C++相关闲碎记录(15)
1、string字符串
#include <iostream>
#include <string>
using namespace std;int main (int argc, char** argv)
{const string delims(" \t,.;");string line;// for every line read successfullywhile (getline(cin,line)) {string::size_type begIdx, endIdx;// search beginning of the first wordbegIdx = line.find_first_not_of(delims);// while beginning of a word foundwhile (begIdx != string::npos) {// search end of the actual wordendIdx = line.find_first_of (delims, begIdx);if (endIdx == string::npos) {// end of word is end of lineendIdx = line.length();}// print characters in reverse orderfor (int i=endIdx-1; i>=static_cast<int>(begIdx); --i) {cout << line[i];}cout << ' ';// search beginning of the next wordbegIdx = line.find_first_not_of (delims, endIdx);}cout << endl;}
}
输入:ajsdk12345e.asfa \jkawefa
输出:e54321kdsja afsa afewakj\
(1)string各项操作

(2)构造函数和析构函数

data() 和 c_str()以字符数组的形式返回string内容,并且在该数组位置[size()]上有一个'\0'结束字符。copy()将string内容复制到调用者提供的字符数组中,其末尾不添加'\0'字符,注意,data()和c_str()返回的字符数组由该string拥有,也就是说,调用者不可以改动它或者释放其内存。
例如:
std::string s("12345");
atoi(s.c_str())
f(s.data, s.length())char buffer[100];
s.copy(buffer, 100); //copy at most 100 characters os s into buffer
s.copy(buffer, 200, 2); //copy at most 100 characters of s into buffer//starting with the third character of s一般而言,整个程序你应该坚持使用string,直到你必须将其内容转化为char*时,注意c_str()和data()的返回值的有效期在下一次调用non-const 成员函数时即告终止。
std::string s;
...
foo(s.c_str()); //s.c_str() is valid during the whole statementconst char* p;
p = s.c_str(); //p refers to the contents of s as a C-string
foo(p); //OK (p is still valid)
s += "ext"; //invalidates p
foo(p); //ERROR: argument p is not valid
(3)赋值操作
const std::string aString("othello");
std::string s;
s = aString;
s = "two\nlines";
a = ' ';
s.assign(aString);
s.assign(aString, 1, 3);
s.assign(aString, 2, std::string::npos);
s.assign("two\nlines");
s.assign("nico", 5);
s.assign(5, 'x');(4)安插和移除字符
const std::string aString("othello");
std::string s;
s += aString;
s += "two\nlines";
s += '\n';
s += {'o', 'k'};
s.append(aString);
s.append(aString, 1, 3); //append "the"
s.append(aString, 2, std::string::npos); // append "hello"
s.append("two\nlines");
s.append("nico", 5); //append character array 'n' 'i' 'c' '0' '\0'
s.append(5, 'x'); //append five characters 'x' 'x' 'x' 'x' 'x'
s.push_back('\n'); s.insert(1, aString);
//注意,成员函数insert()不接受索引+单字符的实参组合,必须传入一个string或者加上一个额外数字
s.insert(0, ' '); //ERROR
s.insert(0, " "); //OK
//你也可以这样尝试
s.insert(0, 1,' '); // ERROR : ambiguous
// 由于insert()具有以下重载形式,上一行会导致令人厌烦的歧义
insert(size_type idx, size_type num, charT c); //position is index
insert(iterator pos, size_type num, charT c); //position is iterator
string的size_type通常被定义为unsigned,string的iterator通常被定义为char*。
