Flink系列之:Apache Kafka SQL 连接器
Flink系列之:Apache Kafka SQL 连接器
- 一、Apache Kafka SQL 连接器
- 二、依赖
- 三、创建Kafka 表
- 四、可用的元数据
- 五、连接器参数
- 六、特性
- 七、Topic 和 Partition 的探测
- 八、起始消费位点
- 九、有界结束位置
- 十、CDC 变更日志(Changelog) Source
- 十一、Sink 分区
- 十二、一致性保证
- 十三、Source 按分区 Watermark
- 十四、安全
- 十五、数据类型映射
一、Apache Kafka SQL 连接器
- Scan Source: Unbounded Sink: Streaming Append Mode
- Kafka 连接器提供从 Kafka topic 中消费和写入数据的能力。
二、依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.0.2-1.18</version></dependency>
三、创建Kafka 表
以下示例展示了如何创建 Kafka 表:
CREATE TABLE KafkaTable (`user_id` BIGINT,`item_id` BIGINT,`behavior` STRING,`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH ('connector' = 'kafka','topic' = 'user_behavior','properties.bootstrap.servers' = 'localhost:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','format' = 'csv'
)
四、可用的元数据
以下的连接器元数据可以在表定义中通过元数据列的形式获取。
R/W 列定义了一个元数据是可读的(R)还是可写的(W)。 只读列必须声明为 VIRTUAL 以在 INSERT INTO 操作中排除它们。
| 键 | 数据类型 | 描述 | R/W |
|---|---|---|---|
| topic | STRING NOT NULL | Kafka 记录的 Topic 名。 | R |
| partition | INT NOT NULL | Kafka 记录的 partition ID。 | R |
| headers | MAP NOT NULL | 二进制 Map 类型的 Kafka 记录头(Header)。 | R/W |
| leader-epoch | INT NULL | Kafka 记录的 Leader epoch(如果可用)。 | R |
| offset | BIGINT NOT NULL | Kafka 记录在 partition 中的 offset。 | R |
| timestamp | TIMESTAMP_LTZ(3) NOT NULL | Kafka 记录的时间戳。 | R/W |
| timestamp-type | STRING NOT NULL | Kafka 记录的时间戳类型。可能的类型有 “NoTimestampType”, “CreateTime”(会在写入元数据时设置),或 “LogAppendTime”。 | R |
以下扩展的 CREATE TABLE 示例展示了使用这些元数据字段的语法:
CREATE TABLE KafkaTable (`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',`partition` BIGINT METADATA VIRTUAL,`offset` BIGINT METADATA VIRTUAL,`user_id` BIGINT,`item_id` BIGINT,`behavior` STRING
) WITH ('connector' = 'kafka','topic' = 'user_behavior','properties.bootstrap.servers' = 'localhost:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','format' = 'csv'
);
格式元信息
连接器可以读出消息格式的元数据。格式元数据的配置键以 ‘value.’ 作为前缀。
以下示例展示了如何获取 Kafka 和 Debezium 的元数据字段:
CREATE TABLE KafkaTable (`event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format`origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format`partition_id` BIGINT METADATA FROM 'partition' VIRTUAL, -- from Kafka connector`offset` BIGINT METADATA VIRTUAL, -- from Kafka connector`user_id` BIGINT,`item_id` BIGINT,`behavior` STRING
) WITH ('connector' = 'kafka','topic' = 'user_behavior','properties.bootstrap.servers' = 'localhost:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','value.format' = 'debezium-json'
);
五、连接器参数
| 参数 | 是否必选 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必选 | (无) | String | 指定使用的连接器,Kafka 连接器使用 ‘kafka’。 |
| topic | required for sink | (无) | String | 当表用作 source 时读取数据的 topic 名。亦支持用分号间隔的 topic 列表,如 ‘topic-1;topic-2’。注意,对 source 表而言,‘topic’ 和 ‘topic-pattern’ 两个选项只能使用其中一个。当表被用作 sink 时,该配置表示写入的 topic 名。注意 sink 表不支持 topic 列表。 |
| topic-pattern | 可选 | (无) | String | 匹配读取 topic 名称的正则表达式。在作业开始运行时,所有匹配该正则表达式的 topic 都将被 Kafka consumer 订阅。注意,对 source 表而言,‘topic’ 和 ‘topic-pattern’ 两个选项只能使用其中一个。 |
| properties.bootstrap.servers | 必选 | (无) | String | 逗号分隔的 Kafka broker 列表。 |
| properties.group.id | 对 source 可选,不适用于 sink | (无) | String | Kafka source 的消费组 id。如果未指定消费组 ID,则会使用自动生成的 “KafkaSource-{tableIdentifier}” 作为消费组 ID。 |
| properties.* | 可选 | (无) | String | 可以设置和传递任意 Kafka 的配置项。后缀名必须匹配在 Kafka 配置文档 中定义的配置键。Flink 将移除 “properties.” 配置键前缀并将变换后的配置键和值传入底层的 Kafka 客户端。例如,你可以通过 ‘properties.allow.auto.create.topics’ = ‘false’ 来禁用 topic 的自动创建。但是某些配置项不支持进行配置,因为 Flink 会覆盖这些配置,例如 ‘key.deserializer’ 和 ‘value.deserializer’。 |
| format | 必选 | (无) | String | 用来序列化或反序列化 Kafka 消息的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:该配置项和 ‘value.format’ 二者必需其一。 |
| key.format | 可选 | (无) | String | 用来序列化和反序列化 Kafka 消息键(Key)的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:如果定义了键格式,则配置项 ‘key.fields’ 也是必需的。 否则 Kafka 记录将使用空值作为键。 |
| key.fields | 可选 | [] | List | 表结构中用来配置消息键(Key)格式数据类型的字段列表。默认情况下该列表为空,因此消息键没有定义。 列表格式为 ‘field1;field2’。 |
