2017年第六届数学建模国际赛小美赛B题电子邮件中的笔迹分析解题全过程文档及程序
2017年第六届数学建模国际赛小美赛
B题 电子邮件中的笔迹分析
原题再现:
笔迹分析是一种非常特殊的调查形式,用于将人们与书面证据联系起来。在法庭或刑事调查中,通常要求笔迹鉴定人确认笔迹样本是否来自特定的人。由于许多语言证据出现在电子邮件中,从广义上讲,笔迹分析还包括如何根据电子邮件的语言特征识别作者的问题。
作者归属是语言学家开始使用语言风格的可识别特征(从词频到首选句法结构)来识别有争议文本的作者的过程。电子邮件内容短小,作者语言风格明显。请构造一个有效的模型,通过捕获电子邮件的语言特征来识别作者。您可以使用安然电子邮件数据集来培训和测试您的模型。
安然电子邮件数据集链接:http://bailando.sims.berkeley.edu/enron_email.html
整体求解过程概述(摘要)
本文开发了一个工具,可以用来识别这类电子邮件的作者。作者的风格可以通过测量文本中的各种茎秆特征来简化为一种模式。电子邮件还包含可测量的宏结构特征。这些特征可与支持向量机(SVM)学习算法一起使用,以分类或将电子邮件的作者身份归属给作者,提供适当的消息样本以供比较。
首先,第3章讨论了实验过程的计划和范围,该实验过程用于确定分析电子邮件的作者特征和识别电子邮件的作者身份是否可行。概述了需要评估的特征列表,并说明了为什么要使用支持向量机(SVM)算法进行这项工作。特征集包括但不限于:基于文档的特征、基于单词的特征、虚词比率、字长频率分布、搭配频率、基于字符的特征和字母2-gram。
接下来,第4章详细介绍了为对电子邮件作者进行系统分类而进行的实验,并报告了实验结果。这是通过首先进行一系列实验来完成的,这些实验旨在揭示纯文本块(不是电子邮件)的成功SVM作者属性的基线值,从而设置特征集、文本大小和消息数量的约束。这些基线实验为该项目的核心——识别电子邮件文本中包含的有用特性的任务——设置了框架。本章报告的实验列表见表12(第25页)。第38页报告了这些结果,证实了迄今使用的方法可作为进一步研究电子邮件数据的基础。
最后,第5章讨论了电子邮件的属性和分析。第5.1节讨论了对电子邮件数据进行的初步实验。电子邮件数据用于本章中讨论的实验,因此可以首次测试电子邮件特定功能的影响。第5.2节概述了如何改进结果。第5.3节确定了电子邮件中讨论主题的影响。本研究的目的是使用加权的宏平均F1度量,在大约85%的水平上实现电子邮件数据的正确分类。本章报告的结果表明,在增加了电子邮件的结构特征之后,这一目标就实现了。本章报告的实验列表见表22(第39页)。
最后一章对本文的主要结论进行了总结。这也为今后的工作提出了一些可能的扩展。
模型假设:
•我们已经考虑的因素发挥着至关重要的作用。
•我们收集的数据是准确的。
•人们的写作习惯没有改变。
问题分析:
问题背景:
许多公司和机构已经开始依赖因特网来处理业务,随着个人使用因特网,特别是自万维网建立以来,电子邮件流量显著增加。Lyman和Varian(2000年)估计,2000年将发送5 000亿至6 000亿封电子邮件,进一步估计到2003年,每年发送的电子邮件将超过2万亿封。在GVU’s1第8次WWW用户调查中(Pitkow等人,1997年),84%的受访者表示电子邮件是不必要的。
随着电子邮件流量的增加,出于不正当的原因,电子邮件的使用量也随之增加。误用的例子包括:发送垃圾邮件或未经请求的商业电子邮件(UCE),这是垃圾邮件的广泛传播;发送威胁;发送恶作剧;以及计算机病毒和蠕虫的传播。此外,贩运毒品或儿童色情制品等犯罪活动很容易通过发送简单的电子邮件来协助和教唆。
本文讨论的问题包括:
•设置使用支持向量机进行分类实验的框架
•选择候选文体特征以解决电子邮件作者分类问题
•确定测试电子邮件作者身份分类是否成功的实验序列
模型的建立与求解整体论文缩略图



全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:(代码和文档not free)
with open('x_C.pickle','rb') as f:x_C = pickle.load(f)f.close()
with open('y.pickle','rb') as f:y = pickle.load(f)f.close()
with open('x_W.pickle','rb') as f:x_W = pickle.load(f)f.close()
with open('x_F.pickle','rb') as f:x_F = pickle.load(f)f.close()
with open('x_L.pickle','rb') as f:x_L = pickle.load(f)f.close()
with open('x_C_W.pickle','rb') as f:x_C_W = pickle.load(f)f.close()
with open('x_C_F.pickle','rb') as f:x_C_F = pickle.load(f)f.close()
with open('x_W_F.pickle','rb') as f:x_W_F = pickle.load(f)f.close()
with open('x_F_L.pickle','rb') as f:x_F_L = pickle.load(f)f.close()
with open('x_F_C_W.pickle','rb') as f:x_F_C_W = pickle.load(f)f.close()
with open('x_F_C_L.pickle','rb') as f:x_F_C_L = pickle.load(f)f.close()
with open('x_F_L_W.pickle','rb') as f:x_F_L_W = pickle.load(f)f.close()
with open('x_F_C_L_W.pickle','rb') as f:x_F_C_L_W = pickle.load(f)f.close()
#test diffrent feaure effect (x_C)
x_train, x_test, y_train, y_test = train_test_split(x_C, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_C accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_W)
x_train, x_test, y_train, y_test = train_test_split(x_W, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_W accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_F)
x_train, x_test, y_train, y_test = train_test_split(x_F, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_F accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_L)