于是第一实参0有两种转换可能,不分优劣,为了获得正确的操作,必须使用如下:
s.insert((std::string::size_tpye)0, 1, ' '); //OKstd::string s = "i18n"; //s:i18n
s.replace(1, 2, "nternationalizatio"); //s:internationalization
s.erase(13); //s:international
s.erase(7, 5); //s:internal
s.pop_back(); //s:interna(since C++11)
s.replace(0, 2, "ex"); //s:externa(5)子字符串和字符串拼接
std::string s("interchangeability");
s.substr() //returns a copy of s
s.substr(11) //returns string("ability")
s.substr(5, 6); //returns string("change")
s.substr(s.find('c')); //returns string("changeability")(6)getline()
读取一行字符,包括前导空白字符,遇到换行或者end-of-file,分行符会被读取出来,但是不会添加到结果上,默认分行符是换行符号,也可以自定义任意符号作为分行符。
while(std::getline(std::cin,s)) {}
while(std::getline(std::cin, s, ':')){}如果自定义了分行符,则换行符就被当做普通字符。
(7)搜索查找
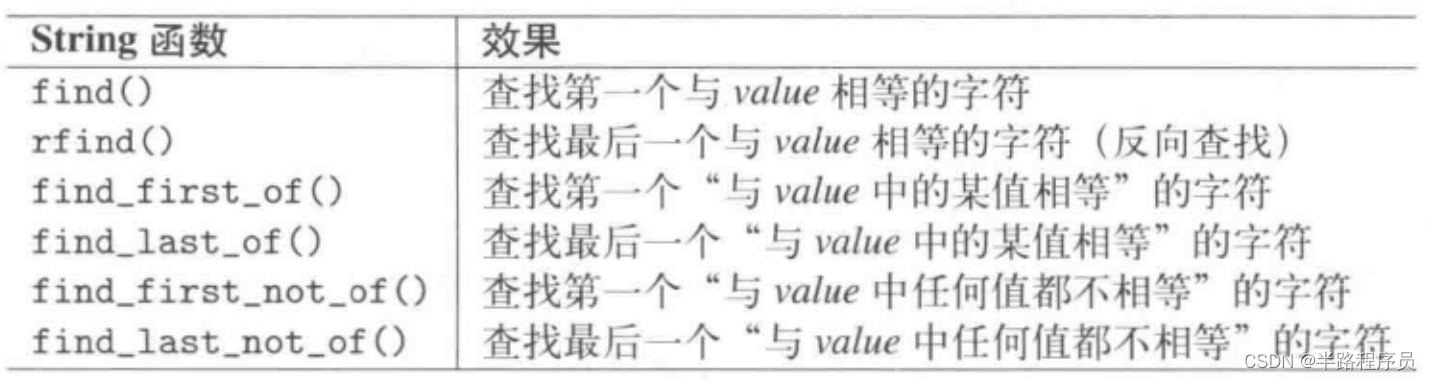
std::string s("Hi Bill, I'm ill, so please pay the bill");
s.find("il"); //returns 4
s.find("il", 10); //returns 13
s.rfind("il"); //returns 37
s.find_first_of("il"); //returns 1
s.find_last_of("il"); //returns 39
s.find_first_not_of("il"); //returns 0
s.find_last_not_of("il"); //returns 36
s.find("hi"); //returns npos(8)npos的意义
如果查找失败,会返回string::npos,使用string的npos值及其类型时要格外小心,若要检查函数返回值,一定要使用类型string::size_type,不能使用int或unsigned作为返回值类型,否则返回值与string::npos之间的比较可能无法正确执行,这是因为npos被设置为-1。
事实上(unsigned long)-1与(unsigned short)-1不同,因此对于下列表达式:
idx == std::string::npos,如果idx的值为-1,由于idx和string::npos类型不同,比较结果可能会是false。
(9)数值转换
自C++11起,C++标准库提供了一些便捷函数,用来将string转换为数值或者反向转换,但是只适用于类型string或者wstring类型,不适用于u16string和u32string。
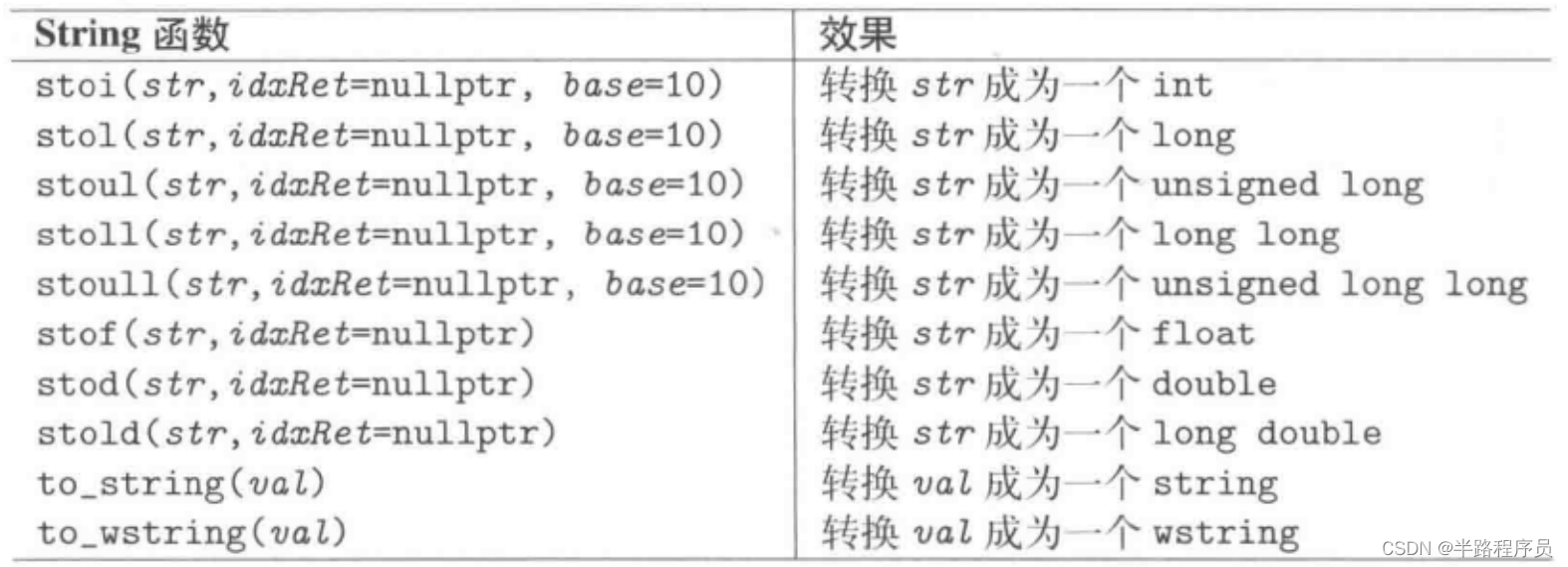
#include <string>
#include <iostream>
#include <limits>
#include <exception>int main()
{try {// convert to numeric typestd::cout << std::stoi (" 77") << std::endl;std::cout << std::stod (" 77.7") << std::endl;std::cout << std::stoi ("-0x77") << std::endl;// use index of characters not processedstd::size_t idx;std::cout << std::stoi (" 42 is the truth", &idx) << std::endl;std::cout << " idx of first unprocessed char: " << idx << std::endl;// use bases 16 and 8std::cout << std::stoi (" 42", nullptr, 16) << std::endl;std::cout << std::stol ("789", &idx, 8) << std::endl;std::cout << " idx of first unprocessed char: " << idx << std::endl;// convert numeric value to stringlong long ll = std::numeric_limits<long long>::max();std::string s = std::to_string(ll); // converts maximum long long to stringstd::cout << s << std::endl;// try to convert backstd::cout << std::stoi(s) << std::endl; // throws out_of_range}catch (const std::exception& e) {std::cout << e.what() << std::endl;}
}
输出:
77
77.7
0
42idx of first unprocessed char: 4
66
7idx of first unprocessed char: 1
9223372036854775807
stoistd::stoi("-0x77")只会解析-0,std::stol("789", &idx, 8)只解析7,因为8在8进制中是一个无效字符。
(10)string iterator使用实例

