【论文解读】ICLR 2024高分作:ViT需要寄存器
来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://arxiv.org/abs/2309.16588
摘要:
Transformer最近已成为学习视觉表示的强大工具。在本文中,我们识别并表征监督和自监督 ViT 网络的特征图中的伪影。这些伪影对应于推理期间主要出现在图像的低信息背景区域中的高范数标记,这些标记被重新用于内部计算。我们提出了一个简单而有效的解决方案,基于向 Vision Transformer 的输入序列提供额外的令牌来填补该角色。我们表明,该解决方案完全解决了监督模型和自监督模型的问题,为密集视觉预测任务上的自监督视觉模型设定了新的技术水平,支持使用更大模型的对象发现方法,最重要的是,用于下游视觉处理的更平滑的特征图和注意力图。
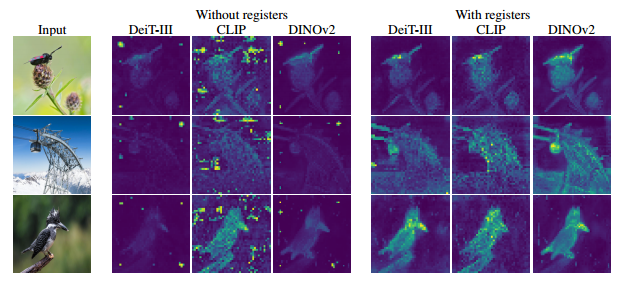
图 1:注册令牌在所有视觉转换器中启用可解释的注意力图,类似于原始的 DINO 方法。注意力图以高分辨率计算,以获得更好的可视化效果。附录 D 提供了更多定性结果。
1.引言
将图像嵌入到可用于计算机视觉中多种目的的通用特征中一直是一个长期存在的问题。在数据规模和深度学习技术允许端到端训练之前,第一种方法依赖于手工原理,例如 SIFT。追求通用特征嵌入在今天仍然有意义,因为为许多特定任务收集有价值的注释数据仍然很困难。这种困难的出现是由于所需的专业知识(例如医疗数据或遥感)或大规模成本。如今,通常为有大量可用数据的任务预训练模型,并提取模型的子集用作特征提取器。多种方法提供了这种可能性;基于分类或文本图像对齐的监督方法允许训练强大的特征模型来解锁下游任务。另外,基于 Transformer 架构的自监督方法因其对下游任务的高预测性能以及某些模型提供无监督分割的有趣能力而引起了广泛关注。

图 2:在现代视觉转换器的注意力图中观察到的伪影的插图。我们考虑使用标签监督 (DeiT-III)、文本监督 (OpenCLIP) 或自我监督(DINO 和 DINOv2)训练的 ViT。有趣的是,除了 DINO 之外的所有模型在注意力图中都表现出峰值异常值。这项工作的目标是了解并减轻这种现象。
特别是,DINO 算法被证明可以生成包含有关图像语义布局的明确信息的模型。事实上,定性结果表明,最后一个注意力层自然地关注图像的语义一致部分,并且通常会生成可解释的注意力图。利用这些特性,LOST等对象发现算法构建在 DINO 之上。此类算法可以通过收集注意力图中的信息来在没有监督的情况下检测对象。他们有效地开启了计算机视觉的新领域。
DINOv2是 DINO 的后续版本,提供了可以处理密集预测任务的功能。 DINOv2 功能通过冻结主干网和线性模型实现了成功的单目深度估计和语义分割。尽管在密集任务上表现强劲,但我们观察到 DINOv2 与 LOST 令人惊讶地不兼容。当用于提取特征时,它的性能令人失望,仅与此场景中的受监督替代主干网相当。这表明 DINOv2 的行为与 DINO 不同。这项工作中描述的调查显着暴露了 DINOv2 特征图中存在的伪影,而这些伪影在该模型的第一个版本中并不存在。这些可以使用简单的方法定性地观察到。同样令人惊讶的是,将相同的观察结果应用于监督视觉变换器会暴露出类似的伪影,如图 2 所示。这表明 DINO 实际上是一个例外,而 DINOv2 模型与视觉变换器的基线行为相匹配。
在这项工作中,我们着手更好地理解这种现象并开发检测这些伪影的方法。我们观察到它们是输出范数大约高 10 倍的标记,并且对应于总序列的一小部分(大约 2%)。我们还表明,这些标记出现在ViT的中间层周围,并且它们仅在对足够大的ViT进行足够长的训练之后才出现。特别是,我们表明这些离群标记出现在与其邻居相似的补丁中,这意味着补丁几乎没有传达额外的信息。
作为我们调查的一部分,我们使用简单的线性模型评估异常标记,以了解它们包含的信息。我们观察到,与非离群标记相比,它们保留的有关其在图像中的原始位置或其块中的原始像素的信息较少。这一观察结果表明,模型在推理过程中丢弃了这些补丁中包含的本地信息。另一方面,在异常值补丁上学习图像分类器比在其他补丁上学习图像分类器产生的准确度要高得多,这表明它们包含有关图像的全局信息。我们对这些元素提出以下解释:模型学习识别包含很少有用信息的补丁,并回收相应的标记来聚合全局图像信息,同时丢弃空间信息。
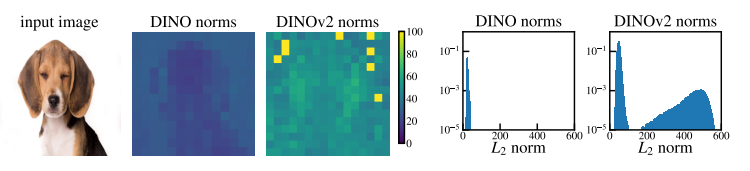
图 3:DINO ViT-B/16 和 DINOv2 ViT-g/14 的局部特征规范比较。我们观察到 DINOv2 有一些异常补丁,而 DINO 不存在这些伪影。对于 DINOv2,虽然大多数补丁令牌的范数在 0 到 100 之间,但一小部分令牌的范数非常高。我们测量范数大于 150 的代币比例为 2.37%。
