成。从活动程序中得出297个任务的子集。对于每个任务,给模型一个高级目标(例如:“读书”)、详细的指令(例如:“我会躺在床上,打开书开始阅读”,以及对环境的描述,其中包括初始状态和环境的对象列表(例如:“我在[家庭办公室]。我可以操作的对象是['邮件','冰箱','电视',…,‘小说’)”。该模型被期望输出一个可执行的计划,它是一个动词-对象指令的有序列表。每个任务都有一个初始状态图和最终状态图,从而能够使用模拟器验证生成的计划,并将最终状态与真实状态进行比较。我们将数据集划分为包含247个任务的训练集和包含50个任务的测试集,数据集中总共使用了25个动词和32个对象。
对比方法
我们认为VirtualHome中的所有动作和对象都是工具。加上一个额外的[END]函数表示计划的结束,我们总共有58个工具。对于这个数据集,我们不需要图1中描述的参数生成过程,因为这些工具不接受参数。在推理过程中,ToolkenGPT交替生成动作工具和对象工具,并以[END]工具结束。toolken嵌入在训练集上进行训练。将该方法与以下基线进行了比较:
上下文学习:提示LLM并将其输出解析为计划。LLM显示了行动列表、3个样例计划和一个具有目标、详细描述和环境描述的新任务。
Translation:使用SentenceRoBERTa-large将动作或对象转换为具有最高余弦相似度的可用动作或对象。
Grounded Decoding:用affordance grounding函数,鼓励LLM生成有效的动作和对象。
结果分析
我们在表3中列出了结果。尽管使用上下文学习的LLM在上下文中明确列出了所有有效的动作和对象,但有时它不能将其预测作为可接受的指令的基础。即使动作和对象是有效的,但在VirtualHome中往往违反物理规律,导致成功率较低。ToolkenGPT不仅通过其设计自然地预测有效的动作和对象,而且还通过从更多的训练任务中学习toolken嵌入来实现最高的成功率。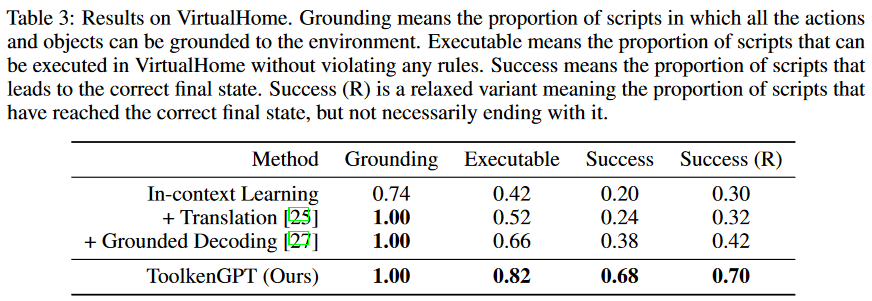 图3展示了一个具体的例子来说明差异。
图3展示了一个具体的例子来说明差异。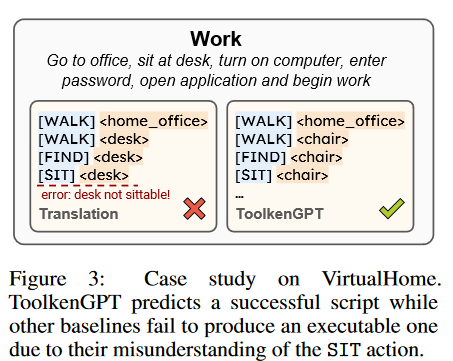
分析
计算损耗
通过实验比较了ToolkenGPT和微调在计算效率和性能方面的差异。本文在LLaMA-7B上实现了这两种方法。结果列在表4中。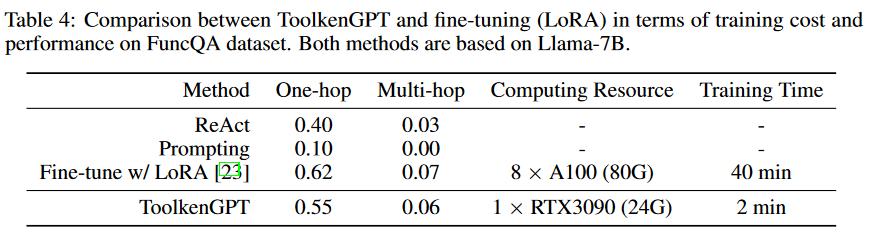 对LLMs进行微调后,在FuncQA上的性能略好于ToolkenGPT。即使我们应用了以效率著称的LoRA,但与训练工具嵌入相比,微调的时间消耗明显更长。
对LLMs进行微调后,在FuncQA上的性能略好于ToolkenGPT。即使我们应用了以效率著称的LoRA,但与训练工具嵌入相比,微调的时间消耗明显更长。