#include <string>
#include <iostream>
#include <algorithm>
#include <cctype>
#include <regex>
using namespace std;int main()
{// create a stringstring s("The zip code of Braunschweig in Germany is 38100");cout << "original: " << s << endl;// lowercase all characterstransform (s.cbegin(), s.cend(), // sources.begin(), // destination[] (char c) { // operationreturn tolower(c);});cout << "lowered: " << s << endl;// uppercase all characterstransform (s.cbegin(), s.cend(), // sources.begin(), // destination[] (char c) { // operationreturn toupper(c);});cout << "uppered: " << s << endl;// search case-insensitive for Germanystring g("Germany");string::const_iterator pos;pos = search (s.cbegin(),s.cend(), // source string in which to searchg.cbegin(),g.cend(), // substring to search[] (char c1, char c2) { // comparison criterionreturn toupper(c1) == toupper(c2);});if (pos != s.cend()) {cout << "substring \"" << g << "\" found at index "<< pos - s.cbegin() << endl;}
}
输出:
original: The zip code of Braunschweig in Germany is 38100
lowered: the zip code of braunschweig in germany is 38100
uppered: THE ZIP CODE OF BRAUNSCHWEIG IN GERMANY IS 38100
substring "Germany" found at index 32
(11)为string打造trait class,允许以大小写无关的方式操作字符
#ifndef ICSTRING_HPP
#define ICSTRING_HPP#include <string>
#include <iostream>
#include <cctype>// replace functions of the standard char_traits<char>
// so that strings behave in a case-insensitive way
struct ignorecase_traits : public std::char_traits<char> {// return whether c1 and c2 are equalstatic bool eq(const char& c1, const char& c2) {return std::toupper(c1)==std::toupper(c2);}// return whether c1 is less than c2static bool lt(const char& c1, const char& c2) {return std::toupper(c1)<std::toupper(c2);}// compare up to n characters of s1 and s2static int compare(const char* s1, const char* s2,std::size_t n) {for (std::size_t i=0; i<n; ++i) {if (!eq(s1[i],s2[i])) {return lt(s1[i],s2[i])?-1:1;}}return 0;}// search c in sstatic const char* find(const char* s, std::size_t n,const char& c) {for (std::size_t i=0; i<n; ++i) {if (eq(s[i],c)) {return &(s[i]);}}return 0;}
};// define a special type for such strings
typedef std::basic_string<char,ignorecase_traits> icstring;// define an output operator
// because the traits type is different from that for std::ostream
inline
std::ostream& operator << (std::ostream& strm, const icstring& s)
{// simply convert the icstring into a normal stringreturn strm << std::string(s.data(),s.length());
}#endif // ICSTRING_HPP#include "icstring.hpp"int main()
{using std::cout;using std::endl;icstring s1("hallo");icstring s2("otto");icstring s3("hALLo");cout << std::boolalpha;cout << s1 << " == " << s2 << " : " << (s1==s2) << endl;cout << s1 << " == " << s3 << " : " << (s1==s3) << endl;icstring::size_type idx = s1.find("All");if (idx != icstring::npos) {cout << "index of \"All\" in \"" << s1 << "\": "<< idx << endl;}else {cout << "\"All\" not found in \"" << s1 << endl;}
}
输出:
hallo == otto : false
hallo == hALLo : true
index of "All" in "hallo": 1相关文章:
C++相关闲碎记录(15)
1、string字符串 #include <iostream> #include <string> using namespace std;int main (int argc, char** argv) {const string delims(" \t,.;");string line;// for every line read successfullywhile (getline(cin,line)) {string::size_type beg…...
汽车IVI中控开发入门及进阶(十一):ALSA音频
前言 汽车中控也被称为车机、车载多媒体、车载娱乐等,其中音频视频是非常重要的部分,音频比如播放各种格式的音乐文件、播放蓝牙接口的音乐、播放U盘或TF卡中的音频文件,如果有视频文件也可以放出音频,看起来很简单,在windows下音乐播放器很多,直接打开文件就能播放各…...
Gradle 之初体验
文章目录 1.安装1)检查 JDK2)下载 Gradle3)解压 Gradle4)环境变量5)验证安装 2.优势总结 Gradle 是一款强大而灵活的构建工具,用于自动化构建、测试和部署项目。它支持多语言、多项目和多阶段的构建&#x…...
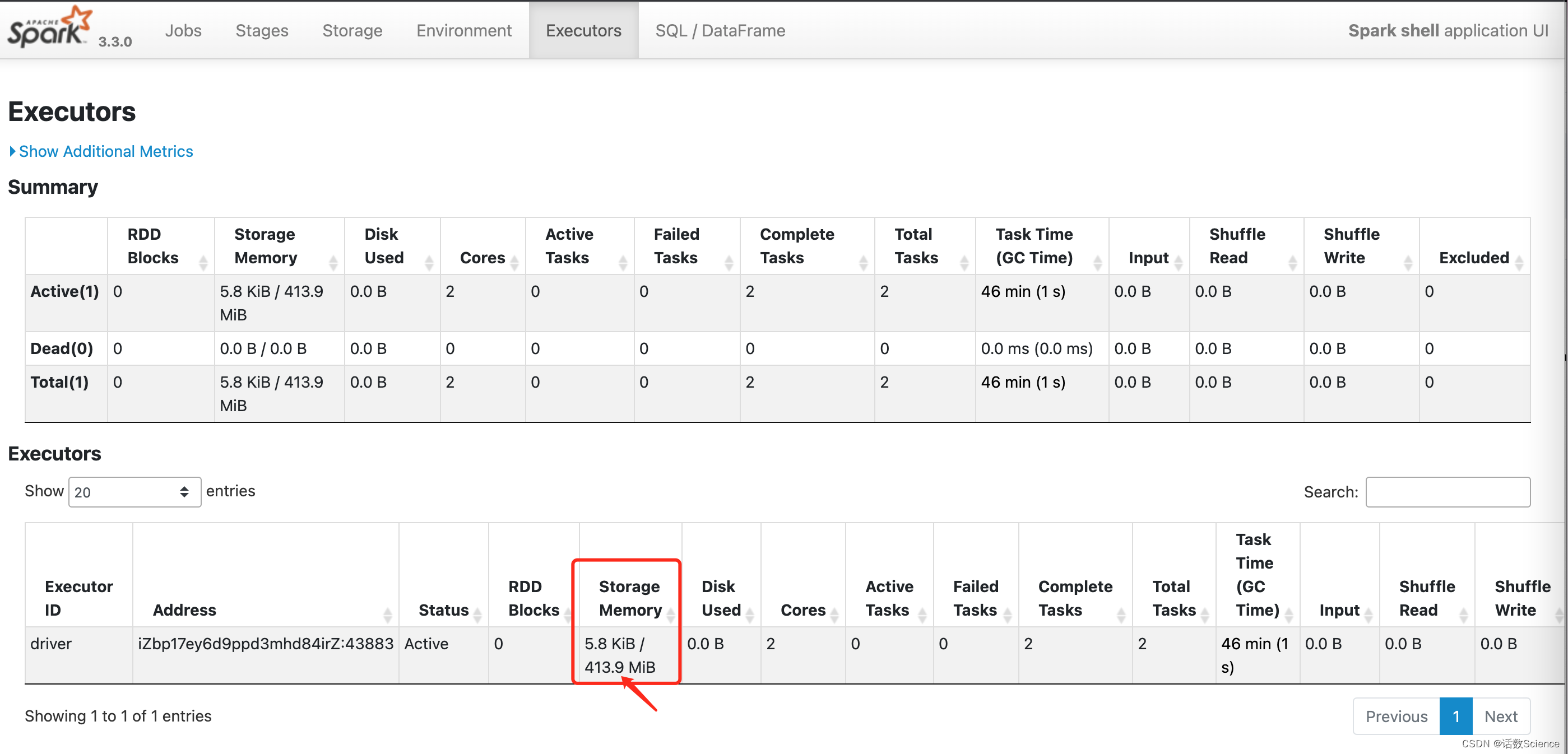
【Spark精讲】Spark内存管理
目录 前言 Java内存管理 Java运行时数据区 Java堆 新生代与老年代 永久代 元空间 垃圾回收机制 JVM GC的类型和策略 Minor GC Major GC 分代GC Full GC Minor GC 和 Full GC区别 Executor内存管理 内存类型 堆内内存 堆外内存 内存管理模式 静态内存管理 …...