这种解释与ViT模型中的内部机制一致,该机制允许在一组受限的令牌内执行计算。为了测试这个假设,我们将额外的标记(我们称之为寄存器)附加到标记序列中,独立于输入图像。我们训练了经过和不经过这种修改的几个模型,并观察到异常值标记完全从序列中消失。因此,模型在密集预测任务中的性能得到提高,并且生成的特征图明显更加平滑。这些平滑的特征图使对象发现方法(如上面提到的 LOST)与更新的模型成为可能。
2.问题表述
如图 2 所示,大多数现代视觉变换器在注意力图中表现出伪影。无监督的 DINO 主干网此前因其局部特征的质量和注意力图的可解释性而受到赞扬。令人惊讶的是,后续 DINOv2 模型的输出已被证明保留了良好的局部信息,但在注意力图中表现出了不良的伪影。在本节中,我们建议研究这些伪影出现的原因和时间。虽然这项工作的重点是减轻所有视觉 Transformer 中的伪影,但我们的分析重点是 DINOv2。
2.1 DINOV2 局部特征中的工件
文物是高标准的离群标记。 我们希望找到一种定量的方法来表征局部特征中出现的人工制品。我们观察到,“工件”补丁和其他补丁之间的一个重要区别是它们在模型输出中嵌入的标记规范。在图 3(左)中,我们比较了给定参考图像的 DINO 和 DINOv2 模型的局部特征范数。我们清楚地看到,伪影补丁的规范远高于其他补丁的规范。我们还在图 3(右)中绘制了小图像数据集上特征范数的分布,这显然是双峰的,这使我们能够为本节的其余部分选择一个简单的标准:将考虑范数高于 150 的标记作为“高标准”代币,我们将研究它们相对于常规代币的属性。这个精心挑选的截止值可能因型号而异。在这项工作的其余部分中,我们交替使用“高范数”和“异常值”。
在大型模型的训练过程中会出现异常值。我们对 DINOv2 训练期间这些异常值斑块出现的条件进行了一些额外的观察。该分析如图 4 所示。首先,这些高范数补丁似乎与该 40 层 ViT 第 15 层周围的其他补丁区分开来(图 4a)。其次,当观察 DINOv2 训练过程中的范数分布时,我们发现这些异常值仅在三分之一的训练后出现(图 4b)。最后,当更仔细地分析不同尺寸的模型(Tiny、Small、Base、Large、Huge 和 Giant)时,我们发现只有三个最大的模型表现出异常值(图 4c)。
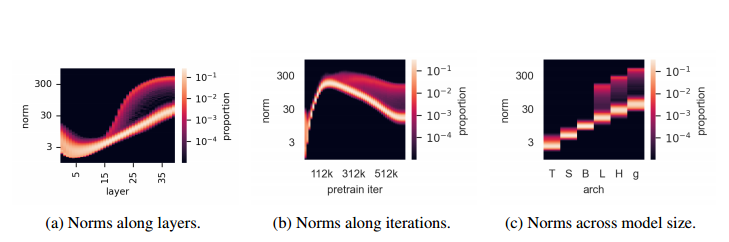
图 4:40 层 DINOv2 ViT-g 模型中离群标记的几个属性的图示。(a):输出标记范数沿层的分布。 (b):训练迭代中的范数分布。 (c):不同模型尺寸的范数分布。训练期间,异常值出现在模型的中间附近;它们与大于并包括 ViT-Large 的型号一起出现。
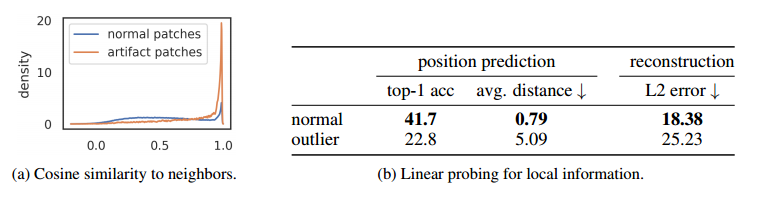
图 5:(a):输入块与其 4 个相邻块之间的余弦相似度分布。我们分别绘制伪影补丁(输出标记的范数超过 150)和正常补丁。 (b):对正常和异常补丁标记的本地信息探测。我们训练两种模型:一种用于预测位置,另一种用于重建输入补丁。异常标记的分数比其他标记低得多,这表明它们存储的本地补丁信息较少。
高范数标记出现在补丁信息冗余的地方。 为了验证这一点,我们在补丁嵌入层之后(在视觉转换器的开头)测量高范数标记与其 4 个邻居之间的余弦相似度。我们在图 5a 中展示了密度图。我们观察到高范数标记出现在与其邻居非常相似的补丁上。这表明这些补丁包含冗余信息,并且模型可以丢弃它们的信息而不损害图像表示的质量。这与定性观察结果(见图 2)相匹配,即它们经常出现在均匀的背景区域中。
高范数标记出现在补丁信息冗余的地方。为了验证这一点,我们在补丁嵌入层之后(在视觉转换器的开头)测量高范数标记与其 4 个邻居之间的余弦相似度。我们在图 5a 中展示了密度图。我们观察到高范数标记出现在与其邻居非常相似的补丁上。这表明这些补丁包含冗余信息,并且模型可以丢弃它们的信息而不损害图像表示的质量。这与定性观察结果(见图 2)相匹配,即它们经常出现在均匀的背景区域中。
高范数令牌几乎不包含本地信息。为了更好地理解这些标记的性质,我们建议探测不同类型信息的补丁嵌入。为此,我们考虑两个不同的任务:位置预测和像素重建。对于每一个任务,我们在补丁嵌入之上训练一个线性模型,并测量该模型的性能。我们比较高范数令牌和其他令牌所实现的性能,看看高范数令牌是否包含与“普通”令牌不同的信息。
• 位置预测。我们训练一个线性模型来预测图像中每个补丁标记的位置,并测量其准确性。我们注意到,该位置信息以绝对位置嵌入的形式注入到第一个 ViT 层之前的标记中。我们观察到,高范数标记的准确度比其他标记低得多(图 5b),这表明它们包含的有关其在图像中位置的信息较少。
• 像素重建。我们训练一个线性模型来根据补丁嵌入预测图像的像素值,并测量该模型的准确性。我们再次观察到,高范数令牌的准确率比其他令牌低得多(图 5b)。这表明高范数标记比其他标记包含更少的用于重建图像的信息。
工件保存着全局信息。 为了评估高范数标记中收集了多少全局信息,我们建议在标准图像表示学习基准上评估它们。对于分类数据集中的每个图像,我们通过 DINOv2-g 转发它并提取补丁嵌入。从这些中,我们随机选择一个标记,无论是高范数还是普通标记。然后将该标记视为图像表示。然后,我们训练逻辑回归分类器以根据该表示来预测图像类别,并测量准确性。我们观察到高范数标记的准确度比其他标记高得多(表 1)。这表明离群标记比其他补丁标记包含更多的全局信息。