| key.fields-prefix | 可选 | (无) | String | 为所有消息键(Key)格式字段指定自定义前缀,以避免与消息体(Value)格式字段重名。默认情况下前缀为空。 如果定义了前缀,表结构和配置项 ‘key.fields’ 都需要使用带前缀的名称。 当构建消息键格式字段时,前缀会被移除,消息键格式将会使用无前缀的名称。 请注意该配置项要求必须将 ‘value.fields-include’ 配置为 ‘EXCEPT_KEY’。 |
| value.format | 必选 | (无) | String | 序列化和反序列化 Kafka 消息体时使用的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:该配置项和 ‘format’ 二者必需其一。 |
| value.fields-include | 可选 | ALL | 枚举类型,可选值:[ALL, EXCEPT_KEY] | 定义消息体(Value)格式如何处理消息键(Key)字段的策略。 默认情况下,表结构中 ‘ALL’ 即所有的字段都会包含在消息体格式中,即消息键字段在消息键和消息体格式中都会出现。 |
| scan.startup.mode | 可选 | group-offsets | Enum | Kafka consumer 的启动模式。有效值为:‘earliest-offset’,‘latest-offset’,‘group-offsets’,‘timestamp’ 和 ‘specific-offsets’。 |
| scan.startup.specific-offsets | 可选 | (无) | String | 在使用 ‘specific-offsets’ 启动模式时为每个 partition 指定 offset,例如 ‘partition:0,offset:42;partition:1,offset:300’。 |
| scan.startup.timestamp-millis | 可选 | (无) | Long | 在使用 ‘timestamp’ 启动模式时指定启动的时间戳(单位毫秒)。 |
| scan.bounded.mode | optional | optional | unbounded | Enum |
| scan.bounded.specific-offsets | optional | yes | (none) | String |
| scan.bounded.timestamp-millis | optional | yes | (none) | Long |
| scan.topic-partition-discovery.interval | 可选 | (无) | Duration | Consumer 定期探测动态创建的 Kafka topic 和 partition 的时间间隔。 |
| sink.partitioner | 可选 | ‘default’ | String | Flink partition 到 Kafka partition 的分区映射关系,可选值有:default:使用 Kafka 默认的分区器对消息进行分区。fixed:每个 Flink partition 最终对应最多一个 Kafka partition。round-robin:Flink partition 按轮循(round-robin)的模式对应到 Kafka partition。只有当未指定消息的消息键时生效。自定义 FlinkKafkaPartitioner 的子类:例如 ‘org.mycompany.MyPartitioner’。 |
| sink.semantic | 可选 | at-least-once | String | 定义 Kafka sink 的语义。有效值为 ‘at-least-once’,‘exactly-once’ 和 ‘none’。 |
| sink.parallelism | 可选 | (无) | Integer | 定义 Kafka sink 算子的并行度。默认情况下,并行度由框架定义为与上游串联的算子相同。 |
六、特性
消息键(Key)与消息体(Value)的格式
Kafka 消息的消息键和消息体部分都可以使用某种 格式 来序列化或反序列化成二进制数据。
消息体格式
由于 Kafka 消息中消息键是可选的,以下语句将使用消息体格式读取和写入消息,但不使用消息键格式。 ‘format’ 选项与 ‘value.format’ 意义相同。 所有的格式配置使用格式识别符作为前缀。
CREATE TABLE KafkaTable (`ts` TIMESTAMP(3) METADATA FROM 'timestamp',`user_id` BIGINT,`item_id` BIGINT,`behavior` STRING
) WITH ('connector' = 'kafka',...'format' = 'json','json.ignore-parse-errors' = 'true'
)
消息体格式将配置为以下的数据类型:
ROW<`user_id` BIGINT, `item_id` BIGINT, `behavior` STRING>
消息键和消息体格式
以下示例展示了如何配置和使用消息键和消息体格式。 格式配置使用 ‘key’ 或 ‘value’ 加上格式识别符作为前缀。
CREATE TABLE KafkaTable (`ts` TIMESTAMP(3) METADATA FROM 'timestamp',`user_id` BIGINT,`item_id` BIGINT,`behavior` STRING
) WITH ('connector' = 'kafka',...'key.format' = 'json','key.json.ignore-parse-errors' = 'true','key.fields' = 'user_id;item_id','value.format' = 'json','value.json.fail-on-missing-field' = 'false','value.fields-include' = 'ALL'
)
消息键格式包含了在 ‘key.fields’ 中列出的字段(使用 ‘;’ 分隔)和字段顺序。 因此将配置为以下的数据类型:
ROW<`user_id` BIGINT, `item_id` BIGINT>
由于消息体格式配置为 ‘value.fields-include’ = ‘ALL’,所以消息键字段也会出现在消息体格式的数据类型中:
ROW<`user_id` BIGINT, `item_id` BIGINT, `behavior` STRING>
重名的格式字段
如果消息键字段和消息体字段重名,连接器无法根据表结构信息将这些列区分开。 ‘key.fields-prefix’ 配置项可以在表结构中为消息键字段指定一个唯一名称,并在配置消息键格式的时候保留原名。
以下示例展示了在消息键和消息体中同时包含 version 字段的情况:
CREATE TABLE KafkaTable (`k_version` INT,`k_user_id` BIGINT,`k_item_id` BIGINT,`version` INT,`behavior` STRING
) WITH ('connector' = 'kafka',...'key.format' = 'json','key.fields-prefix' = 'k_','key.fields' = 'k_version;k_user_id;k_item_id','value.format' = 'json','value.fields-include' = 'EXCEPT_KEY'
)
消息体格式必须配置为 ‘EXCEPT_KEY’ 模式。格式将被配置为以下的数据类型:
消息键格式:
ROW<`version` INT, `user_id` BIGINT, `item_id` BIGINT>消息体格式:
ROW<`version` INT, `behavior` STRING>
七、Topic 和 Partition 的探测
topic 和 topic-pattern 配置项决定了 source 消费的 topic 或 topic 的匹配规则。topic 配置项可接受使用分号间隔的 topic 列表,例如 topic-1;topic-2。 topic-pattern 配置项使用正则表达式来探测匹配的 topic。例如 topic-pattern 设置为 test-topic-[0-9],则在作业启动时,所有匹配该正则表达式的 topic(以 test-topic- 开头,以一位数字结尾)都将被 consumer 订阅。
为允许 consumer 在作业启动之后探测到动态创建的 topic,请将 scan.topic-partition-discovery.interval 配置为一个非负值。这将使 consumer 能够探测匹配名称规则的 topic 中新的 partition。
注意 topic 列表和 topic 匹配规则只适用于 source。对于 sink 端,Flink 目前只支持单一 topic。
八、起始消费位点
scan.startup.mode 配置项决定了 Kafka consumer 的启动模式。有效值为:
- group-offsets:从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。