C语言实现Hoare版快速排序(递归版)
Hoare版 快速排序是由Hoare发明的,所以我们先来讲创始人的想法。我们直接切入主题,Hoare版快速排序的思想是将一个值设定为key,这个值不一定是第一个,如果你选其它的值作为你的key,那么你的思路也就要转换一下…...

git 避免输入用户名 密码 二进制/文本 文件冲突解决
核心概念介绍 工作区是你当前正在进行编辑和修改的文件夹,可见的。 暂存区位于.git/index(git add放入)。 代码库(工作树)位于.git(git commit将暂存区中的更改作为一个提交保存到代码库中,并清空暂存区) 避免输入用户 密码: 方式一: ht…...

[OpenWrt]RAX3000一根线实现上网和看IPTV
背景: 1.我家电信宽带IPTV 2.入户光猫,桥接模式 3.光猫划分vlan,将上网信号IPTV信号,通过lan口(问客服要光猫超级管理员密码,具体教程需要自行查阅,关键是要设置iptv在客户侧的vlan id&#…...
最新50万字312道Java经典面试题52道场景题总结(附答案PDF)
最近有很多粉丝问我,有什么方法能够快速提升自己,通过阿里、腾讯、字节跳动、京东等互联网大厂的面试,我觉得短时间提升自己最快的手段就是背面试题;花了3个月的时间将市面上所有的面试题整理总结成了一份50万字的300道Java高频面…...

html.parser --- 简单的 HTML 和 XHTML 解析器
源代码: Lib/html/parser.py 这个模块定义了一个 HTMLParser 类,为 HTML(超文本标记语言)和 XHTML 文本文件解析提供基础。 class html.parser.HTMLParser(*, convert_charrefsTrue) 创建一个能解析无效标记的解析器实例。 如果…...