x_train, x_test, y_train, y_test = train_test_split(x_L, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_L accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_C_W)
x_train, x_test, y_train, y_test = train_test_split(x_C_W, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_C_W accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_C_F)
x_train, x_test, y_train, y_test = train_test_split(x_C_F, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_C_F accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_W_F)
x_train, x_test, y_train, y_test = train_test_split(x_W_F, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_W_F accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_F_L)
x_train, x_test, y_train, y_test = train_test_split(x_F_L, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_F_L accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_F_C_W)
x_train, x_test, y_train, y_test = train_test_split(x_F_C_W, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_F_C_W accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_F_C_L)
x_train, x_test, y_train, y_test = train_test_split(x_F_C_L, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_F_C_L accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_F_L_W)
x_train, x_test, y_train, y_test = train_test_split(x_F_L_W, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_F_L_W accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent feaure effect (x_F_C_L_W)
x_train, x_test, y_train, y_test = train_test_split(x_F_C_L_W, y, test_size=0.2,
random_state=42)
svclf = SVC(kernel = 'linear')#default with 'rbf'
svclf.fit(x_train,y_train)
pred = svclf.predict(x_test);
print("x_F_C_L_W accuracy: ",sum(pred == y_test)/len(y_test))
#test diffrent kernel effect
new_kernel =['Linear','Polynomial','Radial basis function','Sigmoid tanh']
x_train, x_test, y_train, y_test = train_test_split(x_F_C_L_W, y, test_size=0.2,
random_state=42)
for kernel in new_kernel:svclf = SVC(kernel=kernel)svclf.fit(x_train, y_train)pred = svclf.predict(x_test);print(kernel," accuracy: ", sum(pred == y_test)/len(y_test))
#test diffrent gama effect
gama_lst =[0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1.0, 2.0]
x_train, x_test, y_train, y_test = train_test_split(x_F_C_L_W, y, test_size=0.2,
random_state=42)
for gama in gama_lst:svclf = SVC(kernel = 'linear',gamma=gama)svclf.fit(x_train, y_train)pred = svclf.predict(x_test);print('gama=',gama," accuracy: ", sum(pred == y_test)/len(y_test))
#test diffrent degree effect
x_train, x_test, y_train, y_test = train_test_split(x_F_C_L_W, y, test_size=0.2,
random_state=42)
for degree in range(1,11):svclf = SVC(kernel = 'linear',degree=degree)svclf.fit(x_train, y_train)pred = svclf.predict(x_test);print('gama=',degree," accuracy: ", sum(pred == y_test)/len(y_test))
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2017年第六届数学建模国际赛小美赛B题电子邮件中的笔迹分析解题全过程文档及程序
2017年第六届数学建模国际赛小美赛 B题 电子邮件中的笔迹分析 原题再现: 笔迹分析是一种非常特殊的调查形式,用于将人们与书面证据联系起来。在法庭或刑事调查中,通常要求笔迹鉴定人确认笔迹样本是否来自特定的人。由于许多语言证据出现在电…...