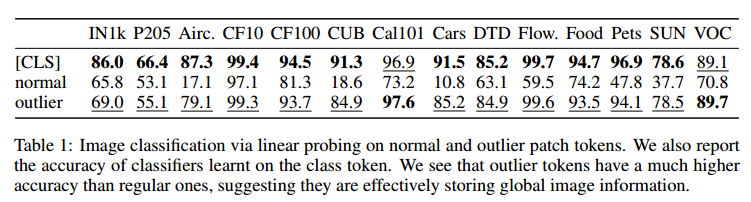
表 1:通过对正常和异常值补丁标记进行线性探测进行图像分类。我们还报告了在类标记上学习的分类器的准确性。我们发现离群标记的准确性比常规标记高得多,这表明它们有效地存储了全局图像信息。
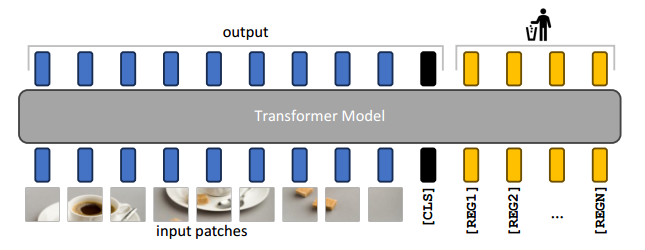
图 6:建议的补救措施和结果模型的图示。我们添加了 N 个额外的可学习输入标记(以黄色表示),模型可以将其用作寄存器。在模型的输出中,在训练和推理期间仅使用补丁标记和 CLS 标记。
2.2 假设和修正
做出这些观察后,我们做出以下假设:经过充分训练的大型模型学习识别冗余标记,并将它们用作存储、处理和检索全局信息的位置。此外,我们认为虽然这种行为本身并不坏,但它发生在补丁令牌内部的事实是不可取的。事实上,它导致模型丢弃局部补丁信息(表 5b),可能会导致密集预测任务的性能下降。
因此,我们提出了一个简单的解决方案来解决这个问题:我们明确地将新的标记添加到序列中,模型可以学习将其用作寄存器。我们在补丁嵌入层之后添加这些标记,具有可学习的值,类似于 [CLS] 标记。在视觉转换器的最后,这些标记被丢弃,并且 [CLS] 标记和补丁标记像往常一样用作图像表示。该机制首次在 Memory Transformers中提出,改进了 NLP 中的翻译任务。有趣的是,我们在这里表明,这种机制承认视觉转换器的自然合理性,解决了否则存在的可解释性和性能问题。
我们注意到,我们还无法完全确定训练的哪些方面导致了 DINOv2 中出现伪影,但在 DINO 中则不然,但图 4 表明将模型大小扩展到 ViT-L 之外,并且更长的训练长度可能会更好。可能的原因。
3.实验
在本节中,我们通过使用附加的 [reg] 寄存器标记训练视觉转换器来验证所提出的解决方案。我们通过定量和定性分析来评估我们方法的有效性。然后,我们减少用于训练的寄存器数量,以检查它们是否不会导致性能回归,评估我们特征之上的无监督对象发现方法,最后对寄存器学习的模式进行定性分析。
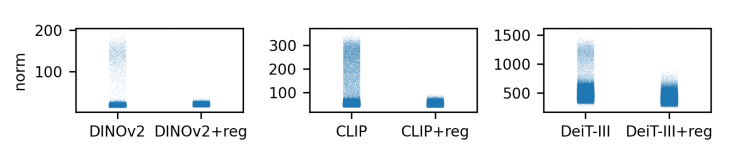
图 7:寄存器令牌对 DINOv2、CLIP 和 DeiTIII 上输出规范分布的影响。使用寄存器令牌可以有效地消除先前存在的规范异常值。
3.1 训练算法和数据
由于所提出的解决方案是一个简单的架构更改,因此我们可以轻松地将其应用于任何训练过程。我们尝试了三种不同的最先进的监督学习、文本监督学习和无监督学习训练方法,如下所述。
DEIT-III是一种简单而强大的监督训练方法,用于在 ImageNet-1k 和 ImageNet-22k 上使用 ViT 进行分类。我们选择这种方法作为标签监督训练的示例,因为它很简单,使用基本 ViT 架构,实现了强大的分类结果,并且易于通过我们的改进来重现和修改。我们使用官方存储库 1 中提供的 ViT-B 设置在 ImageNet-22k 数据集上运行此方法。
OpenCLIP是一种强大的训练方法,用于生成文本图像对齐模型,遵循原始 CLIP 工作。我们选择这种方法作为文本监督训练的示例,因为它是开源的,使用基本 ViT 架构,并且很容易通过我们的改进来重现和修改。我们在基于 Shutterstock 的文本图像对齐语料库上运行 OpenCLIP 方法,该语料库仅包含许可的图像和文本数据。我们使用官方存储库 2 中建议的 ViT-B/16 图像编码器。
DINOv2是一种学习视觉特征的自监督方法,遵循前面提到的 DINO 工作。我们将更改应用于此方法,因为它是我们研究的主要焦点。我们在具有 ViT-L 配置的 ImageNet-22k 上运行此方法。我们使用官方存储库 3 中的代码。
3.2 评估建议的解决方案
如图 1 所示,我们通过使用额外的寄存器标记训练模型来消除伪影。在附录中,我们为图 14 中的更多图像提供了额外的定性结果。为了定量测量这种效果,对于每个模型,我们探测模型输出的特征范数。我们在图 7 中报告了带有和不带有寄存器的所有三种算法的这些范数。我们看到,在使用寄存器进行训练时,模型在输出中没有表现出大范数标记,这证实了最初的定性评估。
性能回归。在上一节中,我们已经展示了所提出的方法从局部特征图中删除了伪影。在这个实验中,我们想要检查注册令牌的使用不会影响这些特征的表示质量。我们对 ImageNet 分类、ADE20k 分割和 NYUd 单目深度估计进行线性探测。我们遵循 Oquab 等人中概述的实验方案。我们总结了第 2 节中描述的模型的性能。 3.1 有和没有寄存器标记见表2a。我们看到,当使用寄存器时,模型不会损失性能,有时甚至工作得更好。为了完整起见,我们还提供了 OpenCLIP 的 ImageNet 上的零样本分类性能(表 2b),该性能保持不变。请注意,由于我们使用的数据源,我们的 OpenCLIP 复制的绝对性能较低。