赵传和源代码就是设计-UMLChina建模知识竞赛第4赛季第23轮
参考潘加宇在《软件方法》和UMLChina公众号文章中发表的内容作答。在本文下留言回答。 只要最先答对前3题,即可获得本轮优胜。第4题为附加题,对错不影响优胜者的判定,影响的是优胜者的得分。 所有题目的回答必须放在同一条消息中࿰…...
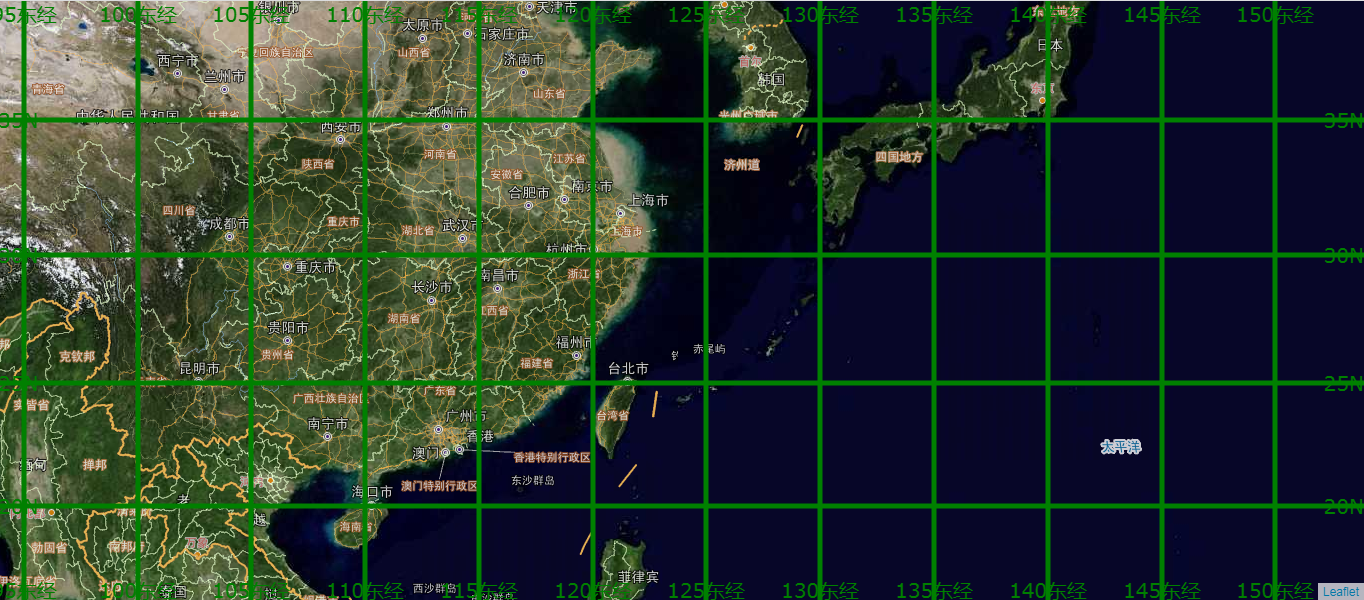
Leaflet.Graticule源码分析以及经纬度汉化展示
目录 前言 一、源码分析 1、类图设计 2、时序调用 3、调用说明 二、经纬度汉化 1、改造前 2、汉化 3、改造效果 总结 前言 在之前的博客基于Leaflet的Webgis经纬网格生成实践中,已经深入介绍了Leaflet.Graticule的实际使用方法和进行了简单的源码分析。认…...
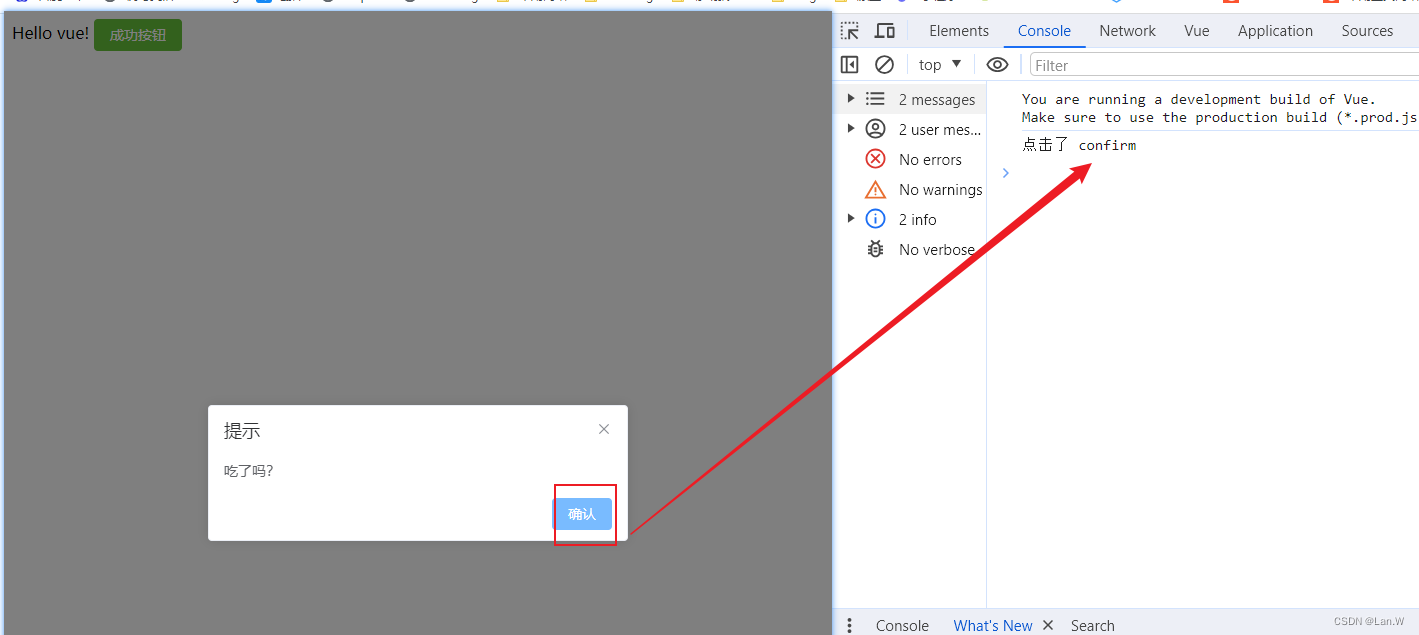
html 中vue3 的setup里调用element plus的弹窗 提示