CentOS安装Python解释,CentOS设置python虚拟环境,linux设置python虚拟环境
一、安装python解释器 1、创建解释器安装的目录:/usr/local/python39 cd /usr/local mkdir python39 2、下载依赖 yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make libffi-devel xz-devel …...
在线智能防雷监控(检测)系统应用方案
在线智能防雷监控系统是一种利用现代信息技术,对防雷设施的运行状态进行实时监测、管理和控制的系统,它可以有效提高防雷保护的安全性、可靠性和智能化程度,降低运维成本和风险,为用户提供全方位的防雷解决方案。 在线智能防雷监控…...
flutter + firebase 云消息通知教程 (android-安卓、ios-苹果)
如果能看到这篇文章的 一定已经对手机端的 消息推送通知 有了一定了解。 国内安卓厂商这里不提都有自己的FCM 可自行查找。(国内因无法科学原因 ,不能使用谷歌服务)只说海外的。 目前 adnroid 和 ios 推送消息分别叫 FCM 和 APNs。这里通过…...

2024年PMP考试新考纲-PMBOK第七版-项目管理原则真题解析
从战争中学习战争。对于参加2024年PMP考试的小伙伴来说,最有效的学习方式是这样地:①阅读了教材(PMBOK6、7和敏捷),了解基本概念;②反复刷近期的PMP考试真题,查漏补缺。 为此,华研荟…...
vscode开发python环境配置
前言 vscode作为一款好用的轻量级代码编辑器,不仅支持代码调试,而且还有丰富的插件库,可以说是免费好用,对于初学者来说用来写写python是再合适不过了。下面就推荐几款个人觉得还不错的插件,希望可以帮助大家更好地写…...

数据库客户案例:每个物种都需要一个数据库!
1、GERDH——花卉多组学数据库 项目名称:GERDH:花卉多组学数据库 链接地址:https://dphdatabase.com 项目描述:GERDH包含了来自150多种园艺花卉植物种质的 12961个观赏植物。将不同花卉植物转录组学、表观组学等数据进行比较&am…...
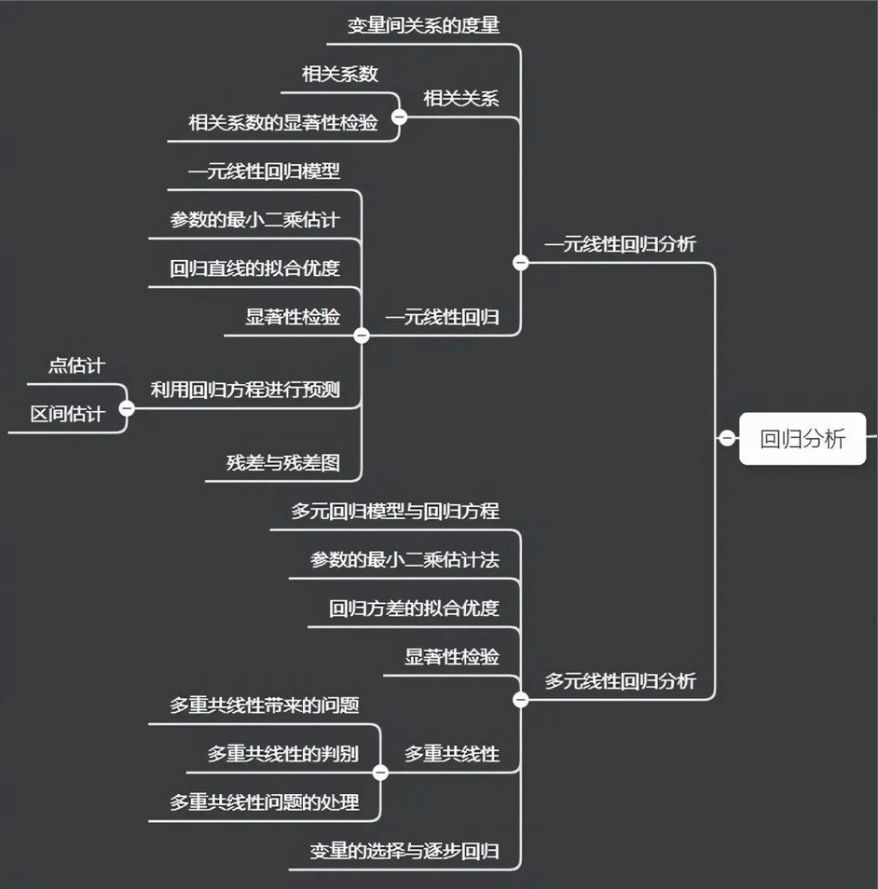
数据分析思维导图
参考: https://zhuanlan.zhihu.com/p/567761684?utm_id0 1、数据分析步骤地图 2、数据分析基础知识地图 3、数据分析技术知识地图 4、数据分析业务流程 5、数据分析师能力体系 6、数据分析思路体系 7、电商数据分析核心主题 8、数据科学技能书知识地图 9、数据挖掘…...