消融学习
ToolkenGPT的设计有利于工具选择和参数完成。为了理解它们各自对性能的贡献,我们进一步实现了一个将ReAct-style的提示和参数完成的子程序(工具模式)相结合的基线。在工具模式下,LLM只使用所选工具对样例进行提示,这将提供比ReAct提示更相关的知识。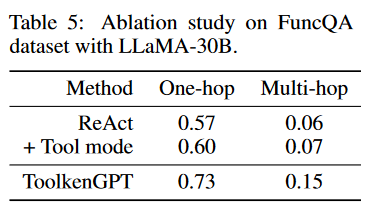 如表5所示,添加工具模式确实可以通过提高参数补全的准确性来改进普通的ReAct提示方法。然而,ToolkenGPT仍然在很大程度上优于这个改进的基线,这表明toolken嵌入有效地帮助LLM决定何时调用以及调用哪个工具。
如表5所示,添加工具模式确实可以通过提高参数补全的准确性来改进普通的ReAct提示方法。然而,ToolkenGPT仍然在很大程度上优于这个改进的基线,这表明toolken嵌入有效地帮助LLM决定何时调用以及调用哪个工具。
训练数据
因为有两种不同的训练数据来源,并且很容易处理或合成更多的数据,所以在KAMEL上扩展实验。对每个工具的ToolkenGPT(sup)和ToolkenGPT(syn)进行了10/20/40的训练样本采样,并报告了在包含30个工具的测试集上的精度。结果汇总在表6中。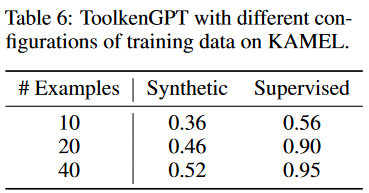 在相同的数据规模预算下,使用监督数据进行训练可以获得更好的性能。尽管在大多数合成数据实例中没有观察到明显的错误,但合成数据和测试集之间的分布差距可能会阻止toolken嵌入的良好表现。更大的训练集有利于提高两个数据源的性能。
在相同的数据规模预算下,使用监督数据进行训练可以获得更好的性能。尽管在大多数合成数据实例中没有观察到明显的错误,但合成数据和测试集之间的分布差距可能会阻止toolken嵌入的良好表现。更大的训练集有利于提高两个数据源的性能。
总结
提出了ToolkenGPT,一种用大量外部工具来增强LLM的新方法。该方法为每个工具引入了toolken嵌入的概念,使LLM能够像生成单词标记一样轻松地调用和使用不同的工具。该方法克服了当前微调和上下文学习范式的限制,使LLM能够适应更大的工具集,并使用广泛的样例数据来学习工具嵌入。ToolkenGPT能够快速适应和利用新工具,表明它有能力跟上不断发展的大规模工具的步伐。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
相关文章:
ToolkenGPT:用大量工具增强LLM
深度学习自然语言处理 原创作者:cola 用外部工具增强大型语言模型(LLM)已经成为解决复杂问题的一种方法。然而,用样例数据对LLM进行微调的传统方法,可能既昂贵又局限于一组预定义的工具。最近的上下文学习范式缓解了这一问题,但有…...