引入Elementplus之后,在setup()方法外面导入ElMessageBox const {ElMessageBox} ElementPlus 源码 : <!DOCTYPE html> <html> <head><meta charset"UTF-8"><!-- import Vue before Elemen…...
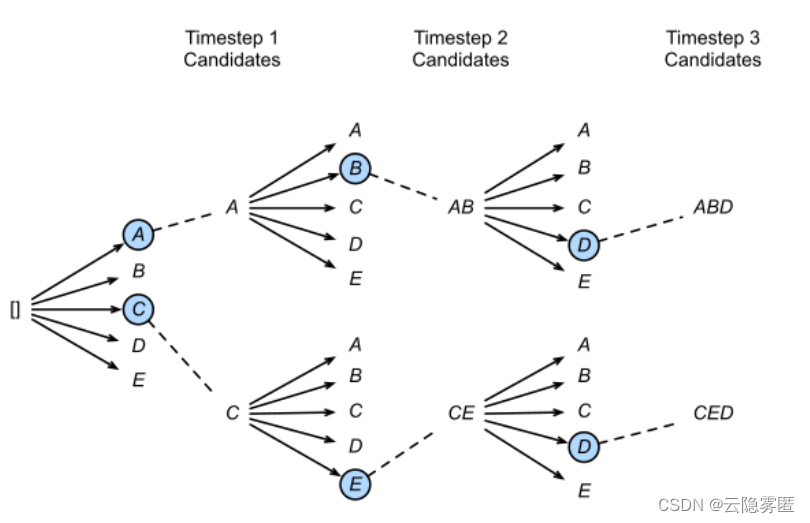
对话系统之解码策略(Top-k Top-p Temperature)
一、案例分析 在自然语言任务中,我们通常使用一个预训练的大模型(比如GPT)来根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,…...
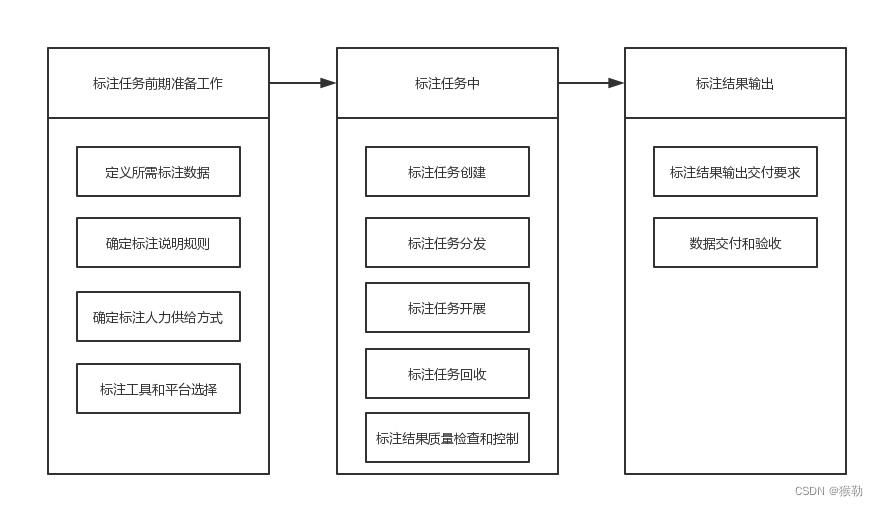
《面向机器学习的数据标注规程》摘录
说明:本文使用的标准是2019年的团体标准,最新的国家标准已在2023年发布。 3 术语和定义 3.2 标签 label 标识数据的特征、类别和属性等。 3.4 数据标注员 data labeler 对待标注数据进行整理、纠错、标记和批注等操作的工作人员。 【批注】按照定义…...