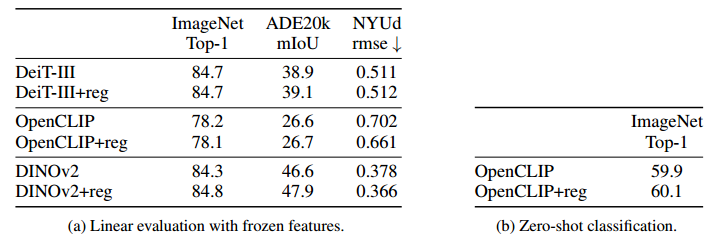
表 2:我们训练的模型(有或没有寄存器)的下游性能评估。我们考虑对所有三个模型的冻结特征进行线性探测,并对 OpenCLIP 模型进行零样本评估。我们发现使用寄存器不仅不会降低性能,甚至在某些情况下还可以略微提高性能。
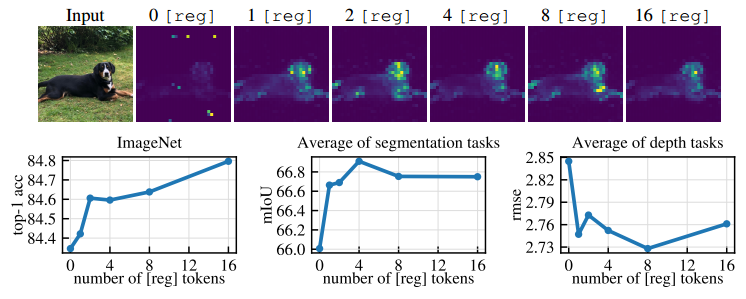
图 8:DINOv2 模型使用的寄存器令牌数量的减少。 (上):作为寄存器数量函数出现的伪像的定性可视化。 (下):三个任务(ImageNet、ADE-20k 和 NYUd)的性能与所用寄存器数量的函数关系。虽然一个寄存器足以消除伪影,但使用更多寄存器可以提高下游性能。
注册令牌的数量。如第 2 节所述。 2.2,我们建议通过添加寄存器标记来减轻特征图的伪影。在这个实验中,我们研究了此类令牌的数量对局部特征和下游性能的影响。我们使用 0、1、2、4、8 或 16 个寄存器训练 DINOv2 ViT-L/14 模型。在图 8 中,我们报告了该分析的结果。在图 8(上)中,我们定性研究了注意力图,并观察到当添加至少一个寄存器时可见伪影消失。然后,我们按照 Oquab 等人的协议,在图 8(底部)中检查下游评估基准的性能。对于密集任务来说,似乎存在最佳的寄存器数量,增加一个寄存器可以带来最大的好处。这种最佳效果可能是由于伪影的消失而导致更好的局部特征。然而,在 ImageNet 上,使用更多寄存器时性能会提高。在我们所有的实验中,我们保留了 4 个寄存器令牌。
3.3 对象发现
最近的无监督对象发现方法依赖于局部特征图的质量和平滑度。通过利用 DINO Caron 等人,这些方法显着超越了之前的最先进技术。然而,当应用于 DINOv2 Oquab 等人等现代骨干网或 Touvron 等人的监督骨干网时,该算法会导致性能不佳。我们认为可以通过本工作中提出的方法来缓解这种情况。我们使用第 3.1 节中描述的算法(带或不带寄存器)对从训练的骨干网络中提取的特征运行 LOST。我们在 PASCAL VOC 2007 和 2012 以及 COCO 20k 上运行对象发现。对于 DeiT 和 OpenCLIP,我们使用值;对于 DINOv2,我们使用键。由于输出特征可能具有不同的条件,因此我们手动向特征的克矩阵添加偏差。该实验的结果如表 3 所示。对于所有模型和所有数据集,添加用于训练的寄存器可以提高无监督对象发现性能。 DINOv2 在 VOC2007 上的性能仍然无法与 Simeoni 等人的工作中报告的 DINO 相匹配。然而,带有寄存器的模型得到了 20.1 corloc 的改进(55.4 vs 35.3)。
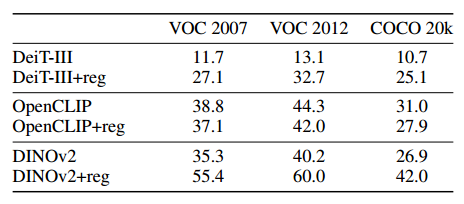
表 3:在具有和不具有寄存器的模型上使用 LOST进行无监督对象发现。我们评估了在 VOC 2007、2012 和 COCO 上接受不同程度监督训练的三种模型。我们使用 corloc 来衡量性能。我们观察到,添加寄存器令牌使所有模型在对象发现中使用更加可行。

图 9:[CLS] 和寄存器标记的注意力图比较。注册令牌有时会以类似于槽注意力的方式关注特征图的不同部分。请注意,模型从来没有要求这种行为,而是在训练中自然出现的。
3.4 寄存器的定性评估
在最后的实验中,我们定性地探讨了注册令牌的行为。我们想要验证它们是否都表现出相似的注意力模式,或者是否会自动出现差异。为此,我们绘制了该类的注意力图,并注册标记来修补标记。可视化的结果如图 9 所示。我们看到寄存器没有完全对齐的行为。一些选定的寄存器表现出有趣的注意力模式,关注场景中的不同对象。虽然没有任何东西强制这种行为,但它们的激活具有一些自然的多样性。我们把对寄存器正规化的研究留到以后的工作。
4.相关工作
4.1 使用预训练模型进行特征提取
自从在 ImageNet-1k上预训练 AlexNetCNN 模型以来,使用预训练的神经网络模型来提取视觉特征已经经受住了时间的考验。最近的模型已经使用现代架构升级了相同的设置,例如 ResNet(用于 DETR、Carion 等人,2020 年)甚至 Vision Transformers。由于 Transformers 在训练过程中能够轻松处理不同的模式,因此现成的主干网络现在通常在标签监督(例如 ImageNet-22k 上的 DeiT-III)或文本监督(例如 CLIP (Radford) 上进行训练) et al, 2021)),提供强大的视觉基础模型,可以很好地缩放模型大小,并在检测和分割。
在这种情况下,监督依赖于标签或文本对齐形式的注释;数据集偏差尚未得到很好的表征,但它们推动了学习并塑造了学习模型。另一种方法是不使用监督,让模型通过旨在要求理解图像内容的借口任务从数据中学习。使用 Vision Transformers 通过多种方法探索了这种自我监督学习范式:MAE(He et al, 2022)训练模型来重建图像隐藏区域的像素值,然后应用微调来解决新任务。采用不同的方法,自蒸馏方法系列展示了使用冻结主干的强大性能,使得特定任务下游的域转换具有更强的鲁棒性楷模。