- earliest-offset:从可能的最早偏移量开始。
- latest-offset:从最末尾偏移量开始。
- timestamp:从用户为每个 partition 指定的时间戳开始。
- specific-offsets:从用户为每个 partition 指定的偏移量开始。
默认值 group-offsets 表示从 Zookeeper/Kafka 中最近一次已提交的偏移量开始消费。
如果使用了 timestamp,必须使用另外一个配置项 scan.startup.timestamp-millis 来指定一个从格林尼治标准时间 1970 年 1 月 1 日 00:00:00.000 开始计算的毫秒单位时间戳作为起始时间。
如果使用了 specific-offsets,必须使用另外一个配置项 scan.startup.specific-offsets 来为每个 partition 指定起始偏移量, 例如,选项值 partition:0,offset:42;partition:1,offset:300 表示 partition 0 从偏移量 42 开始,partition 1 从偏移量 300 开始。
九、有界结束位置
配置选项 scan.bounded.mode 指定 Kafka 消费者的有界模式。有效的枚举是:
group-offsets:以特定消费者组的 ZooKeeper / Kafka 代理中提交的偏移量为界。这是在给定分区的消费开始时进行评估的。latest-offset:以最新偏移量为界。这是在给定分区的消费开始时进行评估的。timestamp:以用户提供的时间戳为界。specific-offsets:以用户为每个分区提供的特定偏移量为界。
如果未设置配置选项值 scan.bounded.mode ,则默认为无界表。
如果指定了时间戳,则需要另一个配置选项 scan.bounded.timestamp-millis 来指定自 1970 年 1 月 1 日 00:00:00.000 GMT 以来的特定有界时间戳(以毫秒为单位)。
如果指定了 Specific-offsets,则需要另一个配置选项 scan.bounded.specific-offsets 来为每个分区指定特定的有界偏移量,例如选项值partition:0,offset:42;partition:1,offset:300表示分区0的偏移量42和分区1的偏移量300。如果未提供分区的偏移量,则不会从该分区消耗数据。
十、CDC 变更日志(Changelog) Source
Flink 原生支持使用 Kafka 作为 CDC 变更日志(changelog) source。如果 Kafka topic 中的消息是通过变更数据捕获(CDC)工具从其他数据库捕获的变更事件,则你可以使用 CDC 格式将消息解析为 Flink SQL 系统中的插入(INSERT)、更新(UPDATE)、删除(DELETE)消息。
在许多情况下,变更日志(changelog) source 都是非常有用的功能,例如将数据库中的增量数据同步到其他系统,审核日志,数据库的物化视图,时态表关联数据库表的更改历史等。
Flink 提供了几种 CDC 格式:
- debezium
- canal
- maxwell
十一、Sink 分区
配置项 sink.partitioner 指定了从 Flink 分区到 Kafka 分区的映射关系。 默认情况下,Flink 使用 Kafka 默认分区器 来对消息分区。默认分区器对没有消息键的消息使用 粘性分区策略(sticky partition strategy) 进行分区,对含有消息键的消息使用 murmur2 哈希算法计算分区。
为了控制数据行到分区的路由,也可以提供一个自定义的 sink 分区器。‘fixed’ 分区器会将同一个 Flink 分区中的消息写入同一个 Kafka 分区,从而减少网络连接的开销。
十二、一致性保证
默认情况下,如果查询在 启用 checkpoint 模式下执行时,Kafka sink 按照至少一次(at-lease-once)语义保证将数据写入到 Kafka topic 中。
当 Flink checkpoint 启用时,kafka 连接器可以提供精确一次(exactly-once)的语义保证。
除了启用 Flink checkpoint,还可以通过传入对应的 sink.semantic 选项来选择三种不同的运行模式:
- none:Flink 不保证任何语义。已经写出的记录可能会丢失或重复。
- at-least-once (默认设置):保证没有记录会丢失(但可能会重复)。
- exactly-once:使用 Kafka 事务提供精确一次(exactly-once)语义。当使用事务向 Kafka 写入数据时,请将所有从 Kafka 中消费记录的应用中的 isolation.level 配置项设置成实际所需的值(read_committed 或 read_uncommitted,后者为默认值)。
十三、Source 按分区 Watermark
- Flink 对于 Kafka 支持发送按分区的 watermark。Watermark 在 Kafka consumer 中生成。
- 按分区 watermark 的合并方式和在流 shuffle 时合并 Watermark 的方式一致。 Source 输出的 watermark 由读取的分区中最小的 watermark 决定。
- 如果 topic 中的某些分区闲置,watermark 生成器将不会向前推进。 你可以在表配置中设置 ‘table.exec.source.idle-timeout’ 选项来避免上述问题。
十四、安全
要启用加密和认证相关的安全配置,只需将安全配置加上 “properties.” 前缀配置在 Kafka 表上即可。下面的代码片段展示了如何配置 Kafka 表以使用 PLAIN 作为 SASL 机制并提供 JAAS 配置:
CREATE TABLE KafkaTable (`user_id` BIGINT,`item_id` BIGINT,`behavior` STRING,`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH ('connector' = 'kafka',...'properties.security.protocol' = 'SASL_PLAINTEXT','properties.sasl.mechanism' = 'PLAIN','properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";'
)
另一个更复杂的例子,使用 SASL_SSL 作为安全协议并使用 SCRAM-SHA-256 作为 SASL 机制:
CREATE TABLE KafkaTable (`user_id` BIGINT,`item_id` BIGINT,`behavior` STRING,`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH ('connector' = 'kafka',...'properties.security.protocol' = 'SASL_SSL',/* SSL 配置 *//* 配置服务端提供的 truststore (CA 证书) 的路径 */'properties.ssl.truststore.location' = '/path/to/kafka.client.truststore.jks','properties.ssl.truststore.password' = 'test1234',/* 如果要求客户端认证,则需要配置 keystore (私钥) 的路径 */'properties.ssl.keystore.location' = '/path/to/kafka.client.keystore.jks','properties.ssl.keystore.password' = 'test1234',/* SASL 配置 *//* 将 SASL 机制配置为 as SCRAM-SHA-256 */'properties.sasl.mechanism' = 'SCRAM-SHA-256',/* 配置 JAAS */'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";'
)
如果在作业 JAR 中 Kafka 客户端依赖的类路径被重置了(relocate class),登录模块(login module)的类路径可能会不同,因此请根据登录模块在 JAR 中实际的类路径来改写以上配置。例如在 SQL client JAR 中,Kafka client 依赖被重置在了 org.apache.flink.kafka.shaded.org.apache.kafka 路径下, 因此 plain 登录模块的类路径应写为 org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule。
十五、数据类型映射
Kafka 将消息键值以二进制进行存储,因此 Kafka 并不存在 schema 或数据类型。Kafka 消息使用格式配置进行序列化和反序列化,例如 csv,json,avro。 因此,数据类型映射取决于使用的格式。
相关文章:

Flink系列之:Apache Kafka SQL 连接器
Flink系列之:Apache Kafka SQL 连接器 一、Apache Kafka SQL 连接器二、依赖三、创建Kafka 表四、可用的元数据五、连接器参数六、特性七、Topic 和 Partition 的探测八、起始消费位点九、有界结束位置十、CDC 变更日志(Changelog) Source十一…...

灰盒测试简要学习指南!
在本文中,我们将了解什么是灰盒测试、以及为什么要使用它,以及它的优缺点。 在软件测试中,灰盒测试是一种有用的技术,可以确保发布的软件是高性能的、安全的并满足预期用户的需求。这是一种从外部测试应用程序同时跟踪其内部操作…...
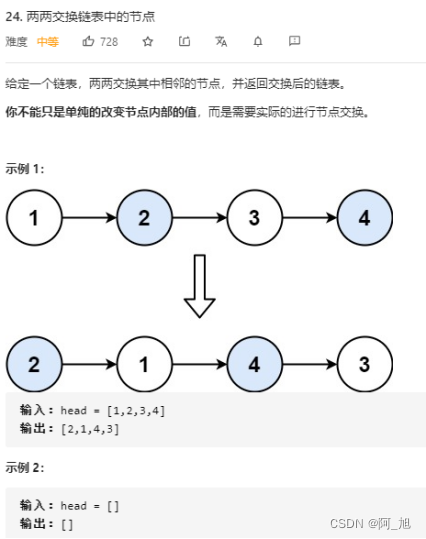
【经典LeetCode算法题目专栏分类】【第7期】快慢指针与链表
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 快慢指针 移动零 class…...
springboot解决XSS存储型漏洞
springboot解决XSS存储型漏洞 XSS攻击 XSS 攻击:跨站脚本攻击(Cross Site Scripting),为不和 前端层叠样式表(Cascading Style Sheets)CSS 混淆,故将跨站脚本攻击缩写为 XSS。 XSS(跨站脚本攻击):是指恶意攻击者往 Web 页面里插…...

