【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse
【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse
- 1)导入相关依赖
- 2)代码实现
- 2.1.resources
- 2.1.1.appconfig.yml
- 2.1.2.log4j.properties
- 2.1.3.log4j2.xml
- 2.1.4.flink_backup_local.yml
- 2.2.utils
- 2.2.1.DBConn
- 2.2.2.CommonUtils
- 2.2.3.RemoteConfigUtil
- 2.2.4.ClickhouseUtil
- 2.3.flatmap
- 2.3.1.FlatMapFunction
- 2.4.sink
- 2.4.1.ClickHouseCatalog
- 2.5.Kafka2ClickHouse
- 2.5.1.Kafka2chApp
- 2.5.2.Kafka2Ck-ODS
需求描述:
1、数据从 Kafka 写入 ClickHouse。
2、相关配置存放于 Mysql 中,通过 Mysql 进行动态读取。
3、此案例中的 Kafka 是进行了 Kerberos 安全认证的,如果不需要自行修改。
4、先在 ClickHouse 中创建表然后动态获取 ClickHouse 的表结构。
5、Kafka 数据为 Json 格式,通过 FlatMap 扁平化处理后,根据表结构封装到 Row 中后完成写入。
6、写入时转换成临时视图模式,利用 Flink-Sql 实现数据写入。
7、本地测试时可以编辑 resources.flink_backup_local.yml 通过 ConfigTools.initConf 方法获取配置。
1)导入相关依赖
这里的依赖比较冗余,大家可以根据各自需求做删除或保留。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>gaei.cn.x5l</groupId><artifactId>kafka2ch</artifactId><version>1.0.0</version><properties><hbase.version>2.3.3</hbase.version><hadoop.version>3.1.1</hadoop.version><spark.version>3.0.2</spark.version><scala.version>2.12.10</scala.version><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.0</flink.version><scala.binary.version>2.12</scala.binary.version><target.java.version>1.8</target.java.version><maven.compiler.source>${target.java.version}</maven.compiler.source><maven.compiler.target>${target.java.version}</maven.compiler.target><log4j.version>2.17.2</log4j.version><hadoop.version>3.1.2</hadoop.version><hive.version>3.1.2</hive.version></properties><dependencies><!-- 基础依赖 开始--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- 基础依赖 结束--><!-- TABLE 开始--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId><version>1.14.0</version><scope>provided</scope></dependency><!-- 使用 hive sql时注销,其他时候可以放开 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><!-- TABLE 结束--><!-- sql 开始--><!-- sql解析 开始 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- sql解析 结束 --><!-- sql连接 kafka -->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-sql-connector-kafka_${scala.binary.version}</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>--><!-- sql 结束--><!-- 检查点 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-state-processor-api_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- 有状态的函数依赖 开始 --><!-- <dependency>--><!-- <groupId>org.apache.flink</groupId>--><!-- <artifactId>statefun-sdk-java</artifactId>--><!-- <version>3.0.0</version>--><!-- </dependency>--><!-- 有状态的函数依赖 结束 --><!-- 连接Kafka -->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>--><dependency><groupId>commons-lang</groupId><artifactId>commons-lang</artifactId><version>2.5</version><scope>compile</scope></dependency><!-- DataStream 开始 --><!-- <dependency>--><!-- <groupId>org.apache.flink</groupId>--><!-- <artifactId>statefun-flink-datastream</artifactId>--><!-- <version>3.0.0</version>--><!-- </dependency>--><!-- DataStream 结束 --><!-- 本地监控任务 开始 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- 本地监控任务 结束 --><!-- DataStream 开始 --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><!-- hdfs --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.1</version><!-- <exclusions>--><!-- <exclusion>--><!-- <groupId>org.apache.curator</groupId>--><!-- <artifactId>curator-client</artifactId>--><!-- </exclusion>--><!-- </exclusions>--></dependency><!-- https://mvnrepository.com/artifact/org.apache.curator/curator-client --><!-- <dependency>--><!-- <groupId>org.apache.curator</groupId>--><!-- <artifactId>curator-client</artifactId>--><!-- <version>5.3.0</version>--><!-- </dependency>--><!-- 重点,容易被忽略的jar --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-auth</artifactId><version>${hadoop.version}</version></dependency><!-- rocksdb_2 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- 其他 --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.1.23</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.18</version><scope>provided</scope></dependency><dependency><groupId>gaei.cn.x5l.bigdata.common</groupId><artifactId>x5l-bigdata-common</artifactId><version>1.3-SNAPSHOT</version><exclusions><exclusion><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId></exclusion><exclusion><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId></exclusion><exclusion><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId></exclusion></exclusions></dependency><!-- <dependency>--><!-- <groupId>org.apache.flink</groupId>--><!-- <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>--><!-- <version>${flink.version}</version>--><!-- </dependency>--><!-- 将 flink-connector-kafka_2.12 改为 flink-sql-connector-kafka_2.12 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-clickhouse</artifactId><version>1.14.3-SNAPSHOT</version><!--<systemPath>${project.basedir}/lib/flink-connector-clickhouse-1.12.0-SNAPSHOT.jar</systemPath>--><!--<scope>system</scope>--></dependency><dependency><groupId>gaei.cn.x5l</groupId><artifactId>tsp-gb-decode</artifactId><version>1.0.0</version></dependency><dependency><groupId>org.jyaml</groupId><artifactId>jyaml</artifactId><version>1.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.44</version><scope>runtime</scope></dependency><dependency><groupId>gaei.cn.x5l.flink.common</groupId><artifactId>x5l-flink-common</artifactId><version>1.4-SNAPSHOT</version></dependency></dependencies><build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${target.java.version}</source><target>${target.java.version}</target></configuration></plugin><!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --><!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.0.0</version><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>org.apache.flink:force-shading</exclude><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>org.apache.logging.log4j:*</exclude><exclude>org.apache.flink:flink-runtime-web_2.11</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.owp.flink.kafka.KafkaSourceDemo</mainClass></transformer><!-- flink sql 需要 --><!-- The service transformer is needed to merge META-INF/services files --><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/><!-- ... --></transformers></configuration></execution></executions></plugin></plugins><pluginManagement><plugins><!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --><plugin><groupId>org.eclipse.m2e</groupId><artifactId>lifecycle-mapping</artifactId><version>1.0.0</version><configuration><lifecycleMappingMetadata><pluginExecutions><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><versionRange>[3.0.0,)</versionRange><goals><goal>shade</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><versionRange>[3.1,)</versionRange><goals><goal>testCompile</goal><goal>compile</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution></pluginExecutions></lifecycleMappingMetadata></configuration></plugin></plugins></pluginManagement></build></project>
2)代码实现
2.1.resources
2.1.1.appconfig.yml
mysql.url: "jdbc:mysql://1.1.1.1:3306/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&connectTimeout=60000&socketTimeout=60000"
mysql.username: "test"
mysql.password: "123456"
mysql.driver: "com.mysql.jdbc.Driver"
2.1.2.log4j.properties
log4j.rootLogger=info, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
2.1.3.log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration monitorInterval="5"><Properties><property name="LOG_PATTERN" value="%date{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n" /><property name="LOG_LEVEL" value="ERROR" /></Properties><appenders><console name="console" target="SYSTEM_OUT"><PatternLayout pattern="${LOG_PATTERN}"/><ThresholdFilter level="${LOG_LEVEL}" onMatch="ACCEPT" onMismatch="DENY"/></console><File name="log" fileName="tmp/log/job.log" append="false"><PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/></File></appenders><loggers><root level="${LOG_LEVEL}"><appender-ref ref="console"/><appender-ref ref="log"/></root></loggers>
</configuration>
2.1.4.flink_backup_local.yml
clickhouse:connector: 'clickhouse'database-name: 'dwd'driver: 'ru.yandex.clickhouse.ClickHouseDriver'jdbcurl: 'jdbc:clickhouse://10.1.1.1:8123/dwd?socket_timeout=480000'password: 'X8v@123456!%$'reissueInterval: 3sink.batch-size: '200000'sink.flush-interval: '3000000'sink.ignore-delete: 'true'sink.max-retries: '3'sink.partition-key: 'toYYYYMMDD(sample_date_time)'sink.partition-strategy: 'balanced'table-name: 'test_local'url: 'clickhouse://10.1.1.1:8123,10.1.1.1:8123,10.1.1.1:8123,10.1.1.1:8123,10.1.1.1:8123'username: 'test'
hdfs:checkPointPath: 'hdfs://nameserver/user/flink/rocksdbcheckpoint'checkpointTimeout: 360000checkpointing: 300000maxConcurrentCheckpoints: 1minPauseBetweenCheckpoints: 10000restartInterval: 60restartStrategy: 3