在这项工作中,我们将分析重点放在自监督学习上,更具体地说是 DINOv2 方法,该方法已被证明对于学习局部特征特别有效。我们表明,尽管基准测试得分很高,但 DINOv2 功能仍表现出不良的伪影,并且在学习过程中纠正这些伪影可以进一步提高基准性能。这些现象更加令人惊讶,因为 DINOv2 建立在 DINO 之上,而 DINO 没有表现出伪影的迹象。然后,我们通过在 DeiT-III 和 CLIP 上进行测试进一步表明,校正技术也适用于监督训练范例。
4.2 Transformers 中的附加代币
使用特殊标记扩展 Transformer 序列在 BERT 中得到了普及。然而,大多数方法都会添加新令牌,要么为网络提供新信息,例如 BERT 中的 [SEP] 令牌和 AdaTape 中的磁带令牌,要么收集这些令牌中的信息,并使用它们的输出值作为模型的输出:
• 用于分类:作为 BERT 和 ViT 中的 [CLS] 标记
• 用于生成学习:如 BERT 和 BEiT 中的 [MASK]
• 用于检测:作为 DETR 中的对象查询、YOLOS 中的检测令牌和 ViDT;
• 用于在解码之前从可能的多种模态中积累信息,作为感知器中的潜在标记数组。
与这些作品不同的是,我们添加到序列中的标记不添加任何信息,并且它们的输出值不用于任何目的。它们只是寄存器,模型可以在前向传递过程中学习存储和检索信息。与我们的工作更接近的 Memory Transformer提出了一种简单的方法,使用添加到标记序列的记忆标记来改进 Transformer 模型,从而提高翻译性能。在后续工作中,Bulatov 等人解决了复杂的复制-重复-反向任务。 Sandler 等人将这条线扩展到视觉领域进行微调,但观察到此类标记不能很好地跨任务转移。相反,我们在预训练阶段不进行微调并使用额外的标记来改进下游所有任务获得的特征。更重要的是,我们的研究在第 2 节中提供了以下新见解。 2:通过记忆代币实现的机制已经自然地出现在 Vision Transformers 中;我们的研究表明,此类代币使我们无法创建而是隔离这种现有行为,从而避免附带副作用。
5.结论
在这项工作中,我们暴露了 DINOv2 模型的特征图中的伪影,并发现这种现象存在于多个现有的流行模型中。我们描述了一种简单的方法来检测这些伪影,方法是观察它们对应于 Transformer 模型输出处具有离群规范值的标记。通过研究它们的位置,我们提出了一种解释,该解释可以自然地从低信息区域回收令牌,并将它们重新调整为不同的推理角色。根据这种解释,我们提出了一个简单的修复方案,包括向输入序列附加不用作输出的额外标记,并且发现这完全消除了伪影,提高了密集预测和对象发现的性能。此外,我们还表明,所提出的解决方案还消除了 DeiT-III 和 OpenCLIP 等监督模型中存在的相同工件,从而证实了我们解决方案的通用性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ViT200”获取全部190+篇ViT论文+代码合集
码字不易,欢迎大家点赞评论收藏!
相关文章:
【论文解读】ICLR 2024高分作:ViT需要寄存器
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2309.16588 摘要: Transformer最近已成为学习视觉表示的强大工具。在本文中,我们识别并表征监督和自监督 ViT 网络的特征图中的伪影。这些…...
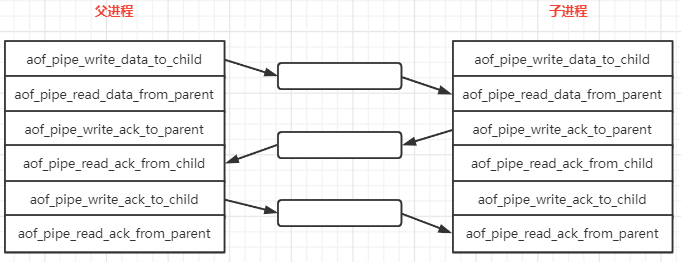
【Redis】AOF 基础
因为 Redis AOF 的实现有些绕, 就分成 2 篇进行分析, 本篇主要是介绍一下 AOF 的一些特性和依赖的其他函数的逻辑,为下一篇 (Redis AOF 源码) 源码分析做一些铺垫。 AOF 全称: Append Only File, 是 Redis 提供了一种数据保存模式, Redis 默认不开启。 AOF 采用日志的形式来记…...
C语言—每日选择题—Day50
一天一天的更新,也是达到50天了,精选的题有250道,博主累计做了不下500道选择题,最喜欢的题型就是指针和数组之间的计算呀,不知道关注我的小伙伴是不是一直在坚持呢?文末有投票,大家可以投票让博…...
[C/C++]——内存管理
学习C/C的内存管理 前言:一、C/C的内存分布二、C语言中动态内存管理方式三、C中动态内存管理方式3.1、new/delete操作符3.1.2、new/delete操作内置类型3.1.3、new/delete操作自定义类型 3.2、认识operator new和operator delete函数3.3、了解new和delete的实现原理3…...
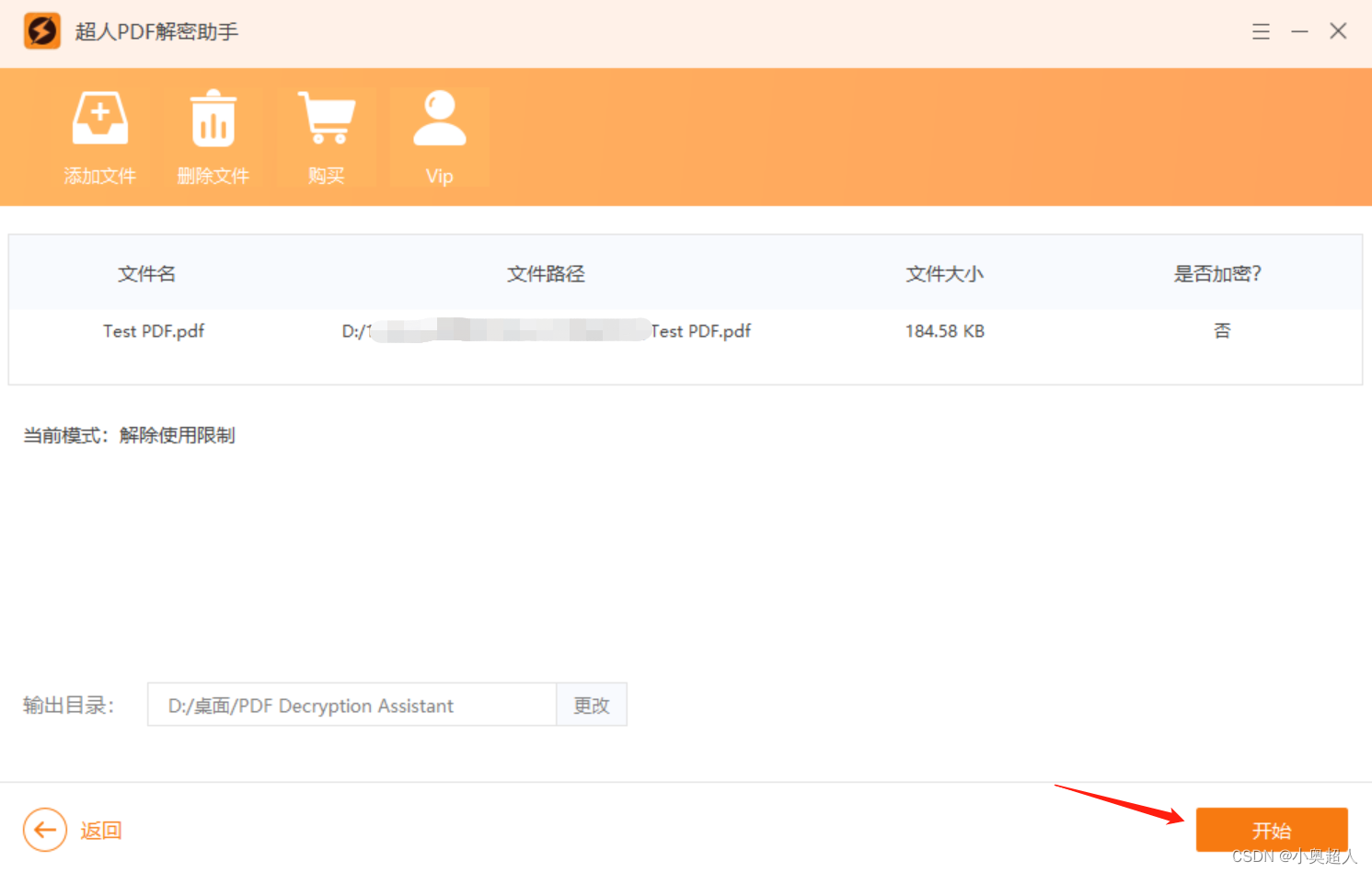
PDF文件的限制编辑,如何设置?