I.MX6ULL_Linux_驱动篇(47)linux RTC驱动
RTC 也就是实时时钟,用于记录当前系统时间,对于 Linux 系统而言时间是非常重要的,就和我们使用 Windows 电脑或手机查看时间一样,我们在使用 Linux 设备的时候也需要查看时间。本章我们就来学习一下如何编写 Linux 下的 RTC 驱动程…...
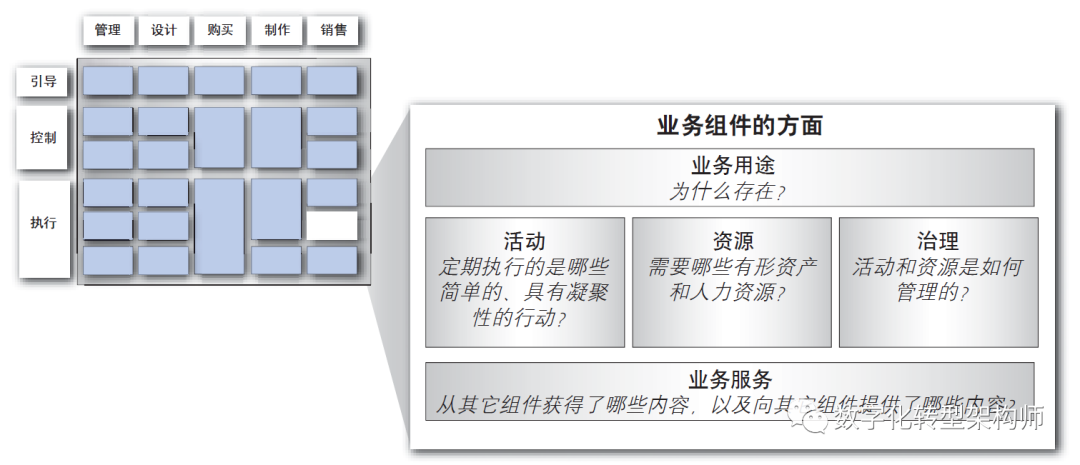
详解IBM企业架构框架模型CBM
(一):什么是CBM IBM的CBM是组件化业务模型(Component Business Model),是IBM在2003年提出的一种业务架构方法论。 目的是通过将企业的业务活动划分为一些独立、模块化、可重用的业务组件,来识…...
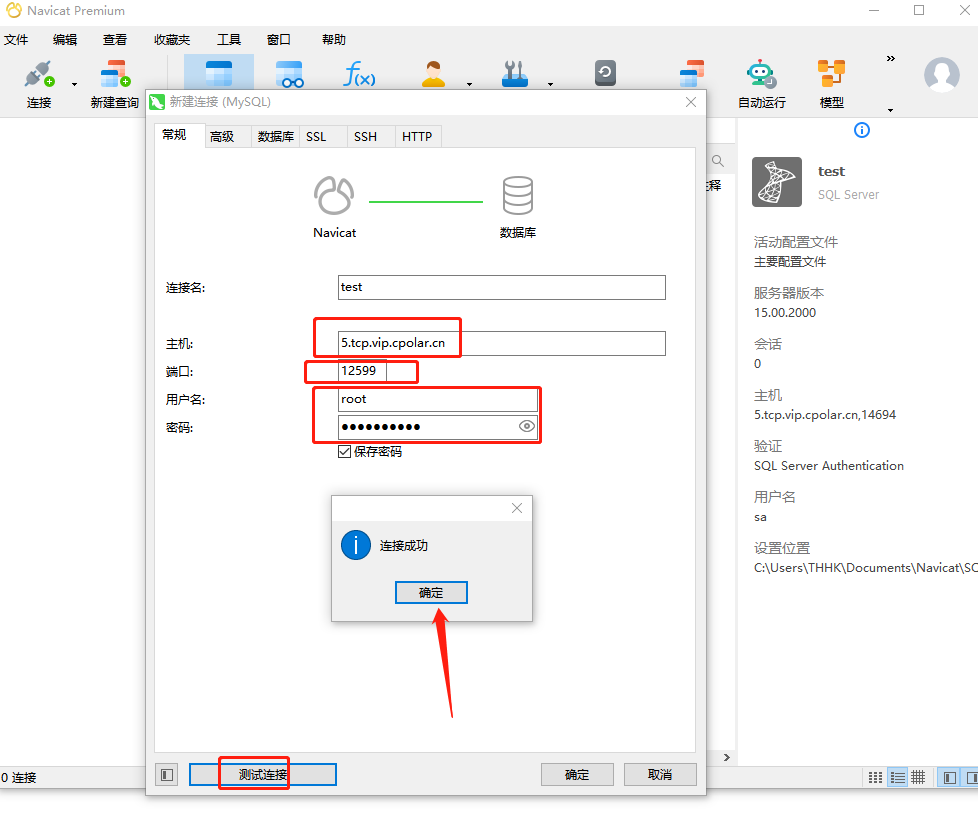
宝塔面板安装MySQL数据库并通过内网穿透工具实现公网远程访问
文章目录 前言1.Mysql 服务安装2.创建数据库3.安装 cpolar3.2 创建 HTTP 隧道 4.远程连接5.固定 TCP 地址5.1 保留一个固定的公网 TCP 端口地址5.2 配置固定公网 TCP 端口地址 前言 宝塔面板的简易操作性,使得运维难度降低,简化了 Linux 命令行进行繁琐的配置,下面简单几步,通…...
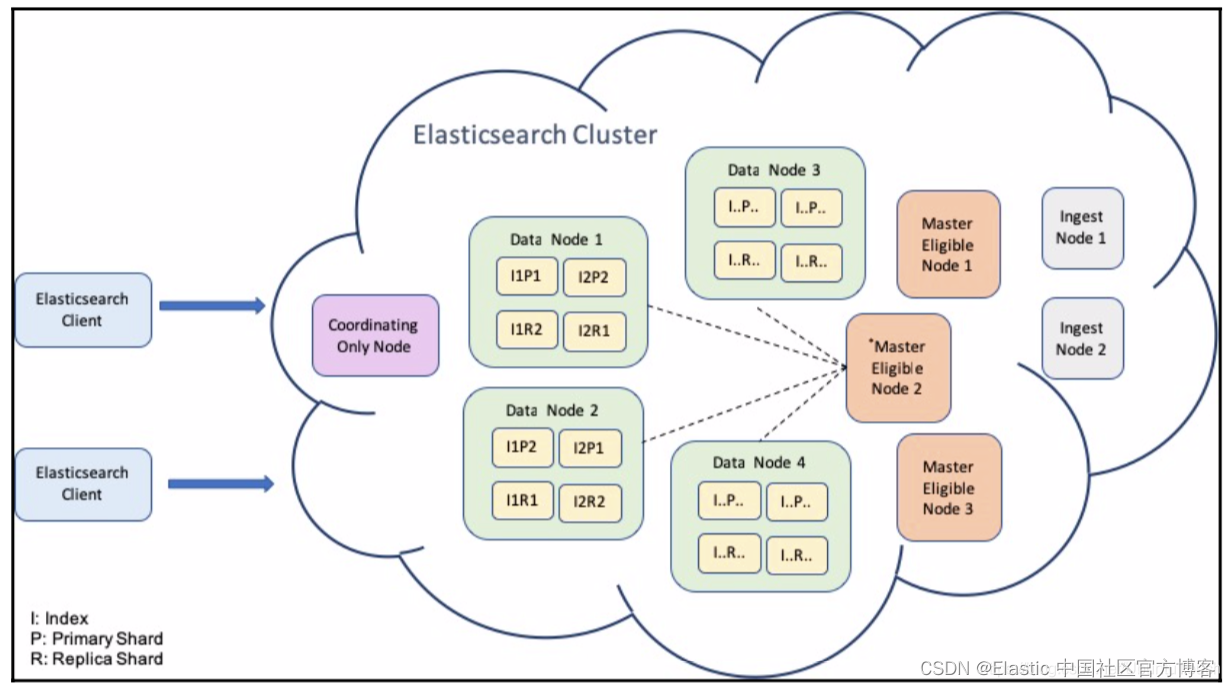
Elasticsearch 性能调优基础知识
Elastic Stack 已成为监控任何环境或应用程序的实际解决方案。 从日志、指标和正常运行时间到性能监控甚至安全,Elastic Stack 已成为满足几乎所有监控需求的一体化解决方案。 Elasticsearch 通过提供强大的分析引擎来处理任何类型的数据,成为这方面的基…...