网络基础【网线的制作、OSI七层模型、集线器、交换机介绍、路由器的配置】
目录 一.网线的制作 1.1.网线的标准 1.2.水晶头的做法 二.OSI七层模型、集线器、交换机介绍 集线器(Hub): 交换机(Switch): 三.路由器的配置 3.1.使用 3.2.常用的功能介绍 1、如何管理路由器 2、家…...

C++中的继承(二)
文章目录 前言多继承虚继承虚继承的底层组合 前言 上一篇文章我们C的正常继承其实已经讲完了,但是后面还有一个大坑。 实际当中继承有单继承和多继承。 单继承就是直接继承一个类。 只有一个直接父类的就叫做单继承。 如果是单继承那就比较简单。 现实世界除了有…...

sklearn多项式回归和线性回归
什么是线性回归? 回归分析是一种统计学方法,用于研究自变量和因变量之间的关系。它是一种建立关系模型的方法,可以帮助我们预测和解释变量之间的相互作用。 回归分析通常用于预测一个或多个因变量的值,这些因变量的值是由一个或多…...
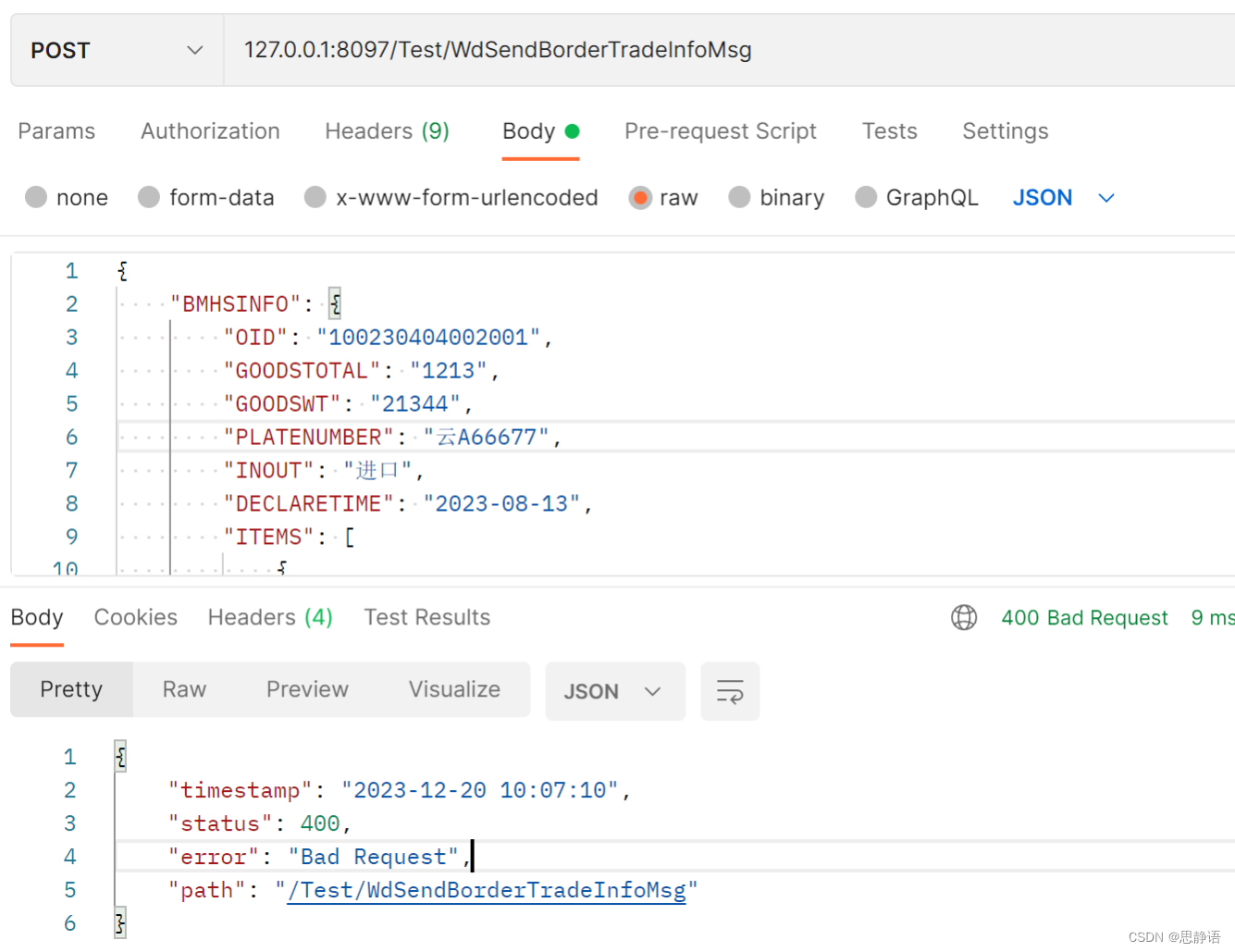
Postman报:400 Bad Request
● 使用Postman发送Post请求报400,入参为JSON; 二、分析 1、Postman请求并没有请求到后台Api(由于语法错误,服务器无法理解请求); 2、入参出错范围:cookie、header、body、form-data、x-www-f…...