想要给PDF文件设置一个密码防止他人对文件进行编辑,那么我们可以对PDF文件设置限制编辑,设置方法很简单,我们在PDF编辑器中点击文件 – 属性 – 安全,在权限下拉框中选中【密码保护】 然后在密码保护界面中,我们勾选【…...
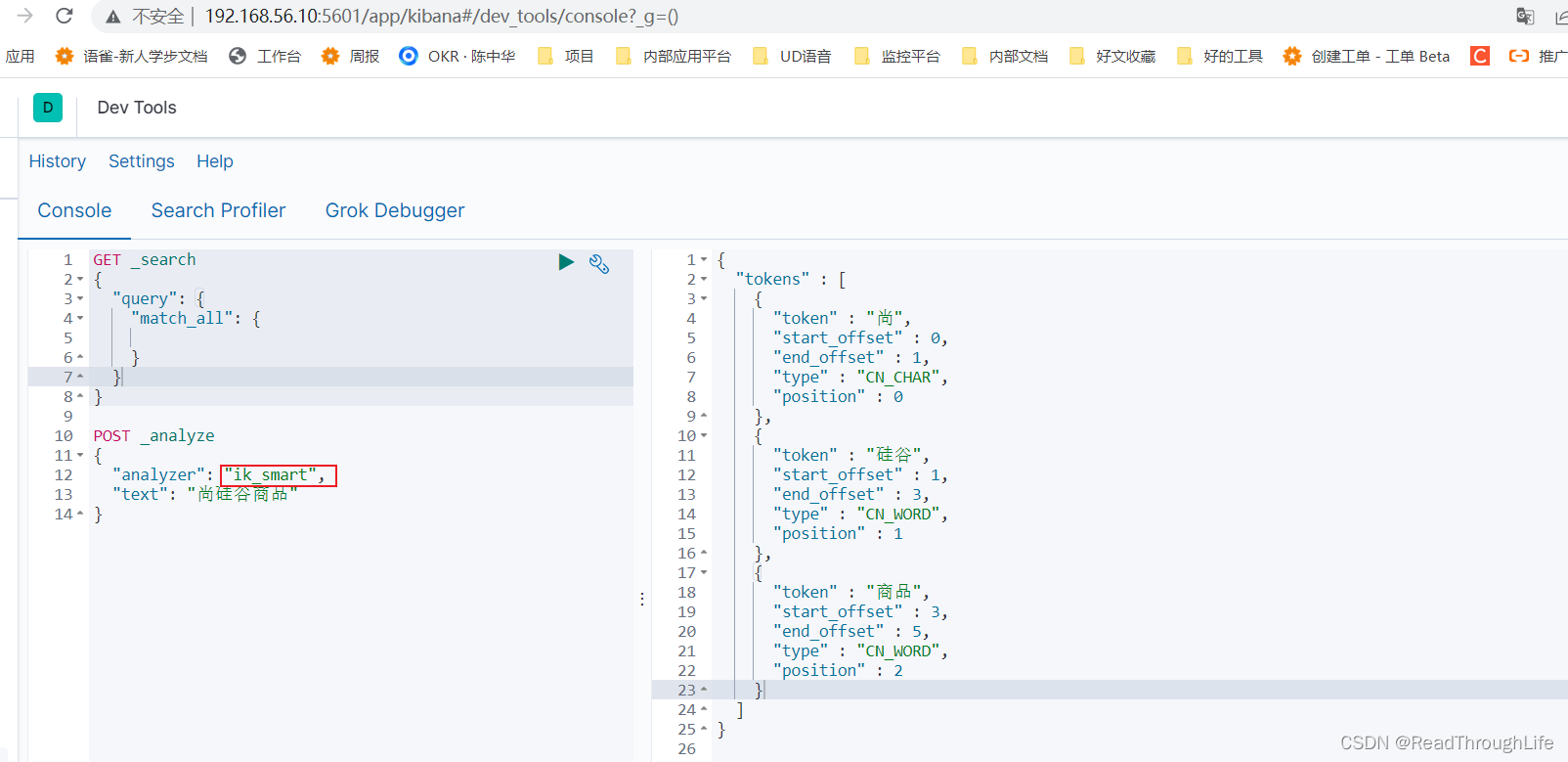
Linux 中使用 docker 安装 Elasticsearch 及 Kibana
Linux 中使用 docker 安装 Elasticsearch 及 Kibana 安装 Elasticsearch 和 Kibana安装分词插件 ik_smart 安装 Elasticsearch 和 Kibana 查看当前运行的镜像及本地已经下载的镜像,确认之前没有安装过 ES 和 Kibana 镜像 docker ps docker images从远程镜像仓库拉…...