速盾网络:网络安全守护者
速盾网络作为一家专业的网络安全服务提供商,致力于为企业和个人提供全面、高效、可靠的网络安全解决方案。以下是速盾网络的主要业务介绍: 一、CDN加速 速盾网络拥有全球化的CDN加速网络,通过分布在全球各地的节点,为客户提供快速…...

jmeter如何参数化?Jmeter参数化设置的5种方法
jmeter如何参数化?我们使用jmeter在进行测试的时候,测试数据是一项重要的准备工作,每次迭代的数据当不一样的时候,需要进行参数化,从参数化的文件中来读取测试数据。那么,你知道jmeter如何进行参数化吗&…...
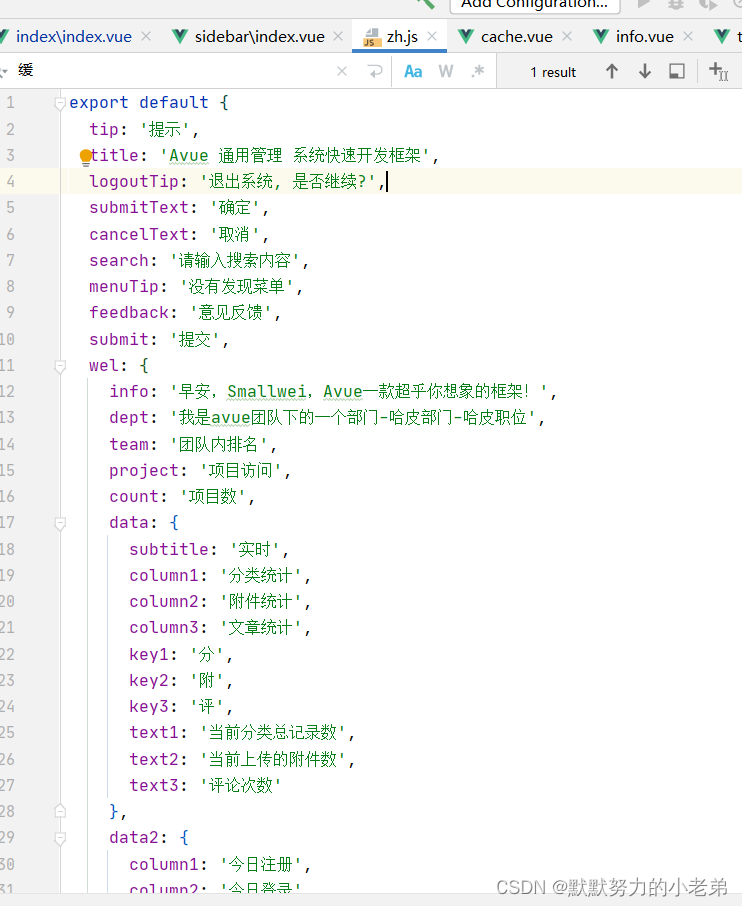
01AVue入门(持续学习中)
1.使用AVue开发简单的前端页面直接简单到起飞,他是Element PlusVueVite开发的,不需要向元素的前端代码一样一个组件要传很多参数,他可以使用Json文本来控制我们要传入的数据结构来决定显示什么 //我使用的比较新,我们也可以使用cdn直接使用script标签直接引入 2.开发中遇到的坑…...