apache poi_5.2.5 实现表格内某一段单元格的复制
apache poi_5.2.5 实现表格内,某一段单元格的复制。 实现思路 1.定位开始位置 2.从开始位置之后,在行索引集合中添加行索引下标 3.截至到结束位置。 4.对行索引集合去重,并循环行索引集合 5.利用XWPFTableRow对像的getCtRow().copy()方法&a…...

Oracle重建索引详解
更新:2023-05-17 18:08 一、Oracle重建索引命令 Oracle重建索引可以通过ALTER INDEX命令来完成。下面是示例代码: ALTER INDEX index_name REBUILD [PARAMETERS];其中,index_name是需要重建的索引名称,PARAMETERS是可选的重建参…...

众和策略证券开户首选:股票增持是好还是坏?大股东增持规定?
股票增持是好仍是坏? 股东增持在一定程度上反映股东对个股比较看好,大量的买单,增加了市场上的多方力气,会推动股价上涨,是一种利好消息。 一般大股东会增持可能是上市公司运营成绩较好,具有较大的发展前…...

UE4移动端最小包优化实践
移动端对于包大小有着严苛的要求,然而UE哪怕是一个空工程打出来也有90+M,本文以一个复杂的工程为例,探索怎么把包大小降低到最小。 一、工程简介 工程包含代码、插件、资源、iOS原生库工程。 二、按官方文档进行基础优化 官方文档 1、勾选Use Pak File和Create comp…...