VGG(pytorch)
VGG:达到了传统串型结构深度的极限 学习VGG原理要了解CNN感受野的基础知识 model.py import torch.nn as nn import torch# official pretrain weights model_urls {vgg11: https://download.pytorch.org/models/vgg11-bbd30ac9.pth,vgg13: https://download.pytorch.org/mo…...

celery/schedules.py源码精读
BaseSchedule类 基础调度类,它定义了一些调度任务的基本属性和方法。以下是该类的主要部分的解释: __init__(self, nowfun: Callable | None None, app: Celery | None None):初始化方法,接受两个可选参数,nowfun表…...
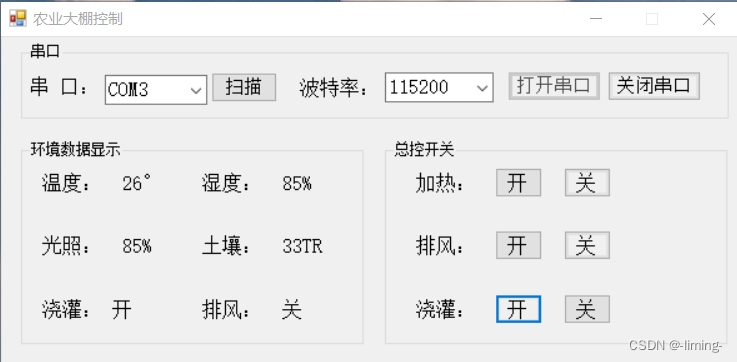
单片机上位机(串口通讯C#)
一、简介 用C#编写了几个单片机上位机模板。可定制!!! 二、效果图...