在Flutter中使用PhotoViewGallery指南
介绍 Flutter中的PhotoViewGallery是一个功能强大的插件,用于在应用中展示可缩放的图片。无论是构建图像浏览器、相册应用,还是需要在应用中查看大图的场景,PhotoViewGallery都是一个不错的选择。 添加依赖 首先,需要在pubspec…...

c语言中的static静态(1)static修饰局部变量
#include<stdio.h> void test() {static int i 1;i;printf("%d ", i); } int main() {int j 0;while (j < 5){test();j j 1;}return 0; } 在上面的代码中,static修饰局部变量。 当用static定义一个局部变量后,这时局部变量就是…...

生信算法4 - 获取overlap序列索引和序列的算法
生信序列基本操作算法 建议在Jupyter实践,python版本3.9 1. 获取overlap序列索引和序列的算法实现 # min_length 最小overlap碱基数量3个 def getOverlapIndexAndSequence(a, b, min_length3):""" Return length of longest suffix of a matching…...

springboot 学习网站
Spring Boot 系列教程https://www.docs4dev.com/ Spring Boot 教程汇总 http://www.springboot.wiki/ Spring Cloud 微服务教程 http://www.springboot.wiki/ 1、自定义banner https://www.cnblogs.com/cc11001100/p/7456145.html 2、事件和监听器 https://blog.csd…...
论文笔记:A review on multi-label learning
一、介绍 传统的监督学习是单标签学习,但是现实中一个实例可能对应多个标签。这篇文章介绍了多标签分类的定义和评价指标、多标签学习的算法还有其他相关的任务。 二、问题相关定义 2.1 多标签学习任务 假设 X R d X R^d XRd,表示d维的输入空间&am…...
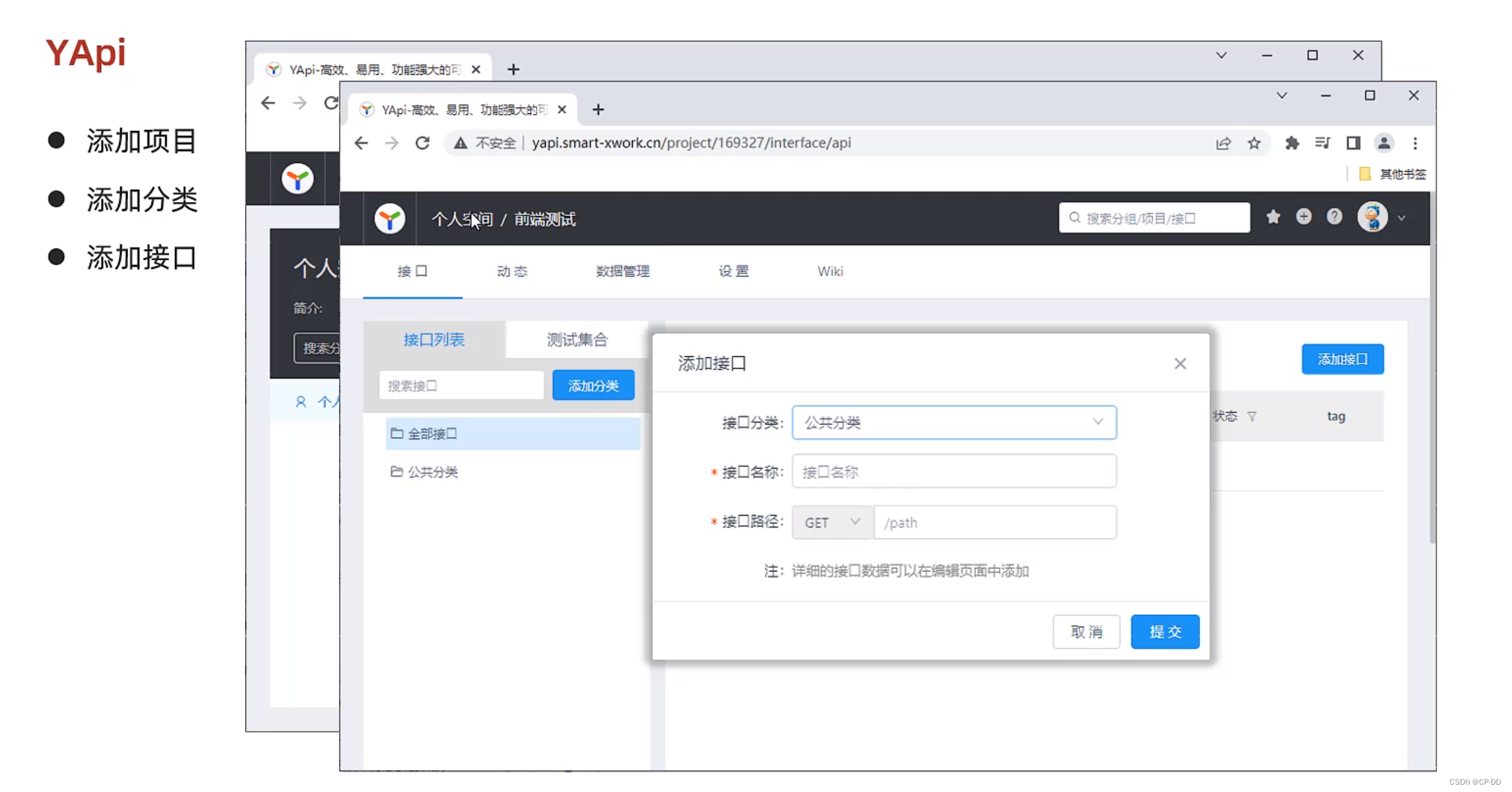
接口文档 YAPI介绍
YAPI介绍 YAPI使用流程...

LeetCode 300最长递增子序列 674最长连续递增序列 718最长重复子数组 | 代码随想录25期训练营day52
动态规划算法10 LeetCode 300 最长递增子序列 2023.12.15 题目链接代码随想录讲解[链接] int lengthOfLIS(vector<int>& nums) {//创建变量result存储最终答案,设默认值为1int result 1;//1确定dp数组,dp[i]表示以nums[i]为结尾的子数组的最长长度ve…...

Improving IP Geolocation with Target-Centric IP Graph (Student Abstract)
ABSTRACT 准确的IP地理定位对于位置感知的应用程序是必不可少的。虽然基于以路由器为中心(router-centric )的IP图的最新进展被认为是前沿的,但一个挑战仍然存在:稀疏IP图的流行(14.24%,少于10个节点,9.73%孤立)限制了图的学习。为了缓解这个问题,我们将目标主机(ta…...

华为技面三轮面试题
1. 最长回文子串 -- 中心扩散法 给你一个字符串 s,找到 s 中最长的回文子串。 如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。 示例 1: 输入:s "babad" 输出:"bab" 解释&…...