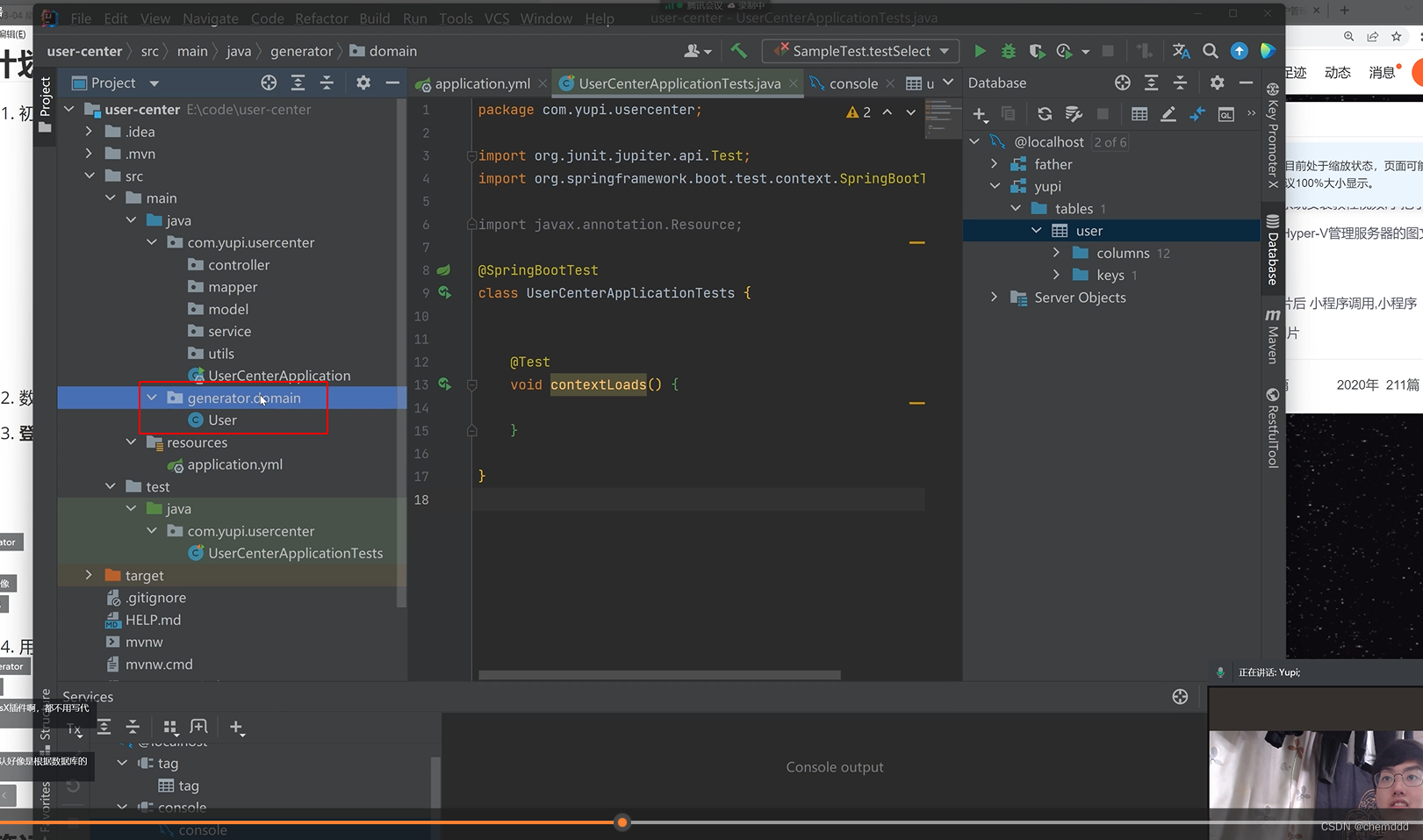
用户管理第2节课--idea 2023.2 后端--实现基本数据库操作(操作user表) -- 自动生成
一、插件 Settings... 1.1 File -- Settings 1.2 Settings -- Plugins 1.2.1 搜索框,也可以直接搜索 1.3 Plugins -- 【输入 & 搜索】mybatis 1.3.1 插件不同功能介绍 1.3.2 翻译如下 1.4 选中 Update,更新下 1.4.1 更新中 1.4.2 Restart IDE 1…...
java开发面试:常见业务场景之单点登录SSO(JWT)、权限认证、上传数据的安全性的控制、项目中遇到的问题、日志采集(ELK)、快速定位系统的瓶颈
单点登录(SSO) 单点登录,Single Sign On(简称SSO),只需要登录一次,就可以访问所有信任的应用系统。 如果是单个tomcat服务,session可以共享,如果是多个tomcat,那么服务s…...