初识Flask
摆上中文版官方文档网站:https://flask.github.net.cn/quickstart.html 开启实验之路~~~~~~~~~~~~~ from flask import Flaskapp Flask(__name__) # 使用修饰器告诉flask触发函数的URL,绑定URL,后面的函数用于返回用户在浏览器上看到的内容…...

JeecgBoot jmreport/queryFieldBySql RCE漏洞复现
0x01 产品简介 Jeecg Boot(或者称为 Jeecg-Boot)是一款基于代码生成器的开源企业级快速开发平台,专注于开发后台管理系统、企业信息管理系统(MIS)等应用。它提供了一系列工具和模板,帮助开发者快速构建和部署现代化的 Web 应用程序。 0x02 漏洞概述 Jeecg Boot jmrepo…...
机器学习---模型评估
1、混淆矩阵 对以上混淆矩阵的解释: P:样本数据中的正例数。 N:样本数据中的负例数。 Y:通过模型预测出来的正例数。 N:通过模型预测出来的负例数。 True Positives:真阳性,表示实际是正样本预测成正样…...

Windows下OpenClaw保姆级教程:Phi-3-mini-128k-instruct模型接入指南
Windows下OpenClaw保姆级教程:Phi-3-mini-128k-instruct模型接入指南 1. 为什么选择OpenClawPhi-3-mini组合 去年我在处理日常文档工作时,发现大量重复性操作占据了80%的时间——整理会议纪要、生成周报草稿、批量重命名文件。直到偶然在技术社区看到O…...

从数据小白到战斗大师:GBFR Logs如何帮你玩转《碧蓝幻想:Relink》
从数据小白到战斗大师:GBFR Logs如何帮你玩转《碧蓝幻想:Relink》 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/…...

Dubbo 框架核心解析与手写实现思路
在微服务架构中,远程服务调用是最基础、最核心的能力。RPC 作为分布式系统的通信基石,让跨进程、跨机器的方法调用像本地调用一样简单。Apache Dubbo 作为国内最主流的 Java RPC 框架,从单纯的远程调用组件,逐步演进为一站式微服务…...

工业机器人离线编程与仿真——RobotStudio基础学习3.27
工业机器人离线编程与仿真——RobotStudio基础学习 一、工业机器人离线编程认知 1.1 工业机器人常用编程方法 工业机器人主流编程方法分为示教编程和离线编程两类,二者核心差异体现在编程环境、对生产的影响等方面,具体对比见下表: 示教编…...

res-downloader资源捕获完全指南:从证书配置到多平台资源下载的解决方案
res-downloader资源捕获完全指南:从证书配置到多平台资源下载的解决方案 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloade…...

OpenClaw跨平台控制:千问3.5-9B远程操作家中电脑
OpenClaw跨平台控制:千问3.5-9B远程操作家中电脑 1. 为什么需要远程控制家中电脑? 去年冬天的一个深夜,我正躺在异地酒店的床上,突然想起家里电脑上还有个未完成的报表需要提交。如果按照传统方式,我可能需要麻烦家人…...

令牌管理:AI开发中的成本控制与效率优化——Tiktokenizer全维度应用指南
令牌管理:AI开发中的成本控制与效率优化——Tiktokenizer全维度应用指南 【免费下载链接】tiktokenizer Online playground for OpenAPI tokenizers 项目地址: https://gitcode.com/gh_mirrors/ti/tiktokenizer 一、行业痛点分析:AI开发中的隐形成…...

如何解决OpenHTMLtoPDF在容器化环境中的字体加载NullPointerException问题
如何解决OpenHTMLtoPDF在容器化环境中的字体加载NullPointerException问题 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section…...

如何进行有效的友链seo优化_seo优化需要注意哪些要点
如何进行有效的友链SEO优化 在网络世界中,SEO(搜索引擎优化)是提升网站可见性和流量的关键手段之一。而在SEO优化的过程中,友链(友情链接)也是一种重要的手段。如何进行有效的友链SEO优化,是许…...
揭秘Zotero PDF Translate离线翻译方案:学术研究数据安全新范式
揭秘Zotero PDF Translate离线翻译方案:学术研究数据安全新范式 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode.com/gh…...