2022蓝桥杯c组求和
题目名字 求和 题目链接 题意 输入的每个数都要两两相乘,然后再加起来,求最后总和; 思路 每个数乘这个数的前缀和即可 算法一:前缀和 实现步骤 先把前缀和写出来再写for循环每个数都乘以自己的前缀和; 实现步骤 直接…...
Altium Designer学习笔记11
画一个LED的封装: 使用这个SMD5050的封装。 我们先看下这个芯片的功能说明: 5050贴片式发光二极管: XL-5050 是单线传输的三通道LED驱动控制芯片,采用的是单极性归零码协议。 数据再生模块的功能,自动将级联输出的数…...
TTS | 2019~2023年最新增强/生成情绪的语音合成调研(20231211更新版)
本博客主要是 增强/生成情绪的语音合成调研,论文按照时间顺序排列,且有些论文为期刊会议论文,有的是arxiv论文,在本文中,标识如下: 【🔊ICML 】【✨Interspeech 】【🫧ICASSP】 20…...

搜狗输入法v模式 | 爱莉希雅皮肤
搜狗输入法v模式 | 爱莉希雅皮肤 前言爱莉希雅皮肤v模式 前言 搜狗输入法有v模式,v模式是一个转换和计算的功能组合。拥有数字转换、日期转换、算式计算、函数计算等功能。本文介绍如何使用v模式,并附赠一个爱莉希雅的皮肤,可通过百度网盘下…...

2023年阿里云云栖大会-核心PPT资料下载
一、峰会简介 历经14届的云栖大会,是云计算产业的建设者、推动者、见证者。2023云栖大会以“科技、国际、年轻”为基调,以“计算,为了无法计算的价值”为主题,发挥科技平台汇聚作用,与云计算全产业链上下游的先锋代表…...

JavaScript实战:制作一个待办事项列表应用
JavaScript实战:制作一个待办事项列表应用 引言 在本教程中,我们将一步步创建一个简单的待办事项列表应用,这不仅会帮助你学习基本的JavaScript编程概念,还会教会你如何处理事件以及操作DOM。这个项目是面向初学者的,…...