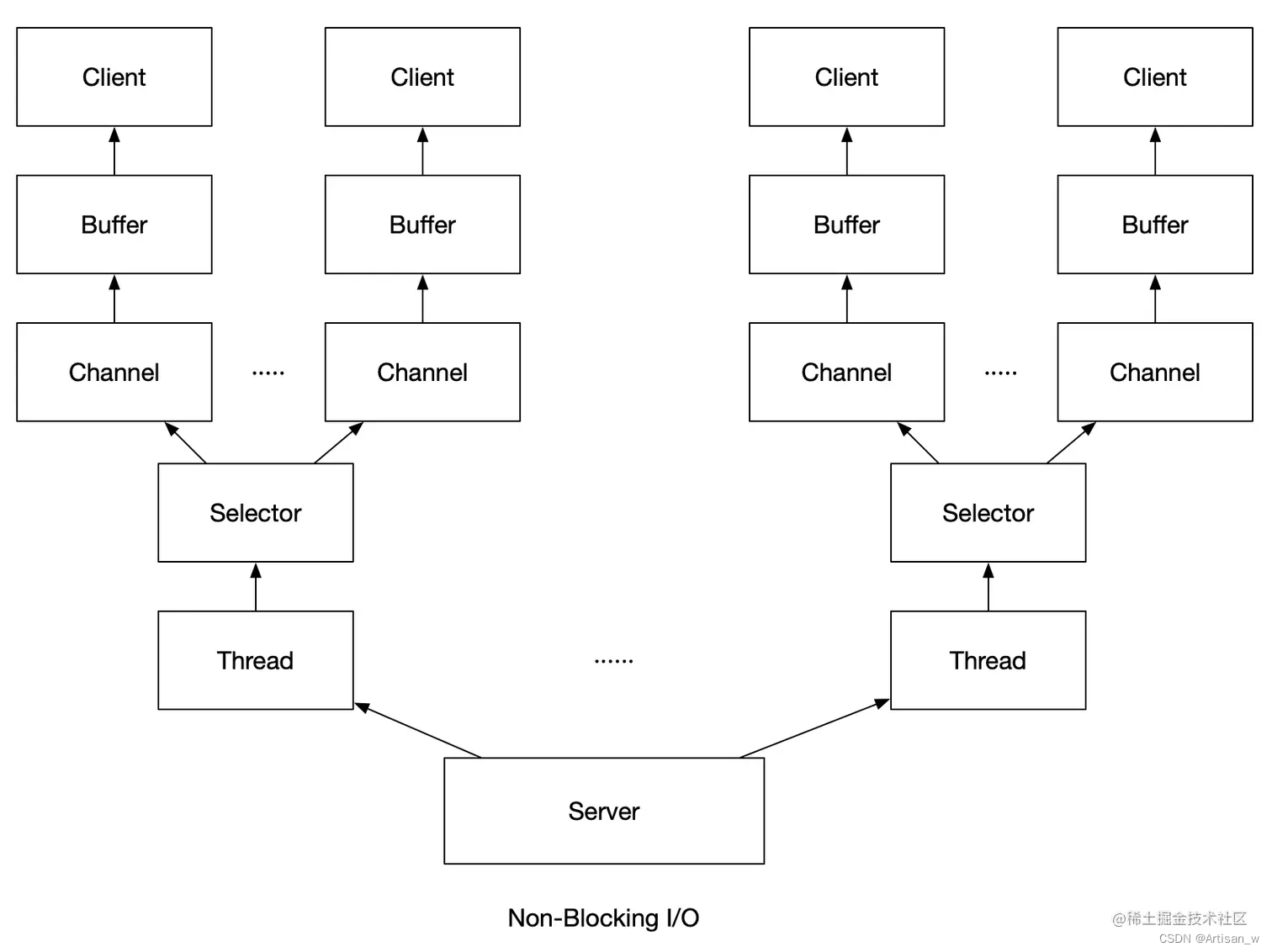
Java网络编程原理与实践--从Socket到BIO再到NIO
文章目录 Java网络编程原理与实践--从Socket到BIO再到NIOSocket基本架构Socket 基本使用简单一次发送接收客户端服务端 字节流方式简单发送接收客户端服务端 双向通信客户端服务端 多次接收消息客户端服务端 Socket写法的问题BIO简单流程BIO写法客户端服务端 BIO的问题 NIO简述…...
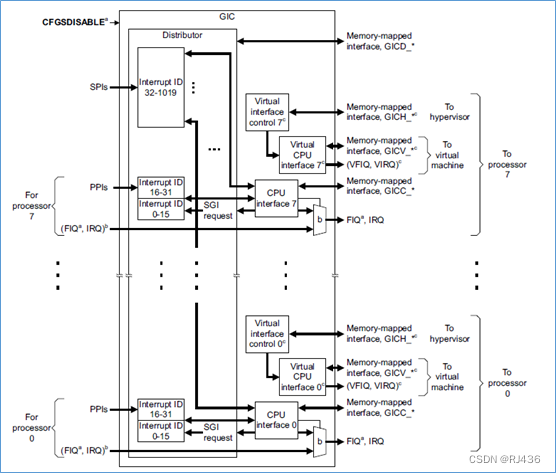
ARM GIC(三) gicv2架构
ARM的cpu,特别是cortex-A系列的CPU,目前都是多core的cpu,因此对于多core的cpu的中断管理,就不能像单core那样简单去管理,由此arm定义了GICv2架构,来支持多核cpu的中断管理 一、gicv2架构 GICv2,支持最大8个core。其框图如下图所示: 在gicv2中,gic由两个大模块组成: …...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...