kafka-consumer:prop:auto.offset.reset: 'earliest'bootstrap.servers: 'kfk01:9092,kfk02:9092,kfk03:9092'enable.auto.commit: 'false'fetch.max.bytes: '52428700'group.id: 'test'isKerberized: '1'keytab: 'D:/keytab/test.keytab'krb5Conf: 'D:/keytab/krb5.conf'max.poll.interval.ms: '300000'max.poll.records: '1000'principal: 'test@PRE.TEST.COM'security_protocol: 'SASL_PLAINTEXT'serviceName: 'kafka'session.timeout.ms: '600000'useTicketCache: 'false'topics: 'topicA,topicB'
kafka-producer:defaultTopic: 'kafka2hive_error'prop:acks: 'all'batch.size: '1048576'bootstrap.servers: 'kfk01:9092,kfk02:9092,kfk03:9092'compression.type: 'lz4'key.serializer: 'org.apache.kafka.common.serialization.StringSerializer'retries: '3'value.serializer: 'org.apache.kafka.common.serialization.StringSerializer'
2.2.utils
2.2.1.DBConn
import java.sql.*;public class DBConn {private static final String driver = "com.mysql.jdbc.Driver"; //mysql驱动private static Connection conn = null;private static PreparedStatement ps = null;private static ResultSet rs = null;private static final CallableStatement cs = null;/*** 连接数据库* @return*/public static Connection conn(String url,String username,String password) {Connection conn = null;try {Class.forName(driver); //加载数据库驱动try {conn = DriverManager.getConnection(url, username, password); //连接数据库} catch (SQLException e) {e.printStackTrace();}} catch (ClassNotFoundException e) {e.printStackTrace();}return conn;}/*** 关闭数据库链接* @return*/public static void close() {if(conn != null) {try {conn.close(); //关闭数据库链接} catch (SQLException e) {e.printStackTrace();}}}
}
2.2.2.CommonUtils
@Slf4j
public class CommonUtils {public static StreamExecutionEnvironment setCheckpoint(StreamExecutionEnvironment env) throws IOException {
// ConfigTools.initConf("local");Map hdfsMap = (Map) ConfigTools.mapConf.get("hdfs");env.enableCheckpointing(((Integer) hdfsMap.get("checkpointing")).longValue(), CheckpointingMode.EXACTLY_ONCE);//这里会造成offset提交的延迟env.getCheckpointConfig().setMinPauseBetweenCheckpoints(((Integer) hdfsMap.get("minPauseBetweenCheckpoints")).longValue());env.getCheckpointConfig().setCheckpointTimeout(((Integer) hdfsMap.get("checkpointTimeout")).longValue());env.getCheckpointConfig().setMaxConcurrentCheckpoints((Integer) hdfsMap.get("maxConcurrentCheckpoints"));env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.setRestartStrategy(RestartStrategies.fixedDelayRestart((Integer) hdfsMap.get("restartStrategy"), // 尝试重启的次数,不宜过小,分布式任务很容易出问题(正常情况),建议3-5次Time.of(((Integer) hdfsMap.get("restartInterval")).longValue(), TimeUnit.SECONDS) // 延时));//设置可容忍的检查点失败数,默认值为0表示不允许容忍任何检查点失败env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);//设置状态后端存储方式env.setStateBackend(new RocksDBStateBackend((String) hdfsMap.get("checkPointPath"), true));
// env.setStateBackend(new FsStateBackend((String) hdfsMap.get("checkPointPath"), true));
// env.setStateBackend(new HashMapStateBackend(());return env;}public static FlinkKafkaConsumer<ConsumerRecord<String, String>> getKafkaConsumer(Map<String, Object> kafkaConf) throws IOException {String[] topics = ((String) kafkaConf.get("topics")).split(",");log.info("监听的topic: {}", topics);Properties properties = new Properties();Map<String, String> kafkaProp = (Map<String, String>) kafkaConf.get("prop");for (String key : kafkaProp.keySet()) {properties.setProperty(key, kafkaProp.get(key).toString());}if (!StringUtils.isBlank((String) kafkaProp.get("isKerberized")) && "1".equals(kafkaProp.get("isKerberized"))) {System.setProperty("java.security.krb5.conf", kafkaProp.get("krb5Conf"));properties.put("security.protocol", kafkaProp.get("security_protocol"));properties.put("sasl.jaas.config", "com.sun.security.auth.module.Krb5LoginModule required "+ "useTicketCache=" + kafkaProp.get("useTicketCache") + " "+ "serviceName=\"" + kafkaProp.get("serviceName") + "\" "+ "useKeyTab=true "+ "keyTab=\"" + kafkaProp.get("keytab").toString() + "\" "+ "principal=\"" + kafkaProp.get("principal").toString() + "\";");}properties.put("key.serializer", "org.apache.flink.kafka.shaded.org.apache.kafka.common.serialization.ByteArrayDeserializer");properties.put("value.serializer", "org.apache.flink.kafka.shaded.org.apache.kafka.common.serialization.ByteArrayDeserializer");FlinkKafkaConsumer<ConsumerRecord<String, String>> consumerRecordFlinkKafkaConsumer = new FlinkKafkaConsumer<ConsumerRecord<String, String>>(Arrays.asList(topics), new KafkaDeserializationSchema<ConsumerRecord<String, String>>() {@Overridepublic TypeInformation<ConsumerRecord<String, String>> getProducedType() {return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>() {});}@Overridepublic boolean isEndOfStream(ConsumerRecord<String, String> stringStringConsumerRecord) {return false;}@Overridepublic ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {return new ConsumerRecord<String, String>(record.topic(),record.partition(),record.offset(),record.timestamp(),record.timestampType(),record.checksum(),record.serializedKeySize(),record.serializedValueSize(),new String(record.key() == null ? "".getBytes(StandardCharsets.UTF_8) : record.key(), StandardCharsets.UTF_8),new String(record.value() == null ? "{}".getBytes(StandardCharsets.UTF_8) : record.value(), StandardCharsets.UTF_8));}}, properties);return consumerRecordFlinkKafkaConsumer;}
}
2.2.3.RemoteConfigUtil
public class RemoteConfigUtil {private static final Logger log = LoggerFactory.getLogger(RemoteConfigUtil.class);private static Connection conn = null;private static PreparedStatement ps = null;private static ResultSet rs = null;public static Map<String, Object> mapConf;public RemoteConfigUtil() {}public static Map<String, Object> getByAppNameAndConfigName(String appName, String ConfigName) throws SQLException {if (mapConf != null && mapConf.size() > 0) {return mapConf;} else {Map<String, String> ymlMap = LocalConfigUtil.getYmlMap("/appconfig");String username = (String)ymlMap.get("mysql.username");String password = (String)ymlMap.get("mysql.password");String url = (String)ymlMap.get("mysql.url");String driver = (String)ymlMap.get("mysql.driver");Connection conn = JdbcUtil.getConnection(url, username, password, driver);PreparedStatement preparedStatement = null;Map var14;try {String sql = "select config_context from base_app_config where app_name = '%s' and config_name = '%s'";preparedStatement = conn.prepareStatement(String.format(sql, appName, ConfigName));ResultSet rs = preparedStatement.executeQuery();String config_context;for(config_context = ""; rs.next(); config_context = rs.getString("config_context")) {}rs.close();log.info("配置信息config_context: {}", config_context);if (StringUtils.isNotBlank(config_context)) {System.out.println(JSONObject.toJSONString(JSONObject.parseObject(config_context), new SerializerFeature[]{SerializerFeature.PrettyFormat}));}mapConf = (Map)JSON.parseObject(config_context, Map.class);var14 = mapConf;} finally {if (preparedStatement != null) {preparedStatement.close();}if (conn != null) {conn.close();}}return var14;}}
}2.2.4.ClickhouseUtil
public class ClickhouseUtil {public ClickhouseUtil() {}public static List<SchemaPo> getSchemaPoList(Map<String, Object> chMapConf) throws SQLException {List schemaPos = new ArrayList();Connection connection = null;try {String jdbcurl = (String) chMapConf.get("jdbcurl");String driver = (String) chMapConf.get("driver");String userName = (String) chMapConf.get("username");String password = (String) chMapConf.get("password");String databaseName = (String) chMapConf.get("database-name");String tableName = (String) chMapConf.get("table-name");connection = JdbcUtil.getConnection(jdbcurl, userName, password, driver);DatabaseMetaData metaData = connection.getMetaData();ResultSet colRet = metaData.getColumns((String) null, databaseName, tableName, "%");System.out.println("表字段信息:");while (colRet.next()) {String columnName = colRet.getString("COLUMN_NAME");String columnType = colRet.getString("TYPE_NAME");schemaPos.add(new SchemaPo(columnName, columnType));System.out.println(columnName + " " + columnType);}} finally {try {if (connection != null) {connection.close();}} catch (SQLException var18) {var18.printStackTrace();}}return schemaPos;}public static String getCreateSinkTableSql(Map<String, Object> clickhouse, String sinkTableName, List<SchemaPo> schemaPos) {StringBuilder sinkTableSql = new StringBuilder();String userName = (String) clickhouse.get("username");String password = (String) clickhouse.get("password");String connector = (String) clickhouse.get("connector");String databaseName = (String) clickhouse.get("database-name");String url = (String) clickhouse.get("url");String tableName = (String) clickhouse.get("table-name");String sinkBatchSize = (String) clickhouse.get("sink.batch-size");String sinkFlushInterval = (String) clickhouse.get("sink.flush-interval");String sinkMaxRetries = (String) clickhouse.get("sink.max-retries");String sinkPartitionStrategy = (String) clickhouse.get("sink.partition-strategy");String sinkPartitionKey = (String) clickhouse.get("sink.partition-key");String sinkIgnoreDelete = (String) clickhouse.get("sink.ignore-delete");sinkTableSql.append(String.format("CREATE TABLE %s (\n", sinkTableName));int i = 0;Iterator var17 = schemaPos.iterator();while (var17.hasNext()) {SchemaPo schemaPo = (SchemaPo) var17.next();++i;String signal = schemaPo.getSignal();String type = schemaPo.getType();if ("UInt64".equalsIgnoreCase(type)) {type = "BIGINT";} else if ("Map(String,String)".equalsIgnoreCase(type)) {type = "Map<String,String>";} else if ("Datetime".equalsIgnoreCase(type)) {type = "Timestamp(0)";} else {type = "String";}sinkTableSql.append(String.format(" `%s` %s", signal, type));sinkTableSql.append(i == schemaPos.size() ? ")" : ",\n");}sinkTableSql.append("WITH(\n");sinkTableSql.append(String.format("'connector' = '%s',\n", connector));sinkTableSql.append(String.format("'url' = '%s',\n", url));sinkTableSql.append(String.format("'username' = '%s',\n", userName));sinkTableSql.append(String.format("'password' = '%s',\n", password));sinkTableSql.append(String.format("'url' = '%s',\n", url));sinkTableSql.append(String.format("'database-name' = '%s',\n", databaseName));sinkTableSql.append(String.format("'table-name' = '%s',\n", tableName));sinkTableSql.append(String.format("'sink.batch-size' = '%s',\n", sinkBatchSize));sinkTableSql.append(String.format("'sink.flush-interval' = '%s',\n", sinkFlushInterval));sinkTableSql.append(String.format("'sink.max-retries' = '%s',\n", sinkMaxRetries));sinkTableSql.append(String.format("'sink.partition-strategy' = 'hash',\n"));sinkTableSql.append(String.format("'sink.partition-key' = 'sample_date_time',\n"));sinkTableSql.append(String.format("'sink.ignore-delete' = '%s'\n", sinkIgnoreDelete));sinkTableSql.append(" )");return sinkTableSql.toString();}//转换成ck需要的格式public static Row convertRow(Map<String, String> resultMap, List<SchemaPo> schemaPos) {Row row = new Row(schemaPos.size());for (int i = 0; i < schemaPos.size(); i++) {SchemaPo schemaPo = schemaPos.get(i);String valueStr = resultMap.get(schemaPo.getSignal());if (StringUtils.isBlank(valueStr)) {row.setField(i, null);continue;}if ("UInt64".equalsIgnoreCase(schemaPo.getType())) {Long svalue = Long.valueOf(valueStr);row.setField(i, Math.abs(svalue));} else if ("Int64".equalsIgnoreCase(schemaPo.getType())) {Long svalue = Long.valueOf(valueStr);row.setField(i, Math.abs(svalue));} else if ("Int32".equalsIgnoreCase(schemaPo.getType())) {Integer svalue = Integer.valueOf(valueStr);row.setField(i, svalue);} else if ("datetime".equalsIgnoreCase(schemaPo.getType())) {try {Date svalue = (new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")).parse(valueStr);Timestamp timestamp = new Timestamp(svalue.getTime());row.setField(i, timestamp);} catch (Exception ex) {System.out.println(ex.getMessage());System.out.println(Arrays.toString(ex.getStackTrace()));}} else {row.setField(i, valueStr);}}return row;}}2.3.flatmap
2.3.1.FlatMapFunction
public interface FlatMapFunction {public FlatMapFunction<ConsumerRecord<String, String>, Row> newInstance(List<SchemaPo> schemaPos);
}
2.4.sink
2.4.1.ClickHouseCatalog
public class ClickHouseCatalog extends AbstractCatalog {private static final Logger LOG = LoggerFactory.getLogger(ClickHouseCatalog.class);public static final String DEFAULT_DATABASE = "default";private final String baseUrl;private final String username;private final String password;private final boolean ignorePrimaryKey;private final Map<String, String> properties;private ClickHouseConnection connection;public ClickHouseCatalog(String catalogName, Map<String, String> properties) {this(catalogName, (String)properties.get("database-name"), (String)properties.get("url"), (String)properties.get("username"), (String)properties.get("password"), properties);}public ClickHouseCatalog(String catalogName, @Nullable String defaultDatabase, String baseUrl, String username, String password) {this(catalogName, defaultDatabase, baseUrl, username, password, Collections.emptyMap());}public ClickHouseCatalog(String catalogName, @Nullable String defaultDatabase, String baseUrl, String username, String password, Map<String, String> properties) {super(catalogName, defaultDatabase == null ? "default" : defaultDatabase);Preconditions.checkArgument(!StringUtils.isNullOrWhitespaceOnly(baseUrl), "baseUrl cannot be null or empty");Preconditions.checkArgument(!StringUtils.isNullOrWhitespaceOnly(username), "username cannot be null or empty");Preconditions.checkArgument(!StringUtils.isNullOrWhitespaceOnly(password), "password cannot be null or empty");this.baseUrl = baseUrl.endsWith("/") ? baseUrl : baseUrl + "/";this.username = username;this.password = password;this.ignorePrimaryKey = properties.get("catalog.ignore-primary-key") == null || Boolean.parseBoolean((String)properties.get("catalog.ignore-primary-key"));this.properties = Collections.unmodifiableMap(properties);}public void open() throws CatalogException {try {Properties configuration = new Properties();configuration.putAll(this.properties);configuration.setProperty(ClickHouseQueryParam.USER.getKey(), this.username);configuration.setProperty(ClickHouseQueryParam.PASSWORD.getKey(), this.password);configuration.setProperty("socket_timeout", "600000");String jdbcUrl = ClickHouseUtil.getJdbcUrl(this.baseUrl, this.getDefaultDatabase());BalancedClickhouseDataSource dataSource = new BalancedClickhouseDataSource(jdbcUrl, configuration);dataSource.actualize();this.connection = dataSource.getConnection();LOG.info("Created catalog {}, established connection to {}", this.getName(), jdbcUrl);} catch (Exception var4) {throw new CatalogException(String.format("Opening catalog %s failed.", this.getName()), var4);}}public synchronized void close() throws CatalogException {try {this.connection.close();LOG.info("Closed catalog {} ", this.getName());} catch (Exception var2) {throw new CatalogException(String.format("Closing catalog %s failed.", this.getName()), var2);}}public Optional<Factory> getFactory() {return Optional.of(new ClickHouseDynamicTableFactory());}public synchronized List<String> listDatabases() throws CatalogException {try {PreparedStatement stmt = this.connection.prepareStatement("SELECT name from `system`.databases");Throwable var2 = null;try {ResultSet rs = stmt.executeQuery();Throwable var4 = null;try {List<String> databases = new ArrayList();while(rs.next()) {databases.add(rs.getString(1));}return databases;} catch (Throwable var31) {var4 = var31;throw var31;} finally {if (rs != null) {if (var4 != null) {try {rs.close();} catch (Throwable var30) {var4.addSuppressed(var30);}} else {rs.close();}}}} catch (Throwable var33) {var2 = var33;throw var33;} finally {if (stmt != null) {if (var2 != null) {try {stmt.close();} catch (Throwable var29) {var2.addSuppressed(var29);}} else {stmt.close();}}}} catch (Exception var35) {throw new CatalogException(String.format("Failed listing database in catalog %s", this.getName()), var35);}}public CatalogDatabase getDatabase(String databaseName) throws DatabaseNotExistException, CatalogException {if (this.listDatabases().contains(databaseName)) {return new CatalogDatabaseImpl(Collections.emptyMap(), (String)null);} else {throw new DatabaseNotExistException(this.getName(), databaseName);}}public boolean databaseExists(String databaseName) throws CatalogException {Preconditions.checkArgument(!StringUtils.isNullOrWhitespaceOnly(databaseName));return this.listDatabases().contains(databaseName);}public void createDatabase(String name, CatalogDatabase database, boolean ignoreIfExists) throws DatabaseAlreadyExistException, CatalogException {throw new UnsupportedOperationException();}public void dropDatabase(String name, boolean ignoreIfNotExists, boolean cascade) throws DatabaseNotEmptyException, CatalogException {throw new UnsupportedOperationException();}public void alterDatabase(String name, CatalogDatabase newDatabase, boolean ignoreIfNotExists) throws DatabaseNotExistException, CatalogException {throw new UnsupportedOperationException();}public synchronized List<String> listTables(String databaseName) throws DatabaseNotExistException, CatalogException {if (!this.databaseExists(databaseName)) {throw new DatabaseNotExistException(this.getName(), databaseName);} else {try {PreparedStatement stmt = this.connection.prepareStatement(String.format("SELECT name from `system`.tables where database = '%s'", databaseName));Throwable var3 = null;try {ResultSet rs = stmt.executeQuery();Throwable var5 = null;try {List<String> tables = new ArrayList();while(rs.next()) {tables.add(rs.getString(1));}return tables;} catch (Throwable var32) {var5 = var32;throw var32;} finally {if (rs != null) {if (var5 != null) {try {rs.close();} catch (Throwable var31) {var5.addSuppressed(var31);}} else {rs.close();}}}} catch (Throwable var34) {var3 = var34;throw var34;} finally {if (stmt != null) {if (var3 != null) {try {stmt.close();} catch (Throwable var30) {var3.addSuppressed(var30);}} else {stmt.close();}}}} catch (Exception var36) {throw new CatalogException(String.format("Failed listing tables in catalog %s database %s", this.getName(), databaseName), var36);}}}public List<String> listViews(String databaseName) throws DatabaseNotExistException, CatalogException {throw new UnsupportedOperationException();}public CatalogBaseTable getTable(ObjectPath tablePath) throws TableNotExistException, CatalogException {if (!this.tableExists(tablePath)) {throw new TableNotExistException(this.getName(), tablePath);} else {Map<String, String> configuration = new HashMap(this.properties);configuration.put("url", this.baseUrl);configuration.put("database-name", tablePath.getDatabaseName());configuration.put("table-name", tablePath.getObjectName());configuration.put("username", this.username);configuration.put("password", this.password);String databaseName = tablePath.getDatabaseName();String tableName = tablePath.getObjectName();try {DistributedEngineFullSchema engineFullSchema = ClickHouseUtil.getAndParseDistributedEngineSchema(this.connection, tablePath.getDatabaseName(), tablePath.getObjectName());if (engineFullSchema != null) {databaseName = engineFullSchema.getDatabase();tableName = engineFullSchema.getTable();}} catch (Exception var6) {throw new CatalogException(String.format("Failed getting engine full of %s.%s.%s", this.getName(), databaseName, tableName), var6);}return new CatalogTableImpl(this.createTableSchema(databaseName, tableName), this.getPartitionKeys(databaseName, tableName), configuration, "");}}private synchronized TableSchema createTableSchema(String databaseName, String tableName) {try {PreparedStatement stmt = this.connection.prepareStatement(String.format("SELECT * from `%s`.`%s` limit 0", databaseName, tableName));Throwable var4 = null;TableSchema var24;try {ClickHouseResultSetMetaData metaData = (ClickHouseResultSetMetaData)stmt.getMetaData().unwrap(ClickHouseResultSetMetaData.class);Method getColMethod = metaData.getClass().getDeclaredMethod("getCol", Integer.TYPE);getColMethod.setAccessible(true);List<String> primaryKeys = this.getPrimaryKeys(databaseName, tableName);TableSchema.Builder builder = TableSchema.builder();for(int idx = 1; idx <= metaData.getColumnCount(); ++idx) {ClickHouseColumnInfo columnInfo = (ClickHouseColumnInfo)getColMethod.invoke(metaData, idx);String columnName = columnInfo.getColumnName();DataType columnType = ClickHouseTypeUtil.toFlinkType(columnInfo);if (primaryKeys.contains(columnName)) {columnType = (DataType)columnType.notNull();}builder.field(columnName, columnType);}if (!primaryKeys.isEmpty()) {builder.primaryKey((String[])primaryKeys.toArray(new String[0]));}var24 = builder.build();} catch (Throwable var21) {var4 = var21;throw var21;} finally {if (stmt != null) {if (var4 != null) {try {stmt.close();} catch (Throwable var20) {var4.addSuppressed(var20);}} else {stmt.close();}}}return var24;} catch (Exception var23) {throw new CatalogException(String.format("Failed getting columns in catalog %s database %s table %s", this.getName(), databaseName, tableName), var23);}}private List<String> getPrimaryKeys(String databaseName, String tableName) {if (this.ignorePrimaryKey) {return Collections.emptyList();} else {try {PreparedStatement stmt = this.connection.prepareStatement(String.format("SELECT name from `system`.columns where `database` = '%s' and `table` = '%s' and is_in_primary_key = 1", databaseName, tableName));Throwable var4 = null;try {ResultSet rs = stmt.executeQuery();Throwable var6 = null;try {List<String> primaryKeys = new ArrayList();while(rs.next()) {primaryKeys.add(rs.getString(1));}return primaryKeys;} catch (Throwable var33) {var6 = var33;throw var33;} finally {if (rs != null) {if (var6 != null) {try {rs.close();} catch (Throwable var32) {var6.addSuppressed(var32);}} else {rs.close();}}}} catch (Throwable var35) {var4 = var35;throw var35;} finally {if (stmt != null) {if (var4 != null) {try {stmt.close();} catch (Throwable var31) {var4.addSuppressed(var31);}} else {stmt.close();}}}} catch (Exception var37) {throw new CatalogException(String.format("Failed getting primary keys in catalog %s database %s table %s", this.getName(), databaseName, tableName), var37);}}}private List<String> getPartitionKeys(String databaseName, String tableName) {try {PreparedStatement stmt = this.connection.prepareStatement(String.format("SELECT name from `system`.columns where `database` = '%s' and `table` = '%s' and is_in_partition_key = 1", databaseName, tableName));Throwable var4 = null;try {ResultSet rs = stmt.executeQuery();Throwable var6 = null;try {List<String> partitionKeys = new ArrayList();while(rs.next()) {partitionKeys.add(rs.getString(1));}return partitionKeys;} catch (Throwable var33) {var6 = var33;throw var33;} finally {if (rs != null) {if (var6 != null) {try {rs.close();} catch (Throwable var32) {var6.addSuppressed(var32);}} else {rs.close();}}}} catch (Throwable var35) {var4 = var35;throw var35;} finally {if (stmt != null) {if (var4 != null) {try {stmt.close();} catch (Throwable var31) {var4.addSuppressed(var31);}} else {stmt.close();}}}} catch (Exception var37) {throw new CatalogException(String.format("Failed getting partition keys of %s.%s.%s", this.getName(), databaseName, tableName), var37);}}public boolean tableExists(ObjectPath tablePath) throws CatalogException {try {return this.databaseExists(tablePath.getDatabaseName()) && this.listTables(tablePath.getDatabaseName()).contains(tablePath.getObjectName());} catch (DatabaseNotExistException var3) {return false;}}public void dropTable(ObjectPath tablePath, boolean ignoreIfNotExists) throws TableNotExistException, CatalogException {throw new UnsupportedOperationException();}public void renameTable(ObjectPath tablePath, String newTableName, boolean ignoreIfNotExists) throws TableNotExistException, TableAlreadyExistException, CatalogException {throw new UnsupportedOperationException();}public void createTable(ObjectPath tablePath, CatalogBaseTable table, boolean ignoreIfExists) throws TableAlreadyExistException, DatabaseNotExistException, CatalogException {throw new UnsupportedOperationException();}public void alterTable(ObjectPath tablePath, CatalogBaseTable newTable, boolean ignoreIfNotExists) throws TableNotExistException, CatalogException {throw new UnsupportedOperationException();}public List<CatalogPartitionSpec> listPartitions(ObjectPath tablePath) throws TableNotExistException, TableNotPartitionedException, CatalogException {return Collections.emptyList();}public List<CatalogPartitionSpec> listPartitions(ObjectPath tablePath, CatalogPartitionSpec partitionSpec) throws TableNotExistException, TableNotPartitionedException, PartitionSpecInvalidException, CatalogException {return Collections.emptyList();}public List<CatalogPartitionSpec> listPartitionsByFilter(ObjectPath tablePath, List<Expression> filters) throws TableNotExistException, TableNotPartitionedException, CatalogException {return Collections.emptyList();}public CatalogPartition getPartition(ObjectPath tablePath, CatalogPartitionSpec partitionSpec) throws PartitionNotExistException, CatalogException {throw new PartitionNotExistException(this.getName(), tablePath, partitionSpec);}public boolean partitionExists(ObjectPath tablePath, CatalogPartitionSpec partitionSpec) throws CatalogException {throw new UnsupportedOperationException();}public void createPartition(ObjectPath tablePath, CatalogPartitionSpec partitionSpec, CatalogPartition partition, boolean ignoreIfExists) throws TableNotExistException, TableNotPartitionedException, PartitionSpecInvalidException, PartitionAlreadyExistsException, CatalogException {throw new UnsupportedOperationException();}public void dropPartition(ObjectPath tablePath, CatalogPartitionSpec partitionSpec, boolean ignoreIfNotExists) throws PartitionNotExistException, CatalogException {throw new UnsupportedOperationException();}public void alterPartition(ObjectPath tablePath, CatalogPartitionSpec