js 深浅拷贝的区别和实现方法
一:什么浅拷贝: 浅拷贝创建一个新对象,然后将原始对象的所有属性值复制到新对象中。这意味着,如果原始对象的属性值是基本类型(例如数字、字符串),那么这些值会被直接复制到新对象中。但如果属…...
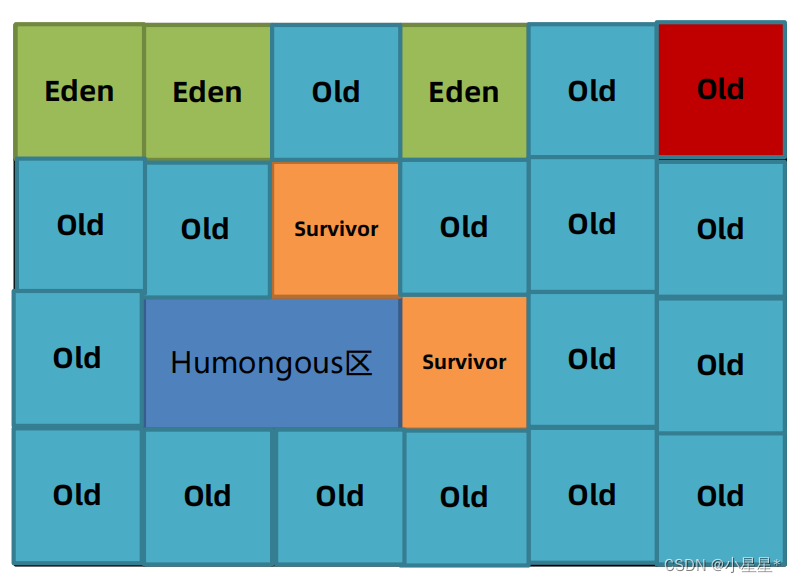
【jvm从入门到实战】(九) 垃圾回收(2)-垃圾回收器
垃圾回收器是垃圾回收算法的具体实现。 由于垃圾回收器分为年轻代和老年代,除了G1之外其他垃圾回收器必须成对组合进行使用 垃圾回收器的组合使用关系图如下。 常用的组合如下: Serial(新生代) Serial Old(老年代) Pa…...

C#基础——匿名函数和参数不固定的函数
匿名函数、参数不固定的函数 匿名函数:没有名字,又叫做lambda表达式,具有简洁,灵活,可读的特性。 具名函数:有名字的函数。 1、简洁性:使用更少的代码实现相同的功能 MyDelegate myDelegate…...
lM-ICP)
PCL 点云匹配 4 之 (非线性迭代点云匹配)lM-ICP
一、IM迭代法 PCL IterativeClosestPointNonLinear 非线性L-M迭代法-CSDN博客 Matlab 非线性迭代法(3)阻尼牛顿法 L-M-CSDN博客 MATLAB实现最小二乘法_matlab最小二乘法-CSDN博客...

MySQL_14.数据库高速缓冲区空间管理
数据库高速缓冲区空间管理 Oracle 用 LRU(Least Recently Used)算法来管理数据高速缓冲区。该算法将最近使用的 数据块按照使用时间的早晚排成队列,当缓冲区占满后,调入新的数据块时,必须清除已有的数据 块,…...
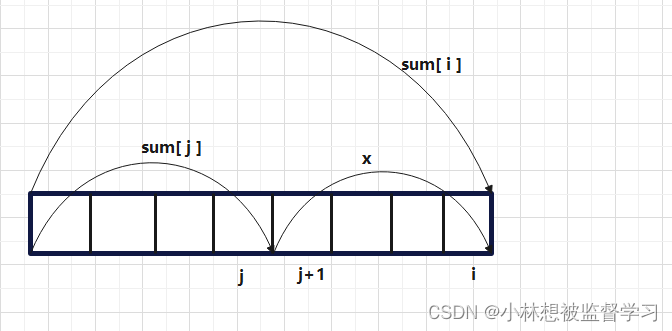
leetcode 974. 和可被 K 整除的子数组(优质解法)
代码: class Solution {public int subarraysDivByK(int[] nums, int k) {HashMap<Integer,Integer> hashMapnew HashMap();hashMap.put(0,1);int count0; //记录子数组的个数int last0; //前一个下标的前缀和int now0; //当前下标的前缀和for(int i0;…...