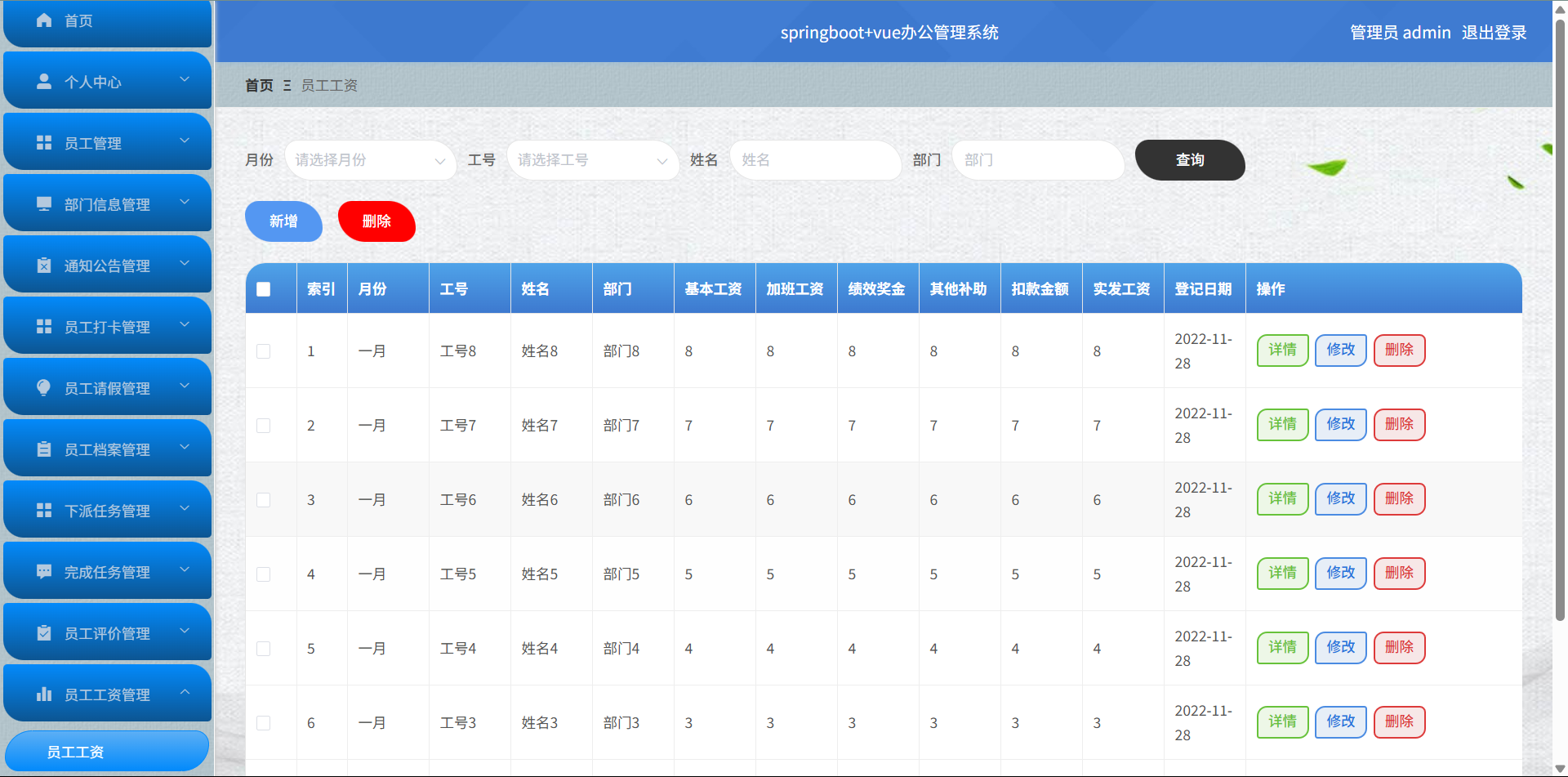
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...