partitionSpec, CatalogPartition newPartition, boolean ignoreIfNotExists) throws PartitionNotExistException, CatalogException {throw new UnsupportedOperationException();}public List<String> listFunctions(String dbName) throws DatabaseNotExistException, CatalogException {return Collections.emptyList();}public CatalogFunction getFunction(ObjectPath functionPath) throws FunctionNotExistException, CatalogException {throw new FunctionNotExistException(this.getName(), functionPath);}public boolean functionExists(ObjectPath functionPath) throws CatalogException {return false;}public void createFunction(ObjectPath functionPath, CatalogFunction function, boolean ignoreIfExists) throws FunctionAlreadyExistException, DatabaseNotExistException, CatalogException {throw new UnsupportedOperationException();}public void alterFunction(ObjectPath functionPath, CatalogFunction newFunction, boolean ignoreIfNotExists) throws FunctionNotExistException, CatalogException {throw new UnsupportedOperationException();}public void dropFunction(ObjectPath functionPath, boolean ignoreIfNotExists) throws FunctionNotExistException, CatalogException {throw new UnsupportedOperationException();}public CatalogTableStatistics getTableStatistics(ObjectPath tablePath) throws TableNotExistException, CatalogException {return CatalogTableStatistics.UNKNOWN;}public CatalogColumnStatistics getTableColumnStatistics(ObjectPath tablePath) throws TableNotExistException, CatalogException {return CatalogColumnStatistics.UNKNOWN;}public CatalogTableStatistics getPartitionStatistics(ObjectPath tablePath, CatalogPartitionSpec partitionSpec) throws PartitionNotExistException, CatalogException {return CatalogTableStatistics.UNKNOWN;}public CatalogColumnStatistics getPartitionColumnStatistics(ObjectPath tablePath, CatalogPartitionSpec partitionSpec) throws PartitionNotExistException, CatalogException {return CatalogColumnStatistics.UNKNOWN;}public void alterTableStatistics(ObjectPath tablePath, CatalogTableStatistics tableStatistics, boolean ignoreIfNotExists) throws TableNotExistException, CatalogException {throw new UnsupportedOperationException();}public void alterTableColumnStatistics(ObjectPath tablePath, CatalogColumnStatistics columnStatistics, boolean ignoreIfNotExists) throws TableNotExistException, CatalogException, TablePartitionedException {throw new UnsupportedOperationException();}public void alterPartitionStatistics(ObjectPath tablePath, CatalogPartitionSpec partitionSpec, CatalogTableStatistics partitionStatistics, boolean ignoreIfNotExists) throws PartitionNotExistException, CatalogException {throw new UnsupportedOperationException();}public void alterPartitionColumnStatistics(ObjectPath tablePath, CatalogPartitionSpec partitionSpec, CatalogColumnStatistics columnStatistics, boolean ignoreIfNotExists) throws PartitionNotExistException, CatalogException {throw new UnsupportedOperationException();}
}
2.5.Kafka2ClickHouse
2.5.1.Kafka2chApp
public class Kafka2chApp {private static final Logger log = LoggerFactory.getLogger(Kafka2chApp.class);private static String SINK_TABLE = "sinkTable";private static String KAFKA_TEMP_VIEW = "kafkaTempView";/*** @param appName mysql配置表对应字段* @param configName mysql配置表对应字段* @throws Exception*/public static void run(String appName, String configName, FlatMapFunction FlatMapFunction) throws Exception {log.info("Kafka2chApp.run传参appName:{}, configName:{}", appName, configName);// 获得数据库中的配置Map<String, Object> mapConf = RemoteConfigUtil.getByAppNameAndConfigName(appName, configName);if (mapConf == null || mapConf.size() == 0) return;Map<String, Object> clickhouseConf = (Map<String, Object>) mapConf.get("clickhouse");Map<String, Object> kafkaConsumerConf = (Map<String, Object>) mapConf.get("kafka-consumer");Map<String, Object> hdfsConf = (Map<String, Object>) mapConf.get("hdfs");// long beforeTime2Dropout = System.currentTimeMillis() - (Long) mapConf.get("before2DropoutHourStep") * 3600;// long after2DropoutTime = System.currentTimeMillis();// 初始化TableEnv & 获得流StreamExecutionEnvironment streamEnv = StreamEnv.getStreamEnv(hdfsConf);streamEnv.setParallelism(ckP);StreamTableEnvironment tableEnv = TableEnv.getTableEnv();// 处理List<SchemaPo> schemaPos = ClickhouseUtil.getSchemaPoList(clickhouseConf);TypeInformation[] types = getTypeInformationArray(schemaPos);// TypeInformation[] types = (schemaPos);String[] fieldNames = SchemaPoUtil.getFieldLists(schemaPos);FlatMapFunction<ConsumerRecord<String, String>, Row> flatMapFunction = x5lFlatMapFunction.newInstance(schemaPos);DataStreamSource<ConsumerRecord<String, String>> stream;SingleOutputStreamOperator<Row> infos;stream = streamEnv.addSource(CommonUtils.getKafkaConsumer(kafkaConsumerConf));System.out.println("Source 设置并行度为"+streamEnv.getParallelism());}infos = stream.flatMap(flatMapFunction);infos = infos.map(e -> e,new RowTypeInfo(types, fieldNames));System.out.println("map 设置并行度为"+streamEnv.getParallelism());}// 创建kafka数据临时视图tableEnv.createTemporaryView(KAFKA_TEMP_VIEW, infos);// 创建存放kafka数据的clickhouse映射表// String createSinkTableSql = ClickhouseUtil.getCreateSinkTableSql(clickhouseConf, SINK_TABLE, schemaPos);Map<String, String> props = new HashMap<>();props.put(ClickHouseConfig.DATABASE_NAME, (String) clickhouseConf.get("database-name"));props.put(ClickHouseConfig.URL, (String) clickhouseConf.get("url"));props.put(ClickHouseConfig.USERNAME, (String) clickhouseConf.get("username"));props.put(ClickHouseConfig.PASSWORD, (String) clickhouseConf.get("password"));props.put(ClickHouseConfig.SINK_FLUSH_INTERVAL, (String) clickhouseConf.get("sink.flush-interval"));props.put(ClickHouseConfig.SINK_BATCH_SIZE, (String) clickhouseConf.get("sink.batch-size"));Catalog cHcatalog = new ClickHouseCatalog("clickhouse", props);tableEnv.registerCatalog("clickhouse", cHcatalog);tableEnv.useCatalog("clickhouse");// Arrays.stream(tableEnv.listCatalogs()).forEach(e -> System.out.println("catalog: " + e));// Arrays.stream(tableEnv.listDatabases()).forEach(e -> System.out.println("database: " + e));// System.out.println(tableEnv.listTables().length);// Arrays.stream(tableEnv.listTables()).forEach(e -> System.out.println("table: " + e));// tableEnv.executeSql(createSinkTableSql);// System.out.println(tableEnv.executeSql("select * from " + KAFKA_TEMP_VIEW).getTableSchema());//拼接sqlString insertSql = "insert into `" + clickhouseConf.get("table-name") + "` select * from default_catalog.default_database." + KAFKA_TEMP_VIEW;// System.out.println("insertSql: " + insertSql);// log.info("insertSql: ", insertSql);//执行sqltableEnv.executeSql(insertSql);// 测试打印infos结果/*infos.print();streamEnv.executeAsync();*/}public static TypeInformation[] getTypeInformationArray(List<SchemaPo> schemaPos) {// String[] fieldNames = new String[columnTypeMap.size()];TypeInformation[] types = new TypeInformation[schemaPos.size()];int i = 0;for (SchemaPo po : schemaPos) {if ("String".equalsIgnoreCase(po.getType())) {types[i] = Types.STRING;} else if ("Int64".equalsIgnoreCase(po.getType())) {types[i] = Types.LONG;} else if ("UInt64".equalsIgnoreCase(po.getType())) {types[i] = Types.LONG;} else if ("Int32".equalsIgnoreCase(po.getType())) {types[i] = Types.INT;} else if ("Int8".equalsIgnoreCase(po.getType())) {types[i] = Types.INT;} else if ("datetime".equalsIgnoreCase(po.getType())) {types[i] = Types.SQL_TIMESTAMP;} else if ("Map(String,String)".equalsIgnoreCase(po.getType())) {types[i] = Types.MAP(Types.STRING, Types.STRING);} else {types[i] = Types.STRING;}i++;}return types;}}
2.5.2.Kafka2Ck-ODS
public class Kafka2Ck-ODS implements FlatMapFunction {private static Logger logger = Logger.getLogger(Kafka2Ck-ODS.class);public static void main(String[] args) throws Exception {Kafka2chApp.run(Kafka2Ck-ODS.class.getName(), args[0], new Kafka2Ck-ODS());}@Overridepublic FlatMapFunction<ConsumerRecord<String, String>, Row> newInstance(List<SchemaPo> schemaPos) {return new FlatMapFunction<ConsumerRecord<String, String>, Row>() {@Overridepublic void flatMap(ConsumerRecord<String, String> record, Collector<Row> out) throws Exception {// System.out.println("record ===> " +record); // 测试String value = record.value();try {HashMap<String, Object> infoMap = JSON.parseObject(value, HashMap.class);// 处理dataListMap中的数据for (Map.Entry<String, String> entry : dataListMap.entrySet()) {String key = entry.getKey();String value1 = entry.getValue();resultMap.put(key.toLowerCase(), value1);}Row row = TableEnv.getRowBySchemaPo1(resultMap, schemaPos);out.collect(row);} catch (Exception e) {e.printStackTrace();System.out.printf("数据异常,原因是%s,topic为%s,key为%s,value为%s%n", e.getMessage(), record.topic(), record.key(), record.value());}}};}
}
相关文章:

【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse
【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse 1)导入相关依赖2)代码实现2.1.resources2.1.1.appconfig.yml2.1.2.log4j.properties2.1.3.log4j2.xml2.1.4.flink_backup_local.yml 2.2.utils2.2.1.DBConn2.2.2.CommonUtils2.…...

浅谈Redis分布式锁(下)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 自定义Redis分布式锁的…...

Django Rest Framework框架的安装
Django Rest Framework框架的安装 Django Rest Framework框架的安装 1.DRF简介2.安装依赖3.安装使用pip安装添加rest_framework应用 1.DRF简介 Django REST Framework是Web api的工具包。它是在Django框架基础之上,进行了二次开发。 2.安装依赖 链接python安装 …...
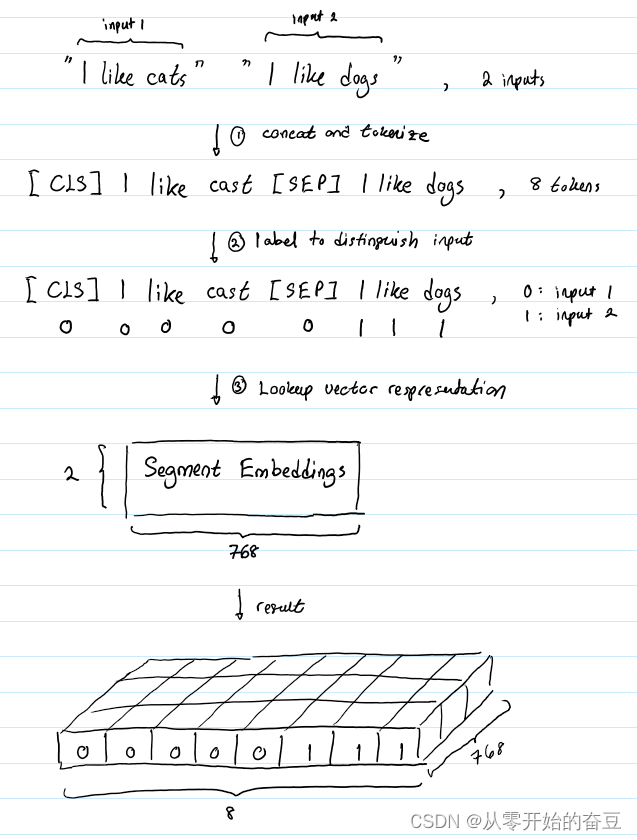
深度学习(七):bert理解之输入形式
传统的预训练方法存在一些问题,如单向语言模型的局限性和无法处理双向上下文的限制。为了解决这些问题,一种新的预训练方法随即被提出,即BERT(Bidirectional Encoder Representations from Transformers)。通过在大规模…...
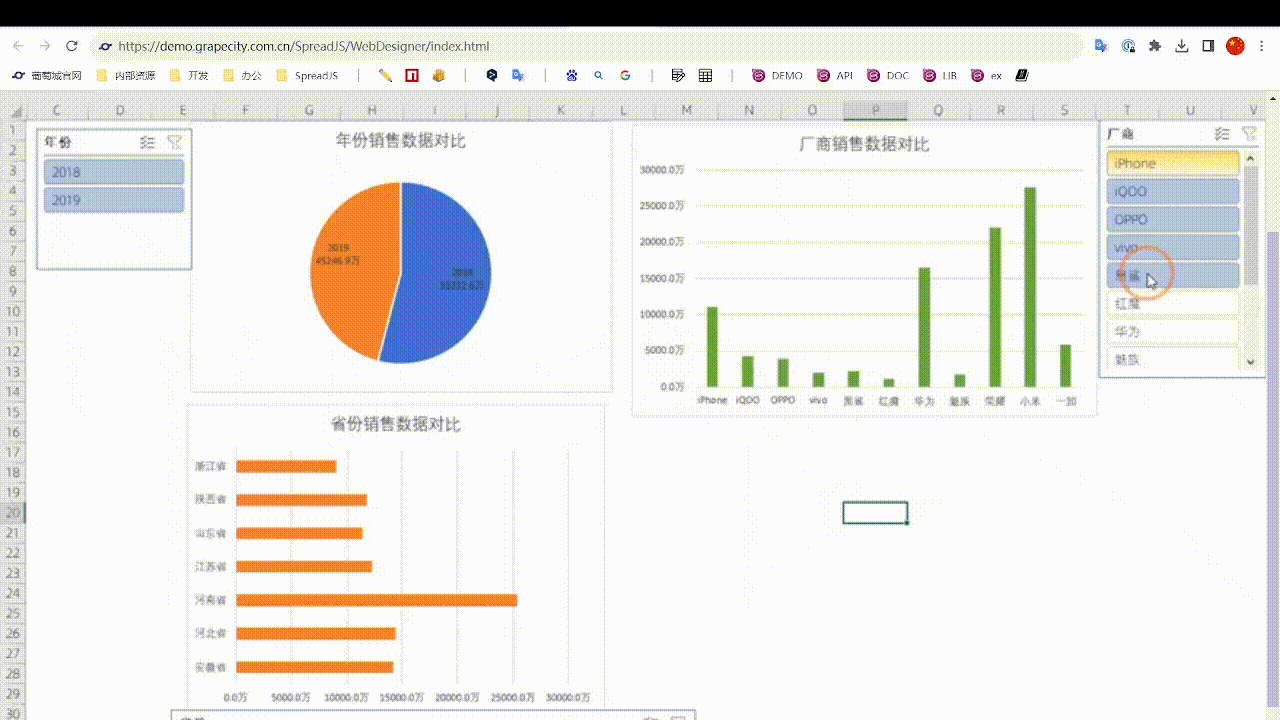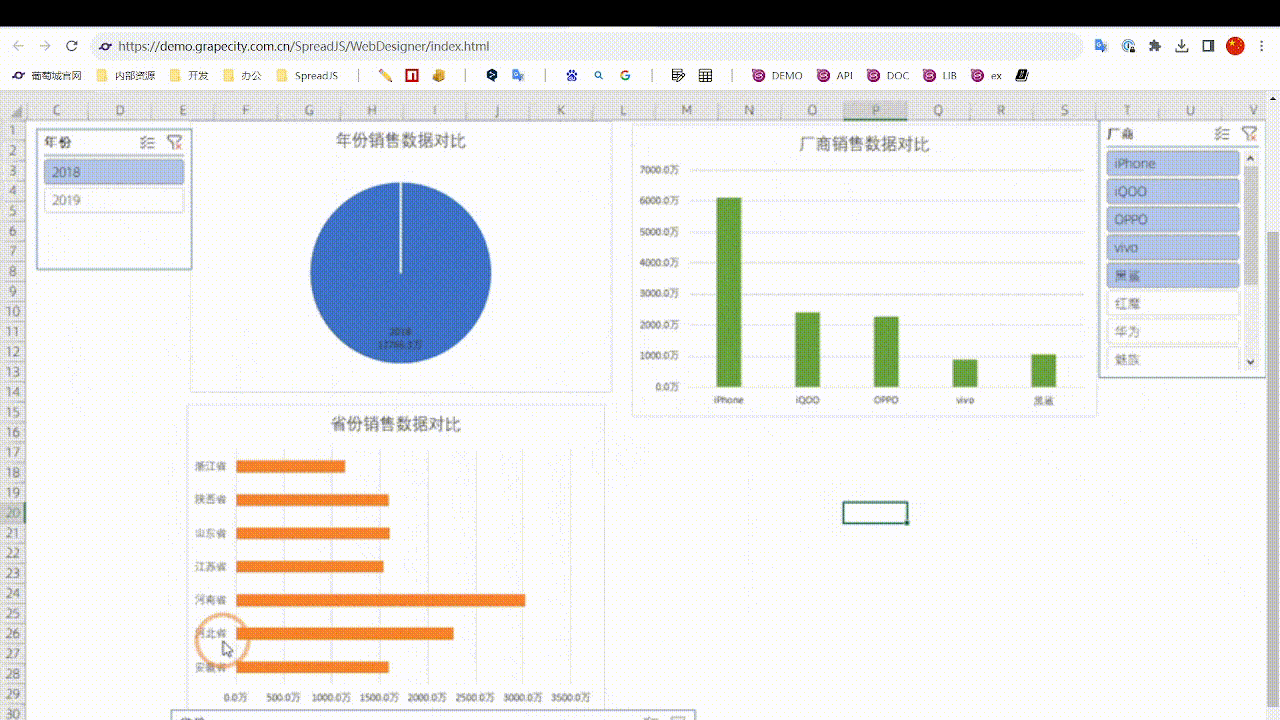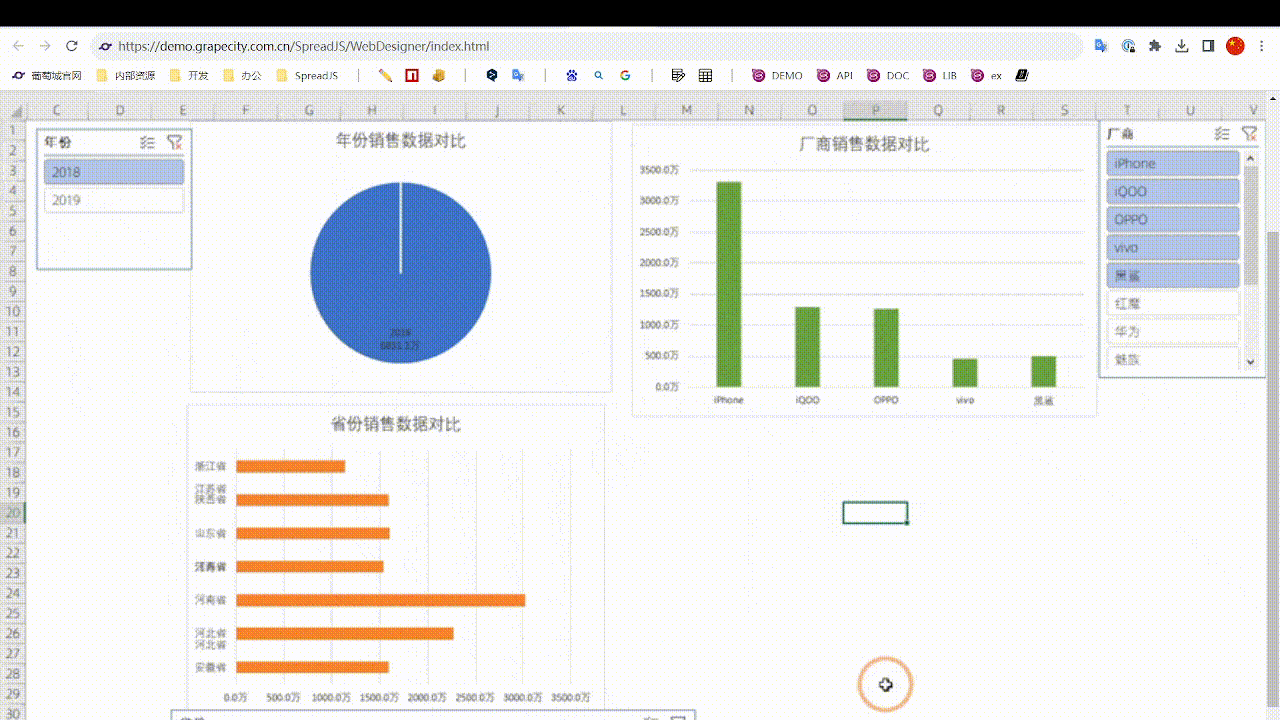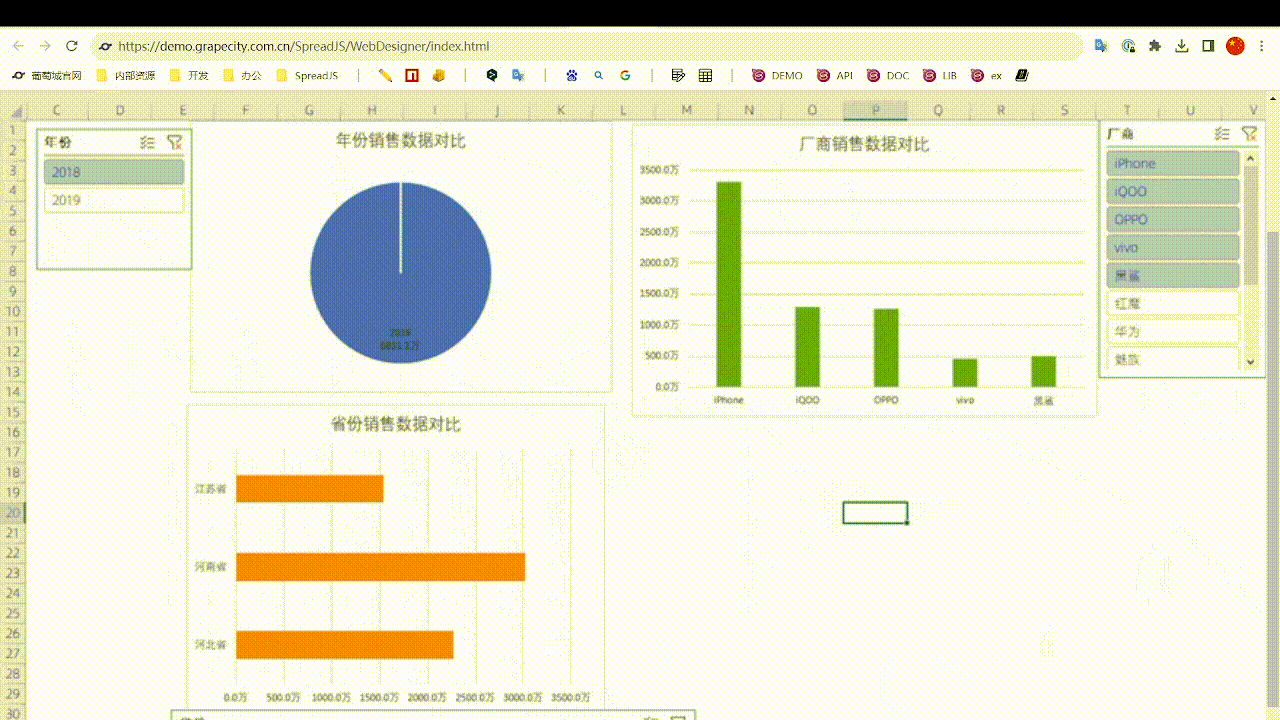
如何用Excel制作一张能在网上浏览的动态数据报表
前言 如今各类BI产品大行其道,“数据可视化”成为一个热门词汇。相比价格高昂的各种BI软件,用Excel来制作动态报表就更加经济便捷。今天小编就将为大家介绍一下如何使用葡萄城公司的纯前端表格控件——SpreadJS来实现一个Excel动态报表: 实…...
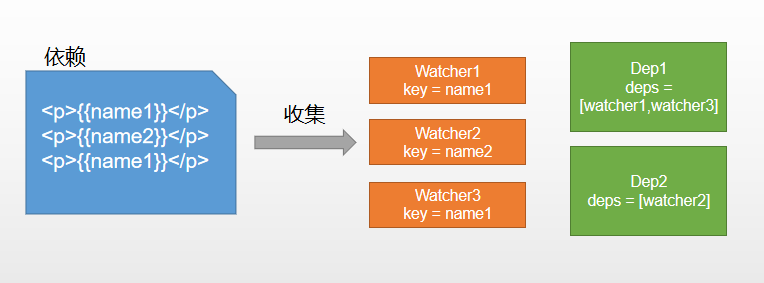
双向数据绑定是什么
一、什么是双向绑定 我们先从单向绑定切入单向绑定非常简单,就是把Model绑定到View,当我们用JavaScript代码更新Model时,View就会自动更新双向绑定就很容易联想到了,在单向绑定的基础上,用户更新了View,Mo…...