【技术】MySQL 日期时间操作
MySQL 日期时间操作 MySQL 系统时间MySQL 时间格式化MySQL 年月日时分秒周MySQL 日期计算时分秒时差日期差日期加减 MySQL 系统时间 now():系统时间,年月日时分秒current_date:系统时间,年月日current_time:系统时间&…...

测试理论知识三:测试用例、测试策略
1.测试用例 完全的测试是不可能的,对任何程序的测试必定是不完全的,那么,最显然的测试策略就是努力使测试尽可能完全。 进行测试前,推荐先使用黑盒测试的方法设计测试用例,然后使用白盒测试方法来补充的测试用例。 2…...
【clickhouse】在CentOS中离线安装clickhouse
https://packages.clickhouse.com/rpm/stable/ 通过如下命令检查是否安装过clickhouse [root172 ~]# rpm -qa | grep clickhouse 把rpm安装包放到opt/lzh目录 按照如下命令顺序安装 [root172 /]# rpm -ivh /opt/lzh/clickhouse-common-static-22.1.2.2-2.x86_64.rpm [root…...

Qwen3-ASR-1.7B部署案例:AI初创公司低成本构建ASR SaaS服务
Qwen3-ASR-1.7B部署案例:AI初创公司低成本构建ASR SaaS服务 想象一下,你是一家AI初创公司的技术负责人,老板给你下了个任务:两周内,为公司的新产品上线一个语音转文字(ASR)功能。要求是识别要准…...

HY-Motion 1.0保姆级教程:解决CUDA OOM、Prompt截断等常见问题
HY-Motion 1.0保姆级教程:解决CUDA OOM、Prompt截断等常见问题 1. 前言:为什么需要这篇教程 你是不是也遇到过这样的情况:好不容易下载了HY-Motion 1.0这个强大的3D动作生成模型,准备大展身手,结果一运行就遇到CUDA内…...

3分钟快速找回QQ号:手机号逆向查询终极指南
3分钟快速找回QQ号:手机号逆向查询终极指南 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾经因为忘记QQ号而无法登录重要应用?或者需要验证手机号与QQ的绑定关系?今天我要介绍的这款Pyth…...

ComfyUI图片生成视频大模型技术选型与实战:从原理到生产环境部署
最近在搞一个AI视频生成的项目,用到了ComfyUI这个可视化工作流工具。说实话,刚开始选模型的时候真是眼花缭乱,Stable Diffusion Video、ModelScope、RunwayML……每个都说自己好,但实际用起来坑真不少。今天就把我趟过的路和总结的…...
,只提供代码,有相关的readme文...)
一种路径优化和速度优化算法实现(仿照百度Apollo方案),只提供代码,有相关的readme文...
一种路径优化和速度优化算法实现(仿照百度Apollo方案),只提供代码,有相关的readme文件。 自动驾驶 ,路径优化,速度优化,pnc。 的代码最近在折腾自动驾驶的路径规划模块,发现实际落地…...

YOLOv8改进:MixUp with Consistency——基于混合增强与一致性正则化的鲁棒性目标检测算法
1. 引言目标检测作为计算机视觉领域的核心任务之一,在实际应用中面临着诸多挑战,如光照变化、遮挡、图像噪声以及数据分布偏移等问题。YOLOv8作为当前最先进的目标检测器之一,凭借其高效的网络结构和优秀的性能表现,已在工业界和学…...

如何安全高效地管理Cookie:Get cookies.txt LOCALLY本地处理终极实践指南
如何安全高效地管理Cookie:Get cookies.txt LOCALLY本地处理终极实践指南 【免费下载链接】Get-cookies.txt-LOCALLY Get cookies.txt, NEVER send information outside. 项目地址: https://gitcode.com/gh_mirrors/ge/Get-cookies.txt-LOCALLY 在数字时代&a…...

档案宝 档案管理系统怎么样?为什么企业选择他?
在当今信息化高速发展的时代,企业档案管理已经从传统的纸质化时代迈向了数字化、智能化的新阶段。随着企业规模的不断扩大和业务类型的日益复杂,档案管理面临着前所未有的挑战:档案数量激增、查找困难、存储空间紧张、安全隐患突出等问题严重…...
在腾讯云一键部署超全攻略)
OpenClaw怎么搭建?2026年3月OpenClaw(Clawdbot)在腾讯云一键部署超全攻略
OpenClaw怎么搭建?2026年3月OpenClaw(Clawdbot)在腾讯云一键部署超全攻略。本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环…...

Phi-4-Reasoning-Vision简单调用:Python API封装与REST接口调用示例
Phi-4-Reasoning-Vision简单调用:Python API封装与REST接口调用示例 1. 项目概述 Phi-4-Reasoning-Vision是基于微软Phi-4-reasoning-vision-15B多模态大模型开发的高性能推理工具,专为双卡4090环境优化。该工具严格遵循官方SYSTEM PROMPT规范…...