4面百度软件测试工程师的面试经验总结
没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2023年7月,我有幸成为了百度的一名测试工程师,从外包辞职了历经1000…...
textarea文本框回车enter的时候自动提交表单,根据内容自动高度
切图网近期一个bootstrap5仿chatgpt页面的项目遇到的,textarea文本框回车enter的时候自动提交表单,根据内容自动高度,代码如下,亲测可用。 <textarea placeholder"Message ChatGPT…" name"" rows"&q…...
dubbo框架技术文档-《spring-boot整合dubbo框架搭建+配置文件》框架的本地基础搭建
阿丹: 目前流行的微服务更多的就是dubbo和springcould微服务。之前阿丹没有出过dubbo相关的文章,因为之前接触springcould的微服务概念比较多一点,但是相对于springcould来说,springcould服务之间的调用是大多是使用了nacos&#…...
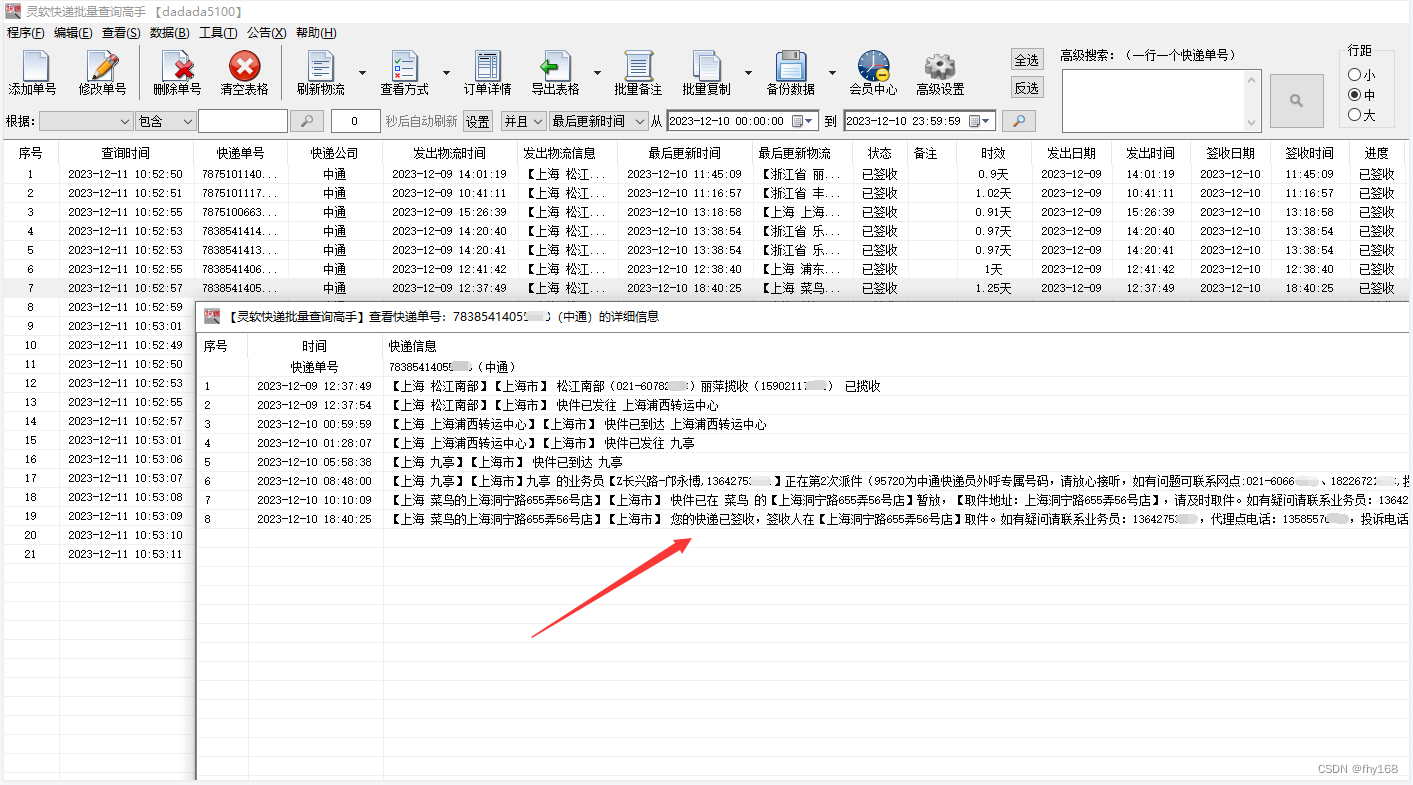
中通快递单号查询入口,将指定某天签收的单号筛选出来
批量查询中通快递单号的物流信息,将指定某天签收的单号筛选出来。 所需工具: 一个【快递批量查询高手】软件 中通快递单号若干 操作步骤: 步骤1:运行【快递批量查询高手】软件,并登录 步骤2:点击主界面左…...
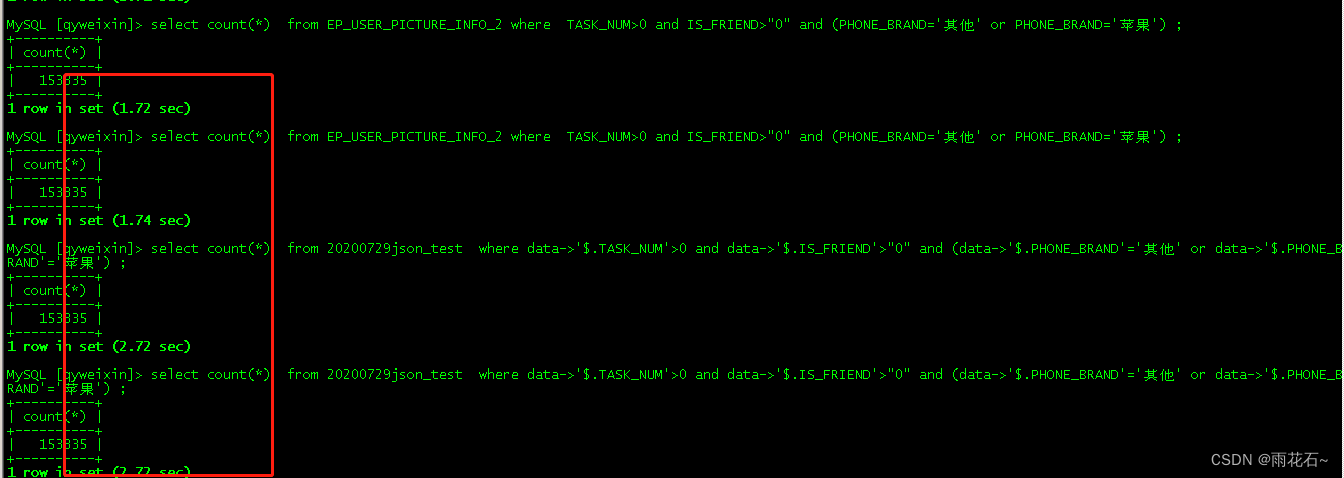
MySQL-含json字段表和与不含json字段表查询性能对比
含json字段表和与不含json字段表查询性能对比 说明: EP_USER_PICTURE_INFO_2:不含json字段表 20200729json_test:含有json字段表 其中20200729json_test 标准ID、MANAGER_NO、PHONE_NO 为非json字段 data为json字段 2个表中MANAGER_NO、PHONE_NO都创建了各自的索引 测试…...