Linux arm架构下构建Electron安装包
上篇文章我们介绍 Electron 基本的运行开发与 windows 安装包构建简单流程,这篇文章我们从零到一构建 Linux arm 架构下安装包,实际上 Linux arm 的构建流程,同样适用于 Linux x86 环境,只不过需要各自的环境依赖,Linu…...
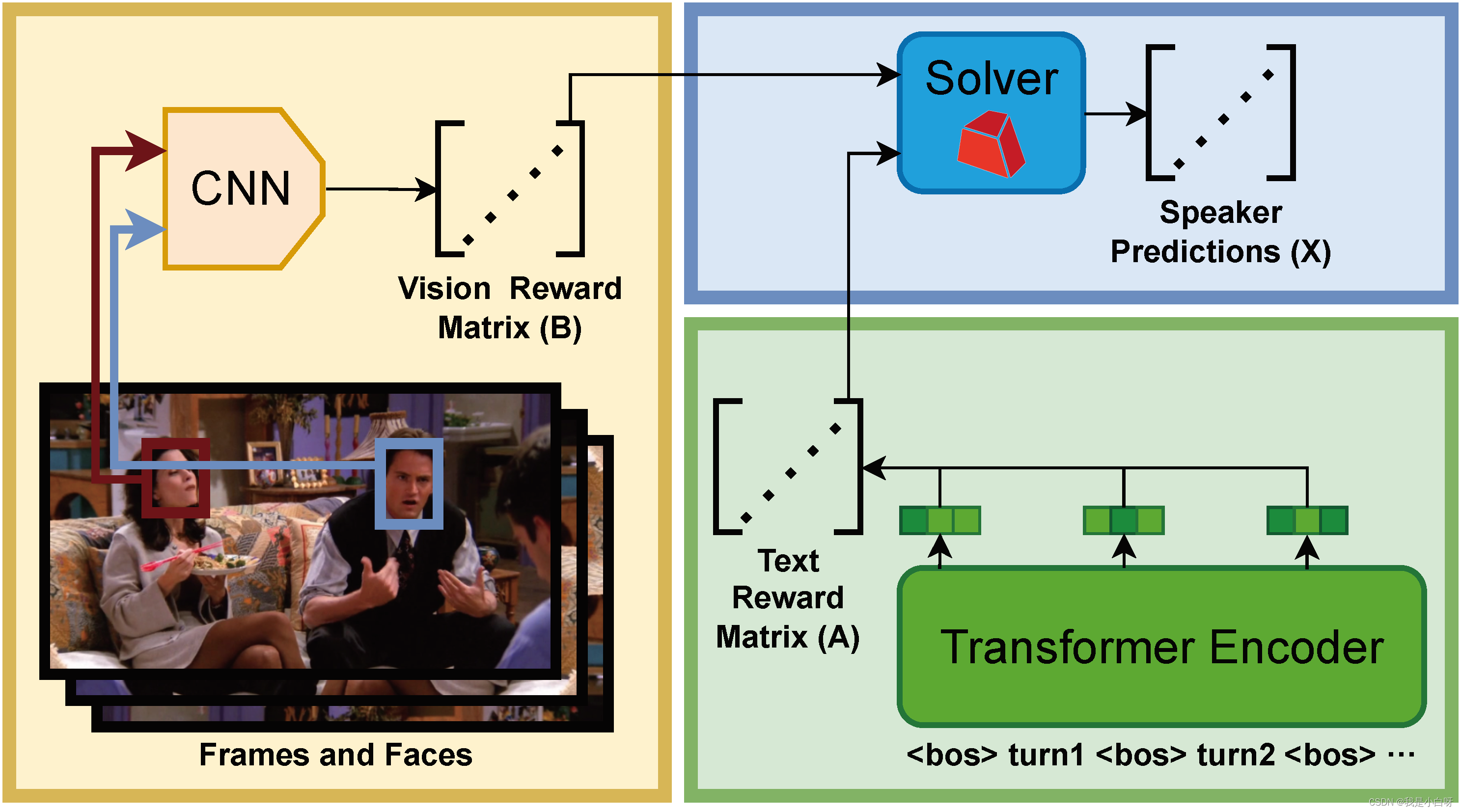
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 NLP 部分 概述NLP 简介文本处理词嵌入上下文理解 文本数据加载to_device 函数构造数据加载样本数量 len获取样本 getitem 分词构造函数调用函数轮次嵌入 RobertaRoberta 创新点NSP (Next Sentence Prediction…...

推免那些事
平生第一次搞推免,也是最后一次。错失了一些机会,也有幸获得了一些机会,值得祝庆,也值得反思。 以下记录为个人流水账。 个人背景 我的背景可以算不是非常好了,况且今年211受歧视比较严重。 学校:211&…...

华清远见嵌入式学习——QT——作业2
作业要求: 代码运行效果图: 登录失败 和 最小化 和 取消登录 登录成功 和 X号退出 代码: ①:头文件 #ifndef LOGIN_H #define LOGIN_H#include <QMainWindow> #include <QLineEdit> //行编辑器类 #include…...
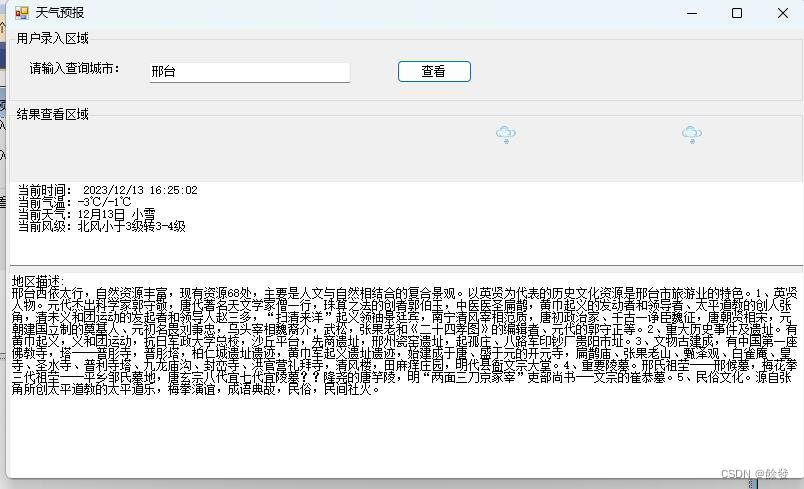
C# Winfrm 编写一个天气查看助手
#前言# 最近这个北方的天气啊经常下雪,让我想起来我上学时候写的那个天气预报小功能了,今天又复现了一下,哈哈哈,大家当个乐子看哈! 1.创建项目 2.添加引用 上图所示,下载所需天气预报标识,网站…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...