鱼眼标定方式
鱼眼作用 人单眼水平视角最大可达156度,垂直方向150度。为了增加可视范围,摄像头可以通过畸变参数扩大视野,一般100度到200度的fov。所以鱼眼是为了看的视野更大,注意在一定分辨率下,fov边缘的像素点稀疏,…...

详解Keras3.0 KerasNLP Models: GPT2 GPT2Tokenizer
1、GPT2Tokenizer 用于将文本数据转换为适合训练和预测的格式,主要功能是将输入的文本进行分词、编码等操作,以便在神经网络中使用 keras_nlp.models.GPT2Tokenizer(vocabulary, merges, **kwargs) 参数说明 vocabulary:一个字典&#x…...

2016年第五届数学建模国际赛小美赛B题直达地铁线路解题全过程文档及程序
2016年第五届数学建模国际赛小美赛 B题 直达地铁线路 原题再现: 在目前的大都市地铁网络中,在两个相距遥远的车站之间运送乘客通常需要很长时间。我们可以建议在两个长途车站之间设置直达班车,以节省长途乘客的时间。 第一部分…...

三秦通ETC续航改造
前些天开车时ETC每隔2分钟滴滴响一下,重插卡提示电池电压低 2.8V。看来应该是电池不行了。去银行更换ETC应该是需要费用的。还有一种办法是注销掉,然后去别的银行办一个。不过我想自己更换电池试一下。 首先拆下ETC,我使用的办法是开水烫。烧…...
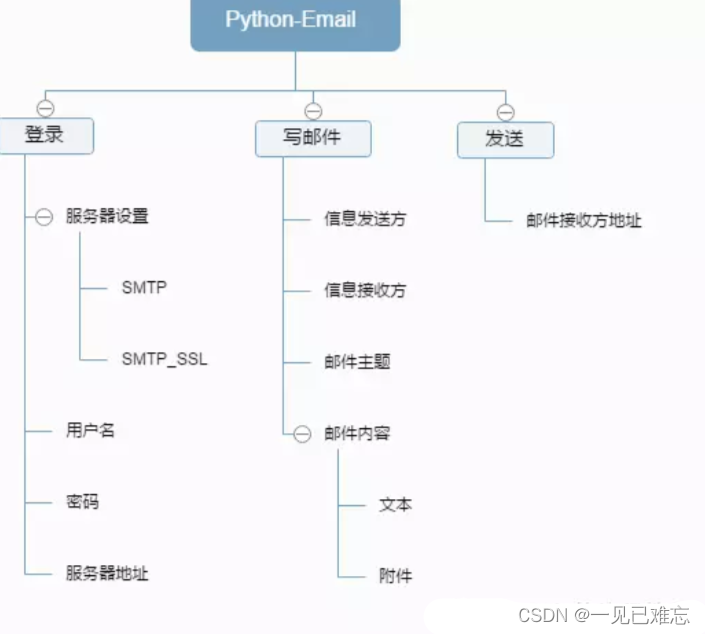
使用Python实现发送Email电子邮件【第19篇—python发邮件】
文章目录 👽使用Python实现发送Email电子邮件🎶实现原理🏃Python实现发送Email电子邮件-基础版👫实现源码🙆源码解析 💇Python实现发送Email电子邮件-完善版👫实现源码🙆源码解析&am…...