如何用Docker快速搭建本地开发环境
📢 声明: 🍄 大家好,我是风筝 🌍 作者主页:【古时的风筝CSDN主页】。 ⚠️ 本文目的为个人学习记录及知识分享。如果有什么不正确、不严谨的地方请及时指正,不胜感激。 直达博主:「…...

SpringDataJPA基础
简介 Spring Data为数据访问层提供了熟悉且一致的Spring编程模版,对于每种持久性存储,业务代码通常需要提供不同存储库提供对不同CURD持久化操作。Spring Data为这些持久性存储以及特定实现提供了通用的接口和模版。其目的是统一简化对不同类型持久性存储…...
程序员如何成为自由的独立开发者?
你是不是那个整天坐在电脑前敲代码的程序员朋友?作为程序员,你是否也曾思考过如何成为一名独立开发者?思考过究竟如何踏上这段充满挑战和创造的旅程? 现在这个数码时代,技术不断演进,越来越多的程序员朋友…...

Ant Design Vue(v1.7.8)a-table组件的插槽功能
本案例中,编写了一个名为stockAdd的vue(v2.5.17)自定义组件,使用a-table组件的插槽功能,创建了一个可编辑的数据表格: 表格用于添加采购的物品,点“新增物品”按键,表格添加一行&…...

笔记69:Conv1d 和 Conv2d 之间的区别
笔记地址:D:\work_file\(4)DeepLearning_Learning\03_个人笔记\4. Transformer 网络变体 a a a a a a a a a a a...
关于马达保护器 的选型 你知道吗
一、智能马达保护器的介绍 在有色冶炼中,根据工艺需求和客户需求,智能电动机保护器的主要应用模式有保护模式、端子控制模式、全通信模式和半通信模式。 4.1保护模式 在保护模式下,智能电动机保护器只利用其自身的保护功能和测量功能&#…...

springboot(ssm高校竞赛管理系统 在线竞赛平台 Java系统
springboot(ssm高校竞赛管理系统 在线竞赛平台 Java系统 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0) 数…...
SDXL使用animateDiff和hotshot-xl进行文生视频
截至2023.12.8号,目前市面上有两款适用于SDXL的文生视频开源工具,分别是AnimateDiff和hotshot-xl。 一、工具下载链接 (1)AnimateDiff的webui版本的git链接: GitHub - continue-revolution/sd-webui-animatediff: A…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...