Docker基本命令和Docker怎么自己制作镜像
基本命令 启动新的容器(指定容器名称和端口映射【主机端口:容器端口】) docker run --name 容器名 -p 8080:80 镜像名 启动新的容器(交互式) docker run -it centos7-with-jdk /bin/bash 特权方式启动容器 docker run -d --…...
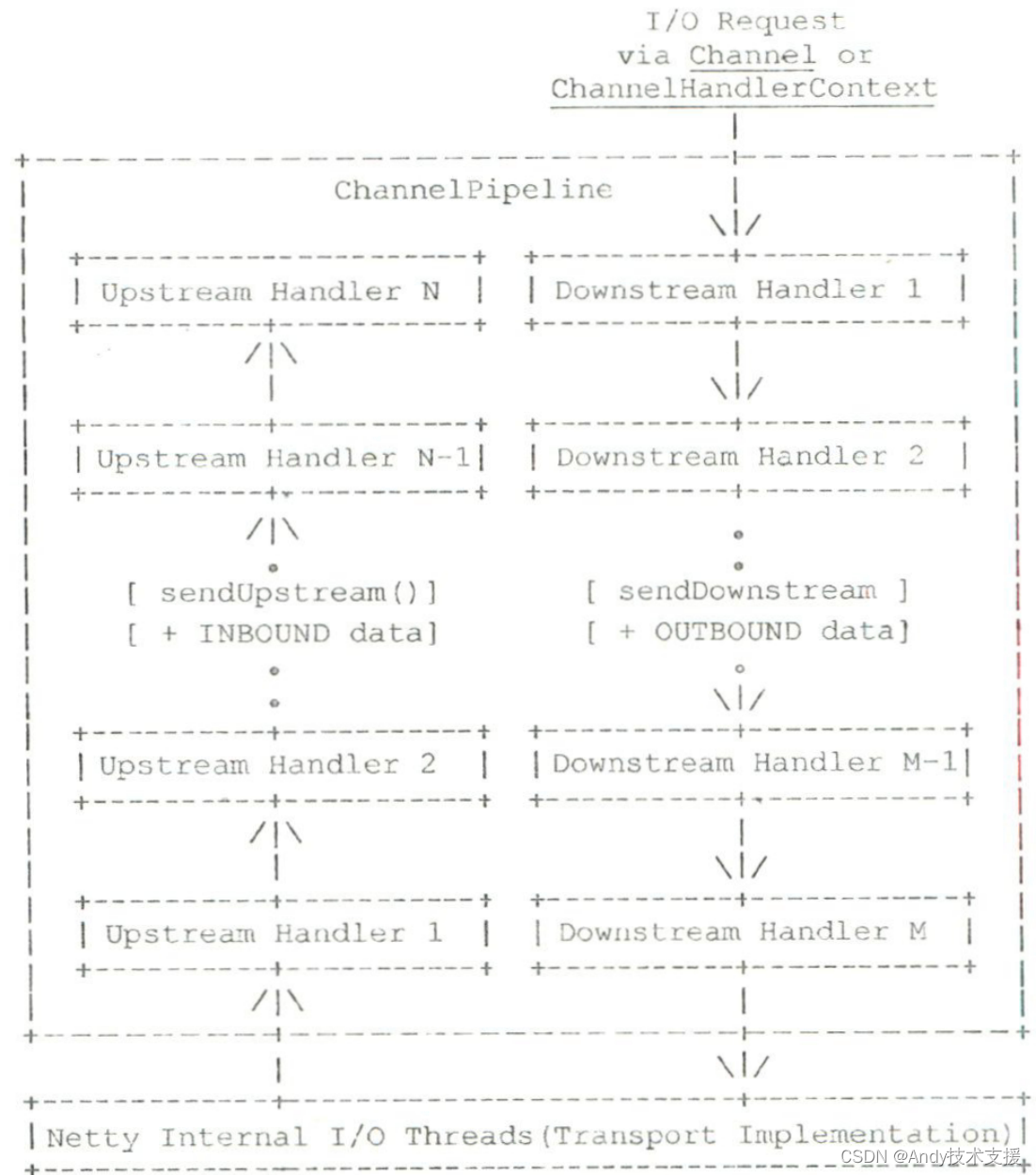
Netty-2-数据编解码
解析编解码支持的原理 以编码为例,要将对象序列化成字节流,你可以使用MessageToByteEncoder或MessageToMessageEncoder类。 这两个类都继承自ChannelOutboundHandlerAdapter适配器类,用于进行数据的转换。 其中,对于MessageToMe…...
伽马校正:FPGA
参考资料: Tone Mapping 与 Gamma Correction - 知乎 (zhihu.com) Book_VIP: 《基于MATLAB与FPGA的图像处理教程》此书是业内第一本基于MATLAB与FPGA的图像处理教程,第一本真正结合理论及算法加速方案,在Matlab验证,以及在FPGA上…...

【SpringCloud笔记】(8)服务网关之GateWay
GateWay 概述简介 官网地址: 上一代网关Zuul 1.x:https://github.com/Netflix/zuul/wiki(有兴趣可以了解一下) gateway:https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/…...

Compose常用布局
Compose布局基础知识 上一节对Compose做了简单的介绍,本章节主要介绍Compose中常用的布局,其中包括三个基础布局(Colmun、Row、Box);以及其他常用布局(ConstraintLayout 、BoxWithConstraints、HorizontalP…...
使用keytool查看Android APK签名
文章目录 一、找到JDK位置二、使用方法2.1 打开windows命令行工具2.2 查看签名 三、如何给APK做系统签名呢? 一、找到JDK位置 安卓AS之后,可选择继续安装JDK,如本文使用amazon版本默认位置:C:\Users\66176.jdks\corretto-1.8.0_342可通过自…...

数据库学习日常案例20231221-oracle libray cache lock分析
1 问题概述: 阻塞的源头为两个ddl操作导致大量的libray cache lock 其中1133为gis sde的create table as语句。 其中697为alter index语句。...

【数据结构】最短路径算法实现(Dijkstra(迪克斯特拉),FloydWarshall(弗洛伊德) )
文章目录 前言一、Dijkstra(迪克斯特拉)1.方法:2.代码实现 二、FloydWarshall(弗洛伊德)1.方法2.代码实现 完整源码 前言 最短路径问题:从在带权有向图G中的某一顶点出发,找出一条通往另一顶点…...

算法模板之队列图文详解
🌈个人主页:聆风吟 🔥系列专栏:算法模板、数据结构 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. ⛳️模拟队列1.1 🔔用数组模拟实现队列1.1.1 👻队列的定…...

Skija图像处理大全:编解码、滤镜与合成技术
Skija图像处理大全:编解码、滤镜与合成技术 【免费下载链接】skija Java bindings for Skia 项目地址: https://gitcode.com/gh_mirrors/sk/skija Skija作为Java绑定的Skia图形库,为开发者提供了强大的图像处理能力。本文将带您探索Skija在图像编…...

ScriptGen Modern Studio在短视频/微短剧创作中的应用实战
ScriptGen Modern Studio在短视频/微短剧创作中的应用实战 1. 短视频创作的新工具革命 短视频和微短剧行业正在经历前所未有的爆发式增长。根据最新行业报告,2023年短视频内容创作量同比增长超过60%,而专业级微短剧的市场规模预计将在2025年突破千亿大…...

Nunchaku-flux-1-dev在网络安全领域的应用:威胁检测与防御
Nunchaku-flux-1-dev在网络安全领域的应用:威胁检测与防御 1. 引言 网络安全问题越来越复杂,传统的防护手段常常力不从心。每天都有新的攻击手法出现,企业安全团队疲于应对。有没有一种更智能的方式,能够自动识别威胁、快速响应…...

RAG系统里最容易被低估的环节:深度解析检索优化策略,提升大模型应用效果!
本文深入剖析了RAG系统中检索环节的重要性,指出检索错误是导致大模型应用效果不佳的关键因素。文章从表达鸿沟、粒度鸿沟和意图鸿沟三重鸿沟出发,详细介绍了Query侧优化(如Query Rewriting、Multi-Query、HyDE)、索引侧优化&#…...

终极指南:如何为Evil Icons添加专属品牌图标
终极指南:如何为Evil Icons添加专属品牌图标 【免费下载链接】evil-icons Simple and clean SVG icon pack with the code to support Rails, Sprockets, Node.js, Gulp, Grunt and CDN 项目地址: https://gitcode.com/gh_mirrors/ev/evil-icons Evil Icons是…...

未发表!25年顶级SCI算法SOO优化CNN-LSTM-Attention一键实现多步预测!多步预测全家桶更新啦!
目录 多步预测案例 多步预测教程 创新点与原理 ①创新点一:基于CNN-LSTM的多尺度特征联合提取架构 ②创新点二:融合SE通道注意力机制的自适应特征重标定策略 ③创新点三:基于SOO智能算法的超参数自适应寻优 结果展示 全家桶目录 获取…...

实测对比:图解法和微变等效电路法分析放大电路,到底哪个更准?
实测对比:图解法和微变等效电路法分析放大电路,到底哪个更准? 在模拟电路设计中,共射放大电路的分析是每个电子工程师必须掌握的核心技能。面对同样的电路,工程师们常陷入方法论的选择困境:是采用直观形象的…...

OpenClaw开发提效指南:Qwen3-14b_int4_awq辅助日志分析与命令执行
OpenClaw开发提效指南:Qwen3-14b_int4_awq辅助日志分析与命令执行 1. 为什么开发者需要OpenClaw 作为一名全栈开发者,我每天要处理数十个项目的日志文件、执行测试脚本、生成汇总报告。这些重复性工作不仅枯燥,还容易出错。直到我发现OpenC…...

Linux CFS 的调度周期调整:任务数量对调度粒度的影响
一、简介1.1 背景与重要性在实时嵌入式系统、高性能计算(HPC)和云计算基础设施中,Linux 完全公平调度器(Completely Fair Scheduler, CFS)是默认的进程调度算法。CFS 自 Linux 2.6.23 版本引入以来,一直是 …...

通义千问1.5-1.8B-Chat商业应用:企业智能助手快速落地方案
通义千问1.5-1.8B-Chat商业应用:企业智能助手快速落地方案 1. 企业智能助手市场现状与需求 当前企业运营面临人力成本上升、服务标准化不足、数据分析需求激增等挑战。传统解决方案往往需要投入大量资源进行定制开发,而基于大模型的智能助手提供了快速…...